Original Link: https://www.anandtech.com/show/4486/server-rendering-hpc-benchmark-session
Rendering and HPC Benchmark Session Using Our Best Servers
by Johan De Gelas on September 30, 2011 12:00 AM ESTIntroduction to Server Benchmarking
Each time we publish a new server platform review, several of our readers inquire about HPC and rendering benchmarks. We're always willing to accommodate reasonable requests, so we're going to start expanding beyond our usual labor intensive virtualization benchmarks. This article is our first attempt. It was a bumpy ride, but this first attempt produced some very interesting insights.
The core counts of modern servers have increased at an incredible pace, making many benchmarks useless if we want to assess the maximum throughput. Just three years ago, we could still run benchmarks like Fritz Chess, Winrar, and zVisuel to satisfy our curiosity. We also performed real-world benchmarks like MySQL OLAP on our octal-core servers. All these benchmarks are pretty useless now on our 48-core Magny-Cours and 80-thread Westmere-EX systems. The number of applications that can really take advantage of the core counts found in quad- and even dual-socket servers continues to get lower and lower.
Most servers are now running hypervisors and virtualization of some form, so we naturally focused on virtualized environments. However, many of our readers are hardware enthusiasts, so while we wait for the new server platforms such as Intel's Romley-EP (Sandy Bridge EP) and AMD's Interlagos (Bulldozer) to appear, we decided to expand our benchmark suite. Our first attempt is not very ambitious: we'll tackle Cinebench (rendering) and Stars Euler 3D CFD (HPC). Both are quick and easy benchmarks to perform... or at least that'ss what we expected going in. On the plus side, our testing results are a lot more interesting than we imagined they would be.
Quad Xeon: the Quanta QSCC-4R Benchmark Configuration

| CPU |
Quad Intel Xeon "Westmere-EX" E7-4870 (10 core/20 threads at 2.4GHz, 2.8GHz Turbo, 30MB L3, 32nm) |
| RAM | 32 x 4GB (128GB) Samsung Registered DDR3-1333 at 1066MHz |
| Motherboard | QCI QSSC-S4R 31S4RMB00B0 |
| Chipset | Intel 7500 |
| BIOS version | QSSC-S4R.QCI.01.00.S012,031420111618 |
| PSU | 4 x Delta DPS-850FB A S3F E62433-004 850W |
The quad Xeon configuration is equipped with 128GB RAM to make sure that all memory channels are filled.
Dual Xeon: ASUS RS700-E6/RS4 Configuration
| CPU |
Dual Intel Xeon “Westmere” X5670 (6 core/12 threads at 2.93GHz, 3.33GHz Turbo, 12MB L3, 32nm) |
| RAM | 12 x 4GB (48GB) ECC Registered DDR3-1333 |
| Motherboard | ASUS Z8PS-D12-1U |
| Chipset | Intel 5520 |
| BIOS version | Version 1.003 |
| PSU | Delta Electronics DPS-770 AB 770W |
The dual Xeon server in contrast "only" has 48GB. This has no influence on the benchmark results, as the benchmarks use considerably less RAM.
Quad Opteron: Dell PowerEdge R815 Benchmarked Configuration

| CPU |
Quad AMD Opteron "Magny-Cours" 6174 (12 cores at 2.2GHz, 12MB L3, 45nm) |
| RAM | 16x4GB (64GB) Samsung Registered DDR3-1333 at 1333MHz |
| Motherboard | Dell Inc 06JC9T |
| Chipset | AMD SR5650 |
| BIOS version | v1.1.9 |
| PSU | 2 x Dell L1100A-S0 1100W |
We reviewed the powerful but compact Dell R815 here. This time we're running 64GB, though again the amount of RAM was selected to make sure memory performance is optimized rather than for usage requirements.
Cinebench R11.5
Cinebench, based on MAXON's software CINEMA 4D, is probably one of the most popular benchmarks around, and it is pretty easy to perform this benchmark on your own home machine. However, it gets a little bit more complicated when you try to run it on an 80 thread server: the benchmark only supports 64 threads.
First we tested single threaded performance, to evaluate the performance of each core.
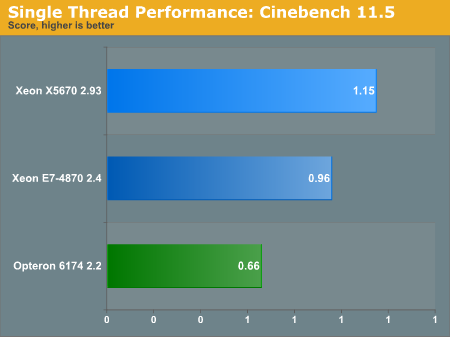
A Core i7-970, which is based on the same "Westmere" architecture gets about 1.2 at 3.2GHz, so there is little surprise that a slightly lower clocked Xeon 5670 is able to reach a 1.15 score. It is interesting to note however that the Westmere core inside the massive Westmere-EX gets a better score than expected. Considering that Cinebench scales almost perfectly with clockspeed, you would expect a score of about 0.9. The E7 can boost clockspeed by 17% from 2.4 to 2.8GHz, while the previously mentioned i7-970 gets only an 8% boost at most (from 3.2 to 3.46GHz). And of course, the massive L3-cache may help too.
The Opteron at 2.2GHz performs like its Phenom II desktop counterparts. A 3.2GHz Phenom II gets a score of about 0.92, so we are not surprised with the 0.66 for our 2.2GHz core.
When we started benchmarking Cinebench on our Xeon E7 platform, we ran into trouble. Cinebench only supports 64 threads at the most and recognized only 32 of our 40 available cores and 80 threads. The results were pretty bad. To get a decent result out of the Xeon E7, we had to disable Hyper-Threading and we forced Cinebench to start up 40 threads. We included a Core i7-970 (Hyper-Threading on) to give you an idea of how a powerful workstation/desktop compares to these servers. This kind of software is run a lot on fast workstations after all.

Even cheap servers will outperform a typical single socket workstation by almost a factor of two. The quad socket machines can offer up to three or four times as much performance. For those of you who can't get enough: you can find some dual Opteron numbers here. The dual Opteron 6174 scores about 15, and a dual Opteron 2435 2.6 "Istanbul" gets about 9.
Cinebench scales very easily as can be noticed from looking at the 32 core and 40 core results of the Xeon E7-4870. Increase the core count by 25% and you get a 22.4% performance increase. The Opteron scales slightly worse. Compare the 48-core result with the 32 core one: a 50% increase in core counts gets you "only" a 37% increase in performance.
Below you can see the rendering performance of two top machines rendering with different numbers of cores.
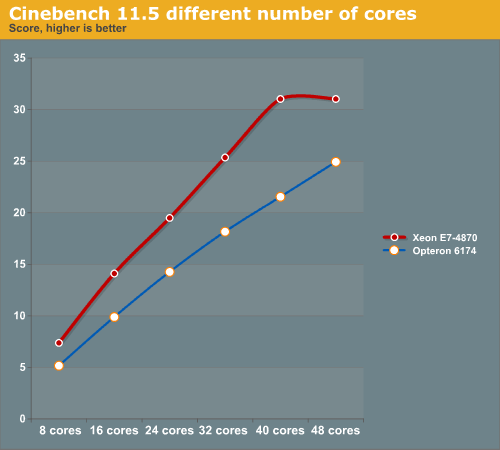
You need about 48 2.2GHz Opteron cores to match 32 Xeon cores. The good news for AMD is that even these 8-core Westmere-EX CPUs are almost twice as expensive. That means that quad AMD Opteron 61xx systems are a viable choice for rendering, at least in CINEMA 4D (assuming it has the same 64-thread limitation as Cinebench). AMD has carved out a niche here, which is one reason why there will be cheaper 4 socket Romley EP systems in the near future.
STARS Euler3D CFD
The STARS Euler3D CFD benchmark got popular thanks to Scott of Techreport.com. It is a computational fluid dynamics (CFD) benchmark based on the STARS Euler3D structural analysis routines developed at CASELab, the Computational AeroServoElasticity Laboratory at Oklahoma State University. Since the benchmark has been used for years by Scott, we felt it was a good place to start our HPC benchmarking adventure: we could check if our results are in the right ballpark.
The benchmark is downloadable and described in great detail here. The benchmark score is reported as a CFD cycle frequency in Hertz, with higher results being better.
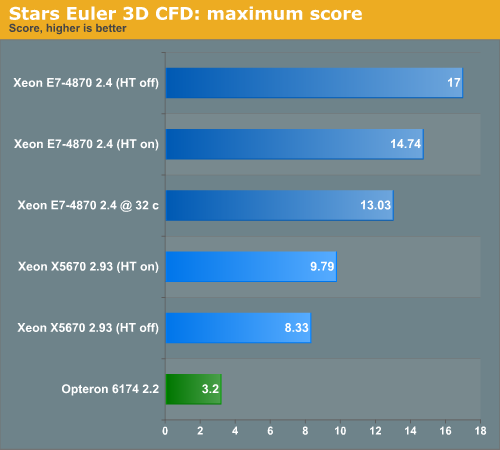
The Xeon E7 scales quite nicely on the condition that you disable Hyper-Threading. The benchmark is able to take advantage of Hyper-Threading, which can be seen on the dual Xeon system. However, the threads work on the same data grid, so the more threads, the more locking contention rears its ugly head. Here's a more detailed look at scaling with the number of threads:
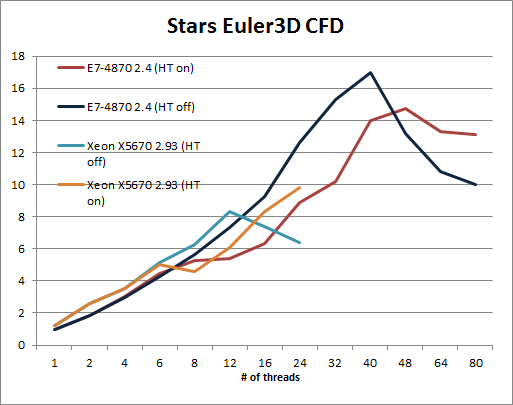
The Hyper-Threading enabled Xeon X5670 performs worse than the non-HT setup until we run more than 12 threads. Once we do that it can offer a decent performance boost (17%). The benchmark however does not scale enough to take advantage of 80 threads. Hyper-Threading offers better resource utilization but that does not negate the negative performance effect of the overhead of running 80 threads. Once we pass 40 threads on the E7-4870, performance starts to level off and even drop.
Of course, you are probably more interested in the other server result. What happened to the Opteron scores? Why is the 48 core Opteron five times slower than the 40 core Xeon E7? Let's investigate further.
Investigating the Opteron Performance Mystery
What really surprised us was the Opteron's abysmal performance in Stars Euler3D CFD. We did not believe the results and repeated the benchmark at least 10 times on the quad Opteron system. Let us delve a little deeper.
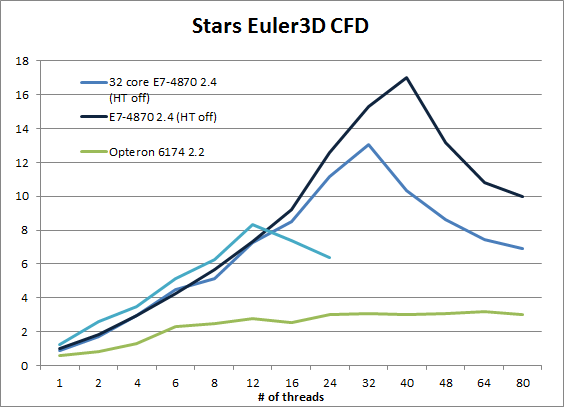
Notice that the Intel Xeons scale very well until the number of threads is higher than the physical core count. The performance of the 40 core E7-4870 only drops when we use 48 threads (with HT off). The Opteron however only scales reasonably well from 1 to 6 threads. Between 6 and 12 threads scaling is very mediocre, but at least performance increases. From there, the performance curve is essentially flat.
The Opteron Performance Remedy?
We contacted Charles of Caselab with our results. He gaves us a few clues:
1. The Euler3d CFD solver uses an unstructured grid (spider web appearance with fluid states stored at segment endpoints). Thus, adjacent physical locations do not (cannot!) map to adjacent memory locations.
2. The memory performance benchmark relevant to Euler3D appears to be the random memory recall rate and NOT the adjacent-memory-sweep bandwidth.
3. Typical memory tests (e.g. Stream) are sequential "block'' based. Euler3D effectively tests random access memory performance.
So sequential bandwidth is not the answer. In fact, in most "Streamish" benchmarks (including our own compiled binaries), the Quad Opteron was close to 100GB/s while the Quad Xeon E7 got only between 37 and 55GB/s. So far it seems that only the Intel compiled stream binaries are able to achieve more than 55GB/s. So we have a piece of FP intensive software that performs a lot of random memory accesses.
On the Opteron, performance starts to slow down when we use more than 12 threads. With 24 or even better 48 threads the application spawns more threads than the available cores within the local socket. This means that remote memory accesses cannot be avoided. Could it be that the performance is completely limited by the threads that have to go the furthest (2 hops)? In others words, some threads working on local memory finish much faster, but the whole test cannot complete until the slowest threads (working on remote memory) finish.
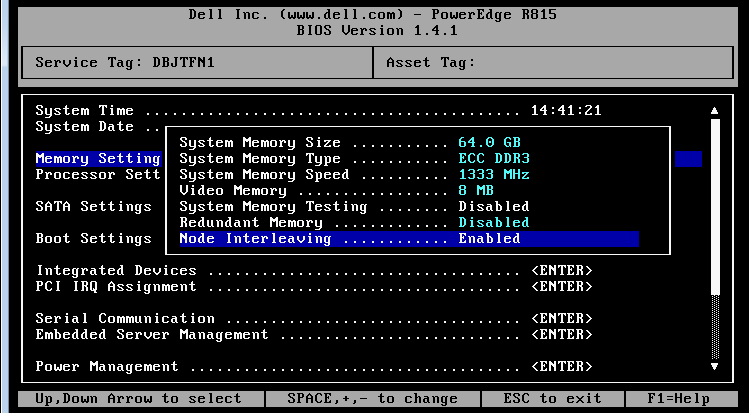
We decided to enable "Node Interleaving" in the BIOS of our Dell R815. This means that data is striped across all four memory controllers. Interleaved accesses are slower than local-only accesses because three out of four operations traverse the HT link. However, all threads should now experience a latency that is more or less the same. We prevent the the worst-case scenario where few threads are seeing 2-hop latency. Let us see if that helped.
Testing the Opteron HPC Remedy
The results of memory node interleaving are pretty spectacular, at least in terms of improving Opteron performance.
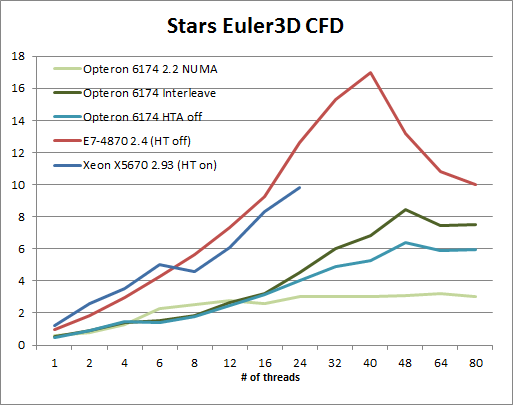
Once we disable NUMA, our Opteron server scales properly. Performance is multiplied by 3 when we run the benchmark with 48 threads. So memory interleaving does the trick, but since memory interleaving increases the traffic between the CPU nodes, we decided to test with HT assist (a 1MB snoop filter) on and off.
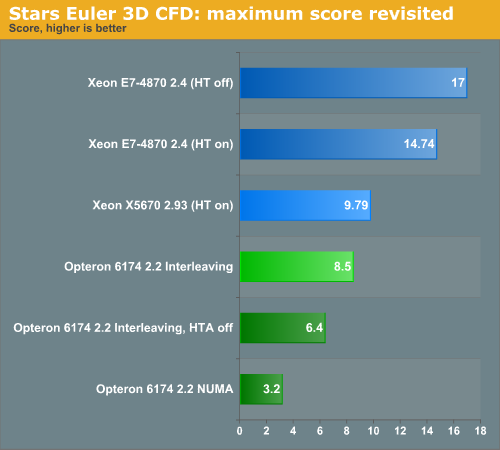
Notice how this benchmark relies on the CPU interconnects: when we disable HT assist but leave interleaving on, we lose more than 25% performance. HT assist avoids many unnessary broadcasts on the HT interconnects. What is more, we did test the Xeon E7 with memory node interleaving (4-way) but this did not improve or decrease performance in any substantial way.
There's even more good news for the Opteron: the score on Cinebench R11.5 rendering improved from 25 (NUMA) to 26.3. (memory node interleaving). It's hardly spectacular, but that's still a nice and free of charge 5% performance boost, assuming you're running workloads that will benefit.
The Big Question: Why?
The big question is why the Opteron performs so much better with memory node interleaving while this has no effect whatsoever on the Xeons. Only a very detailed profiling could gives us the absolute and accurate answer, but that is a bit beyond the scope of this article (and our time constraints). However, we already have a few interesting clues:
- Enabling HT assist improves performance by 32% (8.5 vs 6.4), which indicates that snoop traffic is a serious bottleneck. That is also a result of using memory node interleaving, which increases the data traffic between the sockets as data is striped over the memory nodes.
- The application is very sensitive to latency.
The Xeon E7 has a Global Coherence Engine with Directory Assisted Snoop (DAS). As described by David Kanter here, the Coherence Engine makes use of an innovative 2-hop protocol that achieves much lower snoop latency. Intel's Coherence Engine is quite a bit more advanced than the 3-hop protocol combined with the snoop filter that AMD uses on the current Opterons. This might be one explanation why the Xeon E7 does not need memory node interleaving to get good performance in an application that spawns more threads than the core count of one CPU socket.
Conclusion
It is interesting to note that Cinebench also benefits from node interleaving, although it is a lot less extreme than what we witnessed in STARS Euler3D CFD. That could indicate there are quite a few (HPC) applications which could benefit from memory node interleaving despite the fact that most operating systems are now well optimized for NUMA. We suspect that almost any application that spawns threads accross four sockets and works on a common dataset will see some benefit from node interleaving on AMD's quad Opteron platform.
That said, virtualization is not such an application, as most VMs are limited to 4-8 vCPUs. In such setups, the dataset can be kept locally with a bit of tuning, and since the release of vSphere 4.0, ESX is pretty good at this.
Looking at the performance results, the Xeons dominated the CFD benchmark, even with the interleaving enabled on Opterons. However, this doesn't mean that the current 12-core opteron is a terrible choice for HPC use. We know that the AMD Opteron performs very well in some important HPC benches, as you can read here. That benchmark was compiled with an Intel Fortran compiler (ifort 10.0), and you might wonder why it was compiled that way. We asked Charles, the software designer, to answer that question:
"I spent some time with the gfortran compiler but the results were fairly bad. [...] That's why we pay big money for Intel's Fortran compiler!"
What that benchmark and this article show is how careful we must be when looking at performance results for many-threaded workloads and servers. If you just run the CFD benchmark on a typical server configurations, you might conclude that a 12-core Xeon is more than three times faster than a 48-core Opteron setup. However, after some tinkering we begin to understand what is actually going on, and while the final result still isn't particularly impressive (the 12-core/24-thread Xeon still bested the 48-core Opteron by 15%, and the quad Xeon E7-4870 is nearly twice as fast as the best Opteron result so far), there's still potential for improvement.
To Be Continued...
Remember, this is only our first attempt at HPC benchmarking. We'll be looking into more ambitious testing later, and we're hoping to incorporate your feedback. What Let us know your suggestions for benchmarks and other tests you'd like to see us run on these servers (and upcoming hardware as well), and we'll work to make it happen.






