Original Link: https://www.anandtech.com/show/8776/arm-challinging-intel-in-the-server-market-an-overview
ARM Challenging Intel in the Server Market: An Overview
by Johan De Gelas on December 16, 2014 10:00 AM EST
Introduction to ARM Servers
"Intel does not have any competition whatsoever in the midrange and high-end (x86) server market". We came to that rather boring conclusion in our review of the Xeon E5-2600 v2. That date was September 2013.
At the same time, the number of announcements and press releases about ARM server SoCs based on the new ARMv8 ISA were almost uncountable. AppliedMicro was announcing their 64-bit ARMv8 X-Gene back in late 2011. Calxeda sent us a real ARM-based server at the end of 2012. Texas Instruments, Cavium, AMD, Broadcom, and Qualcomm announced that they would be challenging Intel in the server market with ARM SoCs. Today, the first retail products have finally appeared in the HP Moonshot server.

There has been no lack of muscular statements about the ARM Server SoCs. For example, Andrew Feldman, the founder of micro server pioneer Seamicro and the former head of the server department at AMD stated: "In the history of computers, smaller, lower-cost, and higher-volume CPUs have always won. ARM cores, with their low-power heritage in devices, should enable power-efficient server chips." One of the most infamous silicon valley insiders even went so far as to say, "ARM servers are currently steamroller-ing Intel in key high margin areas but for some reason the company is pretending they don’t exist."
Rest assured, we will not stop at opinions and press releases. As people started talking specifications, we really got interested. Let's see how the Cavium Thunder-X, AppliedMicro X-Gene, Broadcom Vulcan, and AMD Opteron A1100 compare to the current and future Intel Server chips. We are working hard to get all these contenders in our lab, and we are having some success, but it is too soon for a full blown shoot out.
Micro Servers and Scale-out Servers
Micro servers were the first the target of the ARM licensees. Typically, a discussion about Micro servers quickly turns into a wimpy versus brawny core debate. One of the reasons for that is that Seamicro, the inventor of the micro server, first entered the market with Atom CPUs. The second reason is that Calxeda, the pioneer of ARM based servers, had to work with the fact that the Cortex-A9 core was a wimpy core that could not deal with most server workloads. Wikipedia also associates micro servers with very low power SoCs: “Very low power and small size server based on System-on-Chip, typically centered around ARM processor”.
Micro servers are typically associated with low end servers that serve static HTML, cache web objects, and/or function as slow storage servers. It's true that you will not find a 150W high-end Xeon inside a micro server, but that does not mean that micro servers are defined by low power SoCs. In fact, the most successful micro servers are based on 15-45W Xeon E3s. Seamicro, the pioneer of micro servers, clearly indicated that there was little interest in the low power Atom based systems, but that sales spiked once they integrated Xeon E3s.
Currently micro servers are still a niche market. But micro servers are definitely not hype; they are here to stay, although we don't think they will be as dominant as rack servers or even blade servers in the near future. To understand why we would make such a bold statement, it is important to understand the real reason why micro servers exist.
Let us go back to the past decade (2005-2010). Virtualization was (and is) embraced as the best way to make enterprises with many heterogeneous applications running on underutilized servers more efficient. RAM capacity and core counts shot up. Networking and storage lagged but caught up – more or less – as flash storage, 10 Gbit Ethernet, and SRIOV became available. But the trend to notice was that virtualization made servers more I/O feature rich: the number and speed of network NICs and PCI-e expansion slots for storage increased quickly. Servers based on the Xeon E5 and Opterons have become "software defined datacenters in a box" with virtual switching and storage. The main driver for buying complex servers with high processor counts and more I/O devices is simple: professionals want the benefits that highly integrated virtualization software brings. Faster provisioning, high availability (HA), live migration (vMotion), disaster recovery (DR), keeping old services alive (running on Windows 2000 for example): virtualization made everything so much easier.
But what if you did not need those features because your application is spread among many servers and can take a few hardware outages? What if you do not need the complex hardware sharing features such as SRIOV and VT-d? The prime example is an application like Facebook, but quite a few smaller web farms are in a similar situation. If you do not need the features that come with enterprise virtualization software, you are just adding complexity and (consultancy/training) costs to your infrastructure.
Unfortunately, as always, the industry analysts came with unrealistic high predictions for the new micro server market: in 2016, they would be 10% of the market, no less than "a 50 fold jump"! The simple truth is that there is a lot of demand for "non-virtualized" servers, but they do not all have to be as dense and low power as the micro servers inside the Boston Viridis. The "very low power", extremely dense micro servers with their very low power SoCs are not a good match for most workloads out there, with the exception of some storage and memcached machines. But there is a much larger market for servers denser than the current rack servers, but less complex and cheaper than the current blade servers, and there's a demand for systems with a relatively strong SoC, currently the SoCs with a TDP in the 20W-80W range.
Not convinced? ARM and the ARM licensees are. The first thing that Lakshmi Mandyam, the director of ARM servers systems at ARM, emphasized when we talked to her is that ARM servers will be targeting scale-out servers, not just micro servers. The big difference is that micro servers are using (very) low power CPUs, while scale-out servers are just servers that can run lots and lots of threads in parallel.
The Current Intel offerings
Before we can discuss the ARM server SoCs, we want to look at what they are up against: the current low end Xeons. We have described the midrange Xeon E5s in great detail in earlier articles.
The Xeon E3-12xx v3 is nothing more than a Core i5/i7 "Haswell" dressed up as a server CPU: a quad-core die, 8MB L3 cache, and two DDR3 memory channels. You pay a small premium – a few tens of dollars – for enabling ECC and VT-d support. Motherboards for the Xeon E3 are also only a few tens of dollar more expensive than a typical desktop board, and prices are between the LGA-1150 and LGA-2011 enthusiast boards. The advantages are remote management courtesy of a BMC, mostly an Aspeed AST chip.
For the enthusiasts that are considering a Xeon E3, the server chip has also disadvantages over it's desktop siblings. First of all, the boards consume quite a bit more power while in sleep state: 4-6W instead of the typical <1W of the desktop boards. The reason is that server boards come with a BMC and that these boards are supposed to be running 24/7 and not sleeping. So less time is invested in reducing the power usage in sleep mode: for example the voltage regulators are chosen to live long. Also, these boards are much more picky when it comes to DIMMs and expansions cards meaning that users have to check the hardware compatibility lists for the motherboard itself.
Back to the server world, the main advantage of the Xeon E3 is the single-threaded performance. The Xeon E3-1280 v3 runs the Haswell cores at 3.6GHz base clock and can boost to 4GHz. There are also affordable LP (Low Power) 25W TDP versions available, e.g. the Xeon E3-1230L v3 (1.8GHz up to 2.8GHz ) and E3-1240L v3 (2GHz up to 3GHz). These chips seemed to be in very limited supply when they were announced and were very hard to find last year. Luckily, they have been available in greater quantities since Q2 2014. It also worth noting that the Xeon E3 needs a C220 chipset (C222/224/226) for SATA, USB, and Ethernet, which adds 0.7W (idle) to 4.1W (TDP).
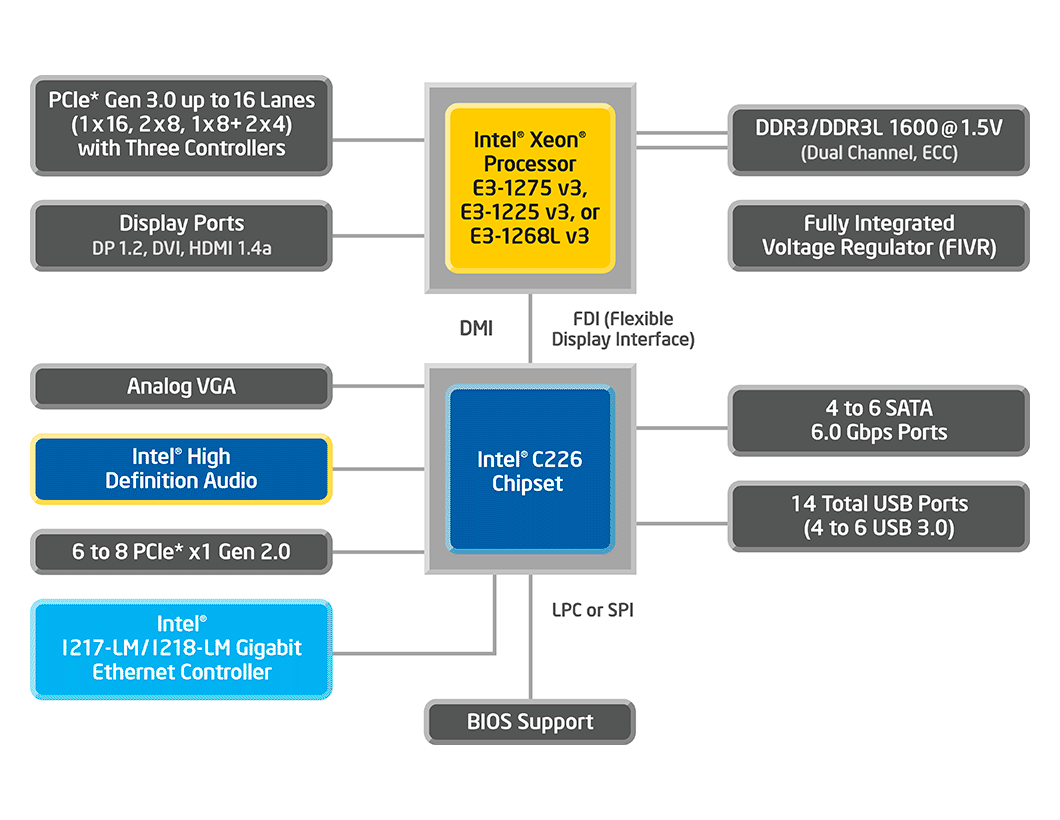
The weak points are the limited memory channels (bandwidth), the fact that Xeon E3 server is limited to eight threads, and the very limited (for a server) 32GB RAM capacity (4 Slots x 8 DIMMs). Intelligent Memory or I'M is one of the vendors that is trying to change this. Unfortunately their 16GB DIMMs will only work with the Atom C2000, leading to the weird situation that the Atom C2000 supports more memory than the more powerful Xeon E3. We'll show you our test results of what this means soon.
The Atom C2000 is Intel's server SoC with a power envelope ranging from 6W (dual-core at 1.7GHz) to 20W (octal-core at 2.4GHz). USB 2.0, Ethernet, SATA3, SATA2 and the rest (IO APIC, UART, LPC) are all integrated on the die, together with four pairs of Silvermont Cores sharing 1MB L2 cache. The Silvermont architecture should process about 50% more instructions per clock cycle than previous Atoms due an improved branch prediction, the loop stream detector (like the LSD in Sandy Bridge) and out-of-order execution. However the Atom micro architecture is still a lot simpler than Haswell.
Silvermont has much smaller buffers (for example, the load buffer only has 10 entries, where Haswell has 72!), no memory disambiguation, it executes x86 instructions (and not RISC-like micro-ops), and it can process at the most two integer and two floating point instructions, with a maximum of two instructions per cycle sustained. The Haswell architecture can process and sustain up to five instructions with "ideal" software. AES-NI and SSE 4.2 instructions are available with the C2000, but AVX instructions are not.
The advantages of the Atom C2000 are the low power and high integration -- no additional chip is required. The disadvantages are the relatively low single-threaded performance and the fact that the power management is not as advanced as the Haswell architecture. Intel also wants a lot of money for this SoC: up to $171 for the Atom C2750. The combination of an Atom C2000 and the FCBGA11 motherboard can quickly surpass $300 which is pretty high compared to the Xeon E3.
The ARM Based Challengers
Calxeda, AppliedMicro and ARM – in that order – have been talking about ARM based servers for years now. There were rumors about Facebook adopting ARM servers back in 2010.
Calxeda was the first to release a real server, the Boston Viridis, launched back in the beginning of 2013. The Calxeda ECX-1000 was based on a quad Cortex-A9 with 4MB L2. It was pretty slow in most workloads, but it was incredibly energy efficient. We found it to be a decent CPU for low-end web workloads. Intel's alternative, the S1260, was in theory faster, but it was outperformed in real server workloads by 20-40% and needed twice as much power (15W versus 8.3 W).
Unfortunately, the single-threaded performance of the Cortex-A9 was too low. As a result, you needed quite a bit of expensive hardware to compete with a simple dual socket low power Xeon running VMs. About 20 nodes (5 daughter cards) of micro servers or 80 cores were necessary to compete with two octal-core Xeons. The fact that we could use 24 nodes or 96 SoCs made the Calxeda based server faster, but the BOM (Bill of Materials) attached to so much hardware was high.
While the Calxeda ECX-1000 could compete on performance/watt, it could not compete on performance per dollar. Also, the 4GB RAM limit per node made it unattractive for several markets such as web caching. As a result, Calxeda was relegated to a few niche markets such as the low end storage market where it had some success, but it was not enough. Calxeda ran out of venture capital, and a promising story ended too soon, unfortunately.
AppliedMicro X-Gene
Just recently, AppliedMicro showed off their X-Gene ARM SoCs, but those are 40nm SoCs. The 28nm "ShadowCat" X-Gene 2 is due for the H1 of 2015. Just like Atom C2000, the AppliedMicro X-Gene ARM SoC has four pairs of cores that share an L2 cache. However, the similarity ends there. The core is a lot beefier and it features 4-wide issue with an execution backend with four integer pipelines and three FP pipelines (one 128-bit FP, one Load, one Store). The 2.4GHz octal-core X-Gene also has a respectable 8MB L3 cache and can access up to four memory channels, with an integrated dual 10GB Ethernet interface. In other words, the X-Gene is made to go after the Xeon E3, not the Atom C2000.
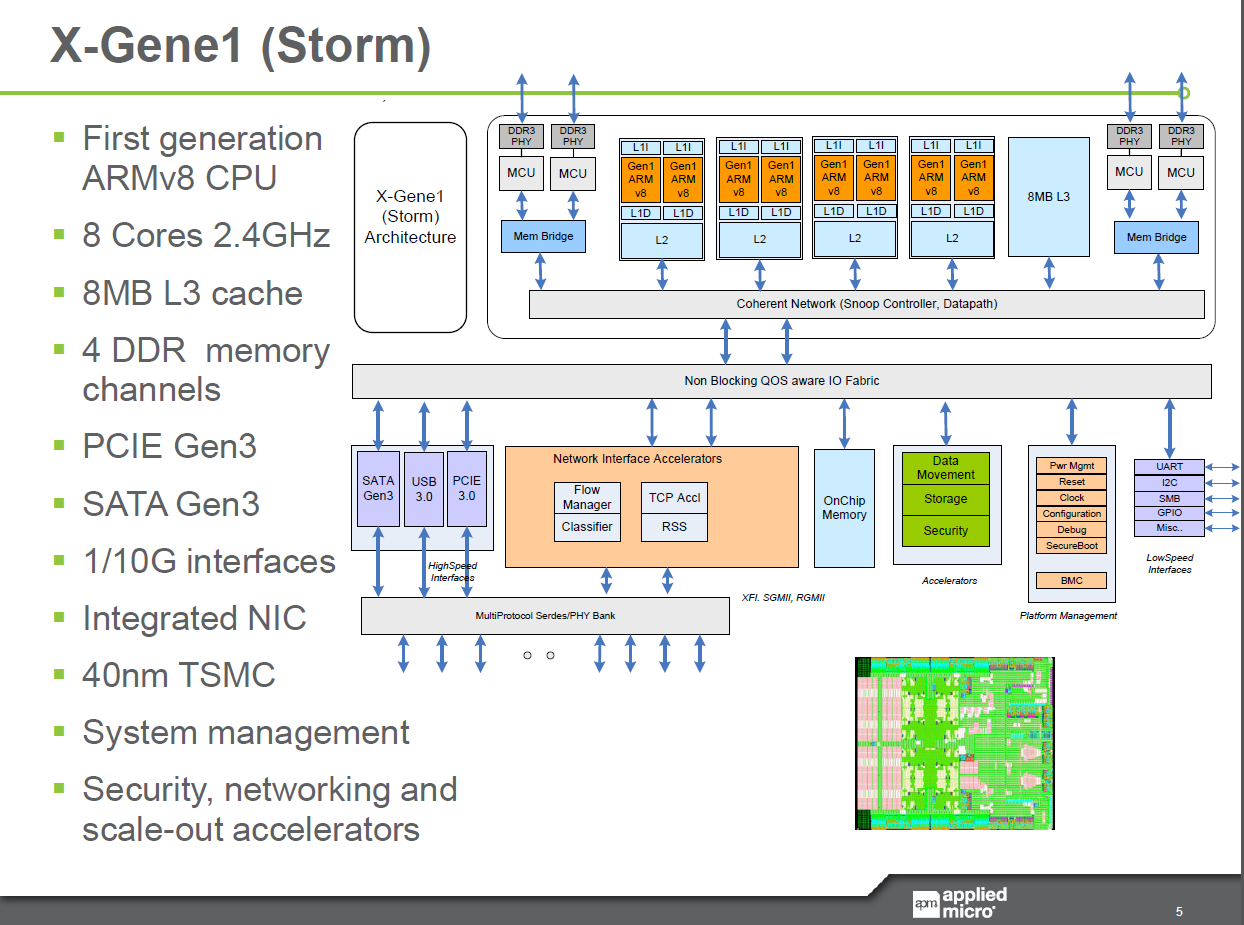
Of course, the AppliedMicro chip has been delayed many times. There were already performance announcements in 2011. The X-Gene1 8-core at 3GHz was supposed to be slightly slower than a quad-core Xeon E3-1260L "Sandy Bridge" at 2.4GHz in SPECINT_Rate2006.
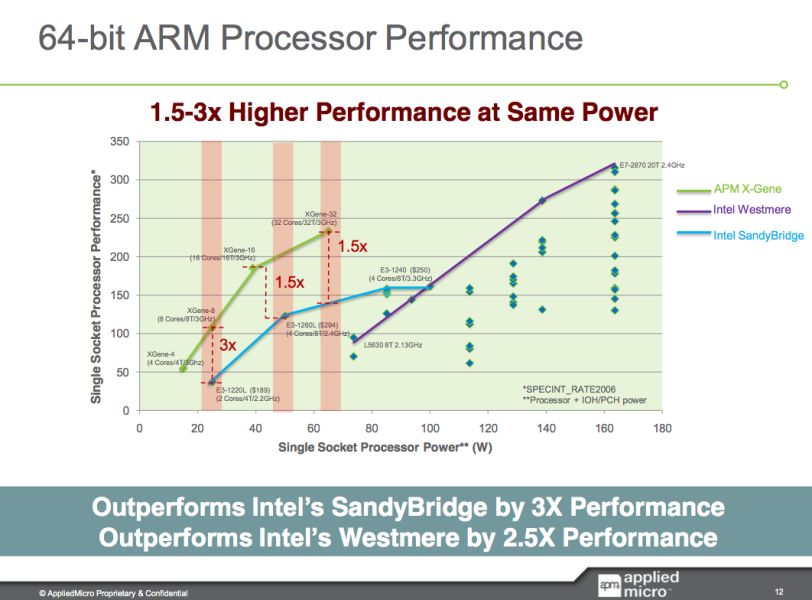
Considering that the Haswell E3 is about 15-17% faster clock for clock, performance should be around Xeon E3-1240L V3 at 2GHz. But the X-Gene1 only reached 2.4GHz and not 3GHz, so it looks like an E3-1240L v3 will probably outperform the new challenger by a considerable margin. The E3-1230L (v1) was a 45W chip and the E3-1240L v3 is a 25W TDP chip, and as a result we also expect the performance/watt of an E3-1240L to be considerably better. Back in 2011, the SoC was expected to ship in late 2012 and have two years lead on the competition. It turned out to be two months.
Only a thorough test like our Calxeda review will really show what the X-Gene can do, but it is clear that AppliedMicro needs the X-Gene2 to be competitive. If AppliedMicro executes well with X-Gene2, it could get ahead once again... this time hopefully with a lead of more than two months.

Indeed, early next year, things could get really interesting: the X-Gene2 will double to the amount of cores to 16 (at 2.4GHz) or up the clock speed to 2.8GHz (8-cores) courtesy of TSMC's 28nm process technology. The X-Gene2 is supposed to offer 50% more performance/watt with the same amount of cores.
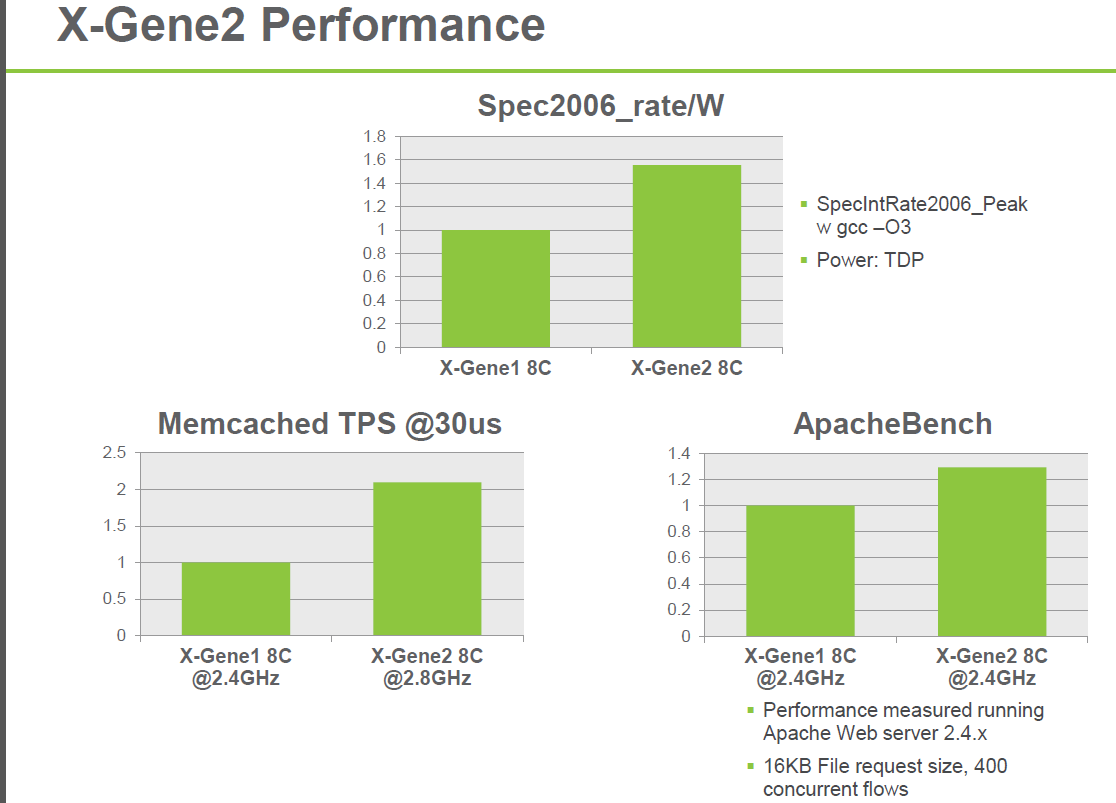
AppliedMicro also announced the Skylark architecture inside X-Gene3. Courtesy of TSMC's 16nm node, the chip should run at up to 3GHz or have up to 64 cores. The chip should appear in 2016, but you'll forgive us for saying that we first want to see and review the X-Gene2 before we can be impressed with the X-Gene3 specs. We have seen too many vendors with high numbers on PowerPoint presentations that don't pan out in the real world. Nevertheless, the X-Gene2 looks very promising and is already running software. It just has to find a place in a real server in a timely fashion.
Cavium Thunder-X
A few months ago, we talked briefly with the people of Cavium. Cavium is specialized in designing MIPS SoCs that enable intelligent networking, communications, storage, video, and security applications. The picture below sums it all up: present and future.
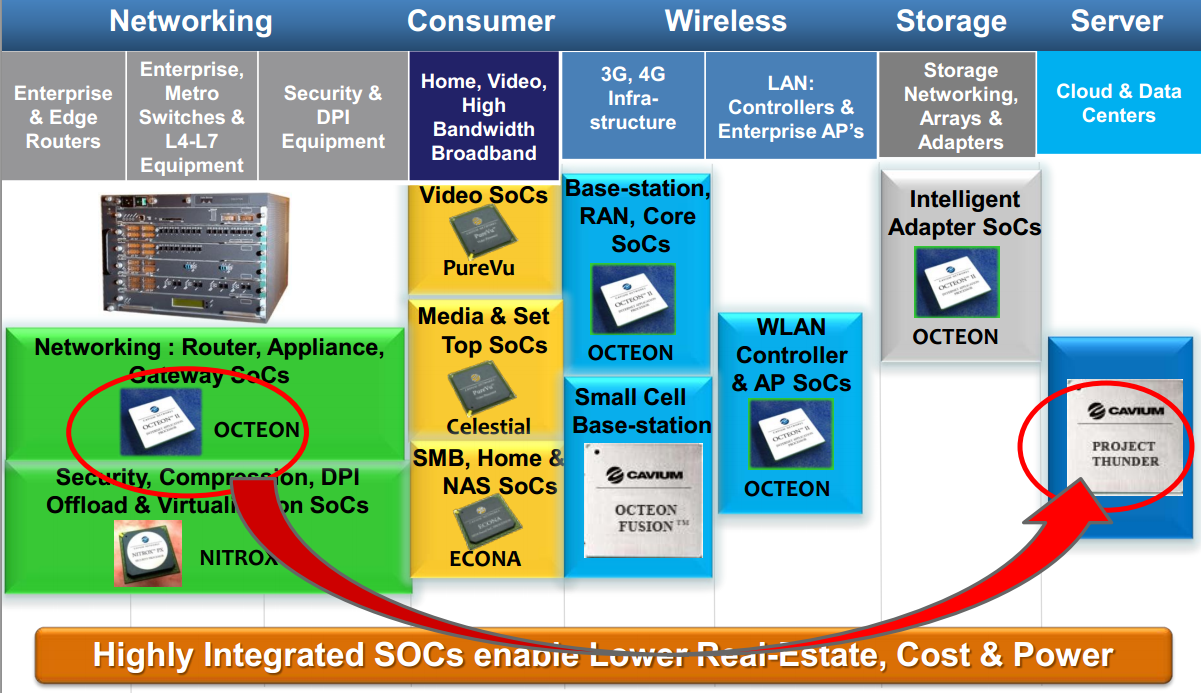
Cavium's "Thunder Project" started from Cavium's existing Octeon III network SoC, the CN78xx. Cavium's bread and butter has been integrating high speed network capabilities in SoCs, so you will be able to choose between SoCs that have 100 Gbit Ethernet and 10GBit Ethernet. PCI-Express roots and multiple SATA ports are all integrated. There is no doubt that Cavium can design a highly integrated feature-rich SoC, but what about the processing core?

The MIPS cores inside the Octeon are much simpler – dual-issue in-order – but also much smaller and need very little power compared to a typical server core. Four (28nm) MIPS cores can fit in the space of one (32nm) Sandy Bridge core.
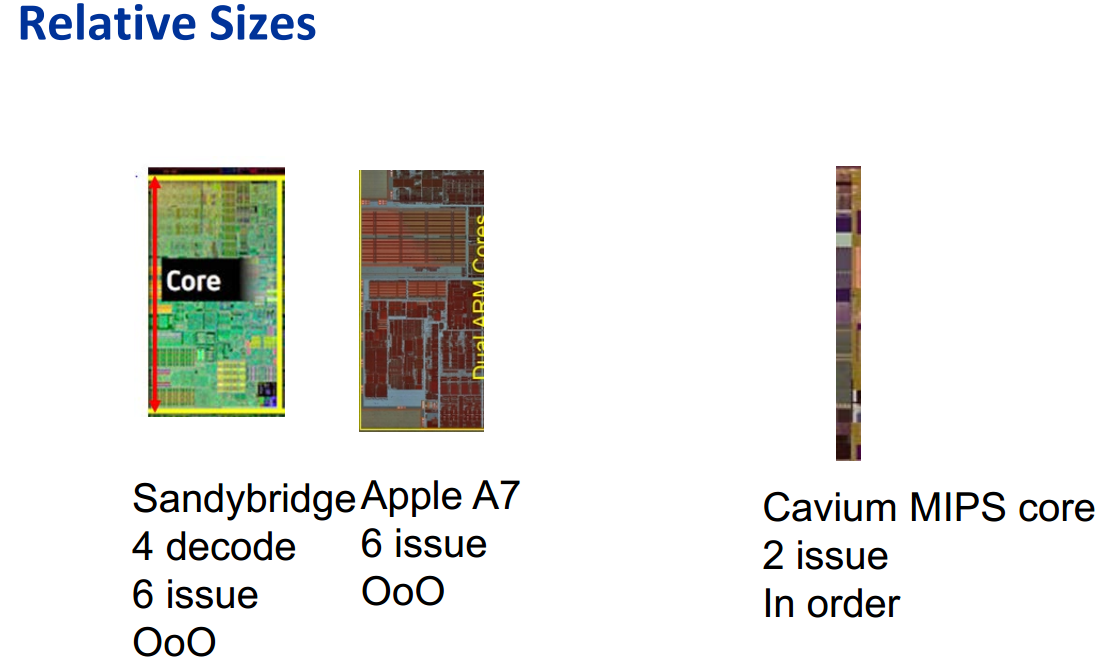
Replace the MIPS decoders with ARMv8 decoders and you are almost there. However, while the Cavium Thunder-X is definitely not made to run SAP, server workloads are bit more demanding than network processing, so Cavium needed to beef up the Octeon cores. The new Thunder-X cores are still dual-issue, but they're now out-of-order instead of in-order, and the pipeline length has been increased from eight to nine stages to allow for higher clocks. Each core has a 78KB L1 Instruction cache and a 32KB data cache.
The 37-way 78KB L1 I cache is certainly odd, but it might be more than just "network processor heritage". Our own testing and a few academic studies have shown that scale-out workloads such as memcached have a higher than normal (meaning the typical SPECIntRate2006 characterization) I-cache miss rate. The reason is that these applications run a lot of kernel code, and more specifically the code of the network stack. As a result, the software footprint is much higher than expected.
Another reason why we believe Cavium has done it's homework is the fact that more die area is spent on cores (up to 48) than on large caches; an L3 cache is nowhere to be found. The Thunder-X has only one centralized relatively low latency 16MB L2 cache running at full core speed. A lot of academic studies have confirmed that a large L3 cache is a waste of transistors for scale-out workloads. Besides the most used instructions that reside in the I-cache, there is a huge amount of less frequently used kernel code that does not fit in an L3 cache. In other words, an L3 cache just adds more latency to requests that missed the L1 cache and that will end up in the DRAM anyway. That is also the reason why Cavium made sure that a beefy memory controller is available: the Thunder-X comes with four DDR3/4 72-bit memory controllers and it currently supports the fastest DRAM available for servers: DDR4-2133.
On the flip side, having 48 cores with a relatively small 32KB D-cache that access one centralized 16MB L2 cache also means that the Thunder-X is less suited for some "traditional" server workloads such as SQL databases. So a Thunder-X core is simpler and probably quite a bit weaker than an ARM Cortex-A57 in some ways, let alone an X-Gene core. The fact that the Thunder-X spends a lot less transistors on cache than on cores clearly indicates that it is targeting other workloads. Single-threaded performance is likely to be lower than that of the AMD Seattle and X-Gene, but it could be close enough: the Thunder-X will run at 2.5GHz, courtesy of Global Foundries' 28nm process technology. Cavium is claiming that even the top SKU will keep the TDP below 100W.
There is more. The Thunder-X uses Cavium's proprietary Coherent Processor Interconnect (CCPI) and can thus work in a dual socket NUMA configuration. As a result, a Thunder-X based server can have up to 96 cores and is capable of supporting 1TB of memory, 512GB per socket. Multiple 10/40GBE, PCIe Root Complex, and SATA controllers are integrated in the SoC. Depending on SKU, TCP/IP Sec offload and SSL accelerators are also integrated.

The recent launch of Cavium's Thunder-X SKUs make it clear that Cavium is trying to compete with the venerable Xeon E5 in some niche but large markets:
- ThunderX_CP: For cloud compute workloads such as public and private clouds, web caching, web serving, search, and social media data analytics.
- ThunderX_ST: For cloud storage, big data, and distributed databases.
- TunderX_NT: For telecom/NFV server and embedded networking applications.
- ThunderX_SC: For secure computing applications
Considering Cavium's background and expertise, it is pretty obvious that ThunderX_NT and SC should be very capable challengers to the Xeon E5 (and Xeon-D), but only a thorough review will tell how well the ThunderX_CP will do. One of the strongest points of Calxeda was the highly integrated fabric that lowered the total power consumption and network latency of such a server cluster. Just like AMD/Seamicro, Cavium is well positioned to make sure that the Thunder-X based server clusters also have this high level of network/compute integration.
AMD Opteron A1100
The 28nm octal-core AMD Opteron A1100 is a lot more modest and aims at the low end Xeon E3s. Stephen has described the chip in more detail. To ensure a quick time to market, the AMD Opteron A1100 is made of existing building blocks already designed by ARM: the Cortex-A57 core and the Cache Coherent Network or CCN.
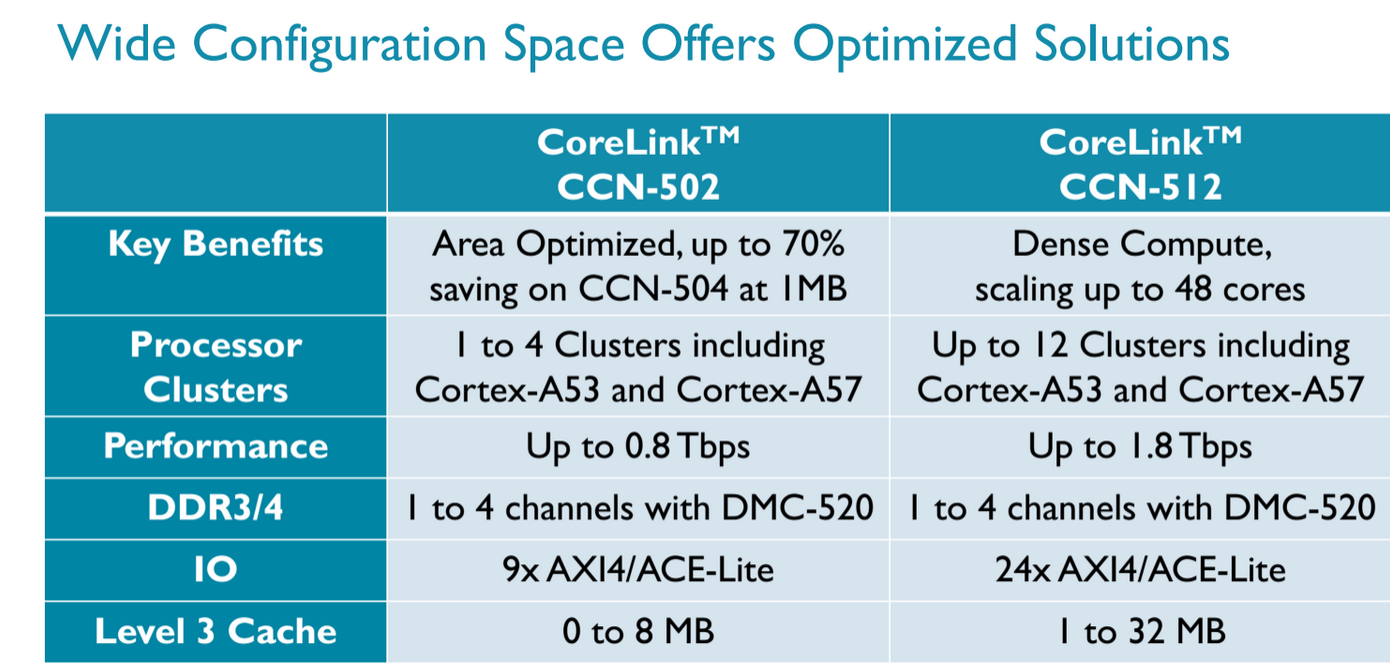
The AMD Opteron A1100 is one of the few vendors that uses the ARM interconnect. ARM put a lot of work into this design to enable ARM licensees to build SoCs with lots of accelerators and cores. CCN is thus a way of attaching all kinds of cores, processors, and co-processors ("accelerators") coherently to a fast crossbar, which also connects to four 64-bit memory controllers, integrated NICs, and L3 cache. CCN is very comparable to the ring bus found inside all Xeon processors beginning with "Sandy Bridge". The top model is the CCN-512 which supports up to 12 clusters of quad-cores. This could result in an SoC with 32 (8x4) A57 cores and four accelerators for example.
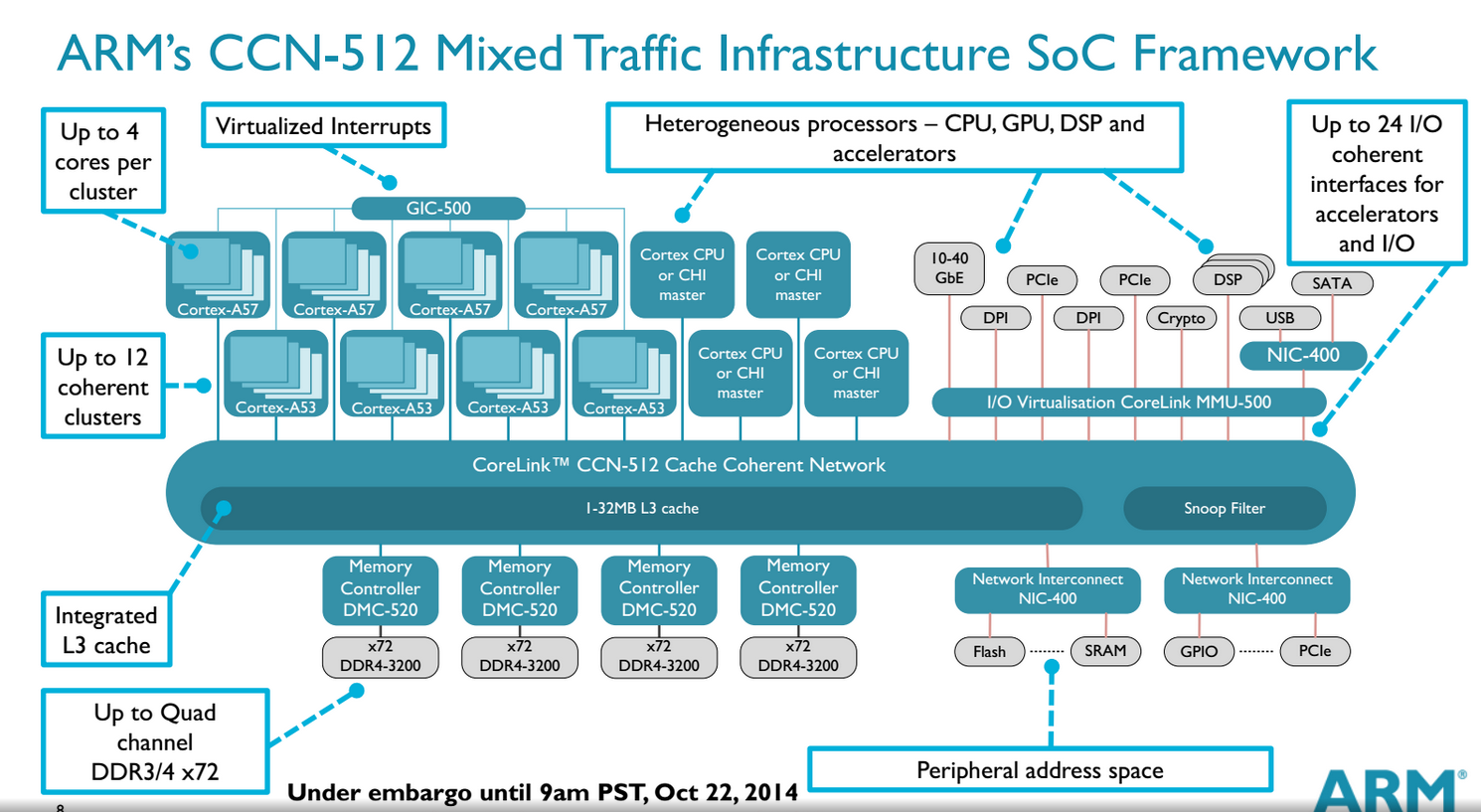
AMD would not tell us which CCN they are using but we suspect that it is CCN-504. The reason is this CCN was available around the time work started on the Opteron A1100 and the fact that AMD mentions the ARM bus architecture AMBA 5 in their slides. And it also makes sense: the CCN-504 supports up to 4 x 4 cores and supports the Cortex-A57.
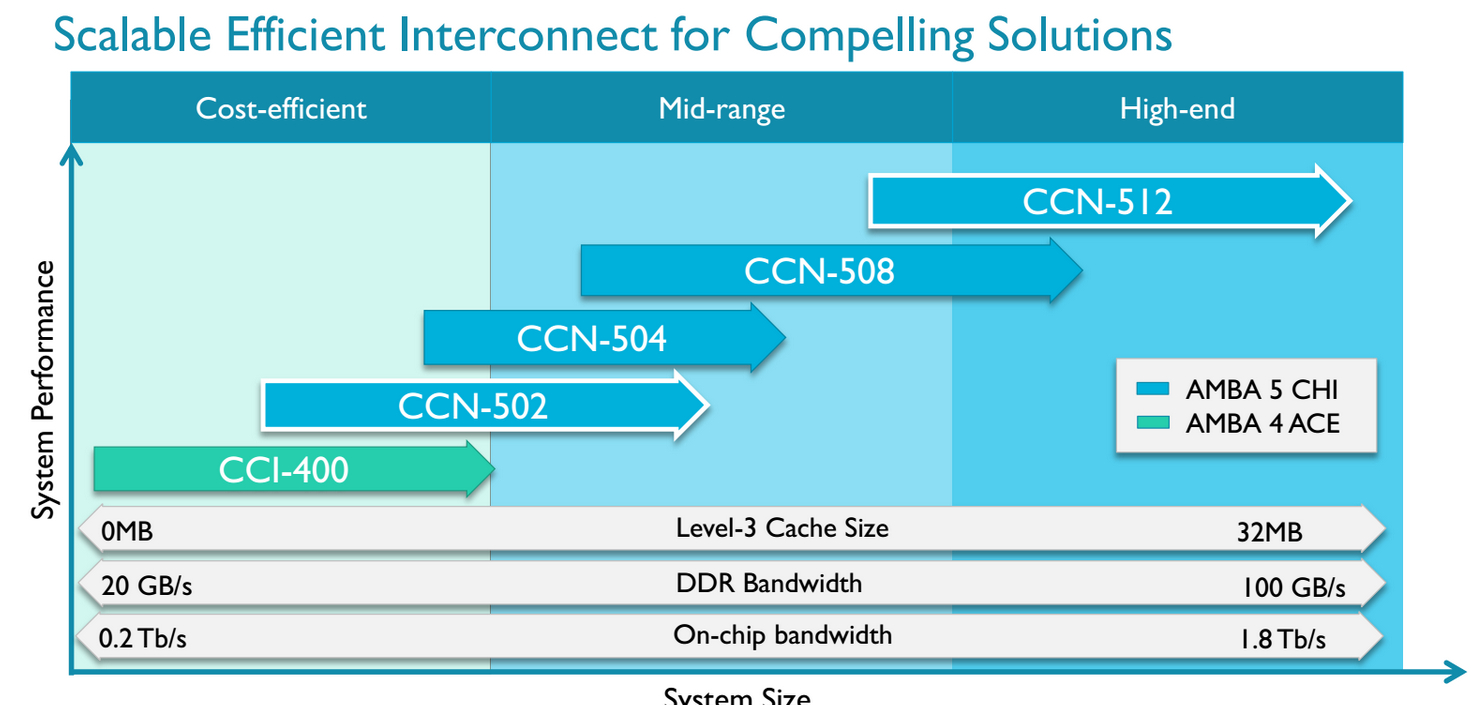
It was rumored that the A1100 still used the CCI-400 interconnect, which is used by smartphone SoCs, but that interconnect uses the AMBA 4 architecture. Meanwhile the CCN-502 was announced in October 2014, way too late to be inside the A1100.
The AMD Opteron A1100 consists of four pairs of "standard" triple issue Cortex-A57 cores and 1MB L2 cache, with 8MB L3 cache.
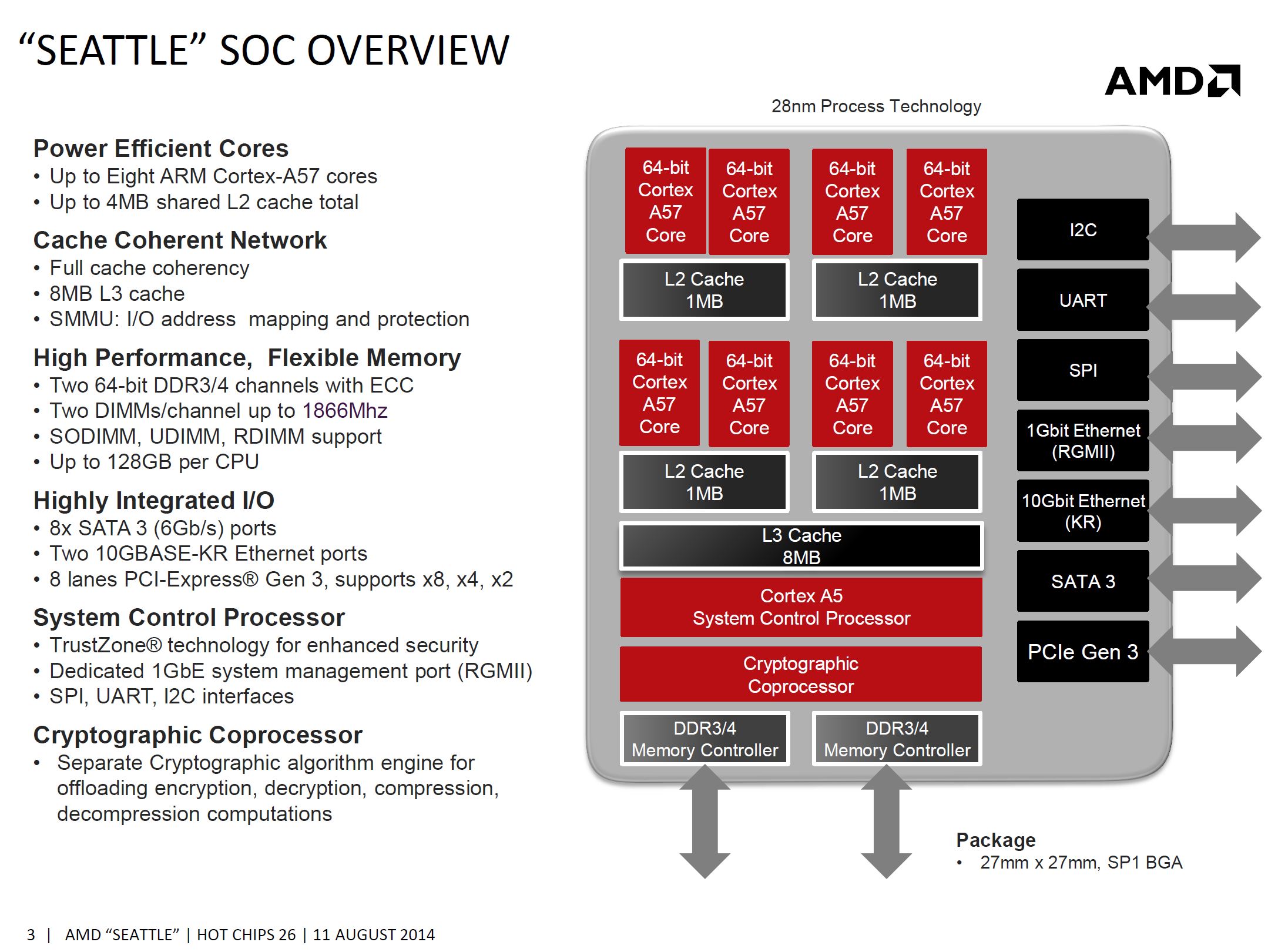
The key differentiator is the cryptographic processor that can accelerate RSA (Secure Connection/hand shake) and AES (encrypting the data you send and receive) and SHA (part of the authentication). Intel uses the PCIe Quick Assist 89xx-SCC add-in card or the special Intel Communication chipset to provide a cryptographic coprocessor. These coprocessors are mostly used in professional firewalls/routers. As far as we know such cryptographic processors are of limited use in most https web services. Most modern x86 cores now support AES-NI, and these instructions are well supported. As a result, the current x86 CPUs from AMD and Intel outperform many co-processors when it comes to real world AES encoding/decoding of encrypted data streams.
A cryptographic coprocessor could still be useful for the RSA asymmetric encrypted handshake, but it remains to be seen if offloading the handshakes will really be faster than letting the CPU take care of it, as each offload operation causes all kinds of overhead (such as a system call). A cryptographic coprocessor running on the same coherent network as the main cores could be a lot more efficient than a PCIe device though. It has a lot of potential, but AMD could not give us much info on the current state of software support.
Broadcom Vulcan
Broadcom is late to the 64-bit Server SoC party, but the Broadcom Vulcan is one of the most ambitious designs.

Each core can have four threads in flight. Some might call it "super-threading" or even "fine grained multi-threading" as only one thread is active in each cycle. The Vulcan core, inspired by previous network processors, has four instruction pointers (registers with the next instruction address) and four sets of architectural registers similar to the Oracle (previously SUN) Tx architecture.
Although similar, the fine grained multi-threading of the Vulcan seems much more advanced than the "Barrel-processor" approach of SUN's UltraSPARC T1 which cycled continuously between the four threads in flight. The thread scheduler seems to decide with some intelligence which thread it should fetch instructions from instead of just cycling round robin between threads.
32 Bytes are fetched each cycle, good for eight instructions. The ARMv8 decoder is capable of decoding four of those ARMv8A instructions into four micro-ops. Six micro-ops can be executed per cycle: four integer and two floating point/NEON (128-bit) micro-ops.
Broadcom promises that it will offer 90% of the performance of the Haswell Core. To reach 3GHz speed, Broadcom will use TSMC's 16nm FINFET technology.
Qualcomm
Qualcomm, the company behind the hugely successful "Krait" mobile chips, has also announced that it will enter the 64-bit ARM server SoC market. However, Qualcomm has presented little else than the "end of the x86 era, cloud changes everything" presentations that only make non-technical analysts excited, so we are waiting for something more substantial.
If it was any other company, we would have ignored the product as vaporware. But this is Qualcomm, the most successful ARM SoC company of the past years. The current high-end mobile chip, the 20nm Snapdragon 810 with four A57 core at 2GHz (and four A53) shows how well Qualcomm executes. Qualcomm has an impressive track record, so although they have yet to show anything tangible in the server area they are a force to be reckoned with.
Intel's Future: Xeon-D
Intel's response to all of these competitors is relatively simple. The Atom C2000 might not be strong enough to turn the ARM tide and the Xeon E3 might lose a performance per watt battle here and there due to the extra PCH chip it needs. So take the two and unify the advantages of the Xeon E3 and Atom C2000 in one chip, the Xeon-D. Then use Intel's main industry advantage, the most advanced process technology, in this case the 14nm 2nd generation of trigate transistors.
The Xeon-D should have it all (almost): a Broadwell core that can go as low as 2W per core at 1.2GHz. It can also deliver great single-threaded performance if necessary, as one core can go as high as 2.9GHz! Some people have said that Intel will have a very hard time offering the same richness of integrated hardware blocks as the ARM licensees, but frankly the Xeon-D has almost everything a server application can need: several PCIe 3.0 root complex (24 lanes), 10GbE Ethernet, and PCH logic (6x SATA, USB 3.0/2.0, 8 lanes of PCIe 2.0 and 1GB Ethernet) are all integrated.
Eight of those Broadwell cores will find a place in a 45W SoC. Considering Intel needs 6W to run two cores (and a small integrated GPU) at 1.4GHz, we would not be surprised if the new Xeon-D could reach 1.8GHz or more and that Turbo Boost clocks will be above 3GHz.
The only disadvantage that the SoC has compared to some of the ARM SoCs is the dual-channel memory controller. The Xeon-D will be available in Q3 2015. While roadmaps should always be read with caution, it must be said that Intel rarely delays its products more than a few months. Intel has been executing very well, almost like clock work.
Overview of the Competitors
Let's sum everything up in one big table.
| ARM/Intel SoC 2015 Comparison | ||||||||
| SoC | Intel Xeon-D | Intel Atom C2000 | AppliedMicro X-Gene 1 (X-Gene 2) |
AMD A1100 | Cavium Thunder-X | Broadcom Vulcan | ||
| Architecture | Broadwell | Silvermont | Storm (ShadowCat) | A57 | Thunder-X | Vulcan | ||
| Cores Socket |
8 single |
8 single |
8 (16) sngle |
4-8 single |
16-48 dual |
20? | ||
| Max. CPU Clockspeed | GHz | 2.4GHz | 2.4GHz (2.8GHz) |
2GHz | 2.5 Ghz | 3GHz | ||
| Process technology | Intel 14nm | Intel 22nm | TSMC 40nm (TSMC 28nm) |
GF 28nm | GF 28nm | TSMC 16nm | ||
| L1 Cache | 32KB I 32KB D |
32KB I 24KB D |
32KB I (*) 32KB D (*) |
48KB I 32KB D |
78KB I 32KB D |
32KB I 32KB D |
||
| Decode | 4 | 2 | 4 | 3 | 2 | 4 | ||
| Max. IPC (int) | 5 | 2 | 4 | 3 | 2 | 4 | ||
| Exe Ports | 8 | 4 | 8 | 8 | 4? | 6 | ||
| Max. FP Performance | 2x 256 bit | 1x 128 bit | 2x 128 bit | 2x 128 bit | 2x 128 bit | 2x 128 bit | ||
| OoO buffer | 192 | 32 | >100 | 128 | 40 | 180 | ||
| L2 Cache | 8x 256KB | 4x 1MB | 4x 256KB? (*) | 4x 1MB | 16MB | 20x 256KB | ||
| L3 Cache | 8MB? | - | 8MB | 8MB | - | ? | ||
| Max. RAM | 128GB | 64GB | 128GB | 128GB | 1TB | ? | ||
| Memory Bus Width | 2x 64-bit | 2 x 64-bit | 4x 64-bit | 2x 64-bit | 4x 64-bit | 4x 64-bit | ||
| DRAM (best) | DDR4- 2133 |
DDR3- 1600 |
DDR3- 1866 |
DDR3- 1866 |
DDR4- 2133 |
DDR4- 2133 |
||
| TDP (top SKU) | 45W | 20W | 40W (25 W?) |
25W | +/- 95 W | ? | ||
| Available | Q2-Q3 2015 |
Early 2014 |
Now (Q2 2015?) |
Q1-Q2 2015 |
Q1 2015 |
Q3 2015 |
||
(*) Deduced from Ganesh's article about the Helix SoCs
These are paper specifications of course, so they should be interpreted with a grain of salt. It looks like the AMD A1100 should top the Atom C2000 and go after the low end of the Xeon E3. AMD's Opteron A1100 is already available, but the current development kits do not hit the clock speed and performance targets.
The Thunder-X single-threaded performance in "traditional workloads" might only be at the level of the Atom C2000, but scale-out and network/crypto acceleration could give some remarkable results in certain workloads. The Cavium SoC is the hardest to predict and will show a very variable performance profile as it also incorporates many very specialized hardware accelerators. The Thunder-X reference servers are announced and should be available in the coming weeks.
The X-Gene is currently the widest ARM architecture with extra hardware acceleration mostly focused on networking. The X-Gene TDP was great on paper (25W when announced) but there are many indications (40W TDP) that AppliedMicro really needs the 28nm X-Gene 2 to be truly competitive in the performance/watt battle arena. The X-Gene 2 should be available around Q2 2015.
Performance
The first SPECIntRate 2006 estimates were published by "CPU meister" Andreas Stiller. If we combine his findings with what we know and what is available at SPEC.org, we get the benchmark graph below.
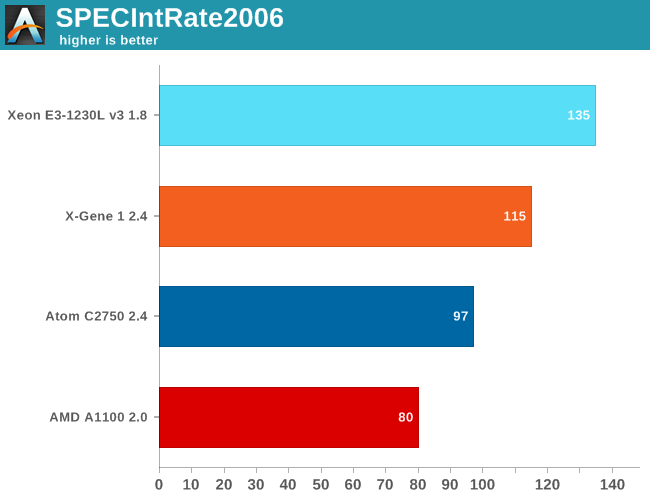
Intel's own published SPECintrate scores are up to 20% higher, so at first sight the ARM competition is not there yet. However, we prefer to show the "lower numbers" as they have not been benchmarked with masterfully set ICC configuration settings.
The most aggressive architecture, the X-Gene, is quite a bit slower than the Xeon E3-1230L. The latter needs about 40W per node (SoC + chipset), while an X-Gene node would need almost 60W. AppliedMicro really needs the 28nm 2.8GHz X-Gene 2, which apparently can offer a 50% better performance per watt increase in SPECintrate 2006.
However, we have shown you that while SPECintrate 2006 is the standard often used, popular with most CPU designers, analysts and academic researchers, it is a pretty bad predictor of server performance. We should not discount the chances of the server ARM SoCs too quickly. A mediocre SPECint SoC can still perform well in server applications.
More Competition
There is no doubt that customers would benefit from Intel being challenged in the server market. There have been people arguing that the server market is healthy even with only one dominant player, since Intel is doomed to compete with previous Intel CPUs and cannot afford to slow down its update cycle. We disagree, as it is clear that the lack of competition is causing Intel to price its top Xeon EP quite a bit higher. In the midrange, there is no pressure to offer much better performance per dollar: a small increase is what we get. The recently launched Xeon E5 v3 is barely 15% faster at the same price than the Xeon E5 v2. So we would definitely like to see some healthy competition.
Are Economies of Scale and Volume Enough?
Yes, economies of scale is one of the reasons that Intel was able to overtake the RISC competition. However, simply accounting Intel's success back at the end of previous century to being the player with the highest unit sales is short sighted. Look at the table below, which describes the situation back in late 1995:
| Vendor | CPU | SPECint95 | SPECfp95 |
| Intel | Pentium Pro 200 | 8.2 | 6.8 |
| Digital | Alpha 21164 333 MHz | 9.8 | 13.4 |
| MIPS (SGI) | R8000 90 MHz | 5.5 | 12 |
| SUN | Ultra I 167 MHz | 6.6 | 9.4 |
| HP | PA7200-RISC 120MHz | 6.4 | 9.1 |
There are three things you should note. First, excluding the Alpha 21164, Intel managed to outperform every RISC competitor out there with their first server chip in integer performance. Intel managed this by excellent execution and innovative micro-architecture features (such as the 256KB SRAM + core MCM package and out-of-order micro-ops back-end). Intel also had a process technology lead and used 350nm while the rest of the competition was still stuck at 500nm.
Second, Intel was lucky that the top performer – Alpha – had the lowest marketshare, software base, and marketing power. Third, the server and workstation market was divided between the RISC Players. Software development was very fragmented among the RISC platforms.
So in a nutshell, there were several reasons why Intel succeeded at breaking into the server market besides their larger user base in the desktop world:
- Focused investments in a vertical production line and excellent execution, and as a result the best process technology in the world
- The performance and technology leader was not the strongest player in the market
- The market was fragmented, so divide and conquer was much easier
Currently, the ARM SoC challengers do not have those advantages. As far as we know, Intel's process is still the most advanced process technology on the planet. Samsung is probably close but at the moment their next generation process is not available to the Intel competitors.
Right now, Intel dominates - or more accurately owns - the server market. Every possible piece of expensive software runs on Intel, which is a very different situation from back in the RISC world of the nineties, where many pieces of important software only ran on certain RISC CPUs. Today, the server market is anything but fragmented. That makes the scale advantage of the ARM competitors a very weak argument. Intel's user base – the growing server market and declining desktop market – is large enough to sustain heavy R&D investments for a long time, contrary to the RISC vendors in the nineties which had to share a very profitable but again fragmented market.
If you're not convinced, just imagine the Alpha 21164 was the dominant RISC Server CPU, with 90-95% server market share. Just imagine that instead of having some server applications running only on SPARC or on HP PA-RISC, that every server software ran on Alpha. Now combine this with the fact that Windows on Alpha was available. It is pretty obvious that it would be have been a lot harder for Intel to break into the server and workstation market had this been the case.
So just because ARM SoCs are sold in the billions does not mean they will automatically overtake Intel server CPUs. Intel beat the RISC players because the market was fragmented, and because none of them were executing as well as Intel. For ARM alternatives to really gain traction, they need to do a lot more than simply compete in a few niche markets, as Calxeda has shown.
The Evolving Server Market
The previous page might give you the impression that we do not give the ARM players a chance against mighty Intel. That is not the case, but we believe that the wrong arguments are often used. Intel's success was also a result of the huge amount of Windows desktop users that were enthusiastic about using their Windows knowledge in a professional environment. The combination of Windows NT and the success of the Pentium Pro was very powerful.
ARM also has such a "Trojan software horse" and it is called the Linux based cloud. We're not saying anything new when we say that cloud services have really taken off and that the Internet of Things will make cloud services even more important. Those cloud services have been creating a tsunami of innovation and are based on open source projects such as Hadoop, Spark, Openstack, MongoDB, Cassandra, good old Apache, and hundreds of others. That software stack is ported or being ported to the ARM software ecosystem.

But you probably knew that. Let's make it more concrete. Just a while ago we visited the Facebook hardware lab. Being a server hardware enthusiast, we felt like a child in a large toy store. Let me introduce you to Facebook's Open Vault, part of the the Open Compute Project:
... is a simple and cost-effective storage solution with a modular I/O topology that’s built for the Open Rack. The Open Vault offers high disk densities, holding 30 drives in a 2U chassis, and can operate with almost any host server.
Mat Corddry, director of hardware of engineering showed us the hardware:

The first incarnation of the "honey badger" micro server is based on Avoton. But nothing is stopping Facebook from using an ARM micro server in their Open Vault machines if it offers the same capabilities and is cheaper and/or lower power. As cheap storage is extremely important in the "Big Data" age, this is just one of the opportunities that the "smaller" ARM server SoCs have. But it also makes another point: they have to beat the Intel SoCs that are already known and used.
RISC vs. CISC Revisited
The RISC vs. CISC discussion is never ending. It started as soon as the first RISC CPUs entered the market in the mid eighties. Just six years ago, Anand reported that AMD's CTO, Fred Weber was claiming:
Fred said that the overhead of maintaining x86 compatibility was negligible, at the time around 10% of the die was the x86 decoder and that percentage would only shrink over time.
Just like Intel today, AMD claimed that the overhead of the complex x86 ISA was dwindling fast as the transistor budget grew exponentially with Moore's law. But the thing to remember is that high ranking managers will always make statements that fit their current strategy and vision. Most of the time there is some truth in it, but the subtleties and nuances of the story are the first victims in press releases and statements.
Now in 2014, it is good to put an end to all this discussion: the ISA is not a game changer, but it matters! AMD is now in a very good position to judge as it will develop x86 and ARM CPUs by the same team, lead by the same CPU architecture veteran. We listened carefully to what Jim Keller, the head of the AMD CPU architect team, had to say in the 4th minute of this YouTube video:
"The big fundamental thing is that ARMv8 ISA has more registers (32), a three operand ISA, and spends less transistors on decoding and dealing with the complexities of x86. That allows us to spend more transistors on performance... ARM gives us some inherent architectural efficiency."
You can debate until you drop, but there is no denying that the x86 ISA requires more pipeline stages and thus transistors to decode than any decent RISC ISA. As x86 instructions are variable length, fetching instructions is less efficient and requires more transistors. The instruction cache is also larger as you need to store pre-decode information. The back-end might deal with RISC-like micro-ops but as the end result must adhere to rules of the x86 ISA, thus transistors are spent on exception handling and condition codes.
It's true that the percentage of transistors spent on decoding has dwindled over the years. But the number of cores has increased significantly. As a result, the x86 tax is not imaginary.
Hardware Accelerators
While we feel that the ARMv8 ISA is definitely a competitive advantage for the ARM server SoCs, the hardware accelerators are a big mystery: we have no idea how large the performance or power advantage is in real software. It might be spectacular or it might be just another "offload works only in the rare case where all these conditions are met". Nevertheless, it is interesting to see how the ARM server SoC has many different integrated accelerators.
Most of them are the usual IPSec, TCP offloading engines, and Cryptographic accelerators. It will be interesting to see if the ARM ecosystem can offer more specialized devices that can really outperform the typical Intel offerings.
One IP block that got my attention was the the Regex accelerators of Cavium. Regular expression accelerators are specialized in pattern recognition and can be very useful for search engines, network security, and data analytics. That seems exactly what we need in the current killer apps. But the devil is in the details: it will need software support, and preferably on a wide scale.
Conclusions So Far
Of one thing we are sure: the "cheaper, smaller, higher volume option historically wins" is a very weak argument to make when claiming that ARM SoCs will overtake Intel in the server market. It is hard to make all of the puzzle pieces come together: performance, power, volume, and software. Low prices and volume are not enough. We would love to see some real competition in the server market, but Intel is a lot better positioned today to fend off attacks than the RISC players were back in the 90s.
The current ARM server SoCs are a lot more powerful than Calxeda's ECX-1000, but they do not face a hopelessly outdated Atom S1200 anymore. The Atom C2000 is a huge step forward and the Xeon E3 has continued to evolve in such a way that even eight of the best ARM cores cannot deliver more raw integer processing power than a quad-core E3 with SMT. Meanwhile, the Xeon-D will offer all the advantages of the high performance "Broadwell" architecture, the flexibility of Intel's Turbo Boost, Intel's excellent process technology, and the highly integrated Atom C2000 SoC in one very competitive package.
The first – albeit very rough – performance data indicates that the server ARMada is not ready (yet?) to take on the best Intel Xeons in a broad range of server applications, at least in terms of performance. However, the ARM challengers do have an opportunity. Despite the massive number of Intel SKUs, Intel's market segmentation is rather crude and assumes that all customers can easily be categorized into three (maybe four) large groups: For low budgets, get the low range Xeon E3 (e.g. E3-1220 v3). Pay a bit more and you get Hyper-Threading and higher clock speeds (E3-1240 v3). Pay slightly more and you get another speed bump. Pay much more and you get four memory channels. We'll throw in more cores and a larger cache as a bonus (Xeon E5).
What if I have a badly scaling HPC application (low core count) that needs a lot of memory bandwidth? There is no Xeon E3 with quad channel. What if I need massive amounts of memory but moderate processing power? The Xeon E3 only supports 32GB. What if my application needs lots of cores and bandwidth but does not benefit from large and slow LLC caches? There is no Xeon E5 for that; I can only choose one of the most expensive E5s. And these examples are not invented; applications like these exist in the real world and are not exotic exceptions. What if my application benefits from a certain hardware accelerator? Buy a few 100k of SoCs and we'll talk. Intel's market segmentation is based largely on the assumption that every need (I/O, caches, memory bandwidth, memory capacity) is proportional to processing power.
The ARM based challengers have the potential to serve those "odd" but relatively large markets better. The cost to develop new SoCs is lower and ARMv8 has the inherent RISC advantage of spending fewer transistors on ISA complexity. This lowers the Intel advantage of process technology leadership.
Cavium has a clear focus and targets the scale-out, telecom, and storage markets. We are very curious how the first chip which is specialized for "scale-out" applications will perform. It has been a long time since we have seen such a specialized SoC and it is crystal clear that performance will vary a lot depending on the application. Our first impression is that the chip will be ideal running lots of network intensive virtual machines on top of a hypervisor, such as Xen or KVM.
AppliedMicro's X-Gene seems to target a much wider range of applications, attacking the Intel Xeon E3 and the fastest Atom C2000. The hardware accelerators and quad-channel memory should give it an edge in some server applications while staying close enough in others. Much will depend on how quickly the X-Gene 2 is available in real servers. The X-Gene 2 "ShadowCat" is already up and running, so we have high hopes.
Broadcom seems to have a similar approach. Broadcom is late but is a market leader with deep pockets and an impressive list of customers. The same is true for Qualcomm. But we needs specs and not just broad and vague statements before we dedicate more words to the server plans of Qualcomm.
AMD's Opteron A1100 is definitely betting on undercutting Intel's low-end Xeons in price and features. Everything about it screams "time to market, inexpensive but proven low power design". The more ambitious AMD ARM SoCs will come later, however, as the current A1100 is missing a crucial feature: a link to the Freedom Fabric. The network fabric is a critical feature as OEMs can then build a low power, high performance networked micro server cluster. It was the strongest point of the Calxeda based servers as it kept power per node low, offered very low latency network, and lowered the investments in expensive network gear (Cisco et al.). AMD is a well known brand with the enterprise folks and has a lot of unique server/HPC IP.
Last but not least, many enterprises in the IT world including HP, Facebook and Google want to see more competition in the server market. So all ARM licensees can count on some goodwill to make it happen.
We from our side have been preparing as well. We have developed several new benchmarks to test this new breed of servers. Hard numbers say more than just words, but you'll have to wait for part two of this series for those.






