Original Link: https://www.anandtech.com/show/3863/amd-discloses-bobcat-bulldozer-architectures-at-hot-chips-2010
AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTThree years ago AMD told me about two architectures that would be the future of the company: Bobcat and Bulldozer. Here are some excerpts from an article I wrote after that meeting with AMD.
“Due out in the first half of 2009, AMD's Bulldozer core is the true revolutionary successor to the K8 architecture. While Barcelona and Shanghai are both evolutionary improvements to the current core, Bulldozer is the first ground-up redesign since the K7.”
“If Bulldozer is the architecture that will compete with Nehalem, Bobcat is what will compete with Silverthorne. Bobcat is yet another ground up design from AMD, also due out in the 2009 timeframe, but it will address a more power constrained portion of the market. Systems that require a 1 - 10W TDP will use Bobcat, while Bulldozer is limited to the 10 - 100W range (obviously with some overlap between the two). “
Well, 2009 didn’t happen. Nor will 2010. Bobcat is the closest with production in Q4 2010 and system availability in Q1 2011. Bulldozer is strictly 2011. The long road to a major redesign isn’t unusual and although we’re no where near the point of measuring performance of these parts, we’re getting closer.
AMD has Bobcat and Bulldozer silicon back in its labs and things apparently look good. Later today at Hot Chips 22, AMD will present further details on both of its next generation architectures. What we have here now is a sneak peak of what AMD is going to unveil at the conference later today.
The Three Chip Roadmap
While AMD is committed to a two architecture roadmap going forward (Bobcat and Bulldozer) we’ll see three fairly different chips addressing the various market segments in 2011.
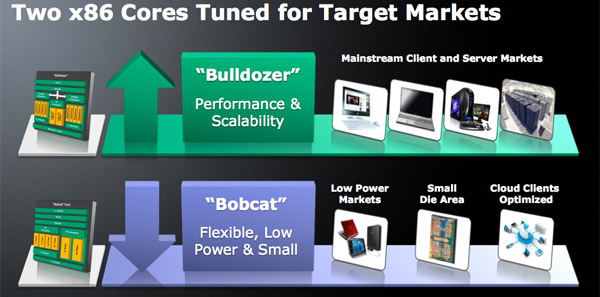
Bobcat will do low end/low power (think netbooks and nettops), Llano will do mainstream notebooks (e.g. MacBook, HP Envy equivalent) and Bulldozer will be used for high end desktops and servers. Llano actually uses a Phenom II derived core so it’s technically a third architecture but I’d expect its market to eventually be split between Bobcat and Bulldozer based designs.
I’m going to start with Bobcat first as it’s the closest to production.
It’s an Out of Order Atom
Ever since the Pentium Pro (P6), we have been blessed with out of order microprocessor architectures - these being designs that can execute instructions out of program order to improve performance. Out of order architectures let you schedule independent instructions ahead of others that are either waiting for data from main memory or waiting for specific execution resources to free up. The resulting performance boost comes at the expense of power and die size. All of the tracking logic to make sure that instructions executed out of order still retire in order eats up die area as well as more power.
When Intel designed the Atom processor it went back to an in-order design as a way of reducing power. Intel has committed to using in-order architectures in Atom for 4 - 5 years post introduction (that would end sometime in the 2012 - 2013 time frame).
For smartphones, Intel’s commitment to in-order makes sense. Average power consumption under load needs to remain at less than 1W and you simply can’t hit that with an out-of-order Atom at 45nm.
For netbooks and notebooks however, the tradeoff makes less sense. Jarred has often argued that a CULV notebook is a far better performer than a netbook at very similar price/battery life metrics. No one is pleased with Atom’s performance in a netbook, but there’s clearly demand for the form factor and price point. Where there’s an architectural opportunity like this, AMD is usually there to act.
Over the past decade AMD has refrained from copying an Intel design, instead AMD usually looks to leapfrog Intel by implementing forward looking technologies earlier than its competitor. We saw this with the 64-bit K8 and the cache hierarchy of the original Phenom and Phenom II processors. Both featured design decisions that Intel would later adopt, they were simply ahead of their time.
With Atom stuck in an in-order world for the near future, AMD’s opportunity to innovate is clear.
The Architecture
Admittedly I was caught off guard by Bobcat’s architecture: it’s a dual-issue design, the first AMD has introduced since the K6 and also the same issue width Intel chose for Atom. Where AMD and Intel diverge however is in the execution side: Bobcat is a fully out of order architecture.
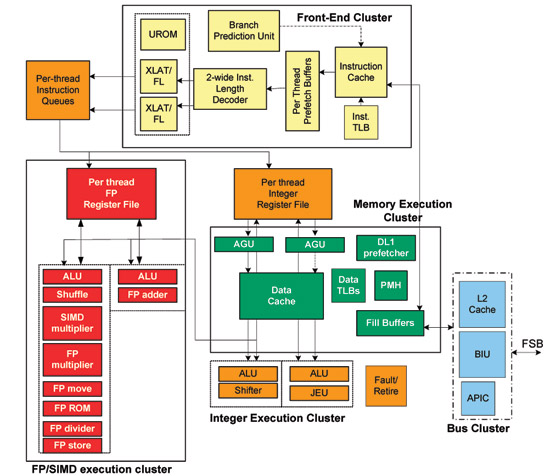
The move to out of order should provide a healthy single threaded performance boost over Atom, assuming AMD can ramp clocks up. Bobcat has a 15 stage integer pipeline, very close to Atom's 16 stage pipe. The two pipeline diagrams are below:
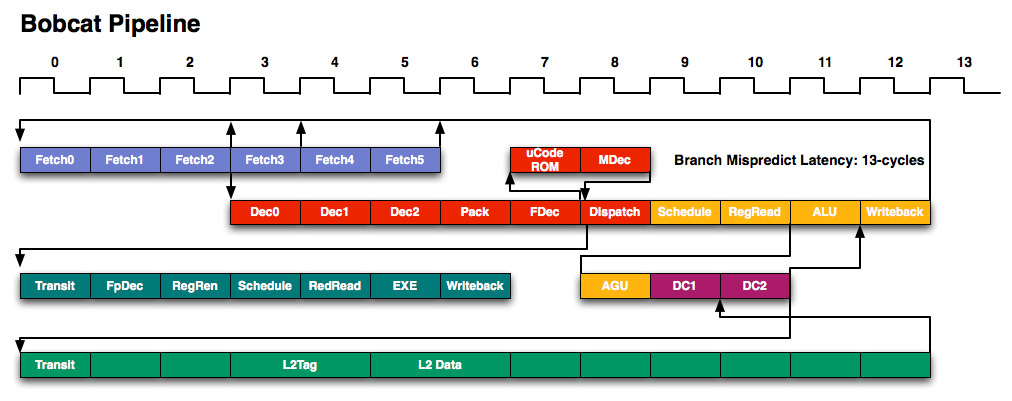
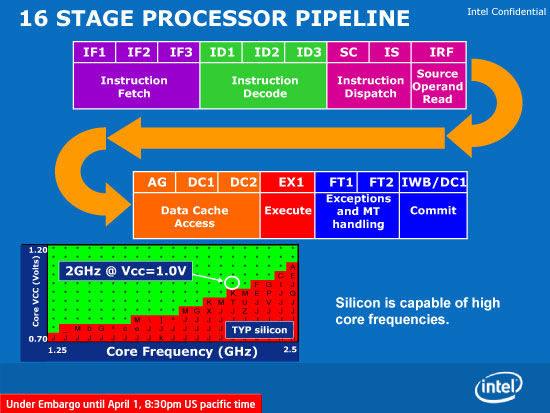
Intel's Atom pipeline
You’ll note that there are technically six fetch stages, although only the first three are included in the 15 stage number I mentioned above. AMD mentioned that the remaining three stages are used for branch prediction, but in a manner it is unwilling to disclose at this time due to competitive concerns.
Bobcat has two independent, dual ported integer scheduler. One feeds two ALUs (one of which can perform integer multiplies) while the other feeds two AGUs (one for loads and one for stores).
The FPU has a single dual ported scheduler that feeds two independent FPUs. Similar to the Atom processor, only one of the ports can handle floating point multiplies. The FP mul and add units can perform two single precision (32-bit) multiplies/adds per cycle. Like the integer side, the FPU uses a physical register file to reduce power.
Bobcat supports SSE1-3, with future versions adding more instructions as necessary.
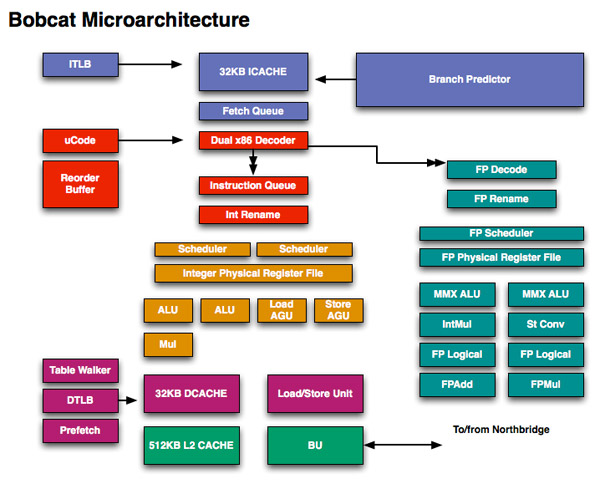
Bobcat supports out of order loads and stores similar to Intel’s Core architecture as well.
The Bobcat core has a 3-cycle 64KB L1 (32KB instruction + 32KB data cache) that’s 8-way set associative. The L2 cache is a 17-cycle, 512KB 16-way set associative cache. I originally measured Atom’s L1 and L2 at 3 and 18 cycles respectively (I’ve heard numbers as low as 15 for Atom’s L2) so AMD is definitely in the right ballpark here.
Intel's Atom Microarchitecture
Unlike the original Atom, Bobcat will never ship as a standalone microprocessor. Instead it will be integrated with other cores and a GPU and sold as a single SoC. The first incarnation of Bobcat will be a processor due out in early 2011 for netbooks and thin and light notebooks called Ontario. Ontario will integrate two Bobcat cores with an AMD GPU manufactured on TSMC’s 40nm process (Bobcat will be the first x86 core made at TSMC). This will be the first Fusion product to hit the market.
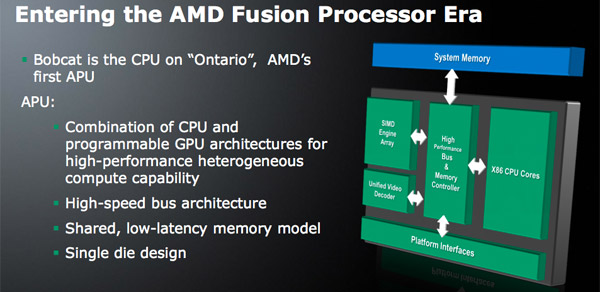
Note that there's an on-die memory controller but it's actually housed in between the CPU and GPU in order to equally serve both masters.
Physical Register Files to Save Power
The original x86 instruction set has a very limited number of registers (8). In order to maintain backwards compatibility with legacy x86 code, the ISA and associated registers were preserved. To scale performance with wide out of order architectures however, we needed larger register files. The solution was to enable register renaming, where the hardware could have additional registers not defined in the x86 spec and rename them on the fly.
Register renaming is done in all modern day x86 processors. There are two approaches to register renaming. The current Phenom II/Opteron approach actually carries the data from renamed registers along with the instruction as it moves through queues before it gets executed. You effectively create very wide instructions, which is horribly power inefficient (moving data on a chip takes a lot of power) although it gets the job done from a performance standpoint.
The alternative is something that we don’t see used in any current generation microprocessors. Instead of carrying data along with the instructions, you simply carry pointers to the data with those instructions. There’s added management complexity but you don’t have to worry about moving lots of data around, and therefore avoid much of the power penalty.

Bobcat (as well as Bulldozer) uses physical register files to save power. Intel actually did this in the Pentium 4 but hasn’t used PRFs since. AMD argues that with power as a major driver of design, PRFs will be necessary in future architectures.
Bobcat’s Performance Expectations
With nearly the same pipeline depth as Atom (15 vs. 16 stages), nearly the same cache latencies, the same instruction issue width and presumably competitive clock speeds (~1.5GHz), Bobcat based microprocessors should inherently outperform Atom thanks to its out of order architecture.
Atom does hold an advantage in that each core is multithreaded, so heavily threaded apps may have an advantage on Intel’s architecture. That being said, by far the biggest issue we have with Atom based netbooks is their single threaded performance that contributes to an overall slow user experience. Bobcat should hopefully address that.
On the threaded side, AMD does have another solution. As I mentioned before, Bobcat won’t be used in a microprocessor by itself - Ontario will feature two of them. AMD said that future designs are expected to integrate 2 or 4 Bobcat cores, while there are no plans to produce a single core version it’s always possible.
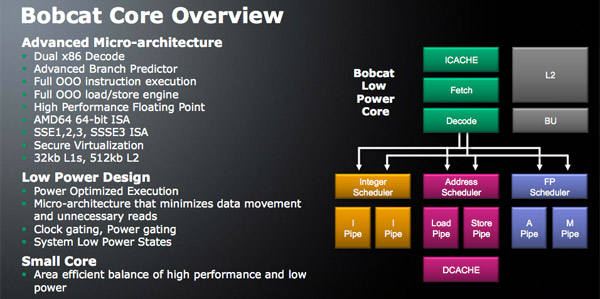
I believe a dual core Ontario based on Bobcat, if clocked high enough, could deliver a good enough balance of single and multithreaded performance to really challenge Atom in the netbook space. The assumption is that graphics performance will be much better than Atom with Ontario integrating an AMD GPU.
AMD’s official line is that Ontario will be able to deliver 90% of the performance of a mainstream notebook in less than half the die area. AMD isn’t just looking to compete with Atom, but go after even the CULV market with Ontario. Only time will tell if the latter is over zealous.
Power Concerns
AMD calls Bobcat sub-1W capable, which seems to imply that short of a smartphone Bobcat could go anywhere Atom could go. Technically, if AMD wanted to, even getting one into a smartphone wouldn’t be impossible - it would just require a healthy investment in chipsets.

It remains to be seen how good TSMC’s 40nm process will be compared to Atom’s Intel-manufactured 45nm transistors in terms of power consumption. Presumably the out of order aspect of the design will guarantee higher power consumption than Atom, but for the netbook/CULV notebook market the added performance may be worth the added power consumption.
Bulldozer
AMD already gave us a good amount of detail on Bulldozer earlier this year. We’ll start with a quick refresher.
With Nehalem, Intel moved to a more modular design process that would allow it the ability to quickly configure different versions of the chip to hit various markets. With Bulldozer, AMD is doing the same.
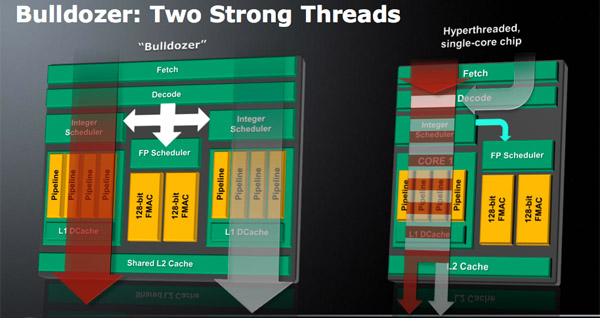
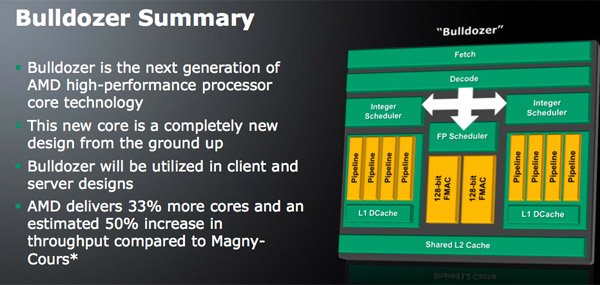
The basic building block is the Bulldozer module. AMD calls this a dual-core module because it has two independent integer cores and a single shared floating point core that can service instructions from two independent threads. The two thread machine is larger than a single core but smaller than two cores with straight duplication of resources.
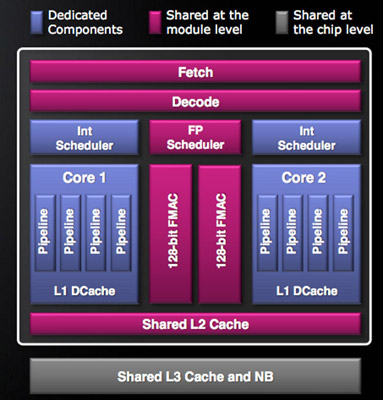
All else being the same, it should give you more threaded performance than a single SMT (Hyper Threaded) core but less than two dedicated cores. The savings are obviously on the die side. AMD tells us that the second integer core increases the Bulldozer module die by around 12%, despite significantly increasing performance in threaded integer applications.
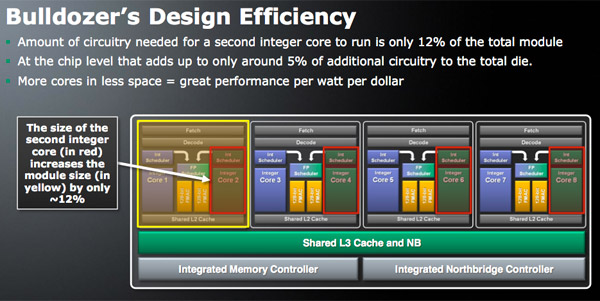
Processors may implement anywhere from one to four Bulldozer modules and will be referred to as 2 to 8 core CPUs. Each core appears to the OS as a logical processor similar to what you get with Hyper Threading. A CPU with four Bulldozer modules would appear as an 8-threaded processor under Task Manager in Windows.
AMD argues that the Bulldozer module is ideal provisioning of hardware. With SMT (Hyper Threading) you force too much into a single core, while with traditional multicore you often waste hardware as any idle resources are duplicated across the chip.
Bulldozer CPUs will be AMD’s first 32nm processors manufactured at GlobalFoundries.
The new details today are about everything inside of the Bulldozer module.
A Real Redesign
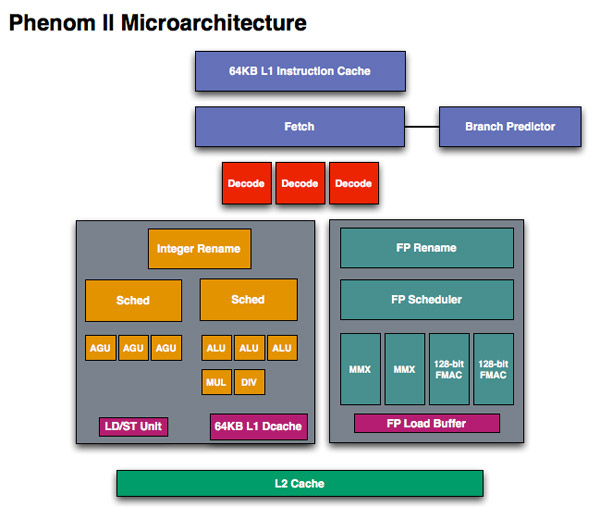
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
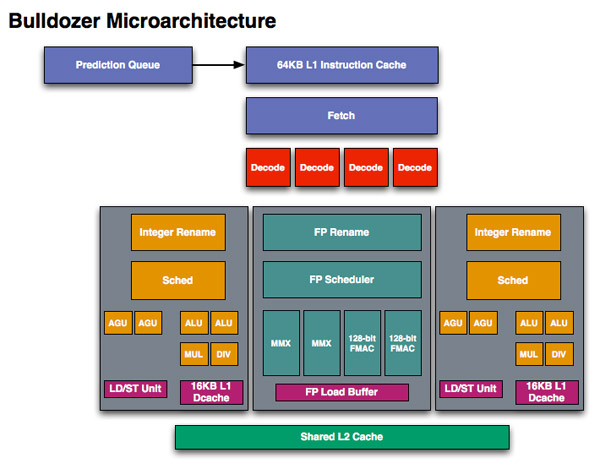
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.
Branch Prediction and a Deeper Pipeline
Bulldozer will use a deeper pipeline with less logic per stage compared to current Phenom II/Opteron processors. AMD argues that this will ensure clock speed won’t be a problem with the design and we should expect to see Bulldozer based products at similar if not higher clock speeds than what we have today with Phenom II.
With a deeper pipe, branch prediction becomes more important and Bulldozer has a significant change in the way branch prediction works.
In Phenom II, the branch prediction and instruction fetch logic are run in lockstep - when one stalls, the other also stalls. Branches are predicted as they are encountered. If the fetch logic grabs an x86 branch instruction, the prediction logic works in parallel to predict the likely target of that branch. However if the branch is incorrectly predicted, subsequent branches aren’t predicted until the current mispredict is correctly resolved. As a result, the fetch logic and prefetchers can’t work and potential performance is lost.
In Bulldozer the branch prediction and fetch logic are decoupled. The predictor now produces a queue of future fetch addresses. Even if there’s a mispredict the branch predictor can continue to fill its prediction queue with targets. The fetch logic can then check this queue of addresses against what’s in the instruction cache to avoid future misses in L1.
Prefetchers
With Phenom AMD implemented comparable prefetching logic to what Intel did with Core. In Bulldozer, AMD is ramping up the aggressiveness of those prefetchers. There are independent prefetchers at both the L1 and L2 levels that support larger numbers of strides and large stride sizes (both compared to what exists in current AMD architectures). There’s also a non-strided data prefetcher that looks at correlated cache misses and uses that data to prefetch into the caches.
AMD unfortunately didn’t go into more detail on its prefetchers other than to promise that they are much more aggressive than what we have today. Aggressive prefetching usually means there’s a good amount of memory bandwidth available so I’m wondering if we’ll see Bulldozer adopt a 3 - 4 channel DDR3 memory controller in high end configurations similar to what we have today with Gulftown.
Power Gating & Real Turbo Mode
Each Bulldozer module in a processor can be clocked and power gated independently. This has two implications. You can now power off cores (in sets of two) that aren’t in use and save tons of idle power. You can also use the power savings to drive up the frequency of other cores in a Bulldozer CPU. With Bulldozer, AMD should have something functionally equivalent to Intel’s Turbo Boost modes. Since clock speed and power gating is controlled at the module level and not the core level there will still be some differences between the two but this should be much better than AMD’s current Core Turbo technology.
There’s of course extensive clock gating around the chip, but obviously the big change is power gating which AMD hasn’t had up to this point (Bobcat is also power gated).
Performance and Availability
While Bobcat is going to be in production in Q4 of this year, with system availability in Q1 of 2011 - Bulldozer is still a 2011 project and AMD isn’t giving any guidance as to when in 2011.
Parts are already back and in AMD’s labs but we have no indication of performance or rollout schedule. Given Bobcat’s schedule, I’d say that the first Bulldozer CPUs will be out no earlier than Q2 2011 and AMD’s unwillingness to specify what half of the year would imply that it’ll be a late Q2/early Q3 launch.
The first Bulldozer parts will be server focused, with high end desktop CPUs following but still in 2011.
Final Words
The Bulldozer and Bobcat architectures are the update AMD has needed badly over the past couple of years. AMD has done reasonably well in the mainstream market despite not having them, but I’m eager to see both in action.
I’m pretty much sold on Bobcat. The architecture looks like an out of order Atom, which is exactly what we need to drive the performance of netbooks up. I’m curious to see exactly how well Ontario and other Bobcat based designs perform vs. Atom and CULV notebooks, but it looks like AMD will at least have the architecture to compete in the small form factor portable market in a major way.
Note that we still don’t have full disclosure on the AMD GPU that’s going to be paired with Bobcat. We’ve said that ION really improves on the netbook experience but doesn’t make up for the anemic Atom CPU. With AMD’s Ontario we may get the best of both worlds: a faster CPU and competent GPU.
We’re also not that far away from Bobcat availability. The real trick here will be making sure that AMD’s partners are lined up to deliver some killer designs based on the part. After the recent FTC settlement there shouldn’t be any pressure on any OEMs to avoid shipping competitive Bobcat based netbooks/notebooks next year. Let’s hope AMD can deliver as we definitely need competition in that market.
Bulldozer I'm excited about, but more cautious - partly because we don't know what Sandy Bridge will bring, and partly because we're further away from Bulldozer than Bobcat. In many ways the architecture looks to be on-par with what Intel has done with Nehalem/Westmere. We finally have a wider front end, branch fusion, power gating/true turbo and more aggressive prefetching. Whether or not AMD can surpass Sandy Bridge’s performance really boils down to how many Bulldozer modules you get at what price. If 2 module (4-core) Bulldozer CPUs go up against dual-core Sandy Bridge things could get very interesting.






