Original Link: https://www.anandtech.com/show/7457/the-radeon-r9-290x-review
The AMD Radeon R9 290X Review
by Ryan Smith on October 24, 2013 12:01 AM EST- Posted in
- AMD
- Radeon
- GPUs
- Hawaii
- Radeon 200

To say it’s been a busy month for AMD is probably something of an understatement. After hosting a public GPU showcase in Hawaii just under a month ago, the company has already launched the first 5 cards in the Radeon 200 series – the 280X, 270X, 260X, 250, and 240 – and AMD isn’t done yet. Riding a wave of anticipation and saving the best for last, today AMD is finally launching the Big Kahuna: the Radeon R9 290X.
The 290X is not only the fastest card in AMD’s 200 series lineup, but the 290 series in particular also contains the only new GPU in AMD’s latest generation of video cards. Dubbed Hawaii, with the 290 series AMD is looking to have their second wind between manufacturing node launches. By taking what they learned from Tahiti and building a refined GPU against a much more mature 28nm process – something that also opens the door to a less conservative design – AMD has been able to build a bigger, better Tahiti that continues down the path laid out by their Graphics Core Next architecture while bringing some new features to the family.
Bigger and better isn’t just a figure of speech, either. The GPU really is bigger, and the performance is unquestionably better. After vying with NVIDIA for the GPU performance crown for the better part of a year, AMD fell out of the running for it earlier this year after the release of NVIDIA’s GK110 powered GTX Titan, and now AMD wants that crown back.
| AMD GPU Specification Comparison | ||||||
| AMD Radeon R9 290X | AMD Radeon R9 280X | AMD Radeon HD 7970 | AMD Radeon HD 6970 | |||
| Stream Processors | 2816 | 2048 | 2048 | 1536 | ||
| Texture Units | 176 | 128 | 128 | 96 | ||
| ROPs | 64 | 32 | 32 | 32 | ||
| Core Clock | 727MHz? | 850MHz | 925MHz | 880MHz | ||
| Boost Clock | 1000MHz | 1000MHz | N/A | N/A | ||
| Memory Clock | 5GHz GDDR5 | 6GHz GDDR5 | 5.5GHz GDDR5 | 5.5GHz GDDR5 | ||
| Memory Bus Width | 512-bit | 384-bit | 384-bit | 256-bit | ||
| VRAM | 4GB | 3GB | 3GB | 2GB | ||
| FP64 | 1/8 | 1/4 | 1/4 | 1/4 | ||
| TrueAudio | Y | N | N | N | ||
| Transistor Count | 6.2B | 4.31B | 4.31B | 2.64B | ||
| Typical Board Power | ~300W (Unofficial) | 250W | 250W | 250W | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 40nm | ||
| Architecture | GCN 1.1 | GCN 1.0 | GCN 1.0 | VLIW4 | ||
| GPU | Hawaii | Tahiti | Tahiti | Cayman | ||
| Launch Date | 10/24/13 | 10/11/13 | 12/28/11 | 12/15/10 | ||
| Launch Price | $549 | $299 | $549 | $369 | ||
We’ll dive into the full architectural details of Hawaii a bit later, but as usual let’s open up with a quick look at the specs of today’s card. Hawaii is a GCN 1.1 part – the second such part from AMD – and because of that comparisons with older GCN parts are very straightforward. For gaming workloads in particular we’re looking at a GCN GPU with even more functional blocks than Tahiti and even more memory bandwidth to feed it, and 290X performs accordingly.
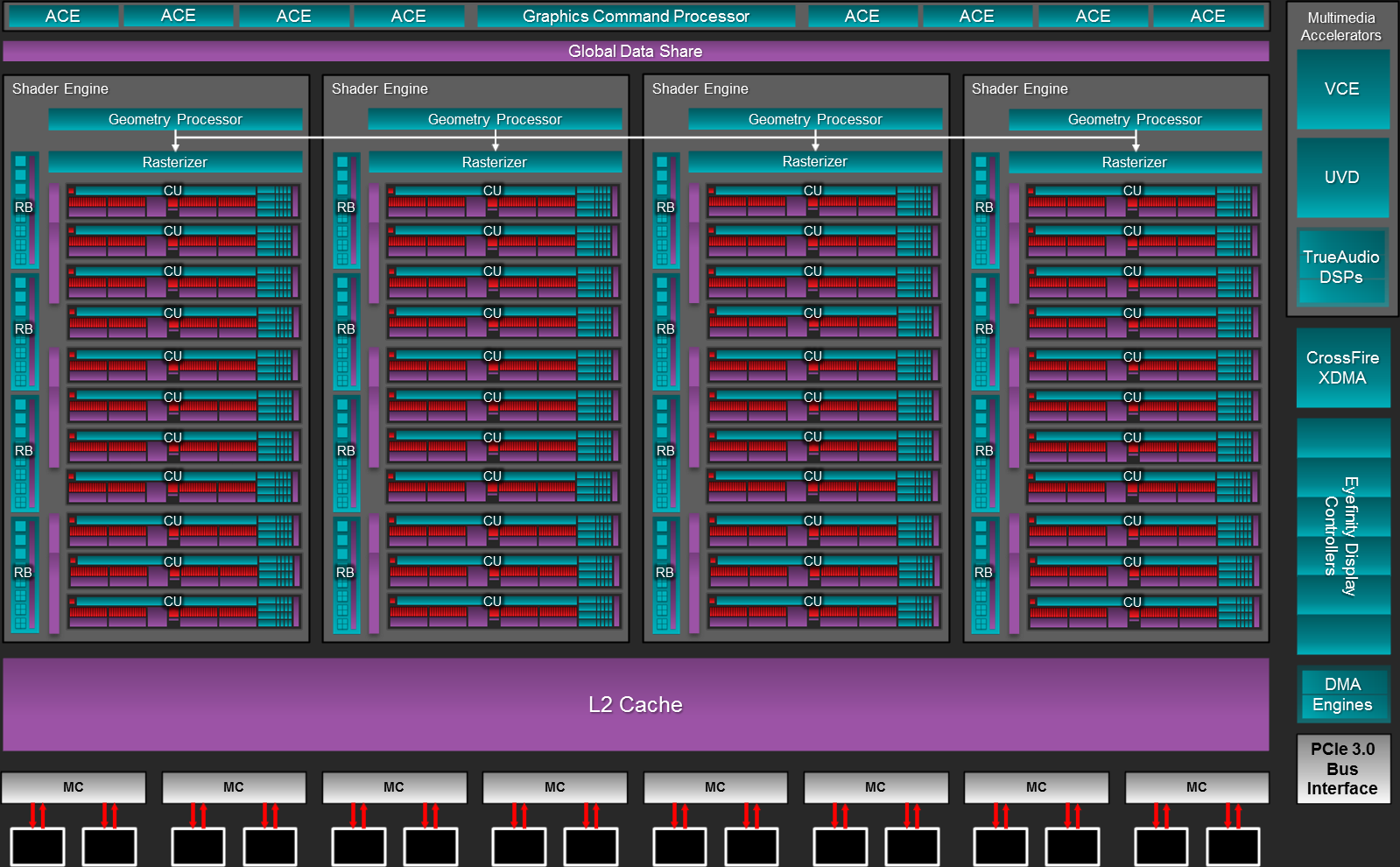
Compared to Tahiti, AMD has significantly bulked up both the front end and the back end of the GPU, doubling each of them. The front end now contains 4 geometry processor and rasterizer pairs, up from 2 geometry processors tied to 4 rasterizers on Tahiti, while on the back end we’re now looking at 64 ROPs versus Tahiti’s 32. Meanwhile in the computational core AMD has gone from 32 CUs to 44, increasing the amount of shading/texturing hardware by 38%.
On the other hand GPU clockspeeds on 290X are being held consistent versus the recently released 280X, with AMD shipping the card with a maximum boost clock of 1GHz (they’re unfortunately still not telling us the base GPU clockspeed), which means any significant performance gains will come from the larger number of functional units. With that in mind we’re looking at a video card that has 200% of 280X’s geometry/ROP performance and 138% of its shader/texturing performance. In the real world performance will trend closer to the increased shader/texturing performance – ROP/geometry bottlenecks don’t easily scale out like shading bottlenecks – so for most scenarios the upper bound for performance increases is that 38%.
Meanwhile the job of feeding Hawaii comes down to AMD’s fastest memory bus to date. With 280X and other Tahiti cards already shipping with a 384-bit memory bus running at 6GHz – and consuming quite a bit of die space to get there – to increase their available memory bandwidth AMD has opted to rebalance their memory configuration in favor of a wider, lower clockspeed memory bus. For Hawaii we’re looking at a 512-bit memory bus paired up with 5GHz GDDR5, which brings the total amount of memory bandwidth to 320GB/sec. The reduced clockspeed means that AMD’s total memory bandwidth gains aren’t quite as large as the increase in the memory bus size itself, but compared to the 288GB/sec on 280X this is still an 11% increase in memory bandwidth and a move very much needed to feed the larger number of ROPs that come with Hawaii. More interesting however is that in spite of the larger memory bus the total size of AMD’s memory interface has gone down compared to Tahiti, and we’ll see why in a bit.
At the same time because AMD’s memory interface is so compact they’ve been able to move to a 512-bit memory bus without requiring too large a GPU. At 438mm2 and composed of 6.2B transistors Hawaii is still the largest GPU ever produced by AMD – 18mm2 bigger than R600 (HD 2900) – but compared to the 365mm2, 4.31B transistor Tahiti AMD has been able to pack in a larger memory bus and a much larger number of functional units into the GPU for only a 73mm2 (20%) increase in die size. The end result being that AMD is able to once again significantly improve their efficiency on a die size basis while remaining on the same process node. AMD is no stranger to producing these highly optimized second wind designs, having done something similar for the 40nm era with Cayman (HD 6900), and as with Cayman the payoff is the ability to increase performance an efficiency between new manufacturing nodes, something that will become increasingly important for GPU manufacturers as the rate of fab improvements continues to slow.

Moving on, let’s quickly talk about power consumption. With Hawaii AMD has made a number of smaller changes both to the power consumption of the silicon itself, and how it is defined. On the tech side of matters AMD has been able to reduce transistor leakage compared to Tahiti, directly reducing power consumption of the GPU as a result, and this is being paired with changes to certain aspects of their power management system, with implementing advanced power/performance management abilities that vastly improve the granularity of their power states (more on this later).
However at the same time how power consumption is being defined is getting far murkier: AMD doesn’t list the power consumption of the 290X in any of their documentation or specifications, and after asking them directly we’re only being told that the “average gaming scenario power” is 250W. We’ll dive into this more when we do a breakdown of the changes to PowerTune on 290X, but in short AMD is likely underreporting the 290X’s power consumption. Based on our test results we’re seeing 290X draw more power than any other “250W” card in our collection, and in reality the TDP of the card is almost certainly closer to 300W. There are limits to how long the card can sustain that level of power draw due to cooling requirements, but given sufficient cooling the power limit of the card appears to be around 300W, and for the moment we’re labeling it as such.

Left To Right: 6970, 7970, 290X
Finally, let’s talk about pricing, availability, and product positioning. As AMD already launched the rest of the 200 series 2 weeks ago, the launch of the 290X is primarily filling out the opening at the top of AMD’s product lineup that the rest of the 200 series created. The 7000 series is in the middle of its phase out – and the 7990 can’t be too much farther behind – so the 290X is quickly going to become AMD’s de-facto top tier card.
The price AMD will be charging for this top tier is $549, which happens to be the same price as the 7970 when it launched in 2012. This is about $100-$150 more expensive than the outgoing 7970GE and $250 more expensive than 280X, with the 290X offering an average performance increase over 280X of 30%. Meanwhile when placed against NVIDIA’s lineup the primary competition for 290X will be the $650 GeForce GTX 780, a card that the 290X can consistently beat, making AMD the immediate value proposition at the high-end. At the same time however NVIDIA will have their 3 game Holiday GeForce Bundle starting on the 28th, making this an interesting inversion of earlier this year where it was AMD offering large game bundles to improve the competitive positioning of their products versus NVIDIA’s. As always, the value of bundles are ultimately up to the buyer, especially in this case since we’re looking at a rather significant $100 price gap between the 290X and the GTX 780.
Finally, unlike the 280X this is going to be a very hard launch. As part of their promotional activities for the 290X retailers have already been listing the cards while other retailers have been taking pre-orders, and cards will officially go on sale tomorrow. Note that this is a full reference launch, so everyone will be shipping identical reference cards for the time being. Customized cards, including the inevitable open air cooled ones, will come later.
| Fall 2013 GPU Pricing Comparison | |||||
| AMD | Price | NVIDIA | |||
| $650 | GeForce GTX 780 | ||||
| Radeon R9 290X | $550 | ||||
| $400 | GeForce GTX 770 | ||||
| Radeon R9 280X | $300 | ||||
| $250 | GeForce GTX 760 | ||||
| Radeon R9 270X | $200 | ||||
| $180 | GeForce GTX 660 | ||||
| $150 | GeForce GTX 650 Ti Boost | ||||
| Radeon R7 260X | $140 | ||||
A Bit More On Graphics Core Next 1.1
With the launch of Hawaii, AMD is finally opening up a bit more on what Graphics Core Next 1.1 entails. No, they still aren’t giving us an official name – most references to GCN 1.1 are noting that 290X (Hawaii) and 260X (Bonaire) are part of the same IP pool – but now that AMD is in a position where they have their new flagship out they’re at least willing to discuss the official feature set.
So what does it mean to be Graphics Core Next 1.1? As it turns out, the leaked “AMD Sea Islands Instruction Set Architecture” from February appears to be spot on. Naming issues with Sea Islands aside, everything AMD has discussed as being new architecture features in Hawaii (and therefore also in Bonaire) previously showed up in that document.
As such the bulk of the changes that come with GCN 1.1 are compute oriented, and clearly are intended to play into AMD’s plans for HSA by adding features that are especially useful for the style of heterogeneous computing AMD is shooting for.
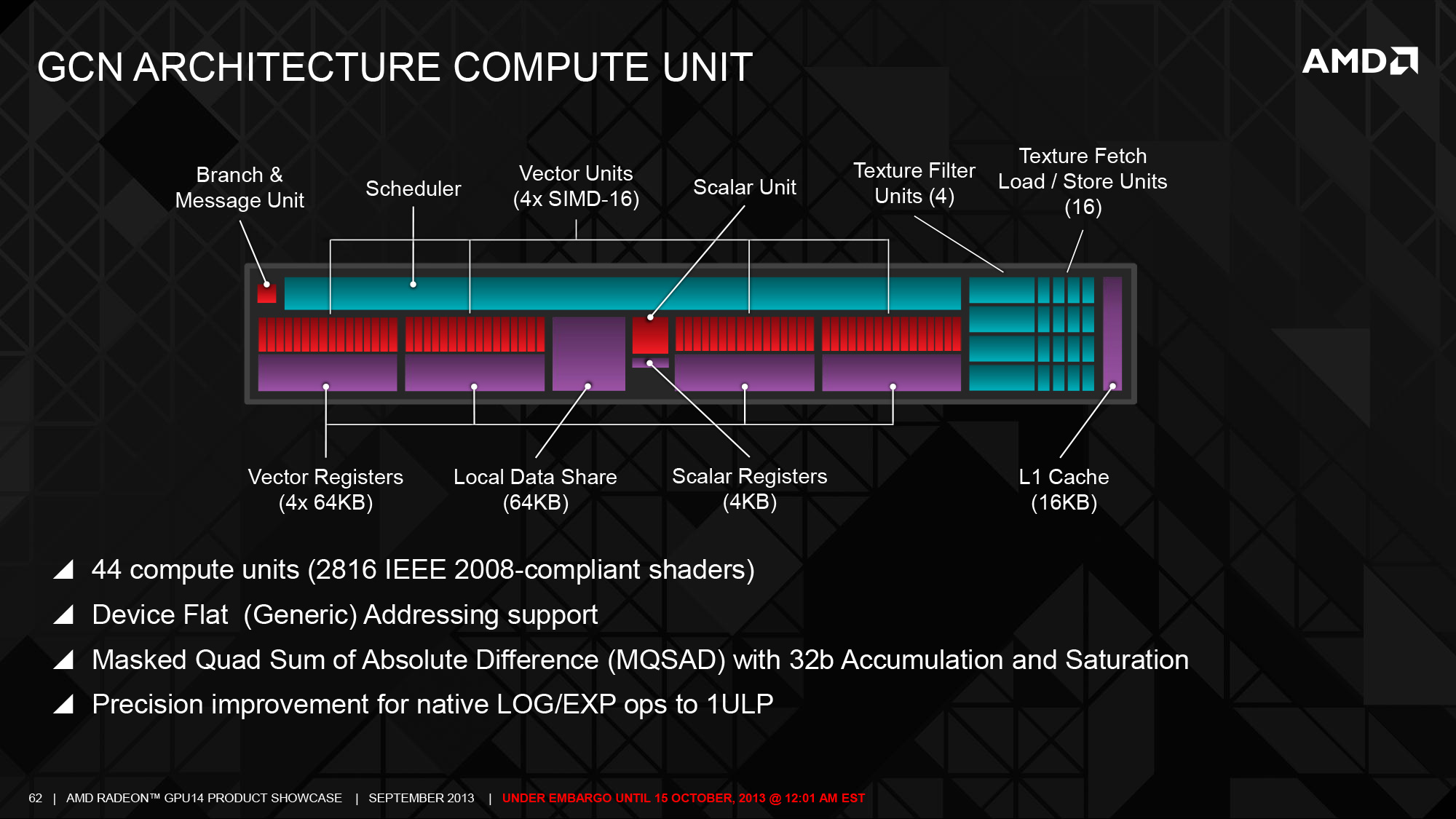
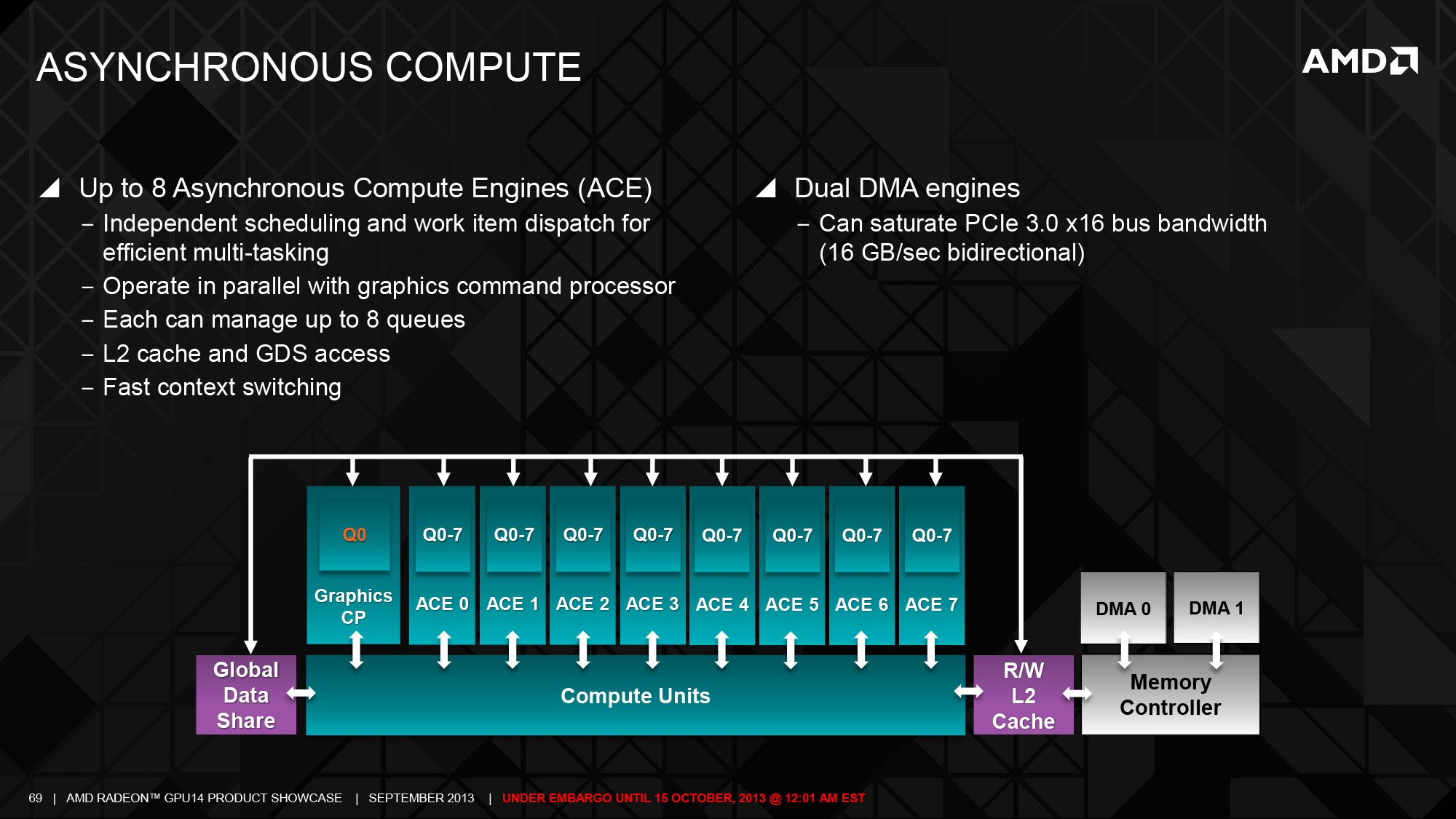
The biggest change here is support for flat (generic) addressing support, which will be critical to enabling effective use of pointers within a heterogeneous compute context. Coupled with that is a subtle change to how the ACEs (compute queues) work, allowing GPUs to have more ACEs and more queues in each ACE, versus the hard limit of 2 we’ve seen in Southern Islands. The number of ACEs is not fixed – Hawaii has 8 while Bonaire only has 2 – but it means it can be scaled up for higher-end GPUs, console APUs, etc. Finally GCN 1.1 also introduces some new instructions, including a Masked Quad Sum of Absolute Differences (MQSAD) and some FP64 floor/ceiling/truncation vector functions.
Along with these architectural changes, there are a couple of other hardware features that at this time we feel are best lumped under the GCN 1.1 banner when talking about PC GPUs, as GCN 1.1 parts were the first parts to introduce this features and every GCN 1.1 part (at least thus) far has that feature. AMD’s TrueAudio would be a prime example of this, as both Hawaii and Bonaire have integrated TrueAudio hardware, with AMD setting clear expectations that we should also see TrueAudio on future GPUs and future APUs.
AMD’s Crossfire XDMA engine is another feature that is best lumped under the GCN 1.1 banner. We’ll get to the full details of its operation in a bit, but the important part is that it’s a hardware level change (specifically an addition to their display controller functionality) that’s once again present in Hawaii and Bonaire, although only Hawaii is making full use of it at this time.
Finally we’d also roll AMD’s power management changes into the general GCN 1.1 family, again for the basic reasons listed above. AMD’s new Serial VID interface (SIV2), necessary for the large number of power states Hawaii and Bonaire support and the fast switching between them, is something that only shows up starting with GCN 1.1. AMD has implemented power management a bit differently in each product from an end user perspective – Bonaire parts have the states but lack the fine grained throttling controls that Hawaii introduces – but the underlying hardware is identical.
With that in mind, that’s a short but essential summary of what’s new with GCN 1.1. As we noted way back when Bonaire launched as the 7790, the underlying architecture isn’t going through any massive changes, and as such the differences are of primarily of interest to programmers more than end users. But they are distinct differences that will play an important role as AMD gears up to launch HSA next year. Consequently what limited fracturing there is between GCN 1.0 and GCN 1.1 is primarily due to the ancillary features, which unlike the core architectural changes are going to be of importance to end users. The addition of XDMA, TrueAudio, and improved power management (SIV2) are all small features on their own, but they are features that make GCN 1.1 a more capable, more reliable, and more feature-filled design than GCN 1.0.
Hawaii: Tahiti Refined
Thus far when we’ve been discussing Hawaii, it’s typically been in comparison to Tahiti, and there’s good reason for that. Besides the obvious parallel of being AMD’s new flagship GPU, finally succeeding Tahiti after just short of 2 years, in terms of design Hawaii looks and acts a lot like an improved Tahiti. The underlying architecture is still Graphics Core Next, and a lot of the compute functionality that gave Tahiti its broad applicability to graphics and compute alike is equally present in Hawaii, so in many ways Hawaii looks and behaves like a bigger Tahiti. But as we’ve seen over the years with these second wind parts, there’s are a lot of finer details involved taking an existing architecture and building it bigger, never mind the subtle feature additions that come with Hawaii.

The biggest addition with Hawaii is of course the increased number of functional units. 2 years in and against GPUs like NVIDIA’s GK110, AMD has a clear need to produce a larger, more powerful GPU if they wish to stay competitive with NVIDIA at the high end while also delivering newer, faster products for their regular customers. In doing so there’s a need to identify bottlenecks in the existing design (Tahiti) to figure out what changes will pay off the most for their die size and power consumption cost, and conversely what changes would have little payoff. The end result is that we’re seeing AMD significantly scale up some of the smaller areas of the chip, while taking a more nuanced approach on scaling up the larger areas.
But before we get too deep here, we want to quickly point out that with Hawaii AMD is making a significant change to how they’re logically representing the architecture in public, which although is striking does not mean the underlying low-level organization is nearly as different as the high-level changes would imply. At a high level the biggest change here is that AMD is now segmenting their hardware into “shader engines”. Conceptually the idea is similar to NVIDIA’s SMXes, with each Shader Engine (SE) representing a collection of hardware including shaders/CUs, geometry processors, rasterizers, and L1 cache. Furthermore ROPs are also being worked into the Shader Engine model, with each SE taking on a fraction of the ROPs for the purposes of high level overviews. What remains outside of the SEs is the command processor and ACEs, the L2 cache and memory controllers, and then the various dedicated, non-duplicated functionality such as video decoders, display controllers, DMA controllers, and the PCIe interface.

Moving forward, AMD designs are going to scale up and down both with respect to the number of SEs and in the number of CUs in each SE. This distinction is important because unlike NVIDIA’s SMX model, where the company can only scale down hardware by cutting whole SMXes, AMD can technically maintain up to 4 SEs while scaling down the number of CUs within each SE. So despite what the SE model implies, AMD’s scaling abilities are status quo for GCN in as much as they can continue to scale down for lower tier parts without sacrificing geometry or ROP performance. In reality of course the physical layout of Hawaii and other GPUs will deviate by even less, as the ROPs are still going to be tied into the memory controllers, the geometry processors are still closely integrated with the command processor, etc. Still, as a high level model it’s likely a better fit for how the underlying hardware really works, as it provides a more intuitive view on how the number of geometry processors, rasterizers, and ROPs are closedly related, or how the individual CUs are lumped together into CU arrays.
With that in mind, we’ll start or low level overview with a look at both the front end and the back end of Hawaii. Of all the aspects of the GPU AMD has scaled up compared to Hawaii, it’s at the front end and the back end that we’ll find the biggest changes due to the fact that AMD has doubled the number of functional units in most of the elements that reside here.
At the very front, in conjunction with the ACE improvements inherient to GCN 1.1, AMD has scaled up the number of ACEs from 2 in Tahiti to 8 in Hawaii. With each ACE now containing 8 work queues this brings the total number of work queues to 64. Unlike most of the other changes we’ll be going over today, the ACE increase has limited applicability for gaming, and while AMD isn’t talking about non-Radeon Hawaii products at this time, given what we know about GCN 1.1 there’s a clear applicability not only towards HSA, but also to more traditional GPU compute setups such as the FirePro S series. For GPU compute the additional ACEs and queues will help improve AMD’s real world compute performance by improving the utilization of the CUs, while the DMA engine improvements that come with the increased number of ACEs will help keep the CUs fed with data from the CPU and other GPUs.
Moving on, there are a number of back end and front end changes AMD has made to improve rendering performance, and the increased number of geometry processors is at the forefront of this. With Hawaii AMD has doubled the number of geometry engines from 2 to 4, and more closely coupling those with the existing 4 rasterizer setup they inherit. The increase in geometry processors comes at an appropriate time for the company as the last time the number of geometry processors was increased was with the 6900 series in 2010, when the company moved to 2 such processors. One of the side effects of the new consoles coming out this year is that cross-platform games will be able to use a much larger number of primitives than before – especially with the uniform addition of D3D11-style tessellation – so there’s a clear need to ramp up geometry performance to keep up with where games are expected to go.

Further coupled with this are more generalized improvements designed to improve geometry efficiency overall. Alongside the additional geometry processors AMD has also improved both on-chip and off-chip data flows, with off-chip buffering being improved to further improve AMD’s tessellation performance, while the Local Data Store can now be tapped by geometry shaders to reduce the need to go off-chip at all. More directly applicable is that the inter-stage storage (parameter and position caches) used by the geometry processors has also been increased in order to keep up with the overall increase in the number of processors.
On a side note, with every architectural revision/launch we try to get AMD’s engineers to give us an idea of what aspects they’re most proud of, and while they typically downplay the question (it’s a team effort, after all) for Hawaii the geometry processor changes have been a recurring theme of something where the engineering team is particularly proud of its work. As it turns out adding geometry processors is actually a quite a bit harder than it sounds, as the additional processors bring with it the need to balance geometry workloads across the processor cluster. When splitting up the geometry workload there are dependency issues that must be addressed, and to maximize efficiency there are load balancing/partitioning matters that must be taken into account as there’s no guarantee geometry is evenly distributed over the entire viewport. Consequently AMD’s engineers are quite happy with how this turned out due to the effort involved.
Meanwhile at the other end of the rendering pipeline we have AMD’s back end changes, which have been made in concert with the changes to the front end. The big change here is that for the first time since the 5870 (Cypress) back in 2009, AMD has increased the number of ROPs, going from 32 on Tahiti/Pitcairn to 64 on Hawaii. As ROPs are primarily tasked with jobs that are resolution dependent such as final pixel resolution and depth testing, the workload placed on ROPs has increased much more slowly over the years than the workload placed on shaders or even geometry processors. Similarly, for that reason scaling up the ROPs alone typically doesn’t have a big impact on rendering performance, hence ROP upgrades have come far more sparingly.

With Hawaii the increase in the number of ROPs comes down to a few different factors. To a large extent it’s merely a matter of “it’s time”, where the performance increases finally justify the die space increases. But AMD’s focus on 4K resolution workloads also plays a significant part, as 4K represents a significant increase in the ROP workload, and hence the need for more ROPs to pick up the work. Consequently while we can’t easily compare ROP performance across vendors, increasing the number of ROPs is one of the ways AMD will extend their high resolution performance advantage over NVIDIA, by being sure they have plenty of capacity to chew through 4K scenes.
Working in conjunction with the ROPs of course is the L2 cache, forming the second member of the ROP/L2/MC triumvirate, and like the number of ROPs this is being increased. L2 cache is more closely tied to the memory controllers than the ROPs, so while Tahiti had 32 ROPs and 768KB of L2 paired with 6 memory controllers, Hawaii gets double the ROPs but a smaller 33% increase in the L2 cache in accordance with the 33% increase in memory controllers. The end result is that Hawaii packs a full 1MB of L2 cache, and that the total bandwidth available out of the L2 cache has also been increased by 33% to a full 1TB. The L2 cache plays a role in every aspect of rendering, and as the primary backstop for the ROPs and secondary backstop for the CUs it’s critical to avoiding relatively expensive off-chip memory operations.
Lastly we have the final member of the ROP/L2/MC triumvirate, which is the memory interface. Tahiti for all of its strengths and weaknesses possesses a very large memory interface (as a percentage of die space), which has helped it reach 6GHz+ memory speeds on a 384-bit memory bus at the cost of die size. As there’s a generally proportional relationship between memory interface size and memory speeds, AMD has made the interesting move of going the opposite direction for Tahiti. Rather than scale up a 384-bit memory controller even more, they opted to scale down an even larger 512-bit memory controller with impressive results.

The result of AMD’s memory interface changes is that between the die space savings from the lower speed controllers coupled with a number of smaller tweaks to improve density, AMD has been able to implement the larger 512-bit memory interface while still reducing the size of the memory interface by 20% as compared to Tahiti. Furthermore these space savings still allow for a meaningful increase in memory bandwidth despite the lower memory clockspeeds, with AMD being able to increase their memory bandwidth by over 10% (as compared to 280X), from 288GB/sec to 320GB/sec. The end result is a very neat and clean (and impressive) improvement in AMD’s memory controllers, with AMD reducing their interface size and increasing their memory bandwidth at the same time. The 512-bit memory bus does have some externalities to it – specifically increased PCB costs and requiring more GDDR5 memory modules than Tahiti (16 vs. 12) – but these are ultimately countered by the die space savings that AMD is realizing from the smaller memory interface.
Meanwhile compared to AMD’s front end and back end changes, the Hawaii’s CU changes are much more straightforward. Besides optimizing the CUs for die size and giving them the appropriate GCN 1.1 functionality, very little has changed here. The end result is a simple increase in the number of CUs, going from 32 on Tahiti to 44 on Hawaii, with AMD continuing to distribute them evenly over the 4 Shader Engines. Shading/texturing remains the primary bottleneck for most games today, so while the CU increase is straightforward the performance implications are not to be ignored. Much of AMD’s 30% performance increase comes from this 38% increase in CUs. GCN was after all designed from the start to scale up well in this respect, so with Hawaii AMD is executing on those plans.
Moving on, having completed our look at the design of Hawaii, let’s discuss the die size of Hawaii a bit. Unlike NVIDIA, AMD doesn’t traditionally go above 400mm2 dies, and for good reason. NVIDIA holds the lion’s share of the high end, high margin workstation market, and while AMD market share has been slowly increasing from the historic lows of a couple of years ago it’s still well behind NVIDIA’s. Consequently AMD doesn’t have that high margin market to help bootstrap the production of large GPUs, requiring that they stay smaller to stay within their means.
With Hawaii AMD still isn’t entering the big die race that defines NVIDIA’s flagship GPUs, but AMD is going larger than ever before. At 438mm2 Hawaii is AMD’s biggest GPU yet, and despite AMD’s improvements in area efficiency Hawaii is still 73mm2 (20%) larger than Tahiti. The fact that AMD is able to improve their gaming performance by 30% over Tahiti means that this is a very good tradeoff to make, it just means that AMD is treading new ground in doing so.
Similarly, at 6.2 billion transistors Hawaii is AMD’s largest GPU yet by transistor count, outpacing the 4.31B Tahiti by 1.89B transistors, an increase of 44%. Now transistor counts alone don’t mean much, but the fact that AMD was able to increase their transistor density by this much is a significant accomplishment for the company.
Meanwhile on a historical basis it’s worth pointing out that while AMD’s “small die” strategy effectively died with Cayman in 2010, this marks the first time since R600 that AMD has dared to go this big. R600, AMD’s previously largest GPU, ended up being rather ill-fated, which in turn spurred on the small die strategy that defined the R700 and Evergreen GPU families. Hawaii won’t be a repeat of R600 – in particular AMD isn’t going to be repeating the unfortunate circumstance of building a large GPU against a new architecture and a new manufacturing node all at the same time – so they are certainly on far more solid ground this time. Ultimately the success of Hawaii will be based on sales and profit margins as always, but based on the performance we’re seeing and the state of AMD’s market, AMD shouldn’t have any trouble justifying a 400mm2 GPU at this point. This is yet another benefit of being a second wind product: AMD gets to build their large GPU against a mature manufacturing process, as opposed to the immature process that Tahiti had to work with.
XDMA: Improving Crossfire
Over the past year or so a lot of noise has been made over AMD’s Crossfire scaling capabilities, and for good reason. With the evolution of frame capture tools such as FCAT it finally became possible to easily and objectively measure frame delivery patterns. The results of course weren’t pretty for AMD, showcasing that Crossfire may have been generating plenty of frames, but in most cases it was doing a very poor job of delivering them.
AMD for their part doubled down on the situation and began rolling out improvements in a plan that would see Crossfire improved in multiple phases. Phase 1, deployed in August, saw a revised Crossfire frame pacing scheme implemented for single monitor resolutions (2560x1600 and below) which generally resolved AMD’s frame pacing in those scenarios. Phase 2, which is scheduled for next month, will address multi-monitor and high resolution scaling, which faces a different set of problems and requires a different set of fixes than what went into phase 1.
The fact that there’s even a phase 2 brings us to our next topic of discussion, which is a new hardware DMA engine in GCN 1.1 parts called XDMA. Being first utilized on Hawaii, XDMA is the final solution to AMD’s frame pacing woes, and in doing so it is redefining how Crossfire is implemented on 290X and future cards. Specifically, AMD is forgoing the Crossfire Bridge Interconnect (CFBI) entirely and moving all inter-GPU communication over the PCIe bus, with XDMA being the hardware engine that makes this both practical and efficient.

But before we get too far ahead of ourselves, it would be best to put the current Crossfire situation in context before discussing how XDMA deviates from it.
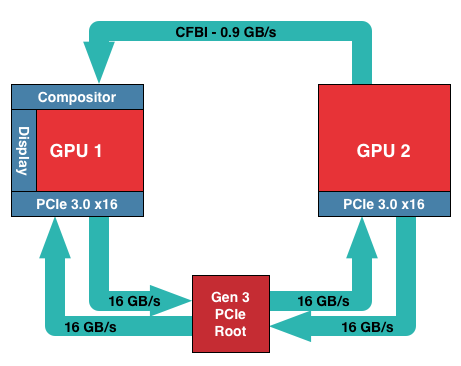
In AMD’s current CFBI implementation, which itself dates back to the X1900 generation, a CFBI link directly connects two GPUs and has 900MB/sec of bandwidth. In this setup the purpose of the CFBI link is to transfer completed frames to the master GPU for display purposes, and to so in a direct GPU-to-GPU manner to complete the job as quickly and efficiently as possible.
For single monitor configurations and today’s common resolutions the CFBI excels at its task. AMD’s software frame pacing algorithms aside, the CFBI has enough bandwidth to pass around complete 2560x1600 frames at over 60Hz, allowing the CFBI to handle the scenarios laid out in AMD’s phase 1 frame pacing fix.
The issue with the CFBI is that while it’s an efficient GPU-to-GPU link, it hasn’t been updated to keep up with the greater bandwidth demands generated by Eyefinity, and more recently 4K monitors. For a 3x1080p setup frames are now just shy of 20MB/each, and for a 4K setup frames are larger still at almost 24MB/each. With frames this large CFBI doesn’t have enough bandwidth to transfer them at high framerates – realistically you’d top out at 30Hz or so for 4K – requiring that AMD go over the PCIe bus for their existing cards.
Going over the PCIe bus is not in and of itself inherently a problem, but pre-GCN 1.1 hardware lacks any specialized hardware to help with the task. Without an efficient way to move frames, and specifically a way to DMA transfer frames directly between the cards without involving CPU time, AMD has to resort to much uglier methods of moving frames between the cards, which are in part responsible for the poor frame pacing we see today on Eyefinity/4K setups.
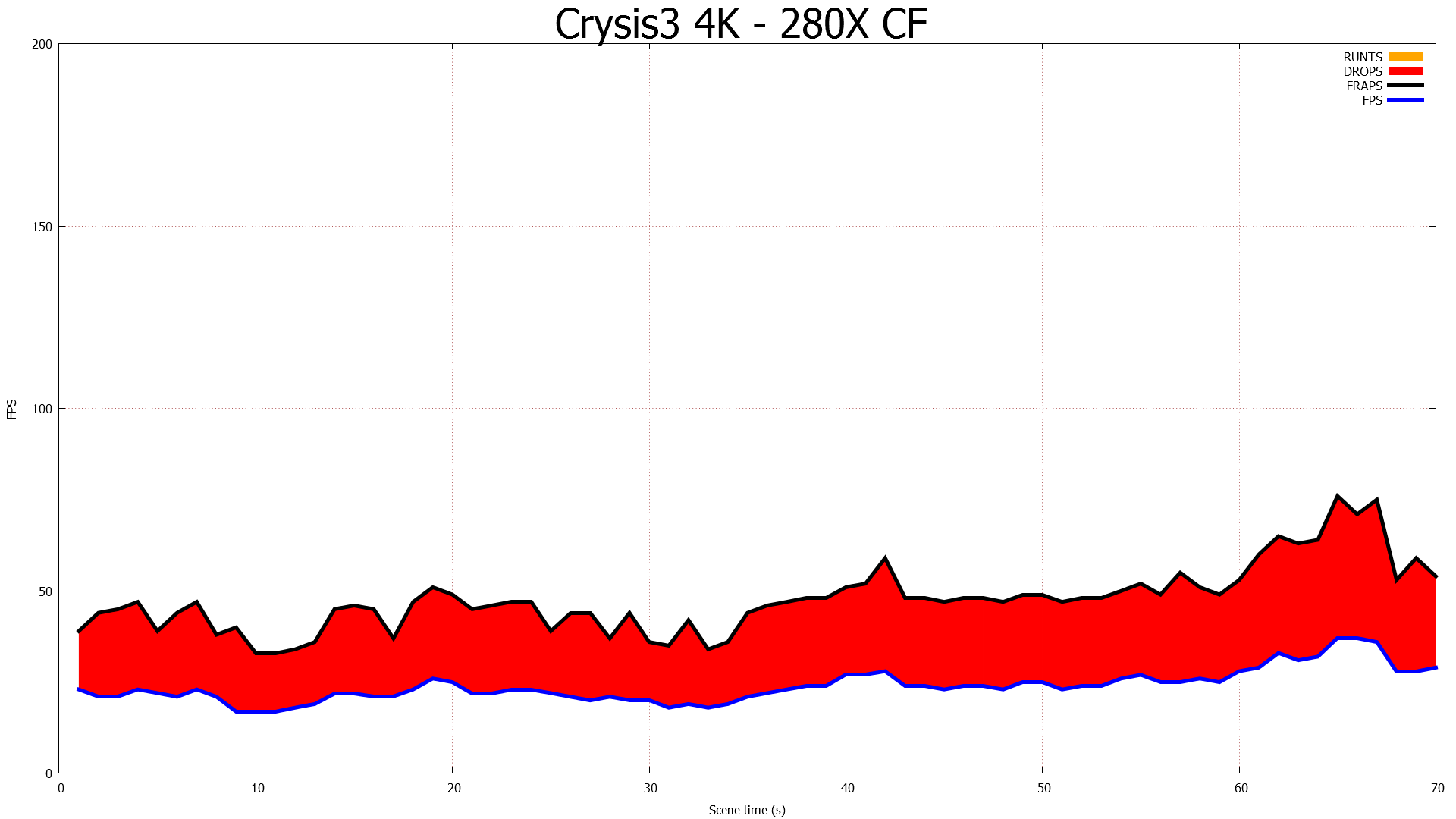
CFBI Crossfire At 4K: Still Dropping Frames
For GCN 1.1 and Hawaii in particular, AMD has chosen to solve this problem by continuing to use the PCIe bus, but by doing so with hardware dedicated to the task. Dubbed the XDMA engine, the purpose of this hardware is to allow CPU-free DMA based frame transfers between the GPUs, thereby allowing AMD to transfer frames over the PCIe bus without the ugliness and performance costs of doing so on pre-GCN 1.1 cards.
With that in mind, the specific role of the XDMA engine is relatively simple. Located within the display controller block (the final destination for all completed frames) the XDMA engine allows the display controllers within each Hawaii GPU to directly talk to each other and their associated memory ranges, bypassing the CPU and large chunks of the GPU entirely. Within that context the purpose of the XDMA engine is to be a dedicated DMA engine for the display controllers and nothing more. Frame transfers and frame presentations are still directed by the display controllers as before – which in turn are directed by the algorithms loaded up by AMD’s drivers – so the XDMA engine is not strictly speaking a standalone device, nor is it a hardware frame pacing device (which is something of a misnomer anyhow). Meanwhile this setup also allows AMD to implement their existing Crossfire frame pacing algorithms on the new hardware rather than starting from scratch, and of course to continue iterating on those algorithms as time goes on.
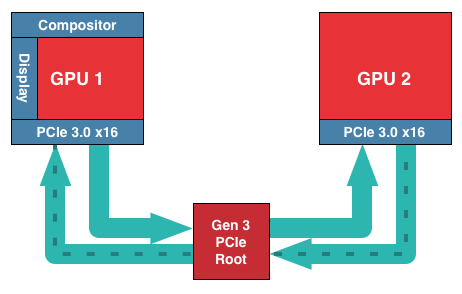
Of course by relying solely on the PCIe bus to transfer frames there are tradeoffs to be made, both for the better and for the worse. The benefits are of course the vast increase in memory bandwidth (PCIe 3.0 x16 has 16GB/sec available versus .9GB/sec for CFBI) not to mention allowing Crossfire to be implemented without those pesky Crossfire bridges. The downside to relying on the PCIe bus is that it’s not a dedicated, point-to-point connection between GPUs, and for that reason there will bandwidth contention, and the latency for using the PCIe bus will be higher than the CFBI. How much worse depends on the configuration; PCIe bridge chips for example can both improve and worsen latency depending on where in the chain the bridges and the GPUs are located, not to mention the generation and width of the PCIe link. But, as AMD tells us, any latency can be overcome by measuring it and thereby planning frame transfers around it to take the impact of latency into account.
Ultimately AMD’s goal with the XDMA engine is to make PCIe based Crossfire just as efficient, performant, and compatible as CFBI based Crossfire, and despite the initial concerns we had over the use of the PCIe bus, based on our test results AMD appears to have delivered on their promises.
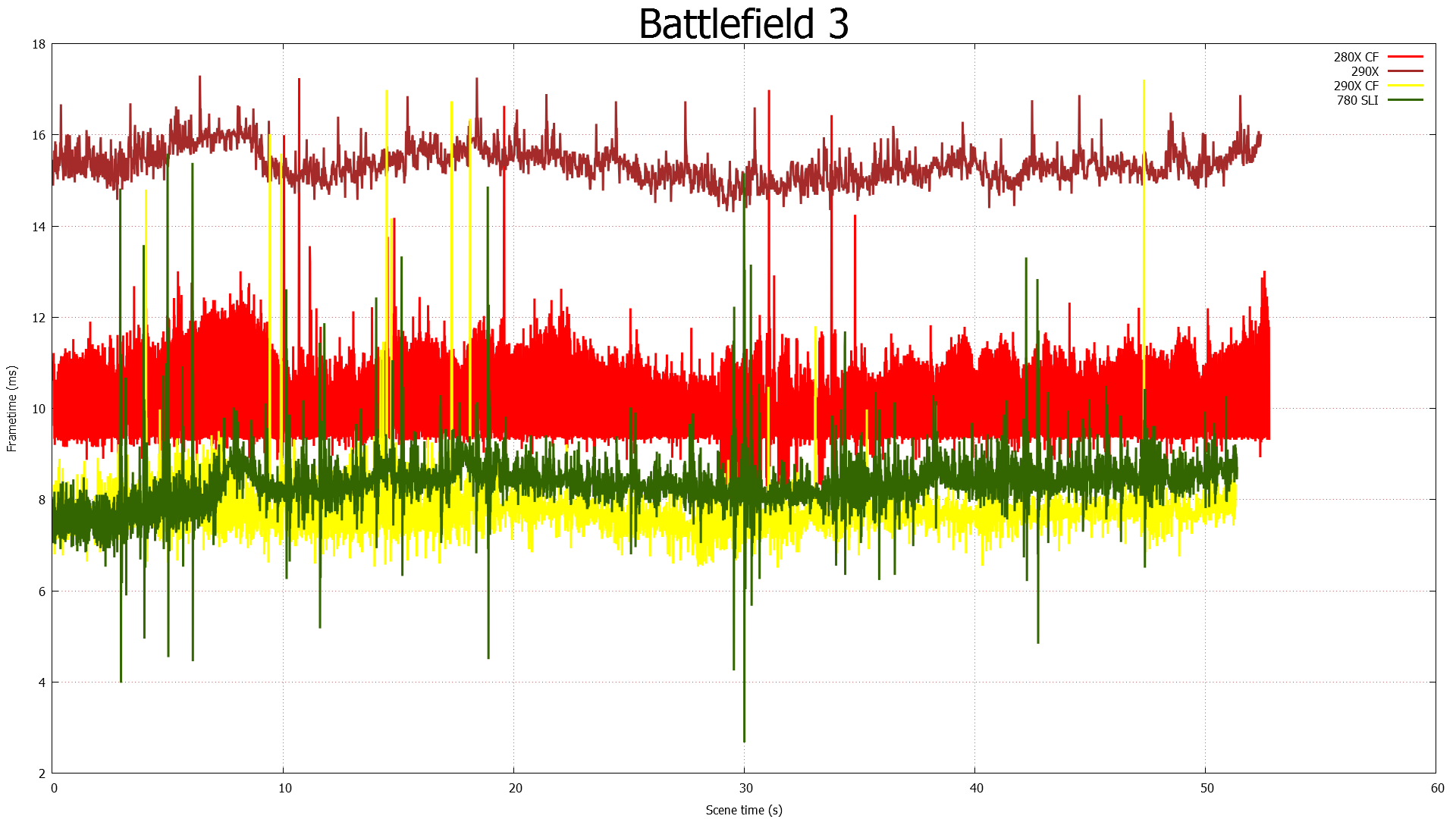

The XDMA engine alone can’t eliminate the variation in frame times, but in its first implementation it’s already as good as CFBI in single monitor setups, and being free of the Eyefinity/4K frame pacing issues that still plague CFBI, is nothing short of a massive improvement over CFBI in those scenarios. True to their promises, AMD has delivered a PCie based Crossfire implementation that incurs no performance penalty versus CFBI, and on the whole fully and sufficiently resolves AMD’s outstanding frame pacing issues. The downside of course is that XDMA won’t help the 280X or other pre-GCN 1.1 cards, but at the very least going forward AMD finally has demonstrated that they have frame pacing fully under control.
On a side note, looking at our results it’s interesting to see that despite the general reuse of frame pacing algorithms, the XDMA Crossfire implementation doesn’t exhibit any of the distinct frame time plateaus that the CFBI implementation does. The plateaus were more an interesting artifact than a problem, but it does mean that AMD’s XDMA Crossfire implementation is much more “organic” like NVIDIA’s, rather than strictly enforcing a minimum frame time as appeared to be the case with CFBI.
PowerTune: Improved Flexibility & Fan Speed Throttling
The final new technology being introduced with Hawaii and 290X is the latest iteration of AMD’s PowerTune technology. Although not being given a formal name to differentiate it from previous incarnations of PowerTune, the latest iteration brings with it a number of important changes that will significantly alter how the 290X and future cards will behave and how those behaviors can be adjusted.
In a nutshell, with the latest iteration of PowerTune AMD is gaining the necessary hardware monitoring and adjustment abilities to modernize PowerTune, bringing it functionally up to par with NVIDIA’s GPU Boost 2.0, which itself was introduced earlier this year. This includes not only the ability to do fine grained clockspeed/voltage stepping, that alone being a major improvement over what Tahiti could do, but also far more flexible control over the video card to control it by power consumption, temperature, or even fan speeds/noise.
Diving right into matters, to once again use Tahiti as a baseline for comparison here, PowerTune as implemented on pre-GCN 1.1 cards like Tahiti has 3 (non-boost) or 4 (boost) power management clockspeed/voltage states. These are idle, intermediate (low-3D), high (full-3D), and for the cards that use it, boost. When for whatever reason PowerTune needed to clamp down on power usage to stay within the card’s designated limits, it could either jump states or merely turn down the clockspeed within a state, depending on how far over the throttle point the card was operating at. In practice state jumps were rare – it’s a big gap between high and intermediate – so for non-boost cards it would merely turn down the GPU clockspeed within the high state until power consumption was where it needed to be, while boost cards would either do the same within the boost state, or less frequently drop to the high state and then modulate.
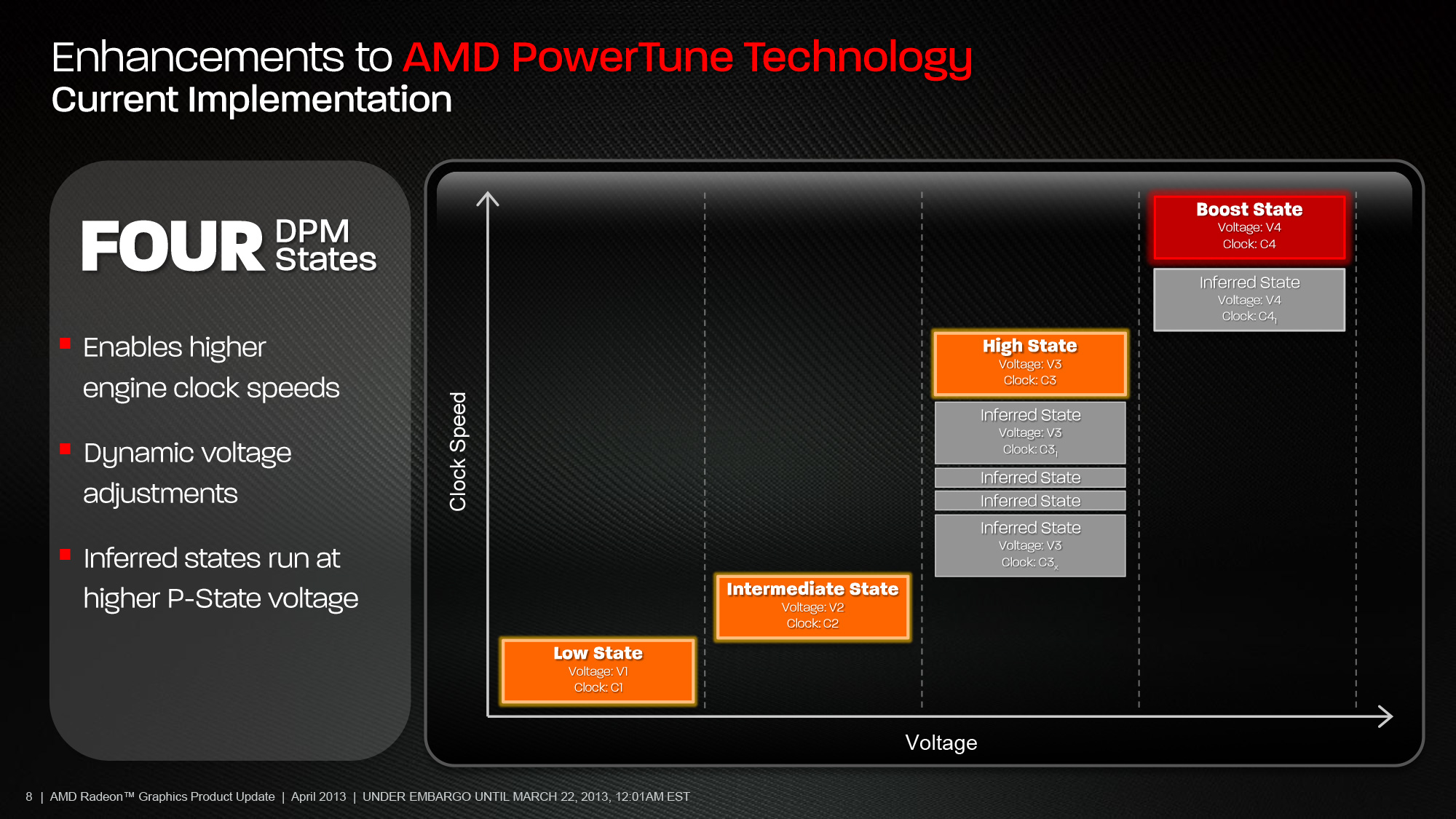
Power States Available In Tahiti & Other GCN 1.0 GPUs
Modulating clockspeeds in such a manner is a relatively easy thing to implement, but it’s not without its drawbacks. That drawback being that semiconductor power consumption scales at a far greater rate with voltage than it does with clockspeed. So although turning down clockspeeds does reduce power consumption, it doesn’t do so by a large degree. If you want big power savings, you need to turn down the voltage too, and to do so in a fine grained manner.
Now given the limitations of Tahiti and other pre-GCN 1.1 cards, in order to implement fine grained power states significant changes needed to be made to both the GPU and the card, which is why AMD has not been able to bring this about until Hawaii and Bonaire. As power management is primarily handled by an external controller, the GPU needs to have a telemetry interface to provide the necessary data to the external controller and the ability/programming to quickly jump between states. Meanwhile the external controller needs to capable enough to handle the telemetry data (it’s a lot of data) and able to quickly switch between states (the faster the better).

With that in mind, for GCN 1.1 AMD set out to solve those problems by giving GCN 1.1 parts the necessary telemetry interface to be paired with equally capable 3rd party voltage controllers. Dubbed the Serial VID Interface (SVI2), the interface is the lynchpin of AMD’s latest iteration of PowerTune. In short, by adding this interface and thereby providing the necessary data to the external controller AMD finally has the ability to support a large number of states and to rapidly switch between them.
For the 290X and 260X, when combined with the IR 3567B controller AMD is currently using, this means translates into the ability to switch voltages as frequently as every 10 microseconds, and to do so by switching between upwards of 255 voltage steps. This massive increase in flexibility in turn allows AMD to control for power consumption, temperature, and even noise in ways that weren’t practical with the coarse grained power management features of GCN 1.0 cards.
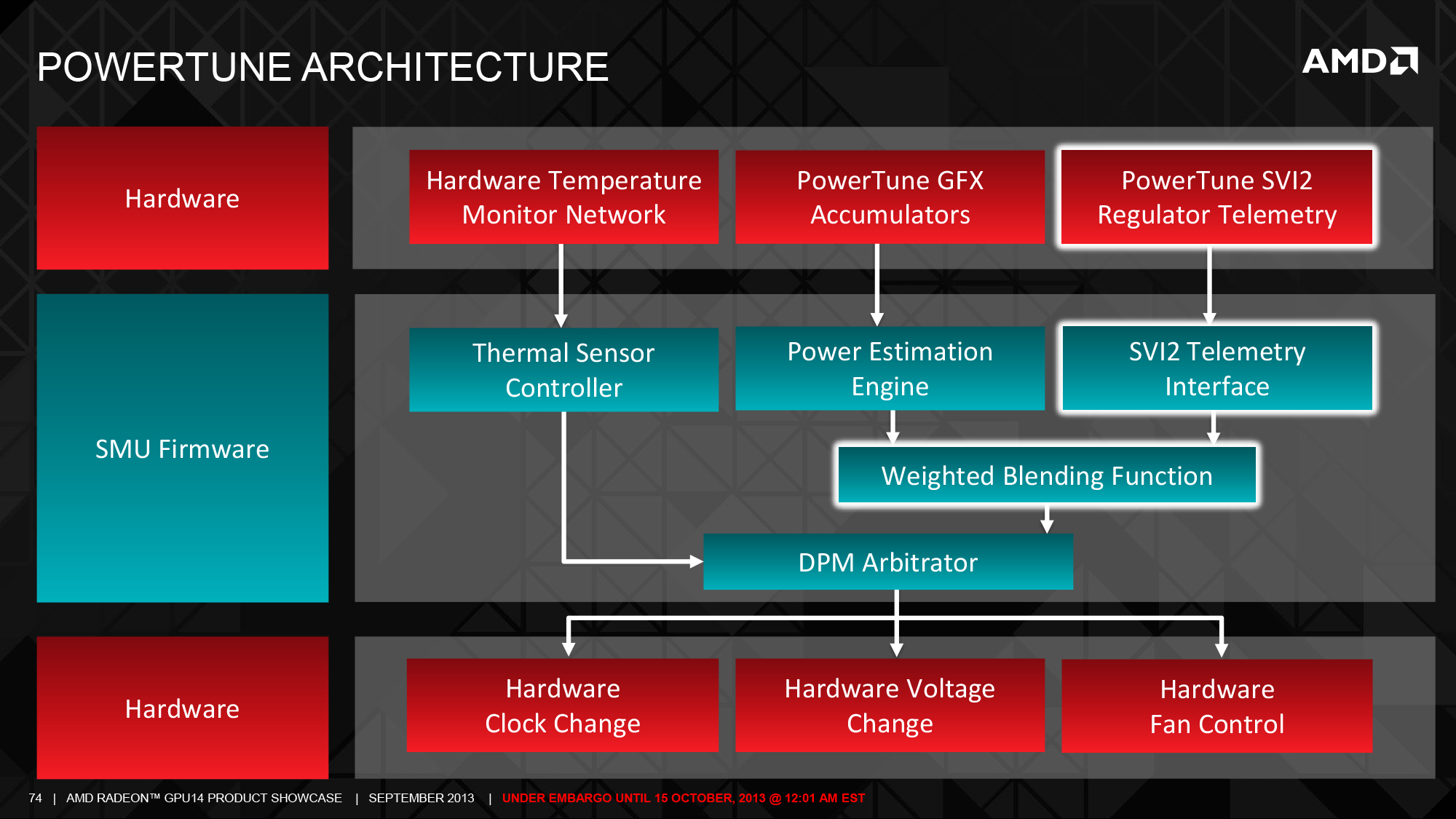
With this level of flexibility in hand, AMD has significantly overhauled PowerTune, both with respect to how PowerTune operates and how the user can manipulate it. Starting under the hood, the inferred states used Tahiti and other GCN 1.0 GPUs are gone, replaced with a wide number of real power states, thereby giving AMD the ability to reduce power consumption in a fine grained manner with real voltage changes as opposed to resorting to ineffective clock speed modulation. Coupled with that is a new, relaxed (“fuzzy”) fan control scheme, which is based around the concept of slowing down the fan speed response time in order to avoid rapid changes in noise and pitch, and thereby avoiding drawing attention to the card (this being very similar to NVIDIA’s adaptive fan controller).
Equally significant however are the changes to the actual system management algorithms used by PowerTune. Taking a page from GPU Boost 2, now that AMD can properly step between a large number of voltage stages they’re also giving 290X cards the ability to throttle based on a larger number of conditions. On top of traditional power limit throttling, 290X in particular gains the ability to throttle based on explicit temperature limits, and even explicit fan speed limits.
Bringing this all together, for the first card to feature the full suite of these new capabilities AMD has set some very interesting throttle points that’s unlike anything they or NVIDIA have ever quite done before. Out of the box, in the card’s default “quiet” mode (more on modes later), the 290X has a 95C temperature throttle, a 40% fan speed throttle, and an unofficially estimated 300W power throttle. Meanwhile in the card’s alternative “uber” mode, those throttle points are 95C, 55% fan speed, and 300W respectively.
| AMD Radeon R9 290X Throttle Points | |||||||||||
| Card | Quiet Mode (Default) | Uber Mode | |||||||||
| Temperature | 95C | 95C | |||||||||
| Fan Speed | 40% (~2100 RPM) | 55% (~3050 RPM) | |||||||||
| Power (Estimated) | 300W | 300W | |||||||||
The addition of the fan speed throttle in turn is very much an X factor that changes how the entire system operates. Whereas previous AMD cards are primarily throttled by power and implicit temperature limits, and more recent NVIDIA cards are throttled by power and explicit temperature limits (with temperature serving as a proxy for fan speeds and noise) AMD takes this one step further by making the fan speed its own throttle, creating a new relationship between temperature and fan speeds that doesn’t exist in the old power management paradigms.
The end result of having the fan speed throttle is that for the 290X (and presumably future cards) the temperature throttle become a joint clause where both conditions have to be met to trigger throttling. So long as power limits are being met (you can never violate the power limit) a 290X will not throttle unless both the fan speed throttle point and the temperature throttle point is reached. And even then, the temperature throttle point has a direct impact on the behavior of the fan, with the GPU temperature (relative to the throttle point) being used as one of the principle inputs on fan speed. In that sense the temperature throttle point becomes a simple abstraction for the underlying fan curve itself.
Boost Throttle Priority: Power = Fan Speed + Temperature
Now there is one exception to this that’s worth pointing out. The above is applicable to the 290X’s boost states, which is where it should be spending all of its time under load. However if for whatever reason the card has to drop out of the boost states and revert to the base clockspeed state of 727MHz, then the relationship between fan speed and temperature becomes reversed, and the card will outright violate fan speed throttles in order to maintain the target temperature while also staying at the base clockspeed.
Base Throttle Priority: Power = Temperature > Fan Speed
The end result of this scheme is that for the bulk of gaming scenarios the 290X will be throttled not on power consumption or even by temperature alone (since you will eventually always hit 95C in Quiet mode), but rather on fan speed/noise, a method unlike anything NVIDIA or AMD have done previously. By doing this AMD has established a direct, simple relationship between performance and noise. If a card is too loud, it can be turned down at the cost of performance. Or if a card needs more performance, then it can be increased (to a point) at the cost of noise. And as noise is going to be the most visible aspect of the power/temp/noise triumvirate to the end user, this in turn gives the end user a high level of control over what’s usually the biggest drawback to running a high power, high performance video card. It really is that much better than any of the management paradigms that have come before it, and it is something we’d fully expect NVIDIA to copy in due time.
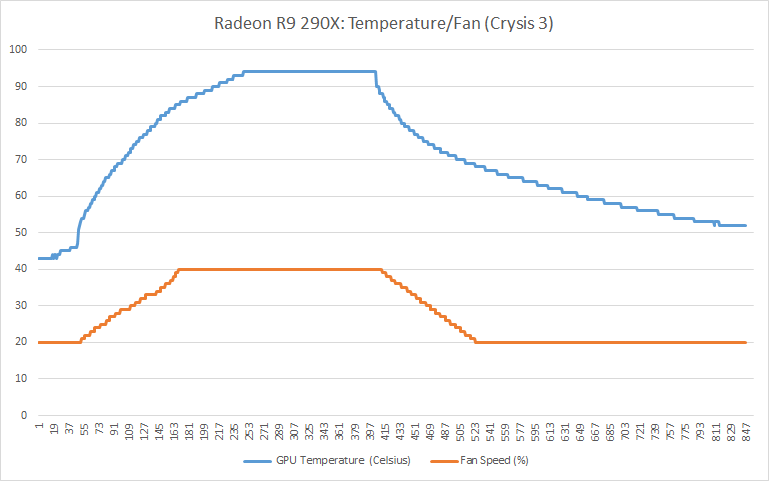
Before moving on from the subject of throttling however, let’s briefly touch on what’s undoubtedly going to prove to be a controversial element to the 290X’s power tune implementation: AMD’s 95C temperature throttle. Simply put, no desktop 28nm card thus far has been designed/intended to operate at such a high sustained temperature by default. NVIDIA’s explicit throttle point for the 700 series is 80C, and AMD’s implicit throttle point for Tahiti cards is also in the 80C range, putting both cards well below 95C under regular operation. Now to be clear both are spec’ed to allow temperatures up to 95C (i.e. TjMax), however that 95C throttle point is not the point where either party has previously designed their equilibrium points around.
So why the sudden change on AMD’s behalf? There are a few reasons for it. But first and foremost, let’s talk about the physical costs of higher temperatures. All other elements being held equal, temperatures affect silicon devices in 3 important ways: longevity, power consumption (leakage), and attainable clockspeeds. For longevity there’s a direct relationship between temperature and the electromigration effect, with higher temperatures causing electromigration and ultimately ASIC failure to occur sooner than lower temperatures. For power consumption there is a direct relationship between temperature and power consumption, such that higher temperatures will increase static transistor leakage and therefore increase power consumption, even under identical workloads. And finally, there is a weak relationship between temperature and attainable clockspeeds, such that the switching performance of silicon transistors drop as they become warmer, making it harder to attain high clockspeeds (which is part of the reason why record setting overclocks are with GPUs well into the negative Celsius range).
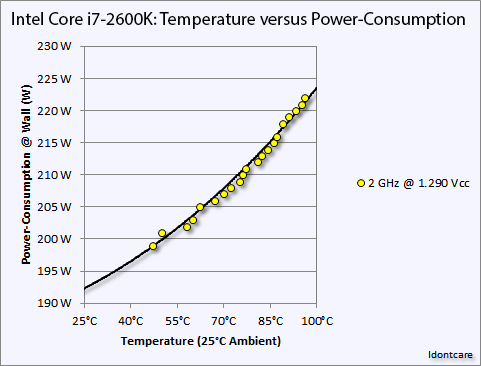
An example of the temperature versus power consumption principle on an Intel Core i7-2600K. Image Credit: AT Forums User "Idontcare"
The important part to take away from all of this however is that these relationships occur across the entire range of temperatures a product is rated to operate under, and more importantly that all of these factors are taken into consideration in product planning. The 95C maximum operating temperature that most 28nm devices operate under is well understood by engineering teams, along with the impact to longevity, power consumption, and clockspeeds when operating both far from it and near it. In other words, there’s nothing inherently wrong with letting an ASIC go up to 95C so long as it’s appropriately planned for. And this, more than anything else, is what has changed for 290X and Hawaii.
As a second wind product, one of the biggest low-level changes AMD has made to Hawaii relative to Tahiti is that they have been able to significantly clamp down on their leakage. Not that Tahiti was a particularly leaky chip (and not that it was particularly leakless either), but as the first GPU to roll out of TSMC it was very conservatively designed and had to be able to deal with the leakage and other nagging issues that come with an immature fabrication process. Hawaii in turn is designed against a very mature 28nm process, and designed in such a way that AMD doesn’t have to be conservative. As a result Hawaii’s leakage, though not quantified, is said to be notably reduced versus Tahiti.
What this means for 290X in turn is that one of the biggest reasons for keeping temperatures below 95C has been brought under control. AMD no longer needs to keep temperatures below 95C in order to avoid losing significant amounts of performance to leakage. From a performance perspective it has become “safe” to operate at 95C.
Meanwhile from a longevity perspective, while the underlying silicon hasn’t necessarily changed AMD’s understanding of ASIC longevity on TSMC’s 28nm process has. Nearly two years of experience in shipping 28nm GPUs means that AMD has hard evidence for how long a GPU can last at various temperatures, and the maturation of the 28nm process in turn has extended that longevity by improving both the quality and consistency of the GPUs that come out of it. Ultimately there is always going to be a longevity cost to increasing temperatures – and only AMD knows what that cost is – but as the entity ultimately responsible for warrantying their GPUs, at this point AMD is telling us that Hawaii will meet all of their longevity requirements even with the higher operating temperatures.
With that in mind, why would AMD even want to increase their operating temperatures to 95C? In short, to take full advantage of Newton’s Law of Cooling. Newton’s Law of Cooling dictates that the greater the gradient between a heat source and its environment, the more heat energy can be transferred. Or in other words, AMD is able to remove more heat energy from the GPU with the same cooling apparatus simply by operating at a higher temperature. Ergo a 290X operating at 95C can consume more power (operate at greater performance levels) while requiring no increase in cooling (noise) over what a 290X that operates at a lower temperature would require.
Now admittedly none of this makes 95C any less unsettling when first looking at temperatures, as we have become accustomed to 80C range temperatures over the years. But so long as the longevity of Hawaii matches AMD’s claims then this ultimately won’t be an issue. 95C will just be a number, and high ASIC temperatures will be another tool to maximize cooling performance. With that in mind, it will be interesting to see what AMD’s board partners do with their eventual custom Hawaii designs, assuming that they follow the same cooling paradigm as AMD. How much quieter would a Gigabyte Windforce or Asus DirectCU II based Hawaii card be able to operate if it was allowed to (and capable of) operating at 95C sustained? The answer to that, we expect, should prove to be a lot of fun.
Having established in detail how the latest iteration of PowerTune works, let’s finally talk about how this iteration of PowerTune will affect end-user tweaking and overclocking.
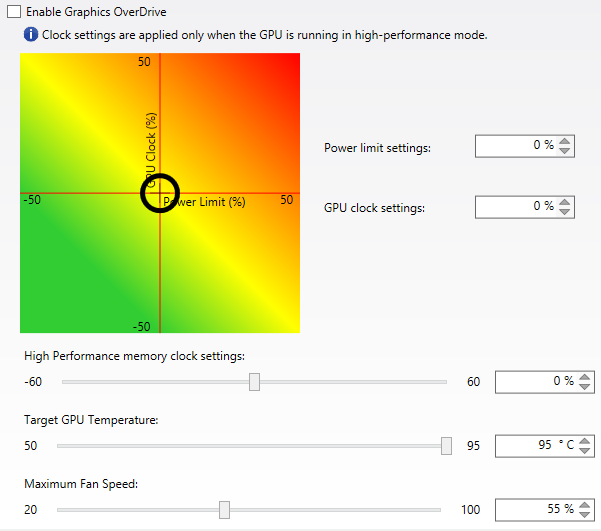
As to be expected, AMD has opted to expose all of their new PowerTune power controls via their Overdrive control panel, and as such users have full control over both overclocking and throttle controls. On the throttle side this includes both the traditional power limit controls, and new controls to set the target GPU temperature and the maximum fan speed. These follow the rules we noted earlier, so adjusting the GPU temperature target for example causes the fan speed to ramp up more quickly, or bringing down the maximum fan speed will result in a greater throttle on overall performance.
Meanwhile overclocking controls have also received a facelift, and unlike the throttle controls we’ve having a harder time getting behind these changes. In short, Overdrive now adjusts the GPU and memory clockspeed on a relative percentage basis rather than an absolute frequency basis. On the one hand this brings consistency with how power adjustments have always worked, and yet on the other hand we can’t help but feel that percentage based overclocking is decidedly unhelpful and unintuitive. 10% is far less meaningful than 100MHz in this context, and it’s going to get even worse once we see factory overclocked cards and multiple tiers of Hawaii cards. Consequently we’d really rather have the original absolute frequency basis controls back. AMD is simply abstracting clockspeeds by too much.
Finally, along with the traditional sliders and settings boxes, AMD has introduced one final graphical element into Overdrive, and that is a 2D heatmap for overclocking. Placing the power limit on the X axis and the GPU clockspeed on the Y axis, the heatmap provides a simple graphical representation of the impact is of adjusting those values. The heatmap is a bit imprecise, and I suspect most seasoned overclockers will stick to punching in numbers directly, but otherwise it’s a nifty simplification of overclocking.
With the above in mind, the last factor we’re waiting to see play out is how 3rd party utilities such as MSI’s Afterburner choose to implement these new controls. AMD meets and exceeds GPU Boost 2.0 with respect to flexibility, but monitoring/reporting was never a strong suit for Overdrive. Just based on our own experiences in putting this article together, an equivalent to NVIDIA’s “reason” throttling flags would be incredibly helpful as it’s not always obvious why the 290X is throttling, especially if it’s throttling for power reasons. If AMD can provide that data to 3rd party utilities, then combined with the rest of the functionality we’ve seen they would have an unquestionable claim to bragging rights on whose power management technology is better.
Meet The Radeon R9 290X
Now that we’ve had a chance to discuss the features and the architecture of GCN 1.1 and Hawaii, we can finally get to the hardware itself: AMD’s reference Radeon R9 290X.
Other than the underlying GPU and the livery, the reference 290X is actually not a significant deviation from the reference design for the 7970. There are some changes that we’ll go over, but for better and for worse AMD’s reference design is not much different from the $550 card we saw almost 2 years ago. For cooling in particular this means AMD is delivering a workable cooler, but it’s not one that’s going to complete with the efficient-yet-extravagant coolers found on NVIDIA’s GTX 700 series.

Starting as always from the top, the 290X measures in at 10.95”. The PCB itself is a bit shorter at 10.5”, but like the 7970 the metal frame/baseplate that is affixed to the board adds a bit of length to the complete card. Meanwhile AMD’s shroud sports a new design, one which is shared across the 200 series. Functionally it’s identical to the 7970, being made of similar material and ventilating in the same manner.

Flipping over to the back of the card quickly, you won’t find much here. AMD has placed all 16 RAM modules on the front of the PCB, so the back of the PCB is composed of resistors, pins, mounting brackets, and little else. AMD continues to go without a backplate here as the backplate is physically unnecessary and takes up valuable breathing room in Crossfire configurations.
Pulling off the top of the shroud, we can see in full detail AMD’s cooling assembling, including the heatsink, radial fan, and the metal baseplate. Other than angling the far side of the heatsink, this heatsink is essentially unchanged from the one on the 7970. AMD is still using a covered aluminum block heatsink designed specifically for use in blower designs, which runs most of the length of the card between the fan and PCIe bracket. Connecting the heatsink to the GPU is an equally large vapor chamber cooler, which is in turn mounted to the GPU using AMD’s screen printed, high performance phase change TIM. Meanwhile the radial fan providing airflow is the same 75mm diameter fan we first saw in the 7970. Consequently the total heat capacity of this cooler will be similar, but not identical to the one on the 7970; with AMD running the 290X at a hotter 95C versus the 80C average of the 7970, this same cooler is actually able to move more heat despite being otherwise no more advanced.


Top: 290X. Bottom: 7970
Moving on, though we aren’t able to take apart the card for pictures (we need it intact for future articles), we wanted to quickly go over the power and RAM specs for the 290X. For power delivery AMD is using a traditional 5+1 power phase setup, with power delivery being driven by their newly acquired IR 3567B controller. This will be plenty to drive the card at stock, but hardcore overclockers looking to attach the card to water or other exotic cooling will likely want to wait for something with a more robust power delivery system. Meanwhile despite the 5GHz memory clockspeed for the 290X, AMD has actually equipped the card with everyone’s favorite 6GHZ Hynix R0C modules, so memory controller willing there should be quite a bit of memory overclocking headroom to play with. 16 of these modules are located around the GPU on the front side of the PCB, with thermal pads connecting them to the metal baseplate for cooling.
Perhaps the biggest change for the 290X as opposed to the 7970 is AMD’s choice for balancing display connectivity versus ventilation. With the 6970 AMD used a half-slot vent to fit a full range of DVI, HDMI, and DisplayPorts, only to drop the second DVI port on the 7970 and thereby utilize a full slot vent. With the 290X AMD has gone back once more to a stacked DVI configuration, which means the vent is once more back down to a bit over have a slot in size. At this point both AMD and NVIDIA have successfully shipped half-slot vent cards at very high TDPs, so we’re not the least bit surprised that AMD has picked display connectivity over ventilation, as a half-slot vent is proving to be plenty capable in these blower designs. Furthermore based on NVIDIA and AMD’s latest designs we wouldn’t expect to see full size vents return for these single-GPU blowers in the future, at least not until someone finally gets rid of space-hogging DVI ports entirely.


Top: R9 290X. Bottom: 7970
With that in mind, the display connectivity for the 290X utilizes AMD’s new reference design of 2x DL-DVI-D, 1x HDMI, and 1x DisplayPort. Compared to the 7970 AMD has dropped the two Mini DisplayPorts for a single full-size DisplayPort, and brought back the second DVI port. Note that unlike some of AMD’s more recent cards these are both physically and electrically DL-DVI ports, so the card can drive 2 DL-DVI monitors out of the box; the second DVI port isn’t just for show. The single DVI port on the 7970 coupled with the high cost of DisplayPort to DL-DVI ports made the single DVI port on the 7970 an unpopular choice in some corners of the world, so this change should make DVI users happy, particularly those splurging on the popular and cheap 2560x1440 Korean IPS monitors (the cheapest of which lack anything but DVI).
But as a compromise of this design – specifically, making the second DVI port full DL-DVI – AMD had to give up the second DisplayPort, which is why the full sized DisplayPort is back. This does mean that compared to the 7970 the 290X has lost some degree of display flexibility howwever, as DisplayPorts allow for both multi-monitor setups via MST and for easy conversion to other port types via DVI/HDMI/VGA adapters. With this configuration it’s not possible to drive 6 fully independent monitors on the 290X; the DisplayPort will get you 3, and the DVI/HDMI ports the other 3, but due to the clock generator limits on the 200 series the 3 monitors on the DVI/HDMI ports must be timing-identical, precluding them from being fully independent. On the other hand this means that the PC graphics card industry has effectively settled the matter of DisplayPort versus Mini DisplayPort, with DisplayPort winning by now being the port style of choice for both AMD and NVIDIA. It’s not how we wanted this to end up – we still prefer Mini DisplayPort as it’s equally capable but smaller – but at least we’ll now have consistency between AMD and NVIDIA.

Moving on, AMD’s dual BIOS functionality is back once again for the 290X, and this time it has a very explicit purpose. The 290X will ship with two BIOSes, a “quiet” bios and an “uber” BIOS, selectable with the card’s BIOS switch. The difference between the two BIOSes is that the quiet BIOS ships with a maximum fan speed of 40%, while the uber BIOS ships with a maximum fan speed of 50%. The quiet BIOS is the default BIOS for the 290X, and based on our testing will hold the noise levels of the card equal to or less than those of the reference 7970.

| AMD Radeon Family Cooler Comparison: Noise & Power | |||||||||||
| Card | Load Noise - Gaming | Estimated TDP | |||||||||
| Radeon HD 7970 | 53.5dB | 250W | |||||||||
| Radeon R9 290X Quiet | 53.3dB | 300W | |||||||||
| Radeon R9 290X Uber | 58.9dB | 300W | |||||||||
However because of the high power consumption and heat generation of the underlying Hawaii GPU, in quiet mode the card is unable to sustain its full 1000MHz boost clock for more than a few minutes; there simply isn’t enough cooling occuring at 40% to move 300W of heat. We’ll look at power, temp, and noise in full a bit later in our benchmark section, but average sustained clockspeeds are closer to 900MHz in quiet mode. Uber mode and its 55% fan speed on the other hand is fast enough (and just so) to move enough air to keep the card at 1000MHz in all non-TDP limited workloads. The tradeoff there is that the last 100MHz of clockspeed is going to be incredibly costly from a noise perspective, as we’ll see. The reference 290X would not have been a viable product if it didn’t ship with quiet mode as the default BIOS.
Finally, let’s wrap things up by talking about miscellaneous power and data connectors. With AMD having gone with bridgeless (XDMA) Crossfire for the 290X, the Crossfire connectors that have adorned high-end AMD cards for years are now gone. Other than the BIOS switch, the only thing you will find at the top of the card are the traditional PCIe power sockets. AMD is using the traditional 6pin + 8pin setup here, which combined with the PCIe slot power is good for delivering 300W to the card, which is what we estimate to be the card’s TDP limit. Consequently overclocking boards are all but sure to go the 8pin + 8pin route once those eventually arrive.
A Note On Crossfire, 4K Compatibility, Power, & The Test
Before we dive into our formal testing, there are a few brief testing notes that bear mentioning.
First and foremost, on top of our normal testing we did some additional Crossfire compatibility testing to see if AMD’s new XDMA Crossfire implementation ran into any artifacting or other issues that we didn’t experience elsewhere. The good news there is that outside of the typical scenarios where games simply don’t scale with AFR – something that affects SLI and CF equally – we didn’t see any artifacts in the games themselves. The closest we came to a problem was with the intro videos for Total War: Rome 2, which have black horizontal lines due to the cards trying to AFR render said video at a higher framerate than it played at. Once in-game Rome was relatively fine; relatively because it’s one of the games we have that doesn’t see any performance benefit from AFR.
Unfortunately AMD’s drivers for 290X are a bit raw when it comes to Crossfire. Of note, when running at a 4K resolution, we had a few instances of loading a game triggering an immediate system reboot. Now we’ve had crashes before, but nothing quite like this. After reporting it to AMD, AMD tells us that they’ve been able to reproduce the issue and have fixed it for the 290X launch drivers, which will be newer than the press drivers we used. Once those drivers are released we’ll be checking to confirm, but we have no reason to doubt AMD at this time.
Speaking of 4K, due to the two controller nature of the PQ321 monitor we use there are some teething issues related to using 4K right now. Most games are fine at 4K, however we have found games that both NVIDIA and AMD have trouble with at one point or another. On the NVIDIA side Metro will occasionally lock up after switching resolutions, and on the AMD side GRID 2 will immediately crash if using the two controller (4K@60Hz) setup. In the case of the latter dropping down to a single controller (4K@30Hz) satisfies GRID while allowing us to test at 4K resolutions, and with V-sync off it doesn’t have a performance impact versus 60Hz, but it is something AMD and Codemasters will need to fix.
Furthermore we also wanted to offer a quick update on the state of Crossfire on AMD’s existing bridge based (non-XDMA) cards. The launch drivers for the 290X do not contain any further Crossfire improvements for bridge based cards, which means Eyefinity Crossfire frame pacing is still broken for all APIs. Of particular note for our testing, the 280X Crossfire setup ends up in a particularly nasty failure mode, simply dropping every other frame. It’s being rendered, as evidenced by the consumption of the Present call, however as our FCAT testing shows it’s apparently not making it to the master card. This has the humorous outcome of making the frame times rather smooth, but it makes Crossfire all but worthless as the additional frames are never displayed. Hopefully AMD can put a fork in the matter once and for all next month.
A Note On Testing Methodologies & Sustained Performance
Moving on to the matter of our testing methodology, we want to make note of some changes since our 280X review earlier this month. After having initially settled on Metro: Last Light for our gaming power/temp/noise benchmark, in a spot of poor planning on our part we have discovered that Metro scales poorly on SLI/CF setups, and as a result doesn't push those setups very hard. As such we have switched from Metro to Crysis 3 for our power/temp/noise benchmarking, as Crysis 3 was our second choice and has a similar degree of consistency to it as Metro while scaling very nicely across both AMD and NVIDIA multi-GPU setups. For single-GPU cards the impact on noise is measurably minor, as the workloads are similar, however power consumption will be a bit different due to the difference in CPU workloads between the benchmarks.
We also want to make quick note of our testing methodologies and how they are or are not impacted by temperature based throttling. For years we have done all of our GPU benchmarking by looping gaming benchmarks multiple times, both to combat the inherent run-to-run variation that we see in benchmarking, and more recently to serve as a warm-up activity for cards with temperature based throttling. While these methods have proved sufficient for the Radeon 7000 series, the GeForce 600 series, and even the GeForce 700 series, due to the laws of physics AMD's 95C throttle point takes longer to get to than NVIDIA's 80C throttle point. As a result it's harder to bring the 290X up to its sustained temperatures before the end of our benchmark runs. It will inevitably hit 95C in quiet mode, but not every benchmark runs long enough to reach that before the 3rd or 4th loop.
For the sake of consistency with past results we have not altered our benchmark methodology. However we wanted to be sure to point out this fact before getting to benchmarking, so that there’s no confusion over how we’re handling the matter. Consequently we believe our looping benchmarks run long enough to generally reach sustained performance numbers, but in all likelihood some of our numbers on the shortest benchmarks will skew low. For the next iteration of our benchmark suite we’re most likely going to need to institute a pre-heating phase for all cards to counter AMD’s 95C throttle point.
The Drivers
The press drivers for the 290X are Catalyst 13.11 Beta v5 (The “v” is AMD’s nomenclature), which identify themselves as being from the driver branch 13.250. These are technically still in the 200 branch of AMD’s drivers, but this is the first appearance of 250, as Catalyst 13.11 Beta v1 was still 13.200. AMD doesn’t offer release notes on these beta drivers, but we found that they offered distinct improvements in GRID 2 and to a lesser extent Battlefield 3, and have updated our earlier results accordingly.
Meanwhile for NVIDIA we’re using the recently released “game ready” 331.58 WHQL drivers.
| CPU: | Intel Core i7-4960X @ 4.2GHz |
| Motherboard: | ASRock Fatal1ty X79 Professional |
| Power Supply: | Corsair AX1200i |
| Hard Disk: | Samsung SSD 840 EVO (750GB) |
| Memory: | G.Skill RipjawZ DDR3-1866 4 x 8GB (9-10-9-26) |
| Case: | NZXT Phantom 630 Windowed Edition |
| Monitor: | Asus PQ321 |
| Video Cards: |
AMD Radeon R9 290X XFX Radeon R9 280X Double Dissipation AMD Radeon HD 7970 GHz Edition AMD Radeon HD 7970 AMD Radeon HD 6970 AMD Radeon HD 5870 NVIDIA GeForce GTX Titan NVIDIA GeForce GTX 780 NVIDIA GeForce GTX 770 |
| Video Drivers: |
NVIDIA Release 331.58 AMD Catalyst 13.11 Beta v1 AMD Catalyst 13.11 Beta v5 |
| OS: | Windows 8.1 Pro |
Metro: Last Light
As always, kicking off our look at performance is 4A Games’ latest entry in their Metro series of subterranean shooters, Metro: Last Light. The original Metro: 2033 was a graphically punishing game for its time and Metro: Last Light is in its own right too. On the other hand it scales well with resolution and quality settings, so it’s still playable on lower end hardware.
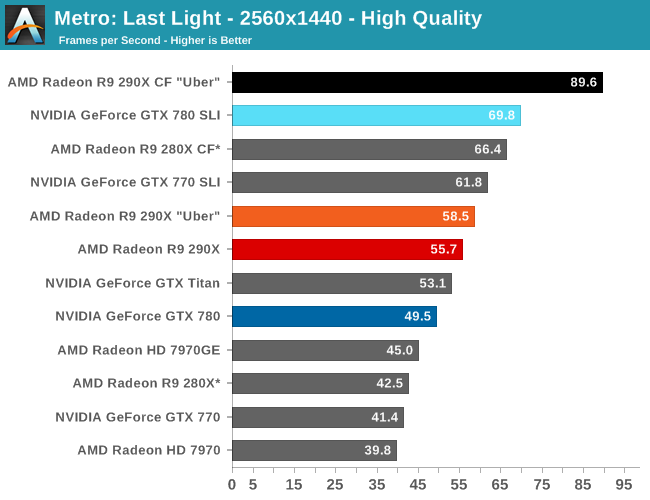
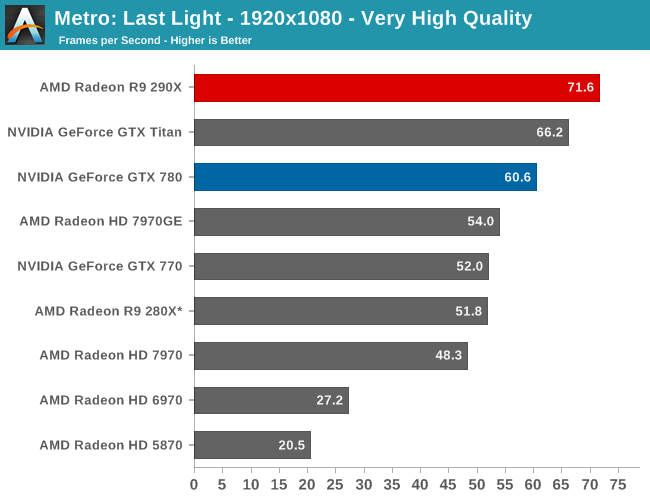
For the bulk of our analysis we’re going to be focusing on our 2560x1440 results, as monitors at this resolution will be what we expect the 290X to be primarily used with. A single 290X may have the horsepower to drive 4K in at least some situations, but given the current costs of 4K monitors that’s going to be a much different usage scenario.
With that said, for focusing on 4K on most games we’ve thrown in results both at a high quality setting, and a lower quality setting that makes it practical to run at 4K off of a single card. Given current monitor prices it won’t make a ton of sense to try to go with reduced quality settings just to save $550 – and consequently we may not keep the lower quality benchmarks around for future articles – but for the purposes of looking at a new GPU it’s useful to be able to look at single-GPU performance at framerates that are actually playable.
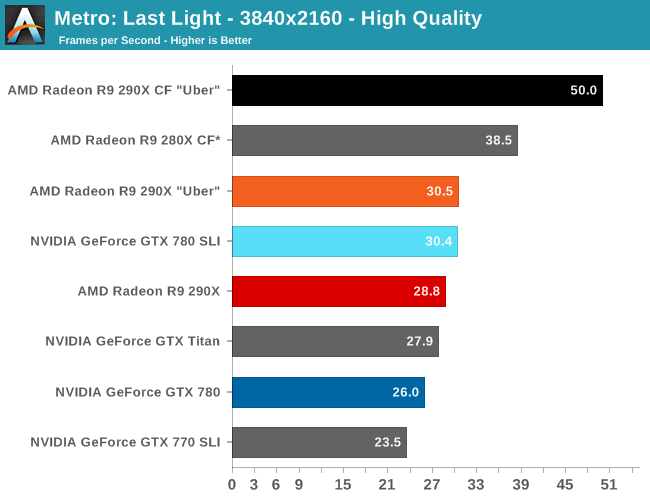
With that said, starting off with Metro at 2560 the 290X hits the ground running on our first benchmark. At 55fps it’s just a bit shy of hitting that 60fps average we love to cling to, but among all of our single-GPU cards it is the fastest, beating even the traditional powerhouse that is GTX Titan. Consequently the performance difference between 290X and GTX 780 (290X’s real competition) is even greater, with the 290X outpacing the GTX 780 by 13%, all the while being $100 cheaper. As we’ll see these results are a bit better than the overall average, but all told we’re not too far off. For as fast as GTX 780 is, 290X is going to be appreciably (if not significantly) faster.
290X also does well for itself compared to the Tahiti based 280X. At 2560 the 290X’s performance advantage stands at 31%, which as we alluded to earlier is greater than the increase in die size, offering solid proof that AMD has improved their performance per mm2 of silicon despite the fact that they’re still on the same 28nm manufacturing process. That 31% does come at a price increase of 83% however, which although normal for this price segment serves as a reminder that the performance increases offered by the fastest video cards with the biggest GPUs do not come cheaply.
Meanwhile for one final AMD comparison, let’s quickly look at the 290X in uber mode. As the 290X is unable to sustain the power/heat workload of a 1000MHz Hawaii GPU for an extended period of time, at its stock (quiet settings) it has to pull back on performance in order to meet reasonable operational parameters. Uber mode on the other hand represents what 290X and the Hawaii can do when fully unleashed; the noise costs won’t be pretty (as we’ll see), but in the process it builds on 290X’s existing leads and increases them by another 5%. And that’s really going to be one of the central narratives for 290X once semi-custom and fully-custom cards come online: Despite being a fully enabled part, 290X does not give us everything Hawaii is truly capable of.
Moving on, let’s talk about multi-GPU setups and 4K. Metro is a solid reminder that not every game scales similarly across different GPUs, and for that matter that not every game is going to significantly benefit from multi-GPU setups. Metro for its part isn’t particularly hospitable to multi-GPU cards, with the best setup scaling by only 53% at 2560. This is better than some games that won’t scale at all, but it won’t be as good as those games that see a near-100% performance improvement. Which consequently is also why we dropped Metro as a power benchmark, as this level of scaling is a poor showcase for the power/temp/noise characteristics of a pair of video cards under full load.
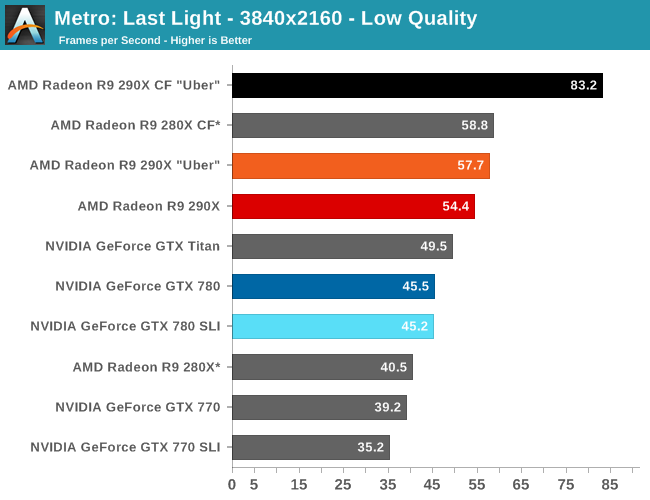
The real story here of course is that it’s another strong showing for AMD at both 2560 and 4K. At 2560 the 290X CF sees better performance scaling than the GTX 780 SLI – 53% versus 41% – further extending the 290X’s lead. Bumping the resolution up to 4K makes things even more lopsided in AMD’s favor, as at this point the NVIDIA cards essentially fail to scale (picking up just 17%) while the 290X sees an even greater scaling factor of 63%. As such for those few who can afford to seriously chase 4K gaming, the 290X is the only viable option in this scenario. And at 50fps average for 4K at high quality, 4K gaming at reasonable (though not maximum) quality settings is in fact attainable when it comes to Metro.
Meanwhile for single-GPU configurations at 4K, 4K is viable, but only at Metro’s lowest quality levels. This will be the first of many games where such a thing is possible, and the first of many games where going up to 4K in this manner further improves on AMD’s lead at 4K. Again, we’re not of the opinion that 4K at these low quality settings is a good way to play games, but it does provide some insight and validationg into AMD’s claims that their hardware is better suited for 4K gaming.
Company of Heroes 2
Our second benchmark in our benchmark suite is Relic Games’ Company of Heroes 2, the developer’s World War II Eastern Front themed RTS. For Company of Heroes 2 Relic was kind enough to put together a very strenuous built-in benchmark that was captured from one of the most demanding, snow-bound maps in the game, giving us a great look at CoH2’s performance at its worst. Consequently if a card can do well here then it should have no trouble throughout the rest of the game.
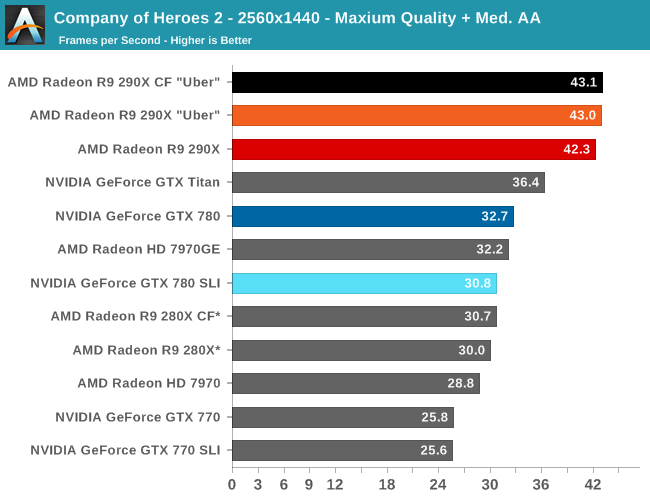
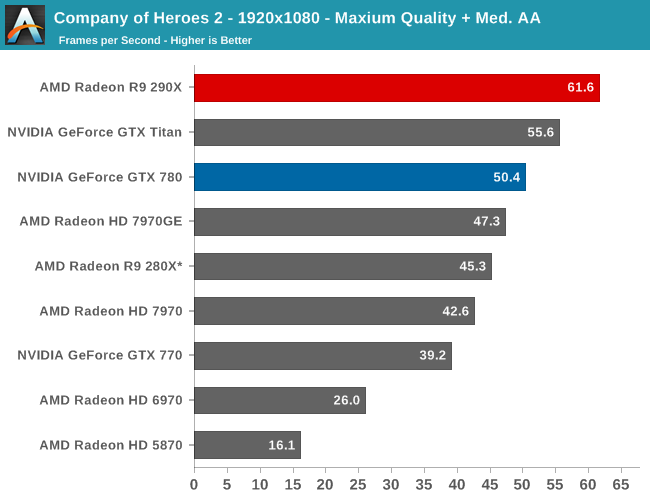
Our first strategy game is also our first game that is flat out AFR incompatible, and as a result the only way to get the best performance out of Company of Heroes 2 is with the fastest single-GPU card available. To that end this is a very clear victory for the 290X, and in fact will be the largest lead for the 290X of all of our benchmarks. At 2560 it’s a full 29% faster than the GTX 780, which all but puts the 290X in a class of its own. This game also shows some of the greatest gains for the 290X over the 280X, with the 290X surpassing its Tahti based predecessor by an equally chart topping 41%. It’s not clear what it is at this time that Company of Heroes 2 loves about 290X in particular, but as far as this game is concerned AMD has put together an architecture that maps well to the game’s needs.
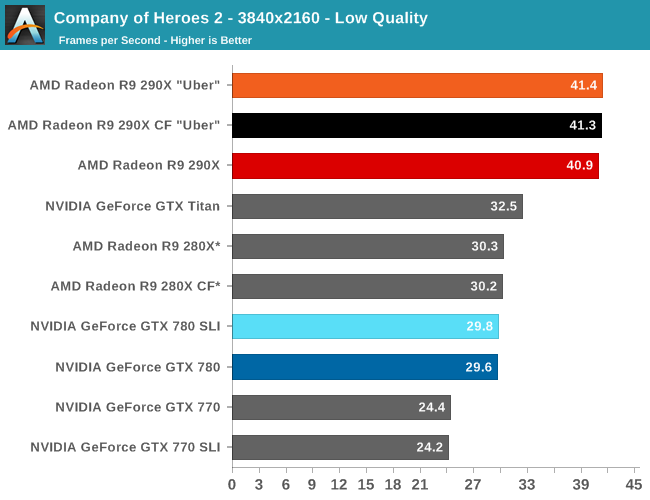
Briefly, because of a lack of AFR compatibility 4K is only barely attainable with any kind of GPU setup. In fact we’re only throwing in the scale-less SLI/CF numbers to showcase that fact. We had to dial down our quality settings to Low on CoH2 in order to get a framerate above 30fps; even though we can be more liberal about playable framerates on strategy games, there still needs to be a cutoff for average framerates around that point. As a result 280X, GTX Titan, and 290X are the only cards to make that cutoff, with 290X being the clear winner. But the loss in quality to make 4K achievable is hardly worth the cost.
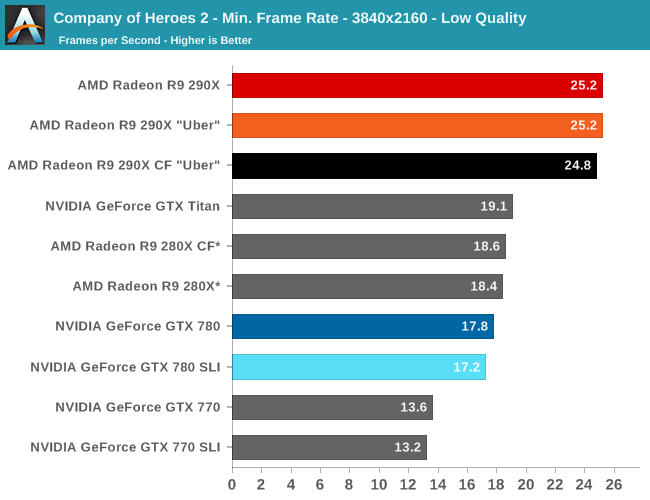
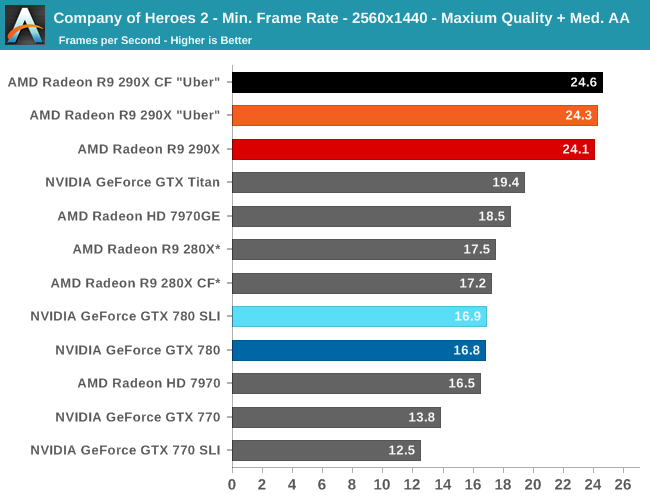
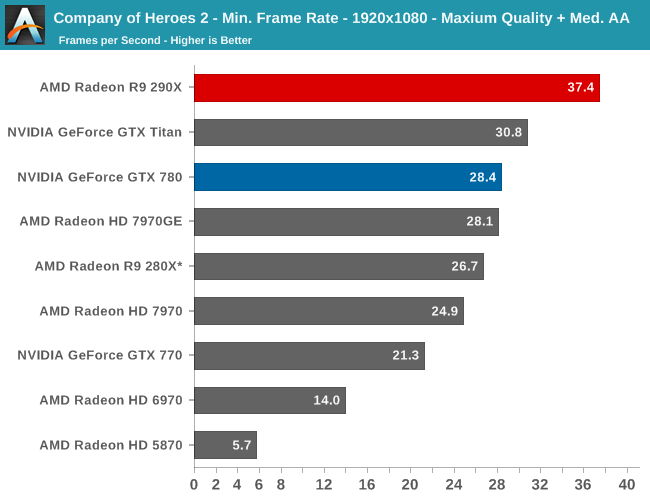
Moving on to minimum framerates, we see that at its most stressful points that nothing, not even 290X, can keep its minimums above 30fps. For a strategy game this is bearable, but we certainly wouldn’t mind more performance. AMD will be pleased though, as their performance advantage over the GTX 780 is only further extended here; a 29% average performance advantage becomes a 43% minimum performance advantage at 2560.
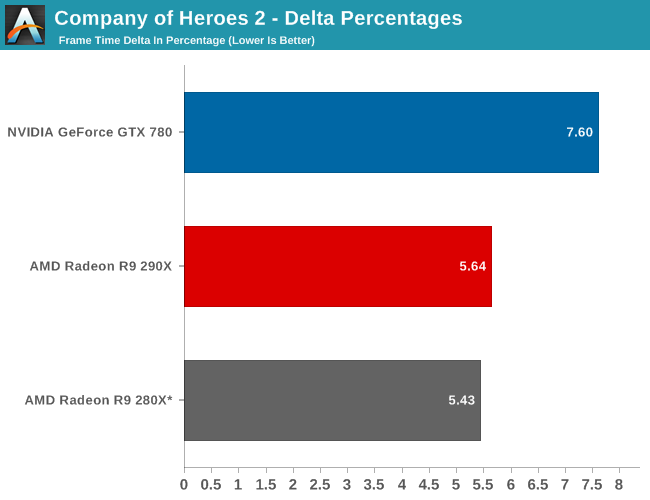
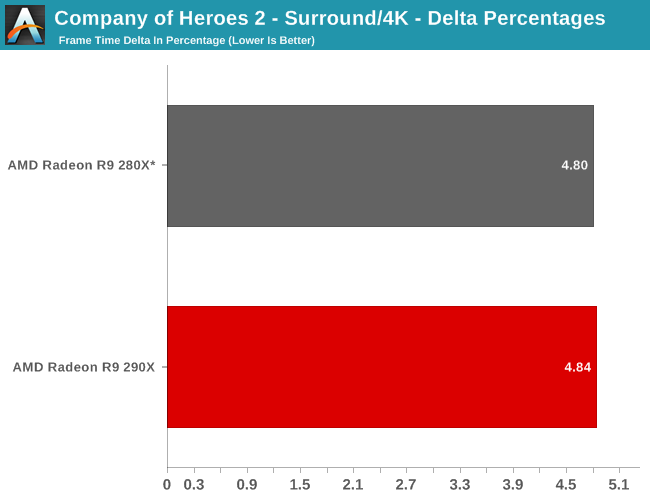
Finally, while we don’t see any performance advantages from AFR on this game we did run our FCAT benchmarks anyhow to quickly capture the delta percentages. Company of Heroes 2 has a higher than average variance even among single cards, which results in deltas being above 5%. The difference between 5% and 7% is not going to be too significant in practice here, but along with AMD’s performance advantage they do have slightly more consistent frame times than the GTX 780. Though in both the case of the 280X and the 290X we’re looking at what are essentially the same deltas, so while the 290X improves on framerates versus the 280X, it doesn’t bring with it any improvements in frame time consistency.
Bioshock Infinite
Bioshock Infinite is Irrational Games’ latest entry in the Bioshock franchise. Though it’s based on Unreal Engine 3 – making it our obligatory UE3 game – Irrational had added a number of effects that make the game rather GPU-intensive on its highest settings. As an added bonus it includes a built-in benchmark composed of several scenes, a rarity for UE3 engine games, so we can easily get a good representation of what Bioshock’s performance is like.
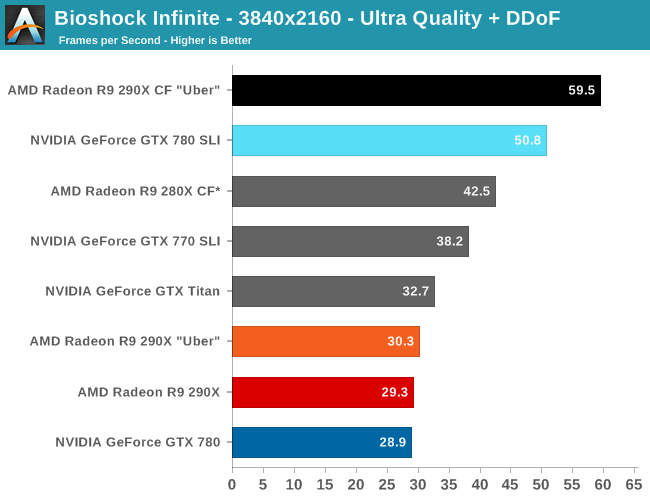
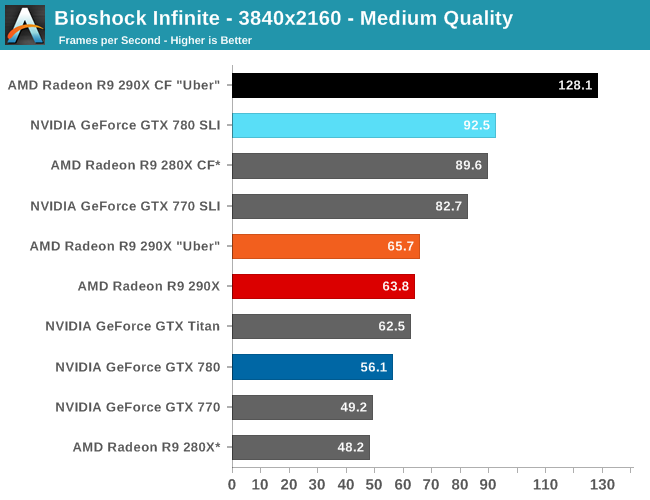
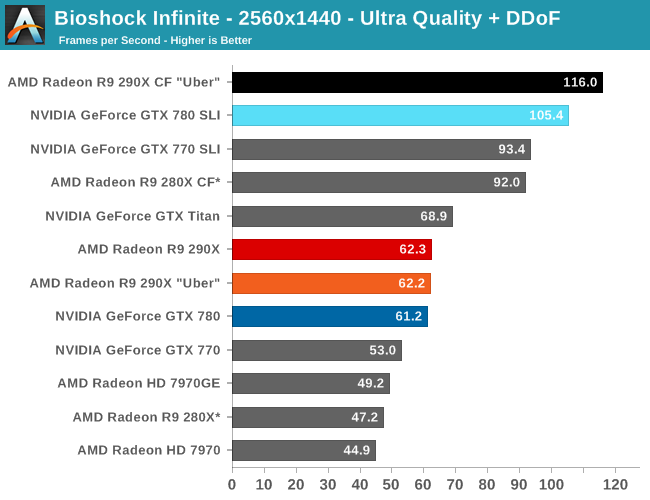
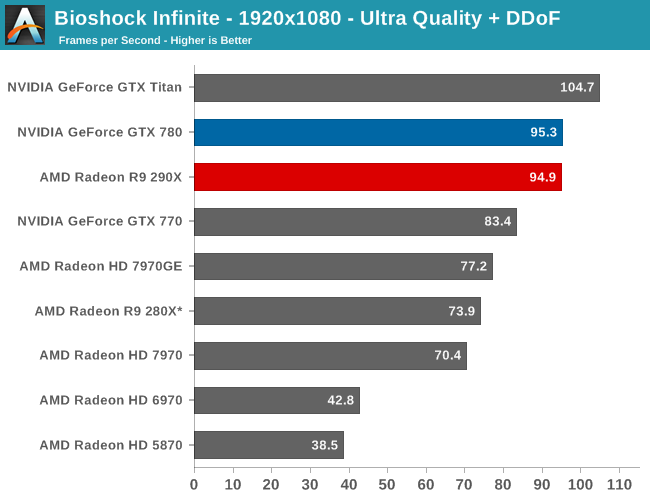
The first of the games AMD allowed us to publish results for, Bioshock is actually a straight up brawl between the 290X and the GTX 780 at 2560. The 290X’s performance advantage here is just 2%, much smaller than the earlier leads it enjoyed and essentially leaving the two cards tied, which also makes this one of the few games that 290X can’t match GTX Titan. At 2560 everything 290X/GTX 780 class or better can beat 60fps despite the heavy computational load of the depth of field effect, so for AMD 290X is the first single-GPU card from them that can pull this off.
Meanwhile at 4K things end up being rather split depending on the resolution we’re looking at. At Ultra quality the 290X and GTX 780 are again tied, but neither is above 30fps. Drop down to Medium quality however and we get framerates above 60fps again, while at the same time the 290X finally pulls away from the GTX 780, beating it by 14% and even edging out GTX Titan. Like so many games we’re looking at today the loss in quality cannot justify the higher resolution, in our opinion, but it presents another scenario where 290X demonstrates superior 4K performance.
For no-compromises 4K gaming we once again turn our gaze towards the 290X CF and GTX 780 SLI, which has AMD doing very well for themselves. While AMD and NVIDIA are nearly tied at the single GPU level – keep in mind we’re in uber mode for CF, so the uber 290X has a slight performance edge in single GPU mode – with multiple GPUs in play AMD sees better scaling from AFR and consequently better overall performance. At 95% the 290X achieves a nearly perfect scaling factor here, while the GTX 780 SLI achieves only 65%. Curiously this is better for AMD and worse for NVIDIA than the scaling factors we see at 2560, which are 86% and 72% respectively.
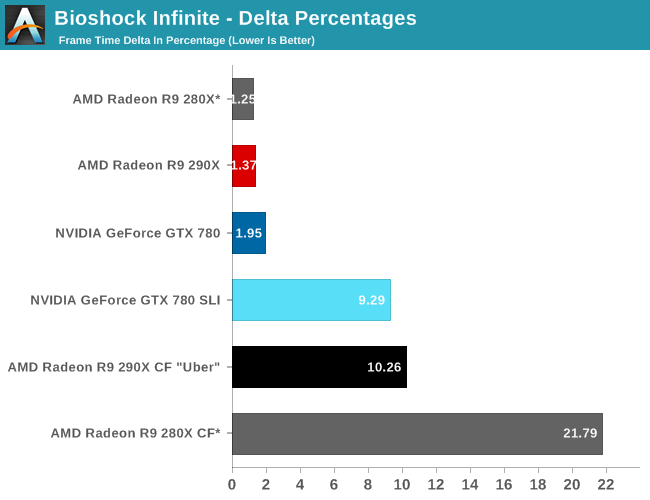
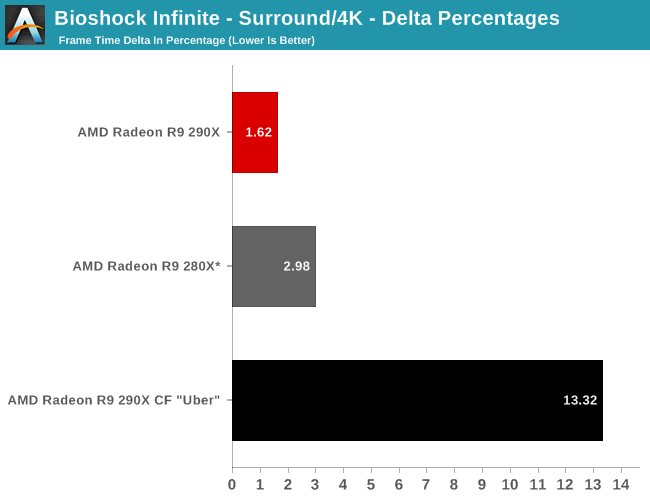
Moving on to our FCAT measurements, it’s interesting to see just how greatly improved the frame pacing is for the 290X versus the 280X, even with the frame pacing fixes in for the 280X. Whereas the 280X has deltas in excess of 21%, the 290X brings those deltas down to 10%, better than halving the variance in this game. Consequently the frame time consistency we’re seeing goes from being acceptable but measurably worse than NVIDIA’s consistency to essentially equal. In fact 10% is outright stunning for a multi-GPU setup, as we rarely achieve frame rates this consistent on those setups.
Finally for 4K gaming our variance increases a bit, but not immensely so. Despite the heavier rendering workload and greater demands on moving these large frames around, the delta percentages keep to 13%.
Battlefield 3
Our major multiplayer action game of our benchmark suite is Battlefield 3, DICE’s 2011 multiplayer military shooter. Its ability to pose a significant challenge to GPUs has been dulled some by time and drivers, but it’s still a challenge if you want to hit the highest settings at the highest resolutions at the highest anti-aliasing levels. Furthermore while we can crack 60fps in single player mode, our rule of thumb here is that multiplayer framerates will dip to half our single player framerates, so hitting high framerates here may not be high enough.
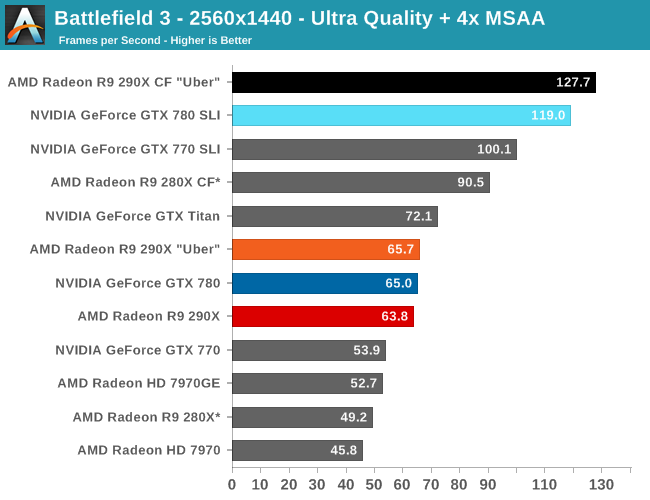
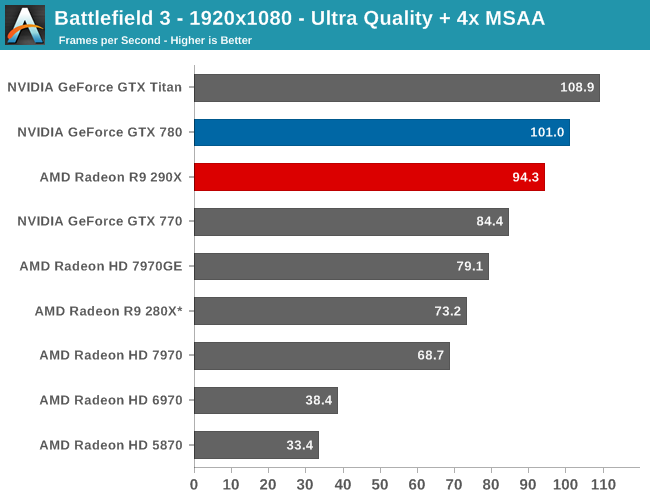
For our Battlefield 3 benchmark NVIDIA cards have consistently been the top performers over the years, and as a result this is one of the hardest fights for any AMD card. So how does the 290X fare? Very well, as it turns out. The slowest game for the 290X (relative to the GTX 780) has it losing to the GTX 780 by just 2%, effectively tying NVIDIA’s closest competitor. Not only is the 290X once again the first single-GPU AMD card that can break 60fps average on a game at 2560 – thereby ensuring good framerates even in heavy firefights – but it’s fully competitive with NVIDIA in doing so in what’s traditionally AMD’s worst game. At worst for AMD, they can’t claim to be competitive with GTX Titan in this one.
Moving on to 4K gaming, none of these single-GPU cards are going to cut it at Ultra quality; the averages are decent but the minimums will drop to 20fps and below. This means we either drop down to Medium quality, where 290X is now performance competitive with GTX Titan, or we double up on GPUs, which sees the 290X CF in uber mode take top honors. This game happens to be another good example of how the 290X is scaling into 4K better than the GTX 780 and other NVIDIA cards are, as not only does AMD’s relative positioning versus NVIDIA cards improve, but in heading to 4K AMD picks up a 13% lead over the GTX 780. The only weak spot here for AMD will be performance scaling for multiple GPUs, as while the 290X enjoys a 94% scaling factor at 2560, that drops to 60% at 4K, at a time where NVIDIA’s scaling factor is 76%. The 290X has enough of a performance lead for the 290X CF to hold out over the GTX 780 SLI, but the difference in scaling factors will make it cut close.
Meanwhile in an inter-AMD comparison, this is the first game in our benchmark suite where the 290X doesn’t beat the 280X by at least 30%. Falling just short at 29.5%, it’s a reminder that despite the similarities between 290X (Hawaii) and 280X (Tahiti), the performance differences between the two will not be consistent.
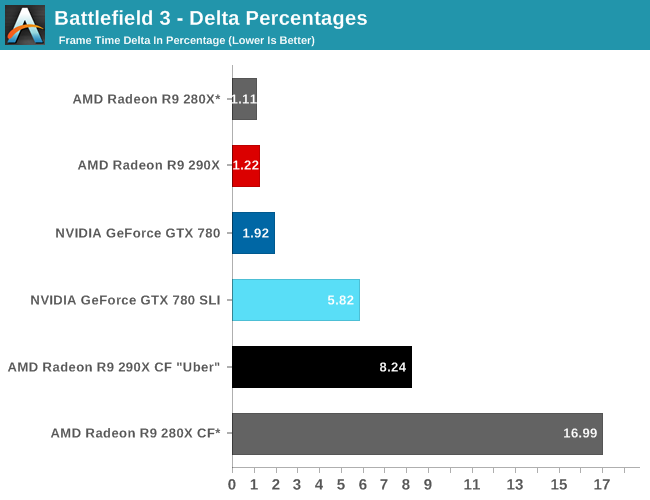
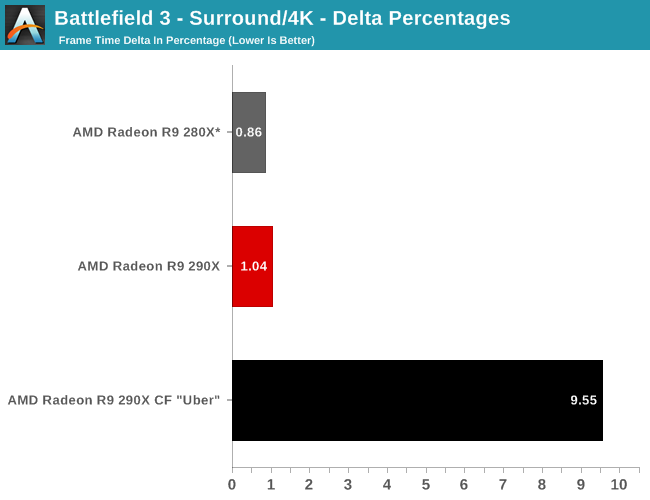
Looking at our delta percentages, this is another strong showing for the 290X CF, especially as compared to the 280X CF. AMD has once again halved their variance as compared to the 280X CF, bringing it down to sub-10% levels. This despite the theoretical advantage that the dedicated CFBI should give the 280X. However AMD can’t claim to have the lowest variance of any multi-GPU setup, as this is NVIDIA’s best game, with the GTX 780 SLI seeing a variance of only 6%. It’s a shame not all games can be like this (for either vendor) since there would be little reason not to go with a multi-GPU setup if this was the typical AFR experience as opposed to the best AFR experience.
Finally, looking at delta percentages under 4K shows that AMD’s variance has once again risen slightly compared to the variance at 2560x1440, but not significantly so. The 290X CF still holds under 10% here.
Crysis 3
Still one of our most punishing benchmarks, Crysis 3 needs no introduction. With Crysis 3, Crytek has gone back to trying to kill computers and still holds “most punishing shooter” title in our benchmark suite. Only in a handful of setups can we even run Crysis 3 at its highest (Very High) settings, and that’s still without AA. Crysis 1 was an excellent template for the kind of performance required to drive games for the next few years, and Crysis 3 looks to be much the same for 2013.
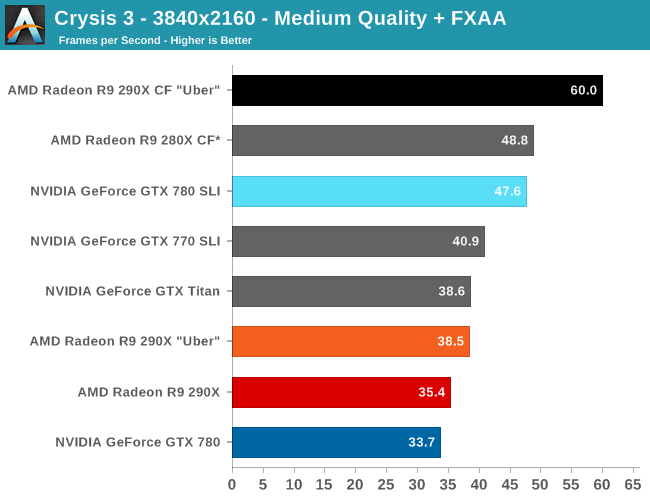
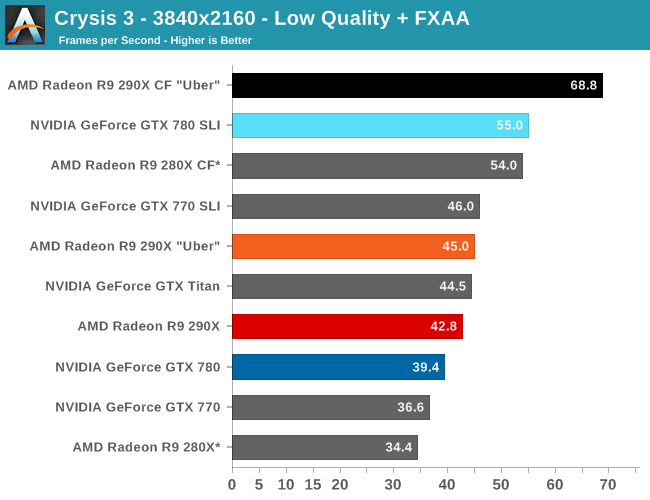
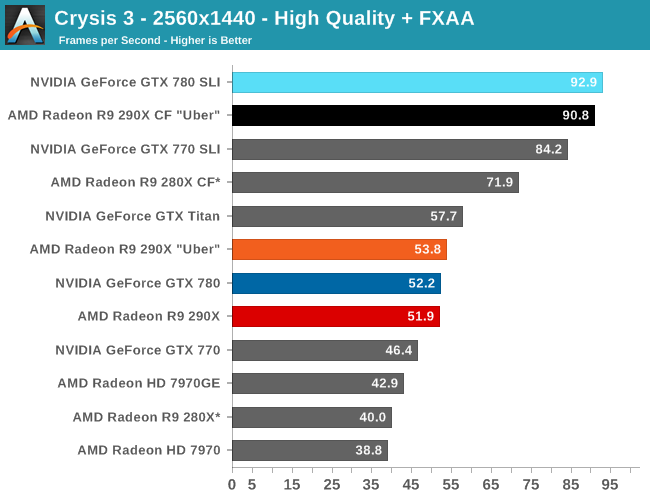
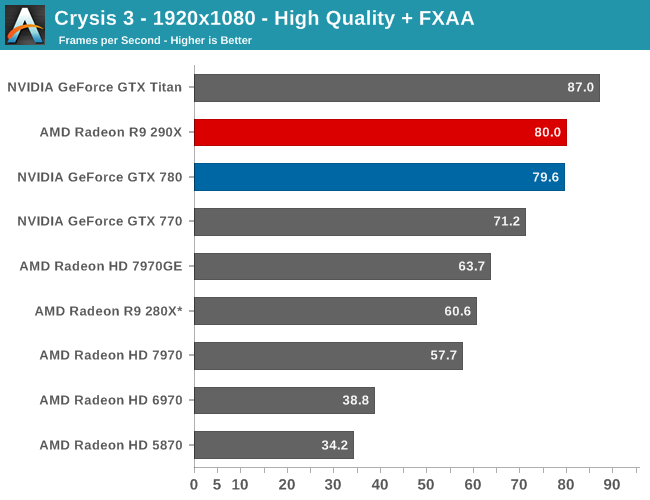
Much like Battlefield 3, at 2560 it’s a neck and neck race between the 290X and the GTX 780. At 52fps neither card stands apart, and in traditional Crysis fashion neither card is fast enough to pull off 60fps here – never mind the fact that we’re not even at the highest quality levels.
Meanwhile if we bump up the resolution to 4K, things get ugly, both in the literal and figurative senses. Even at the game’s lowest quality settings neither card can get out of the 40s, though as usual the 290X pulls ahead in performance at this resolution.
As such, for 60fps+ on Crysis 3 we’ll have to resort to AFR, which gives us some interesting results depending on which resolution we’re looking at. For 2560 it’s actually the GTX 780 SLI that pulls ahead, beating the 290X in scaling. However at 4K it’s the 290X CF that pulls ahead, enjoying a 53% scaling factor to the GTX 780’s 40%. Interestingly both cards see a reduction in scaling factors here versus 2560, despite the fact that both cards are having no problem reaching full utilization. Something about Crysis 3, most likely the sheer workload the game throws out at our GPUs, is really bogging things down at 4K. Though to AMD’s credit despite the poorer scaling factor at 4K the 290X CF in uber mode is just fast enough to hit 60fps at Medium quality, and not a frame more.
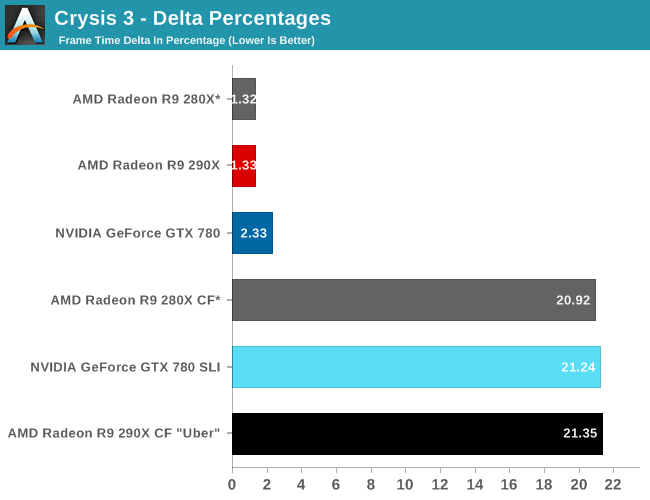
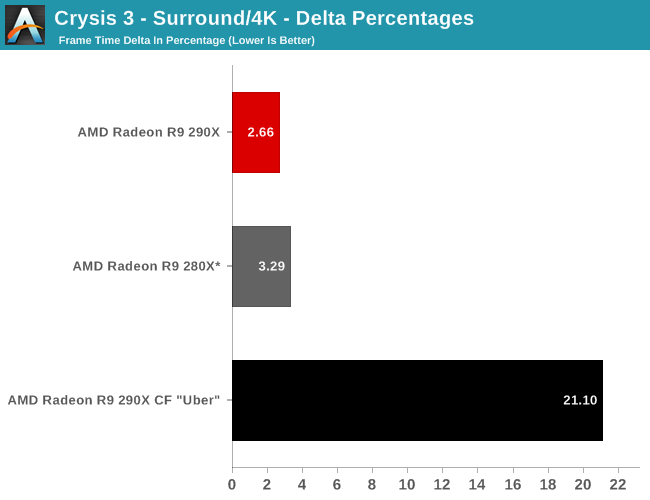
Moving on to our look at delta percentages, all of our AFR setups are acceptable here, but nothing is doing well. 20-21% variance is the order of the day, a far cry from the 1-2% variance of single card setups. This is one of those games where both vendors need to do their homework, as we’re going to be seeing a lot more of CryEngine 3 over the coming years.
As for 4K, things are no better but at least they’re no worse.
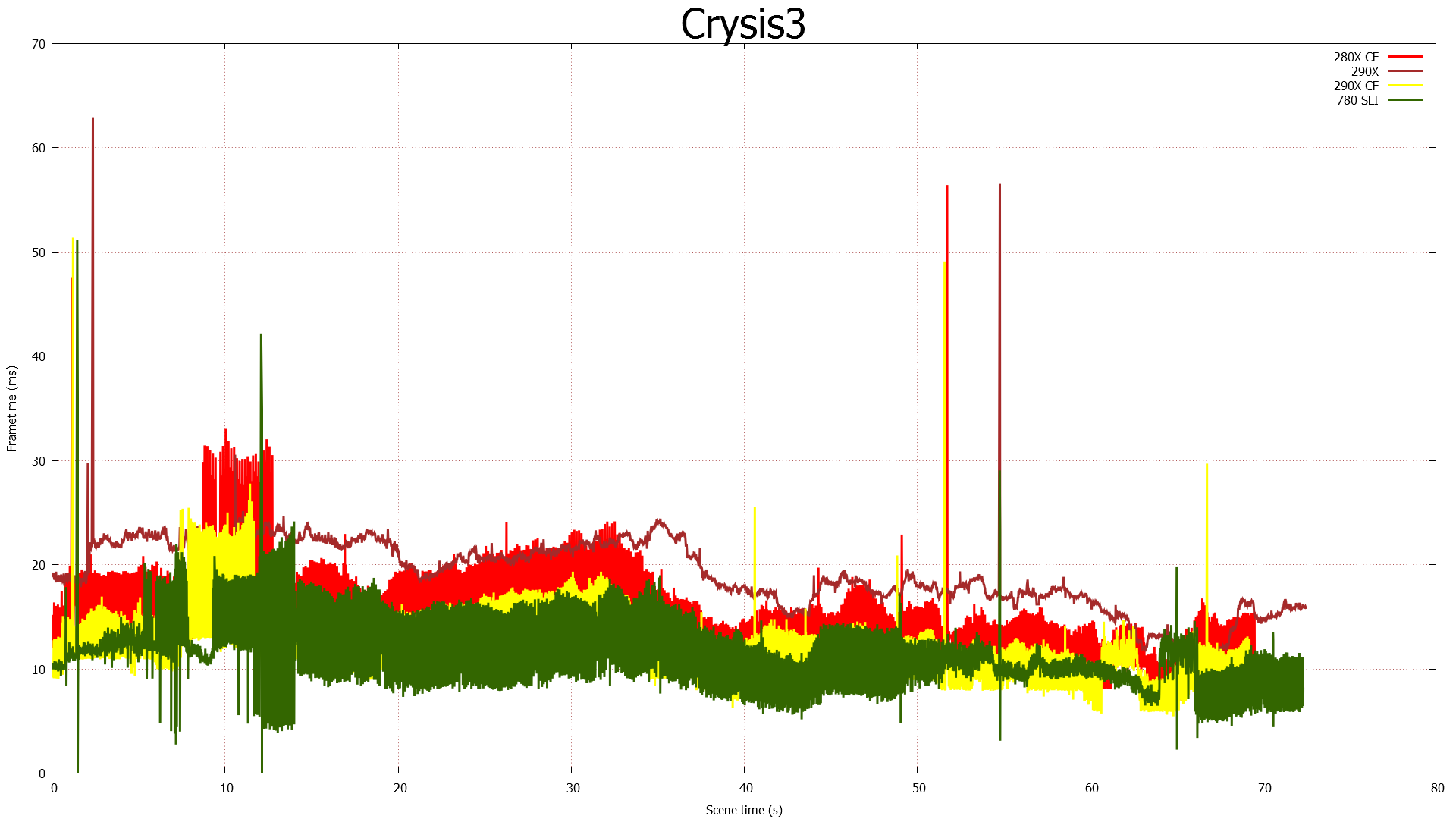
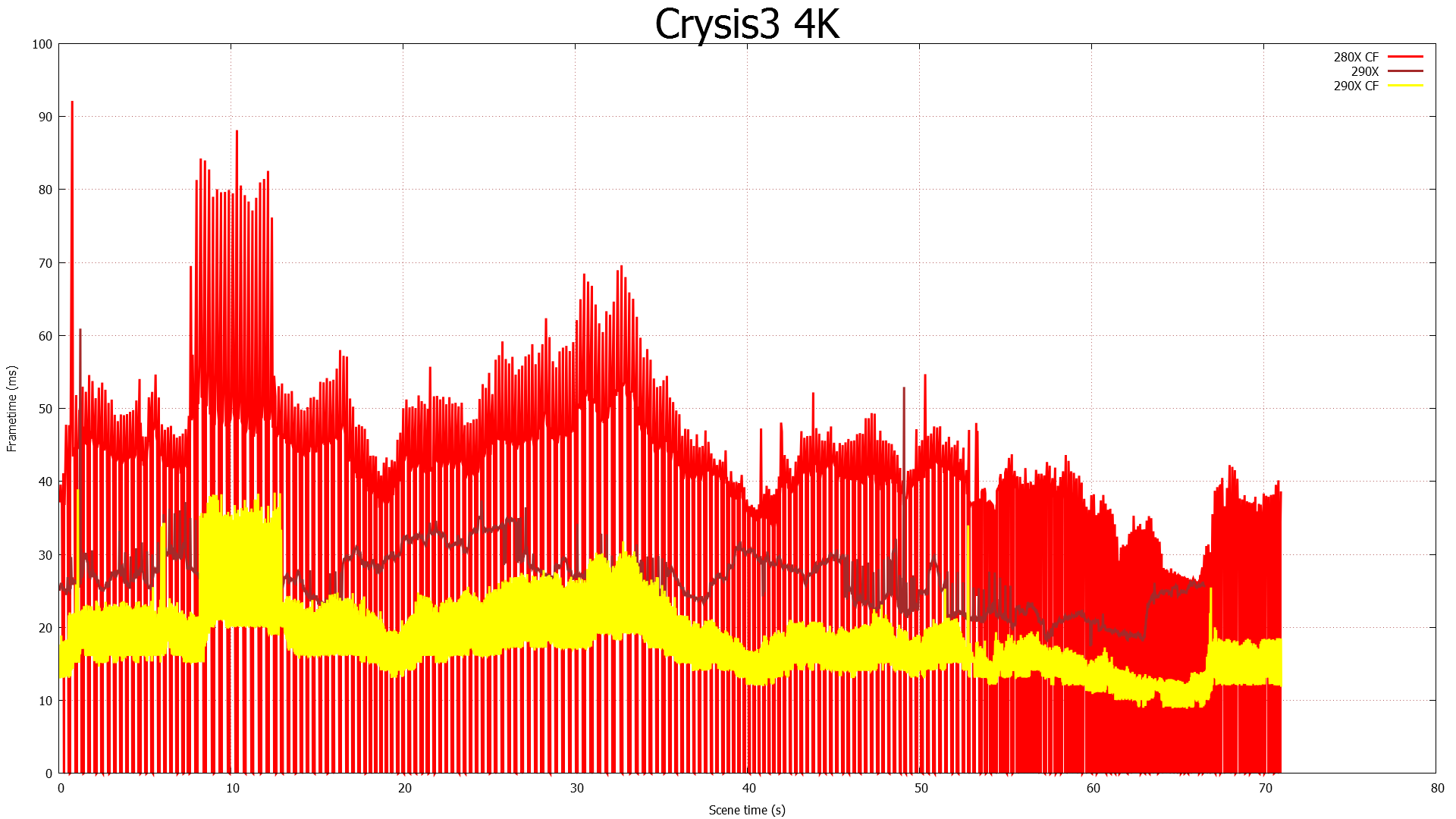
Crysis
Up next is our legacy title for 2013/2014, Crysis: Warhead. The stand-alone expansion to 2007’s Crysis, at over 5 years old Crysis: Warhead can still beat most systems down. Crysis was intended to be future-looking as far as performance and visual quality goes, and it has clearly achieved that. We’ve only finally reached the point where single-GPU cards have come out that can hit 60fps at 1920 with 4xAA, never mind 2560 and beyond.
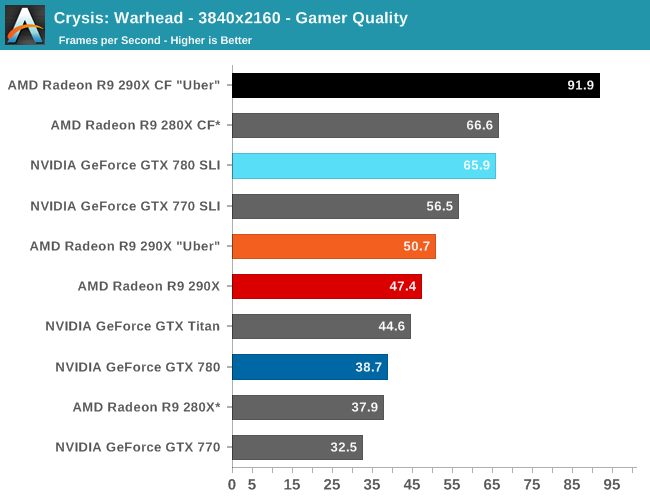
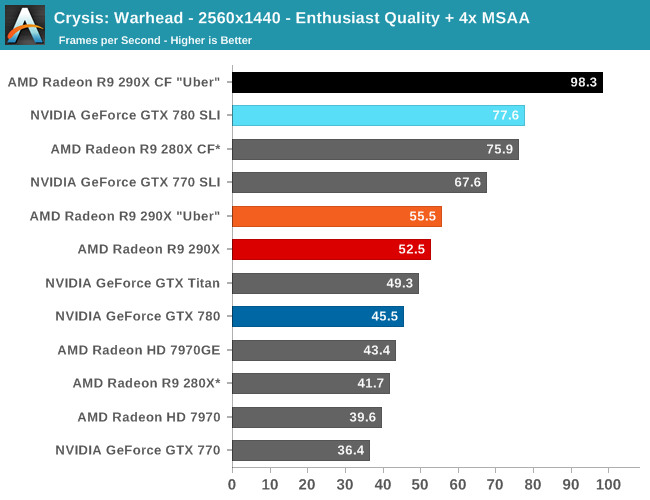
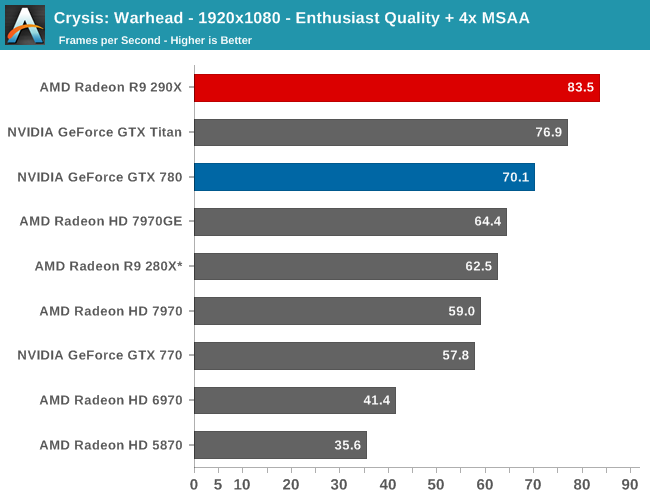
Unlike games such as Battlefield 3, AMD’s GCN cards have always excelled on Crysis: Warhead, and as a result at all resolutions and all settings the 290X tops our charts for single-GPU performance. At 2560 this is a 15% performance advantage for the 290X, pushing past GTX 780 and GTX Titan to be the only card to break into the 50fps range. While at 4K that’s a 22% performance advantage, which sees 290X and Titan become the only cards to even crack 40fps.
But of course if you want 60fps in either scenario, you need two GPUs. At which point 290X’s initial performance advantage, coupled with its AFR scaling advantage (77/81% versus 70%) only widens the gap between the 290X CF and GTX 780 SLI. Though either configuration will get you above 60fps in either resolution.
Meanwhile the performance advantage of the 290X over the 280X is lower here than it is in most games. At 2560 it’s just a 26% gain, a bit short of the 30% average.290X significantly bulks up on everything short of memory bandwidth and rasterization versus 280X, so the list of potential bottlenecks is relatively short in this scenario.
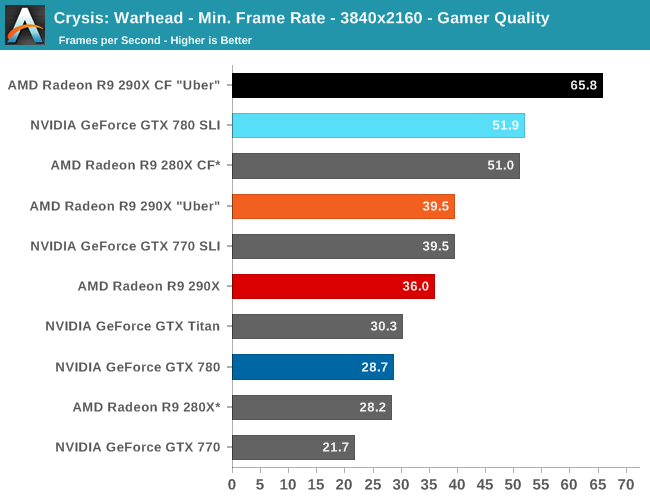
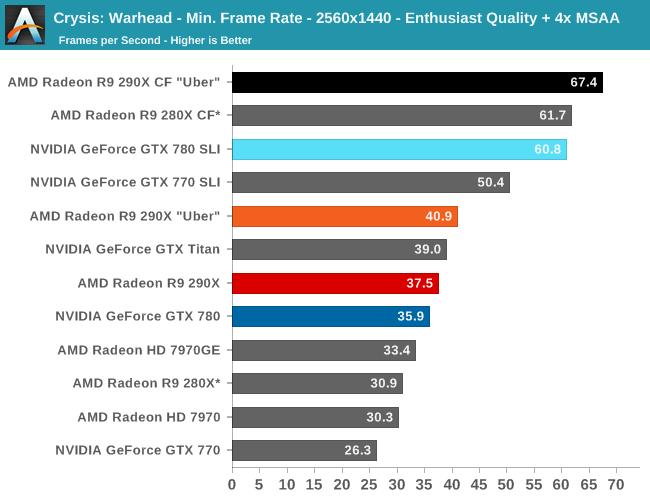
Interestingly, despite the 290X’s stellar performance when it comes to average framerates, the performance advantage with minimum framerates is more muted. 290X still beats GTX 780, but only by 4% at 2560. We’re not CPU bottlenecked, as evidenced by the AFR scaling, so there’s something about Crysis that leads to the 290X crashing a bit harder in the most strenuous scenes.
Total War: Rome 2
The second strategy game in our benchmark suite, Total War: Rome 2 is the latest game in the Total War franchise. Total War games have traditionally been a mix of CPU and GPU bottlenecks, so it takes a good system on both ends of the equation to do well here. In this case the game comes with a built-in benchmark that plays out over a forested area with a large number of units, definitely stressing the GPU in particular.
For this game in particular we’ve also gone and turned down the shadows to medium. Rome’s shadows are extremely CPU intensive (as opposed to GPU intensive), so this keeps us from CPU bottlenecking nearly as easily.
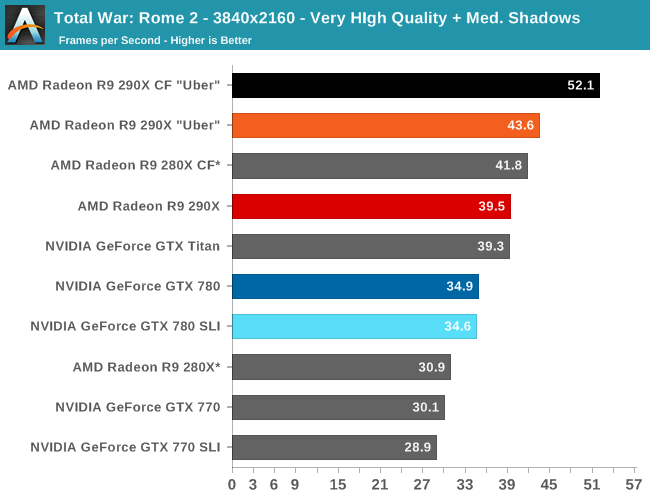
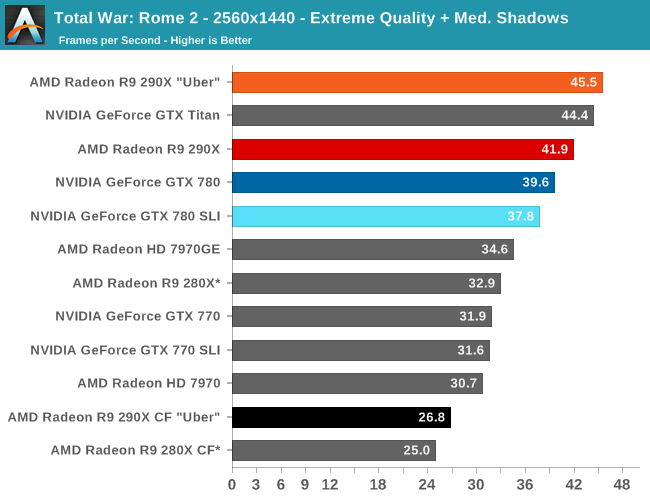
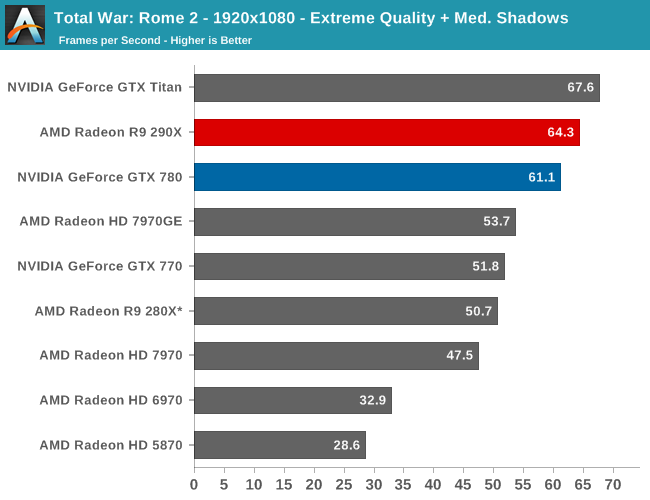
With Rome 2 no one is getting 60fps at 2560, but then again as a strategy game it’s hardly necessary. In which case the 290X once again beats the GTX 780 by a smaller than average 6%, essentially sitting in the middle of the gap between the GTX 780 and GTX Titan.
Meanwhile at 4K we can actually get some relatively strong results out of even our single card configurations, but we have to drop our settings down by 2 notches to Very High to do so. Though like all of our 4K game tests, it turns out well for AMD, with the 290X’s lead growing to 13%.
AFR performance is a completely different matter though. It’s not unusual for strategy games to scale poorly or not at all, but Rome 2 is different yet. The GTX 780 SLI consistently doesn’t scale at all, however with the 290X CF we see anything from massive negative scaling at 2560 to a small performance gain at 4K. Given the nature of the game we weren’t expecting anything here at all, and though getting any scaling is a nice turn of events to have negative scaling like this is a bit embarrassing for AMD. At least NVIDIA can claim to be more consistent here.
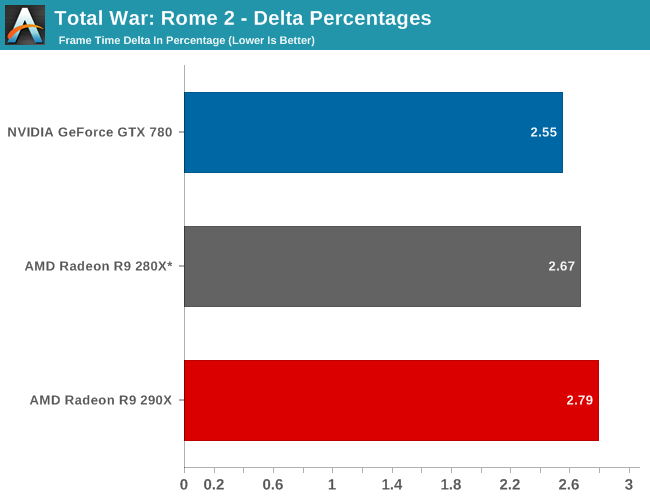
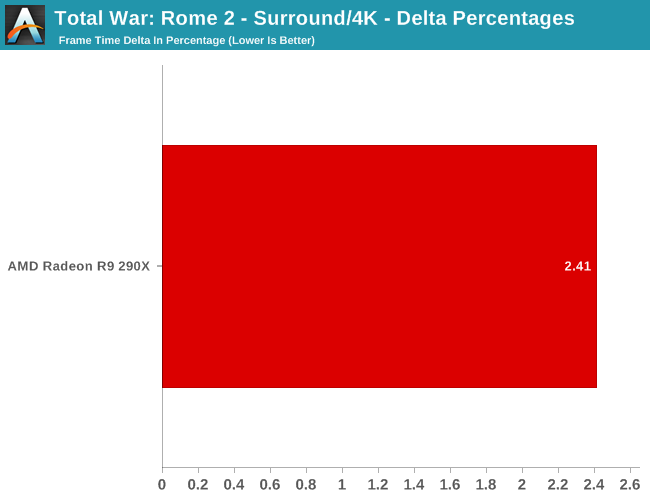
Without working AFR scaling, our deltas are limited to single-GPU configurations and as a result are unremarkable. Sub-3% for everyone, everywhere, which is a solid result for any single-GPU setup.
Hitman: Absolution
The second-to-last game in our lineup is Hitman: Absolution. The latest game in Square Enix’s stealth-action series, Hitman: Absolution is a DirectX 11 based title that though a bit heavy on the CPU, can give most GPUs a run for their money. Furthermore it has a built-in benchmark, which gives it a level of standardization that fewer and fewer benchmarks possess.
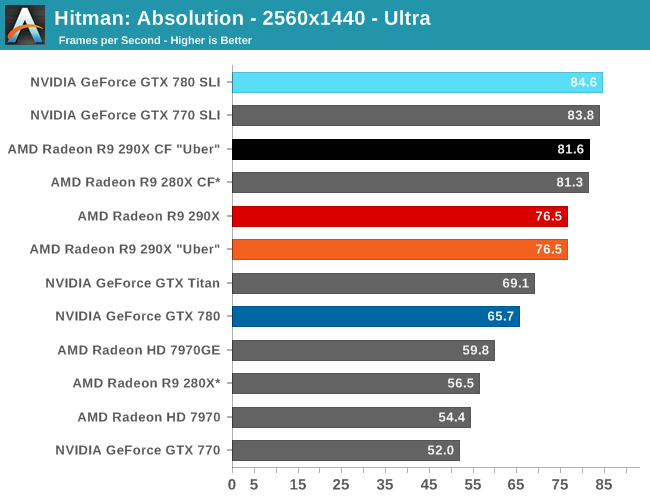
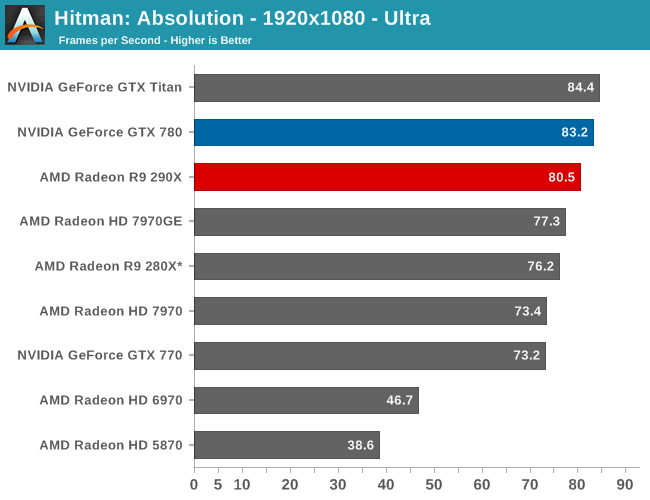
Hitman is another game that makes the 290X shine, with the 290X taking a 16% lead over the GTX 780. In fact we’re getting very close to being CPU limited here, which may be limiting just how far ahead the 290X can pull. However this also means there’s plenty of GPU headroom for enabling MSAA, which we don’t use in this benchmark.
Moving on to 4K, the 290X once again extends its lead, this time by among the largest such leads to 30% over the GTX 780. This is actually good enough for 43fps even at Ultra quality, but for better than that you’ll need multiple GPUs.
To that end we’re CPU limited at 2560, though for some reason the GTX 780 SLI fares a bit better regardless. Otherwise at 4K the GTX 780 SLI achieves better scaling than the 290X CF – 64% versus 56% –so while it can’t take the lead it does at least close the gap some. Though enough of a gap remains that the GTX 780 SLI will still come a bit short of 60fps at 4K Ultra settings, which makes the 290X CF the only setup capable of achieving that goal.
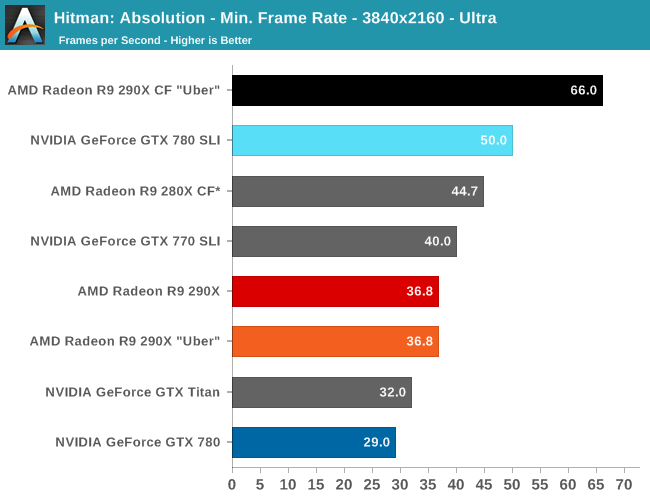
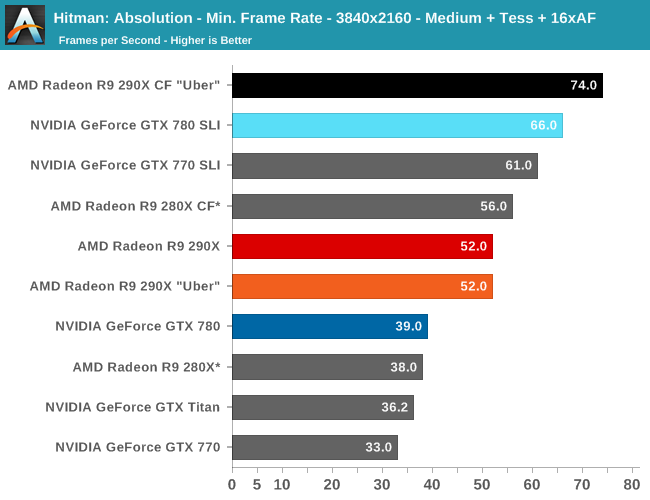
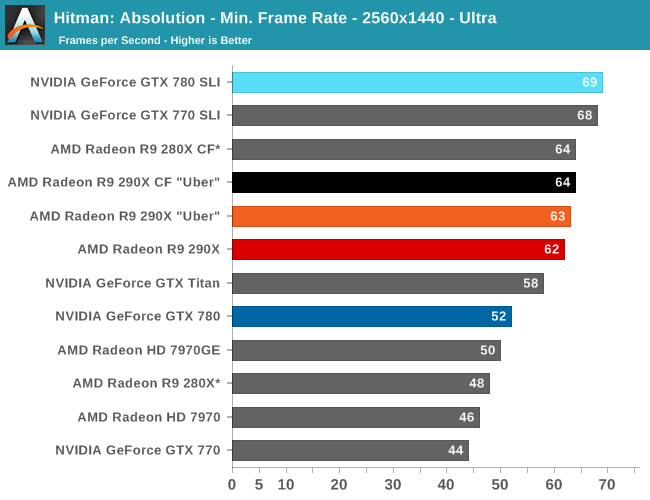
When it comes to minimum framerates the 290X is able to build on its lead just a bit more here at both 2560 and 4K. In both cases the performance advantage over the GTX 780 grows by a further 3%.
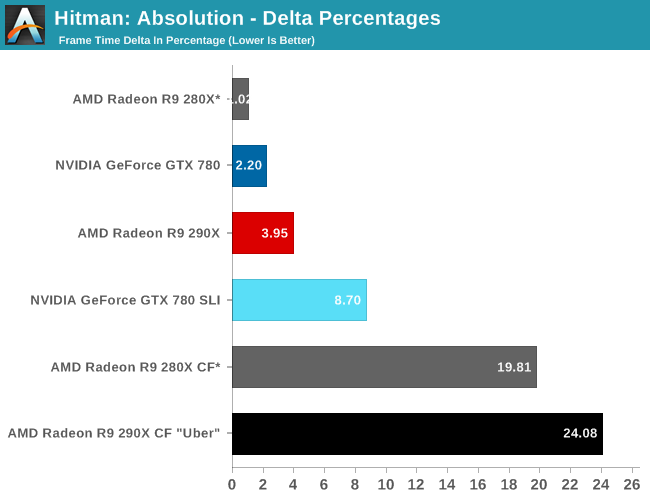
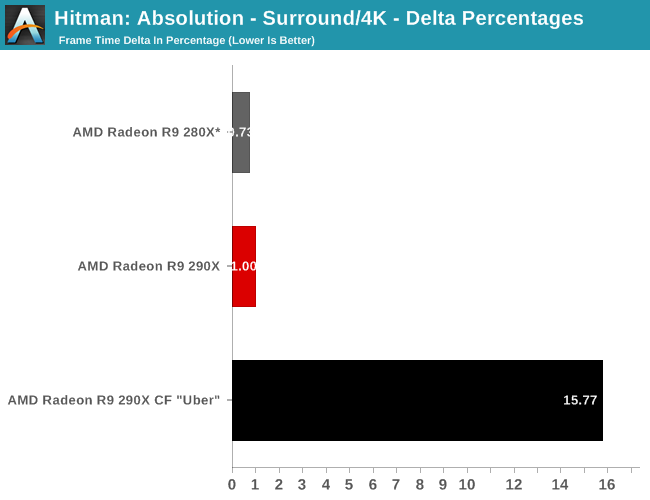
Finally, for our delta percentages we can see that unfortunately for AMD they are regressing a bit here. The variance for the 290X CF at 2560 is 24%, which is greater than what the 280X CF was already seeing, and significantly greater than the GTX 780 SLI. Consequently Hitman is a good example of how although AMD’s CF frame pacing situation is generally quite good, there are going to be games where they need to buckle down a bit more and get it under control, as evidenced by what NVIDIA has been able to achieve. Though it is interesting to note that AMD’s frame pacing at 4K improves over 2K, by over 8%. AMD would seem to have an easier time keeping frame times under control when they’re outright longer, which isn’t wholly surprising since it means there’s more absolute time to resolve the matter.

GRID 2
The final game in our benchmark suite is also our racing entry, Codemasters’ GRID 2. Codemasters continues to set the bar for graphical fidelity in racing games, and with GRID 2 they’ve gone back to racing on the pavement, bringing to life cities and highways alike. Based on their in-house EGO engine, GRID 2 includes a DirectCompute based advanced lighting system in its highest quality settings, which incurs a significant performance penalty but does a good job of emulating more realistic lighting within the game world.
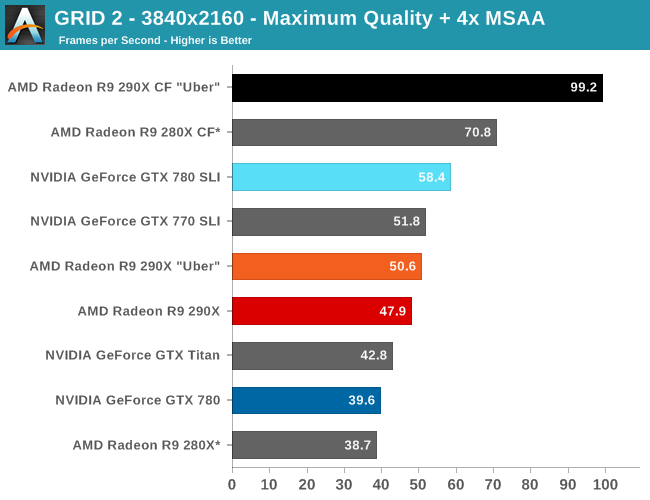
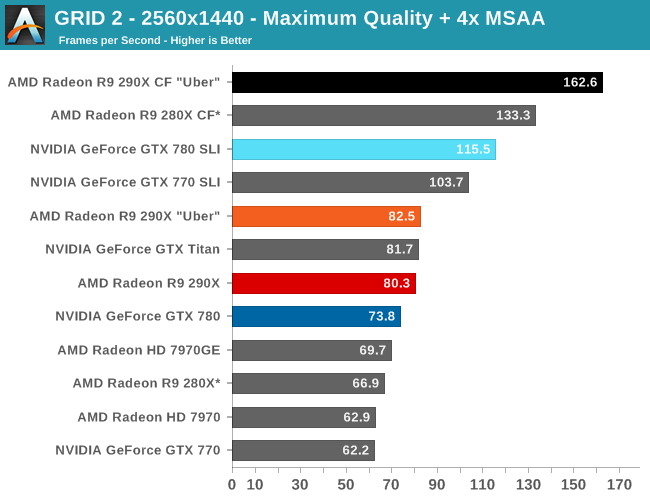
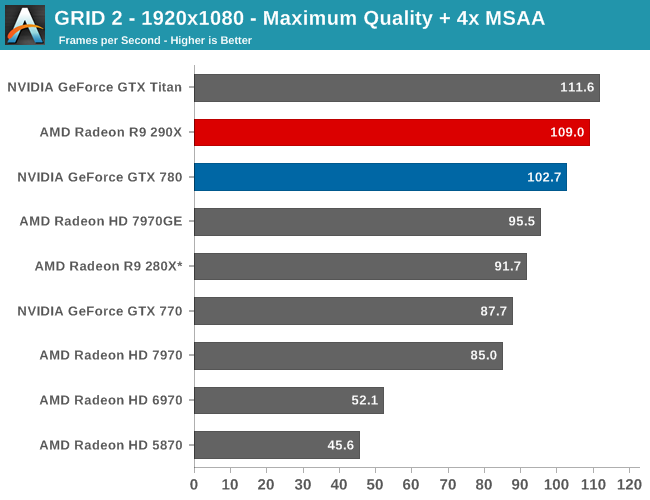
For as good looking as GRID 2 is, it continues to surprise us just how easy it is to run with everything cranked up, even the DirectCompute lighting system and MSAA (Forward Rendering for the win!). At 2560 the 290X has the performance advantage by 9%, but we are getting somewhat academic since it’s 80fps versus 74fps, placing both well above 60fps. Though 120Hz gamers may still find the gap of interest.
Moving up to 4K, we can still keep everything turned up including the MSAA, while pulling off respectable single-GPU framerates and great multi-GPU framerates. To no surprise at this point, the 290X further extends its lead at 4K to 21%, but as usually is the case you really want two GPUs here to get the best framerates. In which case the 290X CF is the runaway winner, achieving a scaling factor of 96% at 4K versus NVIDIA’s 47%, and 97% versus 57% at 2560. This means the GTX 780 SLI is going to fall just short of 60fps once more at 4K, leaving the 290X CF alone at 99fps.
Unfortunately for AMD their drivers coupled with GRID 2 currently blows a gasket when trying to use 4K @ 60Hz, as GRID 2 immediately crashes when trying to load with 4K/Eyefinity enabled. We can still test at 30Hz, but those stellar 4K framerates aren’t going to be usable for gaming until AMD and Codemasters get that bug sorted out.
Finally, it’s interesting to note that for the 290X this is the game where it gains the least on the 280X. The 290X performance advantage here is just 20%, 5% lower than any other game and 10% lower than the average. The framerates at 2560 are high enough that this isn’t quite as important as in other games, but it does show that the 290X isn’t always going to maintain that 30% lead over its predecessor.
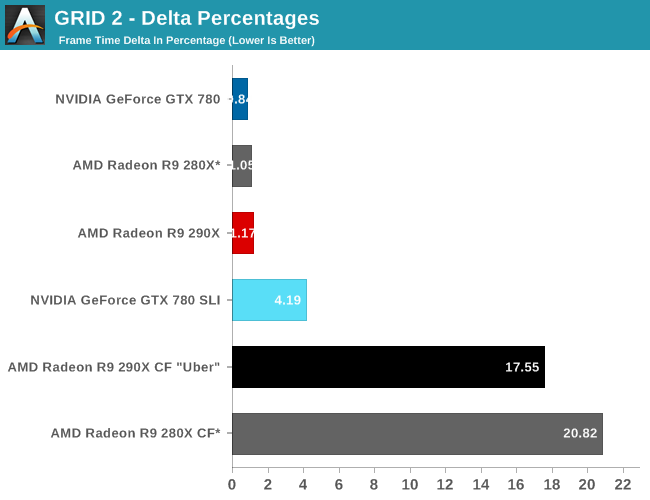
Without any capturable 4K FCAT frametimes, we’re left with the delta percentages at 2560, which more so than any other game are simply not in AMD’s favor. The GTX 780 SLI is extremely consistent here, to the point of being almost absurdly so for a multi-GPU setup. 4% is the kind of variance we expect to find with a single-GPU setup, not something incorporating multiple GPUs. AMD on the other hand, though improving over the 280X by a few percent, is merely adequate at 17%. The low frame times will further reduce the real world impact of the difference between the GTX 780 SLI and 290X CF here, but this is another game AMD could stand some improvements, even if it costs AMD some of the 290X’s very strong CF scaling factor.
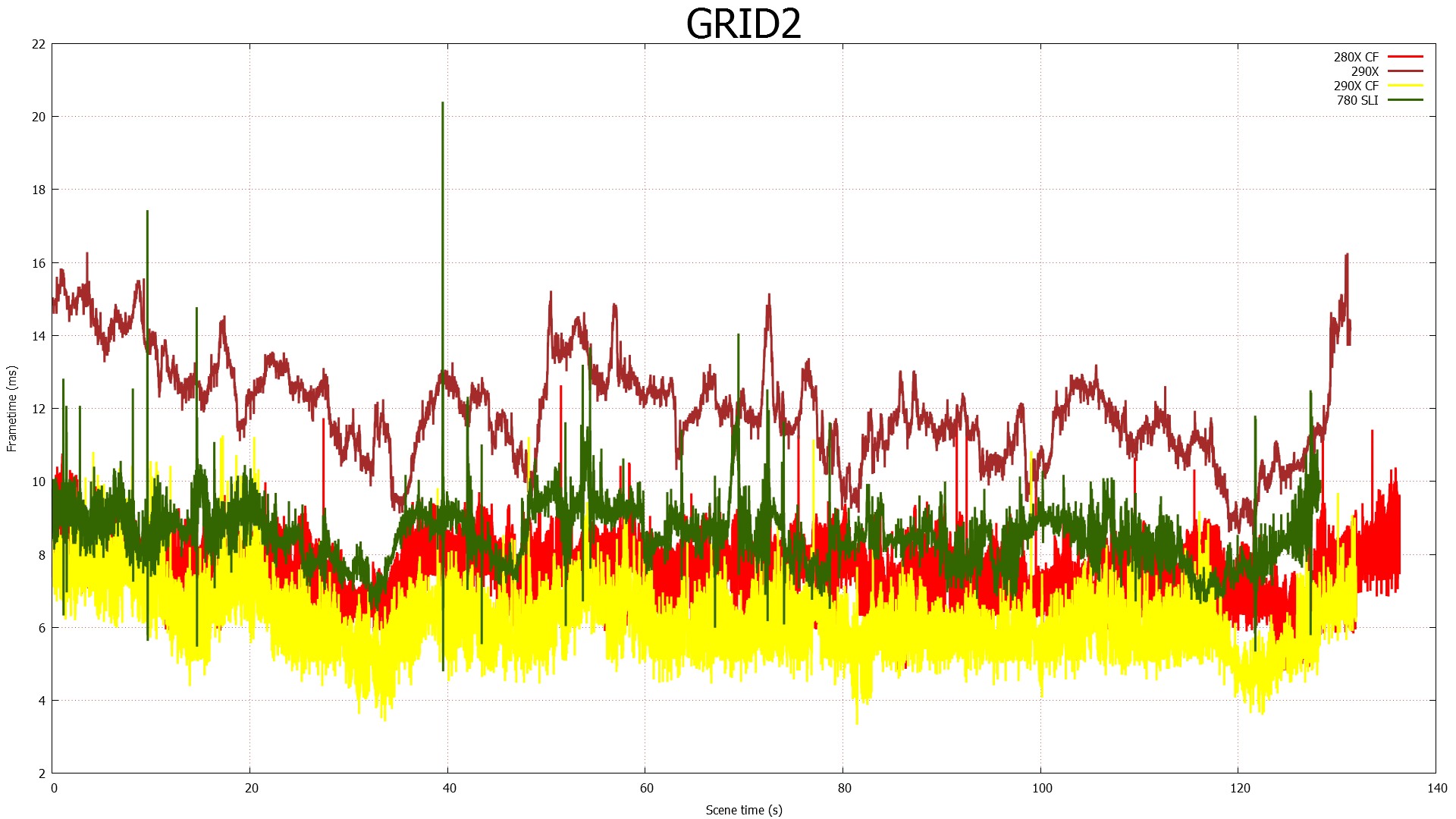
Synthetics
As always we’ll also take a quick look at synthetic performance. The 290X shouldn’t pack any great surprises here since it’s still GCN, and as such bound to the same general rules for efficiency, but we do have the additional geometry processors and additional ROPs to occupy our attention.
Right off the bat then, the TessMark results are something of a head scratcher. Whereas NVIDIA’s performance here has consistently scaled well with the number of SMXes, AMD’s seeing minimal scaling from those additional geometry processors on Hawaii/290X. Clearly Tessmark is striking another bottleneck on 290X beyond simple geometry throughput, though it’s not absolutely clear what that bottleneck is.
This is a tessellation-heavy benchmark as opposed to a simple massive geometry bencehmark, so we may be seeing a tessellation bottleneck rather than a geometry bottleneck, as tessellation requires its own set of heavy lifting to generate the necessary control points. The 12% performance gain is much closer to the 11% memory bandwidth gain than anything else, so it may be that the 280X and 290X are having to go off-chip to store tessellation data (we are after all using a rather extreme factor), in which case it’s a memory bandwidth bottleneck. Real world geometry performance will undoubtedly be better than this – thankfully for AMD this is the pathological tessellation case – but it does serve of a reminder of how much more tessellation performance NVIDIA is able to wring out of Kepler. Though the nearly 8x increase in tessellation performance since 5870 shows that AMD has at least gone a long way in 4 years, and considering the performance in our tessellation enabled games AMD doesn’t seem to be hurting for tessellation performance in the real world right now.
Moving on, we have our 3DMark Vantage texture and pixel fillrate tests, which present our cards with massive amounts of texturing and color blending work. These aren’t results we suggest comparing across different vendors, but they’re good for tracking improvements and changes within a single product family.
Looking first at texturing performance, we can see that texturing performance is essentially scaling 1:1 with what the theoretical numbers say it should. 36% better texturing performance over 280X is exactly in line with the increased number of texture units versus 280X, at the very least proving that 290X isn’t having any trouble feeding the increased number of texture units in this scenario.
Meanwhile for our pixel fill rates the results are a bit more in the middle, reflecting the fact that this test is a mix of ROP bottlenecking and memory bandwidth bottlenecking. Remember, AMD doubled the ROPs versus 280X, but only gave it 11% more memory bandwidth. As a result the ROPs’ ability to perform is going to depend in part on how well color compression works and what can be recycled in the L2 cache, as anything else means a trip to the VRAM and running into those lesser memory bandwidth gains. Though the 290X does get something of a secondary benefit here, which is that unlike the 280X it doesn’t have to go through a memory crossbar and any inefficiencies/overhead it may add, since the number of ROPs and memory controllers is perfectly aligned on Hawaii.
Compute
Jumping into pure compute performance, we’re going to have several new factors influencing the 290X as compared to the 280X. On the front end 290X/Hawaii has those 8 ACEs versus 280X/Tahiti’s 2 ACEs, potentially allowing 290X to queue up a lot more work and to keep itself better fed as a result; though in practice we don’t expect most workloads to be able to put the additional ACEs to good use at the moment. Meanwhile on the back end 290X has that 11% memory bandwidth boost and the 33% increase in L2 cache, which in compute workloads can be largely dedicated to said computational work. On the other hand 290X takes a hit to its double precision floating point (FP64) rate versus 280X, so in double precision scenarios it’s certainly going to enter with a larger handicap.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
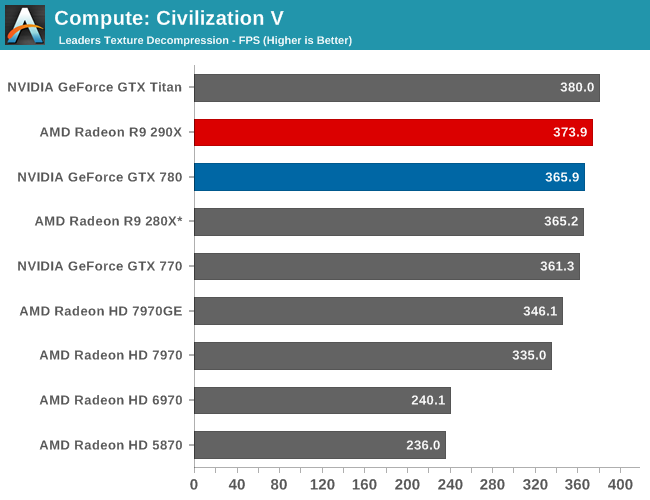
Unfortunately Civ V can’t tell us much of value, due to the fact that we’re running into CPU bottlenecks, not to mention increasingly absurd frame rates. In the 3 years since this game was released high-end CPUs are around 20% faster per core, whereas GPUs are easily 150% faster (if not more). As such the GPU portion of texture decoding has apparently started outpacing the CPU portion, though this is still an enlightening benchmark for anything less than a high-end video card.
For what it is worth, the 290X can edge out the GTX 780 here, only to fall to GTX Titan. But in these CPU limited scenarios the behavior at the very top can be increasingly inconsistent.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
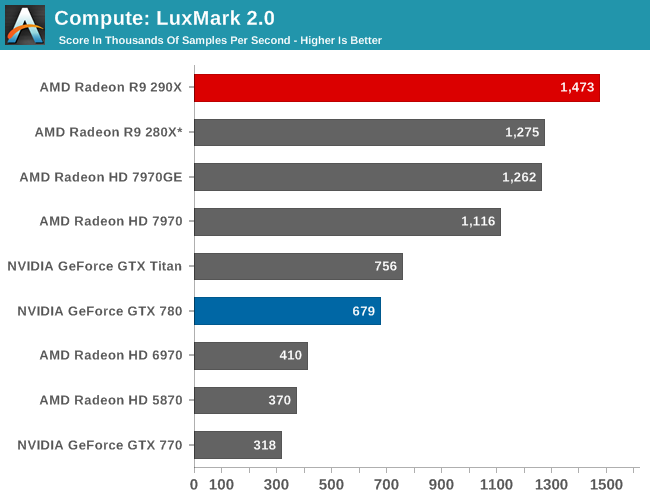
LuxMark by comparison is very simple and very scalable. 290X packs with it a significant increase in computational resources, so 290X picks up from where 280X left off and tops the chart for AMD once more. Titan is barely half as fast here, and GTX 780 falls back even further. Though the fact that scaling from the 280X to 290X is only 16% – a bit less than half of the increase in CUs – is surprising at first glance. Even with the relatively simplistic nature of the benchmark, it has shown signs in the past of craving memory bandwidth and certainly this seems to be one of those times. Feeding those CUs with new rays takes everything the 320GB/sec memory bus of the 290X can deliver, putting a cap on performance gains versus the 280X.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
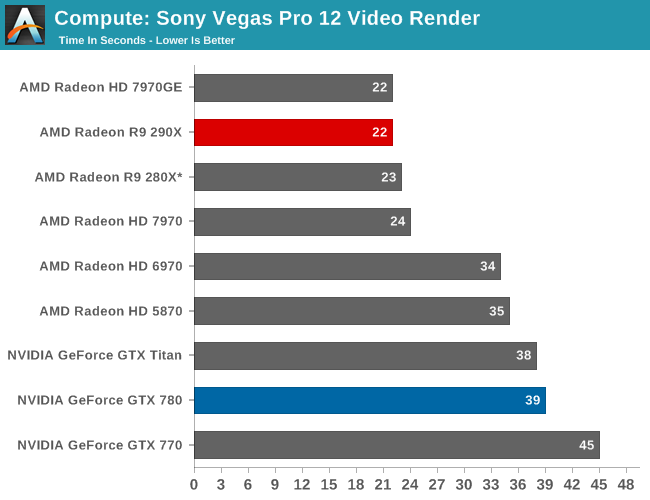
Vegas is another title where GPU performance gains are outpacing CPU performance gains, and as such earlier GPU offloading work has reached its limits and led to the program once again being CPU limited. It’s a shame GPUs have historically underdelivered on video encoding (as opposed to video rendering), as wringing significantly more out of Vegas will require getting rid of the next great CPU bottleneck.
Our 4th benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.
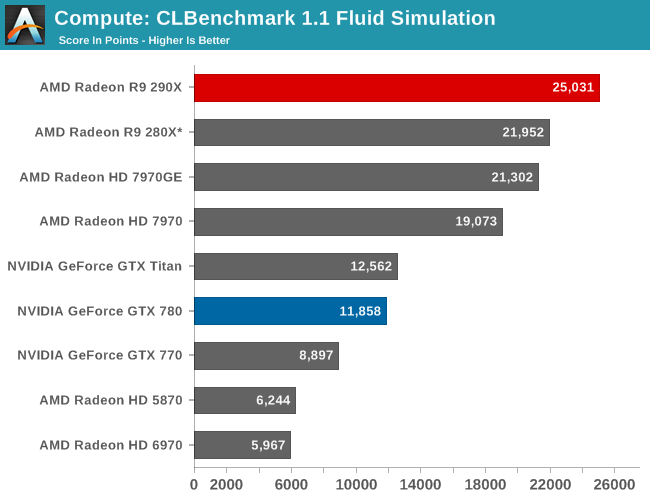

Curiously, the 290X’s performance advantage over 280X is unusual dependent on the specific sub-test. The fluid simulation scales decently enough with the additional CUs, but the computer vision benchmark is stuck in the mud as compared to the 280X. The fluid simulation is certainly closer than the vision benchmark towards being the type of stupidly parallel workload GPUs excel at, though that doesn’t fully explain the lack of scaling in computer vision. If nothing else it’s a good reminder of why professional compute workloads are typically profiled and optimized against specific target hardware, as it reduces these kinds of outcomes in complex, interconnected workloads.
Moving on, our 5th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.
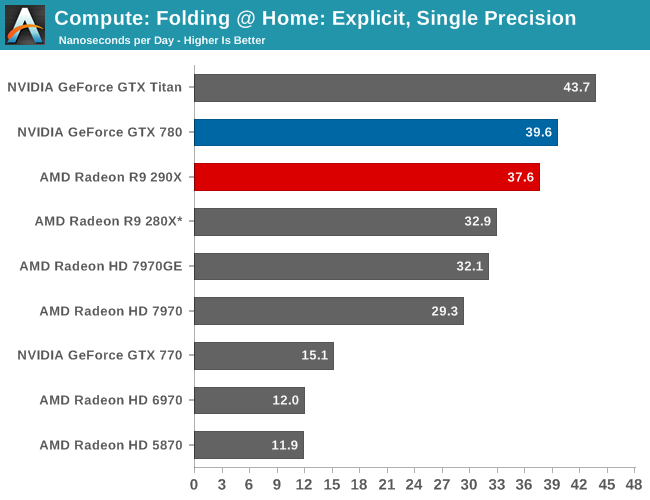

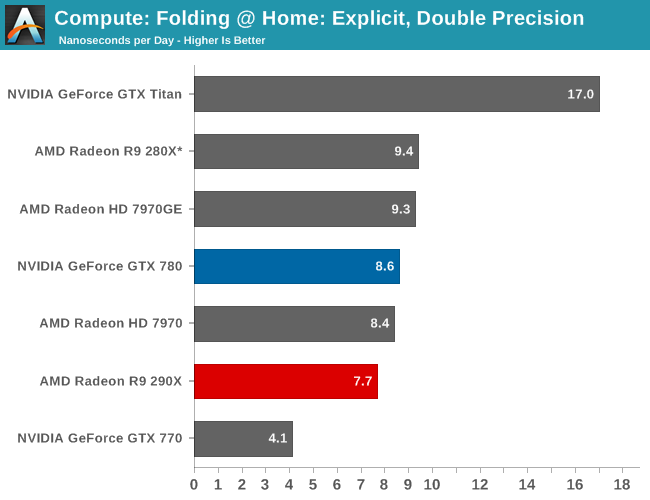
With FAHBench we’re not fully convinced that it knows how to best handle 290X/Hawaii as opposed to 280X/Tahiti. The scaling in single precision explicit is fairly good, but the performance regression in the water-free (and generally more GPU-limited) implicit simulation is unexpected. Consequently while the results are accurate for FAHCore 17, it’s hopefully something AMD and/or the FAH project can work out now that 290X has been released.
Meanwhile double precision performance also regresses, though here we have a good idea why. With DP performance on 290X being 1/8 FP32 as opposed to ¼ on 280X, this is a benchmark 290X can’t win. Though given the theoretical performance differences we should be expecting between the two video cards – 290X should have about 70% of the FP 64 performance of 280X – the fact that 290X is at 82% bodes well for AMD’s newest GPU. However there’s no getting around the fact that the 290X loses to GTX 780 here even though the GTX 780 is even more harshly capped, which given AMD’s traditional strength in OpenCL compute performance is going to be a let-down.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
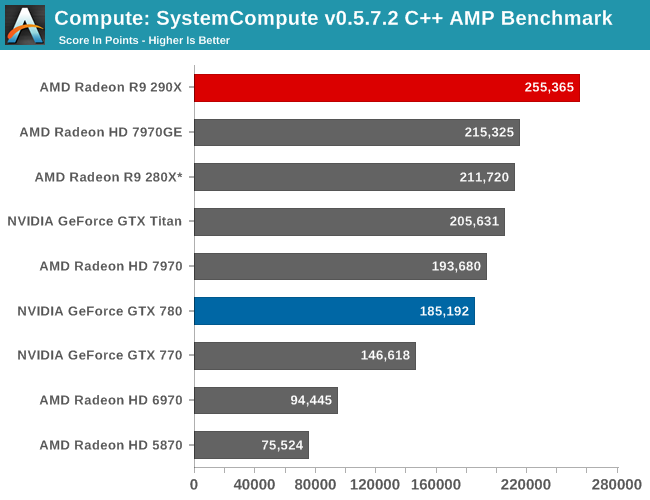
SystemCompute and the underlying C++ AMP environment scales relatively well with the additional CUs offered by 290X. Not only does the 290X easily surpass the GTX Titan and GTX 780 here, but it does so while also beating the 280X by 18%. Or to use AMD’s older GPUs as a point of comparison, we’re up to a 3.4x improvement over 5870, well above the improvement in CU density alone and another reminder of how AMD has really turned things around on the GPU compute side with GCN.
Power, Temperature, & Noise
As always, last but not least is our look at power, temperature, and noise. Next to price and performance of course, these are some of the most important aspects of a GPU, due in large part to the impact of noise. All things considered, a loud card is undesirable unless there’s a sufficiently good reason – or sufficiently good performance – to ignore the noise.
For the 290X we’re going to be seeing several factors influencing the power, temperature, and noise characteristics of the resulting card. At the lowest level are those items beholden to the laws of physics: mainly, the fact that AMD has increased their die size by 20% while retaining the same manufacturing process, the same basic architecture, and the same boost clockspeeds. As a result there is nowhere for power consumption to go but up, even with leakage having been clamped down on versus 280X/Tahiti. The question of course being by how much, and is it worth the performance increase?
Meanwhile 290X also introduces the latest iteration of PowerTune, which significantly alters AMD’s power management strategy. Not only does AMD gain the ability to do fine grained clockspeed/voltage steps, and thereby improving their efficiency versus Tahiti, but alongside those improvements is the new PowerTune temperature and fan speed throttling model. AMD will of course need that as we’ll see, as they have equipped the 290X with a cooling solution almost identical to that of the 7970 despite the fact that TDP has been increased by roughly 50W, putting an even greater workload on the cooler to move all the heat Hawaii can produce.
Seeing as how we don’t have accurate voltage/VID readings at this time, we’ll jump right into clockspeeds. As we stated in our high level overview of the new PowerTune and the 290X, the 290X has two modes, quiet and uber. Both operate at the same clockspeeds and same power restrictions, but quiet mode utilizes a maximum fan speed of 40% while uber mode goes to 55%. The 15% difference conceals a roughly 1000rpm difference in the fan speed, so there are certainly good reasons for AMD to offer both, as uber mode can get very loud as we’ll see. At the same time however while quiet mode will be able to keep noise in check, it’s going to come up short on letting the 290X run at its full potential. In quiet mode throttling is inevitable; there’s simply not enough airflow to allow the 290X to sustain 1000MHz, as our clockspeed table below indicates.
| Radeon R9 290X Average Clockspeeds | ||||
| Quiet (Default) | Uber | |||
| Boost Clock | 1000MHz | 1000MHz | ||
| Metro: LL |
923MHz
|
1000MHz
|
||
| CoH2 |
970MHz
|
990MHz
|
||
| Bioshock |
985MHz
|
1000MHz
|
||
| Battlefield 3 |
980MHz
|
1000MHz
|
||
| Crysis 3 |
925MHz
|
1000MHz
|
||
| Crysis: Warhead |
910MHz
|
1000MHz
|
||
| TW: Rome 2 |
907MHz
|
1000MHz
|
||
| Hitman |
990MHz
|
1000MHz
|
||
| GRID 2 |
930MHz
|
1000MHz
|
||
| Furmark |
727MHz
|
870MHz
|
||
As we noted in our testing methodology section, these aren’t the lowest clockspeeds we’ve seen in those games but rather the average clockspeeds we hit in the final loop of our standard looped benchmark procedures. As such sustained performance can dip even lower, though by how much is going to of course depend on ambient temperatures and the cooling capabilities of the chassis itself. We believe our looping benchmarks run long enough to generally reach sustained performance numbers, but in all likelihood some of our numbers on the shortest benchmarks will skew low.
Anyhow, as we can see, in everything, even the shortest benchmark, the sustained clockspeeds are below 1000MHz. Out of all of our games Rome 2 fares the worst in this regard, dropping to 907MHz, while other games like Metro and Crysis aren’t far behind at 910MHz-930MHz. FurMark does one better yet and drops to 727MHz, which we believe to be 290X’s unlisted base clockspeed, indicating it has to drop out of boost mode entirely to bring performance/heat in check with cooling under quiet mode. 290X simply cannot sustain its peak boost clocks under quiet mode; there’s not enough cooling to handle the estimated 300W of heat 290X produces at those performance levels.
Which is why AMD has uber mode. In uber mode the fan speeds are high enough (if just so) to provide the cooling necessary to keep up with the 290X in every gaming workload. Only Company of Heroes 2 doesn’t do 1000MHz sustained, and while AMD’s utilities don’t provide all of the diagnostic data we’d like, we strongly suspect we’re TDP limited in CoH2 for a portion of the benchmark run, which is why we can’t sustain 1000MHz. In any case for most workloads uber mode should be enough to sustain the 290X’s best performance, though it’s not without a significant noise cost.
Consequently this is why we’re so dissatisfied with how AMD is publishing the specifications for the 290X. The lack of a meaningful TDP specification is bad enough, but given the video card’s out of the box (quiet mode performance) it’s disingenuous at best for the only published clockspeed number to be the boost clock. 290X simply cannot sustain 1000MHz in quiet mode under full load.
NVIDIA, when implementing GPU boost, had the sense to advertise not only the base clockspeed, but an “average” boost clock that in our experience underestimates the real clockspeeds they sustain. AMD on the other hand is advertising clockspeeds that by default cannot be sustained. And even Intel, by comparison, made sure to advertise both their base and boost GPU clockspeeds in the ARK and other specification sources, even with the vast gulf between them in some SKUs.
Given this, we find AMD’s current labeling practices troubling. Although seasoned buyers are going to turn to reviews like ours, where the value of a card will be clearly spelled out with respect to both performance and price, to only list the boost clock is being deceitful at best. AMD needs to list the base clockspeeds, and they’d be strongly advised to further list an average clockspeed similar to NVIIDA’s boost clock. Even those numbers won’t be perfect, but it will at least be a reasonable compromise over listing an “up to” number that is currently for all intents and purposes unreachable.
In any case, let’s finally get to the power, temperature, and noise data.
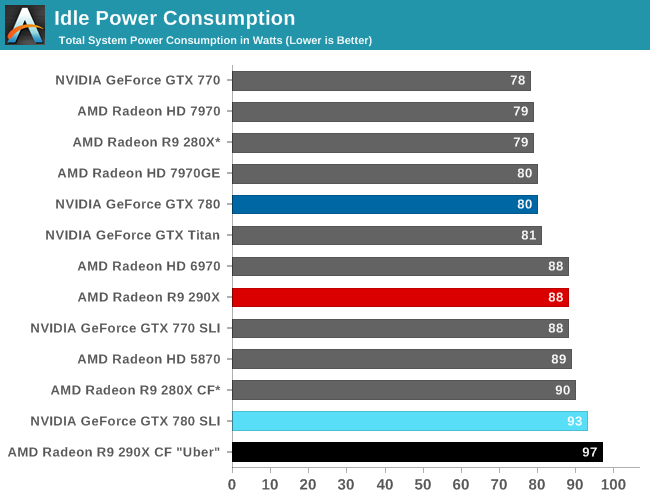
Idle power is not in AMD’s favor, and next to the Crossfire issues we were seeing in our gaming tests this appears to be another bug in their drivers. For what we know about GCN and Hawaii 88W at the wall is too high even after compensating for the additional memory and the larger GPU die. However if we plug in a 7970 on the Cat 13.11 beta v5 drivers and run the same power test, we find that power consumption rises about 6-8W at the wall versus Cat 13.11 beta v1. For reasons that we cannot fully determine, the v5 drivers are causing GCN setups to consume additional power at idle. This is not reflected in as a workload on the GPU nor the CPU so it’s not clear where the power leak is occurring (though temperature data points us to the GPU), but somewhere, somehow AMD has started unnecessarily burning power at idle.
We would fully expect that at some point AMD will be able to get this bug fixed, at which point idle power consumption (at the wall) for 290X should be in the low 80s range. But for the moment 88W is an accurate portrayal of 290X’s power consumption, making it several watts worse than GTX 780 at this time.
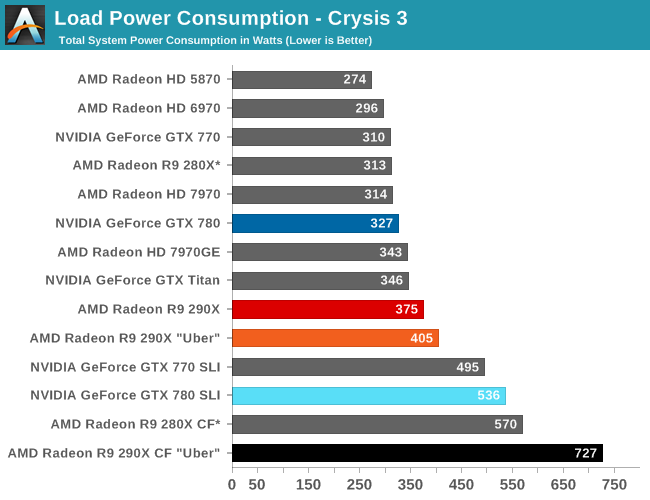
As a reminder, starting with the 290X we’ve switch from Metro: Last Light to Crysis 3 for our gaming power/temp/noise results, as Metro exhibits poor scaling on multi-GPU setups, leading to GPU utilization dropping well below 100%.
For this review Crysis 3 actually ends up working out very well as a gaming workload, due to the fact that the 290X and the GTX 780 (its closest competitor) achieve virtually identical framerates at around 52fps. As a result the power consumption from the rest of the system should be very similar, and the difference between the two in wall power should be almost entirely due to the video cards (after taking into account the usual 90% efficiency curve).
With that in mind, as we can see there’s no getting around the fact that compared to both 280X and GTX 780, power consumption has gone up. At 375W at the wall the 290X setup draws 48W more than the GTX 780, 29W more than GTX Titan, and even 32W more than the most power demanding Tahiti card, 7970GE. NVIDIA has demonstrated superior power efficiency throughout this generation and 290X, though an improvement itself, won’t be matching NVIDIA on this metric.
Overall our concern with power on high end cards has to do more with the ramifications of trying to remove/cool that additional heat than the power consumption itself – though summer does present its own problems – but still it’s clear that AMD’s 9% average performance advantage over the GTX 780 is going to come at a cost of more than a 9% increase in power consumption. Or versus the GTX Titan, which the 290X generally ties, 290X is still drawing more power. The fact that AMD is delivering better performance than a GTX 780 should not be understated, but neither should the fact that they consume more power while doing so.
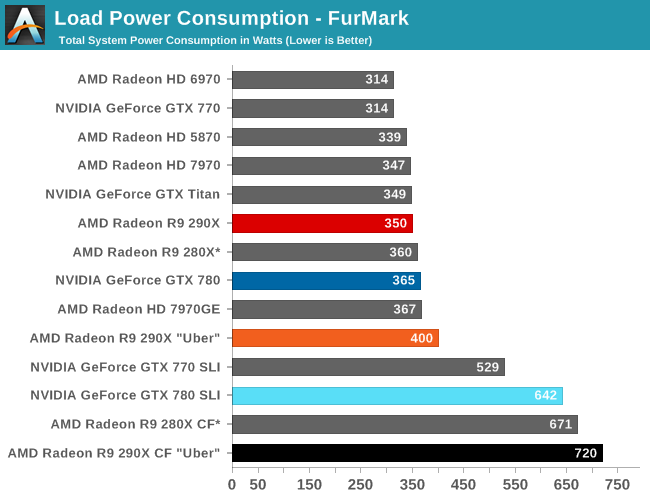
FurMark, our pathological case, confirms what we were just seeing with Crysis. At this point 290X’s power consumption has fallen below GTX 780’s, but only because at this point we know that 290X has needed to significantly downclock itself to get to this point. GTX 780 throttles here too for the same reason, but not as much as 290X does. Consequently this puts the worst case power scenario for the GTX 780 at worse than the quiet mode 290X, but between this and Crysis the data suggests that the 290X is operating far closer to its limit than the GTX 780 (or GTX Titan) is.
Meanwhile we haven’t paid a lot of attention to the uber mode 290X until now, so now is a good time to do so. The 290X in uber mode still has to downclock for power reasons, but it stays in its boost state until the 290X in quiet mode. Based on this we believe the 290X uber is drawing near its peak power consumption for both FurMark and Crysis 3, which besides neatly illustrating the real world difference between quiet and uber modes in terms of how much heat they can move, means that we should be able to look at uber mode to get a good idea of what the 290X’s maximum power consumption is. To that end based on this data we believe the PowerTune/TDP limit for 290X is 300W, 50W higher than the “average gaming scenario power” they quote. This is also fairly consistent compared to the Tahiti based 7970 and its ilk, which have an official PowerTune limit of 250W.
Ultimately 300W single-GPU cards have been a rarity, and seemingly for good reason. That much heat is not easy to dissipate coming off of a single heat source (GPU), and the only other 300W cards we’ve seen are not cards with impressive acoustics. Given where AMD was with Tahiti we’re in no way surprised that power consumption has gone up with the larger GPU, but there are consequences to be had for having this much power going through a single card. Not the least of which is the fact that AMD’s reference cooler can’t actually move 300W of heat at reasonable noise levels, hence the use of quiet and uber modes.
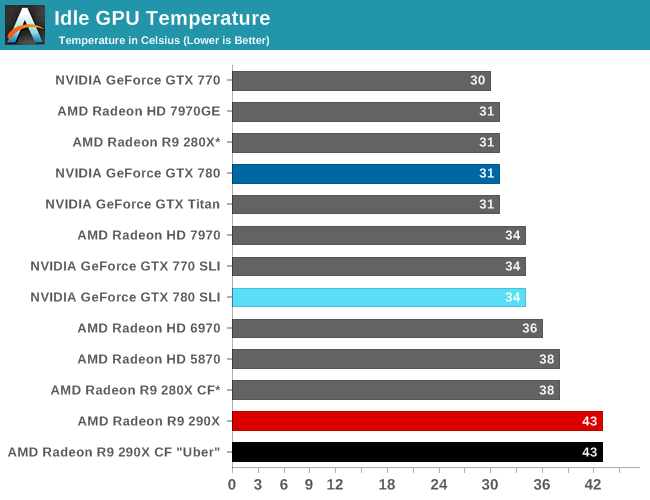
Given the earlier idle power consumption numbers we were seeing, to see AMD’s idle temperatures run high is not unexpected. 43C isn’t a problem in and of itself, but it is indicative that the idle power leak is coming from the GPU rather than a CPU load from the drivers.
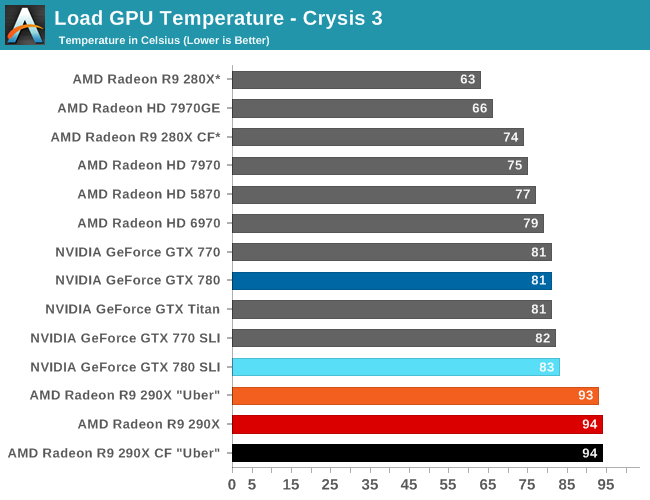
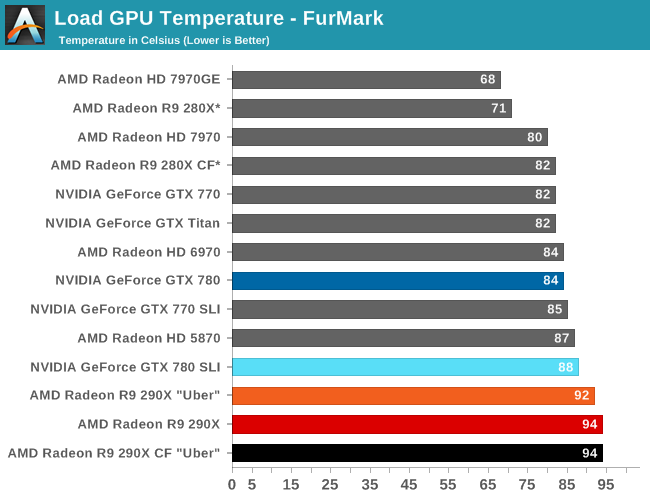
Given what we know about the new PowerTune and AMD’s design goals for 290X, the load temperatures are pretty much a given at this point. In quiet mode the 290X will hit 94C/95C and will eventually throttle under any game. We won’t completely go over the technical rationale for this (if you’ve missed our PowerTune page, please check that out first), but in short the temperatures we’re seeing, though surprising at first, are accounted for in AMD’s design. The Hawaii GPU should meet the necessary longevity targets even at 95C sustained, and static leakage should be low enough that it’s not causing a significant power consumption problem. It’s certainly a different way of thinking, but with a mature 28nm process and the very fast switching of PowerTune it’s also a completely practical design.
It’s still going to take some getting used to, though.
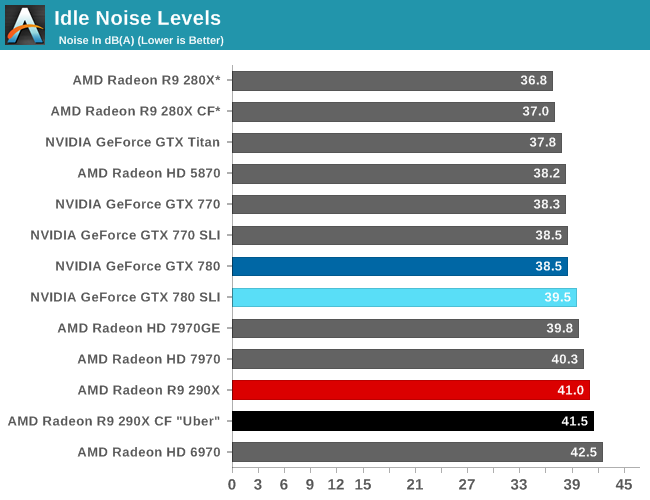
Moving on to our noise testing, due to the fact that the 290X reference cooler is based on the 7970’s reference cooler there’s little to surprise here. 41dB is by no means bad, but the 7970 never did particularly well here either, and neither will the 290X. This level of idle noise will not impress anyone concerned about the matter, especially when 2 GTX 780s in SLI is still quieter by 1.5dB. It’s going to be enough that the 290X is at least marginally audible at idle.
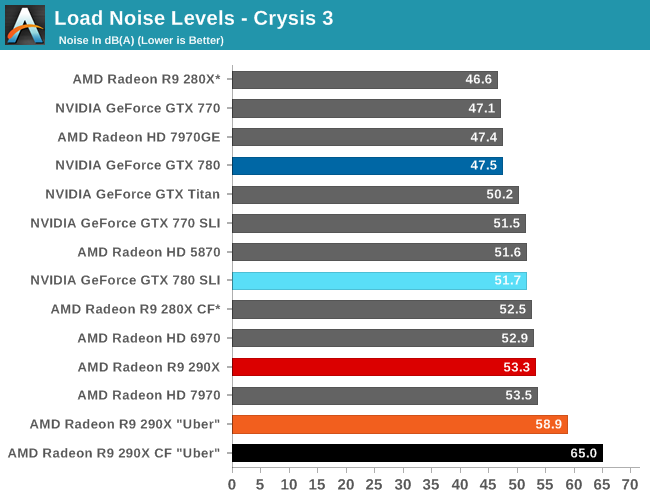
Having previously seen power consumption and temperatures under gaming, we finally get to what in most cases should be the most important factor: noise. In reusing the 7970’s reference cooler – having previously proven to be a mediocre design as far as noise is concerned – AMD has put themselves into a tough situation with the 290X. At 53.3dB the 290X is running at its 40% default fan speed limit, meaning we’re seeing both the worst case scenario for noise but also one that’s going to occur in every game. To that end it’s marginally quieter than the reference 7970 itself, and louder than everything else we’ve tested, including SLI setups.
At this point the 290X is 1.6dB louder than GTX 780 SLI, 3.1dB louder than GTX Titan, and a very significant 5.8dB louder than GTX 780. GTX 780 may border on overbuilt as far as cooling goes, but the payoff is in situations like this where the difference in noise under load is going to be very significant.
As an aside, for anyone wondering why the 290X in quiet mode and the 7970 have such similar noise levels under gaming workloads, there’s a good reason for that. The 290X quite mode’s 40% maximum fan speed was specifically chosen to match the noise characteristics of the original reference 7970, to lead to this exact outcome of it being no louder than the 7970. Meanwhile uber mode’s 55% maximum fan speed was chosen to match the noise characteristics of the reference 7970GE, which was never released in public and was absurdly loud.
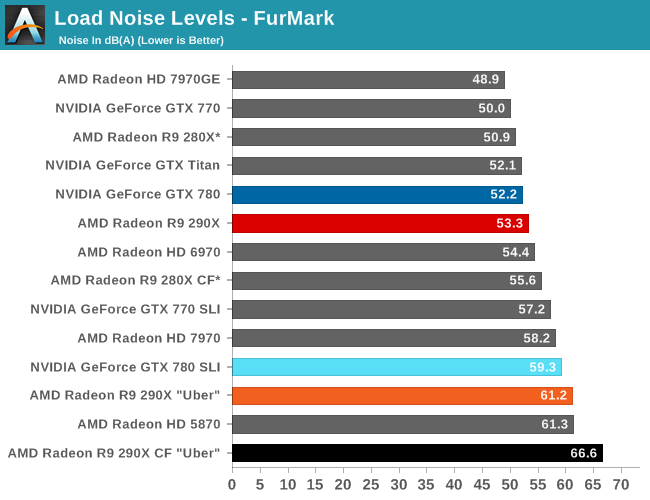
Finally with FurMark, having already reached our 40% fan speed limit for the 290X we’re merely seeing every other card catch up. What little good news for the 290X here is that the gap between the GTX 780/Titan and the 290X closes to a hair over 1dB – a nearly insignificant difference – but it won’t change the fact that our gaming workload is a better representation of what to expect under a typical workload, and as a result a better representation of how much noisier the 290X is than the GTX 780 and its ilk.
In the end it’s clear that AMD needed to make tradeoffs to get the 290X out at its performance levels, and to do so at $550. That compromise has been in 290X’s power consumption, and more directly in the amount of noise 290X generates. Which is not to say that the power and noise situation fully negates what AMD has brought to the table in terms of price and performance – though it goes without saying we would have liked to see a better cooler – but it does mean buyers will need to act on those tradeoffs.
For a high end card the power consumption is not particularly concerning right now, but the noise issue will be a problem for some buyers. Everyone has their own cutoff of course, but in our book 53.3dB is at the upper range of reasonable noise levels, if not right at the edge. The 290X is no worse than (and no better than) the 7970 in this regard, which means we’re looking at an acceptable noise level that will work for some buyers and chassis and won’t work for others. For buyers specifically seeking out an ultra-quiet blower then there is no alternative to GTX 780, otherwise in the face of what 290X can do it would be very hard to justify a card $100 more expensive and $10 slower over these noise results. AMD still holds the edge overall, even if it’s not a clean sweep.
Up next, let’s talk about uber mode for a moment. We’ve focused on quiet mode for the bulk of our writeup not only because it’s the default mode, but because it’s the only mode that makes sense. Uber mode makes the 290X’s performance look even better, particularly in our most thermally stressful games, but ultimately the performance difference is never more than 5%. 5% is simply not worth the additional noise. It’s unfortunate that AMD is having to hold back the 290X’s performance like this to get noise levels to a reasonable level, but we simply can’t justify running the 290X that loud for a bit more performance.
It’s also for that reason that the 290X CF is in the tightest spot of them all, as AMD’s suggestion is that 290X CF users run in uber mode. 290X CF’s performance is great, but a pair of cards just compounds the problem. Short of running closed headphones, 290X CF in uber mode is just too much. 290X CF in quiet mode should be significantly better, just as how the single card configuration is, but that’s something we’ll have to look into at another time, as we didn’t have time to run that set of benchmarks for this article.
With all of the above in mind, we expect it will be interesting to see what AMD’s partners cook up once we see semi-custom and fully-custom designs hit the market. Open air coolers should handily outperform the AMD blower as far as noise is concerned – at the usual tradeoff of dumping that 300W of heat into the chassis – but we’d like to see one of AMD’s partners take a crack at a better blower. We’ve seen what kind of results NVIDIA can pull off with their high end blower; even if AMD won’t make such a high quality cooler the reference cooler, it would be to AMD’s benefit to have at least one partner offering something that can compete with the GTX 780 on the noise front while retaining the blower design. Whether we’ll see such a card however is another matter entirely.
Final Words
Bringing this review to a close, going into this launch AMD has been especially excited about the 290X and it’s easy to see why. Traditionally AMD has not been able to compete with NVIDIA’s big flagship GPUs, and while that hasn’t stopped AMD from creating a comfortable spot for themselves, it does mean that NVIDIA gets left to their own devices. As such while the sub-$500 market has been heavily competitive this entire generation, the same could not be said about the market over $500 until now. And although a niche of a niche in terms of volume, this market segment is where the most powerful of video cards reside, so fierce competition here not only brings down the price of these flagship cards sooner, but in the process it inevitably pushes prices down across the board. So seeing AMD performance competitive with GTX Titan and GTX 780 with their own single-GPU card is absolutely a breath of fresh air.
Getting down to business then, AMD has clearly positioned the 290X as a price/performance monster, and while that’s not the be all and end all of evaluating video cards it’s certainly going to be the biggest factor to most buyers. To that end at 2560x1440 – what I expect will be the most common resolution used with such a card for the time being – AMD is essentially tied with GTX Titan, delivering an average of 99% of the performance of NVIDIA’s prosumer-level flagship. Against NVIDIA’s cheaper and more gaming oriented GTX 780 that becomes an outright lead, with the 290X leading by an average of 9% and never falling behind the GTX 780.
Consequently against NVIDIA’s pricing structure the 290X is by every definition a steal at $549. Even if it were merely equal to the GTX 780 it would still be $100 cheaper, but instead it’s both faster and cheaper, something that has proven time and again to be a winning combination in this industry. Elsewhere the fact that it can even tie GTX Titan is mostly icing on the cake – for traditional gamers Titan hasn’t made a lot of sense since GTX 780 came out – but nevertheless it’s an important milestone for AMD since it’s a degree of parity they haven’t achieved in years.
But with that said, although the 290X has a clear grip on performance and price it does come at the cost of power and cooling. With GTX Titan and GTX 780 NVIDIA set the bar for power efficiency and cooling performance on a high-end card, and while it’s not necessarily something that’s out of AMD’s reach it’s the kind of thing that’s only sustainable with high video card prices, which is not where AMD has decided to take the 290X. By focusing on high performance AMD has had to push quite a bit of power through 290X, and by focusing on price they had to do so without blowing their budget on cooling. The end result is that the 290X is more power hungry than any comparable high-end card, and while AMD is able to effectively dissipate that much heat the resulting cooling performance (as measured by noise) is at best mediocre. It’s not so loud as to be intolerable for a single-GPU setup, but it’s as loud as can be called reasonable, never mind preferable.
On that note, while this specific cooler implementation leaves room for improvement the underlying technology has turned out rather well thanks to AMD’s PowerTune improvements. Now that AMD has fine grained control over GPU clockspeeds and voltages and the necessary hardware to monitor and control the full spectrum of power/temp/noise, it opens up the door to more meaningful ways of adjusting the card and monitoring its status. Admittedly a lot of this is a retread of ground NVIDIA already covered with GPU Boost 2, but AMD’s idea for fan throttling is in particular a more intuitive method of controlling GPU noise than trying to operate by proxy via temperature and/or power.
Meanwhile 290X Crossfire performance also ended up being a much welcomed surprise thanks in large part to AMD’s XDMA engine. The idea of exclusively using the PCI-Express bus for inter-GPU communication on a high-end video card was worrying at first given the inherent latency that comes PCIe, but to the credit of AMD’s engineers they have shown that it can work and that it works well. AMD is finally in a position where their multi-GPU frame pacing is up to snuff in all scenarios, and while there’s still some room for improvement in further reducing overall variance we’re to the point where everything up to and including 4K is working well. AMD still faces a reckoning next month when they attempt to resolve their frame pacing issues on their existing products, but at the very least going forward AMD has the hardware and the tools they need to keep the issue under control. Plus this gets rid of Crossfire bridges, which is a small but welcome improvement.
Wrapping things up, it’s looking like neither NVIDIA nor AMD are going to let today’s launch set a new status quo. NVIDIA for their part has already announced a GTX 780 Ti for next month, and while we can only speculate on performance we certainly don’t expect NVIDIA to let the 290X go unchallenged. The bigger question is whether they’re willing to compete with AMD on price.
GTX Titan and its prosumer status aside, even with NVIDIA’s upcoming game bundle it’s very hard right now to justify GTX 780 over the cheaper 290X, except on acoustic grounds. For some buyers that will be enough, but for 9% more performance and $100 less there are certainly buyers who are going to shift their gaze over to the 290X. For those buyers NVIDIA can’t afford to be both slower and more expensive than 290X. Unless NVIDIA does something totally off the wall like discontinuing GTX 780 entirely, then they have to bring prices down in response to the launch of 290X. 290X is simply too disruptive to GTX 780, and even GTX 770 is going to feel the pinch between that and 280X. Bundles will help, but what NVIDIA really needs to compete with the Radeon 200 series is a simple price cut.
Meanwhile AMD for their part would appear to have one more piece to play. Today we’ve seen the Big Kahuna, but retailers are already listing the R9 290, which based on AMD’s new naming scheme would be AMD’s lower tier Hawaii card. How that will pan out remains to be seen, but as a product clearly intended to fill in the $250 gap between 290X and 280X while also making Hawaii a bit more affordable, we certainly have high expectations for its performance. And if nothing else we’d certainly expect it to further ratchet up the pressure on NVIDIA.






