Original Link: https://www.anandtech.com/show/6290/making-sense-of-intel-haswell-transactional-synchronization-extensions
Making Sense of the Intel Haswell Transactional Synchronization eXtensions
by Johan De Gelas on September 20, 2012 12:15 AM ESTMulti-core and Locking
Intel has released additional information on their Transactional Synchronization technology (TSX), which is basically a instruction set architecture (ISA) extension to make hardware accelerated transactional memory possible. What does that mean in the real world?
The more cores you get in a system, the more threads you need to keep them busy. Unfortunately, doing so is not that easy: threads have to work on shared data and need locks to make sure that the end result is correct. A thread has to acquire a lock, which may necessitate waiting until another thread releases the lock. That can lead to serious lock contention which can result in bad scaling, even to the point where more cores (and threads) can lead to a performance loss instead of a gain.
We measured this in a real-world benchmark (based upon MySQL InnoDB) and showed that spinning locks were indeed to blame. Spinlocks that are "busy waiting" too much do more than just destroying the scalability of your multi-core server: they can waste quite a bit of energy. As cores hardly perform any useful work and can no longer go to sleep, a torrent of spinlocks can wreak havoc on a server's performance per watt ratio. The following chart, based upon measurements on a HPC benchmark, is another example. Looking at the performance that you get from each core helps to summarize the problem.
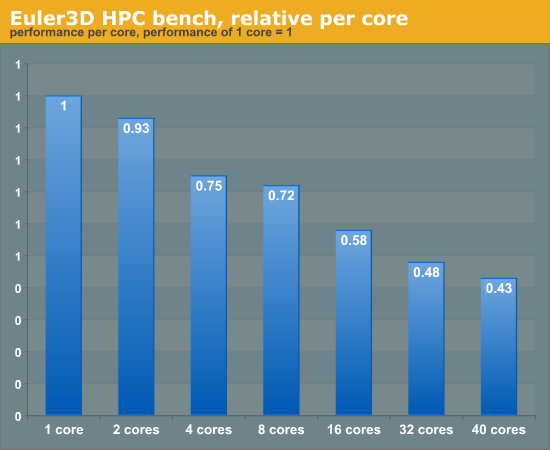
The HPC bench shows how the more cores the software uses, the less performance we get per core. When 16 cores are working, each core offers only 60% of the performance of a single threaded run. A shared data structure is the problem. Careful tuning could make this software scale better, but this would require a substantial amount of time and effort.
The root of the locking problems is that locking is a trade-off. Suppose you have a shared data structure such as a small table or list. If the developer is time constrained, which is often the case, the easiest way to guarantee consistency is to let a certain thread lock the entire data structure (e.g. the table lock of MySQL MyISAM). The thread acquires the lock and then executes its code (the critical section). Meanwhile all other threads are blocked until the thread releases the lock on the structure. However, locking a piece of data is only necessary if two threads want to write to it. The classical example is a sequence of two bank transactions:
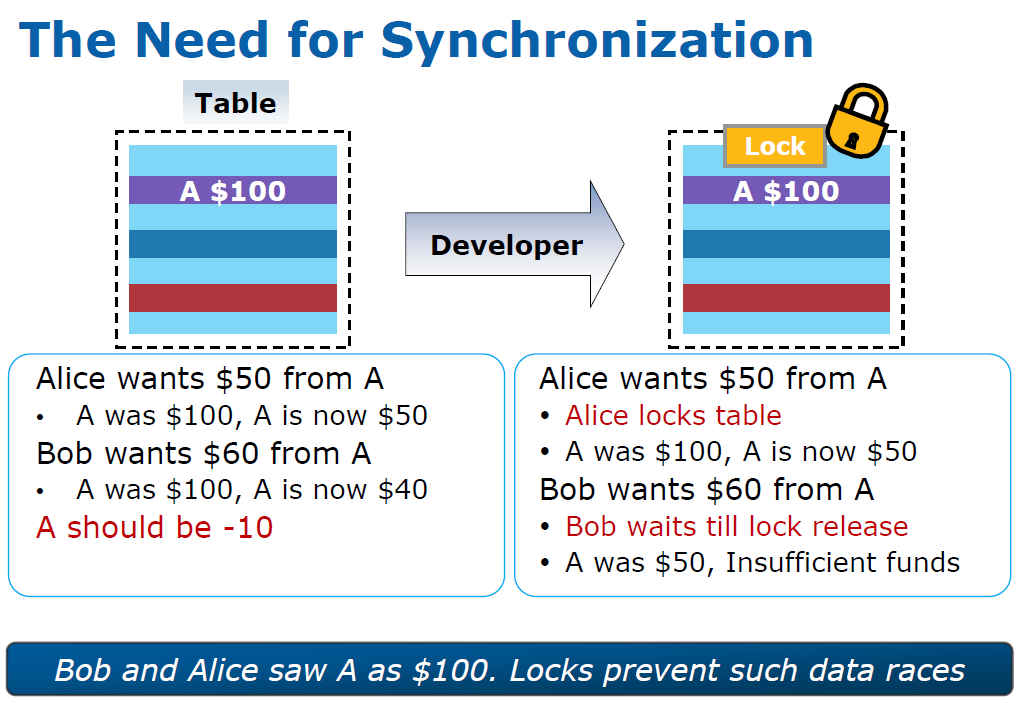
Locking an entire data structure is something else. You can imagine that the other threads might all write to different values and should be able to do a lot of work in parallel. The coarse grained locking of entire structures is generally not necessary, but it makes the developers' job easier.
The developer could rewrite his/her code and apply a much finer grained locking, but this is a pretty complex and time consuming task, and the critical code section will probably need several variables to do its job. In that case you can get deadlocks: one thread locks variable A, another thread variable B. They both need A and B, and they keep trying to get a lock on the other variable. There is a reason why getting good multi-core scalability requires a large investment of time and money.
Haswell's TSX
The new Transactional Synchronization eXtensions (TSX) extend the x86 ISA with two new interfaces: HLE and RTM.
Restricted Transactional Memory (RTM) uses Xbegin and Xend, allowing developers to mark the start and end of a critical section. The CPU will thread this piece of code as an atomic transaction. Xbegin also specifies a fall back path in case the transaction fails. Either everything goes well and the code runs without any lock, or the shared variable(s) that the thread is working on is overwritten. In that case, the code is aborted and the transaction has failed. The CPU will now execute the fall back path, which is most likely a piece of code that does coarse grained locking. RTM enabled software will only run on Haswell and is thus not backwards compatible, so it might take a while before this form of Hardware Transactional Memory is adopted.
The most interesting interface in the short term is Hardware Lock Elision or HLE. It first appeared in a paper by Ravi Rajwar and James Goodman in 2001. Ravi is now a CPU architect at Intel and presented TSX together with his colleague Martin Dixon TSX at IDF2012.
The idea is to remove the locks and let the CPU worry about consistency. Instead of assuming that a thread should always protect the shared data from other threads, you optimistically assume that the other threads will not overwrite the variables that the thread is working on (in the critical section). If another thread overwrites one of those shared variables anyway, the whole process will be aborted by the CPU, and the transaction will be re-executed but with a traditional lock.
If the lock removing or elision is successful, all threads can work in parallel. If not, you fall back to traditional locking. So the developer can use coarse grained locking (for example locking the entire shared structure) as a "fall back" solution, while Lock Elision can give the performance that software with a well tuned fine grained locking library would get.
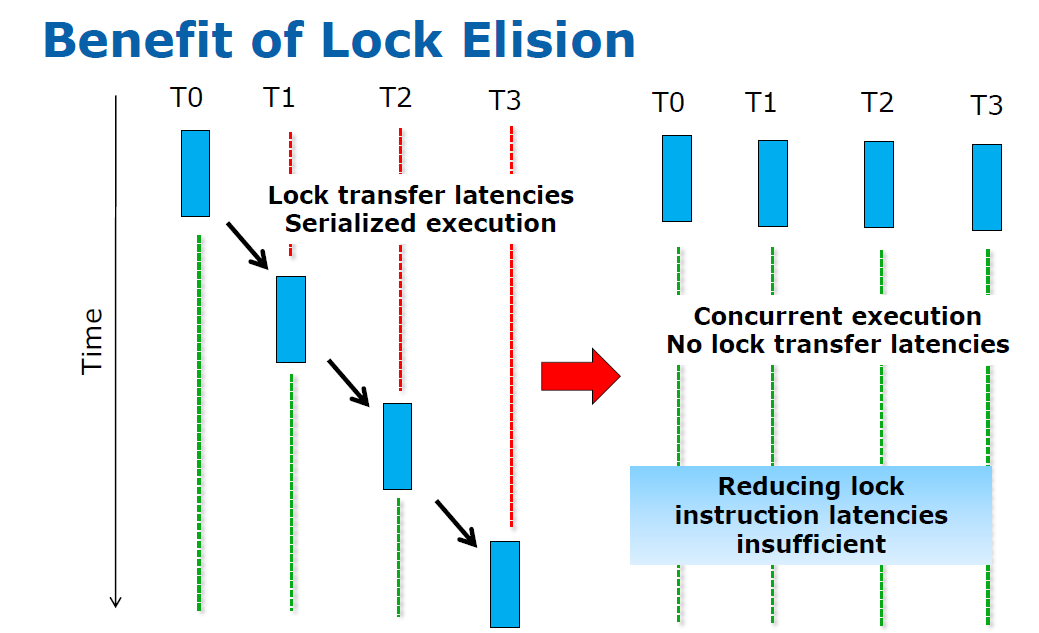
According to Ravi and Martin, the beauty is that the developer of your locking libraries simply has to add a few HLE instructions without breaking backwards compatibility. The developer uses the new TSX enabled library and gets the benefits of TSX if his application is run on Haswell or a later Intel CPU.
Easy to Use?
As we mentioned, HLE is backwards compatible. How does that work? If developers rely on libraries like glibc for locking, Intel claims only those libraries have to be changed. Take a look at the slide below:
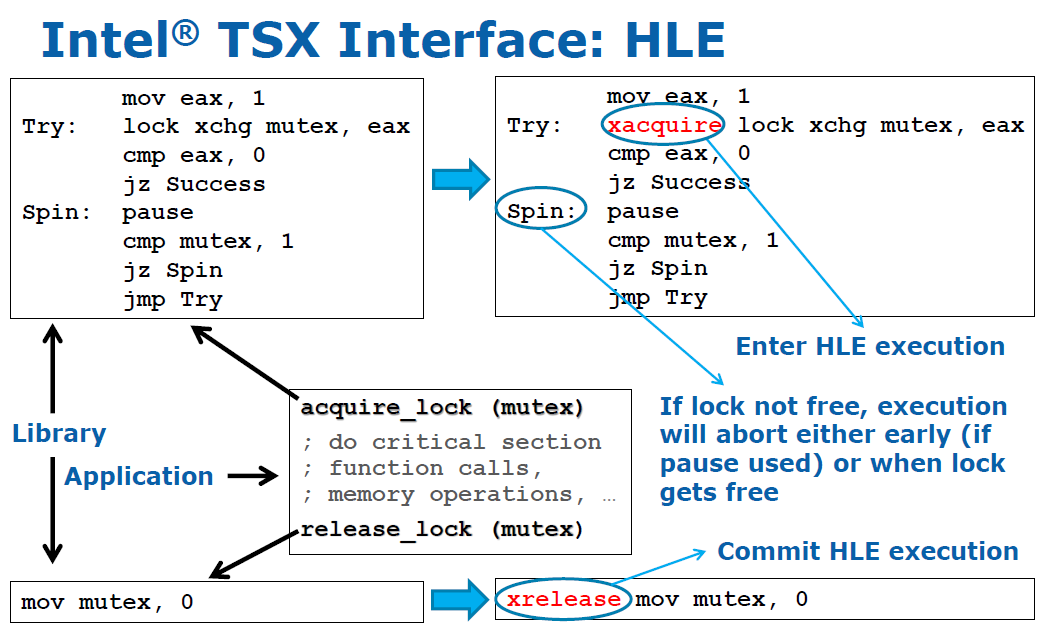
Notice the rectangle with the pointer "application". For the developer of such an application that uses dynamic linking nothing changes. The library simply has to place xacquire in front of each lock (here a spinlock) and xrelease at the end of each lock. So (dynamic) linking to a new library and running it on an Intel Haswell CPU should let your application use TSX. If you run the same application plus a TSX enabled library on a previous generation CPU, it will still run but will not use TSX (HLE).
TSX Performance
Ravi and Marting gave some vague but still rather interesting performance data:
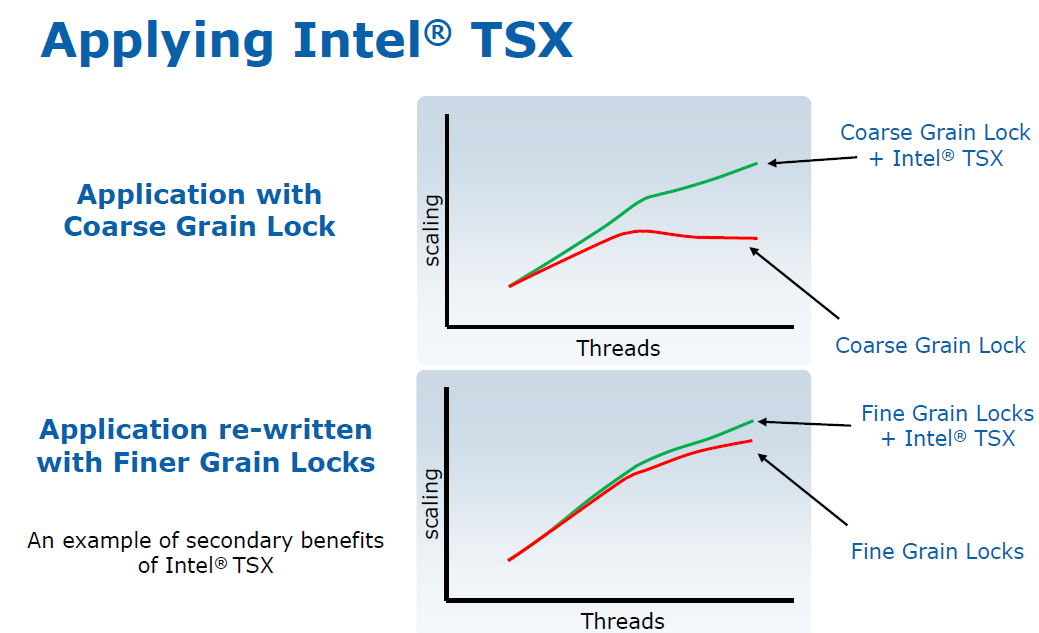
According to Intel, using an application that previously used a coarse grained lock (like the older MyISAM storage engines of MySQL) together with a TSX enabled library should improve scaling spectacularly. What's interesting is that even applications with finely grained locks should benefit from using TSX. As TSX uses the L1-cache to buffer the writes (David Kanter describes this in great detail here) and does not lock (unless re-execute/rollback takes place), there is less memory activity and especially less synchronization traffic. Or in other words, cache lines are less "thrown around".
There are some corner cases for which HLE/RTM will not work of course. The whole "CPU does the fine grained locks" is based upon tagging the L1 (64 B) cachelines and there are 512 of them to be specific (64 x 512 = 32 KB). There is only one "lock tag" per cacheline. More than one lock to the same cacheline will cause HLE/RTM to abort as the CPU cannot track the two locks separately in that case.
Second, all the "to be locked" variables of a TSX enabled piece of code must be placed into the L1-cache. If a piece of critical code needs to lock variables from more than 8 cachelines that all map to the slots of the same set, HLE is not going to work: the L1 is 8-way set-associative. Anything that interrupts the transaction will abort the transaction: non-maskable interrupts (interrupts that cannot be ignored), VM exits, faults...the list goes on. Still, there are many cases where TSX can definitely help, and code can be written to accommodate the requirements and limitations.
Conclusion
TSX will be supported by GCC v4.8, Microsoft's latest Visual Studio 2012, and of course Intel's C compiler v13. GLIBC support (rtm-2.17 branch) is also available. So it looks like the software ecosystem is ready for TSX. The coolest thing about TSX (especially HLE) is that it enables good scaling on our current multi-core CPUs without an enormous investment of time in the fine tuning of locks. In other words, it can give developers "fined grained performance at coarse grained effort" as Intel likes to put it.
In theory, most application developers will not even have to change their code besides linking to a TSX enabled library. Time will tell if unlocking good multi-core scaling will be that easy in most cases. If everything goes according to Intel's plan, TSX could enable a much wider variety of software to take advantage of the steadily increasing core counts inside our servers, desktops, and portables.






