Original Link: https://www.anandtech.com/show/17024/apple-m1-max-performance-review
Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Apple
- MacBook
- Laptops
- Apple M1 Pro
- Apple M1 Max

Last week, Apple had unveiled their new generation MacBook Pro laptop series, a new range of flagship devices that bring with them significant updates to the company’s professional and power-user oriented user-base. The new devices particularly differentiate themselves in that they’re now powered by two new additional entries in Apple’s own silicon line-up, the M1 Pro and the M1 Max. We’ve covered the initial reveal in last week’s overview article of the two new chips, and today we’re getting the first glimpses of the performance we’re expected to see off the new silicon.
The M1 Pro: 10-core CPU, 16-core GPU, 33.7bn Transistors
Starting off with the M1 Pro, the smaller sibling of the two, the design appears to be a new implementation of the first generation M1 chip, but this time designed from the ground up to scale up larger and to more performance. The M1 Pro in our view is the more interesting of the two designs, as it offers mostly everything that power users will deem generationally important in terms of upgrades.
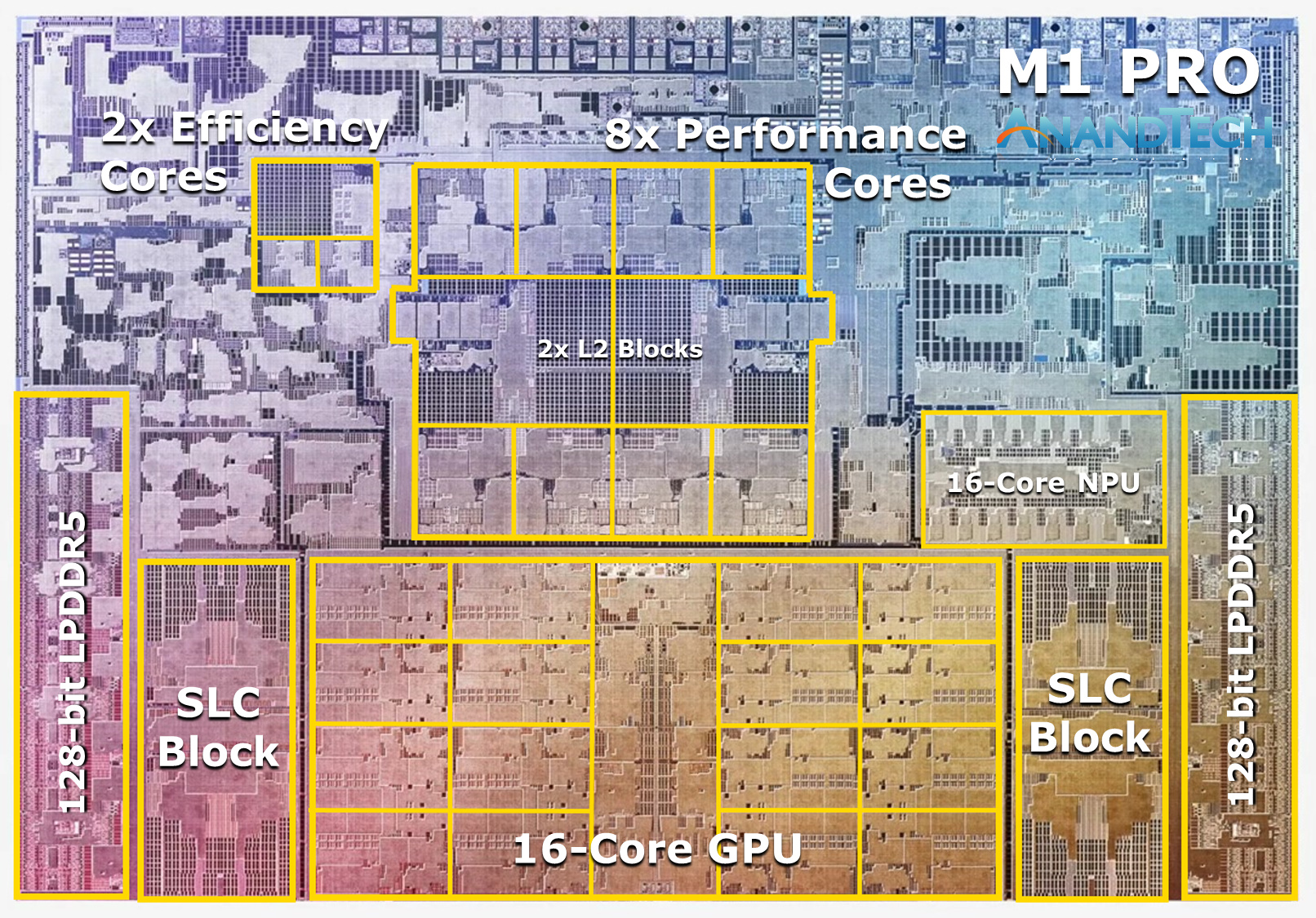
At the heart of the SoC we find a new 10-core CPU setup, in a 8+2 configuration, with there being 8 performance Firestorm cores and 2 efficiency Icestorm cores. We had indicated in our initial coverage that it appears that Apple’s new M1 Pro and Max chips is using a similar, if not the same generation CPU IP as on the M1, rather than updating things to the newer generation cores that are being used in the A15. We seemingly can confirm this, as we’re seeing no apparent changes in the cores compared to what we’ve discovered on the M1 chips.
The CPU cores clock up to 3228MHz peak, however vary in frequency depending on how many cores are active within a cluster, clocking down to 3132 at 2, and 3036 MHz at 3 and 4 cores active. I say “per cluster”, because the 8 performance cores in the M1 Pro and M1 Max are indeed consisting of two 4-core clusters, both with their own 12MB L2 caches, and each being able to clock their CPUs independently from each other, so it’s actually possible to have four active cores in one cluster at 3036MHz and one active core in the other cluster running at 3.23GHz.
The two E-cores in the system clock at up to 2064MHz, and as opposed to the M1, there’s only two of them this time around, however, Apple still gives them their full 4MB of L2 cache, same as on the M1 and A-derivative chips.
One large feature of both chips is their much-increased memory bandwidth and interfaces – the M1 Pro features 256-bit LPDDR5 memory at 6400MT/s speeds, corresponding to 204GB/s bandwidth. This is significantly higher than the M1 at 68GB/s, and also generally higher than competitor laptop platforms which still rely on 128-bit interfaces.
We’ve been able to identify the “SLC”, or system level cache as we call it, to be falling in at 24MB for the M1 Pro, and 48MB on the M1 Max, a bit smaller than what we initially speculated, but makes sense given the SRAM die area – representing a 50% increase over the per-block SLC on the M1.
The M1 Max: A 32-Core GPU Monstrosity at 57bn Transistors
Above the M1 Pro we have Apple’s second new M1 chip, the M1 Max. The M1 Max is essentially identical to the M1 Pro in terms of architecture and in many of its functional blocks – but what sets the Max apart is that Apple has equipped it with much larger GPU and media encode/decode complexes. Overall, Apple has doubled the number of GPU cores and media blocks, giving the M1 Max virtually twice the GPU and media performance.


The GPU and memory interfaces of the chip are by far the most differentiated aspects of the chip, instead of a 16-core GPU, Apple doubles things up to a 32-core unit. On the M1 Max which we tested for today, the GPU is running at up to 1296MHz - quite fast for what we consider mobile IP, but still significantly slower than what we’ve seen from the conventional PC and console space where GPUs now can run up to around 2.5GHz.
Apple also doubles up on the memory interfaces, using a whopping 512-bit wide LPDDR5 memory subsystem – unheard of in an SoC and even rare amongst historical discrete GPU designs. This gives the chip a massive 408GB/s of bandwidth – how this bandwidth is accessible to the various IP blocks on the chip is one of the things we’ll be investigating today.
The memory controller caches are at 48MB in this chip, allowing for theoretically amplified memory bandwidth for various SoC blocks as well as reducing off-chip DRAM traffic, thus also reducing power and energy usage of the chip.
Apple’s die shot of the M1 Max was a bit weird initially in that we weren’t sure if it actually represents physical reality – especially on the bottom part of the chip we had noted that there appears to be a doubled up NPU – something Apple doesn’t officially disclose. A doubled up media engine makes sense as that’s part of the features of the chip, however until we can get a third-party die shot to confirm that this is indeed how the chip looks like, we’ll refrain from speculating further in this regard.
Huge Memory Bandwidth, but not for every Block
One highly intriguing aspect of the M1 Max, maybe less so for the M1 Pro, is the massive memory bandwidth that is available for the SoC.
Apple was keen to market their 400GB/s figure during the launch, but this number is so wild and out there that there’s just a lot of questions left open as to how the chip is able to take advantage of this kind of bandwidth, so it’s one of the first things to investigate.
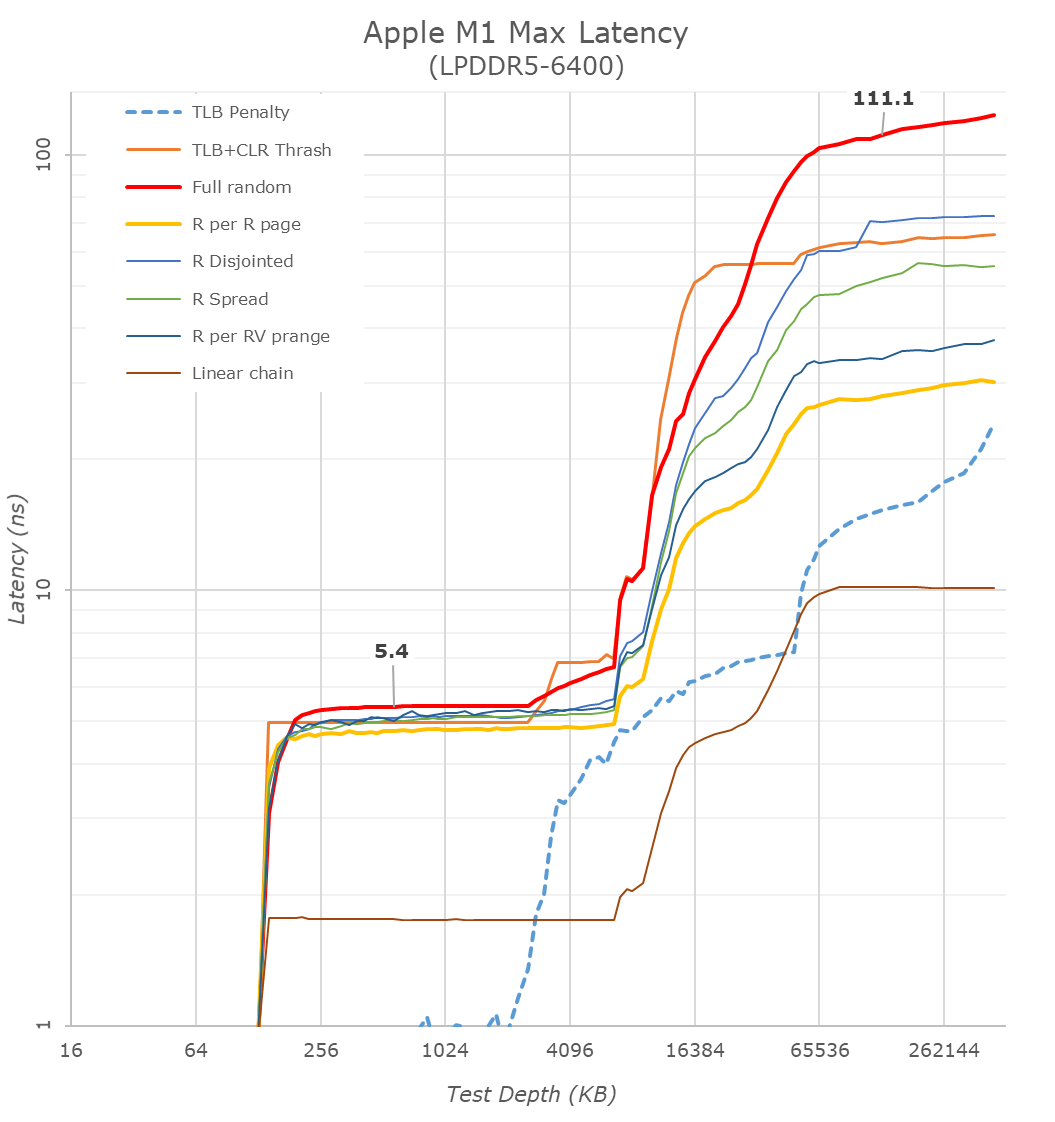
Starting off with our memory latency tests, the new M1 Max changes system memory behaviour quite significantly compared to what we’ve seen on the M1. On the core and L2 side of things, there haven’t been any changes and we consequently don’t see much alterations in terms of the results – it’s still a 3.2GHz peak core with 128KB of L1D at 3 cycles load-load latencies, and a 12MB L2 cache.
Where things are quite different is when we enter the system cache, instead of 8MB, on the M1 Max it’s now 48MB large, and also a lot more noticeable in the latency graph. While being much larger, it’s also evidently slower than the M1 SLC – the exact figures here depend on access pattern, but even the linear chain access shows that data has to travel a longer distance than the M1 and corresponding A-chips.
DRAM latency, even though on paper is faster for the M1 Max in terms of frequency on bandwidth, goes up this generation. At a 128MB comparable test depth, the new chip is roughly 15ns slower. The larger SLCs, more complex chip fabric, as well as possible worse timings on the part of the new LPDDR5 memory all could add to the regression we’re seeing here. In practical terms, because the SLC is so much bigger this generation, workloads latencies should still be lower for the M1 Max due to the higher cache hit rates, so performance shouldn’t regress.
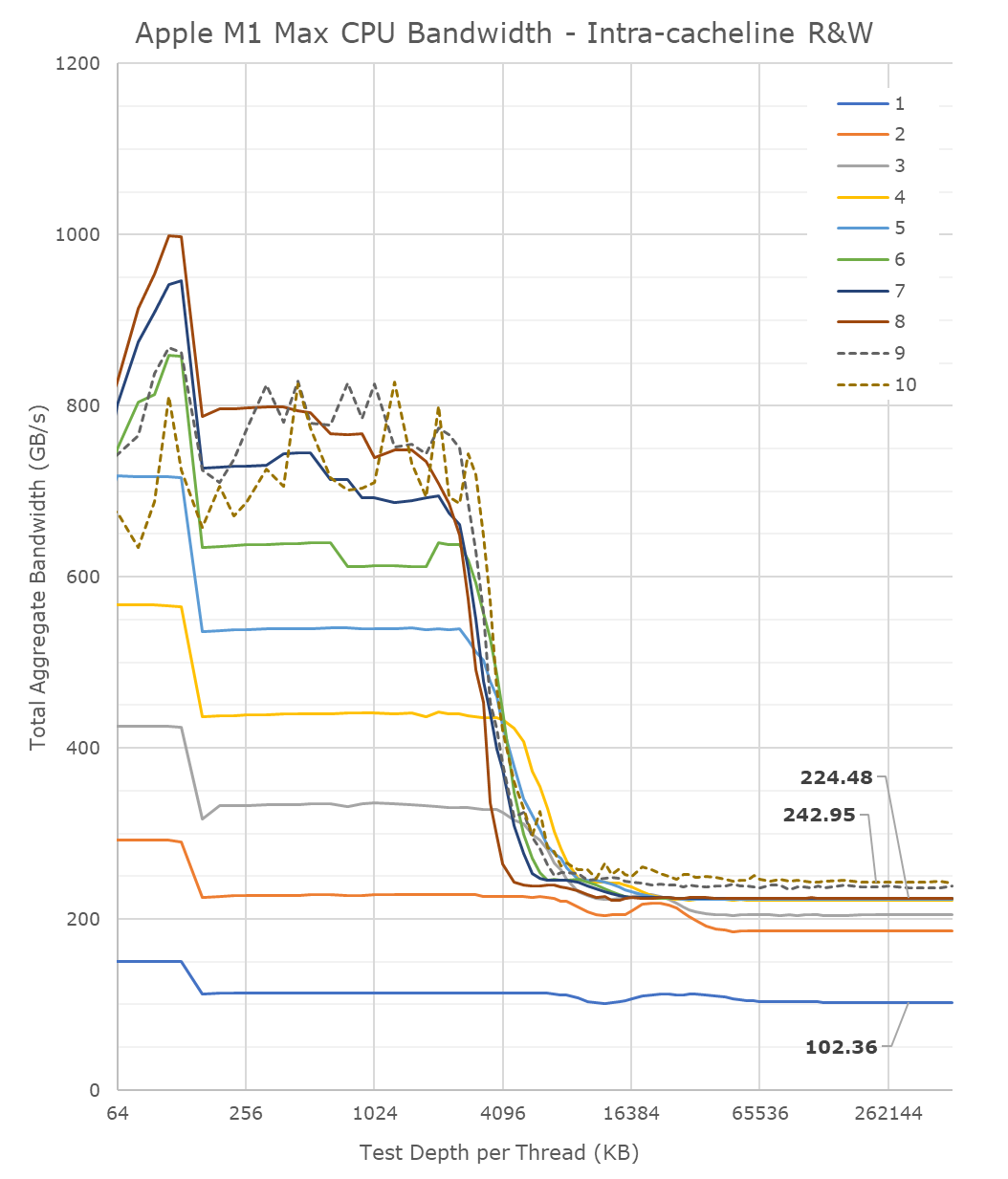
A lot of people in the HPC audience were extremely intrigued to see a chip with such massive bandwidth – not because they care about GPU or other offload engines of the SoC, but because the possibility of the CPUs being able to have access to such immense bandwidth, something that otherwise is only possible to achieve on larger server-class CPUs that cost a multitude of what the new MacBook Pros are sold at. It was also one of the first things I tested out – to see exactly just how much bandwidth the CPU cores have access to.
Unfortunately, the news here isn’t the best case-scenario that we hoped for, as the M1 Max isn’t able to fully saturate the SoC bandwidth from just the CPU side;
From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself. On the M1 Max, it seems that we’re hitting the limit of what a core can do – or more precisely, a limit to what the CPU cluster can do.
The little hump between 12MB and 64MB should be the SLC of 48MB in size, the reduction in BW at the 12MB figure signals that the core is somehow limited in bandwidth when evicting cache lines back to the upper memory system. Our test here consists of reading, modifying, and writing back cache lines, with a 1:1 R/W ratio.
Going from 1 core/threads to 2, what the system is actually doing is spreading the workload across the two performance clusters of the SoC, so both threads are on their own cluster and have full access to the 12MB of L2. The “hump” after 12MB reduces in size, ending earlier now at +24MB, which makes sense as the 48MB SLC is now shared amongst two cores. Bandwidth here increases to 186GB/s.
Adding a third thread there’s a bit of an imbalance across the clusters, DRAM bandwidth goes to 204GB/s, but a fourth thread lands us at 224GB/s and this appears to be the limit on the SoC fabric that the CPUs are able to achieve, as adding additional cores and threads beyond this point does not increase the bandwidth to DRAM at all. It’s only when the E-cores, which are in their own cluster, are added in, when the bandwidth is able to jump up again, to a maximum of 243GB/s.
While 243GB/s is massive, and overshadows any other design in the industry, it’s still quite far from the 409GB/s the chip is capable of. More importantly for the M1 Max, it’s only slightly higher than the 204GB/s limit of the M1 Pro, so from a CPU-only workload perspective, it doesn’t appear to make sense to get the Max if one is focused just on CPU bandwidth.
That begs the question, why does the M1 Max have such massive bandwidth? The GPU naturally comes to mind, however in my testing, I’ve had extreme trouble to find workloads that would stress the GPU sufficiently to take advantage of the available bandwidth. Granted, this is also an issue of lacking workloads, but for actual 3D rendering and benchmarks, I haven’t seen the GPU use more than 90GB/s (measured via system performance counters). While I’m sure there’s some productivity workload out there where the GPU is able to stretch its legs, we haven’t been able to identify them yet.
That leaves everything else which is on the SoC, media engine, NPU, and just workloads that would simply stress all parts of the chip at the same time. The new media engine on the M1 Pro and Max are now able to decode and encode ProRes RAW formats, the above clip is a 5K 12bit sample with a bitrate of 1.59Gbps, and the M1 Max is not only able to play it back in real-time, it’s able to do it at multiple times the speed, with seamless immediate seeking. Doing the same thing on my 5900X machine results in single-digit frames. The SoC DRAM bandwidth while seeking around was at around 40-50GB/s – I imagine that workloads that stress CPU, GPU, media engines all at the same time would be able to take advantage of the full system memory bandwidth, and allow the M1 Max to stretch its legs and differentiate itself more from the M1 Pro and other systems.
Power Behaviour: No Real TDP, but Wide Range
Last year when we reviewed the M1 inside the Mac mini, we did some rough power measurements based on the wall-power of the machine. Since then, we learned how to read out Apple’s individual CPU, GPU, NPU and memory controller power figures, as well as total advertised package power. We repeat the exercise here for the 16” MacBook Pro, focusing on chip package power, as well as AC active wall power, meaning device load power, minus idle power.
Apple doesn’t advertise any TDP for the chips of the devices – it’s our understanding that simply doesn’t exist, and the only limitation to the power draw of the chips and laptops are simply thermals. As long as temperature is kept in check, the silicon will not throttle or not limit itself in terms of power draw. Of course, there’s still an actual average power draw figure when under different scenarios, which is what we come to test here:
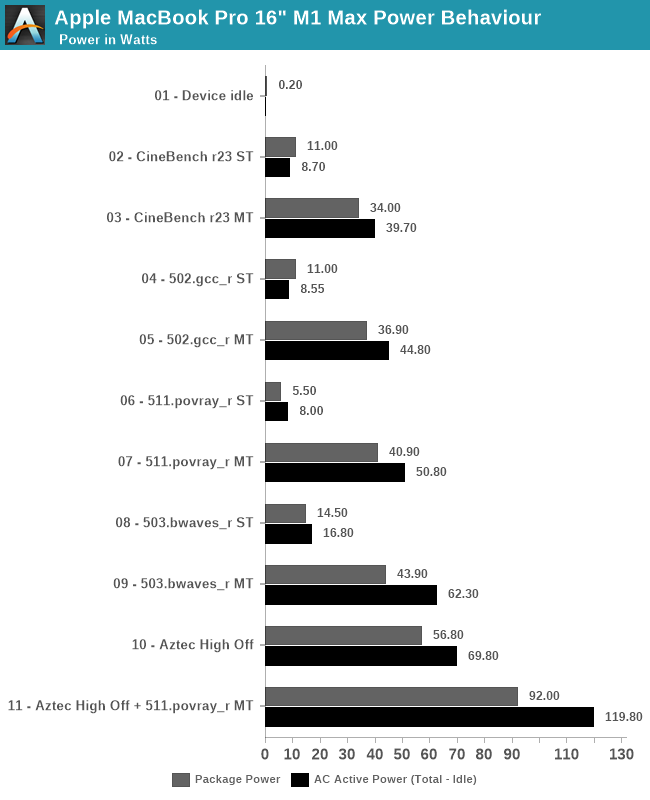
Starting off with device idle, the chip reports a package power of around 200mW when doing nothing but idling on a static screen. This is extremely low compared to competitor designs, and is likely a reason Apple is able achieve such fantastic battery life. The AC wall power under idle was 7.2W, this was on Apple’s included 140W charger, and while the laptop was on minimum display brightness – it’s likely the actual DC battery power under this scenario is much lower, but lacking the ability to measure this, it’s the second-best thing we have. One should probably assume a 90% efficiency figure in the AC-to-DC conversion chain from 230V wall to 28V USB-C MagSafe to whatever the internal PMIC usage voltage of the device is.
In single-threaded workloads, such as CineBench r23 and SPEC 502.gcc_r, both which are more mixed in terms of pure computation vs also memory demanding, we see the chip report 11W package power, however we’re just measuring a 8.5-8.7W difference at the wall when under use. It’s possible the software is over-reporting things here. The actual CPU cluster is only using around 4-5W under this scenario, and we don’t seem to see much of a difference to the M1 in that regard. The package and active power are higher than what we’ve seen on the M1, which could be explained by the much larger memory resources of the M1 Max. 511.povray is mostly core-bound with little memory traffic, package power is reported less, although at the wall again the difference is minor.
In multi-threaded scenarios, the package and wall power vary from 34-43W on package, and wall active power from 40 to 62W. 503.bwaves stands out as having a larger difference between wall power and reported package power – although Apple’s powermetrics showcases a “DRAM” power figure, I think this is just the memory controllers, and that the actual DRAM is not accounted for in the package power figure – the extra wattage that we’re measuring here, because it’s a massive DRAM workload, would be the memory of the M1 Max package.
On the GPU side, we lack notable workloads, but GFXBench Aztec High Offscreen ends up with a 56.8W package figure and 69.80W wall active figure. The GPU block itself is reported to be running at 43W.
Finally, stressing out both CPU and GPU at the same time, the SoC goes up to 92W package power and 120W wall active power. That’s quite high, and we haven’t tested how long the machine is able to sustain such loads (it’s highly environment dependent), but it very much appears that the chip and platform don’t have any practical power limit, and just uses whatever it needs as long as temperatures are in check.
| M1 Max MacBook Pro 16" |
Intel i9-11980HK MSI GE76 Raider |
|||||
| Score | Package Power (W) |
Wall Power Total - Idle (W) |
Score | Package Power (W) |
Wall Power Total - Idle (W) |
|
| Idle | 0.2 | 7.2 (Total) |
1.08 | 13.5 (Total) |
||
| CB23 ST | 1529 | 11.0 | 8.7 | 1604 | 30.0 | 43.5 |
| CB23 MT | 12375 | 34.0 | 39.7 | 12830 | 82.6 | 106.5 |
| 502 ST | 11.9 | 11.0 | 9.5 | 10.7 | 25.5 | 24.5 |
| 502 MT | 74.6 | 36.9 | 44.8 | 46.2 | 72.6 | 109.5 |
| 511 ST | 10.3 | 5.5 | 8.0 | 10.7 | 17.6 | 28.5 |
| 511 MT | 82.7 | 40.9 | 50.8 | 60.1 | 79.5 | 106.5 |
| 503 ST | 57.3 | 14.5 | 16.8 | 44.2 | 19.5 | 31.5 |
| 503 MT | 295.7 | 43.9 | 62.3 | 60.4 | 58.3 | 80.5 |
| Aztec High Off | 307fps | 56.8 | 69.8 | 266fps | 35 + 144 | 200.5 |
| Aztec+511MT | 92.0 | 119.8 | 78 + 142 | 256.5 | ||
Comparing the M1 Max against the competition, we resorted to Intel’s 11980HK on the MSI GE76 Raider. Unfortunately, we wanted to also do a comparison against AMD’s 5980HS, however our test machine is dead.
In single-threaded workloads, Apple’s showcases massive performance and power advantages against Intel’s best CPU. In CineBench, it’s one of the rare workloads where Apple’s cores lose out in performance for some reason, but this further widens the gap in terms of power usage, whereas the M1 Max only uses 8.7W, while a comparable figure on the 11980HK is 43.5W.
In other ST workloads, the M1 Max is more ahead in performance, or at least in a similar range. The performance/W difference here is around 2.5x to 3x in favour of Apple’s silicon.
In multi-threaded tests, the 11980HK is clearly allowed to go to much higher power levels than the M1 Max, reaching package power levels of 80W, for 105-110W active wall power, significantly more than what the MacBook Pro here is drawing. The performance levels of the M1 Max are significantly higher than the Intel chip here, due to the much better scalability of the cores. The perf/W differences here are 4-6x in favour of the M1 Max, all whilst posting significantly better performance, meaning the perf/W at ISO-perf would be even higher than this.
On the GPU side, the GE76 Raider comes with a GTX 3080 mobile. On Aztec High, this uses a total of 200W power for 266fps, while the M1 Max beats it at 307fps with just 70W wall active power. The package powers for the MSI system are reported at 35+144W.
Finally, the Intel and GeForce GPU go up to 256W power daw when used together, also more than double that of the MacBook Pro and its M1 Max SoC.
The 11980HK isn’t a very efficient chip, as we had noted it back in our May review, and AMD’s chips should fare quite a bit better in a comparison, however the Apple Silicon is likely still ahead by extremely comfortable margins.
CPU ST Performance: Not Much Change from M1
Apple didn’t talk much about core performance of the new M1 Pro and Max, and this is likely because it hasn’t really changed all that much compared to the M1. We’re still seeing the same Firestrom performance cores, and they’re still clocked at 3.23GHz. The new chip has more caches, and more DRAM bandwidth, but under ST scenarios we’re not expecting large differences.
When we first tested the M1 last year, we had compiled SPEC under Apple’s Xcode compiler, and we lacked a Fortran compiler. We’ve moved onto a vanilla LLVM11 toolchain and making use of GFortran (GCC11) for the numbers published here, allowing us more apple-to-apples comparisons. The figures don’t change much for the C/C++ workloads, but we get a more complete set of figures for the suite due to the Fortran workloads. We keep flags very simple at just “-Ofast” and nothing else.
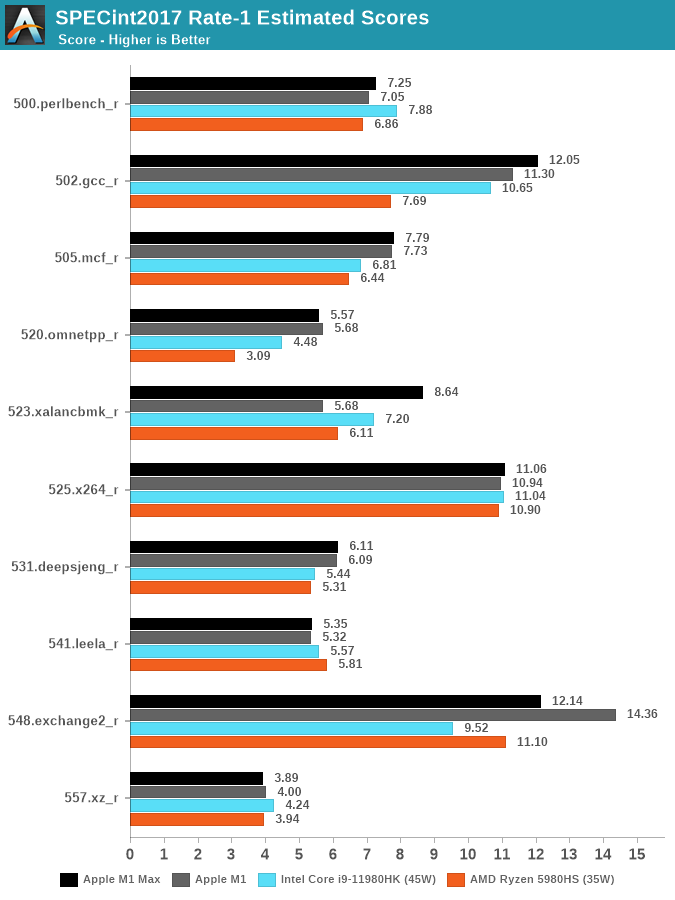
In SPECint2017, the differences to the M1 are small. 523.xalancbmk is showcasing a large performance improvement, however I don’t think this is due to changes on the chip, but rather a change in Apple’s memory allocator in macOS 12. Unfortunately, we no longer have an M1 device available to us, so these are still older figures from earlier in the year on macOS 11.
Against the competition, the M1 Max either has a significant performance lead, or is able to at least reach parity with the best AMD and Intel have to offer. The chip however doesn’t change the landscape all too much.
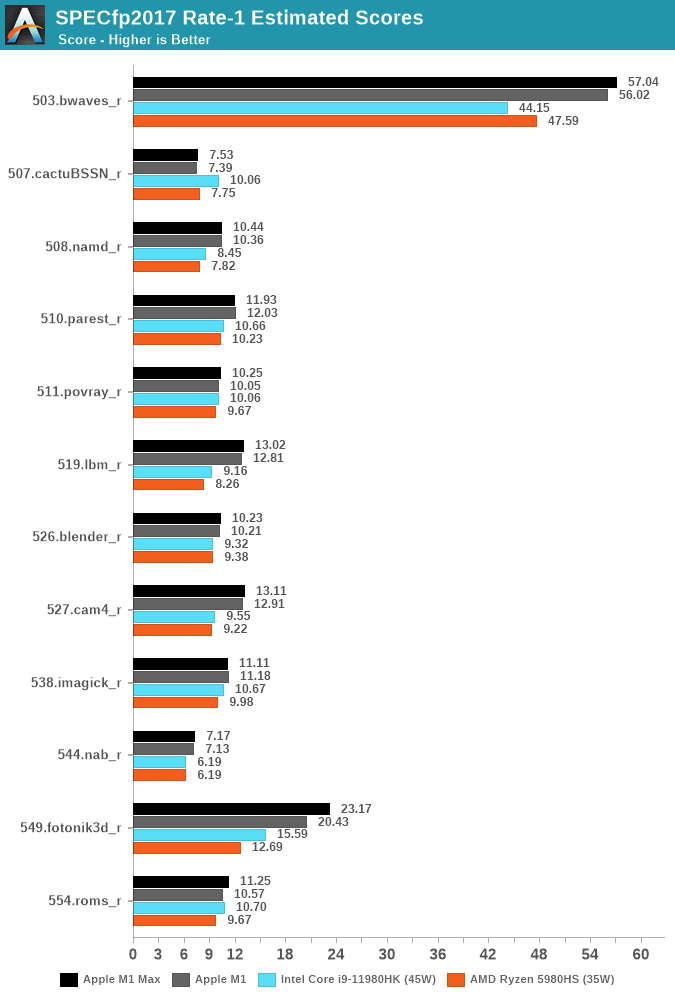
SPECfp2017 also doesn’t change dramatically, 549.fotonik3d does score quite a bit better than the M1, which could be tied to the more available DRAM bandwidth as this workloads puts extreme stress on the memory subsystem, but otherwise the scores change quite little compared to the M1, which is still on average quite ahead of the laptop competition.
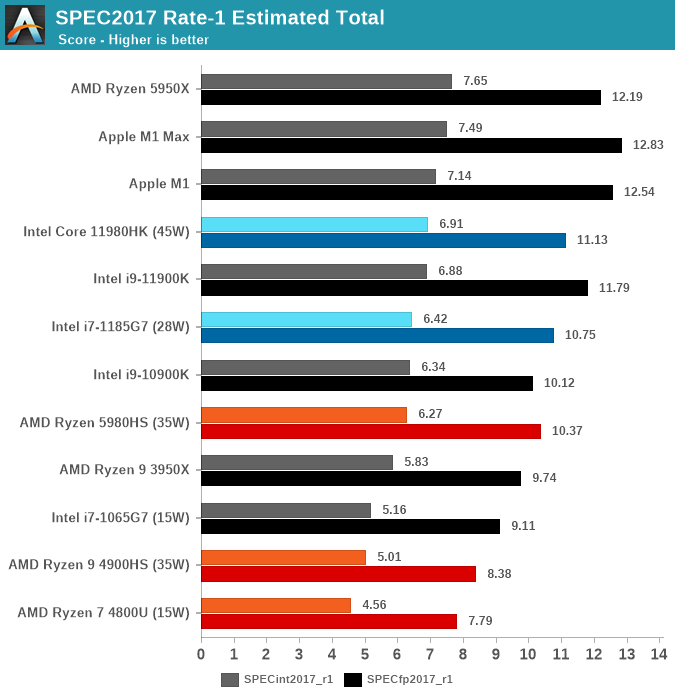
The M1 Max lands as the top performing laptop chip in SPECint2017, just shy of being the best CPU overall which still goes to the 5950X, but is able to take and maintain the crown from the M1 in the FP suite.
Overall, the new M1 Max doesn’t deliver any large surprises on single-threaded performance metrics, which is also something we didn’t expect the chip to achieve.
CPU MT Performance: A Real Monster
What’s more interesting than ST performance, is MT performance. With 8 performance cores and 2 efficiency cores, this is now the largest iteration of Apple Silicon we’ve seen.
As a prelude into the scores, I wanted to remark some things on the previous smaller M1 chip. The 4+4 setup on the M1 actually resulted that a significant chunk of the MT performance being enabled by the E-cores, with the SPECint score in particular seeing a +33% performance boost versus just the 4 P-cores of the system. Because the new M1 Pro and Max have 2 less E-cores, just assuming linear scaling, the theoretical peak of the M1 Pro/Max should be +62% over the M1. Of course, the new chips should behave better than linear, due to the better memory subsystem.
In the detailed scores I’m showcasing the full 8+2 scores of the new chips, and later we’ll talk about the 8 P scores in context. I hadn’t run the MT scores of the new Fortran compiler set on the M1 and some numbers will be missing from the charts because of that reason.
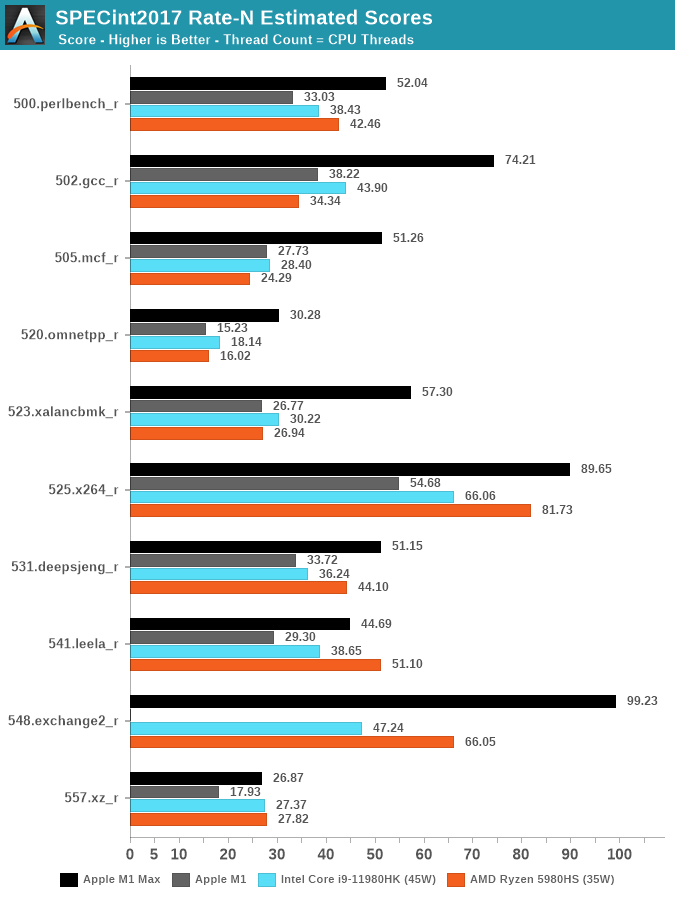
Looking at the data – there’s very evident changes to Apple’s performance positioning with the new 10-core CPU. Although, yes, Apple does have 2 additional cores versus the 8-core 11980HK or the 5980HS, the performance advantages of Apple’s silicon is far ahead of either competitor in most workloads. Again, to reiterate, we’re comparing the M1 Max against Intel’s best of the best, and also nearly AMD’s best (The 5980HX has a 45W TDP).
The one workload standing out to me the most was 502.gcc_r, where the M1 Max nearly doubles the M1 score, and lands in +69% ahead of the 11980HK. We’re seeing similar mind-boggling performance deltas in other workloads, memory bound tests such as mcf and omnetpp are evidently in Apple’s forte. A few of the workloads, mostly more core-bound or L2 resident, have less advantages, or sometimes even fall behind AMD’s CPUs.
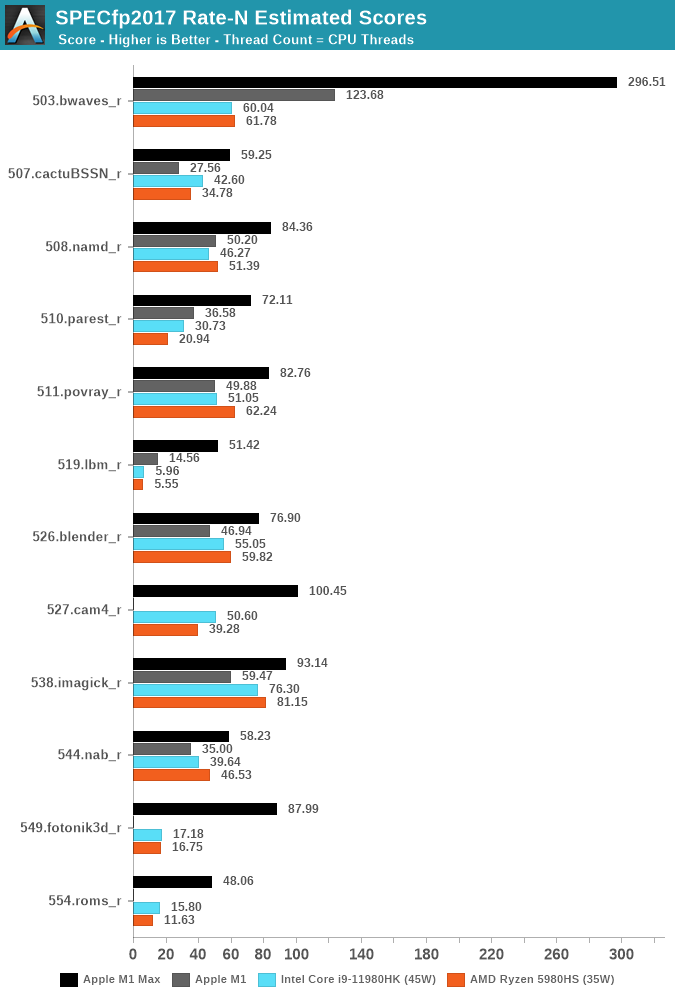
The fp2017 suite has more workloads that are more memory-bound, and it’s here where the M1 Max is absolutely absurd. The workloads that put the most memory pressure and stress the DRAM the most, such as 503.bwaves, 519.lbm, 549.fotonik3d and 554.roms, have all multiple factors of performance advantages compared to the best Intel and AMD have to offer.
The performance differences here are just insane, and really showcase just how far ahead Apple’s memory subsystem is in its ability to allow the CPUs to scale to such degree in memory-bound workloads.
Even workloads which are more execution bound, such as 511.porvray or 538.imagick, are – albeit not as dramatically, still very much clearly in favour of the M1 Max, achieving significantly better performance at drastically lower power.
We noted how the M1 Max CPUs are not able to fully take advantage of the DRAM bandwidth of the chip, and as of writing we didn’t measure the M1 Pro, but imagine that design not to score much lower than the M1 Max here. We can’t help but ask ourselves how much better the CPUs would score if the cluster and fabric would allow them to fully utilise the memory.
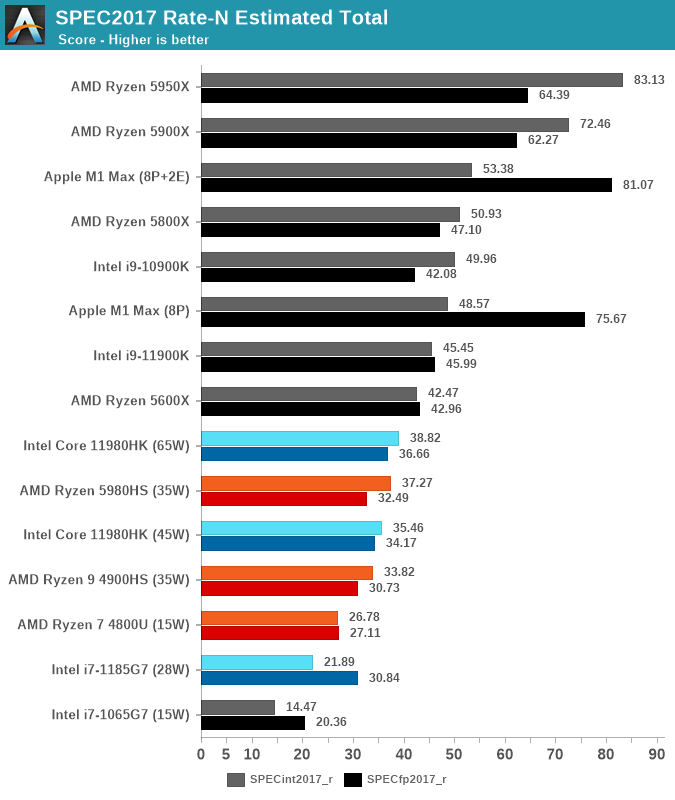
In the aggregate scores – there’s two sides. On the SPECint work suite, the M1 Max lies +37% ahead of the best competition, it’s a very clear win here and given the power levels and TDPs, the performance per watt advantages is clear. The M1 Max is also able to outperform desktop chips such as the 11900K, or AMD’s 5800X.
In the SPECfp suite, the M1 Max is in its own category of silicon with no comparison in the market. It completely demolishes any laptop contender, showcasing 2.2x performance of the second-best laptop chip. The M1 Max even manages to outperform the 16-core 5950X – a chip whose package power is at 142W, with rest of system even quite above that. It’s an absolutely absurd comparison and a situation we haven’t seen the likes of.
We also ran the chip with just the 8 performance cores active, as expected, the scores are a little lower at -7-9%, the 2 E-cores here represent a much smaller percentage of the total MT performance than on the M1.
Apple’s stark advantage in specific workloads here do make us ask the question how this translates into application and use-cases. We’ve never seen such a design before, so it’s not exactly clear where things would land, but I think Apple has been rather clear that their focus with these designs is catering to the content creation crowd, the power users who use the large productivity applications, be it in video editing, audio mastering, or code compiling. These are all areas where the microarchitectural characteristics of the M1 Pro/Max would shine and are likely vastly outperform any other system out there.
Section by Ryan Smith
GPU Performance: 2-4x For Productivity, Mixed Gaming
Arguably the star of the show for Apple’s latest Mac SoCs is the GPU, as well as the significant resources that go into feeding it. While Apple doesn’t break down how much of their massive, 57 billion transistor budget on the M1 Max went to the GPU, it and its associated hardware were the only thing to be quadrupled versus the original M1 SoC. Last year Apple proved that it could develop competitive, high-end CPU cores for a laptop; now they are taking their same shot on the GPU side of matters.
Driving this has been one of the biggest needs for Apple – and one of the greatest friction points between Apple and former partner Intel – which is GPU performance. With tight control over their ecosystem and little fear over pushing (or pulling) developers forward, Apple has been on the cutting edge of expanding the role of GPUs within a system for nearly the past two decades. GPU-accelerated composition (Quartz Extreme), OpenCL, GPU-accelerated machine learning, and more have all been developed or first implemented by Apple. Though often rooted in efficiency gains and getting incredibly taxing tasks off of the CPU, these have also pushed up Apple’s GPU performance requirements.
This has led to Apple using Intel’s advanced Iris iGPU configurations over most of the last 10 years (often being the only OEM to make significant use of them). But even Iris was never quite enough for what Apple would like to do. For their largest 15/16-inch MacBook Pros, Apple has been able to turn to discrete GPUs to make up the difference, but the lack of space and power for a dGPU in the 13-inch MacBook Pro form factor has been a bit more constraining. Ultimately, all of this has pushed Apple to develop their own GPU architecture, not only to offer a complete SoC for lower-tier parts, but also to be able to keep the GPU integrated in their high-end parts as well.

It’s the latter that is arguably the unique aspect of Apple’s position right now. Traditional OEMs have been fine with a small(ish) CPU and then adding a discrete GPU as necessary. It’s cost and performance effective: you only need to add as big of a dGPU as the customer needs performance, and even laptop-grade dGPUs can offer very high performance. But like any other engineering decision, it’s a trade-off: discrete GPUs result in multiple display adapters, require their own VRAM, and come with a power/cooling cost.
Apple has long been a vertically integrated company, so it’s only fitting that they’ve been focused on SoC integration as well. Bringing what would have been the dGPU into their high-end laptop SoCs eliminates the drawbacks of a discrete part. And, again leveraging Apple’s ecosystem advantage, it means they can provide the infrastructure for developers to use the GPU in a heterogeneous computing fashion – able to quickly pass data back and forth with the CPU since they’re all processing blocks on the same chip, sharing the same memory. Apple has already been pushing this paradigm for years in its A-series SoC, but this is still new territory in the laptop space – no PC processor has ever shipped with such a powerful GPU integrated into the main SoC.
The trade-off for Apple, in turn, is that the M1 inherits the costs of providing such a powerful GPU. That not only includes die space for the GPU blocks themselves, but the fatter fabric needed to pass that much data around, the extra cache needed to keep the GPU immediately fed, and the extra external memory bandwidth needed to keep the GPU fed over the long run. Integrating a high-end GPU means Apple has inherited the design and production costs of a high-end GPU.
ALUs and GPU cores aside, the most interesting thing Apple has done to make this possible comes via their memory subsystem. GPUs require a lot of memory bandwidth, which is why discrete GPUs typically come with a sizable amount of dedicated VRAM using high-speed interfaces like HBM2 or GDDR6. But being power-minded and building their own SoC, Apple has instead built an incredibly large LPDDR5 memory interface; M1 Max has a 512-bit interface, four-times the size of the original M1’s 128-bit interface. To be sure, it’s always been possible to scale up LPDDR in this fashion, but at least in the consumer SoC space, it’s never been done before. With such a wide interface, Apple is able to give the M1 Max 400GB/sec (technically, 409.6 GB/sec) of memory bandwidth, which is comparable to the amount of bandwidth found on NVIDIA’s fastest laptop SKUs.
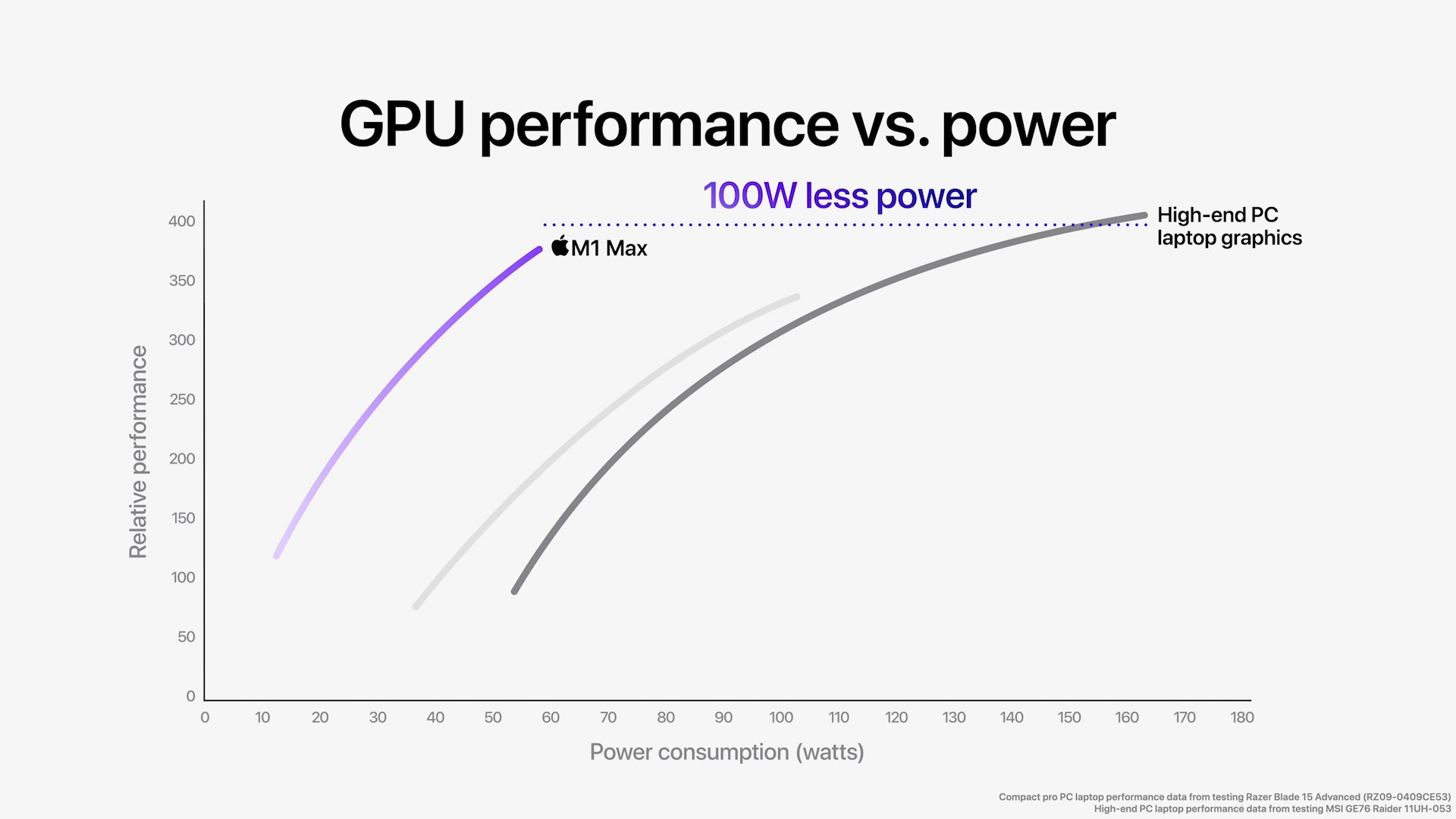
Ultimately, this enables Apple to feed their high-end GPU with a similar amount of bandwidth as a discrete laptop GPU, but with a fraction of the power cost. GDDR6 is very fast per pin – over 2x the rate – but efficient it ain’t. So while Apple does lose some of their benefit by requiring such a large memory bus, they more than make it up by using LPDDR5. This saves them over a dozen Watts under load, not only benefitting power consumption, but keeping down the total amount of heat generated by their laptops as well.
M1 Max and M1 Pro: Select-A-Size
There is one more knock-on effect for Apple in using integrated GPUs throughout their laptop SoC lineup: they needed some way to match the scalability afforded by dGPUs. As nice as it would be for every MacBook Pro to come with a 57 billion transistor M1 Max, the costs and chip yields of such a thing are impractical. The actual consumer need isn’t there either; M1 Max is designed to compete with high-end discrete GPU solutions, but most consumer (and even a lot of developer) workloads simply don’t fling around enough pixels to fully utilize M1 Max. And that’s not meant to be a subtle complement to Apple – M1 Max is overkill for desktop work and arguably even a lot of 1080p-class gaming.
So Apple has developed not one, but two new M1 SoCs, allowing Apple to have a second, mid-tier graphics option below M1 Max. Dubbed M1 Pro, this chip has half of M1 Max’s GPU clusters, half of its system level cache, and half of its memory bandwidth. In every other respect it’s the same. M1 Pro is a much smaller chip – Andrei estimates it’s around 245mm2 in size – which makes it cheaper to manufacture for Apple. So for lower-end 14 and 16-inch MacBook Pros that don’t need high-end graphics performance, Apple is able to offer a smaller slice of their big integrated GPU still paired with all of the other hardware that makes the latest M1 SoCs as a whole so powerful.
| Apple Silicon GPU Specifications | |||||
| M1 Max | M1 Pro | M1 | |||
| ALUs | 4096 (32 Cores) |
2048 (16 Cores) |
1024 (8 Cores) |
||
| Texture Units | 256 | 128 | 64 | ||
| ROPs | 128 | 64 | 32 | ||
| Peak Clock | 1296MHz | 1296MHz | 1278MHz | ||
| Throughput (FP32) | 10.6 TFLOPS | 5.3 TFLOPS | 2.6 TFLOPS | ||
| Memory Clock | LPDDR5-6400 | LPDDR5-6400 | LPDDR4X-4266 | ||
| Memory Bus Width | 512-bit (IMC) |
256-bit (IMC) |
128-bit (IMC) |
||
Taking a quick look at the GPU specifications across the M1 family, Apple has essentially doubled (and then doubled again) their integrated GPU design. Whereas the original M1 had 8 GPU cores, M1 Pro gets 16, and M1 Max gets 32. Every aspect of these GPUs has been scaled up accordingly – there are 2x/4x more texture units, 2x/4x more ROPs, 2x/4x the memory bus width, etc. All the while the GPU clockspeed remains virtually unchanged at about 1.3GHz. So the GPU performance expectation for M1 Pro and M1 Max are very straightforward: ideally, Apple should be able to get 2x or 4x the GPU performance of the original M1.
Otherwise, not reflected in the specifications or in Apple’s own commentary, Apple will need to have scaled up their fabric as well. Connecting 32 cores means passing around a massive amount of data, and the original M1’s fabric certainly wouldn’t have been up to the task. Still, whatever Apple had to do has been accomplished (and concealed) very neatly. From the outside the M1 Pro/Max GPUs behave just like M1, so even with those fabric changes, this is very clearly a virtually identical GPU architecture.
Synthetic Performance
Finally diving into GPU performance itself, let’s start with our synthetic benchmarks.
In an effort to try to get as much comparable data as possible, I’ve started with GFXBench 5.0 Aztec Ruins. This is one of our standard laptop benchmarks, so we can directly compare the M1 Max and M1 Pro to high-end PC laptops we’ve recently tested. As for Aztec Ruins itself, this is a benchmark that can scale from phones to high-end laptops; it’s natively available for multiple platforms and it has almost no CPU overhead, so the sky is the limit on the GPU font.

Aztec makes for a very good initial showing for Apple’s new SoCs. M1 Max falls just short of topping the chart here, coming in a few FPS behind MSI’s GE76, a GeForce RTX 3080 Laptop-equipped notebook. As we’ll see, this is likely to be something of a best-case scenario for Apple since Aztec scales so purely with GPU performance (and has a very good Metal implementation). But it goes to show where Apple can be when everything is just right.
We also see the scalability of the M1 family in action here. The M1->M1 Pro ->M1 Max performance progression is almost exactly 2x at each step,
Since macOS can also run iOS applications, I’ve also tossed in 3DMark Wild Life Extreme benchmark. This is another cross-platform benchmark that’s available on mobile and desktop alike, with the Extreme version particularly suited for measuring PCs and Macs alike. This is run in Unlimited mode, which draws off-screen in order to ensure the GPU is fully weighed down.
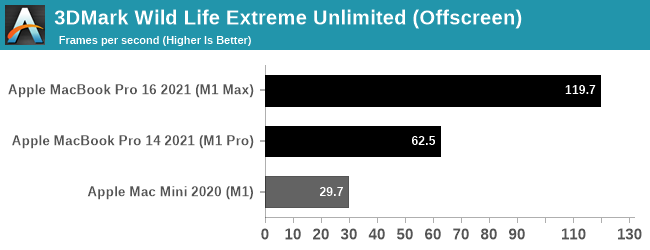
Since 3DMark Wild Life Extreme is not one of our standard benchmarks, we don’t have comparable PC data to draw from. But from the M1 Macs we can once again see that GPU performance is scaling almost perfectly among the SoCs. The M1 Pro doubles performance over the M1, and the M1 Max doubles it again.
Gaming Performance
Switching gears, even though macOS isn’t an especially popular gaming platform, there are plenty of games to be had on the platform, especially as tools like MoltenVK have made it easier for developers to get a Metal API render backend up and running. With that said over, the vast majority of major macOS cross-platform games are still x86 only, so a lot of games are still reliant on Rosetta. Ideally products like the new MacBook Pros will push developers to develop Arm binaries as well, but that will be a bigger ask.
We’ll start with Shadow of the Tomb Raider, which is another one of our standard laptop benchmarks. This gives us a lot of high-end laptop configurations to compare against.
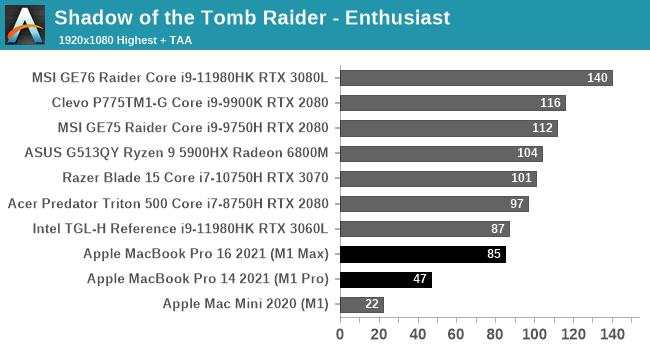
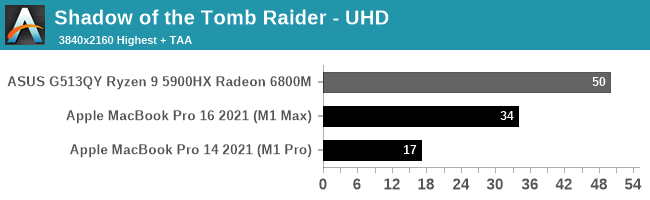
Unfortunately, Apple’s strong GPU performance under our synthetic benchmarks doesn’t extend to our first game. The M1 Macs bring up the tail-end of the 1080p performance chart, and they’re still well behind the Radeon 6800M at 4K.
Digging deeper, there are a couple of factors in play here. First and foremost, the M1 Max in particular is CPU limited at 1080p; the x86-to-Arm translation via Rosetta is not free, and even though Apple’s CPU cores are quite powerful, they’re hitting CPU limitations here. We have to go to 4K just to help the M1 Max fully stretch its legs. Even then the 16-inch MacBook Pro is well off the 6800M. Though we’re definitely GPU-bound at this point, as reported by both the game itself, and demonstrated by the 2x performance scaling from the M1 Pro to the M1 Max.
Our second game is Borderlands 3. This is another macOS port that is still x86-only, and part of our newer laptop benchmarking suite.
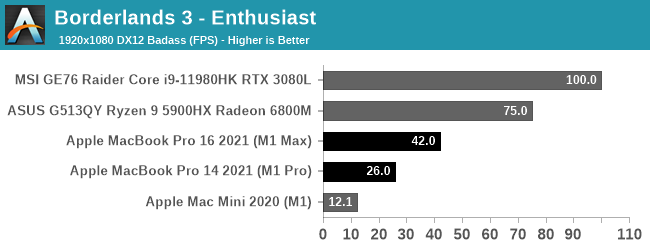

Borderlands 3 ends up being even worse for the M1 chips than Shadow of the Tomb Raider. The game seems to be GPU-bound at 4K, so it’s not a case of an obvious CPU bottleneck. And truthfully, I don’t enough about the porting work that went into the Mac version to say whether it’s even a good port to begin with. So I’m hesitant to lay this all on the GPU, especially when the M1 Max trails the RTX 3080 by over 50%. Still, if you’re expecting to get your Claptrap fix on an Apple laptop, a 2021 MacBook Pro may not be the best choice.
Productivity Performance
Last, but not least, let’s take a look at some GPU-centric productivity workloads. These are not part of our standard benchmark suite, so we don’t have comparable data on hand. But the two benchmarks we’re using are both standardized benchmarks, so the data is portable (to an extent).
We’ll start with Puget System’s PugetBench for Premiere Pro, which is these days the de facto Premiere Pro benchmark. This test involves multiple playback and video export tests, as well as tests that apply heavily GPU-accelerated and heavily CPU-accelerated effects. So it’s more of an all-around system test than a pure GPU test, though that’s fitting for Premiere Pro giving its enormous system requirements.
On a quick note here, this benchmark seems to be sensitive to both the resolution and refresh rate of the desktop – higher refresh rates in particular seem to boost performance. Which means that the 2021 MacBook Pros’ 120Hz ProMotion displays get an unexpected advantage here. So to try to make things more apples-to-apples here, all of our testing is with a 1920x1080 desktop at 60Hz. (For reference, a MBP16 scores 1170 when using its native display)
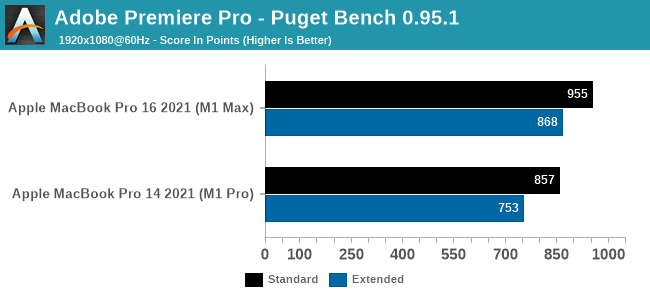
What we find is that both Macs perform well in this benchmark – a score near 1000 would match a high-end, RTX 3080-equipped desktop – and from what I’ve seen from third party data, this is well, well ahead of the 2019 Intel CPU + AMD GPU 16-inch MacBook Pro.
As for how much of a role the GPU alone plays, what we see is that the M1 Max adds about 100 points on both the standard and extended scores. The faster GPU helps with GPU-accelerated effects, and should help with some of the playback and encoding workload. But there are other parts that fall to the CPU, so the GPU alone doesn’t carry the benchmark.
Our other productivity benchmark is DaVinci Resolve, the multi-faceted video editor, color grading, and VFX video package. Resolve comes up frequently in Apple’s promotional materials; not only is it popular with professional Mac users, but color grading and other effects from the editor are both GPU-accelerated and very resource intensive. So it’s exactly the kind of professional workload that benefits from a high-end GPU.
As Resolve doesn’t have a standard test – and Puget Systems’ popular test is not available for the Mac – we’re using a community-developed benchmark. AndreeOnline’s Rocket Science benchmark uses a variety of high-resolution rocket clips, processing them with either a series of increasingly complex blur or temporal noise reduction filters. For our testing we’re using the test’s 4K ProRes video file as an input, though the specific video file has a minimal impact relative to the high cost of the filters.
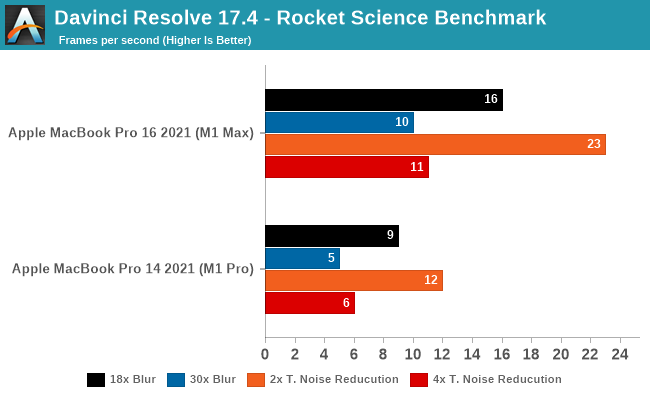
All of these results are well-below real time performance, but it’s to be expected from the complex nature of the filters. Still, the M1 Max comes closer than I was expecting to matching the clip’s original framerate of 25fps; an 18 step blur operation still moves at 16fps, and a 2-step noise resolution is 23fps. This is a fully GPU-bottlenecked scenario, so ramping those up to even larger filter sets has the expected impact to GPU performance.
Meanwhile, this is another case of the M1 Max’s GPU performance scaling very closely to 2x that of the M1 Pro’s. With the exception of 18-step blur, the M1 Max is 80% faster or better. All of which underscores that when a workload is going to be throwing around billions of pixels like Resolve, if it’s GPU-accelerated it can certainly benefit from the M1 Max’s more powerful GPU.
Overall, it’s clear that Apple’s ongoing experience with GPUs has paid off with the development of their A-series chips, and now their M1 family of SoCs. Apple has been able to scale up the small and efficient M1 into a far more powerful configuration; Apple built SoCs with 2x/4x the GPU hardware of the original M1, and that’s almost exactly what they’re getting out of the M1 Pro and M1 Max, respectively. Put succinctly, the new M1 SoCs prove that Apple can build the kind of big and powerful GPUs that they need for their high-end machines. AMD and NVIDIA need not apply.
With that said, the GPU performance of the new chips relative to the best in the world of Windows is all over the place. GFXBench looks really good, as do the MacBooks’ performance productivity workloads. For the true professionals out there – the people using cameras that cost as much as a MacBook Pro and software packages that are only slightly cheaper – the M1 Pro and M1 Max should prove very welcome. There is a massive amount of pixel pushing power available in these SoCs, so long as you have the workload required to put it to good use.
However gaming is a poorer experience, as the Macs aren’t catching up with the top chips in either of our games. Given the use of x86 binary translation and macOS’s status as a traditional second-class citizen for gaming, these aren’t apple-to-apple comparisons. But with the loss of Boot Camp, it’s something to keep in mind. If you’re the type of person who likes to play intensive games on your MacBook Pro, the new M1 regime may not be for you – at least not at this time.
Conclusion & First Impressions
The new M1 Pro and M1 Max chips are designs that we’ve been waiting for over a year now, ever since Apple had announced the M1 and M1-powered devices. The M1 was a very straightforward jump from a mobile platform to a laptop/desktop platform, but it was undeniably a chip that was oriented towards much lower power devices, with thermal limits. The M1 impressed in single-threaded performance, but still clearly lagged behind the competition in overall performance.
The M1 Pro and M1 Max change the narrative completely – these designs feel like truly SoCs that have been made with power users in mind, with Apple increasing the performance metrics in all vectors. We expected large performance jumps, but we didn’t expect the some of the monstrous increases that the new chips are able to achieve.
On the CPU side, doubling up on the performance cores is an evident way to increase performance – the competition also does so with some of their designs. How Apple does it differently, is that it not only scaled the CPU cores, but everything surrounding them. It’s not just 4 additional performance cores, it’s a whole new performance cluster with its own L2. On the memory side, Apple has scaled its memory subsystem to never before seen dimensions, and this allows the M1 Pro & Max to achieve performance figures that simply weren’t even considered possible in a laptop chip. The chips here aren’t only able to outclass any competitor laptop design, but also competes against the best desktop systems out there, you’d have to bring out server-class hardware to get ahead of the M1 Max – it’s just generally absurd.
On the GPU side of things, Apple’s gains are also straightforward. The M1 Pro is essentially 2x the M1, and the M1 Max is 4x the M1 in terms of performance. Games are still in a very weird place for macOS and the ecosystem, maybe it’s a chicken-and-egg situation, maybe gaming is still something of a niche that will take a long time to see make use of the performance the new chips are able to provide in terms of GPU. What’s clearer, is that the new GPU does allow immense leaps in performance for content creation and productivity workloads which rely on GPU acceleration.
To further improve content creation, the new media engine is a key feature of the chip. Particularly video editors working with ProRes or ProRes RAW, will see a many-fold improvement in their workflow as the new chips can handle the formats like a breeze – this along is likely going to have many users of that professional background quickly adopt the new MacBook Pro’s.
For others, it seems that Apple knows the typical MacBook Pro power users, and has designed the silicon around the use-cases in which Macs do shine. The combination of raw performance, unique acceleration, as well as sheer power efficiency, is something that you just cannot find in any other platform right now, likely making the new MacBook Pro’s not just the best laptops, but outright the very best devices for the task.






