Original Link: https://www.anandtech.com/show/4014/10g-more-than-a-big-pipe
10G Ethernet: More Than a Big Pipe
by Johan De Gelas on November 24, 2010 2:34 PM EST- Posted in
- Networking
- IT Computing
- 10G Ethernet
I/O Consolidation
In our previous article, we showed that thanks to multi-queue technology, 10G Ethernet can deliver about 9 Gbit/s per second. We compared it with the typical link aggregated quad-port gigabit “NIC”. Quad-port link aggregation (IEEE 802.3 ad) is considered the “sweet spot”, both from a performance and an economic point of view. The results made 10G Ethernet really attractive: 10Gbit Ethernet actually consumed less CPU cycles than the quad-port link aggregated solution while delivering more than twice the bandwidth (9.5 Gbit/s vs 3.8 Gbit/s). It also features lower latency than quad-port NICs.
And 10G is hardly expensive: the least expensive dual 10G NICs cost about 50% ($600-700) more than the quad-port gigabit NICS ($400-450). Even the more expensive 10G cards (>$1000) offer a competitive bandwidth (2x 10G) per dollar ratio and offer a much better performance per watt ratio too. Typical power usage of dual 10G card is between 6W to 14W. The best quad gigabit NICs go as low as 4.3 W, although 8.4W is also possible.
10G Ethernet is much more than “a bigger pipe” for your (virtualized) network traffic. Let our knowledgeable IT professionals commenting on our last 10G Ethernet article enlighten you:
“In the market for a new SAN for a server in preparation for a consolidation/virtualization move, one of my RFP requirements was for 10GbE capabilities now. Some peers of mine have questioned this requirement stating there is enough bandwidth with etherchanneled 4Gb NICs and FC would be the better option if that is not enough. The biggest benefit for 10Gb is not bandwidth, it's port consolidation, thus reducing total cost.”
To understand this just look at the picture below.

A virtualized server might need I/O ports for:
- Console and management traffic (Ethernet)
- VM migration (Ethernet)
- VM Application network I/O (Ethernet)
- Block Storage I/O (Fibre Channel)
- File Storage I/O (Ethernet)
For speed and availability reasons, you quickly end up with two ports for each traffic flow, so you might end up with up to 10 ports coming out of one server. You might even need more: an IP based KVM to access the physical host and another port for server management interface (ILO, DRAC…).
Cleaning Up the Cable Mess
Between 6 and 12 I/O cables on one server is quite a bit. You end up with a complicated NIC configuration as illustrated in this VMware/Intel white paper.
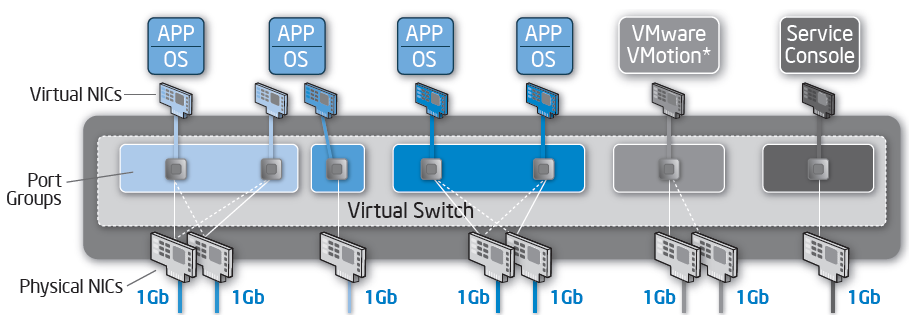
The white paper does not consider the storage I/O, but if you use two FC cards, you are adding another 14W (7W x 2) and two cables. So if we take such a heavy consolidated server as an example you end up with about:
- 10 I/O Cables (without KVM and Server management)
- 2 quad-port NICs x 5W + 2 FC cards x 7W = 24W
24W is not enormous, but in reality this is the best case. Dual socket servers typically need between 200 and 350W, quad socket servers about 250 to 500W in total. So the I/O power consumption is about 5—15% of the total power consumption.
The 10 I/O cables are a bigger problem. The more ports and cables, the higher the chances are that something gets badly configured and the harder it gets to troubleshoot. It does not take much imagination to see that this kind of cabling might waste a lot of sysadmin time and thus money.
The biggest problem is of course cost. Fibre Channel cabling is not cheap, but it is nothing compared to the huge cost of FC HBAs, FC switches, and SFPs. Cabling up to eight Ethernet cables per server is not cheap either: while the cable cost is negligible, someone has to do the pulling and plugging and that task isn't free.
Consolidating to the Rescue
The solution is “I/O convergence” or "I/O consolidation", the latest buzz words for combining all the I/O streams into one cable, the result being the use of one I/O infrastructure (Ethernet cards, cables and switches) to support all I/O streams. Instead of using many different physical interfaces and cables you consolidate all VMotion, console, VM traffic and storage traffic on a single card (dual card for fail-over). This should significantly lower complexity, power, management, and thus cost. If that sounds like marketing speak making it seem a lot easier than it is, you are right: it is indeed hard to accomplish this.
If all that traffic runs through the same cable, the I/O traffic of VM migration or backup routines kicking in could choke the life out of your storage traffic. And once that happens, the whole virtualized cluster comes to a grinding stop as storage traffic is the beginning and end of every operation in that cluster. So it is critical that you reserve some bandwidth for the storage I/O, and thankfully that is pretty easy to do in modern virtualization platforms. VMware calls this traffic shaping, and it allows you to limit the peak and average bandwidth that a certain group of VMs can get. Simply add the VMs to a portgroup and limit the traffic of that portgroup. The same can be done for VMotion traffic: just “shape” the traffic of the vSwitch that is linked to the VMotion kernel port group.
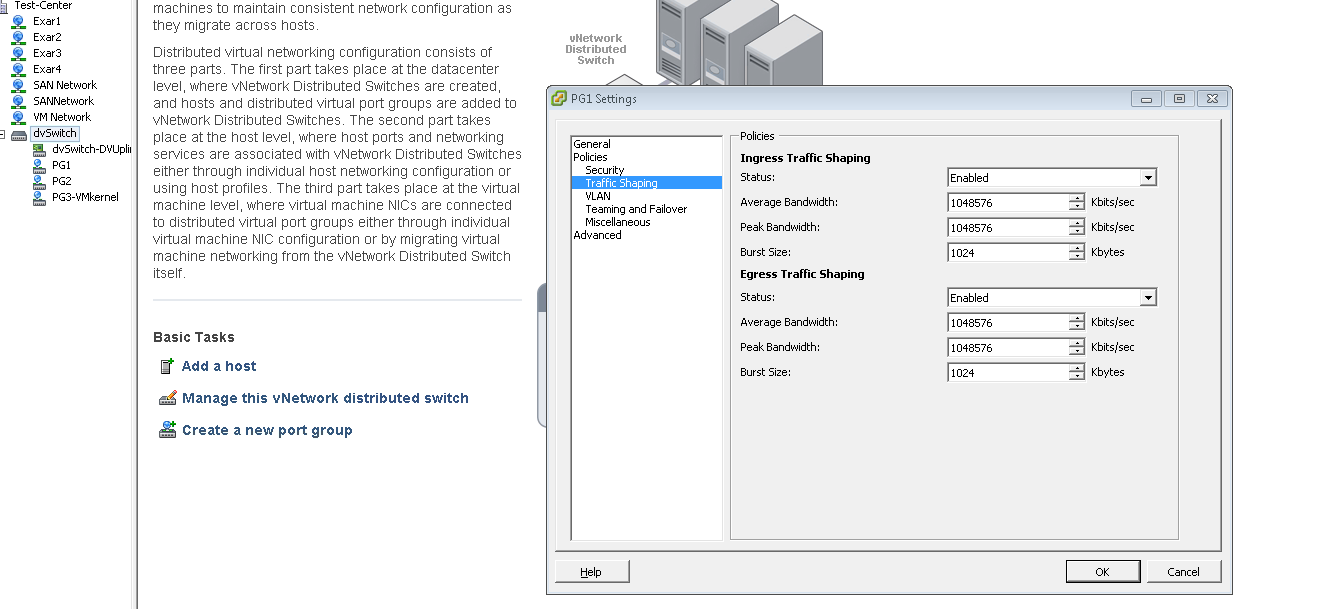
Traffic shaping is very usefull for outbound traffic. Outbound traffic orginates from the memory space that is being managed by and under the control of the hypervisor. It is an entirely different story when it comes to receive/inbound traffic. That kind of traffic is under control of the NIC hardware first. If the NIC drops packets before the hypervisor even sees them, "Ingress Traffic Shaping" won't do any good. There is more.
Outbound traffic shaping is available in all versions of VMware vSphere; it is a feature of the standard vSwitch. Seperate Ingress and Egress traffic shaping is only available on the newly introduced vNetwork Distributed Switch. This advanced virtual switch can only be used if you have the expensive Enterprise Plus license of VMware's vSphere.
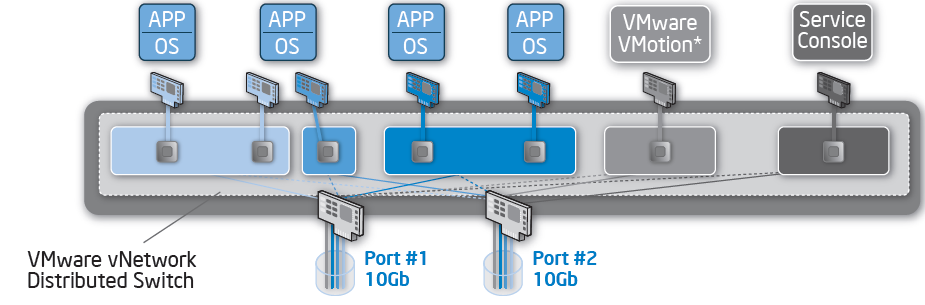
Still, if we combine 10G Ethernet with the right (virtualization) software and configuration, we can consolidate both console, storage (iSCSI, NFS), and “normal” network traffic into two high performance 10GbE NICs. Let us see what other options are available.
Solving the Virtualization I/O Puzzle
Step One: IOMMU, VT-d
The solution for the high CPU load, higher latency, and lower throughput comes in three steps. The first solution was to bypass the hypervisor and assign a certain NIC directly to the network intensive VM. This approach gives several advantages. The VM has direct access to a native device driver, and as such can use every hardware acceleration feature that is available. The NIC is also not shared, thus all the queues and buffers are available to one VM.
However, even though the hypervisor lets the VM directly access the native driver, a virtual machine cannot bypass the hypervisor’s memory management. The guest OS inside that VM does not have access to the real physical memory, but to a virtual memory map that is managed by the hypervisor. So when the hypervisor sends out addresses to the driver, it sends out virtual addresses instead of the expected physical ones (the white arrow).
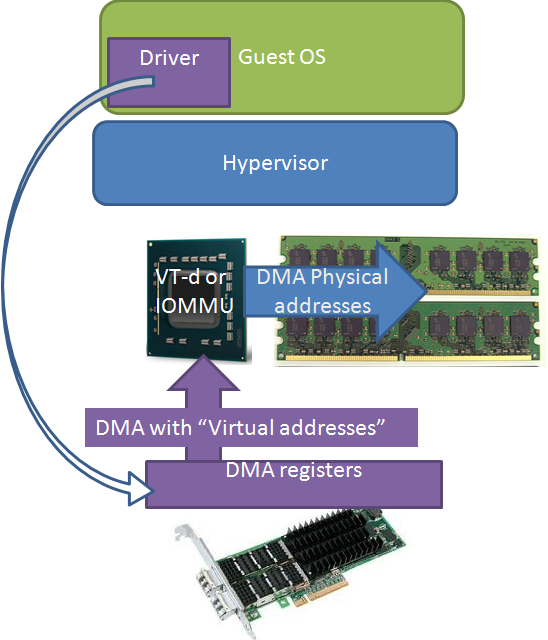
Intel solved this with VT-d, AMD with the “new” (*) IOMMU. The I/O hub translates the virtual or “guest OS fake physical” addresses (purple) into real physical addresses (blue). This new IOMMU also isolates the different I/O devices from each other by allocating different subsets of physical memory to the different devices.
Very few virtualized servers use this feature as it made virtual machine migration impossible. Instead of decoupling the virtual machine from the underlying hardware, direct assignment firmly connected the VM to the underlying hardware. So the AMD IOMMU and Intel VT-d technology is not that useful alone. It is just one of the three pieces of the I/O Virtualization puzzle.
(*) There is also an "old IOMMU" or Graphics Address Remapping Table which did address translations for letting the graphics card access the main memory.
Step Two: Multiple Queues
The next step was making the NIC a lot more powerful. Instead of letting the hypervisor sort all the received packages and send them off to the right VM, the NIC becomes a complete hardware switch that sorts all packages into multiple queues, one for each VM. This gives a lot of advantages.
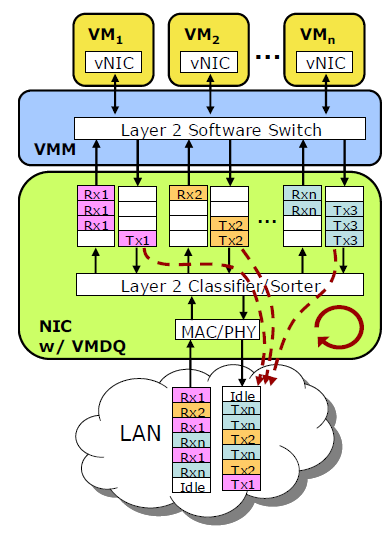
Less interrupts and CPU load. If you let the hypervisor handle the packet switching, it means that CPU 0 (which is in most cases is the one doing the hypervisor tasks) is interrupted and has to examine the received package and determine the destination VM. That destination VM and the associated CPU has to be interrupted. With a hardware switch in the NIC, the package is immediately sent into the right queue, and the right CPU is immediately interrupted to come and get the package.
Less latency. A single queue for multiple VMs that receive and transmit packages can get overwhelmed and drop packets. By giving each VM its own queue, throughput is higher and latency is lower.
Although Virtual Machine Devices Queues solves a lot of problems, there is still some CPU overhead left. Every time the CPU of a certain VM is interrupted, the hypervisor has to copy the data from the hypervisor space into the VM memory space.
The Final Piece of the Puzzle: SR-IOV
The final step is to add a few buffers and Rx/Tx descriptors to each queue of your multi-queued device, and a single NIC can pretend to be a collection of tens of “small” NICs. That is what PCI SIG did, and they call each small NIC a virtual function. According to the PCI SIG SR-IOV specification you can have up to 256 (!) virtual functions per NIC. (Note: the SR-IOV specification is not limited to NICs; other I/O devices can be SR-IOV capable too.)
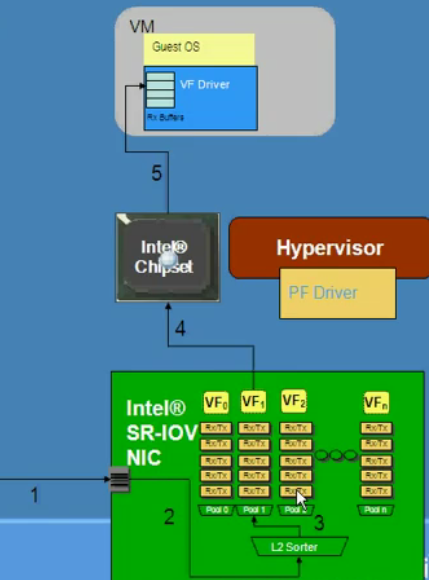
Courtesy of the excellent Youtube movie: "Intel SR-IOV"
Make sure there is a chipset with IOMMU/VT-d inside the system. The end result: each of those virtual functions can DMA packets in and out without any help of the hypervisor. That means that it is not necessary anymore for the CPU to copy the packages from the memory space of the NIC to the memory space of the VM. The VT-d/IOMMU capable chipset ensures that the DMA transfers of the virtual functions happen and do not interfere with each other. The beauty is that the VMs are connecting to these virtual functions by a standard paravirtualized driver (such as VMXnet in VMware), and as a result you should be able to migrate VMs without any trouble.
There you have it: all puzzles pieces are there. Multiple queues, virtual to physical address translation for DMA transfers, and a multi-headed NIC offer you higher throughput, lower latency, and lower CPU overhead than emulated hardware. At the same time, they offer the two advantages that made virtualized emulated hardware so popular: the ability to share one hardware device across several VMs and the ability to decouple the virtual machine from the underlying hardware.
SR-IOV Support
Of course, this is all theory until all software and hardware layers work together to support this. You need a VT-d or IOMMU chipset, the motherboard’s BIOS has to adapted to recognize all those virtual functions, and each virtual function must get memory mapped IO space like other PCI devices. A hypervisor that supports SR-IOV is also necessary. Last but not least, the NIC vendor has to provide you with an SR-IOV capable driver for the operating system and hypervisor of your choice.
With some help of mighty Intel, the opensource hypervisors (Xen, KVM) and the commercial product derivatives (Redhat, Citrix) were first to market with SR-IOV. At the end of 2009, both Xen and KVM had support for SR-IOV, more specifically for Intel 10G Ethernet 82599 controller. The Intel 82599 can offer up to 64 VFs. Citrix announced support for SR-IOV in Xenserver 5.6, so the only ones missing in action are VMware’s ESX and Microsoft’s Hyper-V.
Exar's Neterion Solution
SR-IOV will be supported in ESX 5.0 and the successor of Windows Server 2008. Since VMware’s ESX is the dominant hypervisor in most datacenters, that means that a large part of the already virtualized servers will have to wait a year or more before they can get the benefits of SR-IOV.

Exar, the pioneer of multiple devices queues, saw a window of opportunity. Besides the standard SR-IOV and VMware NetQueue support, the X3100 NICs also have a proprietary SR-IOV implementation.
Poprietary solutions only make sense if they offer enough advantages. Neterion claims that the NIC chip has extensive hardware support for network prioritization and quality of service. That hardware support should be superior to hypervisor traffic shaping, especially on the receive side. After all, if bursty traffic causes the NIC to drop packets on the receive side, there is nothing the hypervisor can do: it never saw those packets pass. To underline this, Neterion equips the X3100 with a massive 64MB receive buffer; for comparison, the competitors have in the best case a 512KB receive buffer. This huge receive buffer should ensure that the QoS is guaranteed even if relatively long bursts of network traffic occur.
Neterion NICs can be found in IBM, HP, Dell, Fujitsu, and Hitachi machines. Neterion is part of Exar and has also access to a world distributor channel. The typical price of this NIC is around $745.
The Competition: Solarflare
Solarflare is a relatively young company, founded in 2001. The main philosophy of Solarflare has been been “make Ethernet [over copper] better” (we added “over copper”). Solarflare NICs support optical media too, but Solarflare made headlines with their 10G Ethernet copper products. In 2006, Solarflare was the first with 10GBase-T PHY. 10GBase-T allows 10Gigabit over the very common and cheap CAT5E and the reasonably priced CAT6 and CAT6A UTP cables. Solarflare is also strongly advocating the use of 10GbE in the HPC world with the claim that the latency of 10GbE can be as low as 4 µs. In June of this year, Solarflare launched the SFN5121T, a dual-ported 10Gbase-T NIC which featured a very reasonable 12.9W power consumption, especially for a UTP based 10GbE product. In January of this year, the company decided to start selling NIC adapters directly to the end-user.

As we got an SFP+ Neterion X3120, we took a look at the optical brother of the SFN5121T, the SFN5122F. Both Solarflare NICs support SR-IOV and and make use of PCIe 2.0. The SFP+ SFN5122F should only consume a very low 4.9W for the complete card. Solarflare pulled this off by designing their own PHYs and reducing the chip count on the NIC. Although our power measurement methods (measured at the wall) are too crude to measure the exact power consumption, we can confirm that the Solarflare NIC consumed the least of the three NICs we tested.
The Solarflare chips are only slightly more expensive than the other NICs. Prices on the web were typically around $815.
The oldies
It is always interesting to get some “historical perspective”. Do these new cards outperform the older ones by a large margin? We included the Neterion XFrame-E for one test, and used the multi-queue pioneer and the Intel 82598, the 10GbE price breaker, as the historical reference for every benchmark. We'll try to add the Intel 82599 which also support SR-IOV, has a larger receive buffer, more queues and is priced around $700. We plugged those NICs in our Supermicro Twin² for testing.
Benchmark Configuration
Each node of our Twin² got an identical NIC. We tested peer-to-peer with Ixchariot 5.4 and Nttcp.

Virtualized node:
Intel Xeon E5504 (2GHz quad-core) and Intel Xeon X5670 (2.93GHz hex-core)
Supermicro X8DTT-IBXF (Intel 5500 Chipset)
24GB DDR3-1066
One WD1000FYPS
Intel X25-E SLC 32GB (for IOmeter tests)
Hypervisor: VMware ESX 4 b261974 (=ESX4.0u2)
The virtualized node was equipped with a low-end quad-core and a high-end hex-core to measure the CPU load. The four VMs use the paravirtualized network driver VMXnet. This virtualized node was attached via an optical (or CX-4 in case of the Intel) cable to an almost identical node running Windows Server 2008 R2 Enterprise. The only difference was the CPU: the Windows 2008 node was equipped with a Xeon E5540 (2.53GHz quad-core).
Drivers:
SuperMicro AOC-STG-I2 (Intel 82598): ESX Default ixgbe 2.0.38.2.5-NAPI (261974, 24/05/2010)
Neterion x3120 IOV: ESX vxge 2.0.28.21239 (293373, 06/09/2010)
Solarflare Solarstorm SFN5122F: ESX sfc 3.0.5.2179 (16/07/2010)
Neterion xFrame-E: s2io 2.2.16.19752 (23/07/2010)
All tests were done with netqueue enabled.
Native Bandwidth: Windows Server 2008
Our first test was done with Windows 2008 Server R2 Enterprise installed on both nodes. We used Ixia IxChariot 5.4 to test throughtput. Two subtests were performed; one with standard Ethernet frame length (1.5KB) and one with 9KB jumbo frames. All tests were done with four threads. One of the most interesting enhancements in Windows Server 2008 is Receive-Side Scaling (RSS), a feature that spreads the receive processing out over several CPU cores. RSS was enabled in the driver properties.
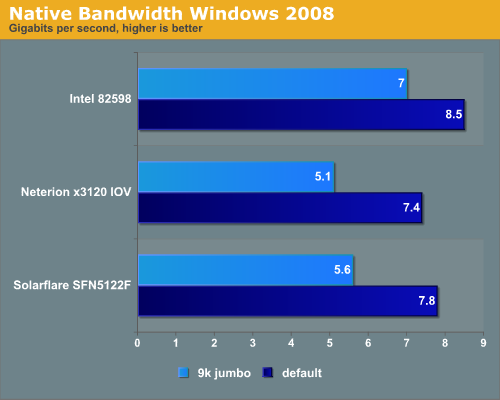
All three NICs perform worse with jumbo frames than without. Jumbo frames lowers the CPU load for every NIC from 13-14% to 10%. Still only 5-5.6 Gbit/s is pretty disappointing. The Solarflare and Neterion NIC are clearly made for virtualized environments. CPU load was around 14% for the Neterion and Intel NICs when we tested with standard Ethernet frames, while Solarflare’s NIC needed 10%. When we enabled Jumbo frames, all NICs needed about 10% of the available CPU power (the Xeon E5504 at 2GHz).
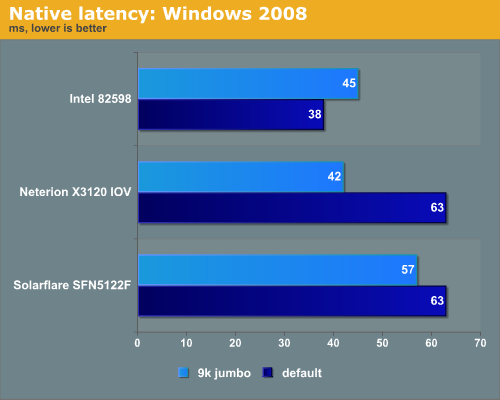
The latency of the Solarflare NIC is higher than the other chips. Since Solarflare has put a lot of effort into an optimized opensource network stack for Linux called “OpenOnload”, we assume that the low latency that Solarflare claims are for Linux NIC latency. That makes sense as Linux is dominant in the HPC cluster world. In HPC clusters, latency matters more than bandwidth.
ESX 4.0 Performance
Let us see what these NICs can do in a virtualized environment. After some testing in ESX 4.1 we had to go back to ESX 4.0 u2 as there were lots of driver issues, and this surely was not the NIC vendors fault solely. Apparantly, VMDirectPath is broken in ESX 4.1, and a bug report has been filed: update 1 should take care of this.
We started NTttcp from the Windows 2008 node:
NTttcp –m 4,0, [ip number] -a 4 –t 120
On the “virtualized node”, we created four virtual machines with Windows 2008. Each VM gets four network load threads. In other words, there are 16 threads active, all sending network traffic through one NIC port.
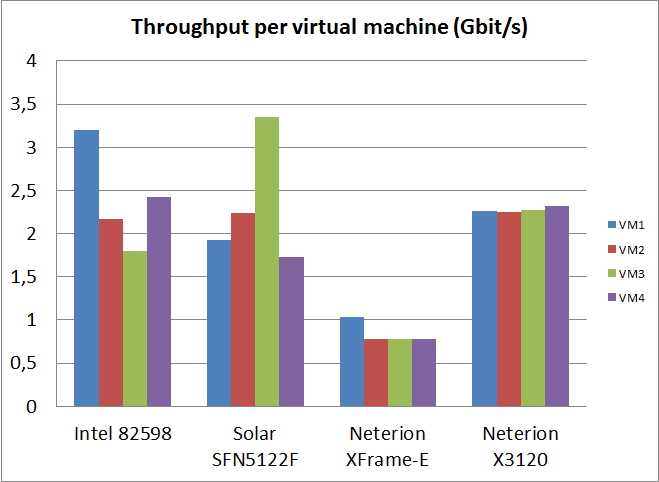
The Intel chip delivered the highest throughput with 9.6 Gb/s, followed closely by the Solarflare (9.2 Gbit/s) and the Neterion X3100 (9.1 Gbit/s). The old Xframe-E was not capable of delivering more than 3.4 Gbit/s. The difference between the top three is hardly worth discussing: few people are going to notice a bandwidth increase of 5%. However, notice that the Neterion NIC is the one that load balances the traffic the fairest over the four VMs. All Virtual machines get the same bandwidth: about 2.2 to 2.3 Gbit/s. The Solarflare SF5122F and Intel 82598 are not that bad either: the lowest bandwidth was 1.8 Gbit/s. Bandwidth tests with the Ixia Chariot 5.4 test suite gave the same numbers. We also measured response times.
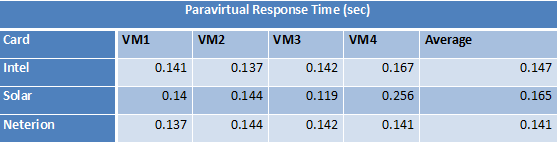
Again, the Neterion X3100 chip stands out with a low response time in all virtual machines. The Solarflare SF5122 drops a stitch here as one VM gets twice the amount of latency. Let us see how much CPU power these NICs needed while they round-robin the network traffic over to the virtual machines. This test was done on the Xeon E5504 (2GHz) and the Xeon X5670 (2.93GHz); Hyper-Threading was disabled on all CPUs.
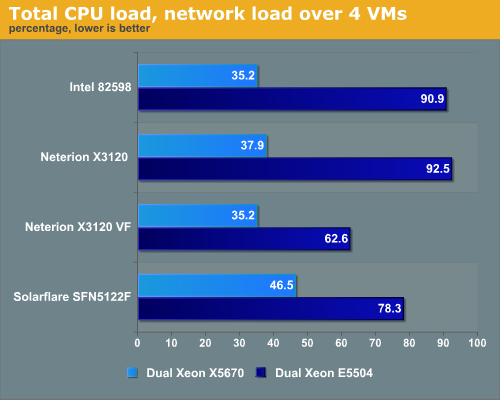
Nine gigabits of paravirtualized network traffic is enough to swamp the dual quad-core 2GHz Xeon CPU in most cases. Although it is one of slowest Xeons now available, it is still impressive that nothing less than eight of these cores are necessary just to run the benchmark and manage the network traffic. So be warned that these 10GbE NICs require some heavy CPU power. The Solarflare chip offers the low-end Xeon some breathing space, the Neterion chip needs the most for it’s almost perfect load balancing services.
But the Neterion chip has a secret weapon: it is the only NIC that can make virtual functions available in VMware ESX. Once you do this, the CPU load is a lot lower: we measured only 63%. This lower CPU load is accompagnied with a small dip in the network bandwidth: we achieved 8.1 Gbit/s instead of 9.1 Gbit/s.
Once we use one of the fastest Xeons available, the picture changes. The Intel and Neterion make better use of the extra cores and higher frequency.
Consolidation and Choking
If we consolidate storage, network, and management traffic in a single or dual 10GbE cable, a simpler, cheaper and easier to manage datacenter is in reach. So how well do the new NICs cope with these I/O demands? We decided to mix a VM with an iSCSI initiator that is sending off lots of storage traffic with three VMs that are demanding lots of “normal” network traffic. In our first scenario we simulate the “I don’t have time to properly configure” scenario. We just hooked up one VM with an iSCSI initiator, and three other VMs were running IxChariot endpoints, creating as much traffic as they like.
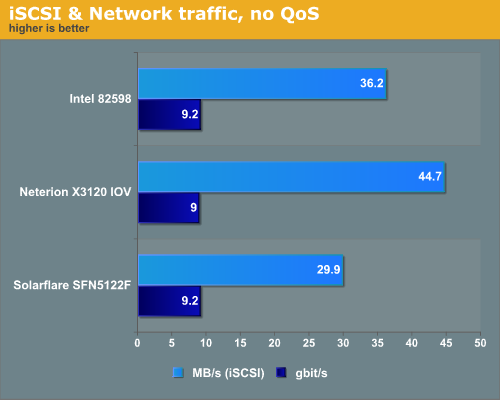
It is easy to notice that the four virtual function NICs allow the Neterion X3120 to spread the load more evenly. The iSCSI VM runs 50% faster on the Neterion chip, which is significant. Reading the disk blocks 50% faster can make a real difference to the end-user, as the user experience is in many applications highly depended on the slow disks.
Let us see how much CPU load was necessary to keep this kind of brutal network traffic under control. The two CPUs on the virtual node were Xeon X5670 2.93GHz.
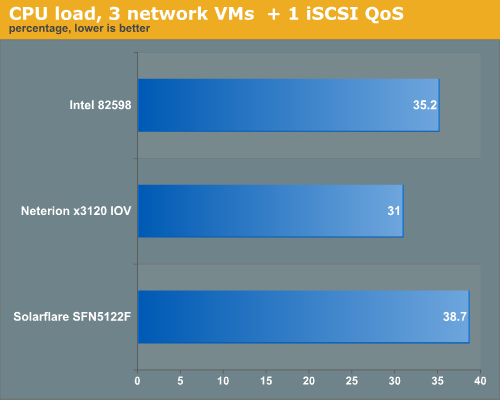
The Neterion chip does a better job at a slightly lower CPU load.
The Real Deal: Consolidated I/O
In the next scenario, we did a lot more thinking before configuring. We reconfigured our VMs as follows:
- The iSCSI VM runs IOmeter as fast as it can
- Two VMs are limited and guaranteed that they would get 2 Gbit/s all the time
- One VM is tested with IxChariot and is allowed to absorb as much bandwidth as possible
It would make more sense to give the iSCSI a certain limited but guaranteed amount of bandwidth. That would avoid the non-restricted “network VM” choking the iSCSI VM. But as IxChariot allows us to plot the graphs over time and we want to create a contention situation, we decided to only limit the IxChariot VMs.

The Solarflare and Intel NICs used the VMware ESX 4.0 ingress and egress traffic shaping, while the Neterion chip uses the hardware QoS and "Multi Function" capabilities.
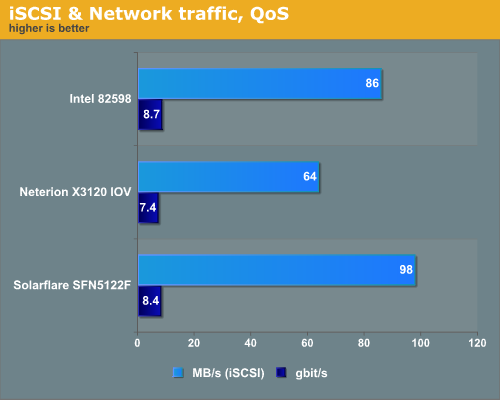
The Solarflare and Intel chip have done a better job from the throughput point of view, but it is only part of the story. The whole idea of Quality of Service and traffic shaping is to guarantee a certain level of performance. So we should also focus on how well the NIC made sure that the 2 QoS VMs got the guaranteed level of 2 Gbit/s.
Quality of Service: Looking Closer
The first chip we look at is the Intel 82598.
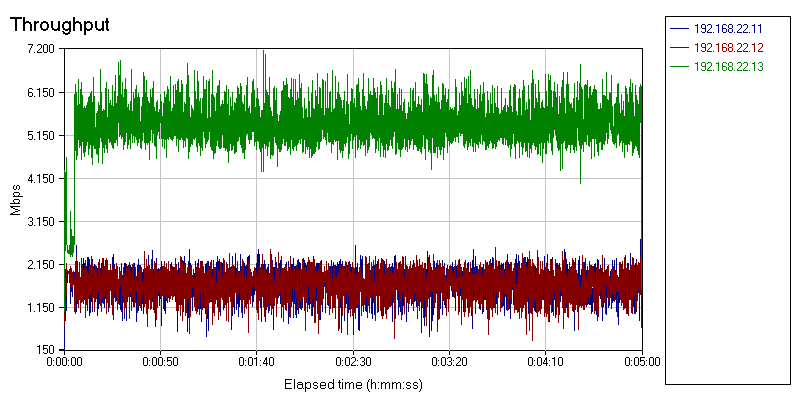
Notice that the blue and red throughput lines vary between 0.5 and 2.2 Gbit per second. As our script consists of 90% receive frames, it is clear that (ingress) software traffic shaping is doing a rather mediocre job. It struggles to keep the bandwidth close to the desired 2 Gbit/s. The same is true for the Solarflare chip.
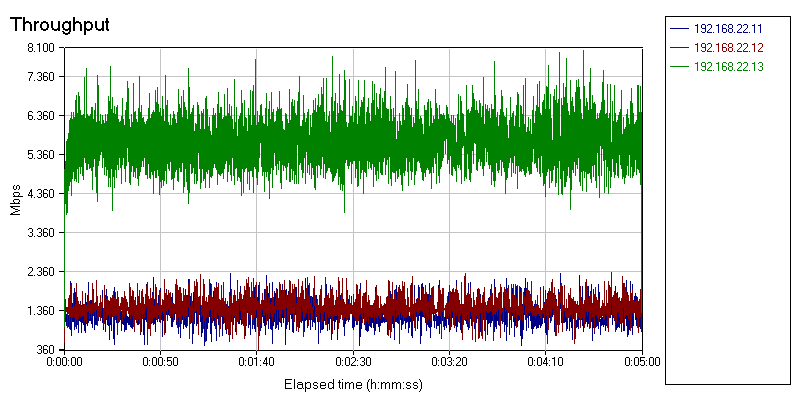
It is important to note that this is only a temporary situation for the Solarflare SF5122F. It does support SR-IOV and can offer up to 256 virtual functions, so the moment ESX supports SR-IOV officialy, the SF5122F should be able to do a lot better. Let us take a look at "Neterion SR-IOV" of the Neterion X3120 NIC.
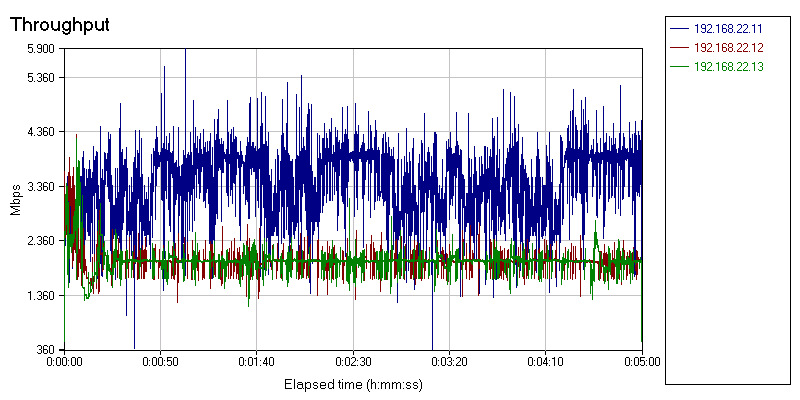
If we ignore the first few seconds, you can clearly see that the red and green line(*) are much closer to the demanded 2 Gbit/s. The two VMs with QoS get 1.4 Gbit/s in the worst case, and most of the time, the bandwidth is very close to 2 gbit/s. The large 64MB receive buffer and hardware QoS in the NIC are paying off.
(*) The blue line is now the VM without any QoS.
Our Impressions
First of all let's discuss the limitations of this review. The Intel chip was the older 82598; we will update this article with our findings on the 82599 as soon as we can.

Neterion X3120 on the left, Solarflare SFN5122F in the middle, Intel 82598/ Supermicro NIC on the right.
We would not chose the Solarflare SFN5122F for a native Windows 2008 Server, as the 82598 already beats it there, so there is little doubt that the Intel 82599 will be the more attractive choice in that case. However, the Solarflare is the card that clearly has the lowest power consumption and an impressive SR-IOV implementation (256 VFs and hardware QoS). So the tests of today (Windows 2008, ESX 4.0 without SR-IOV) are not showing the true potential of this NIC. There are strong indications that the SFN5122F should do quite a bit better with Opensource software as it would get SR-IOV support in KVM and Xen, and a low latency TCP/IP stack with linux. To be continued....
The Neterion X3120 has beaten everybody to the VMware ESX punch. By implementing a sort of "pre-SR-IOV" besides the standard SR-IOV support, Neterion can offer virtual functions before anyone else, and it offers tangible advantages. The X3120 provides lower CPU loads and a more fair distribution of bandwidth—even without QoS—among the virtual machines. Add to this the large receive buffer and hardware QoS and it is a lot easier to guarantee a minimum amount of bandwidth to certain performance critical virtual machines. If you have to live up to an SLA, this should reduces costs. The Neterion NIC allows you to size the number of ports and bandwidth for the "usual expected" peak traffic. Without QoS and VFs you will need to add more ports to meet the needs of "extreme peak" traffic to guarantee that certain critical applications can always attain the promised performance.
The X3120 has a few weakness too, though. The relatively large heatsink gives away the fact that the Neterion NIC consumes the most power of our three NICs; Solarflare definitely did a better job there. Also, the Neterion NIC requires more tuning than the other two to really perform well. So the Neterion X3120 is not perfect, but it is the best NIC on VMware vSphere right now unless you are configuring your server for very low power.
A big thanks to Tijl Deneut for his assistance in benchmarking these NICs.






