Original Link: https://www.anandtech.com/show/8357/exploring-the-low-end-and-micro-server-platforms
X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM EST
The recent announcements of ARM, HP, AppliedMicro, AMD, and Intel make it clear that something is brewing in the low-end and micro server world. For those of you following the IT news that is nothing new, but although there have been lots of articles discussing the new trends, very little has been quantified. Yes, the Xeon E3 and Atom C2000 have found a home in many entry-level and micro servers, but how do they compare in real-world server applications? And how about the first incarnation of the 64-bit ARMv8 ISA, the AppliedMicro X-Gene 1?
As we could not find much more than some vague benchmarks and statements that are hard to relate to the real world, we thought it would be useful to discuss and quantify this part of the enterprise market a bit more. We wanted to measure performance and power efficiency (performance/watt) of all current low-end and micro server offerings, but that proved to be a bit more complex than we initially thought. So we went out for a long journey from testing basic building blocks such as the ASRock Atom board, trying out an affordable Supermicro cloud server with 8 nodes, to ultimately end up with testing the X-Gene ARM cartridge inside an HP Moonshot chassis.
It did not end there. Micro servers are supposed to run scale-out workloads, so we also developed a new scale-out test based on Elasticsearch. It's time for some in depth analysis, based on solid real-world benchmarks.
Target Audience?
This article – as with most of my articles – is squarely targeted at professionals like system administrators and web hosting professionals. However, if you are a hardware enthusiast, the low-end server market does have quite a bit to offer. For example, if you want to make your system more robust, the use of ECC RAM may help. Also, if you want to experiment/work with virtual machines, the Xeons offer VT-d that allows you to directly access I/O devices in a virtual machine (and in some cases, the GPU). Last but not least, server boards support out-of-band remote management which allows you to turn the machine on and off remotely. That can be quite handy if you use your desktop as a file server as well.
Micro and Scale-Out Servers?
The business model of many web companies is based on delivering a service to a large number of users in order to be profitable. This is because the income (advertising or something else) per user is relatively low. Dropbox, Facebook, and Google are the prime examples that everybody knows, but even AnandTech is no exception to this rule. The result is that most web companies need lots of infrastructure but do not have the budget of an IT department that is running a traditional transactional system. Web (hosting) companies need dense, power efficient, and cheap servers to keep the hosting costs low.

Small 1U servers: dense but terrible for administration & power efficiency
Just a few years ago, they had few options. One possible option was half-width or short depth 1U servers, another was the more dense forms of blade servers. As we have shown more than once, 1U servers are not power efficient and need too much cabling, PSUs, etc. Blade servers are more power efficient, reduce the cabling complexity, and the total number of PSUs and fans. But most blade servers have lots of features web companies do not use and are also too expensive to be the ideal solution for all the web companies out there.
The result of the above limitations is that both Facebook and Google developed their own servers, a clear indication that there was a need for a different kind of server. In the process, a new kind of dense server chassis was introduced. At first, the ones with low power nodes with "wimpy" cores were called "micro servers". The more beefy servers targeted at more demanding scale-out software were called "scale-out servers". Since then, SeaMicro, HP, and Supermicro have been developing these simplified blade server chassis that offer density, low power, and low(er) costs.
Each vendor took a different angle. SeaMicro focused on density, capacity, and bandwidth. Supermicro focused on keeping the costs and complexity down. HP went for a flexible solution that could address the largest possible market – from ultra dense micro servers to beefier scale-out servers to specialized purpose servers (video transcoding, VDI etc.). Let's continue with a closer look at the components and servers we tested.
HP Moonshot
We discussed the HP Moonshot back in April 2013. The Moonshot is HP's answer to SeaMicro's SM15000: a large 4.3U chassis with no less than 45 cartridges that share three different fabrics: network, storage, and clustering. Each cartridge can contain one to four micro servers or "nodes". Just like a blade server, cooling (five fans), power (four PSUs), and uplinks are shared.

Back in April 2013, the only available cartridge was based on the anemic Atom S1260, a real shame for such an excellent chassis. Since Q4 2014, HP now offers six different cartridges ranging from the Opteron X2150 (m700) to the rather powerful Xeon E3-1284Lv3 (m710). The different models are all tailored to specific workloads. The m700 is meant to be used in a Citrix virtual desktop environment while the m710 is targeted at video transcoding. We tested the m400 (X-Gene 2.4), m300 (Atom C2750), and m350 (four Atom C2730 nodes) cartridges.
The m400 is the first server we have seen that uses the 64-bit ARMv8 AppliedMicro X-Gene. HP positions the m400 as the heir of mobile computing, and touts its energy efficiency. Other differentiators are memory bandwidth and capacity. The X-Gene has a quad-channel memory controller and as a result is the only cartridge with eight DIMMs. We were very interested in understanding how X-Gene would compare to the Intel Xeons. HP positions the m400 as the micro server for web caching (memcached) and web applications (LAMP). The m400 also comes with beefy storage: you can order a 480GB SSD with a SATA or M.2 interface.
The m300 cartridge is based on the Atom C2750 with support for up to 32GB of RAM. HP positions this cartridge as "web infrastructure in a box". The m400 is mostly about web caching and the web front-end while the m300 seems destined to run the complete stack (front- and back-end). However, it is clear that there is some overlap between the m300 and m400 as there's nothing to stop you from running a complete "web infrastructure" on the m400 if it runs well in 32GB or less.
The m350 cartridge is all about density: you get four nodes in one cartridge. There is a trade-off however: you are limited to 16GB of RAM and can only use M.2 flash storage, limited to 64GB.

Each node of the m350 is powered by one of Intel's most interesting SKUs, the 1.7GHz 8-core Atom C2730 that has a very low 12W TDP. The m350 is positioned as a way to offer managed hosting on physical (as opposed to virtualized) servers in a cost effective way.
Supermicro's MicroCloud SYS-5038ML-H8TRF
Supermicro's 3U MicroCloud chassis is not a competitor for "advanced" micro servers such as AMD's SeaMicro SM15000 or HP's Moonshot. Advanced micro servers save power and keep management costs low due to an integrated fabric that routes networking and storage traffic very fast inside the box and only needs to be attached to the core switch via a few cables outside. You could say that the rack switch has been upgraded and integrated.
The Supermicro MicroCloud is a lot simpler. Only the power and cooling is shared among the nodes; there is no sophisticated integrated network or storage backplane. The MicroCloud still needs a separate switch and storage is pretty straightforward: each node has access to two disks.

Basically the MicroCloud is just a bunch of server nodes that share two redundant power supplies and cooling (4x 8 cm fans). As a result, it is a dense and inexpensive way to bundle eight (up to 24 in some SKUs) low-end servers. It is clearly targeted at the HPC and hyperscale datacenter where people want a "blade-like" server chassis but do not want to pay for features they rarely/never would use (e.g. centralized remote management/KVM, integrated switching, and SAN technology).

We've heard from several resellers that this chassis has been very successful, not in the least for being simple and affordable. Each node has a dual gigabit Intel i350 gigabit controller and one Ethernet interface for remote management; a KVM connector is also available. If you need more networking speed, one PCIe x8 slot is available.
Low-End Server Building Blocks
Micro and low-end servers come in all shapes and forms. Ideally, we would gather them all in our labs and make a performance per watt comparison, taking the features that make management easier into account. The reality is that while lots of servers enter our lab, many of the vendors cannot be easily convinced to ship heavy and expensive server chassis with a few tens of nodes.
In AnandTech tradition, we decided to take a look at the component level instead. By testing simple motherboard/CPU/RAM setups and then combining those measurements with the ones we get from a full blown server, we can get a more complete picture. A simple motherboard/CPU/RAM setup allows us the lowest power numbers possible, and a full blown server measurement tells us how much the more reliable cooling of a full blown server chassis adds.
ASRock's C2750D4I
The mini-ITX ASRock C2750D4I has the Atom "Avoton" C2750 SoC (2.4GHz, eight Silvermont cores) on board. If you are interested in using this board at home, Ian reviewed it in great detail. I'll focus on the server side of this board and use it to find out how well the C2750 stacks up as a server SoC.

Contrary to the Xeon E3, 16GB DIMMs are supported. The dual-channel, four DIMM slot configuration allows you to use up to 64GB. This board is clearly targeted at the NAS market, as ASRock not only made use of the six built-in SATA ports (2x SATA 6G, 4x SATA 3G) of the Atom SoC but also added a Marvell SE9172 (2x SATA 6G) and a Marvell SE9230 (4x SATA 6G) controller. Furthermore, ASRock soldered two Intel i210 gigabit chips and an AST2300 to the board. However, the Atom "Avoton" integrated 16 PCIe lanes only support four PCIe devices. The PCIe x8 slot already needs eight of them and the Marvel SE9230 takes another two PCIe lanes, so the ASRock board needs a PLX 8608 PCIEe switch.
The end result is that the ASRock C2750 board consumes more energy at idle than a simpler micro server board would. We could not get under 26W, and with four DIMMs 31W was needed. That is quite high, as Supermicro and several independent reviews report that the Supermicro A1SAM-2750F needs about 17W in the same configurations.
ASUS P9D-MH
The micro-ATX ASUS P9D-MH is a feature rich Xeon E3 based board. ASUS targets cloud computing, big data, and other network intensive applications. The main distinguishing feature is of course the dual 10 Gigabit SFP+ connectors of the Broadcom 57840S controller.

The C224 chipset provides two SATA 3G ports and four SATA 6G ports. ASUS added the LSI 2308 controller to offer eight SAS ports. The SAS drives can be configured to run in a RAID 0/1/10 setup.
The Xeon E3-1200v3 has 16 integrated PCIe 3.0 lanes. Eight of them are used by the LSI 2308 SAS controller, and the 10 Gigabit Ethernet controller gets four fast lanes to the CPU. That leaves four PCIe 3.0 lanes for a mechanical x8 PCIe slot.
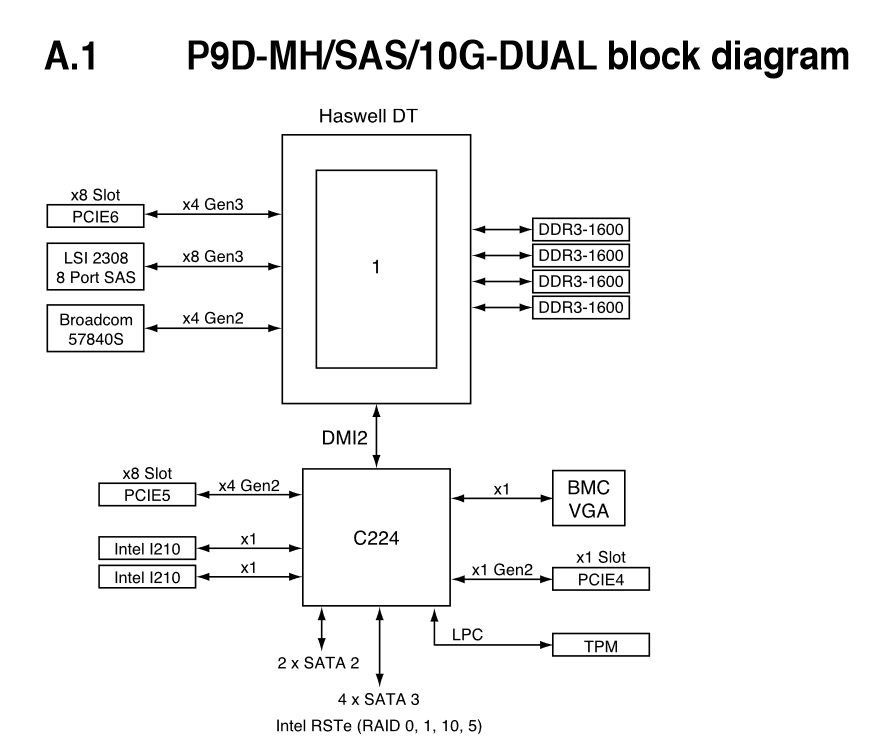
The second x8 PCIe slot gets four PCIe 2.0 slots and connects to the C224 chipset. The remaining PCIe 2.0 lanes are used by the BMC, the PCIe x1 slot, and the dual gigabit Ethernet controller.
Of course, all these features come with a price. With the efficient Xeon E3-1230L (25W TDP) and four 8GB DIMMs, the board consumes 41W at idle.
Quick Overview of the SoCs
In this review, we compare four different SoCs:
- Intel's Xeon E3-1240 v3 3.4GHz
- Intel's Xeon E3-1230L v3 1.8GHz
- Intel's Xeon E3-1265L v2 2.5GHz
- Intel's Atom C2750 2.4GHz
- AppliedMicro's X-Gene 1 2.4GHz
We have discussed the Xeon E3-1200 v3, Atom C2000, and X-Gene in more detail in our previous article. What follows is a quick discussion of why we tested these specific SKUs.
The Intel Xeon E3-1240 v3 is a speedy (3.4GHz, eight threads) Xeon E3 that is still affordable and has a decent TDP (69W). If you want a 6% higher clock (3.6GHz), Intel charges you 2.3X more. The Xeon E3-1240 v3 has an excellent performance per dollar ratio.
The Xeon E3-1230L v3 paper specs are incredible: eight cores that can boost to up to 2.8GHz (with a base clock of 1.8GHz) and a very low TDP of 25W. To see how much progress Intel has made, we compare it with the 45W Intel E3-1265L v2 at 2.5GHz based on the Ivy Bridge core. Will the Haswell core be enough to overcome the 700MHz (1.8 vs 2.5GHz) lower clock speed, which is necessary to make the chip work with a very low 25W TDP? How does this very low power Xeon with the brawny core compare to the Atom C2750?
The Atom C2750 is Intel's fastest Atom-based Xeon. We are very curious to see if there are applications where the eight lean cores can outperform the four wide cores of the Xeon E3.
And last but not least, the X-Gene 2.4GHz, the first server SoC incarnation of the ARMv8-A or AArch64 instruction set. The X-Gene has twice as many memory channels and can support twice as many DIMM slots as its Intel competitors. The cache architecture is a mix of the Atom C2000 and Xeon E3. Just like the Atom, two cores share a smaller L2 cache (256KB vs 1MB). And like the Xeon E3 (and unlike the Atom C2000), the X-Gene also has access to and 8MB L3 cache. Less positive is the antiquated 40nm production process and the fact that power management is much less sophisticated than Intel's solutions. The result is a relatively high 40W TDP.
While not every application was available on the X-Gene, we gathered enough datapoints to do a meaningful comparison. Where will the first productized ARMv8 chip land? Will it be an Atom C2000 or Xeon E3 killer, or neither? What kind of applications run well, and what kind of applications are still running much faster on a x86 chip?
We've added a few CPUs/SoCs to further improve the comparison. We've thrown in the Atom N2800 to mimic one of the worst Intel server CPUs ever (well, maybe "Paxville MP" was worse), the Atom S1260. The Xeon X5470 ("Harpertown", Penryn architecture) is also featured just to satisfy our curiosity and show how much performance has evolved. To understand the performance of the different SoCs, we should also take into account that the Intel chips almost always run at a higher clock speed than the advertised clock speed, thanks to Turbo Boost.
| Overview of Clock Speeds | ||||
| SoC | Max. Turbo Boost | Turbo Boost with Two Cores |
Turbo Boost with All Cores |
TDP |
| Xeon E3-1240v3 3.4 | 3800 | 3600 | 3600 | 80W |
| Xeon E3-1230Lv3 1.8 | 2800 | 2300 | 2300 | 25W |
| Xeon E3-1220v2 3.1 | 3500 | 3500 | 3300 | 69W |
| Xeon E3-1265Lv2 2.5 | 3500 | 3400 | 3100 | 45W |
| Atom C2750 2.4 | 2600 | 2600 | 2400 | 20W |
| X-Gene 1 2.4 | N/A | N/A | 2400 | 40W |
The 1.8GHz clock of the 25W TDP Xeon E3-1230L v3 may seem pretty low, but in reality the chip clocks at 2.3GHz and more. Single-threaded performance is even better with a top speed of 2.8GHz. The same is true for the Xeon E3-1265L v2, which has an even greater delta between the advertised clock speed (2.5GHz) and the actual clock speed (3.1 – 3.4GHz) when we run our benchmarks.
Benchmark Configuration
All tests were done on Ubuntu Server 14.04 LTS. We tested the HP Moonshot remotely. Our special thanks goes out to the team of HP EMEA Moonshot Discovery Lab of Grenoble (France). We tested both the Supermicro MicroCloud and the different motherboard configurations in our lab.
ASRock's C2750D4I
| CPU | Intel Atom C2750 |
| RAM | 4x 8GB DDR3 @1600 or 4x 16GB DDR3 @1333 (Intelligent Memory) |
| Internal Disks | 1x Intel MLC SSD710 200GB |
| Motherboard | ASRock C2750D4I |
| PSU | Supermicro PWS-502 (80+) |
Intel's Xeon E3-1200 v3 – ASUS P9D-MH
| CPU | Intel Xeon processor E3-1240 v3 Intel Xeon processor E3-1230L v3 |
| RAM | 4x 8GB DDR3 @1600 |
| Internal Disks | 1x Intel MLC SSD710 200GB |
| Motherboard | ASUS P9D-MH |
| PSU | Supermicro PWS-502 (80+) |
Intel's Xeon E3-1200 v2
| CPU | Intel Xeon processor E3-1220 v2 Intel Xeon processor E3-1265L v2 |
| RAM | 4x 8GB DDR3 @1600 |
| Internal Disks | 1x Intel MLC SSD710 200GB |
| Motherboard | Intel S1200BTL |
| PSU | Supermicro PWS-502 (80+) |
Supermicro's MicroCloud SYS-5038ML-H8TRF
We enabled four nodes, each with an Intel Xeon E3-1230L v3. Each node was configured with:
| CPU | Intel Xeon processor E3-1230L v3 |
| RAM | 4x 8GB DDR3 @1600 |
| Internal Disks | 1x Intel MLC SSD710 200GB |
| Motherboard | Super X10SLD-F |
| PSU | Dual Supermicro PWS-1K62P-1R (1.6 KW, 80+ Platinum) for 4 nodes |
We first tested with only one PSU, but that did not work out as the firmware kept all Xeons at their minimum clock speed of 800 MHz. Only with both PSUs active were the Xeon able to use all their p-states. Supermicro confirmed that four active nodes should be enough to make the PSU run efficiently.
HP Moonshot
We tested two different cartridges: the m400 and the m300. Below you can find the specs of the m400:
| CPU/SoC | AppliedMicro X-Gene 2.4 |
| RAM | 8x 8GB DDR3 @ 1600 |
| Internal Disks | m2 2280 Solid State 120GB |
| Cartridge | m400 |
And the m300:
| CPU/SoC | Atom C2750 2.4 |
| RAM | 8x 8GB DDR3 @ 1600 |
| Internal Disks | m2 2280 Solid State 120GB |
| Cartridge | m300 |
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs. We use the Racktivity ES1008 Energy Switch PDU to measure power consumption in our lab. We used the HP Moonshot ILO to measure the power consumption of the cartridges.
Memory Subsystem Bandwidth
While the Xeon E5 has ample bandwidth for most applications courtesy of the massive quad-channel memory subsystem, the Xeon E3 and Atom C2000 only have two memory channels. The Xeon E3 and Atom C2000 also do not support the fastest DRAM modules (DDR3-1600, Xeon E5: DDR4-2133), so memory bandwidth can be a problem for some applications.
We measured the memory bandwidth in Linux. The binary was compiled with the Open64 compiler 5.0 (Opencc). It is a multi-threaded, OpenMP based, 64-bit binary. The following compiler switches were used:
-Ofast -mp -ipa
To keep things simple, we only report the Triad sub-benchmark of our OpenMP enabled Stream benchmark.
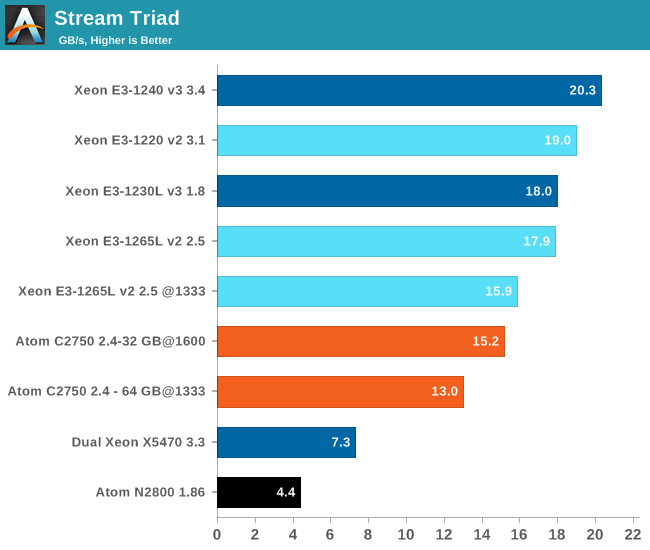
First of all, we should note that the clock speed of the CPU has very little influence on the Stream score. Notice the small difference (12.7%) between the Xeon E3-1240 that can boost to 3.6GHz and the Xeon E3-1230L that is limited to 2.3GHz (Turbo Boost with four cores busy).
The Xeon E3-1200 v3 is slightly more efficient than the Xeon E3-1200 v2; we measured a 7% bandwidth improvement. The Xeon E3 also offers up to 33% more bandwidth than the Atom C2750 with the same DIMMs.
To do an apples-to-apples comparison with the X-Gene 1, we compiled the same OpenMP enabled Stream benchmark (O3 –fopenmp –static).
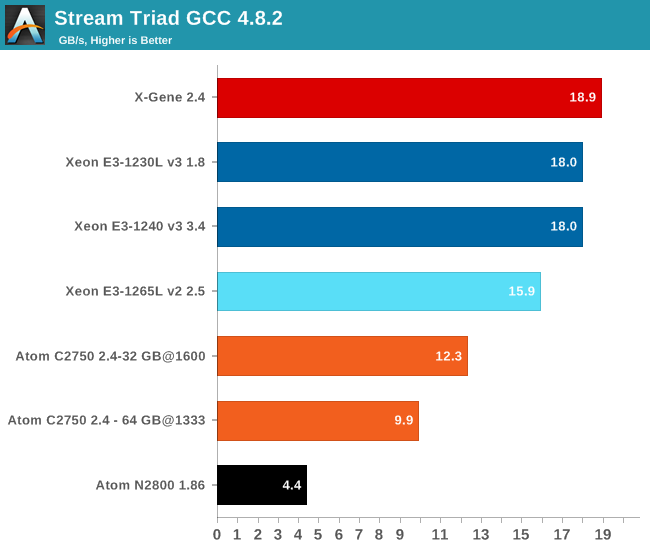
The Xeon E3 has the most efficient memory controller: it can extract almost as much bandwidth as the quad-channel memory controller of the X-Gene and about 46% more than the Atom. Our guess is that the X-Gene still has quite a bit of headroom to improve the memory subsystem. There is work to be done on the compiler side and on the hardware.
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
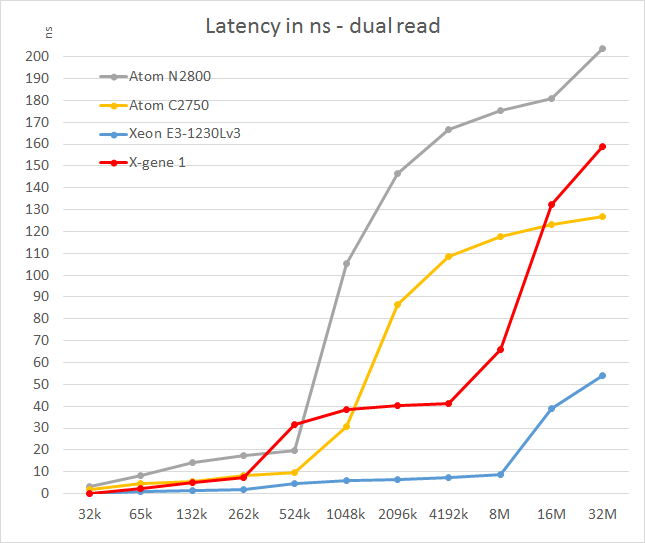
The X-Gene's L2 cache offers slightly better latency than the Atom C2750. That is not surprising as the L2 cache is four times smaller: 256KB vs 1024KB. Still, considering Intel has a lot of experience in building very fast L2 caches and the fact that AMD was never able to match Intel's capabilities, AppliedMicro deserves kudos.
However, the L3 cache seems pretty mediocre: latency tripled and then quadrupled! We are measuring 11-15 cycle latency for the L2 (single read) to 50-80 cycles (single read, up to 100 cycles in dual read) for the L3. Of course, on the C2750 it gets much worse beyond the 1MB mark as that chip has no L3 cache. Still, such a slow L3 cache will hamper performance in quite a few situations. The reason for this is probably that X-Gene links the cores and L3 cache via a coherent network switch instead of a low-latency ring (Intel).
In contrast to the above SoCs, the smart prefetchers of the Xeon E3 keep the latency in check, even at high block sizes. The X-Gene SoC however has the slowest memory controller of the modern SoCs once we go off-chip. Only the old Atom "Saltwell" is slower, where latency is an absolute disaster once the L2 cache (512KB) is not able to deliver the right cachelines.
Single-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
This is more or less the worst-case scenario for "brawny" cores like Haswell or Power 8. Or in other words, it should be the best-case scenario for a less wide "energy optimized" ARM or Atom core, as the wide issue cores cannot achieve their full potential.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
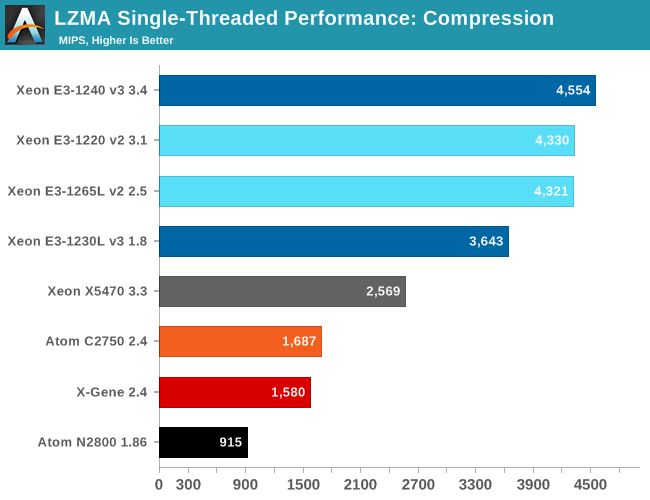
Despite the fact that the X-Gene has a 4-wide core, it is not able to outperform the dual issue Atom "Silvermont" core. Which is disappointing, considering that the AppliedMicro marketing claimed that the X-Gene would reach Xeon E5 levels. A 2.4GHz "Penryn/Harpertown" core reaches about 1860, which means that the X-Gene core still has a lot of catching up to do. It is nowhere near the performance levels of Ivy Bridge or Haswell.
Of course, the ARM ecosystem is still in its infancy. We tried out the new gcc 4.9.2, which has better support for AArch64. Compression became 6% faster, however decompression performance regressed by 4%....
Both the Xeon E3-1265L and E3-1220 v2 can boost to 3.5GHz, so they offer the same integer performance. The only reason that the Xeon E3-1240 v3 can offer higher performance is the slightly higher clock (3.8GHz Turbo Boost). The ultra efficient Xeon E3-1230L is capable of offering 80% of the performance of the 80W Xeon E3-1240. That is an excellent start.
As a long-time CPU enthusiast, you'll forgive me if I find the progress that Intel made from the 45nm "Harpertown" (X5470) to 22nm Xeon E3-1200 v3 pretty impressive. If we disable Turbo Boost, the Xeon E3-1240 at 3.4GHz achieves about 4200. This means that the Haswell architecture has an IPC that is no less than 63% better while running "IPC unfriendly" software.
The Xeon E3-1230L and Atom C2750 run at similar clock speeds in this single threaded task (2.8GHz vs 2.6GHz), but you can see how much difference a wide complex architecture makes. The Haswell Core is able to run about twice as many instructions in parallel as the Silvermont core. Meanwhile the Silvermont core is about 45% more efficient clock for clock than the old Saltwell core of the Atom N2800. The Haswell core result clearly shows that well designed wide architectures remain quite capable in "high ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
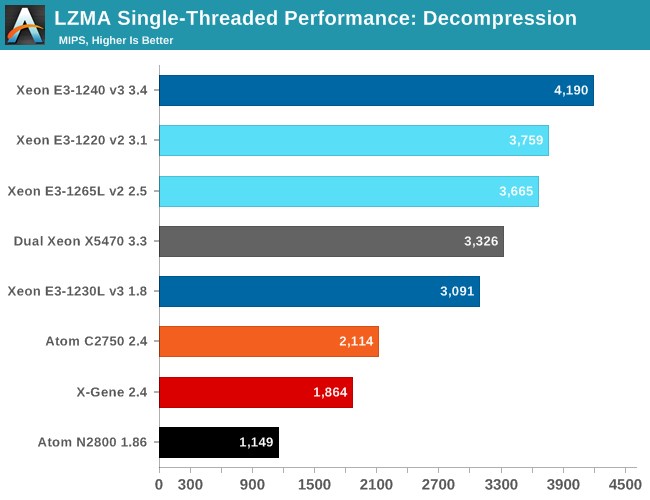
Decompression uses a rather exotic instruction mix and the progress made here is much smaller. The Haswell core is about 15% faster clock for clock than the old Harpertown core. Compared to the Silvermont core, the Haswell core is about 40% more efficient in this kind of software. The X-Gene core is about 10% slower than the Atom C2000.
Multi-Threaded Integer Performance
Next we run the same workload in several active instances to see how well the different CPUs scale.
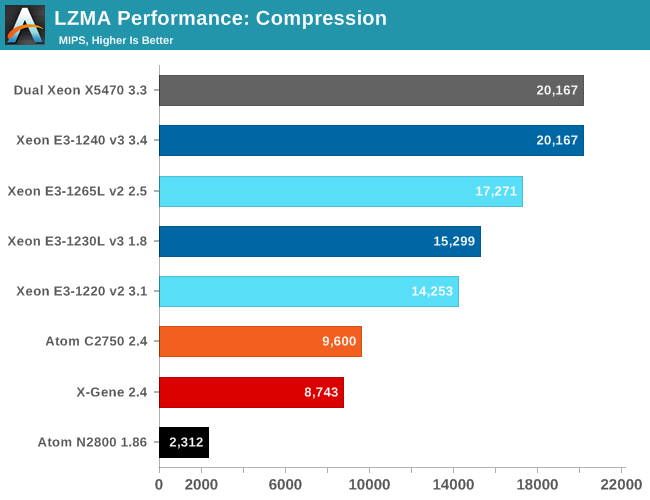
The excellent scaling (7.8X faster with eight cores) of the dual X5470 shows that the multi-threaded version of this benchmark does not rely on the memory subsystem but runs perfectly inside the L2 caches. The eight "real" cores of the Atom run the code 5.7X faster than one core. The Xeon E3-1240 scales by a factor of (almost) 5X and offers twice as much performance...with half the number of cores!
The 1230L v3 only runs 3.9x faster with eight threads, as the clock speed drops by one third from 2.8GHz to 1.8GHz. Still, total performance of the Xeon E3-1230L is 60% better than the Atom C2750 and the X-Gene 1. It is a clear sign that the combination of multi-threading and a complex core offers more raw integer processing power than eight simpler cores.
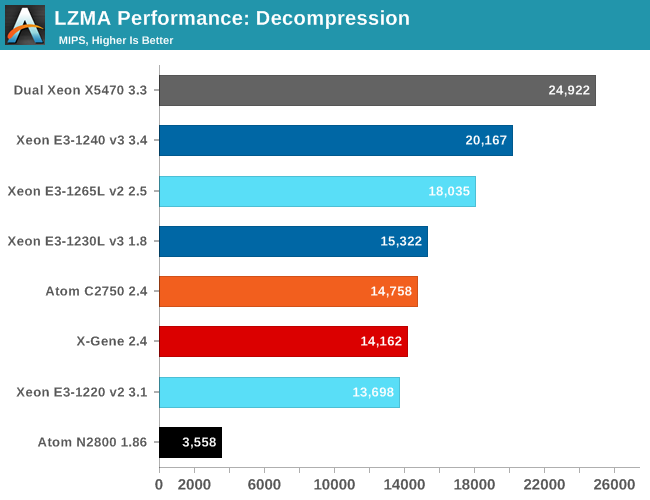
Decompression scales a lot better than compression. The multi-threaded result of the Atom C2750 is no less than 7X better than running one thread. Simultaneous multi-threading helps the Xeon E3 significantly as we found the four logical cores are more or less equal to two "real" ones (+50% performance boost). But the fact that the Xeon E3 has to reduce its clock speed to 1.8GHz to stay inside the power envelope makes the difference with the C2750 and X-Gene 1 relatively small.
However, decompression is a corner case. Memory bandwidth or latency matters little here. The Xeon X5470 scales well (7.73X) and outperforms the newer Xeons.
Java Server Performance
The SPECjbb 2013 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
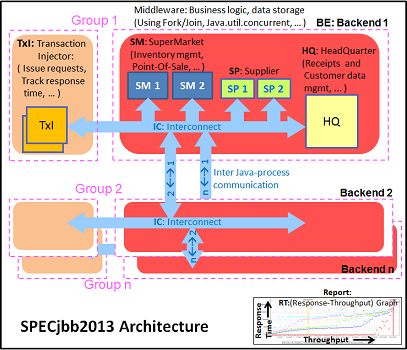
We tested with four groups of transaction injectors and back-ends. We applied a relatively basic tuning to mimic real-world use. Our first run was done with a low amount of memory:
"-server -Xmx4G -Xms4G -Xmn2G -XX:+AlwaysPreTouch -XX:+UseLargePages"
With these settings, the benchmark takes about 20-27GB of RAM. In our second run, we doubled the amount of memory to see if more memory (64GB vs. 32GB) can boost performance even more:
"-server -Xmx8G -Xms8G -Xmn4G -XX:+AlwaysPreTouch -XX:+UseLargePages"
With these settings, the benchmark takes about 43-57GB of RAM. The first metric is basically maximum throughput.
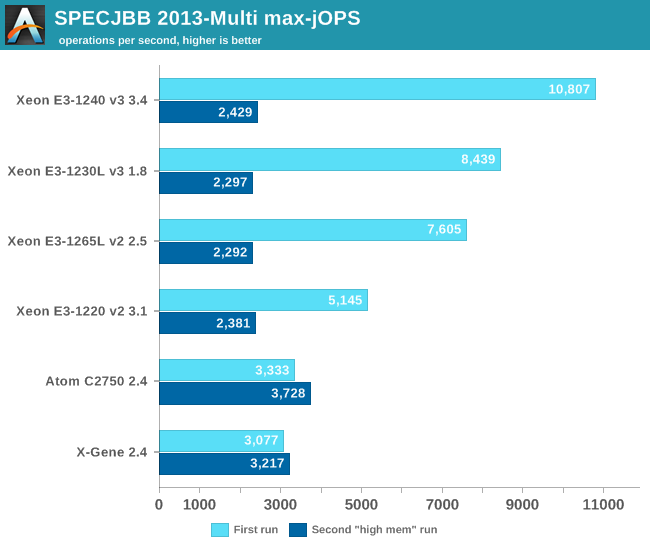
Assigning more memory to your Java VMs than what you have available is of course a bad idea, but now we have some numbers you can use to convince you coworkers of this fact. Although the Atom C2750 and X-Gene perform a little better thanks to fact that they can address twice as much RAM, they are nowhere near the performance of a Xeon E3-1230L if the latter is configured properly.
The Critical-jOPS metric is a throughput metric under response time constraint.
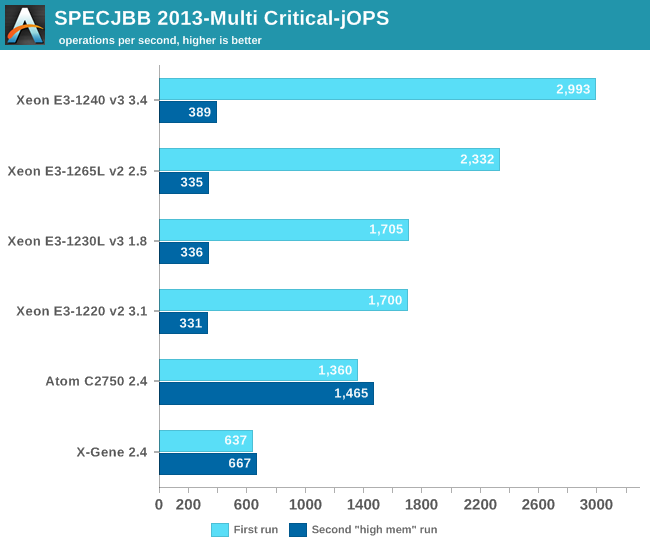
The Xeon E3 Haswell core continues to outperform the Atom by a tangible margin. The X-Gene fails to compete with the Intel SoCs. The conclusion is pretty simple: Java applications run best on a Haswell or Ivy Bridge core.
SPECJBB®2013 is a registered trademark of the Standard Performance Evaluation Corporation (SPEC).
Web Server Performance
Writing about micro and entry level servers without a website benchmark would be unforgiveable. Most websites are based on the LAMP stack: Linux, Apache, MySQL, and PHP. Few people write html/PHP code from scratch these days, so we turned to a Drupal 7.21 based site. The web server is Apache 2.4.7 and the database is MySQL 5.5.38 on top of Ubuntu 14.04 LTS.
Drupal powers massive sites (e.g. The Economist and MTV Europe) and has a reputation of being a hardware resource hog. That is a price more and more developers happily pay for lowering the time to market of their work. We tested the Drupal website with our vApus stress testing framework and increased the number of connections from 5 to 300.
We report the maximum throughput achievable with 95% percent of request being handled faster than 1000 ms. Notice that these numbers are not comparable to the ones in the last Xeon E5 server review, where we measured throughput at 100 ms. We assume that if you deploy a full LAMP stack on micro servers, your first requirement is cost efficiency and not the lowest response time at all times. If you do require the lowest response time, it is a best practice to only deploy the front-end of your web server on such a server. We are looking into developing such a real-world benchmark for a later review.
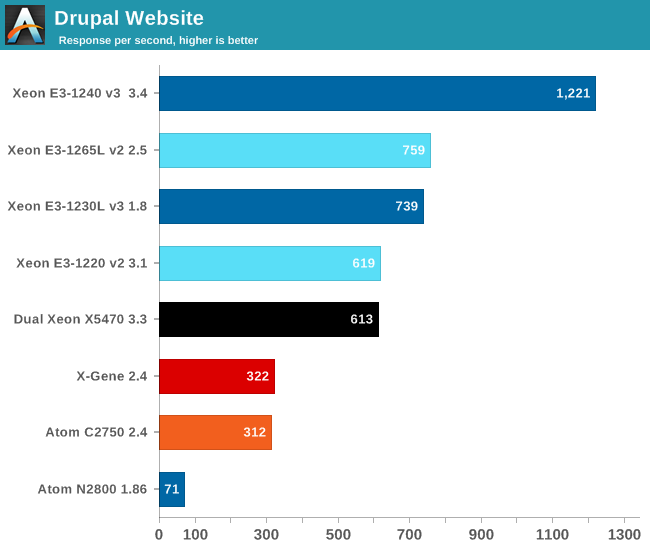
As the website load is a very bumpy curve with very short peaks of high CPU load and lots of lows, the Xeon E3-1200s operate at relatively high frequencies. Website workloads work well with Hyper-Threading as the low instruction level parallelism in one thread leaves a lot of headroom for another thread. Hyper-Threading delivers in this environment: the 8-thread Xeon E3-1265L v2 at 2.5-3.4GHz is quite a bit faster than the Xeon E3-1220 v2 at 3.1-3.3GHz.
We really wonder if anyone ever bought an Atom Saltwell based server of SeaMicro or HP to run web workloads. Those customers were either very brave or very naive; notice how the Xeon E3 is roughly 10 times faster (and as much as 17X faster)!
The Atom C2750 still performs rather poorly and sustain only about 42% of the requests of the Xeon E3-1230L. We suspect that the lack of an L3 cache that allows cores to sync threads quickly is one of the culprits. The MySQL back-end is included in this web benchmark, and this is one of the reasons that our benchmark prefers the Xeon E3. The X-Gene does not benefit much from the rather slow L3 cache and performs more or less like the Atom C2750.
Do not overestimate the effect of including the MySQL backend in our benchmark however. MySQL consumes about 20% of the CPU cycles. There is no denying that high clock speeds and simultaneous multi-threading are a very powerful mix to handle web requests.
According to some academic studies, the Atom C2750 should do better in typical scale-out software such as web search, web front-ends, and media streaming, where no syncing between threads is necessary.
MySQL Performance
For testing real-world SQL server performance with our homemade stress-testing software (vApus), we need a powerful client with lots of bandwidth. That kind of client was not available to us inside the network where the HP Moonshot was located. So we went back to the MySQL Sysbench utility. Sysbench allows us to place an OLTP load on a MySQL test database, and you can chose the regular test or the read only test. We chose read only as even with a flash device, Sysbench is quickly disk I/O limited.
The main reason why we tested with Sysbench is to get a huge amount of queries that only select very small parts (a few or one row) of the tables, so we can see how the SoCs behave in this kind of scenario. Sysbench allows you to test with any number of threads you like, but there is no "think time" feature. That means all queries fire off as quickly as possible, so you cannot simulate "light" and "medium" loads.
The response times are very small, which is typical for an OLTP test. To take them into account, we are showing you the highest throughput at around 3 ms (2.8 ms to 3.3 ms). We tested with 10 million records and 100,000 requests
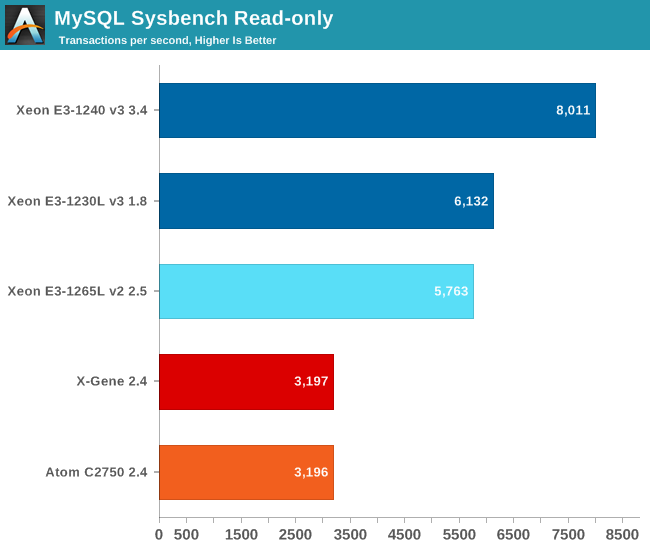
Again, the X-Gene is nowhere near the Xeon E3, but rather a competitor for the Atom C2750. The Xeon E3-1230L v3 outperforms the Xeon E3-1265L2 v2 by a small margin, despite the lower base clock.
Our First Scale-Out Big Data Benchmark: Elasticsearch
Elasticsearch is an open source, full text search engine that can be run on a cluster relatively easy. It's basically like an open source version of Google Search that can be deployed in an enterprise. It should be one of the poster children of scale-out software and is one of the representatives of the so called "Big Data" technologies. Thanks to Kirth Lammens, one of the talented researchers at my lab, we have developed a benchmark that searches through all the Wikipedia content (+/- 40GB). Elasticsearch is – like many Big Data technologies – built on Java (we use the 64-bit server version 1.7.0).
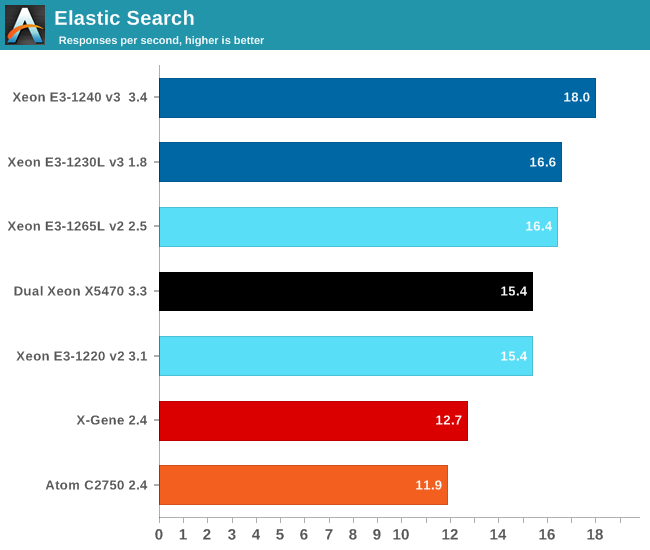
For the first time, the X-Gene has a small but measurable (7%) lead over the Atom C2750. Notice that once again the subtle improvements on the Haswell core allow the 25W E3-1230Lv3, typically running at 2.3GHz, to keep up with the 45W Xeon E3-1265L (running at 2.5-3.1GHz).
There is some truth in the claim that SoCs like the Atom C2750 are built for scale-out workloads. While the Atom C2750 achieved only 40% of the Xeon E3's performance running a LAMP stack, it is capable of reaching about two thirds of the performance of a low power Xeon E3. This is nothing earth shattering, but lots of "slim" cores might do a good job in Elasticsearch and other Big Data technologies.
Saving Power at Idle
Efficiency is very important in many scenarios, so let's start by checking out idle power consumption. We quickly realized that many servers would use simpler boards with much fewer chips than our ASUS P9D-MH, especially in micro servers. It is also clear that it is very hard to make a decent apples-to-apples comparison as the boards are very different. The Xeon 1200 V3 board (ASUS) is very feature rich, the Intel board of our Xeon E3 is simpler, and the board inside the HP m300 is bare bone.
But with some smart measurements and some deduction we can get there. By disabling SAS controllers and other features, we can determine how much a simpler board would consume, e.g. a Xeon E3 board similar to the one in the m300. To estimate the range and impact of the motherboard and other components, we also test the Xeon E3-1230L v3 in two other situations: running on the Supermicro board with cooling not included and on the feature rich ASUS P9D (a small fan is included here). You can find the results below.
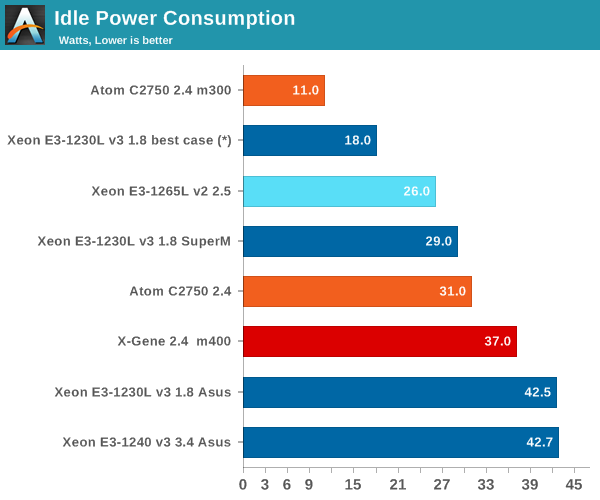
(*) Calculated as if the Xeon E3 was run in an "m300-ish" board.
The Supermicro nodes are quite efficient, with less than 29W per node. We measured this by dividing the measurement of four nodes by four. However, out of the box the fans have a tendency to run at high RPM, resulting in a power consumption of 7W per node in idle and up to 10W per node under load.
The m400 cartridge has eight DIMMs (instead of four) and a 10 Gbit controller (Mellanox Connect-X3 Pro Dual 10 Gbe NIC, disabled). Those features will probably consume a few watts. But this is where reality and marketing collide. If you just read newsbits about the ARM ecosystem, it is all robust and mature: after all, ARM's 64-bit efforts started back in 2012. The reality is that building such an ecosystem takes a lot of time and effort. The ARM server software ecosystem is – understandably – nowhere near the maturity of x86. One peak at the ARM 64-bit kernel discussion and you'll see that there is a lot of work to be done: ACPI and PCIe support for example are still works in progress.
The X-Gene in the HP m400 cartridge runs on a patched kernel that is robust and stable. But even if we substract about 5W for the extra DIMMs and disabled 10GbE NIC, 32W is a lot more than what the Atom C2750 requires. When running idle, the Atom C2750, the four low voltage 8GB DDR3 DIMMs, the 120GB SSD, and the dual 1GbE controller need no more than 11W. Even if we take into account that the power consumption of fans is not included, it shows how well HP engineered these cartridges and how sophisticated the Intel power management is.
For your information, the m350 cartridge goes even lower: 21W for four nodes. Of course, these amazing power figures come with some hardware limitations (two DIMMs per node, only small M.2 flash storage available).
Web infrastructure Power consumption
Next we tested the system under load.
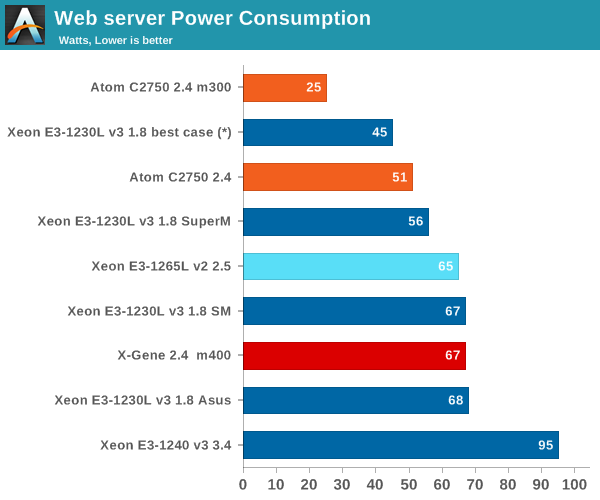
(*) measured/calculated to mimic a Xeon-E3 "m300-ish" board.
Notice how much difference there is between a feature rich motherboard and a micro server cartridge. The ASRock board consumes about twice as much as the HP m300 cartridge and the Supermicro node is in between. In both cases the cost of cooling is not included. Of course, we should not compare the ASRock board and the m300 cartridge directly as they target different markets, but it shows that the energy efficiency of a scale-out server infrastructure depends a lot on the server chassis used. HP's Moonshot really nailed it.
Power efficiency is not the forte of the X-Gene at the moment. The Xeon E3-1230L v3 is able to outperform it by a large margin and consumes a lot less power in the process. Even in combination with our most feature-rich boards such as the ASUS P9D-MH, a Xeon E3-1230L v3 does not consume more than an X-Gene with a much more efficient cartridge.
The War of the SoCs: Performance/Watt
As we mentioned earlier, it is not that easy to determine the performance per watt of the different SoCs. Depending on the motherboard feature richness, performance per watt can vary a lot. We tested the Xeon E3-1240 v3 only on the feature-rich ASUS P9D, while the Atom C2750 is on a very efficient and simple HP m300 cartridge. Given the discrepancies, we cannot simply divide the performance by the power consumption and called it a day. No, we have to do a few calculations to get a good estimate of the performance/watt.
The current idle power of modern Intel CPUs is so low that it is almost irrelevant. All cores but one are put in a deep sleep (power gating), and the one that is still active runs at a very low clock and voltage. We have found that a Xeon E3-1200 v2's (Ivy Bridge) idle power is around 3W, perhaps even less... it is very hard and time consuming to measure correctly. We know from the mobile device reviews that the Haswell idle power is even lower. The Atom core is simpler, but the sleep states are slightly less advanced. Regardless, whether a CPU consumes 1.7W or 2.2W idling is not relevant for our calculation.
If we take the delta between idle power of a system and full load, and add about 3W idle, we're probably very close to the real power consumption of an Intel CPU. The only noise is the loss of the power supply (low because these are highly efficient ones) and the fact that the voltage regulators and DRAM consume a little more at higher load. Again, we are talking about very low numbers.
In the case of the Xeon E3, we also add about 3W for the Intel C224 chipset (0.7W idle, 4.1W TDP). For the X-Gene, we may assume that the idle power is a lot higher. When we calculated the power of the different components (8 DIMMs, disabled 10 GbE, etc.), we estimate that it is about 10W.
For the total system power, the power consumption of one node, we take the m300 numbers as measured. We subtract 7W from the m400 numbers as the m400 has four extra DIMM slots and a 10 GbE NIC. We add 9W to the SoC power of the Xeon E3 as we have found out that 12W is more or less the power that a Xeon E3 node consumes without the SoC.
| Power Consumption Calculations | |||
| SoC | Power Delta = Power Web - Idle (W) |
Power SoC = Power Delta + Idle SoC + Chipset (W) |
Total System Power = Power SoC + Mobo (W) |
| Xeon E3- 1240 v3 3.4 | 95-42 = 53 | 53+3+3 = 59 | 53+3+12 = 68 |
| Xeon E3-1230L v2 1.8 | 68-41 = 27 (45-18 = 27) |
27+3+3 = 33 | 27+3+12 = 42 |
| Xeon E3-1265L v2 2.5 | 65-26 = 39 | 39+3+3 = 45 | 39+3+12 = 54 |
| Atom C2750 2.4 | 25-11 = 13 | 13+3+0 = 16 | 25 |
| X-Gene | 67-37 = 30 | 30+10 = 40 | 67-7 = 60 |
Let's discuss our findings. The Xeon E3-1240 v3 consumes probably about 50W with a high web load and is nowhere near its TDP (80W). The Xeon E3-1265L v2 (45W TDP) and Xeon E3-1230 (25W TDP) consume probably slightly more than their advertised TDP. That is slightly worrying as an integer workload that raises the CPU load to about 85-90% is not the worst situation you can imagine.... a 100% FPU load will go far beyond the TDP numbers then. The Atom C2750 requires the least power.
| Performance per Watt | |||||
| SoC | Total Power (SoC + Chipset) |
Total System Power |
Throughput at 1000ms |
Throughput per Watt (SoC) |
Throughput per Watt (System) |
| Xeon E3- 1240 v3 3.4 | 59 | 68 | 1221 | 20.7 | 18 |
| Xeon E3-1230L v3 1.8 | 33 | 42 | 739 | 22.4 | 17.6 |
| Xeon E3-1265L v2 2.5 | 45 | 54 | 759 | 16.9 | 14.1 |
| Atom C2750 2.4 | 16 | 25 | 312 | 19.5 | 12.5 |
| X-Gene 1 2.4 | 40 | 60 | 322 | 8 | 5.4 |
We are not pretending that our calculations are 100% accurate, but they should be close enough. At the end of the day, a couple Watts more or less is not going to change our conclusion that the Xeon E3-1230L v3 and Xeon E3-1240 v3 are the most efficient processors for these workloads. The Xeon E3-1230L v3 wins because it will require less cooling and less electricity distribution infrastructure using the same dense servers.
The Atom wins if you are power limited but the power efficiency is a bit lower when it comes to serving up a web infrastructure. Lastly, the X-Gene 1 has some catching up to do. The X-Gene 2 promises to be 50% more efficient. The software optimization efforts could bridge the rest of the gap, but we don't have a crystal ball.
Conclusion: the SoCs
The proponents of high core and thread counts are quick to discount the brawny cores for scale-out applications. On paper, wide issue cores are indeed a bad match for such low ILP applications. However, in reality, the high clock speed and multi-threading of the Xeon E3s proved to be very powerful in a wide range of server applications.
The X-Gene 1 is the most potent ARM Server SoC we have ever seen. However, it is unfortunate that AppliedMicro's presentations have created inflated expectations.

AppliedMicro insisted that the X-Gene 1 is a competitor for the powerful Haswell and Ivy Bridge cores. So how do we explain the large difference between our benchmarks and theirs? The benchmark they used is the "wrk" benchmark, which is very similar to Apache Bench. The benchmark will hit the same page over and over again, and unless you do some serious OS and Network tweaking, your server will quickly run out of ports/connections and other OS resources. So the most likely explanation is that the Xeon measurements are achieved at lower CPU load and are bottlenecked by running out of network and OS resources.
This is in sharp contrast with our Drupal test, where we test with several different user patterns and thus requests. Each request is a lot heavier, and as a result available connections/ports are not the bottleneck. Also, all CPUs were in the 90-98% CPU load range when we compared the maximum throughput numbers.
The 40nm X-Gene can compete with the 22nm Atom C2000 performance wise, and that is definitely an accomplishment on its own. But the 40nm process technology and the current "untuned" state of ARMv8 software does not allow it to compete in performance/watt. The biggest advantage of the first 64-bit ARM SoCs is the ability for an ARM processor to use eight DIMM slots and address more RAM. Better software support (compilers, etc.) and the 28nm X-Gene 2 SoC will be necessary for AppliedMicro to compete with the Intel Xeon performance/watt wise.
The Atom C2750's raw performance fails to impress us in most of our server applications. Then again we were pleasantly surprised that its power consumption is below the official TDP. Still, in most server applications, a low voltage Xeon E3 outperforms it by a large margin.
And then there's the real star, the Xeon E3-1230L v3. It does not live up to the promise of staying below 25W, but the performance surpassed our expectations. The result is – even if you take into account the extra power for the chipset – an amazing performance/watt ratio. The end conclusion is that the introduction of the Xeon-D, which is basically an improved Xeon E3 with integrated PCH, will make it very hard for any competitor to beat the higher-end (20-40W TDP) Intel SoCs in performance/watt in a wide range of "scale-out" applications.
Conclusion: the Servers
As our tests with motherboards have shown, building an excellent micro or scale-out server requires much more thought than placing a low power SoC in a rack server. It is very easy to negate the power savings of such an SoC completely if the rest of server (motherboard, fans, etc.) is not built for efficiency.
The Supermicro MicroCloud server is about low acquisition costs and simplicity. In our experience, it is less efficient with low power Xeons as the cooling tends to consume proportionally more (between 7-12W per node with eight nodes installed). The cooling system and power supplies are built to work with high performance Xeon E3 processors.
HP limits the most power efficient SoCs (such as the Atom C2730) to cartridges that are very energy efficient but also come with hardware limitations (16GB max. RAM, etc.). HP made the right choice as it is the only way to turn the advantages of low power SoCs into real-world energy efficiency, but that means the low power SoC cartridges may not be ideal for many situations. You will have to monitor your application carefully and think hard about what you need and what not to create an efficient datacenter.
Of the products tested so far, the HP Moonshot tends to impress the most. Its cleverly designed cartridges use very little power and the chassis allows you to choose the right server nodes to host your application. There were a few application tests missing in this review, namely the web caching (memcached) and web front-end tests, but based on our experiences we are willing to believe that the m300/m350 cartridge are perfect for those use cases.
Still, we would like to see a Xeon E3 low voltage cartridge for a "full web infrastructure" (front- and back-end) solution. That is probably going to be solved once HP introduces a Xeon-D based cartridge. Once that is a reality, you can really "right-size" the Moonshot nodes to your needs. But even now, the HP Moonshot chassis offers great flexibility and efficiency. The flexibility does tend to cost more than other potential solutions – we have yet to find out the exact pricing details – but never before was it so easy to adapt your tier one OEM server hardware so well to your software.






