Original Link: https://www.anandtech.com/show/16007/hot-chips-2020-live-blog-manticore-4096core-riscv-330pm-pt
Hot Chips 2020 Live Blog: Manticore 4096-core RISC-V (3:30pm PT)
by Dr. Ian Cutress on August 18, 2020 6:30 PM EST- Posted in
- Live Blog
- RISC-V
- AI
- Hot Chips 32
- Manticore

06:35PM EDT - Who wants all the RISC-V cores?!?

06:36PM EDT - Ever growing demand for compute
06:36PM EDT - Energy efficiency is critical
06:37PM EDT - lots of CPUs burn power on superfluous elements of out-of-order

06:38PM EDT - Maximise computer datapath with respect to control
06:38PM EDT - Now for Manticore

06:38PM EDT - 220mm2 per chip
06:38PM EDT - (estimated in 22FDX GloFo)
06:38PM EDT - Four chiplets
06:39PM EDT - die-to-die serial link to each other die
06:39PM EDT - 8 GB HBM2 per die private to that die
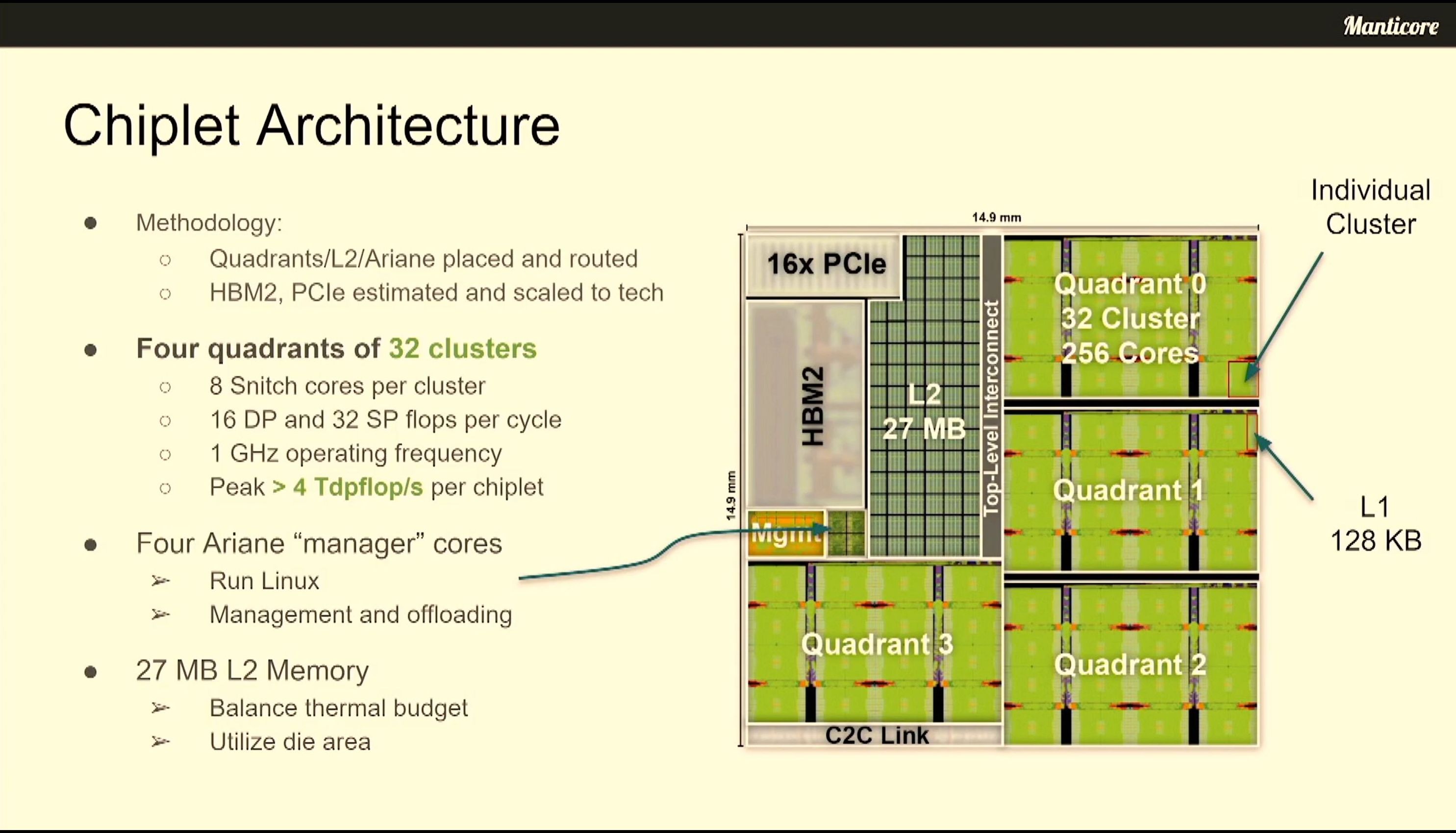
06:40PM EDT - Four quadrants of 32 clusters per chiplet
06:40PM EDT - Clusters can do 64 TB/s with each other
06:41PM EDT - 4x L1 quadrants share an L1 cache
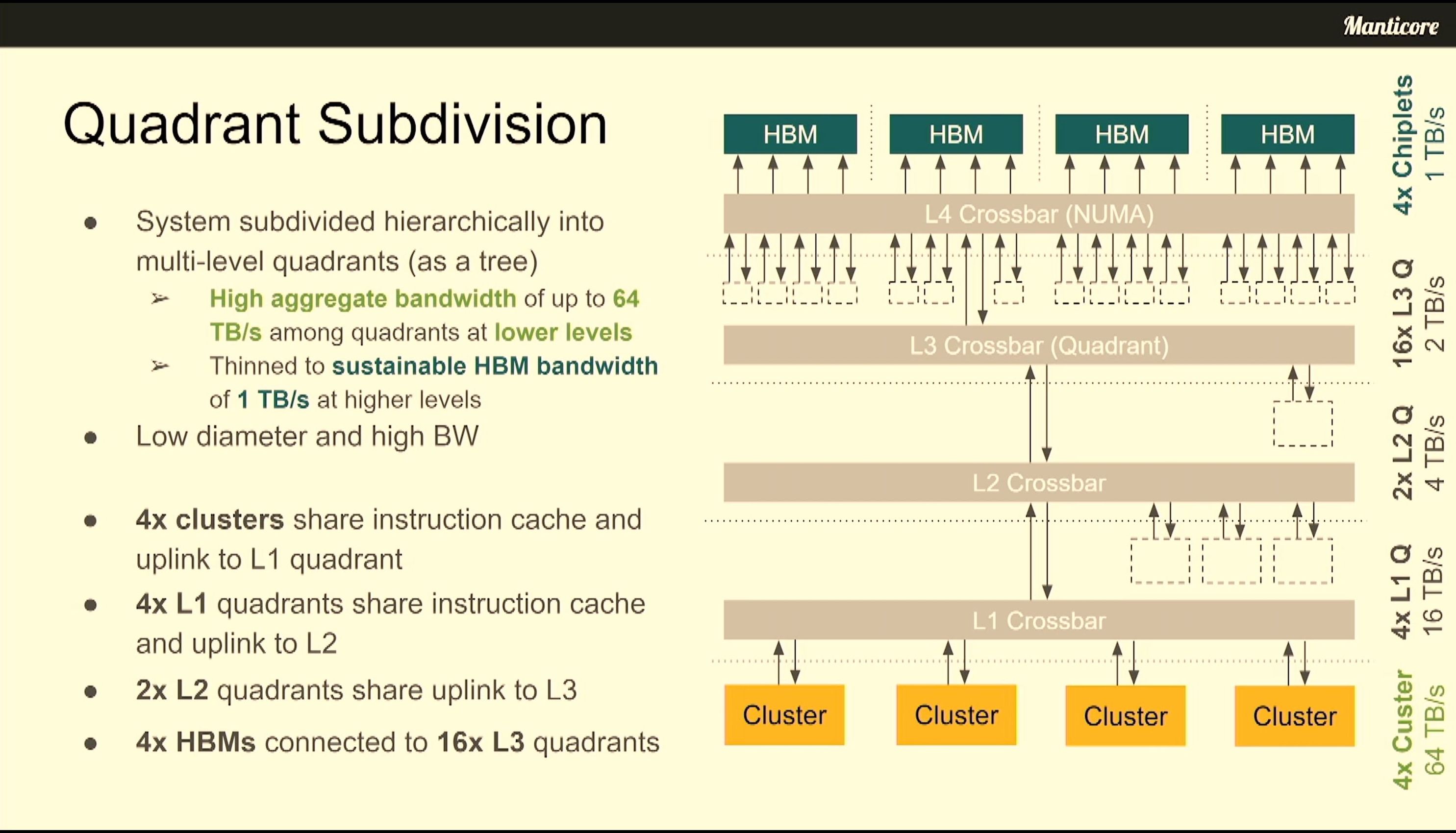
06:41PM EDT - Bandwidth thinning scheme to optimize bandwidth to HBM without affecting floorplan
06:41PM EDT - Support a lot of cluster-to-cluster traffic
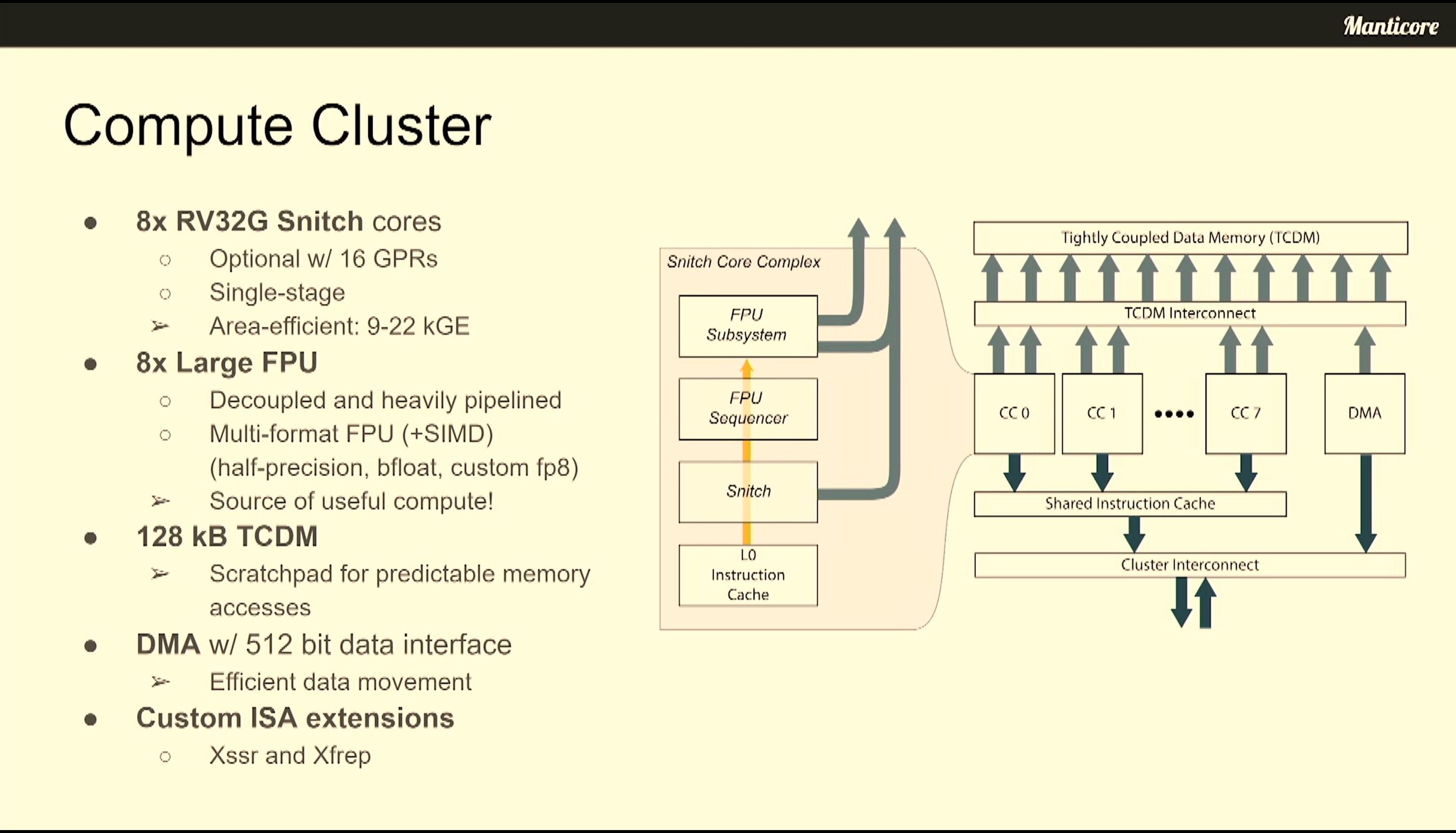
06:42PM EDT - Each compute cluster has 8 RV32G Snitch cores
06:42PM EDT - Each core has a multi-format SIMD compute unit
06:42PM EDT - supports half-precision bfloat, FP8
06:42PM EDT - Custom ISA extensions
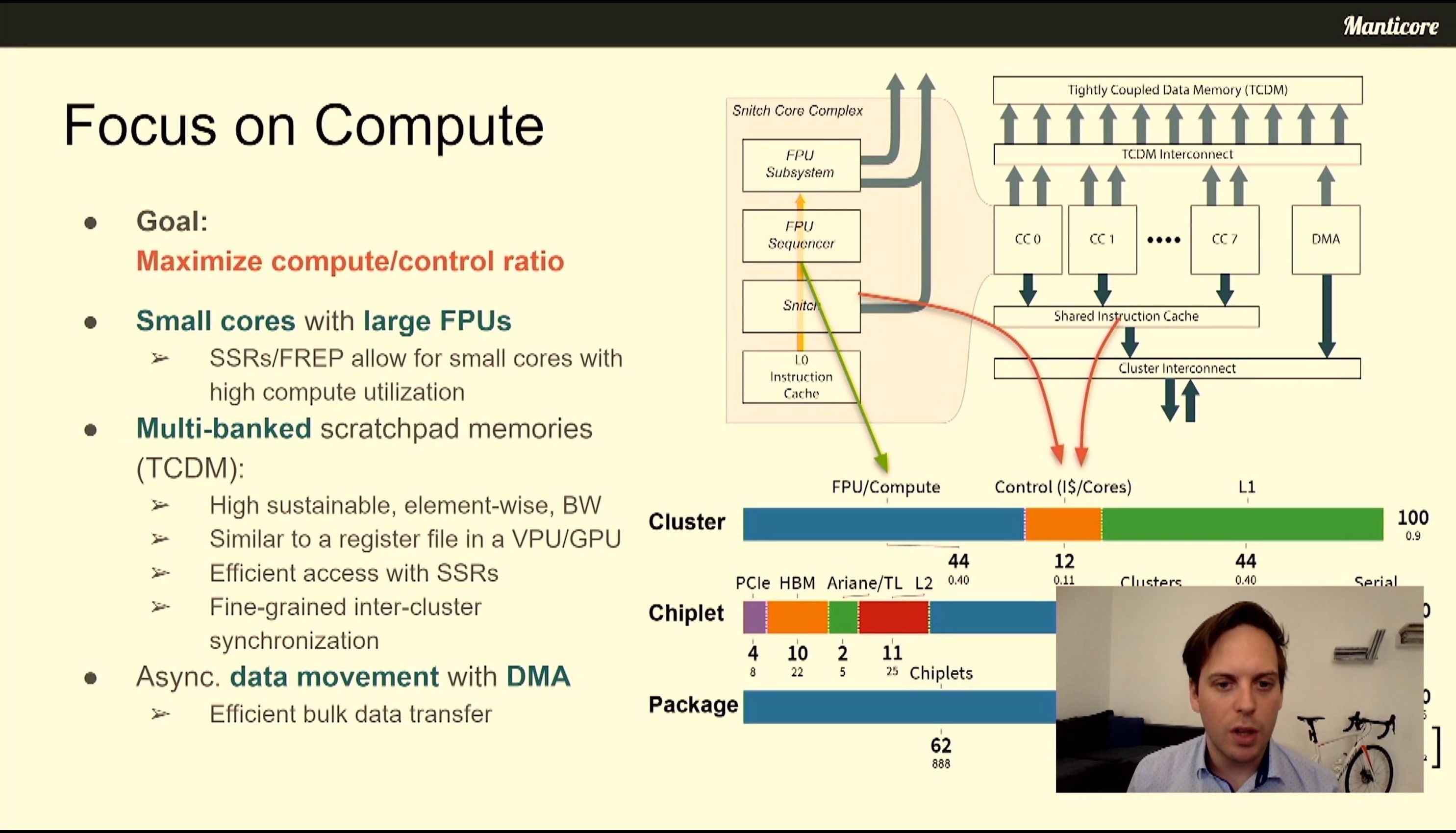
06:44PM EDT - Goal was to maximize compute/control die area ratio
06:44PM EDT - Async with DMA Engine
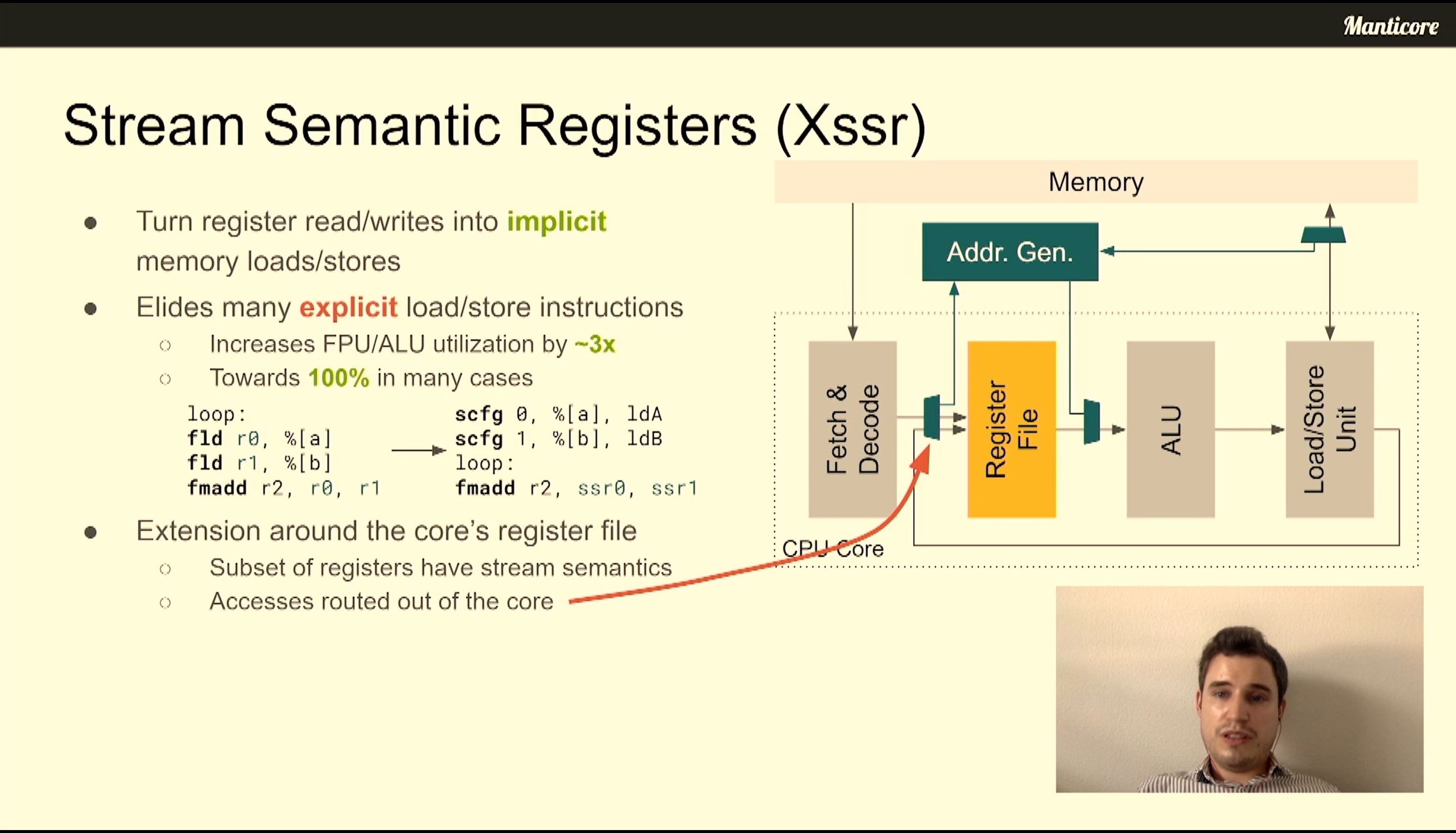
06:44PM EDT - XSSR - Stream semantic registers
06:44PM EDT - Turn register read/writes into implicit memory load/stores
06:45PM EDT - increases FPU/ALU from 3x-5x
06:46PM EDT - Extension in the core register file
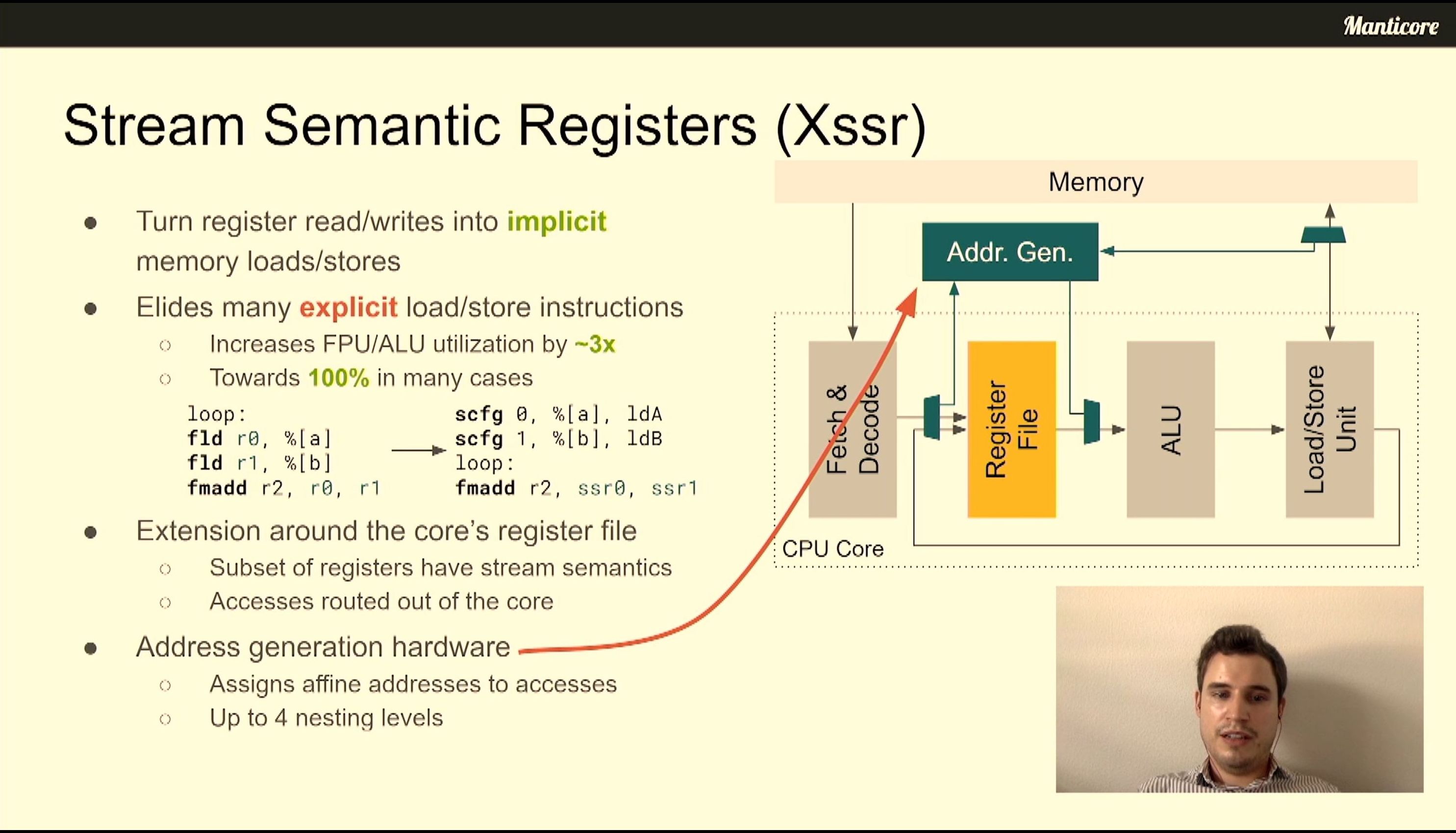

06:47PM EDT - Latency tolerant approach
06:47PM EDT - XFREP - Floating Point Repetition Buffer (programmable micro-loop buffer)
06:48PM EDT - custom instruction indicates start of hardware loop block
06:48PM EDT - 'Psuedo-dual issue' as integer core can work at the same time

06:49PM EDT - SSRs only work on float-only hardware loops
06:49PM EDT - FREP marks the loop
06:50PM EDT - For example, reduction!

06:52PM EDT - single-issue core can saturate an FPU
06:52PM EDT - IPC > 1
06:52PM EDT - FREP acts as instruction amplifier
06:53PM EDT - increased utilization for matmul and dotproduct that might be memory bound
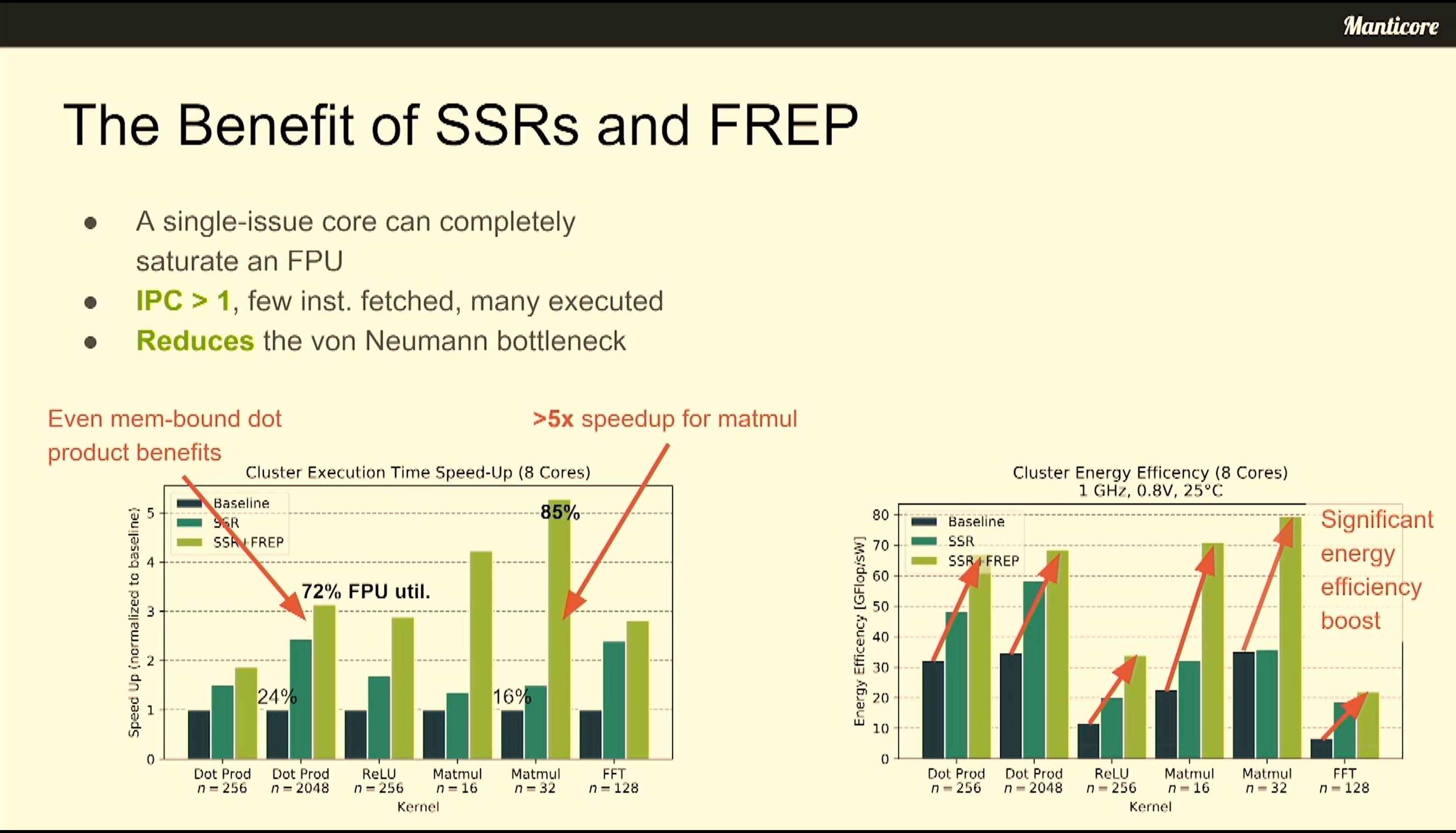
06:54PM EDT - Up to 80 DP GFLOPs/W per cluster
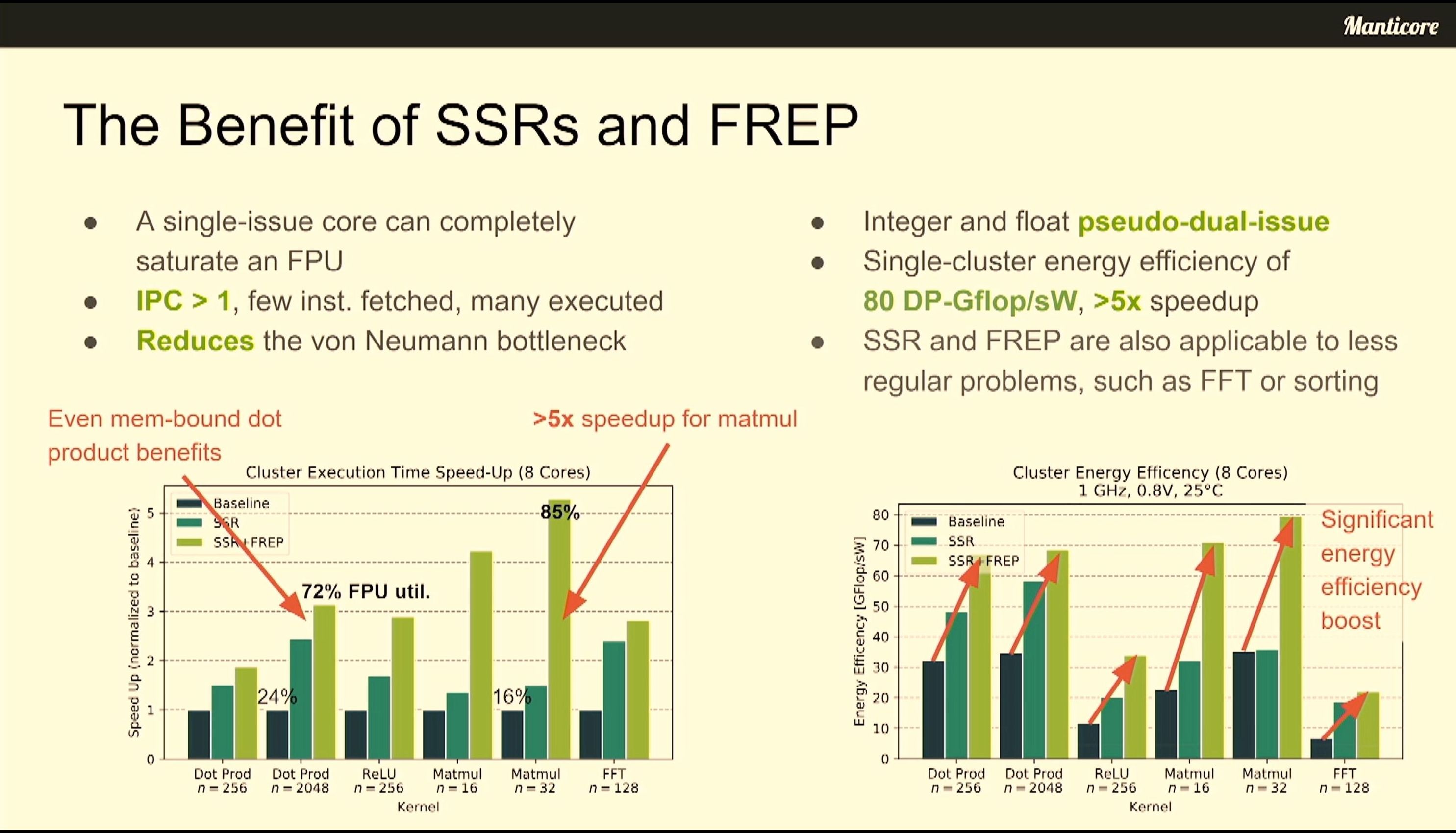
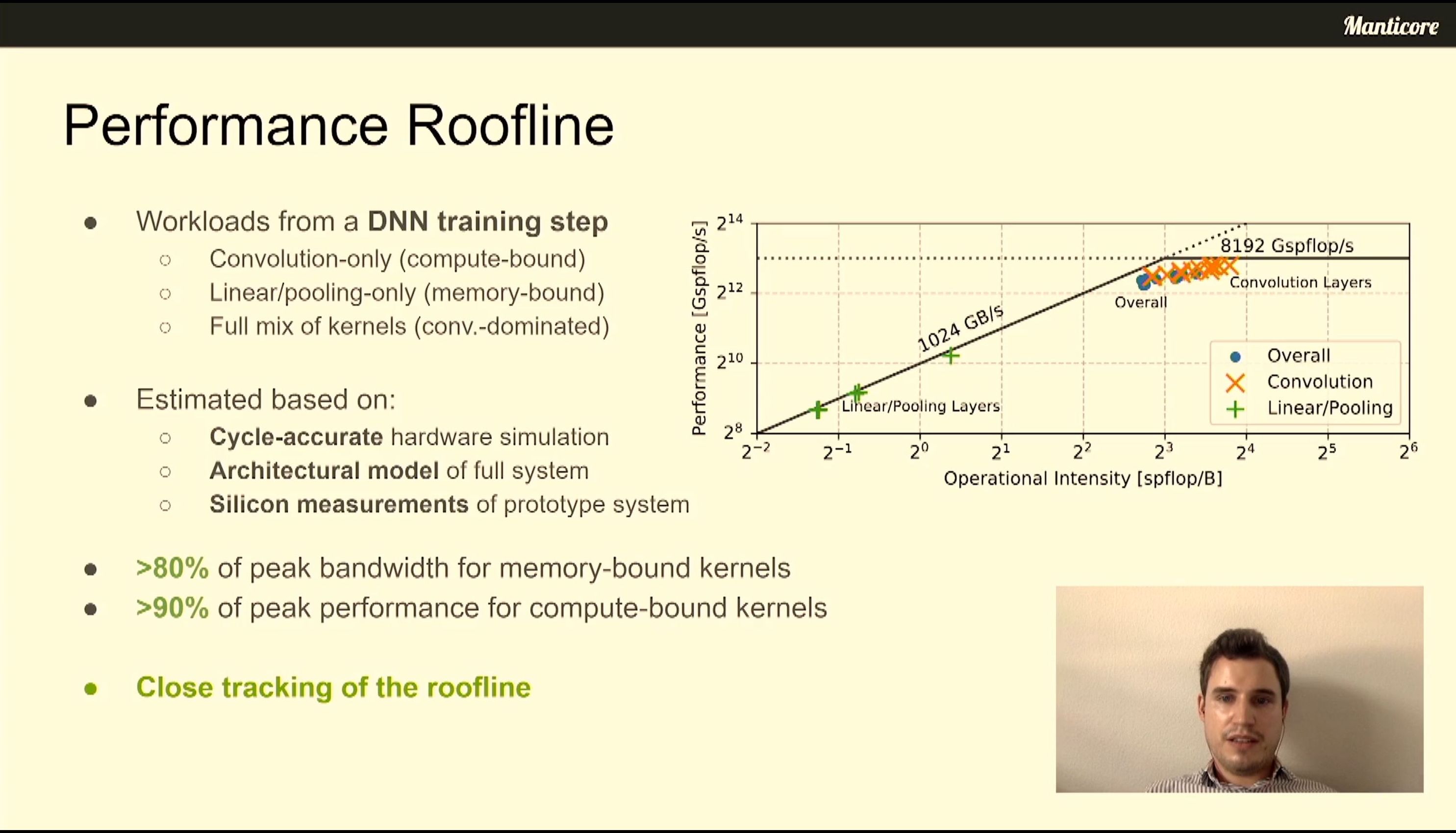
06:55PM EDT - Close tracking of roofline model

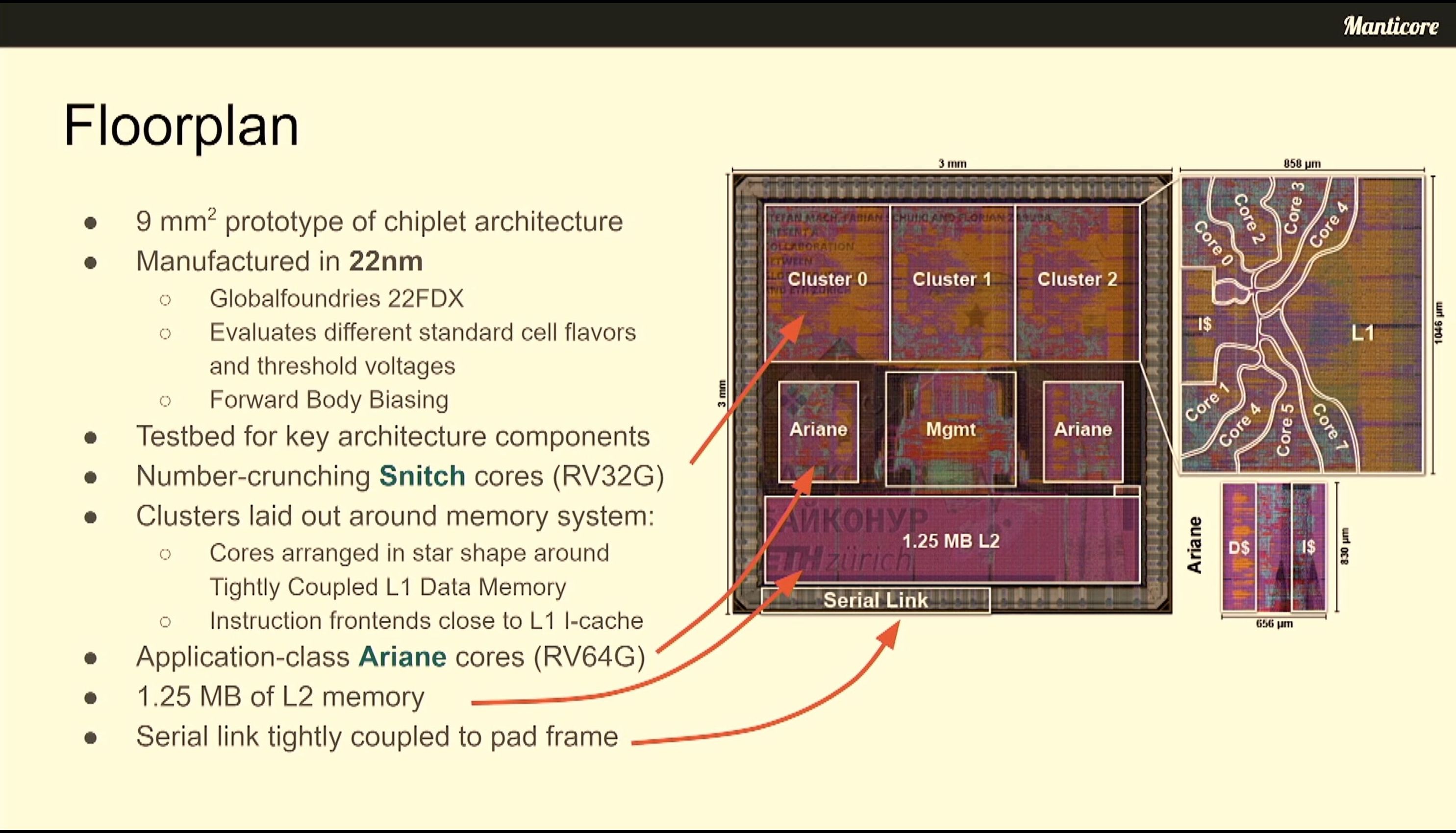
06:56PM EDT - 9mm2 prototype made
06:56PM EDT - 22nm FDX
06:56PM EDT - Forward Body Biasing
06:56PM EDT - This is only a prototype small core of chiplet
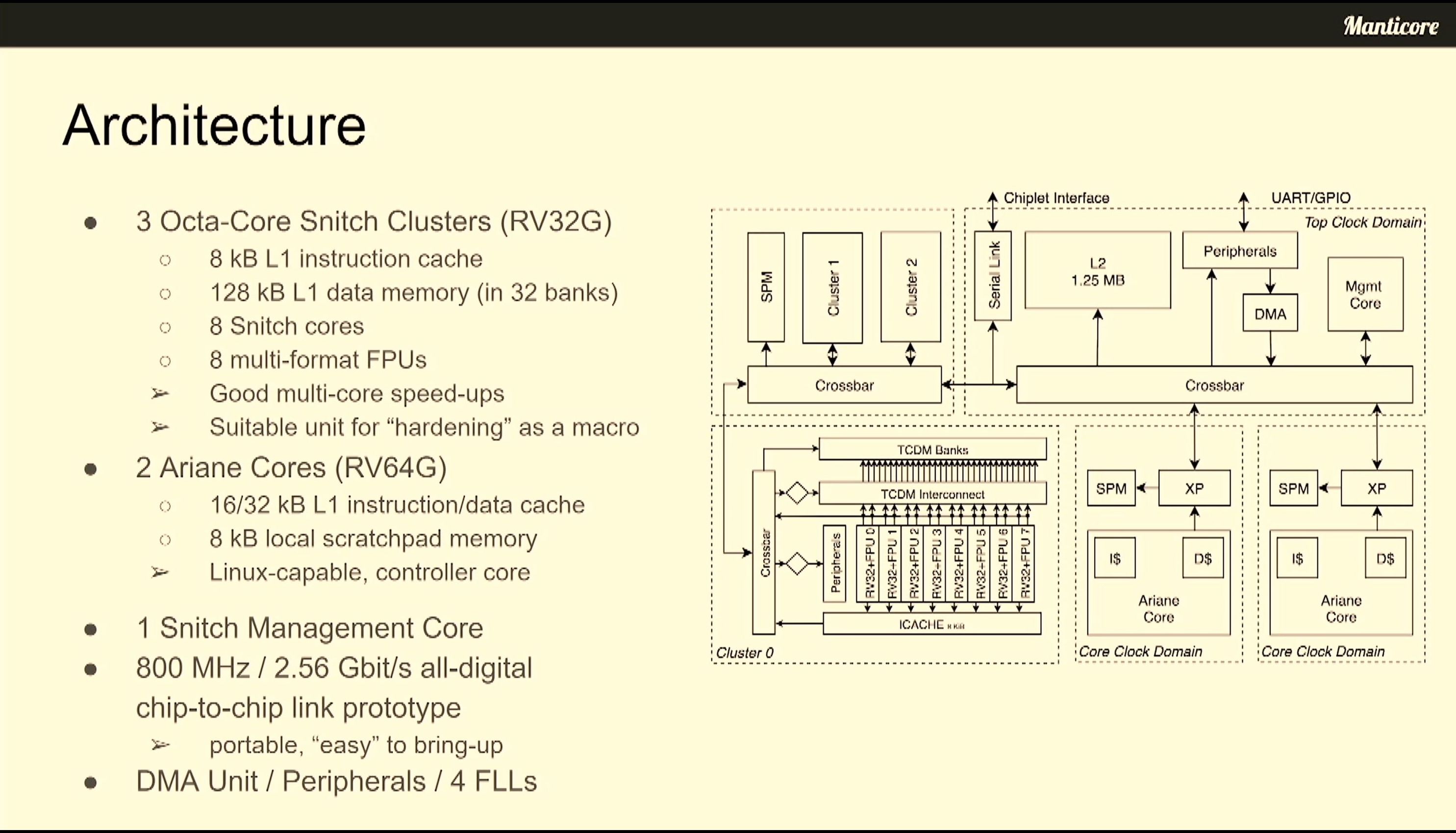
06:57PM EDT - Snitch cores used for DVFS and IO management
06:58PM EDT - Full 4096 core system expected 27 DP Flops/sec
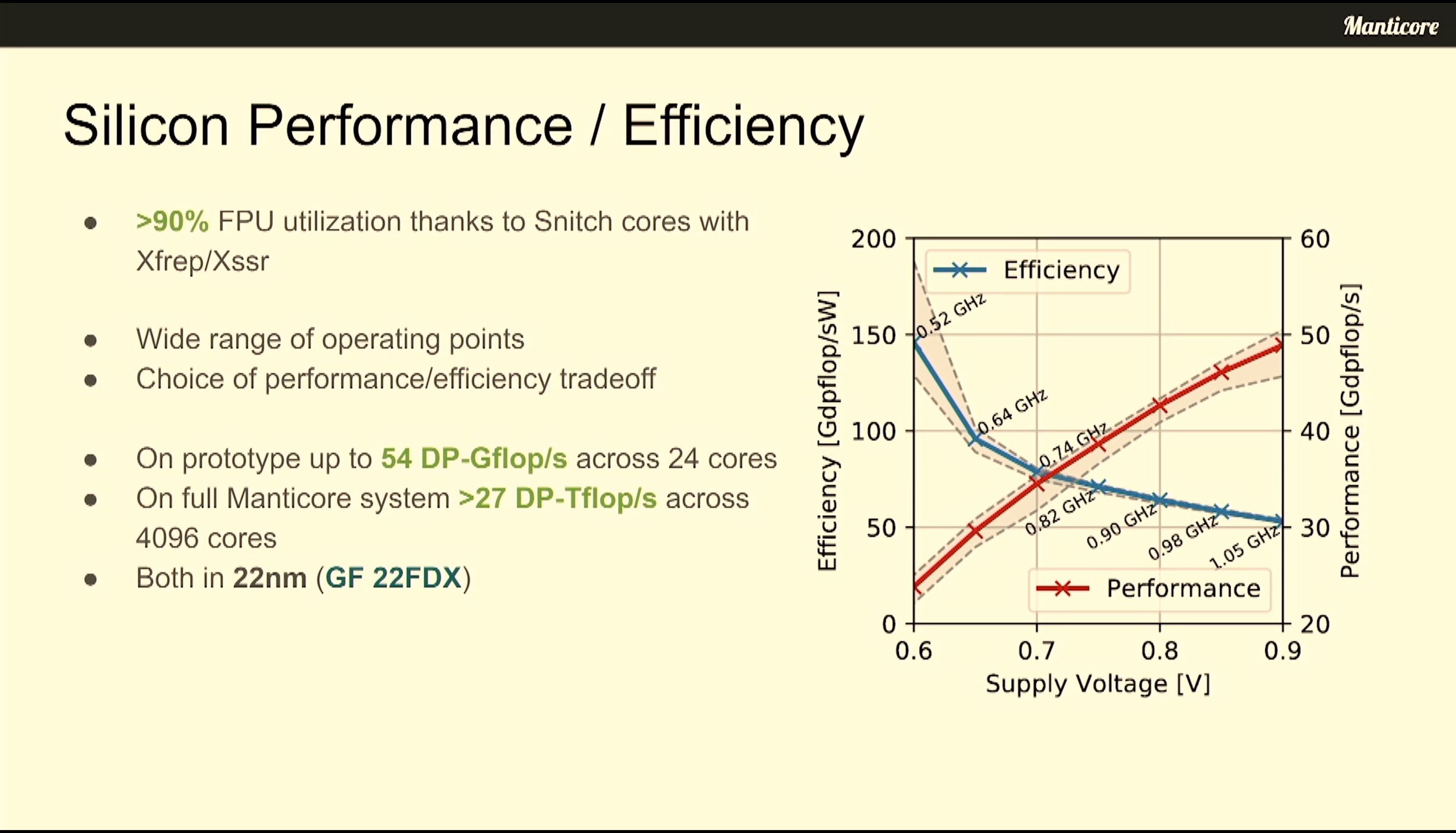
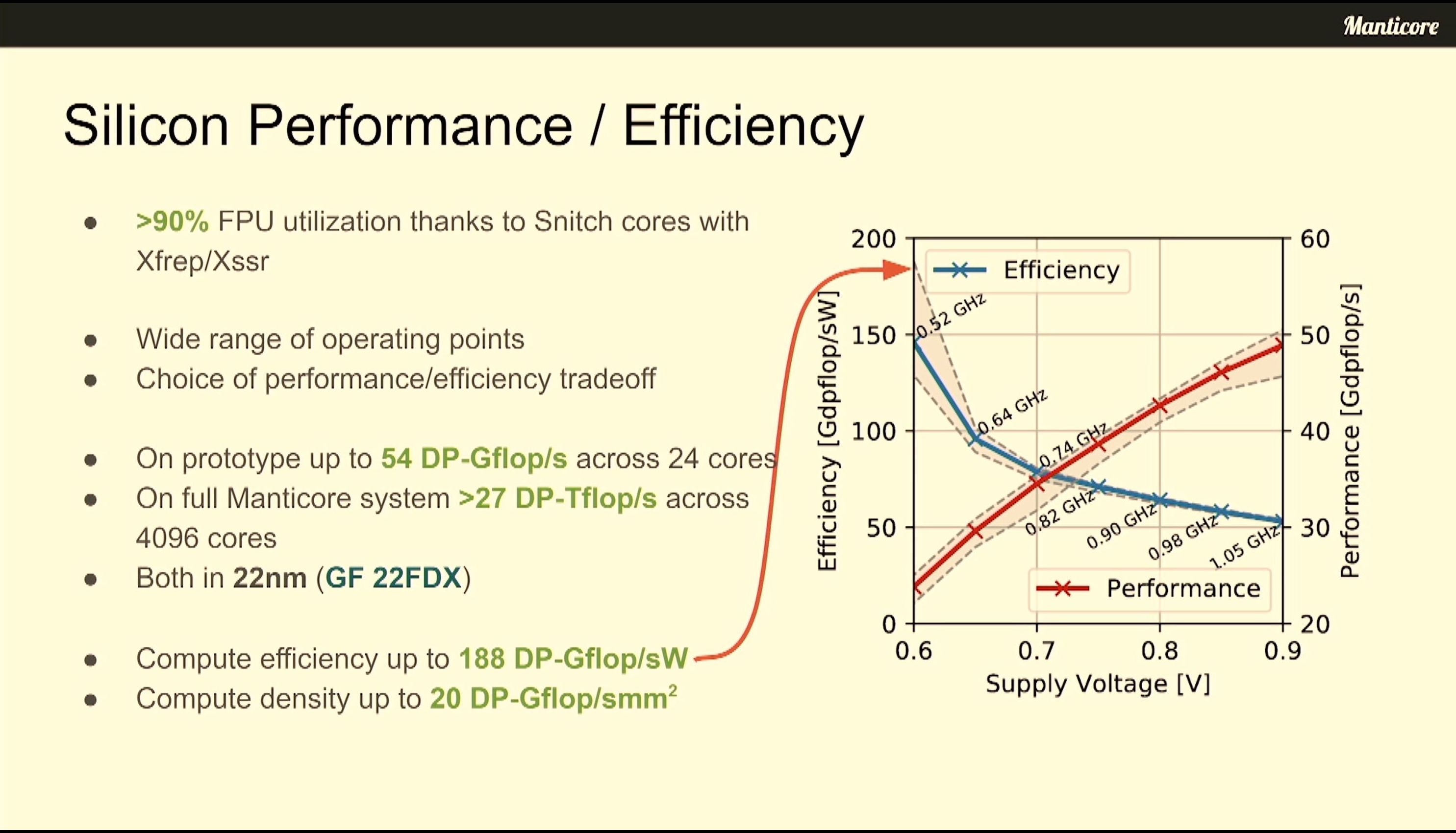
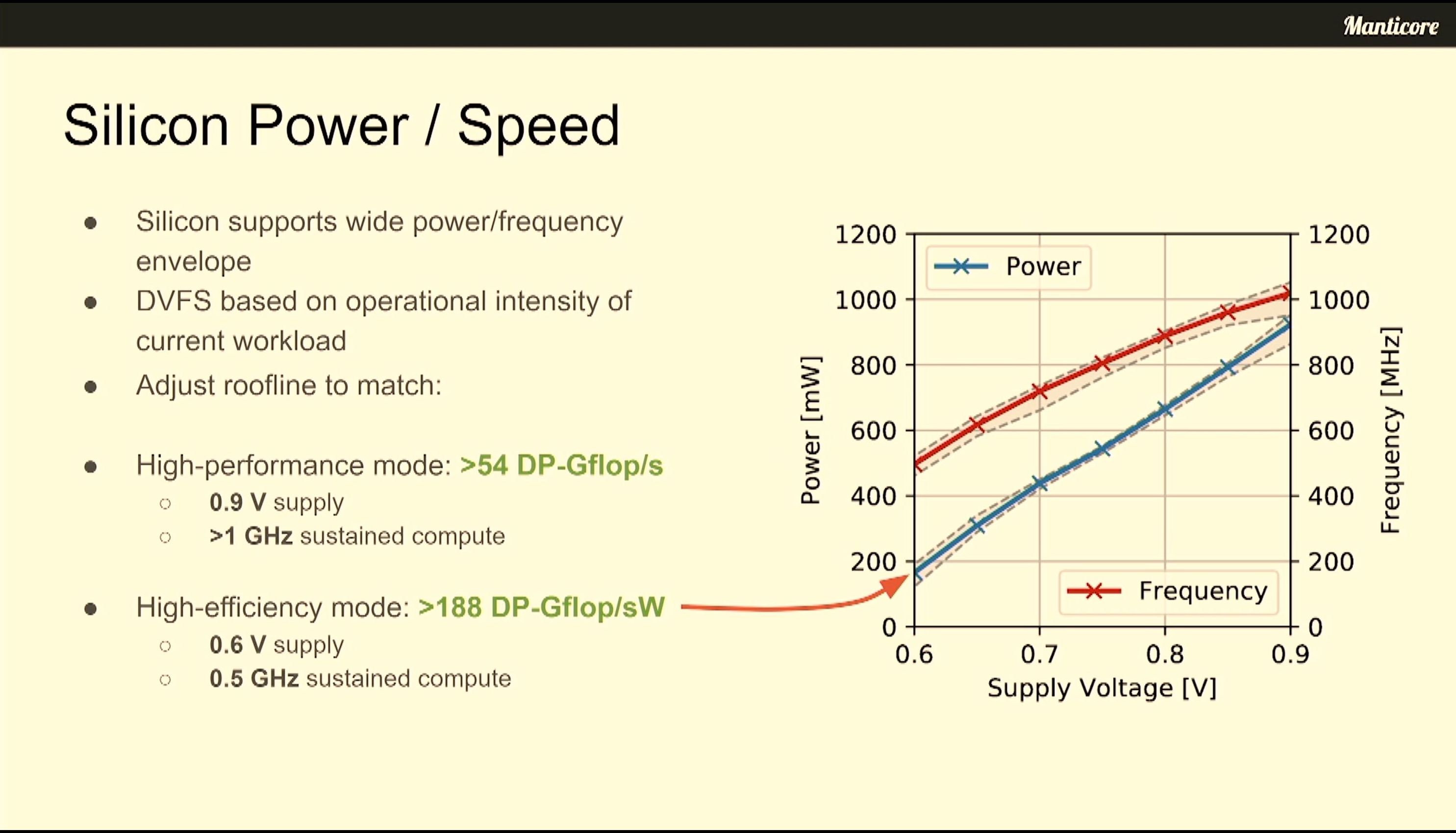

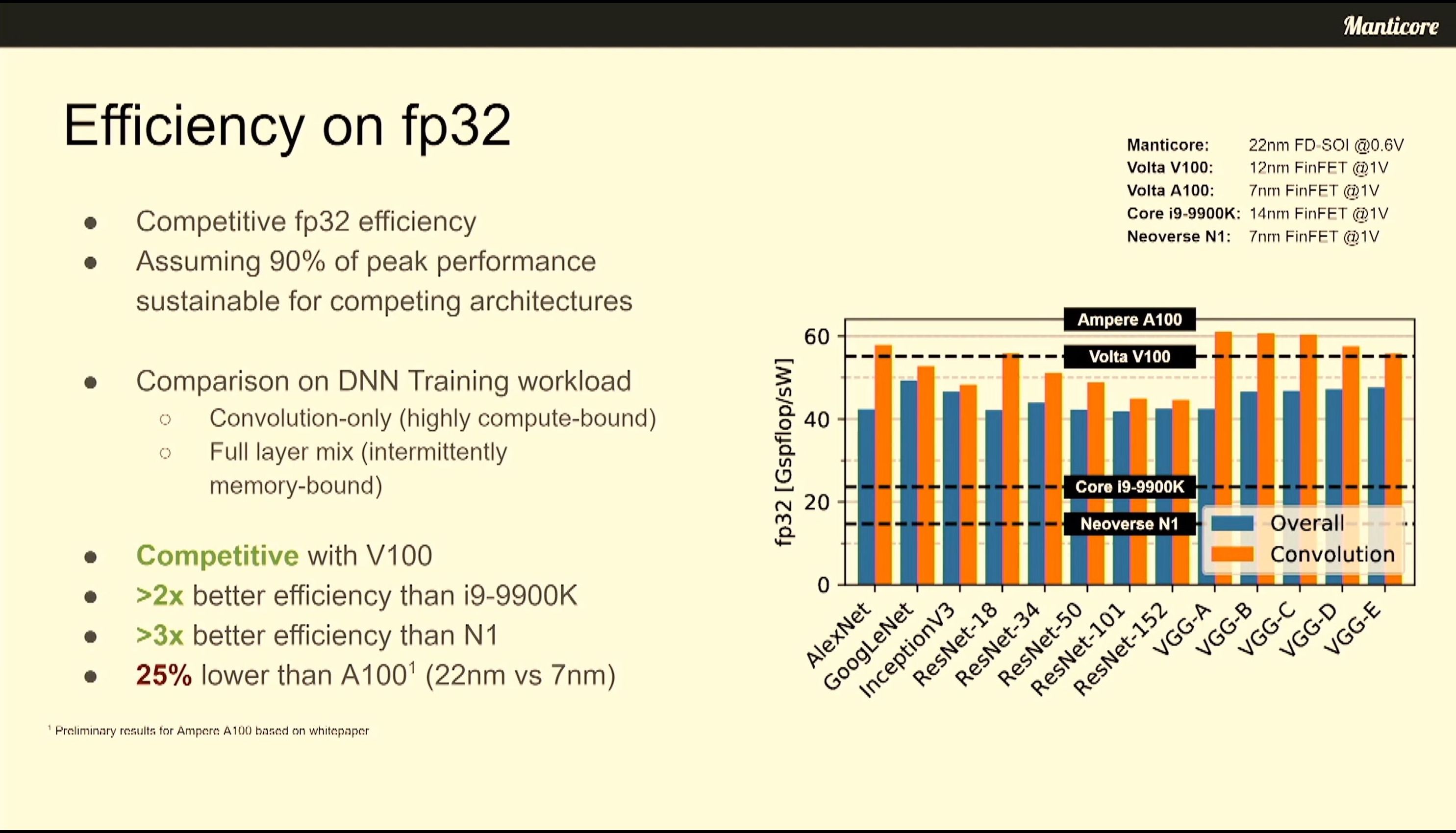
07:00PM EDT - In max perf mode, competitive vs A100 FP64

07:02PM EDT - snitch inside

07:05PM EDT - Q&A time
07:06PM EDT - Q: how does the compiler target the new instrutcions? A: Loop detection to promote loops that have the required characteristics. Might not always hit all cases - so go down QDNN, offer optimized low level kernels that frameworks would support
07:07PM EDT - Q: Productization? A: Concept so far to explore the key components. Wanted lean and mean RISC-V cores. Still missing the key components at SoC level, such as interconnects, which as a university is hard to come by. Looking into to generating and taping out later system in a research concept in the future.
07:08PM EDT - That's a wrap. Short break until the next sesstion, at half-past. Baidu + Alibaba NPUs






