Original Link: https://www.anandtech.com/show/16155/imagination-announces-bseries-gpu-ip-scaling-up-with-multigpu
Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP

It’s almost been a year since Imagination had announced its brand-new A-series GPU IP, a release which at the time the company called its most important in 15 years. The new architecture indeed marked some significant updates to the company’s GPU IP, promising major uplifts in performance and promises of great competitiveness. Since then, other than a slew of internal scandals, we’ve heard very little from the company – until today’s announcement of the new next-generation of IP: the B-Series.
The new Imagination B-Series is an evolution of last year’s A-Series GPU IP release, further iterating through microarchitectural improvements, but most importantly, scaling the architecture up to higher performance levels through a brand-new multi-GPU system, as well as the introduction of a new functional safety class of IP in the form of the BXS series.
The Market Demands Performance: Imagination Delivers it through Multi-GPU
It’s been no secret that the current GPU IP market has been extremely tough on IP providers such as Imagination. Being the only other established IP provider alongside Arm, the company had been seeing an ever-shrinking list of customers due to several factors – one being Arm’s extreme business competitiveness in offering both CPU and GPU IP to customers, and the fact that there’s simply less customers which require licensed GPU IP.
Amongst the current SoC vendors, Qualcomm and their in-house Adreno GPU IP is in a dominant market position, and in recent years had been putting extreme pressure on other vendors – many of these who fall back to Arm’s Mali GPU IP by default. MediaTek had historically been the one SoC vendor who had been using Imagination’s GPUs more often in their designs, however all of the recent Helio of Dimensity products again use Mali GPUs, with seemingly little hope for a SoC win using IMG’s GPU IP.
With Apple using their architectural license from Imagination to design custom GPUs, Samsung betting on AMD’s new aspirations as a GPU IP provider, and HiSilicon both designing their own in-house GPU as well as having an extremely uncertain future, there’s very little left in terms of mobile SoC vendors which might require licensed GPU IP.
What is left are markets outside of mobile, and it’s here that Imagination is trying to refocus: High-performance computing, as well as lucrative niche markets such as automotive which require functional safety features.

Scaling an IP up from mobile to what we would consider high-performance GPUs is a hard task, as this directly impacts many of the architectural balance choices that need to be made when designing a GPU IP that’s actually fit for low-power market such as mobile. Traditionally, this had been always a trade-off between absolute performance, performance scalability and power efficiency – with high performance GPUs simply being not that efficient, while low-power mobile GPUs were unable to scale up in performance.
Imagination’s new B-Series IP solves this conundrum by introducing a new take on an old way of scaling performance: multi-GPU.
Rather than growing and scaling a single GPU up in performance, you simply use multiple GPUs. Now, probably the first thing that will come to user’s minds are parallels to multi-GPU technologies from the desktop space such as SLI or Crossfire, technologies that in recent years have seen dwindling support due to their incompatibility with modern APIs and game engines.
Imagination’s approach to multi-GPU is completely different to past attempts, and the main difference lies in the way workloads are handled by the GPU. Imagination with the B-Series moves away from a “push” workload model – where the GPU driver pushes work to the GPU to render, to a “pull” model, where the GPU decides to pull workloads to process. This is a fundamental paradigm shift in how the GPU is fed work and allows for what Imagination calls a “decentralised design”.
Amongst a group of GPUs, one acts as a “primary” GPU with a controlling firmware processor that divides a workload, say a render frame, into different work tiles that can then the other “slave” GPUs can pull from in order to work on. A tile here is actually the proper sense of the word, as the GPU’s tile-based rendering aspect is central to the mechanism – this isn’t your classical alternate frame rendering (AFR) or split frame rendering (SFR) mechanism. Also, just how a single-GPU tile-based renderer can have varying tile sizes for a given frame, this can also happen in the B-Series’ multi-GPU workload distribution, with varying tile sizes of a single frame being distributed unevenly amongst the GPU group.
The most importantly, this new multi-GPU system that Imagination introduces is completely transparent to the higher-level APIs as well as software workloads, which means that a system running a multi-GPU configuration just sees one single large GPU from a software perspective. This is a big contrast to current discrete multi-GPU implementations, and why Imagination’s multi-GPU technology is a lot more interesting.

From an implementation standpoint, it allows Imagination and their customers a ton of new flexibility in terms of configuration options. From Imagination’s perspective, instead of having to design one large and fat GPU implementation, which might require more work due to timing closure and other microarchitectural scaling concerns, they can just design a more efficient GPU – and allow customers to simply put down multiple of these in an SoC. Imagination claims that this allows for higher-frequency GPUs, and the company projects implementations around 1.5GHz for high-end use-cases such as for cloud computing usages.
For customers, it’s also a great win in terms of flexibility: Instead of having to wait on Imagination to deliver a GPU implementation that matches their exact performance target, it would be possible for a customer to just take one “sweet-spot” building block implementation and scale the configuration themselves all on their own during the design of their SoC, allowing higher flexibility as well as a smaller turn-around time. Particularly if a customer would be designing multiple SoCs for multiple performance targets, they could achieve this easily with just one hardware design from Imagination.
We’ll get into the details of the scaling in the next page, but currently the B-Series multi-GPU support scales up to 4 GPUs. The other interesting aspect of laying down multiple GPUs on an SoC, in contrast to one larger GPU, is that they do not have to be adjacent or even near each other. As they’re independent design blocks, one could do weird stuff such as putting a GPU in each corner of an SoC design.
The only requirements for the SoC vendor are to have the GPUs connected to the SoC’s standard AXI interconnect to memory – something that’s a requirement anyhow. Vendor might have to scale this up for larger MC (Multi-Core) configurations, but they can make their own choices in terms of design requirements. The other requirement to make this multi-GPU setup work is just a minor connection between the GPUs themselves: this are just a few wires that act as interrupt lines between the cores so that they can synchronise themselves – there’s no actual data traffic happening between the GPUs.
Because of this, this is a design that’s particularly fit for today’s upcoming multi-chiplet silicon designs. Whereas current monolithic GPU designs have trouble being broken up into chiplets in the same way CPUs can be, Imagination’s decentralised multi-GPU approach would have no issues in being implemented across multiple chiplets, and still appear as a single GPU to software.

Getting back to the initial point, Imagination is using this new multi-GPU approach to target higher performance designs that previously weren’t available to the company. They note that their more efficient mobile-derived GPU IP through multi-GPU scaling can compete with other current offerings from Nvidia and AMD (Imagination promotes their biggest configuration as reaching up to 6TFLOPs) in PCIe form-factor designs, whilst delivering 70% better compute density – a metric the company defines as TFLOPs/mm². Whilst that metric is relatively meaningless in terms of performance due to the fact that the upper cap on performance is still very much limited by the architecture and the MC4 top scaling limit on the current multi-GPU implementation of the B-Series, it allows for licensees to make for smaller chips that in turn can be extremely cost-effective.

The B-Series covers a slew of actual GPU IP, with the company continuing a segmentation into different performance tiers – the BXT series being the flagship GPU designs, BXM series a more balanced middle-ground GPU IP, and the BXE series being the company’s smallest and most area efficient Vulkan compatible GPU IP. Let’s go over the various GPU implementations in more detail…
Configurations - Up to 4 GPUs at 6TFLOPs
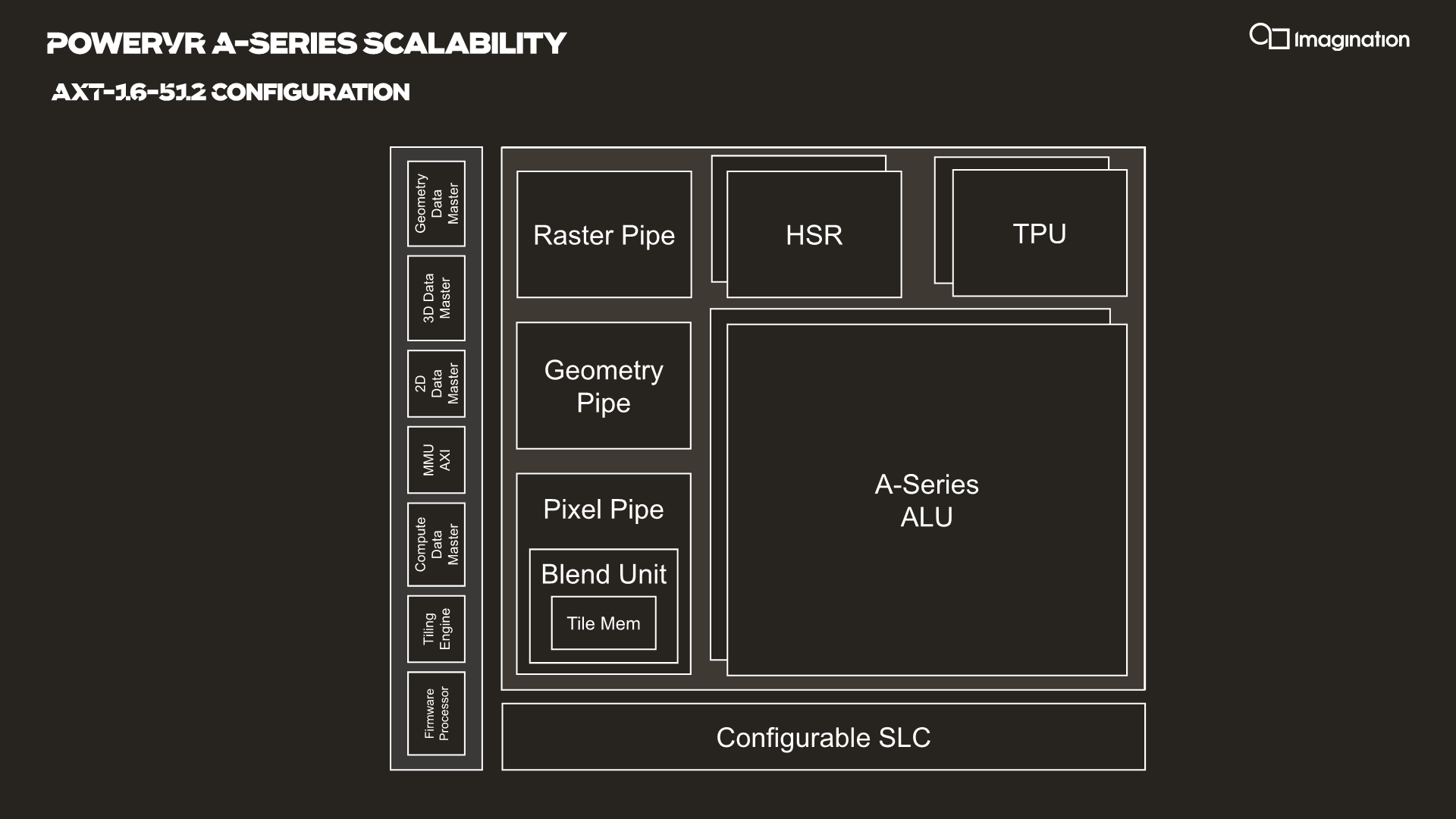
Starting off with the smallest GPU building blocks, it’s good to remind ourselves how an Imagination GPU looks like – the following is from last year’s A-Series presentation:
| PowerVR GPU Comparison | ||||
| AXT-16-512 BXT-16-512 |
GT9524 | GT8525 | GT7200 Plus | |
| Core Configuration |
1 SPU (Shader Processing Unit) - "GPU Core" 2 USCs (Unified Shading Clusters) - ALU Clusters |
|||
| FP32 FLOPS/Clock MADD = 2 FLOPs MUL = 1 FLOP |
512 (2x (128x MADD)) |
240 (2x (40x MADD+MUL)) |
192 (2x (32x MADD+MUL)) |
128 (2x (16x MADD+MADD)) |
| FP16 Ratio | 2:1 (Vec2) | |||
| Pixels / Clock | 8 | 4 | ||
| Texels / Clock | 16 | 8 | 4 | |
| Architecture | A-Series B-Series |
Series-9XTP (Furian) |
Series-8XT (Furian) |
Series-7XT (Rogue) |
Fundamentally and at a high-level, the new B-Series GPU microarchitecture looks very similar to the A-Series. Microarchitecturally, Imagination noted that we should generally expect a 15% increase in performance or increase in efficiency compared to the A-Series, with the building blocks of the two GPU families being generally the same save for some more important additions such as the new IMGIC (Imagination Image Compression) implementation which we’ll cover in a bit.
An XT GPU still consists of the new SPU design which houses the new more powerful TPU (Texture Processing Unit) as well as the new 128-wide ALU designs that is scaled into ALU clusters called USCs (Unified Shading Clusters).

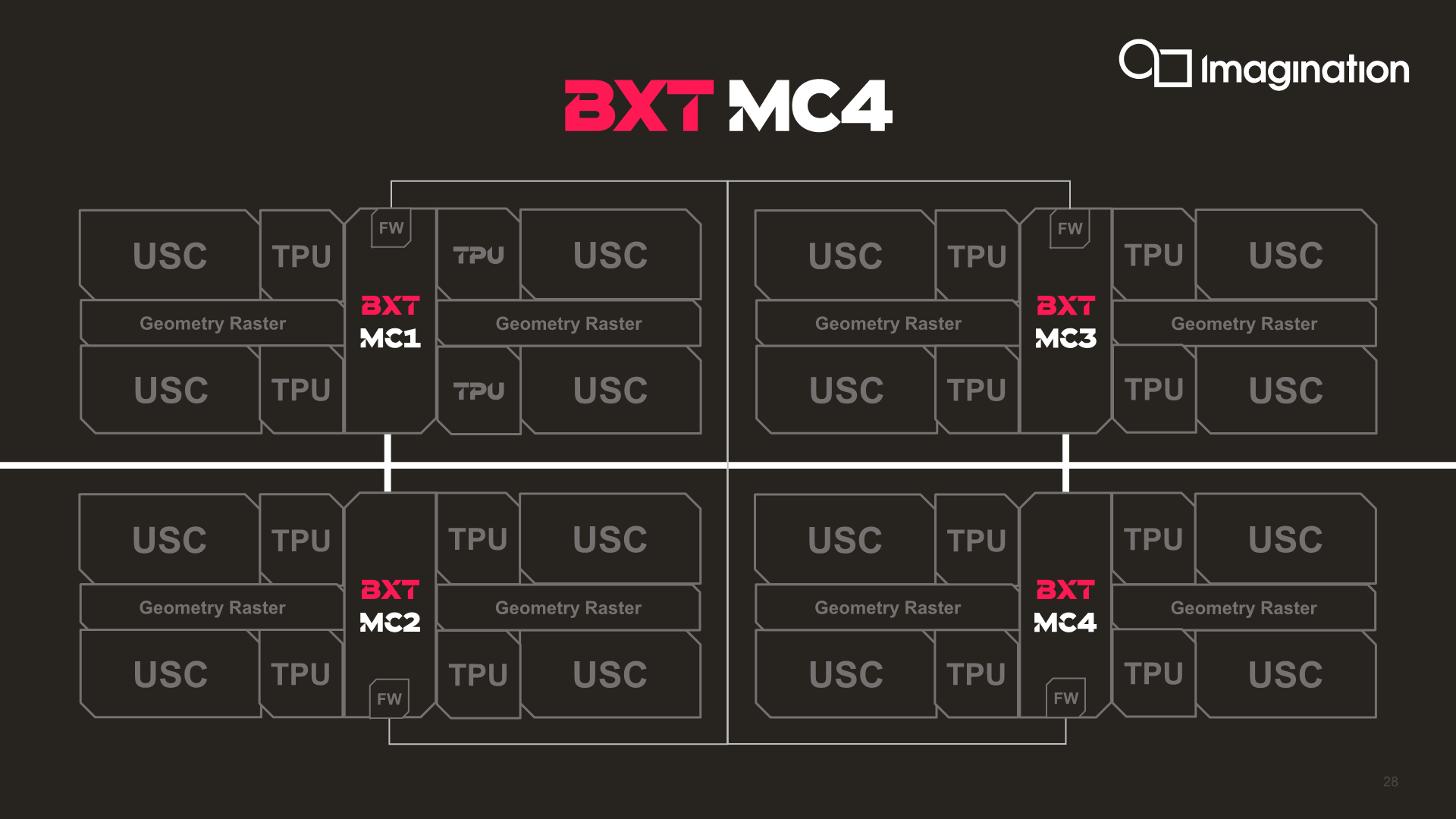
Imagination’s current highest-end hardware implementation in the BXT series is the BXT 32-1024, and putting four of these together creates an MC4 GPU. In a high-performance implementation reaching up to 1.5GHz clock speeds, this configuration would offer up to 6TFLOPs of FP32 computing power. Whilst this isn’t quite enough to catch up to Nvidia and AMD, it’s a major leap for a third-party GPU IP provider that’s been mostly active in the mobile space for the last 15 years.

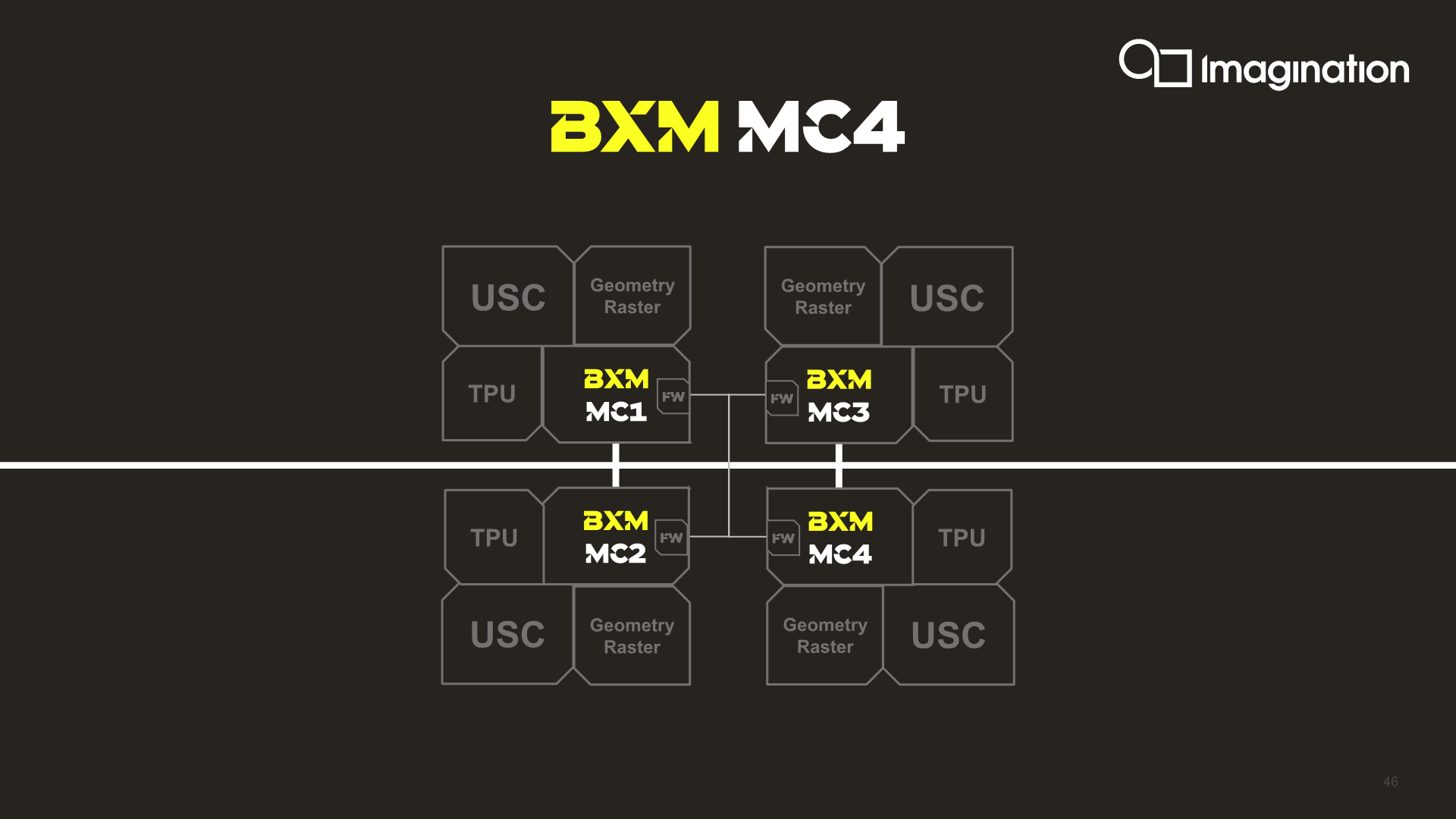
The company’s BXM series continues to see a differentiation in the architecture as some of its implementations do not use the ultra-wide ALU design of the XT series. For example, while the BXM-8-256 uses one 128-wide USC, the more area efficient BXM 4-64 for example continues to use the 32-wide ALU from the 8XT series. Putting four BXM-4-64 GPUs together gets you to a higher performance tier with a better area and power efficiency compared to a larger single GPU implementation.

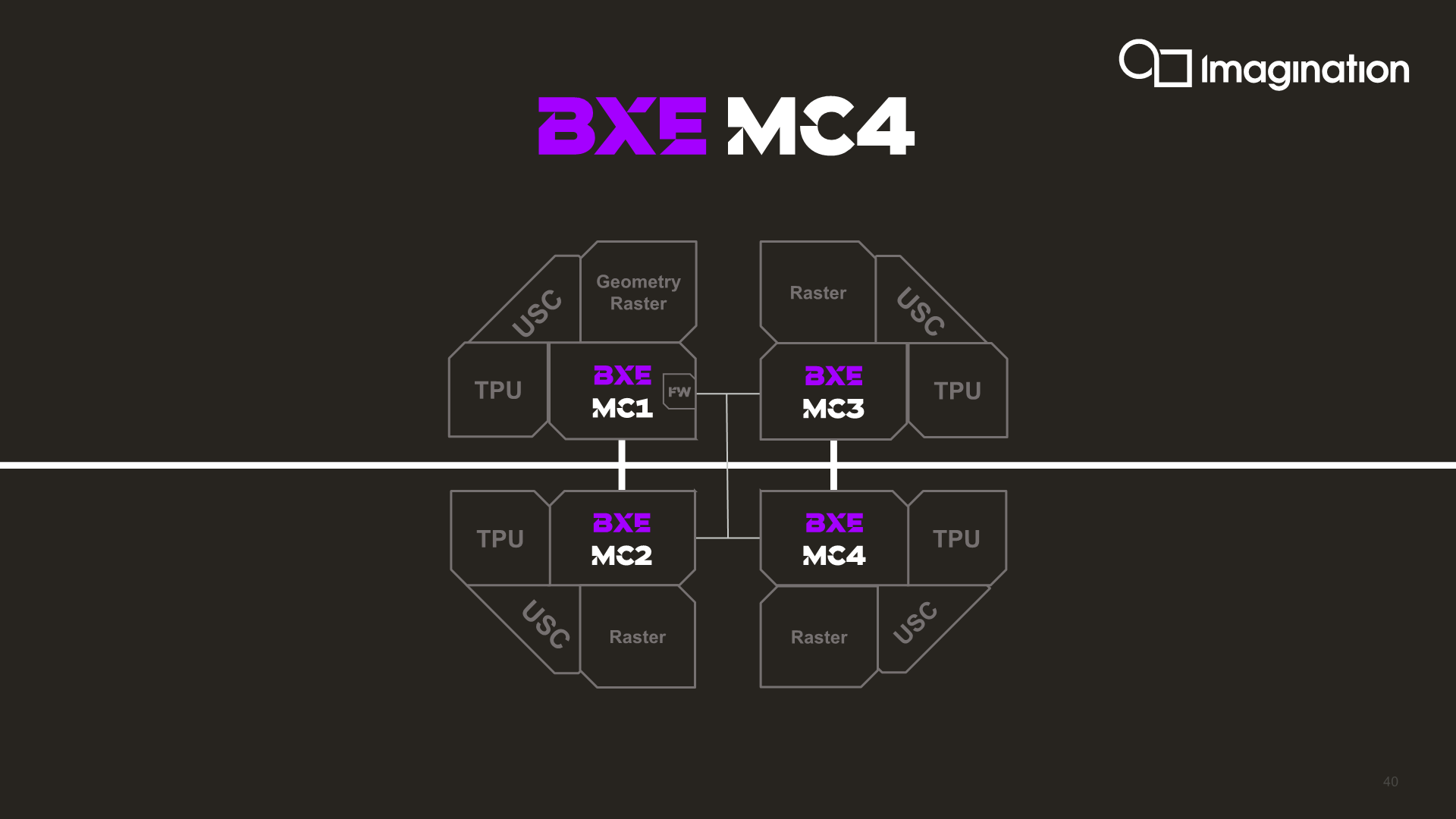
The most interesting aspect of the multi-GPU approach is found in the BXE series, which is Imagination’s smallest GPU IP that purely focuses on getting to the best possible area efficiency. Whilst the BXT and BXM series GPUs until now are delivered as “primary” cores, the BXE is being offered in the form of both a primary as well as a secondary GPU implementation. The differences here is that the secondary variant of the IP lacks a firmware processor as well as a geometry processing, instead fully relying on the primary GPU’s geometry throughput. Imagination says that this configuration would be able to offer quite high compute and fillrate capabilities in extremely minuscule area usage.
| PowerVR Hardware Designs GPU Comparison | ||||||
| Family | Texels/ Clock |
FP32/ Clock |
Cores | USCs | Wavefront Width |
MC Design |
| BXT-32-1024 MC1 | 32 | 1024 | 1 | 4 | 128 | P |
| BXT-16-512 MC1 | 16 | 512 | 1 | 2 | 128 | P |
| BXM-8-256 MC1 | 8 | 256 | 1 | 1 | 128 | P |
| BXM-4-64 MC1 | 4 | 64 | 1 | 1 | 32 | P |
| BXE-4-32 Secondary | 4 | 32 | 1 | 1 | 16 | S |
| BXE-4-32 MC1 | 4 | 32 | 1 | 1 | 16 | P |
| BXE-2-32 MC1 | 2 | 32 | 1 | 1 | 16 | P |
| BXE-1-16 MC1 | 1 | 16 | 1 | 1 | 8 | P |
Putting the different designs into a table, we’re seeing only 8 different hardware designs that Imagination has to create the RTL and do physical design and timing closure on. This is already quite a nice line-up in terms of scaling from the lowest-end area focused IP to something that would be used in a premium high-end mobile SoC.
| PowerVR MC GPU Configurations | ||||||
| Family | Texels/ Clock |
FP32/ Clock |
Cores | USCs | Wavefront Width |
MC Design |
| BXT-32-1024 MC4 | 128 | 4096 | 4 | 16 | 128 | PPPP |
| BXT-32-1024 MC3 | 96 | 3072 | 3 | 12 | 128 | PPP |
| BXT-32-1024 MC2 | 64 | 2048 | 2 | 8 | 128 | PP |
| BXT-32-1024 MC1 | 32 | 1024 | 1 | 4 | 128 | P |
| BXT-16-512 MC1 | 16 | 512 | 1 | 2 | 128 | P |
| BXM-8-256 MC1 | 8 | 256 | 1 | 1 | 128 | P |
| BXM-4-64 MC4 | 16 | 256 | 4 | 4 | 32 | PPPP |
| BXM-4-64 MC3 | 12 | 192 | 3 | 3 | 32 | PPP |
| BXM-4-64 MC2 | 8 | 128 | 2 | 2 | 32 | PP |
| BXM-4-64 MC1 | 4 | 64 | 1 | 1 | 32 | P |
| BXE-4-32 MC4 | 16 | 128 | 4 | 4 | 16 | PSSS |
| BXE-4-32 MC3 | 12 | 96 | 3 | 3 | 16 | PSS |
| BXE-4-32 MC2 | 8 | 64 | 2 | 2 | 16 | PS |
| BXE-4-32 MC1 | 4 | 32 | 1 | 1 | 16 | P |
| BXE-2-32 MC1 | 2 | 32 | 1 | 1 | 16 | P |
| BXE-1-16 MC1 | 1 | 16 | 1 | 1 | 8 | P |
The big flexibility gain for Imagination and their customers is that they can simple take one of the aforementioned hardware designs, and scale these up seamlessly by laying out multiple GPUs. On the low-end, this creates some very interesting overlaps in terms of compute abilities, but offer different fillrate capabilities at different area efficiency options.
At the high-end, the biggest advantage is that Imagination can quadruple their processing power from their biggest GPU configuration. Imagination notes that for the BXT series, they no longer created a single design larger than the BXT-32-1024 because the return on investment would simply be smaller, and involve more complex timing work than if a customer would simply scale performance up via a multi-core implementation.
Introducing IMGIC - A better frame-buffer compression
Besides the multi-GPU scalability, another big feature introduction to the B-Series is the addition of a completely new image compression algorithm, simply dubbed IMGIC, or Imagination Image Compression.
Compression is an integral part of modern GPUs as otherwise the designs would simply be memory bandwidth starved. To date, Imagination has been using PVRIC to achieve this. The problem with PVRIC was that it was a relatively uncompetitive compression format, falling behind in data compression ratio compared to other competitor techniques such as Arm’s AFBC (Arm Frame-Buffer Compression). This resulted in IMG GPUs using up more bandwidth than a comparable Arm GPU.


IMGIC is a completely new and redesigned compression algorithm that replaces PVRIC. Imagination touts this as the most advanced image compression technology, offering extreme bandwidth savings and a lot more flexibility compared to previous PVRIC designs. Amongst the flexibility aspect of things, IMGIC can now work on individual pixels instead of just smaller tiles or pixel groups.
Furthermore, the new algorithm is said to be 8x simpler than PVRIC, meaning the hardware implementation is also much simplified and achieves a significant are area reduction.
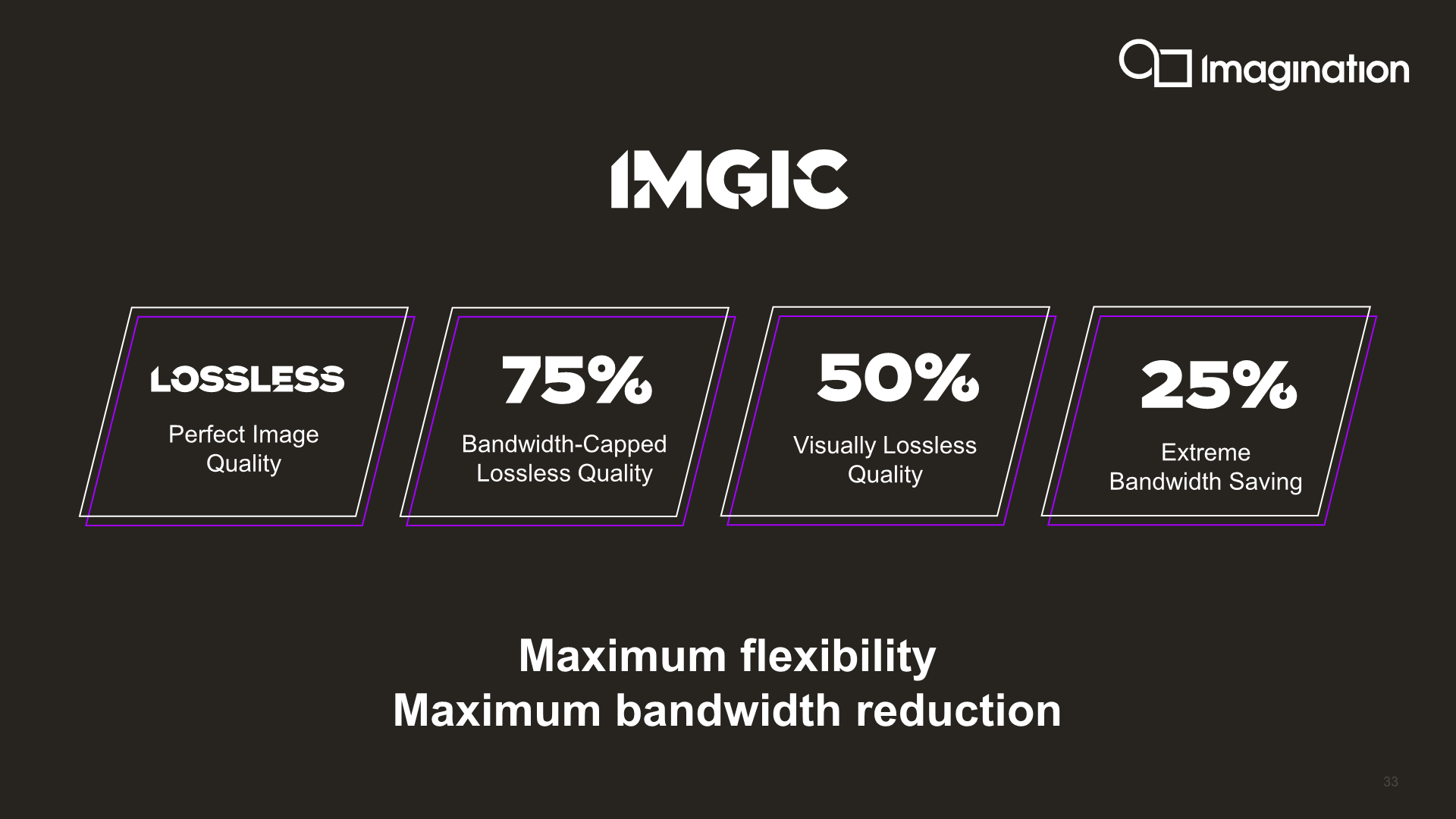
The new implementation gives vendors more scaling options, adding compression ratios down to a lossy 25% for extreme bandwidth savings. SoC vendors can use this to alleviate bandwidth starved scenarios or QoS scenarios where other IPs on the SoC should take priority.

Overall, the B-Series now offers a 35% reduction in bandwidth compared to the A-Series and previous generation Imagination GPU architectures, which is a rather large improvement given that memory bandwidth is a costly matter, both in terms of actual silicon cost as well as energy usage.
Introducing BXS Series: Functional Safety for Autonomy
Besides targeting higher performance design targets, an area where Imagination is putting a higher level of focus on is the automotive and industrial markets. To cover these use-cases, Imagination is today also launching the new “BXS” series of GPU IP – where the S stands for safety.

The new GPU IP line-up mirrors the standard BXT, BXM and BXE configurations, but adds support for ISO 26262 / ASIL-B functional safety features.

Imagination is introducing a new feature called “Tile Region Protection” in which a configurable region of render tiles on the render frame can be marked as safety critical, and for which the GPU can check for correct execution and rendering, allowing it to be ISO 26262 certified.

TRP is implemented from the smallest BXE-equivalent BXS GPU (Frankly Imagination could have done better here than calling the whole safety line-up BXS), allowing for work repletion to achieve fault detection. Furthermore, Imagination allows for end-to-end data integrity protection via CRC checking of all data going in and out of the GPU, further helping the IP achieve safety requirements.

TRP require a single GPU to repeat work, which in turn would mean reduced performance in a system. A more performance-oriented way of scaling things would be a multi-GPU implementation.
A multi-GPU configuration in an automotive design would also server the purpose of partitioning the GPUs for multiple independent workloads; whilst in a consumer implementation you would expect the GPUs to mostly act and appear as a single large unit to a host, automotive use-cases could also have the multiple GPUs act completely independently from each other. It’s also possible to mix- and match GPUs, for example a 4-core implementation could have 3 partitions, with two GPUs working together to pool up resources for a more demanding task such as the infotainment system, while two other GPUs would be handling other independent workloads.
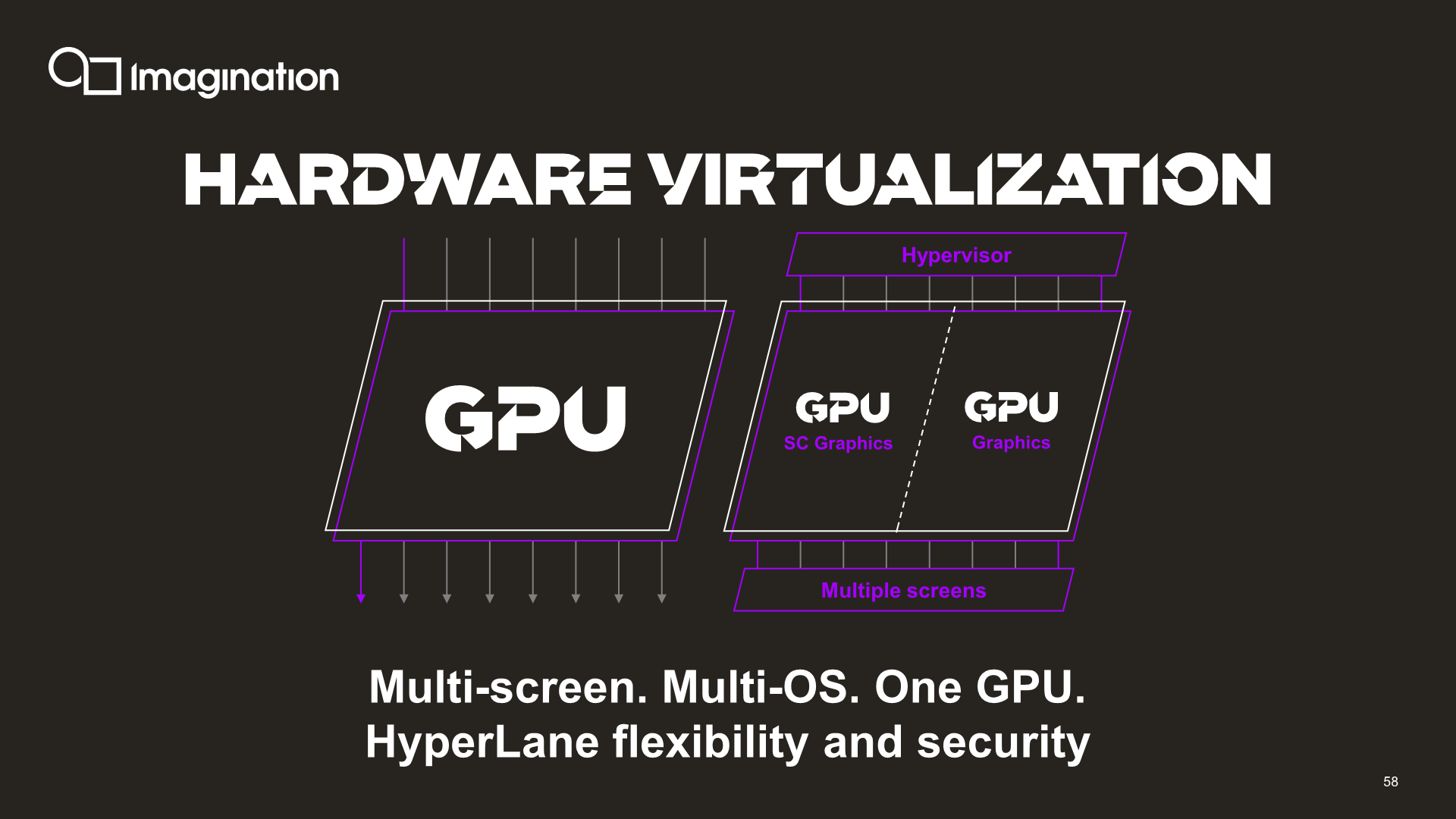
Imagination naturally also continues to support hardware virtualisation within one single GPU with up to 8 “hyperlanes” (guests). So, you could split up a 2-core design into 3 partitions, such as depicted above.

Beyond the addition of safety critical features on the BXS series, the automotive IP also features some specific enhancements in the microarchitecture that allows for better performance scaling for workloads that are more unique to the automotive space. One such aspect is geometry, where automotive vendors have the tendency to use absurd amounts of triangles. Imagination says they’ve tweaked their designs to cover these more demanding use-cases, and together with some MSAA specific optimisations they can reach up to a 60% greater performance for these automotive edge-cases, compared to the regular non-automotive IP.
Performance, Efficiency, and a Raytracing Teaser
Overall, today’s announcement of the B-Series has been actually quite exciting. Although the actual GPU microarchitecture has seen only somewhat minor advancements compared to last year’s A-Series, Imagination’s take on multi-GPU is quite innovative and unlike what we’ve seen in past multi-GPU attempts.
The new “pull” decentralised GPU design is certainly something that offers tremendous flexibility. It won’t be something that has absolutely perfect scaling, as there might be some edge-cases where things might get bottlenecked, however Imagination expects extremely good scaling on average.
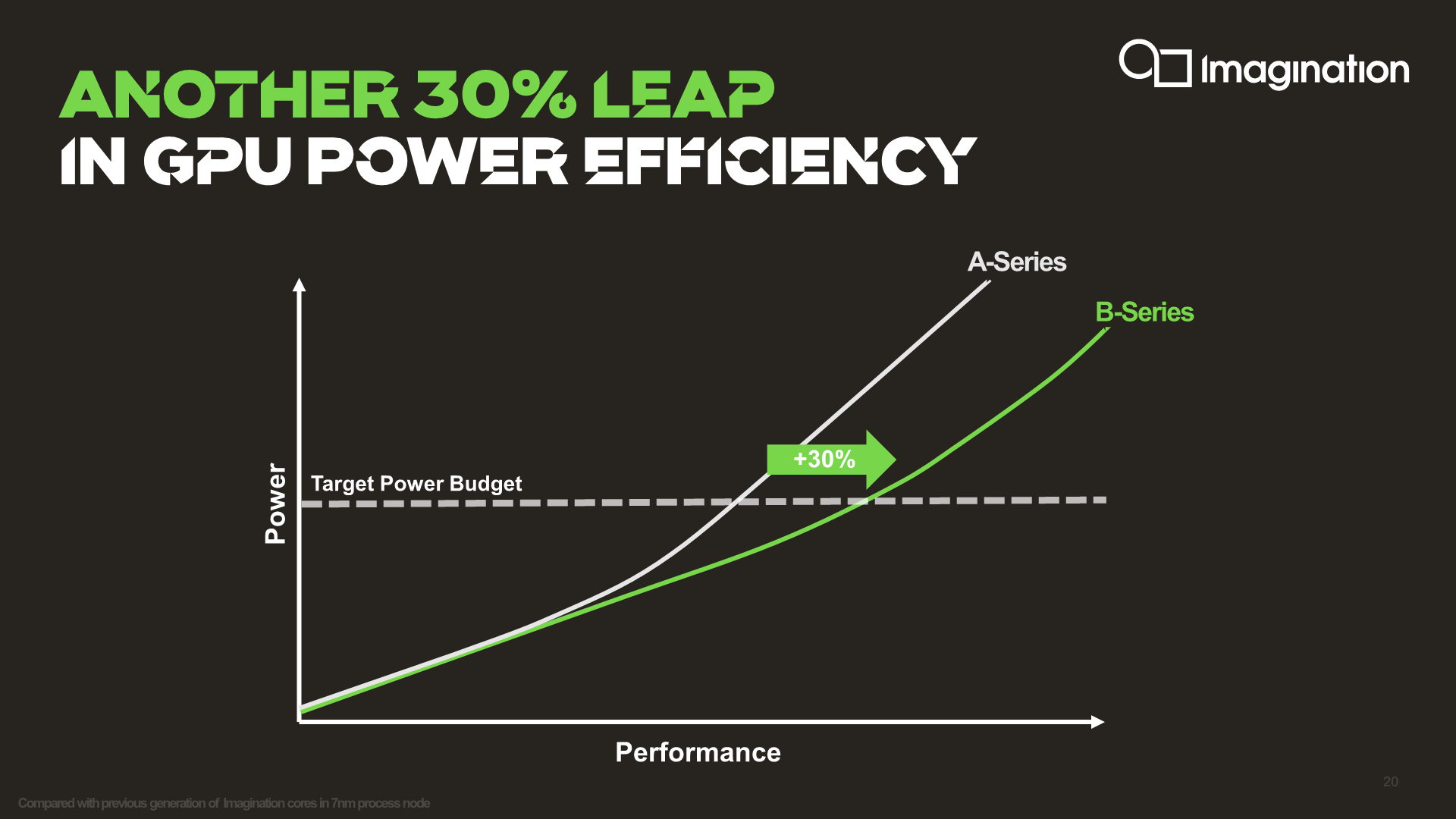
The B-Series’ roadmapped +30% performance improvement is said to have been achieved through both microarchitectural and physical design improvements (around 15%), with the rest being achieved through the PPA advantage of choosing a multi-core GPU configuration.

Probably what’s more important than the GPU IP itself, is that Imagination says they have actually licensed out and delivered the IP customers already – which is a contrast to past generation Imagination GPU IP announcements where things were publicised ahead of not only the IP being delivered, but ahead of it even being completed.
We still haven not seen or heard of any A-Series design wins, so we do hope there will be more news on that in regards to the B-Series.
Industry sources say that the major demand-driver for Imagination GPU IP right now is the high-performance GPU market in China, where there’s apparently a major hunger and need for domestic designs that are disconnected from US suppliers such as AMD and Nvidia.

Innosilicon Fantasy GPU Series
One such design win is Innosilicon’s recently announced “Fantasy” graphics cards series. Innosilicon to date was known as an ASIC IP design house for various miscellaneous IP blocks, such as providing Nivdia’s GDDR6’s memory controllers.
Roger Mao, Vice President of Engineering, Innosilicon, says;
“Imagination’s BXT multi-core GPU IP delivers the level of performance and power efficiency we had been looking for. Innosilicon has a solid track record in delivering first class high-speed and high-bandwidth computing solutions in advanced FinFET process nodes. Building on this success and strong customer demand, we are announcing our upcoming product which is a standalone high-performance 4K/8K PCI-E Gen4 GPU card, set to hit the market very soon, that will power 5G cloud gaming and data centre applications. With a solid foundation in GDDR6 high-speed memory, cache coherent chiplet innovation and high-performance multimedia processor optimisation, a move into a standalone PCI-E form-factor GPU is natural for us. Thanks to BXT’s multi-core scalable architecture, we are able to build a customised solution to meet the high-end data centre demand with fantastic cloud and computing performance.”
If this pivot towards higher-performance computing works out for Imagination remains to be seen. It certainly seems that at least having a tangible design win such as the above would certainly be a big improvement given that we’ve never seen publicly acknowledged 8XT, 9XT, 9XTP or even A-Series silicon.
Level 4 Raytracing for C-Series
Lastly, Imagination is also teasing their future C-Series architecture, confirming that it’ll be a full raytracing capable design. Although Imagination has had Raytracing IP and capable GPUs for the better part of the decade, it took Nvidia’s RTX series as well as AMD’s inclusion of Raytracing in the new generation consoles as well as RDNA2 series to seriously kick-start the RT ecosystem into gear. Imagination is taking full advantage of this revival as it dusted off its RT IP that previously had been shelved a few years ago.
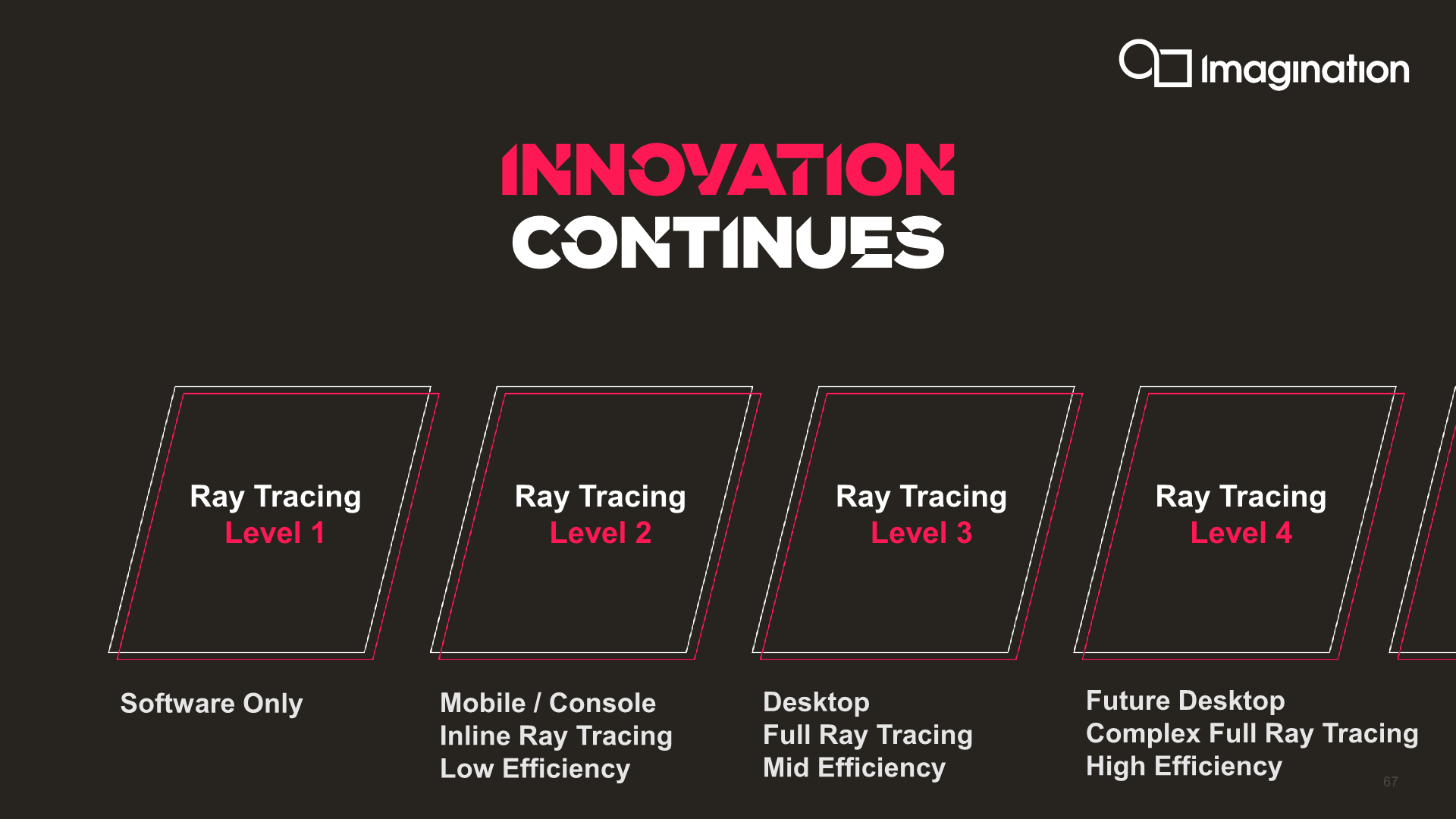
Beyond confirming that the new C-Series will have ray tracing capabilities, Imagination further confirms that this will be an implementation using the company’s fullest of capabilities, including BVH processing and Coherency Sorting in hardware, a capability the company denotes as a “Level 4” ray tracing implementation, which would be more advanced than what current generation Nvidia and AMD GPUs are able to achieve at a “Level 3”.
Imagination explains that they’ve had these capabilities for a long time, and when discussing with customers as to what kind of capabilities they would like to see in future IP, they had chosen to go for the full-blown implementation as this was the better future-proof design choice.
Overall, it seems like Imagination is on a path where it tries to diversify itself to markets other than the typical low-power GPU use-cases. The next few years will definitely be interesting for the company, and particularly the new distributed multi-GPU approach will be something to pay attention to.






