Original Link: https://www.anandtech.com/show/18916/amd-data-center-and-ai-technology-premiere-live-blog-starts-at-10am-pt1700-utc
AMD Data Center and AI Technology Premiere Live Blog (Starts at 10am PT/17:00 UTC)
by Ryan Smith & Gavin Bonshor on June 13, 2023 12:00 PM EST
12:55PM EDT - AMD this morning is hosting their first data center and server-focused event in quite some time. Dubbed the "AMD Data Center and AI Technology Premiere," we're expecting a sizable number of announcements from AMD around their server and AI product portfolio
12:55PM EDT - Highlighting this should be fresh news on AMD's forthcoming MI300 accelerator, the company's first server APU, that combines Zen 4 CPU cores and CDNA 3 GPU cores on to a single chip. Aimed at the very high end of the market, when it ships later this year MI300 will be AMD's flagship accelerator, and their most significant offering yet for the exploding AI market
12:55PM EDT - We're also expecting some additional details on AMD's remaining server CPU products for the year. This includes the density-focused Bergamo CPU, which will offer up to 128 CPU cores based on AMD's Zen 4c architecture. Genoa-X, which is AMD's V-cache equipped version of the EPYC 9004 series, offering up to 1.1GB of L3 cache per chip. And Siena, a 64 core low-cost EPYC chip
12:55PM EDT - And not to be left out, AMD also has their FPGA and networking divisions, courtesy of recent acquisition like Xilinx and Pensando. Those teams have also been hard at work at their own products, which are due for announcements as well

12:56PM EDT - This is AMD's first live event focused on the data center market in a while. The low frequency of these events means that AMD's most recent slate of announcements were during the tail-end of the pandemic, before live events had resumed
12:57PM EDT - So while not AMD's first live event overall, it's certainly their most important data center event in quite some time
12:58PM EDT - The live stream link, for anyone who would like to watch along: https://www.youtube.com/watch?v=l3pe_qx95E0
12:59PM EDT - I am here in person in cloudy San Francisco, where AMD is holding their event. Backing me up, as always, is Gavin Bonshor, who is in decidedly warmer England

12:59PM EDT - AMD has asked everyone to silence their devices; the show is about to begin
01:00PM EDT - One thing to note that, for as important as this show is for AMD's customers, there's also a distinct element of pleasing AMD's shareholders
01:00PM EDT - Which, to be sure, as a company AMD is always looking to do that. But with the explosion in demand for AI products, there's a lot of pressure on AMD to make sure they're going to capture a piece of that pie
01:00PM EDT - And we're starting!
01:01PM EDT - Here's AMD CEO, Dr. Lisa Su
01:01PM EDT - Lisa is greeting the audience
01:01PM EDT - As well as welcoming remote viewers
01:01PM EDT - "We have a lot of products and exciting news to share with you today"

01:01PM EDT - So with no further ado, we're getting started
01:01PM EDT - "AMD technology is truly everywhere"
01:02PM EDT - EPYC processors, Instinct accelerators, and AMD's product ecosystem
01:02PM EDT - "Today we lead the industry" with their EPYC processors

01:02PM EDT - Lisa is going to show how AMD brings their current products together, and how they'll be expanding their portfolio
01:03PM EDT - Every major cloud provider has EPYC instances

01:03PM EDT - EPYC adoption is also growing in the Enterprise market
01:04PM EDT - AMD is still ramping their 4th generation "Genoa" EPYC processors
01:04PM EDT - Genoa technically launched last November

01:04PM EDT - AMD thinks Genoa is still by far the highest performance and most efficient processor in the industry
01:04PM EDT - Performance comparisons between EPYC and Intel's 4th gen Xeon platform (Sapphire Rapids)

01:05PM EDT - "We want leadership performance. But we must have best-in-class energy efficiency"
01:06PM EDT - The vast majority of AI workloads today are still being run on CPUs
01:06PM EDT - So AMD sees themselves as having a big stake - and big advantage - in that market

01:06PM EDT - Expect no shortage of guests today. Starting with AWS VP Dave Brown
01:07PM EDT - AMD and AWS are continuing to collaborate

01:08PM EDT - AWS has introed over 100 different AMD-based instances at this point
01:09PM EDT - AWS has a broad range of customers, who have benefitted from the cost savings of using AMD instances
01:09PM EDT - Brown is talking about the various things AWS's customers have been up to - and how much money they've saved

01:10PM EDT - What's next for the AMD/AWS partnership?
01:11PM EDT - AWS is building new EC2 instances using EPYC 9004 processors and AWS's Nitro system
01:11PM EDT - Announcing M7a instances for general purpose computing
01:12PM EDT - Up to 50% more perf than M6a instances

01:12PM EDT - Preview available today
01:13PM EDT - General availability in Q3
01:13PM EDT - AMD is using AWS today for their data analytics workloads
01:13PM EDT - AMD will be expanding their use of AWS to use the service for more technical workloads like EDA
01:14PM EDT - And that's AWS

01:14PM EDT - "We're really pleased with the response we're getting on Genoa"
01:14PM EDT - Oracle is also announcing new Genoa instances that will be available in July
01:14PM EDT - "Genoa is ramping nicely"
01:15PM EDT - More customres coming online in the coming weeks

01:15PM EDT - Now talking about the breadth of AMD's data center product stack

01:16PM EDT - Cloud computing clients have different needs than AMD's standard EPYC customers
01:16PM EDT - Which brings us to Bergamo

01:16PM EDT - AMD's density-optimized CPU design for higher core counts
01:16PM EDT - 128 cores per socket "for leadership performance and energy efficiency in the cloud"

01:16PM EDT - Lisa loves her chips
01:16PM EDT - "Our chips"
01:17PM EDT - 8 CCDs, each with 16 Zen 4c cores
01:17PM EDT - Same IOD as Genoa

01:17PM EDT - 82 billion transistors
01:17PM EDT - Zen 4c core is 2.48mm2 on TSMC 5nm, versus 3.84mm2 for Zen 4

01:18PM EDT - AMD starts from the same RTL as Zen 4, and then optimize the physical implementation for reduced area
01:18PM EDT - 35% smaller core, and substantially better perf-per-watt

01:18PM EDT - The only real difference between Genoa and Bergamo is the CCDs
01:18PM EDT - 8x12 versus 16x8
01:19PM EDT - Genoa and Bergamo use the same SP5 socket, and can be swapped
01:19PM EDT - Now for performance comparison benchmarks versus Intel's 4th gen Xeon
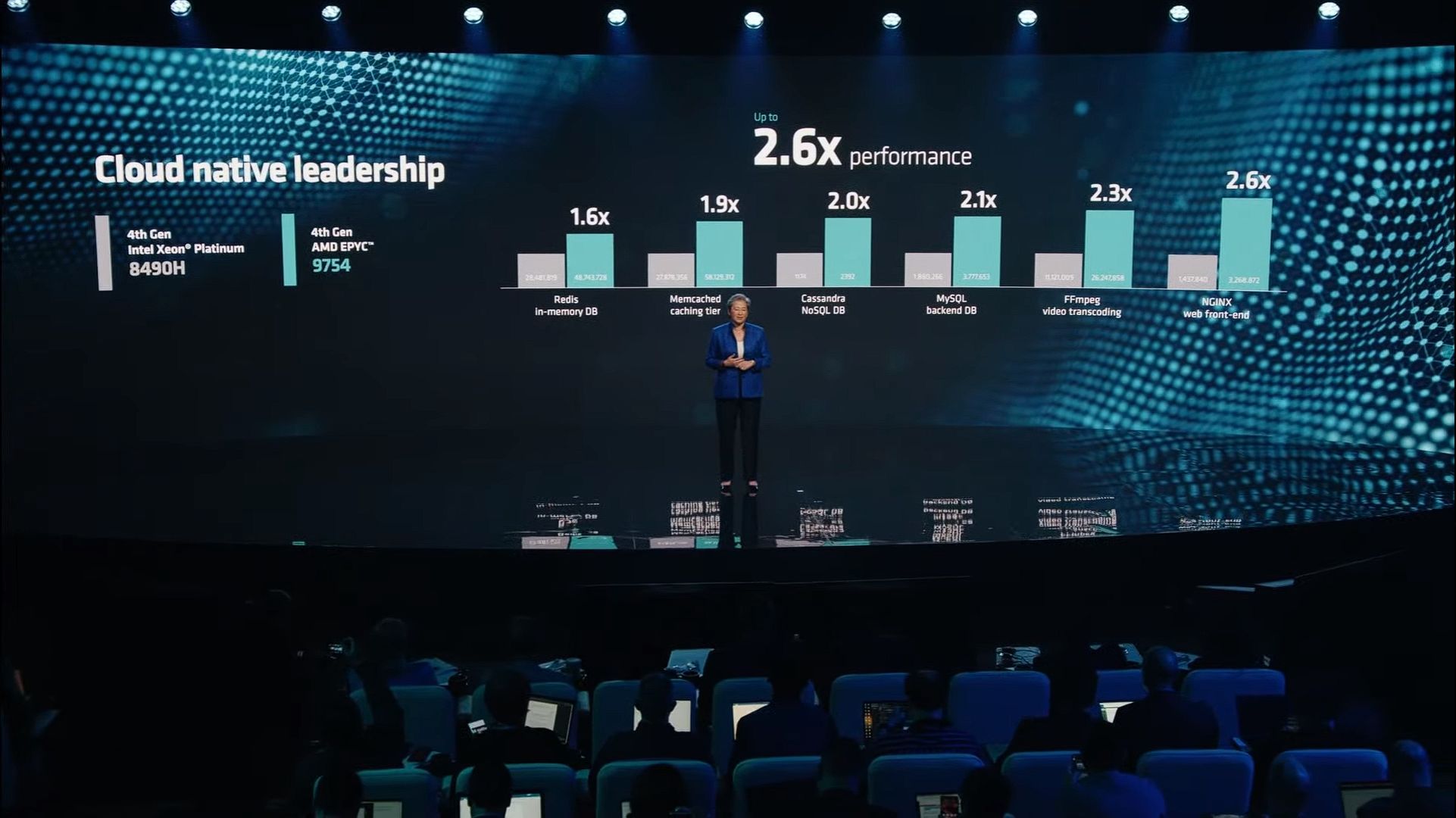
01:19PM EDT - Up to 2.0x energy efficiency

01:20PM EDT - Bergamo is shipping in volume now to AMD's hyperscale customers
01:20PM EDT - And now for another guest: Meta VP Infrastructure, Alexis Bjorlin

01:21PM EDT - Meta and AMD have been collabing on EPYC server design since 2019
01:22PM EDT - Meta is a big supporter and provider for the Open Compute Project (OCP)
01:22PM EDT - So Meta's server designs are in significant use in the world

01:23PM EDT - AMD has proven to be able to meet their commitments to Meta
01:24PM EDT - Some of the insights from Meta have helped to shape Bergamo
01:24PM EDT - Meta will be deploying Bergamo for their next-gen high density server platform
01:24PM EDT - With substantial TCO improvements over Milan

01:25PM EDT - AMD is looking forward to the coming years with their Meta partnership. And that's Meta.
01:25PM EDT - And that's Bergamo as well
01:26PM EDT - Now on to technical computing workloads

01:26PM EDT - Dan McNamara is now taking the stage. SVP and GM of AMD's server business unit
01:26PM EDT - Delivering two new products today

01:27PM EDT - He's starting with a look at how AMD has optimized its designed for the "technical computing" market
01:27PM EDT - AMD's second generation V-cache technology
01:27PM EDT - Over 1GB of L3 cache on a 96 core EPYC CPU
01:27PM EDT - 4th gen EPYC, Genoa-X
01:28PM EDT - Like Bergamo, Genoa-X is available now
01:28PM EDT - 4 new SKUs, from 16 cores to 96 cores

01:28PM EDT - Genoa-X is aimed at technical computing. Workloads that can benefit from substantially larger L3 cache sizes
01:29PM EDT - Now for some performance slides with some EDA workloads
01:29PM EDT - Versus Intel, of course
01:29PM EDT - Platforms featuring Genoa-X will be available next quarter

01:30PM EDT - Another guest: Microsot's GM for Azure (apologies, didn't get the name)

01:31PM EDT - Talking about the history of Azure's HB series instances

01:31PM EDT - Performance comparisons using ANSYS Fluent 2021 R1
01:32PM EDT - 4x performance growth in 4 years
01:32PM EDT - Announcing general availability of HBv4
01:33PM EDT - 1.2TB/sec of memory bandwidth on hBv4

01:34PM EDT - Azure is also offering the HX series for even higher performance (and lower latency)
01:35PM EDT - And now talking a bit about Azure's customer adoption, and what they've been doing with their instances
01:36PM EDT - Azure is going to be 100% renewable energy by 2025

01:36PM EDT - Which is helpful for their customers who are wanting to get to net-zero carbon emissions
01:38PM EDT - Meanwhile, ST Micro has been able to reduce their simulation time by 30%
01:38PM EDT - And that's Azure
01:38PM EDT - VMs with Genoa-X now available
01:39PM EDT - Final piece of the Zen 4 portfolio: Siena
01:39PM EDT - AMD's low-cost EPYC processor for telco and other markets

01:39PM EDT - More on that in the second half of the year
01:39PM EDT - Now on to Forrest Norrad, EVP and GM of AMD's data center solutions business group

01:40PM EDT - Who is bringing on another guest: Jeff Maurona, Managing Director and COO of Citadel Securities
01:40PM EDT - "World's most profitable hedge fund"

01:40PM EDT - As well as the world's largest market-making firm
01:41PM EDT - Citadel is basically doing real-time predictive analytics
01:43PM EDT - Citadel transistioned to AMD in late 2020
01:43PM EDT - EPYC's memory bandwidth in particular has unlocked a lot of performance for Citadel

01:44PM EDT - Citadel finds Xilinx FPGAs to be absolutely essential as well
01:45PM EDT - And that's Citadel
01:45PM EDT - Citadel is using over a million CPU cores in the cloud
01:46PM EDT - Now focusing on AMD's network portfolio. One of their recent expansions via the Pensando acquisition
01:46PM EDT - Networking is an increasingly important part of the data center market - and thus AMD's own offerings

01:47PM EDT - Forrest is talking about the challenges of offering a hybrid cloud environment
01:48PM EDT - Focusing in part on the CPU overhead involved in offering those services while maintaining the necessary isolation
01:48PM EDT - Now talking about the P4 DPU architecture

01:48PM EDT - A purpose-built architecture to provide important services at line rate
01:48PM EDT - While being fully programmable

01:49PM EDT - DPUs offload a good chunk of the CPU overhead
01:49PM EDT - Reducing the need for a set of external appliances

01:50PM EDT - And as part of Pensando SmartNICs, offer multiple new use cases
01:50PM EDT - Available on major public clouds

01:51PM EDT - Deployed into an existing infrastructure, or designed into a new one
01:52PM EDT - AMD is working with HP Aruba to develop a smart switch. An industry-standard switch enhanced with P4 DPUs

01:53PM EDT - And that's how AMD is helping customers evolve their data center environments and make them more efficient
01:53PM EDT - And now back to Lisa Su for a look at AI
01:54PM EDT - (An aurora background? That has to be intentional...)
01:54PM EDT - 3 key areas for AI: broad portfolio of CPUs and GPUs, open and proven software platform, and a deep ecosystem of partners

01:55PM EDT - AMD is uniquely positioned with a broad collection of AI platforms across everything from client to server

01:56PM EDT - Lisa is talking about some of the customers using AMD hardware today for AI tasks, not the least of which being NASA
01:56PM EDT - Meanwhile AMD is expecting more than 70 laptop designs to launch through later this year featuring Ryzen AI
01:57PM EDT - $150B+ opportunity in the data center AI acceleration market

01:57PM EDT - "We are very, very early in the lifecycle of the AI market"
01:57PM EDT - 50% compound annual growth rate, from $30B today
01:58PM EDT - Talking about some of AMD's supercomputer wins, including, of course, Frontier, the industry's first exascale supercomputer

01:59PM EDT - And now rolling a video on the Lumi supercomputer (#3 on the current Top500 list)
02:00PM EDT - More accurate and better models as a result of Lumi
02:00PM EDT - Generative AI requires hardware as well as good software
02:00PM EDT - Now on stage: AMD's President, Victor Peng, to talk about the software side of matters

02:01PM EDT - Peng also heads up AMD's newly formed AI group
02:01PM EDT - AMD software development: open, proven, ready
02:02PM EDT - Talking about some of AMD's accomplishments to date
02:02PM EDT - Recapping Ryzen 7040 series and Ryzen AI

02:03PM EDT - As well as sampling new Vitis AI products
02:03PM EDT - This requires a "leadership software stack"
02:04PM EDT - Recappoing the ROCm stack

02:04PM EDT - A significant portion of which is open source
02:04PM EDT - ROCm in its fifth generation, with a comprehensive suite of AI optimizations
02:04PM EDT - FP8 data type support, optimized kernels, etc

02:05PM EDT - Another guest on stage: Soumith Chintala, the founder of PyTorch and VP at Meta

02:06PM EDT - Recapping PyTorch and what it's used for. One of the most popular AI frameworks on the market
02:06PM EDT - Recently released PyTorch 2.0
02:08PM EDT - How does AMD's collab benefit the developer community?

02:09PM EDT - Removed a lot of the work required/friction in moving platforms
02:10PM EDT - And that's PyTorch
02:10PM EDT - PyTorch 2.0 offers day-0 support for ROCm 5
02:10PM EDT - Now on to talking about AI models

02:11PM EDT - Another guest on stage, Clement Delangue, CEO of Hugging Face
02:11PM EDT - Sharing his thoughts on why open source matters in AI

02:12PM EDT - Giving companies the tools to build AI themselves, rather than just relying on provided tools
02:13PM EDT - AMD and Hugging Face recently formalized their partnership, which is being announced today
02:14PM EDT - Hugging Face is the most used open platform for AI
02:14PM EDT - Over 5000 new models added to their service just last week

02:15PM EDT - And they will be optimizing these models for AMD's platforms
02:16PM EDT - "Democratize AI"
02:17PM EDT - AMD, of course, shares in this vision, which is why they're working with Hugging Face
02:17PM EDT - The rate of innovation for AI is unprecidented
02:18PM EDT - And that's AMD's software stack

02:18PM EDT - Now back to Lisa Su for hardware
02:18PM EDT - "We've made a tremendous amount of progress over the past year with ROCm"
02:18PM EDT - Turning to AI hardware
02:19PM EDT - Generative AI and LLMs have changed the landscape
02:19PM EDT - For both training and inference

02:19PM EDT - At the center of this are GPUs
02:19PM EDT - Turning to the Instinct GPU roadmap
02:19PM EDT - AMD's CDNA 3 GPU architecture
02:19PM EDT - New compute engine, latest data formats, 5/6nm processes

02:20PM EDT - Recapping the MI300, now known as the MI300A
02:20PM EDT - 24 Zen 4 CPU cores, 128GB HBM3 memory
02:20PM EDT - All in a single package with unified memory across the CPU and GPU

02:20PM EDT - MI300A is sampling now
02:20PM EDT - MI300A is slated for use in the El Capitan supercomputer in LLNL
02:21PM EDT - 13 chiplets in MI300A
02:21PM EDT - MI300 is now a family of products
02:21PM EDT - AMD is replacing the Zen CPU chiplets to create a GPU-only version: MI300X

02:22PM EDT - 129GB HBM3, 5.2 TB/second of memory bandwidth, 896GB/ec memory bandwith, 153B transistors
02:22PM EDT - "Leadership generative AI accelerator"
02:22PM EDT - It looks very similar to MI300A. Removed 3 CPU chiplets, added 2 GPU chiplets

02:22PM EDT - 12 5nm and 6nm chiplets in total
02:23PM EDT - So AMD has done an XPU 3+ years before Intel
02:23PM EDT - Comparing MI300X to NVIDIA's H100 accelerator in terms of HBM3 density and bandwidth

02:24PM EDT - AMD supports 8 HBM3 stacks, versus 6 on H100, which gives them a capacity and bandwidtbh advantage
02:24PM EDT - Doing a live demo with the Falcon-40B model running on one MI300X

02:26PM EDT - More memory and more memory bandwidth allows larger models, and also running LLMs on fewer GPUs overall
02:26PM EDT - Which AMD believes will offer a TCO advantage
02:27PM EDT - Also announcing the AMD Instinct Platform

02:27PM EDT - 8-way MI300X configuration
02:27PM EDT - Using an OCP platform (so OAM?)

02:27PM EDT - 1.5TB total HBM3 memory
02:28PM EDT - Making it easier to deploy MI300 into their existing server and AI infrastructure

02:28PM EDT - MI300A began sampling earlier this quarter. MI300X and the 8-way platform sampling in Q3 of this year
02:29PM EDT - Expecting both products to ramp into production later this year

02:29PM EDT - Now wrapping things up
02:29PM EDT - Recapping all of AMD's announcements, and the scope of AMD's overall data center product lineup

02:30PM EDT - And that's a wrap on AMD's data center event
02:30PM EDT - Thanks for joining us. Now off to find out more about MI300X






