Original Link: https://www.anandtech.com/show/7285/intel-xeon-e5-2600-v2-12-core-ivy-bridge-ep
Intel's Xeon E5-2600 V2: 12-core Ivy Bridge EP for Servers
by Johan De Gelas on September 17, 2013 12:00 AM EST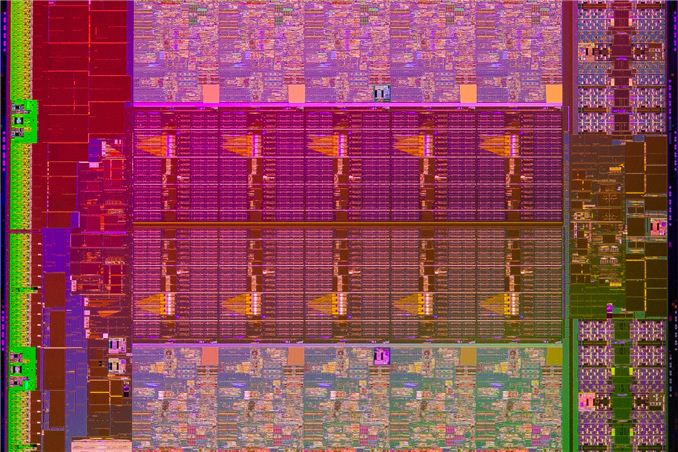
The core architecture inside the latest Xeon is typically a step behind what you find inside the latest desktop and notebook chips. A longer and more thorough validation is one reason, but there is more. The high-end model of the Xeon E5-2600 V2 or "Ivy Bridge EP" is, aside from the core architecture, completely different from the Ivy-bridge "i7 \-3xxx" that was launched in the spring of last year. With up to twelve cores, two integrated memory controllers, no GPU and 30MB L3 cache, it is the big brother of the recently reviewed Ivy-bridge E (Core i7-4960X). Intel has three die flavors of the Ivy-bridge EP:
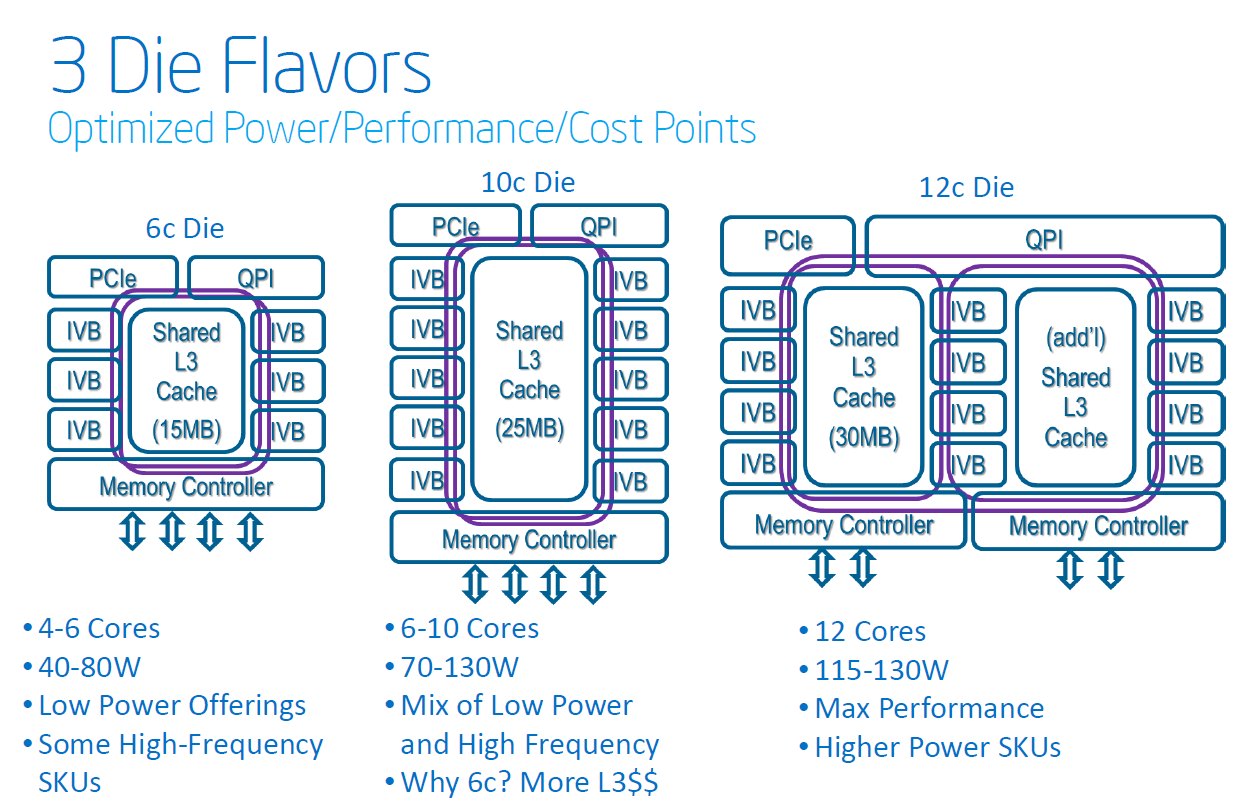
The first one is the one with the lowest core count (4/6 cores), which is found in SKUs targeted at the workstation and enthusiast market (high frequencies) or low power SKUs; this is the core being used in the enthusiast Ivy Bridge-E processors. The second one is targeted at the typical server environment with higher core counts (6 to 10 cores) and a larger L3 cache (25MB). The third and last one is the high performance HPC and server die, with 12 cores, two memory controllers for lower memory latency, and 30MB of L3 cache.
The cool thing about the newest Xeon E5 processors is that they run on the same Romley EP platform as LGA-2011 chips. This should save the OEMs a lot of time and money, and hopefully these savings will trickled down to the customers. Let's see how Intel's latest server update performs, and if it manages to impress more than the enthusiast Ivy Bridge-E.
What Has Improved?
Ivy Bridge is what Intel calls a tick+, a transition to the latest 22nm process technology (the famous P1270 process) with minor architectural optimizations compared to predecessor Sandy Bridge (described in detail by Anand here):
- Divider is twice as fast
- MOVs take no execution slots
- Improved prefetchers
- Improved shift/rotate and split/Load
- Buffers are dynamically allocated to threads (not statically split in two parts for each thread)
Given the changes, we should not expect a major jump in single-threaded performance. Anand made a very interesting Intel CPU generational comparison in his Haswell review, showing the IPC improvements of the Ivy Bridge core are very modest. Clock for clock, the Ivy Bridge architecture performed:
- 5% better in 7-zip (single-threaded test, integer, low IPC)
- 8% better in Cinebench (single-threaded test, mostly FP, high IPC)
- 6% better in compiling (multi-threaded, mostly integer, high IPC)
So the Ivy Bridge core improvements are pretty small, but they are measureable over very different kinds of workloads.
The core architecture improvements might be very modest, but that does not mean that the new Xeon E5-2600 V2 series will show insignificant improvements over the previous Xeon E5-2600. The largest improvement comes of course from the P1270 process: 22nm tri-gate (instead of 32nm planar) transistors. Discussing the actual quality of Intel process technology is beyond our expertise, but the results are tangible:
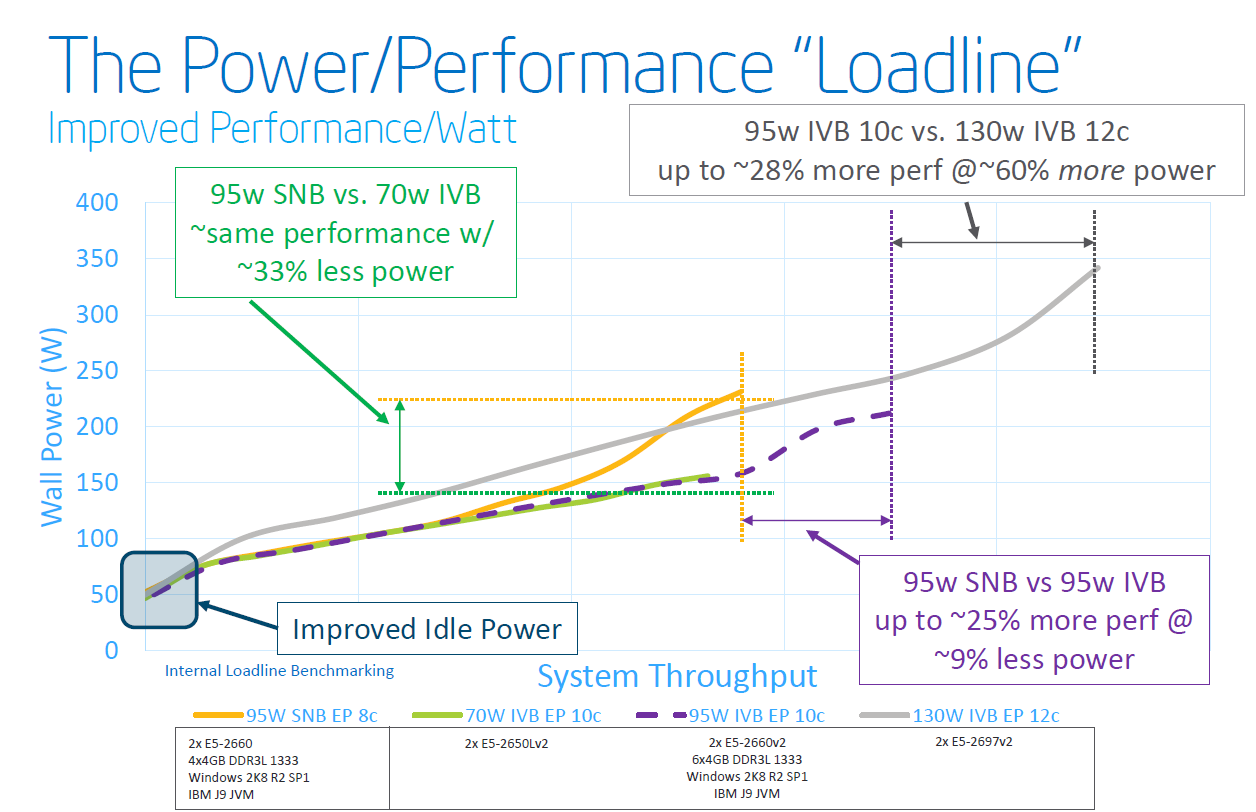
Focus on the purple text: within the same power envelope, the Ivy Bridge Xeon is capable of delivering 25% more performance while still consuming less power. In other words, the P1270 process allowed Intel to increase the number of cores and/or clock speed significantly. This can be easily demonstrated by looking at the high-end cores. An octal-core Xeon E5-2680 came with a TDP of 130W and ran at 2.7GHz. The E5-2697 runs at the same clock speed and has the same TDP label, but comes with four extra cores.
Virtualization Improvements
Each new generation of Xeon has reduced the amount of cycles required for a VMexit or a VMentry, but another way to reduce hardware virtualization overhead is to avoid VMexits all together. One of the major causes of VMexits (and thus also VMentries) are interrupts. With external interrupts, the guest OS has to check which interrupt has the priority and it does this by checking the APIC Task Priority Register (TPR). Intel already introduced an optimization for external interrupts in the Xeon 7400 series (back in 2008) with the Intel VT FlexPriority. By making sure a virtual copy of the APIC TPR exists, the guest OS is capable of reading out that register without a VMexit to the hypervisor.
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparantly, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
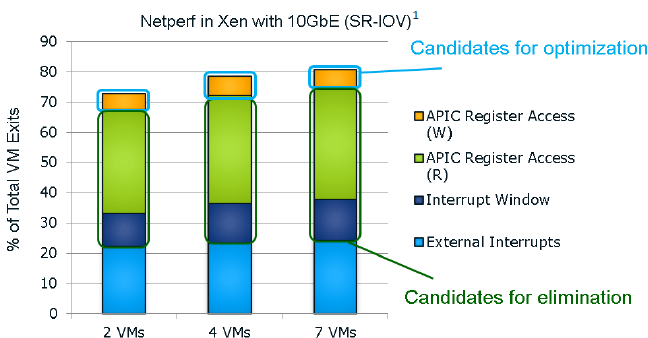
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
Related to this, Sandy Bridge introduced support for large pages in VT-d (faster DMA for I/O, chipset translates virtual addresses to physical), but in fact still fractioned large pages into 4KB pages. Ivy Bridge fully supports large pages in VT-d.
Only Xen 4.3 (July 2013) and KVM 1.4 (Spring 2013) support these new features. Both VMware and Microsoft are working on it, but the latest documents about vSphere 5.5 do not mention anything about APICv. AMD is working on an alternative called Advanced Virtual Interrupt Controller (AVIC). We found AVIC inside the AMD64 programmer's manual at page 504, but it is not clear which Opterons will support it (Warsaw?).
Other Improvements
One of the improvements that caught our attention was the "Fast Access of FS & GS base registers". We were under the impression that segment registers were not used in a modern OS with 64-bit flat addressing (with the exception of the Binary Translation VMM of VMware), but the promise of "Critical optimization for large thread-count server workloads" in Intel's Xeon E5-2600 V2 presentation seems to indicate otherwise.
Indeed no modern operating system uses the segment registers, but FS and GS registers are an exception. The GS register (for 64-bit; FS for 32-bit x86) points to the Thread Local Storage descriptor block. That thread block stores unique information for each thread and is accessed quite a bit when many threads are running concurrently.
That sounds great, but unfortunately operating system support is not sufficient to benefit from this. An older Intel presentation states that this feature is implement by adding "Four new instructions for ring-3 access of FS & GS base registers". The GCC compiler 4.7 (and later) has a flag called "-fsgsbase" to recompile your source code to make use of this. So although Ivy Bridge could make user thread switching a lot faster, it will take a while before commercial code actually implements this.
Other ISA optimizations (Float16 to and from SP conversion) will be useful for some image/video processing applications, but we cannot imagine that many server applications will benefit from this. HPC/render farms on the other hand may find this useful.
The Uncore
The uncore part has some modest improvements too. The snoop directory has now three states (Exclusive, Modified, Shared) instead of two and it improves server performance in 2-socket configurations as well. In Sandy Bridge the snoop directoy was disabled in 2-socket configurations as it hampered performance (which is also a best practice on the Opterons).
Also, the snoop broadcoasting got a lot more "opportunistic". If lots of traffic is going on, broadcasts are avoided; if very little is going on, it "snoops away". If it is likely that the snoop directory will not have the entry, the snoop is issued prior to directory feedback. "Opportunistic" snooping makes sure that snooping traffic is reduced and as a result the multi-core performance scales better. Which is quite important when your are dealing with up to 24 physical cores in a system.
Wrapping up, maximum PCI Express bandwidth when performing two thirds reads and one third writes has been further improved from 80GB/s (using quad-channel 1600 MT/s DDR3) to 90GB/s. T here are now two memory controllers instead of one to reduce latency. Bandwidth is also improved thanks to the support for DDR3- 1866. Lastly, the half width QPI mode is disabled in turbo mode, as it is very likely that there is a lot of traffic between the interconnects between the sockets. Turbo mode is after all triggered by heavy CPU activity.
SKUs and Pricing
Before we start with the benchmarks, we first want to see what you get for your money. Let's compare the AMD chips with Intel's offerings. To reduce the clutter, we did not list all of the SKUs but have tried to include useful points of comparison.
| AMD vs. Intel 2-socket SKU Comparison | |||||||||
|
Xeon E5 |
Cores/ Threads |
TDP |
Clock Speed (GHz) |
Price | Opteron |
Modules/ Integer cores |
TDP |
Clock Speed (GHz) |
Price |
| High Performance | High Performance | ||||||||
| 2697v2 | 12/24 | 130W | 2.7-3.5 | $2614 | |||||
| 2695v2 | 12/24 | 115W | 2.4-3.2 | $2336 | |||||
| 2687Wv2 | 8/16 | 150W | 3.4-4.0 | $2108 | |||||
| 2680v2 | 10/20 | 115W | 2.8-3.6 | $1723 | |||||
| 2680(*) | 8/16 | 130W | 2.7-3.5 | $1723 | |||||
| 2660v2 | 10/20 | 115W | 2.2-3.0 | $1389 | 6386SE | 8/16 | 140W | 2.8-3.5 | $1392 |
| Midrange | Midrange | ||||||||
| 2650v2 | 8/16 | 95W | 2.6-3.4 | $1166 | 6380 | 8/16 | 115W | 2.5-3.4 | $1088 |
| 2640v2 | 8/16 | 95W | 2.0-2.5 | $885 | |||||
| 6376 | 8/16 | 115W | 2.3-3.2 | $703 | |||||
| Budget | Budget | ||||||||
| 2630v2 | 6/12 | 80W | 2.6-3.1 | $612 | 6348 | 6/12 | 115W | 2.8-3.4 | $575 |
| 2620v2 | 6/12 | 80W | 2.1-2.6 | $406 | 6234 | 6/12 | 115W | 2.4-3.0 | $415 |
| Power Optimized | Power Optimized | ||||||||
| 2650Lv2 | 10/20 | 70W | 1.7-2.1 | $1219 | |||||
| 2630Lv2 | 6/12 | 70W | 2.4-2.8 | $612 | 6366HE | 8/16 | 85W | 1.8-3.1 | $575 |
(*) Sandy Bridge based Xeon, for reference purposes
The lack of competition at the high-end cannot be more obvious. AMD simply does not have anything competitive at the moment in that part of the market. However, Intel and the OEMs still have to convince the data center people to keep the upgrade cycles relatively short. If you look at the the E5 2680 v2, you get two extra cores, a 100MHz clock speed bump and a lower TDP compared to the predecessor E5 2680. Intel charges more for the best Xeons, but you do get more for your money.
The most expensive Xeon (at 130W TDP) is a lot more expensive, but that is no surprise given the fact that it it is an expensive chip to make with such a massive die (12 cores, 30MB L3, two separate memory controllers).
Every Opteron has been relegated to the lower-end and midrange segments, and it is not looking good. We know that the AMD Opteron needs more threads or clock speed to keep up with the previous Xeon E5 performance wise. The midrange and budget AMD Opterons no longer have that advantage, and they need more power too. A price cut looks to be necessary, although an Opteron server is typically less expensive than a similar Xeon system.
Benchmark Configuration & method
This review is mostly focused on performance. We have included the Xeon E5-2697 v2 (12 cores at 2.7-3.5GHz) and Xeon E5-2650L v2 (10 cores at 1.7GHz-2.1GHz) to categorize the performance of the high-end and lower-midrange new Xeons. That way, you can get an idea of where the rest of the 12 and 10 core Xeon SKUs will land. We also have the previous generation E5-2690 and E5-2660 so we can see the improvements from the new architecture. This also allows us to gauge how competitive the Opteron "Piledriver" 6300 is.
Intel's Xeon E5 server R2208GZ4GSSPP (2U Chassis)
| CPU |
Two Intel Xeon processor E5-2697 v2 (2.7GHz, 12c, 30MB L3, 130W) Two Intel Xeon processor E5-2690 (2.9GHz, 8c, 20MB L3, 135W) Two Intel Xeon processor E5-2660 (2.2GHz, 8c, 20MB L3, 95W) Two Intel Xeon processor E5-2650L v2 (1.7GHz, 10c, 25MB L3, W) |
| RAM |
64GB (8x8GB) DDR3-1600 Samsung M393B1K70DH0-CK0 or 128GB (8 x 16GB) Micron MT36JSF2G72PZ – BDDR3-1866 |
| Internal Disks | 2 x Intel MLC SSD710 200GB |
| Motherboard | Intel Server Board S2600GZ "Grizzly Pass" |
| Chipset | Intel C600 |
| BIOS version | SE5C600.86B (August the 6th, 2013) |
| PSU | Intel 750W DPS-750XB A (80+ Platinum) |
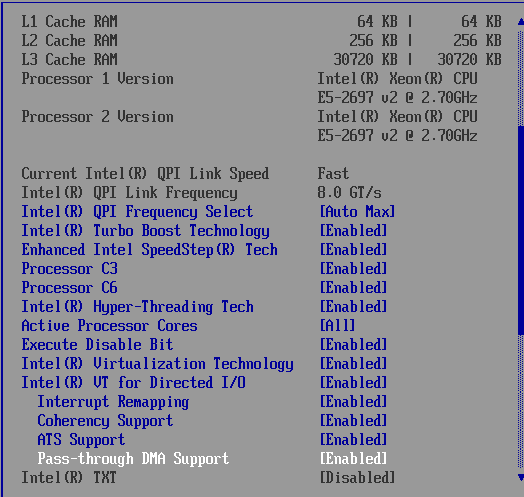
The Xeon E5 CPUs have four memory channels per CPU and support up to DDR3-1866, and thus our dual CPU configuration gets eight DIMMs for maximum bandwidth. The typical BIOS settings can be found below.
Supermicro A+ Opteron server 1022G-URG (1U Chassis)
| CPU |
Two AMD Opteron "Abu Dhabi" 6380 at 2.5GHz Two AMD Opteron "Abu Dhabi" 6376 at 2.2GHz |
| RAM | 64GB (8x8GB) DDR3-1600 Samsung M393B1K70DH0-CK0 |
| Motherboard | SuperMicro H8DGU-F |
| Internal Disks | 2 x Intel MLC SSD710 200GB |
| Chipset | AMD Chipset SR5670 + SP5100 |
| BIOS version | v2.81 (10/28/2012) |
| PSU | SuperMicro PWS-704P-1R 750Watt |
The same is true for the latest AMD Opterons: eight DDR3-1600 DIMMs for maximum bandwidth. You can check out the BIOS settings of our Opteron server below.
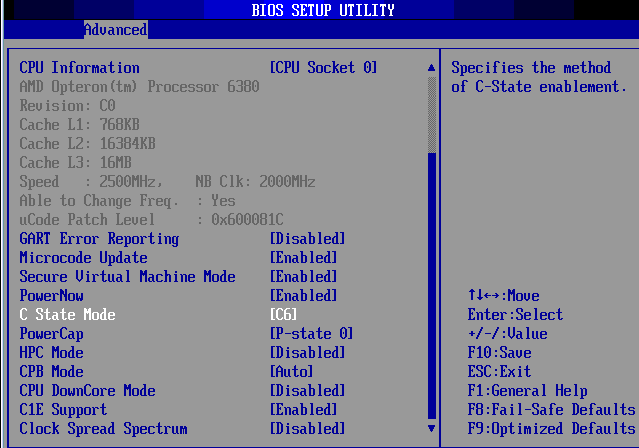
C6 is enabled, TurboCore (CPB mode) is on.
Common Storage System
To minimize different factors between our tests, we use our common storage system to provide LUNs via iSCSI. The applications are placed on a RAID-50 LUN of ten Cheetah 15k5 disks inside a Promise JBOD J300, connected to an Adaptec 5058 PCIe controller. For the more demanding applications (Zimbra, PhpBB), storage is provided by a RAID-0 of Micron P300 SSDs, with a 6 Gbps Adaptec 72405 PCIe raid controller.
Software Configuration
All vApus testing is done on ESXi vSphere 5 — VMware ESXi 5.1. All vmdks use thick provisioning, independent, and persistent. The power policy is "Balanced Power" unless otherwise indicated. All other testing is done on Windows 2008 Enterprise R2 SP1. Unless noted otherwise, we use the "High Performance" setting on Windows 2008 R2 SP1.
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) powerline. The room temperature is monitored and kept at 23°C by our Airwell CRACs. We use the Racktivity ES1008 Energy Switch PDU to measure power consumption. Using a PDU for accurate power measurements might seem pretty insane, but this is not your average PDU. Measurement circuits of most PDUs assume that the incoming AC is a perfect sine wave, but it never is. However, the Rackitivity PDU measures true RMS current and voltage at a very high sample rate: up to 20,000 measurements per second for the complete PDU.
Virtualization Performance: ESXi 5.1 & vApus FOS Mark 2 (beta)
We introduced our new vApus FOS (For Open Source) benchmark in our review of the Facebook "Open Compute" servers. In a nutshell, it is a mix of four VMs with open source workloads: two PhpBB websites (Apache2, MySQL), one OLAP MySQL "Community server 5.1.37" database, and one VM with VMware's open source groupware Zimbra 7.1.0.
As we try to keep our benchmarks up to date, some changes have been made to the original vApus FOS Mark. We've added more realistic workloads and tuned them in accordance with optimizations performed by our industry partners.
With our latest and greatest version (a big thanks to Wannes De Smet), we're able to:
- Simulate real-world loads
- Measure throughput, response times, and energy usage for a each concurrency
- Scale to 80 (logical) core servers and beyond
We have a grouped our different workloads into what we call a 'tile'. A tile consists of four VMs, each running a different load:
- A phpBB forum atop a LAMP stack. The load consists of navigating through the forum, creating new threads, and posting replies. There are also large res pictures on the pages, causing proper network load.
- Zimbra, which is stressed by navigating the site, sending emails, creating appointments, adding and searching contacts, etc.
- Our very own Drupal-based website. We create new posts, send contact emails, and generate views in this workload.
- A MySQL database from a news aggregator, loaded with queries from the aggregator for an OLAP workload.
Each VM's hardware configuration is specced to fit each workload's needs. These are the detailed configurations:
| Workload | CPUs | Memory (GB) | OS | Versions |
|---|---|---|---|---|
| phpBB | 2 | 4 | Ubuntu 12.10 | Apache 2.2.22, MySQL server 5.5.27 |
| Zimbra | 4 | 4 | Ubuntu 12.04.3 | Zimbra 8 |
| Drupal | 4 | 10 | Ubuntu 12.04.2 | Drupal 7.21, Apache 2.2.22, MySQL server 5.5.31 |
| MySQL | 16 | 8 | Ubuntu 12.04.2 | MySQL server 5.5.31 |
Depending on the system hardware, we place a number of these tiles on the stressed system to max it out and compare its performance to other servers. Developing a new virtualization benchmark takes a lot of time, but we wanted to give you our first results. Our benchmark is still in beta, so results are not final yet. Therefore we only tested one system, the Intel system, using three CPUs.

Intel reports that the Xeon E5-2697 v2 is 30% faster than the Xeon E5-2690 on SPECvirt_sc2010. Our current benchmark is slightly less optimistic, however it is pretty clear that the Ivy Bridge based Xeons are tangibly faster.
We also measured the power needed to run the three tiles of vApusMark FOS 2013 beta. It is by no means realistic, but even then, peak power remains an interesting metric since all CPUs are tested in the same server.
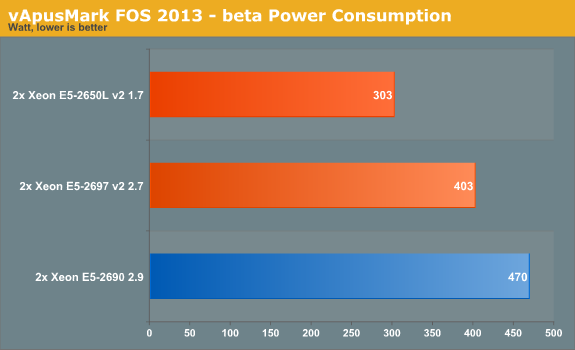
According to our measurements, the Xeon E5 2697 v2 needs only 85% of the peak power of the Xeon E5-2690. That is considerable power savings, considering that we get 22% more throughput. Also note that the virtualization improvements (vApic, VT-d large pages) are not implemented in ESXi 5.1.
SAP S&D
The SAP S&D 2-Tier benchmark has always been one of my favorites. This is probably the most real-world benchmark of all server benchmarks done by the vendors. It is a full blown application living on top of a heavy relational database. And don't forget that SAP is one of the most successful software companies out there, the market leader of Enterprise Resource Planning.
SAP is thus an application that misses the L2 cache much more than most applications out there, with the exception of some exotic HPC apps. We made an in depth profile of SAP S&D here.

The result of the Xeon E5-2697 V2 is based upon testing done by preliminary reports of Intel and OEMs. The E5-2697V2 is about 38% faster than the best Xeon E5-2690. Since the cost of the CPU is not relevant in an SAP project, we can say that the new Xeon simply mops the floor with the competition.
Java Server Performance
The SPECjbb 2013 benchmark is based on a "usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases and data-mining operations". It uses the latest Java 7 features and makes use of XML, compressed communication and messaging with security.
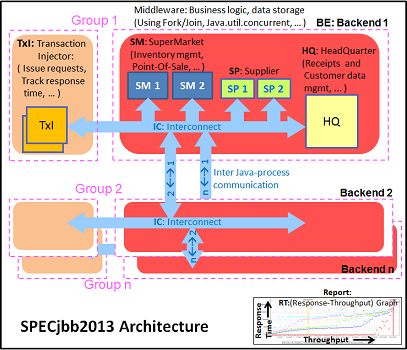
We tested with four groups of transaction injectors and backends. We applied a relatively basic tuning to mimic real world use.
"-server -Xmx4G -Xms4G -Xmn1G -XX:+AggressiveOpts -XX:+UseLargePages-server -Xmx4G -Xms4G -Xmn1G -XX:+AggressiveOpts -XX:+UseLargePages"
With these settings, the benchmark takes about 43GB of RAM. The first metric is basically maximum throughput.

The newest Xeon E5 2697 v2 delivers 33% better performance. The Opteron 6380 needs a 50% clock advantage to stay ahead of the 10-core Xeon E5. This illustrates how large the gap is between the Opterons and even the midrange Xeons. A 10-core Xeon E5-2660 V2 at 2.2GHz costs a bit more than the Opteron 6380 but will deliver a significantely better performance per watt, considering the very low 95W TDP.
The Critical-jOPS metric, is a throughput metric under response time constraint.
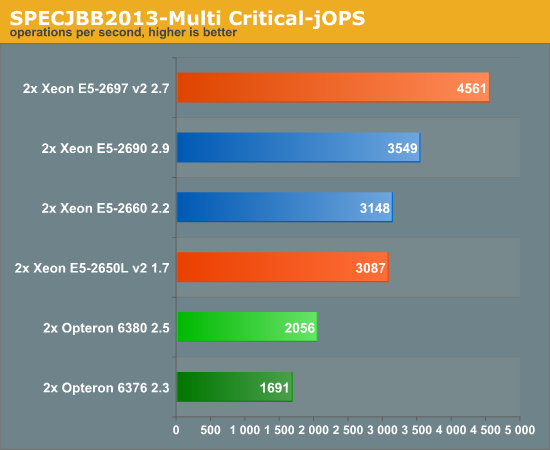
We have to admit we have our doubts. The Critical-jOPS measurements do not seem to be very repeateable and it is not completely clear how it is calculated. However, it confirms earlier measurements of our own that the Xeons are better at responding quickly at a given throughput. Again, the new Xeon 2697 v2 performs about 30% better than the Xeon E5 2690.
SPECJBB®2013 is a registered trademark of the Standard Performance Evaluation Corporation (SPEC).
Rendering Performance: Cinebench
Cinebench, based on MAXON's CINEMA 4D software, is probably one of the most popular benchmarks around as it is pretty easy to perform this benchmark on your own home machine. The benchmark supports up to 64 threads, more than enough for our 24- and 32-thread test servers. First we test single-threaded performance, to evaluate the performance of each core.
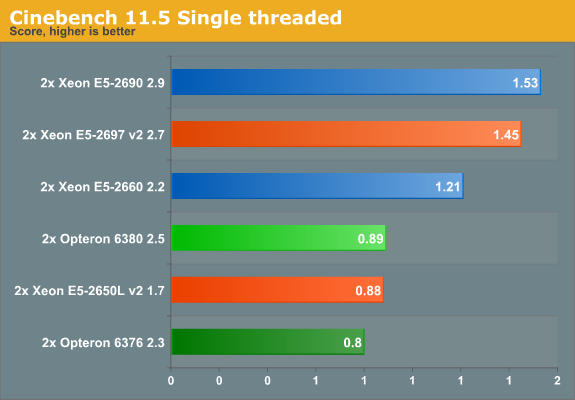
Cinebench achieves an IPC between 1.4 and 1.8 and is mostly dominated by SSE2 code. There is little improvement in that area, and the older 2.9-3.8GHz E5-2690 has the clock speed advantage over the new 2.7-3.5GHz E5-2697 v2. Also of note is that i n this type of code, one Piledriver core again needs 50% higher clock speed to keep up with the Ivy Bridge core.
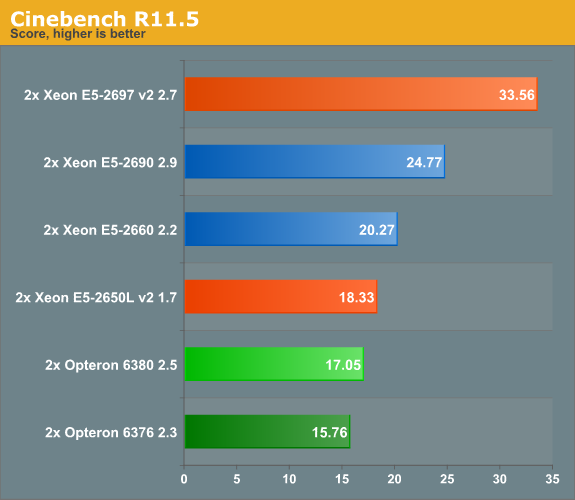
Once we run up to 48 threads, the new Xeon can outperform its predecessor by a wide margin of ~35%. It is interesting to compare this with the Core i7-4960x results , which is the same die as the "budget" Xeon E5s (15MB L3 cache dies). The six-core chip at 3.6GHz scores 12.08. It is clear that chosing cores over clock speed is a good strategy in rendering farms: the dual E5-2650L offers 50% better performance in a power budget that is more or less the same (2x70W vs 130W).
LS-DYNA
LS-DYNA is a "general purpose structural and fluid analysis simulation software package capable of simulating complex real world problems", developed by the Livermore Software Technology Corporation (LSTC). It is used by the automobile, aerospace, construction, military, manufacturing and bioengineering industries. Even simple simulations take hours to complete, so even a small performance increase results in tangible savings. Add to this the fact that many of our readers have been asking that we perform some benchmarking with HPC workloads and we have reasons enough to include our own LS-DYNA benchmarking.
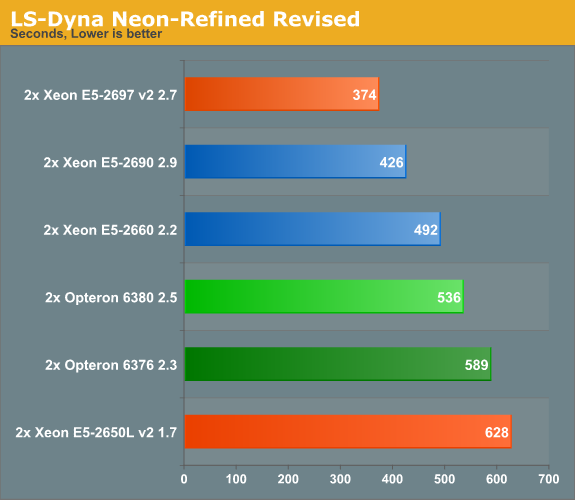
These numbers are not directly comparable with AMD's and Intel's benchmarks as we did not perform any special tuning besides using the message passing interface (MPI) version of LS-DYNA (ls971_mpp_hpmpi) to run the LS-DYNA solver to get maximum scalability. This is the HP-MPI version of LS-DYNA 9.71. Our first test is a refined and revised Neon crash test simulation.
The second test is the "Three Vehicle Collision Test" simulation, which runs a lot longer.
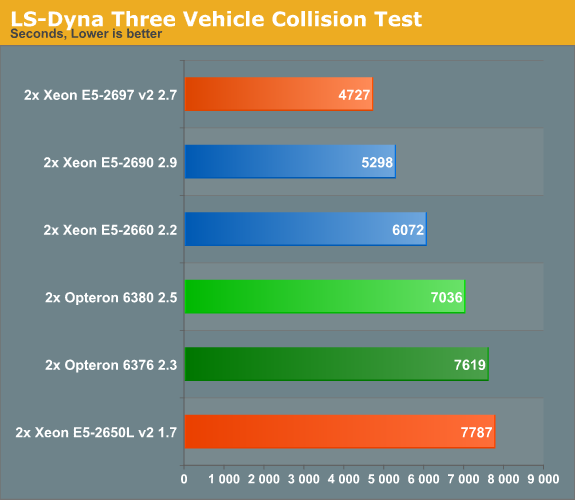
We have already seen that SSE/FP performance has not really improved, and this is another example. The "Ivy Bridge EP" is only 12% faster, despite having more cores.
LS-DYNA Power Consumption
For HPC buyers, peak power tends to be a very important metric. As HPC systems are run at close to 100% CPU load, the energy consumption is at its peak for a long time. Peak power thus also determines the cooling and energy requirements. This is in sharp contrast with most other servers, where calculating the power and amps based on the peak load of a complete rack is considered wasteful as it is highly unlikely that all servers will hit 100% CPU load at the same time.
We took the 95th percentile of our power numbers. Note that the Xeon E5 numbers are not directly comparable to the Opteron numbers as the CPUs are tested in servers with different form factors.
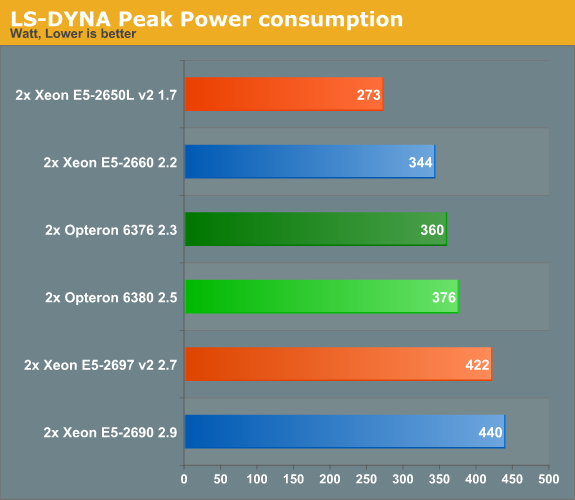
The power savings of the new Xeon E5 2697 are not as spectacular as we witnessed in our virtualization benchmark, but they are still measureable. Our best guess is that the Ivy Bridge architecture efficiency has mostly improved for integer dominated workloads, less for floating point.
7-Zip 9.2
7-zip is a file archiver with a high compression ratio. 7-Zip is open source software, with most of the source code available under the GNU LGPL license. The benchmark uses the LZMA method.
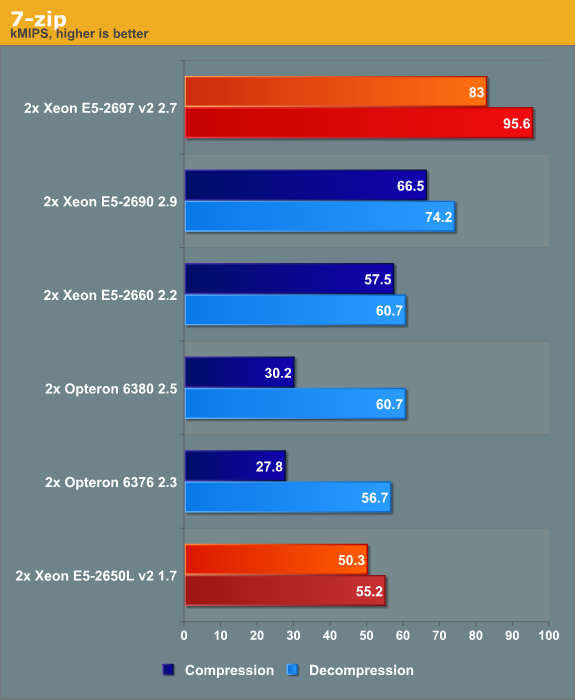
Again, the Xeon E5 "Ivy Bridge EP" is about 30% better than Xeon E5 "Sandy Bridge EP". Remember that the bad compression numbers of the Opteron are related to scaling problems over four NUMA nodes.
Conclusions
Intel has again done a remarkably good job with the Xeon "Ivy Bridge EP". Adding more cores can easily lead to bad scaling or even to situations where performance decreases. The new Xeon E5 adds about 30% performance across the line, in more or less the same power envelope. Single-threaded performance does not suffer either (though it also fails to improve in most scenarios). Even better, Intel's newest CPU works inside the same socket as its predecessor. That's no small feat, as there have been changes in core count and uncore, and as a result the electrical characteristics change too.
At the end of last year, AMD was capable of mounting an attack on the midrange Xeons by introducing Opterons based on the "Piledriver" core. That core improved both performance and power consumption, and Opteron servers were tangibly cheaper. However, at the moment, AMD's Opteron is forced to leave the midrange market and is relegated to the budget market. Price cuts will once again be necessary.
Considering AMD's "transformed" technology strategy , we cannot help but be pessimistic about AMD's role in the midrange and high-end x86 server market. AMD's next step is nothing more than a somewhat tweaked "Opteron 6300". Besides the micro server market, only the Berlin CPU (4x Steamroller, integrated GPU) might be able to turn some heads in HPC and give Intel some competition in that space. Time will tell.
In other words, Intel does not have any competition whatsoever in the midrange and high-end x86 server market. The best Xeons are now about 20% more expensive, but that price increase is not tangible in most markets. The customers buying servers for ERP, OLTP and virtualization will not feel this, as a few hundred dollars more (or even a couple thousand) for the CPUs pales in comparison to the yearly software licenses. The HPC people will be less happy but many of them are spending their money on stream processors like the Xeon Phi, AMD Firestream, or NVIDIA Tesla. Even in the HPC market, the percentage of the budget spent on CPUs is decreasing.
Luckily, Intel still has to convince people that upgrading is well worth the trouble. As a result you get about 25% more multi-threaded/server performance, about 5-10% higher single-threaded performance (a small IPC boost and a 100MHz speed bump), and sligthly lower power consumption for the same price. It may not be enough for some IT departments, but those that need more performance within the same power envelope will probably find a lot to like with the new Xeons.






