Original Link: https://www.anandtech.com/show/5058/amds-opteron-interlagos-6200
Bulldozer for Servers: Testing AMD's "Interlagos" Opteron 6200 Series
by Johan De Gelas on November 15, 2011 5:09 PM ESTIntroducing AMD's Opteron 6200 Series
When virtualization started to get popular (ca. 2005-2007), there was a fear that this might slow the server market down. Now several years later, the server market has rarely disappointed and continues to grow. For example, IDC reported a 12% increase in revenue when comparing Q1 2010 and Q1 2011. The server market in total accounted for $12 billion revenue and almost two million shipments in Q1 2011, and while the best desktop CPUs generally sell for $300, server chips typically start at $500 and can reach prices of over $3000. With the high-end desktop market shrinking to become a niche for hardcore enthusiasts--helped by the fact that moderate systems from several years back continue to run most tasks well--the enterprise market is very attractive.
Unfortunately for AMD, their share of the lucrative server market has fallen to a very low percentage (4.9%) according IDC's report early this year (some report 6-7%). It is time for something new and better from AMD, and it seems that the Bulldozer architecture is AMD's most server-centric CPU architecture ever. We quote Chuck Moore, Chief Architect AMD:
By having the shared architecture, reducing the size and sharing things that aren’t commonly used in their peak capacity in server workloads, “Bulldozer” is actually very well aligned with server workloads now and on into the future. In fact, a great deal of the trade-offs in Bulldozer were made on behalf of servers, and not just one type of workload, but a diversity of workloads.
This alginment with server workloads can also be found in the specs:
|
Opteron 6200 "Interlagos" |
Opteron 6100 "Magny-cours" |
Xeon 5600 "Westmere" |
|
| Cores (Modules)/Threads | 8/16 | 12/12 | 6/12 |
| L1 Instructions | 8x 64 KB 2-way | 12x 64 KB 2-way | 6x 32 KB 4-way |
| L1 Data | 16x 16 KB 4-way | 12x 64 KB 2-way | 6x 32 KB 4-way |
| L2 Cache | 4x 2MB | 12x 0.5MB | 6x 256 KB |
| L3 Cache | 2x 8MB | 2x 6MB | 12MB |
| Memory Bandwidth | 51.2GB/s | 42.6GB/s | 32GB/s |
| IMC Clock Speed | 2GHz | 1.8GHz | 2GHz |
| Interconnect | 4x HT 3.1 (6.4 GT/s) | 4x HT 3.1 (6.4 GT/s) | 2x QPI (4.8-6.4 GT/s) |
The new Opteron has loads of cache, faster access to memory and more threads than ever. Of course, a good product is more than a well designed microarchitecture with impressive specs on paper. The actual SKUs have to be attractively priced, reach decent clock speeds, and above all offer a good performance/watt ratio. Let us take a look at AMD's newest Opterons and how they are positioned versus Intel's competing Xeons.
| AMD vs. Intel 2-socket SKU Comparison | |||||||||
| Xeon |
Cores/ Threads |
TDP |
Clock (GHz) |
Price | Opteron |
Modules/ Threads |
TDP |
Clock (GHz) |
Price |
| High Performance | High Performance | ||||||||
| X5690 | 6/12 | 130W | 3.46/3.6/3.73 | $1663 | |||||
| X5675 | 6/12 | 95W | 3.06/3.33/3.46 | $1440 | |||||
| X5660 | 6/12 | 95W | 2.8/3.06/3.2 | $1219 | |||||
| X5650 | 6/12 | 95W | 2.66/2.93/3.06 | $996 | 6282 SE | 8/16 | 140W | 2.6/3.0/3.3 | $1019 |
| Midrange | Midrange | ||||||||
| E5649 | 6/12 | 80W | 2.53/2.66/2.8 | $774 | 6276 | 8/16 | 115W | 2.3/2.6/3.2 | $788 |
| E5640 | 4/8 | 80W | 2.66/2.8/2.93 | $774 | |||||
| 6274 | 8/16 | 115W | 2.2/2.5/3.1 | $639 | |||||
| E5645 | 6/12 | 80W | 2.4/2.53/2.66 | $551 | 6272 | 8/16 | 115W | 2.0/2.4/3.0 | $523 |
| 6238 | 6/12 | 115W | 2.6/2.9/3.2 | $455 | |||||
| E5620 | 4/8 | 80W | 2.4/2.53/2.66 | $387 | 6234 | 6/12 | 115W | 2.4/2.7/3.0 | $377 |
| High clock / budget | High clock / budget | ||||||||
| X5647 | 4/8 | 130W | 2.93/3.06/3.2 | $774 | |||||
| E5630 | 4/8 | 80W | 2.53/2.66/2.8 | $551 | 6220 | 4/8 | 115W | 3.0/3.3/3.6 | $455 |
| E5607 | 4/4 | 80W | 2.26 | $276 | 6212 | 4/8 | 115W | 2.6/2.9/3.2 | $266 |
| Power Optimized | Power Optimized | ||||||||
| L5640 | 6/12 | 60W | 2.26/2.4/2.66 | $996 | |||||
| L5630 | 4/8 | 40W | 2.13/2.26/2.4 | $551 | 6262HE | 8/16 | 85W | 1.6/2.1/2.9 | $523 |
The specifications (16 threads, 32MB of cache) and AMD's promises that Interlagos would outperform Magny-cours by a large margin created the impression that the Interlagos Opteron would give the current top Xeons a hard time. However, the newest Opteron cannot reach higher clock speeds than the current Opteron (6276 at 2.3GHz), and AMD positions the Opteron 6276 2.3GHz as an alternative to the Xeon E5649 at 2.53GHz. As the latter has a lower TDP, it is clear that the newest Opteron has to outperform this Xeon by a decent margin. In fact most server buyers expect a price/performance bonus from AMD, so the Opteron 6276 needs to perform roughly at the level of the X5650 to gain the interest of IT customers.
Judging from the current positioning, the high-end is a lost cause for now. First, AMD needs a 140W TDP chip to compete with the slower parts of Intel's high-end armada. Second, Sandy Bridge EP is coming out in the next quarter--we've already seen the desktop Sandy Bridge-E launch, and adding two more cores (four more threads) for the server version will only increase the performance potential. The Sandy Bridge cores have proven to be faster than Westmere cores, and the new Xeon E5 will have eight of them. Clock speeds will be a bit lower (2.0-2.5GHz), but we can safely assume that the new Xeon E5 will outperform its older brother by a noticeable margin and make it even harder for the new Opteron to compete in the higher end of the 2P market.
At the low-end, we see some interesting offerings from AMD. Our impression is that the 6212 at 2.6-2.9GHz is very likely to offer a better performance per dollar ratio than the low-end Xeons E560x that lack Hyper-Threading and turbo support.
Okay, we've done enough analyzing of paper specs; let's get to the hardware and the benchmarks. Before we do that, we'll elaborate a bit on what a server centric architecture should look like. What makes server applications tick?
What Makes Server Applications Different?
The large caches and high integer core (cluster) count in one Orochi die (four CMT module Bulldozer die) made quite a few people suspect that the Bulldozer design first and foremost was created to excel in server workloads. Reviews like our own AMD FX-8150 launch article have revealed that single-threaded performance has (slightly) regressed compared to the previous AMD CPUs (Istanbul core), while the chip performs better in heavy multi-threaded benchmarks. However, high performance in multi-threaded workstation and desktop applications does not automatically mean that the architecture is server centric.
A more in depth analysis of the Bulldozer architecture and its performance will be presented in a later article as it is out of the scope of this one. However, many of our readers are either hardcore hardware enthusiasts or IT professionals that really love to delve a bit deeper than just benchmarks showing if something is faster/slower than the competition, so it's good to start with an explanation of what makes an architecture better suited for server applications. Is the Bulldozer architecture a “server centric architecture”?
What makes a server application different anyway?
There have been extensive performance characterizations on the SPEC CPU benchmark, which contains real-world HPC (High Performance Computing), workstation, and desktop applications. The studies of commercial web and database workloads on top of real CPUs are less abundant, but we dug up quite a bit of interesting info. In summary we can say that server workloads distinguish themselves from the workstation and desktop ones in the following ways.
They spend a lot more time in the kernel. Accessing the network stack, the disk subsystem, handling the user connections, syncing high amounts of threads, demanding more memory pages for expending caches--server workloads make the OS sweat. Server applications spend about 20 to 60% of their execution time in the kernel or hypervisor, while in contrast most desktop applications rarely exceed 5% kernel time. Kernel code tends to be very low IPC (Instructions Per Clockcycle) with lots of dependencies.
That is why for example SPECjbb, which does not perform any networking and disk access, is a decent CPU benchmark but a pretty bad server benchmark. An interesting fact is that SPECJBB, thanks to the lack of I/O subsystem interaction, typically has an IPC of 0.5-0.9, which is almost twice as high as other server workloads (0.3-0.6), even if those server workloads are not bottlenecked by the storage subsystem.
Another aspect of server applications is that they are prone to more instruction cache misses. Server workloads are more complex than most processing intensive applications. Processing intensive applications like encoders are written in C++ using a few libraries. Server workloads are developed on top of frameworks like .Net and make of lots of DLLs--or in Linux terms, they have more dependencies. Not only is the "most used" instruction footprint a lot larger, dynamically compiled software (such as .Net and Java) tends to make code that is more scattered in the memory space. As a result, server apps have much more L1 instruction cache misses than desktop applications, where instruction cache misses are much lower than data cache misses.
Similar to the above, server apps also have more L2 cache misses. Modern desktop/workstation applications miss the L1 data cache frequently and need the L2 cache too, as their datasets are much larger than the L1 data cache. But once there, few applications have significant L2 cache misses. Most server applications have higher L2 cache misses as they tend to come with even larger memory footprints and huge datasets.
The larger memory footprint and shrinking and expanding caches can cause more TLB misses too. Especially virtualized workloads need large and fast TLBs as they switch between contexts much more often.
As most server applications are easier to multi-thread (for example, a thread for each connection) but are likely to work on the same data (e.g. a relational database), keeping the caches coherent tends to produce much more coherency traffic, and locks are much more frequent.
Some desktop workloads such as compiling and games have much higher branch misprediction ratios than server applications. Server applications tend to be no more branch intensive than your average integer applications.
Quick Summary
The end result is that most server applications have low IPC. Quite a few workstation applications achieve 1.0-2.0 IPC, while many server applications execute 3 to 5 times fewer instructions on average per cycle. Performance is dominated by Memory Level Parallelism (MLP), coherency traffic, and branch prediction in that order, and to a lesser degree integer processing power.
So is "Bulldozer" a server centric architecture? We'll need a more in-depth analysis to answer this question properly, but from a high level perspective, yes, it does appear that way. Getting 16 threads and 32MB of cache inside a 115W TDP power consumption envelope is no easy feat. But let the hardware and benchmarks now speak.
Inside Our Interlagos Test System
When a new server arrives, we cannot resist to check out the hardware of course.

The Supermicro A+ server 1022G-URF offers 16 DIMM slots, good for a maximum of 256GB of RAM.

Supermicro's motherboard are L-shaped, allowing you to add an extra "Supermicro UIO" PCIe card on top of the "normal" horizontal PCIe 2.0 x16 slot. Two redundant 80Plus Gold PSUs are available.
The board reports a 5.2 GT/s HT link to the chipset. The interconnect between the NUMA nodes runs at 6.4 GT/s.

We configured the C-state mode to C6 as this is required to get the highest Turbo Core frequencies. Also note that you can cap the CPU to a lower clock speed (P-state) by setting a PowerCap.
Benchmark Configuration
Since AMD sent us a 1U Supermicro server, we had to resort to testing our 1U servers again. That is why we went back to the ASUS RS700 for the Xeon. It is a bit unfortunate as on average 1U servers have a relatively worse performance/watt ratio than other form factors such as 2U and blades. Of course, 1U still makes sense in low cost, high density HPC environments.
Supermicro A+ server 1022G-URG (1U Chassis)
| CPU |
Two AMD Opteron "Bulldozer" 6276 at 2.3GHz Two AMD Opteron "Magny-Cours" 6174 at 2.2GHz |
| RAM | 64GB (8x8GB) DDR3-1600 Samsung M393B1K70DH0-CK0 |
| Motherboard | SuperMicro H8DGU-F |
| Internal Disks |
2 x Intel SLC X25-E 32GB or 1 x Intel MLC SSD510 120GB |
| Chipset | AMD Chipset SR5670 + SP5100 |
| BIOS version | v2.81 (10/28/2011) |
| PSU | SuperMicro PWS-704P-1R 750Watt |
The AMD CPUS have four memory channels per CPU. The new Interlagos Bulldozer CPU supports DDR3-1600, and thus our dual CPU configuration gets eight DIMMs for maximum bandwidth.
Asus RS700-E6/RS4 1U Server
| CPU |
Two Intel Xeon X5670 at 2.93GHz - 6 cores Two Intel Xeon X5650 at 2.66GHz - 6 cores |
| RAM | 48GB (12x4GB) Kingston DDR3-1333 FB372D3D4P13C9ED1 |
| Motherboard | Asus Z8PS-D12-1U |
| Chipset | Intel 5520 |
| BIOS version | 1102 (08/25/2011) |
| PSU | 770W Delta Electronics DPS-770AB |
To speed up testing, we tested with the Intel Xeon and AMD Opteron system in parallel. As we didn't have more than eight 8GB DIMMs, we used our 4GB DDR3-1333 DIMMs. The Xeon system only gets 48GB, but this is no disadvantage as our benchmark with the highest memory footprint (vApus FOS, 5 tiles) uses no more than 36GB of RAM.
We measured the difference between 12x4GB and 8x8GB of RAM and recalculated the power consumption for our power measurements (note that the differences were very small). There is no alternative as our Xeon has three memory channels and cannot be outfitted with the same amount of RAM as our Opteron system (four channels).
We chose the Xeons based on AMD's positioning. The Xeon X5649 is priced at the same level as the Opteron 6276 but we didn't have the X5649 in the labs. As we suggested earlier, the Opteron 6276 should reach the performance of the X5650 to be attractive, so we tested with the X5670 and X5650. We only tested with the X5670 in some of the tests because of time constraints.
Common Storage System
For the virtualization tests, each server gets an adaptec 5085 PCIe x8 (driver aacraid v1.1-5.1[2459] b 469512) connected to six Cheetah 300GB 15000 RPM SAS disks (RAID-0) inside a Promise JBOD J300s. The virtualization testing requires more storage IOPs than our standard Promise JBOD with six SAS drives can provide. To counter this, we added internal SSDs:
- We installed the Oracle Swingbench VMs (vApus Mark II) on two internal X25-E SSDs (no RAID). The Oracle database is only 6GB large. We test with two tiles. On each SSD, each OLTP VM accesses its own database data. All other VMs (web, SQL Server OLAP) are stored on the Promise JBOD (see above).
- With vApus FOS, Zimbra is the I/O intensive VM. We spread the Zimbra data over the two Intel X25-E SSDs (no RAID). All other VMs (web, MySQL OLAP) get their data from the Promise JBOD (see above).
We monitored disk activity and phyiscal disk adapter latency (as reported by VMware vSphere) was between 0.5 and 2.5 ms.
Software configuration
All vApus testing was done one ESXi vSphere 5--VMware ESXi 5.0.0 (b 469512 - VMkernel SMP build-348481 Jan-12-2011 x86_64) to be more specific. All vmdks use thick provisioning, independent, and persistent. The power policy is "Balanced Power" unless indicated otherwise. All other testing was done on Windows 2008 R2 SP1.
Other notes
Both servers were fed by a standard European 230V (16 Amps max.) powerline. The room temperature was monitored and kept at 23°C by our Airwell CRACs.
We used the Racktivity ES1008 Energy Switch PDU to measure power. Using a PDU for accurate power measurements might same pretty insane, but this is not your average PDU. Measurement circuits of most PDUs assume that the incoming AC is a perfect sine wave, but it never is. However, the Rackitivity PDU measures true RMS current and voltage at a very high sample rate: up to 20,000 measurements per second for the complete PDU.
Virtualization Performance: Linux VMs on ESXi
We introduced our new vApus FOS (For Open Source) server workloads in our review of the Facebook "Open Compute" servers. In a nutshell, it a mix of four VMs with open source workloads: two PhpBB websites (Apache2, MySQL), one OLAP MySQL "Community server 5.1.37" database, and one VM with VMware's open source groupware Zimbra 7.1.0. Zimbra is quite a complex application as it contains the following components:
- Jetty, the web application server
- Postfix, an open source mail transfer agent
- OpenLDAP software, user authentication
- MySQL is the database
- Lucene full-featured text and search engine
- ClamAV, an anti-virus scanner
- SpamAssassin, a mail filter
- James/Sieve filtering (mail)
All VMs are based on a minimal CentOS 5.6 setup with VMware Tools installed. All our current virtualization testing is on top of the hypervisor which we know best: ESXi (5.0). CentOS 5.6 is not ideal for the Interlagos Opteron, but we designed the benchmark a few months ago. It took us weeks to get this benchmark working and repeatable (especially the latter is hard). For example it was not easy to get Zimbra fully configured and properly benchmarked due to the complex usage patterns and high I/O usage. Besides, the reality is that VMs often contain older operating systems. We hope to show some benchmarks based on Linux kernel version 3.0 or later in our next article.
We tested with five tiles (one tile = four VMs). Each tile needs seven vCPUs, so the test requires 35 vCPUs.
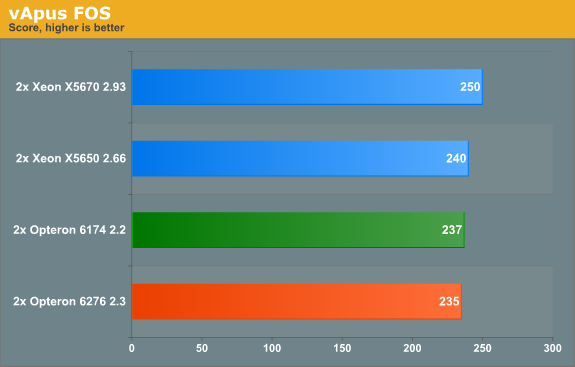
The Opteron 6276 stays close to the more expensive Xeons. That makes the Opteron server the one with the best performance per dollar. Still, we feel a bit underwhelmed as the Opteron 6276 fails to outperform the previous Opteron by a tangible margin.
The benchmark above measures throughput. Response times are even more important. Let us take a look at the table below, which gives you the average response time per VM:
| vApus FOS Average Response Times (ms), lower is better! | ||||||||
| CPU | PhpBB1 | PHPBB2 | MySQL OLAP | Zimbra | ||||
| AMD Opteron 6276 | 737 | 587 | 170 | 567 | ||||
| AMD Opteron 6174 | 707 | 574 | 118 | 630 | ||||
| Intel Xeon X5670 | 645 | 550 | 63 | 593 | ||||
| Intel Xeon X5650 | 678 | 566 | 102 | 655 | ||||
The Xeon X5670 wins a landslide victory in MySQL. MySQL has always scaled better with clock speed than with cores, so we expect that clock speed played a major role here. The same is true for our first VM: this VM gets only one CPU and as result runs quicker on the Xeon. In the other applications, the Opteron's higher (integer) core count starts to show. However, AMD cannot really be satisfied with the fact that the old Opteron 6174 delivers much better MySQL performance. We suspect that the high latency L2 cache and higher branch misprediction penalty (20 vs 12) is to blame. MySQL performance is characterized by a relatively high amount of branches and a lot of accesses to the L2. The Bulldozer server does manage to get the best response time on our Zimbra VM, however, so it's not a complete loss.
Performance per watt remains the most important metric for a large part of the server market. So let us check out the power consumption that we measured while we ran vApus FOS.
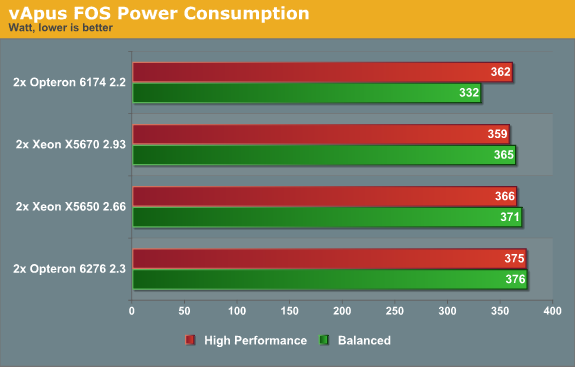
The power consumption numbers are surprising to say the least. The Opteron 6174 needs quite a bit less energy than the two other contenders. That is bad news for the newest Opteron. We found out later that some tinkering could improve the situation, as we will see further.
Measuring Real-World Power Consumption, Part One
The Equal Workload (EWL) version of vApus FOS is very similar to our previous vApus Mark II "Real-world Power" test. To create a real-world “equal workload” scenario, we throttle the number of users in each VM to a point where you typically get somewhere between 20% and 80% CPU load on a modern dual CPU server. The amount of requests is the same for each system, hence "equal workload".
The CPU Load on the Opteron 6276 looked like this:
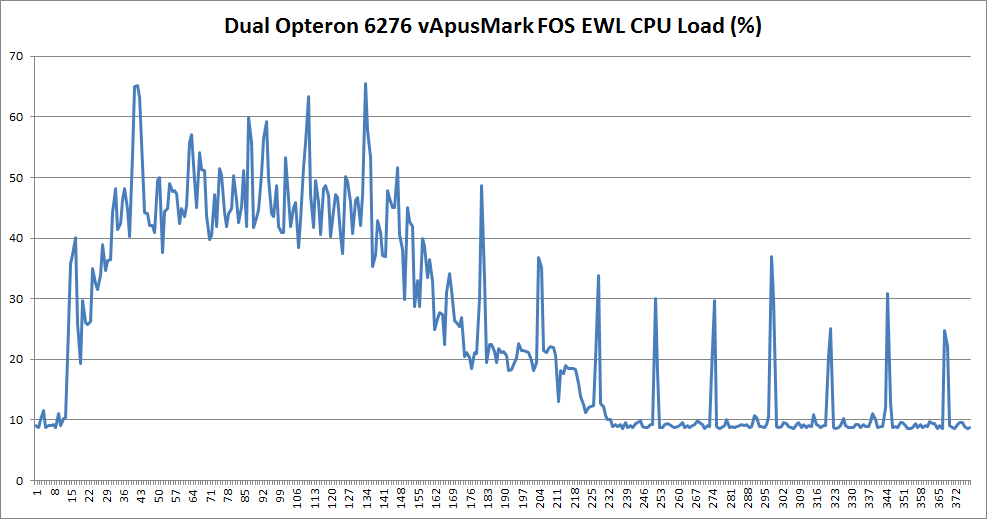
The CPU load is typically around 30-50%, with peaks up to 65%. At the end of the test, we get to a low 10%, which is ideal for the machine to boost to higher CPU clocks (Turbo) and race to idle. First we check out the response times.
| vApus FOS Response times (ms) | ||||||||
| CPU | PhpBB1 | PHPBB2 | MySQL OLAP | Zimbra | ||||
| AMD Opteron 6276 | 134 | 47 | 3.6 | 44 | ||||
| AMD Opteron 6174 | 118 | 41 | 3.8 | 45 | ||||
| Intel Xeon X5670 | 76 | 27 | 2.2 | 28 | ||||
ESXi and our Interlagos "Opteron" probably don't understand each other fully, given the newness of the architecture. Some extensive monitoring with ESXtop shows that the lower CPU load is spread among all the cores, and the result is that the Opteron 6276 never reaches its highest clock speed (3.2GHz). That helps make the response times significantly higher than on the Xeon, although they are acceptable. Again, the Interlagos Opteron fails to really beat the "Magny-cours" Opteron.
Our main focus of this benchmark is of course energy consumption.
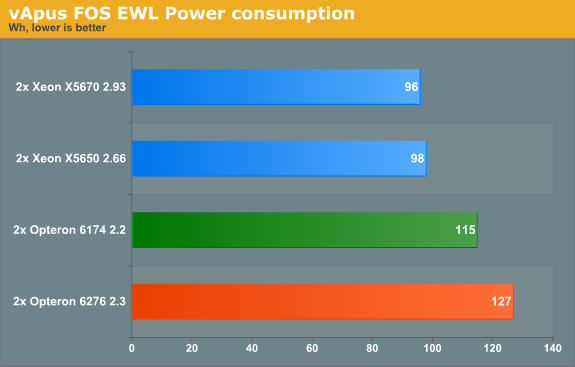
The Xeon consumes 25% less power, and the older Opteron about 10% less. The performance/Watt ratio of the newest Opteron looks rather bad when running on top of ESX. We shall delve into this deeper in the next several pages.
Virtualization Performance: ESX + Windows
vApus Mark II has been our own virtualization benchmark suite that tests how well servers cope with virtualizing "heavy duty applications" on top of Windows Server 2008. We explained the benchmark methodology here. The vApus Mark II tile consist of five VMs:
- 3x IIS webservers running Windows 2003 R2, each getting two vCPUs
- One MS SQL Server 2008 x64 running on top of Windows 2008 R2 x64. This VM has eight vCPUs, which makes EPT/RVI (Hardware Assisteds Paging) very important.
- An OLTP Oracle 11G R2 database VM on top of Window 2008R2 x64. The VM runs the Swingbench 2.2 "Calling Circle" benchmark.
We test with two tiles, good for 36 vCPUs.
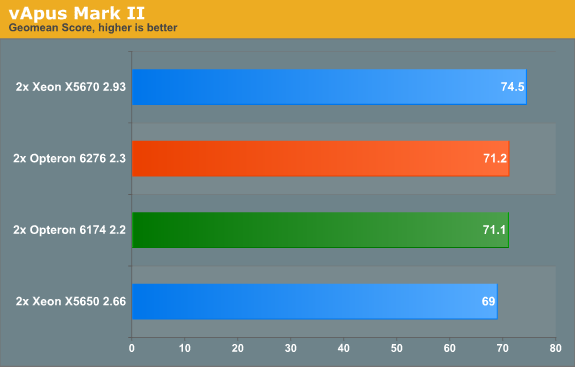
Again, the Opteron 6276 delivers a very respectable performance per dollar, delivering 96% of a Xeon that costs almost twice as much. But the fact remains that the new Opteron cannot create a decent performance gap with the old Opteron.
The Xeon has a lower power consumption on paper (95W), so let us check out power consumption.
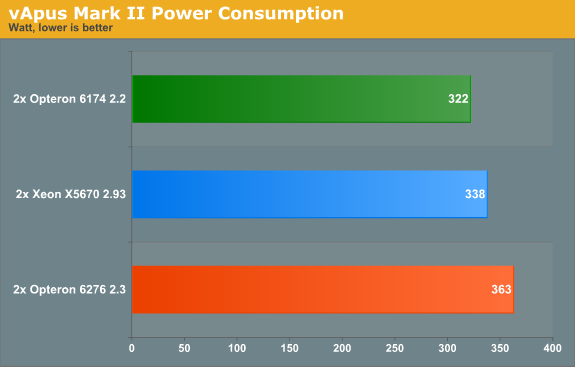
After this benchmark we were convinced that for some reason the power management features of the Opteron 6276 are not properly used with ESX. We investigated the matter in more detail.
Measuring Real-World Power Consumption, Part Two
First, we wanted to check if the Interlagos power management problems were specific to ESXi. Therefore, we measured the power consumption when running Windows 2008 R2 SP1 x64. We set the power management policy to "Balanced" and "High Performance".
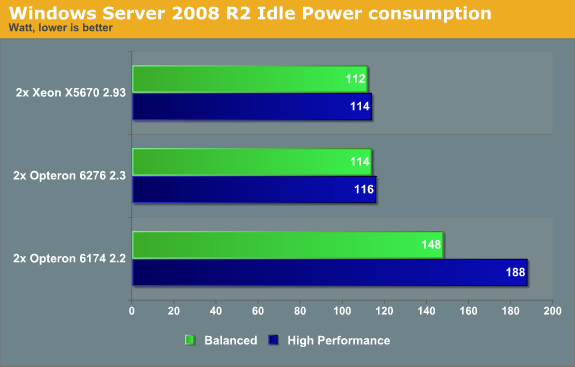
Wow, that is a lot better! The core gating of the Bulldozer cores is first rate, as good as the Xeons of today. Idle power draw is a serious problem of the Opteron 6174: it is between 30 to 63% higher! So even if the ESX scheduler does not really understand how to handle the power management features of the "Bulldozer" Opteron, the question remains why the Opteron 6276 cannot even beat the Opteron 6174 when running idle in ESXi.
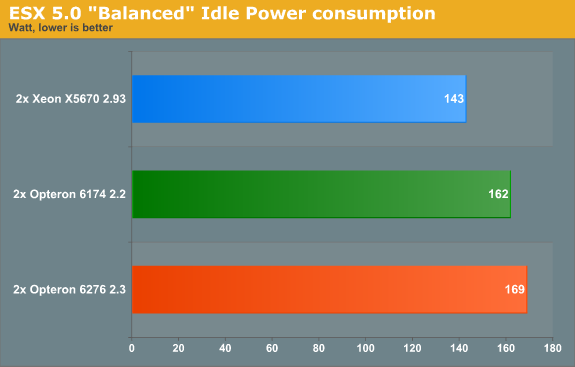
While I was testing the power consumption on Windows, my colleague Tijl Deneut dug up some interesting information about the ESX power manager. The Balanced Power policy (the default power policy for ESXi 5) is rather simple: it uses an algorithm that exploits only the processor’s P-states and C-state C0 and C1. So "Balanced" does not make very good use of the deeper sleep states. So we went for custom, which is the same as "Balanced" until you start to customize of course. We enabled the other C-states and things started to make sense.
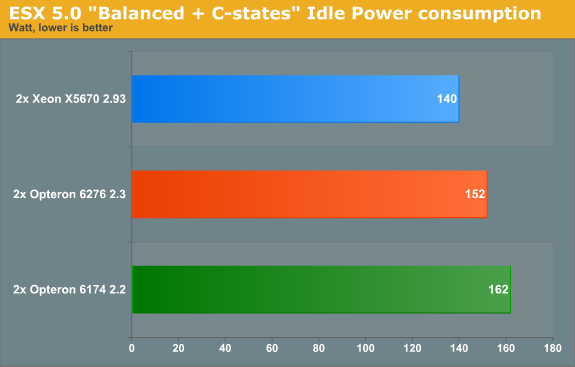
After some tinkering, the Opteron 6276 does quite a bit better and saves 17W (10%). The Xeon reduces power consumption by 3W, and the Opteron 6174's less advanced power management is not able to save any more power. So enabling the C-states is an important way to improve the power consumption of the Opteron "Interlagos" with ESXi 5.
Power Management in Windows Server 2008 SP2
Enabling the C-states in ESX 5i might bring the Opteron 6276 an improved performance/watt ratio. The question is whether the low power consumption at light loads will negate the performance impact. Although power consumption is lowered by using the "C-state enable" tweak, it is not spectacular: 10% lower energy consumption in idle will probably not give the Opteron 6276 an amazing performance/watt ration in ESXi. The impact of this tweak will make a difference in our EWL testing, not in the "full speed ahead" benchmarks. Also, our vApus FOS EWL testing showed that the Xeon consumed 25% less energy, so it will remain ahead.
As the virtualization benchmarks require more time to run, we will have to delay investigating them for a later article. But what about Windows 2008 R2? The idle power of the Opteron 6276 was excellent there. So which power policy should be chosen in Windows 2008? We compared Opteron performance in "High performance" to the Opteron 6276 performance when the power management policy was set to "Balanced.
|
Opteron 6276 "High Performance" |
Opteron 6276 "High Performance" + C6 enable. |
Xeon X5670 "High performance" vs. Xeon X5670 "Balanced" |
|
| Cinebench Single-threaded | +16% | +18% | +1% |
| Cinebench Multi-threaded | +5% | +5% | +1% |
| Blender | +4% | +13% | +1% |
| Encryption/Decryption AES | +43% / +42% | +43% / +44% | +28% / +28% |
| Encryption/Decryption Twofish/Serpent | +8% / +8% | +8 / +8% | +0 / +0% |
| Compression/decompression | +9% / +4% | +9 / +4% | +0 / +2% |
If we combine the our idle power consumption measurements with these numbers, things get a lot clearer. The "balanced" power policy disables turbo. Therefore, the maximum performance boost from enabling "high performance" should be 13%. The TrueCrypt benchmarks show much larger increases (see (*)), which we honestly don't understand. The performance boost (40%) is only possible if the CPU boosts to 3.2GHz, but that is not supposed to happen. First, the TrueCrypt software is well threaded and uses all clusters (32 threads). Second, we disabled C6, so normally the CPU is not able to boost to 3.2GHz. Third, our monitoring clearly indicated a 2.6GHz clock as expected.
We also did a quick x264 4.0 benchmark (1st pass) which is lightly threaded and showed the same performance (46%!) increase by simply switching from "Balanced" to "High performance" (turbo limited to 2.6GHz, no C6). The Xeon only got a 13% increase in performance..
Closer monitoring reveals that "Balanced" frequently reduces the cores to 1.4GHz. So we have a similar situation as the one where we found power management problems on the AMD "Istanbul" Opteron when the power policy was set to "Balanced".
Basically "Balanced" brings the clock speed down to a low P-state even when a thread is demanding the maximum processing power. Or in other words, the power manager is too eager to bring the clock speed down instead of looking ahead: the polling is blind for the very near future. The result is that quite often the workload gets processed at 1.4GHz (for a short time).
In contrast, the high performance setting does not make use of frequency scaling besides Turbo. So the CPU runs at 2.3GHz at the very minimum and frequently reaches 2.6GHz. So if you buy an Opteron 6200 server, it is strongly advised to chose the "High Performance" setting. Under light load, the balanced power manager saves a few percentage of power running idle, but in our opinion, it is not worth the large performance degradation. Notice also that the Xeon hardly suffers from the same problem with the exception of the AES-NI enabled TrueCrypt bench, and even then the performance impact is significantly lower.
In a nutshell: the power policy "Balanced" strongly favors the Xeon as the performance impact is non-existent or much lower. Let us see some raw performance numbers.
Rendering Performance: Cinebench
Cinebench, based on MAXON's software CINEMA 4D, is probably one of the most popular benchmarks around, and it is pretty easy to perform this benchmark on your own home machine. The benchmark supports 64 threads, more than enough for our 24- and 32-thread test servers. First we tested single-threaded performance, to evaluate the performance of each core.
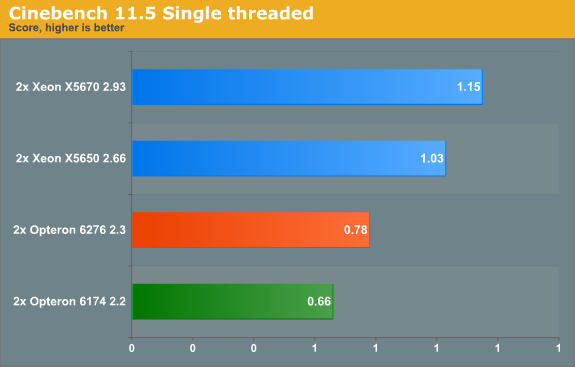
Single-threaded performance is relatively poor when you do not enable Turbo Core: with that setting the Opteron 6276 scores only 0.57. So the single-threaded FP performance is about 10% lower, probably a result of the higher FP/SSE latencies of the Interlagos FPU. However, the 6276 Opteron can boost the clock speed to 3.2GHz. This 39% clock speed boost leads to a 37% (!) performance boost. The difference with the older "Istanbul" based Opteron "Magny-cours" 61xx can only get larger once software with support for the powerful FMAC and AVX capable units is available. Also newer compilers will take the longer FP latencies into account and will probably boost performance by a few percent even without using FMAC or AVX.
Before we look at the Multi-threaded benchmark, Andreas Stiller, the legendary German C't Journalist ("Processor Whispers") sent me this comment:
"You should be aware that Cinebench 11.5 is using Intel openMP (libguide40.dll), which does not support AMD-NUMA"
So while Cinebench is a valid bench as quite a few people use the Intel OpenMP libraries, it is not representative of all render engines. In fact, Cinebench probably only represent the smaller part of the market that uses the Intel OpenMP API. On dual CPU systems, the Opteron machines run a bit slower than they should; on quad CPU systems, this lack of "AMD NUMA" awareness will have a larger impact.
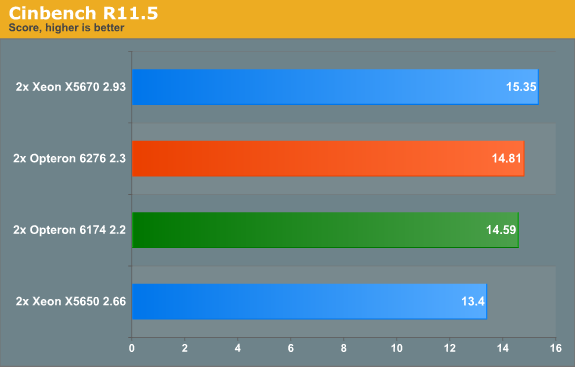
We did not expect that the latest Opteron would outperform the previous one by a large margin. Cinebench is limited by SSE processing power. The ICC 11.0 compiler was the fastest compiler of its time for SSE/FP intensive software, even for the Opterons (up to 24% faster than the competing compilers), but it has no knowledge of newer architectures. And of course, the intel compiler does favor the Xeons.
The Opteron 6200 has a total of eight dual issue (if you count only those pipes that do calculations) FPUs, while the Opteron 6100 has a total of 12 dual issue FPUs. The only advantage that the 6200 has (if you do not use the FMAC or AVX capabilities) is that it can interleave two FP threads on one module. So you get 16 FP threads that can dispatch one FP per clock versus 12 FP threads that can dispatch two FP per clock. That capability is especially handy when your threads are blocked by memory accesses. This is hardly the case in Cinebench (but it is probably the reason why Interlagos does so well in some HPC tests) and as a result, the Opteron 6276 cannot pull away from the Opteron 6174.
Anand reported that the best Core i7 (2600K, 4 cores/8 threads, 3.4GHz) achieves 6.86. So considering that a dual Opteron 6200 is cheaper than the dual Xeon, and more manageable than two workstations, such a renderfarm may make some sense.
Rendering Performance: 3DSMax 2012
As requested, we're reintroducing our 3DS Max benchmark. We used the "architecture" scene which is included in the SPEC APC 3DS Max test. As the Scanline renderer is limited to 16 threads, we chose the iray render engine, which is basically an automatically configuring Mental Ray render engine. Note that these numbers are in no way comparable to the ones we have obtained before as those were all performed with the scanline render engine!

We rendered at 720p (1280x720) resolution. We measured the time it takes to render 10 frames (from 20 to 29) with SSE enabled. We recorded the time and then calculated (3600 seconds * 10 frames / time recorded) how many frames a certain CPU configuration could render in one hour. All results are reported as rendered images per hour; higher is thus better. We used the 64-bit version of 3ds Max 2008 on 64-bit Windows 2008 R2 SP1.
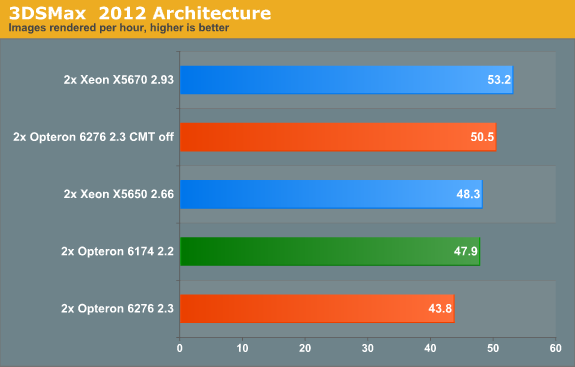
Something really weird happened here: once we disable CMT, the Opteron 6276 performs much better. Rendering performance is quite good as the Opteron 6276 beats the Xeon X5650.
Maxwell Render Suite
The developers of Maxwell Render Suite--Next Limit--aim at delivering a renderer that is physically correct and capable of simulating light exactly as it behaves in the real world. As a result their software has developed a reputation of being powerful but slow. And "powerful but slow" always attracts our interest as such software can be quite interesting benchmarks for the latest CPU platforms. Maxwell Render 2.6 was released less than two weeks ago, on November 2, and that's what we used.

We used the "Benchwell" benchmark, a scene with HDRI (high dynamic range imaging) developed by the user community. Note that we used the "30 day trial" version of Maxwell. We converted the time reported to render the scene in images rendered per hour to make it easier to interprete the numbers.
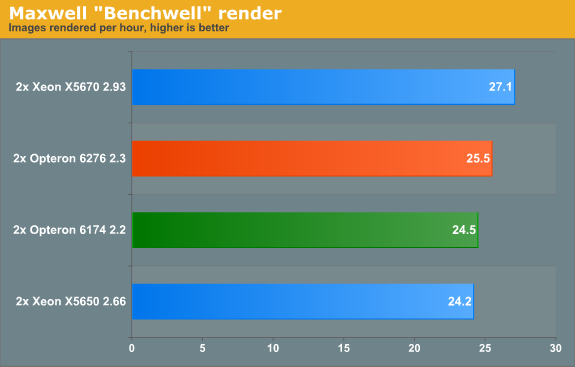
Since Magny-cours made its entrance, AMD did rather well in the rendering benchmarks and Maxwell is no difference. The Bulldozer based Opteron 6276 gives decent but hardly stunning performance: about 4% faster than the predecessor. Interestingly, the Maxwell renderer is not limited by SSE (Floating Point) performance. When we disable CMT, the AMD Opteron 6276 delivered only 17 frames per second. In other words the extra integer cluster delivers 44% higher performance. There is a good chance that the fact that you disable the second load/store unit by disabling CMT is the reason for the higher performance that the second integer cluster delivers.
Rendering: Blender 2.6.0
Blender is a very popular open source renderer with a large community. We tested with the 64-bit Windows version 2.6.0a. If you like, you can perform this benchmark very easily too. We used the metallic robot, a scene with rather complex lighting (reflections) and raytracing. To make the benchmark more repetitive, we changed the following parameters:
- The resolution was set to 2560x1600
- Antialias was set to 16
- We disabled compositing in post processing
- Tiles were set to 8x8 (X=8, Y=8)
- Threads was set to auto (one thread per CPU is set).
To make the results easier to read, we again converted the reported render time into images rendered per hour, so higher is better.
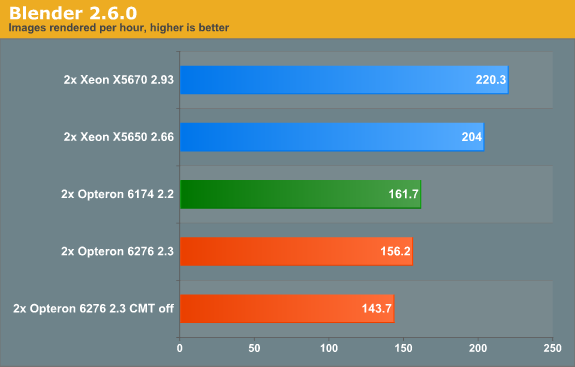
Last time we checked (Blender 2.5a2) in Windows, the Xeon X5670 was capable of 136 images per hour, while the Opteron 6174 did 113. So the Xeon was about 20% faster. Now the gap widens: the Xeon is now 36% faster. The interesting thing that we discovered is that the Opteron is quite a bit faster when benchmarked in linux. We will follow up with some Linux numbers in the next article. The Opteron 6276 is in this benchmark 4% slower than its older brother, again likely due in part to the newness of its architecture.
TrueCrypt 7.1 Benchmark
TrueCrypt is a software application used for on-the-fly encryption (OTFE). It is free, open source and offers full AES-NI support. The application also features a built-in encryption benchmark that we can use to measure CPU performance. First we test with the AES algorithm (256-bit key, symmetric).

You can compare those numbers directly with Anand's benchmark here. The Core i7-2600K at 3.4GHz delivers 3.4GB/s and the AMD FX-8150 at 3.6GHz about the same 3.3GB/s. We get about 2.3 times the performance here with four times as many "cores", but at 2.3GHz instead of 3.6GHz.
We also test with the heaviest combination of the cascaded algorithms available: Serpent-Twofish-AES.

The combination benchmark is limited by the slowest algorithms: twofish and serpent. The huge advantage that the architectures (Opteron "Bulldozer" and Xeon "Westmere") which support AES-NI had has evaporated: the Opteron 6174 keeps up with the best Xeons. The Opteron 6276 can leverage its higher threadcount as this benchmark scales extremely well.
It is good to realize that these benchmarks are not real-world but rather synthetic. It would be better to test a website that does some encrypting in the background or a fileserver with encrypted partitions. In that case the encryption software is only a small part of the total code being run. A large performance (dis)advantage might translate into a much smaller performance (dis)advantage in that real-world situation.
For example, eight times faster encryption resulted in a website with 23% higher throughput and a 40% faster encrypted file (see here). The advantage that the Xeon had in the first benchmark will not be noticeable, and the Opteron's 24% higher performance will translate into a few percentage points. But this is a benchmark where AMD's efforts to get a 16 integer cores inside a 115W TDP pay off.
7-Zip 9.2
7-zip is a file archiver with a high compression ratio. 7-Zip is open source software, and most of the source code is under the GNU LGPL license
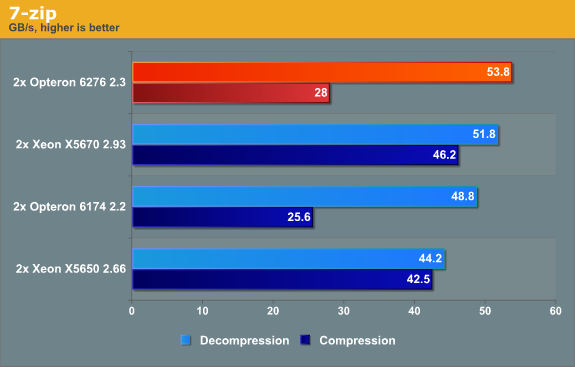
Compression is more CPU intensive than decompression, and the latter depends a little more on memory bandwidth. When it comes to load/stores and memory bandwidth, the Opteron 6276 is unbeateable. We've also seen indications that Bulldozer's cache does very well in reads but not so well in writes, and that could account for some of the gap between the compress/decompress results.
Compression is for a part determined by the quality of the branch predictor (higher than normal branch mispredictions on mediocre branch predictors). The Opteron 6276 has a better branch predictor than the Opteron 6174, but the branch misprediction penalty has grown from 12 to 20 cycles. As a result, a single branch intensive thread runs slower (see Anand's tests) on the newest AMD architecture. Luckily, the AMD Opteron 6276 can compensate for this with its 16 threads (vs 12 threads for the Opteron 6172) and a little bit of help from Turbo Core.
Intel still has the best branch predictors in the industry. The result is that the Xeon is by far the fastest compressor. The end result is that the Xeon is the more rounded CPU in this discipline.
Conclusions
To help summarize the current situation in the server CPU market, we have drawn up a comparison table of the performance we have measured so far. We'll compare the new Interlagos Opteron 6276 against the outgoing Opteron 6174 as well as teh Xeon X5650.
|
Opteron 6276 vs. Opteron 6174 |
Opteron 6276 vs. Xeon X5650 |
|
| ESXi + Linux | -1% | -2% |
| ESXi + Windows | = | +3% |
| Cinebench | +2% | +9% |
| 3DS Max 2012 (iRay) | -9% to + 4% | -10% to +3% |
| Maxwell Render | +4% | +6% |
| Blender | -4% | -24% |
| Encryption/Decryption AES | +265% / +275% | +2% / +7% |
| Encryption/Decryption Twofish/Serpent | +25% / +25% | 31% / 46% |
| Compression/decompression | +10% / +10% | -33%/ +22% |
Let us first discuss the virtualization scene, the most important market. Unfortunately, with the current power management in ESXi, we are not satisfied with the Performance/watt ratio of the Opteron 6276. The Xeon needs up to 25% less energy and performs slightly better. So if performance/watt is your first priority, we think the current Xeons are your best option.
The Opteron 6276 offers a better performance per dollar ratio. It delivers the performance of $1000 Xeon (X5650) at $800. Add to this that the G34 based servers are typically less expensive than their Intel LGA 1366 counterparts and the price bonus for the new Opteron grows. If performance/dollar is your first priority, we think the Opteron 6276 is an attractive alternative.
And then there is Windows Server 2008 R2. Typically we found that under heavy load (benchmarking at 85-100% CPU load) the power consumption was between 3% (integer) to 7% (FP) higher on the Opteron 6276 than on the Xeons and Opteron 6100, a lot better than under ESXi. Add to this the fact that the new Opteron energy usage at low load is excellent and you understand that we feel that there is no reason to go for the Opteron 6100 anymore. Again, AMD still understands that it should price its CPUs more attractive than the competition, so from the price/performance/watt point of view, the Opteron 6276 is a good cost effective alternative to the Xeon...on the condition that you enable the "high performance" policy and that AMD keeps the price delta the same in the coming months.
That is the good news. We cannot help but to feel a bit disappointed too. AMD promised us (in 2009/2010) that the Opteron 6200 would be significantly faster than the 6100: "unprecedented server performance gains". That is somewhat the case if you recompile your software with the latest and greatest optimized compiler as AMD's own SPEC CINT (+19%), CFP 2006 (+11%) and Linpack benchmarks (+32%) show.
One of the real advantages of a new processor architecture (prime examples where the K7 and K8) is if it performs well in older software too, without requiring a recompile. For some people of the HPC world, recompiling is acceptable and common, but for everybody else (that is probably >95% of the market!), it's best if existing binaries run faster. Administrators generally are not going to upgrade and recompile their software just to make better use of a new server CPU. Hopefully AMD's engineers have been looking into improving the legacy software performance of their latest chip the last few months, because it could use some help.
On the other side of the coin, it is clear that some of the excellent features of the new Opteron are not leveraged by the current software base. The deeper sleep and more advanced core gating is not working to its full potential, and the current operating systems frequently don't appear to know how to get the best from Turbo Core. The clock can be boosted by 39% when half of the cores are active, but an 18% boost was the best we saw (in a single-threaded app!). Simply turning the right knobs gave some tangible power savings (see ESXi) and some impressive performance improvements (see Windows Server 2008).
In short, we're going to need to do some additional testing and take this server out for another test drive, and we will. Stay tuned for a follow-up article as we investigate other options for improving performance.







{kind=link}