Original Link: https://www.anandtech.com/show/4955/the-bulldozer-review-amd-fx8150-tested
The Bulldozer Review: AMD FX-8150 Tested
by Anand Lal Shimpi on October 12, 2011 1:27 AM ESTAMD has been trailing Intel in the x86 performance space for years now. Ever since the introduction of the first Core 2 processors in 2006, AMD hasn't been able to recover and return to the heyday of the Athlon 64 and Athlon 64 X2. Instead the company has remained relevant by driving costs down and competing largely in the sub-$200 microprocessor space. AMD's ability to hold on was largely due to its more-cores-for-less strategy. Thanks to aggressive pricing on its triple and hexa-core parts, for users who needed tons of cores, AMD has been delivering a lot of value over the past couple of years.
Recently however Intel has been able to drive its per-core performance up with Sandy Bridge, where it's becoming increasingly difficult to recommend AMD alternatives with higher core counts. The heavily threaded desktop niche is tough to sell to, particularly when you force users to take a significant hit on single threaded performance in order to achieve value there. For a while now AMD has needed a brand new architecture, something that could lead to dominance in heavily threaded workloads while addressing its deficiencies in lightly threaded consumer workloads. After much waiting, we get that new architecture today. Bulldozer is here.

It's branded the AMD FX processor and it's only available in a single die configuration. Measuring 315mm2 and weighing in at around 2 billion transistors (that's nearly GPU-sized fellas), Bulldozer isn't that much smaller than existing 45nm 6-core Phenom II designs despite being built on Global Foundries' 32nm SOI process. Both die area and transistor count are up significantly over Sandy Bridge, which on Intel's 32nm HKMG process is only 995M transistors with a die size of 216mm2. This is one big chip.
| CPU Specification Comparison | ||||||||
| CPU | Manufacturing Process | Cores | Transistor Count | Die Size | ||||
| AMD Bulldozer 8C | 32nm | 8 | 1.2B* | 315mm2 | ||||
| AMD Thuban 6C | 45nm | 6 | 904M | 346mm2 | ||||
| AMD Deneb 4C | 45nm | 4 | 758M | 258mm2 | ||||
| Intel Gulftown 6C | 32nm | 6 | 1.17B | 240mm2 | ||||
| Intel Nehalem/Bloomfield 4C | 45nm | 4 | 731M | 263mm2 | ||||
| Intel Sandy Bridge 4C | 32nm | 4 | 995M | 216mm2 | ||||
| Intel Lynnfield 4C | 45nm | 4 | 774M | 296mm2 | ||||
| Intel Clarkdale 2C | 32nm | 2 | 384M | 81mm2 | ||||
| Intel Sandy Bridge 2C (GT1) | 32nm | 2 | 504M | 131mm2 | ||||
| Intel Sandy Bridge 2C (GT2) | 32nm | 2 | 624M | 149mm2 | ||||
Update: AMD originally told us Bulldozer was a 2B transistor chip. It has since told us that the 8C Bulldozer is actually 1.2B transistors. The die size is still accurate at 315mm2.
Architecturally Bulldozer is a significant departure from anything we've ever seen before. We'll go into greater detail later on in this piece, but the building block in AMD's latest architecture is the Bulldozer module. Each module features two integer cores and a shared floating point core. FP hardware is larger and used less frequently in desktop (and server workloads), so AMD decided to share it between every two cores rather than offer a 1:1 ratio between int/fp cores on Bulldozer. AMD advertises Bulldozer based FX parts based on the number of integer cores. Thus a two module Bulldozer CPU, has four integer cores (and 2 FP cores) and is thus sold as a quad-core CPU. A four module Bulldozer part with eight integer cores is called an eight-core CPU. There are obvious implications from a performance standpoint, but we'll get to those shortly.
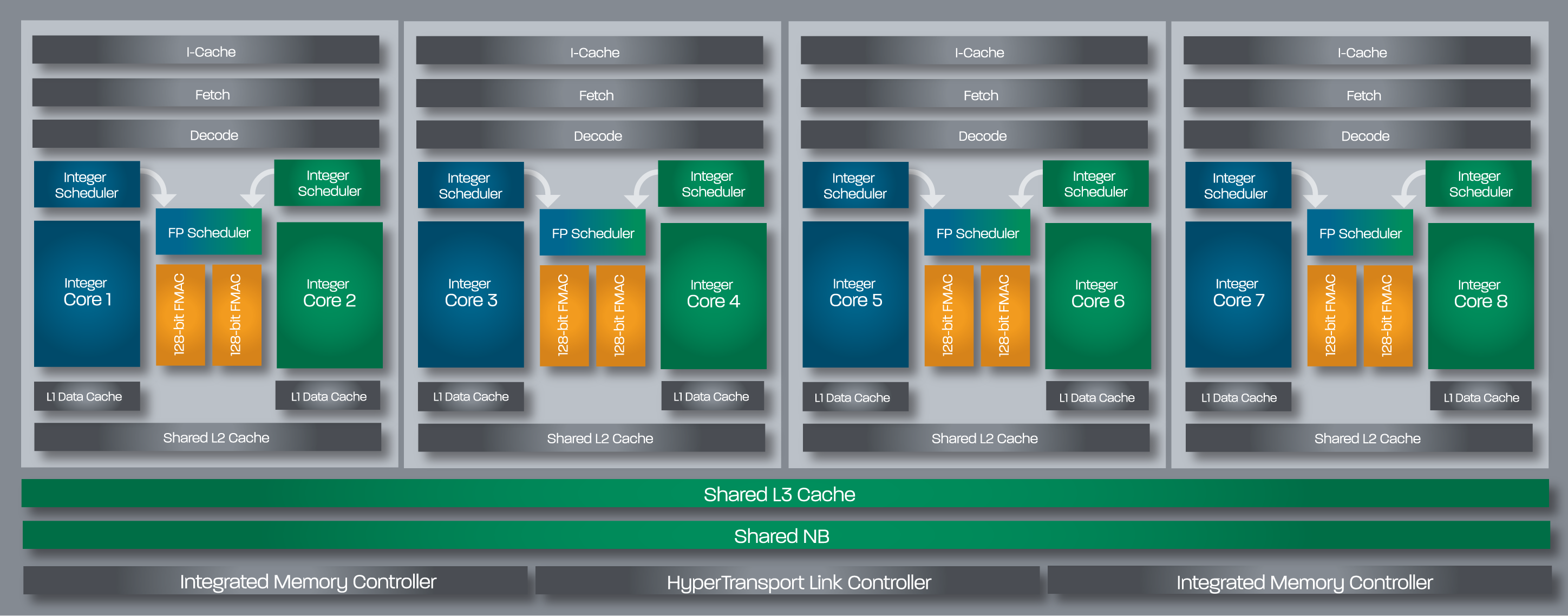
The FX Lineup
There are a total of 7 AMD FX CPUs that AMD is announcing today, although only four are slated for near-term availability.
| CPU Specification Comparison | |||||||||
| Processor | Cores | Clock Speed | Max Turbo | NB Clock | L2 Cache | TDP | Price | ||
| AMD FX-8150 | 8 | 3.6GHz | 4.2GHz | 2.2GHz | 8MB | 125W | $245 | ||
| AMD FX-8120 | 8 | 3.1GHz | 4.0GHz | 2.2GHz | 8MB | 95W/125W | $205 | ||
| AMD FX-8100* | 8 | 2.8GHz | 3.7GHz | 2GHz | 8MB | 95W | N/A | ||
| AMD FX-6100 | 6 | 3.3GHz | 3.9GHz | 2GHz | 6MB | 95W | $165 | ||
| AMD FX-4170* | 4 | 4.2GHz | 4.3GHz | 2.2GHz | 4MB | 125W | N/A | ||
| AMD FX-B4150* | 4 | 3.8GHz | 4GHz | 2.2GHz | 4MB | 95W | N/A | ||
| AMD FX-4100 | 4 | 3.6GHz | 3.8GHz | 2GHz | 4MB | 95W | $115 | ||
| AMD Phenom II X6 1100T | 6 | 3.2GHz | 3.6GHz | 2GHz | 3MB | 125W | $190 | ||
| AMD Phenom II X4 980 | 4 | 3.7GHz | N/A | 2GHz | 2MB | 125W | $170 | ||
The FX-8150, 8120, 6100 and 4100 are what's launching today. The first digit in AMD's FX model numbers indicates the number of cores with the 8150 and 8120 boasting eight, while the 6100 only has six active integer cores (three Bulldozer modules). The FX-4100 features four integer cores. L2 cache scales with core count (2MB per module), while the L3 cache size remains fixed at 8MB regardless of SKU.
North Bridge and L3 cache frequency alternate between 2.0GHz and 2.2GHz depending on the part. TDPs range between 95W and 125W as well, with the FX-8120 being offered in both 125W and 95W versions.
There's only a single Bulldozer die. The 6 and 4 core versions simply feature cores disabled on the die. AMD insists this time around, core unlocking won't be possible on these harvested parts.
The huge gap in clock speed between the 8120 and 8150 are troubling. Typically we see linear frequency graduations but the fact that there's a 16% difference between these two SKUs seems to point to process problems limiting yield at higher frequencies—at least for the 8-core version.
Outside of the quad-core and hex-core Bulldozer pats, the only other FX processor able to exceed the 3.3GHz clock speed of the Phenom II X6 1100T is the 8150. And if you include quad-core Phenom II parts in the mix, only two Bulldozer parts ship at a higher stock frequency than the Phenom II X4 980. Granted Turbo Core will help push frequencies even higher, but these low base frequencies are troubling. For an architecture that was designed to scale to clock speeds 30% higher than its predecessor, Bulldozer doesn't seem to be coming anywhere close.
The entire FX lineup ships unlocked, which allows for some easy overclocking as you'll see soon enough.






Motherboard Compatibility
AMD is certifying its FX processors for use on Socket-AM3+ motherboards. Owners of standard AM3 motherboards may be out of luck, although motherboard manufacturers can choose to certify their boards for use with Bulldozer if they wish to do so. From AMD's perspective however, only AM3+ motherboards with BIOS/UEFI support for Bulldozer are officially supported.

All existing AM2/AM2+/AM3/AM3+ heatsinks should work with the FX processor; they simply need to be rated for the TDP of the processor you're looking to cool.

For this review, AMD supplied us with ASUS' Crosshair V Formula AM3+ motherboard based on AMD's 990FX chipset.
AMD does offer six 6Gbps SATA ports on its 990FX chipset, a significant upgrade from the two 6Gbps ports on Intel's 6-series chipsets. Unbuffered ECC memory is also supported for those who desire the added security, once again a feature not supported on Intel's consumer grade 6-series chipsets.
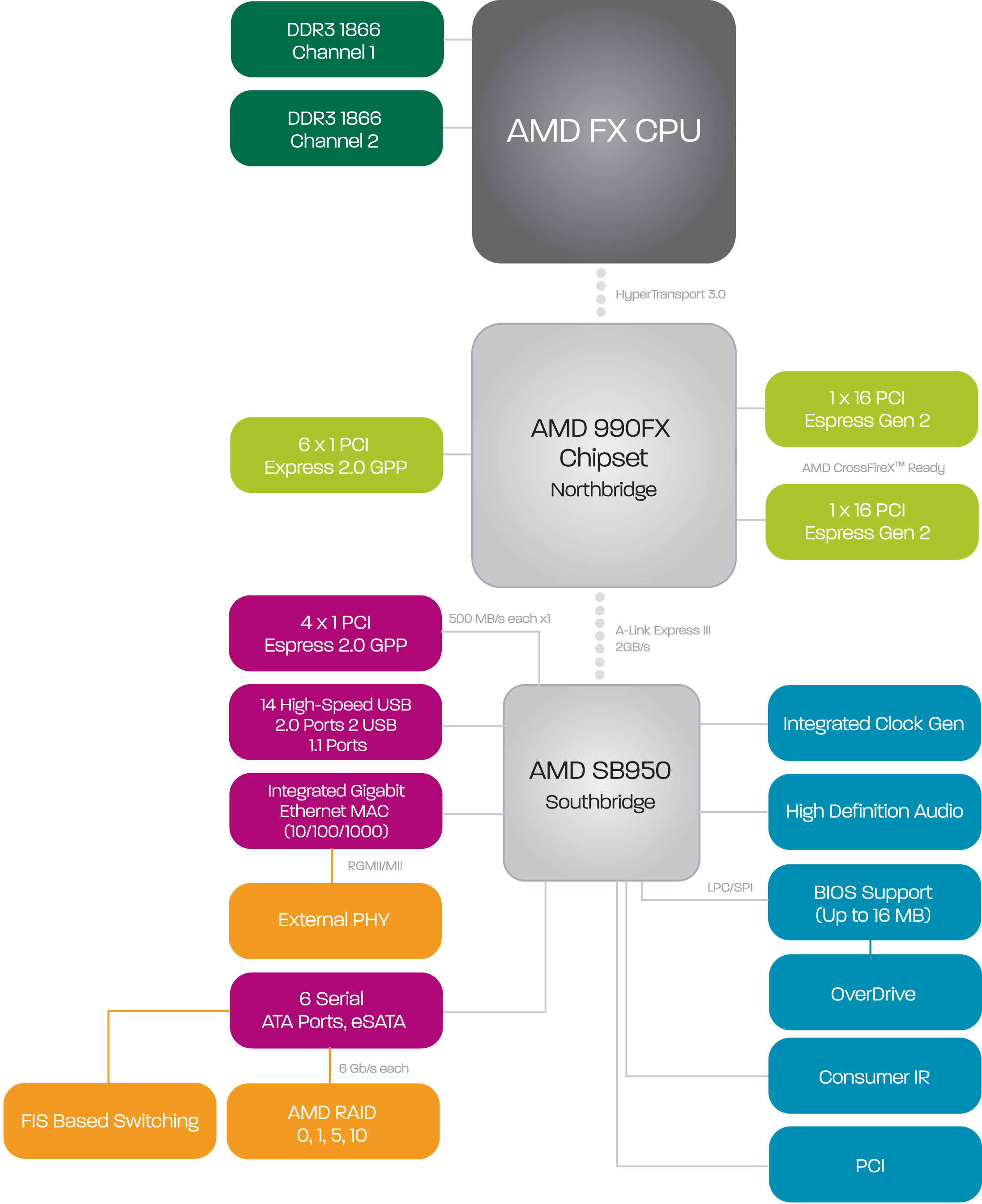
Despite AMD's trend towards releasing APUs with integrated GPUs (thus requiring a new socket), AMD insists that the AM3+ platform will live to see one more processor generation before it's retired.
AMD's Liquid CPU Cooling System
Alongside its new FX processors AMD is introducing its first branded liquid cooling system manufactured by Asetek.

AMD's cooling system is similar to other offerings from companies like Antec and Corsair. The system is self contained, you never have to worry about adding any more liquid to it.
Attach the cooling module to your CPU socket via a simple bracket, and affix the radiator to your case and you're good to go. The radiator is cooled via two 120mm fans, also included in the box.

AMD doesn't have an exact idea on pricing or availability of its liquid cooling solution, but I'm told to expect it to be around $100 once available. My sample actually arrived less than 12 hours ago, so expect a follow up with performance analysis later this week.
The Roadmap
For the first time in far too long, AMD is actually being very forthcoming about its future plans. At a recent tech day about Bulldozer, AMD laid out its CPU core roadmap through 2014. The code names are below:
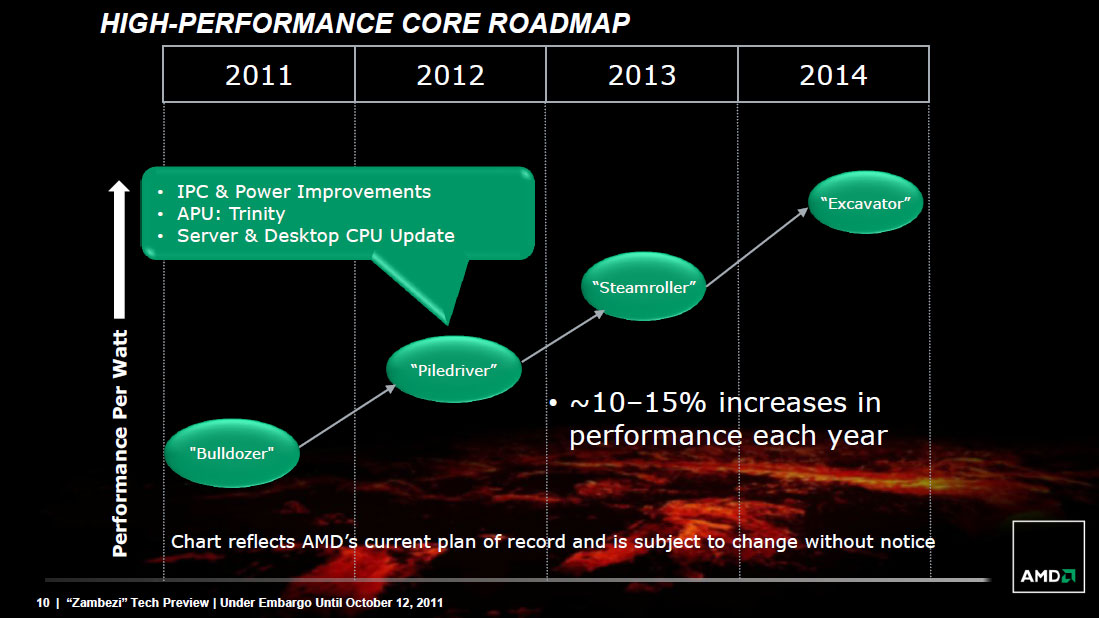
Piledriver you already know about, it's at the heart of Trinity, which is the 2—4 core APU due out in early 2012. Piledriver will increase CPU core performance by around 10—15% over Bulldozer, although it will initially appear in a lower performance segment. Remember that final generation of AM3+ CPU I mentioned earlier? I fully expect that to be a GPU-less Piledriver CPU due out sometime in 2012.
Steamroller will follow in 2013, again improving performance (at the core level) by around 10—15%. Excavator will do the same in 2014. AMD believes that these performance increases will be sufficient to keep up with Intel over time, however I'll let you be the judge of that once we get to the Bulldozer performance numbers.
The other thing to note about AMD's roadmap is it effectively puts the x86 business on an annual cadence, in line with what we've seen from the AMD GPU folks. Although AMD isn't talking about what process nodes to expect all of these cores at, it looks like AMD will finally have an answer to Intel's tick-tock release schedule moving forward.
The Architecture
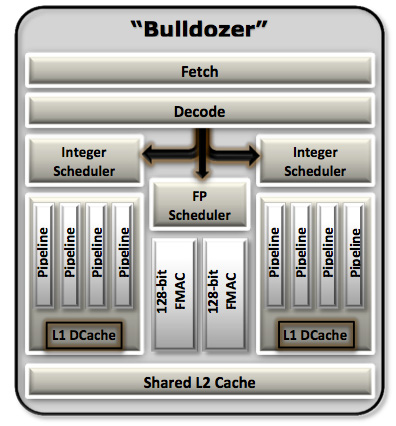
We'll start, logically, at the front end of a Bulldozer module. The fetch and decode logic in each module is shared by both integer cores. The role this logic plays is to fetch the next instruction in the thread being executed, decode the x86 instruction into AMD's own internal format, and pass the decoded instruction onto the scheduling hardware for execution.
AMD widened the K8 front end with Bulldozer. Each module is now able to fetch and decode up to four x86 instructions from a single thread in parallel. Each of the four decoders are equally capable. Remembering that each Bulldozer module appears as two cores, the front end can only pick 4 instructions to fetch and decode from a single thread at a time. A single Bulldozer module can switch between threads as often as every clock.
Decode hardware isn't very expensive on its own, but duplicating it four times across multiple cores quickly adds up. Although decode width has increased for a single core, multi-core Bulldozer configurations can actually be at a disadvantage compared to previous AMD architectures. Let's look at the table below to understand why:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
For a single instruction thread, Bulldozer offers more front end bandwidth than its predecessor. The front end is wider and just as capable so this makes sense. But note what happens when we scale up core count.
Since fetch and decode hardware is shared per module, and AMD counts each module as two cores, given an equivalent number of cores the old Phenom II actually offers a higher peak instruction fetch/decode rate than the FX. The theory is obviously that the situations where you're fetch/decode bound are infrequent enough to justify the sharing of hardware. AMD is correct for the most part. Many instructions can take multiple cycles to decode, and by switching between threads each cycle the pipelined front end hardware can be more efficiently utilized. It's only in unusually bursty situations where the front end can become a limit.
Compared to Intel's Core architecture however, AMD is at a disadvantage here. In the high-end offerings where Intel enables Hyper Threading, AMD has zero advantage as Intel can weave in instructions from two threads every clock. It's compared to the non-HT enabled Core CPUs that the advantage isn't so clear. Intel maintains a higher instantaneous decode bandwidth per clock, however overall decoder utilization could go down as a result of only being able to fill each fetch queue from a single thread.
After the decoders AMD enables certain operations to be fused together and treated as a single operation down the rest of the pipeline. This is similar to what Intel calls micro-ops fusion, a technology first introduced in its Banias CPU in 2003. Compare + branch, test + branch and some other operations can be fused together after decode in Bulldozer—effectively widening the execution back end of the CPU. This wasn't previously possible in Phenom II and obviously helps increase IPC.
A Decoupled Branch Predictor
AMD didn't disclose too much about the configuration of the branch predictor hardware in Bulldozer, but it is quick to point out one significant improvement: the branch predictor is now significantly decoupled from the processor's front end.
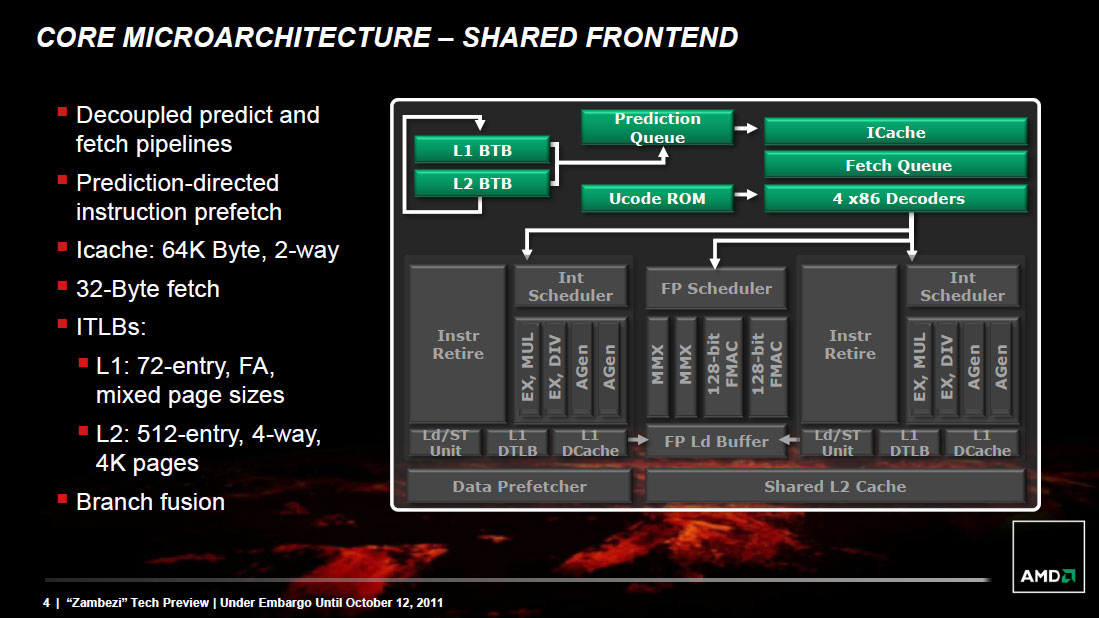
The role of the branch predictor is to intercept branch instructions and predict their target address, rather than allowing for tons of cycles to go by until the branch target is known for sure. Branches are predicted based on historical data. The more data you have, and the better your branch predictors are tuned to your workload, the more accurate your predictions can be. Accurate branch prediction is particularly important in architectures with deep pipelines as a mispredict causes more instructions to be flushed out of the pipe. Bulldozer introduces a significantly deeper pipeline than its predecessor (more on this later), and thus branch prediction improvements are necessary.
In both Phenom II and Bulldozer, branches are predicted in the front end of the pipe alongside the fetch hardware. In Phenom II however, any stall in the fetch pipeline (e.g. fetching an instruction that wasn't in cache) would stop the whole pipeline including future branch predictions. Bulldozer decouples the branch prediction hardware from the fetch pipeline by way of a prediction queue. If there's a stall in the fetch pipeline, Bulldozer's branch prediction hardware is allowed to run ahead and continue making future predictions until the prediction queue is full.
We'll get to the effectiveness of this approach shortly.
Scheduling and Execution Improvements
As with Sandy Bridge, AMD migrated to a physical register file architecture with Bulldozer. Data is now only stored in one location (the physical register file) and is tracked via pointers back to the PRF as operations make their way through the execution engine. This is a move to save power as copying data around a chip is hardly power efficient.
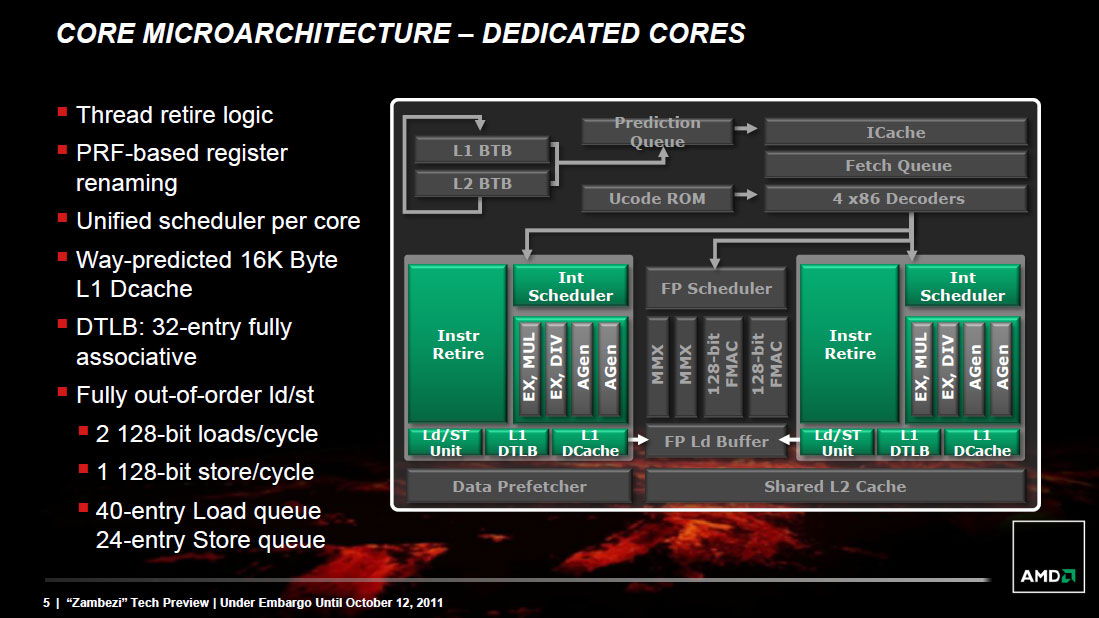
The buffers and queues that feed into the execution engines of the chip are all larger on Bulldozer than they were on Phenom II. Larger data structures allows for better instruction level parallelism when trying to execute operations out of order. In other words, the issue hardware in Bulldozer is beefier than its predecessor.
Unfortunately where AMD took one step forward in issue hardware, it does a bit of a shuffle when it comes to execution resources themselves. Let's start with the positive: Bulldozer's integer execution cores.
Integer Execution
Each Bulldozer module features two fully independent integer cores. Each core has its own integer scheduler, register file and 16KB L1 data cache. The integer schedulers are both larger than their counterparts in the Phenom II.
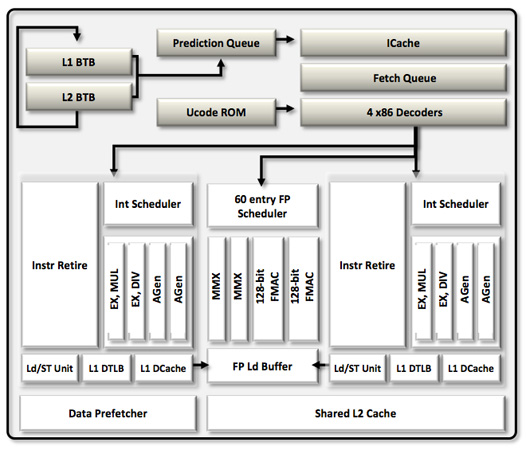
The biggest change here is each integer core now has two ports instead of three. A single integer core features two AGU/ALU ports, compared to three in the previous design. AMD claims the third ALU/AGU pair went mostly unused in Phenom II, and as a result it's been removed from Bulldozer.
With larger structures feeding into the integer cores, AMD should be able to have an easier time of making use of the integer units than in previous designs. AMD could, in theory, execute more integer operations per core in Phenom II however AMD claims the architecture was typically bound elsewhere.
The Shared FP Core
A single Bulldozer module has a single shared FP core for use by up to two threads. If there's only a single FP thread available, it is given full access to the FP execution hardware, otherwise the resources are shared between the two threads.
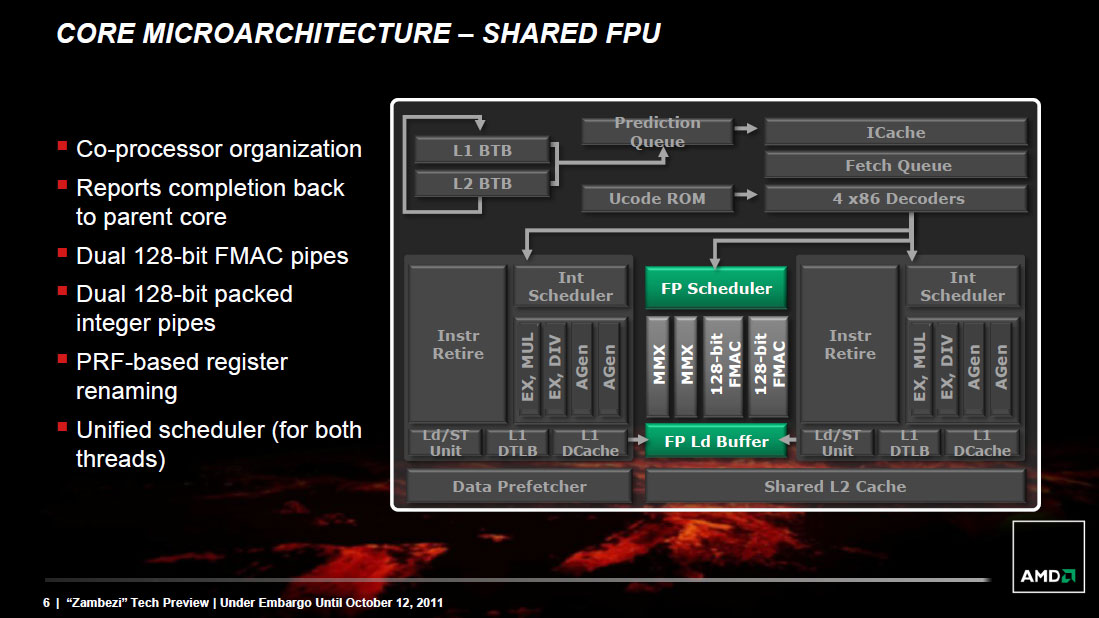
Compared to a quad-core Phenom II, AMD's eight-core (quad-module) FX sees no drop in floating point execution resources. AMD's architecture has always had independent scheduling for integer and floating point instructions, and we see the same number of execution ports between Phenom II cores and FX modules. Just as is the case with the integer cores, the shared FP core in a Bulldozer module has larger scheduling hardware in front of it than the FPU in Phenom II.
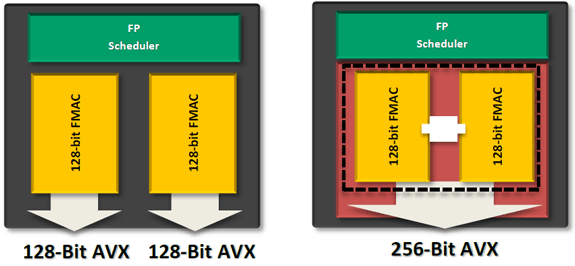
The problem is AMD had to increase the functionality of its FPU with the move to Bulldozer. The Phenom II architecture lacks SSE4 and AVX support, both of which were added in Bulldozer. Furthermore, AMD chose Bulldozer as the architecture to include support for fused multiply-add instructions (FMA). Enabling FMA support also increases the relative die area of the FPU. So while the throughput of Bulldozer's FPU hasn't increased over K8, its capabilities have. Unfortunately this means that peak FP throughput running x87/SSE2/3 workloads remains unchanged compared to the previous generation. Bulldozer will only be faster if newer SSE, AVX or FMA instructions are used, or if its clock speed is significantly higher than Phenom II.
Looking at our Cinebench 11.5 multithreaded workload we see the perfect example of this performance shuffle:

Despite a 9% higher base clock speed (more if you include turbo core), a 3.6GHz 8-core Bulldozer is only able to outperform a 3.3GHz 6-core Phenom II by less than 2%. Heavily threaded floating point workloads may not see huge gains on Bulldozer compared to their 6-core predecessors.
There's another issue. Bulldozer, at least at launch, won't have to simply outperform its quad-core predecessor. It will need to do better than a six-core Phenom II. In this comparison unfortunately, the Phenom II has the definite throughput advantage. The Phenom II X6 can execute 50% more SSE2/3 and x87 FP instructions than a Bulldozer based FX.
Since the release of the Phenom II X6, AMD's major advantage has been in heavily threaded workloads—particularly floating point workloads thanks to the sheer number of resources available per chip. Bulldozer actually takes a step back in this regard and as a result, you will see some of those same workloads perform worse, if not the same as the outgoing Phenom II X6.
Compared to Sandy Bridge, Bulldozer only has two advantages in FP performance: FMA support and higher 128-bit AVX throughput. There's very little code available today that uses AMD's FMA instruction, while the 128-bit AVX advantage is tangible.
Cache Hierarchy and Memory Subsystem
Each integer core features its own dedicated L1 data cache. The shared FP core sends loads/stores through either of the integer cores, similar to how it works in Phenom II although there are two integer cores to deal with now instead of just one. Bulldozer enables fully out-of-order loads and stores, an improvement over Phenom II putting it on parity with current Intel architectures. The L1 instruction cache is shared by the entire bulldozer module, as is the L2 cache.
The instruction cache is a large 64KB 2-way set associative cache, similar in size to the Phenom II's L1 cache but obviously shared by more "cores". A four-core Phenom II would have 256KB of total L1 I-Cache, while a four core Bulldozer will have half of that. The L1 data caches are also significantly smaller than Bulldozer's predecessor. While Phenom II offered a 64KB L1 D-Cache per core, Bulldozer only offers 16KB per integer core.

The L2 cache is much larger than what we saw in multi-core Phenom II designs however. Each Bulldozer module has a private 2MB L2 cache.
There's a single 8MB L3 cache that's shared among all Bulldozer modules on a chip. In its first incarnation, AMD has no plans to offer a desktop part without an L3 cache. However AMD indicated that the L3 cache was only really useful in server workloads and we might expect future Bulldozer derivatives (ahem, Trinity?) to forgo the L3 cache entirely as a result.
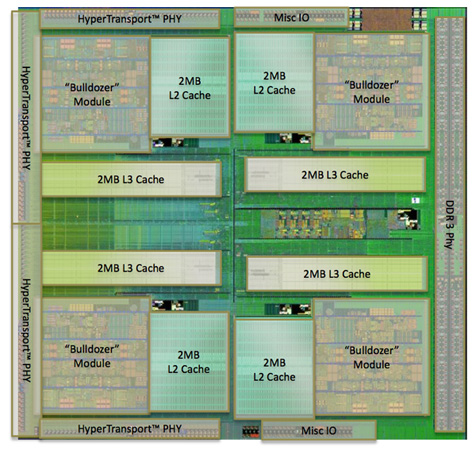
Cache accesses require more clocks in Bulldozer, due to a combination of size and AMD's desire to make Bulldozer a very high clock speed part...
The Pursuit of Clock Speed
Thus far I have pointed out that a number of resources in Bulldozer have gone down in number compared to their abundance in AMD's Phenom II architecture. Many of these tradeoffs were made in order to keep die size in check while adding new features (e.g. wider front end, larger queues/data structures, new instruction support). Everywhere from the Bulldozer front-end through the execution clusters, AMD's opportunity to increase performance depends on both efficiency and clock speed. Bulldozer has to make better use of its resources than Phenom II as well as run at higher frequencies to outperform its predecessor. As a result, a major target for Bulldozer was to be able to scale to higher clock speeds.
AMD's architects called this pursuit a low gate count per pipeline stage design. By reducing the number of gates per pipeline stage, you reduce the time spent in each stage and can increase the overall frequency of the processor. If this sounds familiar, it's because Intel used similar logic in the creation of the Pentium 4.
Where Bulldozer is different is AMD insists the design didn't aggressively pursue frequency like the P4, but rather aggressively pursued gate count reduction per stage. According to AMD, the former results in power problems while the latter is more manageable.
AMD's target for Bulldozer was a 30% higher frequency than the previous generation architecture. Unfortunately that's a fairly vague statement and I couldn't get AMD to commit to anything more pronounced, but if we look at the top-end Phenom II X6 at 3.3GHz a 30% increase in frequency would put Bulldozer at 4.3GHz.
Unfortunately 4.3GHz isn't what the top-end AMD FX CPU ships at. The best we'll get at launch is 3.6GHz, a meager 9% increase over the outgoing architecture. Turbo Core does get AMD close to those initial frequency targets, however the turbo frequencies are only typically seen for very short periods of time.
As you may remember from the Pentium 4 days, a significantly deeper pipeline can bring with it significant penalties. We have two prior examples of architectures that increased pipeline length over their predecessors: Willamette and Prescott.
Willamette doubled the pipeline length of the P6 and it was due to make up for it by the corresponding increase in clock frequency. If you do less per clock cycle, you need to throw more clock cycles at the problem to have a neutral impact on performance. Although Willamette ran at higher clock speeds than the outgoing P6 architecture, the increase in frequency was gated by process technology. It wasn't until Northwood arrived that Intel could hit the clock speeds required to truly put distance between its newest and older architectures.
Prescott lengthened the pipeline once more, this time quite significantly. Much to our surprise however, thanks to a lot of clever work on the architecture side Intel was able to keep average instructions executed per clock constant while increasing the length of the pipe. This enabled Prescott to hit higher frequencies and deliver more performance at the same time, without starting at an inherent disadvantage. Where Prescott did fall short however was in the power consumption department. Running at extremely high frequencies required very high voltages and as a result, power consumption skyrocketed.
AMD's goal with Bulldozer was to have IPC remain constant compared to its predecessor, while increasing frequency, similar to Prescott. If IPC can remain constant, any frequency increases will translate into performance advantages. AMD attempted to do this through a wider front end, larger data structures within the chip and a wider execution path through each core. In many senses it succeeded, however single threaded performance still took a hit compared to Phenom II:

At the same clock speed, Phenom II is almost 7% faster per core than Bulldozer according to our Cinebench results. This takes into account all of the aforementioned IPC improvements. Despite AMD's efforts, IPC went down.
A slight reduction in IPC however is easily made up for by an increase in operating frequency. Unfortunately, it doesn't appear that AMD was able to hit the clock targets it needed for Bulldozer this time around.
We've recently reported on Global Foundries' issues with 32nm yields. I can't help but wonder if the same type of issues that are impacting Llano today are also holding Bulldozer back.
Power Management and Real Turbo Core
Like Llano, Bulldozer incorporates significant clock and power gating throughout its design. Power gating allows individual idle cores to be almost completely powered down, opening up headroom for active cores to be throttled up above and beyond their base operating frequency. Intel's calls this dynamic clock speed adjustment Turbo Boost, while AMD refers to it as Turbo Core.
The Phenom II X6 featured a rudimentary version of Turbo Core without any power gating. As a result, Turbo Core was hardly active in those processors and when it was on, it didn't stay active for very long at all.
Bulldozer's Turbo Core is far more robust. While it still uses Llano's digital estimation method of determining power consumption (e.g. the CPU knows ALU operation x consumes y-watts of power), the results should be far more tangible than what we've seen from any high-end AMD processor in the past.
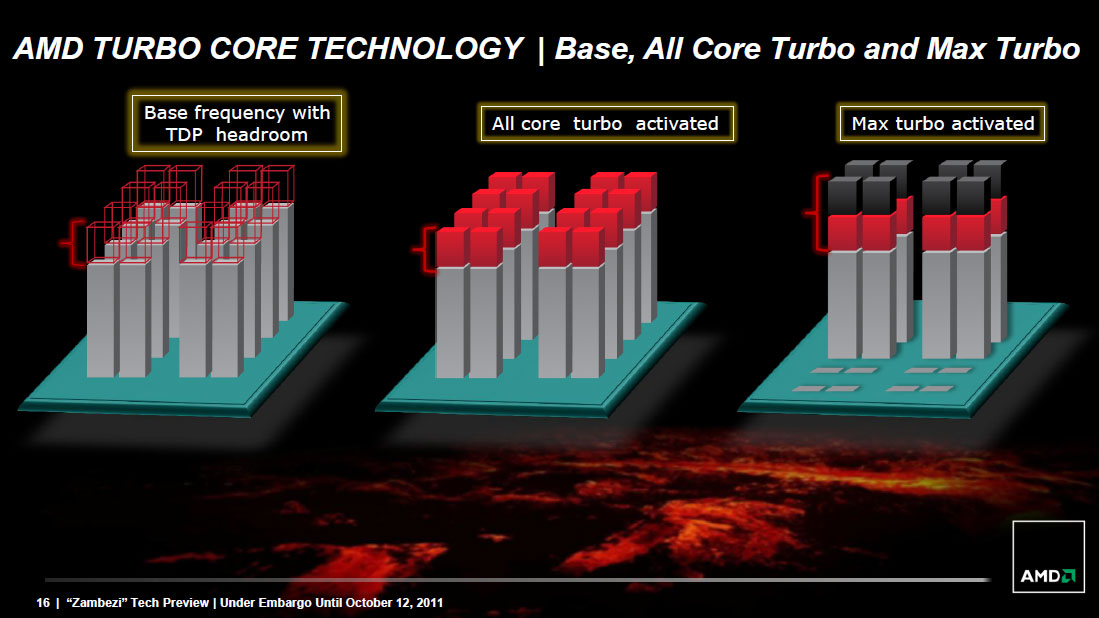
Turbo Core's granularity hasn't changed with the move to Bulldozer however. If half (or fewer) of the processor cores are active, max turbo is allowed. If any more cores are active, a lower turbo frequency can be selected. Those are the only two frequencies available above the base frequency.
AMD doesn't currently have a Turbo Core monitoring utility so we turned to Core Temp to record CPU frequency while running various workloads to measure the impact of Turbo Core on Bulldozer compared to Phenom II X6 and Sandy Bridge.
First let's pick a heavily threaded workload: our x264 HD benchmark. Each run of our x264 test is composed of two passes: a lightly threaded first pass that analyzes the video, and a heavily threaded second pass that performs the actual encode. Our test runs four times before outputting a result. I measured the frequency of Core 0 over the duration of the test.
Let's start with the Phenom II X6 1100T. By default the 1100T should run at 3.3GHz, but with half or fewer cores enabled it can turbo up to 3.7GHz. If Turbo Core is able to work, I'd expect to see some jumps up to 3.7GHz during the lightly threaded passes of our x264 test:
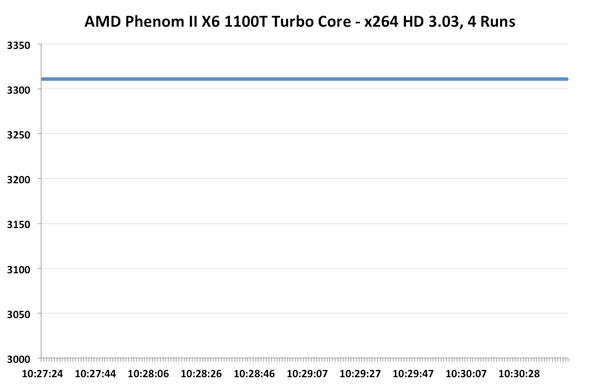
Unfortunately we see nothing of the sort. Turbo Core is pretty much non-functional on the Phenom II X6, at least running this workload. Average clock speed is a meager 3.31GHz, just barely above stock and likely only due to ASUS being aggressive with its clocking.
Now let's look at the FX-8150 with Turbo Core. The base clock here is 3.6GHz, max turbo is 4.2GHz and the intermediate turbo is 3.9GHz:
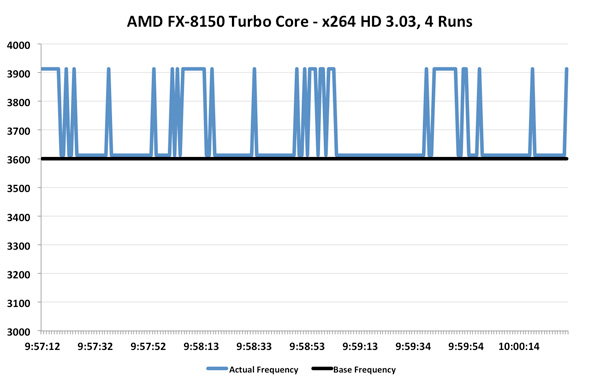
Ah that's more like it. While the average is only 3.69GHz (+2.5% over stock), we're actually seeing some movement here. This workload in particular is hard on any processor as you'll see from Intel's 2500K below:
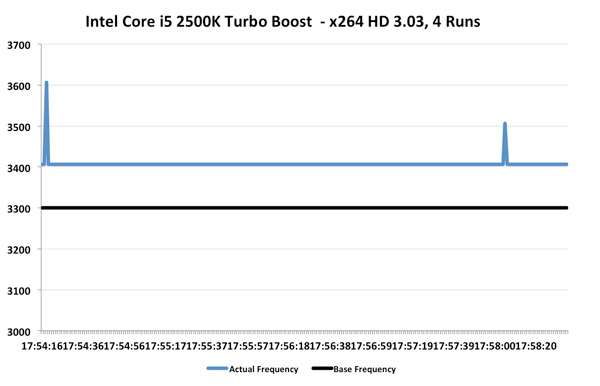
The 2500K runs at 3.3GHz by default, but thanks to turbo it averages 3.41GHz for the duration of this test. We even see a couple of jumps to 3.5 and 3.6GHz. Intel's turbo is a bit more consistent than AMD's, but average clock increase is quite similar at 3%.
Now let's look at the best case scenario for turbo: a heavy single threaded application. A single demanding application, even for a brief period of time, is really where these turbo modes can truly shine. Turbo helps launch applications quicker, make windows appear faster and make an easy time of churning through bursty workloads.
We turn to our usual favorite Cinebench 11.5, as it has an excellent single-threaded benchmark built in. Once again we start with the Phenom II X6 1100T:
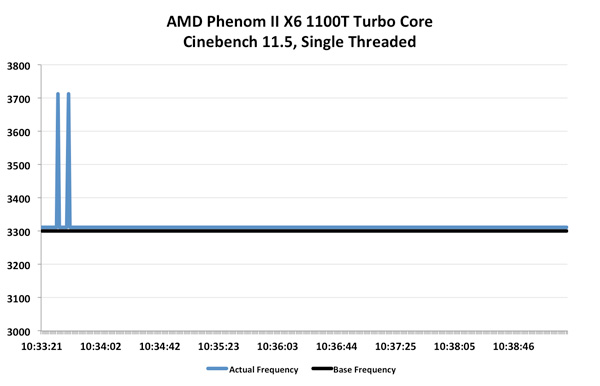
Turbo Core actually works on the Phenom II X6, albeit for a very short duration. We see a couple of blips up to 3.7GHz but the rest of the time the chip remains at 3.3GHz. Average clock speed is once again, 3.31GHz.
Bulldozer does far better:
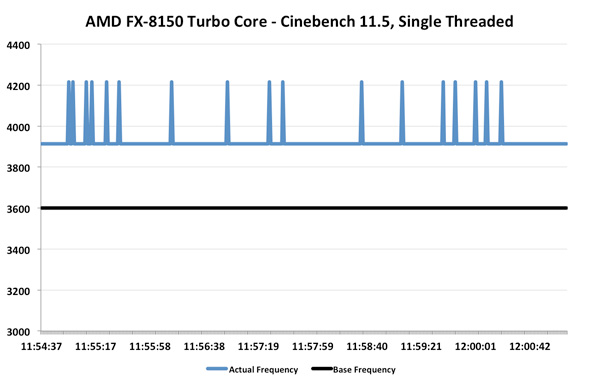
Here we see blips up to 4.2GHz and pretty consistent performance at 3.9GHz, exactly what you'd expect. Average clock speed is 3.93GHz, a full 9% above the 3.6GHz base clock of the FX-8150.
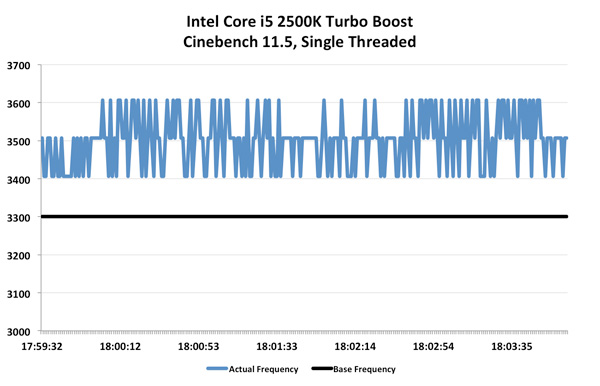
Intel's turbo fluctuates much more frequently here, moving between 3.4GHz and 3.6GHz as it runs into TDP limits. The average clock speed remains at 3.5GHz, or a 6% increase over the base. For the first time ever, AMD actually does a better job at scaling frequency via turbo than Intel. While I would like to see more granular turbo options, it's clear that Turbo Core is a real feature in Bulldozer and not the half-hearted attempt we got with Phenom II X6. I measured the performance gains due to Turbo Core across a number of our benchmarks:
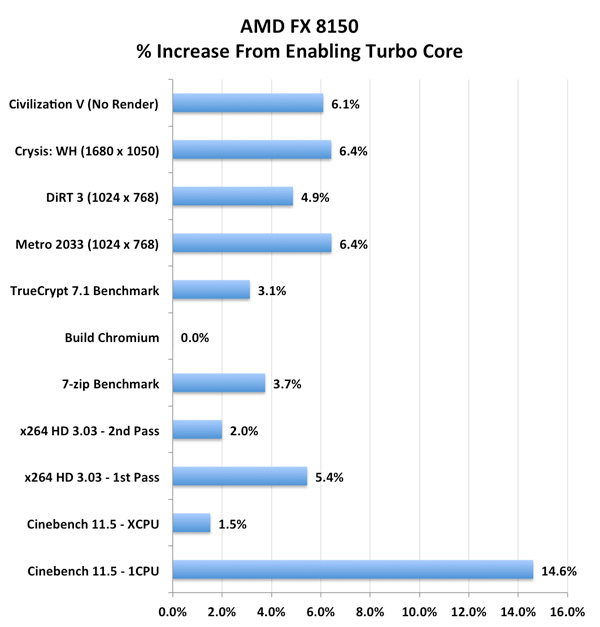
Average performance increased by just under 5% across our tests. It's nothing earth shattering, but it's a start. Don't forget how unassuming the first implementations of Turbo Boost were on Intel architectures. I do hope with future generations we may see even more significant gains from Turbo Core on Bulldozer derivatives.
Independent Clock Frequencies
When AMD introduced the original Phenom processor it promised more energy efficient execution by being able to clock each core independently. You could have a heavy workload running on Core 0 at 2.6GHz, while Core 3 ran a lighter thread at 1.6GHz. In practice, we felt Phenom's asynchronous clocking was a burden as the CPU/OS scheduler combination would sometimes take too long to ramp up a core to a higher frequency when needed. The result, at least back then, was that you'd get significantly lower performance in these workloads that shuffled threads from one core to the next. The problem was so bad that AMD abandoned asynchronous clocking altogether in Phenom II.
The feature is back in Bulldozer, and this time AMD believes it will be problem free. The first major change is with Windows 7, core parking should keep some threads from haphazardly dancing around all available cores. The second change is that Bulldozer can ramp frequencies up and down much quicker than the original Phenom ever could. Chalk that up to a side benefit of Turbo Core being a major part of the architecture this time around.
Asynchronous clocking in Bulldozer hasn't proven to be a burden in any of our tests thus far, however I'm reluctant to embrace it as an advantage just yet. At least not until we've had some more experience with the feature under our belts.
The Impact of Bulldozer's Pipeline
With a new branch prediction architecture and an unknown, but presumably significantly deeper pipline, I was eager to find out just how much of a burden AMD's quest for frequency had placed on Bulldozer. To do so I turned to the trusty N-Queens solver, now baked into the AIDA64 benchmark suite.
The N-Queens problem is simple. On an N x N chessboard, how do you place N queens so they cannot attack one another? Solving the problem is incredibly branch intensive, and as a result it serves as a great measure of the impact of a deeper pipeline.
The AIDA64 implementation of the N-Queens algorithm is heavily threaded, but I wanted to first get a look at single-core performance so I disabled all but a single integer/fp core on Bulldozer, as well as the competing processors. I also looked at constant frequency as well as turbo enabled speeds:

Unfortunately things don't look good. Even with turbo enabled, the 3.6GHz Bulldozer part needs another 25% higher frequency to equal a 3.6GHz Phenom II X4. Even a 3.3GHz Phenom II X6 does better here. Without being fully aware of the optimizations at work in AIDA64 I wouldn't put too much focus on Sandy Bridge's performance here, but Intel is widely known for focusing on branch prediction performance.
If we let the N-Queens benchmark scale to all available threads, the performance issues are easily masked by throwing more threads at the problem:

However it is quite clear that for single or lightly threaded operations that are branch heavy, Bulldozer will be in for a fight.
Cache and Memory Performance
I mentioned earlier that cache latencies are higher in order to accommodate the larger caches (8MB L2 + 8MB L3) as well as the high frequency design. We turned to our old friend cachemem to measure these latencies in clocks:
| Cache/Memory Latency Comparison | ||||||
| L1 | L2 | L3 | Main Memory | |||
| AMD FX-8150 (3.6GHz) | 4 | 21 | 65 | 195 | ||
| AMD Phenom II X4 975 BE (3.6GHz) | 3 | 15 | 59 | 182 | ||
| AMD Phenom II X6 1100T (3.3GHz) | 3 | 14 | 55 | 157 | ||
| Intel Core i5 2500K (3.3GHz) | 4 | 11 | 25 | 148 | ||
Cache latencies are up significantly across the board, which is to be expected given the increase in pipeline depth as well as cache size. But is Bulldozer able to overcome the increase through higher clocks? To find out we have to convert latency in clocks to latency in nanoseconds:

We disable turbo in order to get predictable clock speeds, which lets us accurately calculate memory latency in ns. The FX-8150 at 3.6GHz has a longer trip down memory lane than its predecessor, also at 3.6GHz. The higher latency caches play a role in this as they are necessary to help drive AMD's frequency up. What happens if we turn turbo on and peg the FX-8150 at 3.9GHz? Memory latency goes down. Bulldozer still isn't able to get to main memory as quickly as Sandy Bridge, but thanks to Turbo Core it's able to do so better than the outgoing Phenom II.

L3 access latency is effectively a wash compared to the Phenom II thanks to the higher clock speeds enabled by Turbo Core. Latencies haven't really improved though, and Bulldozer has a long way to go before it reaches Sandy Bridge access latencies.
The Test
To keep the review length manageable we're presenting a subset of our results here. For all benchmark results and even more comparisons be sure to use our performance comparison tool: Bench.
| Motherboard: |
ASUS P8Z68-V Pro (Intel Z68) ASUS Crosshair V Formula (AMD 990FX) |
| Hard Disk: |
Intel X25-M SSD (80GB) Crucial RealSSD C300 |
| Memory: | 2 x 4GB G.Skill Ripjaws X DDR3-1600 9-9-9-20 |
| Video Card: | ATI Radeon HD 5870 (Windows 7) |
| Video Drivers: | AMD Catalyst 11.10 Beta (Windows 7) |
| Desktop Resolution: | 1920 x 1200 |
| OS: | Windows 7 x64 |
Windows 7 Application Performance
3dsmax 9
Today's desktop processors are more than fast enough to do professional level 3D rendering at home. To look at performance under 3dsmax we ran the SPECapc 3dsmax 8 benchmark (only the CPU rendering tests) under 3dsmax 9 SP1. The results reported are the rendering composite scores.

As our first heavily threaded, predominantly FP workload we see the FX-8150 come out swinging. A tangible upgrade from the Phenom II X6, the 8150 is hot on the heelds of the Core i5 2400, however it is unable to compete with the 2500K and 2600K.
Cinebench R10 & 11.5
Created by the Cinema 4D folks we have Cinebench, a popular 3D rendering benchmark that gives us both single and multi-threaded 3D rendering results.

As I alluded to earlier, single threaded performance is going to be a bit of a disappointment with Bulldozer and here you get the first dose of reality. Even considering its clock speed and Turbo Core advantage, the FX-8150 is slower than the Phenom II X6 1100T. Intel's Core i5 2500K delivers nearly 50% better single threaded performance here than the FX-8150.

Crank up the threads and the FX-8150 shines, finally tying the 2500K at a comparable price point.
Even with more modern workloads, the FX-8150 isn't able to compete in single threaded speed. Here the 2500K is 44% faster.
Modern multithreaded workloads however do quite well on Bulldozer. The gains over the old Phenom II X6 1100T are unfortunately not as large as we would expect them to be.
7-Zip Benchmark

Heavily threaded workloads obviously do well on the FX series parts, here in our 7-zip test the FX-8150 is actually faster than Intel's fastest Sandy Bridge.
PAR2 Benchmark
Par2 is an application used for reconstructing downloaded archives. It can generate parity data from a given archive and later use it to recover the archive
Chuchusoft took the source code of par2cmdline 0.4 and parallelized it using Intel’s Threading Building Blocks 2.1. The result is a version of par2cmdline that can spawn multiple threads to repair par2 archives. For this test we took a 708MB archive, corrupted nearly 60MB of it, and used the multithreaded par2cmdline to recover it. The scores reported are the repair and recover time in seconds.

Once again, throw more threads at the processor and the FX-8150 can outperform the Core i5 2500K.
TrueCrypt Benchmark
TrueCrypt is a very popular encryption package that offers full AES-NI support. The application also features a built-in encryption benchmark that we can use to measure CPU performance with:

Bulldozer adds AES-NI acceleration, a feature that wasn't present in the Phenom II X6. As a result the FX-8150 is among the fastest at real time AES encryption/decryption, second only to the 2600K. Intel's artificial segmentation using Hyper Threading comes back to haunt it here as the 2500K is significantly slower than the 8-threaded beast.
x264 HD 3.03 Benchmark
Graysky's x264 HD test uses x264 to encode a 4Mbps 720p MPEG-2 source. The focus here is on quality rather than speed, thus the benchmark uses a 2-pass encode and reports the average frame rate in each pass.

As I mentioned earlier, the first pass of our x264 HD benchmark is a lightly threaded task. As such, the FX-8150 doesn't do very well here. Even the old Phenom II is able to inch ahead of AMD's latest. And Sandy Bridge obviously does very well.

The second pass is more thread heavy, allowing the FX-8150 to flex its muscle and effectively tie the 2600K for first place.
AMD also sent along a couple of x264 binaries that were compiled with AVX and AMD XOP instruction flags. We ran both binaries through our x264 test, let's first look at what enabling AVX does to performance:
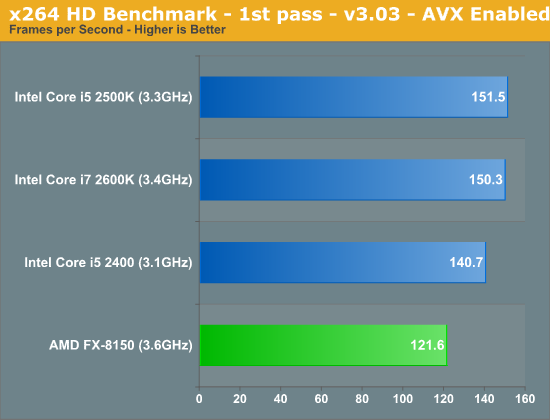
Everyone gets faster here, but Intel continues to hold onto a significant performance lead in lightly threaded workloads.
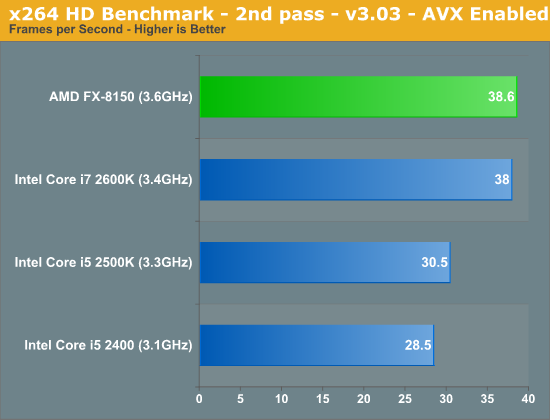
The standings don't change too much in the second pass, the frame rates are simply higher across the board. The FX-8150 is an x86 transcoding beast though, roughly equalling Intel's Core i7 2600K. Although not depicted here, the performance using the AMD XOP codepath was virtually identical to the AVX results.
Adobe Photoshop CS4
To measure performance under Photoshop CS4 we turn to the Retouch Artists’ Speed Test. The test does basic photo editing; there are a couple of color space conversions, many layer creations, color curve adjustment, image and canvas size adjustment, unsharp mask, and finally a gaussian blur performed on the entire image.
The whole process is timed and thanks to the use of Intel's X25-M SSD as our test bed hard drive, performance is far more predictable than back when we used to test on mechanical disks.
Time is reported in seconds and the lower numbers mean better performance. The test is multithreaded and can hit all four cores in a quad-core machine.

Photoshop performance improves tangibly over the Phenom II X6, unfortunately it's not enough to hang with the enthusiast Sandy Bridge parts.
Compile Chromium Test
You guys asked for it and finally I have something I feel is a good software build test. Using Visual Studio 2008 I'm compiling Chromium. It's a pretty huge project that takes over forty minutes to compile from the command line on a dual-core CPU. But the results are repeatable and the compile process will easily stress more than 8 threads on a CPU so it works for me.
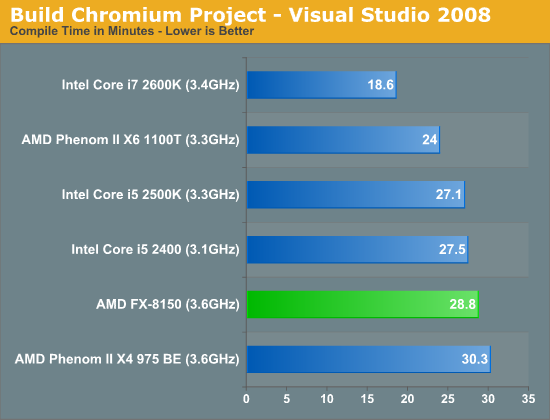
Our compiler test has traditionally favored heavily threaded architectures, but here we found the Phenom II X6 1100T to offer a tangible performance advantage over Bulldozer. While AMD is certainly competitive here, this is an example of one of those situations where AMD's architectural tradeoffs simply don't pay off—not without additional clock speed that is.
Excel Monte Carlo
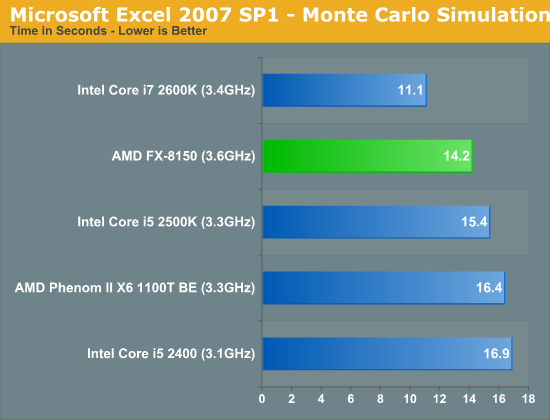
Our final application test is another win for AMD over the Core i5 2500K. The victory is entirely a result of Intel's Hyper Threading restrictions though, the eight-thread 2600K is able to easily outperform Bulldozer. Either way, AMD delivers better performance here for less money.
Gaming Performance
AMD clearly states in its reviewer's guide that CPU bound gaming performance isn't going to be a strong point of the FX architecture, likely due to its poor single threaded performance. However it is useful to look at both CPU and GPU bound scenarios to paint an accurate picture of how well a CPU handles game workloads, as well as what sort of performance you can expect in present day titles.
Civilization V
Civ V's lateGameView benchmark presents us with two separate scores: average frame rate for the entire test as well as a no-render score that only looks at CPU performance.
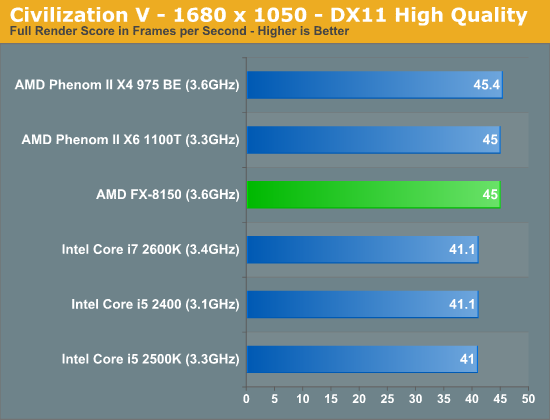
While we're GPU bound in the full render score, AMD's platform appears to have a bit of an advantage here. We've seen this in the past where one platform will hold an advantage over another in a GPU bound scenario and it's always tough to explain. Within each family however there is no advantage to a faster CPU, everything is just GPU bound.

Looking at the no render score, the CPU standings are pretty much as we'd expect. The FX-8150 is thankfully a bit faster than its predecessors, but it still falls behind Sandy Bridge.
Crysis: Warhead

In CPU bound environments in Crysis Warhead, the FX-8150 is actually slower than the old Phenom II. Sandy Bridge continues to be far ahead.
Dawn of War II

We see similar results under Dawn of War II. Lightly threaded performance is simply not a strength of AMD's FX series, and as a result even the old Phenom II X6 pulls ahead.
DiRT 3
We ran two DiRT 3 benchmarks to get an idea for CPU bound and GPU bound performance. First the CPU bound settings:

The FX-8150 doesn't do so well here, again falling behind the Phenom IIs. Under more real world GPU bound settings however, Bulldozer looks just fine:

Dragon Age

Dragon Age is another CPU bound title, here the FX-8150 falls behind once again.
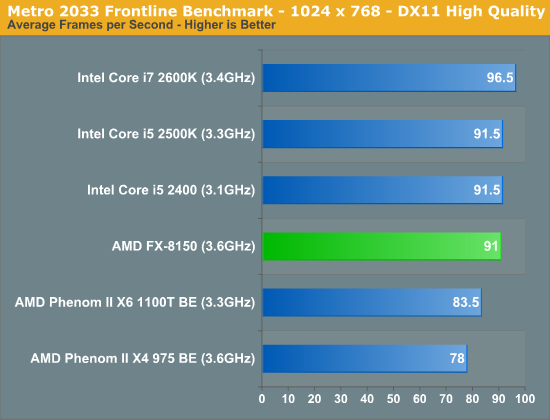
Metro 2033
Metro 2033 is pretty rough even at lower resolutions, but with more of a GPU bottleneck the FX-8150 equals the performance of the 2500K:

Rage vt_benchmark
While id's long awaited Rage title doesn't exactly have the best benchmarking abilities, there is one unique aspect of the game that we can test: Megatexture. Megatexture works by dynamically taking texture data from disk and constructing texture tiles for the engine to use, a major component for allowing id's developers to uniquely texture the game world. However because of the heavy use of unique textures (id says the original game assets are over 1TB), id needed to get creative on compressing the game's textures to make them fit within the roughly 20GB the game was allotted.
The result is that Rage doesn't store textures in a GPU-usable format such as DXTC/S3TC, instead storing them in an even more compressed format (JPEG XR) as S3TC maxes out at a 6:1 compression ratio. As a consequence whenever you load a texture, Rage needs to transcode the texture from its storage codec to S3TC on the fly. This is a constant process throughout the entire game and this transcoding is a significant burden on the CPU.
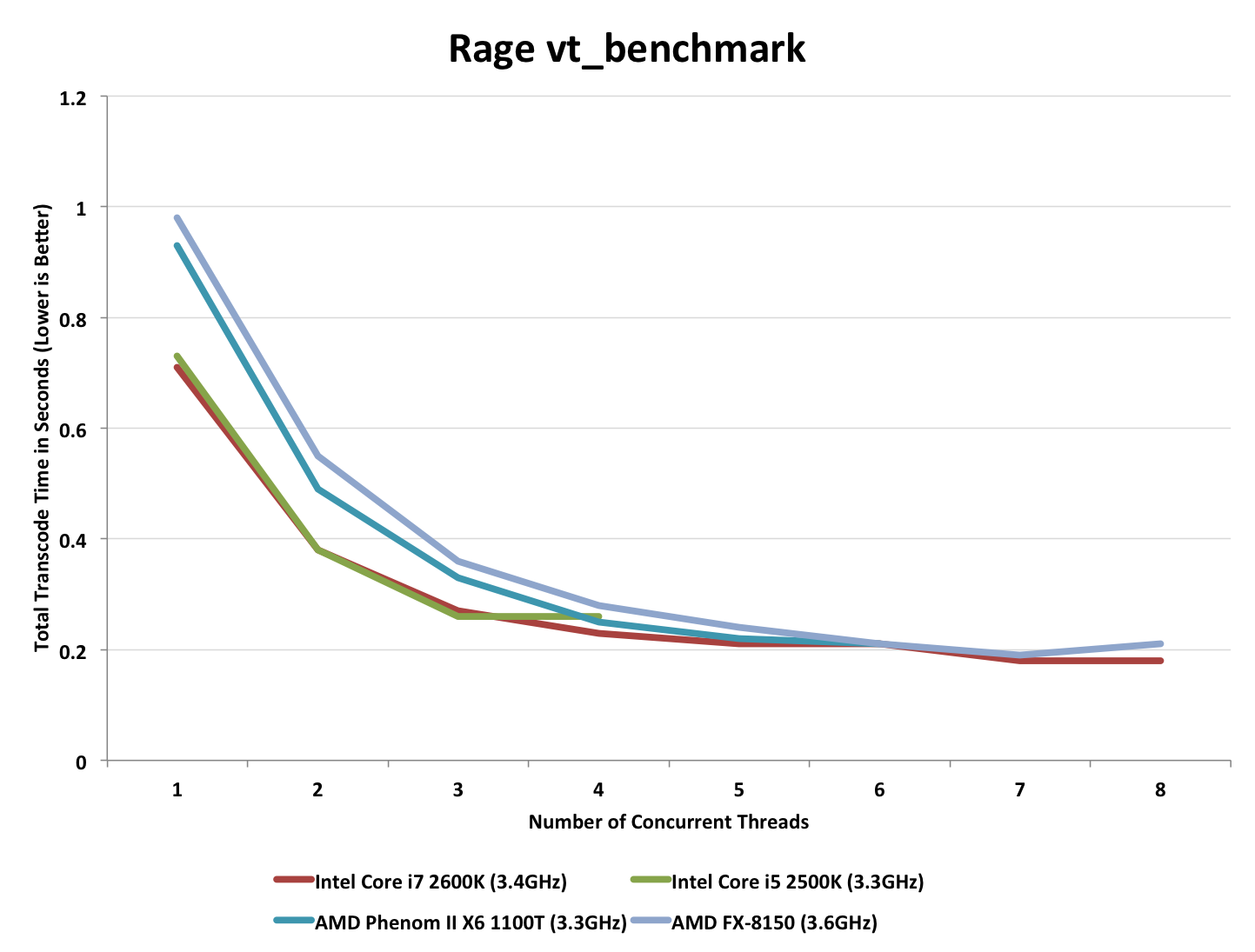
The Benchmark: vt_benchmark flushes the transcoded texture cache and then times how long it takes to transcode all the textures needed for the current scene, from 1 thread to X threads. Thus when you run vt_benchmark 8, for example, it will benchmark from 1 to 8 threads (the default appears to depend on the CPU you have). Since transcoding is done by the CPU this is a pure CPU benchmark. I present the best case transcode time at the maximum number of concurrent threads each CPU can handle:

The FX-8150 does very well here, but so does the Phenom II X6 1100T. Both are faster than Intel's 2500K, but not quite as good as the 2600K. If you want to see how performance scales with thread count, check out the chart below:
Starcraft 2

Starcraft 2 has traditionally done very well on Intel architectures and Bulldozer is no exception to that rule.
World of Warcraft

Power Consumption
Performing cross-platform power consumption comparisons is difficult simply because there is a lot of variance between motherboards. Looking at the AMD family alone to start with, the FX-8150's additional power and clock gating really pays off as Bulldozer idles at a significantly lower power level than the Phenom IIs. Sandy Bridge still appears to be a bit cooler.

Under load however, Bulldozer consumes quite a bit of power easily outpacing the Phenom II X6:

I suppose Global's 32nm process in combination with Bulldozer's high frequency targets are to blame here.
Overclocking
AMD indicated the FX-8150 was good for around 4.6GHz using air cooling, 5GHz using water cooling and beyond with more aggressive cooling methods. In our experience with the platform, hitting 4.6GHz, stable, on a stock AMD HSF was not an issue. Moving beyond 4.6GHz on air saw a significant decrease in stability however. I could boot and run benchmarks at 4.7GHz but I'd almost always encounter a crash. I couldn't hit 5GHz on air.
Final Words
In many cases, AMD's FX-8150 is able to close the gap between the Phenom II X6 and Intel's Core i5 2500K. Given the right workload, Bulldozer is actually able to hang with Intel's fastest Sandy Bridge parts. We finally have a high-end AMD CPU with power gating as well as a very functional Turbo Core mode. Unfortunately the same complaints we've had about AMD's processors over the past few years still apply here today: in lightly threaded scenarios, Bulldozer simply does not perform. To make matters worse, in some heavily threaded applications the improvement over the previous generation Phenom II X6 simply isn't enough to justify an upgrade for existing AM3+ platform owners. AMD has released a part that is generally more competitive than its predecessor, but not consistently so. AMD also makes you choose between good single or good multithreaded performance, a tradeoff that we honestly shouldn't have to make in the era of power gating and turbo cores.
Bulldozer is an interesting architecture for sure, but I'm not sure it's quite ready for prime time. AMD clearly needed higher clocks to really make Bulldozer shine and for whatever reason it was unable to attain that. With Piledriver due out next year, boasting at least 10-15% performance gains at the core level it seems to me that AMD plans to aggressively address the shortcomings of this architecture. My only concern is whether or not a 15% improvement at the core level will be enough to close some of the gaps we've seen here today. Single threaded performance is my biggest concern, and compared to Sandy Bridge there's a good 40-50% advantage the i5 2500K enjoys over the FX-8150. My hope is that future derivatives of the FX processor (perhaps based on Piledriver) will boast much more aggressive Turbo Core frequencies, which would do wonders at eating into that advantage.

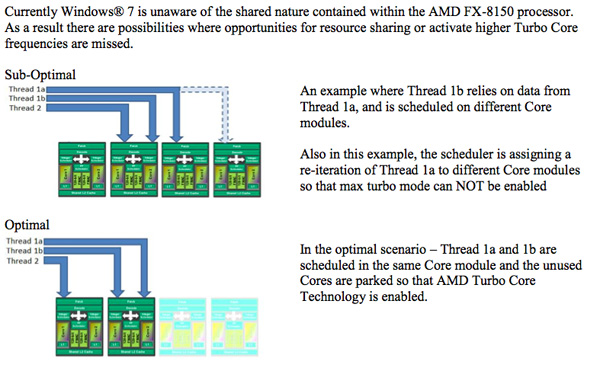
AMD also shared with us that Windows 7 isn't really all that optimized for Bulldozer. Given AMD's unique multi-core module architecture, the OS scheduler needs to know when to place threads on a single module (with shared caches) vs. on separate modules with dedicated caches. Windows 7's scheduler isn't aware of Bulldozer's architecture and as a result sort of places threads wherever it sees fit, regardless of optimal placement. Windows 8 is expected to correct this, however given the short lead time on Bulldozer reviews we weren't able to do much experimenting with Windows 8 performance on the platform. There's also the fact that Windows 8 isn't expected out until the end of next year, at which point we'll likely see an upgraded successor to Bulldozer.
So what do you do if you're buying today? If you have an existing high-end Phenom II system, particularly an X4 970 or above or an X6 of any sort, I honestly don't see much of a reason to upgrade. You're likely better off waiting for the next (and final) iteration of the AM3+ lineup if you want to stick with your current platform. If you're considering buying new, I feel like the 2500K is a better overall part. You get more predictable performance across the board regardless of application type or workload mix, and you do get features like Quick Sync. In many ways, where Bulldozer is a clear win is where AMD has always done well: heavily threaded applications. If you're predominantly running well threaded workloads, Bulldozer will typically give you performance somewhere around or above Intel's 2500K.

I was hoping for Bulldozer to address AMD's weakness rather than continue to just focus on its strengths. I suspect this architecture will do quite well in the server space, but for client computing we may have to wait a bit longer for a more competitive part from AMD. The true culprit for Bulldozer's lackluster single-threaded performance is difficult to track down. The easy answer would seem to be clock speed. We've heard of issues at Global Foundries and perhaps Bulldozer is the latest victim. If AMD's clock targets were 30% higher than Phenom II, it simply didn't make them with the FX-8150. I've heard future derivatives will focus more on increasing IPC indepedent of process technology and clock speed, but if you asked me what was the one limit to success I would say clock speed. As a secondary factor, AMD appeared to make some tradeoffs to maintain a reasonable die size at 32nm. Even then Bulldozer can hardly be considered svelte. I suspect as AMD is able to transition to smaller transistor geometries, it will be able to address some of Bulldozer's physical shortcomings.
The good news is AMD has a very aggressive roadmap ahead of itself; here's hoping it will be able to execute against it. We all need AMD to succeed. We've seen what happens without a strong AMD as a competitor. We get processors that are artificially limited and severe restrictions on overclocking, particularly at the value end of the segment. We're denied choice simply because there's no other alternative. I don't believe Bulldozer is a strong enough alternative to force Intel back into an ultra competitive mode, but we absolutely need it to be that. I have faith that AMD can pull it off, but there's still a lot of progress that needs to be made. AMD can't simply rely on its GPU architecture superiority to sell APUs; it needs to ramp on the x86 side as well—more specifically, AMD needs better single threaded performance. Bulldozer didn't deliver that, and I'm worried that Piledriver alone won't be enough. But if AMD can stick to a yearly cadence and execute well with each iteration, there's hope. It's no longer a question of whether AMD will return to the days of the Athlon 64, it simply must. Otherwise you can kiss choice goodbye.






