Original Link: https://www.anandtech.com/show/947
ATI’s Radeon 9700 (R300) – Crowning the New King
by Anand Lal Shimpi on July 18, 2002 5:00 AM EST- Posted in
- GPUs
The frustration has been building at ATI for years now; every GPU they’ve released and every inch of progress they’ve made has been spoiled by NVIDIA. One month after the Radeon first launched, updated Detonator3 drivers gave the GeForce2 GTS the performance boost necessary to outperform the Radeon. And who could forget the release of NVIDIA’s Detonator4 drivers, strategically circulated right before the preview release of ATI’s Radeon 8500 that completely tilted the performance in NVIDIA’s favor.
Every single time we would talk to ATI, they would always tell us that the next time things would be different, that the next time they will beat NVIDIA and as you all know, that next time never seemed to happen.
With the GeForce4 release, NVIDIA extended their lead by a very healthy margin. ATI’s flagship Radeon 8500 could barely keep up with NVIDIA’s entry-level $200 Ti 4200, not to mention the beating that the top of the line Ti 4600 delivered.
When ATI started talking about R300 and hinted that it would be significantly faster than anything NVIDIA had up their sleeves, we were understandably skeptical. The progression from there is best summed up by what our own Matthew Witheiler had to say about the R300:
“It all started with Carmack's endorsement of the card; that was huge for them. Now it has erupted into something that I didn’t think was possible”
Matthew’s final statement sums up the feelings all of us at AnandTech had about the R300; we were impressed that John Carmack provided such a glowing endorsement of the technology back at Quakecon, but we were floored once we actually saw working silicon in action.
As you’re about to see, ATI has finally released a GPU that is not only the unequivocal performance leader but also the first to market with the DirectX 9 features that NVIDIA will not be delivering until November.
Before we dig into the architecture behind the R300 we need to get something out in the open: the Radeon 9700, the first R300 based card from ATI, will be in stores no later than 30-days from now. The card retails for a MSRP of $399 and with all that ATI has been able to show us that far, we have no reason not to believe them on this.
It’s time to crown a new king, let’s have a look at the head we’re placing it on today.
The Chip behind the Name
As we originally hypothesized back at Computex, the R300 is a 0.15-micron chip but it is also fully DirectX 9 compliant. Being DirectX 9 compliant means that the R300 pipeline is fully floating point from start to finish, which increases the transistor count of the chip tremendously. The combination of a fully floating point pipeline and features such as the chip’s 8 rendering pipelines give the R300 a transistor count of over 110 million transistors. While this is less than what we’re estimating for NV30, it’s definitely higher than any currently available GPU. Note that the Matrox Parhelia is an 80M transistor chip, also manufactured on a 0.15-micron process.
One of the problems associated with having this many transistors on a 0.15-micron chip is that the chip will inevitably be extremely large; this poses two problems, packaging and yield.
The R300 chip itself has over 1,000 pins, more than AMD’s forthcoming ClawHammer CPU. Part of the reason for the increase in pin count is the move to a 256-bit memory bus, but a good number of those pins are power delivery pins to feed the massive chip. Because of the incredible pincount of the chip, ATI is the first to use a Flip-Chip package (FCBGA) for a GPU with the R300.

As you can see from the picture above, the R300 looks a lot like a modern-day CPU like the Pentium 3, Pentium 4 (without the heatspreader) or Athlon XP. The benefits of a FC-BGA package include the ability to route 1,000+ pins properly as well as improved cooling, which is definitely necessary for such a complex chip running at such high clock speeds.
The next problem you run into with such a complex chip is this issue of yield; in order for the R300 to be competitive, clock speeds would have to be at least equal to that of the GeForce4. NVIDIA was able to hit 300MHz on their 0.15-micron process, but that was for a 63M transistor chip. The transistor count is almost double with the R300, yet ATI was shooting for greater than 300MHz.
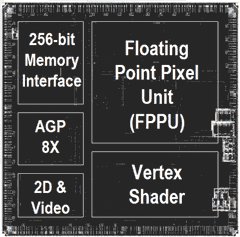
The R300 die, note the large amount taken up by the FPPU.
According to one of ATI’s chip architects, the reason they were able to reach such high clock speeds when 3DLabs and Matrox were unable to go much beyond 200MHz was because they took a different approach to the chip design. An admittedly very “Intel-like” approach, ATI didn’t go as far as to hand pick transistors but they did a considerable amount of the R300 design by hand thus enabling them to reach decent clock speeds at profitable yields.
By the time you read this, ATI still will not have decided on the clock speeds for the R300, but the card we tested was running at a core clock of 325MHz. Officially, ATI is shooting for above a 300MHz core clock and from our discussions with them it seems like they are realistically aiming for at least the 325MHz with which we tested.
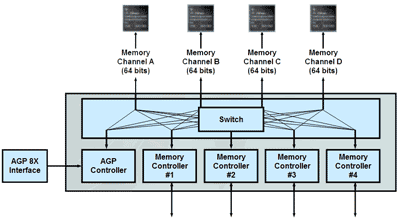
Like the Matrox Parhelia, the R300 supports a 256-bit DDR memory bus made up of four individual load-balanced 64-bit memory controllers à la NVIDIA’s Crossbar architecture. ATI is targeting memory clock speeds greater than 300MHz, and the board we tested ran at 310MHz DDR (effectively 620MHz). ATI is quick to point out that the R300 can support DDR-II, but we would expect that a slight redesign of the memory controller might be necessary to truly enable support. But we’ll talk about the future of the R300 much later in this article…

The rest of the R300 specs are as follows:
• 0.15-micron GPU
• 110+ million transistors
• 8 pixel rendering pipelines, 1 texture unit per pipeline, can do 16 textures per pass
• 4 programmable vect4 vertex shader pipelines
• 256-bit DDR memory bus
• up to 256MB of memory on board, clocked at over 300MHz (resulting in a minimum of 19.2GB/s of memory bandwidth)
• AGP 8X Support
• Full DX9 Pixel and Vertex Shader Support
• Single Full Speed 165MHz integrated TMDS transmitter
As we’ve started doing with our GPU overviews, we’ll take you through the R300 pipeline to help better explain the technology.
The 3D Pipeline – R300 Style
The R300 does not change the way the 3D pipeline works at a high-level, but in order to meet the forthcoming DirectX 9 specifications, ATI had to introduce a number of improvements to the pipeline. The thing to remember here is that because both R300 and NV30 will be DirectX 9 compliant, they will both have very similar pipelines.
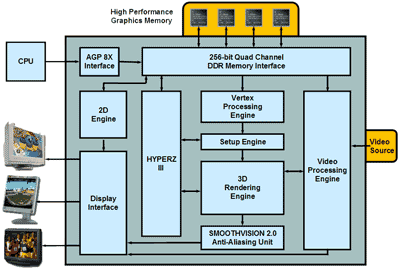
We have already explained how 3D rendering works in the past, but as a refresher we will walk you through each stage of the pipeline once again, but this time from the perspective of the R300 and how ATI does things with their latest chip. We’ll also draw comparisons to the GeForce4 and other competing solutions where appropriate.
The 2nd with AGP 8X
The first stage in the 3D pipeline is the most obvious, sending commands and data to be executed on the graphics chip. This function is initiated by the software running on the host CPU, sent over the AGP bus and finally reaching the graphics processor, which is contacted using the graphics drivers.
The R300 improves on previous chips by implementing an AGP 8X interface between the GPU and the North Bridge of your motherboard’s chipset. As you’ll remember from our P4X333 Review, the AGP 8X specification (AGP 3.0) runs at 66MHz and transfers data eight times per clock cycle. The 32-bit wide AGP bus when running in 8X mode results in a total of 2.1GB/s of bandwidth between the R300 and your PC’s North Bridge.
Although we have yet to see scenarios where even AGP 4X is absolutely necessary, it does make sense to continue to increase the amount of available AGP bandwidth. The R300 is backwards compatible with AGP 4X for use with most present-day systems.
The GeForce4 and all competing solutions currently employ AGP 4X interfaces but by the end of this year you can expect to see updated versions of most major cards with AGP 8X support. ATI can’t claim the title of first with AGP 8X since SiS pulled that off with the Xabre, but claiming AGP 8X support at this point doesn’t really exude a performance advantage.
Vertex Processing – Twice GeForce4’s Triangle Throughput
Now that the GPU knows what data it needs to begin processing and what it needs to actually do to this set of data, it starts working. The data sent to the GPU is sent in the form of the vertices of the polygons that will eventually be displayed on your screen. The first actual execution stage in the graphics pipeline is what has been referred to as T&L for the longest time. This is the transformation of the vertex data that was just sent to the GPU into a 3D scene. The transformation stage requires a lot of highly repetitive floating-point matrix math. Next comes the actual lighting calculations for each of these vertices. In a programmable GPU these initial vertex processing stages are very flexible in that short vertex shader programs can be written to control a number of the characteristics of the vertices to change the shape, look or behavior of a model among other things (e.g. matrix palette skinning, realistic fur, etc..).
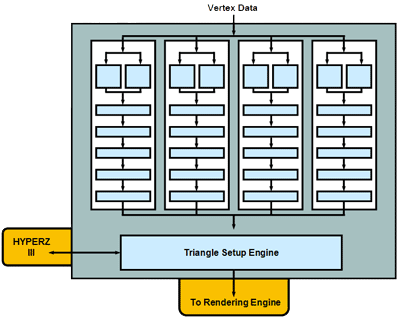
The R300 features four programmable vertex shader pipelines, much like the Matrox Parhelia. The difference between the R300 and the Parhelia is that the R300 has a much improved triangle setup engine, so while the Parhelia can boast incredible vertex throughput rates, the GPU is still limited by its triangle set-up engine. This reason is why, in games with very low triangle counts, that the Parhelia was not able to outperform even the GeForce4 with fewer vertex shader pipelines; with a triangle set-up engine no more powerful than the GeForce4’s, and running at a lower clock speed, the Parhelia did not have the triangle throughput power to backup its vertex shader pipelines.
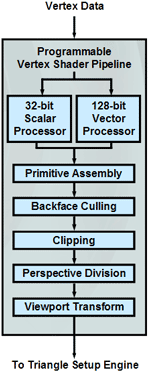
ATI fixed this problem with the R300, and it is able to offer a triangle throughput rate of over 300M triangles per second. Compared to a GeForce4 Ti 4600, this is over twice the triangle throughput which you would expect considering that the R300 has twice as many vertex shader pipelines.
This is the first area in which the R300 truly begins racking up its performance advantage. ATI’s HyperZ technology also comes into play here, but we will save that for its own page explaining the technology.
Vertex Shader 2.0 Support
The R300 also supports the Vertex Shader 2.0 specification, which is a part of Microsoft’s DX9 spec. Along with this, the Hardware Displacement Mapping technology from Matrox’s Parhelia is also supported by the R300, though it will go unused for a while until developers begin taking advantage of it.
The major benefits of the 2.0 spec include flow control and an increase in the number of instructions that can be executed per pass. Flow control support means that vertex shader programs can now contain loops, jumps and subroutines, which are very important to keep shader programs small and efficient by avoiding repetition of code and reducing instruction count.
The benefit of flow control can easily be seen by the following example:
Let’s say we wanted to increment a variable ‘x’ by 1 and after incrementing it by ‘1’ we were going to execute a command the depended on the value of ‘x’. Let’s also assume that in order for this shader program to work that we needed to do this for 5 distinct values of ‘x’.
Without flow control, in this case loops, the program would look like this:
…
x = x + 1
ExecuteCommand(x)
x = x + 1
ExecuteCommand(x)
x = x + 1
ExecuteCommand(x)
x = x + 1
ExecuteCommand(x)
x = x + 1
ExecuteCommand(x)
…
Now using Vertex Shader 2.0 the same can be done using a loop in two lines:
for (x=0;x<5;x++)
ExecuteCommand(X);
The first line initializes a variable ‘x’, increments it by 1 for every run of the loop and continues to execute the next command while the value of ‘x’ is less than 5.
The latter method obviously makes more sense, is easier to write and significantly reduces the size of your code. Imagine writing a similar program that required 100 distinct values of ‘x’, the code just to do that would be 200 lines long but with loops it’s still just two lines.
The new Vertex Shader specification also allows for up to 1024 instructions in a single pass.
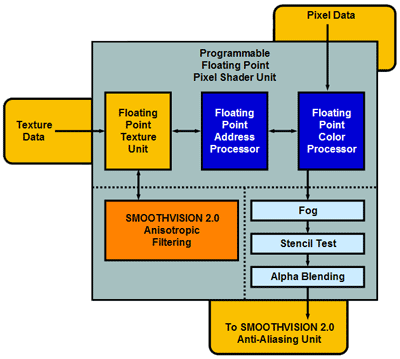
Eight Pixel Rendering Pipelines – The DX9 Era Begins
Part of the reason NVIDIA was able to extend such a large performance lead over the competition was their early adoption of an architecture that implemented four pixel rendering pipelines. This was back in 1999, two full years before ATI implemented four rendering pipelines in their R200 chip back in August of 2001.
![]()
This time around, ATI will be the first to jump on the next-generation bandwagon by outfitting the R300 with eight 128-bit floating point pixel rendering pipelines. This is a huge improvement over the four 64-bit integer rendering pipelines of the GeForce4 and Radeon 8500, and it also explains where a lot of those transistors went in the R300’s design. Not only did ATI double the number of rendering pipelines but they also doubled the precision and moved to a fully floating point pipeline to increase precision further. A fully floating point 3D pipeline will be a DirectX 9 requirement, and moving forward you’ll see the fastest DX9 parts employ a similar 8-pipe configuration.
The R300’s 8-rendering pipelines will give it a significant advantage in fill rate over anything currently available, also contributing to the R300’s performance lead over the competition.
The move to fully floating point pipelines is important as 3D graphics move towards higher fidelity. To illustrate the need for fully floating point pipelines let’s take a generalized situation where a floating point number is handed off to an integer pipeline:
If the original number being sent into an integer pipeline is 10.0523432543890, the number that actually gets sent to the pipeline is rounded or truncated so that it is a whole number. This simplification is not a problem if the result is being used to generate a relatively simple picture, but once you start creating photorealistic images then rounding errors like that can mean the difference between a scene that looks lifelike and one that is clearly computer generated.

An example of what's made possible through FP color.
Over the next year you will see a push from the hardware vendors to finally bring cinematic quality effects to the desktop.
Pixel Shader 2.0 Support
The R300 supports Microsoft’s Pixel Shader 2.0 specification, also a part of DirectX 9. There are a number of improvements this new Pixel Shader specification offers, the below table provided by ATI helps summarize things:
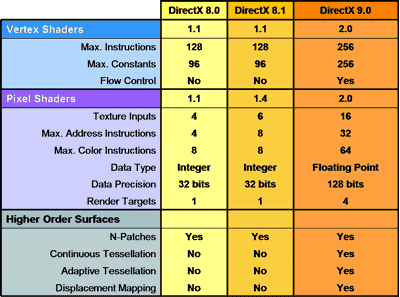
You’ll notice in the table above that the new Pixel Shader specification calls for a maximum of 16 texture inputs. This translates into the ability to apply 16 textures per pass, up from 6 on the GeForce4 and Radeon 8500. To give you an idea of how this fits with forthcoming games, Doom3’s pixel shaders are expected to require five to six texture inputs, which the R300 can do in a single pass. To give credit where it’s due, DX8 solutions can also do that in a single pass, so there is a good deal of headroom to exploit on the R300’s current architecture.
The Pixel Shader 2.0 specification also calls for much more flexible operations that in turn make the chip much more programmable. The R300 can execute up to 160 Pixel Shader instructions per pass and, though this amount is not infinite, the architecture can take multiple passes to process a complex program that is longer than 160 instructions in length.
For now, where this comes in handy the most is in high-end 3D rendering applications. Due to the extremely programmable nature of the R300 (and other forthcoming DX9 GPUs), it will be possible to actually compile and run code (for example 3D Studio Max or RenderMan code) on the GPU itself. Currently 3D rendering is done entirely by your host CPU, but with proper software support, you will be able to render 3D scenes much quicker on these powerful GPUs.

The 160 instructions per pass limitation comes into play with 3D rendering because it forces most complex 3D rendering to be done in multiple passes. This is acceptable for now, mainly because it is much easier and more user-friendly to render a scene in 3D Studio Max at 0.1 fps rather than wait 10 minutes for your CPU to render a single frame.
Once again, you can see the requirement for a fully floating point pipeline, which means that NV30 as well as R300 will both have support for these features that we are going to talk about. One very compelling application for a fully floating point rendering pipeline is higher quality lighting, which is absolutely necessary in order to render lifelike scenes. As good looking as 3D games currently are, they are still far, far away from being lifelike; lower quality textures and a lack of polygon detail are both causes, but a major limitation is lighting.
The additional bits of precision achieved through the new floating point pipelines can be used to more accurately depict lighting. With the old 32-bit integer pipelines each RBGA value was limited to 8-bits, or 256 distinct values. Below you’ll see a very complex scene that we want to adjust the brightness of:

The problem with only 256 distinct values is that, if we increase the brightness of everything by 64x, the brightest light sources in the scene are limited by the number of distinct values that the 8-bit integer components can represent. The end result is that although the entire scene gets brighter, the brightest sources in the scene are no longer proportionally brighter than the rest of the scene.

The same applies to when darkening a scene; if we adjust the brightness to 1/64th the original intensity of the light, everything becomes incredibly dark. Even though everything in the room becomes dark, the sources of light should not become as dark as the rest of the room, which is what happens if you are constrained by the number of values you can use to represent the color components of the scene.

Now, let’s look at the same scene but using floating point color to offer a wide range of brightness levels:

Instead of only having 256 values per component, each color component can now be represented by, in effect, an unlimited number of values, giving you a truly dynamic range of brightness.
DirectX 9 calls for support for Multiple Render Targets (MRTs) which, as the name implies, means the ability to target specific objects in a scene for pixel shader programs. This method will be one of the most common in which complex pixel shader programs are implemented. You won’t see 100+ instruction programs being used on every single object in a scene, but in order to make a few parts of the scene truly stand out MRTs will come in handy.
SMOOTHVISION 2.0 – Multisampling, Finally
When the Radeon 8500 was first released we were very disappointed to discover that ATI’s SMOOTHVISION Anti-Aliasing was a supersampling algorithm and did not employ the more efficient multisampling technique that NVIDIA had already started to use.
We have explained this in the past but the way ATI’s supersampling (Rotated Grid Super-Sampling – RGSS) works is by rendering multiple copies of the scene and shifting each copy by a certain amount off the center. These copies were then blended together to produce the final image. This approach provides excellent texture resolution and gets rid of aliasing at the same time; the downside is that it does so at a huge fill rate penalty, since you’re rendering the scene multiple times.
Multisampling, on the other hand, works by looking at the z-value (depth) of each pixel. Depending on the amount of the pixel that is covered, a weighted average between the foreground and background colors is computed and that’s the final color of the pixel. The benefit of this approach is that you are not rendering multiple copies of a scene at the cost of losing the texture resolution benefits of supersampling and at the expense of even more z-buffer accesses.
The R300 supports both supersampling and multisampling (a change from the R200, which only supports supersampling), but at this point ATI is only going to expose multisampling in the drivers; this may change between now and the first R300 cards’ shipping date.
We mentioned that multisampling increases the number of z-buffer accesses, but because the R300 is equipped with Z Compression, these accesses do not eat into the GPU’s memory bandwidth very much. ATI quotes 50 – 75% z-sample compression using HyperZ III’s Z Compression in their tech-docs.
While we did not get much time to evaluate the image quality of ATI’s multisampling algorithms, ATI insists that it will be higher quality than NVIDIA’s implementation in situations where transparent textures are used. The best example of this is in the DM-Antalus level in UT2003; the gorgeous grass in the level is simply a high resolution texture that is alpha blended, so you can see what’s behind it. According to ATI, NVIDIA’s multisampling algorithm will merely ignore aliasing within these polygon edges due to their transparency whereas the R300 will not. We will be able to provide screenshots in a couple of weeks, once we get our hands on a board for a longer period of time.
SMOOTHVISION 2.0 supports 2X, 4X and 6X AA modes on the R300.
Fixed Anisotropic Filtering, Finally
The R300 fixes another issue that many complained about with the R200, and that is in regards to its anisotropic filtering. With the Radeon 8500, ATI introduced their adaptive anisotropic filtering algorithm that determined the number of samples that should be taken based on the rotation along the x and y axes with respect to the user. The end result of this method was that in situations where the highest degree of anisotropic filtering was necessary, the GPU would take the maximum amount of samples set in the driver (16X was the max you could set on the slider).
The only problem with ATI’s algorithm was that they did not take into account what would happen if there was rotation along the x, y and z axes. In most cases, with rotation along the z axis also thrown in, the GPU would default to the lowest filtering method supported – bilinear – which looked pretty bad.
The R300 not only supports trilinear alongside anisotropic but they also fixed the z-rotation issue. Once again, we will have to spend some more time with a card in order to get a better idea if the problem is truly fixed or not, but from what we can tell, they have done a solid job.
We’ve already encouraged NVIDIA to offer a similar form of anisotropic filtering, since the difference between ATI’s adaptive algorithm and NVIDIA’s approach where everything is anisotropically filtered is negligible in most cases; the main difference is that ATI’s method incurs a noticeably smaller performance hit.
According to ATI, there’s no performance hit with bilinear filtering enabled and 16X anisotropic filtering on the R300 and a small performance hit with trilinear enabled. We didn’t have enough benchmarking time with the card to define what a “small performance hit” was but based on our experience with the R200, we would estimate 10%, at most.
HyperZ III
ATI was the first to market with their occlusion culling technology that they have called HyperZ. The third generation of HyperZ is present in the R300 and it basically contains faster versions of the three components present HyperZ II on the Radeon 8500.
ATI has not shed too much light on the improvements, but at this point it just seems like HyperZ III is faster simply because of the faster clock rate of the R300 GPU, the inclusion of "Early Z" (explained below) and maybe increases in the number of pixels Hierarchical Z can discard at a single time; there’s nothing wrong with that, there’s just not much new about it.
In case you’ve forgotten, here’s a quick explanation of the role of HyperZ III:
ATI's HyperZ technology is essentially composed of three features that work in conjunction with one another to provide for an "increase" in memory bandwidth. In reality, the increase is simply a more efficient use of the memory bandwidth that is there. The three features are: Hierarchical Z, Z-Compression and Fast Z-Clear. Before we explain these features and how they impact performance, you have to first understand the basics of conventional 3D rendering.
As we briefly mentioned before, the Z-buffer is a portion of memory dedicated to holding the z-values of rendered pixels. These z-values dictate what pixels and eventually what polygons appear in front of one another when displayed on your screen, or, if you're thinking about it in a mathematical sense, the z-values indicate position along the z-axis.
A traditional 3D accelerator processes each polygon as it is sent to the hardware, without any knowledge of the rest of the scene. Since there is no knowledge of the rest of the scene, every forward facing polygon must be shaded and textured. The z-buffer, as we just finished explaining, is used to store the depth of each pixel in the current back buffer. Each pixel of each polygon rendered must be checked against the z-buffer to determine if it is closer to the viewer than the pixel currently stored in the back buffer.
Checking against the z-buffer must be performed after the pixel is already shaded and textured. If a pixel turns out to be in front of the current pixel, the new pixel replaces (or is blended with, in the case of transparency) the current pixel in the back buffer and the z-buffer depth updated. If the new pixel ends up behind the current pixel, the new pixel is thrown out and no changes are made to the back buffer (or blended in the case of transparency). When pixels are drawn for no reason, this is known as overdraw. Drawing the same pixel three times is equivalent to an overdraw of 3, which in some cases is typical. Once the scene is complete, the back buffer is flipped to the front buffer for display on the monitor.
What we've just described is known as "immediate mode rendering"
and has been used since the 1960's for still frame CAD rendering, architectural
engineering, film special effects, and now, in most 3D accelerators found inside
your PC. Unfortunately, this method of rendering results in quite a bit of overdraw,
where objects that are not visible are being rendered.
One method of attacking this problem is to implement a Tile Based Rendering
architecture, such as what we saw with the PowerVR based KYRO II graphics accelerator
from ST Micro. While that may be the ideal way of handling it, developing such
an algorithm requires quite a bit of work; it took years for Imagination Technologies
(the creator of the PowerVR chips) to get to the point they are today with their
Tile Based Rendering architecture.
Although the R300 doesn't implement a Tile Based Rendering architecture, it does borrow some deferred rendering features to increase efficiency in memory requests. From the above example of how conventional 3D rendering works, you can guess that quite a bit of memory bandwidth is spent on accesses to the Z-buffer in order to check to see if any pixels are in front of the one being currently rendered. ATI's HyperZ increases the efficiency of these accesses, so instead of attacking the root of the problem (overdraw), ATI went after the results of it (frequent Z-buffer accesses).
The first part of the HyperZ technology is the Hierarchical Z feature. This feature basically allows for the pixel being rendered to be checked against the z-buffer before the pixel actually hits the rendering pipelines. This allows useless pixels to be thrown out early, before the R300 has to render them. The R300 does add what ATI is calling Early Z that further sub-divides the Z-buffer down to the pixel level so that the card can achieve close to 100% efficiency in discarding occluded (hidden) pixels.
Next we have Z-Compression. As the name implies, no data is lost during the compression This compression algorithm compresses the data in the Z-buffer, thus allowing it to take up less space, which in turn conserves memory bandwidth during accesses to the Z-buffer.
The final piece of the HyperZ puzzle is the Fast Z-Clear feature. Fast Z-Clear is nothing more than a feature that allows for the quick clearing of all data in the Z-buffer after a scene has been rendered. Apparently, ATI's method of clearing the Z-buffer is dramatically faster than other conventional methods.
As we mentioned before, ATI’s HyperZ III comes in handy with improving
AA performance courtesy of their Z-Compression.
Video through the 3D Pipeline
A very impressive feature that the R300 supports is the ability to insert a video stream into the 3D pipeline instead of just at the DAC level. Not only will this remove the need to use overlay to playback a video stream but it also enables the display of multiple simultaneous video streams.
Just like the RV250, FULLSTREAM is supported; to quote from our Radeon 9000 Pro Review:

(a) FULLSTREAM disabled, (b) FULLSTREAM enabled
“The ability to run pixel shader programs on video streams is promising, and ATI’s FULLSTREAM technology is one such implementation. With appropriate software support (currently only through RealPlayer), FULLSTREAM can smooth out the blocky compression artifacts that are normally seen in low bandwidth video. The end result is that the video stream is much less blocky but much more blurry.”
We’ll definitely be hearing more about the video features of the R300 and ATI’s new Rage Theater chip this fall when ATI releases a R300 version of the All-in-Wonder Radeon.
Introducing the Card – Radeon 9700
With all this talk about the R300 chip, it is finally time to talk about the first card that implements the chip – the Radeon 9700.

The Radeon 9700 features, sadly, only one DVI port and one VGA port to take advantage of Hydravision, which is still included in the R300 core. While we would like to see a dual DVI option for a $399 card, we may have to wait for the FireGL version of the card for that.


Clock speeds have not been set at the time of publication but ATI is definitely saying over 300MHz for both core and memory. When ATI visited us in North Carolina just a couple of weeks ago, they mentioned that they were hoping for over 325MHz core and memory but we will see what happens over this coming month. The card we tested ran its core at 325MHz and its memory ran at 310MHz DDR. The card is made by ATI on a red PCB and will be sold that way (an indication of ATI’s fiery passion?). The Radeon 9700 will be available within the next 30 days at $399 as we mentioned above.

The board does feature a power connector, as it draws more power than the AGP 3.0 specification allows. A floppy power connector is present on the board but ATI will be shipping all Radeon 9700s with an adaptor to use the larger 4-pin power connectors.

So much for a Unified Driver Architecture
When ATI showed us the Radeon 8500, they promised that they would finally be moving to a Unified Driver Architecture (UDA) like NVIDIA. But after conversing with one of ATI’s software engineers, we have learned that the R300’s DirectX drivers are completely new.
For starters, they are not based off of the Radeon 8500’s DX drivers, which means that the move to a UDA back with the Radeon 8500 was never really made since the next-generation architecture cannot use the codebase from the previous generation UDA. The benefit of this is that a number of the DirectX problems ATI had in the past should now be fixed. That benefit is also a significant downside because anything that was fixed in the old drivers may now be broken in the new R300 drivers. ATI has told us that the R300’s DirectX drivers will be the basis for the next-generation UDA for future chips; all we can say to this is that for ATI’s sake, they had better be.
ATI’s drivers have always been their weakness and, unfortunately, it does not look like much has changed with the R300. On the positive side, we didn’t encounter any performance, compatibility or image quality issues with the current build of the R300 drivers during our time with it. The card and its drivers ran through our entire benchmark suite just fine; but it is obvious that a significant amount of time has been wasted by redesigning the R300 drivers and we hope that no issues crop up in other games, though it is hard to believe that they will not.
ATI has come too far with the R300 to let drivers hold it back this time, hopefully with their renewed dedication to software engineering, we will not see many, if any, issues with the R300’s drivers upon its release.
The Test
As we know our AnandTech readers well, we thought you might like to see some benchmarks of the beast. ATI allowed us to the test the R300 on our own testbeds and we eagerly jumped at the opportunity.
Because ATI has yet to finalize drivers and clock speeds, we were only allowed to publish percent improvements over a GeForce4 Ti 4600. We have published Ti 4600 numbers in many other articles, so you can get a good idea on what sort of performance levels the R300 will be able to deliver.
We will run a much larger suite of tests including our CPU scaling tests (that you all love oh-so-much and that take us oh-so-long to run ;)…), once we get a final version of the card running at final clock speeds with shipping drivers.
What’re you waiting for? If you’re anything like any of the AnandTech guys, you can’t wait to see how this thing performs and for once, ATI does not disappoint
| Windows
XP Professional Test Bed |
|
| Hardware
Configuration |
|
| CPU | Intel
Pentium 4 2.4B 133.3MHz x 18.0 |
| Motherboard | ASUS
P4T533-E Intel 850E Chipset |
| RAM | 2
x 128MB PC800 Kingston RIMMs |
| Sound | None |
| Hard Drive | 80GB
Maxtor D740X |
| Video Cards (Drivers) | ATI Radeon 9700
(128MB) |
Unreal Tournament 2003 (DM-Antalus)
We used the same build of Unreal Tournament 2003 as we used in our recent GPU shootout, be sure to read that story for more information on the demo and the levels we benchmarked. As a quick refresher, DM-Antalus is a mostly outdoor level that makes decent use of quad texturing.
|
Right off the bat we know that this thing has power, at 1024x768 in the most stressful UT2003 test we can throw at it the Radeon 9700 is already 38% faster than the GeForce4 Ti 4600.
|
Crank the resolution up to 1280x1024 and the Radeon 9700 is now 48% faster than the GeForce4 Ti 4600, no driver release in the world could get rid of that performance gap.
|
Finally, at 1600x1200 the Radeon 9700 can play Unreal Tournament 2003 at the highest detail settings just fine; the R300 manages to outperform the fastest GeForce4 by an incredible 54%.
Unreal Tournament 2003 (DM-Asbestos)
Our second benchmarking level in UT2003 is DM-Asbestos, which is primarily an indoor level and garners noticeably higher frame rates.
|
At "lower" resolutions, the DM-Asbestos benchmark is more CPU limited than GPU limited which is why the Radeon 9700 outperforms the Ti 4600 by "only" 18%.
|
Cranking up the resolution helps a bit as ATI can extend the lead to 25%...
|
And at 1600x1200 the biggest lead the Radeon 9700 can maintain is 27%, which isn't bad for a benchmark that is very CPU bound.
Jedi Knight 2
|
We've known Jedi Knight 2 to be a very CPU bound benchmark, and thus the Radeon 9700 scores approximately on-par with a GeForce4 Ti 4600. Even the NV30 will perform the same as these two parts here.
|
There's no change at 1280x1024, it's pretty sad when a 2.4GHz Pentium 4 can't feed these cards data quick enough to avoid it becoming the bottleneck.
|
Finally at 1600x1200 the Radeon 9700 begins to pull away, with a 10% lead. This is a situation where 4X AA would help as the Radeon 9700 has performance to burn at this point.
Serious Sam 2: The Second Encounter
We ran Serious Sam 2 with the Extreme Quality settings enabled but we left anisotropic filtering disabled, which normally tilts the benchmark in favor of ATI since NVIDIA anisotropic filtering algorithm takes a larger performance hit. Keep this in mind as the Radeon 9700 continues to perform incredibly well:
|
At 1024x768 the Radeon 9700 can only outperform the Ti 4600 by 15%, but let's stress the card a bit more and see what happens...
|
That's more like it, a 40% differential is what we're paying $400 for. Can we get 50%?
|
...you've got it, a 50% performance lead at 1600x1200 in Serious Sam 2. Impressive but we're still recovering from how fast this thing is under UT2003.
Quake III Arena
We had to include Quake III Arena for completeness, even though the Ti 4600 already gets ungodly frame rates under the benchmark.
|
At 1024x768 the benchmark is mostly CPU bound and thus we only see a 4% performance advantage, but once we crank up the resolution...
|
...4% turns into 23% and there's still some juice left.
|
Just when you thought that Quake III Arena couldn't get any faster, the Radeon 9700 manages to outperform the Ti 4600 at 1600x1200 by 37%.
SMOOTHVISION 2.0 - Anti-Aliasing Performance
We didn't have much time with the Radeon 9700 so we couldn't run a full suite of AA tests nor take screen shots, but we did run a few numbers under UT2003 and Quake III Arena just to whet your appetite:
|
At 1600x1200 with 4X AA enabled, the Radeon 9700 is 2.51x faster than the GeForce4 Ti 4600. While the frame rates are high enough to be playable, even the almighty Radeon 9700 would need to back down to 1280x1024 with 4X AA enabled to be smooth as silk.
|
A 2.28x performance advantage here; it's a good thing that SMOOTHVISION now employs a multisampling algorithm otherwise the performance advantage wouldn't be nearly as great.
|
We end, once again, with Quake III Arena and the Radeon 9700's 2.49x performance advantage. Granted that at 1600x1200 this is more of a memory bandwidth test than anything, which the Radeon 9700 has about twice what the GeForce4 has, but it's still impressive.
As we mentioned before, this is more of a preview and we'll run through a much more thorough set of tests in our actual review of the shipping Radeon 9700.
Final Words & ATI’s Roadmap
There’s a new king in town, and it’s the Radeon 9700. There’s nothing NVIDIA could have done to prevent ATI from winning with the R300, there’s no driver they could ever release that would give the GeForce4 the power it needs to topple the Radeon 9700; no, with the Radeon 9700 it will take the NV30 and no less to outperform it.
Based on the current specs of NV30, believe it or not, it will be faster than the Radeon 9700. Since both ATI and NVIDIA must support DirectX 9, you can already guess at a lot of the specifications for NV30. It will obviously have support for Pixel and Vertex Shader 2.0; you can expect it to have 8 pipes and with ATI and Matrox both sporting a 256-bit DDR memory bus, you can also expect it to have one too. The one benefit NVIDIA will have with NV30 will be that it will be manufactured on a 0.13-micron process. Not only does that mean that NVIDIA’s chip will be smaller but it also means that they can run at higher clock speeds, which can give it the edge over the Radeon 9700.
ATI is well aware of this, and the one thing they have going for them is that NV30 won’t be out anytime soon. The 0.13-micron chip has been delayed a bit and the current word is that a November release can be expected, with boards shipping shortly thereafter. The folks over at ATI are banking on NV30 being a 2003 part, so that the Radeon 9700 can close out this year with a bang. If you want the absolute fastest graphics card available, the Radeon 9700 fits the bill better than any GeForce4 or Parhelia; and it will continue to do so for months to come.
The performance you’re paying for with the Radeon 9700 also buys you a card that will last you down the road. ATI has been running Doom3 on the Radeon 9700 for a while now, and Carmack has publicly thrown his support behind the card; keep in mind that it wasn’t too long ago that Carmack wouldn’t even touch the Radeon 8500 because of poor drivers. And for those of you that are wondering whether a 128MB card will be necessary, Doom3 will use at least 80MB of textures.
Our benchmarks from Unreal Tournament 2003 speak for themselves; the Radeon 9700 makes 1600x1200 a playable resolution and 4X AA something you can enable in any currently available game.
ATI has finally done it; they have finally got all of their moons in alignment and released a GPU that’s not only a leader in performance, but in technology as well and they’ve done it months before NVIDIA. Congratulations guys, you’ve done a tremendous job but now a much greater task lies ahead, how to respond to NV30?
Rumors of a 0.13-micron R300 before the end of the year are plentiful, but the likelihood of such an event happening is low. ATI will have a refresh of the R300, most definitely a 0.13-micron part but not between now and December. A 0.13-micron R300, potentially shipping with DDR-II would be a perfect match against NV35 due out next Spring. With ATI’s current lead in development time, we could even see an R300 refresh before NV35.
ATI will release a new product between now and the end of the year however, a couple new products to be exact. There’s the All-in-Wonder Radeon based on the R300, which will finally bring hardware MPEG-2 encoding to an All-in-Wonder card. And then there’s the Radeon 9500, to fill the gap in ATI’s product line. With the Radeon 8500 and 8500LE gone and the Radeon 9000 priced below $149, ATI has nothing to offer between $150 and $399. The Radeon 9500 will be a scaled down version of the Radeon 9700, priced somewhere in between $200 - $300. Our current theory is that the Radeon 9500 will be feature-identical to the Radeon 9700 but with only 4 rendering pipelines and lower clock speeds. ATI hasn’t said much publicly about the Radeon 9500 other than it will be out in Q4 of this year.
And looking towards next year, the RV250 won’t be able to hold it’s own against what NVIDIA has planned for the GeForce4 MX; but after seeing what ATI has been able to pull off with the R300 we can’t wait to see what else they’ve got up their sleeves.
When all is said and done, there’s a reason why ATI and NVIDIA are the two leaders in this market right now. Both companies have figured out the right way of doing things and are currently hard at work bringing the absolute fastest hardware to the market. These two are driving the industry and with the R300 ATI put to rest any speculation that had ever existed about their worthiness as a competitor.
ATI won’t go the route of 3dfx, they’re going the route of NVIDIA and today they just entered the passing lane.






