Original Link: https://www.anandtech.com/show/7161/khronos-siggraph-2013-opengl-44-opencl-20-opencl-12-spir-announced
Khronos @ SIGGRAPH 2013: OpenGL 4.4, OpenCL 2.0, & OpenCL 1.2 SPIR Announced
by Ryan Smith on July 22, 2013 9:00 AM EST
Kicking off this week is the annual SIGGRAPH conference, the graphics industry’s yearly professional event. Outside of the individual vendor events and individual technologies we cover throughout the year, SIGGRAPH is typically the major venue for new technology and standards announcements. And though it isn’t really a gaming conference – this is a show dedicated to professional software and hardware – a number of those announcements do end up being gaming related, if only tangentially. As a result SIGGRAPH offers something for everyone in the graphics/GPU trident, gaming, compute, and professional rendering alike.
Most years the first major announcement to hit the wire comes from the Khronos Group, and this year is no different. The Khronos Group is of course the industry consortium responsible for OpenGL, OpenCL, WebGL, and other open graphics/multimedia standards and APIs, so their announcements carry a great deal of importance for the industry. Khronos membership in turn is a who’s who of technology, and includes virtually every major GPU vendor, both desktop and mobile.
OpenGL 4.4 Specification Released

Khronos’s first announcement for SIGGRAPH 2013 is that the OpenGL 4.4 specification has been ratified and released. This being the 5th edition of OpenGL 4.x, Khronos has continued iterating on OpenGL in concert with their pipelined development process. OpenGL 4.4 follows up on OpenGL 4.3, which last year broke significant ground for OpenGL by introducing compute shaders, ASTC texture compression, and other new functionality for the API.
This year Khronos isn’t making such sweeping changes to OpenGL, but they are adding several new low-level features that should catch the eyes of developers. Most of these are admittedly so low level that it would be difficult for anyone but developers to appreciate, but there are a few items we wanted to go over for their importance and for wider reflection of the state of OpenGL.
The biggest feature hitting the OpenGL core specification in 4.4 is buffer storage (ARB_buffer_storage). Buffer storage is directly targeted at APUs, SoCs, and other GPU/CPU integrated devices where the two processors share memory pools, address space, and other resources. Buffer storage at its most basic level allows developers to control where memory buffer objects are stored in these unified devices, giving developers the ability to specify whether buffers are stored in video memory or system memory, and how those buffers are to be cached. The buffer storage mechanism in turn also formally allows GPUs to access those buffers not being stored locally, giving GPUs a degree of visibility into the contents of system memory where it’s necessary. Like most Khronos additions this is a forward looking feature, with a clear outlook towards what can be done with HSA and HSA-like products that are due to be launching soon.

Khronos’s other major addition with OpenGL 4.4 is enhanced layouts for the OpenGL Shader Language (ARB_enhanced_layouts). The name on this is somewhat self-explanatory in this case, with enhanced layouts dealing with ways to optimize the layout of data in shader programs for greater efficiency. This includes new ways of packing scalar datatypes alongside vectors, and giving developers more control of variable layout inside uniform and storage blocks. Support for constant variables in qualifiers at compile-time is also added through this extension.
Moving on from the OpenGL core, in keeping with the OpenGL development pipeline several new features are being added as official ARB extensions, being promoted (and modified/unified as necessary) from vendor specific extensions. Chief among these new ARB extensions are extensions to support sparse textures (ARB_sparse_texture) and bindless textures (ARB_bindless_texture). You may recognize these features from the launch of AMD’s Radeon HD 7000 series and NVIDIA’s GeForce GTX 600 series respectively, as these two extensions are based on the new hardware features those products introduced and are the evolution of their previous forms as vendor specific extensions.
Sparse textures, also known as partially resident textures, give the hardware the ability to only keep tiles/chunks of textures in resident memory, versus having to load (and unload) whole textures. The most practical application of this technology is to enable megatexture-like texture management in hardware, loading only the necessary tiles of the highest resolution textures; however for professional developers this also opens up a new usage scenario by allowing the use of textures larger than the physical memory of a card, allowing for the use of larger textures without restriction by memory constraints.
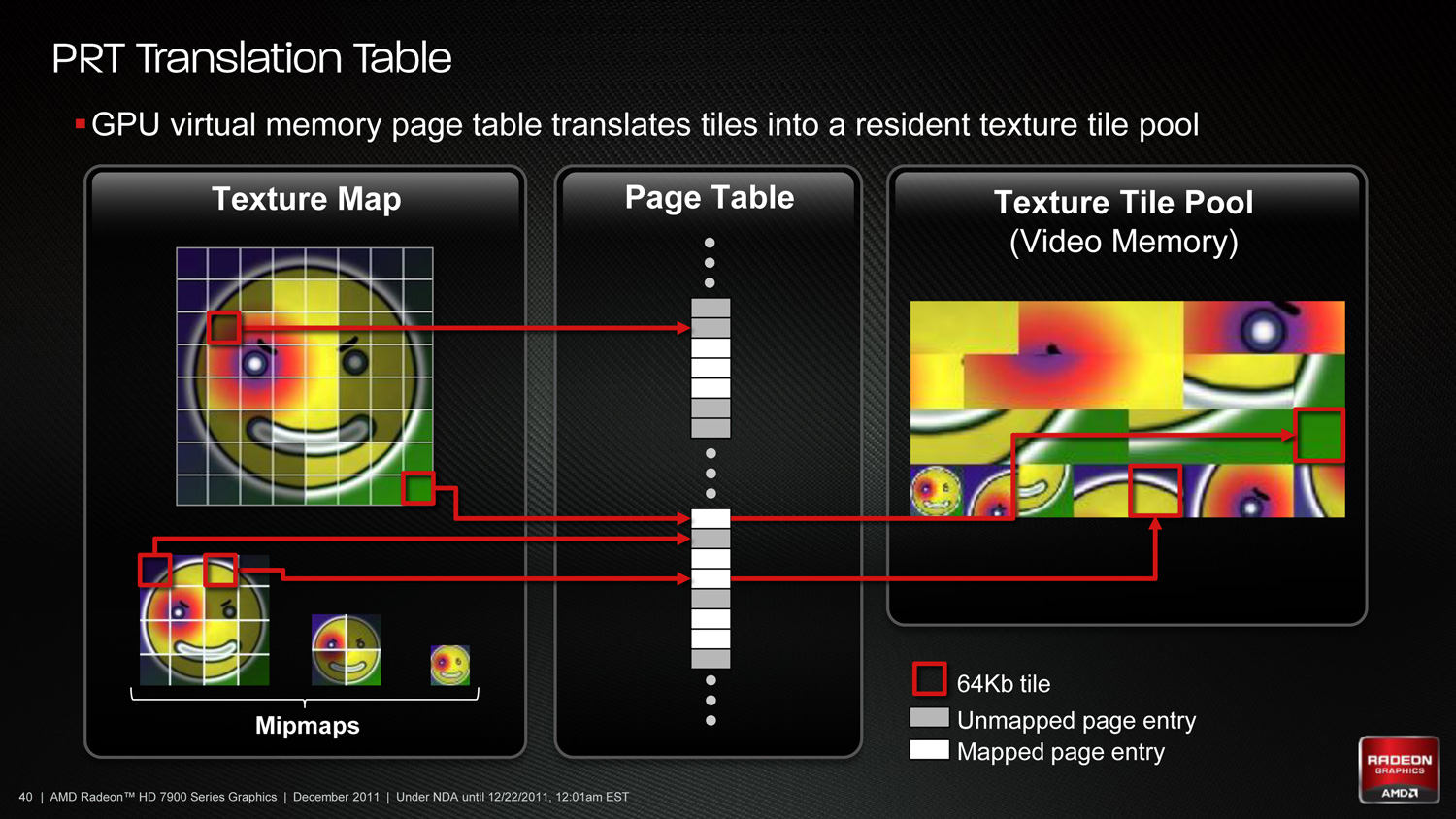
Meanwhile bindless textures functionality does away with the concept of texture “slots” and the limits imposed by the limited number of slots, replacing the fixed size binding table with unlimited redirection through the use of virtual addresses. The primary benefit of this is that it allows the easy addition and use of more textures within a scene (under most DX11 hardware this limit was 128 slots), however there is also a performance angle to this. Since binding and rebinding objects is a task that relies on the CPU, getting rid of binding altogether can improve performance in CPU limited scenarios. Khronos/NVIDIA throws around a 10x best-case number, and while this is certainly the exception rather than the rule it will be interesting to see what the real world benefits are like once applications start coming out utilizing this feature.

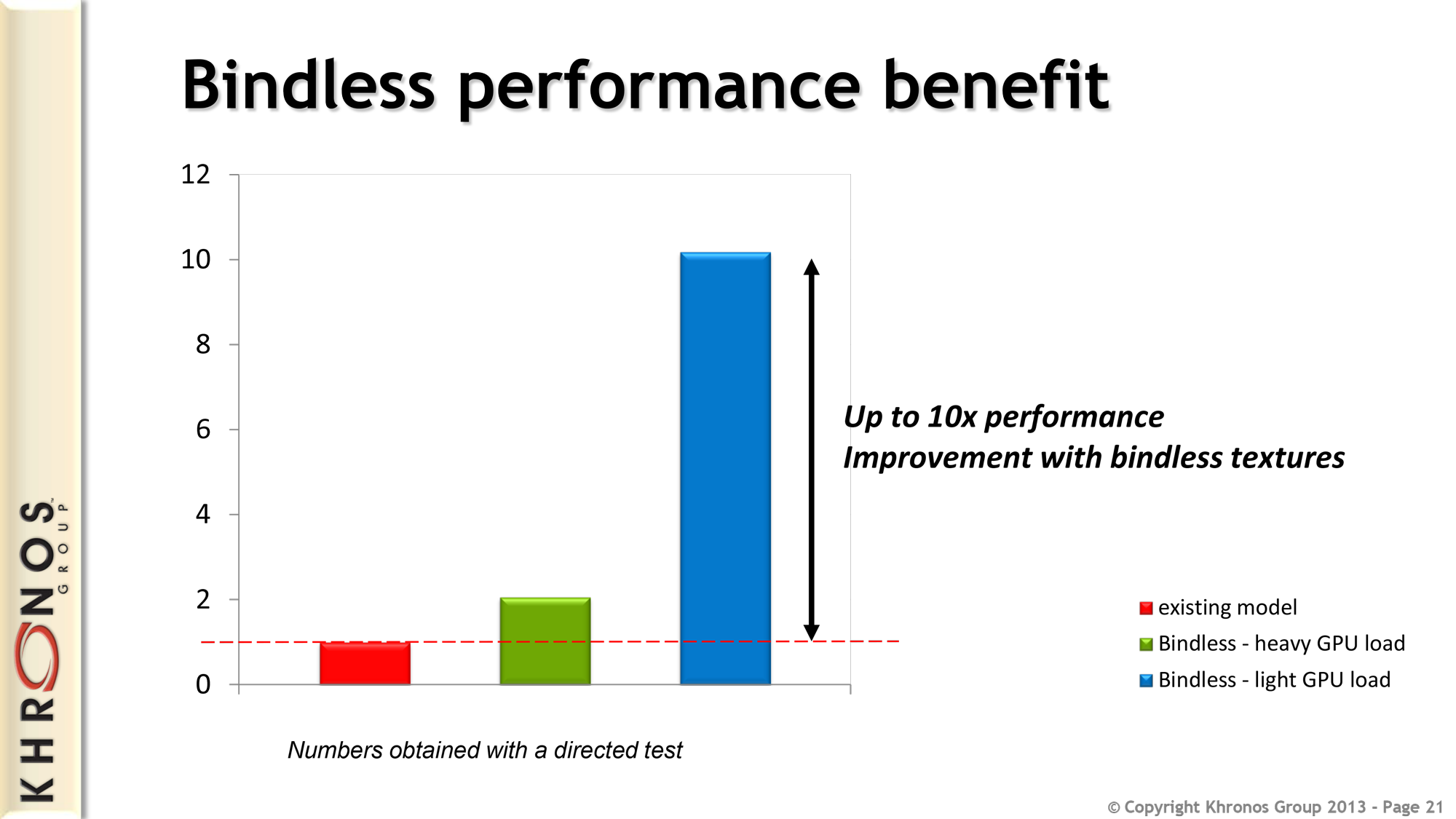
Ultimately both of these features, along with several other ARB extensions, are in the middle of their evolution. The ARB extension stage is essentially a half-way house for major features, allowing features to be further refined and analyzed after being standardized by the ARB. The ultimate goal here is for most of these features to graduate from extensions and become part of the core OpenGL standard in future versions, which means if everything goes smoothly we’d expect to see sparse texture support and bindless texture support in the core standard (and the devices that support it) in the not too distant future.
Finally, in a move that should have developers everywhere jumping with joy, OpenGL finally has official and up to date conformance tests. OpenGL has not had an up to date conformance test since the project was led by SGI almost a decade ago, with the task of developing the tests being a continual work in progress for many years. In the interim the lack of conformance testing has been an obstacle for OpenGL, as there wasn’t an official way to validate implementations against known and expected behaviors, leading to more uncertainty and bugs than anyone was comfortable with.
Now with the completion of the new conformance tests, OpenGL implementations can be tested for their conformance, and in turn those implementations will now need to be conformant before they are approved by Khronos. For developers this means they will be writing software against better devices and drivers, and for device makers they will have an official target to chase rather than having to interpret the sometimes ambiguous OpenGL standards.





OpenCL SPIR 1.2: An Intermediate Format For OpenCL
Moving on from OpenGL, the rest of Khronos’ major news for SIGGRAPH revolves around their OpenCL standard for GPGPU compute. OpenCL was first released in 2008, and has since then been iterated on in conjunction with further software developments and the release of newer, more capable hardware. Khronos in turn is announcing two new OpenCL standards, OpenCL SPIR 1.2 and OpenCL 2.0.
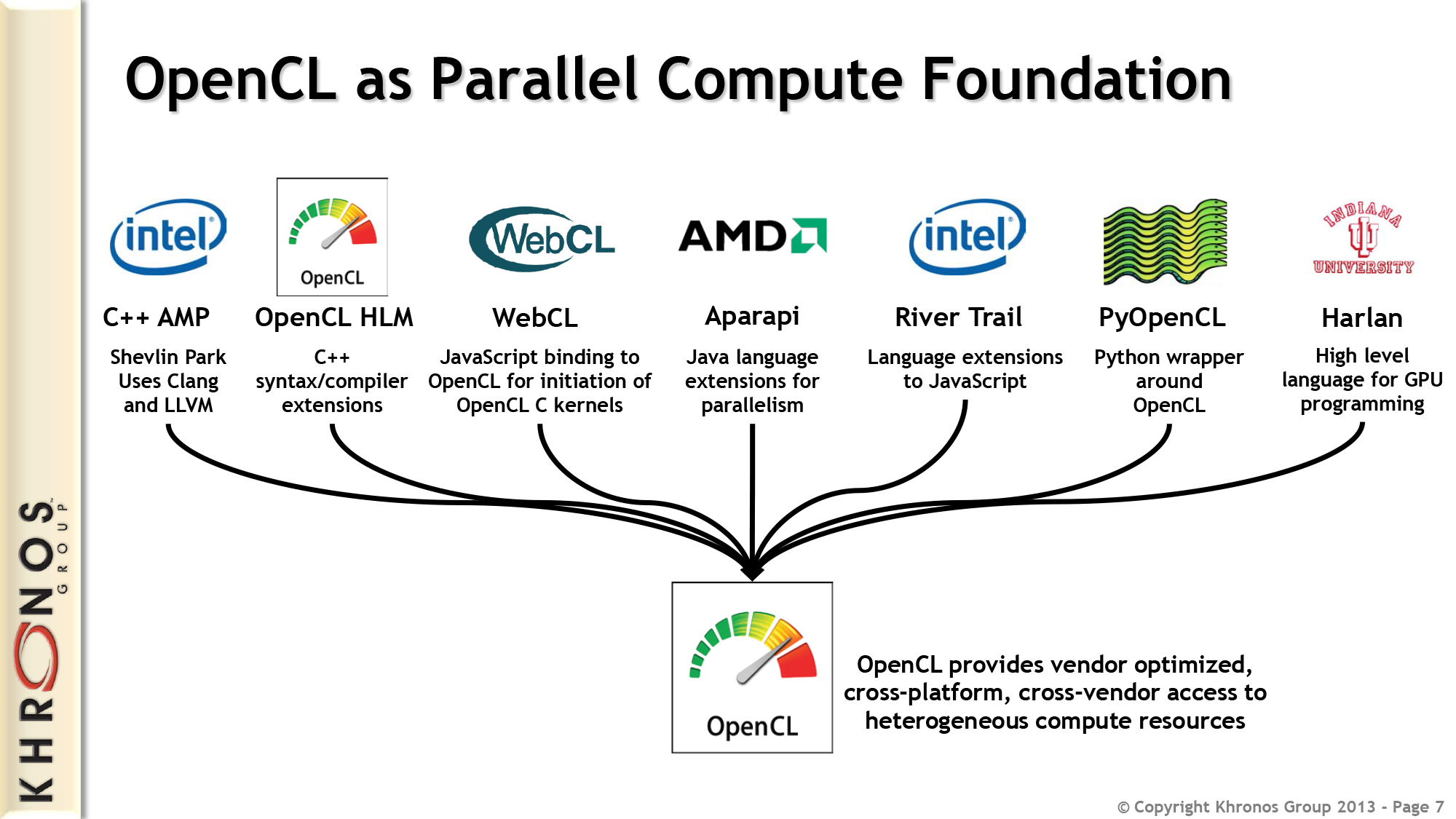
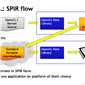
Starting off with OpenCL SPIR 1.2, SPIR is an extension of OpenCL designed around filling in some of the software deployment holes the standard OpenCL software stack exposes. Standing for Standard Portable Intermediate Representation, SPIR is the format and specifications needed to represent OpenCL programs in an intermediate format, between high level C kernels and low level fully compiled binaries.

SPIR seeks to solve one of the outstanding issues with deploying OpenCL programs, which relates to OpenCL’s Just-In-Time (JIT) compilation nature. By default OpenCL programs can be shipped in one of two forms, either as a low-level binary compiled to specific devices, or in a high level form with the original high level C code being compiled all the way down to binary form at runtime; the botton and top of the compilation stack respectively. Importantly, with OpenCL core there is nothing in between, leaving the only options being to expose the original code or put together binaries for each and every device family. To use a Java analogy, OpenCL core lacks the equivalent of an intermediate format like a class file, and this is what SPIR is intended to solve.
SPIR solves this by defining a standard intermediate representation for OpenCL code, along with creating the frontends and backends necessary to support SPIR. With the appropriate systems in place, software vendors would then be able to ship OpenCL programs and kernels compiled down to the SPIR format, with device drivers then consuming the SPIR code and compiling the programs to their final device specific formats.

Ultimately SPIR is primarily being driven by the needs of software vendors, whose needs are expanding as OpenCL stabilizes and matures, and the number of capable devices increases. The exposure of high level code in fully portable (and forward-compatible) programs was not a problem in the early days of OpenCL, but as additional developers come on board and OpenCL programs move from complexity levels similar to OpenGL shaders (simple) to full blown applications (complex) there’s a need to protect code from trivial reverse engineering and source code theft. Though by no means perfect, compiling code to lower levels – be it intermediate or low level – prevents trivial reverse engineering and provides a reasonable level of protection for code. And since the OpenCL JIT model means that low level binaries are not portable to other devices, there is a clear need for an intermediate format that provides similar protection while maintaining portability.
On a technical level, it should come as no great surprise that SPIR will be borrowing heavily from the tag-team duo of LLVM and Clang. LLVM is a widely popular compiler backend, used in both CPU and GPU environments alike. Meanwhile Clang is the C language compiler frontend for LLVM. By going this route Khronos is able to leverage the strengths of LLVM, mainly LLVM’s wide portability and existing high quality intermediate representation format, not to mention the fact that many of the OpenCL vendors already use LLVM for their GPGPU compilers (particularly NVIDIA’s CUDA toolchain).
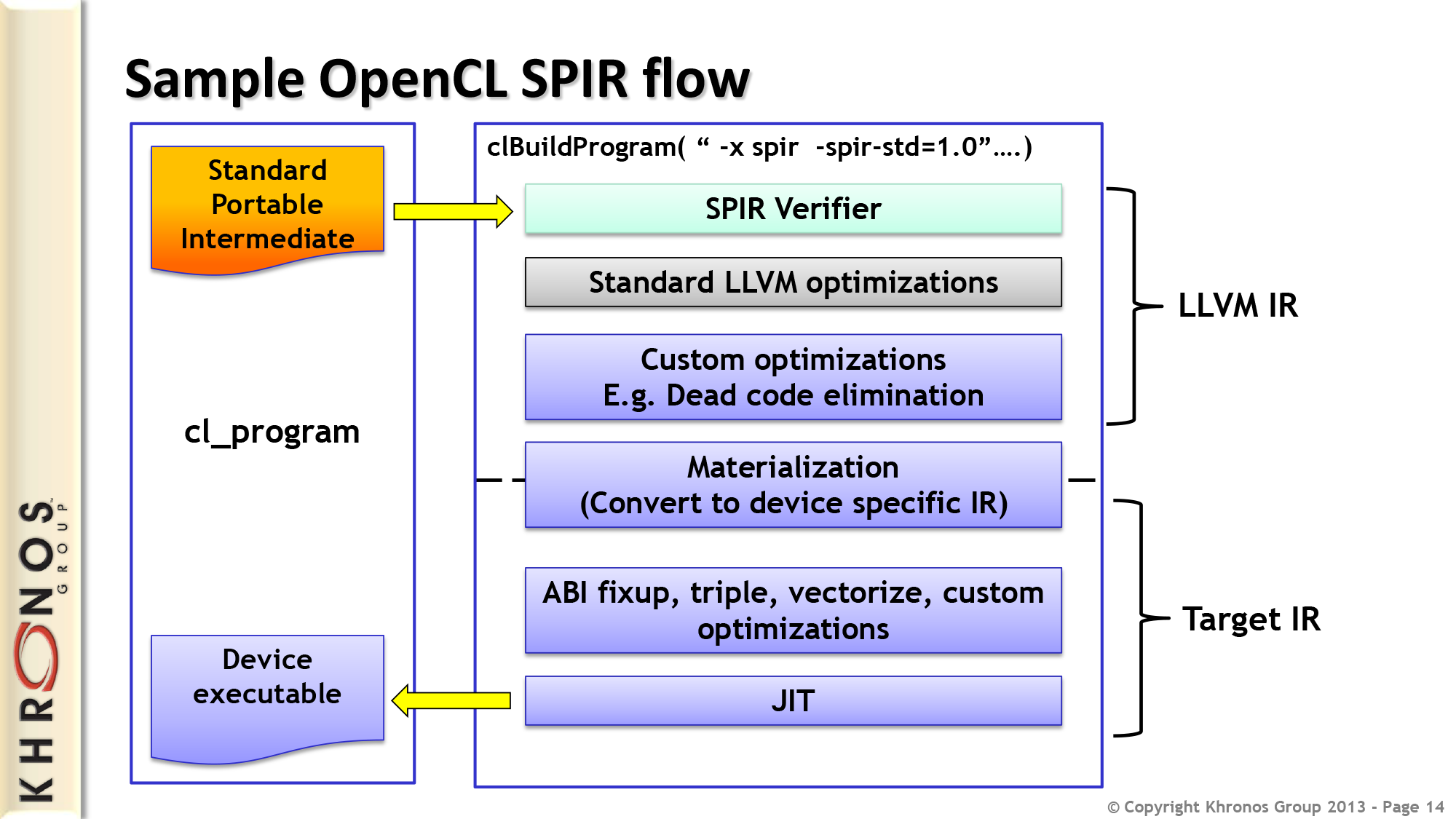
As an added bonus, much like NVIDIA and their use of LLVM for CUDA, by moving to LLVM Khronos gains the ability to quickly and efficiently add support for new high level languages to OpenCL. The separation of backend from the frontend means that Clang merely needs to be extended or replaced to add new languages, and as it stands Clang offers Khronos a very clear path towards enabling C++ in future versions of OpenCL, something that developers have been asking about for quite some time now.
Of course SPIR still needs to do some evolving of its own, along with OpenCL core itself. OpenCL SPIR 1.2 is being released as a provisional specification today, which in Khronos governance means that it’s a proposed specification that’s still open to comments and modification. Khronos’s goal here is to finalize SPIR in 6 months, assuming everything goes well, making this the first standardized version of SPIR. In turn, once OpenCL 2.0 is finalized, the SPIR working group can then begin work on SPIR for OpenCL 2.0.
Ultimately if Khronos plays their cards right, SPIR could drive the kick in adoption that OpenCL has been lacking thus far. The ability to protect programs by shipping intermediate code provides a benefit today, but by moving to LLVM and greatly simplifying the process of adding new languages it also gives OpenCL a new level of flexibility that will help OpenCL in the future.


OpenCL 2.0: What's New
Wrapping things up, Khronos’ other OpenCL announcement for this morning is the announcement of the release of the provisional specification for OpenCL 2.0. Like OpenCL SPIR 1.2 this is a work in progress specification, with Khronos continuing to take comments and leaving the door open for further adjustments, with a goal of finalizing the standard within 6 months.
As an established and maturing standard, the key enhancements and additions slated for OpenCL 2.0 are being designed in part around the technologies and hardware Khronos and its members believe will be the most important over the next few years. Which is to say that a lot of the major functionality going into OpenCL 2.0 is focused around HSA and HSA-like devices where GPU and CPU are capable of sharing memory, pointers, cache, and more. OpenCL 1.x is already capable of running on these devices, but it lacks effective means to take advantage of the interconnected hardware, which is where OpenCL 2.0’s additions come in.

The biggest addition here is that OpenCL 2.0 introduces support for shared virtual memory, the basis of exploiting GPU/CPU integrated processors. Kernels will be able to share complex data, including memory pointers, executing and using data without the need to explicitly transfer it from host to device and vice versa. Making effective use of this ability still falls to developers, who will need to figure out what work to send to the GPU and what work to send to the CPU, but as with other, similar proposals, the performance benefits can be immense in the right situations by allowing GPUs to work on parallel code without the need to constantly make expensive swaps with the CPU to move data or get the results of serial code.
Along these lines the addition of atomics from the C11 language standard should also prove beneficial to programmers looking to exploit GPU/CPU synergy, allowing work-items to be visible across work-groups and across devices. Generic address space support is also coming in OpenCL 2.0, alleviating the need in OpenCL 1.x to write a version of a function for each named address space. Instead a single generic function can handle working with all of the named address spaces, simplifying development and cutting down on the amount of code that needs to be cached for execution.
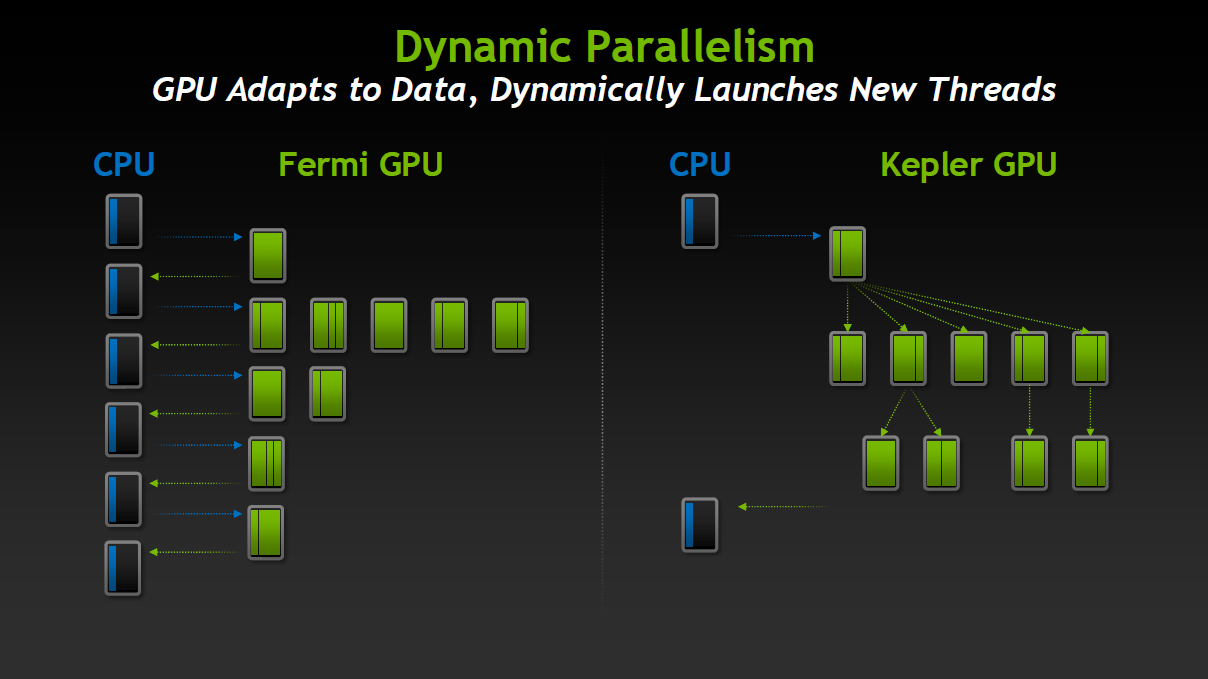
Of course while most of OpenCL 2.0’s feature additions are geared towards integrated CPU/GPU devices, there are some notable features that will be applicable to all devices. Key among these will be dynamic parallelism, which was first introduced with NVIDIA’s Tesla K20 based cards and is currently only available under CUDA. We won’t go too deep on this since we’ve covered it before, but in a nutshell dynamic parallelism allows for kernels to launch other kernels, saving both time and resources by skipping costly host interactions and thereby leaving the host CPU to work on other tasks. Dynamic parallelism is one of K20’s more potent features, so OpenCL developers should be pleased that they’re finally getting a crack at it.
Finally, on the gaming/graphics side OpenCL is getting some new image manipulation functionality that is slated to further enhance the existing OpenCL/OpenGL interoperability capabilities. OpenCL 2.0 will define the ability to work with sRGB color space images, alongside the ability for multiple kernels to read and write to the same OpenCL image. Furthermore OpenCL will now be able to generate images from multi-sampled and mi-mapped OpenGL textures, allowing OpenGL to pass work to OpenCL under more scenarios.








