Original Link: https://www.anandtech.com/show/1810
ATI's Late Response to G70 - Radeon X1800, X1600 and X1300
by Derek Wilson on October 5, 2005 11:05 AM EST- Posted in
- GPUs
Introduction
Today, ATI has finally launched their X1000 series. The long awaited answer to NVIDIA's 7800 series now brings Shader Model 3.0 (among other things) to ATI's platform. The expanded feature set and improved performance of the new X1000 products promise to bring ATI back in contention with NVIDIA's high end parts. For the past few months, NVIDIA has enjoyed their performance lead and will finally face some competition. Will the X1000 series be enough to win out over the 7800 series?
There are plenty of new features available, which take away the exclusive availability of high end SM3.0 features in games like Splinter Cell 3 from NVIDIA. With a top to bottom release, ATI is making sure that their parts are competitive on every level. From a performance standpoint, we can expect the high end to surpass the X850 XT by a large margin. However, the most important aspect of this launch will be whether or not ATI is competitive with performance per dollar versus NVIDIA hardware.
There are a lot of products launching today that we don't yet have in our labs. The cheapest X1300s are of interest, but we only have the more expensive version. All of the cards are the highest performing of their type. We will be very interested in testing the rest of the product line as soon as it becomes available to us.
Speaking of availability, we had strongly hoped to bring out a review of products that could be purchased at retail today. Unfortunately, no one we know of has the card on their shelves or in their web pages for sale today. Some merchants are saying that they may ship in a week or so, but this is certainly not a launch on the level of the 7800 GTX or 7800 GT. We published an insider article on this very subject last night:
Will we add October 5 to the list of memorable dates of 2005 - at least with regard to products launching and shipping on the same day? All vendors we've interviewed tell us that there will be no new ATI SKUs on their warehouse floors on the morning of October 5. Some report that they expect shipments within a few days, and others don't really expect shipments for at least a week; and all report that their initial SKUs will be "built by ATI" branded cards. This is not reminiscent of the GeForce 7xxx nor the Intel 6xx launch earlier this year, where the product was literally waiting to be shipped a week before the launch date. On the other hand, those waiting to buy some of ATI's new SKUs won't have to wait long, according to these vendors. Several vendors will happily accept pre orders, although vendors also tell us that the initial shipments of ATI's SKUs are of relatively low volume; at least when compared to the GeForce 7xxx launches of earlier this year.We had certainly wanted to see something different today on the availability side, but there are plenty of other things to be excited about today. Let's take a look at the new face of ATI: The X1000 series.
Feature Overview
There are quite a few exciting new features being introduced with ATI's new X1000 series. Of course, we have a new line of hardware based on a more refined architecture. But at the end of the day, it's not the way that a company implements a dot product or manages memory latency that sells product; it's what consumers can do with the hardware that counts. ATI will not disappoint with the number of new features thtat they have included in their new top to bottom family of graphics hardware.
To provide a quick overview of the new lineup from ATI, here are the key featuers of the X1000 series.
- Fabbed on TSMC's 90nm process
- Shader Model 3.0 support
- Fulltime/fullspeed fp32 processing for floating point pixel formats
- New "Ring Bus" memory architecture with support for GDDR4
- Antialiasing supported on MRT and fp16 output
- High quality angle independent Anisotropic Filtering
- AVIVO and advanced decode/encode support
Running on a 90nm TSMC process has given ATI the ability to push clock speeds quite high. With die sizes small and transistor counts high, ATI is able to pack a lot of performance in their new architecture. As the feature list indicates, ATI hasn't just waited idly by. But the real measure of what will be enough to put ATI back on top will be how much performance customers get for their money. To start answering that question, we first need to look at the parts launching and their prices.
| ATI X1000 Series Features | ||||
Radeon X1300 Pro |
Radeon X1600 |
Radeon X1800 XL |
Radeon X1800 XT |
|
| Vertex Pipelines | 2 |
5 |
8 |
8 |
| Pixel Pipelines | 4 |
12 |
16 |
16 |
| Core Clock | 600 |
590 |
500 |
625 |
| Memory Size | 256MB |
256MB |
256MB |
512MB |
| Memory Data Rate | 800MHz |
1.38GHz |
1GHz |
1.5GHz |
| Texture Units | 4 |
4 |
16 |
16 |
| Render Backends | 4 |
4 |
16 |
16 |
| Z Compare Units | 4 |
8 |
16 |
16 |
| Maximum Threads | 128 |
128 |
512 |
512 |
| Avaialbility | This Week |
11/30/2005 |
This Week |
11/5/2005 |
| MSRP | $149 |
$249 |
$449 |
$549 |
Along with all these features, CrossFire cards for the new X1000 series will be following in a few months. While we don't have anything to test, we can expect quite a few improvements from the next generation of ATI's multi-GPU solution. First and foremost, master cards will include a dual-link TMDS receiver to allow resolutions greater than 1600x1200 to run. This alone will make CrossFire on the X1000 series infinitely more useful than the current incarnation. We can also expect a better compositing engine built on a faster/larger FPGA. We look forward to checking out ATI's first viable multi-GPU solution as soon as it becomes available to us.
Rather than include AVIVO coverage in this article, we have published a separate article on ATI's X1000 series display hardware. The high points are a 10-bit gamma engine, H.264 accelerated decoding and hardware assisted transcoding. While we won't see transcoding support until the end of the year, we have H.264 decode support today. For more details, please check out our Avivo image quality comparison and technology overview.
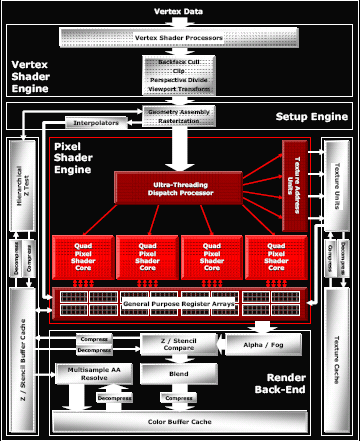
Pipeline Layout and Details
The general layout of the pipeline is very familiar. We have some number of vertex pipelines feeding through a setup engine into a number of pixel pipelines. After fragment processing, data is sent to the back end for things like fog, alpha blending and Z compares. The hardware can easily be scaled down at multiple points; vertex pipes, pixel pipes, Z compare units, texture units, and the like can all be scaled independently. Here's an overview of the high end case.
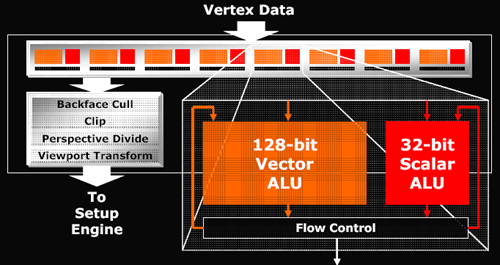
The maximum number of vertex pipelines in the X1000 series that it can handle is 8. Mid-range and budget parts incorporate 5 and 2 vertex units respectively. Each vertex pipeline is capable of one scalar and one vector operation per clock cycle. The hardware can support 1024 instruction shader programs, but much more can be done in those instructions with flow control for looping and branching.
After leaving the vertex pipelines and geometry setup hardware, the data makes its way to the "ultra threading" dispatch processor. This block of hardware is responsible for keeping the pixel pipelines fed and managing which threads are active and running at any given time. Since graphics architectures are inherently very parallel, quite a bit of scheduling work within a single thread can easily be done by the compiler. But as shader code is actually running, some instruction may need to wait on data from a texture fetch that hasn't completed or a branch whose outcome is yet to be determined. In these cases, rather than spin the clocks without doing any work, ATI can run the next set of instructions from another "thread" of data.
Threads are made up of 16 pixels each and up to 512 can be managed at one time (128 in mid-range and budget hardware). These threads aren't exactly like traditional CPU threads, as programmers do not have to create each one specifically. With graphics data, even with only one shader program running, a screen is automatically divided into many "threads" running the same program. When managing multiple threads, rather than requiring a context switch to process a different set of instructions running on different pixels, the GPU can keep multiple contexts open at the same time. In order to manage having any viable number of registers available to any of 512 threads, the hardware needs to manage a huge internal register file. But keeping as many threads, pixels, and instructions in flight at a time is key in managing and effectively hiding latency.
NVIDIA doesn't explicitly talk about hardware analogous to ATI's "ultra threading dispatch processor", but they must certainly have something to manage active pixels as well. We know from our previous NVIDIA coverage that they are able to keep hundreds of pixels in flight at a time in order to hide latency. It would not be possible or practical to give the driver complete control of scheduling and dispatching pixels as too much time would be wasted deciding what to do next.
We won't be able to answer specifically the question of which hardware is better at hiding latency. The hardware is so different and instructions will end up running through alternate paths on NVIDIA and ATI hardware. Scheduling quads, pixels, and instructions is one of the most important tasks that a GPU can do. Latency can be very high for some data and there is no excuse to let the vast parallelism of the hardware and dataset to go to waste without using it for hiding that latency. Unfortunately, there is just no test that we have currently to determine which hardware's method of scheduling is more efficient. All we can really do for now is look at the final performance offered in games to see which design appears "better".
One thing that we do know is that ATI is able to keep loop granularity smaller with their 16 pixel threads. Dynamic branching is dependant on the ability to do different things on different pixels. The efficiency of an algorithm breaks down if hardware requires that too many pixels follow the same path through a program. At the same time, the hardware gets more complicated (or performance breaks down) if every pixel were to be treated completely independently.
On NVIDIA hardware, programmers need to be careful to make sure that shader programs are designed to allow for about a thousand pixels at a time to take the same path through a shader. Performance is reduced if different directions through a branch need to be taken in small blocks of pixels. With ATI, every block of 16 pixels can take a different path through a shader. On G70 based hardware, blocks of a few hundred pixels should optimally take the same path. NV4x hardware requires larger blocks still - nearer to 900 in size. This tighter granularity possible on ATI hardware gives developers more freedom in how they design their shaders and take advantage of dynamic branching and flow control. Designing shaders to handle 32x32 blocks of pixels is more difficult than only needing to worry about 4x4 blocks of pixels.
After the code is finally scheduled and dispatched, we come to the pixel shader pipeline. ATI tightly groups pixel shaders in quads and is calling each block of pixel pipes a quad pixel shader core. This language indicates the tight grouping of quads that we already assumed existed on previous hardware.
Each pixel pipe in a quad is able to handle 6 instructions per clock. This is basically the same as R4xx hardware except that ATI is now able to accommodate dynamic branching on their dedicated branch hardware. The 2 scalar, 2 vector, 1 texture per clock arrangement seems to have worked with ATI in the past enough for them to stick with it again, only adding 1 branch operation that can be issued in parallel with these 5 other instructions.
Of course, branches won't happen nearly as often as math and texture operations, so this hardware will likely be idle most of the time. In any case, having separate hardware for branching that can work in parallel with the rest of the pipeline does make relatively tight loops more efficient than what they could be if no other work could be done while a branch was being handled.
All in all, one of the more interesting things about the hardware is its modularity. ATI has been very careful to make each block of the chip independent of the rest. With high end hardware, as much of everything is packed in as possible, but with their mid-range solution, they are much more frugal. The X1600 line will incorporate 3 quads with 12 pixel pipes alongside only 4 texture units and 8 Z compare units. Contrast this to the X1300 and its 4 pixel pipes, 4 texture units and 4 Z compare units and the "16 of everything" X1800 and we can see that the architecture is quite flexible on every level.
Memory Architecture
One of the newest features of the X1000 series is something ATI calls a "ring bus" memory architecture. The general idea behind the design is to improve memory bandwidth effectiveness while reducing cache misses, resulting in overall better memory performance. The architecture already supports GDDR4, but current boards have to settle for the fastest GDDR3 available until memory makers ship GDDR4 parts.
For quite some time, the high end in graphics memory architecture has been a straight forward 256-bit bus divided into four 64-bit channels on the GPU. The biggest issues with scaling up this type of architecture are routing, packaging and clock speed. Routing 256 wires from the GPU to RAM is quite complex. Cards with large buses require printed circuit boards (PCBs) with more layers than a board with a smaller bus in order to compensate for the complexity.
In order to support such a bus, the GPU has to have 256 physical external connections. Adding more and more external connections to a single piece of silicon can also contribute to complexities in increasing clock speed or managing clock speeds between the memory devices and the GPU. In the push for ever improving performance, increasing clock speed and memory bandwidth are constantly evaluated for cost and benefit.
Rather than pushing up the bit width of the bus to improve performance, ATI has taken another approach: improving the management and internal routing of data. Rather than 4 64-bit memory interfaces hooked into a large on die cache, the GPU hass 4 "ring stops" that connect to each other, graphics memory, and multiple caches and clients within the GPU. Each "ring stop" has 2 32-bit connections to 2 memory modules and 2 outgoing 256-bit connections to 2 other ring stops. ATI calls this a 512-bit Ring Bus (because there are 2 256-bit rings going around the ring stops).
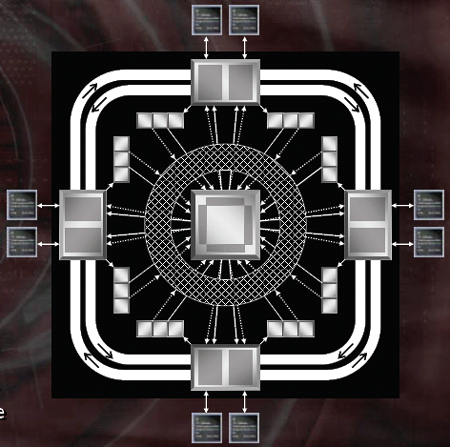
Routing incoming memory through a 512-bit internal bus helps ATI to get data where it needs to go quickly. Each of the ring stops connects to a different set of caches. There are 30+ independent clients that require memory access within an X1000 series GPU. When one of these clients needs data not in a cache, the memory controller forwards the request to the ring stop attached to the physical memory with the data required. That ring stop then forwards the data around the ring to the ring stop (and cache) nearest the requesting client.
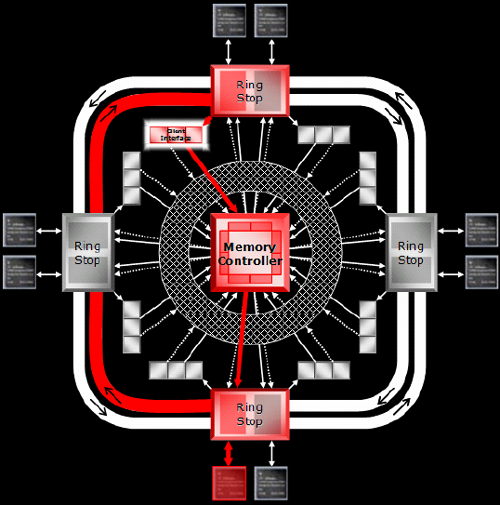
The primary function of memory management shifts to keeping the caches full with relevant information. Rather than having the memory controller on the GPU aggregate requests and control bandwidth, the memory controllers and ring bus work to keep data closer to the hardware that needs it most and can deal with each 32-bit channel independently. This essentially trades bandwidth efficiency for improved latency between memory and internal clients that require data quickly. With writes cached and going though the crossbar switch and the ring bus keeping memory moving to the cache nearest the clients that need data, ATI is able to tweak their caches to fit the new design as well.
On previous hardware, caches were direct mapped or set associative. This means that every address in memory maps to a specific cache line (or set in set associative). With larger caches, direct mapped and set associative designs work well (like L3 and L2 caches on a CPU). If a smaller cache is direct mapped, it is very easy for useful data to get kicked out too early by other data. Conversely, a large fully associative cache is inefficient as the entire cache must be searched for a hit rather than one line (direct mapped) or one block (set associative).
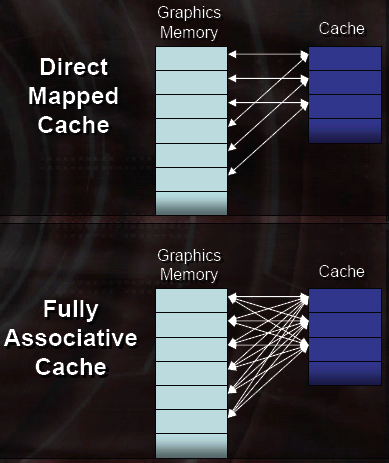
It makes sense that ATI would move to a fully associative cache in this situation. If they had large cache that serviced the entire range of clients and memory, a direct mapped (or more likely some n-way set associative cache) could make sense. With this new ring bus, if ATI split caches into multiple smaller blocks that service specific clients (as it appears they may have done), fully associative caches do make sense. Data from memory will be able to fill up the cache no matter where it's from, and searching smaller caches for hits shouldn't cut into latency too much. In fact, with a couple fully associative caches heavily populated with relevant data, overall latency should be improved. ATI showed us some Z and texture cache miss rates releative to X850. This data indicates anywhere from 5% to 30% improvement in cache miss rates among a few popular games from their new system.
The following cache miss scaling graphs are not data collected by us, but reported by ATI. We do not currently have a way to reproduce data like this. While assuring that the test is impartial and accurate is not possible in this situation (so take it with a grain of salt), the results are interesting enough for us to share them.
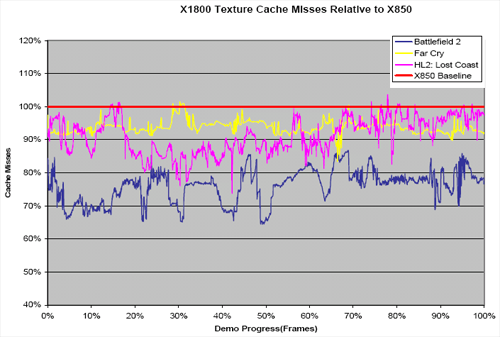
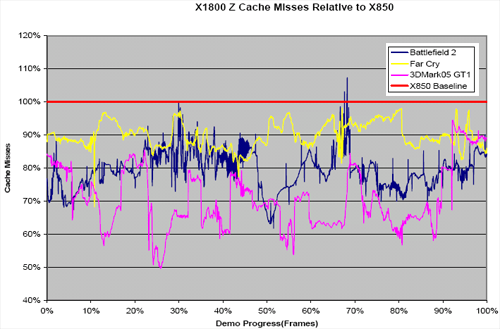
In the end, if common data patterns are known, cache design is fairly simple. It is easy to simulate cache hit/miss data based on application traces. A fully associative cache has its down sides (latency and complexity), so simply implementing them everywhere is not an option. Rather than accepting that fully associative caches are simply "better", it is much safer to say that a fully associative cache fits the design and makes better use of available resources on X1000 series hardware when managing data access patterns common in 3d applications.
Generally, bandwidth is more important than latency with graphics hardware as parallelism lends itself to effective bandwidth utilization and latency hiding. At the same time, as the use of flow control and branching increase, latency could potentially become more important than it is now.
The final new aspect of ATI's memory architecture is programmable bus arbitration. ATI is able to update and adapt the way the driver/hardware prioritizes memory access. The scheme is designed to weight memory requests based on a combination of latency and priority. The priority based scheme allows the system to determine and execute the most critical and important memory requests first while allowing data less sensitive to latency to wait its turn. The impression we have is that requests are required to complete within a certain number of cycles in order to prevent the starvation of any given thread, so the longer a request waits the higher its priority becomes.
ATI's ring bus architecture is quite interesting in and of itself, but there are some added benefits that go along with such a design. Altering the memory interface to connect with each memory device independently (rather than in 4 64-bit wide busses) gives ATI some flexibility. Individually routing lines in 32-bit groups helps to make routing connections more manageable. It's possible to increase stability (or potential clock speed) with simpler connections. We've already mentioned that ATI is ready to support GDDR4 out of the box, but there is also quite a bit of potential for hosting very high clock speed memory with this architecture. This is of limited use to customers who buy the product now, but it does give ATI the potential to come out with new parts as better and faster memory becomes available. The possibility of upgrading the 2 32-bit connections to something else is certainly there, and we hope to see something much faster in the future.
Unfortunately, we really don't have any reference point or testable data to directly determine the quality of this new design. Benchmarks will show how the platform as a whole performs, but whether the improvements come from the pixel pipelines, vertex pipelines, the memory controller, ring architecture, etc. is difficult to say.
High Quality AF
One of the greatest things about the newest high end hardware from NVIDIA and ATI is that advanced filtering features can be enabled at any resolution while still maintaining playable framerates. It may take developers a little while to catch up to the capabilities of the X1800 and 7800 lines, but adding value through advanced quality features is definitely a welcome path for ATI and NVIDIA to take. For this launch, ATI has improved their AA and AF implementations. We also have two brand new features: Adaptive AA and Area Anisotropic filtering.
Starting with Area Anisotropic (or high quality AF as it is called in the driver), ATI has finally brought viewing angle independent anisotropic filtering to their hardware. NVIDIA introduced this feature back in the GeForce FX days, but everyone was so caught up in the FX series' abysmal performance that not many paid attention to the fact that the FX series had better quality anisotropic filtering than anything from ATI. Yes, the performance impact was larger, but NVIDIA hardware was differentiating the Euclidean distance calculation sqrt(x^2 + y^2 + z^2) in its anisotropic filtering algorithm. Current methods (NVIDIA stopped doing the quality way) simply differentiate an approximated distance in the form of (ax + by + cz). Math buffs will realize that the differential for this approximated distance simply involves constants while the partials for Euclidean distance are less trivial. Calculating a square root is a complex task, even in hardware, which explains the lower performance of the "quality AF" equation.
Angle dependant anisotropic methods produce fine results in games with flat floors and walls, as these textures are aligned on axes that are correctly filtered. Games that allow a broader freedom of motion (such as flying/space games or top down view games like the sims) don't benefit any more from anisotropic filtering than trilinear filtering. Rotating a surface with angle dependant anisotropic filtering applied can cause noticeable and distracting flicker or texture aliasing. Thus, angle independent techniques (such as ATI's area aniso) are welcome additions to the playing field. As NVIDIA previously employed a high quality anisotropic algorithm, we hope that the introduction of this anisotropic algorithm from ATI will prompt NVIDIA to include such a feature in future hardware as well.
We sat down with the D3DAFTester to show the difference between NVIDIA and ATI hardware with and without the high quality mode enabled. Here's what we ended up with:
NVIDIA 7800 GTX AF


NVIDIA 7800 GTX AF
Mouse over to cycle images
Adaptive AA
Antialiasing is becoming more and more important as graphics cards get faster. With the 7800 GTX (and the X1800 XT when it comes along), there are very few monitors that can really stress the fill rate potential of these cards. Not everyone has 30" Apple Cinema Displays, and even at resolutions of 1600x1200 we see CPU limitedness start to become a factor. With many 1600x1200 flat panels out there on the market, this "monitor limitedness" will only get worse and worse as graphics cards continue to improve at a significantly faster rate than display technology. Quality enhancing features will get more and more attention in the meantime, and more power can be spent on enhancing a game rather than just rendering it. Thus more focus has recently been put into antialiasing algorithms.
Multisample AA (MSAA) has been the predominant method of antialiasing for quite a few years now, but it is not perfect. MSAA only works around polygon edges by smoothing lines when the area covered by one pixel falls over multiple triangles. SSAA oversamples everything at every pixel and is traditionally implemented by rendering a scene at a larger resolution and then down-sampling the image to fit the display. Lots of power is wasted with SSAA in areas that are covered by the same color, so MSAA wins out in performance while sacrificing a bit of quality.
One of the major down sides of MSAA is its inability to antialias the interior of polygons mapped with a texture that includes transparency. Things like wires, fences, and foliage are often rendered with huge triangles and transparent texture maps. Since MSAA only works on polygon edges, the areas between transparent and opaque parts inside these large polygons can look very jagged. The only way to combat this is to take multiple texture samples per pixel within the same polygon. This can be done by performing multiple texture lookups per pixel rather than simply rendering the scene at a huge resolution.
ATI is including a feature called Adaptive Antialiasing in the Catalyst release that comes along with the X1000 series. Adaptive AA is functionally similar to NVIDIA's Transparency AA. Rather than just doing multi-sample (MSAA), ATI is able to adaptively take multiple texture samples per pixel in areas that would benefit from including additional texture samples (essentially resulting in a combination of MSAA and SSAA where needed). Depending on where ATI determines it is necessary to perform multiple texture samples, poorly designed or easily aliased textures can benefit in addition to those that include transparency.
Unlike NVIDIA's Transparency AA, ATI's Adaptive AA will be available to all ATI hardware owners. How's that for value-add! This could be a very nice thing for X800/X850 series owners stuck with 1280x1024 panels. Apparently ATI has been tweaking this technology for a few years now, but held off on its introduction until this launch. The use of this feature on most older hardware won't be widespread as performance will degrade too much. In these cases, increasing resolution is almost always more effective than increasing AA quality. Here's a look at the Adaptive AA as compared to Transparency AA:
NVIDIA 7800 GTX 4xAA

NVIDIA 7800 GTX 4xAA
Mouse over to cycle images
Continuing down the path to high quality AA, ATI has improved the sub-pixel accuracy of their antialiasing hardware. Rather than being limited to selecting samples on an 8x8 grid, ATI is now able to work with select samples from a 16x16 grid. Moving up from 64 to 256 potential sub-pixels per pixel, ATI has improved the accuracy of their AA algorithm. This accuracy improvement may not be directly noticeable, but this enhancement will also improve the quality of dense AA methods like CrossFire's SuperAA technology. Workstation users will also benefit as this will likely translate to improved point and line antialiasing quality.
The one thing I would ask for from ATI is the ability to turn off "gamma-correct" AA. Such methods only shift inaccuracies between overly dark and overly bright pixels. Consistent results would only be possible if all displays were the same. Since they are not, it's really a six of one half-dozen of the other choice. Putting the decision in the user's hands as to what looks better is always our favored suggestion.
As if all of these enhancements weren't enough to top off ATI's already industry leading antialiasing (NVIDIA's grid aligned sample patterns just can't touch ATI's fully programmable sample patterns in quality), ATI has also vastly improved antialiasing performance with the X1000 generation of hardware. Neither NVIDIA nor previous generation ATI hardware can match the minimal performance hit the X1000 series incurs when enabling standard AA. The performance we see is likely due to a combination of the improvements made to the AA hardware itself along side enhancements to the memory architecture that allow for higher bandwidth and the prioritization of data moving on the ring bus.
Test Setup and Power Performance
Our testing methodology was to try and cover a lot of ground with top to bottom hardware. Including the X1300 through the X1800 line required quite a few different cards and tests to be run. In order to make it easier to look at the data, rather than put everything for each game in one place as we normally do, we have broken up our data into three separate groups: Budget, Midrange, and High End.
We used the latest drivers we had available which are both beta drivers. From NVIDIA, the 81.82 drivers were tested rather than the current release as we expect the rel 80 drivers to be in the end users hands before the X1000 series is easy to purchase.
All of our tests were done on this system:
ATI Radeon Express 200 based system
AMD Athlon 64 FX-55
1GB DDR400 2:2:2:8
120 GB Seagate 7200.7 HD
600 W OCZ PowerStreams PSU
The resolutions we tested range from 800x600 on the low end to 2048x1536 on the high end. The games we tested include:
- Day of Defeat: Source
- Doom 3
- EverQuest 2
- Far Cry
- Splinter Cell: Chaos Theory
- The Chronicles of Riddick
Before we take a look at the performance numbers, here's a look at the power draw of various hardware.

As we can see, this generation draws about as much power as previous generatation products under load at the high end and midrange. The X1300 Pro seems to draw a little more power than we would like to see in a budget part. The card also sports a fan that is just as loud as the X1600 XT. Considering that some of the cards we tested against the X1300 Pro were passively cooled, this is something to note.
Budget Performance
For budget performance, we feel that 1024x768 is the proper target resolution. People spending near the $100 mark can't expect to acheive performance at high resolutions. But with current hardware, we can play games at moderate resolutions without loosing any features.
The X1300 is targeted at the budget market, but we focued on testing our X1300 Pro against slightly higher performing parts because of it's pricing. The X1300 does quite well versus the traditional low end 6200 TC and X300 parts, but can't really compete with the 6600 GT which is priced near the $149 MSRP of the X1300 Pro.
Under Doom 3 (and many OpenGL applications) NVIDIA holds a lead over ATI hardware. While it is understandable that the X1300 Pro isn't able to match preformance with NVIDIA's $150 6600 GT, the $250 MSRP X1600 XT laggs far behind as well. It is quite interesting to note that the X1600 closes that gap (and performs slightly better than the 6600 GT) when 4xAA and 8xAF are enabled at this resolution. But at such low res, the better bet is to increase the setting to 1280x1024 with no AA where the 6600 GT maintains about a 20% performance lead. Doom 3 is also a fairly low contrast game, meaning that jagged edges are already hard to see.
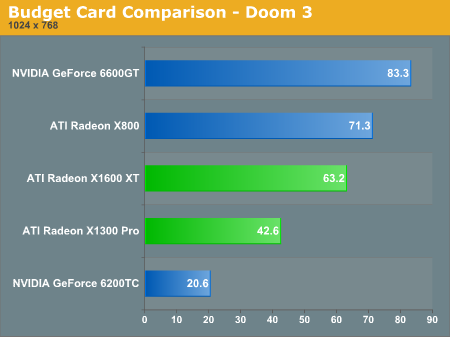
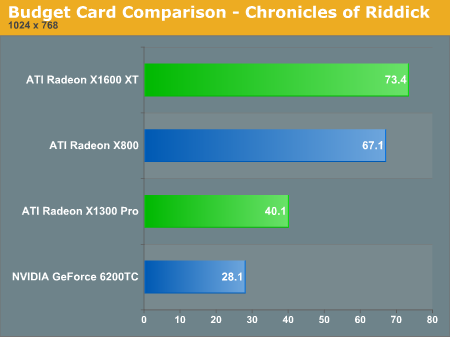
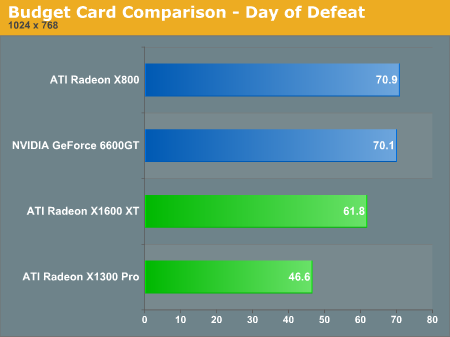
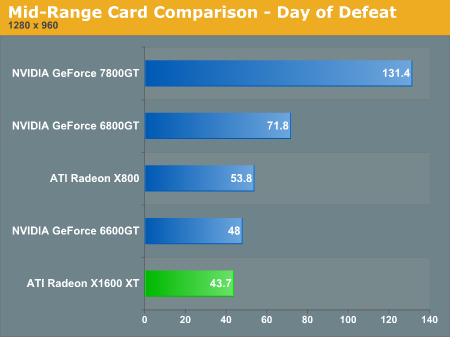
Under Valve's Day of Defeat: Source, the latest resurrection of a past title by Valve (and also the first to feature HDR), The 6600 GT and X800 perform on par with what we would expect while the more expensive X1600 XT lags behind and the X1300 looks to perform where a budget card should. Enabling 4xAA and 8xAF on this game closes the gap between the 6600 GT and X1600 XT: they both run at about 48 fps under this setting, followed by the X800 at nearly a 43 fps average.
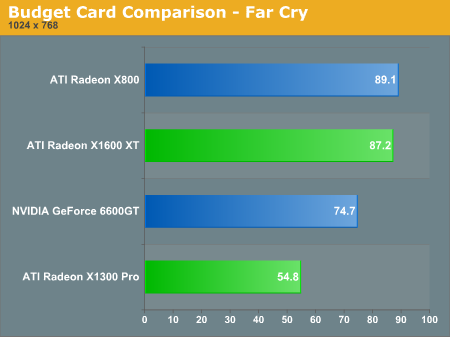
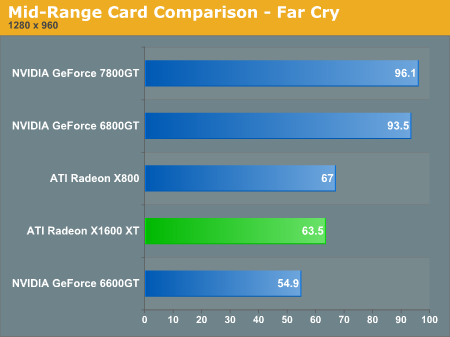
Far Cry provides a victory for the X1600 XT over the 6600 GT, but we still have the expensive X1300 Pro lagging it's closer cost competitor by a large margin.
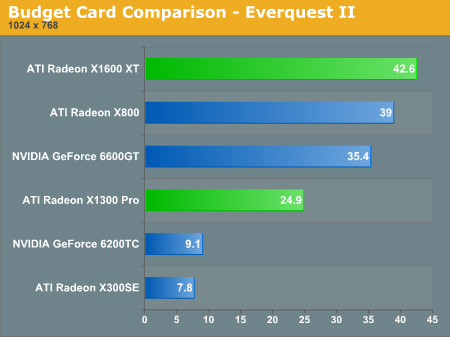
Everquest II on very high quality mode shows the X1600 XT to lead this segment in performance. Current ~$100 parts are shown to perform horribly at this setting scoring single digit framerates. The X1300 Pro is definitely playable at very high quality at 1024x768 (which we would recommend over a lower quality setting at a higher resolution). Extreme quality still doesn't perform very well on any but the most expensive cards out there and really doesn't offer that much more interms of visual quality.
When testing Splinter Cell: Chaos Theory, the new X1000 series of cards give a very good performance. This time around, the X800 and 6600 GT don't perform equally, and it looks as though the additions to the RV5xx architecture can make quite a difference depending on the game being played.
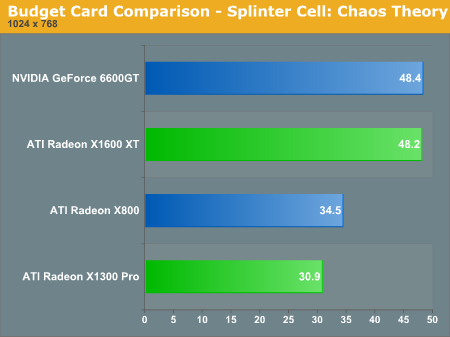
To see the continuing saga of the X1600 XT, we will take a look at midrange performace numbers at 1280x960.
Mid-Range Perforamnce
The X1600 XT costs much more than the 6600 GT and performs only slightly better in some cases. It's real competition should be something more along the lines of the 6800 GT which is able handle more than the new midrange ATI part. $249 for the X1600 XT compared to $288 for the 6800 GT shows the problem with the current pricing.
As we can easily see, the 6800 GT performs quite a bit better than the X1600 XT. From what we see here, the X1600 XT will need to fall well below the $200 mark for it to have real value at these resolutions with the highest settings. The 6600 GT is the clear choice for people who want to run a 1280x1024 LCD panel and play games comfortably with high quality and minimal cost.
Looking at Doom 3, it's clear that the X1600 XT falls fairly far behind. But once again, when 4xAA and 8xAF are enabled the X1600 performs at the level of the 6600 GT.
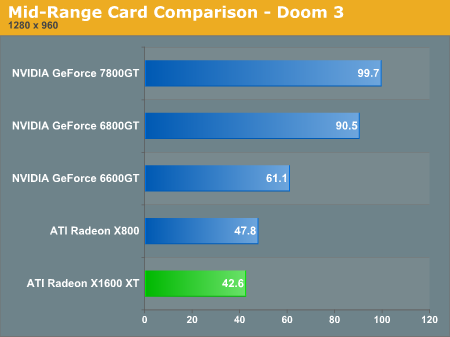
Eventhough this game is based on the engine that powered Half-Life 2 (and traditionally favored ATI hardware), the X1600 XT isn't able to surpass the 6600 GT in performance. The game isn't playable at 1280x960 with 4xAA and 8xAF enabled, but for what it is worth the X1600 XT again scales better than the 6600 GT.
Far Cry and Everquest II are the only two games that show X1600 XT performing beyond the 6600 GT at 1280x960 with no AA or AF. Even though these games scale better with AA and AF enabled on ATI's newest hardware, the framerates are not playable (with the exception of Far Cry). We should see a patch from Crytek in the not too distant future that expands HDR and SM3.0 features. We will have to revisit Far Cry performance when we can get our hands on the next patch.
The X1600 performs exactly on par with the X800 in this test. Both of these ATI midrange cards outpace the 6600 GT from NVIDIA, though the 6800 GT is 50% faster than the X1600 XT. Again, cost could become a major factor in the value of these cards.
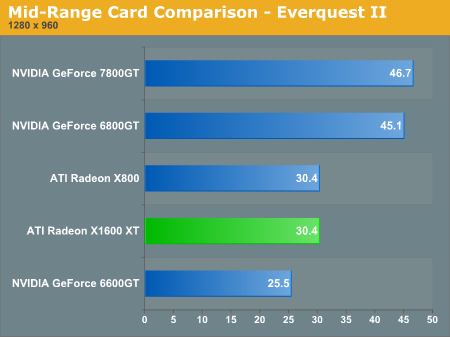
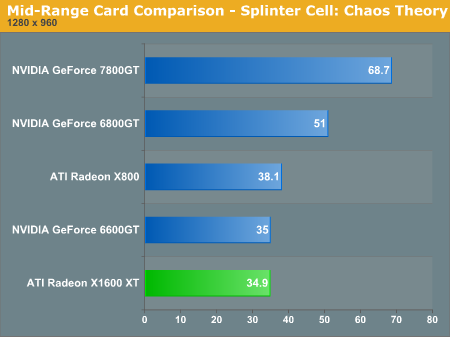
Splinter Cell is a fairly demanding game and the X1600 XT and 6600 GT both perform at the bottom of the heap in this test. Of course, ultra high frame rates are not necessary for this stealth action game, but the game certainly plays more smoothly on the 6800 GT at 51 fps. The 6800 GT also remains playable with AA/AF enabled while the X1600 and 6600 GT do not.
High End and Future Ultra High End Performance
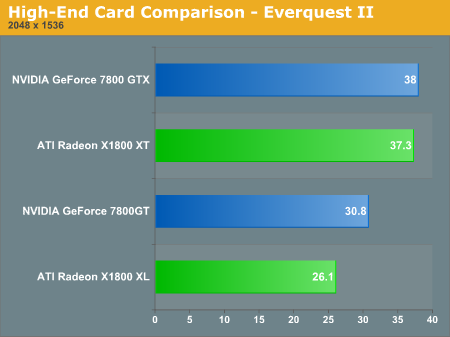
On the high end, the X1800 XL is a solid competitor to the 7800 GT. In some cases, the X1800 XL is able to compete with the 7800 GTX, but not enough to warrant pricing on the same level. The X1800 XT will not be out for at least a month, and while it does offer good competition to the 7800 GTX, we do want to caution everyone to wait until the part is shipping before embracing it.
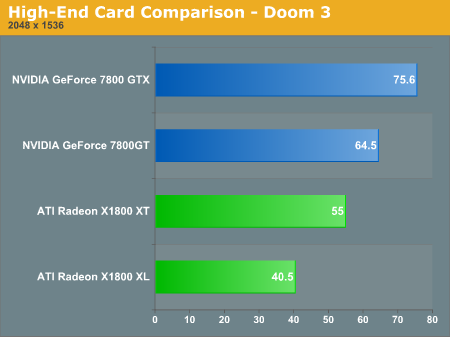
Once again, Doom 3 shows NVIDIA to lead the way in performance, this time even with 4xAA and 8xAF enabled. Even the 6800 GT is able to best ATI's new flagship, the X1800 XT.

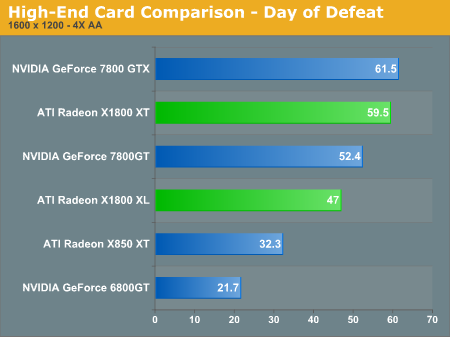
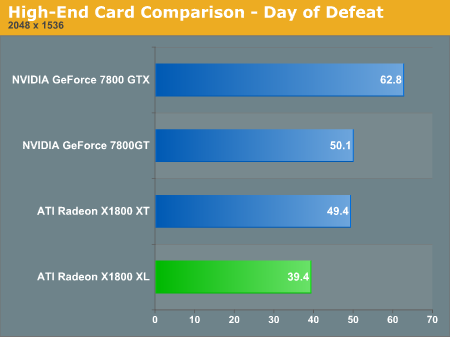
The X1800 XT falls just short of the NVIDIA 7800 GTX at 1600x1200 4xAA/8xAF with a score of 59.5 fps. The X1800 XL and XT are good competitors to the 7800 GTX and 7800 GT parts at this resolution under Day of Defeat. We run with all the quality options on the highest setting (including reflect all).
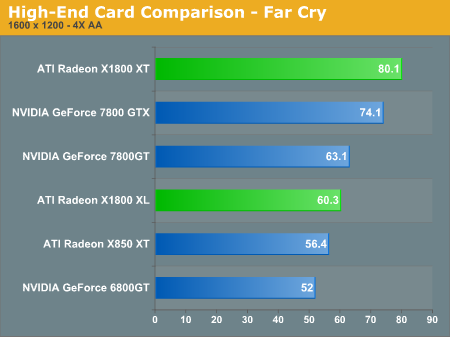
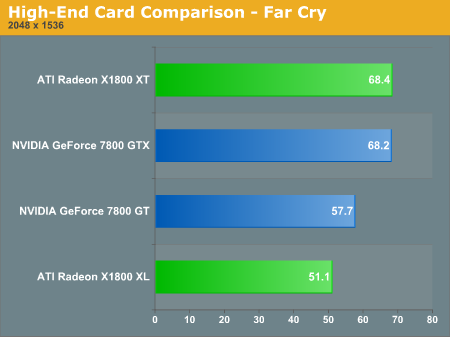
The X1000 line tend to do very well in Far Cry, and the high end parts are no exception. This time around, the defeat isn't that staggering, as the 7800 series seems to keep up well.
With Splinter Cell: Chaos Theory, the X1800 XT dominates. The X1800 XL is competive with the 7800 GTX in this benchmark, which is appropriate based on expected pricing.

Looking at the ultra high end, Doom 3 once again favors the NVIDIA line of parts.

Final Words
Today's launch would have been more spectacular had ATI been able to have parts available immediately. Of course, that doesn't mean that their parts aren't any good. As we can easily tell from the feature set, ATI has built some very competitive hardware. The performance numbers show that the X1000 series are quite capable of handling the demand of modern games, and scaling with AA and AF enabled are quite good as well.The one caveat will be pricing. The 7800 GTX is already available at much less than where the X1800 XT is slated to debut. Granted, the 7800 GTX fell from about $600 to where it is today, but the fact of the matter is that until ATI's new parts are in the market for a while and settle into their price points they won't be viable alternatives to NVIDIA's 6 and 7 series parts.
After market forces have their way with ATI and prices come out more or less on par with performance characteristics, the new X1000 lineup will have quite a bit of value, especially for those who wish to enable AA/AF all the time. While the X1800 XL can be competitive with the 7800 GT, it won't matter much if the street price remains at near the level of the 7800 GTX.
Yes, the X1800 XT is a very powerful card, but it won't be available for some time now. With its 512MB of onboard RAM, the X1800 XT scales especially well at high resolutions, but we would be very interested in seeing what a 512MB version of the 7800 GTX would be capable of doing. Maybe by the time the X1800 XT makes it to market we will have a 512MB 7800 GTX as well.
In the midrange space, the X1600 XT performs okay against the 6600GT, but it is priced nearer the 6800 GT which performs much better for the money. Again, testing the lower clocked or smaller RAM parts would give us a much better idea of the eventual value of the X1600 series of parts.
Until we test the extremely low end X1300 parts, we can't tell how competitive ATI will be in the budget space. It certainly is easier to make a card perform worse, but again the question is the price point ATI can afford to set for their parts.
As far as new features go, we are quite happy with the high quality anisotropic filtering offered by ATI and we hope to see NVIDIA follow suit in future products as well. As for ATI's Adaptive AA, we prefer NVIDIA's Transparency AA in both quality and performance. Unfortunately, Transparency AA is only available on NVIDIA's 7 series hardware while Adaptive AA is able to run on all recent ATI products.
In case we haven't made it quite clear, the bottom line is price. The X1600 and X1300 cards will have to sell for much less than they are currently listed in order to be at all useful. API support is on par, but as developers get time with hardware we will be very interested to see where the performance trend takes us. The features both parts offer are quite similar with the only major advantage in ATI's court with their angle independent AF mode. CrossFire won't be here for at least another month or two, but when it does we will certainly revisit the NVIDIA vs. ATI multi-GPU competition. The newer version of CrossFire looks to fix many of the problems we have with the current incarnation.






