Original Link: https://www.anandtech.com/show/16627/ai-funding-spree-300m-for-groq-676m-for-sambanova
AI Funding Spree: +$300m for Groq, +$676m for SambaNova
by Dr. Ian Cutress on April 19, 2021 7:00 AM EST
The growth of AI has seen a resurgence in venture capital funding for silicon start-ups. Designing AI silicon for machine learning, both for training and inference, has become hot property in Silicon Valley, especially as machine learning compute and memory requirements are coalesced into tangible targets for this silicon to go after. A number of these companies are already shipping high performance processors to customers, and are looking for further funding to help support customers, expand the customer base, and develop next generation products until profitability happens, or the company is acquired. The two latest funding rounds for AI silicon were announced in this past week.
Groq (Series C, $300m, Tensor Streaming Processor)
When Groq’s first product came onto the scene, detailed by the Microprocessor Report back in January 2020, it was described as the first PetaOP processor that eschewed traditional many-core designs and instead implemented a single VLIW-like core with hundreds of functional units. In this method, the data is subject to instruction flow, rather than instructions being reliant on data flow, saving time on synchronicity and decode overhead that many-core processors require.

The end result is a product that implements 400,000 multiply-accumulate units, but the key marketing metric is the deterministic performance. Using this single core methodology, the Groq Chip 1 will take the same time to inference workload without any quality-of-service requirements. In speaking with CEO Jonathan Ross, Groq’s TSP enables workloads that were previously unusable due to long tail quality of service performance degradation (i.e. worst case results take too long). This is especially important in analysis that requires batch size 1, such as video.
The Groq ecosystem also means that distribution across many TSPs simply scales out inferences per second, with multiple Groq Chip 1 parts under the same algorithm all implementing the same deterministic performance.

Jonathan stated to us, as the company has stated in the past, that Groq as a company was built on a compiler-first approach. Historically this sort of approach puts a lot of pressure on the compiler doing the optimization (such as Itanium and other VLIW processors), and often leads to concerns about the product as a whole. However, we were told that the team never touched any silicon design until six months into the software and compiler work, allowing the company to lock down the key aspects of the major ML frameworks before even designing the silicon.
As part of its funding efforts, Groq reached out to us for a company update. All of Groq’s hardware and software work to date has been achieved through two rounds of VC funding, totaling $67.3m, with about $50m being used so far. In that capital they have designed, built, and deployed the Groq Chip 1 TSP to almost a dozen customers, including the audio/visual industry, datacenter, and government labs. The second generation product is also well underway. This latest Series C funding round of $300m, led by Tiger Global Management and D1 Capital, will allow the company to expand from 120 people to 250 by the end of the year, support current and future customers with bigger teams, and enable a progressive roadmap.
Groq stated in our briefing that its second generation product will build on its unique design points, offering alternatives for customers that were interested in the Groq Chip 1 but have other requirements for their workloads. Each generation of Groq’s TSP, according to the company, will have half a dozen unique selling points in the market (some public, some not), with one goal at least to displace as many GPUs as possible with a single TSP in order to give customers the best TCO.
SambaNova (Series D, $676m, Cardinal AI)
The second company this week is SambaNova, whose Series D funding is a staggering $676 million, led by SoftBank’s Vision Fund 2, with new investors Temasek and GIC, joining existing backers such as BlackRock, Intel Capital, GV (formerly Google Ventures) and others. To date SambaNova has generated over $1.1 billion in investment, enabling a $5 billion valuation.

SambaNova’s entry into the AI silicon space is with its Cardinal AI processor. Rather than focusing on machine learning inference workloads, such as trying to identify animals with a known algorithm, the Cardinal AI processor is one of the few dedicated implementations to provide peak training performance. Training is a substantially harder problem than inference, especially as training algorithms are constantly changing and requirements for the biggest datasets are seemingly ever increasing.

The Cardinal AI processor has already featured on AnandTech, when SambaNova announced its eight-socket solution known as the ‘DataScale SN10-8R’. In a quarter rack design, an EPYC Rome x86 system is paired with eight Cardinal processors backed by 12 terabytes of DDR4-3200 memory, and SambaNova can scale this to a half-rack or full-rack solution. Each Cardinal AI processor has 1.5 TB of DDR4, with six memory channels for 153 GB/s bandwidth per processor. Within each eight socket configuration, the chips are connected in an all-to-all fashion with 64x PCIe 4.0 lanes to dedicated switching network silicon (like an NVSwitch) for 128 GB/s in each direction to all other processors. The protocol being used over PCIe is custom to SambaNova. The switches also enable system-to-system connectivity that allows SambaNova to scale as required. SambaNova is quoting that a dual-rack solution will outperform an equivalent DGX-A100 deployment by 40% and will be at a much lower power, or enable companies to coalesce a 16-rack 1024 V100 deployment into a single quarter-rack DataScale system.
SambaNova’s customers are looking for a mix of private and public cloud options, and as a result the flagship offering is a Dataflow-as-a-Service product line allowing customers a subscription model for AI initiatives without purchasing the hardware outright. These subscription systems can be deployed internally to the company with the subscription, and be managed remotely by SambaNova. The company cites that TensorFlow or PyTorch workloads can be rebuilt using SambaNova’s compiler in less than an hour.
SambaNova has not given many more details on its architecture as yet, however they do state that SambaNova can enable AI training that requires large image datasets (50000x50000 pixel images, for example) for astronomy, oil-and-gas, or medical imaging that often require losing resolution/accuracy for other platforms. The Cardinal AI processor can also perform in-the-loop training allowing for model reclassification and optimization of inference-with-training workloads on the fly by enabling a heterogeneous zerocopy-style solution – GPUs instead have to memory dump and/or kernel switch, which can be a significant part of any utilization analysis.
The company has now been through four rounds of funding:
- Series A, $56m, led by Walden International and Google Ventures
- Series B, $150m, led by Intel Capital
- Series C, $250m, led by BlackRock
- Series D, $676m, led by SoftBank
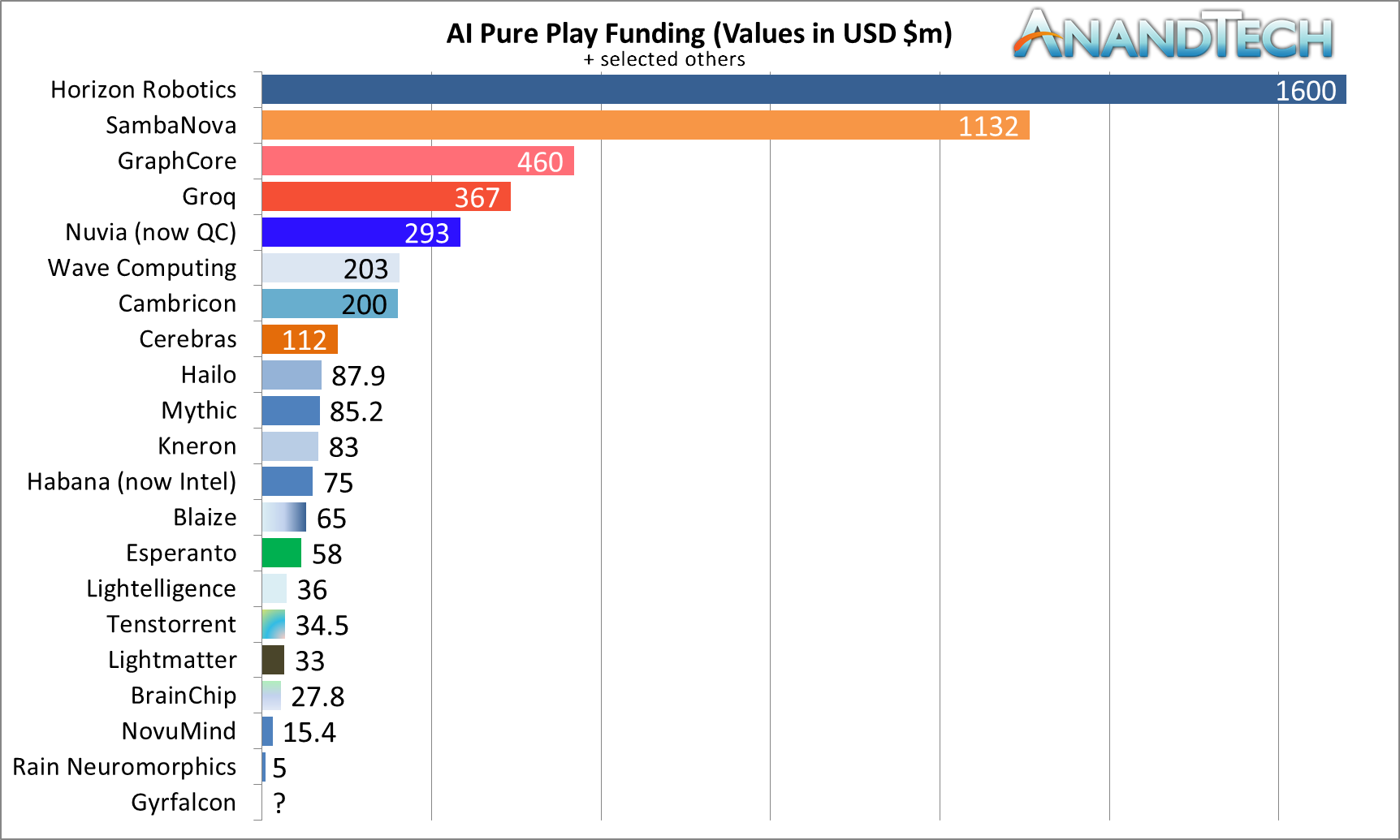
This puts SambaNova almost at the top of AI chip funding with $1132m, just behind Horizon Robotics ($1600m), but ahead of GraphCore ($460m), Groq ($367m), Nuvia ($293m, acquired by Qualcomm), Cambricon ($200m), and Cerebras ($112m).
Related Reading
- SambaNova Breaks Cover: $450M AI Startup with 8-Socket AI Training Solutions (and more)
- Cerebras Wafer Scale Engine News: DoE Supercomputer Gets 400,000 AI Cores
- NVIDIA Unveils Grace: A High-Performance Arm Server CPU For Use In Big AI Systems
- Intel’s New eASIC N5X Series: Hardened Security for 5G and AI Through Structured ASICs
- Qualcomm's Cloud AI 100 Now Sampling: Up to 400TOPs at 75W
- TSMC and Graphcore Prepare for AI Acceleration on 3nm
- Intel Whittles Down AI Portfolio, Folds Nervana in Favor of Habana
- Samsung Kicks Off Mass Production of AI Chip for Baidu: 260 TOPS at 150 W






