Original Link: https://www.anandtech.com/show/4455/amds-graphics-core-next-preview-amd-architects-for-compute
AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTWe’ve just returned from sunny Bellevue, Washington, where AMD held their first Fusion Developer Summit (AFDS). As with other technical conferences of this nature such as NVIDIA’s GTC and Intel’s IDF, AFDS is a chance for AMD to reach out to developers to prepare them for future products and to receive feedback in turn. While AMD can make powerful hardware it’s ultimately the software that runs on it that drives sales, so it’s important for them to reach out to developers to ensure that such software is being made.
AFDS 2011 served as a focal point for several different things going on at AMD. At its broadest, it was a launch event for Llano, AMD’s first mainstream Fusion APU that launched at the start of the week. AMD has invested the future of the company into APUs, and not just for graphical purposes but for compute purposes too. So Llano is a big deal for the company even though it’s only a taste of what’s to come.

The second purpose of course was to provide sessions for developers to learn more about how to utilize AMD’s GPUs for compute and graphics tasks. Microsoft, Acceleware, Adobe, academic researchers, and others were on hand to provide talks on how they’re using GPUs in current and future projects.
The final purpose – and what is going to be most interesting to most outside observers – was to prepare developers for what’s coming down the pipe. AMD has big plans for the future and it’s important to get developers involved as soon as is reasonably possible so that they’re ready to use AMD’s future technologies when they launch. Over the next few days we’ll talk about a couple of different things AMD is working on, and today we’ll start with the first and most exciting project: AMD Graphics Core Next.
Graphics Core Next (GCN) is the architectural basis for AMD’s future GPUs, both for discrete products and for GPUs integrated with CPUs as part of AMD’s APU products. AMD will be instituting a major overhaul of its traditional GPU architecture for future generation products in order to meet the direction of the market and where they want to go with their GPUs in the future.
While graphics performance and features have been and will continue to be important aspects of a GPU’s design, AMD and the rest of the market have been moving towards further exploiting the compute capabilities of GPUs, which in the right circumstances are capable of being utilized as massive parallel processors that can complete a number of tasks in the fraction of the time as a highly generalized CPU. Since the introduction of shader-capable GPUs in 2002, GPUs have slowly evolved to become more generalized so that their resources can be used for more than just graphics. AMD’s most recent shift was with their VLIW4 architecture with Cayman late last year; now they’re looking to make their biggest leap yet with GCN.
GCN at its core is the basis of a GPU that performs well at both graphical and computing tasks. AMD has stretched their traditional VLIW architecture as far as they reasonably can for computing purposes, and as more developers get on board for GPU computing a clean break is needed in order to build a better performing GPU to meet their needs. This is in essence AMD’s Fermi: a new architecture and a radical overhaul to make a GPU that is as monstrous at computing as it is at graphics. And this is the story of the architecture that AMD will be building to make it happen.
Finally, it should be noted that the theme of AFDS 2011 was heterogeneous computing, as it has become AMD’s focus to get developers to develop heterogeneous applications that effectively utilize both AMD’s CPUs and AMD’s GPUs. Ostensibly AFDS is a conference about GPU computing, but AMD’s true strength is not their CPU side or their GPU side, it’s the combination of the two. Bulldozer will be the first half of AMD’s future APUs, while GCN will be the other half.
Prelude: The History of VLIW & Graphics
Before we get into the nuts & bolts of Graphics Core Next, perhaps it’s best to start at the bottom, and then work our way up.
The fundamental unit of AMD’s previous designs has been the Streaming Processor, previously known as the SPU. In every modern AMD design other than Cayman (6900), this is a Very Long Instruction Word 5 (VLIW5) design; Cayman reduced this to VLIW4. As implied by the architectural name, each SP would in turn have 5 or 4 fundamental math units – what AMD now calls Radeon cores – which executed the individual instructions in parallel over as many clocks as necessary. Radeon cores were coupled with registers, a branch unit, and a special function (transcendental) unit as necessary to complete the SP.
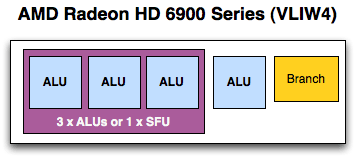
VLIW designs are designed to excel at executing many operations from the same task in parallel by breaking it up into smaller groupings called wavefronts. In AMD’s case a wavefront is a group of 64 pixels/values and the list of instructions to be executed against them. Ideally, in a wavefront a group of 4 or 5 instructions will come down the pipe and be completely non-interdependent, allowing every Radeon core to be fed. When dependent instructions would come down however, fewer instructions could be scheduled at once, and in the worst case only a single instruction could be scheduled. VLIW designs will never achieve perfect efficiency in this regard, but the farther real world utilization is from ideal efficiency, the weaker the benefits of VLIW.
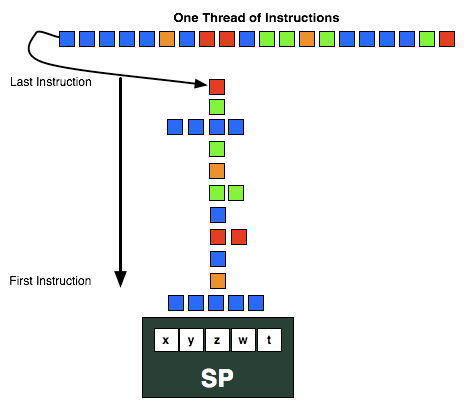
The use of VLIW can be traced back to the first AMD DX9 GPU, R300 (Radeon 9700 series). If you recall our Cayman launch article, we mentioned that AMD initially used a VLIW design in those early parts because it allowed them to process a 4 component dot product (e.g. w, x, y, z) and a scalar component (e.g. lighting) at the same time, which was by far the most common graphics operation. Even when moving to unified shaders in DX10 with R600 (Radeon HD 2900), AMD still kept the VLIW5 design because the gaming market was still DX9 and using those kinds of operations. But as new games and GPGPU programs have come out efficiency has dropped over time, and based on AMD’s own internal research at the time of the Cayman launch the average shader program was utilizing only 3.4 out of 5 Radeon cores. Shrinking from VLIW5 to VLIW4 fights this some, but utilization will always be a concern.
Finally, it’s worth noting what’s in charge of doing all of the scheduling. In the CPU world we throw things at the CPU and let it schedule actions as necessary – it can even go out-of-order (OoO) within a thread if it will be worth it. With VLIW, scheduling is the domain of the compiler. The compiler gets the advantage of knowing about the full program ahead of time and can intelligently schedule some things well in advance, but at the same time it’s blind to other conditions where the outcome is unknown until the program is run and data is provided. Because of this the schedule is said to be static – it’s set at the time of compilation and cannot be changed in-flight.
So why in an article about AMD Graphics Core Next are we going over the quick history of AMD’s previous designs? Without understanding the previous designs, we can’t understand what is new about what AMD is doing, or more importantly why they’re doing it.
AMD Graphics Core Next: Out With VLIW, In With SIMD
The fundamental issue moving forward is that VLIW designs are great for graphics; they are not so great for computing. However AMD has for all intents and purposes bet the company on GPU computing – their Fusion initiative isn’t just about putting a decent GPU right on die with a CPU, but then utilizing the radically different design attributes of a GPU to do the computational work that the CPU struggles at. So a GPU design that is great at graphics and poor at computing work simply isn’t sustainable for AMD’s future.
With AMD Graphics Core Next, VLIW is going away in favor of a non-VLIW SIMD design. In principal the two are similar – run lots of things in parallel – but there’s a world of difference in execution. Whereas VLIW is all about extracting instruction level parallelism (ILP), a non-VLIW SIMD is primarily about thread level parallelism (TLP).
Without getting unnecessarily deep into the differences between VLIW and non-VLIW (we’ll save that for another time), the difference in the architectures is about what VLIW does poorly for GPU computing purposes, and why a non-VLIW SIMD fixes it. The principal issue is that VLIW is hard to schedule ahead of time and there’s no dynamic scheduling during execution, and as a result the bulk of its weaknesses follow from that. As VLIW5 was a good fit for graphics, it was rather easy to efficiently compile and schedule shaders under those circumstances. With compute this isn’t always the case; there’s simply a wider range of things going on and it’s difficult to figure out what instructions will play nicely with each other. Only a handful of tasks such as brute force hashing thrive under this architecture.
Furthermore as VLIW lives and dies by the compiler, which means not only must the compiler be good, but that every compiler is good. This is an issue when it comes to expanding language support, as even with abstraction through intermediate languages you can still run into issues, including issues with a compiler producing intermediate code that the shader compiler can’t handle well.
Finally, the complexity of a VLIW instruction set also rears its head when it comes to optimizing and hand-tuning a program. Again this isn’t normally a problem for graphics, but it is for compute. The complex nature of VLIW makes it harder to disassemble and to debug, and in turn difficult to predict performance and to find and fix performance critical sections of the code. Ideally a coder should never have to work in assembly, but for HPC and other uses there is a good deal of performance to be gained by doing so and optimizing down to the single instruction.
AMD provided a short example of this in their presentation, showcasing the example output of their VLIW compiler and their new compiler for Graphics Core Next. Being a coder helps, but it’s not hard to see how contrived things are under VLIW.
VLIW
// Registers r0 contains "a", r1 contains "b"
// Value is returned in r2
00 ALU_PUSH_BEFORE
1 x: PREDGT ____, R0.x, R1.x
UPDATE_EXEC_MASK UPDATE PRED
01 JUMP ADDR(3)
02 ALU
2 x: SUB ____, R0.x, R1.x
3 x: MUL_e R2.x, PV2.x, R0.x
03 ELSE POP_CNT(1) ADDR(5)
04 ALU_POP_AFTER
4 x: SUB ____, R1.x, R0.x
5 x: MUL_e R2.x, PV4.x, R1.x
05 POP(1) ADDR(6)
Non-VLIW SIMD
// Registers r0 contains "a", r1 contains "b"
// Value is returned in r2
v_cmp_gt_f32 r0,r1 //a > b, establish VCC
s_mov_b64 s0,exec //Save current exec mask
s_and_b64 exec,vcc,exec //Do "if"
s_cbranch_vccz label0 //Branch if all lanes fail
v_sub_f32 r2,r0,r1 //result = a - b
v_mul_f32 r2,r2,r0 //result=result * a
s_andn2_b64 exec,s0,exec //Do "else" (s0 & !exec)
s_cbranch_execz label1 //Branch if all lanes fail
v_sub_f32 r2,r1,r0 //result = b - a
v_mul_f32 r2,r2,r1 //result = result * b
s_mov_b64 exec,s0 //Restore exec mask
VLIW: it’s good for graphics, it’s often not as good for compute.
So what does AMD replace VLIW with? They replace it with a traditional SIMD vector processor. While elements of Cayman do not directly map to elements of Graphics Core Next (GCN), since we’ve already been talking about the SP we’ll talk about its closest replacement: the SIMD.
Not to be confused with the SIMD on Cayman (which is a collection of SPs), the SIMD on GCN is a true 16-wide vector SIMD. A single instruction and up to 16 data elements are fed to a vector SIMD to be processed over a single clock cycle. As with Cayman, AMD’s wavefronts are 64 instructions meaning it takes 4 cycles to actually complete a single instruction for an entire wavefront. This vector unit is combined with a 64KB register file and that composes a single SIMD in GCN.

As is the case with Cayman's SPs, the SIMD is capable of a number of different integer and floating point operations. AMD has not gone into fine detail yet of what those are, but we’re expecting something similar to Cayman with the possible exception of how transcendentals are handled. One thing that we do know is that FP64 performance has been radically improved: the GCN architecture is capable of FP64 performance up to ½ its FP32 performance. For home users this isn’t going to make a significant impact right away, but it’s going to help AMD get into professional markets where such precision is necessary.
Many SIMDs Make One Compute Unit
When we move up a level we have the Compute Unit, what AMD considers the fundamental unit of computation. Whereas a single SIMD can execute vector operations and that’s it, combined with a number of other functional units it makes a complete unit capable of the entire range of compute tasks. In practice this replaces a Cayman SIMD, which was a collection of Cayman SPs. However a GCN Compute Unit is capable of far, far more than a Cayman SIMD.
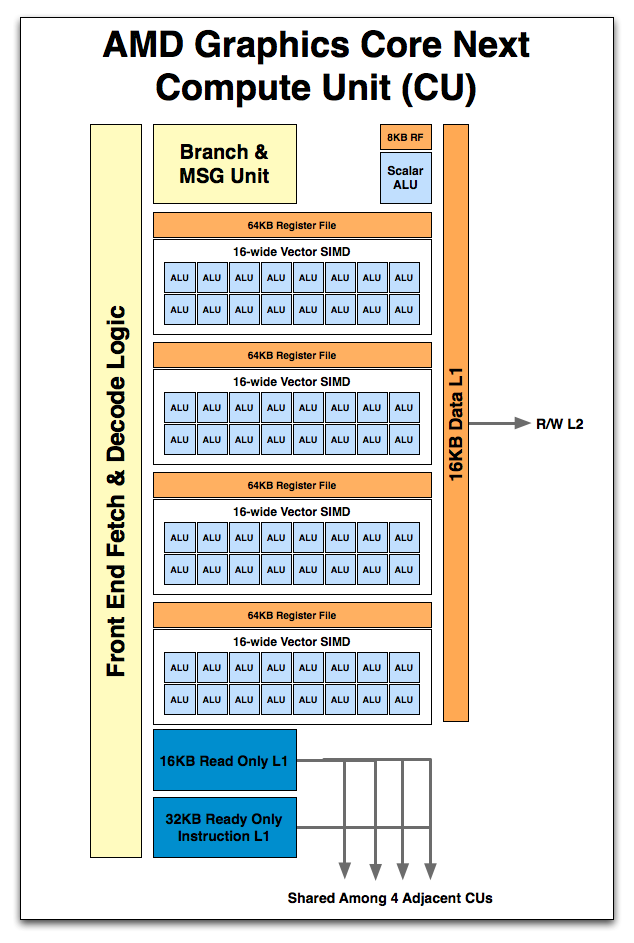
So what’s in a Compute Unit? Just as a Cayman SIMD was a collection of SPs, a Compute Unit starts with a collection of SIMDs. 4 SIMDs are in a CU, meaning that like a Cayman SIMD, a GCN CU can work on 4 instructions at once. Also in a Compute Unit is the control hardware & branch unit responsible for fetching, decoding, and scheduling wavefronts and their instructions. This is further augmented with a 64KB Local Data Store and 16KB of L1 data + texture cache. With GCN data and texture L1 are now one and the same, and texture pressure on the L1 cache has been reduced by the fact that AMD is now keeping compressed rather than uncompressed texels in the L1 cache. Rounding out the memory subsystem is access to the L2 cache and beyond. Finally there is a new unit: the scalar unit. We’ll get back to that in a bit.
But before we go any further, let’s stop here for a moment. Now that we know what a CU looks like and what the weaknesses are of VLIW, we can finally get to the meat of the issue: why AMD is dropping VLIW for non-VLIW SIMD. As we mentioned previously, the weakness of VLIW is that it’s statically scheduled ahead of time by the compiler. As a result if any dependencies crop up while code is being executed, there is no deviation from the schedule and VLIW slots go unused. So the first change is immediate: in a non-VLIW SIMD design, scheduling is moved from the compiler to the hardware. It is the CU that is now scheduling execution within its domain.
Now there’s a distinct tradeoff with dynamic hardware scheduling: it can cover up dependencies and other types of stalls, but that hardware scheduler takes up die space. The reason that the R300 and earlier GPUs were VLIW was because the compiler could do a fine job for graphics, and the die space was better utilized by filling it with additional functional units. By moving scheduling into hardware it’s more dynamic, but we’re now consuming space previously used for functional units. It’s a tradeoff.
So what can you do with dynamic scheduling and independent SIMDs that you could not do with Cayman’s collection of SPs (SIMDs)? You can work around dependencies and schedule around things. The worst case scenario for VLIW is that something scheduled is completely dependent or otherwise blocking the instruction before and after it – it must be run on its own. Now GCN is not an out-of-order architecture; within a wavefront the instructions must still be executed in order, so you can’t jump through a pixel shader program for example and execute different parts of it at once. However the CU and SIMDs can select a different wavefront to work on; this can be another wavefront spawned by the same task (e.g. a different group of pixels/values) or it can be a wavefront from a different task entirely.
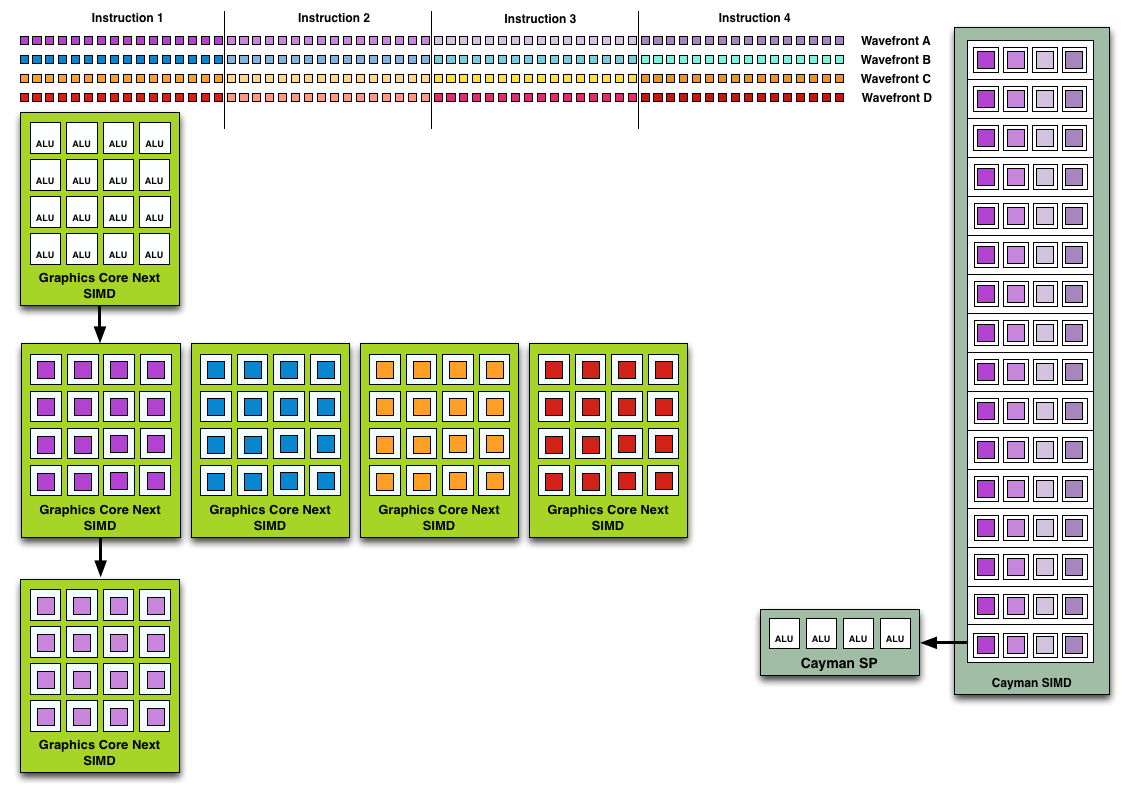
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman had a very limited ability to work on multiple tasks at once. While it could consume multiple wavefronts from the same task with relative ease, its ability to execute concurrent tasks was reliant on the API support, which was limited to an extension to OpenCL. With these hardware changes, GCN can now concurrently work on tasks with relative ease. Each GCN SIMD has 10 wavefronts to choose from, meaning each CU in turn has up to a total of 40 wavefronts in flight. This in a nutshell is why AMD is moving from VLIW to non-VLIW SIMD for Graphics Core Next: instead of VLIW slots going unused due to dependencies, independent SIMDs can be given entirely different wavefronts to work on.
As a consequence, compiling also becomes much easier. With the compiler freed from scheduling tasks, compilation behaves in a rather standard manner, since most other architectures are similarly scheduled in hardware. Writing a compiler still isn’t absolutely easy, but when it comes to optimizing the execution of a program the compiler can focus on other matters, making it much easier for other languages to target GCN. In fact without the need to generate long VLIW instructions or to including scheduling information, the underlying ISA for GCN is also much simpler. This makes debugging much easier since the code generated reflects the fact that scheduling is now done in hardware, which is reflected in our earlier assembly code example.
Now while leaving behind the drawbacks of VLIW is the biggest architectural improvement for compute performance coming from Cayman, the move to non-VLIW SIMDs is not the only benefit. We still have not discussed the final component of the CU: the Scalar ALU. New to GCN, the Scalar unit serves to further keep inefficient operations out of the SIMDs, leaving the vector ALUs on the SIMDs to execute instructions en mass. The scalar unit is composed of a single scalar ALU, along with an 8KB register file.
So what does a scalar unit do? First and foremost it executes “one-off” mathematical operations. Whole groups of pixels/values go through the vector units together, but independent operations go to the scalar unit as to not waste valuable SIMD time. This includes everything from simple integer operations to control flow operations like conditional branches (if/else) and jumps, and in certain cases read-only memory operations from a dedicated scalar L1 cache. Overall the scalar unit can execute one instruction per cycle, which means it can complete 4 instructions over the period of time it takes for one wavefront to be completed on a SIMD.
Conceptually this blurs a bit more of the remaining line between a scalar GPU and a vector GPU, but by having both types of units it means that each unit type can work on the operations best suited for it. Besides avoiding feeding SIMDs non-vectorized datasets, this will also improve the latency for control flow operations, where Cayman had a rather nasty 44 cycle latency.
And Many Compute Units Make A GPU
While the compute unit is the fundamental unit of computation, it is not a GPU on its own. As with SIMDs in Cayman it’s a configurable building block for making a larger GPU, with a GPU implementing a suitable number of CUs in multiples of 4. Like past GPUs this will be the primary way to scale the GPU to the desired die size, but of course this isn’t the only element of the design that scales.
With a suitable number of CUs in hand, it’s time to attach the rest of units that make up a GPU. As this is a high-level overview on the part of AMD they haven’t gone into great deal on what each unit does and how it does it, but as the first GCN product gets closer to launching the picture will take on a more complete form.
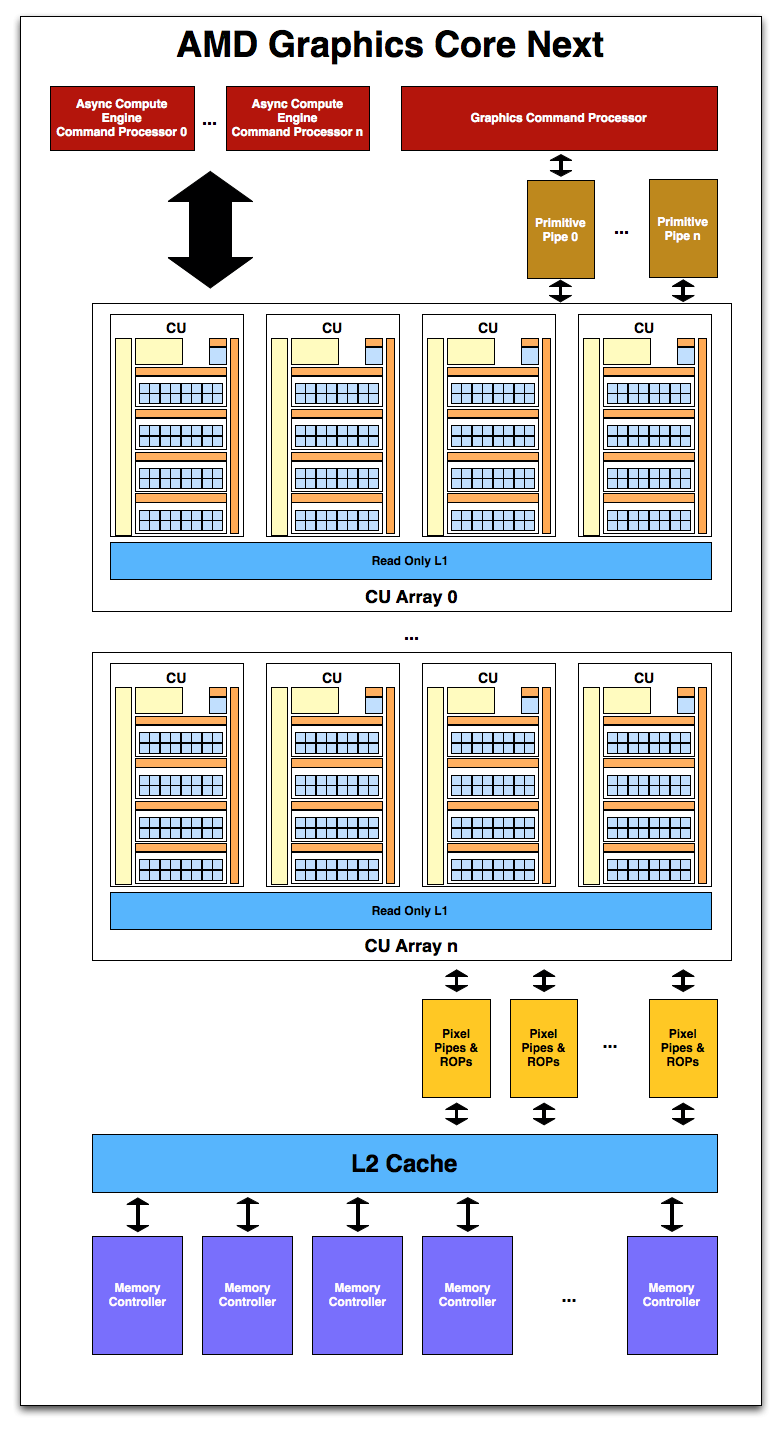
Starting with memory and cache, GCN will once more pair its L2 cache with its memory controllers. The architecture supports 64KB or 128KB of L2 cache per memory controller, and given that AMD’s memory controllers are typically 64bits each, this means a Cayman-like design would likely have 512KB of L2 cache. The L2 cache is write-back, and will be fully coherent so that all CUs will see the same data, saving expensive trips to VRAM for synchronization. CPU/GPU synchronization will also be handled at the L2 cache level, where it will be important to maintain coherency between the two in order to efficiently split up a task between the CPU and GPU. For APUs there is a dedicated high-speed bus between the two, while discrete GPUs will rely on PCIe’s coherency protocols to keep the CPU and dGPU in sync.
Meanwhile on the compute side, AMD’s new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing. As GCN is designed to concurrently work on several tasks, there can be multiple ACEs on a GPU, with the ACEs deciding on resource allocation, context switching, and task priority. AMD has not established an immediate relationship between ACEs and the number of tasks that can be worked on concurrently, so we’re not sure whether there’s a fixed 1:X relationship or whether it’s simply more efficient for the purposes of working on many tasks in parallel to have more ACEs.
One effect of having the ACEs is that GCN has a limited ability to execute tasks out of order. As we mentioned previously GCN is an in-order architecture, and the instruction stream on a wavefront cannot be reodered. However the ACEs can prioritize and reprioritize tasks, allowing tasks to be completed in a different order than they’re received. This allows GCN to free up the resources those tasks were using as early as possible rather than having the task consuming resources for an extended period of time in a nearly-finished state. This is not significantly different from how modern in-order CPUs (Atom, ARM A8, etc) handle multi-tasking.
On the other side of the coin we have the graphics hardware. As with Cayman a graphics command processor sits at the top of the stack and is responsible for farming out work to the various components of the graphics subsystem. Below that Cayman’s dual graphics engines have been replaced with multiple primitive pipelines, which will serve the same general purpose of geometry and fixed-function processing. Primative pipelines will be responsible for tessellation, geometry, and high-order surface processing among other things. Whereas Cayman was limited to 2 such units, GCN will be fully scalable, so AMD will be able to handle incredibly large amounts of geometry if necessary.
After a trip through the CUs, graphics work then hits the pixel pipelines, which are home to the ROPs. As it’s customary to have a number of ROPs, there will be a scalable number of pixel pipelines in GCN; we expect this will be closely coupled with the number of memory controllers to maintain the tight ROP/L2/Memory integration that’s so critical for high ROP performance.
Unfortunately, those of you expecting any additional graphics information will have to sit tight for the time being. As was the case with NVIDIA’s early reveal of Fermi in 2009, AFDS is a development show, and GCN’s early reveal is about the compute capabilities rather than the graphics capabilities. AMD needs to prime developers for GCN now, so that when GCN appears in an APU developers are ready for it. We’ll find out more about the capabilities of the ROPs, the primitive pipelines, the texture mapping units, the display controllers and other dedicated hardware blocks farther down the line.
In the meantime AMD did throw out one graphics tidbit: partially resident textures (PRT). PRTs allow for only part of a texture to actually be loaded in memory, allowing developers to use large textures without taking the performance hit of loading the entire texture into memory if parts of it are going unused. John Carmack already does something very similar in software with his MegaTexture technology, which is used in the id Tech 4 and id Tech 5 engines. This is essentially a hardware implementation of that technology.
Not Just A New Architecture, But New Features Too
So far we’ve talked about Graphics Core Next as a new architecture, how that new architecture works, and what that new architecture does that Cayman and other VLIW architectures could not. But along with the new architecture GCN will bring with it a number of new compute features to further flesh out AMD’s GPU computing capabilities and to cement the GPU’s position as the CPU’s partner rather than a subservient peripheral.
In terms of base features the biggest change will be that GCN will implement the underlying features necessary to support C++ and other advanced languages. As a result GCN will be adding support for pointers, virtual functions, exception support, and even recursion. These underlying features mean that developers will not need to “step down” from higher languages to C to write code for the GPU, allowing them to more easily program for the GPU and CPU within the same application. For end-users the benefit won’t be immediate, but eventually it will allow for more complex and useful programs to be GPU accelerated.
Because the underlying feature set is evolving, the memory subsystem is also evolving to be able to service those features. The chief change here is that the hardware is being adapted to support an ISA that uses unified memory. This goes hand-in-hand with the earlier language features to allow programmers to write code to target both the CPU and the GPU, as programs (or rather compilers) can reference memory anywhere, without the need to explicitly copy memory from one device to the other before working on it. Now there’s still a significant performance impact when accessing off-GPU memory – particularly in the case of dGPUs where on-board memory is many times faster than system memory – so developers and compilers will still be copying data around to keep it close to the processor that’s going to use it, but this essentially becomes abstracted from developers.
Now what’s interesting is that the unified address space that will be used is the x86-64 address space. All instructions sent to a GCN GPU will be relative to the x86-64 address space, at which point the GPU will be responsible for doing address translation to local memory addresses. In fact GCN will even be incorporating an I/O Memory Mapping Unit (IOMMU) to provide this functionality; previously we’ve only seen IOMMUs used for sharing peripherals in a virtual machine environment. GCN will even be able to page fault half-way gracefully by properly stalling until the memory fetch completes. How this will work with the OS remains to be seen though, as the OS needs to be able to address the IOMMU. GCN may not be fully exploitable under Windows 7.

Finally on the memory side, AMD is adding proper ECC support to supplement their existing EDC (Error Detection & Correction) functionality, which is used to ensure the integrity of memory transmissions across the GDDR5 memory bus. Both the SRAM and VRAM memory can be ECC protected. For the SRAM this is a free operation, while for the VRAM there will be a performance overhead. We’re assuming that AMD will be using a virtual ECC scheme like NVIDIA, where ECC data is distributed across VRAM rather than using extra memory chips/controllers.
Elsewhere we’ve already mentioned FP64 support. All GCN GPUs will support FP64 in some form, making FP64 support a standard feature across the entire lineup. The actual FP64 performance is configurable – the architecture supports ½ rate FP64, but ¼ rate and 1/16 rate are also options. We expect AMD to take a page from NVIDIA here and configure lower-end consumer parts to use the slower rates since FP64 is not currently important for consumer uses.
Finally, for programmers some additional hardware changes have been made to improve debug support by allowing debugging tools to tap the GPU at additional points. The new ISA for GCN will already make debugging easier, but this will further that goal. As with other developer features this won’t directly impact end-users, but it will ultimately lead to better software sooner as the features and tools available for debugging GPU programs have been well behind the well-established tools used for debugging CPU programs.
Final Words
As GPUs have increased in complexity, the refresh cycle has continued to lengthen. 6 month cycles have largely given way to 1 year cycles, and even then it can be 2+ years between architecture refreshes. This is not only a product of the rate of hardware development, but a product of the need to give developers time to breathe and to absorb information about new architectures.
The primary purpose of the AMD Fusion Developer Summit and the announcement of the AMD Graphics Core Next is to give developers even more time to breathe by extending the refresh window backwards as well as forwards. It can take months to years to deliver a program, so the sooner an architecture is introduced the sooner a few brave developers can begin working on programs utilizing it; the alternative is that it may take years after the launch of a new architecture before programs come along that can fully exploit the new architecture. One only needs to take a look at the gaming market to see how that plays out.
Because of this need to inform developers of the hardware well in advance, while we’ve had a chance to see the fundamentals of GCN products using it are still some time off. At no point has AMD specified when a GPU will appear using GCN will appear, so it’s very much a guessing game. What we know for a fact is that Trinity – the 2012 Bulldozer APU – will not use GCN, it will be based on Cayman’s VLIW4 architecture. Because Trinity will be VLIW4, it’s likely-to-certain that AMD will have midrange and low-end video cards using VLIW4 because of the importance they place on being able to Crossfire with the APU. Does this mean AMD will do another split launch, with high-end parts using one architecture while everything else is a generation behind? It’s possible, but we wouldn’t make at bets at this point in time. Certainly it looks like it will be 2013 before GCN has a chance to become a top-to-bottom architecture, so the question is what the top discrete GPU will be for AMD by the start of 2012.
Moving on, it’s interesting that GCN effectively affirms most of NVIDIA’s architectural changes with Fermi. GCN is all about creating a GPU good for graphics and good for computing purposes; Unified addressing, C++ capabilities, ECC, etc were all features NVIDIA introduced with Fermi more than a year ago to bring about their own compute architecture. I don’t believe there’s ever been a question whether NVIDIA was “right”, but the question has been whether it’s time to devote so much engineering effort and die space on technologies that benefit compute as opposed to putting in more graphics units. With NVIDIA and now AMD doing compute-optimized GPUs, clearly the time is quickly approaching if it’s not already here.
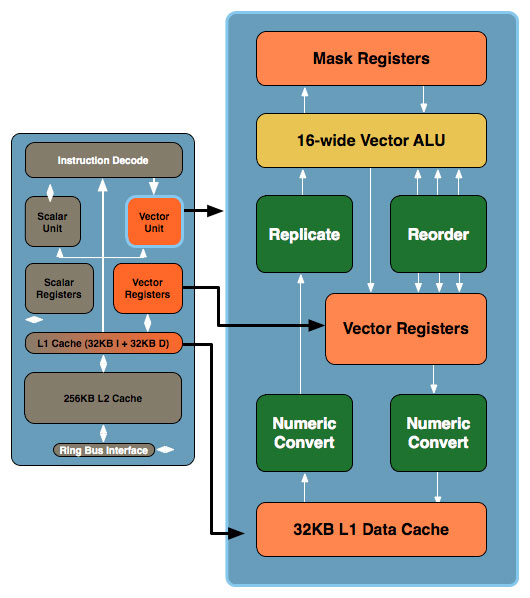
Larrabee As It Was: Scalar + 16-Wide Vector
I can’t help but to also make a comparison to Intel’s aborted Larrabee Prime architecture here. There are some very interesting similarities between Larrabee and GCN, primarily in the dual vector/scalar design and in the use of a 16-wide vector ALU. Processing 16 elements at once is an incredibly common occurrence in GPUs – it even shows up in Fermi which processes half a warp (16 threads) a clock. There are still a million differences between all of these architectures, but there’s definitely a degree of convergence occurring. Previously NVIDIA and AMD converged around VLIW in the days of the graphical GPU, and now we’re converging at a new point for the compute GPU.
Finally, while we’ve talked about the GCN architecture in great detail we haven’t talked about how to program it. Of course there’s OpenCL, but with GCN there’s going to be so much more. Next week we will be taking a look at AMD’s Fusion System Architecture, a high-level abstraction layer that will make GPU programming even more CPU-like, an advancement necessary to bring forth the kind of heterogeneous computing AMD is shooting for. We will also be taking a look at Microsoft’s C++ Accelerated Massive Parallelism (AMP), a C++ extension to bridge the gap between current and future architectures by allowing developers to program for GPUs in C++ even if the GPU doesn’t fully support the C++ feature set.
It’s clear that 2011 is shaping up to be a big year for GPUs, and we’re not even half-way through. So stay tuned, there’s much more to come.






