Original Link: https://www.anandtech.com/show/6757/calxedas-arm-server-tested
Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs

ARM based servers hold the promise of extremely low power and excellent performance per Watt ratios. It's theoretically possible to place an incredible number of servers into a single rack; there are already implementations with as many as 1000 ARM servers in one rack (48 server nodes in a 2U chassis). What's more, all of those nodes consume less than 5KW combined (or around 5W per quad-core ARM node). But whenever a new technology is hyped, it's important to remain objective. The media loves to rave about new trends and people like reading about "some new thing"; however, at the end of the day the system administrator has to keep his IT services working and convince his boss to invest in new technologies.
At first sight, the relatively low performance per core of ARM CPUs seems like a bad match for servers. The dominant CPU in the server market is without doubt Intel's Xeon. The success of the Xeon family is largely rooted in its excellent single-threaded (or per core) performance at moderate power levels (70-95W). Combine this exceptional single-threaded performance with a decent core count and you get good performance in almost any kind of application. Economies of scale and the resulting price levels are also very important, but the server market has been more than willing to pay a little extra if the response times are lower and the energy bills moderate.
A data point proving that single-threaded performance is still important is the evolution of the T-series of Oracle (or Sun if you prefer). The Sun T3 had 16 cores with 128 threads; the T4 however had only 8 cores with 8 threads each, and CEO Larry Ellison touted more than once that single-threaded performance was massively improved, up to five times faster. Do we really need another server with a flock of slow but energy efficient cores? Has history not taught us that a few "bulls" is better than "a flock of chickens"?
History has also shown that the amount of memory per server is very important. Many HPC and virtualization applications are limited by the amount of RAM. The current Cortex-A9 generation of ARM CPUs has a 32-bit address bus and does not support more than 4GB.
And yet, the interest in ARM-based servers is growing, and there is more to it than just hype. Yes, ARM-based CPUs still lack the number crunching power and the massive amount of DIMM slots that Xeon's memory controller can handle, but ARM CPUs score extremely well when it comes to cost and power consumption.
ARM based CPU have also made giant steps forward when it comes to performance. To give you a few data points: a dual ARM Cortex-A9 at 1.2GHz (Samsung Exynos 1.2GHz) introduced in 2011 compresses more than 10 times faster than the typical ARM 11 based cores in 2008. The SunSpider performance increased by a factor 20 according to Anand's measurements on the iPhones (though part of that is almost certainly thanks to browser and software optimizations). The latest ARM Cortex-A15 is again quite a bit more powerful, offering about 50% higher performance. The A57 will add 64-bit support and is estimated to deliver 20 to 30% higher performance. In short, the single-threaded performance is increasing quickly, and the same is true for the amount of RAM that can be addresssed. The ARM Cortex-A9 is limited to 4GB but the Cortex-A15 should be able to address 16GB while the A57 will be able to address a lot more.
It is likely just a matter of time before ARM products can start to chip away at segments of the server market. How much time? The best way to find out is to look at the most mature ARM server shipping today: the Calxeda based Boston Viridis. Just what can this server handle today, where does it have the potential to succeed, and what are its shortcomings? Let's find out.
It's a Cluster, Not a Server
When unpacking our Boston Viridis server, the first thing that stood out is the bright red front panel. That is Boston's way of telling us that we have the "Cloud Appliance" edition. The model with an orange bezel is intended to serve as a NAS appliance, purple stands for "web farm", and blue is more suited for a Hadoop cluster. Another observation is that the chassis looks similar to recent SuperMicro servers; it is indeed a bare bones system filled with Calxeda hardware.

Behind the front panel we find 24 2.5” drive bays, which can be fitted with SATA disks. If we take a look at the back, we can find a standard 750W 80 Plus Gold PSU, a serial port, and four SFP connectors. Those connectors are each capable of 10Gbit speeds, using copper and/or fiber SFP(+) transceivers.
When we open up the chassis, we find somewhat less standard hardware. Mounted on the bottom is what you might call the motherboard, a large, mostly-empty PCB that contains the shared Ethernet components and a number of PCIe slots.

The 10Gb Ethernet Media Access Controller (MAC) is provided on the EnergyCore SoC, but in order to allow every node to communicate via the SFP ports, each node forwards its Ethernet traffic to one of the first four cards (the cards in slots 0-3). These nodes are connected via a XAUI interface to one of the two Vitesse VSC8488 XAUI-to-serial transceivers that in turn control two SFP modules each. Hidden behind an air duct is a Xilinx Spartan-6 FPGA, configured to act as chassis manager.
Each pair of PCIe slots contains what turns this chassis into a server cluster: an EnergyCard (EC). Each EnergyCard contains four SoCs, each with one DIMM slot. An EnergyCard contains thus four server nodes, with each node running on a quad-core ARM CPU.

The chassis can hold as many as 12 EnergyCards, so currently up to 48 server nodes. That limit is only imposed by physical space constraints, as the fabric supports up to 4096 nodes, leaving the potential for significant expansion if Calxeda maintains backwards compatibility with their existing ECs.

The system we received can only hold 6 ECs; one EnergyCard slot is lost because of the SATA cabling, giving us six ECs with four server nodes each, or 24 server nodes in total. Some creative effort has been made to provide air baffles that direct the air through the heat sinks on the ARM chips.

The air baffles are made of a finicky plastic-coated paper, glued to gether and placed on the EC with plastic nails, making it difficult to remove them from an EC by hand. Each EC can be freely placed on the motherboard, with the exception of the Slot 0 card that needs a smaller baffle.
Every EnergyCard is thus fitted with four EnergyCore SoCs, each having access to one miniDIMM slot and four SATA connectors. In our configuration each miniDIMM slot was populated with a Netlist 4GB low-voltage (1.35V instead of 1.5V) ECC PC3L-10600W-9-10-ZZ DIMM. Every SoC provided was hooked up to a Samsung 256GB SSD (MZ7PC256HAFU, comparable to Samsung’s 310 Series consumer SSDs), filling up every disk slot in the chassis. We removed those SSDs and used our iSCSI SAN to boot the server nodes. This way it was easier to compare the system's power consumption with other servers.
Previous EC versions had a microSD slot per node at the back, but in our version it has been removed. The cards are topology-agnostic; each node is able to determine where it is placed. This enables you to address and manage nodes based on their position in the system.
A Closer Look at the Server Node
We’ve arrived at the heart of the server node: the SoC. Calxeda licensed ARM IP and built its own SoC around it, dubbed the Calxeda EnergyCore ECX-1000 SoC. This version is produced by TSMC at 40nm and runs at 1.1GHz to 1.4GHz.
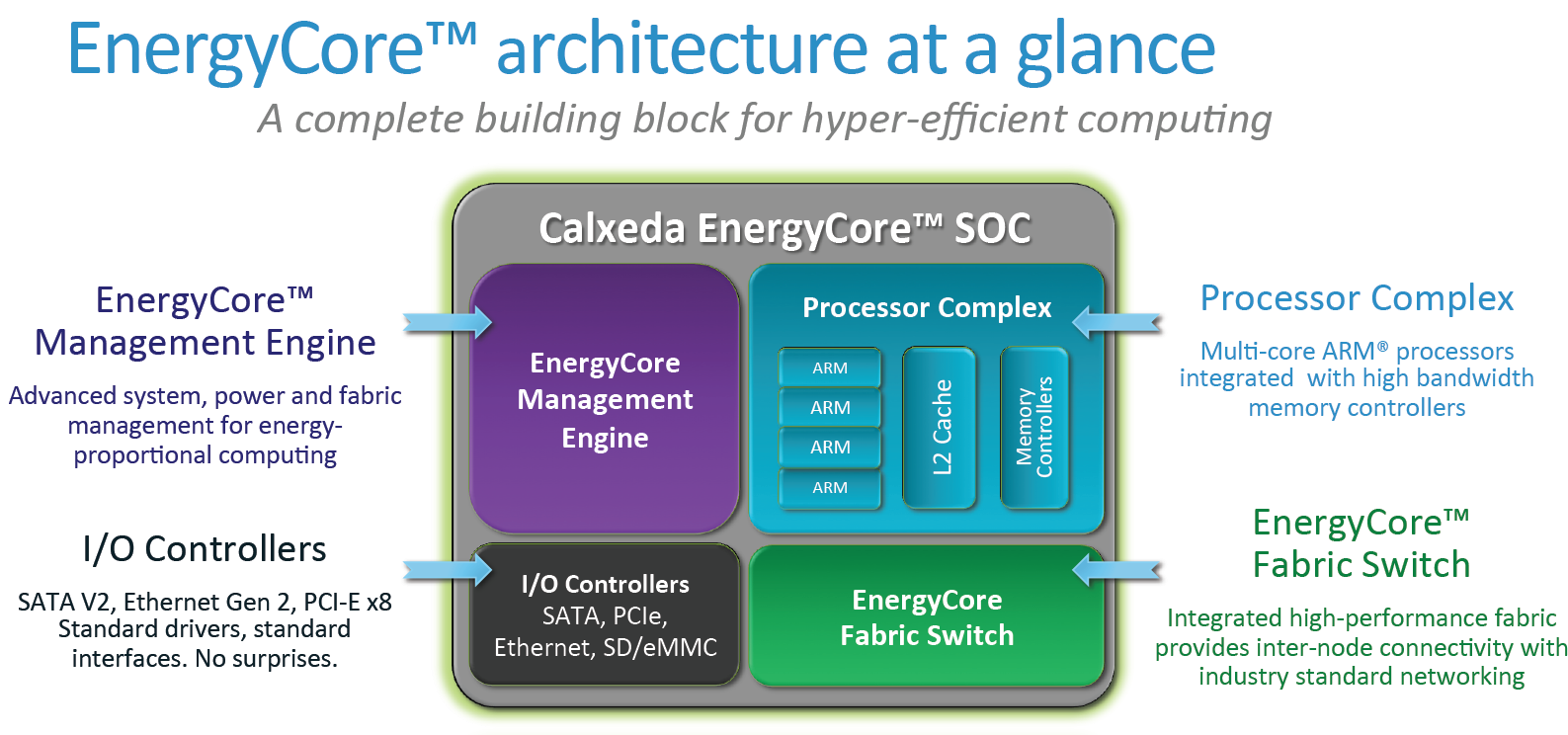
Let’s start with a familiar block on the SoC (black): the external I/O controller. The chip has a SATA 2.0 controller capable of 3Gb/s, a General Purpose Media Controller (GPMC) providing SD and eMMC access, a PCIe controller, and an Ethernet controller providing up to 10Gbit speeds. PCIe connectivity cannot be used in this system, but Calxeda can make custom designs of the "motherboard" to let customers attach PCIe cards if requested.
Another component we have to introduce before arriving at the actual processor is the EnergyCore Management Engine (ECME). This is an SoC in its own right, not unlike a BMC you’d find in conventional servers. The ECME, powered by a Cortex-M3, provides firmware management, sensor readouts and controls the processor. In true BMC fashion, it can be controlled via an IPMI command set, currently implemented in Calxeda’s own version of ipmitool. If you want to shell into a node, you can use the ECME's Serial-over-LAN feature, yet it does not provide any KVM-like environment; there simply is no (mouse-controlled) graphical interface.
The Processor Complex
Having four 32-bit Cortex-A9 cores, each with 32 KB instruction and 32 KB data L1 per-core caches, the processor block is somewhat similar to what we find inside modern smarphones. One difference is that this SoC contains a 4MB ECC enabled L2 cache, while most smartphone SoCs have a 1MB L2 cache.

These four Cortex-A9 cores operate between 1.1GHz and 1.4GHz, with NEON extensions for optimized SIMD processing, a dedicated FPU, and “TrustZone” technology, comparable to the NX/XD extension from x86 CPUs. The Cortex-A9 can decode two instructions per clock and dispatch up to four. This compares well with the Atom (2/2) but of course is nowhere near the current Xeon "Sandy Bridge" E5 (4/5 decode, 6 issue). But the real kicker for this SoC is its power usage, which Calxeda claims to be as low as 5W for the whole server node under load at 1.1GHz and only 0.5W when idling.
The Fabric
The last block in the Soc is the EC Fabric Switch. The EC Fabric switch is an 8X8 crossbar switch that links to five XAUI ports. These external links are used to connect to the rest of the fabric (adjacent server nodes and the SFPs) or to connect SATA 2 ports. The OS on top of server nodes sees two 10Gbit Ethernet interfaces.
As Calxeda advertises their offerings with scaling out as one of the major features, they have created fast and high volume links between each node. The fabric has a number of link topology options and specific optimizations to provide speed when needed or save power when the application does not need high bandwidth. For example, the links of the fabric can be set to operate at 1, 2.5, 5 and 10Gb/s.

A big plus for their approach is that you do not need expensive 10Gbit top-of-rack switches linking up each node; instead you just need to plug in a cable between two boxes making the fabric span across. Please note that this is not the same as in virtualized switches, where the CPU is busy handling the layer-2 traffic; the fabric switch is actually a physical, distributed layer-2 switch that operates completely autonomously—the CPU complex doesn’t need to be powered on for the switch to work.
Software Support
Calxeda supports Ubuntu and Fedora, though any distribution based on the (32-bit) ARM Linux kernel should in theory be able to run on the EnergyCore SoCs. As for availability, there are already prebuilt Highbank kernel images available in the Ubuntu ARM repository and Calxeda has set up a PPA of its own to ease its kernel development.
The company has also joined Linaro—the non-profit organization aiming to bring the open source ecosystem to ARM SoCs.
The ARM Server CPU
A dual Xeon E5 or Opteron 6300 server has much more processing power than most of us need to run one server application. That is the reason why it is not uncommon to see 10, 20 or even more virtual machines running on top of them. Extremely large databases and HPC applications are the noticeable exceptions, but in general, server purchasers are rarely worried about whether or not the new server will be fast enough to run one application.
Returning to our Boston Viridis server, the whole idea behind the server is not to virtualize but to give each server application its own physical node. Each server node has one quad-core Cortex-A9 with 4MB of L2 cache and 4GB of RAM. With that being the case, the question "what can this server node cope with?" is a lot more relevant. We will show you a real world load further in this review, but we thought it would be good to first characterize the performance profile of the EnergyCore-1000 at 1.4GHz. We used four different benchmarks: Stream, 7z LZMA compression, 7z LZMA decompression, and make/gcc building and compiling.
We compare the ECX-1000 (quad-core, 3.8~5W, 40nm) with an Intel Atom 230 (1.6GHz single-core plus Hyper-Threading, 4W TDP, 45nm), Atom N450 (1.66GHz single-core + HTT, 5.5W TDP, 45nm), Atom N2800 (1.86GHz dual-core + HTT, 6.5W, 32nm), and an Intel Xeon E5-2650L (1.8-2.3GHz octal-core, 70W TDP, 32nm).
The best comparable Atom would be the Atom S1200, which is Intel's first micro-server chip. However the latter was not available to us yet, but we are actively trying to get Intel's latest Atom in house for testing. We will update our numbers as soon as we can get an Atom S1200 system. The Atom N2800 should be very close to the S1200, as it has the same architecture, L2 cache size, TDP, and runs at similar clockspeeds. The Atom N2800 supports DDR3-1066 while Centerton will support DDR3-1333, but we have reason to believe (see further) that this won't matter.
The Atom 230/330 and N450 are old 45nm chips (2008-2010). And before you think using the Atom 230 and N450 is useless: the Atom architecture has not changed for years. Intel has lowered the power consumption, increased the clockspeed, and integrated a (slightly) faster memory controller, but essentially the Atom 230 has the same core as the latest Atom N2000. I quote Anand as he puts it succinctly: "Atom is in dire need of an architecture update (something we'll get in 2013)."
So for now, the Atom 230 and N450 numbers give us a good way to evaluate how the improvements in the "uncore" impact server performance. It is also interesting to see where the ECX-1000 lands. Does it outperform the N2800, or is just barely above the older Atom cores?
Benchmark Configuration
First of all, a big thanks to Wannes De Smet, who assisted me the benchmarks. Below you can read the configuration details of our "real servers". The Atom machines are a mix of systems. The Atom 230 is part of a 1U server featuring a Pegatron IPX7A-ION motherboard with 4GB of DDR2-667. The N450 is found inside an ASUS EeePC netbook, and the Atom N2800 is part of Intel's DN2800MT Marshalltown mainboard. The latter has 4GB of DDR3-1333 while the former only has 1GB of DDR2-667.
| Supermicro SYS-6027TR-D71FRF Xeon E5 server (2U Chassis) | |
| CPU |
Two Intel Xeon processor E5-2660 (2.2GHz, 8c, 20MB L3, 95W) Two Intel Xeon processor E5-2650L (1.8GHz, 8c, 20MB L3, 70W) |
| RAM | 64/128GB (8/16x8GB) DDR3-1600 Samsung M393B1K70DH0-CK0 |
| Motherboard | X9DRT-HIBFF |
| Chipset | Intel C600 |
| BIOS version | R 1.1a |
| PSU | PWS-1K28P-SQ 1280W 80 Plus Platinum |
The Xeon E5 CPUs have four memory channels per CPU and support DDR3-1600, and thus our dual CPU configuration gets eight DIMMs for maximum bandwidth. Each core supports Hyper-Threading, so we're looking at 16 cores with 32 threads.
| Boston Viridis Server | |
| CPU | 24x ECX-1000 4c Cortex-A9 1.4GHz |
| RAM | 24x Netlist 4GB (96GB) low-voltage ECC PC3L-10600W-9-10-ZZ DRAM |
| Motherboard | 6x EC-cards |
| Chipset | none |
| Firmware version | ECX-1000-v2.1.5 |
| PSU | SuperMicro PWS-704P-1R 750Watt |
Common Storage System

An iSCSI LIO Unified Target accesses a DataON DNS-1640 DAS. Inside the DAS we have set up eight Intel SSDSA2SH032G1GN (X25-E 32GB SLC) in RAID-0.
Software Configuration
The Xeon E5 server runs VMware ESXi 5.1. All vmdks use thick provisioning, independent, and persistent. The power policy is "Low Power". We chose the "Low Power" policy as this enables C-states while the impact on performance is minimal. All other systems use Ubuntu 12.10. The power management policy is "ondemand". This enables P-states on the Atom and Calxeda ECX-1000.
Measuring Bandwidth
Stream measures "sustainable memory bandwidth" and is thus a good indication of how a CPU will handle data intensive applications. Dr. John McCalpin is the developer and maintainer of the STREAM benchmark.
We compiled with gcc 4.7 on all platforms and used the -O3 -fopen -static settings. It is important to remark that this version of gcc has been optimized by the Linaro group, a non-profit software engineering effort. Linaro's objective is to optimize the kernel and typical tools for the ARM-Cortex A-series CPUs.
On the Intel CPUs we force the threads to make use of Hyper-Threading with taskset. So for example, the four threads measurement is done on two physical cores with four threads. This gives an idea of how a quad-core ARM server node compares to a virtual machine that gets a few physical and few logical cores from the hypervisor. It also allows us to evaluate how two threads on top of an Atom core compare to two ARM cores. When you compare CPUs with similar power consumption, you typically get two ARM cores for each Hyper-Threaded Atom core.
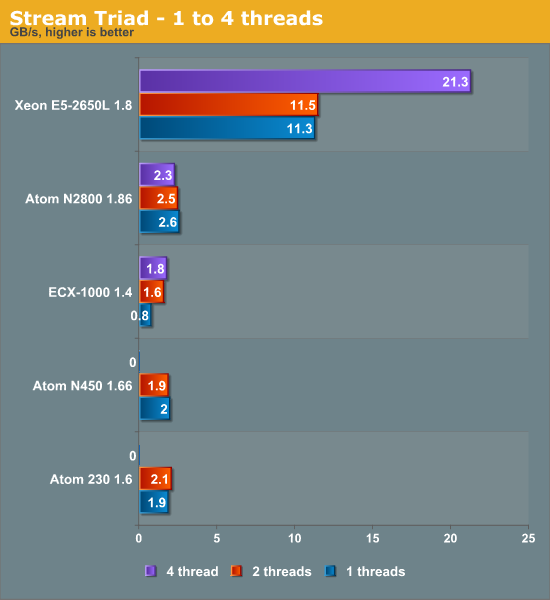
The ARM based server is a pretty bad choice right now for memory intensive workloads. Even with four cores and DDR3-1333, the useable bandwidth is less than one sixth of what one Xeon core can sustain.
In a similar vein, the ECX-1000 is not capable of providing more bandwidth than an Atom system equipped with DDR2-667. However, both the Atom and ARM cores are pretty bad when it comes to bandwidth. Although the specs claim that the CPUs can drive one channel of DDR3-1066, the measured bandwidth comes nowhere near the theoretical 8.5GB/s that such a DIMM can deliver.
Integer Processing
To measure the integer processing potential of the various CPUs, we'll turn to several different workloads. First up, we have 7z LZMA compression and decompression, again looking at performance with one to four threads. On the next page, we'll look at gcc compiler performance.
Compression
Compression is a low IPC workload that's sensitive to memory parallelism and latency. The instruction mix is a bit different, but this kind of workload is still somewhat similar to many server workloads.
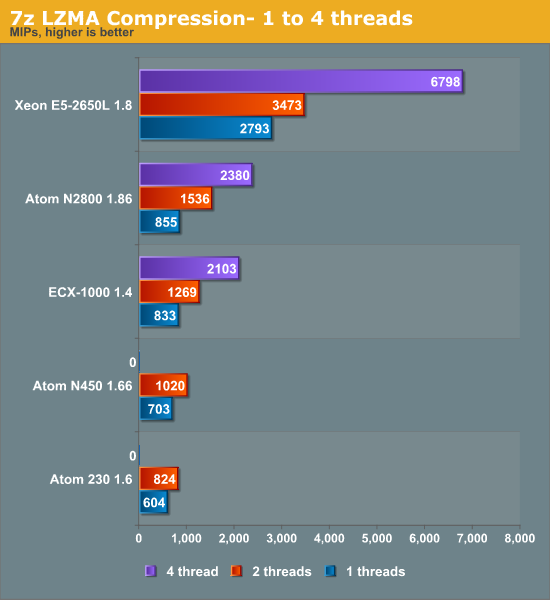
Clock for clock, the out-of-order Cortex-A9 inside the Calxeda EXC-1000 beats the in-order Atom core. A single Cortex-A9 has no trouble beating the older Atoms while likewise coming close to the much higher clocked N2800. The N2800 and ECX-1000 perform similarly.
Decompression
Decompression is pretty branch intensive and depends on the latencies of multiply and shift instructions.
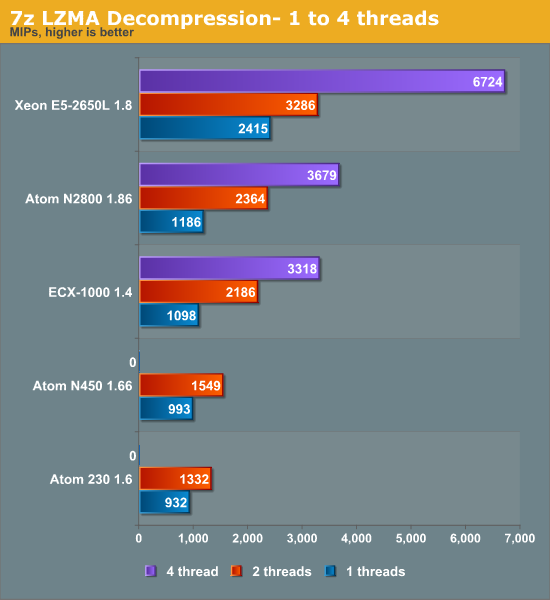
Branch mispredictions are common and the Atom tackles branch mispredictions well with its Simulteanous MultiThreaded (SMT) core. The boost from Hyper-Threading is very large here: a second ARM Cortex-A9 core gives a 52% boost and Hyper-Threading gives a 56% boost. This is very much the exception as far as Hyper-Threading performance is concerned.
Looking at both decompression and compression, it looks like a quad ARM Cortex-A9 is about as fast as one Xeon core (without Hyper-Threading) at the same clock. We need about six Cortex-A9 cores to match the Xeon core with Hyper-Threading enabled. The quad-core ECX-1000 1.4GHz is also close to the dual-core, four-threaded Atom at 1.86GHz. This bodes well for Calxeda as the 6.1W S1240 only runs at 1.6GHz.
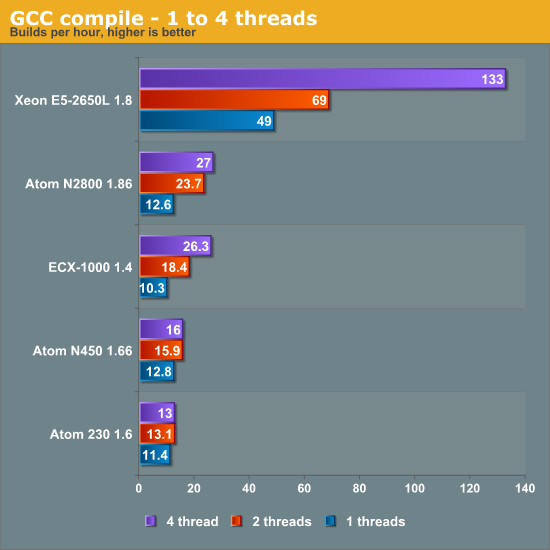
Building and Compiling
We compiled the 7z source by performing a make -jx (with x being the number of threads). Compiling is branch intensive (22%) workload that does mostly loads and stores (about 40%).
Looking at the single-thread performance, the ARM Cortex-A9 and Atom are in the same ballpark. This is the kind of workload where the Sandy Bridge core of the Xeon really shines. You need about eight Cortex-A9 cores to beat one Xeon (without HT). And it must be said: compiling inside a virtual machine on top of the Xeon E5 is a very pleasant experience compared to the long wait times on the Atom and ECX.
Lessons so Far
A quad-core Cortex-A9 performs well in server workloads that are mostly memory latency sensitive. A quad-core Cortex-A9 ECX-1000 at 1.4GHz has no trouble competing with Atoms at slightly higher clockspeeds (1.6GHz). There is only one exception: bandwidth intensive workloads.
Both Atom and ARM based servers have the disadvantage of being rather slow in typical "management" tasks such as compiling, installing, and updating new software. Compiling a rather simple piece of software in a VM with only two Xeon vCPUs (running on one 1 core + HTT) took only 37 seconds. A single-core Atom server needed 275 seconds, while the quad-core ARM ECX-1000 needed 137 seconds.
But the Boston Viridis is much more than just a chassis with 24 server nodes. It has a high performance switching fabric. So it's time to see what this server can do in a real server environment.
Finding a Good Fit
The previous benchmarks have shown that the first Calxeda server is not for the general IT market. As the slide below shows, Calxeda targets four kinds of workloads:
- Web applications
- Middle-tier applications
- Offline analytics
- Storage and file serving
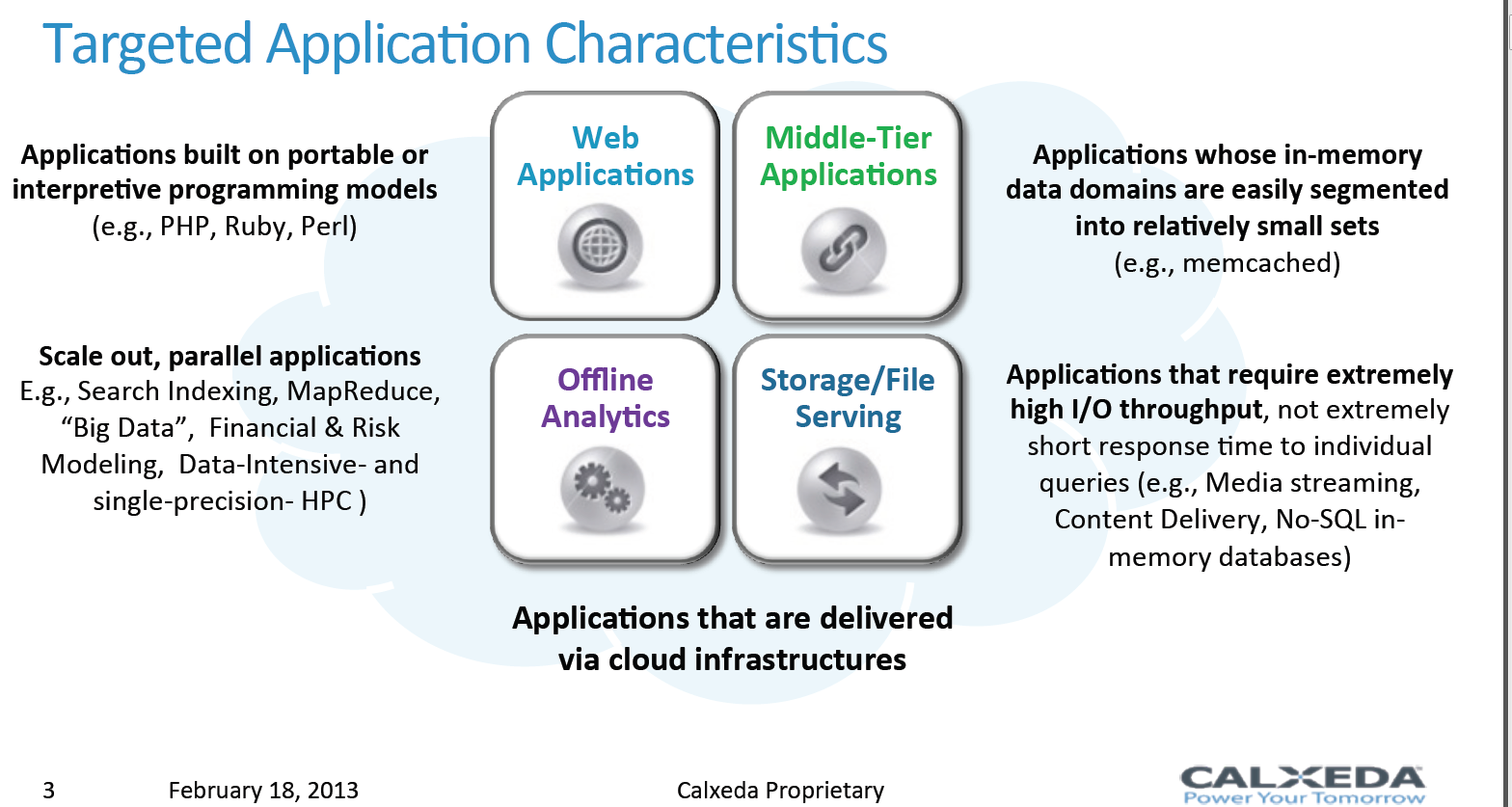
For applications such as Memcache, the ECX-1000 1.4GHz lacks bandwidth and memory capacity. Once a Cortex-A15 based server is available, this can change quickly as performance will improve significantly and the amount of memory per CPU can be quadrupled to 16GB.
We did not test it yet, but our own experience tells us that the majority of the "scale out" applications are out of reach. Especially in the financial and risk modeling world, top performance and ultra low response times are prioritized.
Calxeda based Boston servers are already making inroads as storage servers. There is little doubt that a low power processing unit makes a lot of sense in a storage server.
That leaves the question whether or not Calxeda's latest server can make it in the web server and Content Delivery world. Calxeda claims 5W per server node, and no more than 250W for the complete server chassis with 24 server nodes. That's pretty cool, but currently there is another solution. Two octal-core Xeon E5 deliver no less 32 threads running on top of 16 very potent cores. Add a virtualization layer and you get tens of servers. The only limitation is typically the amount of RAM.
So assume you are a hosting provider. Which server do you use as your building block? You've got two choices:
The standard one, the Intel Xeon E5 server. The advantages are excellent performance whenever you need it, whether your application scales well with more threads or not. The Xeon can address up to 384GB of affordable RAM (16GB DIMMs). If that's not enough, 768GB is possible with more expensive LR-DIMMs.
Those are impressive specs, but what if most of your customers just want to host medium sized web sites, sites that are rich on content but rather low on processing requirements? Can the Boston Viridis server attract such users with a much lower power consumption? How far can you go with slicing and dicing the Xeon's monstruous performance into small virtual pieces? We decided to find out.
Our Real World Test
We've set up two systems, the Xeon system with two different pairs of Xeon CPUs, 128GB and ESXi 5.1. We created 24 virtual machines on top of the Xeon server. Inside each we have a PhpBB (Apache2, MySQL) website with four virtual CPUs and 4GB RAM. The website uses about 8GB of disk space. We simulate up to 75 concurrent users that send new requests every 0.6-2.4 seconds.
The Boston Viridis server gets the same workload, but instead of using virtual machines, we used the 24 physical server nodes.
Since the redesign in late 2010, our vApus stresstesting framework is well suited to hit (virtualized or not) clusters with lots of workloads in parallel. A quad 7400 server is able to spawn 24 testing clients. The server is connected to our Dell PowerConnect 8024F (10Gbit Ethernet), which is connected to the testservers.
vApus hitting 24 web servers in parallel
This way we can simulate a webhosting environment where tens of websites are hit by a few thousands of visitors per second. That might not sound very impressive, but those few thousand requests per second result in a web environment with 100 million hits per day.
Since we made sure that our web server serves up some nice pictures (png), there is some significant network traffic going on. We measured peaks of up to 8Gbit/s, with typical network traffic being about 4 to 6Gbit/s.
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
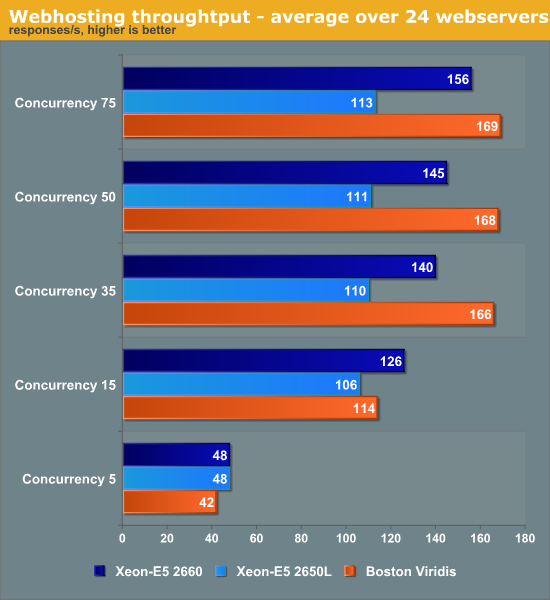
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
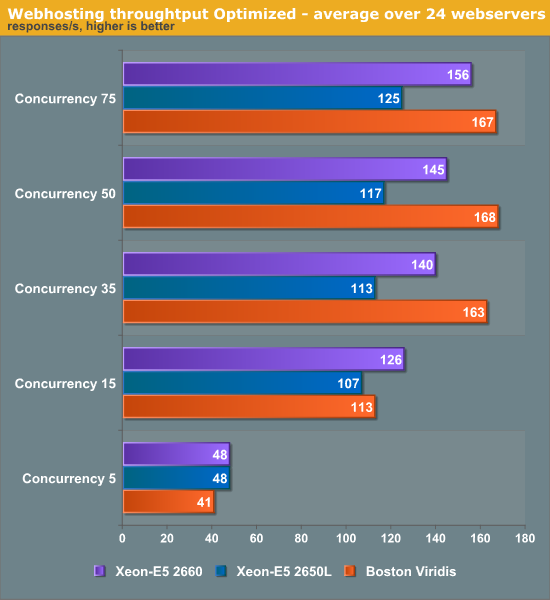
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
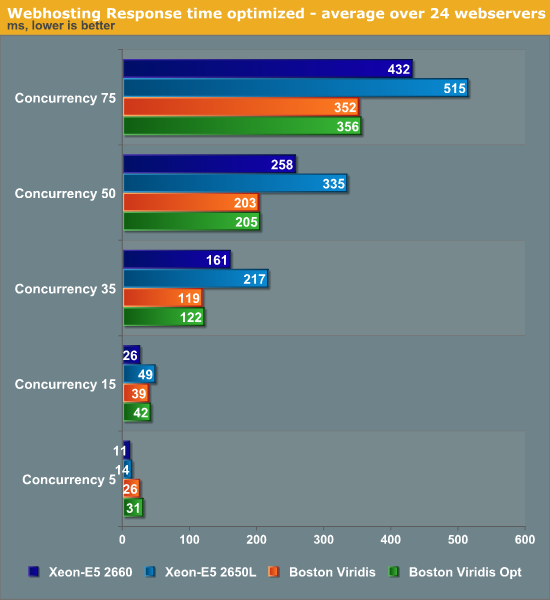
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.
Energy and Power
And now, here's the million dollar question: did Boston and Calxeda succeed in building a server with a spectacular performance/watt ratio? Judge for yourself.
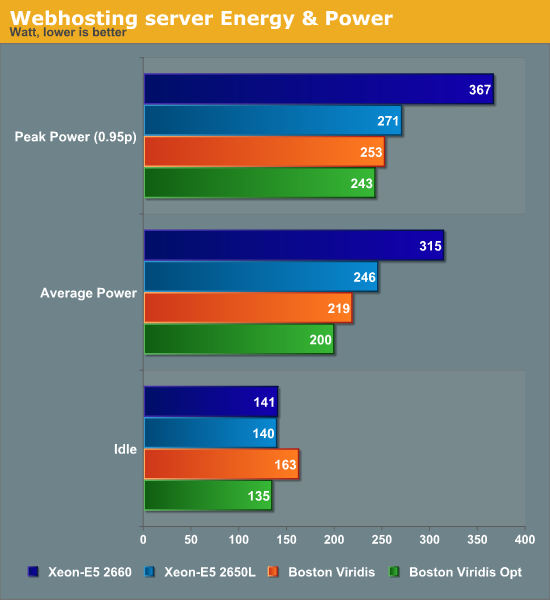
Calxeda really did it: each server needs about 8.3W (200W/24), measured at the wall. That is exactly what Calxeda promised: about 6W (at 1.4GHz) per server node (measured internally), up to 8.5W measured at the wall (again at 1.4GHz). That is nothing short of amazing if you consider the performance numbers.
In addition, the use of cpufreq and the downsizing of the server interconnects pays off here: we get 10% lower power on average and 18% lower power when idle. The optimizations are particularly important for the idle power use, where they spell the difference between using slightly more power and slightly less power than the Intel server.
Pricing
So how much does this Boston Viridis server cost? $20,000 is the official price for one Boston Viridis with 24 nodes at 1.4GHz and 96GB of RAM. That is simply very expensive. A Dell R720 with dual 10 gigabit, 96GB of RAM and two Xeons E5-L2650L is in the $8000 range; you could easily buy two Dell R720 and double your performance. The higher power bill of the Xeon E5 servers is that case hardly an issue, unless you are very power constrained. However, these systems are targeted at larger deployments.
Buy a whole rack of them and the price comes down to $352 per server node, or about $8500 per server. We have some experience with medium quantity sales, and our best guess is that you get typically a 10 to 20% discount when you buy 20 of them. So that would mean that the Xeon E5 server would be around $6500-$7200 and the Boston Viridis around $8500. Considering that you get an integrated (5x 10Gbit) switch and a lower power bill with the Boston Viridis, the difference is not that large anymore.
Calxeda's Roadmap and Our Opinion
Let's be clear: most applications still run better on the Xeon E5. Our CPU benchmarks clearly indicate that any application that accesses the memory frequently or that needs high per thread integer processing power will run better on the Xeon E5. Compiling and installing software simply feels so much faster on the Xeon E5, there is no need to benchmark.
There's more: if your performance requirements are higher than what a quad-core Cortex-A9 can deliver, the Xeon E5 is a lot more flexible and a better choice in most cases. Scaling up is after all a lot easier than using load balancers and other complex software or hardware to scale out. Also, the management software of the Boston Viridis does the job, but Dell's DRAC, HP ILO, and Supermicro's IM are more user friendly.
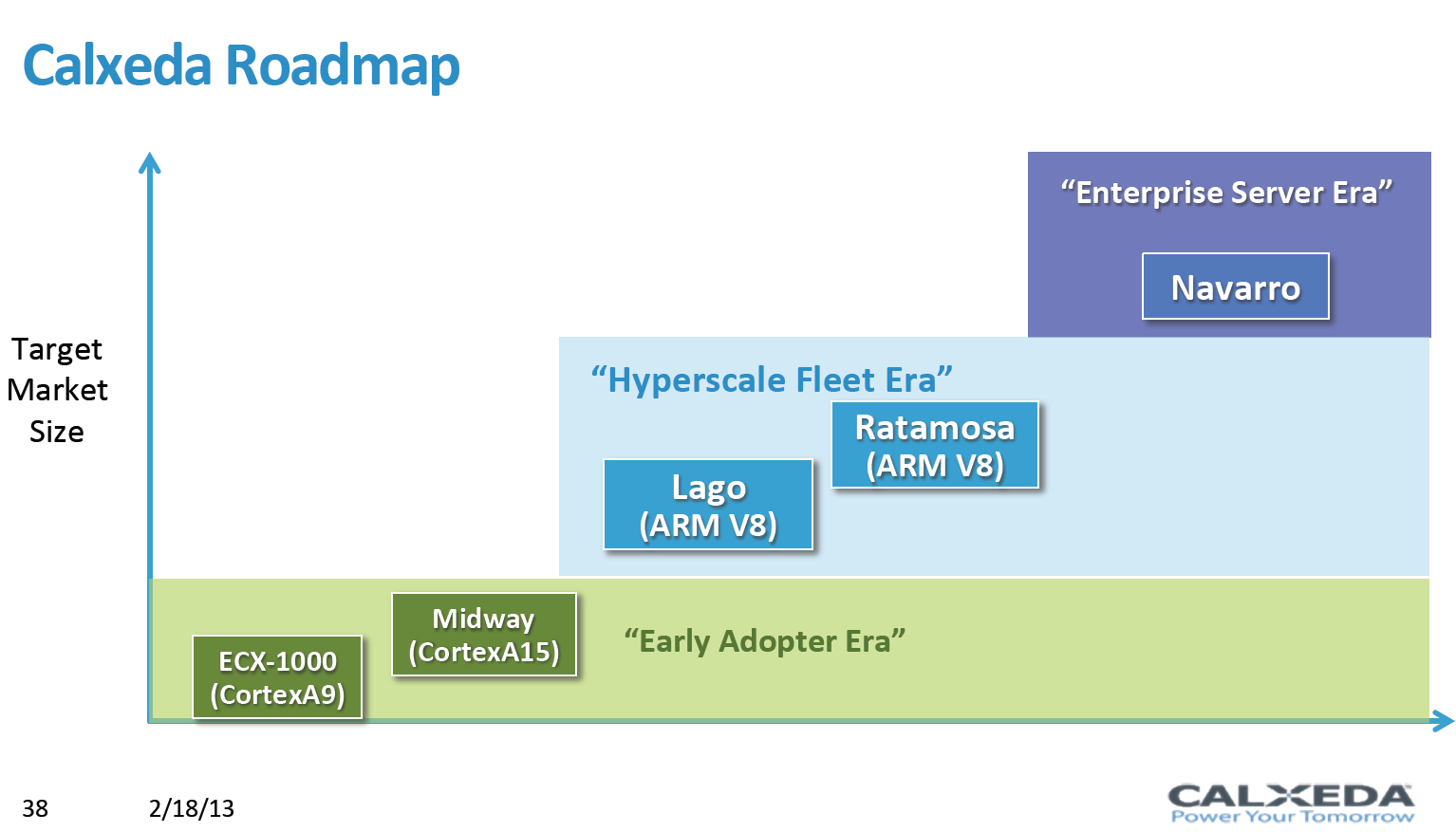
Calxeda is aware of all this, as they label their first "highbank" server architecture with the ECX-1000 SoC as targeted to the "early adopter". That is why we deliberately tested a scenario that would be relevant to the potential early adopters: a cluster of web servers that is relatively network intensive as it serves a lot of media files. This is one of the better scenarios for Calxeda, but not the best: we could imagine that a streaming server or storage server would be an even better fit. Especially the latter catches on, and the storage version of the Boston Viridis sells well.
So on the one hand, no, the current Calxeda servers are no Intel Xeon killers (yet). However, we feel that the Calxeda's ECX-1000 server node is revolutionary technology. When we ran 16 VMs (instead of 24), the dual low power Xeon was capable of achieving the same performance per VM as the Calxeda server nodes. That this 24 node system could offer 50% more throughput at 10% lower power than one of the best Xeon machines available was honestly surprising to us. 8W at the wall per server node—exactly what Calxeda claimed—is nothing short of remarkable, because it means that the 48 server node machine, which is also available, is even more efficient.
To put that 8W number in perspective, the current Intel Atoms that offer similar performance need that kind of power for the SoC alone and are baked with Intel's superior 32nm process technology. The next generation ARM servers are already on the way and will probably hit the market in the third quarter of this year. The "Midway" SoC is based on a 28nm (TSMC) Cortex-A15 chip. A 28nm Cortex-A15 offers 50% higher single-threaded integer performance at slightly higher power levels and can address up to 16GB of RAM. With that it's safe to conclude that the next Calxeda server will be a good match for a much larger range of applications--memcached, larger web, and midrange database servers for examples. By then, virtualization will be available with KVM and Xen, but we think virtualization on ARM will only take off when the ARM A57 core with its 64-bit ARM V8 ISA hits the market in 2014.
Right now, the limited performance of the individual server nodes makes the Boston Viridis attractive for web applications with lower CPU demands in a power constrained data center. But the extremely low energy consumption and the rapidly increasing performance of the ARM cores show great potential for Calxeda's technology. Short term, this is a niche market, but in another year or two this style of approach could easily encroach on Intel's higher end markets.






