Original Link: https://www.anandtech.com/show/2978/amd-s-12-core-magny-cours-opteron-6174-vs-intel-s-6-core-xeon
AMD's 12-core "Magny-Cours" Opteron 6174 vs. Intel's 6-core Xeon
by Johan De Gelas on March 29, 2010 12:00 AM EST- Posted in
- IT Computing
If the Westmere Xeon EP were a car engine, it would've been made by Porsche. With "only" six cores, each core in the new Xeon offers almost twice the performance of the competition. A 32nm CPU that only occupies 248 mm2 the Westmere Xeon EP embodies pure refinement and intelligent performance, both Porsche traits. It's just made in Portland, not Zuffenhausen.
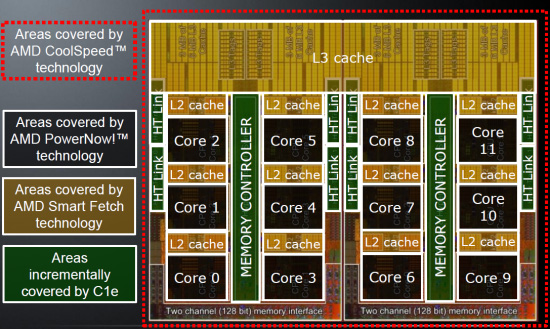
AMD's offering today is very different. Magny-cours is the CPU version of the American muscle car. It's a brutally large 12-core CPU: two dies, each measuring 346mm2 connected by a massive 24 link Hyper Transport pipe. AMD's Magny-cours Opteron has almost two billion transistors and 19.6MB of cache on-die.
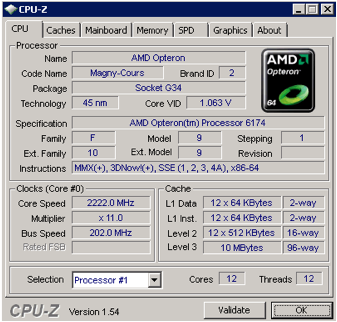
12 cores, 692 mm2 die, 19.6MB of cache on-die
It's not all raw horsepower though. At 2.2GHz this 12-core monster is supposed to be content with only 80 precious watts, and 115W at most. HT assist also makes an appearance to keep CPU-CPU accesses to a necessary minimum, a problem that could get out of hand with 12 cores otherwise. AMD originally added HT assist with its first 6-core Opterons. So Magny-Cours is a like hybrid V12 Dodge Viper with traction control. Will this cocktail of raw core muscle and energy savings be enough to beat the competitor from Portland?
For once we could not resist the temptations of car analogies. As interesting as we found the Xeon Westmere EP, something was missing: a challenger, a competitor to make things more exiting. In the last review, we just knew that the Xeon X5670 would crush the competition. This time is going to be close. AMD still won’t have a chance if your application does not scale well with extra cores. In that case you are better off with the higher clocked and better per-core performance of the Intel CPUs. But it is unclear if Intel will prevail in truly multi-threaded software now that a grim and determined AMD is willing to offer two CPUs for the price of one just to win the race.
Magny-Cours
You probably heard by now that the new Opteron 6100 is in fact two 6-core Istanbul CPUs bolted together. That is not too far from the truth if you look at the micro architecture: little has changed inside the core. It is the “uncore” that has changed significantly: the memory controller now supports DDR-1333, and a lot of time has been invested in keeping cache coherency traffic under control. The 1944-pin (!) organic Land Grid Array (LGA) Multi Chip Module (MCM) is pictured below.
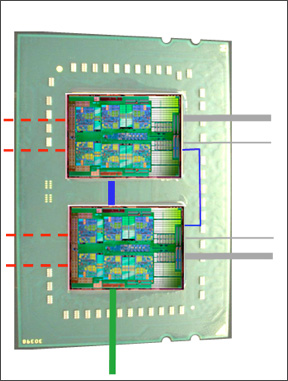
The red lines are memory channels, blue lines internal HT cache coherent connects. The gray lines are external cache HT connections, while the green line is a simple non coherent I/O HT connect.
Each CPU has two DDR-3 channels (red lines). That is exactly the strongest point of this MCM: four fast memory channels that can use DDR-1333, good for a theoretical bandwidth peak of 42.7 GB/s. But that kind of bandwidth is not attainable, not even in theory bBecause the next link in the chain, the Northbridge, only runs at 1.8GHz. We have two 64-bit Northbridges both working at 1.8 GHz, limiting the maximum bandwidth to 28.8 GB/s. That is price AMD’s engineers had to pay to keep the maximum power consumption of a 45nm 2.2 GHz below 115W (TDP).
Adding more cores makes the amount of snoop traffic explode, which can easily result in very poor scaling. It can get worse to the point where extra cores reduce performance. The key technology is HT assist, which we described here. By eliminating unnecessary probes, local memory latency is significantly reduced and bandwidth is saved. It cost Magny-cours 1MB of L3-cache per core (2MB total), but the amount of bandwidth increases by 100% (!) and the latency is reduced to 60% of it would be without HT-assist.
Even with HT-assist, a lot of probe activity is going on. As HT-assist allows the cores to perform directed snoops, it is good to reach each core quickly. Ideally each Magny-cours MCM would have six HT3 ports. One for I/O with a chipset, 2 per CPU node to communicate with the nodes that are off-package and 2 to communicate very quickly between the CPU nodes inside the package. But at 1944 pins Magny-Cours probably already blew the pin budget, so AMD's engineers limited themselves to 4 HT links.
One of the links is reserved for non coherent communication with a possible x16 GPU. One x16 coherent port communicates with the CPU that is the closest, but not on the same package. One port is split in two x8 ports. The first x8 port communicates with the CPU that is the farthest away: for example between CPU node 0 and CPU node 3. The remaing x16 and x8 port are used to make communication on the MCM as fast as possible. Those 24 links connect the two CPU nodes on the package.
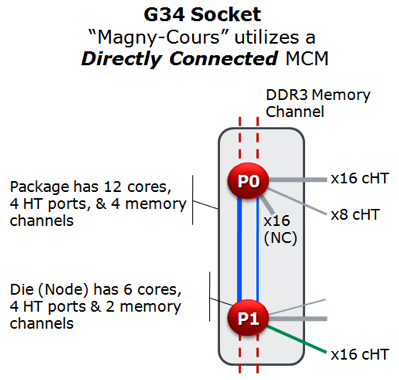
The end result is that a 2P configuration allows fast communication between the four CPU nodes. Each CPU node is connected directly (one hop) with the other one. Bandwidth between CPU node 0 and 2 is twice than that of P0 to P3 however.
Whilte it looks like two Istanbuls bolted together, what we're looking at is the hard work of AMD's engineers. They invested quite a bit of time to make sure that this 12 piston muscle car does not spin it’s wheels all the time. Of course if the underground is wet (badly threaded software), that will still be the case. And that'll be the end of our car analogies...we promise :)
The SKUs
The Opteron 6176 looks a bit ridiculous as it delivers only 4% more performance at 30% higher power and 20% higher prices. The real reason behind this CPU is to battle another tanker, the Nehalem EX that Intel is going to launch tomorrow. The TDP and clockspeeds of that huge chip are very similar. If your application scales poorly and you don't care about power consumption, the X5677 is your champion; it is probably the fastest chip on the market for applications with low thread counts.
| AMD vs. Intel 2-socket SKU Comparison | |||||||||
|
Intel Xeon Model
|
Cores | TDP | Speed (GHz) | Price | AMD Opteron Model | Cores | TDP | GHz | Price |
| W5680 | 6 | 130W | 3.30 GHz | $1663 | 6176 SE | 12 | 105/137W | 2.3 GHz | $1386 |
| X5670 | 6 | 95W | 2.93 GHz | $1440 | |||||
| X5660 | 6 | 95W | 2.80 GHz | $1219 | 6174 | 12 | 80/115W | 2.2 GHz | $1165 |
| X5650 | 6 | 95W | 2.66 GHz | $996 | 6172 | 12 | 80/115W | 2.1 GHz | $989 |
| X5677 | 4 | 130W | 3.46 GHz | $1663 | 2439SE | 6 | 105/137W | 2.8 GHz | ? |
| X5667 | 4 | 95W | 3.06 GHz | $1440 | |||||
| 6168 | 12 | 80/115W | 1.9 GHz | $744 | |||||
| E5640 | 4 | 80W | 2.66 GHz | $744 | 6136 | 8 | 80/115W | 2.4 GHz | $744 |
| E5630 | 4 | 80W | 2.53 GHz | $551 | 6134 | 8 | 80/115W | 2.3 GHz | $523 |
| E5620 | 4 | 80W | 2.40 GHz | $387 | 6128 | 8 | 80/115W | 2.0 GHz | $266 |
| L5640 | 6 | 60W | 2.26 GHz | $996 | 6164 HE | 12 | 65/? W | 1.7 GHz | $744 |
| 6128 HE | 8 | 65/? W | 2.0 GHz | $523 | |||||
| 6124 HE | 8 | 65/? W | 1.8 GHz | $455 | |||||
| L5630 | 4 | 40W | 2.13 GHz | $551 | |||||
| L5620 | 4 | 40W | 1.86 GHz | $440 | |||||
The most interesting parts that AMD offers are the dodeca-core 6174 (2.2GHz), the octal-core 6136 (2.4GHz) and the octal-core low power 6128 (2.0GHz). The 6174 targets those with well scaling multi-threaded applications such as huge databases and virtualized loads. The 8-core 6136 might even be better as most schedulers find it easier to distribute threads and process over a power of 2 cores. Lots of applications also don't scale beyond 16 cores and the chip comes with a 200MHz clockspeed bonus and a very reasonable price.
The 6128 HE is also an interesting one. The 6128 HE might be a good way to reconcile low response times with low power, but we'll have to find that out later.
Benchmark Methods and Systems
First of all, I like to offer my thanks to my colleague Tijl Deneut who helped me out with the complex virtualization benchmarks.
None of our benchmarks required more than 20 GB of RAM. Database files were placed on a two drive RAID-0 Intel X25-E SLC 32GB SSD, with log files on one Intel X25-E SLC 32GB. Adding more drives improved performance by only 1%, so we are confident that storage is not our bottleneck.
Xeon Server 1: ASUS RS700-E6/RS4 barebone
Dual Intel Xeon "Gainestown" X5570 2.93GHz, Dual Intel Xeon “Westmere” X5670 2.93 GHz
ASUS Z8PS-D12-1U
6x4GB (24GB) ECC Registered DDR3-1333
NIC: Intel 82574L PCI-EGBit LAN
PSU: Delta Electronics DPS-770 AB 770W
Opteron Server 1 (Dual CPU): AMD Magny-Cours Reference system (desktop case)
Dual AMD Opteron 6174 2.2 GHz
AMD Dinar motherboard with AMD SR5690 Chipset & SB750 Southbridge
8x 4 GB (32 GB) ECC Registered DDR3-1333
NIC: Broadcom Corporation NetXtreme II BCM5709 Gigabit
PSU: 1200W PSU
Opteron Server 2 (Dual CPU): Supermicro A+ Server 1021M-UR+V
Dual Opteron 2435 "Istanbul" 2.6GHz
Dual Opteron 2389 2.9GHz
Supermicro H8DMU+
32GB (8x4GB) DDR2-800
PSU: 650W Cold Watt HE Power Solutions CWA2-0650-10-SM01-1
vApus/Oracle Calling Circle Client Configuration
First client (Tile one)
Intel Core 2 Quad Q9550 2.83 GHz
Foxconn P35AX-S
GB (2x2GB) Kingston DDR2-667
NIC: Intel PRO/1000
Second client (Tile two)
Single Xeon X3470 2.93GHz
S3420GPLC
Intel 3420 chipset
8GB (4 x 2GB) 1066MHz DDR3
Understanding the Performance Numbers
As Intel and AMD are adding more and more cores to their CPUs, we encounter two main challenges to keep these CPUs scaling. Cache coherency messages can add a lot of latency and absorb a lot of bandwidth, and at the same time all those cores require more and more bandwidth. So the memory subsystem plays an important role. We still use our older stream binary. This binary was compiled by Alf Birger Rustad using v2.4 of Pathscale's C-compiler. It is a multi-threaded, 64-bit Linux Stream binary. The following compiler switches were used:
-Ofast -lm -static -mp
We ran the stream benchmark on SUSE SLES 11. The stream benchmark produces 4 numbers: copy, scale, add, triad. Triad is the most relevant in our opinion, it is a mix of the other three.
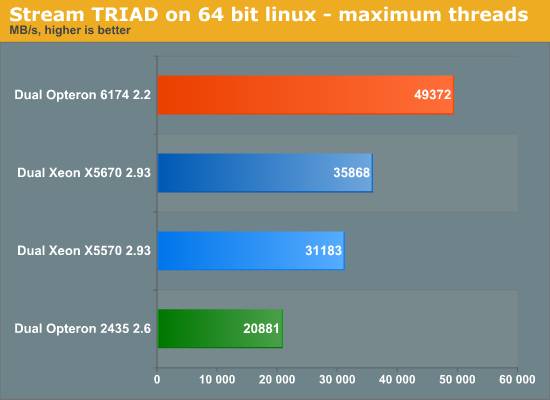
The new DDR3 memory controller gives the Opteron 6100 series wings. Compared to the Opteron 2435 which uses DDR-2 800, bandwidth has increased by 130%. Each core gets more bandwidth, which should help a lot of HPC applications. It is a pity of course that the 1.8 GHz Northbridge is limiting the memory subsystem. It would be interesting to see 8-core versions with higher clocked northbridges for the HPC market.
Also notice that the new Xeon 5600 handles DDR3-1333 a lot more efficiently. We measured 15% higher bandwidth from exactly the same DDR3-1333 DIMMs compared to the older Xeon 5570.
The other important metric for the memory subsystem is latency. Most of our older latency benchmarks (such as the latency test of CPUID) are no longer valid. So we turned to the latency test of Sisoft Sandra 2010.
| Speed (GHz) | L1 (Clocks) | L2 (Clocks) | L3 (Clocks) | Memory (ns) | |
| Intel Xeon X5670 | 2.93GHz | 4 | 10 | 56 | 87 |
| Intel Xeon X5570 | 2.80GHz | 4 | 9 | 47 | 81 |
| AMD Opteron 6174 | 2.20GHz | 3 | 16 | 57 | 98 |
| AMD Opteron 2435 | 2.60GHz | 3 | 16 | 56 | 113 |
With Nehalem, Intel increased the latency of the L1 cache from 3 cycles to 4. The tradeoff was meant to allow for future scaling as the basic architecture evolves. The Xeons have the smallest (256 KB) but the fastest L2-cache. The L3-cache of the Xeon 5570 is the fastest, but the latency advantage has disappeared on the Xeon X5670 as the cache size increased from 8 to 12 MB.
Interesting is also the fact that the move from DDR2-800 to DDR3-1333 has also decreased the latency to the memory system by about 15%. There's nothing but good news for the 12-core Opteron here: more bandwith and lower latency access per core.
Rendering: Cinebench 11.5
The old Cinebench 10 benchmark was limited to 16 threads. Luckily, the new Cinebench 11.5 does not have that limitation. Cinebench only represents a very small part of the 3D Animation market, but the advantage is that this a benchmark that you can perform at home too.
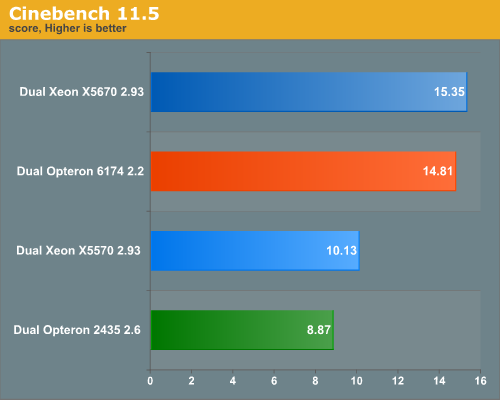
Although the Opteron 6174 manages to stay close to the newest Xeon, the Xeon is the CPU to get. The reason is that the performance difference will grow as you are rendering smaller and less complex scenes. In those cases, the percentage of the serial code will increase. And Amdahl’s law is unrelenting: in that case the CPU with the highest single threaded performance will win. You also get the benefit of higher single threaded performance when you are modeling.
Rendering: Blender 2.5 Alpha 2
| Blender 2.5 Alpha 2 | |
| Operating System | Windows 2008 Enterprise R2 (64-bit) |
| Software | Blender 2.5 Alpha 2 |
| Benchmark software | Built-in render engine |
3dsmax 2010 crashed on almost all our servers. Granted, it is not meant to be run on a server but on a workstation. We’ll try some tests with Backburner later when the 2011 version is available. In the meantime, it is time for something less bloated and especially less expensive: Blender.
Blender has been getting a lot of positive attention and judging by its very fast growing community it is on its way to become one of the most popular 3D animation packages out there. The current stable version 2.49 can only render up to 8 threads. Blender 2.5 alpha 2 can go up to 64. To our surprise, the software was pretty stable, so we went ahead and started testing.
If you like, you can perform this benchmark very easily too. We used the “metallic robot”, a scene with rather complex lighting (reflections!) and raytracing. To make the benchmark more repetitive, we changed the following parameters:
- The resolution was set to 2560 x 1600
- Anti-alias was set to 16
- We disabled compositing in post processing
- Tiles were set to 8x8 (X=8, Y=8)
- Threads was set to auto (one thread per CPU is set).

Let us first check out the results on Windows 2008 R2:

At first the Opteron 6174 results were simply horrible: 44.6 seconds, slower than the dual Opteron six-core!
Ivan Paulos Tomé, the official maintainer of the Brazilian Blender 3D Wiki, gave us some interesting advice. The default number of tiles is apparently set of 5x5. This result in a short period of 100% CPU load on the Opteron 6174 and a long period where the CPU load drops below 30%. We first assumed that 8x6, two times as many tiles as the number of CPUs would be best. After some experimenting, we found that 8x8 is the best for all machines. The Xeons and six-core Opterons gained 10%, while the 12-core Opteron became 40% (!) faster. This underlines that the more cores you have, the harder they are to make good use of.
Blender can be run on several operating systems, so let us see what happens under 64 bit Linux (Suse SLES 11).
Rendering: Blender 2.5 Alpha 2 on SLES 11
| Blender 2.5 Alpha 2 | |
| Operating System | SUSE SLES 11, Linux Kernel 2.6.27.19-5-default SMP |
| Software | Blender 2.5 Alpha 2 |
| Benchmark software | Built-in render engine |
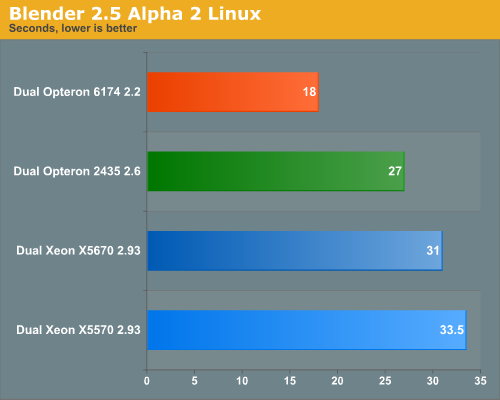
What happened here? Not only is Blender 50 to 70% faster on Linux, the tables have turned. As the software is still in Alpha 2 phase, it is good to take the results with a grain of salt, but still. For some reason, the Linux version is capable of keeping the cores fed much longer. On Windows, the first half of the benchmark is spent at 100% CPU load, and then it quickly goes down to 75, 50 and even 25% CPU load. In Linux, the CPU load, especially on the Opteron 6174 stays at 99-100% for much longer.
So is the Opteron 6174 the one to get? We are not sure. If these benchmarks are still accurate when we test with the final 2.5 version, there is a good chance that the octal-core 6136 2.4 GHz will be the Blender champion. It has a much lower price and slightly higher performance per core for less complex rendering work. We hope to follow up with new benchmarks. It is pretty amazing what Blender does with a massive number of cores. At the same time, we imagine Intel's engineers will quickly find out why the blender engine fails to make good use of the the dual Xeon X5670's 24 logical cores. This is far from over yet…
OLTP benchmark Oracle Charbench “Calling Circle”
| Oracle Charbench Calling Circle | |
| Operating System | Windows 2008 Enterprise Edition (64-bit) |
| Software | Oracle 10g Release 2 (10.2) for 64-bit Windows |
| Benchmark software | Swingbench/Charbench 2.2 |
| Database Size: | 9GB |
Calling Circle is an Oracle OLTP benchmark. We test with a database size of 9 GB. To reduce the pressure on our storage system, we increased the SGA size (Oracle buffer in RAM) to 10 GB and the PGA size was set at 1.6 GB. A calling circle tests consists of 83% selects, 7% inserts and 10% updates. The “calling circle” test is run for 10 minutes. A run is repeated 6 times and the results of the first run are discarded. The reason is that the disk queue length is sometimes close to 1, while the subsequent runs have a DQL (Disk Queue Length) of 0.2 or lower. In this case it was rather easy to run the CPUs at 99% load. Since DQLs were very similar, we could keep our results from the Nehalem article.

As we noted in our previous article, we work with a relatively small database. The result is that the benchmark doesn't scale well beyond 16 cores. The Opteron 6174 has a 10MB L3 cache for 12 cores, while the Opteron 2435 has 6MB L3 for 6 cores. The amount of cache might explain why the Intel Xeons scale a lot better in this benchmark. For this kind of OLTP workload is the Opteron 6174 not the right choice. To go back to the car analogy earlier: the muscle car is burning rubber while spinning its wheels, but is not making much progress.
SAP S&D 2-Tier
| SAP S&D 2-Tier | |
| Operating System | Windows 2008 Enterprise Edition |
| Software | SAP ERP 6.0 Enhancement package 4 |
| Benchmark software | Industry Standard benchmark version 2009 |
| Typical error margin | Very low |
The SAP SD (sales and distribution, 2-tier internet configuration) benchmark is an interesting benchmark as it is a real world client-server application. We decided to take a look at SAP's benchmark database. The results below all run on Windows 2003 Enterprise Edition and MS SQL Server 2005 database (both 64-bit). Every 2-tier Sales & Distribution benchmark was performed with SAP's latest ERP 6 enhancement package 4. These results are NOT comparable with any benchmark performed before 2009. The new 2009 version of the benchmark produces scores that are 25% lower. We analyzed the SAP Benchmark in-depth in one of our earlier articles. The profile of the benchmark has remained the same:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency!)
- Very sensitive to sync ("cache coherency") latency
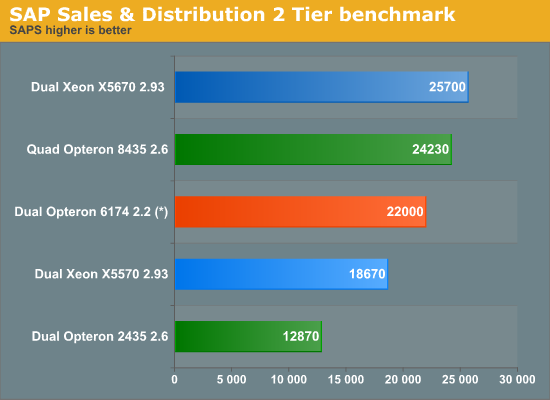
(*) Estimate
The last time we discussed the SAP S&D 2-tier benchmark, we had to estimate the Xeon X5670 results. Since then HP has benchmarked its latest G6 servers, giving us results for the X5670. The performance is nothing short of astonishing. The dual Xeon X5670 outperforms a quad Opteron 8345 at 2.6 GHz. The Magny-Cours Opteron can only compete based on its somewhat lower price. We doubt that the SAP buyers care about a few hundred dollars though. A quad Opteron 6174 might have a chance against the Nehalem EX performance wise, but the SAP market will probably prefer the extensive RAS list of the Xeon Nehalem EX. The ERP market is most likely going to be dominated by Intel based servers.
Decision Support benchmark: Nieuws.be
| Decision Support benchmark Nieuws.be | |
| Operating System | Windows 2008 Enterprise RTM (64 bit) |
| Software | SQL Server 2008 Enterprise x64 (64 bit) |
| Benchmark software | vApus + real-world "Nieuws.be" Database |
| Database Size | > 100GB |
| Typical error margin | 1-2% |
The Flemish/Dutch Nieuws.be site is one of the newest web 2.0 websites, launched in 2008. It gathers news from many different sources and allows the reader to completely personalize his view on all this news. Needles to say, the Nieuws.be site is sitting of top of a pretty large database, more than 100 GB and growing. This database consists of a few hundred separate tables, which have been carefully optimized by our lab (the Sizing Server Lab).
Almost all of the load on the database are selects (99%), about 5% of them are stored procedures. Network traffic averages 6.5MB/s and peaks at 14MB/s. So our Gigabit network connection has still a lot of headroom. Disk Queue Length (DQL) is at 2 in the first round of tests, but we only report the results of the subsequent rounds where the database is in a steady state. We measured a DQL close to 0 during these tests, so there is no tangible intervention of the harddisks.
We now use an new even heavier log. As the Nieuws.be application became more popular and more complex, the database has grown and queries have become more complex too. The results are no longer comparable to previous results. They are similar, but much lower.

Pretty amazing performance here. And while AMD gets a pat on the back, it is the hard working people of Microsoft SQL Server team we should send our kudos to. Our calculations show that SQL Server adds about 80% of performance when adding an extra 12 cores, which is simply awesome scaling. The result of this scaling is that for once, you can notice which CPUs have real cores vs. ones that have virtual (Hyper Threading) cores: the 12-core Opteron 6174 outperforms the best Xeon by 20%. The people with transaction databases should go for the Intel CPUs, while the data miners should consider the latest Opteron. The architectures that AMD and Intel have chosen are complete opposites, and the result is that the differences between the different software categories are very dramatic. Profile your software before you make a choice! It has never been so important.
Virtualization & Consolidation
VMmark - which we discussed in great detail here - tries to measure typical consolidation workloads: a combination of a light mail server, database, fileserver, and website with a somewhat heavier java application. One VM is just sitting idle, representative of workloads that have to be online but which perform very little work (for example, a domain controller). In short, VMmark goes for the scenario where you want to consolidate lots and lots of smaller apps on one physical server.
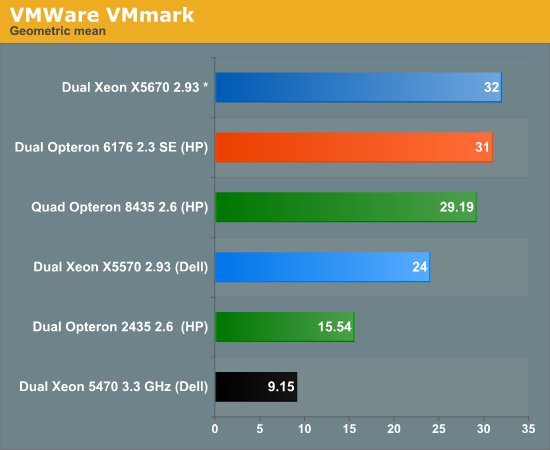
(*) preliminary benchmark data
Cisco has produced the first VMmark score for the Xeon X5600 series. The Cisco server with two X5680s at 3.3GHz achieved an impressive 35.83 score with 26 VMmark tiles. Twenty-six tiles, that is good for 156 VMs! Based on this number we can estimate where the Xeon X5670 will land. The 6174 numbers are based on AMD’s own preliminary data.
VMmark is a clear victory for the Intel CPUs. Contrary to the SAP market, AMD can play the pricing card here. As long as you do not require dynamic resource scheduling, the software licences costs are nowhere like those of typical ERP projects. So the pricing of the hardware matters more. Also, contrary to other applications, there is no bonus for single threaded performance. The usage models of Databases, 3D Animation software and other all include scenarios where a number of cores will be idling while the others are working very hard. In a virtualization scenario where you are running tons of VMs, single threaded performance does not matter. So while Intel is clearly winning here, servers based on the newest Opteron might still be on the shortlist of those looking for good performance per dollar.
vApus Mark I: Performance-Critical Applications Virtualized
Our vApus Mark I benchmark is not a VMmark replacement. It is meant to be complimentary: while VMmark uses runs 60 to 120 light loads, vApus Mark I runs 8 heavy VMs on 24 virtual CPUs (vCPUs). Our current vApus Stressclient is being improved to scale to much higher amount of vCPUs, but currently we limit the benchmark to 24 virtual CPUs.
A vApus Mark I tile consists of one OLTP, one OLAP and two heavy websites are combined in one tile. These are the kind of demanding applications that still got their own dedicated and natively running machine a year ago. vApus Mark I shows what will happen if you virtualize them. If you want to fully understand our benchmark methodology: vApus Mark I has been described in great detail here. We have changed only one thing compared to our original benchmarking: we used large pages as it is generally considered as a best practice (with RVI, EPT).
The current vApus Mark I uses two tiles. Per tile we have 4 VMs with 4 server applications:
- A SQL Server 2008 x64 database running on Windows 2008 64-bit, stress tested by our in-house developed vApus test (4 vCPUs).
- Two heavy duty MCS eFMS portals running PHP, IIS on Windows 2003 R2, stress tested by our in house developed vApus test (each 2 vCPUs).
- One OLTP database, based on Oracle 10G Calling Circle benchmark of Dominic Giles (4 vCPUs).
The beauty is that vApus (stress testing software developed by the Sizing Servers Lab) uses actions made by real people (as can be seen in logs) to stress test the VMs, not some benchmarking algorithm.
Update: We have noticed that the CPU load of Magny-cours is at 70-85%, while the Six-core "Istanbul" is running at 80-95%". As we have noted before, 24 cores is at the limit of our current benchmark until we launch vApus Mark 2. We have reason to believe that the opteron 6174 has quite a bit of headroom left. The results above are not wrong, but do not show the full potential of the 6174. We are checking the CPU load numbers of the six-core Xeon X5670 as we speak. Expect an update in the coming days.

The AMD Opteron 6174 performs well here, but disappoints a bit at the same time. vApus Mark I does not scale as well as VMmark. The reason is simple: as we used 4 virtual CPUs for both the OLTP as the OLAP virtual machine, scaling depends more on the individual applications. One VM with 4 virtual CPUs will not scale as well as 16 VMs sharing the same 4 virtual CPUs. Also, we use heavy database applications that typically like a decent amount of cache. The difference with the Xeon X5670 is small though. Servers based on both CPUs will make excellent virtualization platforms.
Next, the same test with Hyper-V, the hypervisor beneath Windows 2008 R2. We are testing with Hyper-V R2 6.1.7600.16385 (21st of July 2009).
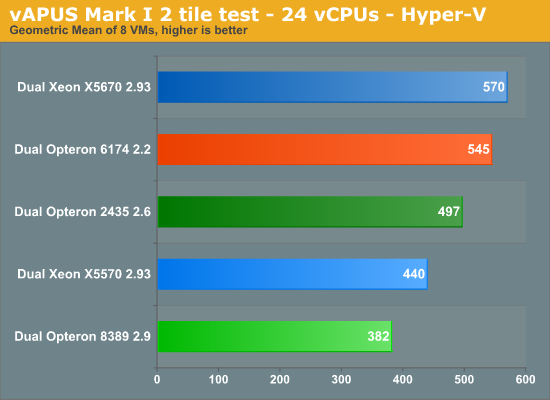
Based on the excellent results of the Dual Opteron 2435 we expected AMD to take the crown in this benchmark, but that did not happen. We only had one week to get all of the Opteron testing done (AMD didn't have any hardware until the last minute), so we could not analyze this in depth. For some reason, the Opteron 6174 does not scale very well in our vApus benchmark. Compared to a 2.2GHz six-core, we only see a 30% increase in performance, about the same as Intel gets out of adding 2 extra cores to their Xeon. Part of the reason might be our benchmark: at the moment we are limited to 24 CPUs. We’ll investigate this in more detail in the coming quarter when vApus v2 is available.
The difference with the Xeon X5670 is small though, and the slightly lower price of the Opteron makes up for the slightly lower performance.
HPC and Encryption Benchmarks
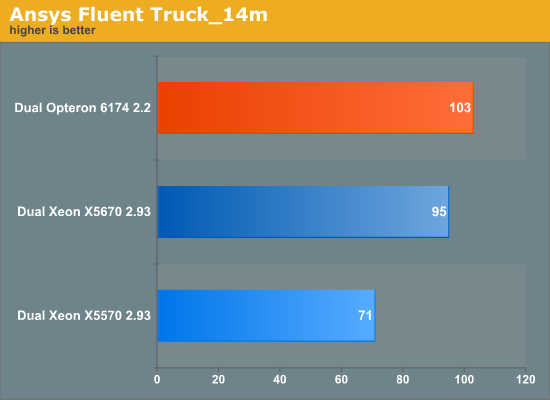
Just a few days prior to today's launch, we were able to get access to the benchmark numbers that Intel and AMD produced for LSDyna’s (Crash simulation) and Fluent (fluid dynamics) from Ansys. The first benchmark is the Ansys Fluent Truck_14 m benchmark.
The next one is LS Dyna “Neon refined revised”.
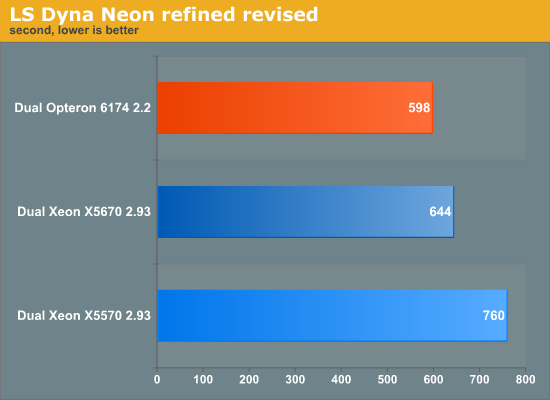
In both cases, the four memory channels and 12 core mix per CPU seem to pay off: AMD can beat Intel again in the HPC benchmarks, although the advantage is small.
Next we ran Sisoft Sandra 2010's encryption benchmark. Do remember that this is a completely synthetic benchmark. A 100% encryption performance advantage might translate in a very small performance advantage in a real world application. For example the code run on a website might only include a small part of encryption code.


Once the Xeon X5670's AES instructions can do their work, encryption is lightening fast. Here the new Xeon is 19 times faster than its older brother and 9 times faster than the best Opteron. Encryption can be broken up easily in smaller parts, it scales extremely well. The result is that the CPU with the most threads, the Xeon 5670 and Opteron 6174 easily outperform their older brothers in cryptographic hash functions.
Power Consumption
The Magny-Cours Opteron arrived one week ago, which is barely enough time to do virtualization benchmarking. So we have to postpone extensive power testing to a later date. The Opteron 6174 came in a desktop reference system which is in no way comparable to our Xeon X5670 1U server. We do have an six-core Opteron based system which is very similar to the Opteron 6174 reference system: the motherboard is also equipped with the new AMD SR5670 chipset and housed in the same desktop system. We can tell you that the idle power of the Opteron 6174 is a few watts lower than the six-core Opteron 2435. Both throttle back to 800 MHz, but the Opteron 6100 series gets a real C1E mode.
C1E mode can only be entered if all CPUs are idle. In a dual socket system, both CPUs enter C1E or they don’t. C1E mode is entered only after longer periods of inactivity. All cores flush their L1 and L2 caches to the L3-cache. Then all cores are clockgated (C1). Once that happens, the Hyper Transport links are put in a lower power state. This allows the chipset to enter a lower power state as well. Only when all these previous steps are done, both sockets are in C1E. DMA events will make the sockets go out of the C1E state. So C1E probably won't happen much on server systems. The C1E state is only entered if absolutely no processing is happening at all.
The C1E mode can reduce power quite a bit:
- Core clocks are turned off (Clockgate C1 state)
- L3, North Bridge, and memory controller all divide their clock frequencies (but are not clockgated!)
- All HyperTranspor links transition to LS2 low power state (LDT_STOP_L)
- DRAM DLL’s disabled
- Memory Transitions from precharge power down mode to self refresh mode (low power)
According to AMD, at full load a 1.7GHz 65W ACP Opteron 6164 HEwould consume about 4% more power than a 2.1 GHz 55W ACP 6-core Opteron 2425 HE. AMD measured 225W for the former, 215W for the latter. We measured 263W on the same system at full load with an Opteron 6174. That's 48W more, or about 24W per CPU. Assuming that the low power CPUs were running at their ACP (65W), we can conclude that the 2.2 GHz Magny-Cours needs about 89W. While the new twelve-core Opteron clearly needs a bit more power than the six-core Opteron, it's not a dramatic increase.
Final Words
The beancounters will probably point out that AMD’s strategy of bolting two CPU dies at 346 mm² together is quite costly. But this is the server CPU market, margins are quite a bit higher. Let AMD worry about the issue of margins. If AMD is willing to sell us - IT professionals - two CPUs for the price of one, we will not complain. It means that the fierce competitive market is favoring the customer. The bottom line is: is this twelve-core Opteron a good deal? For users waiting to use it in a workstation we have our doubts. You’ll benefit from the extra cores when rendering complex scenes, but in all other scenarios (quick simple rendering, modeling) the higher clocked and higher IPC Xeon X5600 series is simply the better choice.
Applications based on transactional databases (OLTP and ERP) are also better off with new Xeon. The SAP and our own Oracle Calling Circle benchmark all point in the same direction. Intel has a tangible performance advantage in both benchmarks.
Data mining applications clearly benefit from having “real” instead of “logical” cores. For datamining, we believe the 12-core Opteron is the clear winner. It offers 20% better performance at 20% lower prices, a good deal if you ask us. Intel’s relatively high prices for its six-core are challenged. The increased competition turns this into a buyers market again.
And then there is the most important segment: the virtualization market. We estimate that the new Opteron 6174 is about 20% slower than the Xeon 5670 in virtualized servers with very high VM counts. The difference is a lot smaller in the opposite scenario: a virtualized server with a few very heavy VMs. Here the choice is less clear. At this point, we believe both server CPUs consume about the same power, so that does not help either to make up our minds. It will depend on how the OEMs price their servers. The Opteron 6100 series offers up to 24 DIMMs slots, the Xeon is “limited” to 18. In many cases this allows the server buyer to achieve higher amount of memory with lower costs. You can go for 96 GB of memory with affordable 4 GB DIMMs, while the Intel server is limited to 72 GB there. That is a small bonus for the AMD server.
The HPC market seems to favor AMD once again. AMD holds only a small performance advantage, and this market is very cost sensitive. The lower price will probably convince the HPC people to go for the AMD based servers.
All in all, this is good news for the IT professional that is a hardware enthusiast. Profiling your application and matching it to the right server CPU pays off and that is exactly what set us apart from the average IT professional.






