Original Link: https://www.anandtech.com/show/1994
Speech Recognition - Ready for Prime Time?
by Jarred Walton on April 21, 2006 9:00 AM EST- Posted in
- Smartphones
- Mobile
The machine had been delivered two days ago on her first adult birthday. She had said, "But father, everybody - just everybody in the class who has the slightest pretensions to being anybody has one. Nobody but some old drips would use hand machines - "
The salesman had said, "There is no other model as compact on the one hand and as adaptable on the other. It will spell and punctuate correctly according to the sense of the sentence. Naturally, it is a great aid to education since it encourages the user to employ careful enunciation and breathing in order to make sure of the correct spelling, to say nothing of demanding a proper and elegant delivery for correct punctuation."
Even then her father had tried to get one geared for type-print as if she were some dried-up, old-maid teacher. But when it was delivered, it was the model she wanted - obtained perhaps with a little more wail and sniffle than quite went with the adulthood of fourteen - and copy was turned out in a charming and entirely feminine handwriting, with the most beautifully graceful capitals anyone ever saw. Even the phrase, "Oh, golly." somehow breathed glamour when the Transcriber was done with it.
--Isaac Asimov, Second Foundation - 1953
Here at AnandTech, we do our best to cover the topics that will interest our readers. Naturally, some topics are of interest to the vast majority of readers, while others target a more limited audience. At first glance, this article falls squarely into the latter category. However, when we think about where computers started and where they are now, and then try to extrapolate that and determine where they are heading in the future, certainly the User Interface has to play a substantial part in making computers easier to use for a larger portion of the population. Manual typewriters gave way to keyboards; text interfaces have been replaced by GUIs (mostly); and we have mice, trackballs, touchpads, and WYSIWYG interfaces now. Unfortunately, we have yet to realize the vision of Isaac Asimov and other science fiction writers where computers can fully understand human speech.
Why does any of this really matter? I mean, we're all basically familiar with using keyboards and mice, and they seem to get the job done quite well. Certainly, it's difficult to imagine speech recognition becoming the preferred way of playing games. (Well, some types of games at least.) There are also people in the world that can type at 140 wpm or faster -- wouldn't they just be slowed down by trying to dictate to the computer instead of typing?
There are plenty of seemingly valid concerns, and change can be a difficult process. However, think back for a moment to the first time you saw Microsoft's new wheel mouse. I don't know how other people reacted, but the first time I saw one I thought it was the stupidest gimmick I had ever seen. I already had a three button mouse, and while the right mouse button was generally useful, the middle mouse button served little purpose. How could turning the middle mouse button into a wheel possibly make anything better? Fast forward to today, and it irritates me to no end if I have to use a mouse that doesn't have a wheel. In fact, when I finally tried out the wheel mouse, it only took about two hours of use before I was hooked. I've heard the same thing from many other people. In other words, just because something is different or you haven't tried it before, don't assume that it's worthless.
There are a couple areas in which speech recognition can be extremely useful. For one, there are handicapped people that don't have proper control over their arms and hands, and yet they can speak easily. Given how pervasive computers have become in everyday life, flat out denying access to certain people would be unconscionable. Many businesses are finding speech recognition to be useful as well -- or more appropriately, voice recognition. (The difference between speech recognition and voice recognition is that voice recognition generally only has to deal with a limited vocabulary.) As an example, warehousing job functions only require a relatively small vocabulary of around 400 words, and allowing a computer system to interface with the user via earphones and a microphone can free up the hands to do other things. The end result is increased productivity and reduced errors, which in turn yields better profitability.
Health Considerations
There's at least one more area that can be a direct benefit to many people -- I know it has certainly helped me. Typing on the keyboard for many hours every day is not the healthiest of practices. Every keyboard on the market today carries a warning about repetitive stress injuries (RSI), and with good reason. Not everyone will have problems, and not everyone that has problems will experience the same degree of discomfort. However, the more you type and the older you get, the greater your chance for developing RSI from computer use. Needless to say, I am one of the many people in the world who has developed carpal tunnel syndrome (CTS).
There are many things you can do to try and combat carpal tunnel problems. Some people feel that ergonomic keyboards will help, and at least for me I found it to be more comfortable than a regular keyboard. Getting a better chair and desk will also help -- you want a chair and desk that will put your wrists and hands in the proper position in order to minimize strain; if you're not comfortable sitting at your computer, you should probably invest in a new chair at the very least.
Even with modifications to your work area, though, there's a reasonable chance that you'll still have difficulty. You might consider surgery, but while that will generally help 70% of people initially, many find that discomfort returns within a couple years. The simple fact of the matter is that the best way to avoid RSI complications is to eliminate the repetitive activity that's causing the problem in the first place. That means that if typing on a keyboard is giving you CTS, the best way to alleviate the problem is to not type on a keyboard anymore. That makes it rather difficult to write for a living, as you can imagine.
Of course, it usually isn't necessary to completely stop an activity that's causing RSI. The phrase itself gives you an idea of how to avoid difficulties: avoid excessive repetition. Typing 20 pages of text per day on a computer would probably cause anyone to get CTS eventually. Typing 10 pages per day would probably cause problems for many people, but not for everyone. Typing five pages per day would likely only affect a smaller portion of the population. Finally, if you could cut it down to one or two pages per day, most people would be fine. That brings us to the present topic: speech recognition. Used properly, speech recognition has the potential to eliminate a large portion of your typing, among other things.
Languages are complex enough that learning a new language is always difficult. We spend years growing up in an environment, learning the language, learning the rules, developing our own accent, etc. No two people in the world are going to sound exactly alike, and it goes without saying that everyone makes periodic mistakes in grammar and pronunciation while speaking. Programming a computer so that it understands everything that we say, corrects the mistakes, and gets all the grammar correct as well is a daunting task at best. Nevertheless, speech recognition has so many potential benefits that it is considered one of the Holy Grail landmarks that we want to achieve, and research on the problem has been in progress for decades.
As time has passed, computers have gotten faster and the algorithms have improved, and we're at the point now where real-time speech recognition is actually feasible. Mistakes will still be made, and dealing with different accents and/or speech impediments only serves to make things more difficult, but for many people it is now possible to get accuracy higher than 90%. That isn't that great, as it means one or two mistakes per sentence, but it's a good place to start. I've got a couple pieces of software that purport to achieve higher than 90% accuracy rates after training, so that will allow us to perform some real world benchmarks.
The Contenders
When I first made the decision to try out speech recognition, there was an overwhelming favorite on the market: Dragon NaturallySpeaking. I had never used it before, but I'd heard about it and it was generally well-regarded. I picked up a copy of Dragon NaturallySpeaking 8.0 Preferred and commenced using it. The training process took about 20 minutes, another 20 or 30 minutes was spent scanning my documents for words and speech patterns, and then it was basically done and I was ready to start dictating. I've now been using Dragon NaturallySpeaking for several months, and during that time training has further improved the accuracy.
Dragon isn't a particularly cheap piece of software, but when you consider the versatility it offers and the fact that I've already spent about $700 on a desk, chair, and keyboard in an attempt to make an "ergonomic workspace," spending another $100-$200 is hardly a concern. The $100 Standard version apparently has reduced functionality, though apparently the only major difference is that it lacks the ability to transcribe recordings. For home use and personal use, you can get a discount on the Preferred version and buy it for $160. Unless that extra $60 is really important to you, I would have to recommend going with the Preferred version -- you never know when the ability to transcrive a recording will come in handy.
Of course, Microsoft Office 2003 also has built-in speech recognition. I have never heard anyone really talk about it, and I have never tried it myself, but having become familiar with Dragon NaturallySpeaking I figured it was only fair that I give Microsoft's product a shot. After all, practically every business in the world has a copy of Microsoft Office 2003 installed, so perhaps there isn't even a need to go out and purchase separate speech recognition software. One other item that may be of interest is how much processing time each product needs. Voice recognition may or may not benefit from dual core processors, but there's only one way to find out.
I conducted testing on several systems, but eventually settled on using one for the actual benchmarking. If there's interest, I can go back and look at performance on other systems, but for the most part I have found that modern Pentium/Athlon systems are sufficient - with a few exceptions that I'll get to in a moment.
Test System:
AMD Athlon X2 3800+ @ 2.60 GHz (10x260HTT)
2x1024MB Patriot SBLK @ DDR-433 (CPU/12)
Western Digital 250GB 16MB SATA-2 HDD
I began using Dragon NaturallySpeaking on a single core Athlon 64 3200+ socket 754 Newcastle (@2.42 GHz) -- my old primary system, which I have been using for about 18 months. I finally broke down recently and decided it was time to move on to a dual core setup for my main system. Both systems are of course overclocked, because that's the type of user I am. Since this is a look at a software technology as opposed to a hardware article, the system clock speed isn't particularly relevant except as a guideline of what level of performance you can expect.
The major reason for the upgrade is gaming - the old AGP 6800GT wasn't cutting it anymore, and the only reasonable upgrade required PCI Express. (That should tell you something about the amount of processing power most business tasks require - the 754 platform is still more than sufficient for most people!) I figured since I was already switching to socket 939, there was no reason not to add a second processor core. That extra core does help out when I'm trying to do multiple things at once, and Dragon does tend to consume a decent amount of resources. MMO gamers might find it useful as a way of chatting without having to type (and it might just cut down on the use of annoying abbreviations if more people did it, but I digress...). When I'm only dictating, though, I don't really notice the difference between my old system and my new system as far as speech recognition is concerned.
So how do you test and benchmark speech recognition packages? The more real world a test is the better, and what could be more real world than an article written for our web site? How about this very article? I'm going to take the first two pages of the article in their present form (minus the Isaac Asimov quote and potentially some later edits) and dictate the text into a sound file. All punctuation will be dictated, and I will edit the final sound file to remove any speech errors. The final sound file will be played back for both speech recognition packages, and with 1181 words of text we can come up with an accuracy rating.
This first sound file is basically my "dictation voice". There are two elements to training a speech recognition program: first, it learns to recognize your voice; second, you learn to adapt your voice to improve accuracy. After creating this first sound file, I realized that my voice didn't sound very normal to me. I'm okay with that, but I decided a second sound file was needed to stress test the software packages. I read the text a second time for this sound file, with a few minor updates to the text, but this time I spoke in a more natural voice and I didn't go back to correct any errors. I won't count any of my errors against the accuracy score, but this will hopefully provide additional insight into how these two voice recognition packages perform.
Accuracy Testing
In order to try and keep this article coherent, I decided to cut back on the number of test results and reporting. I started doing some comparisons of trained versus untrained installations, but untrained installations are really a temporary solution, since the software will learn as you use it. I have my Dragon installation that I've been using for a while, so that side of the equation is covered. I haven't used Microsoft's speech recognition package nearly as much, but I wanted to make sure I gave it a reasonable chance, so I went through additional training sessions with Office 2003. I also opened several of my articles and had the speech engine learn from their content.
One major advantage of DNS is that it will scan your My Documents folder when you first configure it, and as far as I can tell it adds most of the words in your text documents into its recognition engine. Microsoft Office's speech tool can do this as well, but you have to do it manually, one document at a time. I wanted to be fair to both products, but eventually my patience with Microsoft Office 2003 ran out, so it's not as "trained" as DNS8.
Both Dragon and Microsoft Office have the ability to adjust the speed of speech recognition against accuracy, so I tested performance and accuracy at numerous settings. For Dragon, there are essentially six settings, ranging from minimum accuracy to maximum accuracy. The slider can be adjusted in smaller increments, but if you click in the slider bar it will jump between six positions, with each one bringing a moderate change in performance, and possibly a change in accuracy.
I tested at all six settings, but I'm only going to report results for the minimum, medium, and maximum accuracy scores in the charts. Dragon also has the ability to transcribe a recording directly from a WAV file at maximum speed, so I'll include a separate chart for that. Microsoft's speech engine also has a linear slider, but I chose to limit testing to maximum accuracy, minimum accuracy, as well as the middle value. If you would like to see the other test results, the text is available in this Zip file (1 MB).
At the request of some readers, I have also made the MP3 files available for download. (Don't make fun of my voice recordings without making some of your own, though!)
Precise Dictation (5.3MB)
Natural/Rapid Dictation (4.4 MB)
All of these tests were performed on the X2 system with the "trained" speech profiles. I would like to try to train Microsoft's tool more, but it just doesn't have a very intuitive interface. When you say a word or phrase that DNS doesn't recognize, you simply say "spell that" and provide the correct spelling. In most instances, that will allow DNS to recognize the word(s) in the future. This is particularly useful for names of family/friends/associates/etc. Acronyms can also be trained in this manner, but many acronyms sound similar to other standard words, and they definitely cause recognition difficulties. For example, "Athlon X2" still often comes out as "Athlon axe two" and "SATA" (pronounced, not spelled out) is still recognized as "say to" or "say that".
My experience with using Microsoft's speech tool is that it is best used for rough drafts and that you shouldn't worry about correcting errors initially. Once you've got the basic text in place, then you should go through and manually edit the errors. That's basically what Microsoft's training wizard tells you as well, so immediately their goals seem less ambitious - and thus their market is also more limited. Luckily, the text being dictated here isn't as complex that in some of my articles, so Microsoft does pretty well.
Dictation Accuracy
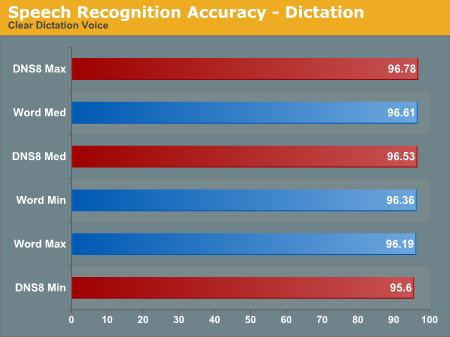
Both packages clearly meet the 90% or higher accuracy claims with practiced dictation. Once you get above 90%, though, every additional accuracy point becomes exponentially more difficult to acquire. With that in mind, the 96% accuracy achieved is impressive. The more specialized your dictation, the higher your chance for getting errors, but for general language both are capable. Somewhat interesting is that the maximum accuracy settings don't actually improve things in all cases. The lowest accuracy setting usually does the worst, but everything above the Medium setting (the default) seems to get both better and worse - some phrases are corrected, and others suddenly get misinterpreted.
The final thing to consider is that in all cases the computer is able to keep up with the user - though maximum accuracy on DNS barely manages to do so. The sound file being dictated here is 9:21 in length and contains 1181 words. At that rate, the software is handling 126 wpm, which is far faster than most people can type. If you're one of the "hunt and peck" crowd, and you find yourself in a situation where you have to do a lot more typing, you might seriously consider trying speech recognition.
Transcription Accuracy

Perhaps the fact that the transcription mode doesn't have to deal with commands and real-time interfacing with the user helps improve accuracy. It may also be that reading a WAV file directly as opposed to hearing it through a microphone helps accuracy. Regardless, it's clear that the transcription mode offers better accuracy than any of the dictation modes. If you're looking at reduction of errors, transcribing a file is 100% more accurate than dictating a file.
Realistically, transcription mode is only useful if you plan on dictating into a recording device while you're away from your computer. Otherwise, you simply spend time dictating a recording, have Dragon transcribe it, and then check for errors. The quality of your recording will also play a role, so if you're using a small portable music device with a tiny microphone, or if you're recording in a noisy environment, it's unlikely that you actually get better accuracy rates compared to sitting in front of a computer dictating into a headset.
There's also some question of how good the transcription mode would be at handling something like the minutes of a meeting, where you have numerous voices, accents, males and females, etc. Still, while you may not use the transcribe mode all that often, we would rather have it than not. Microsoft's speech SDK looks like it has the necessary hooks to allow transcription of a WAV file, but at present we were unable to find any utilities that take advantage of this feature.
Speech Accuracy - Precise Dictation
Moving to a more typical speech pattern and not my stilted dictation voice, how do things change? First, this sound file is 1208 words and 8:11 in length. This is obviously a much more rapid delivery, typical of more casual conversation. At 147 wpm, this is faster than all but the best typists can achieve. The question is, how will the software deal with the faster delivery? We'll start with dictation mode again.
Dictation Accuracy
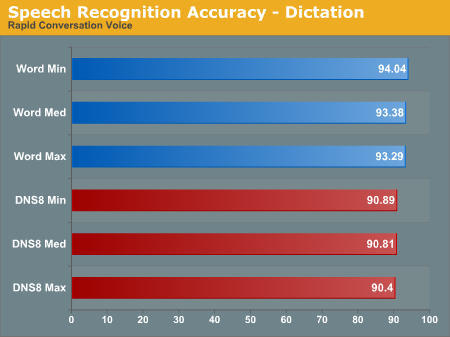
Accuracy drops several percent in both products, but DNS is clearly affected more. In fact, at just over 90% accuracy, there are enough errors that it's questionable whether or not you'd really be saving any time. In this particular instance, Microsoft's speech engine makes half as many mistakes. In a rather odd twist, both products also get more accurate as you turn their accuracy gauge down. It appears that with rapid text, the algorithms almost "overthink" the waveforms.
Transcription Accuracy
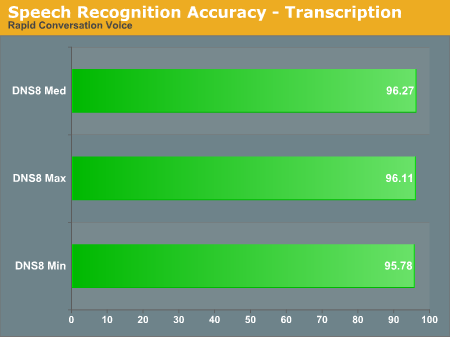
Switching to transcription mode, Dragon once again comes out on top. What's most likely happening is that Dragon is trying to determine whether or not you're issuing commands or dictating text, and it ends up wasting time that could be better spent analyzing your speech patterns. Basically, Dragon has a more complex user interface, and in straight rapid dictation this appears to be a handicap. Trascribing a WAV file shuts off many of the extras, so performance and accuracy improve substantially.
Processor Utilization - Precise Dictation
Now that we have some idea of the accuracy these solutions offer in terms of accuracy, what sort of CPU requirements are we looking at? As with our accuracy charts, we've got a separate section looking at the processor utilization of Dragon NaturallySpeaking when transcribing a WAV file. Below are screenshots of Windows Task Manager showing CPU usage during dictation. In retrospect, finding a utility to track average CPU utilization over time would have been more useful, but these screenshots should suffice for our purposes.
Dictation Processor Utilization
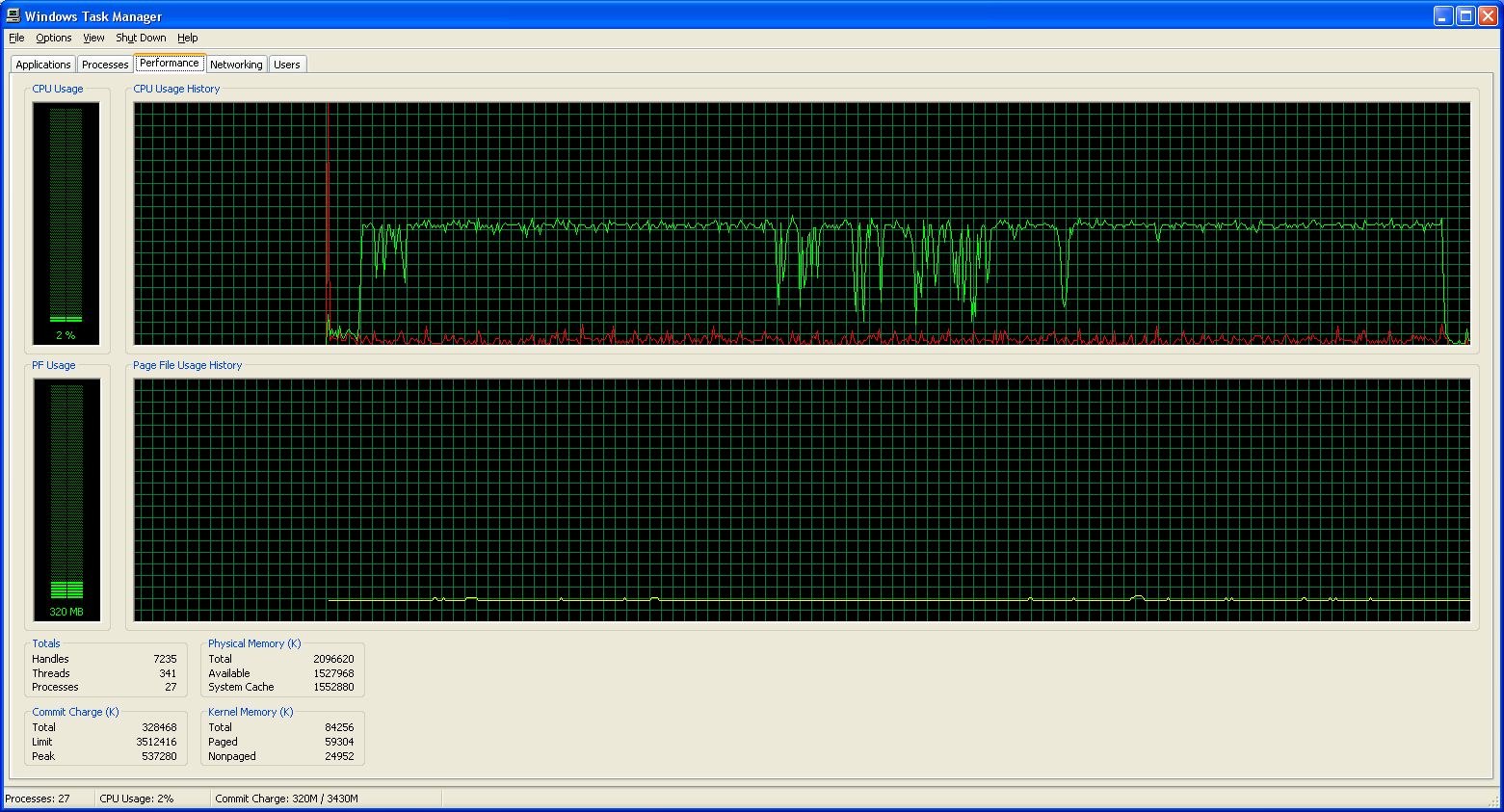 |
| DNS8 Maximum Accuracy |
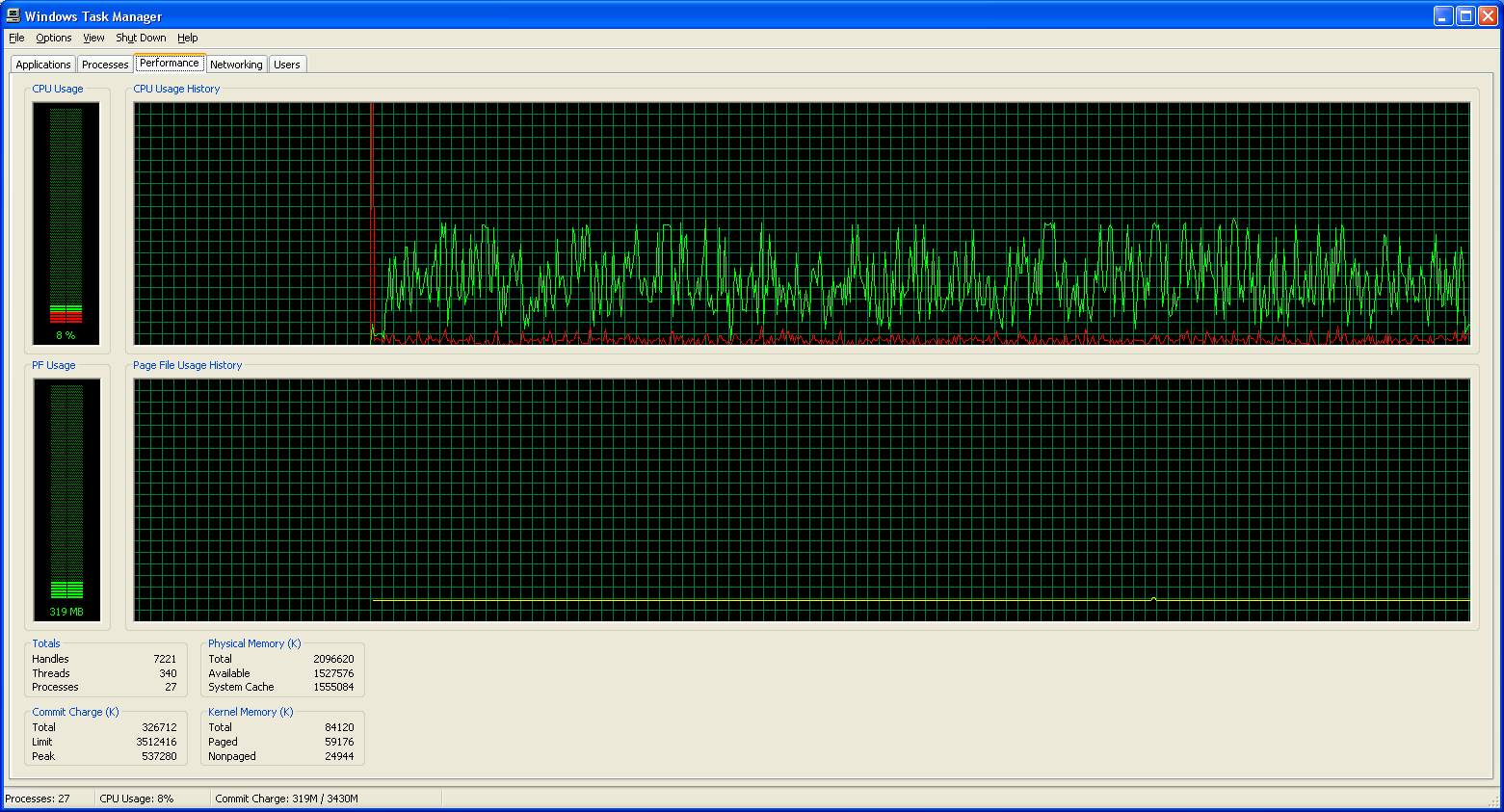 |
| DNS8 Medium Accuracy |
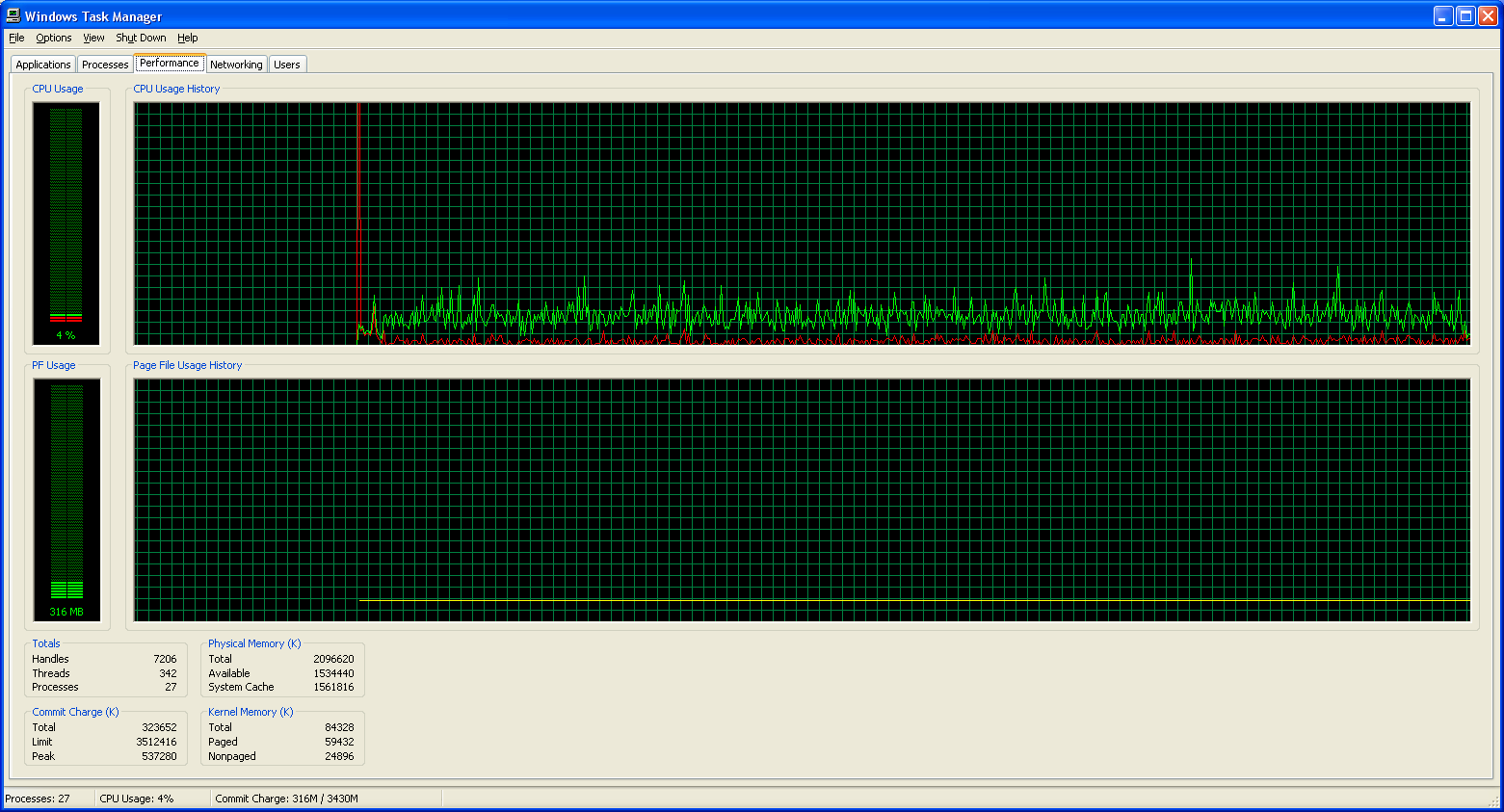 |
| DNS8 Minimum Accuracy |
 |
| MSWord Maximum Accuracy |
 |
| MSWord Medium Accuracy |
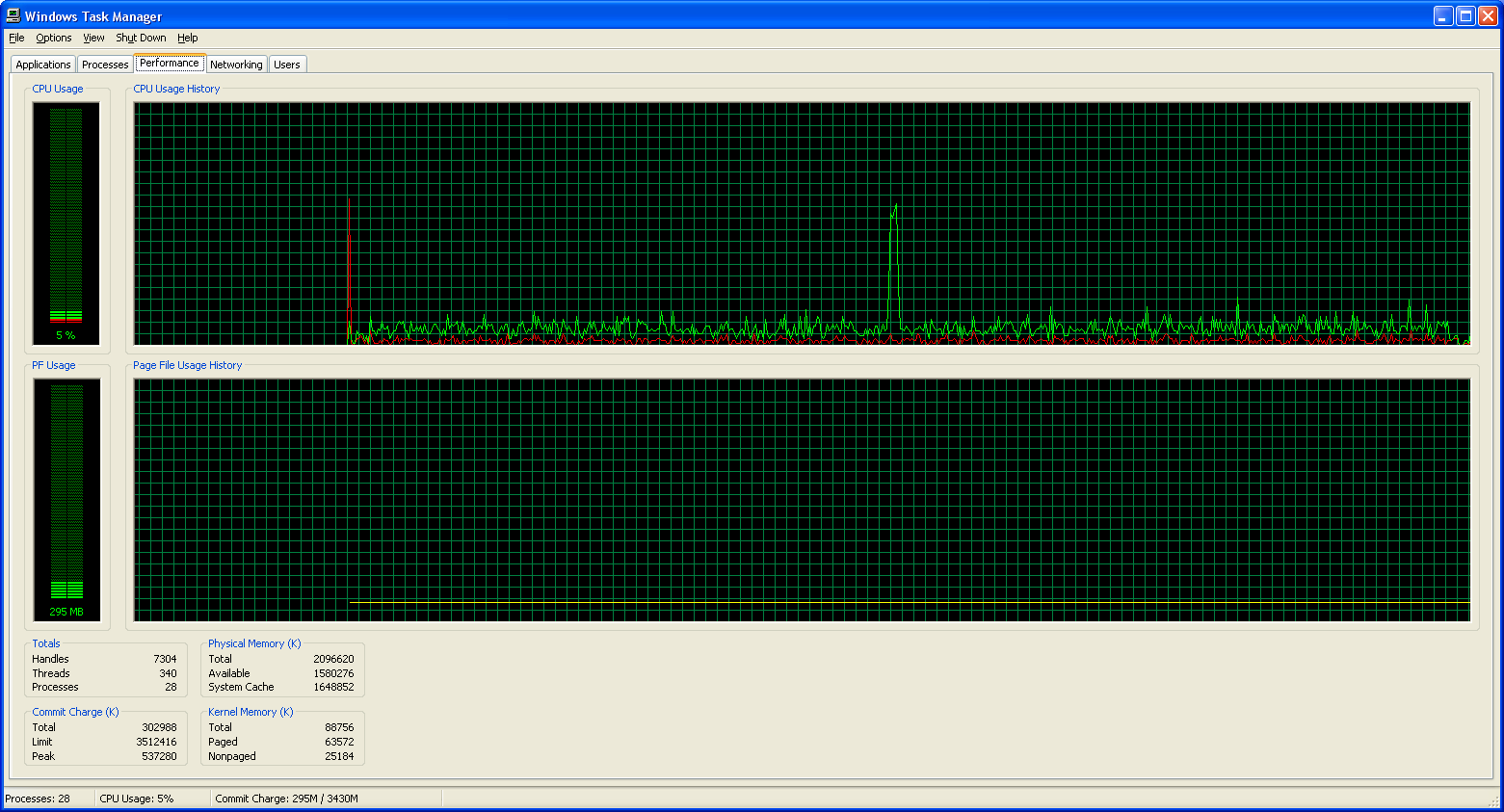 |
| MSWord Minimum Accuracy |
One thing is immediately clear: Dragon NaturallySpeaking requires far more CPU processing time than Microsoft Office. Even at the lowest accuracy setting, Dragon essentially matches the CPU usage of Microsoft's tool at its maximum accuracy setting. However, CPU usage and accuracy are only two of the aspects of this software package, and that much more difficult to describe "user experience" continues to be far preferable to me with Dragon NaturallySpeaking.
The second major point of interest is that having a second processor core does absolutely nothing for these speech recognition packages. (MS might even be able to run without difficulty on a Pentium 3, judging by the CPU usage.) Sure, if you're running multiple applications that are all trying to use the CPU, the second core can be useful. On the other hand, if the only thing you're doing is dictating speech, the current algorithms are clearly single threaded in nature. Given that accurate speech recognition depends in large part on recognizing the context of sounds -- this is especially true for homonyms like their, they're, and there -- there may be some difficulty associated with breaking the task into meaningful, discrete parts. However, difficult does not mean impossible, and with AMD, Intel, and all the other major CPU players moving towards multiple cores, further improvements in accuracy are likely going to require multithreaded algorithms.
Transcription Processor Utilization
| DNS8 Maximum Accuracy |
| DNS8 Medium Accuracy |
| DNS8 Minimum Accuracy |
As with dictating, transcribing an audio file also fails to benefit from multiple CPU cores. The good news is that processing times are much faster, because a single CPU core can chew through the waveforms as fast as possible. While the maximum accuracy mode didn't seem to do all that well with dictating, it did seem to handle a few phrases better when transcribing. It also takes longer, but if you're in a situation where you can start the transcription process and walk away for awhile, that shouldn't matter too much.
Processor Utilization - Rapid Speech
Accuracy was obviously far lower with the faster, more casual delivery. What happens with processor utilization?
Dictation Processor Utilization
.png) |
| DNS8 Maximum Accuracy |
.png) |
| DNS8 Medium Accuracy |
.png) |
| DNS8 Minimum Accuracy |
.png) |
| MSWord Maximum Accuracy |
.png) |
| MSWord Medium Accuracy |
.png) |
| MSWord Minimum Accuracy |
Transcription Processor Utilization
| DNS8 Maximum Accuracy |
| DNS8 Medium Accuracy |
| DNS8 Minimum Accuracy |
Processor requirements go way up with a faster speech delivery, at least with Dragon NaturallySpeaking. Perhaps it's my lack of enunciation when I'm speaking fast, but obviously you end up with not only lower accuracy, but also longer speech recognition times.
When you consider that our test system was able to keep up with our regular delivery when dictating (barely), the fact that it requires 15.7 minutes on maximum accuracy for an 8:11 length file shows how important "user training" really is. When dictating at 120 to 130 wpm, both software packages are able to keep up. At 146 wpm, maximum accuracy ends up processing only 77 words per minute. When you throw in the increased number of errors, rapid delivery is definitely not the preferred way to utilize either of these packages. If "Natural" means "Fast" to you, you might want to mentally rename DNS to Dragon "Enunciate-And-Speak-Slower" Speaking.
Transcribe mode is also slower, but it doesn't take nearly as big of a hit. Also interesting is that both the transcription mode and the dictation mode manage to max out processor usage with Dragon NaturallySpeaking but live dictation takes 2 to 5 times as much CPU time. Clearly, the full speech UI is putting a decent load on the CPU. That makes sense, as continually trying to determine whether the user has spoken a special command (i.e. trying to access the file menu) would create some overhead. Still, being two to three times slower seems a bit extreme. Of course, keep in mind that during normal writing, rarely can you speak at full speed for several minutes; normally, you'll take frequent pauses to think of exactly what you want to say next.
Closing Thoughts
At first glance, both of these speech recognition packages appear pretty reasonable. Dragon is more accurate in transcribe mode, but it also requires more processing time. Both also manage to offer better than 90% accuracy, but as stated earlier that really isn't that great. Having used speech-recognition for several months now, I would say that 95% accuracy is the bare minimum you want to achieve, and more is better. If you already have Microsoft Office 2003, the performance offered might be enough to keep you happy. I can't say that I would be happy with it, unfortunately.
It may simply be that I started with Dragon NaturallySpeaking, but so far every time I've tried to use Microsoft's speech tool, I've been frustrated with the interface. Microsoft does appear to do better when you start speaking rapidly, but I generally only speak in a clause or at most a sentence at a time, and the Microsoft speech engine doesn't seem to do as well with that style of delivery.
Going back to my earlier analogy of the mouse wheel, I can't help but feel that it's something of the same thing. Having experienced the way Dragon does things, the current Microsoft interface is a poor substitute. It almost feels as though the utility reached the point where it was "good enough" and has failed to progress from there. The accuracy is fine, but dealing with the errors and training the tool to properly recognize words for future use is unintuitive at best - I didn't even have to crack the manual for DNS until I wanted to get into some specialized commands! That said, Windows Vista and the new Office Live are rumored to have better speech support, so I will definitely look into those in the future.
In case you were wondering, the vast majority of this article was written using Dragon NaturallySpeaking. There are still many errors being made by the software, but there are far more errors being made by the user. Basically, the software works best if you can think and speak in complete phrases/clauses, as that gives the software a better chance to recognize words from context. Any stuttering, slight pauses, slurring, etc. can dramatically impact the accuracy. It's also important to enunciate your words -- it will certainly help improve the accuracy if you can do so.
I find DNS works very well for my purposes, but I'm sure there are people out there that will find it less than ideal. There are also various language packs available, including several dialects of English, but I can't say how well any of them work from personal experience. I don't really feel that I can say a lot about getting the most out of speech recognition from Microsoft, so the remainder of my comments come from my use of Dragon NaturallySpeaking.
Thoughts on Dragon NaturallySpeaking
Note: I've added some additional commentary on the subject based on email conversations.
One of the questions that many people have is what's the best microphone setup to use? I use a Plantronics headset that I picked up online for about $30, and it hasn't given me any cause for concern. The soft padded earphones are definitely a plus if you're going to use your headset for long periods of time. I've also used a Logitech headset, and it worked fine, but it's not as comfortable for extended use. The location of the microphone -- somewhat closer to your ear than to your mouth -- also seems to make it less appropriate for noisy environments. There are nicer microphones out there, including models that feature active noise cancellation (ANC), and they could conceivably help -- especially in noisy environments. So far, I at least have not found them to be necessary for my needs.
As far as sound hardware goes, I've used integrated Realtek ALC655 audio, integrated Creative Live! 24-bit, and a discrete Creative Audigy 2 ZS card. The ALC655 definitely has some static and popping noises, but it didn't seem to affect speech recognition in any way that I could see. The quality of integrated audio varies by motherboard, of course, but I would suggest you try out whenever you currently have first. Whatever sound card/chipset you're using ought to be sufficient; if it's not, you could try a USB sound pod or upgrade to a nicer sound card that has a better signal to noise ratio. (My Audigy 2ZS works great - that's what was used for recording the sample audio files.)
There's also a recommendation to make sure you're in a quiet environment in order to get best results. I'm not exactly sure what qualifies as quiet, but my living room with an ambient noise level of 50 to 60 dB doesn't appear to present any difficulties. On the other hand, I did try using speech recognition in a data center that had an ambient noise level of over 75 dB. I received a warning that the noise level was too high during the microphone configuration process, but I did have the option to continue. I did so, but within minutes I had to admit defeat. I could either shout at my microphone, or else I could try to get by with less than 50% accuracy rates.
I would say there's a reasonable chance that active noise cancellation microphones could handle such an environment, but I didn't have a need to actually make that investment. In fact, several SRS experts have emailed me and recommended ANC for exactly that sort of situation. It should allow you to use speech recognition even in noisy environments, and it can also help improve accuracy even in quieter environments. If you're serious about using such software, it's worth a look. However, few locations are as noisy as a data center -- trade shows certainly are close -- so most people won't have to worry about excessive noise. Most office environments should be fine, provided you don't mind people overhearing you.
The one area that continues to plague DNS in terms of recognition errors is acronyms. Some do fine, but there are many that continue to be recognized incorrectly, even after multiple attempts to train the software. For example, "Athlon 64 ex 240 800+" is what I get every time I want "Athlon 64 X2 4800+" -- that's when I say "Athlon 64 X2 forty-eight-hundred plus-sign". I can normally get the proper text if I say "Athlon 64 X2 four-thousand eight-hundred plus-sign", but I still frequently get "ask to" or "ax to" instead of "X2". My recent laptop review also generated a lot of "and/end 1710" instead of "M1710", despite my best attempts to train the software. There's a solution for this: creating custom "macros" for acronyms you use a lot. The only difficulty is that you have to spend the time initially to set up the macros, but for long-term use its definitely recommended.
My final comment for now is that the functionality provided by Dragon NaturallySpeaking is far better in Word or DragonPad (the integrated rich text editor that comes with DNS) than in most other applications. If you're using Word or DragonPad, it's relatively simple to go back and correct errors without touching the keyboard. All you have to do is say "select XXX" where XXX is a word or phrase that occurs in the document. DNS will generally select the nearest occurrence of that phrase, and you're presented with a list of choices for correcting it, or you can just speak the new text you want to replace the original text. This is one of those intuitive things I was talking about that Microsoft currently lacks.
There are a few problems with this system. The biggest is that outside of Word and DragonPad, the instant you touch the keyboard or switch to another application, DNS loses all knowledge about any of the previous text. This happens a lot with web browsers and instant messaging clients -- I surf almost exclusively with Firefox, so I can't say whether or not this holds true for Internet Explorer. Another problem is that sometimes the selection gets off by one character, so you end up deleting the last character of the previous word and getting an extra space on the other side. (This only happens outside of Word/DragonPad, as far as I can tell.) I've also had a few occasions where the system goes into "slow motion" when I try to make a correction: the text will start to be selected one character at a time, at a rate of about two characters per second, and then once all the text is selected it has to be unselected again one character at a time. If I'm trying to select a larger phrase, I'm best off just walking away from the computer for a few minutes. (Screaming and yelling at my system doesn't help, unfortunately.) Thankfully, both of those glitches only occur rarely.
Hopefully, some of you will have found this article to be an interesting look at a technology that has continued to improve through the years. It's still not perfect, but speech recognition software has become a regular part of my daily routine. There are certainly people out there who type more than I do, and I would definitely recommend that many of them take a look at speech recognition software. If you happen to be experiencing some RSI/carpal tunnel issues caused by typing, that recommendation increases a hundredfold. I'm certainly no doctor, but the expression "No pain, no gain" isn't always true; some types of pain are your body's way of telling you to knock it off.
If you have any further questions about my experience with speech recognition, send them my way. I don't think I'm a bona fide expert on the subject, but I'll be happy to offer some help if I can.






