Original Link: https://www.anandtech.com/show/3963/zfs-building-testing-and-benchmarking
ZFS - Building, Testing, and Benchmarking
by Matt Breitbach on October 5, 2010 4:33 PM EST- Posted in
- IT Computing
- Linux
- NAS
- Nexenta
- ZFS
If you are in the IT field, you have no doubt heard a lot of great things about ZFS, the file system originally introduced by Sun in 2004. The ZFS file system has features that make it an exciting part of a solid SAN solution. For example, ZFS can use SSD drives to cache blocks of data. That ZFS feature is called the L2ARC. A ZFS file system is built on top of a storage pool made up of multiple devices. A ZFS file system can be shared through iSCSI, NFS, and CFS/SAMBA.
We need a lot of reliable storage to host low cost websites at No Support Linux Hosting. In the past, we have used Promise iSCSI solutions for SAN based storage. The Promise SAN solutions are reliable, but they tend to run out of disk IO long before they run out of disk space. As a result, we have been intentionally under-utilizing our current SAN boxes. We decided to investigate other storage options this year in an effort to improve the performance of our storage without letting costs get completely out of hand.
We decided to spend some time really getting to know OpenSolaris and ZFS. Our theory was that we could build a custom ZFS based server for roughly the same price as the Promise M610i SAN, and the ZFS based SAN could outperform the M610i at that price point. If our theory proved right, we would use the ZFS boxes in future deployments. We also tested the most popular OpenSolaris based storage solution, Nexenta, on the same hardware. We decided to blog about our findings and progress at ZFSBuild.com, so others could benefit from anything we learned throughout the project.
ZFS Features
ZFS includes two exciting features that dramatically improve the performance of read operations. I’m talking about ARC and L2ARC. ARC stands for adaptive replacement cache. ARC is a very fast block level cache located in the server’s memory (RAM). The amount of ARC available in a server is usually all of the memory except for 1GB.
For example, our ZFS server with 12GB of RAM has 11GB dedicated to ARC, which means our ZFS server will be able to cache 11GB of the most accessed data. Any read requests for data in the cache can be served directly from the ARC memory cache instead of hitting the much slower hard drives. This creates a noticeable performance boost for data that is accessed frequently.
As a general rule, you want to install as much RAM into the server as you can to make the ARC as big as possible. At some point adding more memory becomes cost prohibitive, which is where the L2ARC becomes important. The L2ARC is the second level adaptive replacement cache. The L2ARC is often called “cache drives” in the ZFS systems.
These cache drives are physically MLC style SSD drives. These SSD drives are slower than system memory, but still much faster than hard drives. More importantly, the SSD drives are much cheaper than system memory. Most people compare the price of SSD drives with the price of hard drives, and this makes SSD drives seem expensive. Compared to system memory, MLC SSD drives are actually very inexpensive.
When cache drives are present in the ZFS pool, the cache drives will cache frequently accessed data that did not fit in ARC. When read requests come into the system, ZFS will attempt to serve those requests from the ARC. If the data is not in the ARC, ZFS will attempt to serve the requests from the L2ARC. Hard drives are only accessed when data does not exist in either the ARC or L2ARC. This means the hard drives receive far fewer requests, which is awesome given the fact that the hard drives are easily the slowest devices in the overall storage solution.
In our ZFS project, we added a pair of 160GB Intel X25-M MLC SSD drives for a total of 320GB of L2ARC. Between our ARC of 11GB and our L2ARC of 320GB, our ZFS solution can cache over 300GB of the most frequently accessed data! This hybrid solution offers considerably better performance for read requests because it reduces the number of accesses to the large, slow hard drives.
Things to Keep in Mind
There are a few things to remember. The cache drives don’t get mirrored. When you add cache drives, you cannot set them up as mirrored, but there is no need to since the content is already mirrored on the hard drives. The cache drives are just a cheap alternative to RAM for caching frequently access content.
Another thing to remember is you still need to use SLC SSD drives for the ZIL drives. ZIL stands for "ZFS Intent Log", and acts as an intermediary for write caching. Not having ZIL drives severely slows down write access. By adding the ZIL drives you significantly increase write speeds. This is still not as fast as a RAM based write cache on a RAID card, but it is much better than not having anything. Solaris ZFS Best Practices For Log Devices The SLC SSD drives used for ZIL drives dramatically improve the performance of write actions. The MLC SSD drives used as cache drives are used to improve read performance.
It is also important to remember that the L2ARC will require some memory to operate. A portion of the ARC will be used to index and manage the content located in the L2ARC. A general rule of thumb is that 1-2GB of ARC will be used for every 100GB of L2ARC. With a 300GB L2ARC, we will give up 3-6GB of ARC. This will leave us with 5-8GB of ARC memory to use to cache the most frequently accessed files.
Effective Caching to Virtualized Environments
At this point, you are probably wondering how effectively the two levels of caching will be able to cache the most frequently used data, especially when we are talking about 9TB of formatted RAID10 capacity. Will 11GB of ARC and 320GB L2ARC make a significant difference for overall performance? It will depend on what type of data is located on the storage array and how it is being accessed. If it contained 9TB of files that were all accessed in a completely random way, the caching would likely not be effective. However, we are planning to use the storage for virtual machine file systems and this will cache very effectively for our intended purpose.
When you plan to deploy hundreds of virtual machines, the first step is to build a base template that all of the virtual machines will start from. If you were planning to host a lot of Linux virtual machines, you would build the base template by installing Linux. When you get to the step where you would normally configure the server, you would shut off the virtual machine. At that point, you would have the base template ready. Each additional virtual machine would simply be chained off the base template. The virtualization technology will keep the changes specific to each virtual machine in its own child or differencing file.
When the virtualization solution is configured this way, the base template will be cached quite effectively in the ARC (main system memory). This means the main operating system files and cPanel files should deliver near RAM-disk performance levels. The L2ARC will be able to effectively cache the most frequently used content that is not shared by all of the virtual machines, such as the content of the files and folders in the most popular websites or MySQL databases. The least frequently accessed content will be pulled from the hard drives, but even that should show solid performance since it will be RAID10 across 18 drives and none of the frequently accessed read requests will need to burden the RAID10 volume since they are already served from ARC or L2ARC.
Testing the L2ARC
We thought it would be fun to actually test the L2ARC and build a chart of the performance as a function of time. To test and graph usefulness of L2ARC, we set up an iSCSI share on the ZFS server and then ran Iometer from our test blade in our blade center. We ran these tests over gigabit Ethernet.
Iometer Test Details:
25GB working set
4k blocks
100% random
100% read
load 32 (constant)
four hour test
Every ten minutes during the test, we grabbed the “Last performance” values (IOPS, MB/sec) from Iometer and wrote them down to build a performance chart. Our goal was to be able to graph the performance as a function of time so we could illustrate the usefulness of the L2ARC.
We ran the same test using the Promise M610i (16 1TB WD RE3 drives in RAID10) box to get a comparison graph. The Promise box is not a ZFS style solution and does not have any L2ARC style caching feature. We expected the ZFS box to outperform the Promise box, and we expected the ZFS box to increase performance as a function of time because the L2ARC would become more populated the longer the test ran.
The Promise box consistently delivered 2200 to 2300 IOPS every time we checked performance during the entire 4 hour test. The ZFS box started by delivering 2532 IOPS at 10 minutes into the test and delivered 20873 IOPS by the end of the test.
Here is the chart of the ZFS box performance results:
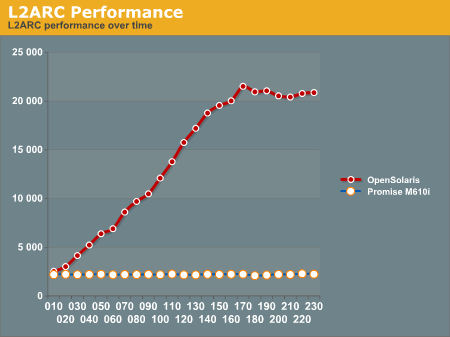
Initially, the two SAN boxes deliver similar performance, with the Promise box at 2200 IOPS and the ZFS box at 2500 IOPS. The ZFS box with a L2ARC is able to magnify its performance by a factor of ten once the L2ARC is completely populated!
Notice that ZFS limits how quickly the L2ARC is populated to reduce wear on the cache drives. It takes a few hours to populate the L2ARC and achieve maximum performance. That seems like a long time when running benchmarks, but it is actually a very short period of time in the life cycle of a typical SAN box.
Other Cool ZFS Features
There are many items that we have not touched on in this article, and those are worthy of mentioning at this time simply because they are enterprise features that are available with OpenSolaris and with Nexenta. These are features that the Promise M610i cannot compete with in any way.
Block Level Deduplication - ZFS can employ block level deduplication, which is to say it can detect identical blocks, and simply keep one copy of the data. This can significantly reduce storage costs, and possibly improve performance when the circumstances allow. One group that recently deployed a Nexenta instance had originally configured the system for 2TB of storage. They were using 1.4TB at the time and wanted to have room to grow. By enabling deduplication they were able to shrink the actual used space on the drives to just under 800GB. This also has implications when randomly accessing data. If you have multiple copies of the same data spread out all over a hard drive, it has to seek to find that data. If it's actually only stored in one place, you can potentially reduce the number of seeks that your drives have to do to retrieve the data.
Compression - ZFS also offers native compression similar to gzip compression. This allows you to save space at the expense of CPU and memory usage. For a system that is simply used for archiving data, this could be a great money and space saver. For a system that is being actively used as a database server, compression may not be the best idea.
Snapshot Shipping - OpenSolaris and Nexenta also offer snapshot shipping. This allows you to snapshot the entire storage array and back it up via SSH to a remote server. Once you ship the initial snapshot, only incremental data changes are shipped, so you can conserve bandwidth while still replicating your data to a remote location. Keep in mind that this is not a block level replication, but a point in time snapshot, so as soon as the snapshot is taken, any new data is not shipped to the remote system.
Nexenta
Nexenta is to OpenSolaris what OpenFiler is to Linux or FreeNAS is to FreeBSD. It is a purpose built version of OpenSolaris designed primarily around storage networking including NFS, CIFS, and iSCSI/FC block based storage. Nexenta has taken a lot of time building a great front-end to manage ZFS enabled storage and integrate a plug-in manager that can extend the abilities of a standard x86 platform to rival the best
Nexenta comes in three flavors, Nexenta Core, Nexenta Community, and Nexenta Enterprise. The availability of these three versions allows you to select what kind of product you want, and what kind of expenditures that you will incur.
Nexenta Core is the most basic of the options, but it is also the most forgiving in terms of licensing. Nexenta Core is a command line interface platform only. It is based on an OpenSolaris kernel, and an Ubuntu Userland. There is no limit to the amount of storage that you can configure or use with Nexenta Core, and it is completely free. Nexenta Core can be found here.
Nexenta Community is the next step up. Nexenta Community is based on Nexenta Core, and includes a great GUI interface for managing all aspects of the storage platform. Nexenta Community is also free, but it is limited to 12TB of used storage. Nexenta Community Edition can be found here.
Nexenta Enterprise is the top-level offering. Nexenta Enterprise is a superset of Nexenta Community with many Enterprise level features, including support options. Nexenta Enterprise is licensed based on RAW storage capacity. You can find pricing information here.
Screenshots of web GUI
Click to enlarge
Click to enlarge
Nexenta has been very easy to use in our testing. After a few minutes of familiarization with the interface everything is pretty straight forward. You can go from a bare installation to something that has an array configured, an iSCSI target configured, and is ready to take data in a matter of 5-10 minutes. All of the features for sending out notifications and for lighting up indicator lights work as expected and are easy to configure. With just a few menu clicks you're ready to enter all of the information that the system needs to notify you about any problems that it encounters.
Some of the shortcomings that we saw in the Nexenta Enterprise offering were in the reporting and support areas of the product. We did not investigate the reporting problem in depth, as it was not pertinent to the performance data of the system. We would expect that with a little troubleshooting it would be something that would be easily resolved. Throughout the testing process though the daily reports stated that there was no network traffic being generated even though we were loading the interface quite heavily during testing.
This brings us to our next issue that we had with Nexenta, and that was the support channels. We would have gladly troubleshot the issues with reporting if we thought it was going to be done in a timely manner. Since we were using the Enterprise Trial license the support was lackluster at best. We were assured by sales representatives that paid-for support is much faster and much better than the "free trial" support. Free Trial support is treated as their lowest priority support queue. We were not impressed with this as we have always thought of a time-limited free trial period to be pre-sales. If you want to convert someone from a non-paying free trial to a paid product, show them how good the product and support is during that period.
Promise M610i
The Promise M610i has been our go-to unit of choice for the last several years in our datacenter. The M610i is a hardware based iSCSI/SATA storage unit that allows you to build your own
We've found them to be reliable, inexpensive, and they perform well for the price point. Over the years we've populated Promise systems with everything from 250GB SATA drives to 1TB SATA drives and everything in between. The performance has remained relatively static though due to the static spindle count and 7200RPM rotating speed of those spindles.
The Promise systems incorporate RAID 0,1,5,6,10, and 1E (a form of RAID10 that allows you to use an odd number of drives). They are hardware controller based, and feature dual gigabit Ethernet ports that can be bonded together. It also incorporates a web-based management interface, automatic notifications, and a host of LED's that indicate power, activity, and failed drives.
For someone that is just starting out in the SAN world the M610i is a very attractive option with little experience necessary. The only drawbacks are when you want to expand the units or if you want better caching. The Promise system allows for a maximum of 2GB of RAM for caching, so if you want additional caching you'll have to shell out for a much more expensive unit. The Promise unit does not allow for adding additional JBOD enclosures. This limits you to a maximum of 16 spindles per system. We would have loved to continue using the M610i's if we could increase the spindle count.
Overall our experiences with the M610i units have been very good. We plan on doing an in-depth review of one of our M610i units at a later date to give a little bit better insight into the management and feature set of the units.
SuperMicro SC846E1-R900B

Click to enlarge
Our search for our ZFS SAN build starts with the Chassis. We looked at several systems from Supermicro, Norco, and Habey. Those systems can be found here :
SuperMicro : SuperMicro SC846E1-R900B
Norco : NORCO RPC-4020
Norco : NORCO RPC-4220
Habey : Habey ESC-4201C
The Norco and Habey systems were all relatively inexpensive, but none came with power supplies, nor did they support daisy chaining to additional enclosures without using any additional SAS HBA cards. You also needed to use multiple connections to the backplane to access all of the drive bays.
The SuperMicro system was by far the most expensive of the lot, but it came with redundant hot-swap power supplies, the ability to daisy chain to additional enclosures, 4 extra hot-swap drive bays, and the connection to the backplane was a single

Click to enlarge
The SuperMicro backplane also gives us the ability without any additional controllers to daisy chain to additional external chassis using the built in expander. This simplifies expansion significantly, allowing us to simply add a cable to the back of the chassis for additional enclosure expansion without having to add an extra HBA.
Given the cost to benefits analysis, we decided to go with the SuperMicro chassis. While it was $800 more than other systems, having a single connector to the backplane allowed us to save money on the SAS HBA card (more on this later). To support all of the other systems, you either needed to have a 24 port RAID card or a SAS controller card that supported 5
We also found that the power supplies we would want for this build would have significantly increased the cost. By having the redundant hot-swap power supplies included in the chassis, we saved additional costs. The only power supply that we found that would come close to fulfilling our needs for the Norco and Habey units was an Athena Power Hot Swap Redundant power supply that was $370 Athena Power Supply. Factoring that in to our purchasing decisions makes the SuperMicro chassis a no-brainer.

Click to enlarge
We moved the SuperMicro chassis into one of the racks in the datacenter for testing as testing it in the office was akin to sitting next to a jet waiting for takeoff. After a few days of it sitting in the office we were all threatening OSHA complaints due to the noise! It is not well suited for home or office use unless you can isolate it.

Click to enlarge
Rear of the SuperMicro chassis. You can also see three network cables running to the system. The one on the left is the connection to the IPMI management interface for remote management. The two on the right are the gigabit ports. Those ports can be used for internal

Click to enlarge
Removing the Power supply is as simple as pulling the plug, flipping a lever, and pulling out the PSU. The system stays online as long as one power supply is in the chassis and active.

Click to enlarge
This is the Power Distribution Backplane. This allows both PSU’s to be active and hot swapable. If this should ever go out, it is field replaceable, but the system does have to go offline.
A final thought on the Chassis selection – SuperMicro also offers chassis with 1200W power supplies. We considered this, but when we looked at the decisions that we were making on hard drive selections, we decided 900W would be plenty. Since we are selecting a hybrid storage solution using 7200
Another consideration would be if you decided to create a highly available system. If that is your goal you would want to use the E2 version of the chassis that we selected, as it supports dual SAS controllers. Since we are using SATA drives and SATA drives only support a single controller we decided to go with the single controller backplane.
Additional Photos :

Click to enlarge
This is the interior of the chassis, looking from the back of the chassis to the front of the chassis. We had already installed the SuperMicro X8ST3-F Motherboard, Intel Xeon E5504 Processor, Intel Heatsink, Intel X25-V SSD drives (for the mirrored boot volume), and cabling when this photo was taken.

Click to enlarge
This is the interior of the chassis, showing the memory, air shroud, and internal disk drives. The disks are currently mounted so that the data and power connectors are on the bottom.

Click to enlarge
Another photo of the interior of the chassis looking at the hard drives. 2.5″ hard drives make this installation simple. Some of our initial testing with 3.5″ hard drives left us a little more cramped for space.

Click to enlarge
The hot swap drive caddies are somewhat light-weight, but that is likely due to the high density of the drive system. Once you mount a hard drive in them though they are sufficiently rigid for any needs. Do not plan on dropping one on the floor though and having it save your drive. You can also see how simple it is to change out an SSD. We used the IcyDock’s for our SSD location because they are tool-less. If an SSD were to go bad, we simply pull the drive out, flip the lid open quick, and drop in a new drive. The whole process would take 30 seconds, which is very handy if the need ever arises.

Click to enlarge
The hot-swap fans are another nice feature. The fan on the right is partially removed, showing how simple it is to remove and install fans. Being able to simply slide the chassis out, open the cover, and drop in new fans without powering the system down is a must-have feature for a storage system such as this. We will be using this in a production environment where taking a system offline just to change a fan is not acceptable.

Click to enlarge
The front panel is not complicated, but it does provide us with what we need. Power on/off, reset, and indicator lights for Power, Hard Drive Activity, LAN1 and LAN2, Overheat, and Power fail (for failed Power Supply).
Motherboard Selection – SuperMicro X8ST3-F

Click to enlarge
Motherboard Top Photo
We are planning on deploying this server with OpenSolaris. As such we had to be very careful about our component selection. OpenSolaris does not support every piece of hardware sitting on your shelf. We had several servers that we tested with that would not boot into OpenSolaris at all. Granted, some of these were older systems with somewhat odd configurations. In any event, component selection needed to be made very carefully to make sure that OpenSolaris would install and work properly.
In the spirit of staying with one vendor, we decided to start looking with SuperMicro. Having one point of contact for all of the major components in a system sounded like a great idea.
Our requirements started with requiring that it support the Intel Xeon Nehalem architecture. The Intel Xeon architecture is very efficient and boasts great performance even at modest speeds. We did not anticipate unusually high loads with this system though, as we will not be doing any type of RAID that would require parity. Our RAID volumes will be mirrored VDEV’s (RAID10). As we did not anticipate large amounts of CPU time, we decided that the system should be single processor based.

Click to enlarge
Single CPU Socket for LGA 1366 Processor
Next on the list is RAM sizing. Taking in to consideration the functionality of the ARC cache in ZFS we wanted our system board to support a reasonable amount of RAM. The single processor systems that we looked at all support a minimum of 24GB of RAM. This is far ahead of most entry level RAID subsystems, most of which ship with 512MB-2GB of RAM (our 16 drive Promise RAID boxes have 512MB, upgradeable to a maximum of 2GB).

Click to enlarge
6 RAM slots supporting a max of 24GB of DDR3 RAM.
For expansion we required a minimum of 2 PCI-E x8 slots for Infiniband support and for additional SAS HBA cards should we need to expand to more disk drives than the system board supports. We found a lot of system boards that had one slot, or had a few slots, but none that had just the right number while supporting all of our other features, then we came across the X8ST3-F. The X8ST3-F has 3 X8 PCI-E slots (one is a physical X16 slot), 1 X4 PCI-E slot (in a physical X8 slot) and 2 32bit PCI slots. We believe that this should more than adequately handle anything that we need to put into this system.

Click to enlarge
PCI Express and PCI slots for Expansion
We also need Dual Gigabit Ethernet. This allows us to maintain one connection to the outside world, plus one connection into our current iSCSI infrastructure. We have a significant iSCSI setup deployed and we will need to migrate that data from the old iSCSI

Click to enlarge
Lastly, we required remote KVM capabilities, which is one of the most important factors in our system. Supermicro provides excellent remote KVM capabilities via their IPMI interface. We are able to monitor system temps, power cycle the system, re-direct CD/
Our search (and phone calls to SuperMicro) lead us to the SuperMicro X8ST3-F. It supported all of our requirements, plus it had an integrated SAS controller. The integrated SAS controller was is an

Click to enlarge
Jumper to switch from RAID to I/T mode and 8 SAS ports.
After speaking with SuperMicro, and searching different forums, we found that several people had successfully used the X8ST3-F with OpenSolaris. With that out of the way we ordered the Motherboard.
Processor Selection – Intel Xeon 5504

Click to enlarge
With the motherboard selection made, we could now decide what processor we wanted to put in this system. We initially looked at the Xeon 5520 series processors, as that is what we use in our BladeCenter blades. The 5520 is a great processor for our Virtualization environment due to the extra cache and hyperthreading, allowing it to work on 8 threads at once. Since our initial design plans dictated that we would be using Mirrored Striped VDEV’s with no parity, we decided that we would not need that much processing power. In keeping with that idea, we selected a Xeon 5504. This is a 2.0ghz processor with 4 cores. Our thoughts are that it should be able to easily handle the load that will be presented to it. If it does not, the system can be upgraded to a Xeon E5520 or even a W5580 processor, with a 3.2ghz operating speed if the system warrants it. Testing will be done to make sure that the system can handle the IO load that we will need to handle.
Cooling Selection – Intel BXSTS100A Active Heatsink with fan

Click to enlarge
We selected an Intel stock heatsink for this build. It has a TDP of 80Watts, which is exactly what our processor is rated at.
Memory Selection – Kingston Value Ram 1333mhz ECC Unbuffered DDR3

Click to enlarge
We decided to initially populate the ZFS server with 12GB of
To get the affordable part of the storage under hand, we had to investigate all of our options when it came to hard drives and available SATA technology. We finally settled on a combination of Western Digital RE3 1TB drives, Intel X25-M G2 SSD’s, Intel X25-E SSD’s, and Intel X25-V SSD’s.

Click to enlarge
The whole point of our storage build was to give us a reasonably large amount of storage that still performed well. For the bulk of our storage we planned on using enterprise grade SATA

Click to enlarge
To accelerate the performance of our ZFS system, we employed the L2ARC caching feature of ZFS. The L2ARC stores recently accessed data, and allows it to be read from a faster medium than traditional rotating

Click to enlarge
To accelerate write performance we selected 32GB Intel X25-E drives. These will be the ZIL (log) drives for the ZFS system. Since ZFS is a copy-on-write file system, every transaction is tracked in a log. By moving the log to SSD storage, you can greatly improve write performance on a ZFS system. Since this log is accessed on every write operation, we wanted to use an SSD drive that had a significantly longer life span. The Intel X25-E drives are an SLC style flash drive, which means they can be written to many more times than an MLC drive and not fail. Since most of the operations on our system are write operations, we had to have something that had a lot of longevity. We also decided to mirror the drives, so that if one of them failed, the log did not revert to a hard-drive based log system which would severely impact performance. Intel quotes these drives as 3300 IOPS write and 35,000 IOPS read. You may notice that this is lower than the X25-M G2 drives. We are so concerned about the longevity of the drives that we decided a tradeoff on IOPS was worth the additional longevity.

Click to enlarge
For our boot drives, we selected 40GB Intel X-25V SSD drives. We could have went with traditional rotating media for the boot drives, but with the cost of these drives going down every day we decided to splurge and use SSD’s for the boot volume. We don’t need the ultimate performance that is available with the higher end SSD’s for the boot volume, but we still realize that having your boot volumes on SSD’s will help reduce boot times in case of a reboot and they have the added bonus of being a low power draw device.
Click to enlarge
Important things to remember!
While building up our ZFS SAN server, we encountered a few issues in not having the correct parts on hand. Once we identified these parts, we ordered them as needed. The following is a breakdown of what not to forget.
Heatsink Retention bracket
We got all of our parts in, and we couldn’t even turn the system on. We neglected to take in to account that the heatsink that we ordered gets screwed down. The bracket needed for this is not included with the heatsink, the processor, the motherboard, or the case. It was a special order item from SuperMicro that we had to source before we could even turn the system on.
The Supermicro part number for the heatsink retention bracket is BKT-0023L – a Google search will lead you to a bunch of places that sell it.

SuperMicro Heatsink Retention Bracket
Reverse Breakout Cable
The motherboard that we chose actually has a built in

Click to enlarge
Reverse Breakout Cable – Discreet Connections.

Click to enlarge
Reverse Breakout Cable – SFF8087 End
Fixed
Dual 2.5″ HDD Tray part number – MCP-220-84603-0N
Single 3.5″ HDD Tray part number – MCP-220-84601-0N
LA or RA power and data cables – We also neglected to notice that when using the 3.5″ HDD trays that there isn’t really any room for cable clearance. Depending on how you mount your 3.5″ HDD’s, you will need Left Angle or Right Angle power and data connections. If you mount the power and data connectors at the top of the case, you’ll need Left Angle cabling. If you can mount the drives so the power and data are at the bottom of the case, you could use Right Angle cabling.

Click to enlarge
Left Angle Connectors

Click to enlarge
Left Angle Connectors connected to a HDD
Power extension cables – We did not run in to this, but we were advised by SuperMicro that it’s something they see often. Someone will build a system that requires 2x 8 pin power connectors, and the secondary 8 pin connector is too short. If you decide to build this project up using a board that requires dual 8 pin power connectors, be sure to order an extension cable, or you may be out of luck.
Fan power splitter – When we ordered our motherboard, we didn’t even think twice about the number of fan headers on the board. We’ve actually got more than enough on the board, but the location of those gave us another item to add to our list. The rear fans in the case do not have leads long enough to reach multiple fan headers. On the system board that we selected there was only one fan header near the dual fans at the rear of the chassis. We ordered up a 3 pin fan power splitter, and it works great.
Test Blade Configuration
Our bladecenters are full of high performance blades that we use to run a virtualized hosting environment at this time. Since the blades that are in those systems are in production, we couldn’t very well use them to test the performance of our ZFS system. As such, we had to build another blade. We wanted the blade to be similar in spec to the blades that we were using, but we also wanted to utilize some of the new technology that has come out since we put many of our blades into production. Our current environment is mixed with blades that are running Dual Xeon 5420 processors w/ 32GB
Following that tradition we decided to use the SuperMicro SBI-7126T-S6 as our base blade. We populated it with Dual Xeon 5620 processors (Intel Xeon Nehalem/Westmere based 32nm quad core), 48GB Registered

Click to enlarge
Front panel of the SBI-7126T-S6 Blade Module

Click to enlarge
Intel X25-V

Click to enlarge
Dual Xeon 5620 processors, 48GB Registered
Our tests will be run using Windows 2008R2 and Iometer. We will be testing iSCSI connections over gigabit Ethernet, as this is what most budget
Price OpenSolaris box
The OpenSolaris box, as tested was quite inexpensive for the amount of hardware added to it. Overall costs for the OpenSolaris system was $6765. The breakdown is here :
|
Part |
Number |
Cost |
Total |
|
1 |
$1,199.00 |
$1,199.00 |
|
|
2 |
$166.00 |
$332.00 |
|
|
1 |
$379.00 |
$379.00 |
|
|
1 |
$253.00 |
$253.00 |
|
|
2 |
$378.00 |
$756.00 |
|
|
2 |
$414.00 |
$828.00 |
|
|
2 |
$109.00 |
$218.00 |
|
|
20 |
$140.00 |
$2,800.00 |
|
|
Total |
|
|
$6,765.00 |
Price of Nexenta
While OpenSolaris is completely free, Nexenta is a bit different, as there are software costs to consider when building a Nexenta system. There are three versions of Nexenta you can choose from if you decide to use Nexenta instead of OpenSolaris. The first is Nexenta Core Platform, which allows unlimited storage, but does not have the GUI interface. The second is Nexenta Community Edition, which supports up to 12TB of storage and a subset of the features. The third is their high end solution, Nexenta Enterprise. Nexenta Enterprise is a paid-for product that has a broad feature set and support, accompanied by a price tag.
The hardware costs for the Nexenta system are identical to the OpenSolaris system. We opted for the trial Enterprise license for testing (unlimited storage, 45 days) as we have 18TB of billable storage. Nexenta charges you based on the number of TB that you have in your storage array. As configured the Nexenta license for our system would cost $3090, bringing the total cost of a Nexenta Enterprise licensed system to $9855.
Price of Promise box
The Promise M610i is relatively simple to calculate costs on. You have the cost of the chassis, and the cost of the drives. The breakdown of those costs is below.
|
Part |
Number |
Cost |
Total |
|
1 |
4170 |
$4,170.00 |
|
|
16 |
$140.00 |
$2,240.00 |
|
|
Total |
|
|
$6,410.00 |
How we tested with Iometer
Our tests are all run from Iometer, using a custom configuration of Iometer. The .icf configuration file can be found here. We ran the following tests, starting at a queue depth of 9, ending with a queue depth of 33, stepping by a queue depth of 3. This allows us to run tests starting below a queue depth of 1 per drive, to a queue depth of around 2 per drive (depending on the storage system being tested).
The tests were run in this order, and each test was run for 3 minutes at each queue depth.
4k Sequential Read
4k Random Write
4k Random 67% write 33% read
4k Random Read
8k Random Read
8k Sequential Read
8k Random Write
8k Random 67% Write 33% Read
16k Random 67% Write 33% Read
16k Random Write
16k Sequential Read
16k Random Read
32k Random 67% Write 33% Read
32k Random Read
32k Sequential Read
32k Random Write
These tests were not organized in any particular order to bias the tests. We created the profile, and then ran it against each system. Before testing, a 300GB iSCSI target was created on each system. Once the iSCSI target was created, it was formatted with NTFS defaults, and then Iometer was started. Iometer created a 25GB working set, and then started running the tests.
While running these tests, bear in mind that the longer the tests run, the better the performance should be on the OpenSolaris and Nexenta systems. This is due to the L2ARC caching. The L2ARC populates slowly to reduce the amount of wear on MLC
Benchmarks
After running our tests on the ZFS system (both under Nexenta and OpenSolaris) and the Promise M610i, we came up with the following results. All graphs have IOPS on the Y-Axis, and Disk Que Lenght on the X-Axis.
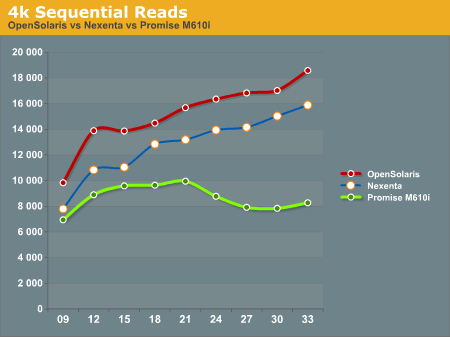
In the 4k Sequential Read test, we see that the OpenSolaris and Nexenta systems both outperform the Promise M610i by a significant margin when the disk queue is increased. This is a direct effect of the L2ARC cache. Interestingly enough the OpenSolaris and Nexenta systems seem to trend identically, but the Nexenta system is measurably slower than the OpenSolaris system. We are unsure as to why this is, as they are running on the same hardware and the build of Nexenta we ran was based on the same build of OpenSolaris that we tested. We contacted Nexenta about this performance gap, but they did not have any explanation. One hypothesis that we had is that the Nexenta software is using more memory for things like the web GUI, and maybe there is less ARC available to the Nexenta solution than to a regular OpenSolaris solution.
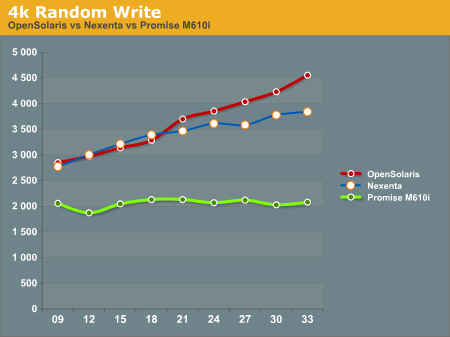
In the 4k Random Write test, again the OpenSolaris and Nexenta systems come out ahead of the Promise M610i. The Promise box seems to be nearly flat, an indicator that it is reaching the limits of its hardware quite quickly. The OpenSolaris and Nexenta systems write faster as the disk queue increases. This seems to indicate a better re-ordering of data to make the writes more sequential the disks.
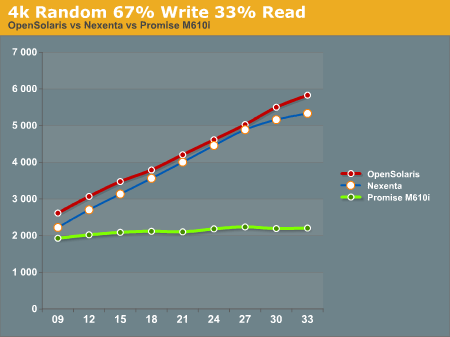
The 4k 67% Write 33% Read test again gives the edge to the OpenSolaris and Nexenta systems, while the Promise M610i is nearly flat lined. This is most likely a result of both re-ordering writes and the very effective L2ARC caching.
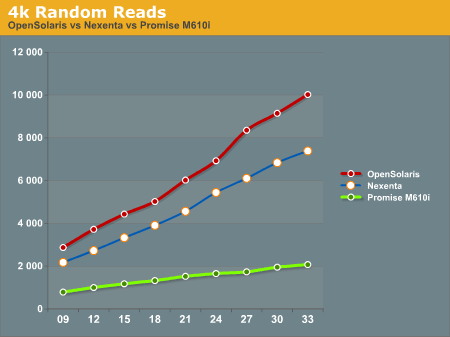
4k Random Reads again come out in favor of the OpenSolaris and Nexenta systems. While the Promise M610i does increase its performance as the disk queue increases, it's nowhere near the levels of performance that the OpenSolaris and Nexenta systems can deliver with their L2ARC caching.
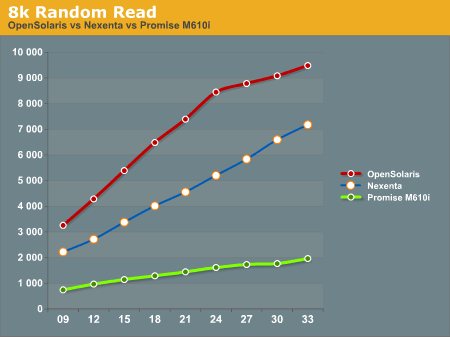
8k Random Reads indicate a similar trend to the 4k Random Reads with the OpenSolaris and Nexenta systems outperforming the Promise M610i. Again, we see the OpenSolaris and Nexenta systems trending very similarly but with the OpenSolaris system significantly outperforming the Nexenta system.
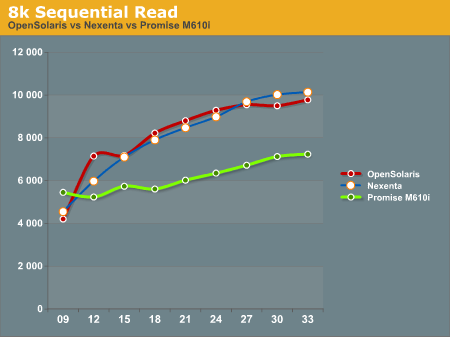
8k Sequential reads have the OpenSolaris and Nexenta systems trailing at the first data point, and then running away from the Promise M610i at higher disk queues. It's interesting to note that the Nexenta system outperforms the OpenSolaris system at several of the data points in this test.
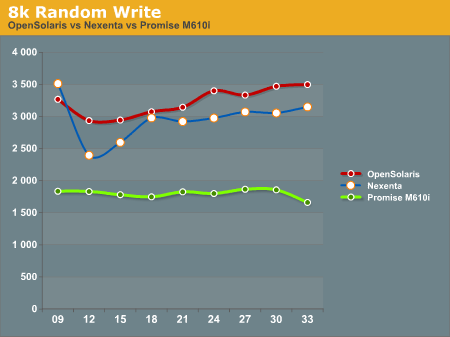
8k Random writes play out like most of the other tests we've seen with the OpenSolaris and Nexenta systems taking top honors, with the Promise M610i trailing. Again, OpenSolaris beats out Nexenta on the same hardware.
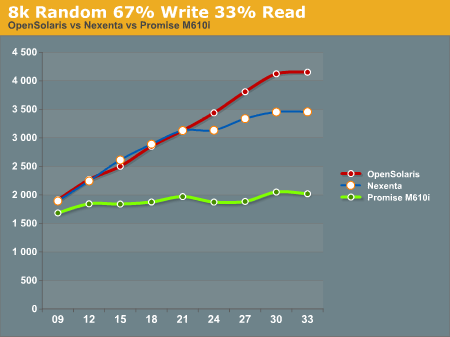
8k Random 67% Write 33% Read again favors the OpenSolaris and Nexenta systems, with the Promise M610i trailing. While the OpenSolaris and Nexenta systems start off nearly identical for the first 5 data points, at a disk queue of 24 or higher the OpenSolaris system steals the show.
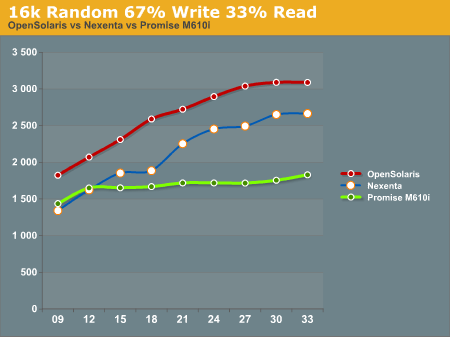
16k Random 67% Write 33% read gives us a show that we're familiar with. OpenSolaris and Nexenta both soundly beat the Promise M610i at higher disk ques. Again we see the pattern of the OpenSolaris and Nexenta systems trending nearly identically, but the OpenSolaris system outperforming the Nexenta system at all data points.
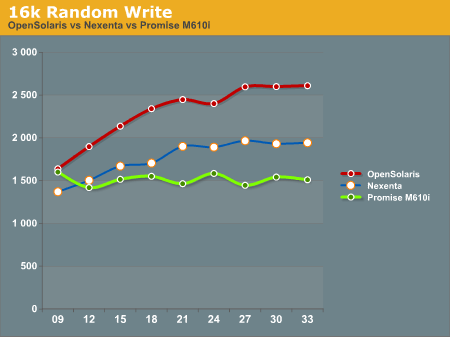
16k Random write shows the Promise M610i starting off faster than the Nexenta system and nearly on par with the OpenSolaris system, but quickly flattening out. The Nexenta box again trends higher, but cannot keep up with the OpenSolaris system.
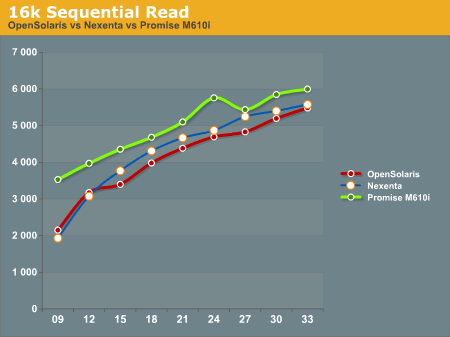
The 16k Sequential read test is the first test that we see where the Promise M610i system outperforms OpenSolaris and Nexenta at all data points. The OpenSolaris system and the Nexenta system both trend upwards at the same rate, but cannot catch the M610i system.
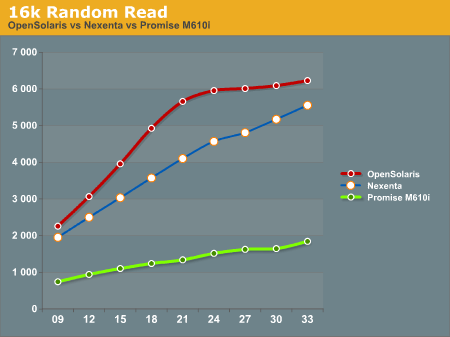
The 16k Random Read test goes back to the same pattern that we've been seeing, with the OpenSolaris and Nexenta systems running away from the Promise M610i. Again we see the OpenSolaris system take top honors with the Nexenta system trending similarly, but never reaching the performance metrics seen on the OpenSolaris system.
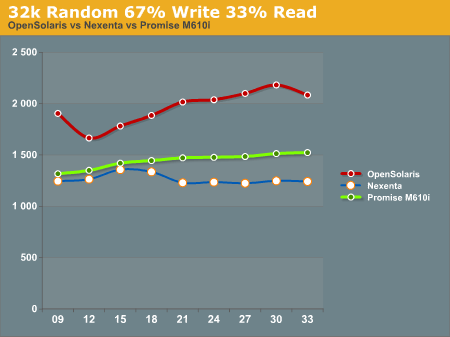
32k Random 67% Write 33% read has the OpenSolaris system on top, with the Promise M610i in second place, and the Nexenta system trailing everything. We're not really sure what to make of this, as we expected the Nexenta system to follow similar patterns to what we had seen before.
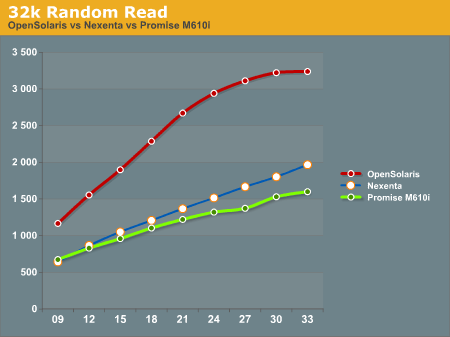
32k Random Read has the OpenSolaris system running away from everything else. On this test the Nexenta system and the Promise M610i are very similar, with the Nexentaq system edging out the Promise M610i at the highest queue depths.
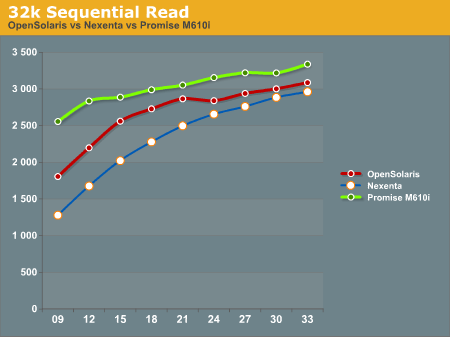
32k Sequential Reads proved to be a strong point for the Promise M610i. It outperformed the OpenSolaris and Nexenta systems at all data points. Clearly there is something in the Promise M610i that helps it excel at 32k Sequential Reads.
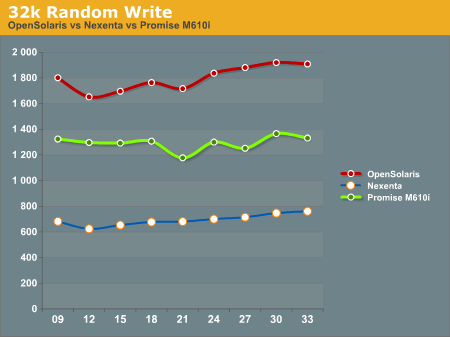
32k random writes have the OpenSolaris system on top again, with the Promise M610i in second place, and the Nexenta system trailing far behind. All of the graphs trend similarly, with little dips and rises, but not ever moving much from the initial reading.
After all the tests were done, we had to sit down and take a hard look at the results and try to formulate some ideas about how to interpret this data. We will discuss this in our conclusion.
Demise of OpenSolaris?
You may have heard some troubling news about the fate of OpenSolaris recently. Based on some of the rumors floating around, you might think OpenSolaris is going away, never to be seen again. Admittedly, OpenSolaris has never been an open source project in quite the same way that Linux has. Sun launched the OpenSolaris project to help promote its commercialware Solaris product. Sun seemed to do a decent job of managing the OpenSolaris project, but Sun is no longer in charge. The project is now at the mercy of Oracle.
The OpenSolaris Governing Body (OGB) has struggled to get Oracle to continue to work with the OpenSolaris project. Oracle’s silent treatment has gotten so bad that the OGB threatened to dissolve itself and return control of the OpenSolaris community to Oracle on August 23 if Oracle did not appoint a liaison to the community by August 16, 2010. It is pretty safe to assume that Oracle, clearly a for profit company, would benefit more from allowing the OGB to dissolve. That would give Oracle the option to do what ever they wanted with OpenSolaris, including simply killing the project.
At this point, two possible outcomes seem the most likely. One possible outcome is that Oracle will continue to offer OpenSolaris but will tighten its grip over the direction of the project. Perhaps Oracle would use the opportunity to make some technical changes within OpenSolaris to limit the scope of the product so as not to compete directly with commercialware offerings.
The other outcome is that a fork will occur in the project, possibly resulting in several different projects. Regardless of Oracle, OpenSolaris appears to be living on through the Illumos project located at http://www.illumos.org/ - There hasn't been much activity yet in the Illumos project, but it's only been announced for a few weeks. We will be closely monitoring this to see if it will be a suitable replacement for OpenSolaris. Illumos was initiated by Nexenta employees in collaboration with OpenSolaris community members and volunteers. While Nexenta does sponsor some of the work, Illumos is independent of Nexenta. Illumos aims to be a common base for multiple community distributions. It is run by the community on a system of meritocracy. Distributions like Nexenta, Belenix and Schillix will move to using Illumos as the base for their distributions, and other distributions have shown interest as well.
Personally, I don’t think the situation is as dire as some people suggest. Oracle now owns MySQL as well as OpenSolaris, yet millions of us continue to use these products. If Oracle does over exert control to the point that it chokes off these open source products, then we can always resort to forking the code and getting behind the new open source projects.
As far as using OpenSolaris, I don’t see Oracle’s ownership as a reason to give up on using OpenSolaris. If you are considering deploying a ZFS based
A final note on the possible demise of OpenSolaris is that OpenSolaris may now be officially dead. According to an internal Oracle announcement that was posted into some mailing lists, Oracle is killing off OpenSolaris and replacing it with Solaris 11 Express. Additionally, Oracle claims they will continue to release open source snapshots of Solaris after each major release instead of releasing nightly builds, but that does not sound like a typical open source project.
Shortcomings of OpenSolaris
OpenSolaris, while a great platform for a storage system does lack some features that we consider necessary for a dedicated storage array. One thing that never worked quite right was the LED's on the front of the chassis. It was very difficult to know which drive was which after they were installed. The drive names shown in the operating system do not correspond with the physical drives in any consistent way. This would make troubleshooting a drive failure very difficult, as you'd not know which drive was which drive. Ideally, a red LED should come on beside the failed drive so it will be easy for a tech to quickly swap the correct drive.
Another shortcoming was the lack of a built-in Web GUI. The Promise system comes with a web interface to create, destroy, and manage logical volumes. OpenSolaris has no such interface. It's all done via command line controls. Granted once you've become familiar with those command line tools, it's not terrible to set up and destroy volumes, but it'd be nice to have a GUI that allowed you the same control while making it easier for first-timers to manage the system.
The last and possibly most important shortcoming of OpenSolaris is the lack of an automatic notification system if there is a failure. No email goes out to page a system administrator if a drive dies, so when the system has a drive failure you may never know that a drive has failed. This presents a very clear danger for usage in the datacenter environment, because most of us just expect to be notified if there is a problem. The Promise solution does this very well and all you have to do is put in an SMTP server address and an email address to send the notification messages to.
All of these can be solved with custom scripting within OpenSolaris. An even easier solution is to simply use Nexenta. They already have the LED's and notifications figured out. It's a very simple to get Nexenta configured to notify you of any failures.
Another solution is to buy third-party LED/FMA code. We have tried the SANtools package and it seems to work pretty well for enabling LED's, but there is still some work to be done before it is as easy as Nexenta. If you use the code from SANtools to control the LED’s, you will still need to write some scripts to polls FMA and send notifications and launch the SANtools script to control the LED’s. You can find the SANtools software here:
While this is very possible to script all of this with FMA, I'm not interested in re-inventing the wheel. Until someone comes up with this code and contributes it into the OpenSolaris project, it is simply not practical for most people to use OpenSolaris directly. OpenSolaris should have code built into the core for notifying the system administrator and for shining the LED on the correct drive.
After the exhaustive building and testing process, we've found several areas where we could have improved the original build.
Improved CPU
When we initially decided which hardware components to use, we thought we would not need very much CPU. While we are not doing any type of parity with our storage, we neglected to account for the checksumming that ZFS does to maintain data integrity. This checksumming consumes significantly more processor time than we had originally anticipated. Many tests were using 70% or more of the CPU. We believe that at this high of CPU utilization that there is significant IO contention. Our next ZFS based storage system will probably be based on a dual socket platform and higher clocked (possibly more cores also) CPU's, giving additional headroom for the checksumming and allowing you to use more advanced features that consume CPU resources like Deduplication and Compression. It is not a noticeable problem when testing with gigabit Ethernet speeds. We have been doing some additional benchmarking using 20Gbps InfiniBand, and we have been able to max out the CPU in the ZFS server well before we approached the limits of 20Gbps networking.
More Memory
Going into this project, we did not really know how much main memory we would need in the ZFS
SAS drives
We thought ZFS's advanced software could overcome some of the inherent problems with slow spindle speeds, and it did up to a certain point. ZFS on OpenSolaris was able to outperform the Promise M610i at basically the same price point. However, we feel we left a lot more performance on the table. Next time we deploy a ZFS server, we plan to use 15k
In the ZFS project, we used
If you decide to use MLC
If you plan to attach a lot of
Strictly from a price vs. performance standpoint, the OpenSolaris ZFS server is a huge success. The test of 4k random performance with 66% writes and 33% reads is one that really excites us. We have historically graphed a lot of performance data about our cloud environment using MRTG, and this test most accurately describes our real world access patterns in our web hosting environment. At a load of 33, OpenSolaris logged nearly triple the performance compared to the Promise M610i. If we can deploy the OpenSolaris box into production and actually see this level of performance, we will be thrilled.
We will obviously consider using Nexenta because Nexenta has the LED’s and notifications working. Nexenta did not deliver as much performance as OpenSolaris did. In the 4k random 66% write 33% read test, Nexenta Enterprise managed to deliver about 90% of the performance of unmodified OpenSolaris. In some 32k tests, Nexenta delivered even less performance. It is tough to justify the cost of the Nexenta Enterprise license when it performs slower than free OpenSolaris. If you need a support path, then Nexenta Enterprise may be worth it.
When we started this project, our goal was to build a ZFS based storage solution that could match the price of a Promise M610i






