Original Link: https://www.anandtech.com/show/6451/the-xeon-phi-at-work-at-tacc
The Xeon Phi at work at TACC
by Johan De Gelas on November 14, 2012 1:44 PM EST- Posted in
- CPUs
- IT Computing
- Intel
- Larrabee
- Xeon
- Cloud Computing
- Xeon Phi
The Xeon Phi family of co-processors was announced in June, but Intel finally disclosed additional details.The Xeon Phi die is a massive chip: Almost 5 billion transistors using Intel's most advanced 22nm process technology with 3D tri-gate transistors.
A maximum of 62 cores can fit on a single die. Each core is a simple in order x86 CPU (derived from the original Pentium) with a 512-bit SIMD unit. There is a twist though: the core can handle 4 threads simultaneously. Nehalem, Sandy and Ivy Bridge also use SMT, but those cores uses SMT mostly to make better use of their ample execution resources.
In case of the Xeon Phi core, the 4 threads are mostly a way to hide memory latency. In the best case, two threads will execute in parallel.
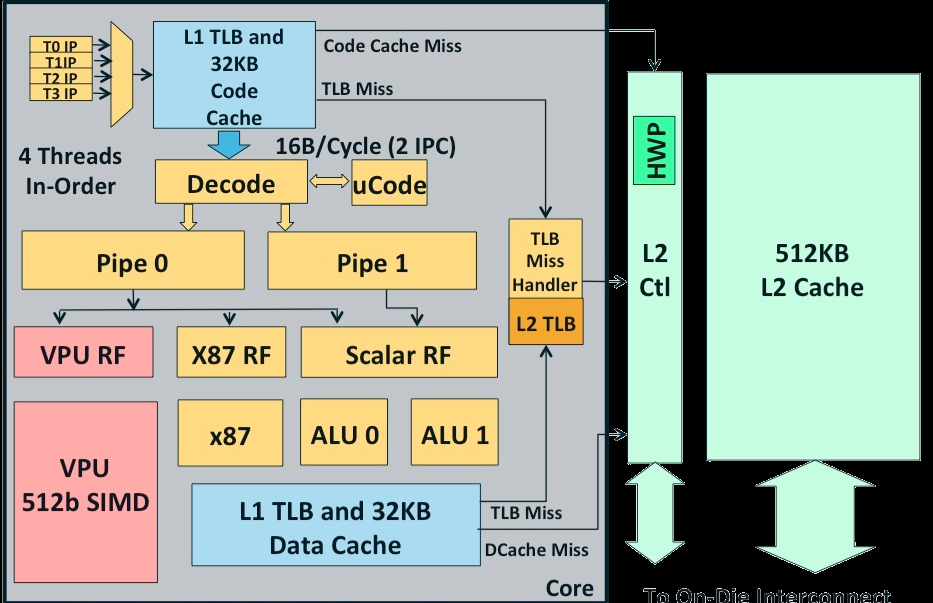
Each of these cores is a 64-bit x86 core. However, only 2% of the core logic (excluding the L2-cache) is spent on x86 logic. The SIMD unit does not support MMX, SSE or AVX: the Xeon Phi has its own vector format.
All of the cores are connected together with a bi-directional ring, similar to what's used in the Xeon E7 and the Sandy Bridge EP CPUs.
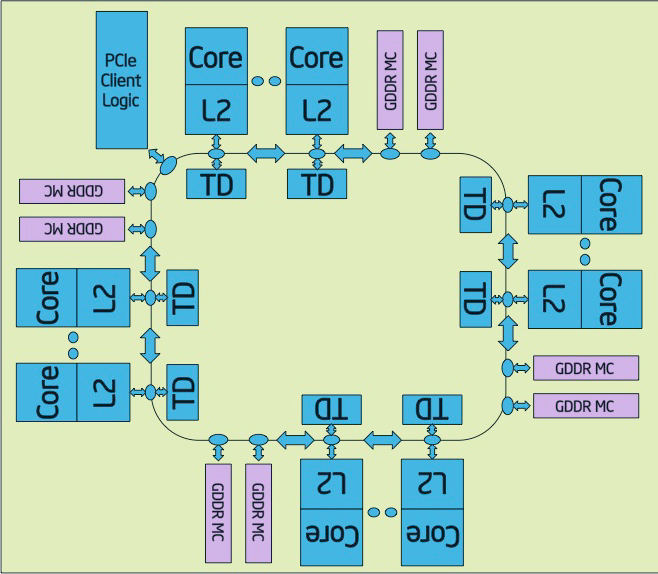
Eight memory channels (512-bit interface) support up to 8 GB of RAM, and PCIe logic is on chip.
The Xeon Phi card comes on a PCIe card, much like a GPU. Given the architecture's origins as a GPU, the form factor should't come as a surprise. Like modern HPC GPUs however, the Xeon Phi card has no display output - its role is strictly for compute.
The Xeon Phi acts as a multi-core system on chip running its own operating system, a modified Linux kernel. Each Xeon Phi card has its own IP address however, the Xeon Phi can not operate on its own. A "normal" Xeon will be be the host CPU, the Xeon Phi card is a coprocessor, similar to the way your CPU and GPU work together.
Below you can see the SKUs that Intel will offer.
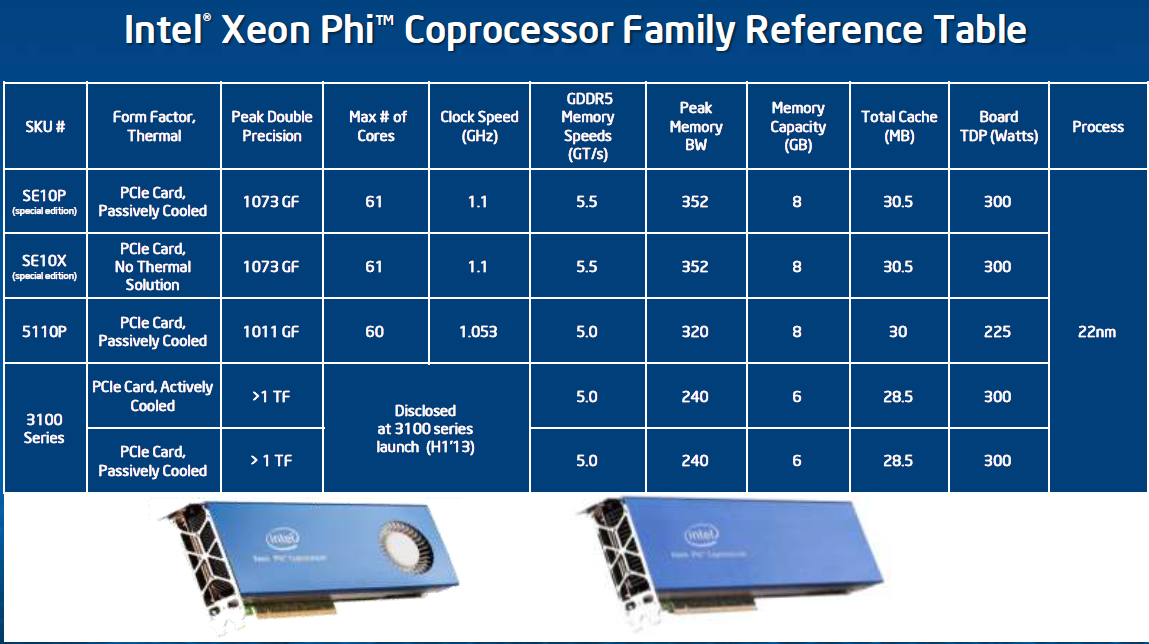
The Xeon Phi inside the Stampede are special edition Xeon Phis.These special editions get 61 cores and run at a slightly higher clockspeed (1.1 GHz).
The commercially avialable 5110P has one core and 50 MHz less than the special edition Phi but comes with 8 GB of ECC memory. The P-suffix indicates that it's passively cooled, relying on the host server for airflow. The 5110P is not cheap at $2699, but it's still more affordable than NVIDIA's Tesla K20 ($3199). The Xeon Phi 5100 series is really intended for more memory bandwidth bound applications thanks to the use of 5GHz GDDR5 and a fully populated 512-bit memory interface.
For compute bound applications however, Intel will offer the Xeon Phi 3100 series in the first half of next year for less than $2000. The Xeon Phi 3100 will come with 6GB of GDDR5 (5GHz data rate) and only a 384-bit memory interface. Core clock should be higher, delivering over 1TFLOP of DP FP performance.
The Xeon Phi cards use a 7GHz PCIe 2.0 interface, as Intel found moving to PCIe 3.0 resulted in slightly higher overhead.
We had the chance to briefly visit Stampede, the first Supercomputer based upon the Xeon Phi. This is one of the supercomputers at the Texas Advanced Computing Center (TACC).
Stampede consist of 6400 PowerEdge C8220X and C8220 server Sleds. Typically these servers contain two octal core Xeon E5s, 32 GB of RAM and one GPU/MIC.

Eight of those server sleds find a home inside the C8000 4U Chassis, together with two power sleds.
Dual ported Mellanox ConnectX with FDR infiniband interfaces connects all those servers together to form one large supercomputer. In each rack you can find on 8 C8000s on average.

Connect 200 racks together and you get the Stampede supercomputer:

The Xeon E5s deliver two Petaflops at the moment. When all Xeon Phi are in place, an additional 8 Petaflops will be available to researchers on Stampede.
Intel Xeon Phi is not a standalone replacement to a GPU. For example, the Xeon Phi has no texture units. As a result remote visualization is done by 128 NVIDIA Tesla K20 GPUs. The rest of the supercomputer: 272 TB total memory and 14PB of disk storage. The complete supercomputer and the necessary cooling will require up to 6 megawatts of power.
One of the big selling points of the Xeon Phi is that you can simply run multi-threaded Xeon code on the Xeon Phi. If you want to get decent performance out of the Xeon Phi, that code should be compiled with the Intel C or fortan Compiler and the Intel MKL math libraries. In that case, Intel claims many "typical applications" get about 2 to 2.5 higher performance with the Xeon Phi. A few exceptions get more.

That is an impressive performance boost, but not earth shattering. These numbers are much more realistic than the typical benchmarks of 100x that are throw around by the GPU folks. Those benchmarks are typically comparing a single threaded non SIMD binaries running on a CPU to a fully threaded carefully tuned application running on a GPU.
The question remains in which applications a cheaper quad CPU solution is more effective. Before the Xeon E5 (Sandy Bridge EP) came out, AMD was quite succesful with their less expensive quad CPU platforms in the HPC world. It will be interesting to compare the performance per dollar and performance per watt of such quad CPU platforms with a CPU + Phi solution. There are certainly applications where the CPU + Phi wins hands down, but we are willing to bet that there are lots of HPC applications where it is a close call (e.g. highly threaded, but harder to vectorize code).
The point is of course that the time investment to get there is a lot lower than is the case with CUDA on NVIDIA's Tesla K20. We have heard from several companies that debugging CUDA code is still a pretty daunting experience. One good example can be found here. The maturity of the Intel compilers and high performance software is a big plus for the Xeon Phi. The numerous papers and OpenMP to CUDA frameworks/translators clearly indicate that porting OpenMP applications to CUDA is not necessarily straightforward. That in contrast with the Xeon Phi, where existing OpenMP applications run faster on the Xeon Phi without a recompile. OpenMP is simply the ecosystem where the Xeon Phi thrives. And Intel has an excellent track record when it comes to supporting OpenMP in its compilers.
The Xeon Phi might also prove to be a bit more flexible and forgiving. The Xeon Phi architecture still, at a high level, resembles a general purpose Xeon core. We're talking about 60 in-order x86 cores with wider SIMD units, a 512KB L2 feeding 4 threads per core.
GPUs on the other hand are built for more "extreme" parallelism: hundreds of stream processors, with small shared L1-caches and one relatively small L2-cache.
We'll have to hold final judgement until we get a Xeon Phi equipped system in house, but our first impressions are that the Xeon Phi looks like a more cost effective, potentially easier to use alternative to high-end GPUs for HPC.






