Original Link: https://www.anandtech.com/show/16315/the-ampere-altra-review
The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra

As we’re wrapping up 2020, one last large review item for the year is Ampere’s long promised new Altra Arm server processor. This year has indeed been the year where Arm servers have had a breakthrough; Arm’s new Neoverse-N1 CPU core had been the IP designer’s first true dedicated server core, promising focused performance and efficiency for the datacentre.
Earlier in the year we had the chance to test out the first Neoverse-N1 silicon in the form of Amazon’s Graviton2 inside of AWS EC2 cloud compute offering. The Graviton2 seemed like a very impressive design, but was rather conservative in its goals, and it’s also a piece of hardware that the general public cannot access outside of Amazon’s own cloud services.
Ampere Computing, founded in 2017 by former Intel president Renée James, built upon initial IP and design talent of AppliedMicro’s X-Gene CPUs, and with Arm Holdings becoming an investor in 2019, is at this moment in time the sole “true” merchant silicon vendor designing and offering up Neoverse-N1 server designs.
To date, the company has had a few products out in the form of the eMAG chips, but with rather disappointing performance figures - understandable given that those were essentially legacy products based on the old X-Gene microarchitecture.
Ampere’s new Altra product line, on the other hand is the culmination of several years of work and close collaboration with Arm – and the company first “true” product which can be viewed as Ampere pedigree.
Today, with hardware in hand, we’re finally taking a look at the very first publicly available high-performance Neoverse based Arm server hardware, designed for nothing less than maximum achievable performance, aiming to battle the best designs from Intel and AMD.
Mount Jade Server with Altra Quicksilver
Ampere has supplied us with the company’s server reference design, dubbed “Mount Jade”, a 2-socket 2U rack unit sever. The server came supplied with two Altra Q80-33 processors, Ampere’s top-of-the-line SKU with each featuring 80 cores running at up to 3.3GHz, with TDP reaching up to 250W per socket.


The server was designed with close collaboration with Wiwynn for this dual socket, and with GIGABYTE for the single socket variant, as previously hinted by the two company’s announcements of leading hyperscale deployments of the Altra platforms. The Ampere-branded Mount Jade DVT reference motherboard comes in a typical server blue colour scheme and features 2 sockets with up to 16 DIMM slots per socket, reaching up to 4TB DRAM capacity per socket, although our review unit came equipped with 256GB per socket across 8 DIMMs to fully populate the chip’s 8-channel memory controllers.


This is also our first look at Ampere’s first-generation socket design. The company doesn’t really market any particular name to the socket, but it’s a massive LGA4926 socket with a pin-count in excess of any other commercial server socket from AMD or Intel. The holding mechanism is somewhat similar to that of AMD’s SP3 system, with a holding mechanism tensioned by a 5-point screw system.

The chip itself is absolutely humongous and amongst the current publicly available processors is the biggest in the industry, out-sizing AMD’s SP3 form-factor packaging, coming in at around 77 x 66.8mm – about the same length but considerably wider than AMD’s counterparts.


Although it’s a massive chip with a huge IHS, the Mount Jade server surprised me with its cooling solution as the included 250W type cooler only made contact with about 1/4th the surface area of the heat spreader.
Ampere here doesn’t have a recessed “lip” around the IHS for the mounting bracket to hold onto the chip like on AMD or Intel systems, so the actual IHS surface is actually recessed in relation to the bracket which means you cannot have a flat surface cooler design across the whole of the chip surface.

Instead, the included 250W design cooler uses a huge vapour chamber design with a “pedestal” to make contact with the chip. Ampere explains that they’ve experimented with different designs and found that a smaller area pedestal actually worked better for heat dissipation – siphoning heat off from the actual chip die which is notably smaller than the IHS and chip package.

The cooler design is quite complex, with vertical fin stacks dissipating heat directly off the vapour chamber, with additional large horizontal fins dissipating heat from 6 U-shaped heat pipes that draw heat from the vapour chamber. It’s definitely a more complex and high-end design than what we’re used to in server coolers.
Although the Mount Jade server is definitely a very interesting piece of hardware, our focus today lies around the actual new Altra processors themselves, so let’s dive into the new Q80-33 80-core chip next.
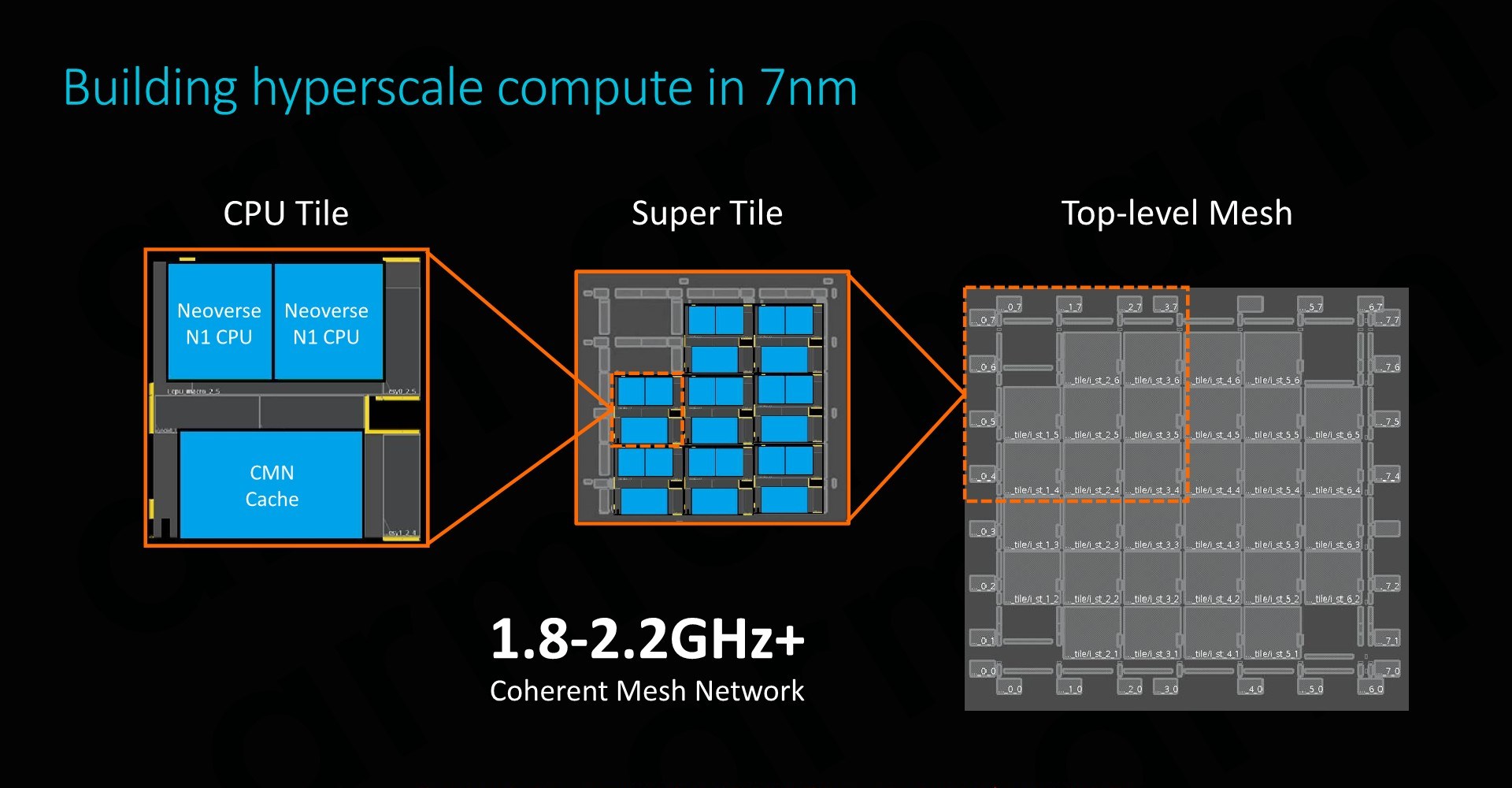
1st Generation Neoverse-N1 80-Core Server SoC
For readers who are familiar with the Neoverse-N1 and our coverage of the Amazon Graviton2, won’t be too surprised at the general system architecture of the new first generation Altra “Quicksilver” design.

The Quicksilver design features up to 80 Neoverse-N1 cores, integrated within an Arm CMN-600 mesh interconnect that features 32MB of distributed system level cache.
Ampere has equipped the CPU cores themselves with the maximum 64KB L1 caches as well as 1MB of private L2 per core. Although the L3 (the SLC) seems quite reasonable at 32MB, this is actually the same size as the 64-core Graviton2 design, meaning the new Altra system actually gets less cache per core at a system level, which is a bit concerning as we also saw the Graviton2 be quite cache-starved in some workloads. Arm had envisioned Neoverse-N1 systems with either 64MB or even 128MB of L3 cache – it’s a practical compromise in this first-generation product, and we’ll investigate the performance impact later throughout the review.
Beyond the higher core-count, what also stands out for the Altra system in comparison to the Graviton2 are the significantly higher clock frequencies up to 3.3GHz for the top SKU, compared to the 2.5GHz of the Amazon chip – a 32% difference that should lead in a corresponding per-core performance advantage for the Ampere system.

On a system side, the Altra Quicksilver chip features 8 DDR4-3200 memory controllers for a theoretical peak 204GB/s per socket bandwidth.
Ampere achieves dual-socket connectivity through two dedicated PCIe Gen4 x16 links at 25GT/s featuring CCIX protocol compatibility. The bandwidth here is half of a comparable AMD Rome system which features up to 4x x16 Gen4 links between sockets, and it’s also the first time we’ll be seeing CCIX’s cache coherency capabilities used in this way, so that’s definitely a unique design on the part of the Altra system.

Altra QuickSilver SKU List
Ampere had revealed their QuickSilver SKU list earlier this summer, but hadn’t yet published prices for the different configuration, something we can finally reveal today:
| Ampere 1st Gen Altra 'QuickSilver' Product List |
||||||
| AnandTech | Cores | Frequency | TDP | PCIe | DDR4 | Price |
| Q80-33 (Tested) |
80 | 3.3 GHz | 250 W | 128x G4 | 8 x 3200 | $4050 |
| Q80-30 | 80 | 3.0 GHz | 210 W | 128x G4 | 8 x 3200 | $3950 |
| Q80-26 | 80 | 2.6 GHz | 175 W | 128x G4 | 8 x 3200 | $3810 |
| Q80-23 | 80 | 2.3 GHz | 150 W | 128x G4 | 8 x 3200 | $3700 |
| Q72-30 | 72 | 3.0 GHz | 195 W | 128x G4 | 8 x 3200 | $3590 |
| Q64-33 | 64 | 3.3 GHz | 220 W | 128x G4 | 8 x 3200 | $3810 |
| Q64-30 | 64 | 3.0 GHz | 180 W | 128x G4 | 8 x 3200 | $3480 |
| Q64-26 | 64 | 2.6 GHz | 125 W | 128x G4 | 8 x 3200 | $3260 |
| Q64-24 | 64 | 2.4 GHz | 95 W | 128x G4 | 8 x 3200 | $3090 |
| Q48-22 | 48 | 2.2 GHz | 85 W | 128x G4 | 8 x 3200 | $2200 |
| Q32-17 | 32 | 1.7 GHz | 45 W | 128x G4 | 8 x 3200 | $800 |
Ampere here covers a very wide spectrum of SKUs, ranging from today’s tested top-model in the form of the 80-core, 3.3GHz 250W Q80-33, down to “small” low-power 32-core 1.7GHz 45W models such as the Q32-17.
Ampere should be praised for their naming scheme here as it’s the most straightforward of any vendor in the industry, directly showcasing the core number and frequency in the model name, with TDP being really the only characteristic which you’d have to look up.
Across the board, all SKUs feature full 128x lanes of PCIe I/O connectivity, and the full 8-channel DDR4-3200 memory capabilities, capable of hosting up to 4TB of DRAM on all models without any artificial feature limitations.
With today’s reveal of the SKU pricing, we finally can make rough comparisons to Intel’s and AMD’s line-up, and Ampere here is incredibly aggressive in terms of their value proposition as they’re vastly undercutting the competition’s models.
An AMD EPYC 7742 with 64 cores and 225W TDP comes in at $6950, while an Intel Xeon Platinum 8280 with 28 cores and 205W TDP comes in at a price tag of $10009 (It's to be noted that a Xeon Gold 6258R features the same specifications as the 8280 - minus the ability to scale beyond 2 sockets, for only $3950). Ampere’s Q80-33 with 80 cores at a 250W TDP comes a price tag of “only” $4050 seems a steal.
Of course, we’re comparing MSRP to MSRP across vendors – and it’s pretty certain large customers making large order won’t be paying MSRP prices – however if this relative MSRP price positioning between vendors is indicative of pricing for larger orders then Ampere is certain to make a large impact on the enterprise market.
I’m writing this as I know the performance of the new Altra system which we’ll expose in the coming pages – so we’ll revisit whole value proposition argument later on in the article.
About TDPs and Frequencies
One important topic I wanted touch upon was the way Ampere describes TDP and frequencies, as it differs considerably from what the public has gotten used to based on AMD or Intel products.
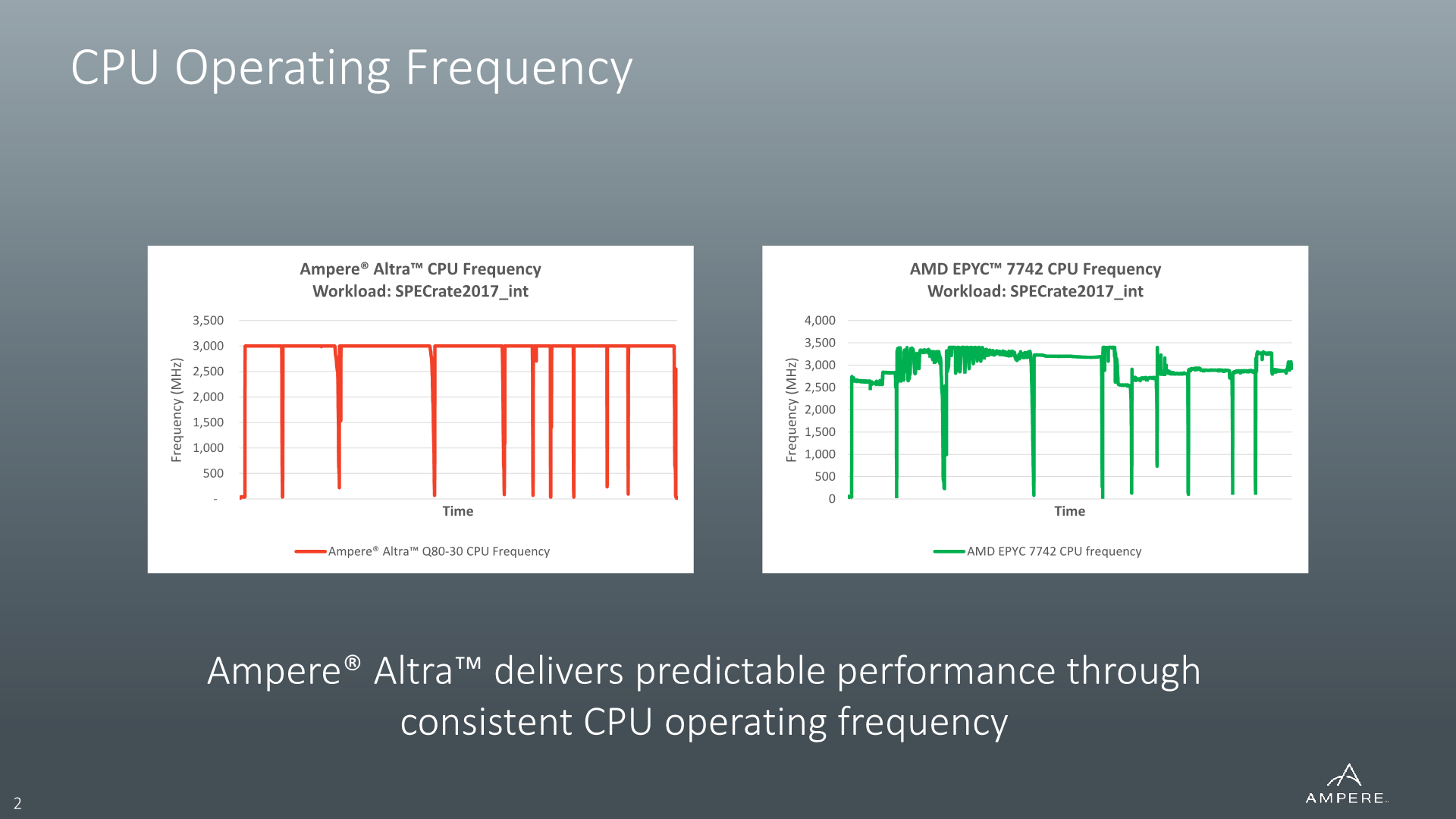
In regards to the described top frequency of the Altra systems, although Ampere calls this a “sustained turbo”, using the turbo nomenclature at all is probably the wrong way to go about it. The peak frequency of the design is simply that – a peak frequency at which the chip normally operates in 99% of scenarios.
This is in contrast to current x86 designs which have “opportunistic turbo” mechanisms which boost their frequencies beyond a guaranteed “base frequency”. In Ampere’s case, the Altra’s described frequency is essentially the de-facto base frequency even though it still operates a normal DVFS scheme and can clock down below that figure during idle or lower utilisation periods.
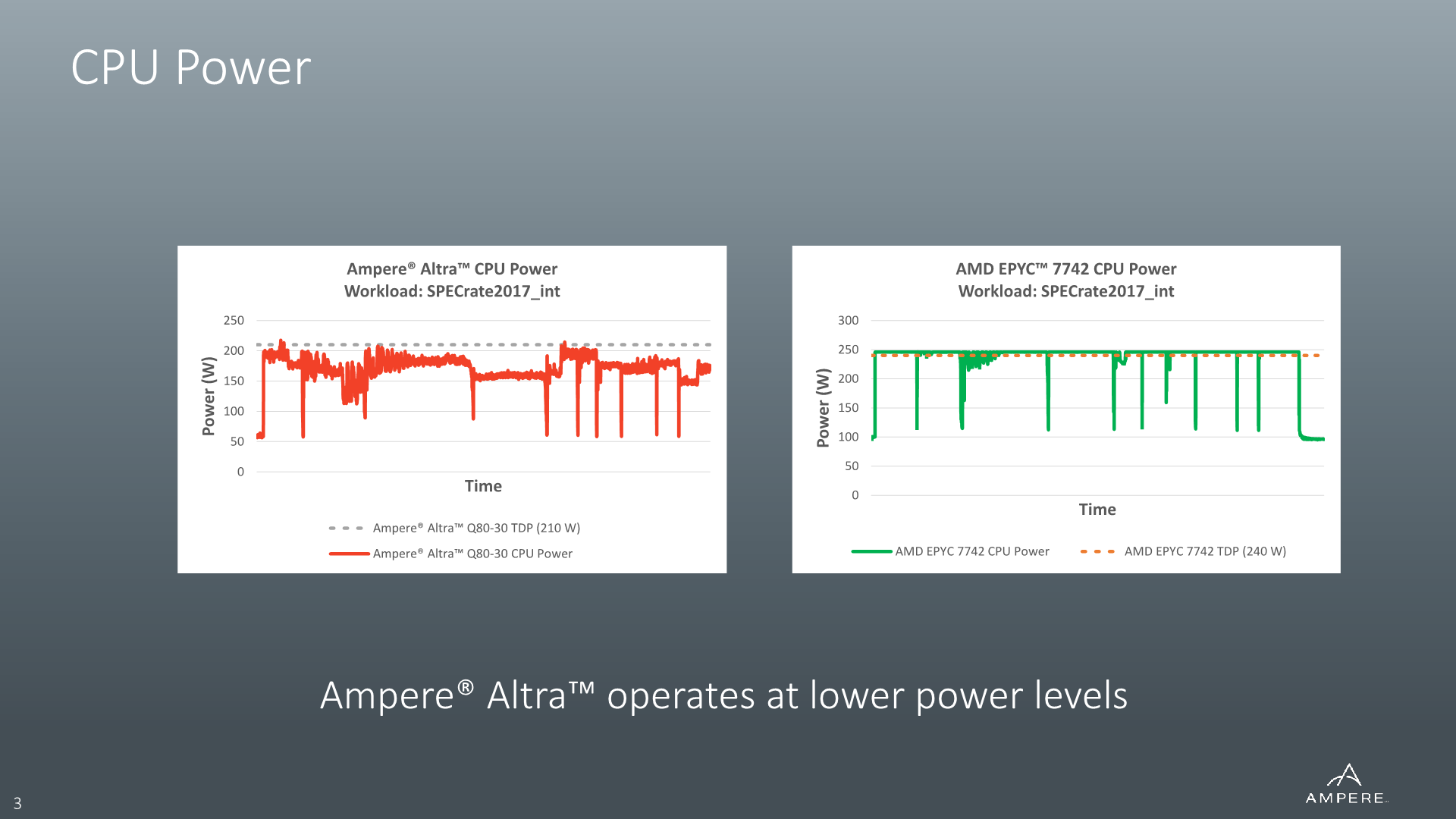
Because frequency is essentially fixed under most workloads, what actually fluctuates between different types of workloads is the power consumption of the processor. The figure described as TDP by Ampere here is the maximum peak small-period average power consumption by the processor.
This comes in contrast to the TDP figures of other systems such as AMD’s EPYC and Xeon CPUs, where the TDP can actually interpreted as a pretty accurate average power consumption figure for the vast majority of workloads. If the processor here under load of a workload that doesn’t particularly result in high power consumption, the designs here will simply increase performance and power by increasing the clock frequency of the design.
For example, a low-IPC high-memory workload on an EPYC 7742 will result in low power consumption on the part of the cores, so the chip will clock them up to 3200MHz on all 64 cores to fill the 225W TDP. A high-IPC workload that stresses the cores and result in higher power might end up with an average runtime frequency of 2600MHz across all cores – but in both cases the average power consumption will always settle around the 225W TDP figure.

So, although for example Ampere’s Altra Q80-33 showcases a 250W TDP figure, its power consumption for the majority of workloads almost always averages below that figure, ranging as low as 180W for some low-IPC workloads. I haven’t actually measured a single average figure across all of our workloads, but a rough estimate across the board for the Q80-33 would be 200W.
In our testing with the Mount Jade server which still had preliminary firmware and which initially had an uncapped TDP, I’ve only ever hit one workload (507.cactuBSSN_r) that consistently broke power consumption in excess of 250W, reaching up to 280W. Re-enabling the TDP cap to 250W of course limited it to that figure on small timescale averages – the Altra’s power management works on a 200µs granularity.
Fundamentally, the Altra’s handling of frequency and power in such a manner is simply a by-product of the Neoverse-N1 cores not being able to clock in higher than 3.3GHz, and the cores being so efficient, that they have power leeway in many workloads, while the x86 player’s implementations simply clock in higher when given the opportunity, because they can – and when in power hungry situations, clocking lower, because they have to.
Topology, Memory Subsystem & Latency
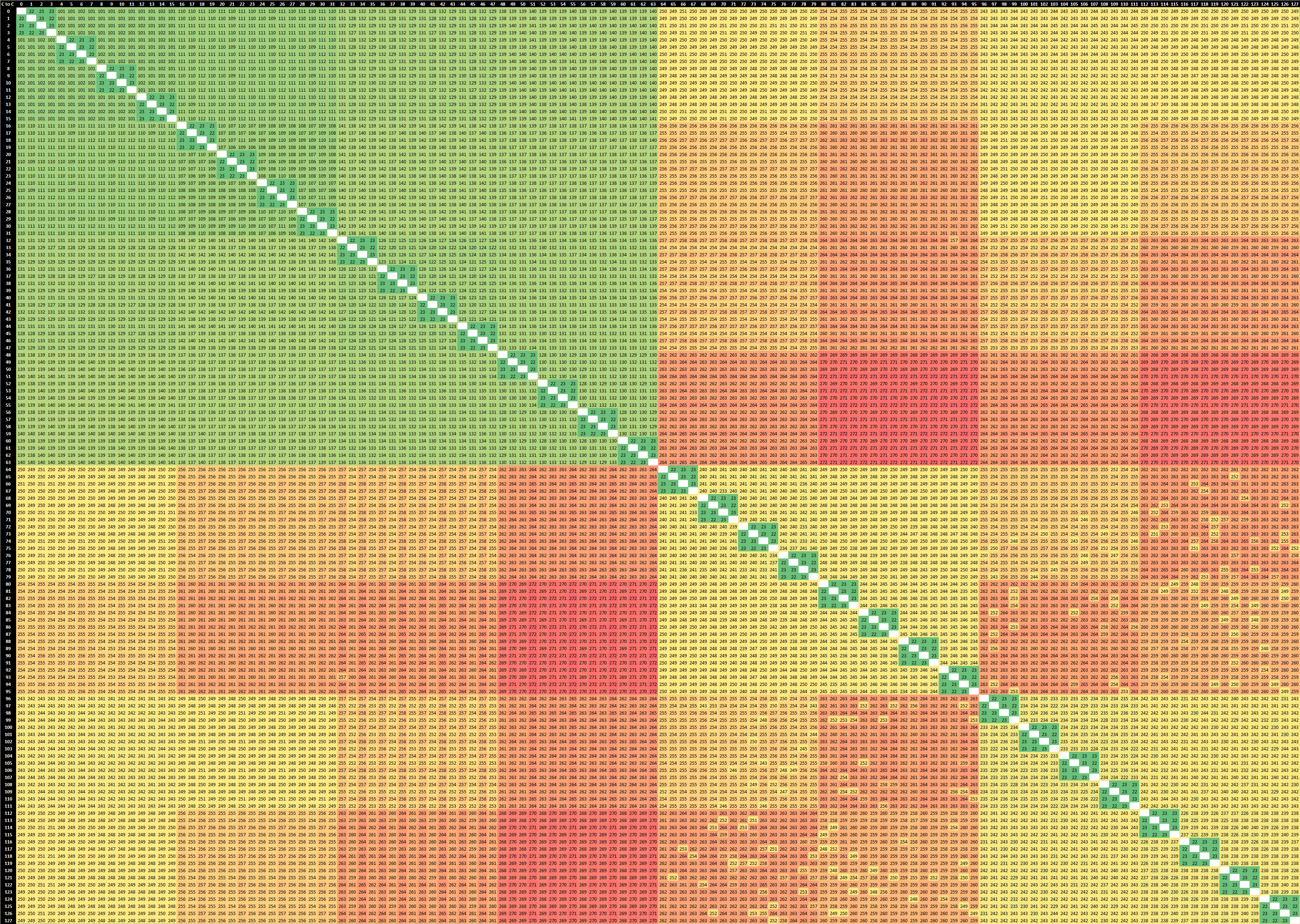
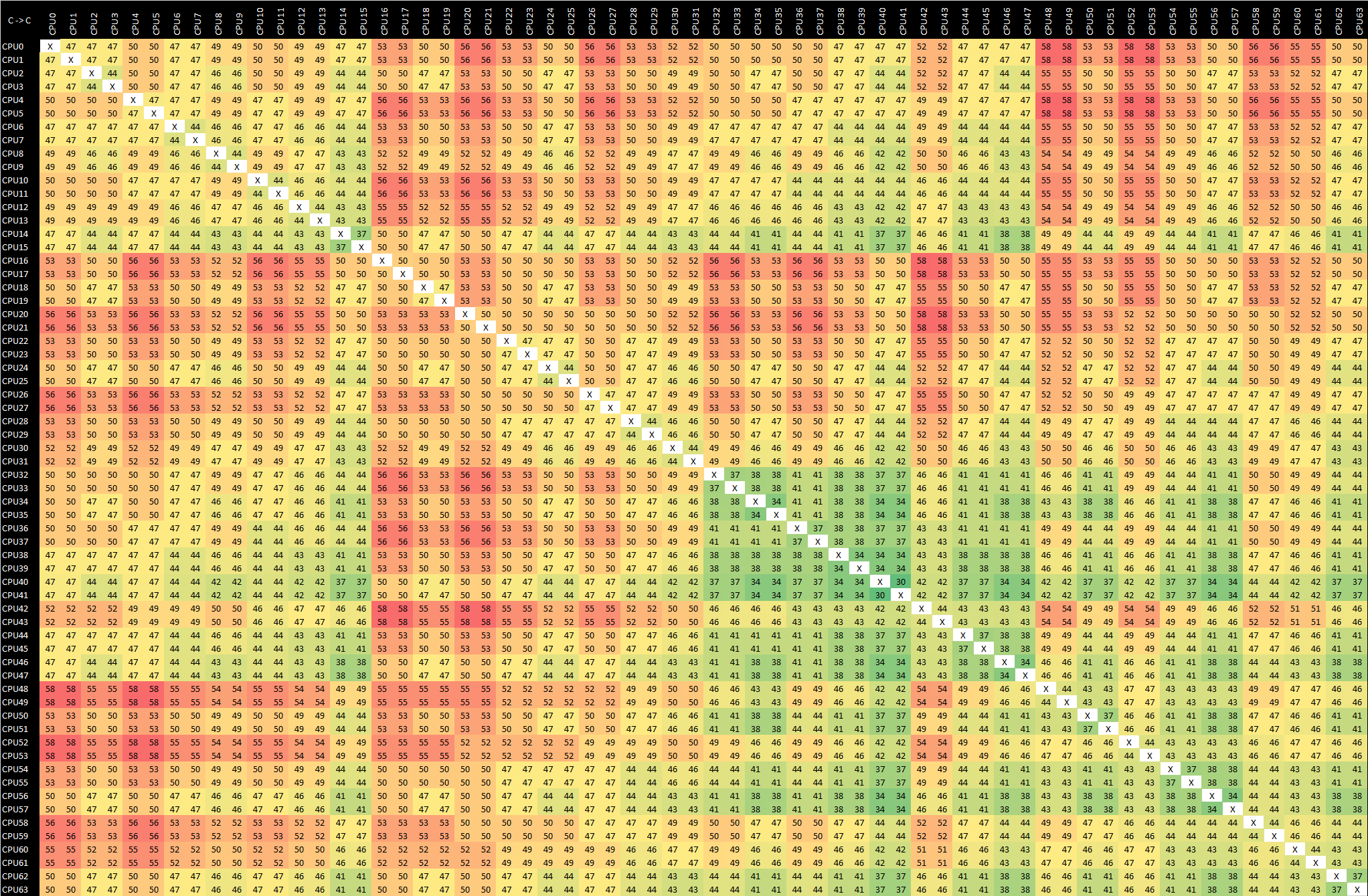
We move onto our usual suite of synthetic tests, trying to expose some of the key hardware characteristics of the systems. The first topic to address is the chip’s physical core topologies, and how inter-core communications take place in the system, particularly interesting since we have access to 2-socket systems.
Due to the sheer core-count of the systems, these result matrices are quite huge so I recommend opening up the full resolution images to inspect the detailed results.
As a reminder, our inter-core bounce test consists of an initial main thread which allocates the synchronisation cache line on the core that the executable is spawned on – we try to fix this to the first NUMA node / CPU group of the first socket. This in turn spawns two ping-pong threads which bounce around based on the shared cache line, and we change the affinity of the threads across the system to test out the various core-to-core latencies. Because of the usage of a common shared cache line – usually how real software works, we’re essentially testing core-to-cacheline-to-core – an important distinction to make for some systems which have different cache line placement and cache coherency algorithms.
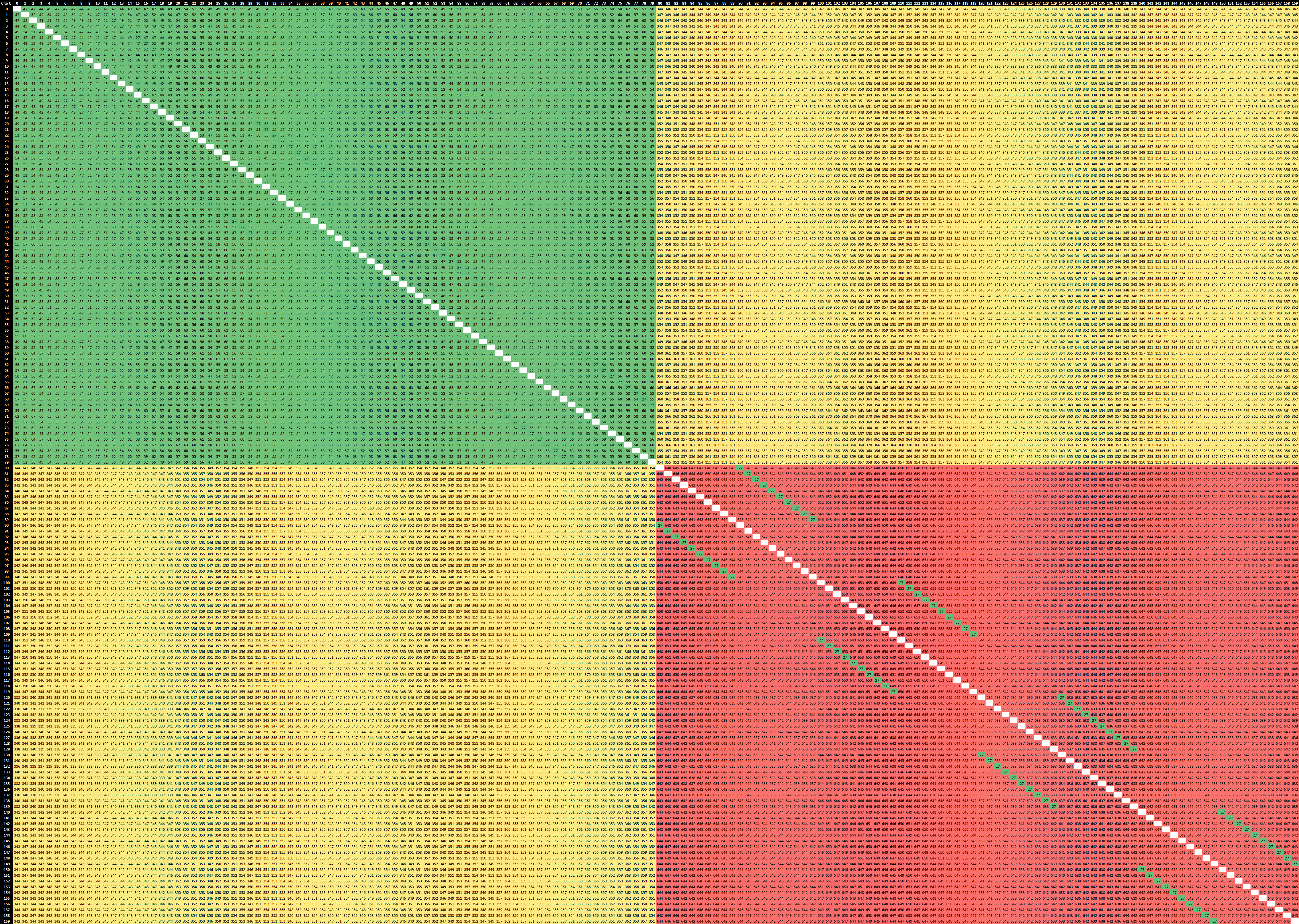
2-Socket Ampere Altra Q80-33
We had already tested the Graviton2 earlier in the year, where we made the distinction between usage of software which compiles to plain Armv8 and exclusive load and excusive store instructions, and the newer Armv8.1 compiled variant of the test which takes advantage of LSE (Large System Extensions) which includes atomic operation instructions – we’re still using the latter variant here on the Altra system.
At first view, in the top-left quadrant of the matrix which represents 80 cores within one single socket, things seem quite similar to the Graviton2 – but not quite. On the Amazon chip’s results what we saw is that the shared cache line remained static within the chip’s mesh structure, meaning cores nearer to that cache slice of the L3 resulted in better latencies compared to cores which were further away.
On the Altra system, the results are quite different here as first of all they’re all more even though it’s a bigger chip with a larger mesh. I tested out the system in a quadrant mode (more on this later) so this might be the reason why things are behaving quite differently to the Graviton2. Interesting to see is this diagonal of results across quarters of a socket landing in at 27ns. I suspect this essentially would represent core-pairs within a single “CPU Tile” within a single mesh node across the chip. If so, then that’s definitely a very different behaviour to the Graviton2.
It actually slipped my mind to re-test this with the chip set to a single monolithic NUMA node so that’s hopefully something I’ll revisit and check if it behaves more similarly to the Graviton2.
When looking at socket-to-socket latencies, we’re looking at latencies of around 350-360ns, which frankly isn’t all that great compared to AMD and Intel’s current multi-socket cache-coherency implementations.
What’s actually quite terrible here, is the inter-core latencies of within the remote socket from the synchronisation shared cache-line. We still very evidently see those 27ns results which we again suspect is within a core-pair CPU tile, but for other cores in the system this actually ends up with a massive latency of around 650ns.
Essentially what the system is doing here, is that one core is sending out a request across the socket, having to be translated from the native AMBA CHI protocol to CCIX, cross the socket, get translated back to CHI to the resident cache line of the initial controller thread, and go back again to the remote socket and incur even further several cache coherency translation penalties.
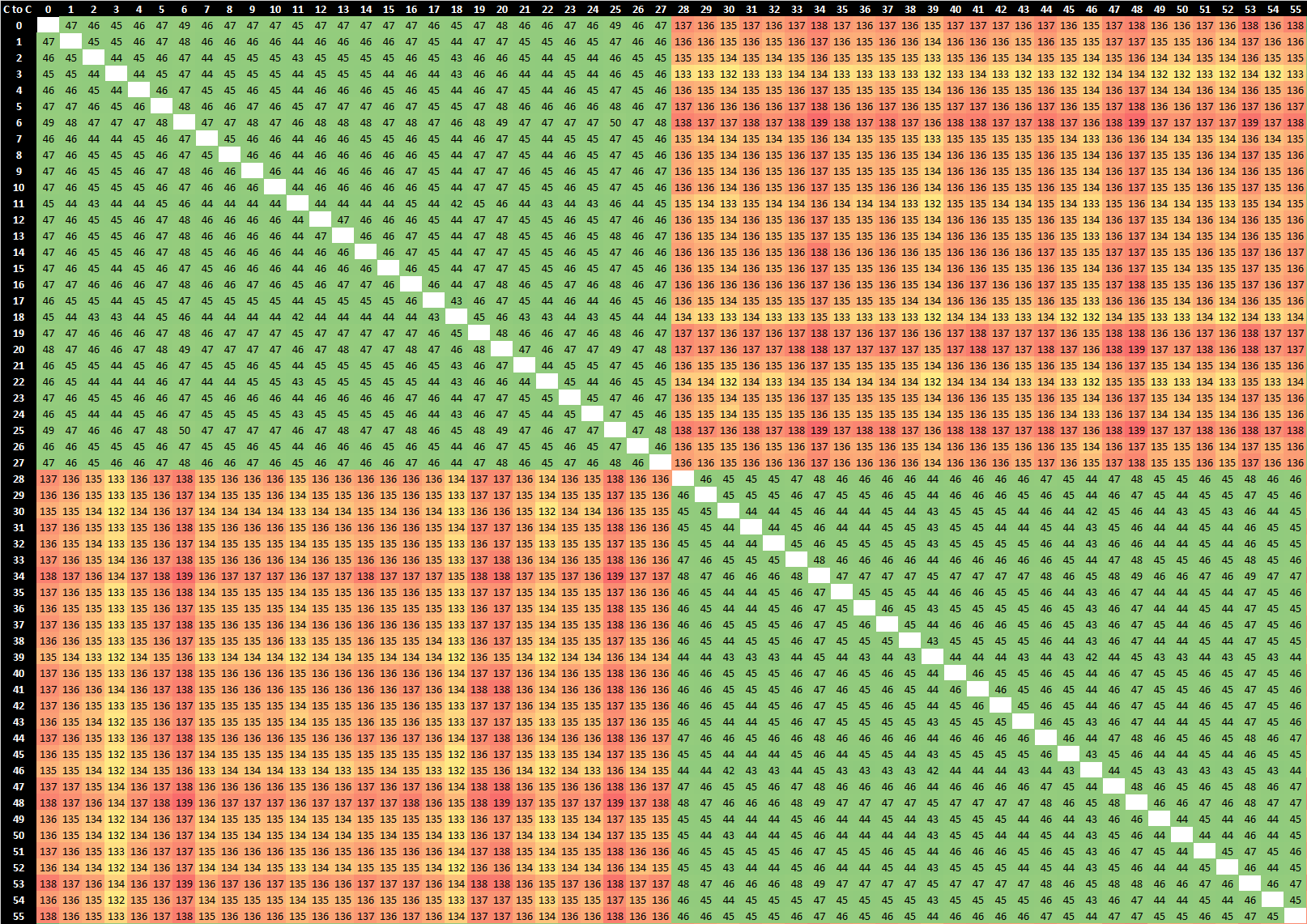
2-Socket Intel Xeon Platinum 8280
Comparing the Altra results to an Intel Xeon Platinum 8280 Cascade Lake 2S system, the latencies within a socket aren’t too different – both implementations are after all monolithic chips with mesh architectures. Keep in mind that the Xeon system here will boost up to 4GHz during the test as we’re only loading 2 cores.
Inter-socket latencies for the Xeon lands in at around 135ns which is very good and a fraction of the Altra system. The chips here use Intel’s UPI interface links and protocols – 3x 10.4GT/s interfaces. In theory the bandwidth here is less than the Altra system, however because it’s all running on the same native protocol across sockets it doesn’t have to incur any penalties as the Altra.
Most importantly, latencies within the second socket are identical to the first socket, meaning the coherency protocols are transferring the shared cache line ownership across sockets even though these are two different NUMA nodes.
2-Socket AMD EPYC 7742
Finally, AMD’s EPYC 7742 here performs middle-of-the-road across the implementations, with the biggest difference being that it’s not a monolithic cache hierarchy across a whole chip, but rather within 4-core CCX clusters within the CPU chiplets, which are then further divided into physical quadrants on the I/O die which connects the 8 chiplets of a single-socket package.
Socket-to-socket, the Rome chip essentially doubles up the worse in-socket latencies. Within the remote socket, AMD is able to locally copy ownership of the shared cache-line within a CCXs, but access latencies between CCXs within the remote socket still seem to have to communicate back to the home socket with similar latencies as the socket-to-socket core figures.
Still, even AMD’s unorthodox system vastly outperforms the socket-to-socket communication of the Ampere Altra by not having to translate between different coherency protocols – that’s the advantage of owning the IP and designing the protocols yourself. Ampere here would have to rely on Arm to release a native AMBA CHI-like implementation to support inter-socket coherency across two mesh systems.
Memory Latency
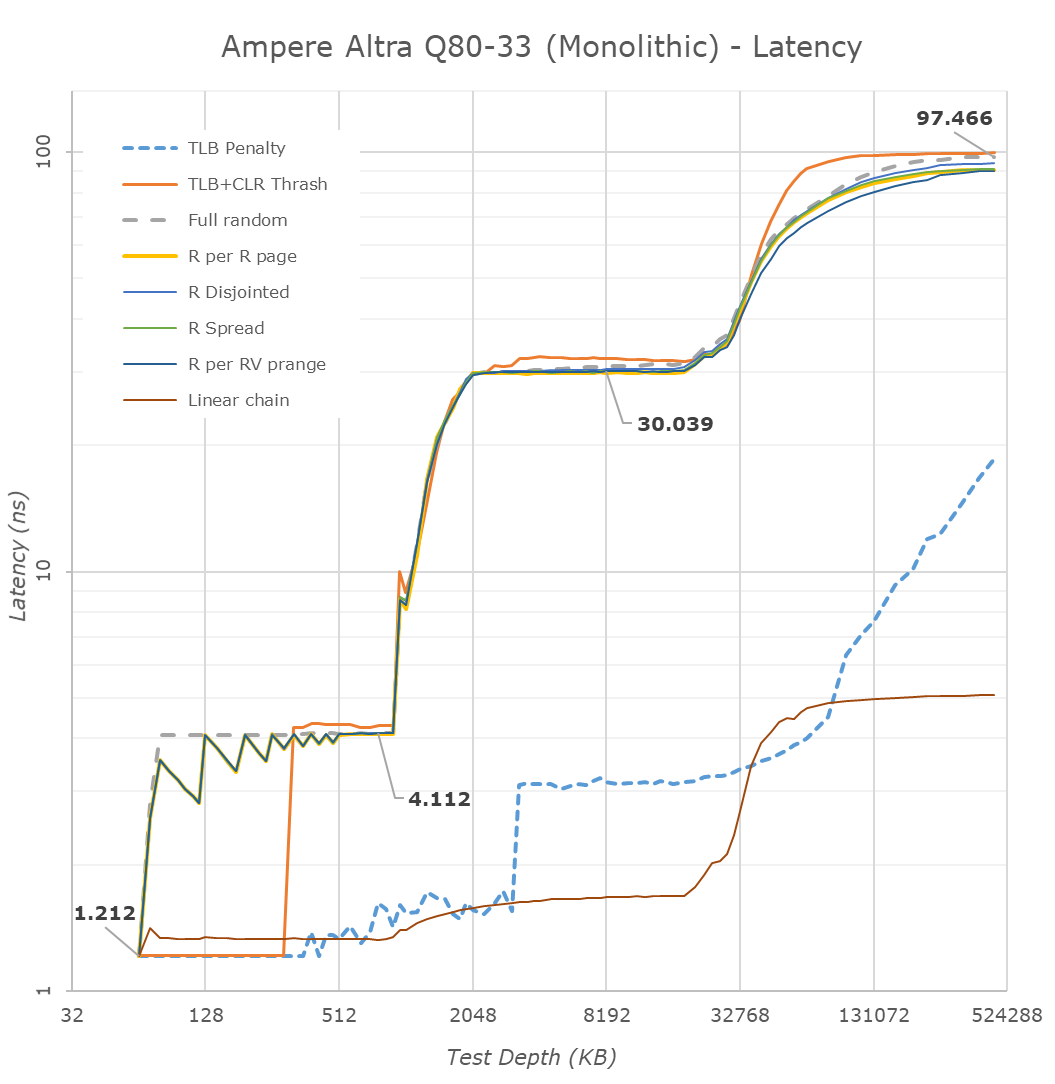
In terms of memory latency, the new Altra Q80-33 and its siblings should be quite straightforward.
Starting off with the monolithic native results of the Altra, we can see the full cache hierarchy of the chip, with the 64KB L1D and 1MB L2 caches of the Neoverse N1 cores, as well as the 32MB L3 cache of the mesh.
What stands out here compared to the Graviton2 results earlier in the year, is that the Altra’s advanced prefetchers are essentially all disabled by default, and all our access patterns are behaving essentially identical, simply exposing the hardware latencies, with only the next-line prefetcher still being active for linear streams.
That’s interesting, and maybe a decision made due to the sheer core-count of the system – every bit of bandwidth is needed for feed all the cores with usable data, so there’s no room speculative prefetching.
DRAM memory latency of the system is excellent at 97ns and below that of the Graviton2 – though one big note we have to make here is that the Altra system is running CentOS with 64KB pages by default, which will give the system some advantage in TLB misses.
Compared to a Xeon 8280, the Altra system still loses out in memory latency even though both are monolithic chips, and the Xeon is actually running slower DDR4-2933 versus DDR-3200 of the Altra and EPYC.
In NPS1 mode, the EPYC 7742 has to interleave memory accesses across all of its I/O die quadrants which on top of the chiplet architecture results in larger memory latency penalties, up to 133ns here at our equal depth measurement point.

One speciality of the Altra is that Ampere actually offering various operating modes when running the chip in different NUMA configurations: You can either treat the chip as a native large monolithic design, just like the hardware is designed, or you can subdivide the mesh and memory controllers into either two hemispheres, or four quadrants. The point of subdividing the chip this way even though it’s a monolithic design seems at first counter-productive, but Ampere says there are practical benefits to this.
The first benefit would be that this allows for better segregation of workloads across cloud workloads. A customer deploying an Altra system in the cloud would want to run multiple virtual machines on a single chip – subdividing the chip into quadrants here has the practical benefit of completely eliminating effects of noisy-neighbours within that quadrant. Furthermore, this actually also subdivides the cache of the mesh system, meaning that the 32MB get divided into 8MB quadrants, something which one can immediately see in the graph.
Beyond reducing cross-chip traffic and reducing noisy neighbours in VM systems, the division slightly also improves latencies. For example, DRAM accesses go down from 97ns to 93ns because a CPU only accesses its two-nearest memory controller channels instead of accessing the further across-the-chip controllers. Similarly, the L3 latency also slightly goes down from 30.0ns to 27.6ns as it has to interleave accesses just across the nearest located quadrant cache node slices, reducing wire latency.
Of course, because the Altra is still a monolithic chip, the benefits aren’t quite as significant as what we see on AMD’s EPYC Rome system which sees DRAM latency go down from 133ns to 117ns due to it no longer hopping around Infinity Fabric nodes across the I/O die quadrants.
Memory Bandwidth
Multi-core memory bandwidth is a topic I don’t really enjoy, due to nuances of different systems and how memory behaves across large systems. The data that you want to showcase has to serve a pre-determined purpose – either you’re trying to benchmark things from a software perspective, or you want to expose hardware capabilities. STREAM is a benchmark that has been abused quite a bit over the years in that it crossed this boundary between scopes far too much, especially across multi-socket systems. The vanilla version is meant to benchmark memory within a single memory node, which is exactly what we’ll be doing. On top of that, we’re also compiling a vanilla copy of the benchmark using plain optimisation flags, further avoiding the rabbit-hole of apples-and-oranges comparisons that are done out there in the wild.
Having that in mind, let’s check out the STREAM Triad results of the various processors:
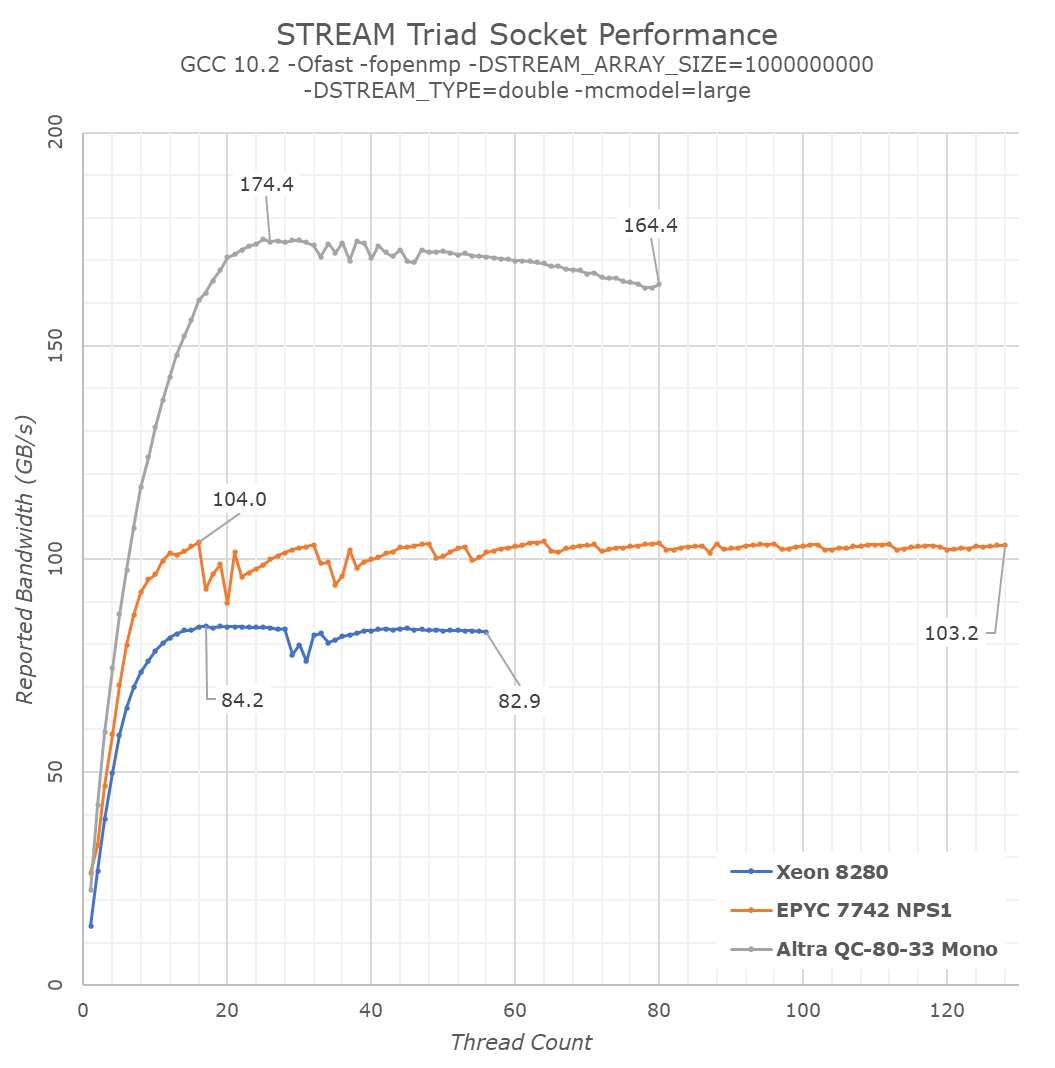
What first comes to light of course the difference between the new Altra processor, and the x86 platforms which appear to be performing much worse. It’s again at this point where we have to disambiguate what we’re measuring, software performance, or hardware behaviour?
From a software standpoint, the Altra indeed vastly outperforms the competition, and the reason for this is an architecture and microarchitecture one. The Neoverse-N1 cores in the Altra system are able to take advantage of Arm’s weaker memory model: the CPU cores will detect that they’re working on a streaming workload, meaning it’s going over large amounts of data with no re-use of the previous results. The CPU thus automatically converts its memory write operations into non-temporal ones.
The difference between “regular” RFO (Read For Ownership) memory writes and non-temporal writes is that the former incurs further cache coherency operations on the part of the hardware. For example, writing a 64B cache-line to memory write from a software perspective here actually results in 128B of hardware traffic as the core has to first read out the target cache line before it can write to it.
For STREAM, for example in the Triad test whose kernel is a[j] = b[j]+scalar*c[j];, the test assumes 3 memory operations, one write to a[j] and two reads out of b[j] and c[j], where in reality for x86 systems it’s actually 4 memory operations, thus 1.33x the reported bandwidth from the test. The memory copy kernel which is c[j] = a[j]; assumes there to be 2 memory operations, while in reality there’s 3, thus 1.5x higher.
It’s possible to compile STREAM to outright explicitly use non-temporal stores on x86 systems, with the test using instructions that hint out to the core to avoid checking the cache line to be written. Essentially this is what various ICC compiled and optimised variants of STREAM do.
Unfortunately, when using such optimised variants of the benchmark you’re no longer testing apples to apples software performance, but rather something else, and tread into the realm of trying to measure what the hardware is doing. In my view that’s not what STREAM is meant for. I have custom tests that showcase vastly higher bandwidth than STREAM on all platforms, but they’re doing something completely different in terms of design.
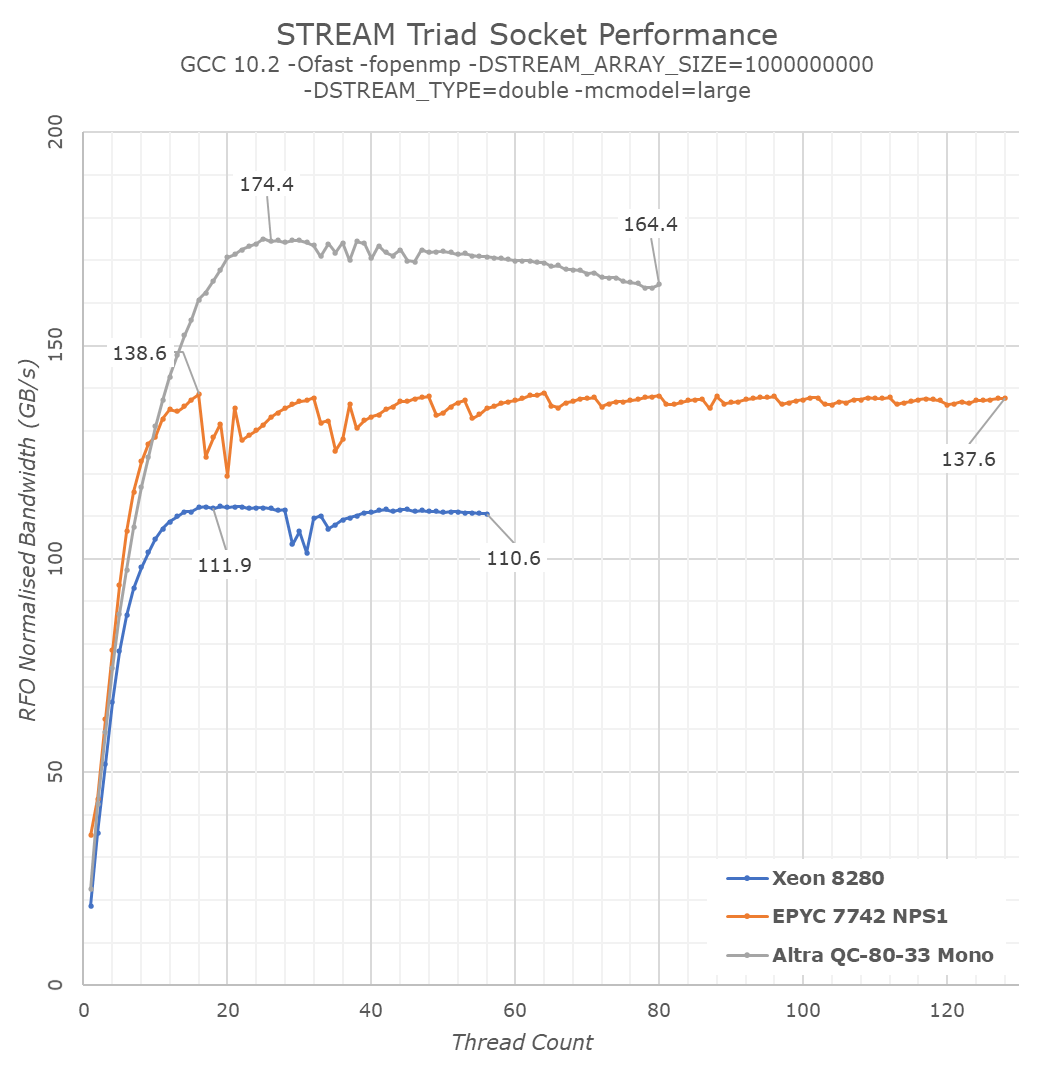
In any case, even if we were to compensate with the 1.33x or 1.5x factors for the x86 systems, they don’t reach the memory performance that the Altra Q80-33 is showcasing here. Arm’s smart usage of the architecture’s memory model flexibility and ability to transforms arbitrary streams into non-temporal operations is a real-world benefit to all software. As a note, this behaviour is also present on mobile cores from Arm from the Cortex-A76 onwards, Samsung’s cores from M4 onwards, and from this year’s Apple Firestorm cores in the A14 and M1.
Test Bed and Setup - Compiler Options
For the rest of our performance testing, we’re disclosing the details of the various test setups:
Ampere "Mount Jade" - Dual Altra Q80-33
Obviously, for the Ampere Altra system we’re using the provided Mount Jade server as configured by Ampere.

The system features 2 Altra Q80-33 processors within the Mount Jade DVT motherboard from Ampere.

In terms of memory, we’re using the bundled 16 DIMMs of 32GB of Samsung DDR4-3200 for a total of 512GB, 256GB per socket.
| CPU | 2x Ampere Altra Q80-33 (3.3 GHz, 80c, 32 MB L3, 250W) |
| RAM | 512 GB (16x32 GB) Samsung DDR4-3200 |
| Internal Disks | Samsung MZ-QLB960NE 960GB Samsung MZ-1LB960NE 960GB |
| Motherboard | Mount Jade DVT Reference Motherboard |
| PSU | 2000W (94%) |
The system came preinstalled with CentOS 8 and we continued usage of that OS. It’s to be noted that the server is naturally Arm SBSA compatible and thus you can run any kind of Linux distribution on it.
Ampere makes special note of Oracle’s active support of their variant of Oracle Linux for Altra, which makes sense given that Oracle a few months ago announced adoption of Altra systems for their own cloud-based offerings.
The only other note to make of the system is that the OS is running with 64KB pages rather than the usual 4KB pages – this either can be seen as a testing discrepancy or an advantage on the part of the Arm system given that the next page size step for x86 systems is 2MB – which isn’t feasible for general use-case testing and something deployments would have to decide to explicitly enable.
The system has all relevant security mitigations activated, including SSBS (Speculative Store Bypass Safe) against Spectre variants.
AMD - Dual EPYC 7742
For our AMD system, unfortunately we had hit some issues with our Daytona reference server motherboard, and moved over to a test-bench setup on a SuperMicro H11DSI0.
We’re also equipping the system with 256GB per socket of 8-channel/DIMM DDR4-3200 memory, matching the Altra system.
| CPU | 2x AMD EPYC 7742 (2.25-3.4 GHz, 64c, 256 MB L3, 225W) |
| RAM | 512 GB (16x32 GB) Micron DDR4-3200 |
| Internal Disks | OCZ Vector 512GB |
| Motherboard | SuperMicro H11DSI0 |
| PSU | EVGA 1600 T2 (1600W) |
As an operating system we’re using Ubuntu 20.10 with no further optimisations. In terms of BIOS settings we’re using complete defaults, including retaining the default 225W TDP of the EPYC 7742’s, as well as leaving further CPU configurables to auto, except of NPS settings where it’s we explicitly state the configuration in the results.
The system has all relevant security mitigations activated against speculative store bypass and Spectre variants.
Intel - Dual Xeon Platinum 8280
For the Intel system we’re also using a test-bench setup with the same SSD and OS image actually – we didn’t have enough RAM to run both systems concurrently.
Because the Xeons only have 6-channel memory, their maximum capacity is limited to 384GB of the same Micron memory, running at a default 2933MHz to remain in-spec with the processor’s capabilities.
| CPU | 2x Intel Xeon Platinum 8280 (2.7-4.0 GHz, 28c, 38.5MB L3, 205W) |
| RAM | 384 GB (12x32 GB) Micron DDR4-3200 (Running at 2933MHz) |
| Internal Disks | OCZ Vector 512GB |
| Motherboard | ASRock EP2C621D12 WS |
| PSU | EVGA 1600 T2 (1600W) |
The Xeon system was similarly run on BIOS defaults on an ASRock EP2C621D12 WS with the latest firmware available.
The system has all relevant security mitigations activated against the various vulnerabilities.
Compiler Setup
For compiled tests, we’re using the release version of GCC 10.2. The toolchain was compiled from scratch on both the x86 systems as well as the Altra system. We’re using shared binaries with the system’s libc libraries.
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
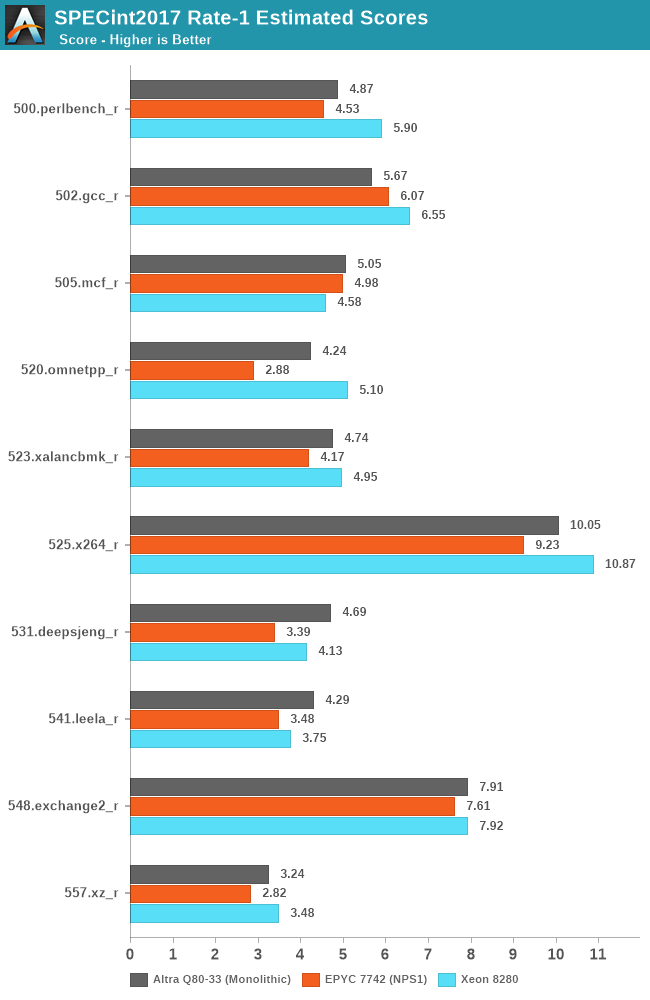
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
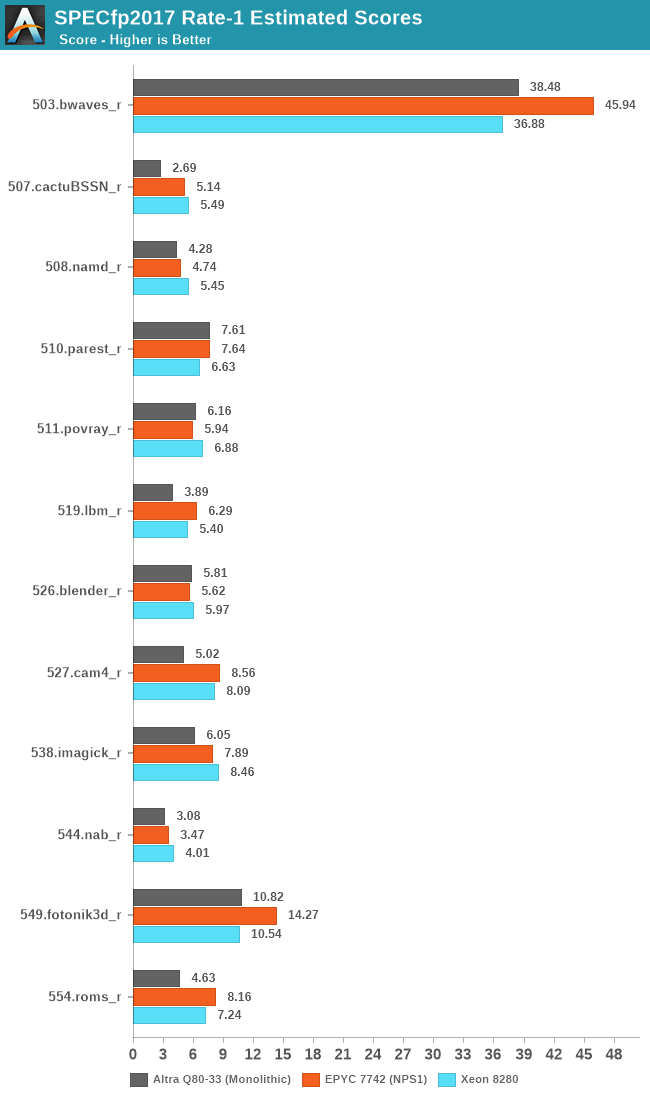
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
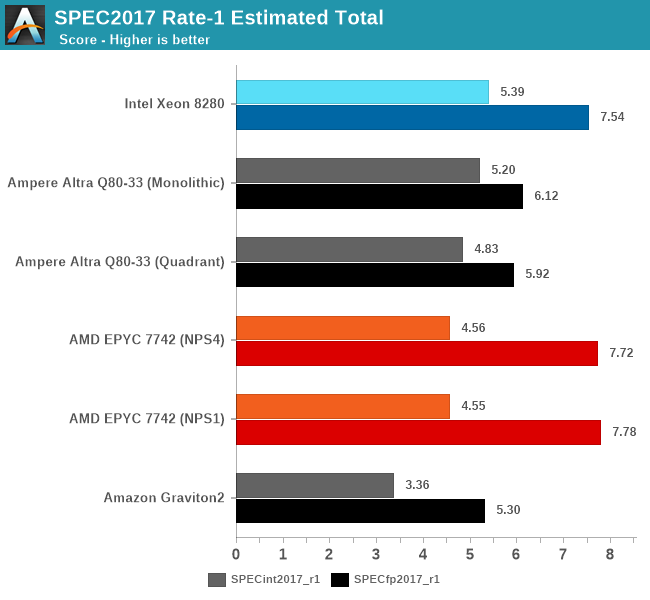
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.
SPEC - Multi-Threaded Performance
While the single-threaded numbers were interesting, what we’re all looking after are the multi-core scores and what exactly 80 Neoverse-N1 cores can achieve within a single, and two sockets.
The performance measurements here were limited to quadrant and NPS4 configurations as that’s actually the default settings in which the Altra system came in, and what also AMD usually says customers want to deploy into production, achieving better performance by reducing cross-chip memory traffic.
The main comparison point here against the Q80-33 is AMD’s EPYC 7742 – 80 cores versus 64 cores with SMT, as well as similar TDPs. Intel’s Xeon 8280 with its 28 cores also comes into play but isn’t a credible competitor against the newer generation silicon designs on 7nm.
I’m keeping the detailed result sets limited to single-socket figures – we’ll check out the dual-socket numbers later on in the aggregate chart – essentially the 2S figures are simply 2x the performance.
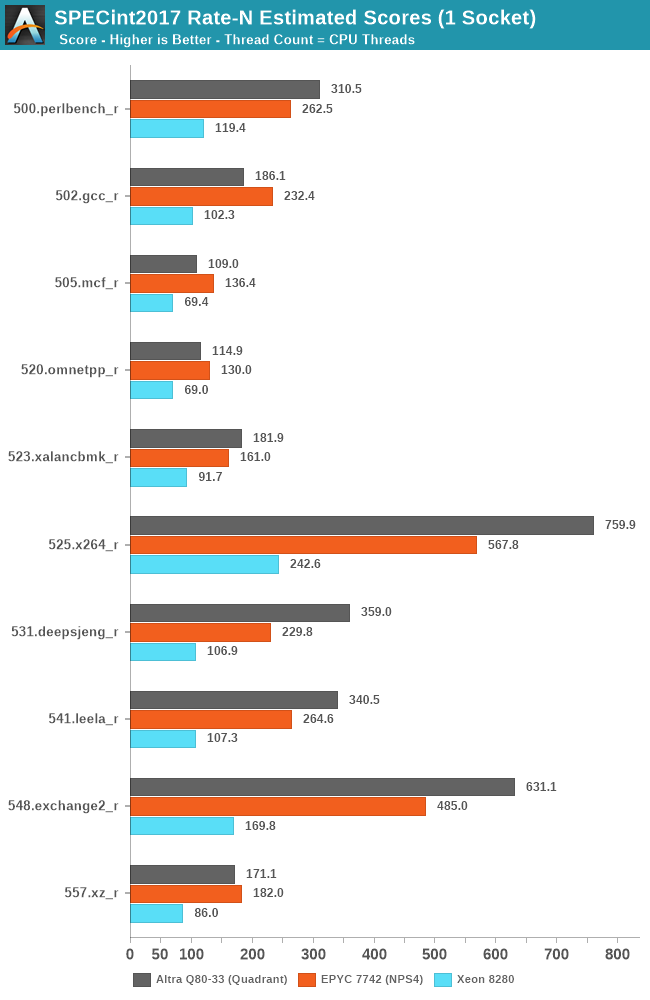
Starting off with SPECint2017, we’re seeing some absolutely smashing figures here on the part of the Altra Q80-33, with several workloads where the chip significantly outperforms the EPYC 7742, but also losing in some other workloads.
Starting off with the losing workloads, gcc, mcf, and omnetpp, these are all workloads with either high cache pressure or high memory requirements.
The Altra losing out in 502.gcc_r doesn’t come as much of a surprise as we also saw the Graviton2 suffering in this workload – the 1MB per core of L2 as well as 400KB per core of shared L3 really isn’t much and pales against the 4MB/core that’s available to the EPYC’s Zen2 cores. The Altra going from 2.5GHz to 3.3GHz and 64 cores to 80 cores only improves the score from 176.9 to 186.1 in comparison to the Graviton2. I’m not including the Graviton2 in the charts as it’s not quite the apples-to-apples comparisons due to compiler and run environments, but one can look up the scores in that review.
Where the Altra does shine however is in more core-local workloads that are more compute oriented and have less of a memory footprint, of which we see quite a few here, such as 525.x264.
What’s really interesting here is that even though the latter tests in the suite are extremely friendly to SMT scaling on the x86 systems, with 531, 541, 548 and 557 scaling up with SMT threads in MT performance by respectively 30, 43, 25 and 36%, AMD’s Rome CPU still manages to lose to the Altra system by considerable amounts – only being slightly favoured in 557.xz_r by a slight margin – so while SMT helps, it’s not enough to counteract the raw 25% core count advantage of the Altra system when comparing 80 vs 64 cores.
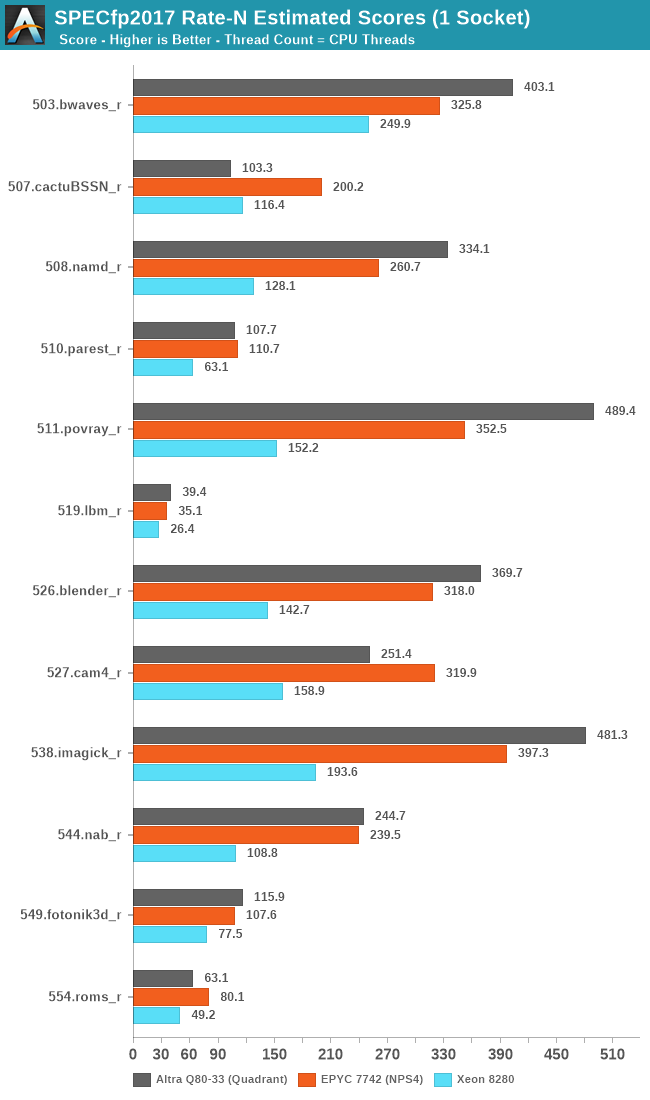
In SPECfp2017, things are also looking favourably for the Altra, although the differences aren’t as favourable except for 511.povray where the raw core count again comes into play.
The Altra again showcases really bad performance in 507.cactuBSSN_r, mirroring the lacklustre single-threaded scores and showing worse performance than a Graviton2 by considerable amounts.
The Arm design does well in 503.bwaves which is fairly high IPC as well as bandwidth hungry, however falls behind in other bandwidth hungry workloads such as 554.roms_r which has more sparse memory stores.
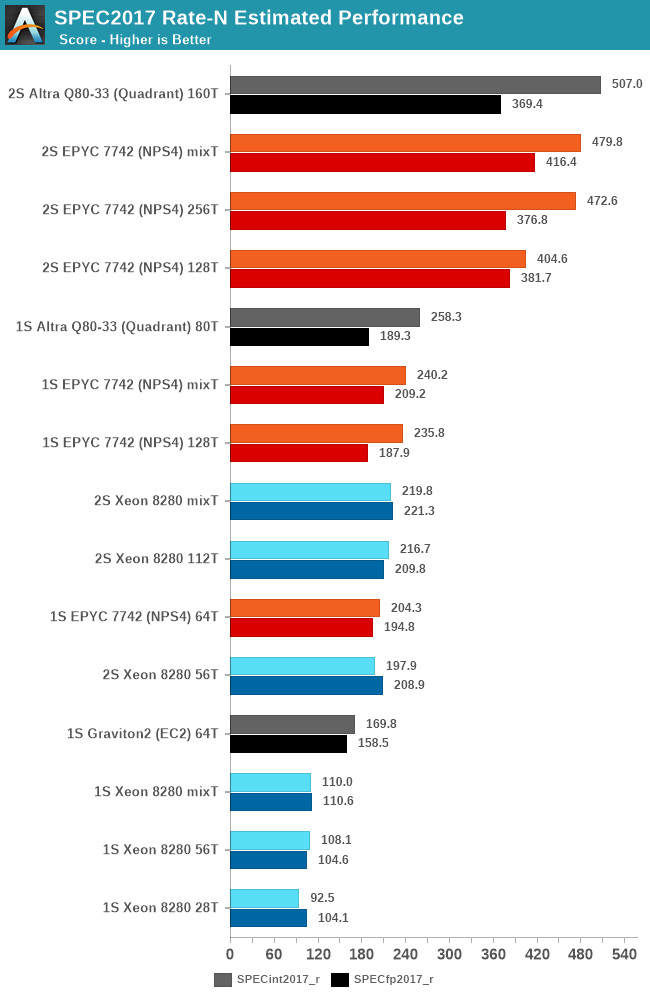
In the overall scores, both across single-socket and dual-socket systems, the new Altra Q80-33 performs outstandingly well, actually edging out the EPYC system by a small margin in SPECint, though it’s losing out in SPECfp and more cache-heavy workloads.
Beyond testing 1-socket and 2-socket scores, I’ve also taken the opportunity of this new round of testing across the various systems to test out 1 thread per core and 2 thread per core scores across the SMT systems.
While there are definitely workloads that scale well with SMT, overall, the technology has a smaller impact on the suite, averaging out at 15% for both EPYC and Xeon.
One thing we don’t usually do in the way we run SPEC is mixing together rate figures with different thread counts, however with such large core counts and threads it’s something I didn’t want to leave out for this piece. The “mixT” result set takes the best performing sub-score of either the 1T or 2T/core runs for a higher overall aggregate. Usually officially submitted SPEC scores do this by default in their _peak submissions while we usually run _base comparative scores. Even with this best-case methodology for the SMT systems, the Altra system still slightly edges out the performance of the EPYC 7742.
Intel’s Cascade Lake Xeon system here really isn’t of any consideration in the competitive landscape as a single-socket Altra system will outperform a dual-socket Xeon.
The Altra QuickSilver still has one weakness and that’s cache-heavy workloads – 32MB of L3 for 80 cores really isn’t near enough to keep up performance scaling across that many cores. In the end of the day however, it’s up to Ampere’s customers to give input what kind of workloads they use and if they stress the caches or not – given that both Amazon and Ampere chose the minimum cache configuration for their mesh implementations, maybe that’s not the case?
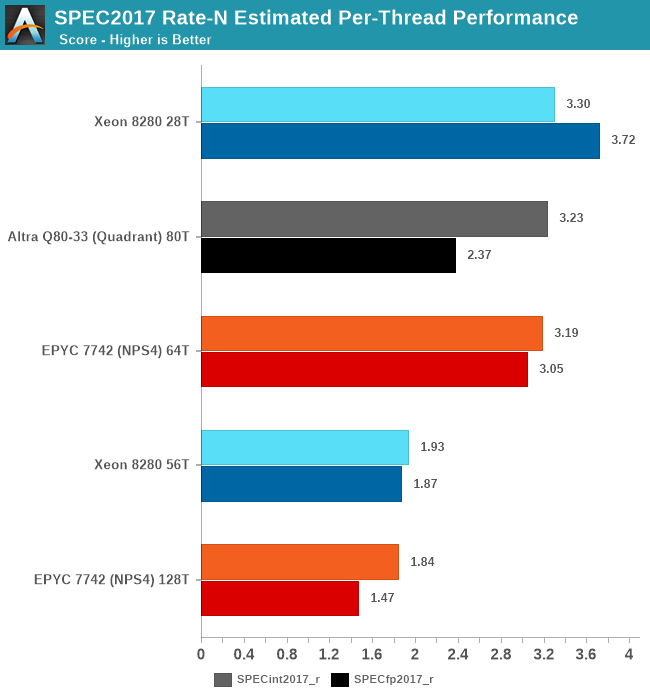
Finally, one last figure I wanted to showcase is the per-thread performance of the different designs. While scaling out multi-threaded performance across vast number of cores is a very important way to scale performance, it’s also important to not take a flock of chickens approach with too weak cores. Especially for customers Ampere is targeting, such as enterprise and cloud service providers, many times users will be running things on a subset of a given processor socket cores, so per-core and per-thread performance remains a very important metric.
Simply dividing the single-socket performance figures by the amount of threads run, we get to an average per-thread performance figure in the context of a fully loaded system, a figure that’s actually more realistic than the single-thread figures of the previous page where the rest of the CPU cores in the systems are doing nothing.
In this regard, Intel’s Xeon offering is still extremely competitive and actually takes the lead position here – although its low core count doesn’t favour it at all in the full throughput metrics of the socket, the per-thread performance is still the best amongst the current CPU offerings out there.
In SPECint, the Altra, EPYC and Xeon are all essentially tied in performance, whilst in SPECfp the Xeon takes the lead with the Altra falling notably behind – with the EPYC Rome chip falling in-between the two.
If per-thread performance is important to you, then obviously enough SMT isn’t an option as this vastly regresses performance in favour of a chance to get more aggregate performance across multiple threads. There’s many vendors or enterprise use-cases which for this reason just outright disable SMT.
SPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon, N=56 for 1S Xeon, and N=128 for 2S and 1S on the EPYC system. I tried running 256 or 160 threads on the 2S EPYC configuration but the benchmark would error out with a critical timeout and I wasn’t able to fully debug as to why it did that.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
Altra & EPYC system:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+AlwaysPreTouch"
Xeon system:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+AlwaysPreTouch"
The reason the Xeon system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks. The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
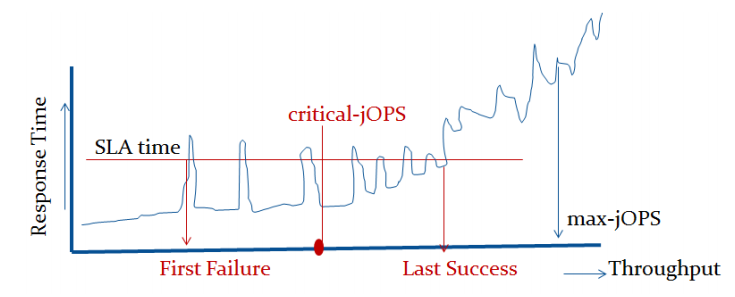
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
Beyond the result figures, the benchmark keeps detailed track of timings of responses and tracks a few important statistical data-points across a response-time curve, as follows:
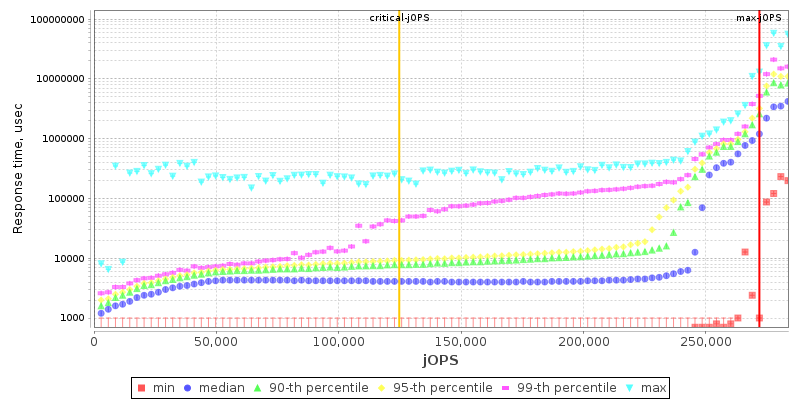
2S EPYC 7742 THP Enabled
I’m starting off with the EPYC results as they’re sort of standard – the max-jOPS here ends up quite high at over 270k, while the critical-jOPS ends up around 125k. The system still manages to retain 90th percentile response times under 20ms up until 230k which is excellent, with 99th percentile results starting to degrade after 110k jOPS.

2S Xeon 8280 THP Enabled
On the Xeon system, we see similar flat 90th percentile response times up until around 120k with 99th percentiles starting to degrade following 90k, but in a much tighter curve than on the EPYC system – while the system here has less overall throughput its scaling up to that throughput limit could be considered to be better.
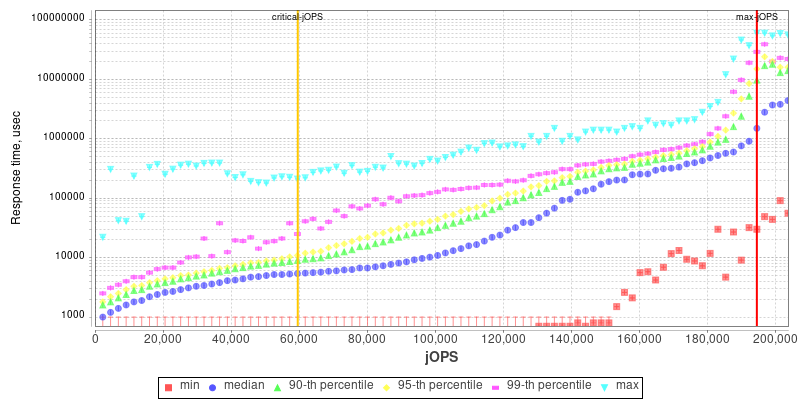
2S Altra Q80-33 THP Enabled
With the EPYC and Xeon systems as context, we’re finally looking at the Altra results, which look very different.
Unlike the x86 systems, 99th and 90th percentile response times degrade earlier on in the throughput curve for the Altra chip. What this actually reminded me of is the STREAM results from earlier in the review where we saw that initially a bunch of cores were able to hit peak bandwidth across the memory controllers, but adding further cores to the mix actually degraded performance, pointing out to suboptimal congestion across the mesh interconnect.
It might be possible that the results here across SPECjbb are hitting a similar level of saturation under load, given that there’s a lot of inter-core communication and memory transactions happening.
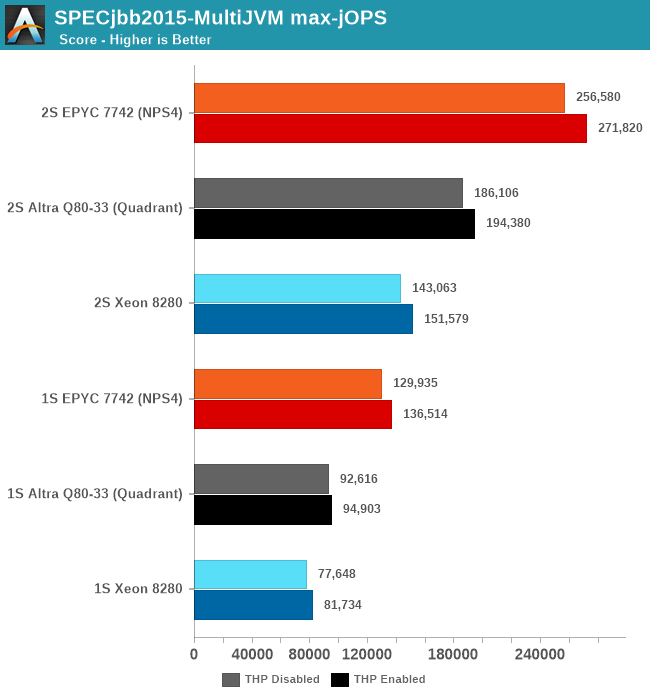
Charting the max-jOPS of the different systems, I ran figures for both 1S and 2S system configurations. Additionally, I also tested out the benchmark both with transparent huge pages always enabled, and to a default not used / madvise state, as we’ve seen in the past that this can have a notable impact on the resulting performance.
Whilst the Altra system is able to beat the Xeon, it’s not sufficient to match the EPYC system which still lies considerably ahead by a good margin. The exact reasons for this discrepancy compared to the x86 systems isn’t immediately clear, as we’re dealing with many layers here. AArch64 OpenJDK JVM performance certainly might not be as mature and optimised as the x86-64 counterparts, and there is certainly a rabbit hole of various optimisations and knobs we could have tried to change things – although we still view these simple default out-of-the-box settings to still be valuable and valid in terms of comparisons.
One thing that did come to mind immediately when I saw the results was SMT. Due to this being a transactional data-plane resident type of workload, SMT will undoubtedly help a lot in terms of performance, so I tested out the EPYC chip figures with SMT disabled, and indeed max-jOPS went down to 209.5k for the 2S THP enabled results, meaning that SMT accounts for a 29.7% performance benefit in this benchmark.
A further indication that the Altra system is being underutilised on the part of the cores and memory-bottlenecked is its power consumption, which even when fully loaded in the RT curve, it generally hovered around 170-180W per socket, while the x86 systems were filling up their TDPs.
It’s generally these kinds of workloads that SMT works best on, and that’s why IBM can deploy SMT4 or SMT8 processors, and the type of workloads Marvell’s ThunderX was trying to carve a niche or itself with SMT4.
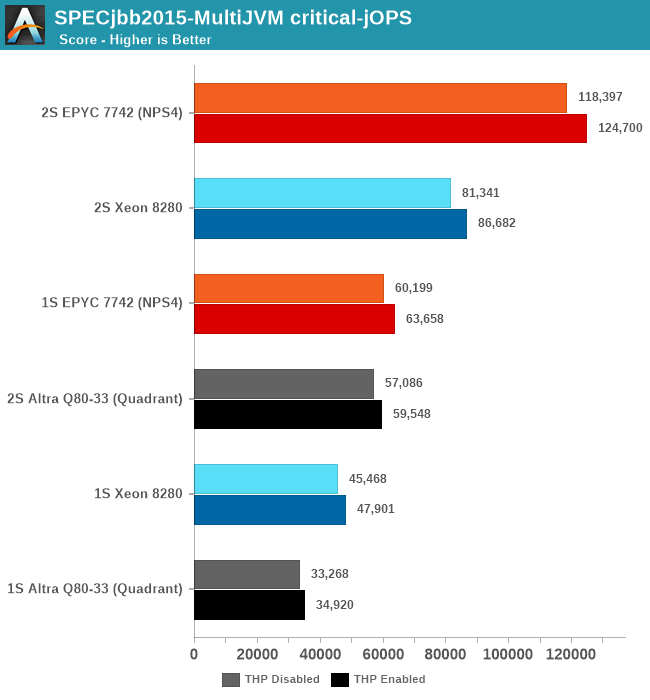
For the critical-jOPS figures, the Altra doesn’t do well at all given its response-time curve. Beyond the lack of SMT (The EPYC here again achieves its high score through a 26.4% contribution of the secondary logical cores), we’re maybe looking at a software side immaturity of out-of-the-box Java performance on Arm systems. The figures here shouldn’t be taken with absolute authority with a conclusion that Java performance on the Altra sucks, but at least we’re seeing signs that it doesn’t look too great.
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk – on a 4KB page system 5GB should be sufficient but on the Altra’s 64KB system it used up to 9.5GB, including the source directory. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
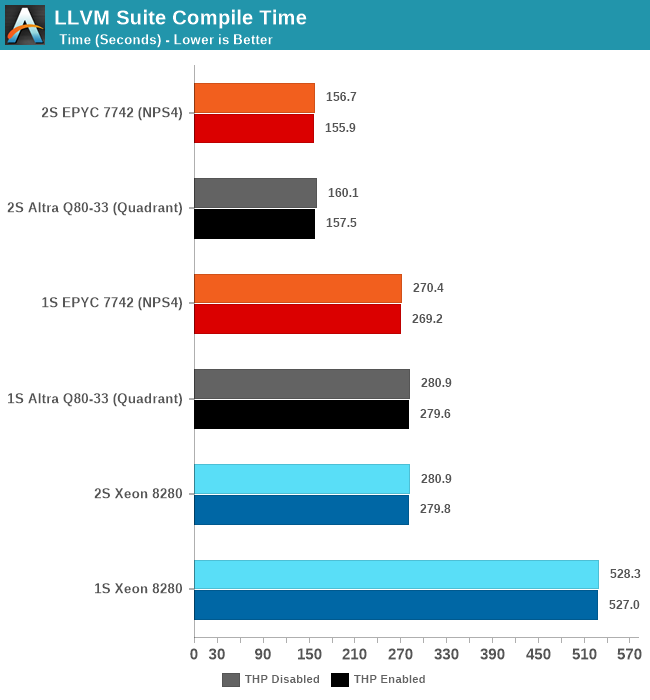
The Altra Q80-33 here performs admirably and pretty much matches the AMD EPYC 7742 both in 1S and 2S configurations. There isn’t exact perfect scaling between sockets because this being a actual build process, it also includes linking phases which are mostly single-threaded performance bound.
Generally, it’s interesting to see that the Altra here fares better than in the SPEC 502.gcc_r MT test – pointing out that real codebases might not be quite as demanding as the 502 reference source files, including a more diverse number of smaller files and objects that are being compiled concurrently.
NAMD
Another rather popular benchmark tool that we’ve actually seen being used by vendors such as AMD in their marketing materials when showcasing HPC performance for their server chips is NAMD. This actually quite an interesting adventure in terms of compiling the tool for AArch64 as essentially there little to no proper support for it. I’ve used the latest source drop, essentially the 2.15alpha / 3.0alpha tree, and compiled it from scratch on GCC 10.2 using the platform’s respective -march and -mtune targets.
For the Xeon 8280 – I did not use the AVX512 back-end for practical reasons: The code which introduces an AVX512 algorithm and was contributed by Intel engineers to NAMD has no portability to compilers other than ICC. Beyond this being a code-path that has no relation with the “normal” CPU algorithm – the reliance on ICC is something that definitely made me raise my eyebrows. It’s a whole other discussion topic on having a benchmark with real-world performance and the balance of having an actual fair and balanced apple to apples comparison. It’s something to revisit in the future as I invest more time into looking the code and see if I can port it to GCC or LLVM.
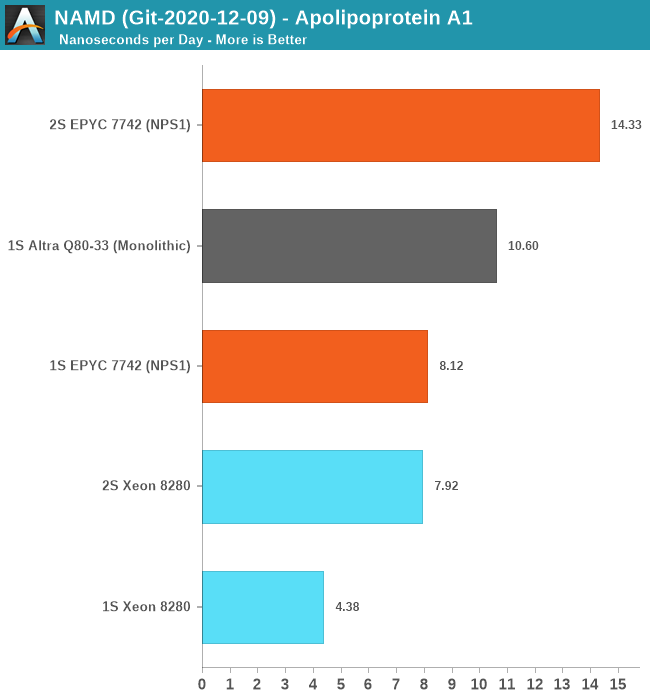
For the single-socket numbers – we’re using the multicore variant of the tool which has predictable scaling across a single NUMA node. Here, the Ampere Altra Q80-33 performed amazingly well and managed to outperform the AMD EPYC 7742 by 30% - signifying this is mostly a compute-bound workload that scales well with actual cores.
For the 2S figures, using the multicore binaries results in undeterministic performance – the Altra here regressed to 2ns/day and the EPYC system also crashed down to 4ns/day – oddly enough the Xeon system had absolutely no issue in running this properly as it had excellent performance scaling and actually outperforms the MPI version. The 2S EPYC scales well with the MPI version of the benchmark, as expected.
Unfortunately, I wasn’t able to compile an MPI version of NAMD for AArch64 as the codebase kept running into issues and it had no properly maintained build target for this. In general, I felt like I was amongst the first people to ever attempt this, even though there are some resources to attempt to help out on this.
I also tried running Blender on the Altra system but that ended up with so many headaches I had to abandon the idea – on CentOS there were only some really old build packages available in the repository. Building Blender from source on AArch64 with all of its dependencies ends up in a plethora of software packages which simply assume you’re running on x86 and rely on basic SSE intrinsics – easy enough to fix that in the makefiles, but then I hit some other compilation errors after which I lost my patience. Fedora Linux seemed to be the only distribution offering an up-to-date build package for Blender – but I stopped short of reinstalling the OS just to benchmark Blender.
So, while AArch64 has made great strides in the past few years – and the software situation might be quite good for server workloads, it’s not all rosy and we’re still have ways to go before it can be considered a first-class citizen in the software ecosystem. Hopefully Apple’s introduction of Apple Silicon Macs will accelerate the Arm software ecosystem.
Conclusion & End Remarks
The server landscape is changing very quickly. While the promise of Arm servers for many years has been just that – this year’s introduction of the Graviton2 marked the tipping point where Arm server chips no longer represented a niche use-case, but rather a real – and competitive option. The only problem with Graviton2 was that this was an internal Amazon-only solution – so you couldn’t really say it was an option against AMD or Intel.
That’s where Ampere Computing steps in, positioning themselves as an open merchant silicon vendor, and the first to use and deploy Arm’s new Neoverse CPU line-up in such a way. The Altra QuickSilver being the very first attempt at this, truly hits it out of the park and matches the high expectations of the silicon.
Ampere’s approach is significantly more aggressive, with more performance, and more power, than what the Graviton2 aimed for – the new 80-core Q80-33 flagship SKU essentially has managed to match the performance of AMD’s flagship Rome chip – the 64-core EPYC 7742. While personally that didn’t surprise me much, I could imagine that for many readers out there this to come as an unexpected turn of events.
The Altra Q80-33 sometimes beats the EPYC 7742, and loses out sometimes – depending the workload. The Altra’s strengths lie in compute-bound workloads where having 25% more cores is an advantage. The Neoverse-N1 cores clocked at 3.3GHz can more than match the per-core performance of Zen2 inside the EPYC CPUs.
There are still workloads in which the Altra doesn’t do as well – anything that puts higher cache pressure on the cores will heavily favours the EPYC as while 1MB per core L2 is nice to have, 32MB of L3 shared amongst 80 cores isn’t very much cache to go around. Generally, I think the mesh interconnect remains a weak-point for this generation of Neoverse products and there’s improvements to be done in the next iteration of designs.

Today we’ve tested the Wiwynn based “Mount Jade” 2S Ampere Altra server – the Altra’s support for dual-socket platforms is functional, but relying on CCIX instead of a native coherency protocol between CPU cores in the two sockets means that performance isn’t nearly as good as the scaling we see from AMD or Intel. The single-socket “Mount Snow” Altra platforms as well as the platform solutions from GIGABYTE might be a better option for some deployments.
In terms of power-efficiency, the Q80-33 really operates at the far end of the frequency/voltage curves at 3.3GHz. While the TDP of 250W really isn’t comparable to the figures of AMD and Intel are publishing, as average power consumption of the Altra in many workloads is well below that figure – ranging from 180 to 220W – let’s say a 200W median across a variety of workloads, with few workloads actually hitting that peak 250W. I would say that yes, the Altra does have a power efficiency advantage over AMD’s EPYC platform, but not something that is overly significant enough to say that it completely changes the landscape.
| Ampere 1st Gen Altra 'QuickSilver' Product List |
||||||
| AnandTech | Cores | Frequency | TDP | PCIe | DDR4 | Price |
| Q80-33 (Tested) |
80 | 3.3 GHz | 250 W | 128x G4 | 8 x 3200 | $4050 |
| Q80-30 | 80 | 3.0 GHz | 210 W | 128x G4 | 8 x 3200 | $3950 |
| Q80-26 | 80 | 2.6 GHz | 175 W | 128x G4 | 8 x 3200 | $3810 |
| Q80-23 | 80 | 2.3 GHz | 150 W | 128x G4 | 8 x 3200 | $3700 |
| Q72-30 | 72 | 3.0 GHz | 195 W | 128x G4 | 8 x 3200 | $3590 |
| Q64-33 | 64 | 3.3 GHz | 220 W | 128x G4 | 8 x 3200 | $3810 |
| Q64-30 | 64 | 3.0 GHz | 180 W | 128x G4 | 8 x 3200 | $3480 |
| Q64-26 | 64 | 2.6 GHz | 125 W | 128x G4 | 8 x 3200 | $3260 |
| Q64-24 | 64 | 2.4 GHz | 95 W | 128x G4 | 8 x 3200 | $3090 |
| Q48-22 | 48 | 2.2 GHz | 85 W | 128x G4 | 8 x 3200 | $2200 |
| Q32-17 | 32 | 1.7 GHz | 45 W | 128x G4 | 8 x 3200 | $800 |
Where Ampere and the Altra definitely is beating AMD in is TCO, or total cost of ownership. Taking the flagship models as comparison points – the Q80-33 costs only $4050 which generally matching the performance of AMD’s EPYC 7742 which still comes in at $6950, essentially 42% cheaper. Of course, performance/$ will vary depending on workloads, but the Altra’s performance is so good that I don’t think it really changes the narrative of that large a cost difference. We’re really on basing this on both companies’ MSRP prices and we know for a fact many customers will be paying less than that for volume purchases and relying on discounts, but that can also apply to Ampere and the Altra.
One will note I didn’t make any mention of Intel yet - Intel’s current Xeon offering simply isn’t competitive in any way or form at this moment in time. Cascade Lake is twice as slow and half as efficient – so unless Intel is giving away the chips at a fraction of a price, they really make no sense. Ice Lake-SP is around the corner, but I don’t expect it to manage to bridge the performance or efficiency gap. Ampere and AMD here have free reign on the server market share – with Ampere having to cross the hurdle to convince customers to switch over from x86 to Arm.
Ampere is already shipping Altra systems to customers, with Oracle’s cloud business being the first big notable win for the company – signifying already very positive reactions in the market.
What we need to keep in mind though, is that today’s comparisons were against AMD’s EPYC 7742 which was launched almost 15 months ago. Rome’s successor, Milan, is already shipping to customers and has already started hitting the channel, and we expect to hear more about the Zen3-based EPYC chips in the coming weeks. I’m not expecting major leaps, but a 20% performance bump is pretty much a safe bet to make – it would beat the Q80-33 in more workloads and shift the balance a bit – but Ampere’s aggressive pricing would still be something for AMD to worry about.
What really excites me, is the potential of future Altra designs. Ampere has already announced that Altra-Max “Mystique” will be coming in 2021 – essentially a 128-core version of the same Neoverse-N1 platform used in the QuickSilver design today. We’ll have to see how that scales, but it’ll certainly be a compute monster. The real big deal will be the 5nm 2022 “Siryn” design – if Ampere adopts the Neoverse-V1 CPU core from Arm, and I hope they will, then that would signify at minimum a +50% performance uplift, which is massive.
The Altra overall is an astounding achievement – the company has managed to meet, and maybe even surpass all expectations out of this first-generation design. With one fell swoop Ampere managed to position itself as a top competitor in the server CPU market. The Arm server dream is no longer a dream, it’s here today, and it’s real.







{kind=link}
{kind=link}