Original Link: https://www.anandtech.com/show/868
Intel's Hyper-Threading Technology: Free Performance?
by Anand Lal Shimpi on January 14, 2002 2:04 PM EST- Posted in
- CPUs
Over the past year we've reported on Simultaneous Multi-Threading (SMT) technology on Intel CPUs. Although it originally started out as a potential meaning behind the codename Jackson Technology, Intel officially revealed their SMT technology at last fall's IDF. The codename Jackson was replaced with a much more fitting title, Hyper-Threading. But before you can understand how Hyper-Threading works you've got to understand the basis of it, more specifically what threads are and how they work.
What makes an application run? What tells your CPU what instructions to execute and on what data? This information is all contained within the compiled code of the application you're running and whenever you (the user) give the application input, the application in turn sends threads off to your CPU telling it what to do in order to respond to that input. To the CPU, a thread is a collection of instructions that must be executed. When you get hit by a rocket in Quake III Arena or when you click open in Microsoft Word, the CPU is sent a set of instructions to execute.
The CPU knows exactly where to get these instructions from because of a little mentioned register known as the Program Counter (PC). The PC points to the location in memory where the next instruction to be executed is stored; when a thread is sent to the CPU, that thread's memory address is loaded into the PC so that the CPU knows where to start executing. After every instruction, the PC is incremented and this process continues until the end of the thread. When the thread is done executing, the PC is overwritten with the location of the next instruction to be operated on. Threads can interrupt one another forcing the CPU to store the current value of the PC on a stack and load a new value into the PC. But the one limitation that does remain is that only one thread can be executed at any given time.
There is a commonly known way around this, and that is to make use of two CPUs; if each CPU can execute one thread at a time, two CPUs can then execute two threads. There are numerous problems with this approach, many of which you should already be familiar with. For starters, multiple CPUs are more expensive than just one. There is also an overhead associated with managing the two CPUs as well as the sharing of resources between the two. For example, until the release of the AMD 760MP chipset, all x86 platforms with multiprocessor support split the available FSB bandwidth between all available CPUs. But the biggest drawback of all happens to be the fact that applications and the operating system must be capable of supporting this type of execution. Being able to dispatch multiple execution threads to hardware is generally referred to as multithreading; OS support is required to enable multithreading while application support is necessary in order to gain a tangible performance increase out of having multiple processors (in most cases). Keep that in mind as we talk about another approach to the same goal - being able to execute more than one thread at a time - it's time to introduce Intel's Hyper-Threading technology.
Face it, we're inefficient
The term efficiency is always thrown around, not only in the corporate environment but also in our daily lives. It's been said that human beings only use a fraction of the power of their brains; it turns out that the same can be said about CPUs.
Take the Pentium 4 for example, the CPU has a total of 7 execution units, two of which can operate on two operations (micro-ops) per clock (these are the double pumped ALUs). And if it were even possible, you wouldn't be able to find software that saturated all of these execution units. The most commonly used desktop software will perform a handful of integer calculations as well as loads and stores but leave the FP units untouched. Whereas a program such as Maya would concentrate almost exclusively on the FP units and leave the ALUs unused. Even applications that primarily use integer operations won't saturate all of the ALUs, especially the "slow" or normal speed integer unit which is primarily used for performing shifts and rotates.
To help better illustrate this let's create a hypothetical CPU with three execution units: an ALU, FPU, and a Load/Store unit for reading from/writing to memory. Let's also assume that our CPU can execute any operation in one clock cycle and it can dispatch operations to all three execution units simultaneously. Now let's feed it a thread that consists of the following instructions:
1+1
10+1
Store Previous Result
The diagram below should help illustrate the saturation level of the execution units (gray denotes an unused execution unit; blue indicates an active execution unit):
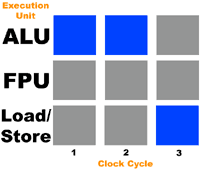
As you can see, during every clock only 33% of the execution units are being used. During this time the FPU goes completely unused. According to Intel, most IA-32 x86 code uses only 35% of the Pentium 4's execution units.
Let's take another thread and send it through our CPU's execution units; this time it will consist of a load, an ADD and a store in that order:
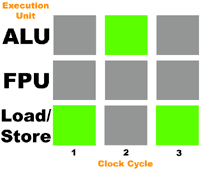
Again we notice the same 33% utilization of execution units.
The type of parallelism we're trying to attain here is known as instruction level parallelism (ILP) where multiple instructions are executed simultaneously because of a CPU's ability to fill their multiple parallel execution units. Unfortunately the reality of most x86 code is that there is not as much ILP as we would like there to be so we must find other ways to improve performance. For example, if we had two of these CPUs in our system then both threads could execute simultaneously. This exploits what is known as thread-level parallelism (TLP) but is also a very costly approach to improving performance.
But what other options are there to make better use of the execution power of today's x86 CPUs?
Introducing Hyper-Threading
There are a number of reasons that execution units aren't always used. Generally speaking, if a CPU isn't able to get data as fast as it would like (a result of FSB/memory bus bottlenecks) then you'll see a drop in execution unit utilization. Another reason, and the issue we'll be talking about today, is a lack of ILP in most execution threads.
Currently the way most CPU manufacturers improve performance within a CPU family is by increasing clock speed and cache sizes. In the case of our hypothetical CPU, doing either or both of those things would improve performance but we're still not using the CPU's full potential. If there was a way for us to execute multiple threads at once we could make more efficient use of the CPU's resources; this is exactly what Intel's Hyper-Threading technology does.
Hyper-Threading is the marketing name applied to a technology that has been around outside of the x86 realm for a little while now - Simultaneous Multi-Threading (SMT). The idea behind SMT is simple; the single physical CPU appears to the OS as two logical processors but the OS does not see any difference between one SMT CPU and two regular CPUs. In both cases the OS dispatches two threads to the "two" CPUs and the hardware takes it from there.
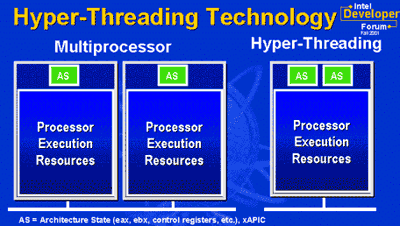
In a Hyper-Threading enabled CPU, each logical processor has its own set of registers (including a separate PC) but in order to minimize the complexity of the technology, Intel's Hyper-Threading does not attempt to simultaneously fetch/decode instructions corresponding to two threads. Instead, the CPU will alternate the fetch/decode stages between the two logical CPUs and only attempt to execute operations from two threads simultaneously thus addressing the problem of poor execution unit utilization.
Hyper-Threading was officially announced at the Intel Developer Forum last fall and it was demonstrated running on a Xeon processor performing a Maya rendering task. In that test the single Xeon with Hyper-Threading enabled was 30% faster than a regular Xeon CPU. The performance benefits were definitely impressive and even more exciting was the unspoken fact that Hyper-Threading is actually present on all Pentium 4 and Xeon cores; it is simply disabled.
The technology has not officially been debuted on a CPU yet however those that have purchased the new 0.13-micron Xeon processors and used them on boards with updated BIOSes may have been surprised with an interesting option - to enable/disable Hyper-Threading.
For now, Intel will be leaving Hyper-Threading disabled by default but all that is necessary in order to enable Hyper-Threading is the presence of a BIOS option to control it. This is only for the workstation/server side of things, for the desktop market there won't be any official mention of Hyper-Threading in the near future although it may be possible for a motherboard manufacturer to enable control via a special BIOS.
But the real question is why would Intel want to leave this performance-enhancing feature disabled?
Understanding Hyper-Threading: It's not a perfect world
Remember those two threads from our earlier example? Let's now assume that our simple CPU features Intel's Hyper-Threading technology and see what happens when we try and simultaneously execute those two threads:

Just as before, the blue boxes indicate that an instruction from thread 1 is being executed while the green boxes indicate than an instruction from thread 2 is being executed. Gray boxes indicate an unused execution unit while the red boxes indicate a conflict where two instructions are attempting to be fed to the same execution unit.
All of the sudden our quest for tender love and parallelism (TLP) has been rewarded with less utilization of our execution resources. Instead of being able to execute both threads in parallel, our CPU will now execute both threads much slower than a non Hyper-Threaded processor would. The reason behind this is actually quite simple; we were attempting to simultaneously execute two very similar threads, both consisted of ADDs, loads and stores. Had we been running a floating point intensive application alongside whatever integer application we were using then we'd be in a much better situation. The real question is, what is more characteristic of the way we use our PCs?
Currently, the way most desktop users use their PCs is much like the example we gave at the beginning of this section where the CPU is given very similar operations to execute. The unfortunate reality here is that with very similar operations there comes additional overhead in managing and dealing with what happens when you run out of one type of execution unit and have twice as many instructions requiring its use. In the majority of cases, if you were to enable Hyper-Threading on a desktop PC you would not see a performance increase, rather a 0 - 10% decrease in performance.
On a workstation there is more potential for Hyper-Threading to result in an overall performance gain, but the term workstation is so broad that it can mean everything from a high-end 3D rendering system to a heavily used desktop PC.
The area where performance gains are the most likely today is under server applications because of the varied nature of the operations sent to the CPU. Transactional database server applications can see a 20 - 30% boost in performance just by enabling Hyper-Threading. Lesser but tangible gains can be seen on web servers as well as other application areas.
Gaining more from Hyper-Threading
Did Intel create Hyper-Threading just for their server line of CPUs? Of course not, they wouldn't have wasted any additional die space on the rest of their CPUs had this been the case. In fact, the NetBurst architecture behind the Pentium 4 and Xeon processors is actually perfect for a SMT enabled core. Let's take our theoretical CPU for one last test; this time we'll give it one more execution unit, a second ALU and let's see what happens when we run those two threads on it:
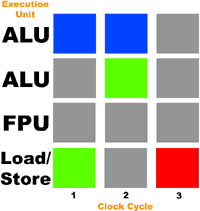
Voila! With a second ALU the only conflict we have left is that final store. Our CPU should begin to remind you of a Pentium 4 which happens to have three integer units (two ALUs and one slower integer unit for shifts/rotates). Even more important is the fact that the Pentium 4's two ALUs can each execute 2 micro-ops per clock, meaning that two ADD instructions each one from two different threads could execute in a single clock on the Pentium 4/Xeon.
But this still doesn't solve our problem; it wouldn't make much sense to keep on outfitting the CPU with more and more execution units in order to gain a performance benefit with Hyper-Threading enabled; that would be too costly from a die standpoint. Instead, Intel is encouraging developer optimization for Hyper-Threading.
Using the HALT instruction it is possible to halt one of the logical processors, thus maximizing performance in applications that would not benefit from Hyper-Threading. So instead of an application becoming slower with Hyper-Threading enabled, one of the logical CPUs will simply be halted and the performance will be equivalent to a single CPU system. Then when an application or task comes around that could benefit from Hyper-Threading, the second logical processor will resume operation.
Intel has a very useful presentation on exactly how developers can code with Hyper-Threading in mind on their Developer website.
Final Words
Although we all got extremely excited when Hyper-Threading was rumored to be on all current Pentium 4/Xeon cores, it will not be the free performance for all that we had wished for. The reasons are simple and the technology has a long way to go before we'll be able to see it and take advantage of it on all platforms, including desktops, but with developer support it definitely can turn out to be a very powerful ally of the Pentium 4, Xeon and future generation Intel processors.
Given today's packaging technology and limitations, Hyper-Threading makes much more sense for the mass market than a dual-core approach such as what AMD is rumored to be considering for the higher-end Sledge Hammer CPUs. Until technologies such as Bumpless Build-Up Layer packaging can be perfected, the costs associated with producing a multi-core CPU may be too high for more than a very small portion of the market.
It's interesting to note how different AMD and Intel have become over the years. From the days of manufacturing essentially clones of Intel CPUs to taking a drastically different approach to the future of workstation and server CPUs, AMD has come a very long way indeed. If the higher-end Sledge Hammer CPUs do end up featuring two cores it will promise much higher performance than Hyper-Threading can offer because of the fact that there will be double the execution units thus avoiding some of the problems we have addressed today. Again, the biggest downside being the manufacturing of such a chip; we have explained in the past the perils of producing complicated CPUs.
Hyper-Threading will be absent from the desktop market for a while but given proper developer support it can easily become yet another technology that makes its way down from the server level to the desktop level.






