Original Link: https://www.anandtech.com/show/6137/the-amd-firepro-w9000-w8000-review-part-1
The AMD FirePro W9000 & W8000 Review: Part 1
by Ryan Smith on August 14, 2012 4:00 AM ESTDespite the wide range of the GPU coverage we do here at AnandTech, from reading our articles you would be hard pressed to notice that AMD and NVIDIA have product lines beyond their consumer Radeon and GeForce brands. Consumer video cards compose the bulk of all video cards shipped, the bulk of revenue booked, and since they’re targeted at a very wide audience, the bulk of all marketing attention. Consequently consumer cards also take up the bulk of the press’s attention, especially since new GPUs are almost always launched in a consumer video card first.
The truth of course is that there’s a great deal more to the GPU marketplace than consumer video cards; abutting the consumer market is the smaller, specialized, but equally important professional market that makes up the rest of the desktop GPU marketplace. Where consumers need gaming performance and video playback, professionals need compute performance, specialized rendering performance, and above all a level of product reliability and support beyond what consumers need. They need the same basic product as consumers – a high performance, feature-packed GPU – but they need to use it in entirely different ways.

As a result of these different needs the GPU marketplace is traditionally split up into three segments: consumer, professional graphics, and compute. Among these segments consumer products typically launch first, with professional and compute products following 6 to 12 months later based on further driver development and qualification needs. The end result is an interesting product cascade that sees the true, unrestricted performance of a GPU only finally unveiled several months after it launches.
This leads us to today’s product review: AMD’s FirePro W9000 video card. Having launched their Graphics Core Next architecture and the first GPUs based on it at the beginning of the year, AMD has been busy tuning and validating GCN for the professional graphics and compute markets, and that process has finally reached its end. This month AMD is launching a complete family of professional video cards, the FirePro W series, led by the flagship W9000.
| AMD FirePro W Series Specification Comparison | ||||||
| AMD FirePro W9000 | AMD FirePro W8000 | AMD FirePro W7000 | AMD FirePro W5000 | |||
| Stream Processors | 2048 | 1792 | 1280 | 768 | ||
| Texture Units | 128 | 112 | 80 | 48 | ||
| ROPs | 32 | 32 | 32 | 32 | ||
| Core Clock | 975MHz | 900MHz | 950MHz | 825MHz | ||
| Memory Clock | 5.5GHz GDDR5 | 5.5GHz GDDR5 | 4.8GHz GDDR5 | 3.2GHz GDDR5 | ||
| Memory Bus Width | 384-bit | 256-bit | 256-bit | 256-bit | ||
| VRAM | 6GB | 4GB | 4GB | 2GB | ||
| Double Precision | 1/4 | 1/4 | 1/16 | 1/16 | ||
| Transistor Count | 4.31B | 4.31B | 2.8B | 2.8B | ||
| TDP | 274W | 189W | <150W | <75W | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | GCN | GCN | GCN | GCN | ||
| Warranty | 3-Year | 3-Year | 3-Year | 3-Year | ||
| Launch Price | $3999 | $1599 | $899 | $599 | ||
As always, the latest rendition of the FirePro family will be taking their place as AMD’s professional graphics card lineup. Having a dedicated professional graphics card lineup allows AMD to offer features and functionality – primarily rigorous application certification against a driver set tuned for high reliability – that while not necessary for consumer cards are critical for professional users; and of course to charge those users accordingly. FirePro also is distinct for being AMD’s only in-house video card offering, with AMD directly producing, selling, and supporting the products as opposed to farming that work out to third party partner companies (as is the case with Radeon cards).
Taking a quick look at the specifications, if you’re familiar at all with AMD’s Radeon HD 7000 series lineup, then the FirePro W series lineup should look very familiar. As with the FirePro V series and past iterations of the FirePro, the latest rendition of the FirePro family is effectively comprised of professional certified versions of existing Radeon HD 7000 series video cards, which means the hardware is nearly identical to AMD’s consumer products.
The big new with this week’s launch of course isn’t just that AMD will be replacing the 40nm FirePro V series with the 28nm FirePro W series, but that they’re doing so with Graphics Core Next, their modern compute-oriented GPU architecture. With FirePro pulling double-duty as both AMD’s professional graphics card and their compute card, this makes GCN all the more important as it brings with it potentially massive compute performance improvements that significantly shore up the V series’ weakness in compute. We’ve often said that the full power of GCN hasn’t been tapped by the consumer-oriented Radeon series, so now with FirePro we’ll finally get to see everything GCN can do.

We’ll dive into greater detail later about the individual products and their specifications, but for now we’ll offer a quick overview of the FirePro W series. Altogether the W series is to initially be composed of 4 cards, the W9000, W8000, W7000, and W5000. The former two are based around AMD’s high-end Tahiti GPU while the latter two are based around their mid-tier Pitcairn GPU, which creates a clear distinction between the two groups. Whereas Tahiti was built for both strong graphics and strong compute performance, Pitcairn is more tuned for graphics, and as FirePro products that distinction has not changed.
As a result high performance computing – particularly double precision – is going to be the domain of W8000 and W9000, along with AMD’s best graphical performance. W7000 and W5000 on the other hand still offer respectable single precision compute performance but lack the double precision performance of the larger cards, making them better suited for pure graphical workloads than for compute or compute mixed with graphics.
Moving on, much like AMD’s consumer product launch earlier this year they will enjoy a couple month lead over NVIDIA in getting 28nm cards out into the professional market. So for the time being AMD will have a generational lead over NVIDIA’s competing products, the Fermi based Quadro series. Unlike the consumer space though the hardware upgrade pace in the professional market is much slower, so while this still gives AMD an advantage it won’t be as significant as their launch advantage in the consumer space.
On that note, when it comes to competition, pricing has been a big part of AMD’s strategy. Typically, AMD has undercut NVIDIA on pricing for equivalent professional products in order to cut into NVIDIA’s very large share of the market. Professional graphics margins are high enough that AMD can afford to sacrifice some of their margin for market share.
For the initial launch however this won’t strictly be the case, due to the fact that the Fermi Quadro series is slowly on its way out – to be replaced by the K5000 and future cards. With a SRP of $3999 for the W9000 it’s roughly as expensive as the Quadro 6000 at current prices, and the situation is similar for the $1599 W8000 compared to the Quadro 5000. Eventually NVIDIA will finish refreshing the Quadro series for Kepler, and when they do it would be reasonable to expect that AMD’s pricing will undercut NVIDIA’s new prices; the Quardo 6000 did have a launch MSRP of $4999, after all.
| Summer 2012 Workstation Video Card Price Comparison | |||||
| AMD | Price | NVIDIA | |||
| FirePro W9000 | $3999 | Quadro 6000 | |||
| FirePro W8000 | $1599-$1799 | Quadro 5000 | |||
| FirePro W7000 | $749-$899 | Quadro 4000 | |||
| FirePro W5000 | $599 | ||||
| $399 | Quadro 2000 | ||||
Finally, on a quick housekeeping note, as you may have noticed in the title we are splitting up this article into two parts. Part 1 will be focusing on the tech, the specs, and the market, while part 2 will focus on benchmarking and our performance analysis. This is so we can get the first part out at the start of this week, as opposed to holding it our extended benchmarking is complete. So if you’re looking for specific figures and performance numbers, please be sure to check back later this week for the full performance rundown.
Introducing the FirePro W Series
Altogether AMD will be launching four cards for the FirePro W series. All of these cards are based on AMD’s Southern Islands GPUs, specifically their Tahiti and Pitcairn GPUs. For the purposes of this article we’ll be reviewing two of these cards, the FirePro W9000 and its younger sibling the W8000, the two Tahiti cards of the family.
Meanwhile, in keeping with past FirePro cards AMD is holding steady on their sales & support methods. AMD will be the sole manufacturer for the FirePro W series, and alongside OEM deals will be selling the cards through the usual 3rd party distributors. All of the FirePro cards come with a 3 year warranty, 24/7 support, and a 3 year production lifecycle.
FirePro W9000
| AMD FirePro W9000 Specs | ||||||
| Single Precision | Double Precision | Pixel Fillrate | Texture Fillrate | Memory Band. | ||
| 4TFLOPs | 1TFLOPs | 31.2 GPixels/sec | 124 GTexels/sec | 264GB/sec | ||
AMD’s first FirePro W series card and the flagship of the family is the W9000. Based on AMD’s Tahiti GPU, this is a fully enabled part with all 32 CUs (2048 SPs in total), all 32 ROPs, and all 6 memory controllers enabled. With absolutely no restrictions on performance this is unquestionably the ultimate Southern Islands card. For that reason, within AMD’s product lineup it replaces the previous flagship FirePro card, the Cypress-based V9800.
The W9000 is clocked at 975MHz for the core clock and 5.5GHz for the memory clock. Compared to its consumer counterpart, the Radeon HD 7970, this is actually 50MHz higher on the core clock, owing to general process improvements and a less conservative stance on clockspeeds from AMD. Meanwhile this is paired with 6GB of GDDR5 RAM – typical for a professional card – in the form of 24 2Gb chips. AMD’s TDP rating for the entire card is 274W, a consequence of having to power a full 6GB of relatively power-hungry GDDR5.
As far as the card’s construction goes, this is a fairly standard AMD workstation card. In AMD’s parlance this is a full length, full height, double slot card, with a total length of 11”, meaning it shouldn’t have any trouble fitting into most mid-tower and larger workstations. Meanwhile cooling for the W9000 is provided by the same type of blower we saw on the 7970, a rather typical and effective blower design and in the process further highlighting the similarities between the two cards. On that note, owing to the fact that it has 6GB of RAM and is not geared towards the consumer market, AMD has outfit a backplate to the card to provide protection for the hardware and to serve as a basic heatsink for the RAM mounted on that side.




Moving on to connectivity, AMD is not taking any chances here, outfitting the card 6 mini-DisplayPort connectors. The significance of this arrangement is that it ensures the card can drive absolutely any kind of 6 monitor configuration with the right adapters, and it means AMD isn’t reliant on still-absent MST hubs to actually provide connectivity for 6 monitors. Unique to the FirePro lineup is the inclusion of a 3pin mini-DIN connector, which allows for the card to be rigged up for 3D display functionality. CrossFire connectors are also present to provide CrossFire Pro support. A synchro header is also available to allow the card to be hooked up to AMD’s FirePro S400 synchronization module.
Taken altogether, as AMD’s flagship FirePro card the W9000 will serve as AMD’s ultra high end FirePro product. Because it’s based on an unrestricted Tahiti GPU AMD is targeting both professional graphics and compute with this card, both of which are tasks it should do well at thanks to the massive collection of functional units the 28nm process affords. Comparatively speaking, because AMD hasn’t greatly increased their ROP count compared to the last generation of FirePro cards the raw pixel throughput has not grown a great deal – on paper the 31.2 GPixels/sec rate is only 15% better than the FirePro V9800 – so the W9000’s biggest performance gains relative to its predecessor are going to be in shading and compute. Performance there is a whopping 4 TFLOPs for single precision (FP32), and 1TFLOP for double precision (FP64). This implies a ¼ double precision execution rate for W9000, which is the same rate we saw for the Tahiti-based 7970. There had been some initial speculation that AMD had artificially capped their double precision rate on their consumer cards (ala NVIDIA), so this confirms that was not the case.
On that note, with a 2 month lead on NVIDIA’s Quadro K5000 and a full 4 month lead on the Tesla K20, AMD is looking to capitalize on their performance lead for the time being. For compute in particular, on paper AMD is well ahead of NVIDIA and as we’ve already seen in consumer reviews of the GCN architecture, they have the means to back up those numbers. Even when the K5000 launches, the W9000 will still be far more powerful in most compute tasks, an interesting turn of events given that the 40nm generation of professional cards had AMD and NVIDIA in the reverse roles.
Finally, for those of you looking to pick up AMD’s latest and greatest in professional graphics, AMD’s street estimated pricing for the W9000 is $3999. Real prices will almost certainly be lower, but there’s no way to tell by how much at this point, making it hard to draw price comparisons with the outgoing Quadro 6000. Meanwhile buyers will want to be aware that because of its high power consumption and high price AMD is expecting this to be a low-volume product, so as currently planned it will not be shipping in any workstations as the default configuration. Buyers will either need to acquire it as a build-to-order upgrade, or purchase one directly to be installed as a self-upgrade.
FirePro W8000
| AMD FirePro W8000 Specs | ||||||
| Single Precision | Double Precision | Pixel Fillrate | Texture Fillrate | Memory Band. | ||
| 3.2TFLOPs | 0.8TFLOPs | 28.8 GPixels/sec | 100 GTexels/sec | 176GB/sec | ||

Below the FirePro W9000 in the FirePro W series is the FirePro W8000. While very similar, unlike the W9000 the W8000 is a lower clocked, lower performing part intended to come in at a lower price. Specifically, it’s based on a partially disabled Tahiti GPU with 1 CU array (4 CUs) disabled, leaving it with 28 CUs that make up 1792 SPs. The memory bus has also been partially disabled, reducing the GPU down to a 256-bit memory bus that’s paired with 4GB of RAM. Notably however, because AMD has decoupled their ROPs from their memory controller, the W8000 still has all 32 ROPs enabled.
Along with the decrease in functional units also comes a slight decrease in clockspeeds. The W8000 ships at a core clock of 900MHz, while the memory clock is maintained at 1375MHz. Taken altogether this gives the W8000 80% of the W9000’s compute, shading, and texturing performance, 92% of its ROP performance, and only 66% of its memory bandwidth. As a result its performance relative to the W9000 is going to depend heavily on whatever is bottlenecking its performance. As a tradeoff for this reduced performance however, power consumption is also greatly reduced, from 274W to 189W, making the W8000 suitable for use in systems which can only provide 150W of external power for a GPU.




Moving on to the build of the card itself, the W8000 is virtually identical to the W9000. It’s based on the same cooler and PCB as the W9000, and except for the model number stamped on the card the two are seemingly identical at first glance. In fact the only meaningful difference between the two cards when it comes to their construction is their connectivity. In a bit of a schizophrenic move by AMD, the W8000 forgoes the 6 miniDP ports for 4 full size DisplayPorts. The reduction in ports makes sense to keep the W9000 more valuable – though the W8000 can still drive 6 displays with a MST hub – but the move to full size DisplayPorts is odd at best, and this kind of inconsistency continues to be a problem throughout the entire graphics industry. In any case, other than the changes to the DisplayPorts the W8000 is otherwise identical, featuring the same 3pin mini-DIN for 3D display functionality, and a pair of CrossFIre connectors for CrossFire Pro.
Ultimately the W8000 fills the expected role as AMD’s lower-priced but still high performance video card. It will be launching at $1599, $2400 less than the W9000, reflecting the significant markup that GPU makers charge for their very best cards. Unlike the W9000 though, the W8000 is a higher volume part and does have some design wins from Dell, who will be shipping it in some of their high-end workstations.
FirePro W7000
| AMD FirePro W7000 Specs | ||||||
| Single Precision | Double Precision | Pixel Fillrate | Texture Fillrate | Memory Band. | ||
| 2.4TFLOPs | 0.15TFLOPs | 30.4 GPixels/sec | 76 GTexels/sec | 153GB/sec | ||

The other set of products launching in the FirePro W series are the W7000 and W5000. Both of these cards are based on AMD’s Pitcairn GPU, which means that unlike the W9000 and W8000 they’re far more focused on graphics performance than compute performance, specifically double precision. Relative to AMD’s outgoing product stack these cards will be replacing the Cayman based FirePro V cards, the V7900 and V5900.
Starting with the larger of the cards, the W7000 is a fully enabled Pitcairn part featuring all 20 CUs enabled, sitting alongside 32 ROPs. This is paired with a 256bit memory bus connected to 4GB of RAM, similar to the higher-end W8000. Consequently the real difference between the W7000 and W8000 comes down to the basic architectural differences between Tahiti and Pitcairn when it comes to compute, along with the generally lower compute and texture performance that having fewer CUs results in.
AMD will be clocking the W7000 at 950MHz for the core and 4.8GHz for the memory. On the GPU performance side of things this gives the W7000 2.4TFLOPs of single precision performance, and a much more meager 0.15TFLOPs of double precision. Meanwhile raw pixel pushing power comes in at a rather high 30.4 GPixels/sec, though compared to the higher-end FirePro W series cards the W7000 won’t have nearly as easy a time reaching that. Finally, with the 4.8GHz memory clock this gives the W7000 a full 153GB/sec of memory bandwidth.
Moving on, the W7000 has an official TDP of <150W, which means it requires only a single 6pin PCIe external power connector. This relatively low TDP means that AMD is also able to get away with it being a single slot card.
Display connectivity is the same as the W8000, with 4 full-size DisplayPorts and the ability to drive a 5th and 6th monitor through the use of a MST hub. 3D display connectivity is also available, but only through the use of an external bracket since there’s not enough room for the 3pin mini-DIN on the single slot card.
Finally, AMD has put the SRP on the W7000 at $899. The W7000 has design wins from both Dell and HP, and as a cheaper part should be much more common than the W8000.
FirePro W5000
| AMD FirePro W5000 Specs | ||||||
| Single Precision | Double Precision | Pixel Fillrate | Texture Fillrate | Memory Band. | ||
| 1.28TFLOPs | 0.08TFLOPs | 26.4 GPixels/sec | 39.6 GTexels/sec | 102GB/sec | ||

The final FirePro W series card is the W5000, AMD’s value part and the smaller sibling of the W7000. This is a notably pared-down part, with only 12 active CUs, giving the card 768SPs. However all 32 ROPs are available, along with 2GB of RAM that is attached to the full 256bit memory bus. With a core clock of 825MHz and a memory clock of 3.2GHz, on paper it should offer around 52% of the shading, compute, and texturing performance of the W7000, along with 66% of the memory bandwidth. This puts theoretical performance at around 1.3TFLOPs for single precision, 0.08TFLOPs for double precision, and 102GB/sec of memory bandwidth.
Along with being AMD’s value part this is also AMD’s only W series card that doesn’t require external power, thanks to its sub-75W TDP. Though this is also why it has so many disabled CUs and a much lower memory clock relative to the W7000.
Meanwhile display connectivity deviates from all of the other W series cards, with AMD dropping to two full size DisplayPorts in order to fit a single DL-DVI port. The inclusion of a DVI port is not wholly unexpected, as cards in this price range are more likely to be sold to users who don’t have a DisplayPort capable monitor, and in the meantime the $80 price of a DisplayPort to DL-DVI adapter starts to become a significant fraction of the card’s overall price. Moving on, like the W7000, 3D display connectivity is once again available via an external bracket, while in an interesting move the W5000 has become the only W series card not capable of being paired with an S400 synchronization module, with the card instead supporting an internal “IntraSystem Framelock” method.
Finally, AMD has priced the W5000 at $599. Like the W7000 this has design wins from both HP and Dell, and thanks to its low power consumption is capable of fitting into virtually any system that can support a full-profile PCIe card.
Setting the Scene: The Professional Graphics Market
Seeing as how this is our first professional video card review in quite some time, we wanted to spend a bit of time discussing the professional video card market in depth before diving into the features of AMD’s hardware. Because the professional graphics market is not particularly price-sensitive (unlikely the consumer market), how it operates is not particularly straightforward. Understanding the professional graphics market also sets the stage for understanding the importance of the FirePro W series; there’s more at stake than just beating NVIDIA’s cards.
The biggest reason that the professional graphics market is of great importance to NVIDIA and AMD isn’t just that it’s another market for them to sell products in, but because it’s not just another market. As we alluded to in our introduction, going by the volume of products shipped the professional graphics market is tiny. Even looking at revenue it’s far smaller than the consumer market. But what revenue hints at and what financial statements prove is that it’s profitable. Extremely profitable.
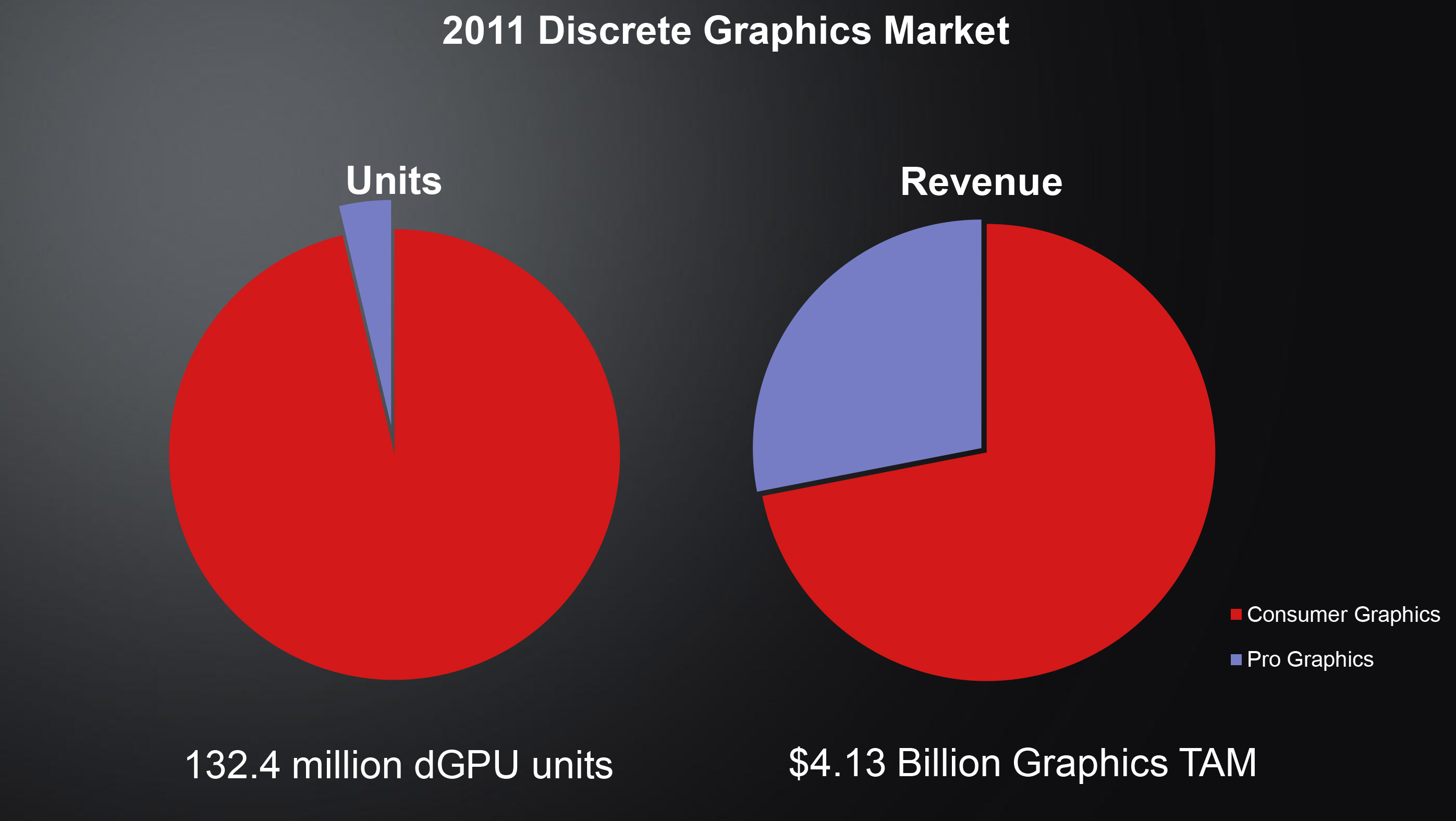
Neither AMD nor NVIDIA specifically break out their complete gross margins on a market segment basis – something that would be difficult to do since both rely on the same GPUs and R&D – but they are very straightforward in telling investors about the overall profitability of the professional market segments. To work with a simple example, take NVIDIA’s product lineup, where NVIDIA could profitably sell a GF110 GPU in the form of a GTX 580 at $500. Meanwhile the Quadro 6000 – a card containing the same GF110 GPU – was released at $5000, 10 times the price. Even after factoring in the unique costs of bringing a professional graphics product to market such as driver validation, support, and a higher individual unit cost, the professional graphics market is incredibly profitable. In the GPU market, just like most other technology markets, professionals will pay a much larger premium for specialized hardware.
The end result is that to make a significant profit in the desktop GPU market you need to hold a sizable share of both the consumer market and the professional market. The professional market will provide a low-volume, high-margin income stream, while the consumer market allows manufacturers to spread out R&D costs over a much larger number of products and to sell binned chips that would never meet professional standards.
But what happens if you don’t have a significant share of both the consumer and professional markets? Unfortunately, that would make you AMD.
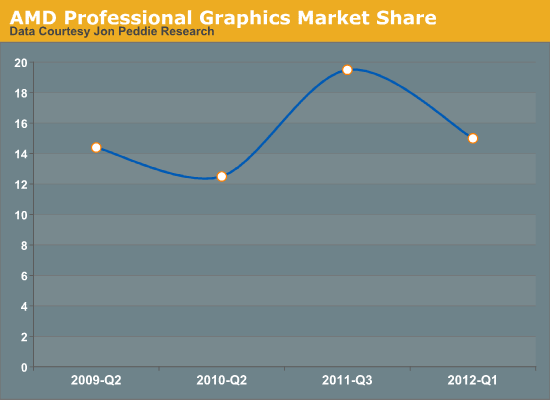
Our apologies for the inconsistent data. JPR does not regularly release detailed market share data to the public
AMD’s professional graphics presence marks a continuing battle for the company. While in the consumer space they have 25% of the total market (including iGPUs) versus NVIDIA’s 15%, and in the discrete market they have 38% to NVIDIA’s 62%, in the professional graphics market they have only a 15% market share. This is better than the near-10% share they had a few years ago, but it’s below the near-20% share they reached last year, and far below where they would like to be.
As it stands AMD’s graphics division regularly turns out a small profit (in the form of operating income) every quarter, but they’re nowhere near NVIDIA’s profitability. It goes without saying that as a business AMD is always seeking to improve their profitability for their shareholders, however they also need to turn a profit to fund R&D of future products. Just as with CPU development, GPU development costs are continuing to rise with every generation, which makes the professional graphics market and its high margins all the more important. AMD is by no means in dire straits, but long-term a sub-20% market share is not where they want to be. A sub-20% market share means that AMD is struggling to stay relevant.
AMD’s Plan of Attack
So how does AMD take back a larger share of the professional graphics market? The short answer is that there is no easy solution.
Traditionally AMD has underpriced NVIDIA on comparable hardware, and while that’s easy to do it only works to a certain extent, as showcased by AMD’s continuing sub-20% market share.
Professional graphics buyers, as it turns out, are not nearly as sensitive to price as consumers, particularly when it comes to something as relatively cheap as a video card. Depending on the job at hand a video card may be a fraction of the cost of lost time, so if buyers believe they’re getting something that is going to be more compatible or more reliable, then they can usually justify the additional cost for what’s roughly the same level of performance.
This is not to say that AMD’s products are unreliable or incompatible, but it means that for the professional graphics market perception is reality. And that perception is largely being driven by NVIDIA, who by all accounts is extremely good at product marketing and promotion and combining that marketing message with solid products. Even if AMD has a superior product they still need to counter NVIDIA’s marketing and their momentum, and that can’t be accomplished just by beating NVIDIA’s price/performance ratio.

As a result AMD has had to learn to play NVIDIA’s game. Realistically, AMD can’t match NVIDIA’s marketing muscle right away (this is where having all the profits confers an advantage), but they can match elements of NVIDIA’s winning strategy.
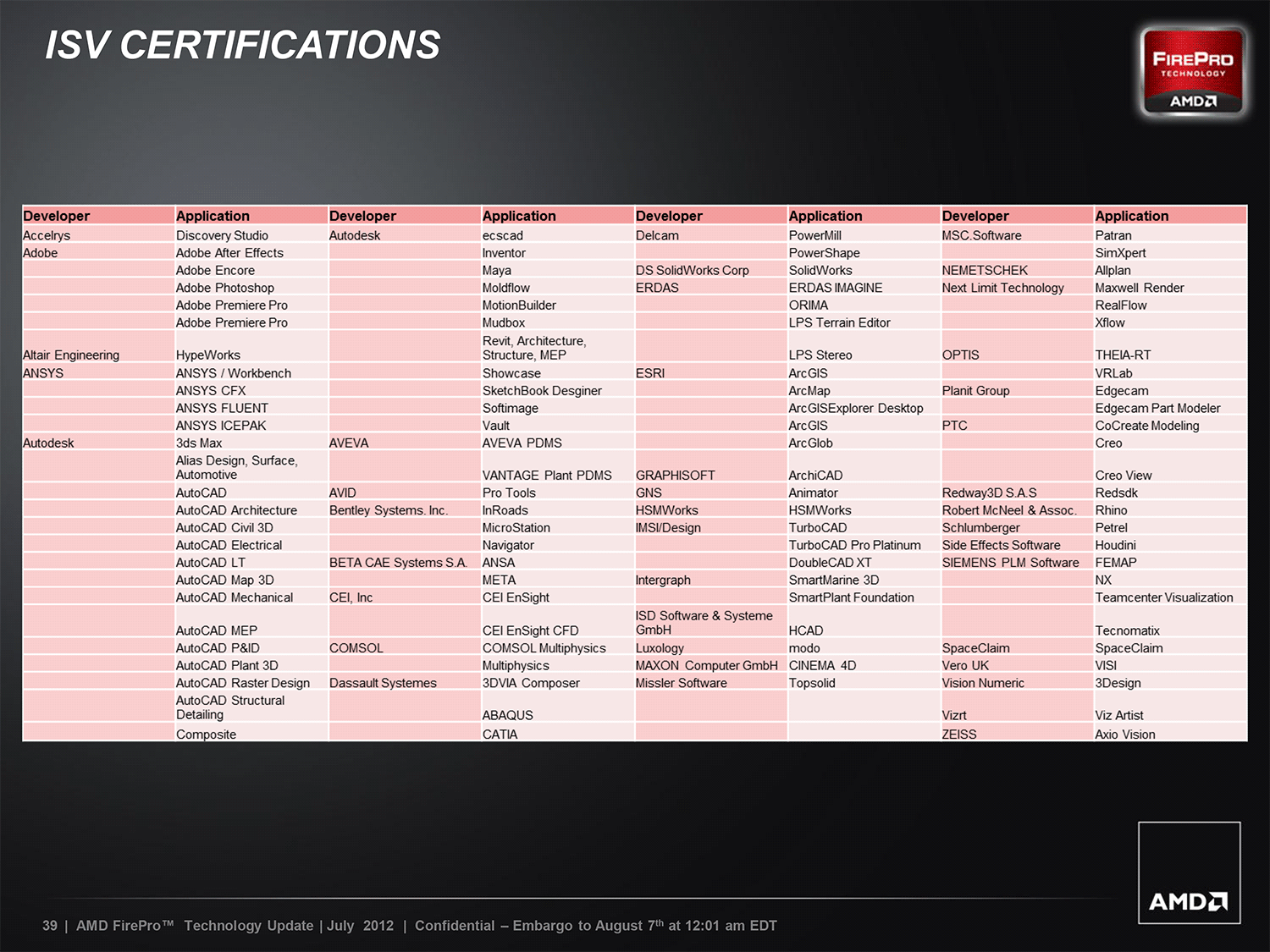
The first most important part of that strategy is to continue to improve their validation and certification process. Most of their customers are buying professional video cards to run very specific and very important applications like AutoCAD, Creo Parametric, CINEMA 4D, and of course Adobe’s Creative Suite. They aren’t necessarily using AMD’s products because they particularly like AMD, but rather because provides the best tool for the job. As a result ISV certifications are essential here, which requires AMD to be proactive in reaching out to ISVs and quick to fix any bugs keeping them from being certified. The more software they can get certified, the wider the market they can sell to.
As AMD has learned however, being proactive doesn’t just mean getting ISV certification, but also directly working with those ISVs. NVIDIA’s work with Adobe on the Mercury Playback Engine for Adobe Premiere Pro CS5 not only earned a lot of press for NVIDIA, but it made their Quadro cards the product to get for serious Premiere users. A well planned partnership will benefit both partners, with the ISV gaining the experience of the GPU vendor and the GPU vendor gaining sales from the users of that software.
To that end, AMD’s big partnership right now is with PTC, who is responsible for a number of CAD programs including Creo Parametric. Like most professional software ISVs, PTC has taken a very conservative stance towards adopting new technologies, meaning their software is slow to make use of new GPU features. In a move similar to NVIDIA’s Adobe partnership, AMD has formed a partnership with PTC to improve Creo Parametric in return for exclusive feature rights for a time.
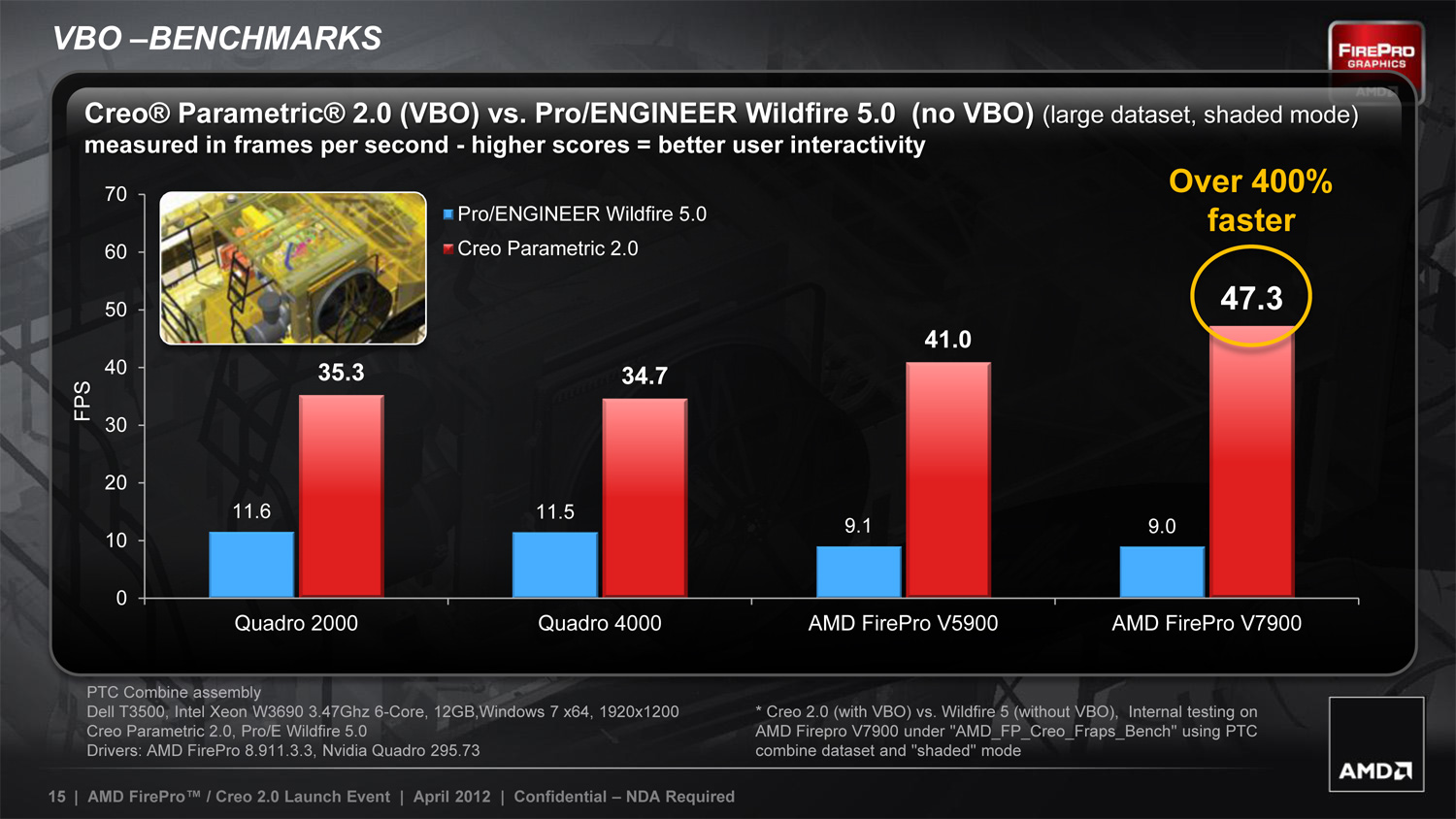
AMD has implemented Vertex Buffer Object (VBO) support and Order Independent Transparency (OIT) support in Cero Parametric, greatly speeding up the software in some cases. In return AMD has a 1 year exclusive on OIT functionality, which means that users who want to take advantage of it would need to use AMD video cards. Whether this partnership will significantly benefit AMD remains to be seen, but at the very least it’s exactly the kind of thing they need to be doing to improve their standing and their sales in the professional graphics community.
Of course ISVs are not the only partners a GPU vendor wants to have, as on the other end of the spectrum you have the hardware. Professional graphics customers buy hardware based on its performance and compatibility with the applications they use, but those same customers are generally looking to buy entire systems, not individual video cards. This makes OEM partnerships the other important partnership for AMD to work on.
AMD already regularly works with OEMs in order to integrate their consumer products, so this generally isn’t a matter of forging new partnerships, but rather making the best use of the partnerships they already have. Here AMD needs to approach OEMs in order to get their FirePro cards certified in the appropriate workstation models, and then actually land design wins for those products. For the W series AMD has already certified with and landed design wins with both Dell and HP. Specifically AMD has design wins with both companies for the W5000 and W7000, while they also have a design win with Dell on the W8000. Meanwhile the W9000 isn’t up for any design wins due to its very high price and low volume, but AMD has told us that they have the option of paying for certification themselves, at which point it would be offered as an optional upgrade for equally high-end workstations.
Bringing things to a close, AMD’s plan of attack has one final plank: compute & OpenCL evangelism. AMD likes to say that they’ve bet the company on OpenCL, and while that’s a bit exaggerated it isn’t too far from the truth. Compute performance is an important aspect of the professional graphics market (NVIDIA has proven that much), and because NVIDIA has their own proprietary compute API it’s not enough for AMD to just have good compute performance – they need to actually convince developers to use OpenCL as opposed to CUDA.
This has been an ongoing process for AMD, and unfortunately it’s one where it’s hard to gauge the results. Over the years AMD has introduced a number of new tools for OpenCL development, and though OpenCL is an open standard officially controlled by the Khronos consortium, in the public eye AMD is by far the most active proponent of OpenCL.
At this point in time AMD believes they’ve finally turned the corner on OpenCL, both in terms of general adoption and in eating into CUDA’s marketshare. Technically speaking OpenCL adoption is always increasing, but the lag time can be quite long between when an ISV announces they’ll be using it and when they actually release products that meaningfully use it. Only in the last year or so have products making meaningful use of it finally shipped, including the Adobe Creative Suite and various Autodesk products. This mirrors a general trend we’ve been seeing on the consumer desktop, where applications like WinZip and Handbrake are also finally making meaningful use of OpenCL.
As for stealing market share from NVIDIA’s CUDA, that ends up being a bit more nebulous. Research by 3rd party firms such as Evans Data Corp has OpenCL already beating CUDA, but because we don’t have access to the details of that research there’s not a lot we can say there. Programming language & API usage has always been difficult to estimate since it requires developers to volunteer information, which is good enough for measuring general trends but is often not good enough for measuring specific numbers. AMD has certainly turned some CUDA developers over to OpenCL, but judging from their respective conferences (GTC and AFDS) and the presentations given, CUDA is still alive and well, and it’s by no means clear as to whether OpenCL has overtaken CUDA. But much like the overall OpenCL adoption rate this is clearly improving.
Finally, it goes without saying that while software, tools, and marketing play a big part of AMD’s OpenCL strategy, hardware is quite often the biggest part of the equation. To that end AMD will be the first to tell you that their previous VLIW architecture wasn’t particularly well suited for compute tasks. VLIW could do very, very well in true brute force operations (e.g. password cracking), but more complex programs mapped poorly to the underlying architecture. So developers looking to write complex compute applications would often find themselves writing for NVIDIA hardware, at which point there’s a strong incentive to write those programs in CUDA In the first place.
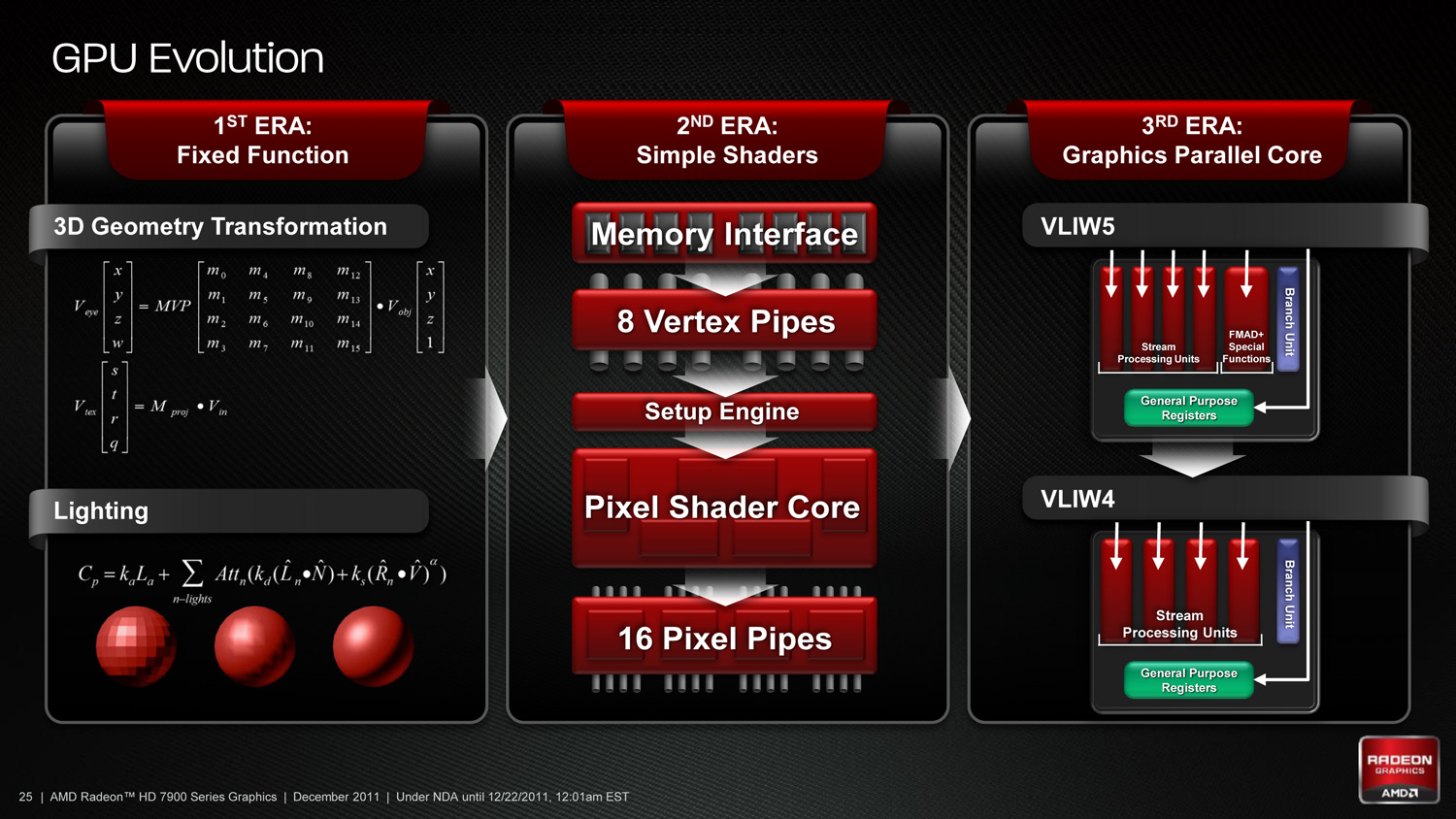
The solution to that problem was for AMD to turn to an entirely different architecture, which was introduced last year as Graphics Core Next. For AMD GCN provides the final piece of the puzzle, bringing together all of their other efforts with a high performance compute architecture. With GCN AMD can finally offer the hardware necessary to rival NVIDIA’s own compute performance, which in turn makes OpenCL more attractive to developers even if they aren’t necessarily intending to target AMD’s hardware right away, as it’s now a viable alternative.
Graphics Core Next: Compute for Professionals
As we just discussed, a big part of AMD’s strategy for the FirePro W series relies on Graphics Core Next, their new GPU architecture. Whereas AMD’s previous VLIW architectures were strong at graphics (and hence most traditional professional graphics workloads), they were ill suited for compute tasks and professional graphics workloads that integrated compute. So as part of AMD’s much larger fundamental shift towards GPU computing, AMD has thrown out VLIW for an architecture that is strong in both compute and graphics: GCN.
Since we’ve already covered GCN in-depth when it was announced last year, we’re not going to go through a complete rehash of the architecture. If you wish to know more, please see our full analysis from 2011. In place of a full breakdown we’re going to have a quick refresher, focusing on GCN’s major features and what they mean for FirePro products and professional graphics users.
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together.
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at.
As a result of these deficiencies in AMD’s fundamental compute and memory architectures, AMD faced a serious roadblock in improving their products for the professional graphics and compute markets. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is what AMD set out to do.
Having established what’s bad about AMD’s VLIW architecture as a compute architecture, let’s discuss what makes a good compute architecture. The most fundamental aspect of compute is that developers want stable and predictable performance, something that VLIW didn’t lend itself to because it was dependency limited. Architectures that can’t work around dependencies will see their performance vary due to those dependencies. Consequently, if you want an architecture with stable performance that’s going to be good for compute workloads then you want an architecture that isn’t impacted by dependencies.
Ultimately dependencies and ILP go hand-in-hand. If you can extract ILP from a workload, then your architecture is by definition bursty. An architecture that can’t extract ILP may not be able to achieve the same level of peak performance, but it will not burst and hence it will be more consistent. This is the guiding principle behind NVIDIA’s Fermi architecture; GF100/GF110 have no ability to extract ILP, and developers love it for that reason.
So with those design goals in mind, let’s talk GCN.
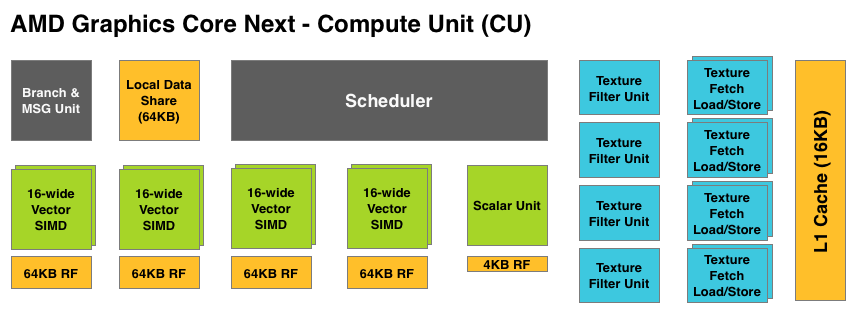
VLIW is a traditional and well proven design for parallel processing. But it is not the only traditional and well proven design for parallel processing. For GCN AMD will be replacing VLIW with what’s fundamentally a Single Instruction Multiple Data (SIMD) vector architecture (note: technically VLIW is a subset of SIMD, but for the purposes of this refresher we’re considering them to be different).
At the most fundamental level AMD is still using simple ALUs, just like Cayman before it. In GCN these ALUs are organized into a single SIMD unit, the smallest unit of work for GCN. A SIMD is composed of 16 of these ALUs, along with a 64KB register file for the SIMDs to keep data in.
Above the individual SIMD we have a Compute Unit, the smallest fully independent functional unit. A CU is composed of 4 SIMD units, a hardware scheduler, a branch unit, L1 cache, a local date share, 4 texture units (each with 4 texture fetch load/store units), and a special scalar unit. The scalar unit is responsible for all of the arithmetic operations the simple ALUs can’t do or won’t do efficiently, such as conditional statements (if/then) and transcendental operations.
Because the smallest unit of work is the SIMD and a CU has 4 SIMDs, a CU works on 4 different wavefronts at once. As wavefronts are still 64 operations wide, each cycle a SIMD will complete ¼ of the operations on their respective wavefront, and after 4 cycles the current instruction for the active wavefront is completed.
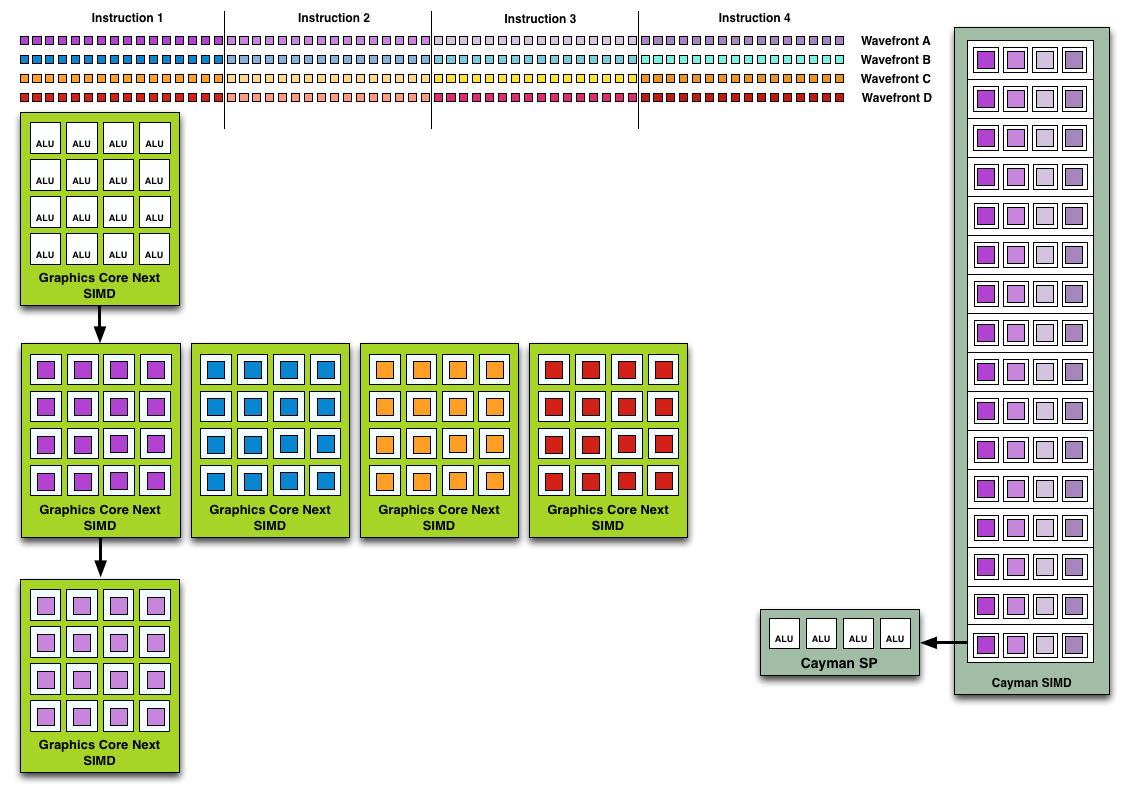
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman by comparison would attempt to execute multiple instructions from the same wavefront in parallel, rather than executing a single instruction from multiple wavefronts. This is where Cayman got bursty – if the instructions were in any way dependent, Cayman would have to let some of its ALUs go idle. GCN on the other hand does not face this issue, because each SIMD handles single instructions from different wavefronts they are in no way attempting to take advantage of ILP, and their performance will be very consistent.
There are other aspects of GCN that influence its performance – the scalar unit plays a huge part – but in comparison to Cayman, this is the single biggest difference. By not taking advantage of ILP, but instead taking advantage of Thread Level Parallism (TLP) in the form of executing more wavefronts at once, GCN will be able to deliver high compute performance and to do so consistently.
Bringing this all together, to make a complete GPU a number of these GCN CUs will be combined with the rest of the parts we’re accustomed to seeing on a GPU. A frontend is responsible for feeding the GPU, as it contains both the command processors (ACEs) responsible for feeding the CUs and the geometry engines responsible for geometry setup.
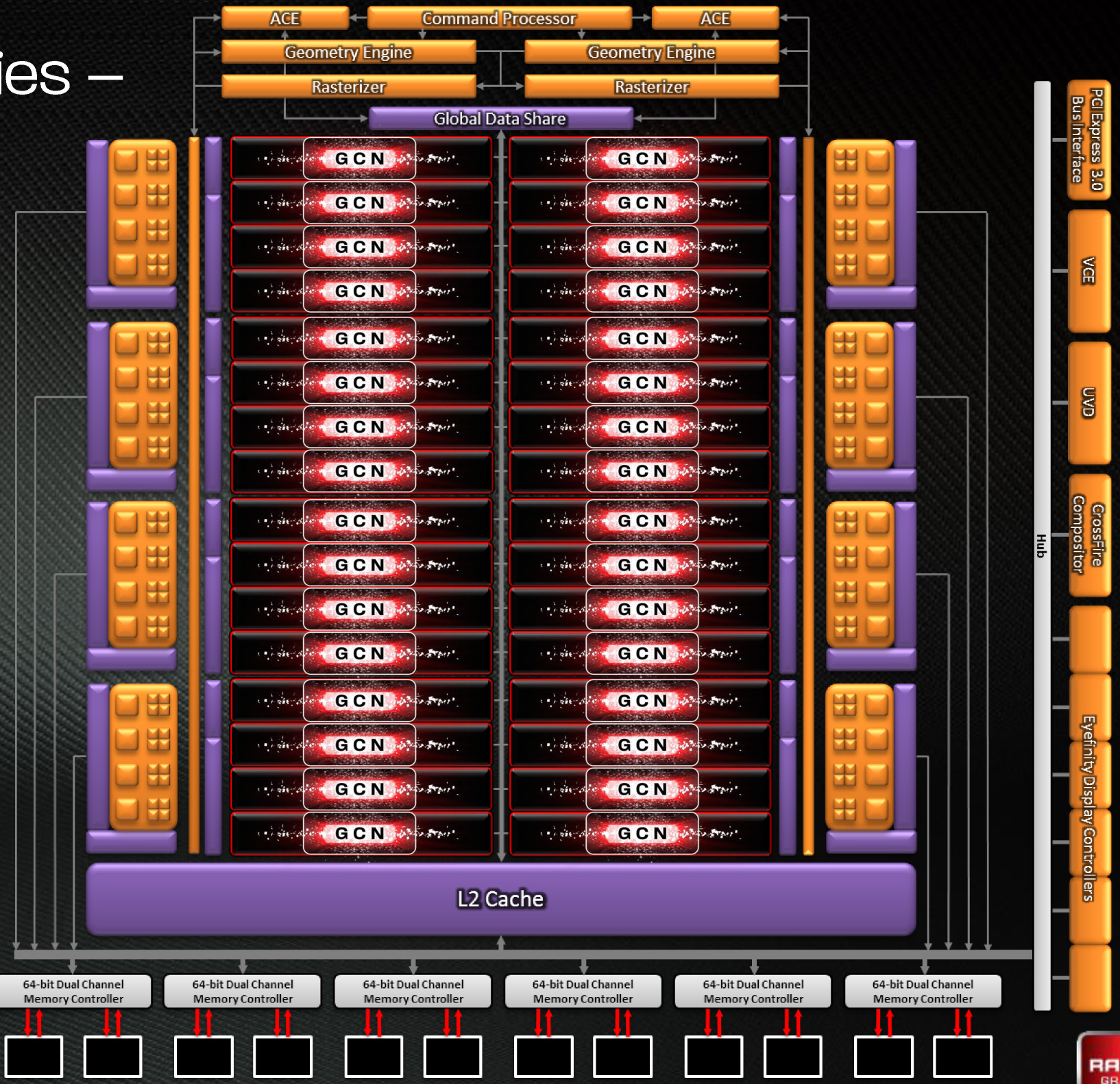
The ACEs are going to be particularly interesting to see in practice – we haven’t seen much evidence that AMD’s use of dual ACEs has had much of an impact in the consumer space, but things are a bit different in the professional space. Having two ACEs gives AMD the ability to work around some context switching performance issues, which is of importance for tasks that need steady graphics and compute performance at the same time. NVIDIA has invested in Maximus technology – Quadro + Tesla in a single system – for precisely this reason, and with the Kepler generation has made it near-mandatory as the Quadro K5000 is a compute-weak product. AMD takes a certain degree of pleasure in having a high-end GPU that can do both of these tasks well, and with the ACEs they may be able to deliver a Maximus-like experience with only a single card at a much lower cost.
Meanwhile coming after the CUs will be the ROPs that handle the actual render operations, the L2 cache, the memory controllers, and the various fixed function controllers such as the display controllers, PCIe bus controllers, Universal Video Decoder, and Video Codec Engine.
At the end of the day because AMD has done their homework GCN significantly improves AMD compute performance relative to VLIW4 while graphics performance should be just as good. Graphics shader operations will execute across the CUs in a much different manner than they did across VLIW, but they should do so at a similar speed. It’s by building out a GPU in this manner that AMD can make an architecture that’s significantly better at compute without sacrificing graphics performance, and this is why the resulting GCN architecture is balanced for both compute and graphics.
The Rest of the FirePro W Series Feature Set
So far we’ve spent quite a bit of time talking about the FirePro W series in reference to AMD’s GCN architecture. Without question GCN is the single biggest change coming from AMD’s past products, but GCN is but one component of the Southern Islands family of GPUs that are the underpinning of this generation of AMD GPU products. Much like we’ve already seen on the desktop side of things there are a number of additional features Southern Islands brings with it that have some specific relevance in the professional graphics market.
Perhaps the single biggest improvement is that Southern Islands finally introduces full Error Correcting Code (ECC) memory support. In prior generations of GPUs AMD did not have any ECC support, with the closest thing being Error Detection & Correction (EDC), which could detect errors introduces across the memory bus (a very real concern with high-speed GDDR5) but no other type of errors. This admittedly isn’t a huge concern for the graphics workloads that past generations of FirePro specialized in, but moving forward for compute workloads it’s a critical feature due to the impact of errors.
So starting with the FirePro W series AMD will have full ECC support in selected models. This will include both ECC for internal SRAM caches (which is actually a free operation), and ECC for the external VRAM (accomplished through the use of a virtual ECC scheme). This functionality is going to be limited to products based on the Tahiti GPU, which means the W9000 and W8000. As Tahiti is AMD’s only GPU specifically configured for maximum compute performance, this comes as no great surprise. Consequently, the Pitcarin based W7000 and W5000 will have no such ECC support, mirroring their lower compute performance and emphasis on graphics.
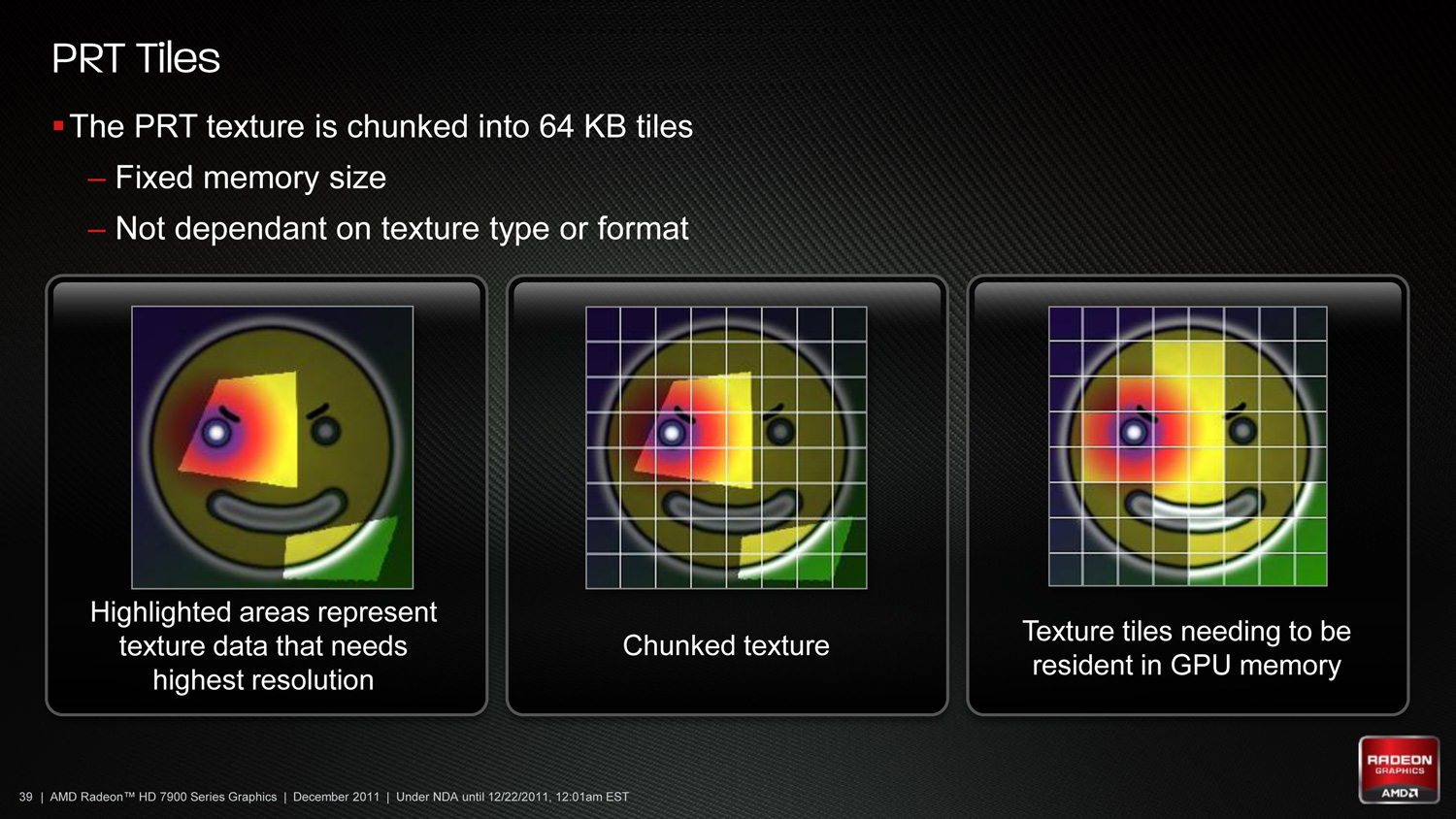
Moving on, it came as a bit of a surprise to see AMD tout their Partially Resident Texture technology as a FirePro feature. We’re accustomed to thinking of PRT as a gaming technology – particularly due to the id Software Megatexture technology – but AMD tells us that it should be applicable to any kind of application using a large data set. More importantly however is the fact that since PRT can only be accessed under OpenGL right now, it’s far more accessible to professional graphics applications (which almost exclusively use OpenGL) as opposed to games and their heavy reliance on Direct3D. In any case we aren’t going to go into great detail about this technology since we’ve covered it before, but it should be interesting to see if AMD’s predictions are right.
Meanwhile, PowerTune marks its return on the FirePro W series. PowerTune, as you may recall, is AMD’s power throttling technology which is responsible for reining in on video card power consumption to keep it below a desired level. AMD has had PowerTune since the last-generation Cayman GPU, but it was only available on that GPU, meaning it wasn’t available on AMD’s top-tier FirePro cards such as the V9800. With The FirePro W series it’s finally available across AMD’s entire lineup, marking the first time it’s available to products like the W7000 and W5000. Given the latter’s sub-75W TDP, PowerTune is going to play an especially important role in making that possible.

Also seeing its introduction in Southern Islands and by extension the FirePro W series is PCI-Express 3.0 support. PCIe 3.0 doubles the effective transfer rate for a PCIe x16 slot to 16GB/sec in each direction, up from 8GB/sec in PCIe 2.0. This won’t make much of a difference for graphics workloads since they rarely consume 8GB/sec in the first place, but for compute workloads this is a critical feature. Any compute workloads that need to constantly send large amounts of data back and forth between the CPU and GPU should significantly benefit from this.
Finally, in another unexpected feature mention within AMD’s marketing materials, AMD is taking the time to mention their Video Codec Engine (VCE) hardware H.264 encoder, which was also introduced in Southern Islands. Both AMD and NVIDIA have been taking the time to mention their hardware video encoders in their respective professional graphics cards, which is unexpected given the fact that these hardware encoders are primarily intended for consumer uses such as quick video transcoding and video conferencing; neither encoder is up to the task of broadcast/archival quality video. Nevertheless, while neither company seems to have a solid idea of what to do with the hardware in the professional market, they’re throwing it out there in order to see what their customers can come up with.
R.I.P: FireStream (2006 - 2012)
It goes without saying that with GCN AMD has significantly improved their GPU compute capabilities across the board. Consumer compute has already benefitted through the Radeon HD 7000 series, while professional graphics will begin benefiting with the FirePro W series, and GCN will be laying the foundation for the Heterogeneous System Architecture (HSA) in 2014. All of AMD’s product lines are benefiting from GCN… all of them but one: FireStream.
For those of you not familiar with FireStream, FireStream is (or rather was) AMD’s line of dedicated GPU compute products. Initially launched in 2006 and based on AMD’s R580 GPU, the FireStream was AMD’s first product geared exclusively towards GPU computing. Since 2006 AMD has regularly updated the product line, releasing new cards based on the RV670, RV770, and RV870 GPUs.
The most recent refresh of the product was the release of the FireStream 9300 series in 2010, which saw the FireStream family move to AMD’s first meaningfully capable OpenCL GPU, the RV870. Since then AMD ended up choosing to skip a 2011 refresh of the product based on their Cayman (VLIW4) GPU, which was a somewhat odd move at the time. While VLIW4 is not the kind of superior compute architecture that GCN is, it was still fundamentally designed to improve AMD’s compute performance, which it did thanks to the use of narrower SIMDs that allowed for a partial shift away from ILP to TLP. Nevertheless, as we found out after the fact with the launch of GCN, major users weren’t interested in moving to VLIW4, almost certainly having early knowledge that VLIW4 would be a dead-end architecture to be replaced by GCN in 2012.

In any case, with the release of GCN and its significant compute enhancements we have been expecting a major update to the FireStream product family. But as it turns out AMD has other plans.
Starting with the launch of the FirePro W series the FireStream family of products is being discontinued entirely. From here on the FirePro family will officially be pulling double-duty as both AMD’s professional graphics product and AMD’s compute product.
So why is AMD choosing now to discontinue the FireStream family at this point in time? Officially, AMD believes the FireStream family to be redundant. AMD’s FireStream cards were nearly identical to their FirePro cards in both build and performance, with the only practical difference being that FireStream cards had most of their display connectors removed. And AMD is right – by all accounts the FireStream 9300 series did very little to differentiate itself from the equivalent FirePro cards.
Meanwhile FireStream as a brand hasn’t kept up with NVIDIA’s Tesla business in the dedicated compute market. NVIDIA’s Tesla business is still a fledging business – it’s grown by leaps and bounds since 2010, but not as much as NVIDIA would like – but even so the company has created several distinctions between Tesla and Quadro that AMD never did replicate with FireStream. Chief among these was a compute-focused driver for Windows (NVIDIA calls it TCC), which stripped away all of the graphics capabilities of the card in order improve compute performance by freeing it from the control of the Windows display driver subsystem. Furthermore NVIDIA went and developed a couple different lines of Tesla cards, branching out into both traditional self-cooled cards for workstations and servers, and purely passive cards meant for specialized rackmount servers. For the FirePro V series AMD does have both active and passive cooled FirePro cards, however the FireStream cards were only available with passive cooling.

FirePro V9800P(assive)
The other limitation for AMD in this arena was of course their GPUs. GCN gives AMD a very potent compute architecture that is unquestionably competitive with Fermi and little Kepler, but there’s one thing NVIDIA will do that AMD won’t: build it big. AMD doesn’t strictly adhere to a small-die strategy (300-400mm2 is now their sweet spot), but they also don’t build 500mm2+ behemoths like NVIDIA. There’s a great deal more to compute performance than die size of course (especially when NVIDIA has disabled functional units on most Fermi Tesla parts for yield and power reasons), but it does lock AMD out of certain markets that desire as much individual GPU performance as possible. GPUs excel at parallel problems, however not every problem scales well across multiple GPUs (mostly due to memory sharing needs), which means there’s still a need for a very large GPU.
As a result of these factors, AMD’s RV870 FireStream cards never did gather a great following. GCN fixes the fundamental compute performance problem that was the chief factor holding back FireStream, but this would appear to be a case of too little, too late for FireStream. Of course AMD will continue to have a very important presence in the overall GPU computing market, but at least for now they’re seceding from producing a dedicated compute product.
In lieu of having a dedicated compute product FirePro will be serving both markets. In fact AMD tells us that there are already plans to build compute clusters out of FirePro W series cards (though they can’t name names at this time), reinforcing the notion that AMD is still active in the compute market even without a dedicated product. The big question of course is how potential customers will respond to this; customers may not be interested in a mixed-function part even if the performance was to be the same. Throwing a further wrench in AMD’s plans will be pricing – they may be underpricing NVIDIA’s best Quadro, but right now they’re going to be charging well more than NVIDIA’s best Tesla card. So there’s a real risk right now that FirePro for compute may be a complete non-starter once Tesla K20 arrives at the end of the year.
Perhaps for that very reason AMD’s promotional focus with FirePro is largely focused on professional graphics right now. Certainly the company is proud of their achievements in compute performance, but going by AMD’s marketing materials AMD is definitely focused on graphics first and foremost with FirePro.
More to Come, So Stay Tuned
Wrapping up the first part of our review of the FirePro W9000 and W8000, we’ve taken a look at the specifications of the new FirePro W series, along with looking at the impact of Graphics Core Next for professional graphics, and how all of this fits together in AMD’s larger plans. AMD’s big goal remains to capture a much larger share of the lucrative professional graphics market from NVIDIA in order to break out of the sub-20% rut they’ve been in for some time. To do that they not only need to deliver solid hardware at a reasonable price, but also exceptionally solid drivers, and major industry partnerships that will advance the state of professional graphics applications and help AMD counter NVIDIA’s strong marketing message at the same time.
Later this week we’ll be publishing our second part of this review, focusing on building a professional graphics test suite and the resulting benchmarks. It goes without saying that benchmarking professional cards comes with quite a few quirks, less so because of the hardware and more because of the typical programs. A typical professional graphics application looks, acts, and renders nothing like a game – in particular shaders are sparingly used – which means that performance bottlenecks are in entirely different places.
This actually poses a recurring problem for the professional graphics industry, since compute/shader performance has been growing by leaps and bounds, while raw texture and pixel throughput has been much more modest. This reflects the consumer market where games are primarily investing in shader effects and 1080P has been a staple resolution for quite some time, but it means that many professional applications aren’t directly tapping much of a modern GPU’s capabilities since shaders aren’t heavily used. Instead some professional applications can tap those resources through the use of compute, which is part of the reason why AMD and NVIDIA both invest in projects that increase the use of compute in the professional graphics market.
Anyhow, we’ll have more on the performance of the FirePro W series later this week with our follow-up article. So until then stay tuned.







