Original Link: https://www.anandtech.com/show/4316/ocz-vertex-3-240gb-review
OCZ Vertex 3 (240GB) Review
by Anand Lal Shimpi on May 6, 2011 1:50 AM ESTThree months ago we previewed the first client focused SF-2200 SSD: OCZ's Vertex 3. The 240GB sample OCZ sent for the preview was four firmware revisions older than what ended up shipping to retail last month, but we hoped that the preview numbers were indicative of final performance.
The first drives off the line when OCZ went to production were 120GB capacity models. These drives have 128GiB of NAND on board and 111GiB of user accessible space, the remaining 12.7% is used for redundancy in the event of NAND failure and spare area for bad block allocation and block recycling.

Unfortunately the 120GB models didn't perform as well as the 240GB sample we previewed. To understand why, we need to understand a bit about basic SSD architecture. SandForce's SF-2200 controller has 8 channels that it can access concurrently, it looks sort of like this:
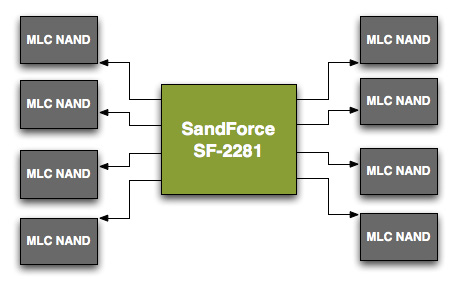
Each arrowed line represents a single 8-byte channel. In reality, SF's NAND channels are routed from one side of the chip so you'll actually see all NAND devices to the right of the controller on actual shipping hardware.
Even though there are 8 NAND channels on the controller, you can put multiple NAND devices on a single channel. Two NAND devices can't be actively transferring data at the same time. Instead what happens is one chip is accessed while another is either idle or busy with internal operations.
When you read from or write to NAND you don't write directly to the pages, you instead deal with an intermediate register that holds the data as it comes from or goes to a page in NAND. The process of reading/programming is a multi-step endeavor that doesn't complete in a single cycle. Thus you can hand off a read request to one NAND device and then while it's fetching the data from an internal page, you can go off and program a separate NAND device on the same channel.
Because of this parallelism that's akin to pipelining, with the right workload and a controller that's smart enough to interleave operations across NAND devices, an 8-channel drive with 16 NAND devices can outperform the same drive with 8 NAND devices. Note that the advantage can't be double since ultimately you can only transfer data to/from one device at a time, but there's room for non-insignificant improvement. Confused?
Let's look at a hypothetical SSD where a read operation takes 5 cycles. With a single die per channel, 8-byte wide data bus and no interleaving that gives us peak bandwidth of 8 bytes every 5 clocks. With a large workload, after 15 clock cycles at most we could get 24 bytes of data from this NAND device.

Hypothetical single channel SSD, 1 read can be issued every 5 clocks, data is received on the 5th clock
Let's take the same SSD, with the same latency but double the number of NAND devices per channel and enable interleaving. Assuming we have the same large workload, after 15 clock cycles we would've read 40 bytes, an increase of 66%.
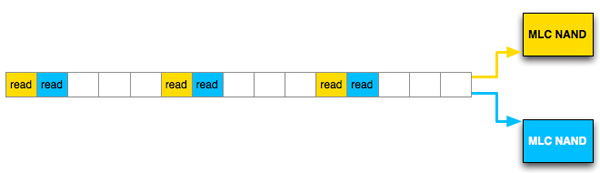
Hypothetical single channel SSD, 1 read can be issued every 5 clocks, data is received on the 5th clock, interleaved operation
This example is overly simplified and it makes a lot of assumptions, but it shows you how you can make better use of a single channel through interleaving requests across multiple NAND die.
The same sort of parallelism applies within a single NAND device. The whole point of the move to 25nm was to increase NAND density, thus you can now get a 64Gbit NAND device with only a single 64Gbit die inside. If you need more than 64Gbit per device however you have to bundle multiple die in a single package. Just as we saw at the 34nm node, it's possible to offer configurations with 1, 2 and 4 die in a single NAND package. With multiple die in a package, it's possible to interleave read/program requests within the individual package as well. Again you don't get 2 or 4x performance improvements since only one die can be transferring data at a time, but interleaving requests across multiple die does help fill any bubbles in the pipeline resulting in higher overall throughput.
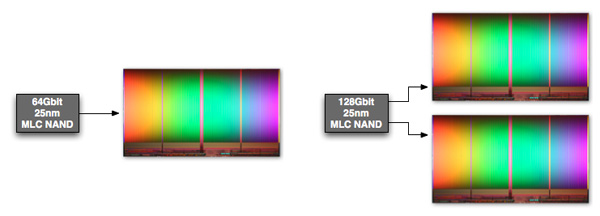
Intel's 128Gbit 25nm MLC NAND features two 64Gbit die in a single package
Now that we understand the basics of interleaving, let's look at the configurations of a couple of Vertex 3s.
The 120GB Vertex 3 we reviewed a while back has sixteen NAND devices, eight on each side of the PCB:

OCZ Vertex 3 120GB - front
These are Intel 25nm NAND devices, looking at the part number tells us a little bit about them.

You can ignore the first three characters in the part number, they tell you that you're looking at Intel NAND. Characters 4 - 6 (if you sin and count at 1) indicate the density of the package, in this case 64G means 64Gbits or 8GB. The next two characters indicate the device bus width (8-bytes). Now the ninth character is the important one - it tells you the number of die inside the package. These parts are marked A, which corresponds to one die per device. The second to last character is also important, here E stands for 25nm.
Now let's look at the 240GB model:

OCZ Vertex 3 240GB - Front

OCZ Vertex 3 240GB - Back
Once again we have sixteen NAND devices, eight on each side. OCZ standardized on Intel 25nm NAND for both capacities initially. The density string on the 240GB drive is 16B for 16Gbytes (128 Gbit), which makes sense given the drive has twice the capacity.
A look at the ninth character on these chips and you see the letter C, which in Intel NAND nomenclature stands for 2 die per package (J is for 4 die per package if you were wondering).

While OCZ's 120GB drive can interleave read/program operations across two NAND die per channel, the 240GB drive can interleave across a total of four NAND die per channel. The end result is a significant improvement in performance as we noticed in our review of the 120GB drive.
| OCZ Vertex 3 Lineup | |||||
| Specs (6Gbps) | 120GB | 240GB | 480GB | ||
| Raw NAND Capacity | 128GB | 256GB | 512GB | ||
| Spare Area | ~12.7% | ~12.7% | ~12.7% | ||
| User Capacity | 111.8GB | 223.5GB | 447.0GB | ||
| Number of NAND Devices | 16 | 16 | 16 | ||
| Number of die per Device | 1 | 2 | 4 | ||
| Max Read | Up to 550MB/s | Up to 550MB/s | Up to 530MB/s | ||
| Max Write | Up to 500MB/s | Up to 520MB/s | Up to 450MB/s | ||
| 4KB Random Read | 20K IOPS | 40K IOPS | 50K IOPS | ||
| 4KB Random Write | 60K IOPS | 60K IOPS | 40K IOPS | ||
| MSRP | $249.99 | $499.99 | $1799.99 | ||
The big question we had back then was how much of the 120/240GB performance delta was due to a reduction in performance due to final firmware vs. a lack of physical die. With a final, shipping 240GB Vertex 3 in hand I can say that the performance is identical to our preview sample - in other words the performance advantage is purely due to the benefits of intra-device die interleaving.
If you want to skip ahead to the conclusion feel free to, the results on the following pages are near identical to what we saw in our preview of the 240GB drive. I won't be offended :)
The Test
| CPU |
Intel Core i7 965 running at 3.2GHz (Turbo & EIST Disabled) Intel Core i7 2600K running at 3.4GHz (Turbo & EIST Disabled) - for AT SB 2011, AS SSD & ATTO |
| Motherboard: |
Intel DX58SO (Intel X58) Intel H67 Motherboard |
| Chipset: |
Intel X58 + Marvell SATA 6Gbps PCIe Intel H67 |
| Chipset Drivers: |
Intel 9.1.1.1015 + Intel IMSM 8.9 Intel 9.1.1.1015 + Intel RST 10.2 |
| Memory: | Qimonda DDR3-1333 4 x 1GB (7-7-7-20) |
| Video Card: | eVGA GeForce GTX 285 |
| Video Drivers: | NVIDIA ForceWare 190.38 64-bit |
| Desktop Resolution: | 1920 x 1200 |
| OS: | Windows 7 x64 |
Random Read/Write Speed
The four corners of SSD performance are as follows: random read, random write, sequential read and sequential write speed. Random accesses are generally small in size, while sequential accesses tend to be larger and thus we have the four Iometer tests we use in all of our reviews.
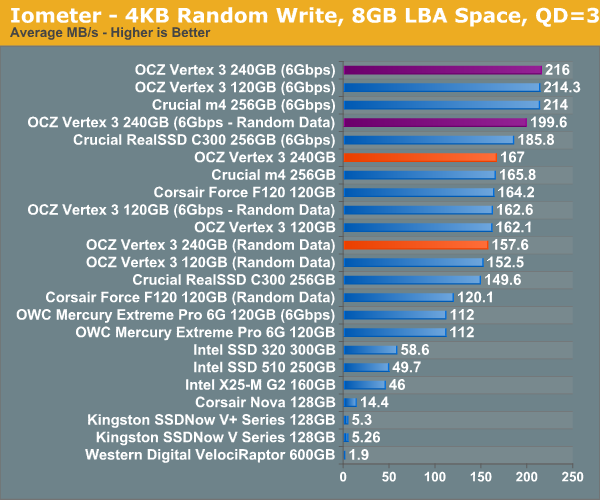
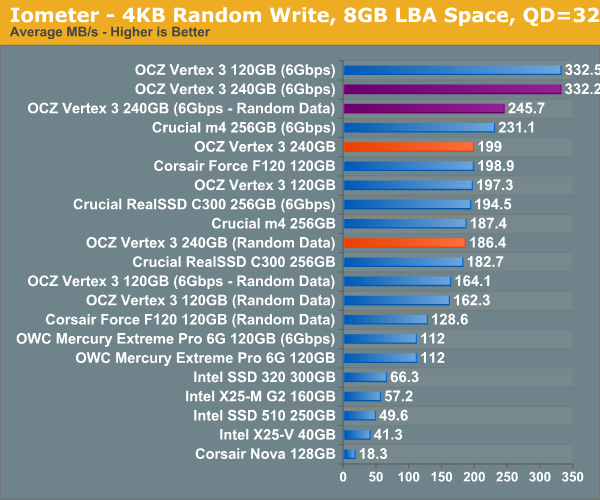
Our first test writes 4KB in a completely random pattern over an 8GB space of the drive to simulate the sort of random access that you'd see on an OS drive (even this is more stressful than a normal desktop user would see). I perform three concurrent IOs and run the test for 3 minutes. The results reported are in average MB/s over the entire time. We use both standard pseudo randomly generated data for each write as well as fully random data to show you both the maximum and minimum performance offered by SandForce based drives in these tests. The average performance of SF drives will likely be somewhere in between the two values for each drive you see in the graphs. For an understanding of why this matters, read our original SandForce article.
Many of you have asked for random write performance at higher queue depths. What I have below is our 4KB random write test performed at a queue depth of 32 instead of 3. While the vast majority of desktop usage models experience queue depths of 0 - 5, higher depths are possible in heavy I/O (and multi-user) workloads:

Sequential Read/Write Speed
To measure sequential performance I ran a 1 minute long 128KB sequential test over the entire span of the drive at a queue depth of 1. The results reported are in average MB/s over the entire test length.


AnandTech Storage Bench 2011
Last year we introduced our AnandTech Storage Bench, a suite of benchmarks that took traces of real OS/application usage and played them back in a repeatable manner. I assembled the traces myself out of frustration with the majority of what we have today in terms of SSD benchmarks.
Although the AnandTech Storage Bench tests did a good job of characterizing SSD performance, they weren't stressful enough. All of the tests performed less than 10GB of reads/writes and typically involved only 4GB of writes specifically. That's not even enough exceed the spare area on most SSDs. Most canned SSD benchmarks don't even come close to writing a single gigabyte of data, but that doesn't mean that simply writing 4GB is acceptable.
Originally I kept the benchmarks short enough that they wouldn't be a burden to run (~30 minutes) but long enough that they were representative of what a power user might do with their system.
Not too long ago I tweeted that I had created what I referred to as the Mother of All SSD Benchmarks (MOASB). Rather than only writing 4GB of data to the drive, this benchmark writes 106.32GB. It's the load you'd put on a drive after nearly two weeks of constant usage. And it takes a *long* time to run.
Here's a high level overview:
1) The MOASB, officially called AnandTech Storage Bench 2011 - Heavy Workload, mainly focuses on the times when your I/O activity is the highest. There is a lot of downloading and application installing that happens during the course of this test. My thinking was that it's during application installs, file copies, downloading and multitasking with all of this that you can really notice performance differences between drives.
2) I tried to cover as many bases as possible with the software I incorporated into this test. There's a lot of photo editing in Photoshop, HTML editing in Dreamweaver, web browsing, game playing/level loading (Starcraft II & WoW are both a part of the test) as well as general use stuff (application installing, virus scanning). I included a large amount of email downloading, document creation and editing as well. To top it all off I even use Visual Studio 2008 to build Chromium during the test.
Digging a little deeper, the test has 2,168,893 read operations and 1,783,447 write operations. The IO breakdown is as follows:
| AnandTech Storage Bench 2011 - Heavy Workload IO Breakdown | ||||
| IO Size | % of Total | |||
| 4KB | 28% | |||
| 16KB | 10% | |||
| 32KB | 10% | |||
| 64KB | 4% | |||
Only 42% of all operations are sequential, the rest range from pseudo to fully random (with most falling in the pseudo-random category). Average queue depth is 4.625 IOs, with 59% of operations taking place in an IO queue of 1.
Many of you have asked for a better way to really characterize performance. Simply looking at IOPS doesn't really say much. As a result I'm going to be presenting Storage Bench 2011 data in a slightly different way. We'll have performance represented as Average MB/s, with higher numbers being better. At the same time I'll be reporting how long the SSD was busy while running this test. These disk busy graphs will show you exactly how much time was shaved off by using a faster drive vs. a slower one during the course of this test. Finally, I will also break out performance into reads, writes and combined. The reason I do this is to help balance out the fact that this test is unusually write intensive, which can often hide the benefits of a drive with good read performance.
There's also a new light workload for 2011. This is a far more reasonable, typical every day use case benchmark. Lots of web browsing, photo editing (but with a greater focus on photo consumption), video playback as well as some application installs and gaming. This test isn't nearly as write intensive as the MOASB but it's still multiple times more write intensive than what we were running last year.
As always I don't believe that these two benchmarks alone are enough to characterize the performance of a drive, but hopefully along with the rest of our tests they will help provide a better idea.
The testbed for Storage Bench 2011 has changed as well. We're now using a Sandy Bridge platform with full 6Gbps support for these tests. All of the older tests are still run on our X58 platform.
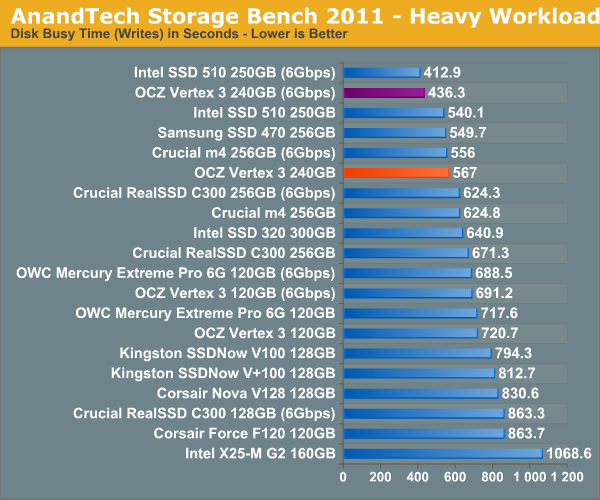
AnandTech Storage Bench 2011 - Heavy Workload
We'll start out by looking at average data rate throughout our new heavy workload test:
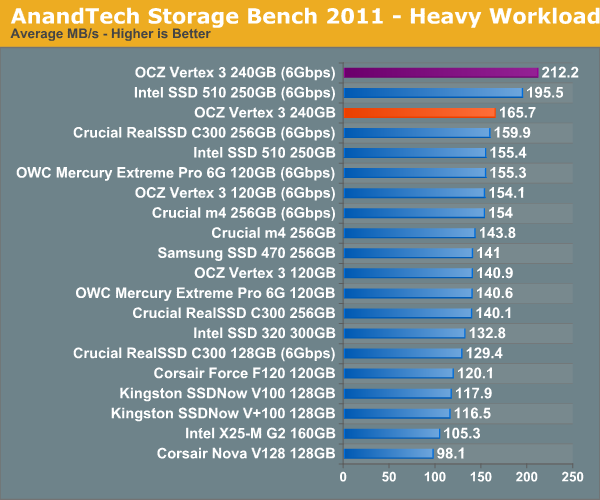
The breakdown of reads vs. writes tells us more of what's going on:

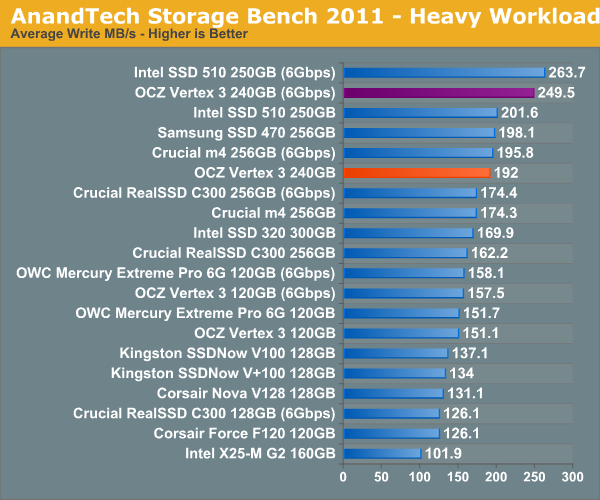
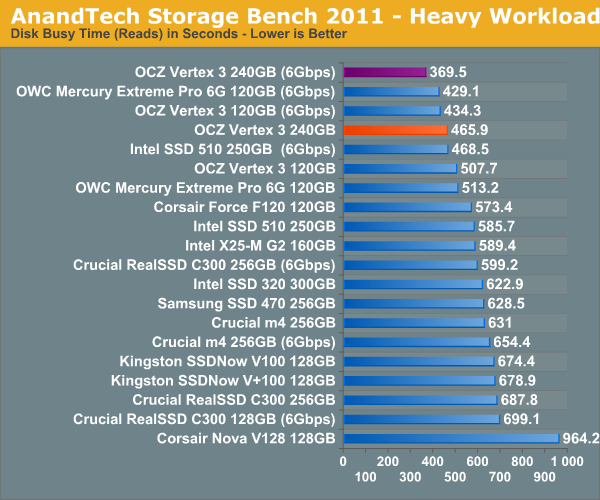
The next three charts just represent the same data, but in a different manner. Instead of looking at average data rate, we're looking at how long the disk was busy for during this entire test. Note that disk busy time excludes any and all idles, this is just how long the SSD was busy doing something:

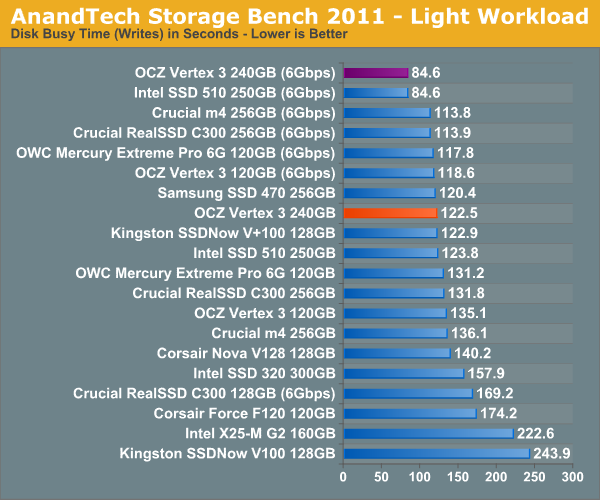
AnandTech Storage Bench 2011 - Light Workload
Our new light workload actually has more write operations than read operations. The split is as follows: 372,630 reads and 459,709 writes. The relatively close read/write ratio does better mimic a typical light workload (although even lighter workloads would be far more read centric).
The I/O breakdown is similar to the heavy workload at small IOs, however you'll notice that there are far fewer large IO transfers:
| AnandTech Storage Bench 2011 - Light Workload IO Breakdown | ||||
| IO Size | % of Total | |||
| 4KB | 27% | |||
| 16KB | 8% | |||
| 32KB | 6% | |||
| 64KB | 5% | |||
Despite the reduction in large IOs, over 60% of all operations are perfectly sequential. Average queue depth is a lighter 2.2029 IOs.





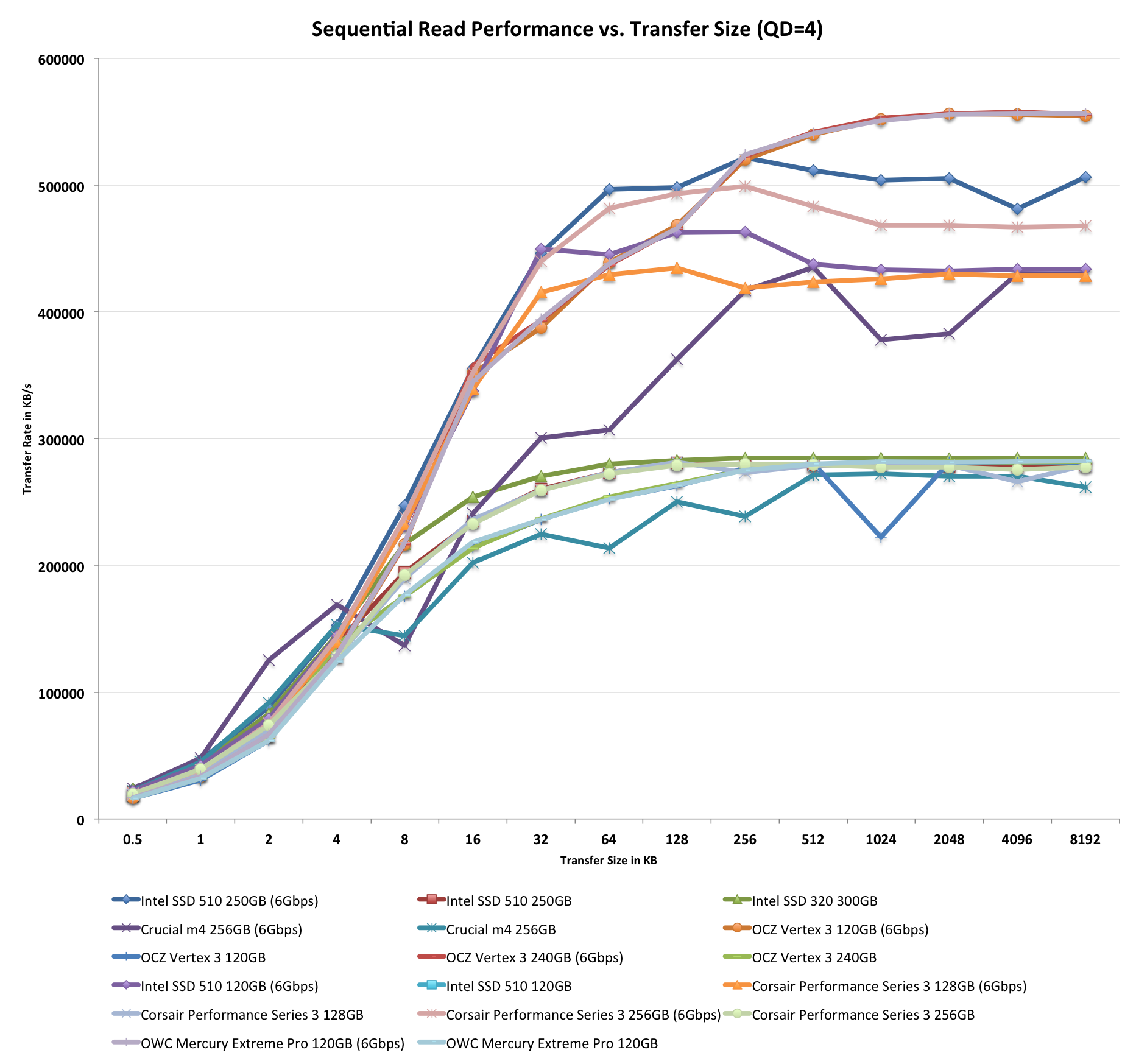
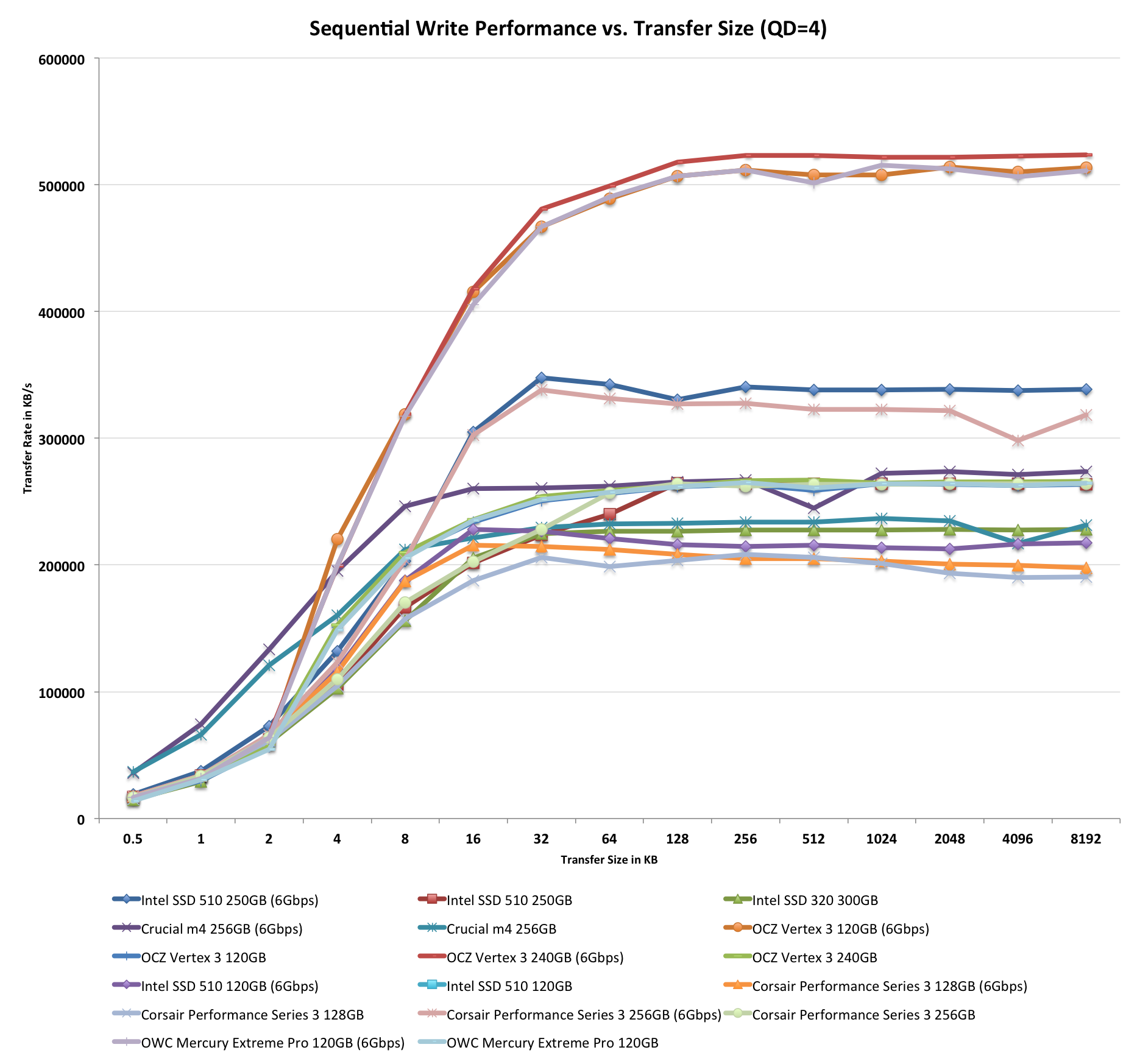
Performance vs. Transfer Size
All of our Iometer sequential tests happen at a queue depth of 1, which is indicative of a light desktop workload. It isn't too far fetched to see much higher queue depths on the desktop. The performance of these SSDs also greatly varies based on the size of the transfer. For this next test we turn to ATTO and run a sequential write over a 2GB span of LBAs at a queue depth of 4 and varying the size of the transfers.
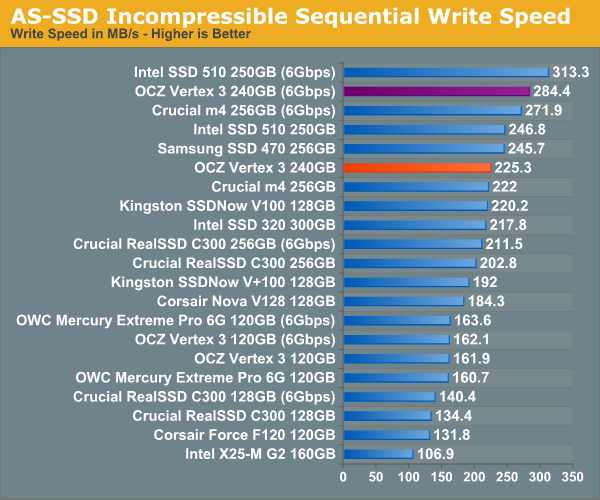
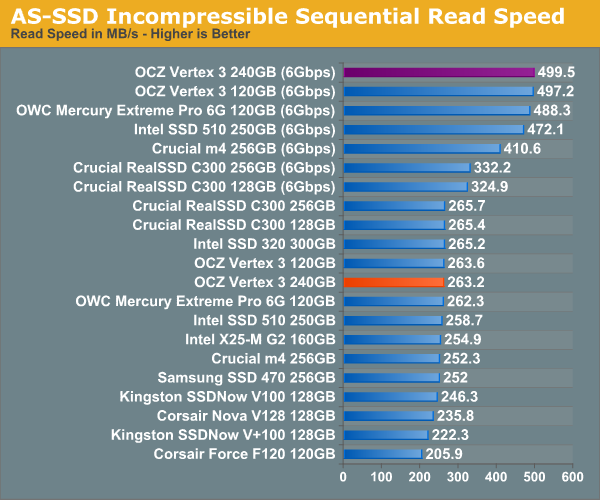
AS-SSD Incompressible Sequential Performance
The AS-SSD sequential benchmark uses incompressible data for all of its transfers. The result is a pretty big reduction in sequential write speed on SandForce based controllers.
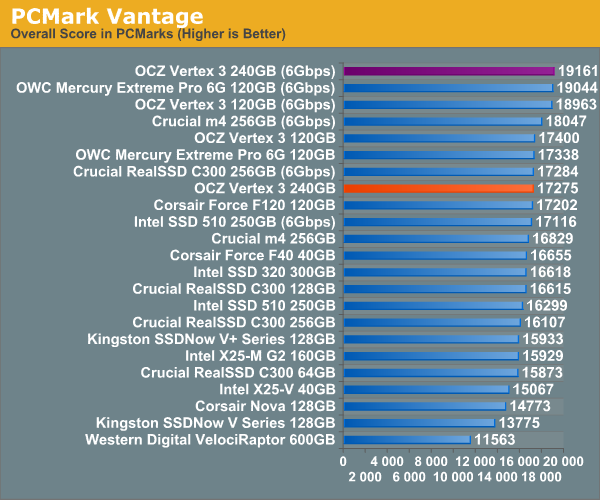
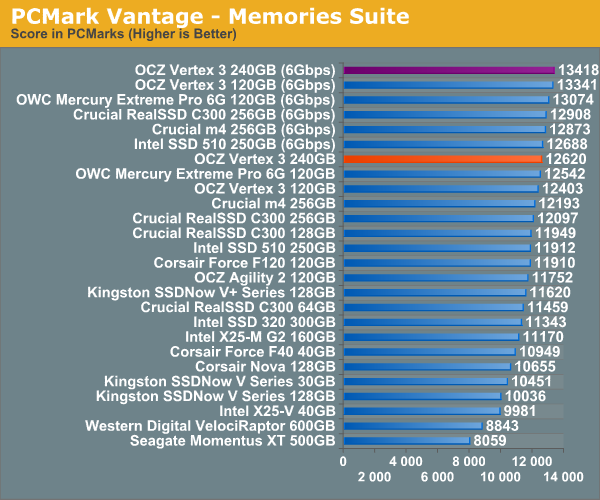
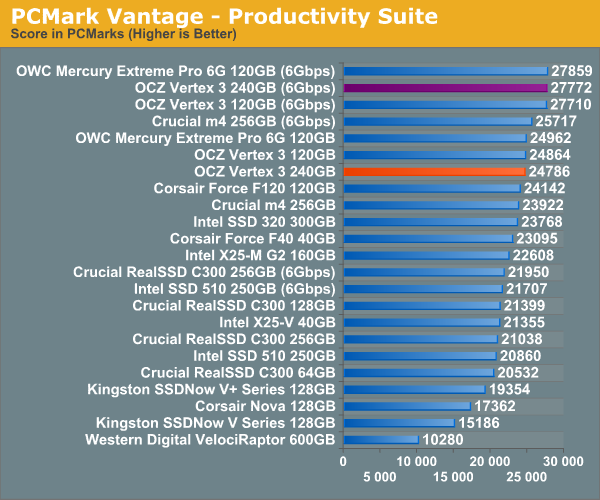
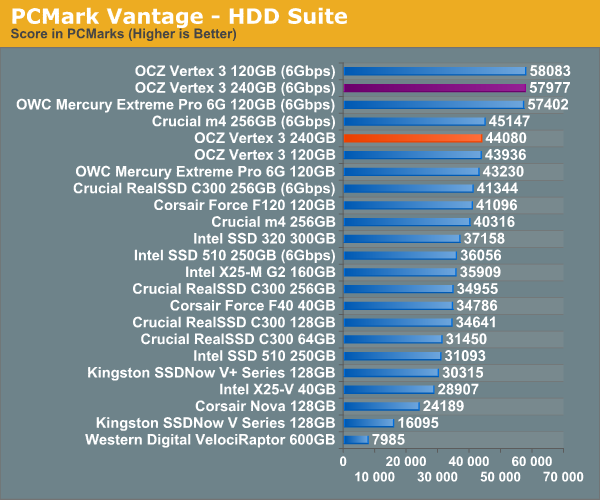
Overall System Performance using PCMark Vantage
Next up is PCMark Vantage, another system-wide performance suite. For those of you who aren’t familiar with PCMark Vantage, it ends up being the most real-world-like hard drive test I can come up with. It runs things like application launches, file searches, web browsing, contacts searching, video playback, photo editing and other completely mundane but real-world tasks. I’ve described the benchmark in great detail before but if you’d like to read up on what it does in particular, take a look at Futuremark’s whitepaper on the benchmark; it’s not perfect, but it’s good enough to be a member of a comprehensive storage benchmark suite. Any performance impacts here would most likely be reflected in the real world.
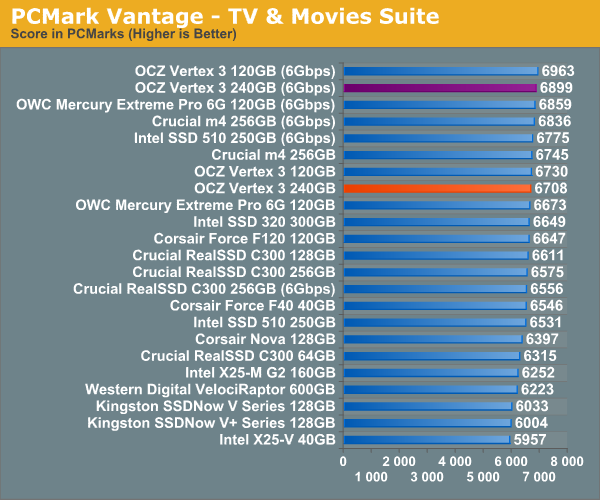
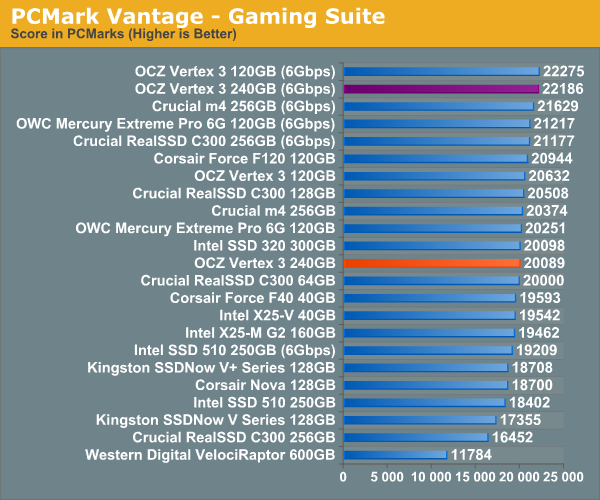
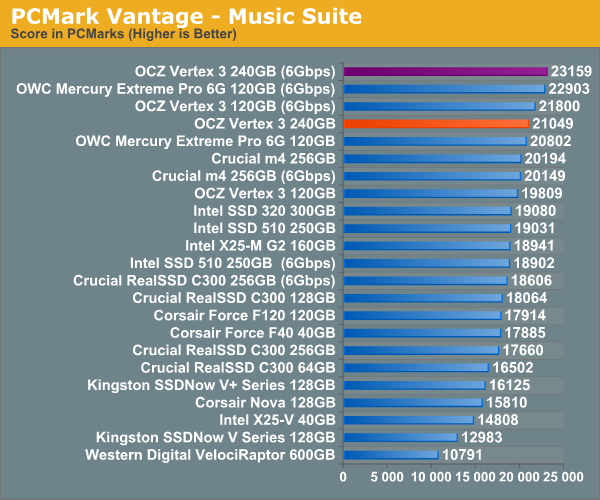
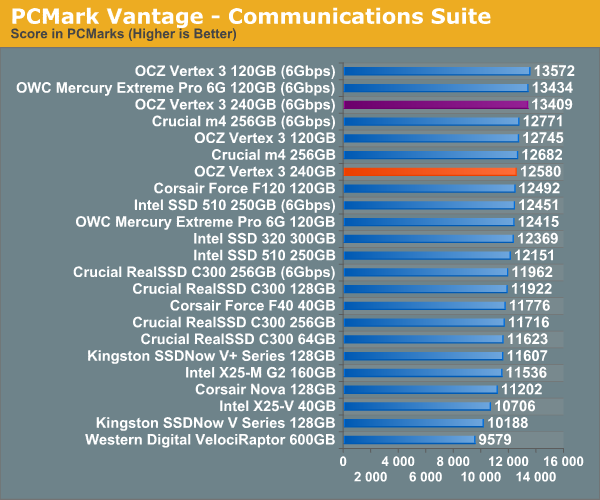
AnandTech Storage Bench 2010
To keep things consistent we've also included our older Storage Bench. Note that the old storage test system doesn't have a SATA 6Gbps controller, so we only have one result for the 6Gbps drives.
The first in our benchmark suite is a light/typical usage case. The Windows 7 system is loaded with Firefox, Office 2007 and Adobe Reader among other applications. With Firefox we browse web pages like Facebook, AnandTech, Digg and other sites. Outlook is also running and we use it to check emails, create and send a message with a PDF attachment. Adobe Reader is used to view some PDFs. Excel 2007 is used to create a spreadsheet, graphs and save the document. The same goes for Word 2007. We open and step through a presentation in PowerPoint 2007 received as an email attachment before saving it to the desktop. Finally we watch a bit of a Firefly episode in Windows Media Player 11.
There’s some level of multitasking going on here but it’s not unreasonable by any means. Generally the application tasks proceed linearly, with the exception of things like web browsing which may happen in between one of the other tasks.
The recording is played back on all of our drives here today. Remember that we’re isolating disk performance, all we’re doing is playing back every single disk access that happened in that ~5 minute period of usage. The light workload is composed of 37,501 reads and 20,268 writes. Over 30% of the IOs are 4KB, 11% are 16KB, 22% are 32KB and approximately 13% are 64KB in size. Less than 30% of the operations are absolutely sequential in nature. Average queue depth is 6.09 IOs.
The performance results are reported in average I/O Operations per Second (IOPS):

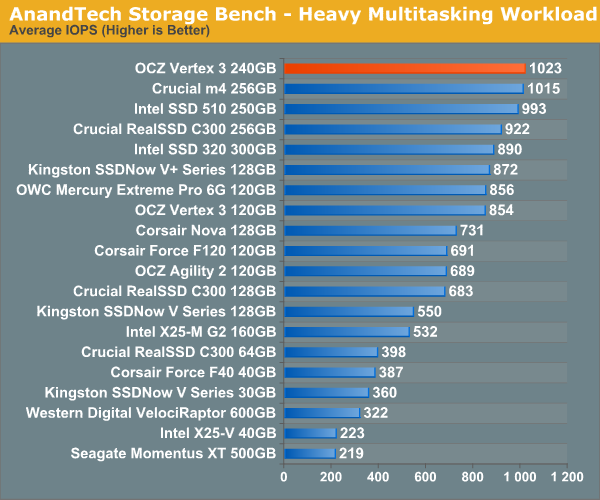
If there’s a light usage case there’s bound to be a heavy one. In this test we have Microsoft Security Essentials running in the background with real time virus scanning enabled. We also perform a quick scan in the middle of the test. Firefox, Outlook, Excel, Word and Powerpoint are all used the same as they were in the light test. We add Photoshop CS4 to the mix, opening a bunch of 12MP images, editing them, then saving them as highly compressed JPGs for web publishing. Windows 7’s picture viewer is used to view a bunch of pictures on the hard drive. We use 7-zip to create and extract .7z archives. Downloading is also prominently featured in our heavy test; we download large files from the Internet during portions of the benchmark, as well as use uTorrent to grab a couple of torrents. Some of the applications in use are installed during the benchmark, Windows updates are also installed. Towards the end of the test we launch World of Warcraft, play for a few minutes, then delete the folder. This test also takes into account all of the disk accesses that happen while the OS is booting.
The benchmark is 22 minutes long and it consists of 128,895 read operations and 72,411 write operations. Roughly 44% of all IOs were sequential. Approximately 30% of all accesses were 4KB in size, 12% were 16KB in size, 14% were 32KB and 20% were 64KB. Average queue depth was 3.59.
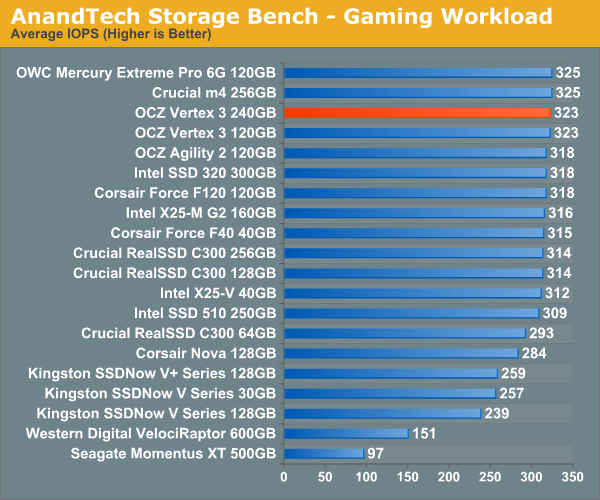
The gaming workload is made up of 75,206 read operations and only 4,592 write operations. Only 20% of the accesses are 4KB in size, nearly 40% are 64KB and 20% are 32KB. A whopping 69% of the IOs are sequential, meaning this is predominantly a sequential read benchmark. The average queue depth is 7.76 IOs.
TRIM Performance
In practice, SandForce based drives running a desktop workload do very well and typically boast an average write amplification below 1 (more writes to the device than actual writes to NAND). My personal SF-1200 drive had a write amplification of around 0.6 after several months of use. However if subjected to a workload composed entirely of incompressible writes (e.g. tons of compressed images, videos and music) you can back the controller into a corner.
To simulate this I filled the drive with incompressible data, ran a 4KB (100% LBA space, QD32) random write test with incompressible data for 20 minutes, and then ran AS-SSD (another incompressible data test) to see how low performance could get:
| OCZ Vertex 3 240GB - Resiliency - AS SSD Sequential Write Speed - 6Gbps | |||||
| Clean | After Torture | After TRIM | |||
| OCZ Vertex 3 240GB | 284.4 MB/s | 278.5 MB/s | 286.3 MB/s | ||
| OCZ Vertex 3 120GB | 162.1 MB/s | 38.3 MB/s | 101.5 MB/s | ||
The 240GB drive is simply more resilient when faced with the same length of workload than the 120GB drive. It's possible that the extra physical spare area the 240GB drive has is responsible for its better behavior after torture. The larger drive may simply have to be tortured for longer in order to see a similar drop in performance. However 20 minutes of incompressible 4KB random writes would still fill up all of the drive's spare area and force the SSD into block recycling in only half that time. SandForce's block cleaning algorithm might do very well on the first pass of filling the drive but fall short after multiple passes where the spare area is overwritten. Either way, a desktop user is highly unlikely to ever encounter any serious slowdown with the 240GB drive.
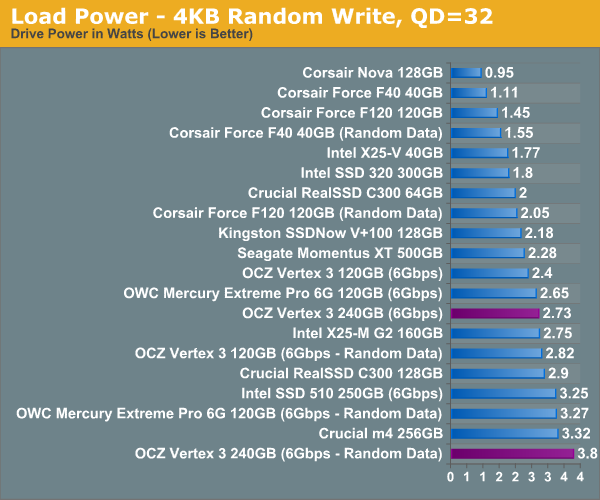
Power Consumption
Power consumption is in line with the 120GB Vertex 3. Our earlier sample had issues with idle power consumption which have since been resolved in the final shipping firmware. Note that all of our tests are conducted with LPM disabled, a feature that seems to be problematic on some combinations of chipsets and SF-2200 hardware.


Final Words
When we previewed the 240GB Vertex 3 it looked like game over for the SandForce competitors this round. With the final hardware tested, I have to agree with our original conclusion. If you're spending $500 on a drive, the 240GB Vertex 3 is your best bet.

There are some mild changes in the results here and there but nothing significant (other than lower power consumption compared to the pre-release sample). Intel's SSD 510 and Crucial's m4 are the closest competitors. The only reason I can see going for Intel's 510 over the 240GB Vertex 3 is the reliability aspect. Intel has typically had lower return rates than OCZ and while OCZ tends to take care of its customers very well, many would just rather not have an issue to begin with. I will say that SandForce reliability has come a long way in the past year but there's still a lot of proving that both SF and OCZ have to do with the Vertex 3 to really cement themselves as a top tier player in the SSD space.






