Original Link: https://www.anandtech.com/show/16529/amd-epyc-milan-review
AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance
by Dr. Ian Cutress & Andrei Frumusanu on March 15, 2021 11:00 AM EST
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Section by Ian Cutress
The arrival of AMD’s 3rd Generation EPYC processor family, using the new Zen 3 core, has been hotly anticipated. The promise of a new processor core microarchitecture, updates to the connectivity and new security options while still retaining platform compatibility are a good measure of an enterprise platform update, but the One True Metric is platform performance. Seeing Zen 3 score ultimate per-core performance leadership in the consumer market back in November rose expectations for a similar slam-dunk in the enterprise market, and today we get to see those results.
AMD EPYC 7003: 64 Cores of Milan
The headline numbers that AMD is promoting with the new generation of hardware is an increase in raw performance throughput of +19%, due to enhancements with the new core design. On top of this, AMD has new security features, optimizations for different memory configurations, and updated performance with the Infinity Fabric and connectivity.

3rd Gen EPYC
Anyone looking for the shorthand specifications on the new EPYC 7003 series, known by its codename Milan, will see great familiarity with the previous generation, however this time around AMD is targeting several different design points.
Milan processors will offer up to 64 cores and 128 threads, using AMD’s latest Zen 3 cores. The processor is designed with eight chiplets of eight cores each, similar to Rome, but this time all eight cores in the chiplet are connected, enabling an effective double L3 cache design for a lower overall cache latency structure. All processors will have 128 lanes of PCIe 4.0, eight channels of memory, with most models supporting dual processor connectivity, and new options for channel memory optimization are available. All Milan processors should be drop-in compatible with Rome series platforms with a firmware update.
| AMD EPYC: Generation on Generation | |||
| AnandTech | EPYC 7001 |
EPYC 7002 |
EPYC 7003 |
| Codename | Naples | Rome | Milan |
| Microarchitecture | Zen | Zen 2 | Zen 3 |
| Core Manufacturing | 14nm | 7nm | 7nm |
| Max Cores/Threads | 32 / 64 | 64 / 128 | 64 / 128 |
| Core Complex | 4C + 8MB | 4C + 16MB | 8C + 32MB |
| Memory Support | 8 x DDR4-2666 | 8 x DDR4-3200 | 8 x DDR4-3200 |
| Memory Capacity | 2 TB | 4 TB | 4 TB |
| PCIe | 3.0 x128 | 4.0 x128 | 4.0 x128 |
| Security | SME SEV |
SME SEV |
SME SEV SNP |
| Peak Power | 180 W | 240 W* | 280 W |
| *Rome introduced 280 W for special HPC mid-cycle | |||
One of the highlights here is that the new generation of processors will offer 280 W models to all customers – previous generations had only 240 W models for all and then 280 W for specific HPC customers, however this time around all customers can enable those high performance parts with the new core design.
This is exemplified if we do direct top-of-stack processor comparisons:
| 2P Top of Stack GA Offerings | |||||
| AnandTech | EPYC 7001 |
EPYC 7002 |
EPYC 7003 |
Intel Xeon |
|
| Processor | 7601 | 7742 | 7763 | 6258R | |
| uArch | Zen | Zen 2 | Zen 3 | Cascade | |
| Cores | 32 | 64 | 64 | 28 | |
| TDP | 180 W | 240 W | 280 W | 205 W | |
| Base Freq | 2200 | 2250 | 2450 | 2700 | |
| Turbo Freq | 3200 | 3400 | 3500 | 4000 | |
| L3 Cache | 64 MB | 256 MB | 256 MB | 37.5 MB | |
| PCIe | 3.0 x128 | 4.0 x128 | 4.0 x128 | 3.0 x48 | |
| DDR4 | 8 x 2666 | 8 x 3200 | 8 x 3200 | 6 x 2933 | |
| DRAM Cap | 2 TB | 4 TB | 4 TB | 1 TB | |
| Price | $4200 | $6950 | $7890 | $3950 | |
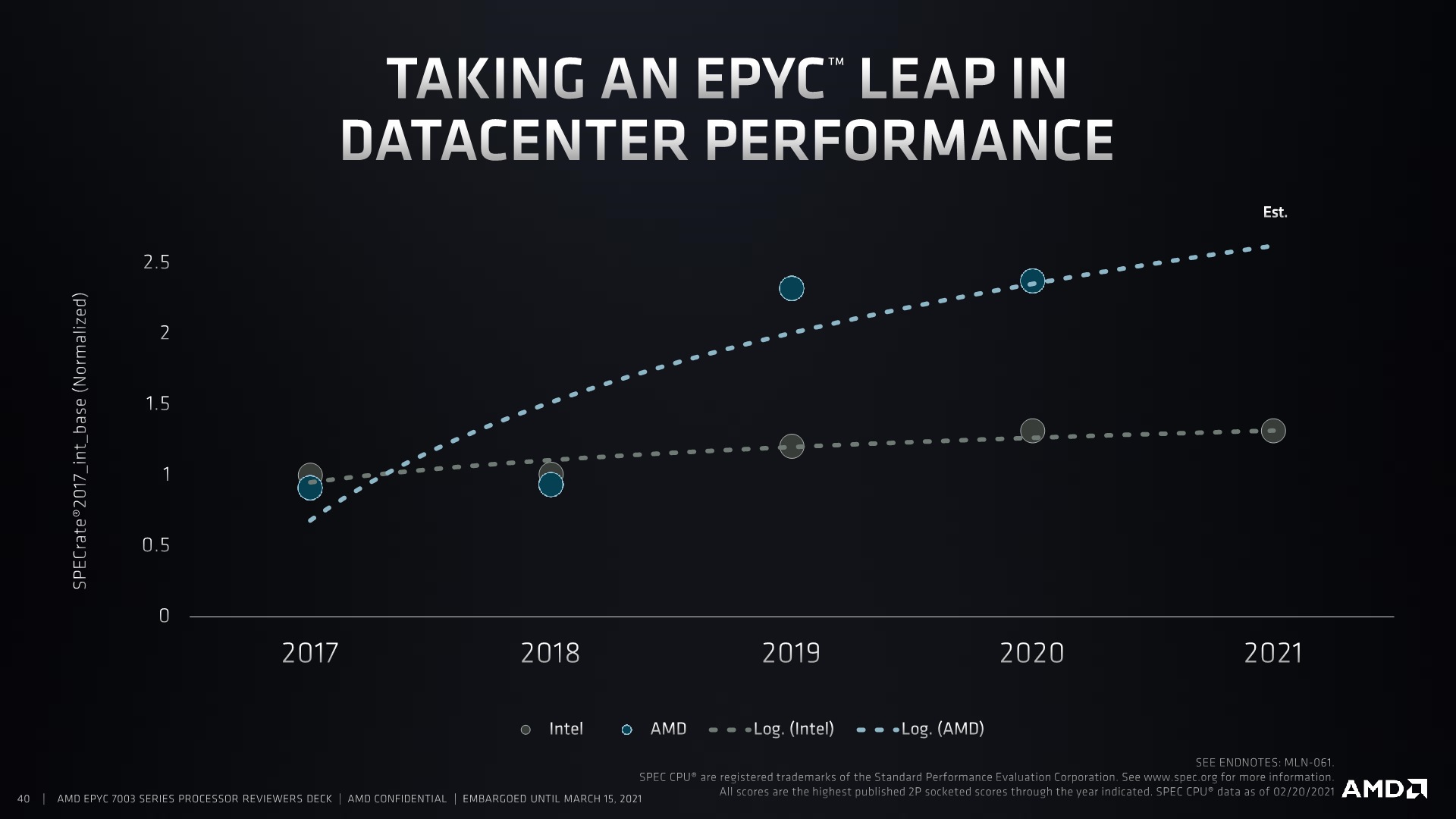
The new top processor for AMD is the EPYC 7763, a 64-core processor at 280 W TDP offering 2.45 GHz base frequency and 3.50 GHz boost frequency. AMD claims that this processor offers +106% performance in industry benchmarks compared to Intel’s best 2P 28-core processor, the Gold 6258R, and +17% over its previous generation 280 W version the 7H12.
Peak Performance vs Per Core Performance
One of AMD’s angles with the new Milan generation is going to be targeted performance metrics, with the company not simply going after ‘peak’ numbers, but also taking a wider view for customers that need high per-core performance as well, especially for software that is invariably per-core performance limited or licensed. With that in mind, AMD’s F-series of ‘fast’ processors is now being crystallized in the stack.
| AMD EPYC 7003 F-SeriesProcessors | ||||||
| Cores Threads |
Base Freq |
Turbo Freq |
L3 (MB) |
TDP (W) |
Price | |
| F-Series | ||||||
| EPYC 75F3 | 32 / 64 | 2950 | 4000 | 256 ( 8 x 32 ) |
280 W | $4860 |
| EPYC 74F3 | 24 / 48 | 3200 | 4000 | 240 W | $2900 | |
| EPYC 73F3 | 16 / 32 | 3500 | 4000 | 240 W | $3521 | |
| EPYC 72F3 | 8 / 16 | 3700 | 4100 | 180 W | $2468 | |
These processors have the peak single threaded values of anything else in AMD’s offering, along with the full 256 MB of L3 cache, and in our results get the best scores on a per-thread basis than anything else we’ve tested for enterprise across x86 and Arm – more details in the review. The F-series processors will come at a slight premium over the others.

AMD EPYC: The Tour of Italy
The first generation of EPYC was launched in June 2017. At that time, AMD was essentially a phoenix: rising from the ashes of its former Opteron business, and with a promise to return to high-performance compute with a new processor design philosophy.
At the time, the traditional enterprise customer base were not initially convinced – AMD’s last foray into the enterprise space with a new generation of paradigm-shifting processor core, while it had successes, fell flat as AMD had to stop itself from going bankrupt. Opteron customers were left with no updates in sight at the time, and to the willingness to jump on an unknown platform from a company that had stung so many in the past was not a positive prospect for many.
At the time, AMD put out a three year roadmap, detailing its next generations and the path the company would take to overcoming the 99% market share behemoth in performance and offerings. These were seen as lofty goals, and many sat back willing to watch others take the gamble.

1st Gen EPYC Launch
As the first generation Naples was launched, it offered impressive some performance numbers. It didn’t quite compete in all areas, and as with any new platform, there were some teething issues to begin. AMD kept the initial cycle to a few of its key OEM partners, before slowly broadening out the ecosystem. Naples was the first platform to offer extensive PCIe 3.0 and lots of memory support, and the platform initially targeted those storage or PCIe heavy deployments.

2nd Gen EPYC Launch
The second generation Rome, launched in August 2019 (+26 months) created a lot more fanfare. AMD’s newest Zen 2 core was competitive in the consumer space, and there were a number of key design changes in the SoC layout (such as moving to a NUMA flat design) that encouraged a number of skeptics to start to evaluate the platform. Such was the interest that AMD even told us that they had to be selective with which OEM platforms they were going to assist with before the official launch. Rome’s performance was good, and it scored a few high-profile supercomputer wins, but more importantly perhaps it showcased that AMD was able to execute on that roadmap back in June 2017.
That flat SoC architecture, along with the updated Zen 2 processor core (which actually borrowed elements from Zen 3) and PCIe 4.0, allowed AMD to start to compete on performance as well as simply IO, and AMD’s OEM partners have consistently been advertising Rome processors as compute platforms, often replacing two Intel 28-core processors for one AMD 64-core processor that also has higher memory support and more PCIe offerings. This also allows for compute density, and AMD was in a place where it could help drive software optimizations for its platform as well, extracting performance, but also moving to parity on the edge cases that its competitors were very optimized for. All the major hyperscalers also evaluated and deployed AMD-based offerings for their customers, as well as internally. AMD’s sticker of approval was pretty much there.

3rd Gen EPYC CPU
And so today AMD is continuing that tour of Italy with a trip to Milan, some +19 months after Rome. The underlying SoC layout is the same as Rome, but we have higher performance on the table, with additional security and more configuration options. The hyperscalers have already been getting the final hardware for six months for their deployments, and AMD is now in a position to help enable more OEM platforms at launch. Milan is drop-in compatible with Rome, which certainly helps, but with Milan covering more optimization points, AMD believes it is in a better position to target more of the market with high performance processors, and high per-core performance processors, than ever before.
AMD sees the launch of Milan as that third step in the roadmap that was shown back in June 2017, and validation on its ability to execute reliably for its customers but also offer above industry standard performance gains for its customers.
The next stop on the tour of Italy is Genoa, set to use AMD’s upcoming Zen 4 microarchitecture. AMD has also said that Zen 5 is in the pipeline.
Competition
AMD is launching this new generation of Milan processors approximately 19 months after the launch of Rome. In that time we have seen the launch of both Amazon Graviton2 and Ampere Altra, built on Arm’s Neoverse N1 family of cores.
| Milan Top-of-Stack Competition | ||||
| AnandTech | EPYC 7003 |
Amazon Graviton2 |
Ampere Altra |
Intel Xeon |
| Platform | Milan | Graviton2 | QuickSilver | Cascade |
| Processor | 7763 | Graviton2 | Q80-33 | 6258R |
| uArch | Zen 3 | N1 | N1 | Cascade |
| Cores | 64 | 64 | 80 | 28 |
| TDP | 280 W | ? | 250 W | 205 W |
| Base Freq | 2450 | 2500 | 3300 | 2700 |
| Turbo Freq | 3500 | 2500 | 3300 | 4000 |
| L3 Cache | 256 MB | 32 MB | 32 MB | 37.5 MB |
| PCIe | 4.0 x128 | ? | 4.0 x128 | 3.0 x48 |
| DDR4 | 8 x 3200 | 8 x 3200 | 8 x 3200 | 6 x 2933 |
| DRAM Cap | 4 TB | ? | 4 TB | 1 TB |
| Price | $7890 | N/A | $4050 | $3950 |
From Intel, the company has divided its efforts between big socket and little socket configurations. For big sockets (4+) there is Cooper Lake, a Skylake derivative for select customers only. For smaller socket configurations (1-2), Intel is set to launch its 10nm Ice Lake portfolio at some point this year, but as yet it still remains silent on exact dates. To that end, all we have to compare Milan to is Intel’s Cascade Lake Xeon Scalable platform, which was the same platform we compared Rome to.
Interesting times for sure.
This Review
For this review, AMD gave us remote access to several identical servers with different processor configurations. We focused our efforts on the top-of-the-stack EPYC 7763, a 280 W 64-core processor, the EPYC 7713, a 225 W 64-core processor, and the EPYC 7F53, a 280 W 32-core processor designed as the halo Milan processor for per-core performance.
On the next page we will go through AMD’s Milan processor stack, and its comparison to Rome as well as the comparison to current Intel offerings. We then go through our test systems, discussions about our SoC structure testing (cache, core-to-core, bandwidth), processor power, and then into our full benchmarks.
- This Page, The Overview
- Milan Processor Offerings
- Test Bed Setups, Compiler Options
- Topology, Memory Subsystem and Latency
- Processor Power: Core vs IO
- SPEC: Multi-Thread Performance
- SPEC: Single-Thread Performance
- SPEC: Per Core Performance Win for 75F3
- SPECjbb MultiJVM: Java Performance
- Compilation and Compute Benchmarks
- Conclusions and End Remarks
These pages can be accessed by clicking the links, or by using the drop down menu below.
Section by Ian Cutress
CPU List and SoC Updates
In the past AMD has promoted its EPYC positioning in terms of single socket and dual socket setups, mostly on the basis that one of its larger processors can enable the same compute as two of Intel’s top-tier offerings. This time around, AMD actually does little direct comparison with Intel as to where its processors stand, instead focusing on the market optimizations for different elements of the market.
AMD market optimizations come in three main flavors: Core Performance, Core Density, Balanced and Optimized.
Every processor in AMD’s lineup will come with the following:
- 8 Channels of DDR4-3200
- 4 TB Memory Support (8 channel, 2DPC)
- 128 lanes of PCIe 4.0
- Simultaneous MultiThreading
- Performance Modes (Fixed Power) and Deterministic Modes (Fixed Frequency)
- 18G Infinity Fabric
- Secure Encrypted Virtualization with Secure Nested Pages
- Syncronized 1:1 Fabric and Memory Clock Speeds
Core Performance Optimized: 7xF3 Series
The Core Optimized processors were segmented out on the last page as a highlighted part of the processor lineup, now known as AMD’s F series of processors. These parts have F in the name, offer up to 32 cores, and the main focus here is on individual core performance peaks as well as sustained performance. Compared to other parts of a similar core count, these have higher TDP values, and charge a premium.
| AMD EPYC 7003 Processors Core Performance Optimized |
||||||
| Cores Threads |
Base Freq |
Turbo Freq |
L3 (MB) |
TDP | Price | |
| F-Series | ||||||
| EPYC 75F3 | 32 / 64 | 2950 | 4000 | 256 MB |
280 W | $4860 |
| EPYC 74F3 | 24 / 48 | 3200 | 4000 | 240 W | $2900 | |
| EPYC 73F3 | 16 / 32 | 3500 | 4000 | 240 W | $3521 | |
| EPYC 72F3 | 8 / 16 | 3700 | 4100 | 180 W | $2468 | |
For this review, one of the processors we have tested is the EPYC 75F3, the 32-core processor offering 4.0 GHz turbo, 2.95 GHz base frequency, and all 256 MB of L3 cache. This processor has four cores per chiplet active, and no doubt these processors use the best voltage/frequency response cores inside each chiplet as manufactured. The $4860 price point is above the $3761 for the next best 32-core processor, showcasing some of that premium.
Users will notice that the 16-core processor is more expensive ($3521) than the 24 core processor ($2900) here. This was the same in the previous generation, however in that case the 16-core had the higher TDP. For this launch, both the 16-core F and 24-core F have the same TDP, so the only reason I can think of for AMD to have a higher price on the 16-core processor is that it only has 2 cores per chiplet active, rather than three? Perhaps it is easier to bin a processor with an even number of cores active.
At the bottom is AMD’s sole 8-core offering, meaning only 1 core per chiplet, and zero contention for L3 cache. It also has a small range in frequency, which should enable deterministic workloads – despite the 180 W listed TDP, a 4.1 GHz Zen 3 core should not need more than 10 W per core, which leaves a lot of power for any configuration that wants to push the IO a little faster (more on that below).
All of these processors are aimed for systems that run software that is limited by single thread workloads, such as EDA tools, or for software that needs a lot of IO but can be limited by per-core licensing restrictions. All of these processors can be use in dual socket configurations.
Core Density Optimized: 48 Cores and Up
As part of the processor lineup, AMD is highlighting all of its high-core count products as being core density optimized, and systems built to take advantage of lower memory channel interleaving configurations (see below) could be built to the scale of 384 cores or 768 threads per 1U.
The new halo top-of-stack processor, the 64-core EPYC 7763, naturally fits into this segment. At 280 W, it adds another 40 W to the top processor publicly available from AMD, along with increasing both base frequency and turbo frequency as well as offering additional IPC gains. The price has increased by just under $1000 to represent where AMD believes it fits into this market.
| AMD EPYC 7003 Processors Core Density Optimized |
||||||
| Cores Threads |
Base Freq |
Turbo Freq |
L3 (MB) |
TDP | Price | |
| EPYC 7763 | 64 / 128 | 2450 | 3400 | 256 MB |
280 W | $7890 |
| EPYC 7713 | 64 / 128 | 2000 | 3675 | 225 W | $7060 | |
| EPYC 7663 | 56 / 112 | 2000 | 3500 | 240 W | $6366 | |
| EPYC 7643 | 48 / 96 | 2300 | 3600 | 225 W | $4995 | |
| P-Series (Single Socket Only) | ||||||
| EPYC 7713P | 64 / 128 | 2000 | 3675 | 256 | 225 W | $5010 |
AMD considers the EPYC 7763 as ‘a step up’ from the previous top-of-stack processor, the 7742. The direct replacement to the 64-core 7742 in this case is the 7713. We’ve tested both of the Milan and the 7742 Rome for this review, so we get to see how much of an uplift the new processors are.
Also part of the Core Density family is the first single socket processor, the 7713P. This is identical to the 7713, however does not support 2P configurations. As a result it comes in at $2000 cheaper.
The other interesting member of the family is the 7663, a 56 core processor. This configuration means that AMD is using 7 cores per chiplet, rather than the full 8, which is a configuration that AMD did not have with the previous generation. It would appear that AMD’s customers have requested a model like this, optimized for their workloads where less cache contention might be needed, or for workloads that won’t scale all the way to 64 cores.
Balanced and Optimized Portfolio
The rest of AMD’s portfolio of Milan processors comes under the ‘Balanced and Optimized’ banner, and this is where AMD will offer its 16-32 core processors as well as the rest of the 1P single socket parts.
| AMD EPYC 7003 Processors | ||||||
| Cores Threads |
Base Freq |
Turbo Freq |
L3 (MB) |
TDP | Price | |
| EPYC 7543 | 32 / 64 | 2800 | 3700 | 256 MB | 225 W | $3761 |
| EPYC 7513 | 32 / 64 | 2600 | 3650 | 128 MB | 200 W | $2840 |
| EPYC 7453 | 28 / 56 | 2750 | 3450 | 64 MB | 225 W | $1570 |
| EPYC 7443 | 24 / 48 | 2850 | 4000 | 128 MB |
200 W | $2010 |
| EPYC 7413 | 24 / 48 | 2650 | 3600 | 180 W | $1825 | |
| EPYC 7343 | 16 / 32 | 3200 | 3900 | 190 W | $1565 | |
| EPYC 7313 | 16 / 32 | 3000 | 3700 | 155 W | $1083 | |
| P-Series (Single Socket Only) | ||||||
| EPYC 7543P | 32 / 64 | 2800 | 3700 | 256 MB | 225 W | $2730 |
| EPYC 7443P | 24 / 48 | 2850 | 4000 | 128 MB | 200 W | $1337 |
| EPYC 7313P | 16 / 32 | 3000 | 3700 | 155 W | $913 | |
Almost all of these processors half the L3 cache to 128 MB, suggesting that these processors only have four active chiplets inside – this allows AMD to optimize its silicon product rather than providing lots of only-half enabled chiplets. This is seen perhaps in the price, as the 8-chiplet 32-core EPYC 7543 is almost $1000 more expensive than the EPYC 7513.
AMD only goes down to 16 cores here – the only 8 core processor is the 72F3 mentioned earlier. Also perhaps striking is that AMD does not go below 155 W TDP, which as we will see later in the review, might be down to some of the IO.
Bonus points for anyone spending $1337 on a processor like the EPYC 7443P.
Full Stack
For those wanting to see all the processors in one table with all the configurable TDP options, here we are. Processors we are testing in this review are highlighted in bold.
| AMD EPYC 7003 Processors | ||||||
| Cores Threads |
Frequency (GHz) |
L3 (MB) |
TDP (Default) / cTDP min / max |
Price | ||
| Base | Max | |||||
| EPYC 7763 | 64 / 128 | 2.45 | 3.40 | 256 ( 8 x 32 ) |
280 / 225 / 280 | $7890 |
| EPYC 7713 | 64 / 128 | 2.00 | 3.675 | 225 / 225 / 240 | $7060 | |
| EPYC 7663 | 56 / 112 | 2.00 | 3.50 | 240 / 225 / 240 | $6366 | |
| EPYC 7643 | 48 / 96 | 2.30 | 3.60 | 225 / 225 / 240 | $4995 | |
| EPYC 7543 | 32 / 64 | 2.80 | 3.70 | 225 / 225 / 240 | $3761 | |
| EPYC 7513 | 32 / 64 | 2.60 | 3.65 | 128 ( 4 x 32 ) |
200 / 165 / 200 | $2840 |
| EPYC 7453 | 28 / 56 | 2.75 | 3.45 | 64 ( 4 x 16 ) |
225 / 225 / 240 | $1570 |
| EPYC 7443 | 24 / 48 | 2.85 | 4.00 | 128 ( 4 x 32 ) |
200 / 165 / 200 | $2010 |
| EPYC 7413 | 24 / 48 | 2.65 | 3.60 | 180 / 165 / 200 | $1825 | |
| EPYC 7343 | 16 / 32 | 3.20 | 3.90 | 190 / 165 / 200 | $1565 | |
| EPYC 7313 | 16 / 32 | 3.00 | 3.70 | 155 / 155 / 180 | $1083 | |
| F-Series | ||||||
| EPYC 75F3 | 32 / 64 | 2.95 | 4.00 | 256 ( 8 x 32 ) |
280 / 225 / 280 | $4860 |
| EPYC 74F3 | 24 / 48 | 3.20 | 4.00 | 240 / 225 / 240 | $2900 | |
| EPYC 73F3 | 16 / 32 | 3.50 | 4.00 | 240 / 225 / 240 | $3521 | |
| EPYC 72F3 | 8 / 16 | 3.70 | 4.10 | 180 / 165 / 200 | $2468 | |
| P-Series (Single Socket Only) | ||||||
| EPYC 7713P | 64 / 128 | 2.00 | 3.675 | 256 ( 8 x 32 ) |
225 / 225 / 240 | $5010 |
| EPYC 7543P | 32 / 64 | 2.80 | 3.70 | 225 / 225 / 240 | $2730 | |
| EPYC 7443P | 24 / 48 | 2.85 | 4.00 | 128 ( 4 x 32 ) |
200 / 165 / 200 | $1337 |
| EPYC 7313P | 16 / 32 | 3.00 | 3.70 | 155 / 155 / 180 | $913 | |
To fill in some of the demands in costs and offering, AMD is also planning to supply 2nd Gen EPYC into the market for a good time, enabling both platforms for customers. These include the 32-core 7532, 24-core 7352, 16-core 7282, and a couple of 8-core processors.
Comparing Gen-on-Gen Pricing
Direct comparisons are always made against the previous generation, and these are the suggested comparisons:
| AMD Third Gen EPYC ("Milan") |
AMD Second Gen EPYC ("Rome") |
|||||||||
| Cores | Freq | TDP (W) |
Price | AMD | Cores | Freq | TDP | Price | ||
| Milan | Rome | |||||||||
| 7763 | 64 | 2.45/3.50 | 280 | $7890 | 7H12 | 64 | 2.60/3.30 | 280 | - | |
| 7742 | 64 | 2.25/3.40 | 225 | $6950 | ||||||
| 7713 | 64 | 2.0/3.675 | 225 | $7060 | 7702 | 64 | 2.00/3.35 | 200 | $6450 | |
| 7662 | 64 | 2.00/3.30 | 225 | $6150 | ||||||
| 7663 | 56 | 2.00/3.50 | 240 | $6366 | ||||||
| 7643 | 48 | 2.30/3.60 | 225 | $4995 | 7642 | 48 | 2.30/3.30 | 225 | $4775 | |
| 7552 | 48 | 2.20/3.30 | 200 | $4025 | ||||||
| 7543 | 32 | 2.80/3.70 | 225 | $3761 | 7542 | 32 | 2.90/3.40 | 225 | $3400 | |
| 7532 | 32 | 2.40/3.30 | 200 | $3350 | ||||||
| 7513 | 32 | 2.60/3.65 | 200 | $2840 | 7502 | 32 | 2.50/3.35 | 180 | $2600 | |
| 7452 | 32 | 2.35/3.35 | 155 | $2025 | ||||||
| 7453 | 28 | 2.75/3.45 | 225 | $1570 | ||||||
| 7443 | 24 | 2.85/4.00 | 200 | $2010 | 7402 | 24 | 2.80/3.35 | 180 | $1783 | |
| 7413 | 24 | 2.65/3.60 | 180 | $1825 | ||||||
| 7352 | 24 | 2.30/3.20 | 155 | $1350 | ||||||
| 7343 | 16 | 3.20/3.90 | 190 | $1565 | ||||||
| 7313 | 16 | 3.00/3.70 | 155 | $1083 | ||||||
| 7302 | 16 | 3.00/3.30 | 155 | $978 | ||||||
| 7282 | 16 | 2.80/3.20 | 120 | $650 | ||||||
Overall there is an uptick from Rome to Milan on pricing.
New Features and SoC Design
In our interview with AMD’s Forrest Norrod, he explained that the original goal of Milan was to update Rome’s 8-core chiplets from Zen 2 to Zen 3, but a number of factors meant that the central IO die also received updates, both on the power side and for Infinity Fabric performance.
Beyond the core updates from Zen 2 to Zen 3, which we’ve covered extensively in our consumer coverage, AMD has enabled several key features with Milan.
Memory Interleaving for 4/6/8 Channel Configurations
The enterprise and datacenter markets involve a vast array of potential workloads, some are compute-bound, some are memory-bound, but the goal has always been to get the work done as quickly as possible, as efficiently as possible, and as cheaply as possible. The larger companies will often optimize their deployments in every way imaginable, and that includes memory.
AMD admits that there is a portion of the market that is very much memory-bound, either in capacity, latency, or bandwidth. These customers will keep demanding higher capacity support, faster memory, or just more memory channels for both capacity or bandwidth. We’ve been told that there is a holistic split at some level between these sorts of customers, and those that are simply compute-bound, which may come to a head with differentiated products in the future. But for now, we have eight-channel DDR4 processors on the market, which is not-enough for some customers, but plenty for others who don’t need all that capacity or bandwidth.
It’s the latter customers where optimizations may occur. For example, if memory bandwidth or capacity is not a limiting factor, then those customers can design systems with fewer memory channels being used. This helps by increasing density, making physical system design simpler, perhaps cooling, but also by disabling those memory channels, more power is available for their compute-bound systems. We came to a point in the previous generation lifecycle where we were starting to see motherboards enter the market with fewer than eight memory slots for these reasons.
In order to get the best performance, or reliable performance, from the memory (and not experience any NUMA or silo effects), the memory installed needs to have effective memory interleaving enabled on what is installed. AMD EPYC in the past has supported 8-channel interleaving and 4-channel interleaving, but for Milan, AMD is also supporting 6-channel interleaving for customers that build in those configurations. Four and Eight are obvious powers of two for AMD to have included by default, but enough demand for Six was there to enable an update to the IO die to support this mode.

AMD has confirmed that 6-channel memory interleaving, when using one module per channel, will be supported on all Milan processors.
Security for Return Programming and Secure Nested Pages
The effects of Spectre, Meltdown, and its variants have repurposed processor security to be more proactive at all the major microprocessor designers and manufacturers. AMD has implemented fixes in hardware for the Spectre variants to which it was susceptible, and hasn’t needed to add additional protection from Meltdown and its variants as AMD CPUs are not naturally vulnerable.
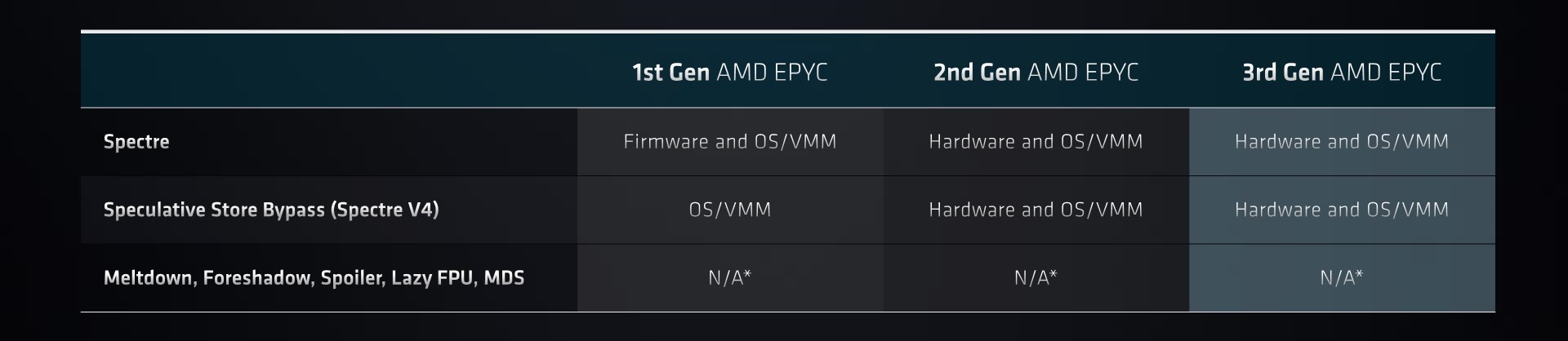
The new segment of attacks beyond these are based on return address programming, and effectively adjusting the control flow of code on the processors by manipulating stack return addresses or jump/control commands. AMD implemented a fix for these sorts of attacks in its Zen 3 core, and these fixes get passed into EPYC Milan, known as ‘Shadow Stacks’. These are hardware based solutions, enabling a minimal effect to performance, but absolutely required for security.

The other segment to AMD’s security updates is Secure Nested Paging, part of AMD’s Secure Encrypted Virtualization technology. These technologies all deal with hyperscalers enabling multiple host instances on a single system, and being able to protect the instances from each other. In previous generation Rome, Secure Encrypted Virtualization allowed a secure hypervisor to isolate these instances or virtual machines from each other in a secure and encrypted way (hence the name).
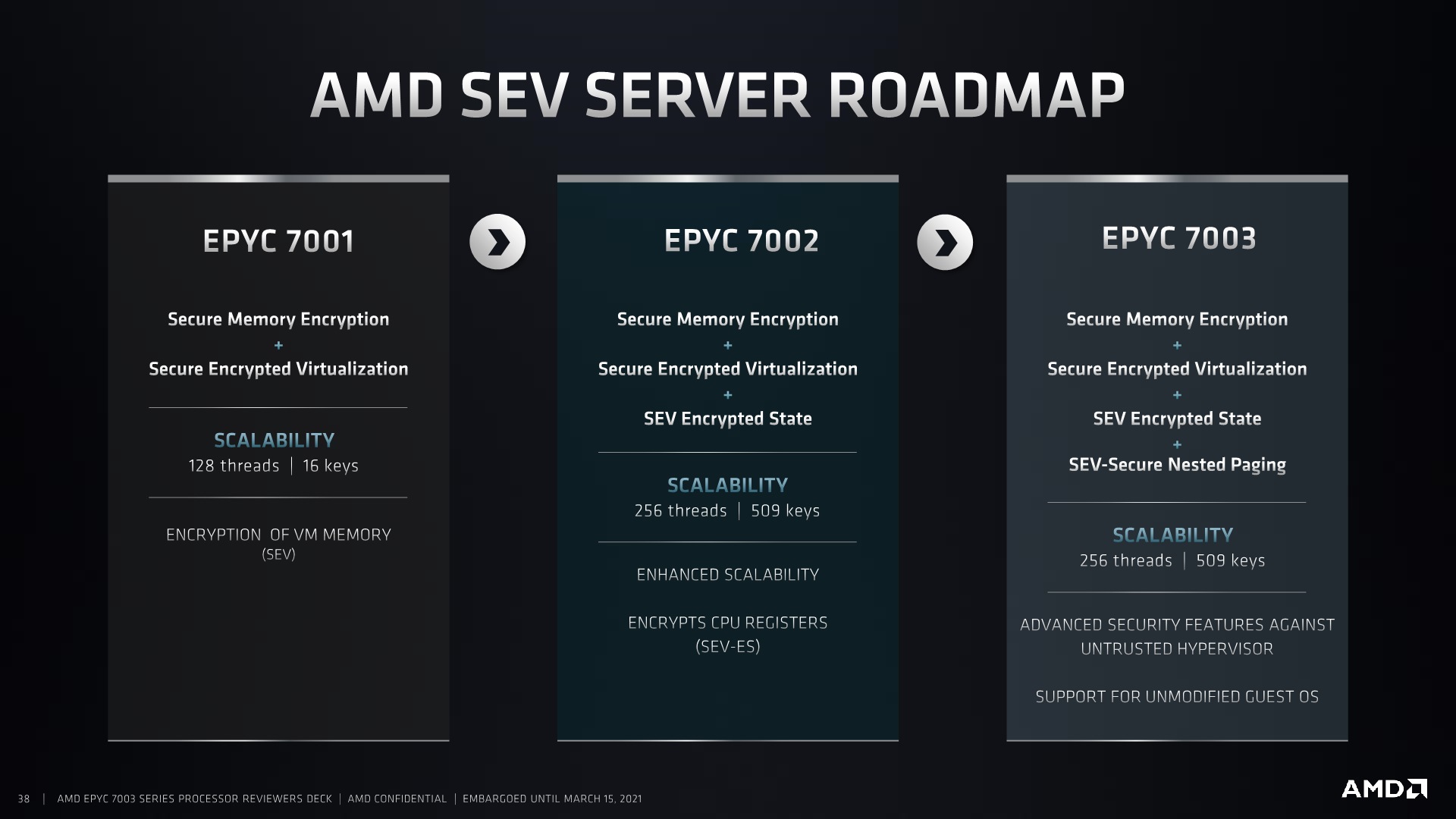
Secure Nested Paging takes this one stage further, and enables additional security of the virtual machines from the hypervisor itself. This allows protection against an untrusted hypervisor, should an attacker get access, as well as support for software running on unmodified guest operating systems for which the software was originally not built for.
Enhanced Memory and IO Performance
One of the big updates from the Zen 2 core complex to the Zen 3 core complex in all of AMD’s product families was the size of that complex, moving from four cores to eight cores. This means that in an eight core chiplet, rather than there being two complexes of four cores and a separated L3 cache, there is now a single eight core complex with a unified cache. As seen in our consumer reviews, this matters a lot for memory-heavy operation as well as branch heavy code. Another benefit is that the control electronics for the complex are now at the edge of the chiplet, providing some small improvement.

We’ll go into how exactly the cache structure changes later in the review.
The other angle to Milan’s performance in IO is on the Infinity Fabric and PCIe. For this generation, AMD has enabled 18 Gbps Infinity Fabric links over its SERDES connections, up from the previous generation 16 Gbps links. This might come across as slightly minor, but it should enable better performance in a competitive core-to-core communications environment.
AMD is also supporting Extended Speed Modes on its PCIe links with Milan. This is part of the PCIe 4.0 standard, and allows customers to enable more bandwidth over the PCIe link to discrete accelerator cards if the motherboard is designed to support those speeds. This requires extra power from the processor, which does take power/performance away from the processor cores, however AMD has stated that because its customers have so many different optimization points, a number of workloads will benefit from this option.

Other Improvements and ISA Enhancements
Also on AMD’s list of updates to Milan are the following:
| INVLPGB | New instruction to use instead of inter-core interrupts to broadcast page invalidates, requires OS/hypervisor support |
| VAES / VPCLMULQDQ | AVX2 Instructions for encryption/decryption acceleration |
| SEV-ES | Limits the interruptions a malicious hypervisor may inject into a VM/instance |
| Memory Protection Keys | Application control for access-disable and write-disable settings without TLB management |
| Process Context ID (PCID) | Process tags in TLB to reduce flush requirements |
| INT8 | Dual INT8 pipes, up from 1, doubles INT8 performance |
Test Bed and Setup - Compiler Options
For the rest of our performance testing, we’re disclosing the details of the various test setups:

AMD - Dual EPYC 7763 / 7713 / 75F3 / 7662
In terms of testing the new EPYC 7003 series CPUs, unfortunately due to our malfunctioning Daytona server, we weren’t able to get first-hand experience with the hardware. AMD graciously gave us remote access to one of their server clusters – we had full controls of the system in terms of BMC as well as BIOS settings.
| CPU | 2x AMD EPYC 7763 (2.45-3.500 GHz, 64c, 256 MB L3, 280W) / 2x AMD EPYC 7713 (2.00-3.365 GHz, 64c, 256 MB L3, 225W) / 2x AMD EPYC 75F3 (3.20-4.000 GHz, 32c, 256 MB L3, 280W) / 2x AMD EPYC 7662 (2.00-3.300 GHz, 64c, 256 MB L3, 225W) |
| RAM | 512 GB (16x32 GB) Micron DDR4-3200 |
| Internal Disks | Varying |
| Motherboard | Daytona reference board: S5BQ |
| PSU | PWS-1200 |
Software wise, we ran Ubuntu 20.10 images with the latest release 5.11 Linux kernel. Performance settings both on the OS as well on the BIOS were left to default settings, including such things as a regular Schedutil based frequency governor and the CPUs running performance determinism mode at their respective default TDPs unless otherwise indicated.
AMD - Dual EPYC 7742
Our local AMD EPYC 7742 system, due to the aforementioned issues with the Daytona hardware, is running on a SuperMicro H11DSI Rev 2.0.
| CPU | 2x AMD EPYC 7742 (2.25-3.4 GHz, 64c, 256 MB L3, 225W) |
| RAM | 512 GB (16x32 GB) Micron DDR4-3200 |
| Internal Disks | Crucial MX300 1TB |
| Motherboard | SuperMicro H11DSI0 |
| PSU | EVGA 1600 T2 (1600W) |
As an operating system we’re using Ubuntu 20.10 with no further optimisations. In terms of BIOS settings we’re using complete defaults, including retaining the default 225W TDP of the EPYC 7742’s, as well as leaving further CPU configurables to auto, except of NPS settings where it’s we explicitly state the configuration in the results.
The system has all relevant security mitigations activated against speculative store bypass and Spectre variants.
Ampere "Mount Jade" - Dual Altra Q80-33
The Ampere Altra system we’re using the provided Mount Jade server as configured by Ampere. The system features 2 Altra Q80-33 processors within the Mount Jade DVT motherboard from Ampere.
In terms of memory, we’re using the bundled 16 DIMMs of 32GB of Samsung DDR4-3200 for a total of 512GB, 256GB per socket.
| CPU | 2x Ampere Altra Q80-33 (3.3 GHz, 80c, 32 MB L3, 250W) |
| RAM | 512 GB (16x32 GB) Samsung DDR4-3200 |
| Internal Disks | Samsung MZ-QLB960NE 960GB Samsung MZ-1LB960NE 960GB |
| Motherboard | Mount Jade DVT Reference Motherboard |
| PSU | 2000W (94%) |
The system came preinstalled with CentOS 8 and we continued usage of that OS. It’s to be noted that the server is naturally Arm SBSA compatible and thus you can run any kind of Linux distribution on it.
The only other note to make of the system is that the OS is running with 64KB pages rather than the usual 4KB pages – this either can be seen as a testing discrepancy or an advantage on the part of the Arm system given that the next page size step for x86 systems is 2MB – which isn’t feasible for general use-case testing and something deployments would have to decide to explicitly enable.
The system has all relevant security mitigations activated, including SSBS (Speculative Store Bypass Safe) against Spectre variants.
Intel - Dual Xeon Platinum 8280
For the Intel system we’re also using a test-bench setup with the same SSD and OS image as on the EPYC 7742 system.
Because the Xeons only have 6-channel memory, their maximum capacity is limited to 384GB of the same Micron memory, running at a default 2933MHz to remain in-spec with the processor’s capabilities.
| CPU | 2x Intel Xeon Platinum 8280 (2.7-4.0 GHz, 28c, 38.5MB L3, 205W) |
| RAM | 384 GB (12x32 GB) Micron DDR4-3200 (Running at 2933MHz) |
| Internal Disks | Crucial MX300 1TB |
| Motherboard | ASRock EP2C621D12 WS |
| PSU | EVGA 1600 T2 (1600W) |
The Xeon system was similarly run on BIOS defaults on an ASRock EP2C621D12 WS with the latest firmware available.
The system has all relevant security mitigations activated against the various vulnerabilities.
Compiler Setup
For compiled tests, we’re using the release version of GCC 10.2. The toolchain was compiled from scratch on both the x86 systems as well as the Altra system. We’re using shared binaries with the system’s libc libraries.
It’s to be noted that for AMD’s latest Zen3-based EPYC 7003 CPUs, GCC 10.2 did not yet offer compatibility with the relevant -znver3 CPU target. Due to our goal to keep apples-to-apples comparisons between the various systems, we’re resorted to using the same -znver2 binaries on the new EPYC 3rd generation parts.
AMD notes performance benefits using a new LLVM 11 based AOCC 3.0 featuring Zen3 performance optimisations. The new compiler version is to be released at the time of publishing, and thus we hadn’t had the opportunity to verify these claims.
Topology, Memory Subsystem & Latency
For users who are already familiar with AMD’s newest Zen3 microarchitecture from our coverage of the new Ryzen 5000 consumer parts, they will remember that one big change the way configures their CPU topology is how the new CCX (Core Complex) is integrated within a CCD (Core Chiplet Die).
Previous generation Zen2 and prior designs of the Zen microarchitecture consisted of CCXs of four CPU cores, with a set amount of L3 cache shared between these four cores – 8MB in the original Zen iterations and 16MB in Zen2 variants. In Zen3, AMD has redesigned their L3 implementation to now support up to 8 physical cores in one core complex. Effectively, AMD is doubling the L3 and cores per CCX. The CCD in turn however instead of housing two CCXs, now only houses one, which effectively means that the total L3 and core count per core chiplet doesn’t change between the generations.
Benefits for the new arrangement is that this enlarges the L3 cache hierarchy from the view of a single CPU core, allowing each core to possibly make use of the full 32MB of cache. Furthermore, because the CCX is now 8 cores instead of 4 cores, inter-core access latencies to other cores can effectively be reduced when workloads are resident on the cores within that CCX. Previously, even if two cores were on the same physical die, but on different CCXs, communications between the two had to take place via external routing through the IOD (I/O Die) of the CPU package, incurring large access penalties. AMD here also makes an interesting argument for larger virtual machines which are bound to a single CCD across 8 cores, something which was previously not possible without performance hits due to spanning a VM across multiple CCXs.
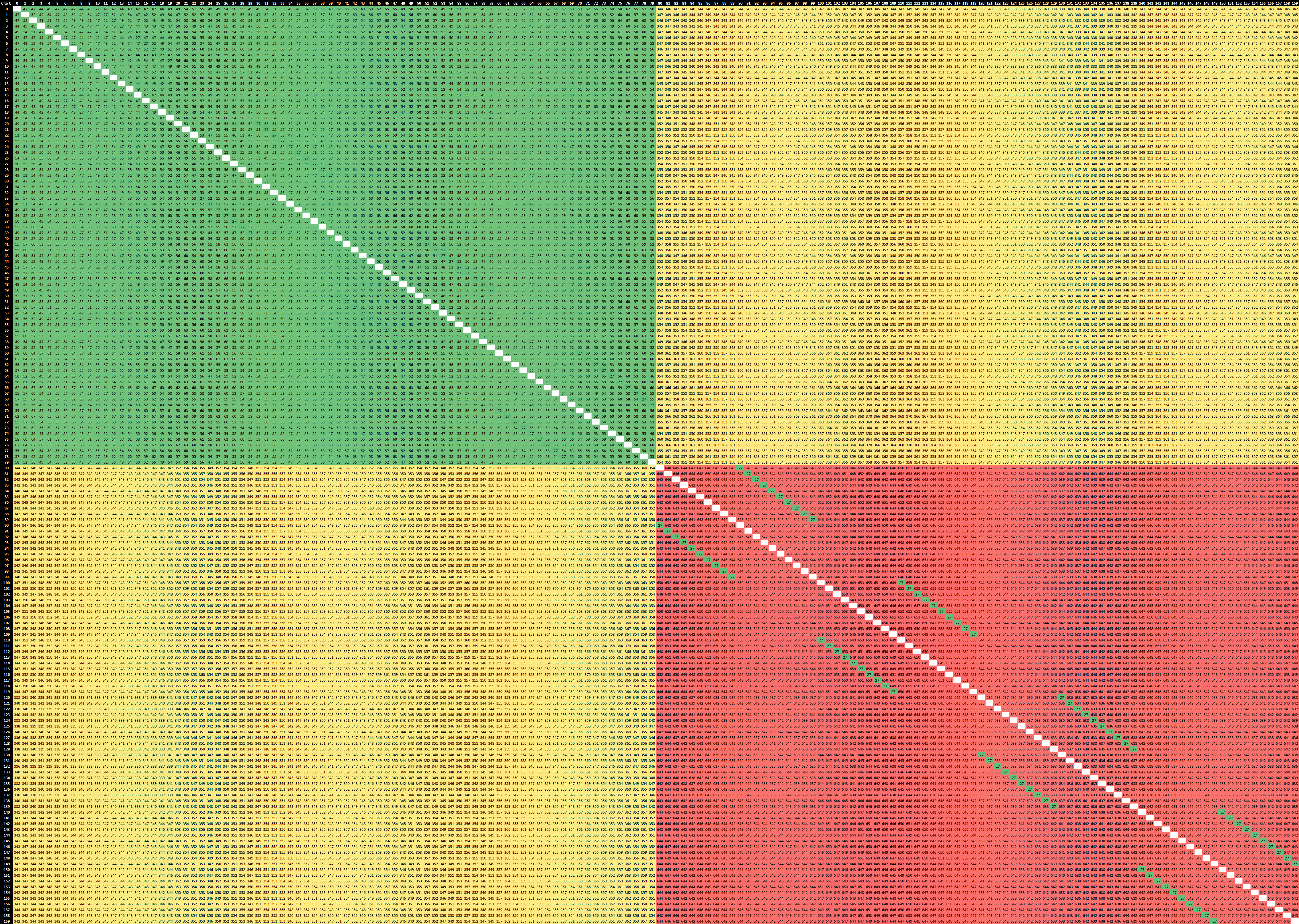
We can test out the physical topology of the CPUs by running our inter-core synchronisation latency test. As a reminder, our inter-core bounce test consists of an initial main thread which allocates the synchronisation cache line on the core that the executable is spawned on – we try to fix this to the first NUMA node / CPU group of the first socket. This in turn spawns two ping-pong threads which bounce around based on the shared cache line, and we change the affinity of the threads across the system to test out the various core-to-core latencies. Because of the usage of a common shared cache line – usually how real software works; we’re essentially testing core-to-cacheline-to-core – an important distinction to make for some systems which have different cache line placement and cache coherency algorithms.

2-Socket AMD EPYC 7763 (Milan)
Right off the bat, what’s immediately visible in the new EPYC 7763 64-core Milan based part is that the CCXs have grown in size, now spanning 8 cores, with the corresponding lower latency results within that cache hierarchy. The result set here is limited to just the physical cores as otherwise the logical SMT siblings would have resulted in a 256 x 256 matrix for a 2-socket system.
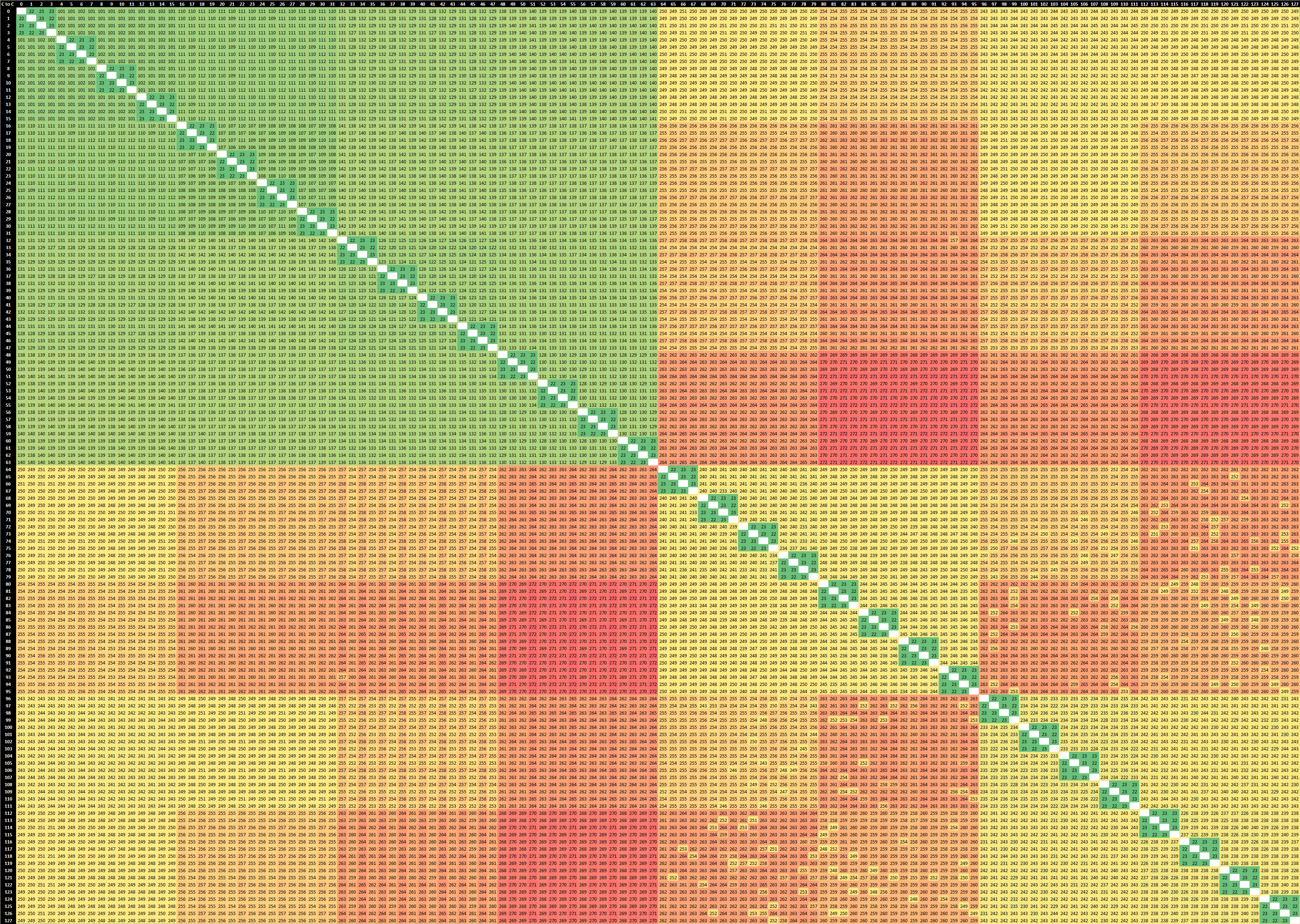
2-Socket AMD EPYC 7742 (Rome)
If we contrast the new Milan design to the Rome-based EPYC 7742, we’re seeing quite a few differences between the two generations. First of all, within the CCX/CCD, we’re not seeing that access latencies aren’t as uniform anymore. Previously we saw latencies at 22-23ns, whereas the new part now varies from 19 to 31ns, which is due to AMD’s doubling of the L3 which has seen a new internal topology between the 8 cache slices. It’s to be noted that the test here ran around 3400MHz between both generation parts.
AMD’s server IO die is divided into quadrants, each featuring two memory controllers and two connections to CCDs. Access latencies between two CCDs in a quadrant is lower than between two CCDs in different quadrants, and we can also see this in the results. The core-to-core latency within a quadrant this generation has improved from a worst-case 112ns to 99ns, about a 10ns improvement. Access to remote quadrants has been reduced from up to 142ns to up to 114ns, which is actually a 24% improvement, which is considerable.
What’s really interesting is that inter-socket latencies have also seen very notable reductions. Whereas the Rome part these went up to 272ns, the new Milan part reduces this down to 202ns, again a large 25% improvement between generations.
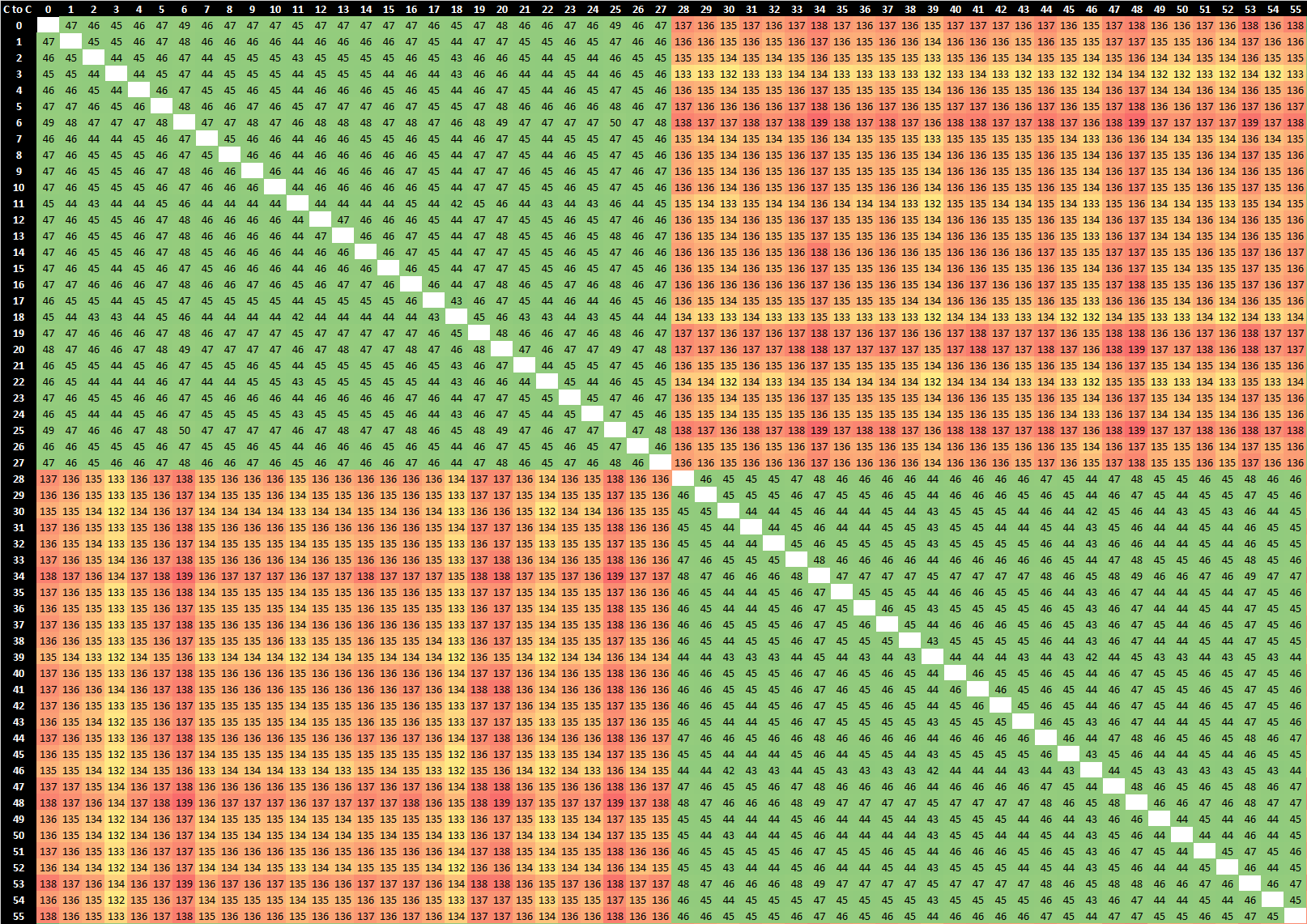
2-Socket Ampere Altra Q80-33 --------- 2-Socket Intel Xeon Platinum 8280
Compared to other competitors which use monolithic silicon designs, AMD lags behind in terms of core-to-core latencies within a single socket, although latencies within a CCX/CCD are more performant. Inter-socket latencies are superior to newcomers such as Ampere’s Altra, however lag behind Intel’s seemingly superior cache coherency protocol, particularly in scenarios where two cores of a same socket access a remote socket cache line, being able to locally copy/mirror it with native performance, something AMD currently is only able to do at a CCX/CCD level.
Memory Latency
Memory latency on Milan is interesting as AMD is now employing a new IOD design. Well – it’s not a completely new design from the previous generation Rome IOD, however it is a redesign with new features, with slightly more transistors and it is a new chip tape-out.

The biggest practical change of the new chip is that the internal Infinity Fabric clock is now coupled with the memory controller clocks / DRAM MEMCLK, at up to DDR3200. The much-improved inter-core latencies discussed above are likely direct result of this change, but it should also have larger impact on the memory latency of the new Milan chips.
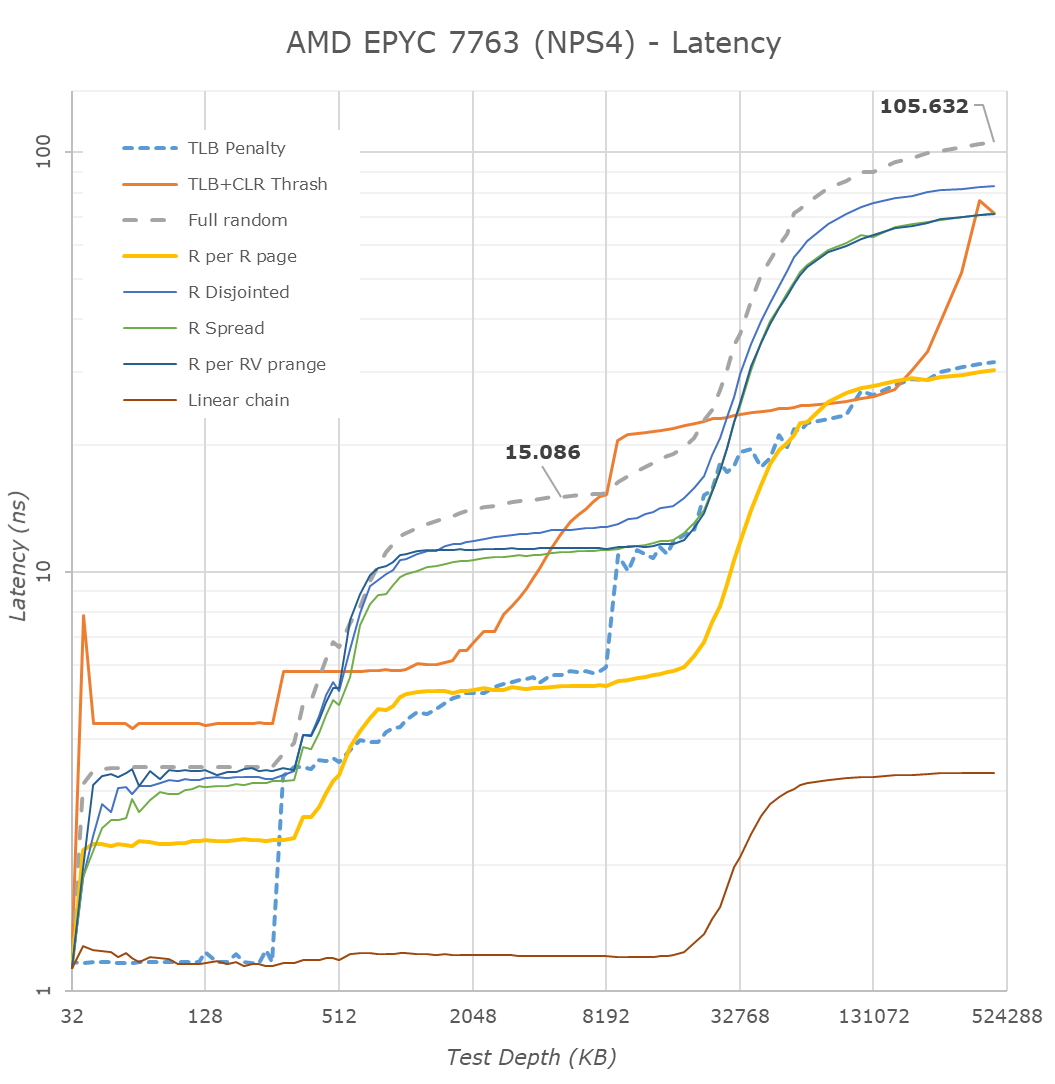
Starting off in NPS4 mode, a NUMA node in which a socket is divided into 4 non-uniform memory address spaces, representing the four physical quadrants of the IOD, each NUMA node and quadrant with the local 2 CCDs and 16 cores only have access to their local 2 memory channels.
Latencies here see a reduction from 118ns down to 105ns, which is a 11% improvement. The 13ns improvement should be a direct result of the new Milan part having to avoid asynchronous clock bridges between the Infinity Fabric and the memory controllers.
The latencies at the lower cache hierarchies within the new L3 and Zen3 cores looks pretty identical to what we’ve measured on the consumer Ryzen 5000 parts – with the only difference of course that the EPYC CPUs are running at lower frequencies.
What I’d say is interesting, is how the prefetchers behave compared to Rome. AMD this generation with Zen3 has changed things up quite a bit with newer generation prefetchers, including a new region-based prefetcher. On the Rome parts we saw that the more advanced prefetchers enabled/disabled themselves depending on access pattern depth. On Milan, this doesn’t seem to be the case, at least for some of our patterns.
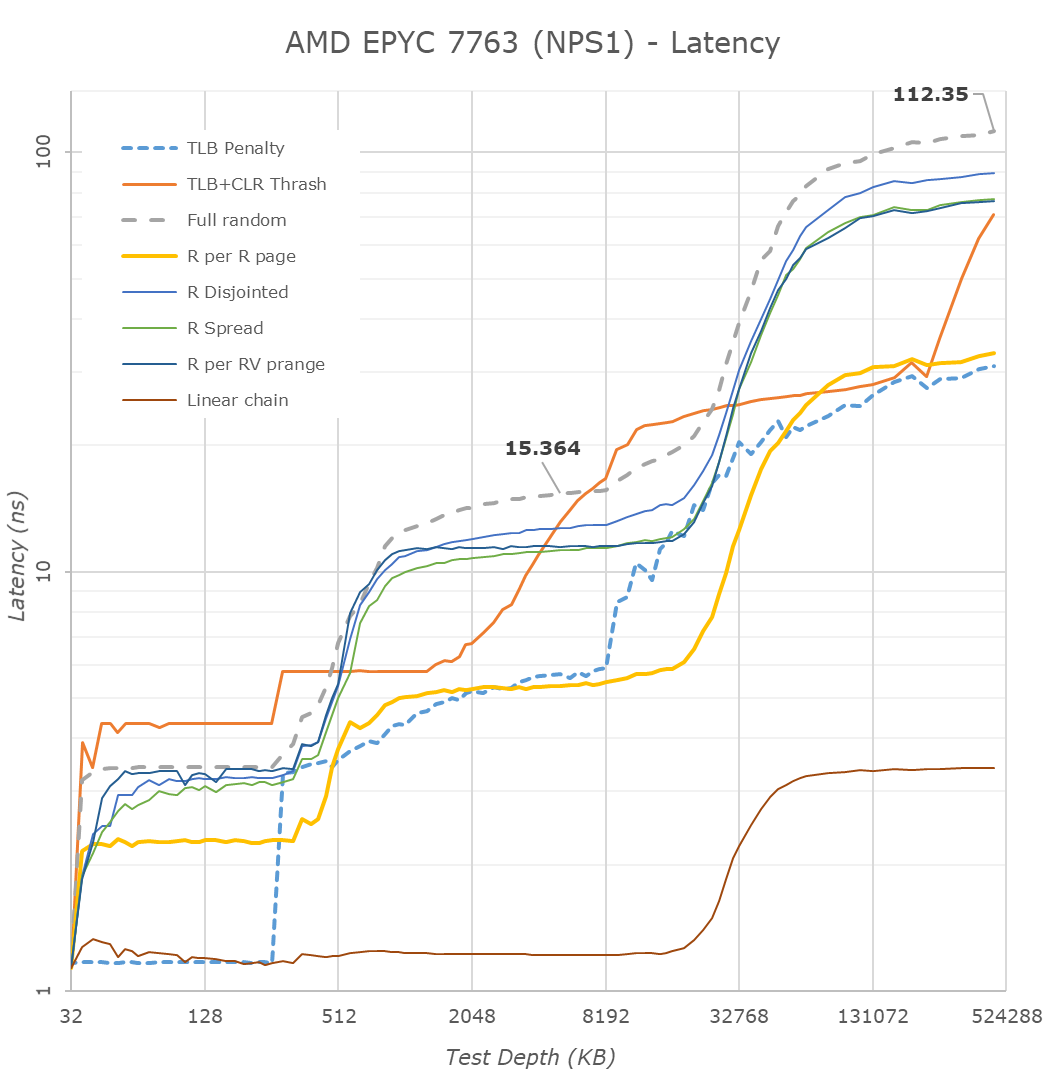
Although the best latencies are to be had in NPS4 mode, sometimes you want just a single large NUMA node with full access to the total memory of a single socket (AMD also offers NPS0 mode with interleaving memory across two sockets, but that’s beyond our scope here). Here, a single CPU will interleave memory accesses across all four quadrants and eight memory channels, but due to the physical design of the chip this naturally means the data has to travel longer distances, and thus latencies are expected to be worse than in NPS4 mode.
Surprisingly, the new 7763 Milan part is showing extremely large improvements in NPS1 mode – reducing latencies from 133ns down to 112ns, a 21ns reduction, representing a 15.8% improvement over the 7742 Rome part. Although naturally still not quite matching monolithic chip access latencies as seen from a Xeon or Altra system, it’s significantly better this generation.
Memory Bandwidth
For memory bandwidth, AMD had advertised a 3-5% improvement in STREAM-Triad compared to previous generation 7002 series CPUs, so let’s put that to the test.
We’re opting for a regularly compiled STREAM binary using GCC 10.2, and are avoiding the use of explicit non-temporal memory accesses as I do not consider them to be real-world for how most workloads behave. I had explained this rationale in our review of the Ampere Altra a few months ago.
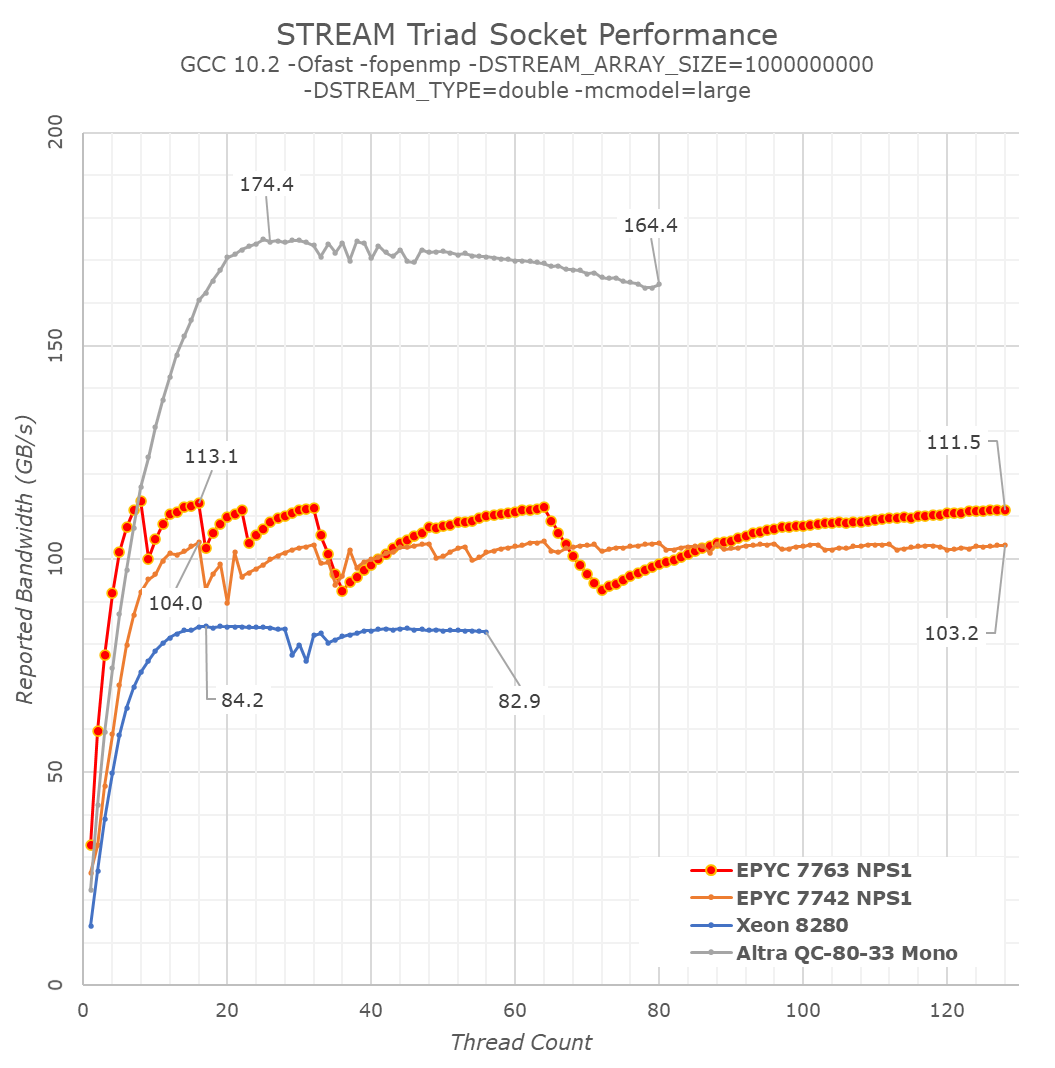
Also, instead of looking at a single test result figure, I charted the bandwidth curves of the system when scaling from 1 thread/core to the full 128 threads of the system.
In terms of peak memory bandwidth, we’re seeing that indeed the new Milan-based chip around 8% higher than the Rome-based predecessor, slightly above AMD’s marketed projections. AMD hadn’t clarified whether these were NPS1 or NPS4 figures, but we prefer using STREAM to measure bandwidth within a single memory node – scaling up to multiple nodes should normally be expected to simply be a multiple of the node.
What’s really interesting in the behaviour of the Milan system is the bandwidth scaling at lower thread/core counts. Here we’re seeing the new 7763 take the lead by considerable margins compared to the competition, and the Milan chip is able to actually reach its peak memory bandwidth with only 8 cores, whereas the Rome-based parts required 16 cores to reach this point. The cause of these excellent results is likely the much-improved load/store capabilities of the new Zen3 cores.
What’s odd here in the bandwidth curve, is the zig-zag pattern, with bandwidth sometimes regresses below earlier achieved peak figures. We’re placing threads with OMP_PLACES="cores" and OMP_PROC_BIND="spread", however this might still not be optimal in terms of spreading load symmetrically across all CCDs in the system.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Power & Efficiency: IOD Power Overhead?
In the server CPU space, especially at higher core counts where the CPUs are limited in their performance by the TDP limits of the design, higher power efficiency infers higher performance. In the context of AMD’s newest Milan parts, before we continue on to the performance benchmarks, I wanted to cover in more detail a few odd aspects of the new parts which differ quite a bit to Rome when it comes to power consumption.
It’s to be noted that during AMD’s presentation and our briefing on Milan, the company hadn’t made a single mention of power or energy efficiency, which was already a bad sign of some things to come.
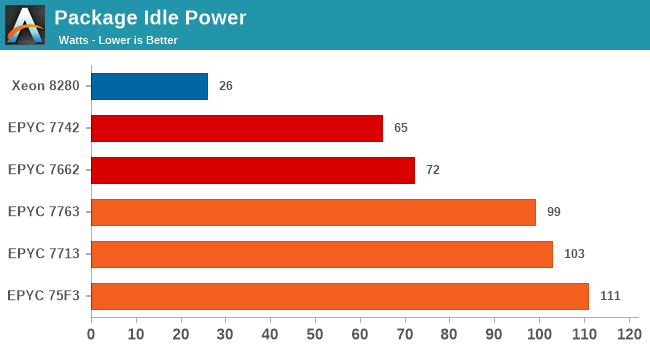
The first thing to appear as quite unusual on the new Milan parts was the idle power consumption of the various new SKUs. On the last generation Rome platform, I had measured package power of a single socket idling at around 65W. Compared to regular desktop CPUs this is quite a lot, however seemed relatively normal given the 8 memory controller channels, tons of I/O, as well as the fact that AMD uses an MCM/chiplet design which could possibly have a power overhead at low load. This figure was already higher than competing monolithic solutions from Intel or Ampere – I don’t have the exact figures at hand here and that’s why I didn’t include them in the chart but I remember seeing around 30-50W idle there.
Unfortunately, on Milan, this figure has seemingly risen to around 100W, reaching up to 111W in our test of the 75F3 system. This 30-40W increase in package power was a bit worrying as that shouldn’t normally be something you’d see in idle situations, where power management normally would kick in to reduce power consumption of the system.
I’ve proceeded to run all our SPEC workloads with power tracing of the system’s package and core power. We’re using AMD’s energy counters to achieve this, and are simply measuring in the start and end energy consumption, meaning there’s zero overhead and we have a precise figure in Joules based on how much the system has consumed during a workload (At least as precise as the numbers are reported). It’s to be noted that while the package power is evident in what it shows, simply the total energy of the socket package, the “core” power consumption metric is limited to just the individual CPU cores and their private L2 caches, without any of the shared L3 or other un-core components.
We’re comparing the power behaviour of four parts: For the Rome SKUs, we’re using an EPYC 7742 as well as an EPYC 7662. For the Milan parts, we’re using the 7663 and the 7713. It’s to be noted that because the EPYC 7663 is normally a 280W part, we’ve tuned down the power consumption via cTDP and PPT to 225W – this is not the way you’d normally operate the part but represents an interesting data-point when comparing things to the three other 225W CPUs.
I’d also like to mention that AMD had made note that the 7713 is meant to be positioned as a successor to the 7662, not the 7742, which is meant to be a higher-binned more power efficient part. However due to due 7713 coming in at almost the same price as the 7742 at launch, and due to the power behaviour of the two chips, I see these to chips as the better apples-to-apples generational comparison, although the argument we’re making also applies to the 7662 comparison.
| Rome vs Milan Power Efficiency | |||||||||||||
| SKU | EPYC 7742 (Rome) |
EPYC 7662 (Rome) |
EPYC 7663 (Milan) |
EPYC 7713 (Milan) |
|||||||||
| TDP Setting | 225W |
225W |
225W (cTDP down) |
225W |
|||||||||
| Perf |
PKG (W) |
Core (W) |
Perf | PKG (W) |
Core (W) |
Perf | PKG (W) |
Core (W) |
Perf | PKG (W) |
Core (W) |
||
| 500.perlbench_r | 268 | 220 | 141 | 238 | 192 | 107 | 253 | 220 | 112 | 239 | 221 | 104 | |
| 502.gcc_r | 239 | 208 | 105 | 228 | 189 | 83 | 246 | 220 | 92 | 240 | 219 | 83 | |
| 505.mcf_r | 141 | 203 | 95 | 139 | 187 | 77 | 153 | 220 | 85 | 153 | 218 | 75 | |
| 520.omnetpp_r | 134 | 207 | 109 | 131 | 189 | 87 | 139 | 220 | 92 | 136 | 217 | 82 | |
| 523.xalancbmk_r | 166 | 205 | 96 | 157 | 189 | 78 | 164 | 219 | 93 | 157 | 218 | 85 | |
| 525.x264_r | 567 | 220 | 147 | 512 | 194 | 114 | 505 | 220 | 113 | 475 | 221 | 105 | |
| 531.deepsjeng_r | 232 | 218 | 138 | 214 | 194 | 109 | 239 | 221 | 114 | 226 | 221 | 106 | |
| 541.leela_r | 264 | 210 | 144 | 243 | 192 | 117 | 250 | 220 | 119 | 240 | 220 | 110 | |
| 548.exchange2_r | 486 | 213 | 150 | 441 | 193 | 119 | 436 | 220 | 121 | 412 | 221 | 113 | |
| 557.xz_r | 184 | 208 | 120 | 174 | 190 | 96 | 178 | 221 | 103 | 171 | 220 | 93 | |
| SPECint2017 | 240 | 210 | 119 | 224 | 190 | 96 | 235 | 220 | 102 | 225 | 219 | 93 | |
| kJ Total | 1745 | 1681 | 1844 | 1904 | |||||||||
| Score / W | 1.143 | 1.176 | 1.066 | 1.028 | |||||||||
| 503.bwaves_r | 334 | 195 | 90 | 329 | 184 | 76 | 354 | 217 | 81 | 354 | 216 | 72 | |
| 507.cactuBSSN_r | 204 | 216 | 118 | 196 | 195 | 93 | 205 | 220 | 94 | 198 | 220 | 86 | |
| 508.namd_r | 261 | 221 | 154 | 233 | 193 | 116 | 229 | 219 | 115 | 217 | 219 | 107 | |
| 510.parest_r | 114 | 204 | 97 | 112 | 186 | 77 | 152 | 221 | 86 | 148 | 219 | 75 | |
| 511.povray_r | 353 | 223 | 160 | 299 | 188 | 114 | 308 | 220 | 119 | 286 | 220 | 111 | |
| 519.lbm_r | 35 | 186 | 84 | 35 | 184 | 77 | 39 | 210 | 76 | 39 | 215 | 72 | |
| 526.blender_r | 327 | 220 | 131 | 295 | 194 | 100 | 316 | 220 | 109 | 299 | 220 | 101 | |
| 527.cam4_r | 336 | 217 | 113 | 320 | 195 | 89 | 359 | 220 | 92 | 343 | 218 | 83 | |
| 538.imagick_r | 401 | 213 | 148 | 356 | 189 | 115 | 377 | 220 | 119 | 355 | 221 | 111 | |
| 544.nab_r | 241 | 218 | 150 | 217 | 193 | 116 | 217 | 220 | 116 | 204 | 221 | 108 | |
| 549.fotonik3d_r | 108 | 194 | 90 | 107 | 183 | 76 | 111 | 213 | 79 | 111 | 216 | 73 | |
| 554.roms_r | 82 | 202 | 94 | 81 | 184 | 74 | 88 | 220 | 83 | 88 | 217 | 73 | |
| SPECfp2017 | 191 | 200 | 101 | 180 | 186 | 83 | 193 | 217 | 88 | 187 | 217 | 80 | |
| kJ Total | 4561 | 4363 | 4644 | 4740 | |||||||||
| Score / W | 0.953 | 0.965 | 0.894 | 0.861 | |||||||||
In terms of absolute power consumption, all the parts generally land in the same 220W range figure, although we do see that in terms of actual measured power the Rome parts are a bit more conservative, especially the 7662. We’re running the CPUs in performance determinism mode – power determinism would always fill out the configured TDP but possibly would have little positive performance impact and certain power efficiency regressions.
What’s interesting to showcase and point out to between the four SKUs is the ratio between the power consumption of the total package and the actual cores which varies between the Rome and Milan generation parts.
Particularly what we’re interested in are workloads that are less memory-bound, and more core-local – in essence more typical compute heavy workloads such as 525.x264 or 511.porvray.
In such workloads, although we’re seeing that between the 7742, 7763, and 7713 (and to a lesser extent, the 7662), all SKUs are posting measured package power consumption figures that are pretty much identical. However, the core power consumption figures are very different, with the Rome 7742 part posting significantly higher figures than the new Milan chips, sometimes up to in the 40-50W range.
It’s exactly in these workloads where we actually see performance of the new Milan parts showcase a regression compared to the Rome parts. Anything that is less memory bound and requires the package power to be allocated towards just the CPU cores is notably favouring the Rome parts, allowing those chips to outperform the newer Milan parts.
The end-result is that although at equal TDP Milan has a theoretical IPC improvement, and does showcase benefits in workloads that are more heavily memory oriented, the actual geomean results of the new chips are actually just generationally flat – all whilst showcasing higher power and energy consumption, meaning that the new chips have perf/W regression of around 15%.
This regression seems to stem from an increase power overhead on the part of the new faster IOD of Milan (New L3 design could also be a factor). Effectively this increased power behaviour is reducing the effective usable power envelope of the actual cores, having a negative effect on performance, counteracting this generation’s IPC improvements at the worst case.
We had communicated our findings to AMD, but with no real resolution to the situation – so it does not seem to be a problem of misconfigured power management on the part of the test platform.

Indeed, charting the SPEC results across scaling thread counts in the system showcases that while at full load the differences between a 7713 and 7742 are almost nothing, at lower utilisations there’s actually a larger advantage in favour of the new Milan part, from 5% at 56 cores and growing larger the less cores are used. We’re seeing a huge >20% performance advantage at <8 threads, likely tied to the fact that at such low thread counts each core can take advantage of the full L3 in each chiplet/CCD.
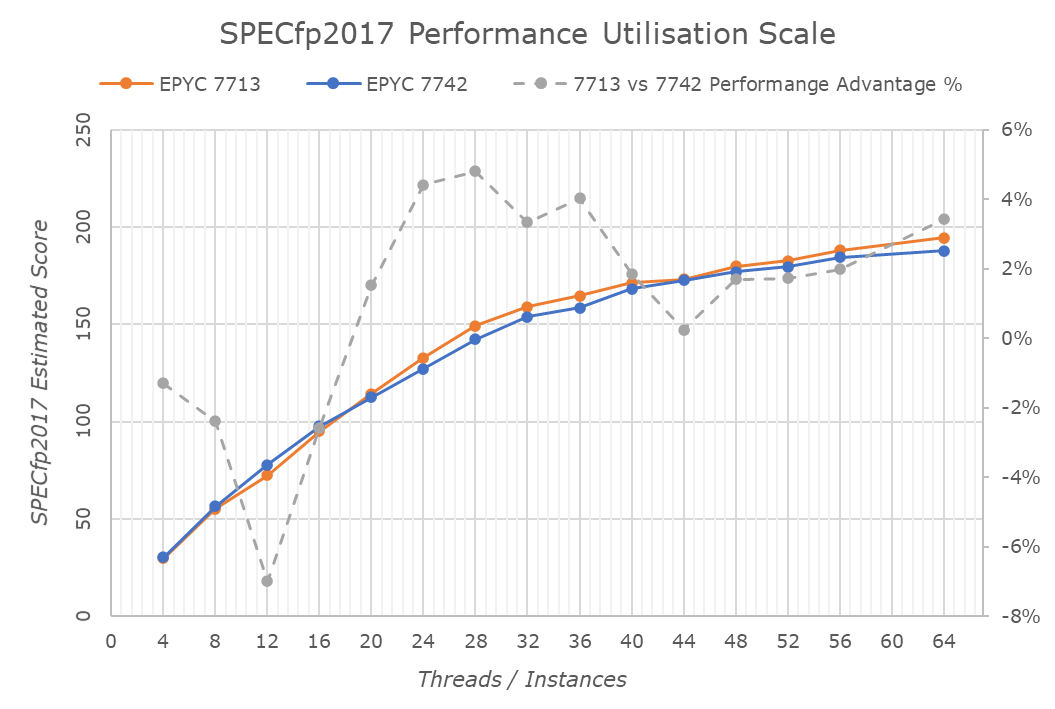
On SPECfp2017, oddly enough the advantages of the new Milan-based 7713 are less pronounced than in SPECint2017, even showcasing performance regressions at lower thread counts. I’m not too sure what the reason here is, but the new Zen3 CCX keeping its aggregate total L3 bandwidth equal whilst serving double the number of cores could have something to do with it, with performance at higher core counts recuperating and being improved due to the new lower-latency and higher clock IOD of Milan.
Whatever the technical background of this new odd power behaviour, it’s clear that it has negative consequences for the new Milan parts, possibly resulting in lower-than-expected generational performance improvements, as we’ll see in the next few pages.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2). For the new Zen3 Milan parts, as GCC 10.2 at the time didn’t have support for the new microarchitecture, we’re using the same Zen2 binaries as on Rome, as otherwise we’d have to rerun all numbers on all platforms with a newer GCC 11 baseline – something we will do in the future but out of the scope of this piece.
In terms of data-points, we’re comparing the new 7763 against a 7742, as well as the top socketed SKUs from the competition, including a Xeon 8280 (Equivalent to a Xeon 6258R), and Ampere’s Arm-based Altra Q80-33. It’s to be noted that the 7763 is a 280W part, and thus lands in higher than the other three chips, but we wanted to compare the top of the stack with the best available parts we had available for testing.
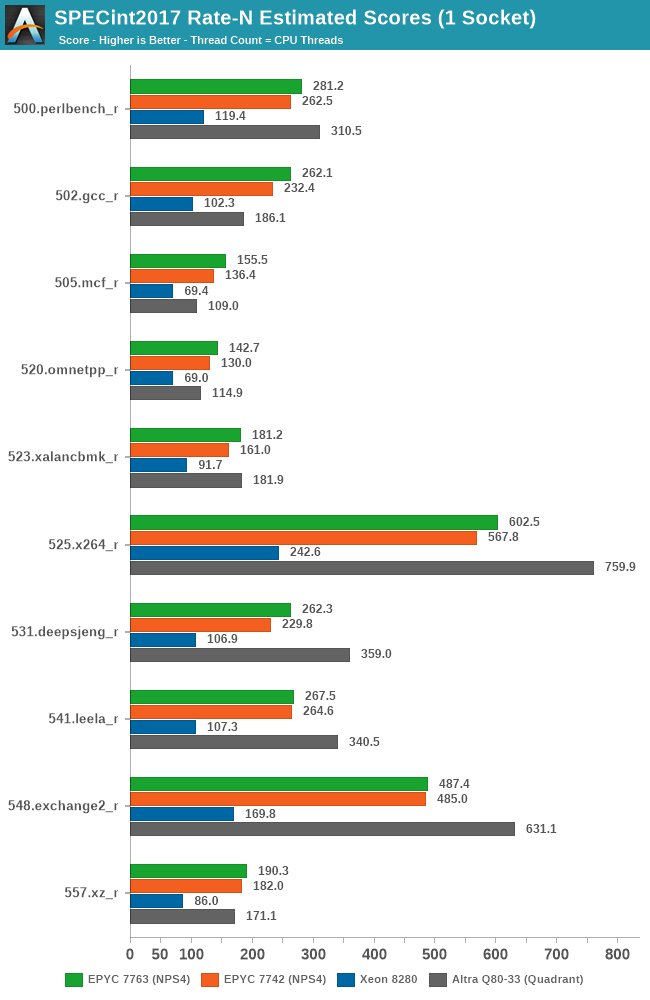
Generationally, the new 7763 does outperform the 7742 across the board, but generally the magnitude isn’t quite as large as you’d expect given the 40W higher TDP of the chip – a performance delta that gets even tighter when configuring the 7742 to a 240W cTDP.
Against the competition, AMD’s traditional adversary Intel doesn’t really stand a chance as the Milan chip is posting well over double the performance in almost all workloads.
The newer competition AMD should worry about is Ampere’s new Altra system – which currently still outperforms the top-end Milan based 7763 in several compute-heavy benchmarks by notably margins. In more memory-heavy workloads, the EPYC more easily beats the Altra due to having essentially 8x the total cache per chip at 256MB vs 32MB.
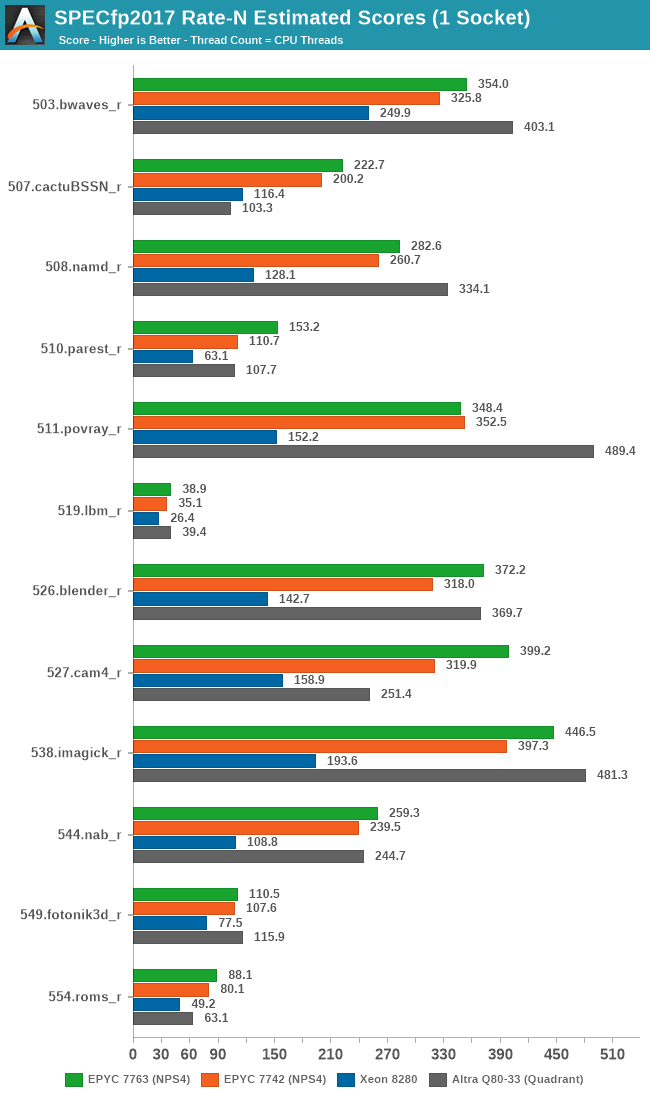
We’re seeing a similar story in SPECfp2017, more oriented towards HPC workloads. The one result that stands out here is 511.povray, in which the 7763 loses out to the previous generation 7742 due to the workload being more core-bound, and the Milan chip having a lesser effective thermal envelope available for the cores, even at the higher 280W TDP.
Intel’s 8280 again really isn’t a viable competition to AMD’s chips, with the Ampere Altra being a closer match for AMD’s EPYC, winning some, losing some.
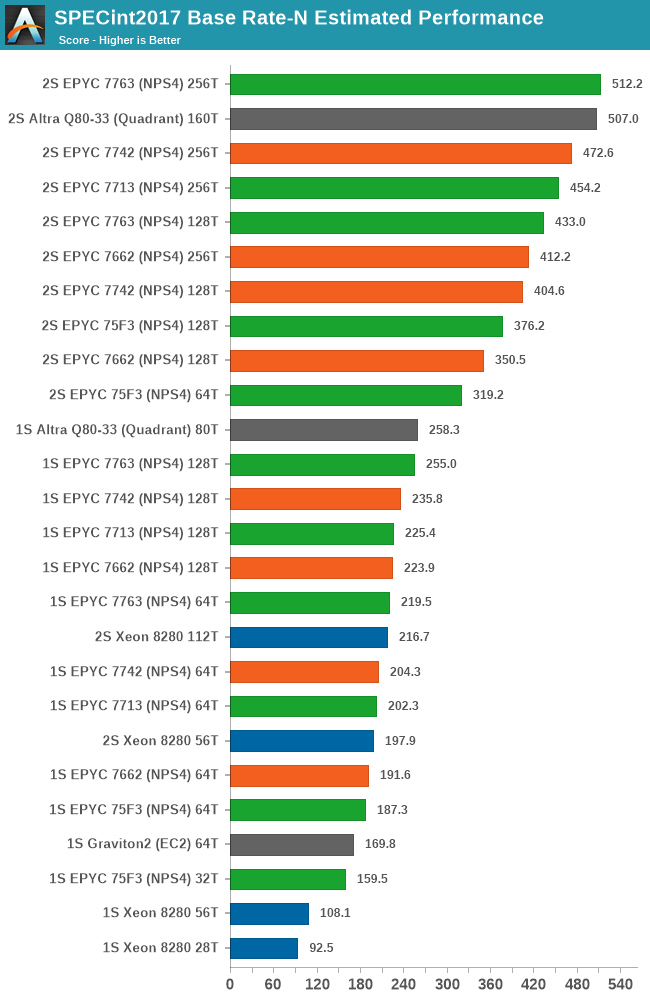
With Milan, AMD is now retaking the performance lead in SPECint2017, although by only a small margin.
Generationally, the EPYC 7763 is 12.8% faster than the 7742 – unfortunately we don’t have figures of the corresponding 280W 7H12 Rome part.
Comparing the 7713 against the 7742, things aren’t looking as great, as the new Milan part sees a 4% performance regression. It’s to be noted again that AMD had claimed the 7713 is a direct successor to the 7662, where it does fare 10% better, however that is a $900 cheaper part.
Amongst the rather luke-warm results of the top-stack Milan SKUs, one result that stands out more is the 32-core frequency optimised 75F3 SKU. Featuring only half the cores, the part still manages to easily compete amongst its 64 core siblings, showcasing 82% of the performance of a 7713. This has rather large implications for per-thread performance of this part which we’ll cover in a later page.
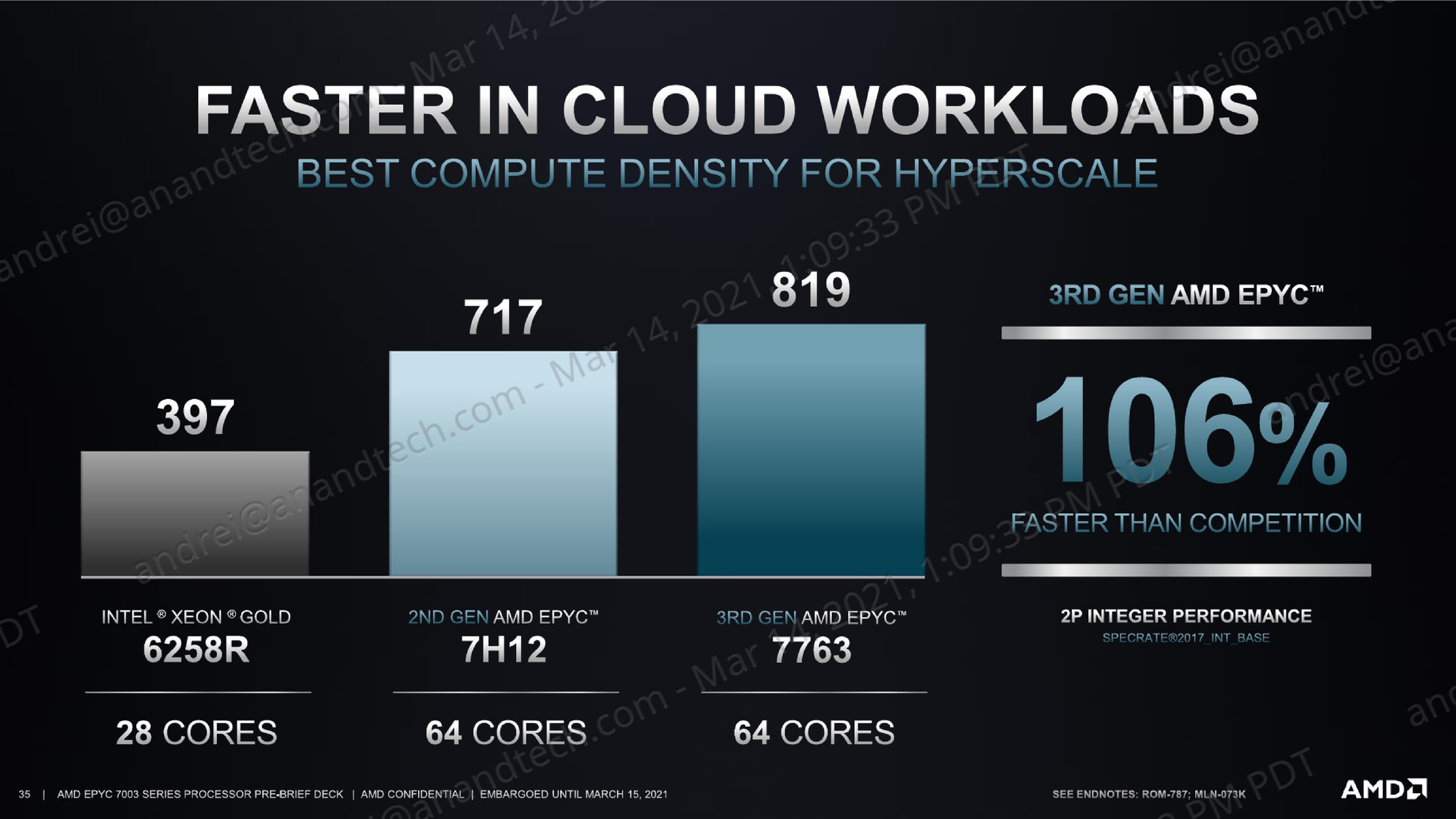
Although AMD’s presentation slides using totally different SPEC result numbers due to very different compiler and optimisation settings, the actual relative positioning we are getting in our internal results actually exceed that of what AMD is presenting, with the 7763 coming in with a +128% advantage over the Intel 8280, a part that’s performance equivalent to the 6258R.
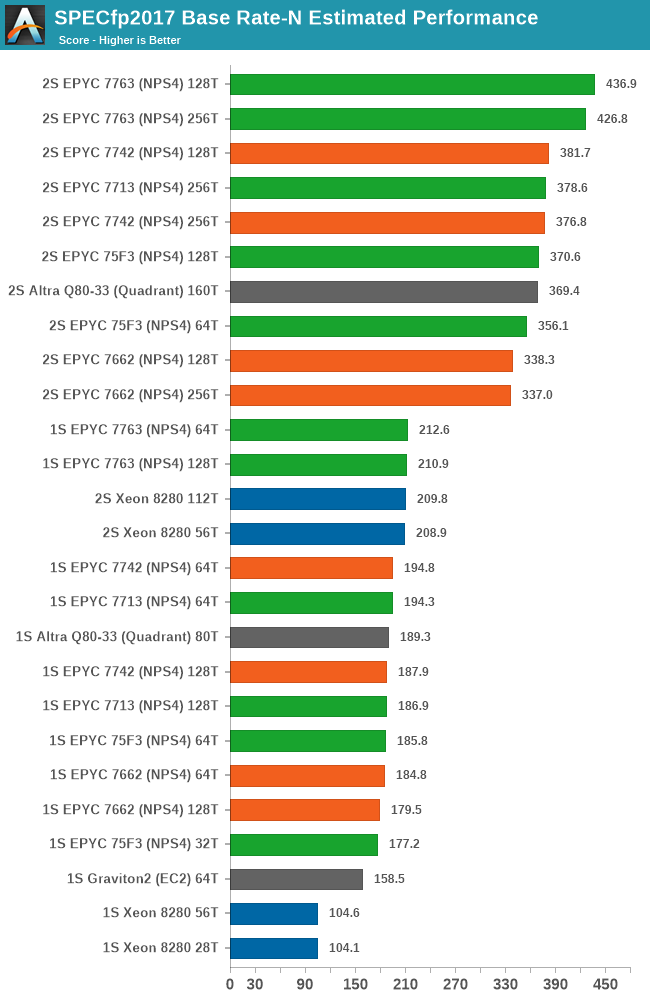
In the SPECfp2017 suite which is more representative of HPC workloads and has a focus more towards memory performance, AMD had always retained their performance leadership, and has now widened it with the new Milan generation. The 7763 performs 14.4% better than the Rome 7742, while the 7713 almost outperforms it by a margin of error.
It’s again the 75F3 which is actually stealing the show, as it manages 97.8% of a 7713, and 85.8% of a 7763 even though it has only half the cores.
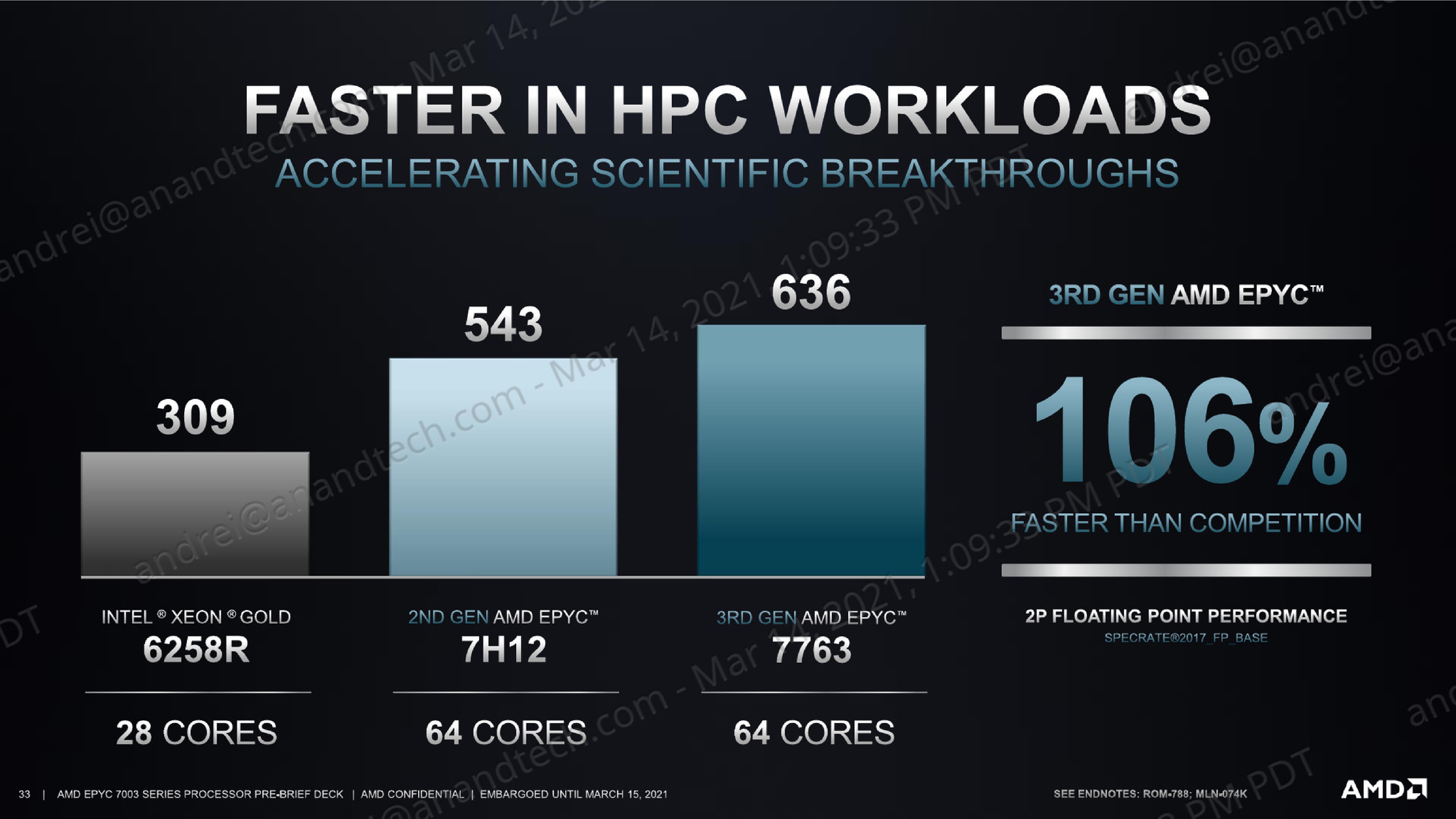
Against the competition and the figures AMD is showing, we’re measuring the 7763 outperforming the 8280 by 108% - near to the 106% the presentation material is showcasing. Intel should be able to make a larger leap with the next generation Ice Lake-SP server chips as the company moves from 6-channel to 8-channel memory, though we’ll have to see if that’s actually enough to catch up to AMD.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Single-Threaded Performance
Single-thread performance of server CPUs usually isn’t the most important metric for most scale-out workloads, but there are use-cases such as EDA tools which are pretty much single-thread performance bound.
Power envelopes here usually don’t matter, and what is actually the performance factor that comes at play here is simply the boost clocks of the CPUs as well as the IPC improvement, and memory latency of the cores. We’re also testing the results here in NPS1 mode as if you have single-threaded bound workloads, you should prefer to use the systems in a single NUMA node mode.
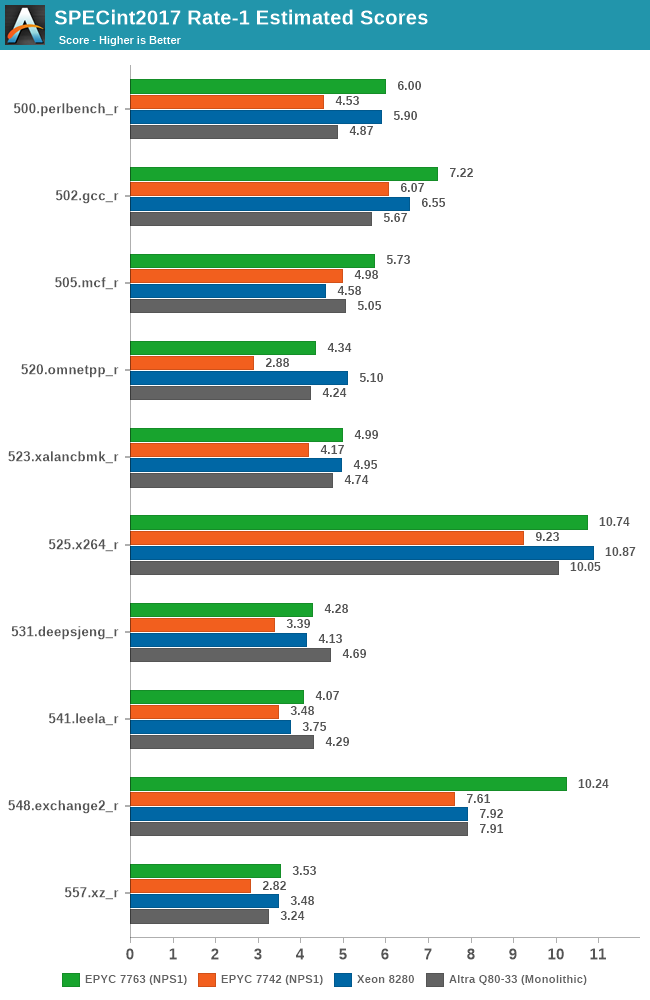
Generationally, the new Zen3-based 7763 improves performance quite significantly over the 7742, even though I noted that both parts boosted almost equally to around 3400MHz in single-threaded scenarios. The uplifts here average over a geomean of +25%, with individual increases from +15 to +50%, with a median of +22%.
The Milan part also now more clearly competes against the best of the competition, even though it’s not a single-threaded optimised part as the 75F3 – we’ll see those scores a bit later.
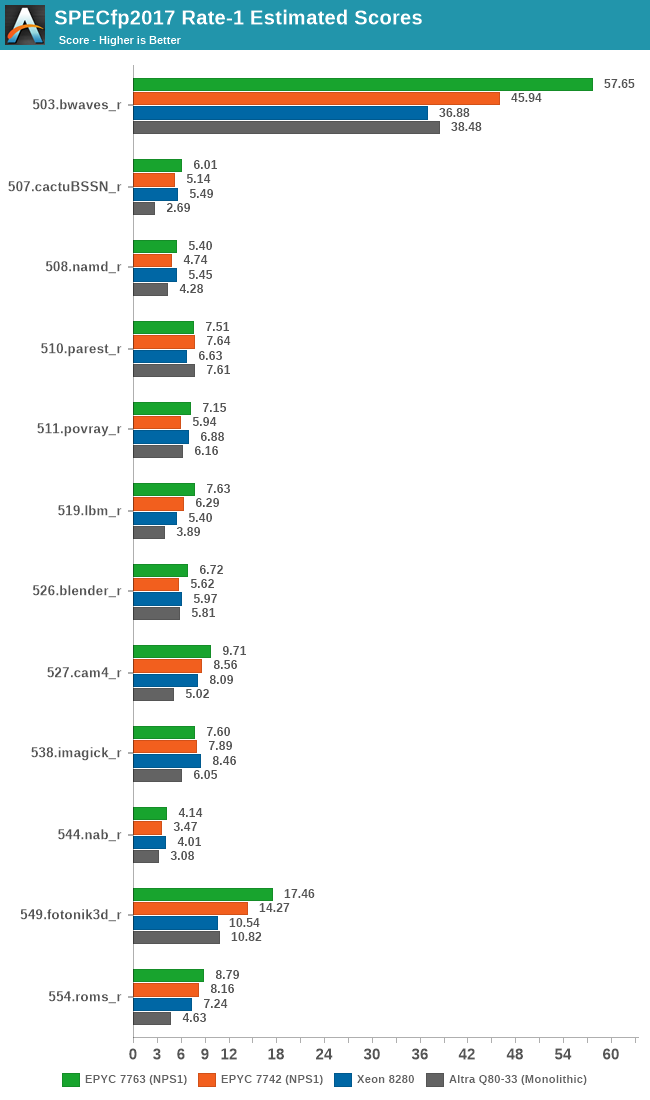
In SPECfp, the Zen3 based Milan chip also does extremely well, measuring an average geomean boost of +14.2% and a median of +18%.
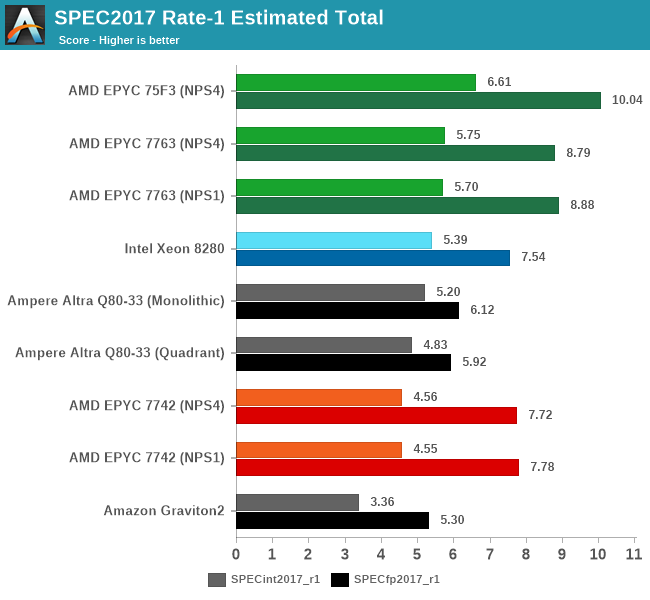
The new 7763 takes a notable lead in single-threaded performance amongst the large core count SKUs in the market right now. More notably, the 75F3 further increases this lead through the higher 4GHz boost clock this frequency optimised part enables.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPEC - Per-Core Win for "F"-Series 75F3
A metric that is actually more interesting than isolated single-thread performance, is actually per-thread performance in a fully loaded system. This actually is a measurement and benchmark figure that would greatly interest enterprises and customers which are running software or workloads that are possibly licensed on a per-core basis, or simply workloads that require a certain level of per-thread service level agreement in terms of performance.
It’s precisely this market that AMD is trying to target with its new “F”-series of processors, and this is where the new 75F3 comes into play. With 32 cores, 4 cores per chiplet with the full 256MB of L3 cache, and a base frequency of 2.95GHz, boosting up to 4.0GHz at a default 280W TDP, is the chip is squeezing out the maximum per-core performance while still offering a massive amount of multi-threaded performance.
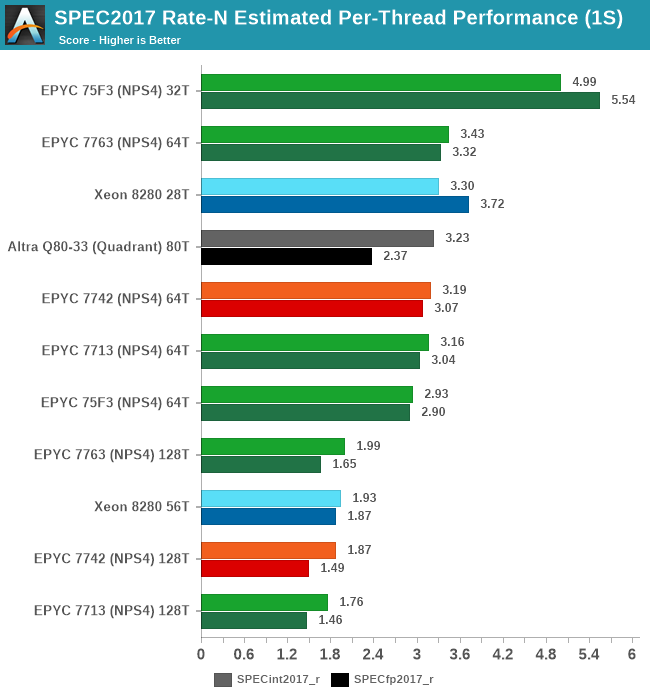
At full load, this ends up with a massive per-thread performance leadership on the part of the 75F3, landing 45% ahead of the 7763 and 51% ahead of the Intel Xeon 8280.
It’s to be noted that limiting the thread count of the higher core-count SKUs will also result in a better per-thread performance metric, for example running a 7713 with only 32 threads will result in a SPECint2017 estimated score of 4.30 – the 75F3 still has a 16% advantage there even though its boost clock is only 8.8% higher at the peak – meaning the 75F3 is achieving higher effective frequencies. Unfortunately, we didn’t have enough time to do the same experiment on the equal 280W 7763 part.
AMD discloses that the biggest generational gains for the Milan stack is found in the lower core-count models, where for example the 7313 and the 7343 outperforms the 7282 and 7302 by 25%. Reason for this is that for example the new 7313 features double the L3 cache, and all the new CPUs are boosting higher with respectively higher TDPs, increasing to 150/190W from 120/155W, as well as landing in at +50% higher price points when comparing generation to generation.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
SPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon, N=56 for 1S Xeon, and N=128 for 2S and 1S on the EPYC system. The 75F3 system had the worker count reduced to 64 and 32 for 2S/1S runs.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
EPYC & Altra systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC "
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon system:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
The reason the Xeon system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks. The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
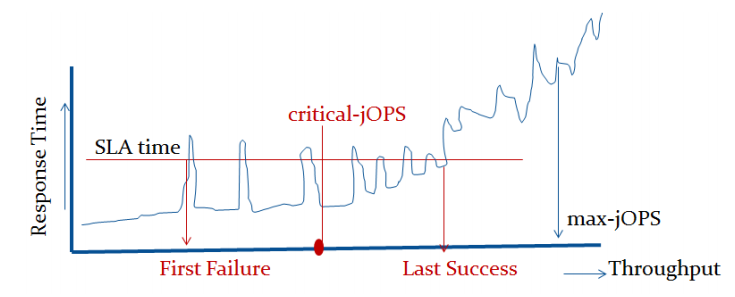
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
Beyond the result figures, the benchmark keeps detailed track of timings of responses and tracks a few important statistical data-points across a response-time curve, as follows:

2S EPYC 7763 THP Enabled
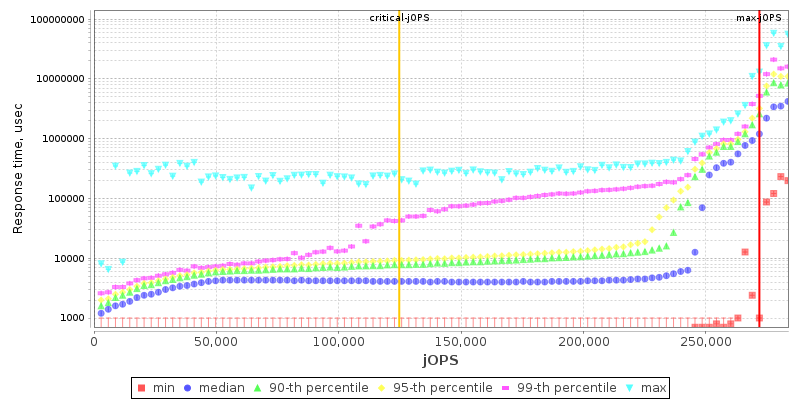
2S EPYC 7742 THP Enabled
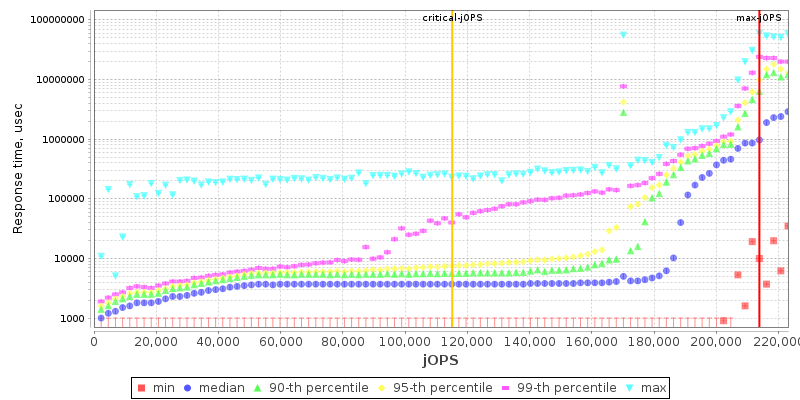
In terms of the response curves of the new Milan 7763 part, the general behaviour doesn’t look that much different to the 7742 other than a weird discrepancy at low load.
2S EPYC 75F3 THP Enabled
The 75F3 part is interesting as due to it focusing more on per-core performance, it tightens the response curve with the -critical performance score being closer to the -max capacity of the system.

2S Xeon 8280 THP Enabled
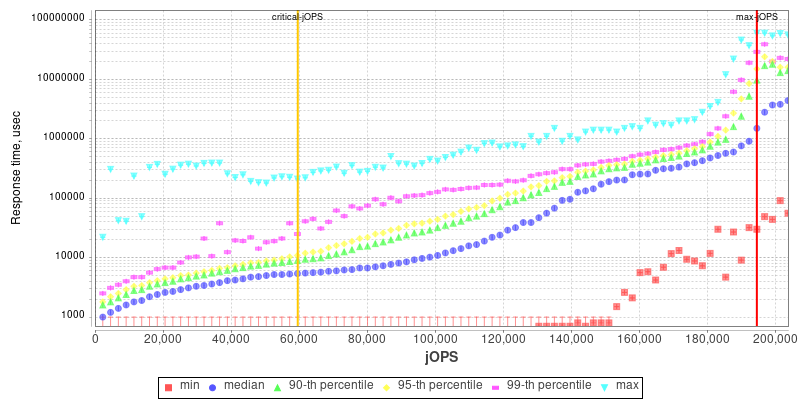
2S Altra Q80-33 THP Enabled
I included the Intel and Altra graphs for context.
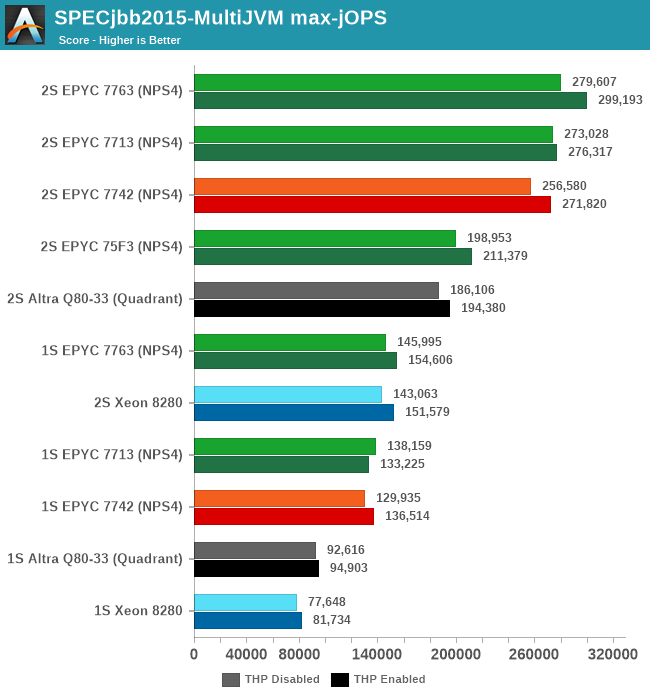
In terms of the -max-jOPS achieved by each system in our settings configuration, the new Zen3 parts fare quite well. The 7763 outperforms the 7742 by +9%, while the 7713 also outperforms the 7742 by +6.4%.
Again, very interesting is to see the 75F3’s maximum throughput reaching 71% of the top SKU’s performance in such scale-out workloads even though it’s only got half the cores available.
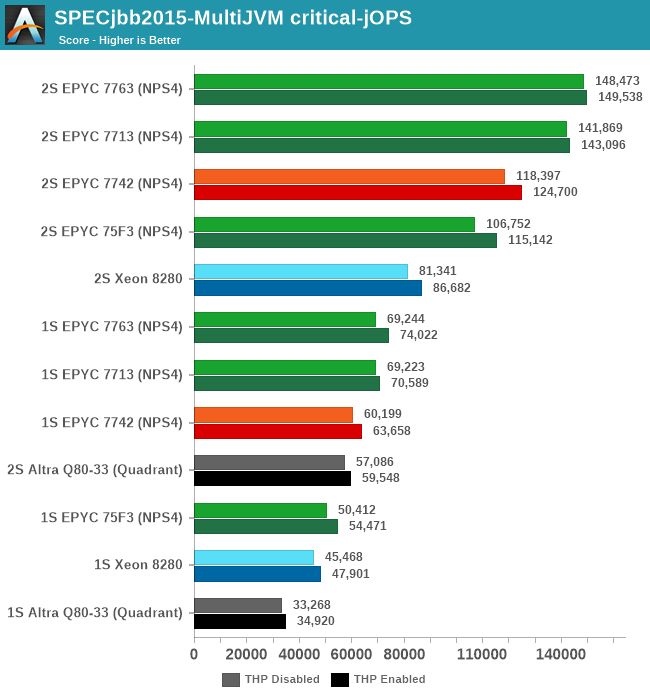
The -critical-jOPS figure is probably the more important metric for SPECjbb given that it covers SLA scenarios, and here the new Milan parts are faring extremely well. The 7763 outperforms the 7742 by +25%, and the 7713 is also not far behind with +19.7%.
The 75F3 is also doing amazingly well, keeping up with the higher core-count parts.
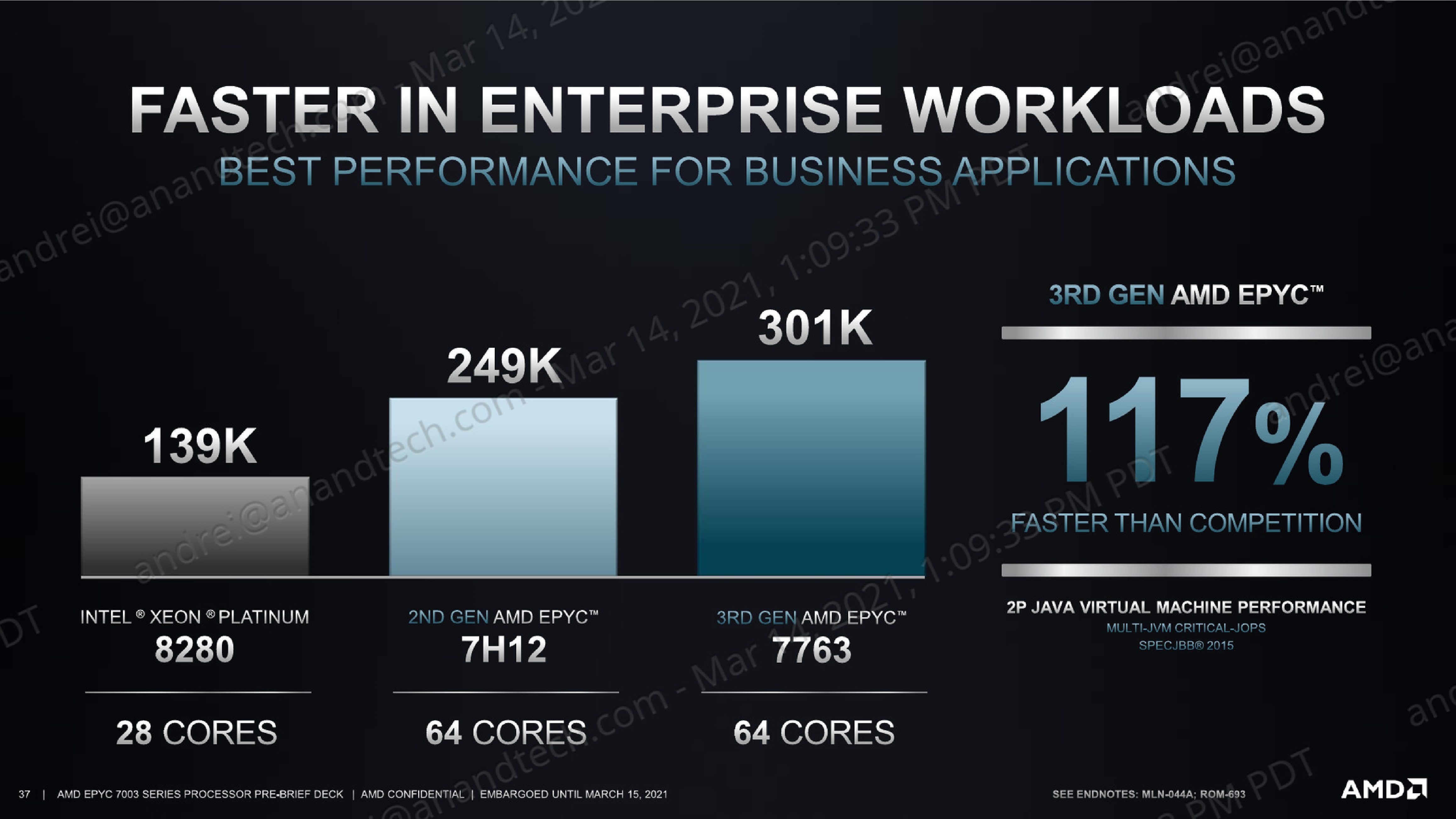
Against the competition, our own and AMD figures differ a bit due to different settings, however we’re still seeing the new Milan top-SKU outperform the 8280 by +82 in performance.
Generally speaking, the generational improvements over Rome in -critical-jOPS figure of SPECjbb are a more reassuring result compared to the other peak full load performance metrics we’ve seen on SPEC CPU. This actually corresponds to the power behaviour of the new chips, with the new Zen3 cores offering notably better per-core performance compared to the Rome predecessor, at least up until the new parts hit a power envelope wall where performance improvements become more limited.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
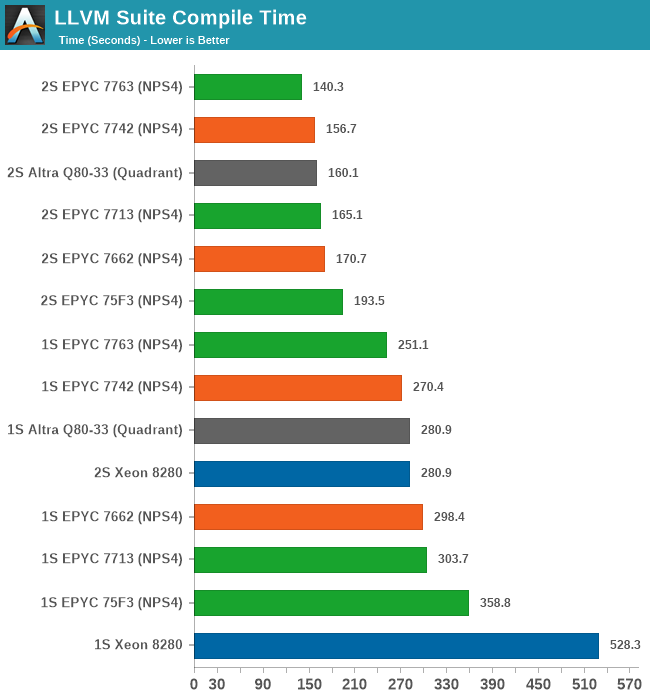
For the new Milan chips, the results are a bit mixed. The higher-power 7763 takes a lead with a +10.5% improvement over the 7742, however the 7713 doesn’t manage to keep up with that predecessor.
The 1S vs 2S scores are interesting as the 2S figures showcase the new Milan chips in a better light due to the higher single-threaded performance of the Zen3 cores. The compilation here also has linking phases which are single-thread performance bottle-necked. This results in scenarios such as the 7713 losing to the 7662 in 1S comparisons, however winning out against the same chip in the 2S comparison, as it’s able to make that advantage count for more.
It’s also great to see the 75F3 keep up with the 64-core counterparts at around 72% of the top-SKU performance.
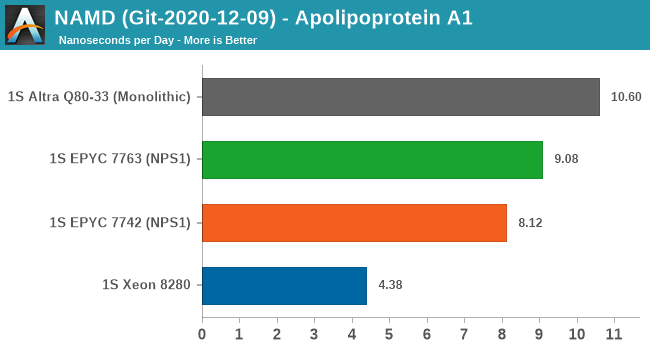
Finally, in NAMD, this is more of a core-local compute workload. We see the 7763 outperform the 7742 by +11.8%, however the Milan chip is still outperformed by the higher core compute capacity of the 80-core Altra chip.
Generally, I have my reservations about NAMD as a benchmark due to its multicore vs MPI variants and scaling anomalies, on top of the whole topic of the benchmark having a completely different algorithm for AVX512 processors.
Disclaimer June 25th: The benchmark figures in this review have been superseded by our second follow-up Milan review article, where we observe improved performance figures on a production platform compared to AMD’s reference system in this piece.
Conclusion: AMD's Return to High Performance Compute
On the crest of this launch, AMD has showcased that it can supply enterprise processors to the market again. After the decade or more of its Opteron brand being successful, and then fading away, the EPYC product lines have delineated a clear roadmap from AMD to re-enter this space. Back in the launch of the first generation EPYC, in June 2017, AMD promised an ambitious three year roadmap involving significant performance improvements and a return to the high-performance x86 compute space, culminating in today’s launch.

The goal throughout that time was to bring customers back into the fold – to show them that AMD has ambitious roadmaps and that the company can execute and deliver, while offering a competitive market. As a result, AMD’s lead OEM partners are now doing sizeable volume, over 10% market share, and AMD is scoring big wins in major computing contracts such as two thirds of the US exascale systems, such as Frontier and El Capitan. Frontier, as we learned in our interview with AMD’s Forrest Norrod, is using a custom EPYC Milan based processor called ‘Trento’, while El Capitan will be designed with the next generation EPYC after Milan, called Genoa.
Two Sides of a Coin
Milan is really an evolution and iteration of the design principles that made Rome, with the new chip being defined by its use of the newer Zen3 microarchitecture and chiplet design, including larger characteristic changes such as the new unified 32MB L3 cache shared amongst 8 cores in a single CCX/CCD. Where we see the direct results of these new improvements is in great uplifts in single-threaded and per-thread performance, with figures routinely reaching +20-25% in a wide variety of workloads. The new Milan parts have cores that better take advantage of the larger caches, and higher boost frequencies across the whole stack means that per-core performance has seen big gains.
Particularly new chips such as the EPYC 75F3 with 32 cores and 4 GHz boost are offering very unique differentiation compared to anything else in the market right now, and AMD is sure to gain a lot of success in use-cases which either are limited by per-core software licensing or have service-level-agreements and require higher per-core performance than delivered by the higher density core SKUs.

Where things aren’t quite as positive is in the generational peak performance metrics under full load of all cores. The problem here seems to be generational regressions on the power consumption of the 'un-core' parts of Milan, i.e everything that isn't the core – meaning most likely the new faster IOD, or possibly the new L3 cache design, is increasing the base power. This means idle power is higher, and power available to the cores (at full load) falls behind, decreasing socket efficiency compared to Rome. So, while AMD has invested into doing a smaller redesign of the IOD in Milan to achieve better latencies and higher memory performance, it has come at a cost of socket efficiency and performance for some of the parts. There’s no real silver lining here to the situation, and it's easily Milan’s glass jaw that hinders it from achieving even better performance.
For the future, if Genoa is able to ditch the 14nm IOD in favour of a more modern process node, and employ advanced packaging technologies such as X3D, and more efficient power management, even a 50 W reduction in power on the part of the un-core parts would actually signify a +50% increase in the power envelope available for the cores, as well as help AMD enable lower total power offerings below 155 W on the latest generation core.
AMD Retains x86 Performance Leadership
From a competitive standpoint, Milan continues to strengthen and maintain a very stark one-sided performance advantage against its biggest competitor, Intel. Rome had already offered more raw socket performance than the best Intel had to offer at the time, and the gap is currently quite large as Intel has not updated in that time. Intel has stated that its Ice Lake Xeon-SP family will come sometime soon, however unless Intel manages to close the core count gap, then AMD looks to be in very good shape.
Meanwhile, as AMD is focused on Intel, the Arm competition has also entered the market with force through 2020, and designs such as the Ampere Altra are able to outperform the new top Milan SKUs in many throughput-bound workloads. AMD still has very clear advantages, such as much superior memory performance through huge caches, or vastly superior per-thread performance with specialised dedicated SKUs. Still, it leaves AMD in a spot as they can’t claim to be the outright performance leader under every scenario, and offers another generational target to consider as it develops future cores.
AMD sets its own bar quite high with Milan - by aggressively emphasising its performance gains in the middle of the product stack, the general enterprise market will look on these parts very favorably. There is always room for improvement, but if AMD equip themselves with a good IO update next generation, EPYC could stand to gain better-than-generational performance in the future. But as it stands, the product is a very solid offering in light of the competition in the market.






