Original Link: https://www.anandtech.com/show/8423/intel-xeon-e5-version-3-up-to-18-haswell-ep-cores-
Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM EST
Simply put, the new Intel Xeon "Haswell EP" chips are multi-core behemoths: they support up to eighteen cores (with Hyper-Threading yielding 36 logical cores). Core counts have been increasing for years now, so it is easy to dismiss the new Xeon E5-2600 v3 as "business as usual", but it is definitely not. Piling up cores inside a CPU package is one thing, but getting them to do useful work is a long chain of engineering efforts that starts with hardware intelligence and that ends with making good use of the best software libraries available.
While some sites previously reported that an "unknown source" told them Intel was cooking up a 14-core Haswell EP Xeon chip, and that the next generation 14 nm Xeon E5 "Broadwell" would be an 18-core design, the reality is that Intel has an 18-core Haswell EP design, and we have it for testing. This is yet another example of truth beating fiction.

18 cores and 45MB LLC under that shiny new and larger heatspreader.
The technical challenge of the first step to make sure that such a multi-core monster actually works is the pinnacle of CPU engineering. The biggest challenge is keeping all those cores fed with data. A massive (up to 45MB) L3 cache will help, but with such massive caches, the latency and power consumption can soar quickly. Such high core counts introduce many other problems as well: cache coherency traffic can grow exponentially, one thread can get too far ahead of another, the memory controller can become a bottleneck, and so on. And there is more than the "internal CPU politics".
Servers have evolved into being small datacenters: in a modern virtualized server, some of the storage and network services that used to be handled by external devices are now software inside of virtual machines (VMware vSAN and NSX for example). In other words, not only are these servers the home of many applications, the requirements of these applications are diverging. Some of these applications may hog the Last Level Cache and starve the others, others may impose a heavy toll on the internal I/O. It will be interesting to see how well the extra cores can be turned into real world productivity gains.
The new Xeon E5 is also a challenge to the datacenter manager looking to make new server investments. With 22 new SKUs ranging from a 3.5GHz quad-core model up to an 18-core 2.3GHz SKU, there are almost too many choices. While we don't have all of the SKUs for testing, we do have several of them, so let's dig in and see what Haswell EP has to offer.
Using a Mobile Architecture Inside a 145W Server Chip
About 15 months after the appearance of the Haswell core in desktop products (June 2013), the "optimized-for-mobile" Haswell architecture is now being adopted into Intel server products.

Left to right: LGA1366 (Xeon 5600), LGA2011 (Xeon E5-2600v1/v2) and LGA2011v3 (E5-2600v3) socket.
Haswell is Intel's fourth tock, a new architecture on the same succesful 22nm process technology (the famous P1270 process) that was used for the Ivy Bridge EP or Xeon E5-2600 v2. Anand discussed the new Haswell architecture in great detail back in 2012, but as a refresher, let's quickly go over the improvements that the Haswell core brings.
Very little has changed in the front-end of the core compared to Ivy Bridge, with the exception of the usual branch prediction improvements and enlarged TLBs. As you might recall, it is the back-end, the execution part, that is largely improved in the Haswell architecture:
- Larger OoO Window (192 vs 168 entries)
- Deeper Load and Store buffers (72 vs 64, 42 vs 36)
- Larger scheduler (60 vs 54)
- The big splash: 8 instead of 6 execution ports: more execution resources for store address calculation, branches and integer processing.
All in all, Intel calculated that integer processing at the same clock speed should be about 10% better than on Ivy Bridge (Xeon E5-2600 v2, launched September 2013), 15-16% better than on Sandy Bridge (Xeon E5-2600, March 2012), and 27% than Nehalem (Xeon 5500, March 2009).

Even better performance improvements can be achieved by recompiling software and using the AVX2 SIMD instructions. The original AVX ISA extension was mostly about speeding up floating point intensive workloads, but AVX2 makes the SIMD integer instructions capable of working with 256-bit registers.
Unfortunately, in a virtualized environment, these ISA extensions are sometimes more curse than blessing. Running AVX/SSE (and other ISA extensions) code can disable the best virtualization features such as high availability, load balancing, and live migration (vMotion). Therefore, administrators will typically force CPUs to "keep quiet" about their newest ISA extensions (VMware EVC). So if you want to integrate a Haswell EP server inside an existing Sandy Bridge EP server cluster, all the new features including AVX2 that were not present in the Sandy Bridge EP are not available. The results is that in virtualized clusters, ISA extensions are rarely used.
Instead, AVX2 code will typically run on a "native" OS. The best known use of AVX2 code is inside video encoders. However, the technology might still prove to be more useful to enterprises that don't work with pixels but with business data. Intel has demonstrated that the AVX2 instructions can also be used for accelerating the compression of data inside in-memory databases (SAP HANA, Microsoft Hekaton), so the integer flavor of AVX2 might become important for fast and massive data mining applications.
Last but not least, the new bit field manipulation and the use of 256-bit registers can speed up quite a few cryptographic algorithms. Large websites will probably be the application inside the datacenter that benefits quickly from AVX2. Simply using the right libraries might speed up RSA-2048 (opening a secure connection), SHA-256 (hashing), and AES-GCM. We will discuss this in more detail in our performance review.
Floating point
Floating point code should benefit too, as Intel has finally included Fused Multiply Add (FMA) instructions. Peak FLOP performance is doubled once again. This should benefit a whole range of HPC applications, which also tend to be recompiled much quicker than the traditional server applications. The L1 and L2 cache bandwidth has also been doubled to better cope with the needs of AVX2 instructions.
Next Stop: the Uncore
Continuing with our review of Haswell architecture, let's again take a step back and use the Xeon 5500 as our reference point. The Xeon 5500 is based on the "Nehalem" architecture, and it helped Intel become dominant in the server market. Before the Xeon 5500, AMD's Opteron was still able to outperform the Xeons in quite a few applications (HPC and virtualization for example), even by significant margins. That changed with Nehalem, so the Xeon 5500 is a good reference point.
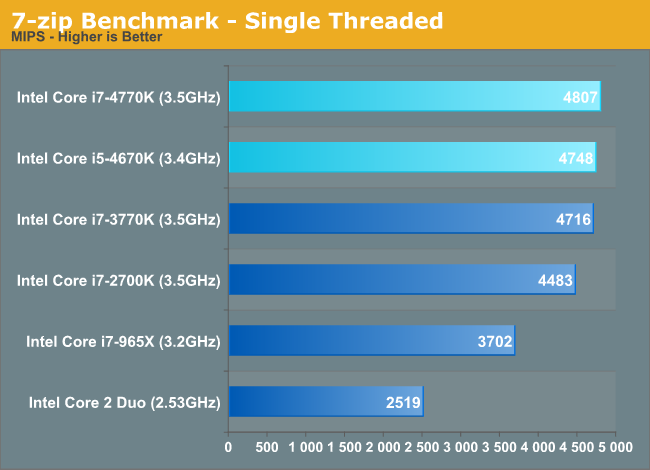
The 27% cumultative IPC (integer only) improvement of Haswell mentioned is more than just theory: Anand's review of the desktop Haswell CPUs confirmed this. The Haswell Core i7-4770k at the same clock speed is about 21% faster than Nehalem. Now that is below the promised 27% performance increase, but 7-zip is among the applications known to have very low IPC.
Let's go back to the server world. Instead of increasing the clock speeds, clock speeds have declined from 2.93-3.2GHz (Xeon 5500) to 2.3-2.6GHz for the latest high-end parts. However, when Turbo Boost is enabled, 2.8 – 3.1GHz is possible with all cores active. So the clock speed of the high end server CPUs is actually 5 to 20% lower and not 10% higher as in the desktop space. The gains Intel has made in IPC are thus partly negated by slightly lower clock speeds.
Clock speed has clearly been traded in for more cores in most of server SKUs. But the additional cores can prove extremely useful. The SAP S&D application – one of the best industry benchmarks – runs about three times faster (see further) on the latest Xeon E5-2699 v3 than on the Xeon 5500.
This clearly puts into perspective how important the uncore part is for Xeons. The uncore parts makes the difference between a CPU that is only good at running a few handpicked benchmarks (like SPECint rate) but fails to achieve much in real applications, vs. an attractive product that can lower the IT costs by running more virtual machines and offering services to more users.
The Magic Inside the Uncore
We were already been spoiled by Ivy Bridge EP as it implemented a pretty complex uncore architecture. With Haswell EP, the communication between memory controllers, LLC, and cores has become even more intricate.
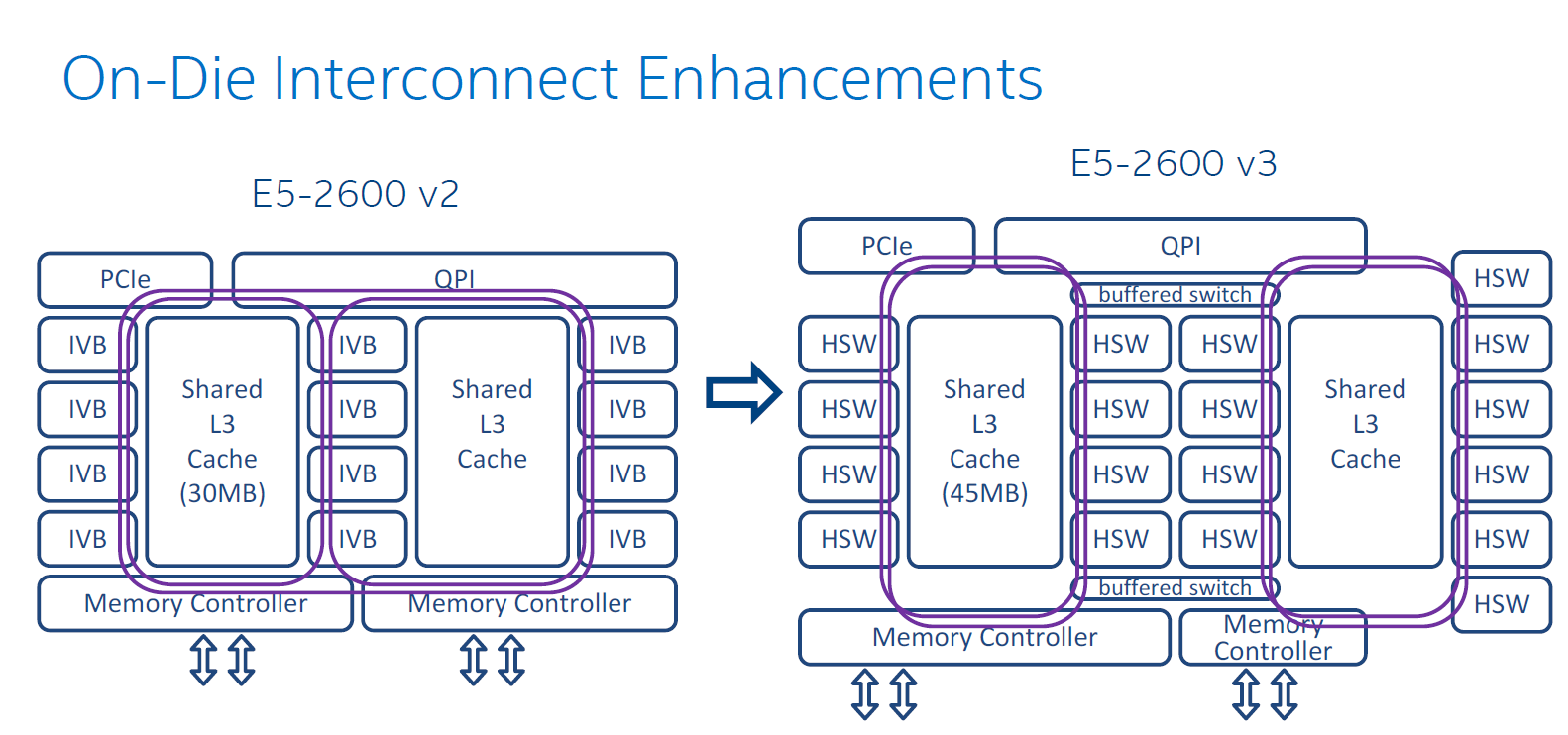
The Sandy Bridge EP CPU consisted of two columns of cores and LLC slices, connected by a single ring bus. The top models of the Ivy Bridge EP had three columns connected by a dual ring bus, with outer and inner rings as pictured above. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The 14 and 18 core SKUs now have four columns of cores and LLC slices, and as a result scheduling gets very complicated. Intel has now segregated the dual ring buses and integrated two buffered switches to simplify scheduling. It's somewhat comparable with the way an Ethernet switch divides a network into segments. Each ring can act independently, and as result the effective bandwidth increases, which is especially helpful when FMA/AVX instructions are working on 256-bit chunks of data.
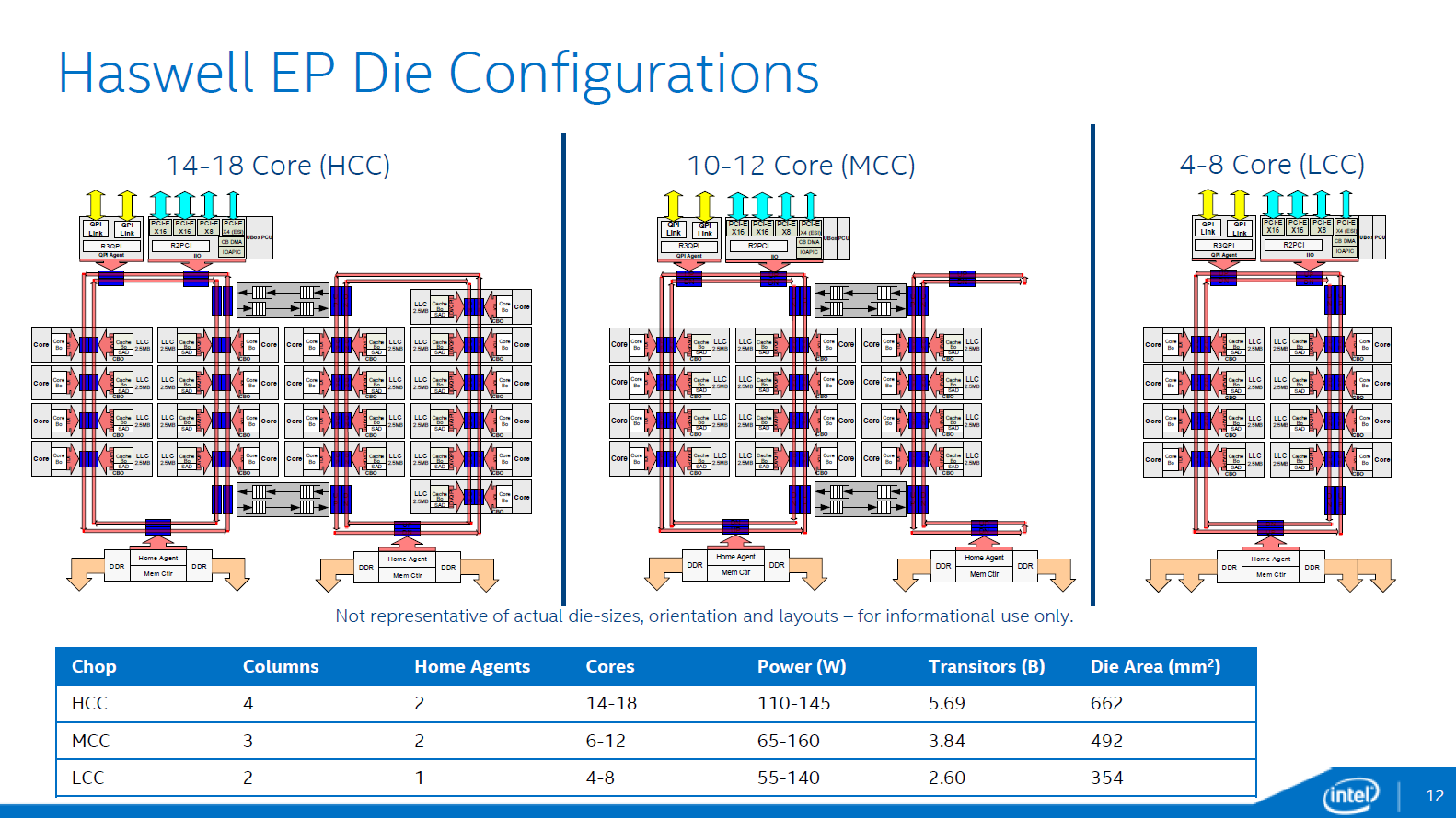
In total there are now three different die configurations. The first one, from four up to eight cores, is very similar to the lower count Ivy Bridge EPs. It has one dual ring, two columns of cores, and only one memory controller. The LLC cache is smaller on this die and has a lower latency.
The second configuration supports 10-12 cores and is a smaller version of the third die configuration that we described above. These dies have two memory controllers. The blue points indicate where data can jump onto the ring buses. Note that the die configurations are not symmetrical. For example an 18-core CPU has 8 cores (4-4) and 20MB LLC on one side, with 25MB LLC and 10 cores on the other. The middle configuration drops six to eight of the cores on the right ring, with an associated amount of LLC.
Data/instructions of one core are not stored in the adjacent cache slice. This could have lowered latency in some cases but it can create hotspots. Data is stored based on the physical address, ensuring all LCC cache slices are uniformly accessed. Transactions take the shortest path.
Rings are one of the entities that work on a separate voltage and frequency, just like cores. So if more I/O or coherency messaging is going on than processing, power can be dynamically allocated to speed up the rings.
Cache Coherency
The Home Agents are used for cache coherency and requests to DRAM. In dies that have two memory controllers, each home agent will use two channels. In dies that have one memory controller, each home agent will address four channels. While the smaller dies have faster LLC caches, Intel estimates that the second memory controller will extract 5% to 10% more bandwidth.
The two socket Haswell EP supports three snooping modes as you can see below. The first, Early Snoop, was available starting with Sandy Bridge EP models. With Ivy Bridge EP a second mode, Home Snoop, was introduced. Haswell EP now adds a third mode, Cluster on Die.
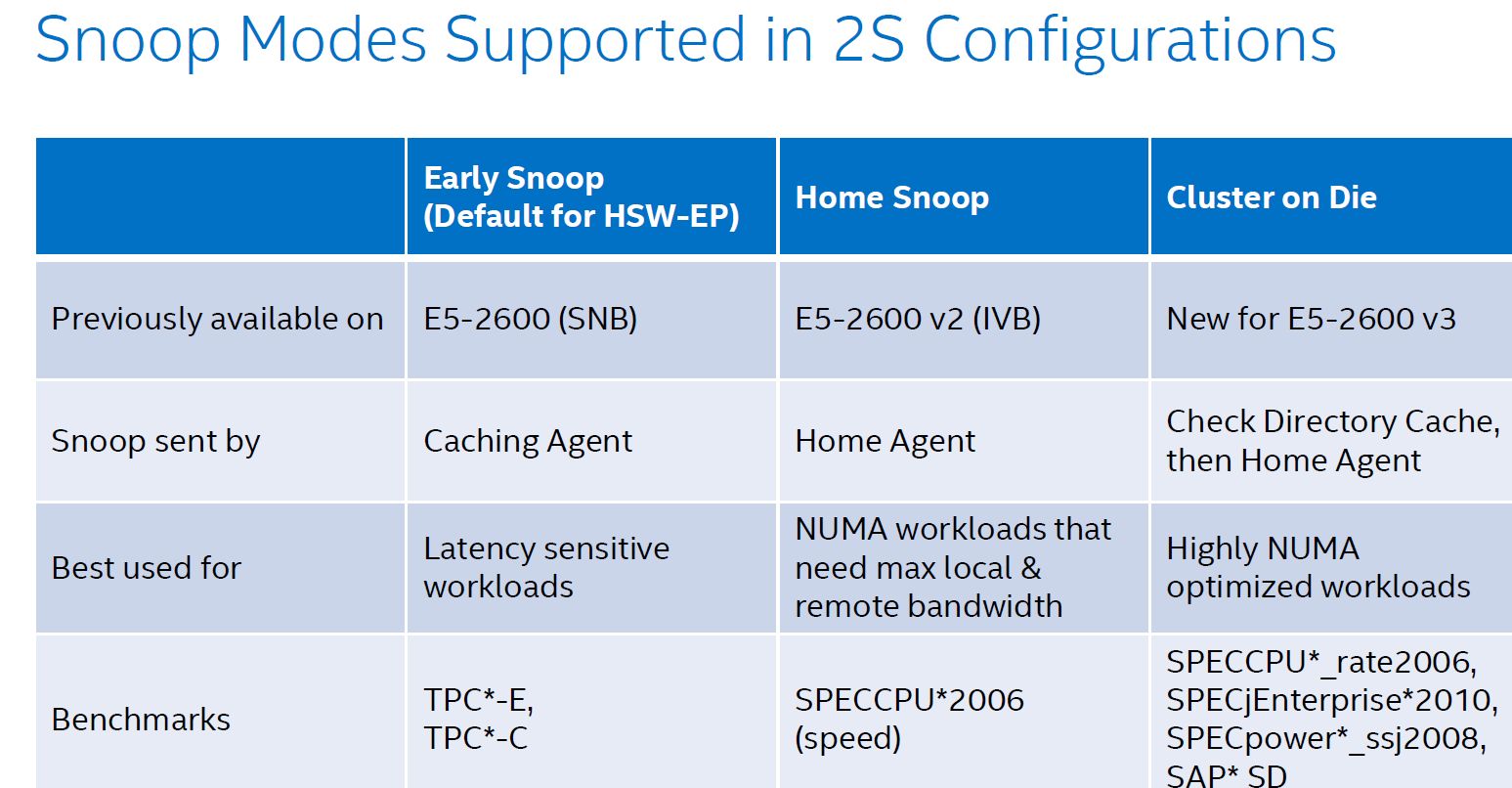
These snoop modes can be set in the BIOS.
Ivy Bridge used home snooping and had a directory in memory. The latest Xeon has directory caches (about 14KB) in each Home Agent. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. Another result is that directory updates in memory are less frequent and there are less broadcast snoops. Cluster On Die mode is the latest addition to the coherency protocols.
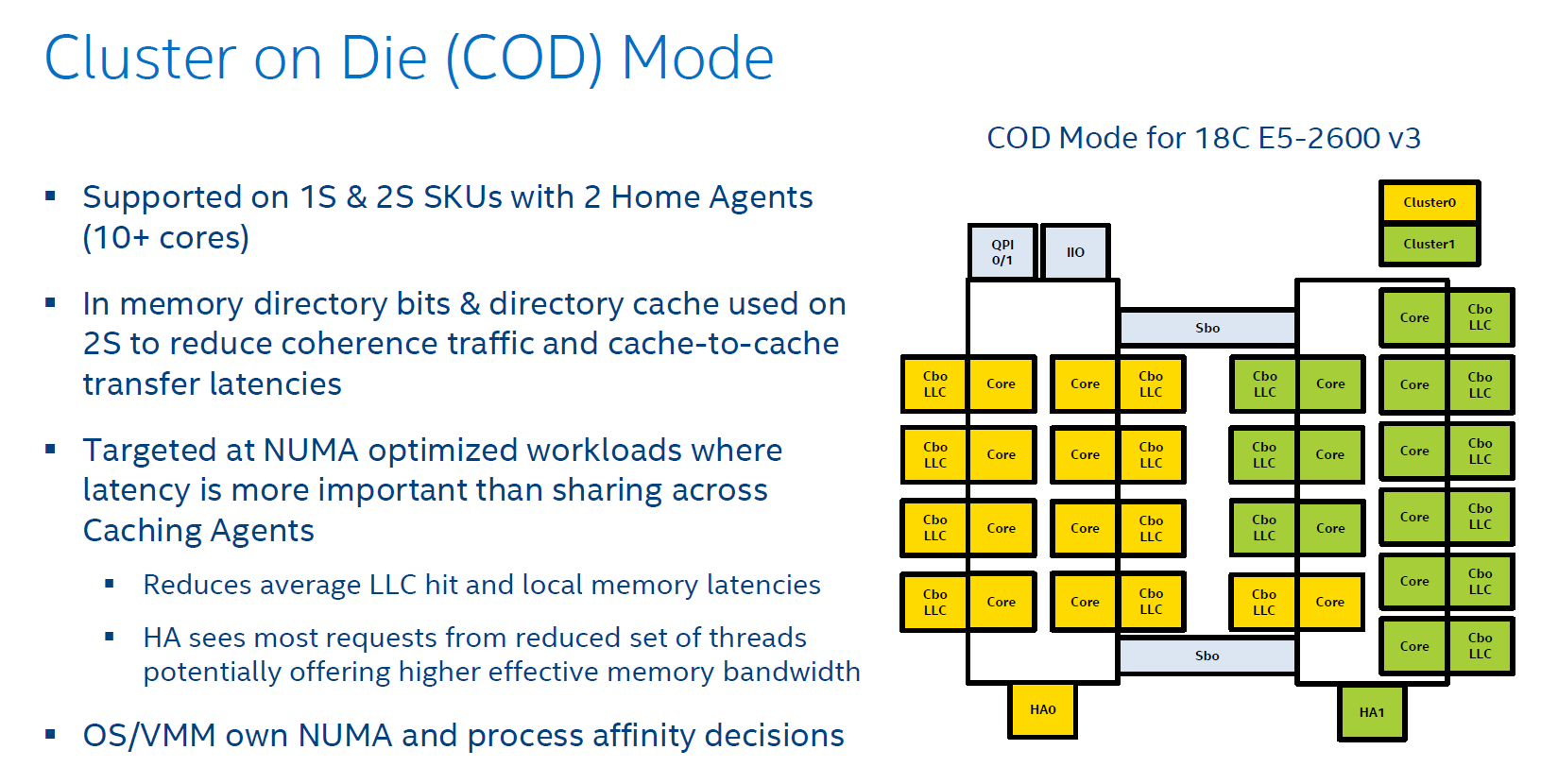
Cluster On Die can be understood as if you split the CPU and LLC into two parts that behave like two CPUs in NUMA. The OS is presented two affinity domains. As a result, the latency of LLC is lowered, but the hitrate is slightly lower. However if your application is NUMA aware, data and instructions are kept close to the part of the CPU that is processing them.
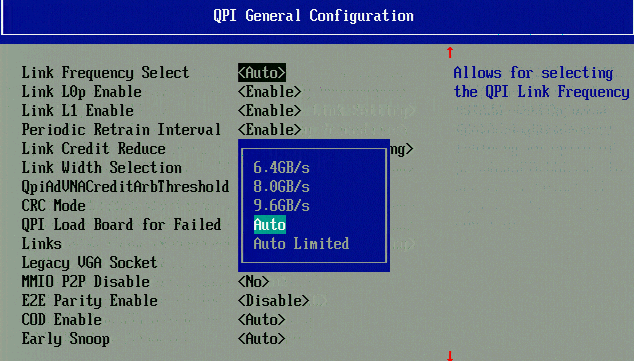
Higher QPI speeds, also notice the "COD" and "Early snoop" option.
And finally, QPI has been sped up to 9.6 GT/s, from 8 GT/s (as you can see in the BIOS shot).
More improvements
The list of (small) improvements is long and we have not been able to test all of them out. But here is an overview of what also improved
- Lower VM Entry/exit latency. The latency of going and forth to the Hypervisor has been improved compared to Westmere. Sandy Bridge slightly increase this compared to Westmere.
- VMCS shadowing. De VM Control Structure can be exposed to hypervisors running on top of the main hypervisor. So you get VT-x inside your nested hypervisor
- EPT Access and Dirty Bits. This makes it easier to move memory pages around, which is essiential for Live Migration / vMotion
- Cache monitoring (CMT) & allocation technology (CAT). CMT allow you to "measure" if a certain Virtual machine hogs the LLC . In certain SKUs is possible have control over the placement of data in the last-level cache.
Most of the improvements listed are specific for virtualized servers. However, cache allocation monitoring is also available for "native" OS.
Power Optimizations
It is well known that the Haswell has been optimized for low idle power. Servers run at idle a lot less than mobile devices and thus more power management capabilities were needed.

In Haswell EP, Intel introduces per core p-states (PCPS). PCPS is not necessarily a blessing, as a wrongly chosen p-state can result in higher response times. However, Intel is convinced PCPS will save power or will at least shift the power to where it is needed: to other cores or to the uncore (rings).
Floating Point intensive code is known to cause power peaks. AVX has doubled the theoretical FLOPS, and the FMA (Fused Multiply Add) of AVX 2.0 promises to double it again.

To cope with the huge difference between the power consumption of Integer and AVX code, Intel is introducing new base and Turbo Boost frequencies for all their SKUs; these are called AVX base/Turbo. For example, the E5-2693 v3 will start from a base frequency of 2.3GHz and turbo up to 3.3GHz when running non-AVX code. When it encounters AVX code however, it will not able to boost its clock to more than 3GHz during a 1 ms window of time. If the CPU comes close to thermal and TDP limits, clock speed will drop down to 1.9GHz, the "AVX base clock".

Here, Intel illustrates how this will work for their top SKU, the Xeon E5-2699 v3. Notice the lower base clock for AVX code (1.9 vs 2.3).
DDR4
Intel and the DRAM world are switching over to DDR4 and with good reason. DDR4 is a large step forward, and some of the highlights of DDR4 include the following:
- Speeds up to 3200 MT/s (1.6GHz Double Data Rate)
- Lower DRAM I/O voltage (1.2 instead of 1.5 V VDDQ)
- Twice the capacity (using the same DRAM chips)
- Improved RAS
The improvements start with the internal organization. A DDR3 chip has eight independent banks, while DDR4 comes with 16 banks, organized in a 4x4 configuration: four bank groups with four banks. More banks mean that more pages can stay open (more page hits, lower latency) at a small power increase, which is completely negated by a whole range of power efficiency features (see further). The power efficiency gains are rather large. Samsung quantifies them in the slide below.
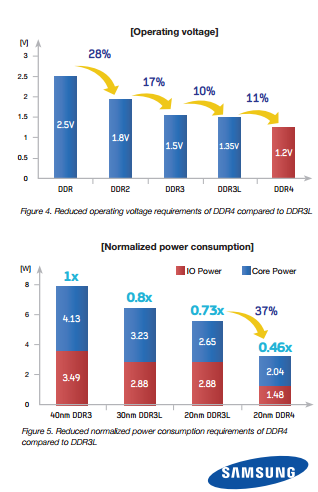
Samsung claims about 21% lower power thanks to the drop in operating voltage (1.5 ->1.2v). Low Power DDR4 will run at 1.05v and will lower the power usage even further. But there is more to DDR4 than lowering the voltage. Samsung claims that, when both are manufactured with the same process technology, the DDR4 runs at 2/3 of the power DDR3L needs.
Micron gives a break down of the features that made DDR4 more power efficient besides the obvious drop in VDDQ.

Note that the total power efficiency increase is 30-35%, and this is not just a result of the VDD reduction (20%). In that sense, DDR4 is a larger step forward than previous DDR technology transistions. Of course, the 30-35% improvement in power efficiency is measured with RAM running at the same speed. It's also possible to run DDR4 at much higher speeds (3200 MT/s vs 1866 MT/s) while sacrificing some of the power savings. The DDR4 memory that we are using for testings runs at 2100 MT/s, a good compromise between a mild speed increase and power efficiency.
A more elaborate discussion will follow in our next server memory article, but each bank also has much smaller rows (four times smaller) and thus the cycle time of the DRAM can be much higher. The result is lower latency.
The improved signal to noise ratio and the extra pins for addressing allow DDR4 to support eight DRAM stacks instead of four (DDR3). As a result, DDR4 can support twice the capacity of DDR3 using the same (4-16Gb) DRAM chips. This will require the use of 3D stacking technology, which will take time to implement. However, since 8Gb chips are now used, Registered DIMMs of 32GB should soon be a reality, as well as 64GB LRDIMMs. We'll discuss this in more detail on the next page.
Capacity: the New Arms Race
Some of the hottest software trends of today are Big Data and In Memory Business Analytics. Both applications benefit from fast processors, but even more importantly they are virtually unsatiable when it comes to RAM capacity. Another important area that's much closer to the daily work of many IT professionals is virtualization. As heavier applications are being virtualized, the typical amount of memory allocated to virtual machines has increased rapidly. As announced on the latest VMworld, vSphere 6 will now support Virtual machines that allocate up to 4TB (!!) of memory. The days where virtual machines were limited to only a fraction of "native" operating systems are behind us.
With the above developments, support for and development of high capacity DIMMs is crucial. Intel has been steadily improving the support for LRDIMMs (here's some additional information on LRDIMMs). The first Xeon E5-2600 had support for LRDIMMs but it only delivered higher capacity at the expense of lower bandwidth and higher latency. The memory controller of the Xeon E5-2600 v2 had several improvements specifically for LRDIMMs and as a result the latency and throughput tax was greatly reduced.
The advent of DDR4 has given the engineers of IDT the opportunity to give LRDIMMs a performance advantage instead of a disadvantage. By introducing data buffers close to the DRAM chips, they managed to reduce the I/O trace lengths tremendously. See the figure below.
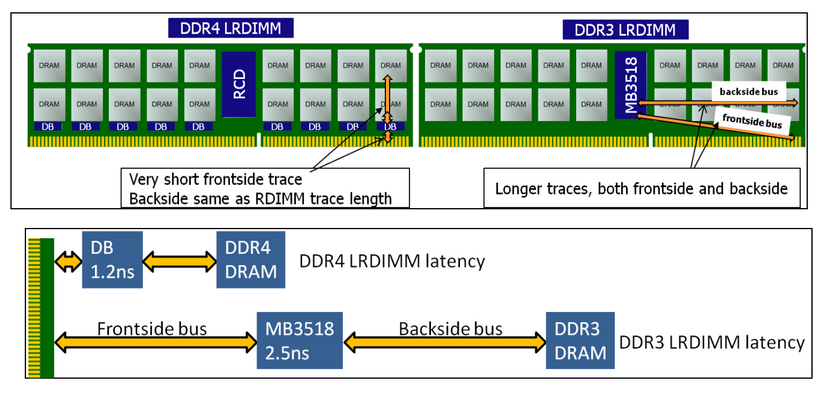
DDR4 and DDR3 LRDIMMs compared, image courtesy of IDT.
The latency overhead of the extra buffering is thus significantly lower on DDR4 LRDIMMs. In other words, compared to Registered DDR4 running at the same speed with 1 DPC (1 DIMM per channel), the latency overhead will be small. As soon as you start to use more DIMMs per channel, LRDIMMs actually offer lower latency as they can run at higher speeds.
Below you can see the evolution of LRDIMM support over the three generations of Xeon E5s. On the far right is the speed of DIMMs on Sandy Bridge EP, in the middle is Ivy Bridge EP, and on the left is the speed of DIMMs on the new Haswell EP Xeon.
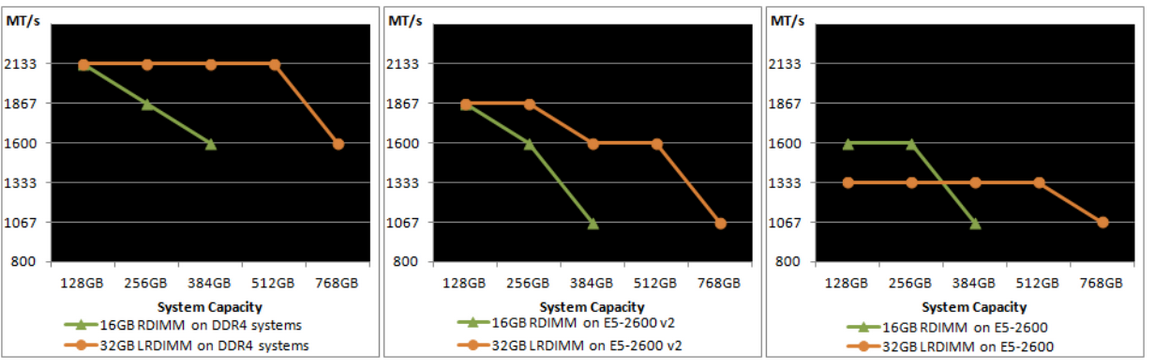
On Sandy Bridge EP (Xeon E5-2600), LRDIMMs were only clocked faster at three DPC. On Ivy Bridge EP (Xeon E5-2600 v2), the LRDIMMs were faster at two and three DPC. And on Haswell EP (Xeon E5-2600 v3), the bandwidth speed gap at two and three DPC has increased while the latency tax (not seen in the picture) has been reduced.

Samsung LRDIMM on top, RDIMM below. Notice the data buffers on the LRDIMM
Several sources tell us that LRDIMMs will be about 20%-25% more expensive. Our task then is to help you decide wether or not the investment is worth it. In this review, we will show some preliminary results.
The latency penalty has been reduced, but what about capacity? As you can see by the 4G marking in the photo above, the DIMMs used in our current servers are still using the mature 4Gbit DRAM chip technology. So currently, the Xeon E5-2600 v2 platform is limited to 384GB of registered DDR4 or 768GB of LRDIMMs. Quad-ranked RDIMMs, which were expensive, slow, and could only be used at 2DPC, are dead. The current 64GB LRDIMMs can be used at 3DPC, but they are Octal (!) ranks using quad-die-packages. As a result they are slow at 3DPC and power hungry.
But the future looks bright. At the end of this year, dual-ranked modules, such as the ones you can see above, will use 8Gb. This results in 64GB LRDIMMs and 32GB RDIMMs. That means the Xeon E5 platform will soon be able to address up to 1.5TB of physical RAM. In the second half of 2015, 128GB LRDIMMs should be available too, allowing up to 3TB of RAM.
SKUs and Pricing
Before we start with the benchmarks, let's first see what you get for your money. To reduce the clutter, we have not listed all of the SKUs but have tried to include useful points of comparison. Also note that we are not comparing pricing or performance with AMD at this point, as AMD has not updated its server CPU offerings for almost 2 years. The Steamroller architecture was very promising and addressed many of the bottlenecks we discovered in the earlier Opteron 6200, but unfortunately it was never made into a high end server CPU. So basically, Intel's only competition right now is the previous generation Xeons, which means Intel has to convince server buyers that upgrading to the latest Xeon pays off.
| Intel Xeon E5 v2 versus v3 2-socket SKU Comparison | |||||||||
| Xeon E5 | Cores/ Threads |
TDP | Clock Speed (GHz) |
Price | Xeon E5 | Cores/ Threads |
TDP | Clock Speed (GHz) |
Price |
| High Performance (20 – 30MB LLC) | High Performance (35-45MB LLC) | ||||||||
| 2699 v3 | 18/36 | 145W | 2.3-3.6 | $4115 | |||||
| 2698 v3 | 16/32 | 135W | 2.3-3.6 | $3226 | |||||
| 2697 v2 | 12/24 | 130W | 2.7-3.5 | $2614 | 2697 v3 | 14/28 | 145W | 2.6-3.6 | $2702 |
| 2695 v2 | 12/24 | 115W | 2.4-3.2 | $2336 | 2695 v3 | 14/28 | 120W | 2.3-3.3 | $2424 |
| "Advanced" (20-30MB LLC) | |||||||||
| 2690 v2 | 10/20 | 130W | 3-3.6 | $2057 | 2690 v3 | 12/24 | 135W | 2.6-3.5 | $2090 |
| 2680 v2 | 10/20 | 115W | 2.8-3.6 | $1723 | 2680 v3 | 12/24 | 120W | 2.5-3.3 | $1745 |
| 2660 v2 | 10/20 | 115W | 2.2-3.0 | $1389 | 2660 v3 | 10/20 | 105W | 2.6-3.3 | $1445 |
| 2650 v2 | 8/16 | 95W | 2.6-3.4 | $1166 | 2650 v3 | 10/20 | 105W | 2.3-3.0 | $1167 |
| Midrange (10 – 20MB LLC) | Midrange (15-25MB LLC) | ||||||||
| 2640 v2 | 8/16 | 95W | 2.0-2.5 | $885 | 2640 v3 | 8/16 | 90W | 2.6-3.4 | $939 |
| 2630 v2 | 6/12 | 80W | 2.6-3.1 | $612 | 2630 v3 | 8/16 | 85W | 2.4-3.2 | $667 |
| Frequency optimized (15 – 25MB LLC) | Frequency optimized (10-20MB LLC) | ||||||||
| 2687W v2 | 8/16 | 150W | 3.4-4.0 | $2108 | 2687W v3 | 10/20 | 160W | 3.1-3.5 | $2141 |
| 2667 v2 | 8/16 | 130W | 3.3-4.0 | $2057 | 2667 v3 | 8/16 | 135W | 3.2-3.6 | $2057 |
| 2643 v2 | 6/12 | 130W | 3.5-3.8 | $1552 | 2643 v3 | 6/12 | 135W | 3.4-3.7 | $1552 |
| 2637 v2 | 4/12 | 130W | 3.5-3.8 | $996 | 2637 v3 | 4/8 | 135W | 3.5-3.7 | $996 |
| Budget (15MB LLC) | Budget (15MB LLC) | ||||||||
| 2609 v2 | 4/4 | 80W | 2.5 | $294 | 2609 v3 | 6/6 | 85W | 1.9 | $306 |
| 2603 v2 | 4/4 | 80W | 1.8 | $202 | 2603 v3 | 6/6 | 85W | 1.6 | $213 |
| Power Optimized (15 – 25MB LLC) | Power Optimized (20-30MB LLC) | ||||||||
| 2650L v2 | 10/20 | 70W | 1.7-2.1 | $1219 | 2650L v3 | 12/24 | 65W | 1.8-2.5 | $1329 |
| 2630L v2 | 6/12 | 70W | 2.4-2.8 | $612 | 2630L v3 | 8/16 | 55W | 1.8-2.9 | $612 |
At the top of the product stack is the new E5-2699 v3, and it's priced accordingly: over $4000 for the most cores Intel has ever put in a Xeon processor. TDP has also gone up compared to the previous generation's top SKU, but for six additional cores that's probably reasonable.
At first glance, the 2695 v3 looks interesting for the performance hungry as it the cheapest "HCC" (High Core Count) option. You get the largest die with the two memory controllers, 35MB LLC, two rings, and TDP is limited to 120W. Of course the question is how well Turbo Boost will compensate for the relatively low base clock.
For those looking for a good balance between price/performance and power, the 2650L v3 offers a 100MHz higher clock, much higher Turbo Boost, two extra cores, and a slightly lower TDP for about $100 more. This SKU looks very tempting for people who do not need the ultimate in processing power, e.g. those looking for a host for their VMs.
Lastly, there is the 2667 v3 which has a high base clock (3.2) and a still reasonable TDP of 135W for all applications that need processing power but do not scale beyond a certain core count.
Those are the SKUs that we have included in this review, so let's see how they fare.
Benchmark Configuration and Methodology
This review - due to time constraints and a failing RAID controller inside our iSCSI storage - concentrates mostly on the performance and performance/watt of server applications running on top of Ubuntu Server 14.04 LTS. To make things more interesting, we tested 4 different SKUs and included the previous generation Xeon E5-2697v2 (high end Ivy Bridge EP), Xeon E5-2680v2 (mid range Ivy Bridge EP) and E5-2690 (high end Sandy Bridge EP). All test have been done with the help of Dieter and Wannes of the Sizing Servers Lab.
We include the Opteron "Piledriver" 6376 server (configuration here) only for nostalgia and informational purposes. It is clear that AMD does not actively competes in the high end and midrange server CPU market anno 2014.
Intel's Xeon E5 Server – "Wildcat Pass" (2U Chassis)
| CPU |
Two Intel Xeon processor E5-2699 v3 (2.3GHz, 18c, 45MB L3, 145W) |
| RAM | 128GB (8x16GB) Samsung M393A2G40DB0 (RDIMM) 256GB (8x32GB) Samsung M386A4G40DM0 (LRDIMM) |
| Internal Disks | 2x Intel MLC SSD710 200GB |
| Motherboard | Intel Server Board Wilcat pass |
| Chipset | Intel Wellsburg B0 |
| BIOS version | Beta BIOS dating August the 9th, 2014 |
| PSU | Delta Electronics 750W DPS-750XB A (80+ Platinum) |
The 32 GB LRDIMMs were added to the review thanks to the help of IDT and Samsung Semiconductor.

The picture above gives you a look inside the Xeon E5-2600v3 based server.
Supermicro 6027R-73DARF (2U Chassis)
| CPU | Two Intel Xeon processor E5-2697 v2 (2.7GHz, 12c, 30MB L3, 130W) Two Intel Xeon processor E5-2680 v2 (2.8GHz, 10c, 25MB L3, 115W) Two Intel Xeon processor E5-2690 (2.9GHz, 8c, 20MB L3, 135W) |
| RAM | 128GB (8x16GB) Samsung M393A2G40DB0 |
| Internal Disks | 2x Intel MLC SSD710 200GB |
| Motherboard | Supermicro X9DRD-7LN4F |
| Chipset | Intel C602J |
| BIOS version | R 3.0a (December the 6th, 2013) |
| PSU | Supermicro 740W PWS-741P-1R (80+ Platinum) |
All C-states are enabled in both the BIOS.
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) powerline. The room temperature is monitored and kept at 23°C by our Airwell CRACs. We use the Racktivity ES1008 Energy Switch PDU to measure power consumption. Using a PDU for accurate power measurements might seem pretty insane, but this is not your average PDU. Measurement circuits of most PDUs assume that the incoming AC is a perfect sine wave, but it never is. However, the Rackitivity PDU measures true RMS current and voltage at a very high sample rate: up to 20,000 measurements per second for the complete PDU.
Memory Subsystem Bandwidth
Let's set the stage first and perform some meaningful low level benchmarks. First, we measured the memory bandwidth in Linux. The binary was compiled with the Open64 compiler 5.0 (Opencc). It is a multi-threaded, OpenMP based, 64-bit binary. The following compiler switches were used:
-Ofast -mp -ipa
The results are expressed in GB per second. Note that we also tested with gcc 4.8.1 and compiler options
-O3 –fopenmp –static
Results were consistently 20% to 30% lower with gcc, so we feel our choice of Open64 is appropriate. Everybody can reproduce our results (Open64 is freely available) and since the binary is capable of reaching higher speeds, it is easier to spot speed differences. First we compared our DDR4-2133 LRDIMMs with the Registered DDR4-2133 DIMMs on the Xeon E5-2695 v3 (14 cores at 2.3GHz, Turbo up to 3.6GHz).
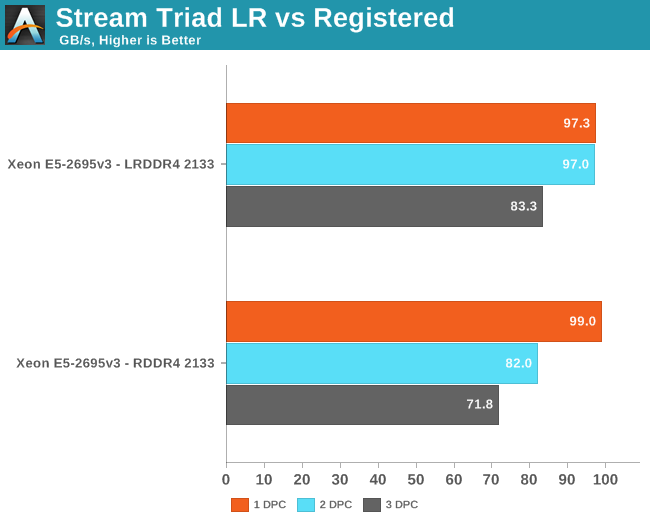
Registered DIMMs are slightly faster at 1DPC, but LRDIMMs are clearly faster when you insert more than one DIMM per channel. We measured a 16% to 18% difference in performance. It's interesting to note that LRDIMMs are supposed to run at 1600 at 3DPC according to Intel's documentation, but our bandwidth measurement points to 1866. The command "dmidecode -type 17" that reads out the BIOS confirmed this.
Next, we compared the different Xeon platforms.
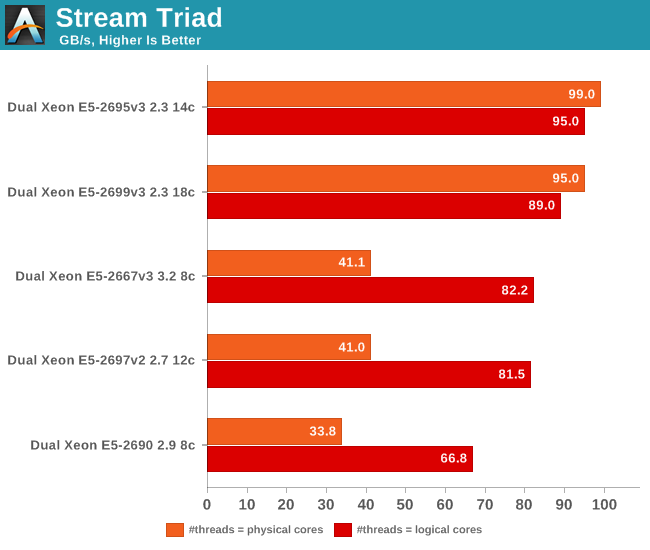
The new Xeon E5-2600 v3 has access to 15-21% more bandwidth than the E5-2600 v2, which uses DDR3-1866, and almost 50% more than the first Xeon E5s (DDR3-1600). Interestingly, the previous generation Xeons and the Xeon E5-2667 v3 need to use one thread per logical thread to use the full potential of the memory controller. The reason that the Xeon E5-2667 v3 shows similar behavior as the previous Xeons is that it is also a die with one dual ring and one memory controller. Also, 16 threads (one per physical core) is probably not enough to get the full potential of a quad channel DDR4-2133 memory subsystem. The new High Core Count (HCC, 14-18 core) Xeon E5 chips perform better with one thread per physical processor.
Although it makes sense that a CPU needs a certain number of threads to get its memory controller working at full speed, it's still interesting to note that the previous 12-core Xeon E5-2697 v2 can only offer 41GB/s at 24 threads while the 14-core Xeon E5-2695 v3 is already delivering more than twice as much bandwidth at 28 threads. Of course, those kind of bandwidth numbers only matter for specific HPC benchmarks as the L3 cache (30-45MB L3) will take care of most of the requests. Latency however always matters.
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readeable we limited ourselves to the CPUs that were different. The Xeon E5-2695 and 2699 have a very similar memory subsytem (dual memory controller) so we tested only the E5-2699.
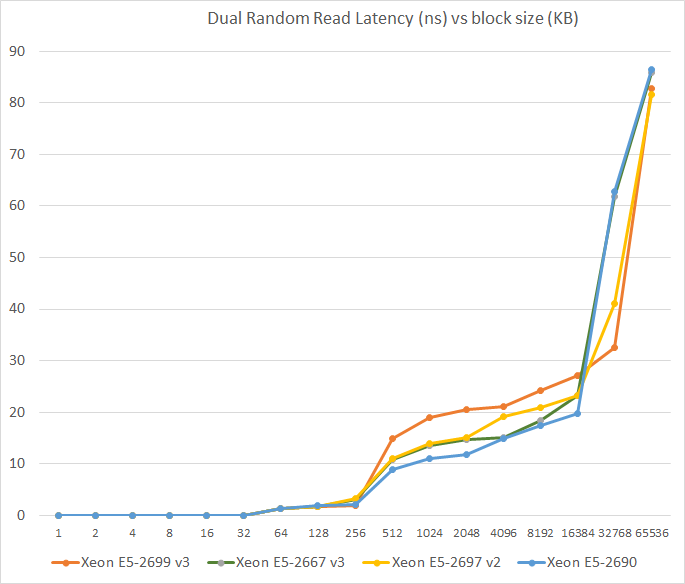
The massive L3 caches do have some disadvantages: latency goes up. The L3 cache of the Xeon E5-2699 v3 (45MB) has a latency between 20 and 32 ns while the 20MB cache of the Xeon E5-2690 hovers between 15 and 20 ns. That translates to about 90 cycles versus 60, which is considerable. However, it's not a case of the Haswell's L3 cache being a lot worse: the 20MB L3 cache of the Xeon E5-2667 v3 is only slightly slower than the Xeon E5-2690 and is still faster than the Xeon E5-2697 v2 (30MB). The main culprit is simply dealing with a huge amount of cache on the E5-2699 v3. In the next test, we will focus on the latency of the DRAM subsystem.
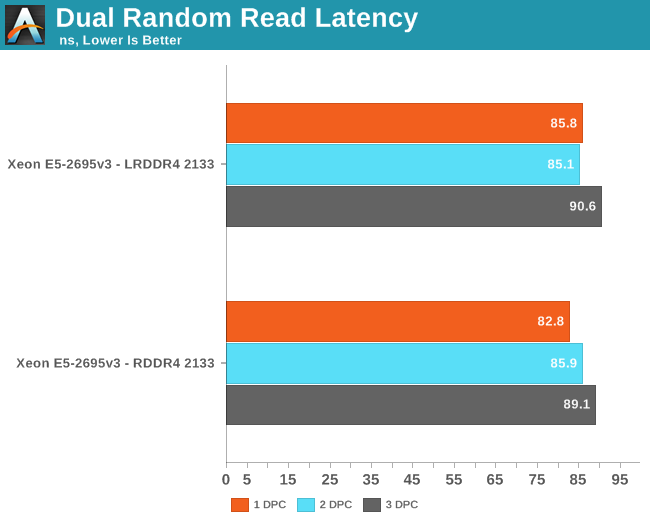
The DRAM subsystem is still three or four times slower than the massive L3 cache. LRDIMMs still have a very small latency overhead – +3.6% at the most – but that is neglible.
DDR4-2133 seems to have the same latency as DDR3-1866 . We measured 81.6 ns on the Xeon E5-2697 v2. Considering that DDR4-2400 is just around the corner, DDR4 will quickly give a performance boost to the new platform.
Single-Threaded Integer Performance
I admit, the following two benchmarks are almost irrelevant for anyone buying a Xeon E5 based machine. But still, we have to quench our curiosity: how much have the new cores been improved? There is a lot that can be said about the sophisticated "uncore" improvements (cache coherency policies, low latency rings, and so on) that allow this multi-core monster to scale, but at the end of the day, good performance starts with a good core. And since we have listed the many subtle core improvements, we could not resist the opportunity to see how each core compares.
The results aren't totally meaningless either, as the profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. And as one more reason to test performance in this manner, the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.1.
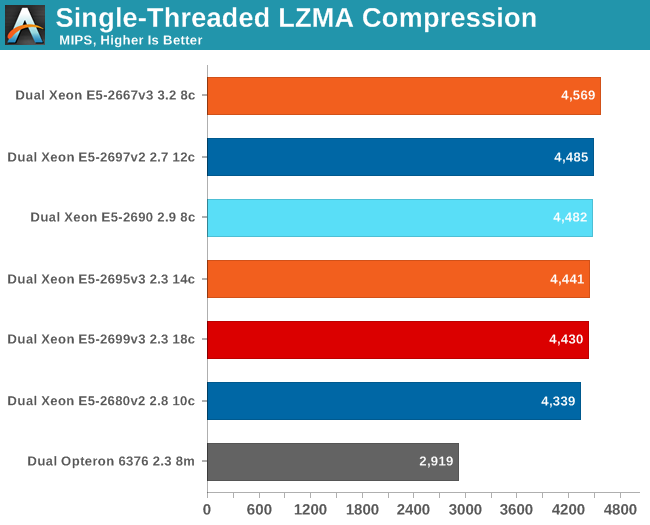
It looks more boring than it is. First of all, judging by the reactions on forums, many people expected that an 18-core E5-2699 v3 at 2.3GHz would be slower than a 3.2GHz Xeon E5-2667 v3. However you actually can have it all. The Xeon E5-2699 v3 and 2695 v3 boost their clock speed to no less than 3.6GHz when only one or two cores are active. The Xeon E5-2667 v3's maximum Turbo Boost is also the same 3.6GHz, so when only a few threads are active, the Xeon E5-2667 v3 has no clock advantage over the "mega/expensive SKUs" other than the fact that the clock speed will not drop lower than 3.2GHz if all cores are running at full bore.
Despite the fact that the Xeon E5-2690 core has lower IPC, it is able to keep up as it can boost the standard clock speed from 2.9 to 3.8GHz. As it is very hard to extract more IPC out of this kind of code, the extra 200MHz is enough to keep up.
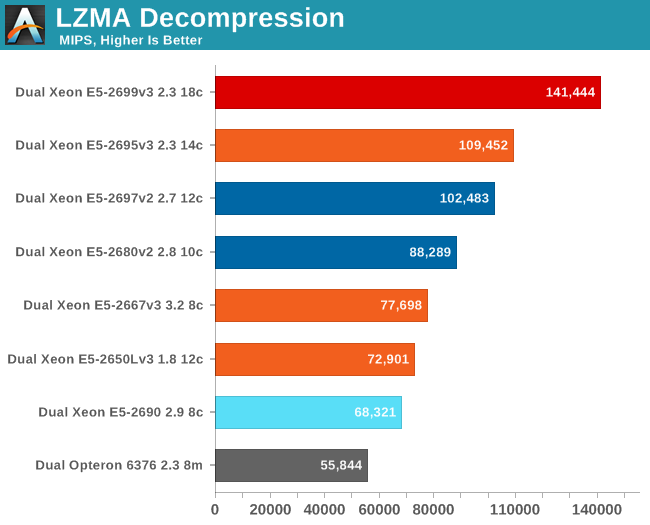
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is very branch intensive and depends on the latencies of the multiply and shift instructions.
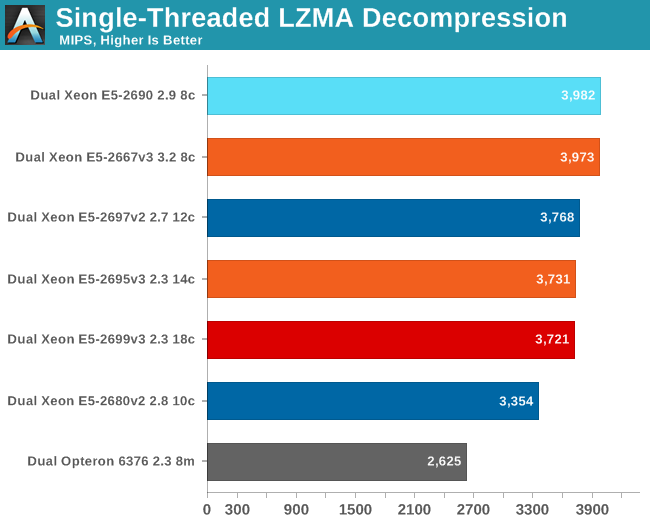
The older Xeon E5 takes the lead as decompression runs at very low IPC and is mostly depended on clock speed and low latency accesses. The new Xeon E5 v3 has slightly higher latency in both L3 cache and memory, so it falls behind.
What makes this benchmark interesting is that it proves that Turbo Boost works very well, even on an 18-core chip with a massive die. This is a big bonus, as especially in situations where you are setting up/preparing a system to be productive, it is very likely that you will be waiting for some single-threaded application to end. It also means that if one heavy request hits the server while it is running at very low load, the response time of the request will be low, keeping the impatient users happy.
Multi-Threaded Integer Performance
While compression and decompression are not real world benchmarks (at least as far as servers go), more and more servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization). Let's now enable multi-threaded workloads and see what happens.
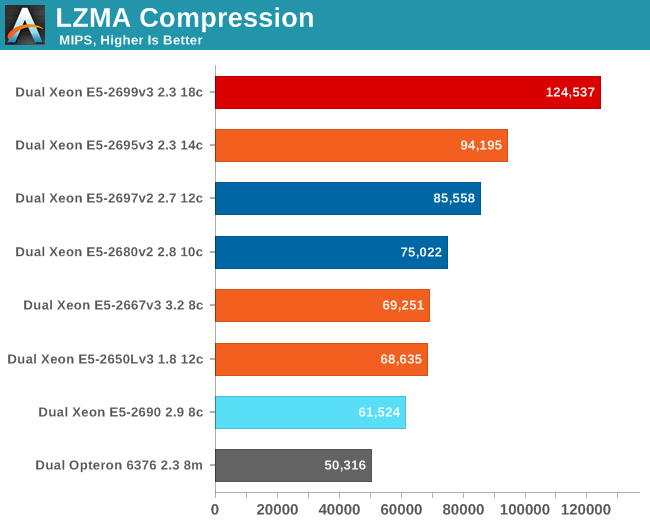
There are no surprises here: the extra cores offer the expected performance boost.
Linux Kernel Compile
A more real world benchmark to test the integer processing power of our Xeon servers is a Linux kernel compile. Although few people compile their own kernel, compiling other software on servers is a common task and this will give us a good idea of how the CPUs handle a complex build.
To do this we have downloaded the 3.11 kernel from kernel.org. We then compiled the kernel with the "time make -jx" command, where x is the maximum number of threads that the platform is capable of using. To make the graph more readeable, the number of seconds in wall time was converted into the number of builds per hour.
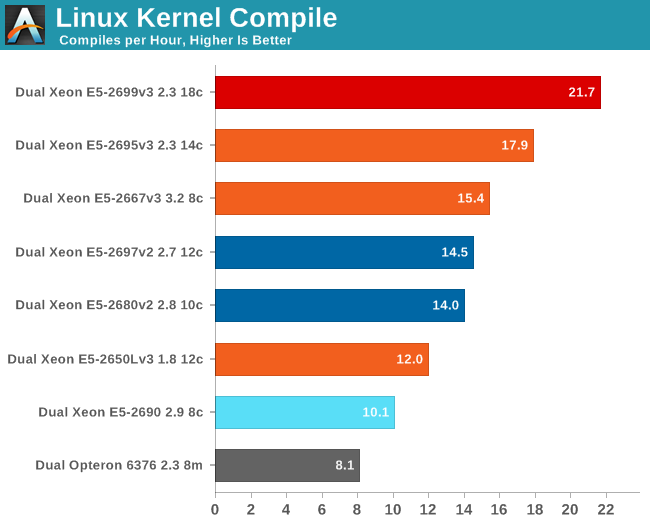
A kernel compile does not scale perfectly with more cores, but the Xeon E5-2699 still holds a healty lead over its 14-core brother. The Haswell architecture's improved integer core plays a larger role here than in compression as the E5-2697 v2 with 50% cores and a maximum clock of 3GHz (all cores Turbo Boost) cannot overtake the 3.2GHz Xeon E5-2667 v3. It is worth noting that the latter cannot Turbo Boost with all cores active.
The advantage over the Sandy Bridge EP is significant: 50% higher performance while the clock speed is only slightly higher as the Xeon E5-2690 can run briefly at 3.3GHz. The new Haswell core is good news for those who regularly deal with large software builds.
SAP S&D
The SAP S&D 2-Tier benchmark has always been one of my favorites. This is probably the most real world benchmark of all server benchmarks done by the vendors. It is a full blown application living on top of a heavy relational database. And don't forget that SAP is one of the most successful software companies out there, the market leader of Enterprise Resource Planning.
We analyzed the SAP Benchmark in-depth in one of our earlier articles:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
Let us see how the new Xeon E5 fares in this ERP benchmark.
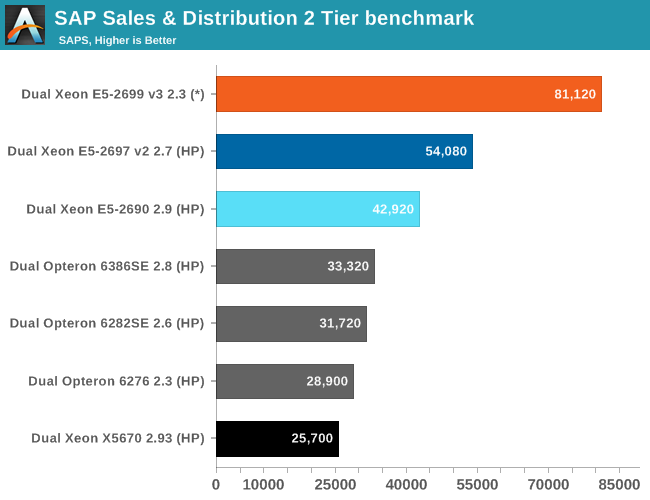
(*) Preliminary data
The SAP application is very well optimized for NUMA, so the Cluster On Die snooping mode gives a small but measureable boost (about 5%). The huge L3 cache is a blessing for SAP S&D, as it misses the L2 cache more often than most server applications. Last and but not least, once you have the caching part covered, SAP S&D scales well with more cores and it shows. Intel has been able to almost double SAP performance in about 2.5 years with one "tick-tock" cycle.
Java Server Performance
According to the documentation, the SPECjbb 2013 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations". It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security. We tested with four groups of transaction injectors and backends.
Several readers commented that we should try to optimize for lower response times instead of just optimizing for maximum throughput, so we have changed our relatively basic tuning. We left out "+AggressiveOpts" as this is still somewhat a risk for stability and the performance does not increase tangibly, and we used "-XX:+AlwaysPreTouch". Also we are more generous with the amount of allocated memory. These results are thus no longer comparable to our previous results. Our full parameters are:
"-server -Xmx8G -Xms8G -Xmn4G -XX:+AlwaysPreTouch -XX:+UseLargePages"
With these settings, the benchmark takes about 47GB-52GB of RAM. The first metric is basically maximum throughput.

Our new tuning has resulted in higher results, and all of the new Xeon scale well. However, if you start looking at it from a performance/watt perspective, the results are good but not spectacular. The power consumption of the Xeon E5-2695 v3 is similar to the Xeon E5-2697 v2, and the former has a 13% performance advantage.
The Critical-jOPS metric, is a throughput metric under response time constraint (SLA).
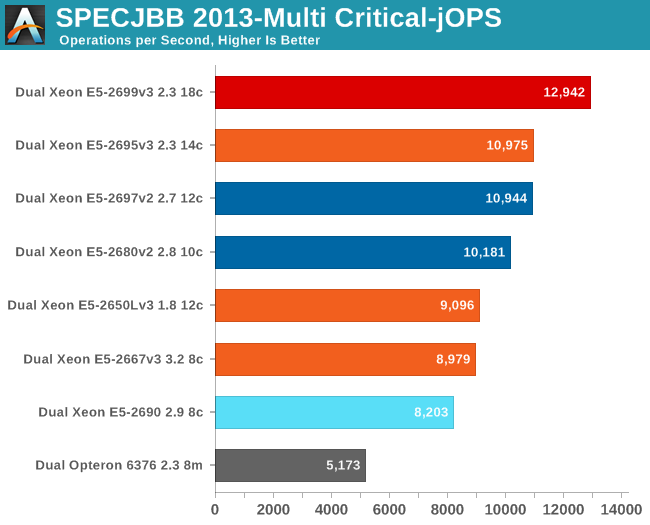
With our new tuning, the critical jOPS make a lot more sense, so we believe we have taken a step forward. Notice that the Xeon E5-2695 v3, despite its clock speed disadvantage (2.3 at least, 2.8 at the most), is capable of keeping up with the Xeon E5-2697 v2 (2.7 at the least, 3GHz at the most). The improvements in Haswell are measureable.
However, it must be said that while this is a step forward if you're buying a server, it's not a large one. You get 13% more throughput and the same response time for a few hundred dollars less (Xeon E5-2695 v3 vs E5-2697 v2).
Website Performance: Drupal 7.21
While there are few web servers that actually need such processing behemoths, we decided to go ahead and test in this area, just for the sake of satifying our curiosity. Most websites are based on the LAMP stack: Linux, Apache, MySQL, and PHP. Few people write HTML/PHP code from scratch these days, so we turned to running a Drupal 7.21 based site. The web server is Apache 2.4.7 and the database is MySQL 5.5.38 on top of Ubuntu 14.04 LTS.
Drupal powers massive sites like The Economist and MTV Europe and has a reputation of being a hardware resources hog. That is a price more and more developers pay happily for lowering the time to market for their work. We tested the Drupal website with our vApus stress testing framework and increased the number of connections from 5 to 1500.
First we report the maximum throughput achievable with 95% percent of requests being handled faster than 100 ms. It is important to note that there's a chance that a user experiences a much slower response time on a request, which could be much longer than 100 ms. Also, as each page view consists of many requests, there's an increased chance that one of the "slow responses" is among them. So the average response time is definitely a very bad indicator of user experience, and ensuring the 95% percentile is still fast enough is a lot safer.
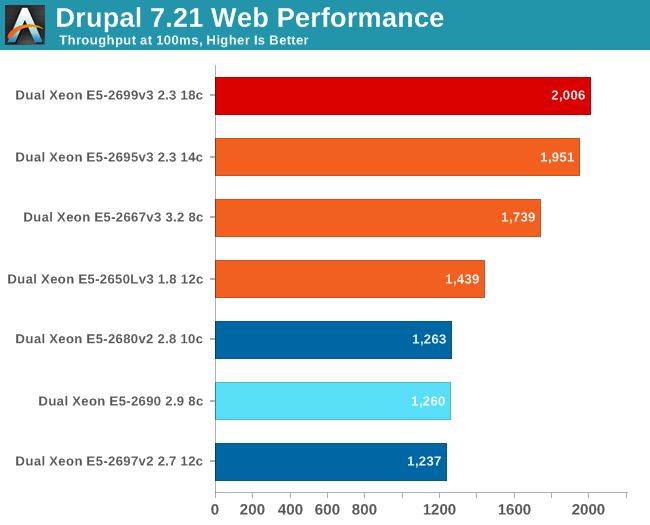
In the case of our Drupal testing, the new Haswell EP Xeons definitely take the lead, but at the top of the stack we don't see a lot of scaling with additional cores – the E5-2699 v3 and the E5-2695 v3 deliver nearly the same result. There are several reasons for this. The first is that the database of our current test website is too small. The second is that we still need to fine tune the configuration of our website to scale better with such high core counts.
We'll remedy this in the future as we adapt our tuning. Right now, it seems that we get good scaling up to 24 physical cores, but beyond that our tuning probably needs more work. Nevertheless, we felt we should share this result as most website owners do not have a specialized "make it scale" engineering team like Google and Facebook. And yes, it is probably better to load balance your website over several smaller nodes.
Still, the results are quite interesting. It looks like the new Xeon v3 scales better. The Xeon E5-2690 has no trouble keeping up – thanks to its higher clock speed – with the Ivy Bridge EP Xeon, which features a higher core count. The Xeon E5-2650L v3 has a lower clock speed but is able to use its higher core count to perform better. One of the reasons might be the fact that synchronization latency has been significantly improved.
Drupal Website: Performance per Watt
When we reviewed the Xeon E5-2600 v2, a performance per watt comparison was much more straightforward. Now we are faced with two different 2U-servers, with many similarities but also with some noteworthy differences. For example, the E5-2600 v3 based server is outfitted with six fans that can pull 1.6A, while our Xeon E5-2600 v2/v1 based server is outfitted with three fans that can pull 0.6A. If all fans are at their maximum RPM, the fans of the first server could easily pull 90W more. Also, our "Wildcat Pass" server still has to mature a bit as we are using a beta BIOS that has quite a few issues. Still, at idle, both servers are in the same ballpark.
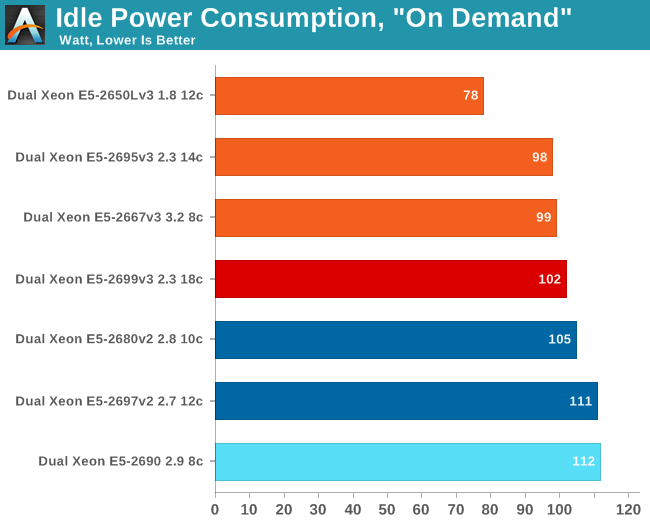
The Haswell-EP reveals its mobile roots. The Idle power of the Xeon E5-2699 v3 is lower despite being a much larger chip than the Xeon E5-2697 v2, while both are baked upon the same process technology.
Next we measure the power consumed while keeping the response time at 100 ms. These are averages measured over a period of time. So basically we are measuring energy consumption, but we report the average power that was consumed over the same period of time.
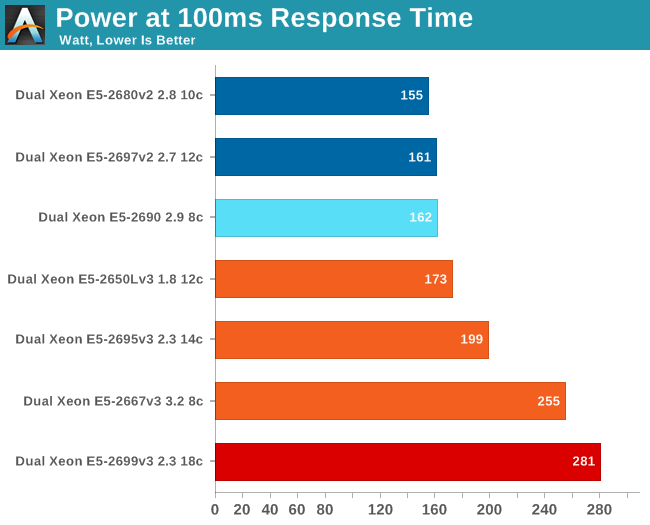
It would be wrong to simply compare the numbers above as the Xeon E5-2695 and 2699 do considerably more work. However, it cannot be denied that the Xeon E5-2699 v3 and Xeon E5-2667 v3 are a lot more power hungry than the rest of the pack. Remember also that, as noted above, the fans of the server that hosted the Xeon E5 v3 consume quite a bit more, but at the moment we have not been able to determine how much.
Let's calculate performance per watt. Take the following graph with a grain of salt as the benchmark is not the most accurate (results tend to vary by 5-8%), but still it gives a rough idea of what you can expect.
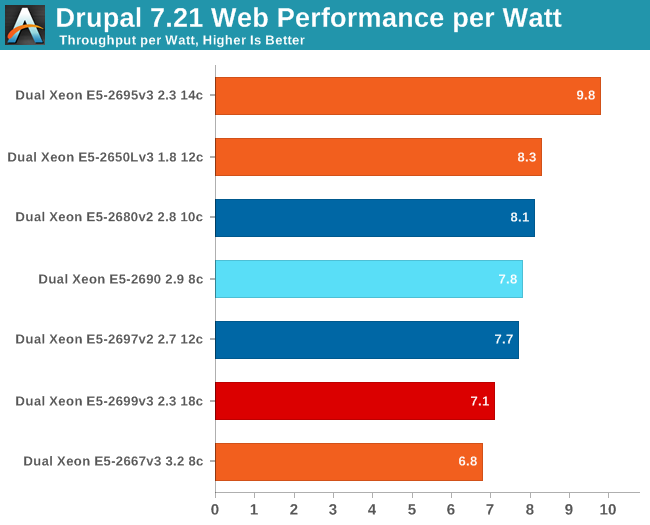
The Xeon E5-2695 v3 is able to Turbo Boost to high clock speeds, which keeps the response time low. At the same time, the power consumption is limited. The Xeon E5-2699 v3 probably fires up the fans a lot higher, and that drives power consumption up as the fans in our server can consume quite a bit.
What this means is that TDP is once again a relatively decent predictor of actual power consumption. The lower TDP of the Xeon E5-2695 v3 (120w) materializes in real world power savings compared to the Xeon E5-2667 v3 (135W TDP) and Xeon E5-2699 v3 (145W TDP).
OpenFoam
Computational Fluid Dynamics is a very important part of the HPC world. Several readers told us that we should look into OpenFoam, and my lab was able to work with the professionals of Actiflow. Actiflow specializes in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFoam to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.
We were allowed to use one of their test cases as a benchmark, but we are not allowed to discuss the specific solver. All tests were done on OpenFoam 2.2.1 and openmpi-1.6.3.
Many CFD calculations do not scale well on clusters, unless you use InfiniBand. InfiniBand switches are quite expensive and even then there are limits to scaling. We do not have an InfiniBand switch in the lab, unfortunately. Although it's not as low latency as InfiniBand, we do have a good 10G Ethernet infrastructure, which performs rather well. So we can compare our newest Xeon server with a basic cluster.
We also found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance. To understand this real world test case better, we'll start with a single-threaded benchmark.
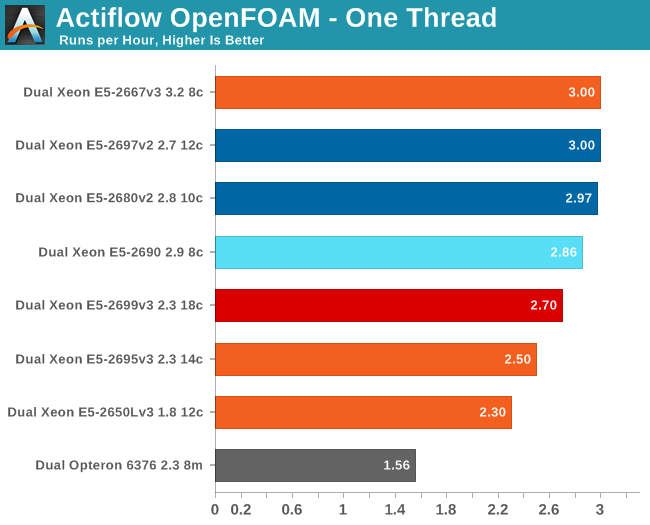
As this is AVX code, the clock speed "rules" change. A 2.3GHz Xeon E5 v3 can fall back to 1.9GHz if necessary, but it may also boost to 3.3GHz if the thermals allow it. The Xeon 2695 v3 has less TDP headroom and as a result it performs slightly slower than the Xeon E5-2699 v3. Still they cannot beat the Xeon E5-2667 v3 in single-threaded HPC performance. The latter is the better chip for this workload as it guarantees 2.7GHz and can boost up to 3.5GHz. As the previous Xeons also support AVX and run between 2.7 and 3.3GHz, they keep up with the Xeon E5-2667 v3.
Of course, most HPC code is now multi-threaded. We next ran OpenFOAM at one thread per physical core, which is about 5% faster than running with one thread per logical core (likely due to AVX).
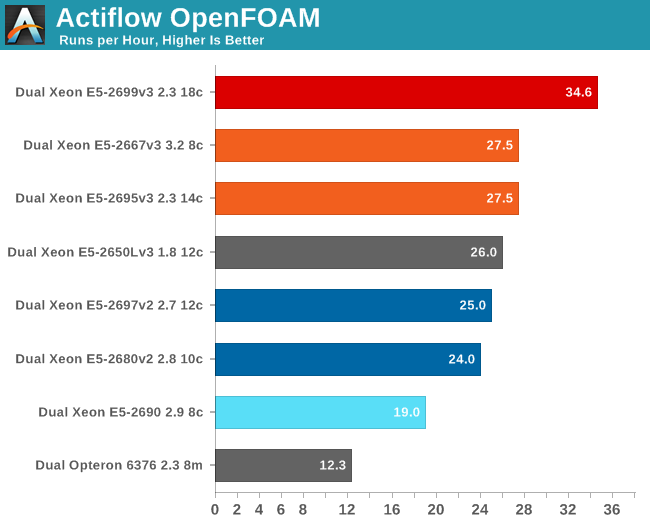
If you work professionally with OpenFOAM, it is clear that it pays off to understand what a certain CPU offers. If money does not matter much, the Xeon E5-2699 v3 does what is has to, which is to beat everybody else despite the fact that OpenFOAM does not scale that well beyond a certain point.
To give you an idea of what we're seeing, with 16 threads on the Xeon E5-2699 v3 we were already running at 30 runs per hour. Despite the fact that our workload is already a pretty heavy one (>600k cells), it is clear you need a larger mesh to really use the best Xeons of today to their full potential.
A less expensive option is the Xeon E5-2667 v3, but the real winner here is the Xeon E5-2650L v3 which costs a full $1000 per CPU les than the Xeon E5-2695 v3 and consumes quite a bit less as we will see on the next page.
Energy and HPC
AVX/FP intensive applications are known to be real power hogs. How bad can it get? We used the OpenFOAM test and measured both average and maximum power (the 95th percentile). Average power tells us how much energy will be consumed for each HPC job while maximum power is important as you have to allocate enough amps to your rack to feed your HPC server/cluster.
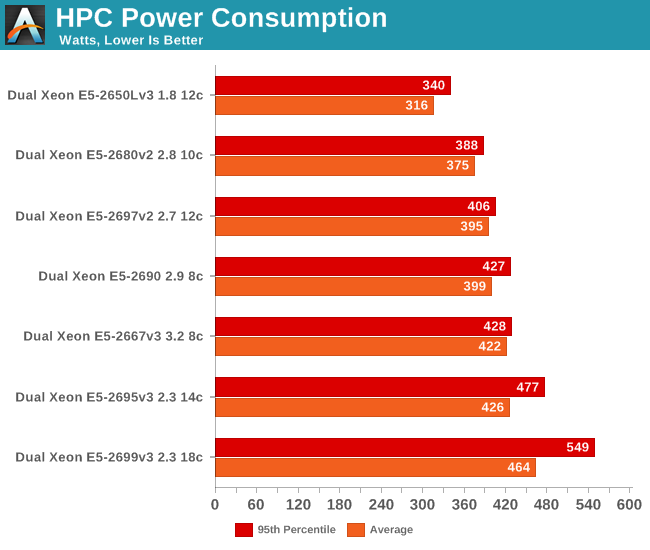
This confirms there is more going on than just the fact that our "Wildcat Pass" server consumes more than the Supermicro server in this test. At peak, the Xeon E5-2699 v3 consumes almost 450W (!!) more than at idle. Even if we assume that the fans take 100W, that means that 350W is going to the CPUs. That's around 175W per socket, and even though it's measured at the wall and thus includes the Voltager regulators, that's a lot of power. The Xeon E5-2699 v3 is a massive powerhouse, but it's one that needs a lot of amps to perform its job.
Interestingly, the Xeon E5-2695 v3 is also using more power than all previous Xeons. The contrast with our Drupal power measurements is very telling. In the Drupal test, the CPU was able to let many of the cores sleep a lot of the time. In OpenFOAM, all the cores are working at full bore and the superior power savings of the Haswell cores deep sleep states do not matter much. But which CPU is the winner? To make this more clear, we have to calculate the actual energy consumed (average power x time ran).
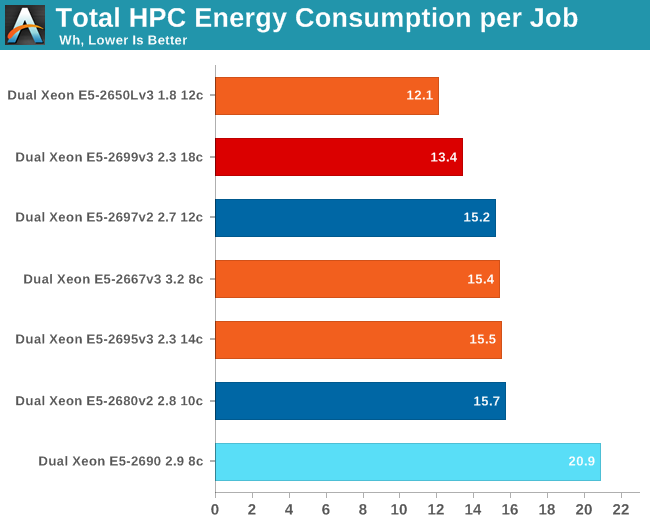
When we look at how much energy is consumed to get the job done, the picture changes. The old Xeon "Sandy Bridge EP" is far behind. It is clear that Intel has improved AVX efficiency quite a bit. The low power Xeon E5-2650L v3 is a clear winner. In second place, the fastest Xeon on the planet actually saves energy compared to the older Xeons, as long as you can provide the peak amps.
LRDIMMs: Capacity and Real World Performance
As we have shown that Intel invested a lot of time to improve the support for LRDIMMs, we also wanted to do a few real world tests to understand when capacity or higher speed at high DPC matters.
First we test with our CDN test. We simulate our CDN test with one CDN server and three client machines on a 10 Gbit/s network. Each client machine simulates thousands of users requesting different files. Our server runs Ubuntu 13.04 with Apache.
The static files requested originate from sourceforge.org, a mirror of the /a directory, containing 1.4TB of data and 173,000 files. To model the real world load for the CDN two different usage patterns or workloads are executed simultaneously, one that accesses a limited set of files more frequently and a second that accesses less frequently requested files. This workload simulates users that are requesting both current as well as older or less frequently accessed files. You can read more about our CDN test here. We used the Xeon E5-2695 v3.
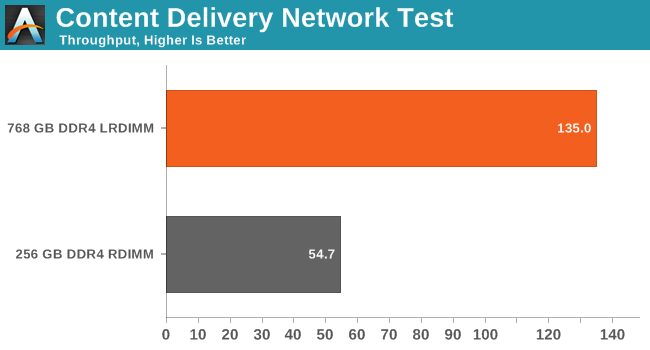
There is no doubt about it: some applications are all about caching and LRDIMMs are incredibly useful in these situations. Some HPC workloads supposedly require a lot of memory as well and can be very sensitive to memory bandwidth. Really? Even with a 35MB L3 cache? We decided to find out.
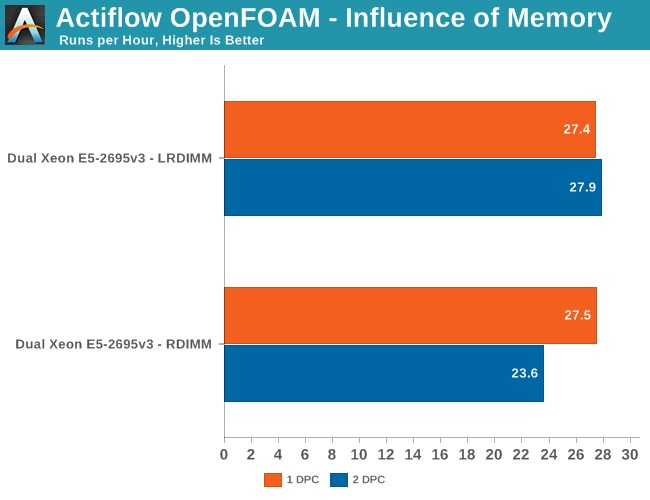
LRDIMMs are just as fast as RDIMM in a 1DPC configuration. Once you plug in two DIMMs per channel, LRDIMMs outperform RDIMMs by 18%. That is quite surprising considering that our CPU is outfitted with an exceptionally large L3. This test clearly shows there are still applications out there craving more memory bandwidth. In the case of OpenFOAM, the amount of bandwidth largely determines how many cores your CPU can keep busy.
Limitations
Where are the virtualization benchmarks? We only got ESXi running a few days before the launch, after performing a necessary BIOS update. A little bit later, disaster struck: our iSCSI target was gone as some of the disks in the RAID-array failed. Unfortunately that means we will have to post our virtualization findings in a later article.
The other main limitation of this review is that we did not have sufficient time to experiment with different servers to measure power consumption. We have started asking around to get different kinds of servers in the lab, and we will be updating our tools to measure power draw of the different components inside the servers soon.
Conclusions so Far...
This has been a massive review and there's a lot of information to digest. However, if there is one thing you should remember it's that there is not one SKU that is the best in every situation. The results vary enormously depending on the workload. Some workloads like our kernel compilation test prefer the higher clocked SKUs, and those who thought the 14-core and 18-core processors at 2.3GHz would only excel in easy scaling software are wrong. Turbo Boost has improved vastly, and the massive core monsters can deftly wield this weapon when few threads are running.
The Xeon E5-2695 v3 is an interesting SKU for those searching for high performance in integer workloads. It is also relatively power efficient, never asking for too many amps, and it performs very well in alomst every (integer!) application. Of course the price tag is heavy, and it only makes sense if you can use all that processing power.
It is clear that server buyers could really benefit from some serious competition in the market, but you can hardly blame Intel at this stage. We hope that AMD can make a comeback in 2015. If not, it does not look like Intel will have any real competition in the midrange server market.
The Xeon E5-2650L v3 however is the true star of this review. It is power efficient (obviously) and contrary to previous low power offerings it still offers a good response time. Perhaps more surprising is that it even performs well in our FP intensive applications.
At the other end of the spectrum, the Xeon E5-2699 v3 is much more power hungry than we are used to from a high end part. It shines in SAP where hardware costs are dwarfed by the consulting invoices and delivers maximum performance in HPC. However, the peak power draw of this CPU is nothing to laugh about. Of course, the HPC crowd are used to powerhogs (e.g. GPGPU), but there's a reason Intel doesn't usually offer >130W TDP processors.
Considering the new Haswell EP processors will require a completely new platform – motherboards, memory, and processors all need to be upgraded – at least initially the parts will mostly be of interest to new server buyers. There are also businesses that demand the absolute fastest servers available and they'll be willing to upgrade, but for many the improvements with Haswell EP may not be sufficient to entice them into upgrading. The 14 nm Broadwell EP will likely be a better time to update servers, but that's still a year or so away.






