Original Link: https://www.anandtech.com/show/7479/server-buying-decisions-memory
Server Buying Decisions: Memory
by Johan De Gelas on December 19, 2013 10:00 AM EST- Posted in
- Memory
- IT Computing
- Cloud Computing
- Enterprise
- server

We reviewed several types of server memory back in August 2012. You still have the same three choices—LRDIMMs, RDIMMs, and UDIMMs—but the situation has significantly changed now. The introduction of the Ivy Bridge EP is one of those changes. The latest Intel Xeon has better support for LR-DIMMs and supports higher memory speeds (up to 1866 MHz).
But the biggest change is that the pricing difference between LRDIMMs and RDIMMs has shrunk a lot. Just a year ago, a 32GB LRDIMM cost $2000 and more, while a more "sensible" 16GB RDIMM costs around $300-$400. You paid about three times more per GB to get the highest capacity DIMMs in your servers. Many servers could benefit from more memory, but that kind of pricing made LRDIMMs only an option for IT projects where hardware costs were dwarfed by other costs like consulting and software licenses. Fifteen months in IT is like half a decade in other industries; just look at the table below.
| Memory type: |
Low voltage |
Ranks |
Price ($) Q4 2013 |
Price ($) perGB |
| 8GB RDIMM—1600 | yes | Dual | 153 | 19 |
| 16GB RDIMM—1600 | yes | Dual | 243 | 15 |
| 8GB RDIMM—1866 | no | Dual | 169 | 21 |
| 16GB RDIMM—1866 | no | Dual | 257 | 16 |
| 32GB RDIMM—1333 | yes | Quad | 808 | 25 |
| 32GB LRDIMM—1333 | yes | dual* | 822 | 26 |
| 32GB LRDIMM—1866 | no | dual* | 822 | 26 |
(*) Quad, but load of dual
If you need a refesher on UDIMMs, RDIMMs and LRDIMMs, check out our technical overview here. The price per GB of LRDIMMs is only 60% higher than that of the best RDIMMs. Quadrank 32GB RDIMMs used to be a lot cheaper than their load reduced competition and that difference is now negligible.
Generally speaking, LRDIMMs are a lot more attractive than their quad ranked RDIMM counterparts with the same capacity. Due to the capacitive load of memory chips on the signal integrity of a memory channel, the clock speed and the number of chips in a channel are limited. To make this more clear, we described the relation between DPC (DIMMs Per Channel), CPU (Sandy Bridge and Ivy Bridge), DIMM type, and DIMM clock speed in the following table. We based this table on the technical server manuals and recommendations of HP, Dell, and Cisco. Low voltage DDR3 works at 1.35V, "normal" DDR3 DIMMs work at 1.5V.
| Memory type: | 2DPC (SB) | 2DPC (IVB) | 3DPC (SB) | 3DPC (IVB) |
| Dual Rank RDIMM - 1600 | 1600 | 1600 | 1066 | 1066/1333 (*) |
| Dual Rank RDIMM - 1866 | 1600 | 1866 | 1066 | 1066/1333 (*) |
| Quad Rank RDIMM - 1333 | 1333 | 1333 | N/A | N/A |
| LRDIMM - 1866 | 1600 | 1866 | 1333 | 1333 |
| LV 16GB RDIMM - 1333 (1.35V) | 1333 | 1333 | N/A | N/A |
| LV 16GB LRDIMM - 1600 (1.35V) | 1600 | 1600 | 1333 | 1333 |
(*) Some servers support 1333 MHz, others limit speed to 1066 MHz
The new Ivy Bridge CPU supports 1866 MHz DIMMs—both LRDIMMs and RDIMMS—up to 2DPC. The load reduced DIMMs support up to 3DPC at 1333 MHz. In most servers, RDIMMs are limited to 1066 MHz at 3DPC. However, the main advantage of LRDIMMs is still capacity: you get twice as much capacity at 1866 MHz. Dual ranked RDIMMs are limited to 16GB while LRDIMMs support 32GB with the same load. 64GB LRDIMMs are now available, but currently (Q4 2013) few servers seem to support them. Notice also that only LRDIMMs support Low Power DIMMs at 3 DPC.
The quad ranked 32GB RDIMMs support only 2DPC and are limited to 1333 MHz. With 40% more speed at 2DPC and the same capacity, and 50% more capacity (3DPC) in your server, the LRDIMMs are simply a vastly superior offering at the same cost. So we can safely forget about quad ranked RDIMMs.
Worth the Price Premium?
The real question is thus whether LRDIMMs are worth the 60% higher cost per GB. Servers that host CPU-bottlenecked (HPC) applications are much better off with RDIMMs, as the budget should be spent on faster CPUs and servers as much as possible. The higher speed that LRDIMMs offer in certain configurations may help for some memory intensive HPC applications, but the memory buffer of LRDIMMs might negate the clock speed advantage as it introduces extra latency. We will investigate this further in the article, but it seems that most HPC applications are not the prime target for LRDIMMs.
Virtualized servers are the most obvious scenario where the high capacity of LRDIMMs can pay off. As the Xeon E5 V2 ("Ivy Bridge EP") increased the core count from maximum 8 to 12, many virtualized servers will run out of memory capacity before they can use all those cores. It might be wiser to buy half as many servers with twice as much memory. A quick price comparison illustrates this:
- An HP DL380 G8 with 24 x 16GB RDIMMs, two E5-2680v2, two SATA disks and a 10 GbE NIC costs around $13000
- An HP DL380 G8 with 24 x 32GB LRDIMMs, two E5-2680v2, two SATA disks and a 10 GbE NIC costs around $26000
At first sight, buying twice as many servers with half as much memory is more attractive than buying half as many servers with twice as much capacity. You get more processing power and more network bandwidth and so on. But those advantages are not always significant in a virtualized environment.
Most software licenses will make you pay more as the server count goes up. The energy bill of two servers with half as much memory is always higher than one server with twice as much memory. And last but not least, if you double the amount of servers, you will increase the time you spend on administering the server cluster.
So if your current CPU load is relatively high, chances are that an LRDIMM equipped server makes sense: the TCO will be quite a bit lower. We have tested this in our previous article and found that having more memory available can reduce the response time of virtualized applications significantly even if you're running at high CPU load. Since that test, little has changed, besides the fact that LRDIMMs have become a lot cheaper. So it is pretty clear that for virtualized clusters, LRDIMMs have become a lot more attractive.
Besides a virtualized cluster, there is another prime candidate: servers that host disk limited workloads, where memory caching can alleviate the bottleneck. Processing power is irrelevant in that case, as the workload is dominated by memory and/or disk accesses. Our Content Delivery Network (CDN) server test is a real world example of this and will quantify the impact of larger memory capacity.
Benchmark method
We used the HP DL 380 Gen8, the best selling server in the world. The good people at Micron helped ensure we could test with 24 DIMMs.
As we were told that the new Xeon E5-26xx V2 ("Ivy Bridge EP") had better support for LRDIMMs than the Xeon E5-26xx ("Sandy Bridge EP"), we tested with both the E5 2680 v2 and the E5-2690 in the Stream and latency tests. For the real-world CDN test (see further) we only use the E5-2680 v2. As the latter test is not limited by the CPU at all (25% load on the E5-2680v2), testing with different CPUs does not make much sense.
Benchmark Configuration: HP DL 380 Gen8 (2U Chassis)
Testing with the HP-DL 380 Gen8 was a very pleasant experience: changing CPUs and DIMMs is extremely easy and does not involve screwdrivers.

The benchmark configuration details can be found below.
| CPU |
Two Intel Xeon processor E5-2680 v2 (2.8GHz, 12c, 25MB L3, 115W) Two Intel Xeon processor E5-2690 (2.9GHz, 8c, 20MB L3, 135W) |
| RAM |
768GB (24x32GB) DDR3-1866 Micron MT72JSZS4G72LZ-1G9 (LRDIMM) or 384GB (24 x 16GB) Micron MT36JSF2G72PZ – DDR3-1866 |
| Internal Disks | One Intel MLC SSD710 200GB |
| BIOS version | P70 09/41/2013 |
| NIC | Dual-port Intel X540-T2 10Gbit NC |
| PSU | HP 750W CS Platinum Plus Hot Plug 750 Watt |
A dual-port Intel X540-T2 10Gbit NC was installed and was connected to the DELL PowerConnect 8024F switch with a 20Gbit bond.
Measuring Stream Throughput
Before we start with the real world tests, it is good to perform a few low level benchmarks. First, we measured the bandwidth in Linux. The binary was compiled with the Open64 compiler 5.0 (Opencc). It is a multi-threaded, OpenMP based, 64-bit binary. The following compiler switches were used:
-Ofast -mp -ipa
The results are expressed in GB per second. Note that we also tested with gcc 4.8.1 and compiler options
-O3 –fopenmp –static
Results were consistently 20 to 30% lower with gcc. So we feel our choice for Open64 is appropriate: everybody can reproduce our results (Open64 is freely available) and as the binary is capable of reaching higher speeds, it is easier to spot speed differences between DIMMs. We equipped the HP with a Sandy Bridge EP Xeon (Xeon 2690) and an Ivy Bridge EP Xeon (Xeon 2680v2). Note that the Stream benchmark is not limited by the CPUs at all. All tests were done with 32 or 40 threads.
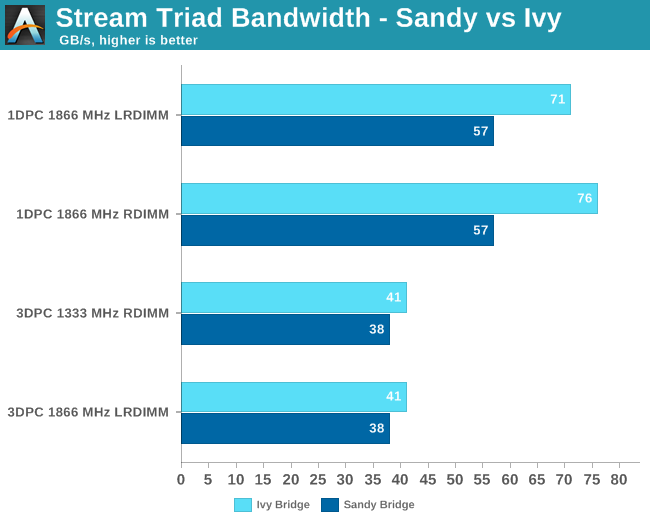
The extra buffering inside the LR-DIMMs has very little impact on the effective bandwidth. RDIMMs deliver only 3% more bandwidth at 1866 MHz, 1DPC. This bandwidth gap is 0 when we run the same test on our "Sandy Bridge EP" Xeon.
At 3DPC, there is no bandwidth gap at all. Both DIMMs are running at the same speed. Also note that the newer Xeon outperforms the older one by 8 to 33% in this test.
Measuring Latency
To measure latency, we use the open source "TinyMemBench" benchmark. The source was compiled for x86 with gcc 4.8.1 and optimization was set to "-O3". We used the latency values measured with the largest buffer size: 64MB. The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
First we tested with 1 DPC. RDIMM-1866 means we use the Micron 1866 RDIMMs. So even though they only work at 1600 MT/s when the Xeon E5-2690 is used, we describe them as "1866". The RDIMM-1600 are Samsung DIMMs which are designed to run at 1600 MT/s.
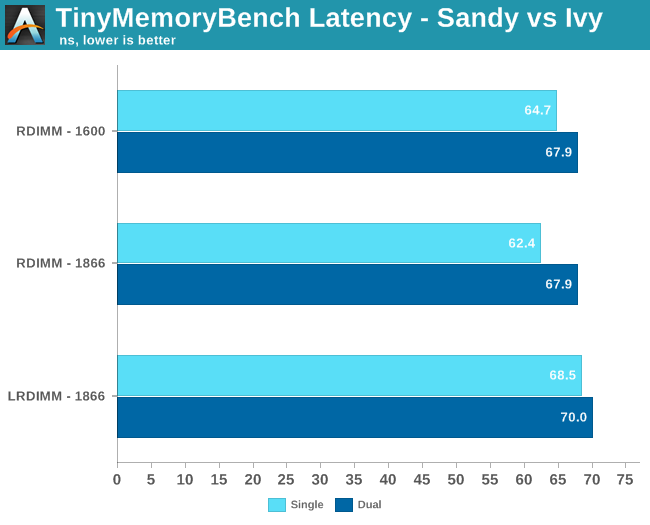
The iMB buffer increases latency by about 5 to 10%. But LRDIMMs are hardly useful when you insert only one DIMM per channel. They are made and bought to run at 3DPC, so that's what we tested neext. Both LRDIMMs and RDIMMs have to clock back to 1333 MT/s at 3DPC.
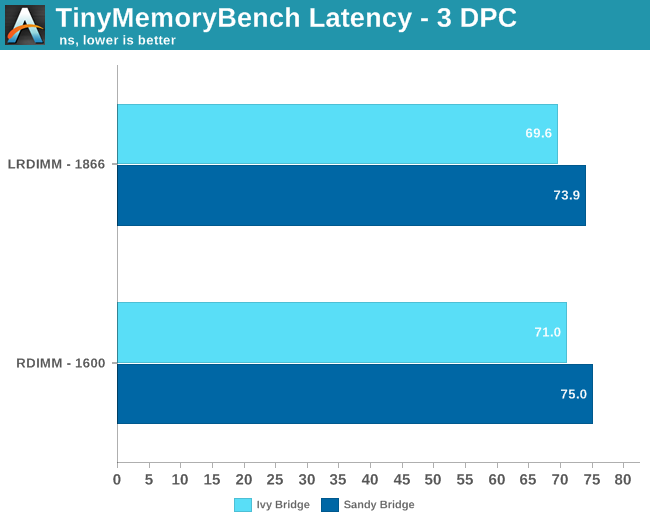
The small latency advantage that RDIMM had is gone. In fact, LRDIMMs seem to have a very small latency advantage over the RDIMMs in this case. Again, memory performance of the Ivy Bridge Xeon is a bit better, but the small clock speed advantage (2.8 vs 2.7 GHz) is probably the simplest and best explanation.
In summary, the differences in latency and bandwidth are pretty small between similar LRDIMMs and RDIMMs. And in that case, it will be nearly impossible to measure any tangible effects on real world applications.
CDN
Serving static files is a common task for web servers. However, it is best to offload this from the application web servers to dedicated web servers that can be configured optimally. Those servers, which together form the Content Delivery Network (CDN), are placed in networks closer to the end-user, saving IP transport costs and improving response times. These CDN servers need to cache files as much as they can, and are thus ideal candidates for some high capacity DIMM testing.
A big thanks to Wannes De Smet, my colleague at the Sizing Servers Lab, part of Howest University for making the CDN test a reality.
Details of the CDN setup
We simulate our CDN test with one CDN server and three client machines in a 10 Gbit/s network. Each client machine simulates thousands of users requesting different files. Our server runs Ubuntu 13.04 with Apache. Apache was chosen over NginX as it uses the file system cache whereas NginX does not. Apache has been optimized to provide maximum throughput.
Apache is set to use the event multi process model, configured as follows:
StartServers 1
MinSpareThreads 25
MaxSpareThreads 75
ThreadLimit 150
ThreadsPerChild 150
MaxClients 1500
MaxRequestsPerChild 0
Each client machine has an X540-T1 10Gbit adapter connected to the same switch as the HP DL380 (see benchmark configuration). To load balance traffic across the two links, the balanced-rr algorithm is selected for the bond. No network optimization has been carried out, as network conditions are optimal.
The static files requested originate from sourceforge.org, a mirror of the /a directory, containing 1.4TB of data or 173000 files. To model real-world load for the CDN two different usage patterns or workloads are executed simultaneously.
The first workload contains a predefined list of 3000 files from the CDN with a combined concurrency of 50 (50 requests per second), resembling files that are “hot” or requested frequently. These files have a high chance to reside in the cache. Secondly, another workload requests 500 random files from the CDN per concurrency (maximum concurrent requests is 45). This workload simulates users that are requesting older or less frequently accessed files.
Test Run
An initial test run will deliver all files straight off an iSCSI LUN. The LUN consists of a Linux bcache volume, with an Intel 720 SSD as cache and three 1TB magnetic disks in RAID-5, handled by an Adaptec ASR72405 RAID adapter, as backing device. Access is provided over a 10Gbit SAN network. Handling these files will fill the page cache, thus filling memory. Linux will automatically use up to 95% of the available RAM memory.
Subsequent runs are measured (both throughput and response time) and will deliver as many files from memory as possible. This depends on the amount of RAM installed and how frequent a file is requested, as the page cache uses a Least Recently Used algorithm to control which pages ought to remain in cache.
The CDN Results
Simulating thousands of users requesting one of the 173325 files on our CDN server was the hardest stress test that we've ever done.
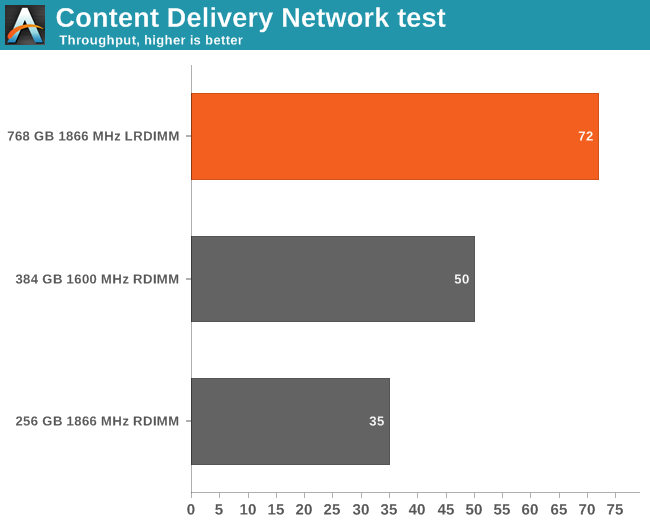
The results are telling: doubling the amount of memory results in a very significant 44% speedup. It also results in tangible reductions in response time. Let us check out the average latency
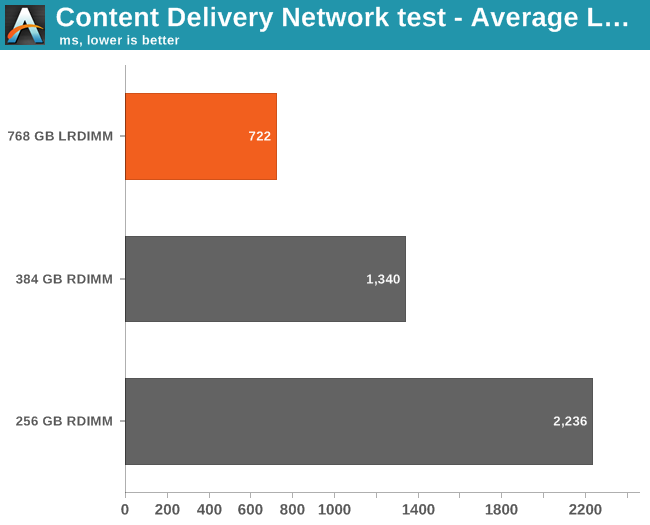
The average latency of the LRDIMM equipped server is exactly half that of the 384GB RDIMM machine and one third (!) of the 2DPC RDIMM machine. That is very tangible advantage that results in big cost savings (half as many servers). Speaking of cost savings, let us find out what the energy bill will look like.
Evaluating Power
We start with the idle numbers.
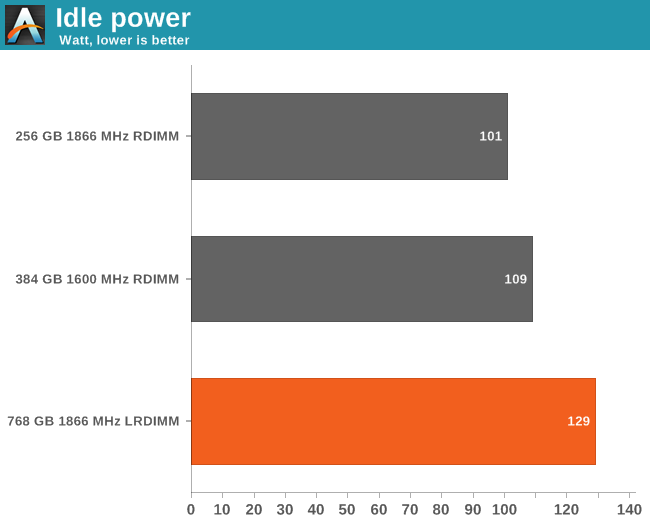
The HP server consumes very little, about twice as much as a decent desktop at idle despite the 24 DIMMs and 20 physical cores. The LRDIMM iMB consumes about 1 additional Watt per DIMM. Next, let's look at the average power consumed during our CDN test.
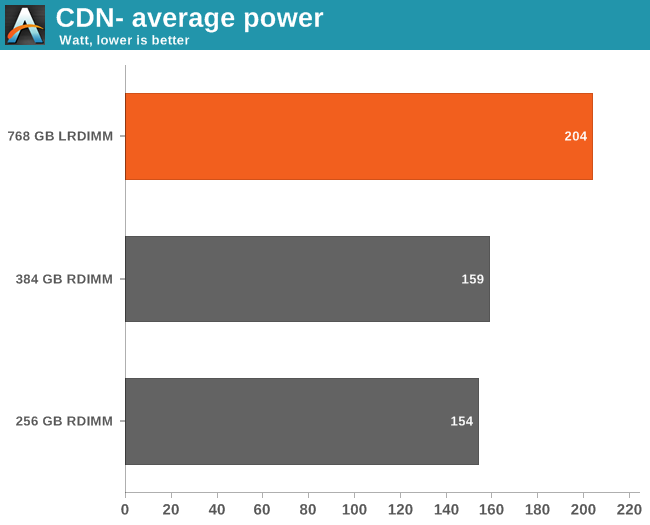
The LRDIMM server consumes 45 Watts more, or about 28%. Note that this does not mean that LRDIMMs significantly increase the power consumption. The CPU is working quite a bit harder when running with 768GB RAM as it is able to get more out of the RAM cache instead of waiting for the disks.
Two RDIMM servers would require 320W, which is still a lot more than the 204W the HP 380 Gen8 consumed with 768GB.
Conclusion
LRDIMMs offer the same bandwidth and latency as RDIMMs, but offer up to twice as much capacity for a 60% higher price per GB. Whether the price premium is worth paying depends on the applications you run. We don't think most HPC applications will benefit, but it is a totally different story for virtualization and caching servers.
We knew that servers like Memcached and file caching servers were natural candidates for running on top of an LRDIMM based server. In our newly developed CDN test we have quantified the performance impact of having twice as much memory available in such a CDN server.
The results are pretty spectacular: throughput is on average 44% better and even better, response times are cut in half. Considering that one LRDIMM equipped server is about as expensive as two RDIMM servers with half the DRAM capacity, it is pretty clear that the Total Cost of Ownership (TCO) of LRDIMM servers is a lot lower. The much lower price per GB make LRDIMMs attractive for a whole new range of caching servers.






