Original Link: https://www.anandtech.com/show/7170/impact-disruptive-technologies-professional-storage-market
The Impact of Disruptive Technologies on the Professional Storage Market
by Johan De Gelas on August 5, 2013 9:00 AM EST- Posted in
- IT Computing
- SSDs
- Enterprise
- Enterprise SSDs

Introduction: Enterprise Storage 101
Since the introduction of x86 based servers at the end of the 20th century, the cost of server hardware has declined rapidly while the performance per watt and performance per dollar has increased rapidly. This pushed the server market to evolve from closed, proprietary, and most importantly extremely expensive mainframe and proprietary RISC servers into today's highly competitive x86 server market. However, the professional storage market is still ruled by the proprietary, legacy systems.
Today, you can get a very powerful server that can cope with most server workloads for something like $5000. Even better, you can run tens of workloads in parallel by virtualizing them. But go to the storage market with four or even five times the budget and you will likely return with a low end SAN.

Worse yet is that there is good chance this expensive device will choke regularly due to the use of a storage intensive application. We quote a market survey conducted in march 2013:
Forty-four percent of respondents said disproportionate storage-related costs were an obstacle preventing them from virtualizing more of their workloads. Forty-two percent said the same about performance degradation or the inability to meet performance expectations.
Note that the study does not mention the percentage of customers stuck in denial :-). The performance per dollar of the average SAN array is mediocre at best, and the storage capacity per dollar is simply awful.
You might think that the hardware inside a SAN is vastly superior to what can be found in your average server, but that is not the case. EMC (the market leader) and others have disclosed more than once that “the goal has always to been to use as much standard, commercial, off-the-shelf hardware as we can”. So your SAN array is probably nothing more than a typical Xeon server built by Quanta with a shiny bezel. A decent professional 1TB drive costs a few hundred dollars. Place that same drive inside a SAN appliance and suddenly the price per terabyte is multiplied by at least three, sometimes even 10! When it comes to pricing and vendor lock-in you can say that storage systems are still stuck in the “mainframe era” despite the use of cheap off-the-shelf hardware.
So why do EMC, NetApp, and the other giants in the storage market charge so much for what is essentially a Xeon based server, an admittedly well designed and reliable storage backplane, and some unreliable and slow performing hard drives? The reason is not some complex market situation that can only be explained by financial experts. No, the key is simply the basic component of a storage system: the unreliable and slow magnetic disk.
As we all know, the magnetic disk is the component that fails most in the data center, and it is by far the slowest core component in modern computers. Building a reliable and somewhat performant storage system based upon such a mediocre storage component can only be done with complex software. And complex software is yet another prime reason why IT services fail. So only a few companies that were able to build a solid reputation gained enough trust to succeed in the storage market.
This is why EMC, NetApp, IBM, and HP rule the storage market today even though they are charging an arm and a leg for a few terabytes of capacity. Professional buyers trust the devices these vendors make and are willing to pay a huge premium just to be sure that they get good reliability and decent but hardly compelling performance and capacity.
The Winds of Change
My reason for writing this article is that a wind of change is blowing through the storage market. The success of cloud storage such as Amazon S3 and Syncplicity has opened the way to new methods of archiving, making backups, and even disaster recovery. But the biggest disruptor is of course flash memory, and more specifically PCIe SSDs.
PCIe SSDs are not bandwidth limited by the SATA/SAS wiring and (if implemented well) protocol overhead. As a result, PCIe drives have up to three times as many channels of flash memory. And well-designed PCIe SSDs do not have to carry the burden of RAID controllers and protocols that were architectured for hard drives with completely different characteristics than flash memory. But even if they use a PCIe/SAS bridge, PCIe SSDs offer higher reliability and vastly superior performance than the best enterprise drives. But there is much more going on.
As PCIe SSDs offer large capacities (up to 10TB!) and performance in a very small form factor, they open new markets. It is interesting to see the completely new solutions that are now available, solutions that are much better suited for certain workloads. One example of a workload where traditional SANs fall short is virtual desktops.
Virtual Desktops
Virtual desktops like Xendesktop or VMware View have been promising significant energy and cost savings, but these savings almost never materialize in reality. The energy saving claims made a few years ago were ridiculous; they were based on the assumption that we are still using power hogging desktops. Replace those with thin clients and you magically get massive energy savings.
The reality is that most of the IT professionals already use a 20-30W portable instead of an old 150W desktop, and the extra server load was not helping save energy either. Even if portables were not used, many business desktops today sip small amounts of energy. And if there was any miraculous energy saving, the additional complex storage system would be the final blow. The end result of desktop virtualization is often higher instead of lower energy bills. But perhaps worse is that knowledge workers hated most of the virtual desktops project with a passion. Suddenly several actions that used to complete without any noticeable response time became laggy.
Although there were serious costs savings if your desktop deployment and management was just organized chaos, every organization that replaced PCs with virtual desktops faced the need for huge investments. As lots of people boot up their virtual desktop in the morning, massive amounts of data is written and read in a rather random way: the so called “boot storm”. The solution was to boot up the desktops in a staggered way, tens of minutes before the arrival of the users, and to perform all kinds of special optimizations all over the software stack. But that is hardly more than a band-aid: what about unexpected hot fix patches, or what if people arrive a little bit earlier on occasion?

Data source: NetApp News 2013
Astute readers understand that the administration of virtual desktops is quite a bit more complex than the traditional setup with roaming profiles and saving files on a centralized file server. Only the most recent and high-end SANs could really deal with these specific requirements. Granted, some of the essential storage tasks like backup and archiving are a lot easier once you have a SAN in place… but mostly after you have invested in all kinds of expensive management software. When you start to invest in a complex SAN platform, the costs seem to multiply like rabbits.
In short, although a fast SAN seemed to be an enabler, they were also a deal breaker in the virtual desktop world. They're too slow and/or too expensive, and they're also power hungry.
Several companies feel they have a much better alternative and it is very interesting to see how the Fusion–IO and Intel PCIe SSDs are being turned into innovative and specialized alternatives for the typical SAN solution. Let's discuss a few of these over the next several pages.
Nutanix: No More SAN
It is not a secret that even though a SAN comes with all the virtues of centralized data, network storage comes with a network bandwidth and latency penalty. By simply attaching a flash array directly to a system (DAS), we can measure the extra latency compared to SAN (Storage Area Network). It amounts to between 0.3 and 0.8 ms depending on whether you use Fibre Channel or iSCSI over copper wires.

So the minimal latency was 50% to 100% higher in a lightly loaded SAN than when the same SSD was running inside the server. However, this was the minimal latency. This can quickly grow to several milliseconds when the network load goes up.
Nutanix believes that virtualized servers should use local storage, clustered together in a virtual storage pool. Each of the virtual machines connects to a storage VM. That storage VM is typically an iSCSI target inside a VM, also called a VSA or Virtual Storage Appliance. The VSA on each server node are clustered together by the Nutanix Distributed File System (NDFS). NDFS makes sure that if one node dies, the other nodes are still able to access the necessary files to run.
.jpg)
The VSA also leverages the latest flash technology. The most accessed data is on a Fusion-IO or Intel S3700 SSDs, depending on the Nutanix node model. The “colder” (not frequently accessed) data is automatically transferred to the SATA terabyte disks. It's basically another level of caching, only with larger data caches than we see in the desktop world.

Using what seems to be a Supermicro Twin or Twin² chassis, even an entry level four node Nutanxi NX-3050 should support up to 400 virtual desktops with a power consumption of about 1.1 KW. Compare this with your typical SAN array that typically needs 700W just for one midrange array, and you probably need several expansion modules before you can even think about supporting 400 virtual desktops.
Unfortunately, we cannot verify the claims of Nutanix right now, but our experience tells us that from a power and performance point of view it will be very hard for the typical "server plus SAN infrastructure" to beat the much simpler “integrate everything inside a dense server” platform. The only disadvantage is that the number of DIMM slots inside such server nodes is limited. That is why even the largest Nutanix hosts do not support more than 256GB per node, which might be a limitation in some virtualization environments.
Starting at $22000 per node, the Nutanix nodes are hardly cheap, but since you don’t need a SAN the total investment is a lot lower than the traditional approach, especially for virtual desktops. Nutanix seems to have convinced quite a few people as it claims it is the fastest growing IT infrastructure startup ever, with an $80 million annual run rate. Now they just need to prove they have the reliability and support infrastructure to win over additional customers.
CloudFounders: No More RAID
CloudFounders, a startup of former Terremark and SUN execs, also leverages a flash cache, but the building blocks are very different. Just like Nutanix, there is a VSA (Virtual Storage Appliance) that tries to make the best out of a local flash cache. The cool thing is that the backend, the second tier of storage, is not a traditional RAID based volume. The backend is either an object storage initiator that links to Amazon S3 or a storage device based upon erasure encoding called Distribute Storage System (DSS). Let's start with the DSS backend.
DSS is an object oriented storage system that uses “Bitspread”, an advanced and flexible erasure encoding system developed by the people of Amplidata. Amplidata is a startup with a mix of Belgian and US based infrastructure experts. Some of the directors are working for both CloudFounders and Amplidata. But there is a solid technical reason why CloudFounders chose to go with the Amplidata storage system. Bitspread is meant to be the “big storage alternative” to RAID.
As you probably know or have experienced hands-on, the current RAID implementations—RAID 5 and RAID 6—have reached their limitations now that we have terabyte disks. A few terabyte disks in RAID 5 can take days to rebuild. The result is that the RAID array performance and reliability is heavily degraded. RAID 6 is more reliable (although hardly 100%) but is not exactly a good performer for writes, which is another reason why VDI does not work well on a low end or midrange SAN.
“Bitspread” erasure encoding, also called Forward Error Correction Code (FEC), encodes data in “check-blocks”. The beauty is that you can configure the durability policy. In other words you can choose over how many disks these check-blocks should be spread and how many check-blocks you can lose before it becomes a problem. For example you could ask it to spread the datablock over 18 drives and tell the codec to make sure you can recover the original datablock from 12 check-blocks. So it's only if you lose more than 6 drives at once that you lose your data. As the codec requires only 12 of the check blocks to rebuild the original data object, a failure of two drives does not mean the rebuild should happen urgently. The rebuild can be done in the background at a very slow pace while the reliability stays high. You can also have the check-blocks spread over several storage modules, ensuring that you even survive a failure of a complete disk enclosure.
Bitspread: original data (yellow) is split up, encoded with high redundancy (green) and then spread over many disks and enclosures.
For those who are not convinced that the small startup Amplidata is onto something: Intel and Dr. Sam Siewert of Trellis Logic explain in this paper why it can even be mathematically proven that the Reed-Solomon based erasure codes of RAID 6 are a dead end road for large storage systems. The paper concludes:
"Amplida's Bitspread is an efficient, scalable and practical alternative to the stop-gap of combined RAID levels like 6+1."
And that is exactly the reason why CloudFounders chose to build their storage system on the Amplidata backend.
The DSS based on “Bitspread” works with objects and is thus not a block device. A volume driver must be installed that converts the DSS into a block device. This way the hypervisor can connect to an iSCSI target that is running on top of the volume driver, as an iSCSI target requires a block device and does not recognize the format of the DSS.
Bitspread is a lot more CPU intensive and needs more storage room than traditional RAID algorithms. To reduce the CPU impact, Amplidata leverages the SSE 4.2 capabilities of the latest Xeons. As Bitspread copes so well with disk failures, it is natural to use relatively slow SATA disks, which negates the capacity disadvantage compared to RAID 6. Decent media transfer can still be achieved as the DSS typically spreads the check-blocks over many disks.
CloundFounders: Cloud Storage Router
The latency of DSS on top of slow SATA disks is of course pretty bad. CloudFounders solves this by using an intelligent flash cache that caches both reads and writes. The so-called “Storage Accelerator” is part of the Cloud Storage Router and runs on top of the DSS backend.

First of all, the typical 4KB writes are all stored on the SSD. The 4KB are aggregated into a Storage Container Object (SCO), typically 16MB in size. As a result, the flash cache is used for what it can do best (working with 4KB blocks) and the DSS SATA backend will only see sequential writes of 16MB. The large SATA magnetic disks perform a lot better with large sequential writes than small random ones.
A server with virtual machines can connect to several Cloud Storage Routers. Blocks of a virtual disk can be spread over several flash caches. The result is that performance can scale with the number of nodes where Cloud Storage Routers are active. The magic to make this work is that the metadata is distributed among all cloud storage routers (using a Paxos distributed database), so “hot blocks” can be transferred from several flash caches of several nodes at the same time. The metadata also contains a hash of each 4KB block. As hash codes of each 4KB block in the cache are compared, the cache is “deduped” and each 4KB block is written only once.
As the blocks of virtual disk are distributed over the DSS, the failure of compute or storage nodes does not need to be disruptive. Compute node failure can be solved by enabling VMware HA, storage nodes failures can be solved by configuring the DSS durability policy. As the metadata is distributed, the remaining cloud storage routers will be able to find the blocks on the DSS that belong to a certain virtual disk.
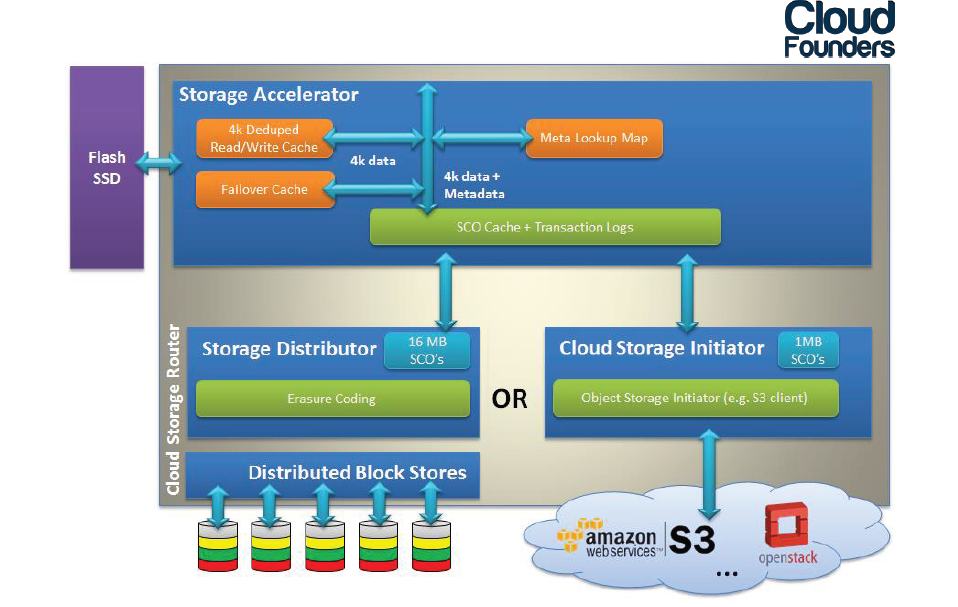
Last but not least, the Cloud Storage Routers can also distribute the check blocks over cloud storage like Amazon S3 or an Openstack Swift implementation. The data is also secure as the blocks are encoded and spread over many volumes. Only the Cloud Storage Routers know how to assemble the data.
Highly scalable, very reliable, and very flexible (e.g. when used with Amazon S3): the CloudFounder Storage Router sounds almost too good to be true. We have setup a Storage Router in our lab and can confirm that it can do some amazing things like replicating an ESXi VM across the globe and booting it as a Hyper-V VM. We are currently designing some benchmarks to compare it with traditional storage systems, so we hope to report back with some solid tests. But it is safe to say that the combination of Bitspread and the Cloud Storage Router is very different from the traditional RAID enabled SAN and storage gateway.
NetApp: Flash Anywhere
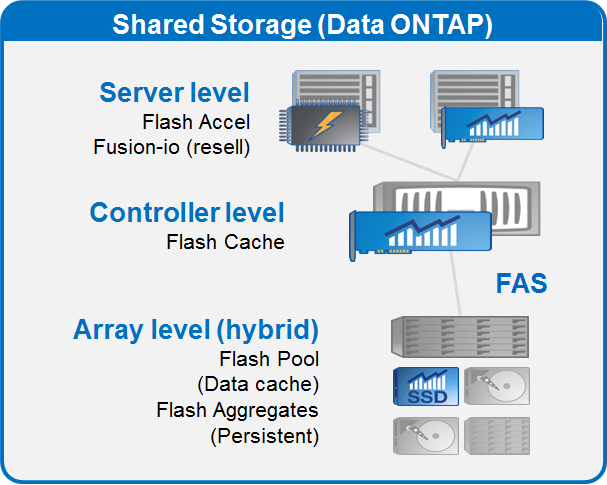
Nutanix, CloudFounders/Amplidata, and Fusion-IO (covered on page eight) are clearly challenging the current market leaders NetApp and EMC. We decided to take a closer look at how the giants respond by looking at the latest products of NetApp. NetApp's first step with using flash memory was called “flash cache”. NetApp simply added a PCIe flash card and inserted it into its FAS V6200 storage arrays.

It was a quick way of adding some performance, but it was far from exploiting the true potential of NAND memory. First of all, the flash cache was only used for reads and secondly the cache used a very simple but hardly efficient FIFO eviction algorithm. Case studies (done by NetApp Customers) with applications with a typical read/write mix reported about 30% more IOPs and on average 20% lower response times when arrays with 10K RPM SAS disks where replaced by an array with a massive flash cache and slightly slower 7200 RPM disks.
Considering how large the gap is between flash memory and magnetic disks, and the small gap between 10K and 7.2K RPM disks, that is rather underwhelming. Part of the reason is of course that these arrays already have a healthy amount (4-8GB) of NVRAM (Non Volatile RAM) that caches the hottest data and makes writes more sequential. However, the list price of a flash cache module is anywhere between $16000 (256GB) and $50000 (1TB).
In a published benchmark, six FAS6240 with 192 15K RPM disks (costing $1.5 million in total!) achieved about 250k IOPs, or about 40K IOPs per array. To sum it up: it's a very high premium for an underwhelming but very welcome performance boost. Only customers who use read dominated applications (like warehouse / OLAP app) can really expect excellent performance.
NetApp: Automatic Tiering and More Flash Goodness
Most vendors did not do much better than NetApp as they used an advocated automatic tiering, meaning that hot data was moved from the slow magnetic disks to the flash disk. Although it sounds nice, the reality was that it did not solve some performance bottlenecks. As the process was not real-time, you could be hitting the disks a lot for a piece of data before the data was finally moved towards the flash tier. Also migrating data around is not very energy friendly as it wastes a lot of processing and storage bandwidth.
To sum it up: NetApp's Flash Cache did better than the "automatic flash tier" of other vendors, but the flash cache performance/dollar ratio was not exactly something to write home about.
Last year, NetApp went a step further. The storage arrays could be expanded with a “flash pool”, a storage pool consisting of a RAID group of SSDs (100, 200, or 800GB) that caches the random reads and writes of the volumes inside a magnetic hard disk pool. All writes are first written to the NVRAM and then flushed to the disks. However, an overwrite of random write is written to the flash pool. This greatly improves performance when you update the same data over and over again in a small time period because the update is only propagated to the disks when the data is not changed for some time. Sequential writes and reads are still sent to the disks, which is an intelligent way to make the most of your SSDs. Also, the flash pool is an LRU (Least Recently Used) cache.
It is ironic to notice that NetApp quotes customers who reported 100s of ms for critical requests in case studies. While the case studies did make the flash based SAN shine, they also show how a few years ago, SAN arrays were expensive and not delivering. Luckily, those customers now report that flash pools reduced the response time to 5 ms. It is good that the newest NetApp technology has accelerated this, but it is also a clear example that even high-end SANs failed to deliver good performance to customers just a year ago.
But flash pool and flash cache do not give the performance benefits that server side flash cache delivered with Fusion-IO. So something really interesting happened: NetApp announced Flash Accel, making sure its SANs could work together with server side flash caches. Even more interesting is that NetApp is not charging anything for this software, probably to make sure that the current NetApp customers do not get lured away by other server side storage solutions.
Existing customers can simply download the ESXi 5.0/Windows 2008 agent. Each VM needs to get an agent and an ESXi host, so Flash Accel works at the moment with only a limited number of configurations. However, it's quite disruptive to witness a typical SAN vendor promoting server side caching. Just a year ago, most SAN vendors were downplaying this trend.
Fusion-IO: the Pioneer
Fusion-IO is telling everyone that wants to listen that it is much more than the vendor of extremely fast PCIe flash cards. Despite the fact that it sells quite a few cards to the storage giants like NetApp, Fusion-IO wants nothing less than to completely change and conquer the storage market.
Fusion-IO's first succesful move was to sell extremely fast ioDrives to the people who live from scale-out applications like Facebook and Apple. These companies ditched their traditional SAN environments very quickly as replacing centralized shared storage by a model where hundreds of servers have a local PCIe flash storage system gave them up to ten times more storage performance at a fraction of the cost of a high-end SAN system.
Ditching your centralized storage is not for everyone of course: your application has to handle replication and thus be able to survive the loss of many server nodes. But as we all know, that is exactly what Google, Facebook, and other scale-out companies did: build applications that replicate data between nodes so that nobody has to worry about a few failing nodes.

The Iodrive: up to 3TB, hundreds of thousands of IOPS
Although scale-out customers were extremely important to Fusion-IO, the company also went also after the virtualization market where centralized storage is king. The ioTurbine is a Hypervisor plug-in that enables server side caching on a virtualized host with a Fusion-IO flash card. The beauty is that ioTurbine does not disable the typical goodies that centralized storage offers in a virtualized environment such as vMotion and High Availability. ioTurbine works with ESXi, Windows 2012/2008 and RHEL.
Fusion-IO ION Data Accelerator is the next generation SAN: PCIe Flash cards inside any decent x86 server, like the Supermicro 6037 or the HP DL380p. ION is typically used for high-end database clusters. Fusion-IO promises that this shared storage can deliver no less than 1 million IOPs.
With the acquisition of NexGen Storage, Fusion-IO is also targeting the midrange market by offering a “flashpool” kind of product. The key difference is that NexGen Storage can use write-back caching, while most vendors do no or limited writing on the flash disks. The Fusion-IO software is also able to provision a certain amount of IOPs for each LUN.
.jpg)
But more than anything else, the Fusion-IO products are offering extreme speeds. Even a one array NexGen N5 series targeted at SMBs promise 100K-300K IOPs, more than any of the much more expensive midrange SANs can offer right now.

The fastest product, the 10TB ioDrive octal, costs around $100k and delivers 1 million IOPs. Even if those numbers are inflated, it is roughly an order of magnitude faster and cheaper (per GB) than the NetApp “Flash Cache”.
Conclusions
The storage market is finally waking up from its long hibernation. After years of high prices for underperforming SAN storage systems, Fusion-IO is challenging the storage giants with products that are engineered to take MLC flash to its full potential. The result is that even relatively cheap storage systems can deliver higher IOPs than the fastest SANs of the traditional SAN vendors.

NetApp did not fall asleep though: it integrated flash everywhere they could. If your budget is limited, you will not be very enthusiastic as the flash acceleration comes with a huge premium. If you are running expensive software and are already a NetApp customer, however, these new innovations are probably the only way to offer excellent response times. As you can reduce the spindle count, the price per TB and performance per dollar get a lot better.
But the age of the storage OS of the traditional SAN vendors is showing: adding flash everywhere and updating the OS is not as efficient as engineering a product from the ground up to make the most of flash. It is clear that NetApp and EMC have the best solutions for the traditional storage market, but they are facing heavy competition in the much faster growing "Hybrid Array" and "All Flash Array" markets. And many customer are looking beyond the traditional SANs.
Nutanix has lured away lots of customers who wanted something less complex to run VDI. CloudFounders has and will make heads turn as those with large amounts of data cannot ignore the fact that the current RAID algorithms cannot cope with tens of terrabytes very well, let alone Petabytes. The Bitspread technology of Amplidata allowed CloudFounders to build a storage system that comes with an unseen flexibility and availability. The current SAN vendors can only match this with their most expensive clusters and storage gateways, while CloudFounders uses very inexpensive Supermicro servers and SATA disks.
The storage market is changing, and those who ignore the winds of change will have to spend a lot of cash only to end up with fewer IOPs.






