Original Link: https://www.anandtech.com/show/16005/hot-chips-2020-live-blog-google-tpuv2-and-tpuv3-230pm-pt
Hot Chips 2020 Live Blog: Google TPUv2 and TPUv3 (2:30pm PT)
by Dr. Ian Cutress on August 18, 2020 5:30 PM EST

05:36PM EDT - No TPUv4 info in this talk, just fyi. Google often talks about these chips well after deployment
05:36PM EDT - Here's the history
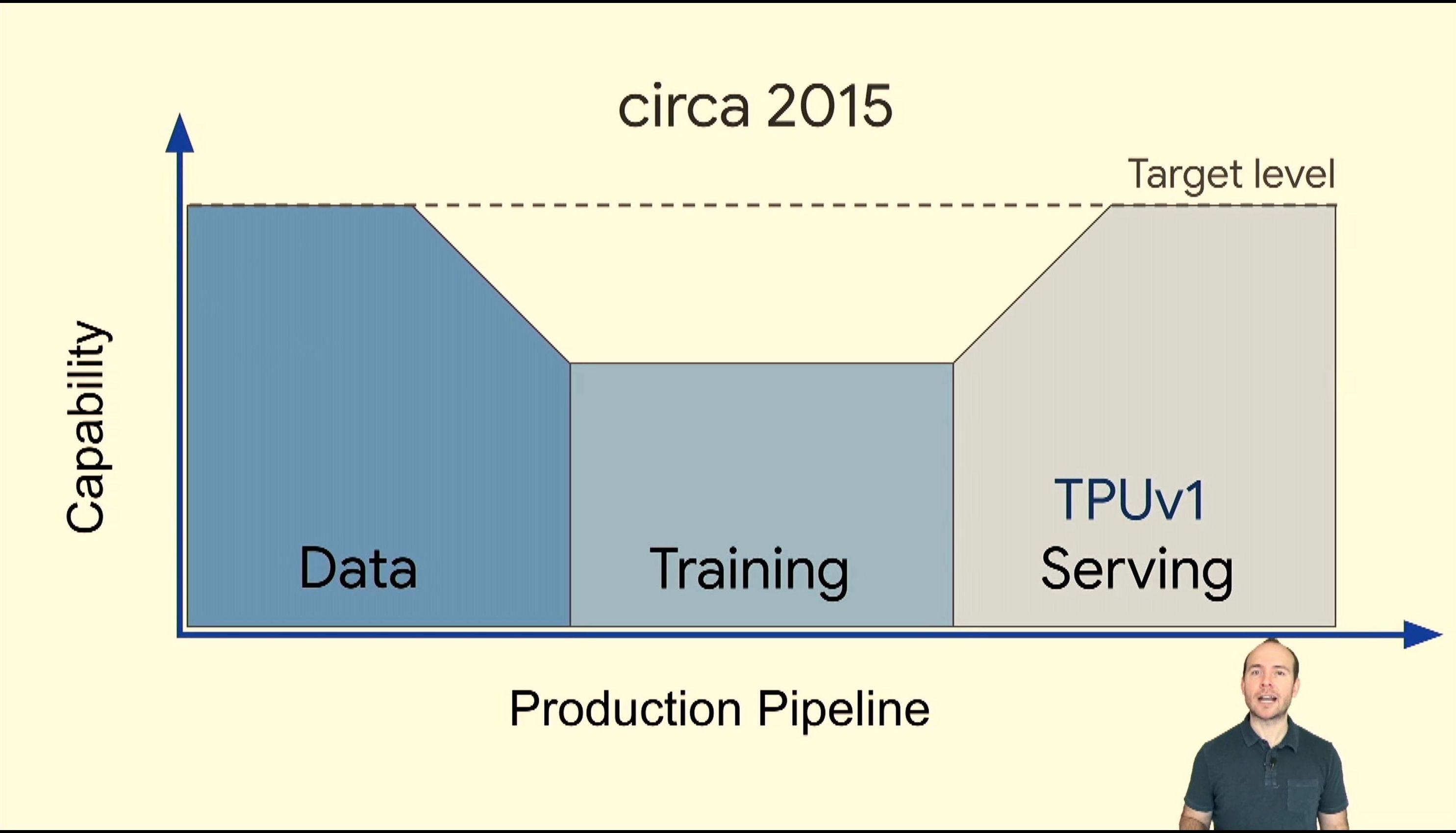
05:36PM EDT - TPUv1 in 2015 for inference
05:36PM EDT - TPUv2 for Training in 2017
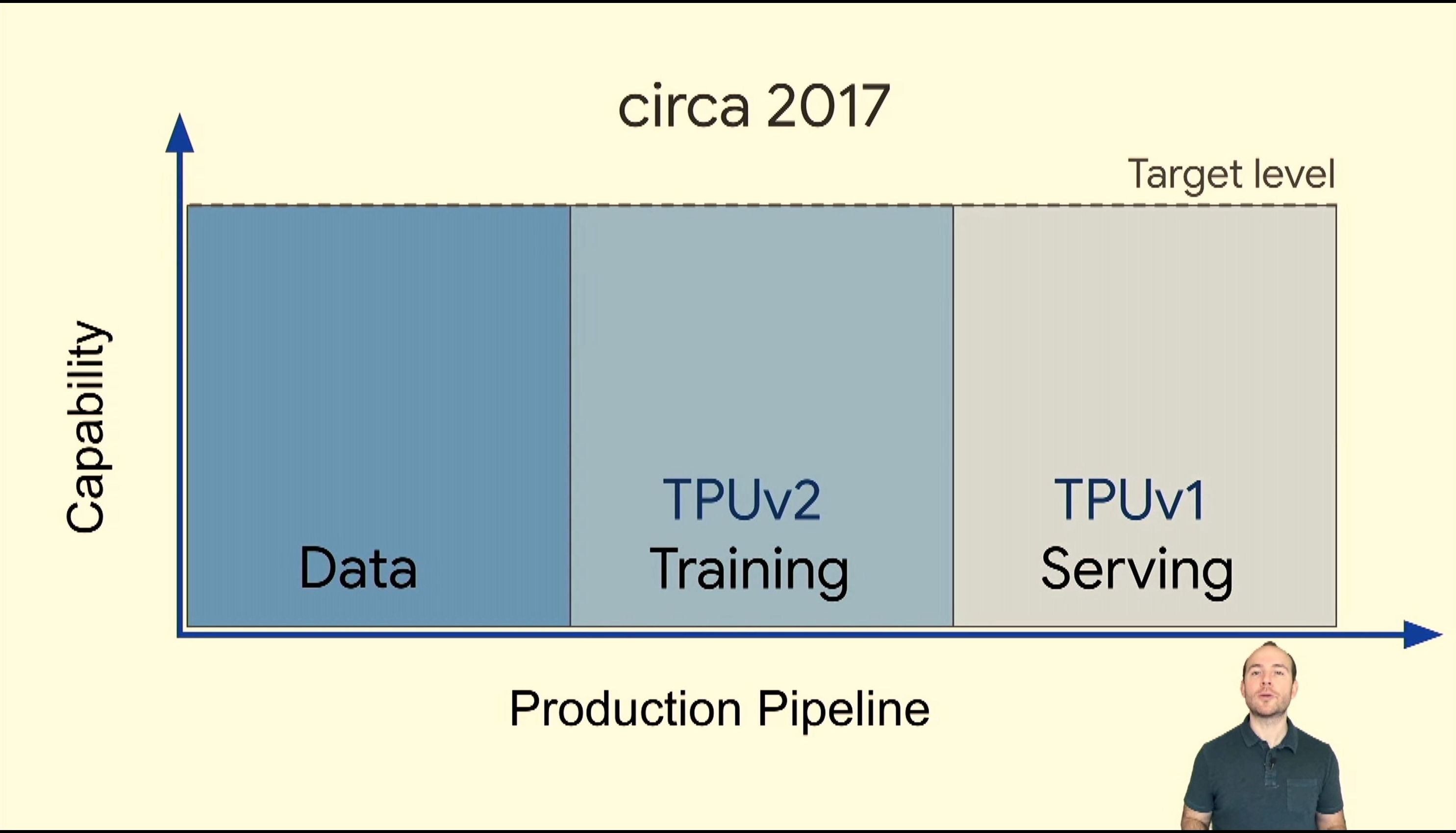
05:37PM EDT - ML training has unique challenges
05:37PM EDT - type of compute, amount of compute

05:37PM EDT - Training is exaflop or zettaflop, while inference is 1 GOP
05:37PM EDT - Training is sensitive
05:37PM EDT - Training is experimentation - moving targets
05:38PM EDT - Scale up vs Scale out
05:38PM EDT - Inference can be scaled out
05:38PM EDT - Training is harder to scale out
05:38PM EDT - Bottlenecked by off-chip datapaths

05:38PM EDT - Constraint for time vs staffing
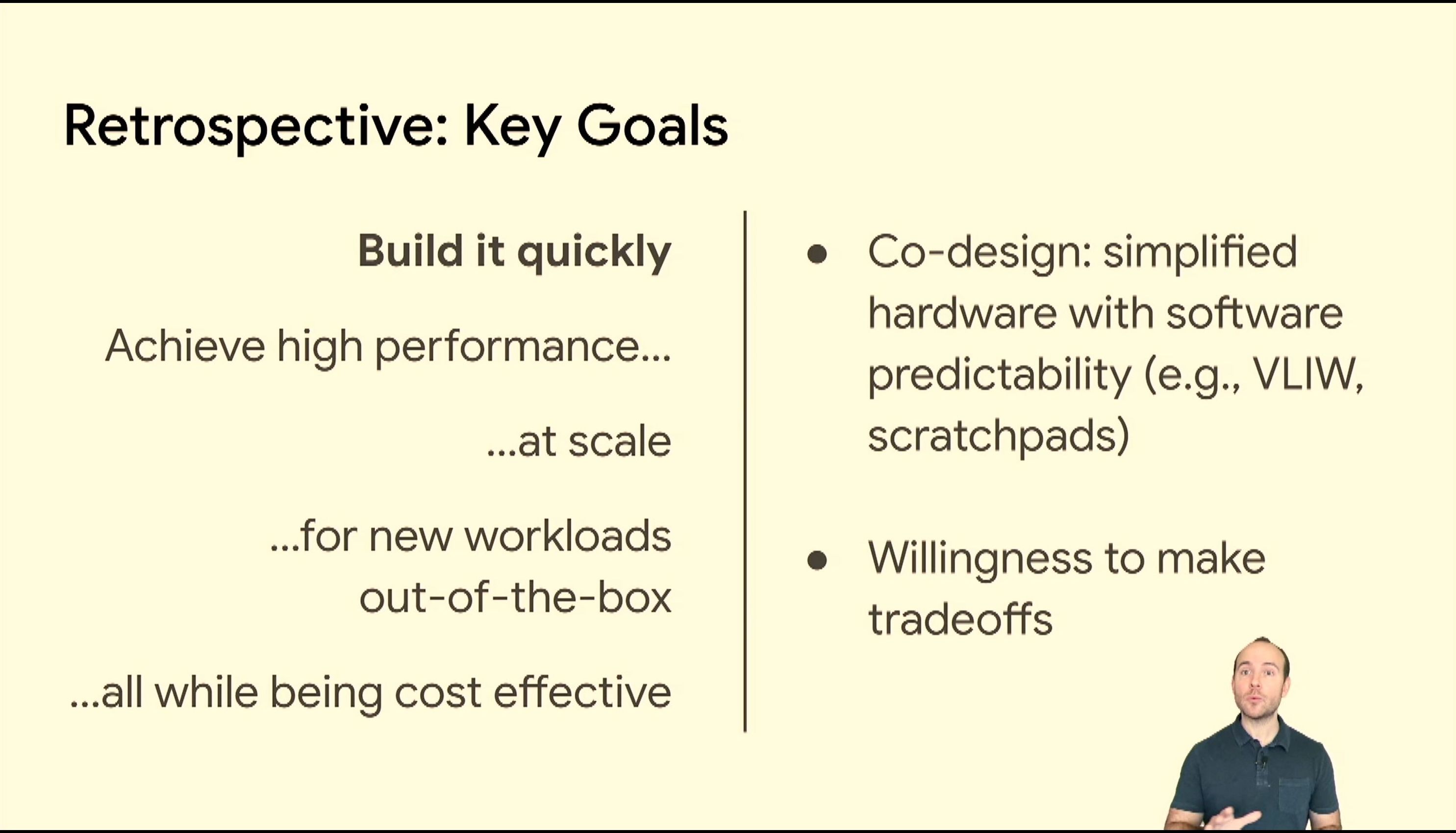
05:38PM EDT - Be ambitious on a budget

05:39PM EDT - Key goals first, all goals need to be 'ok' or 'good enough'
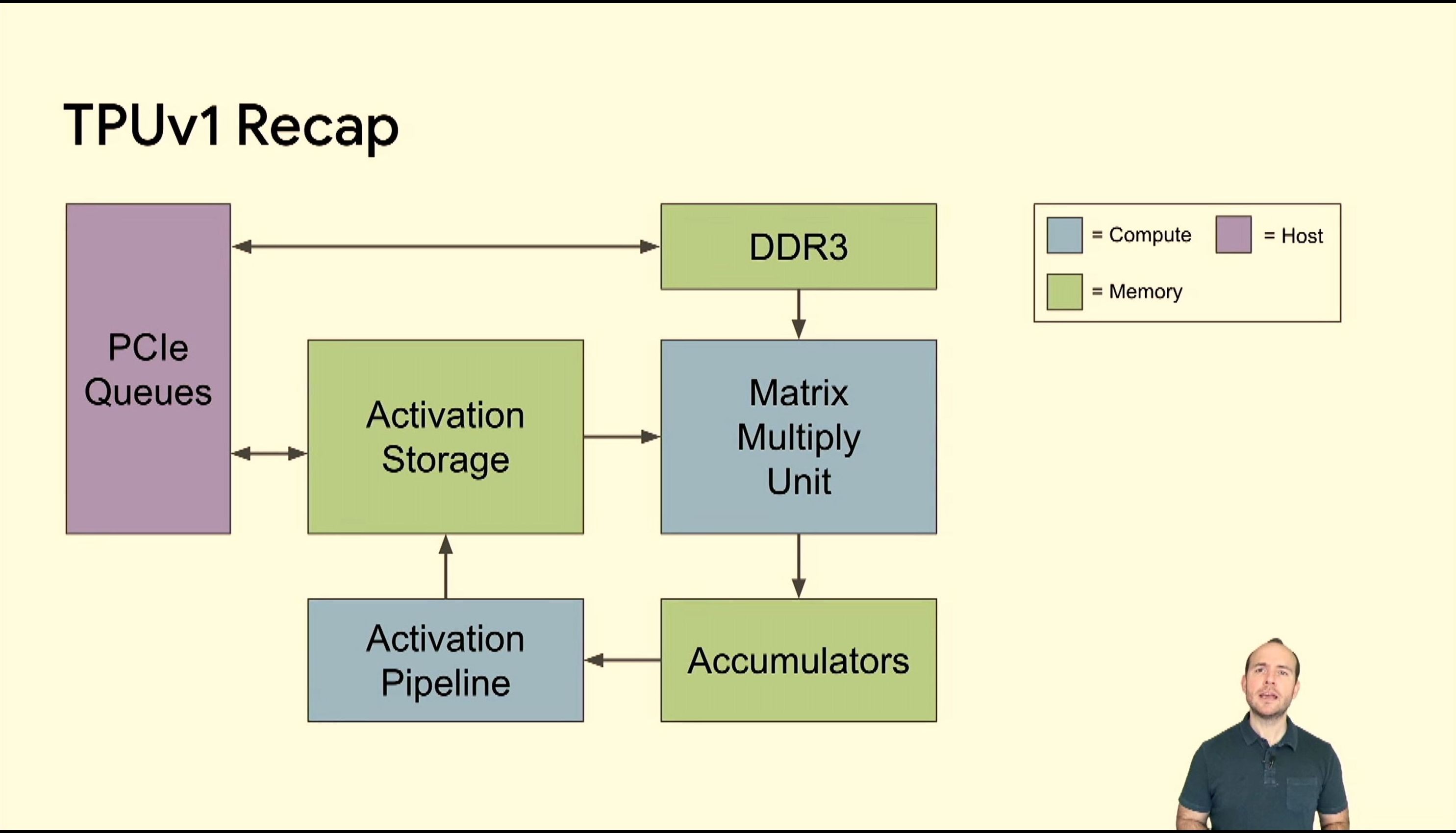
05:39PM EDT - Here's TPU1
05:39PM EDT - The central cycle is where the compute happens
05:39PM EDT - TPUv2 makes changes
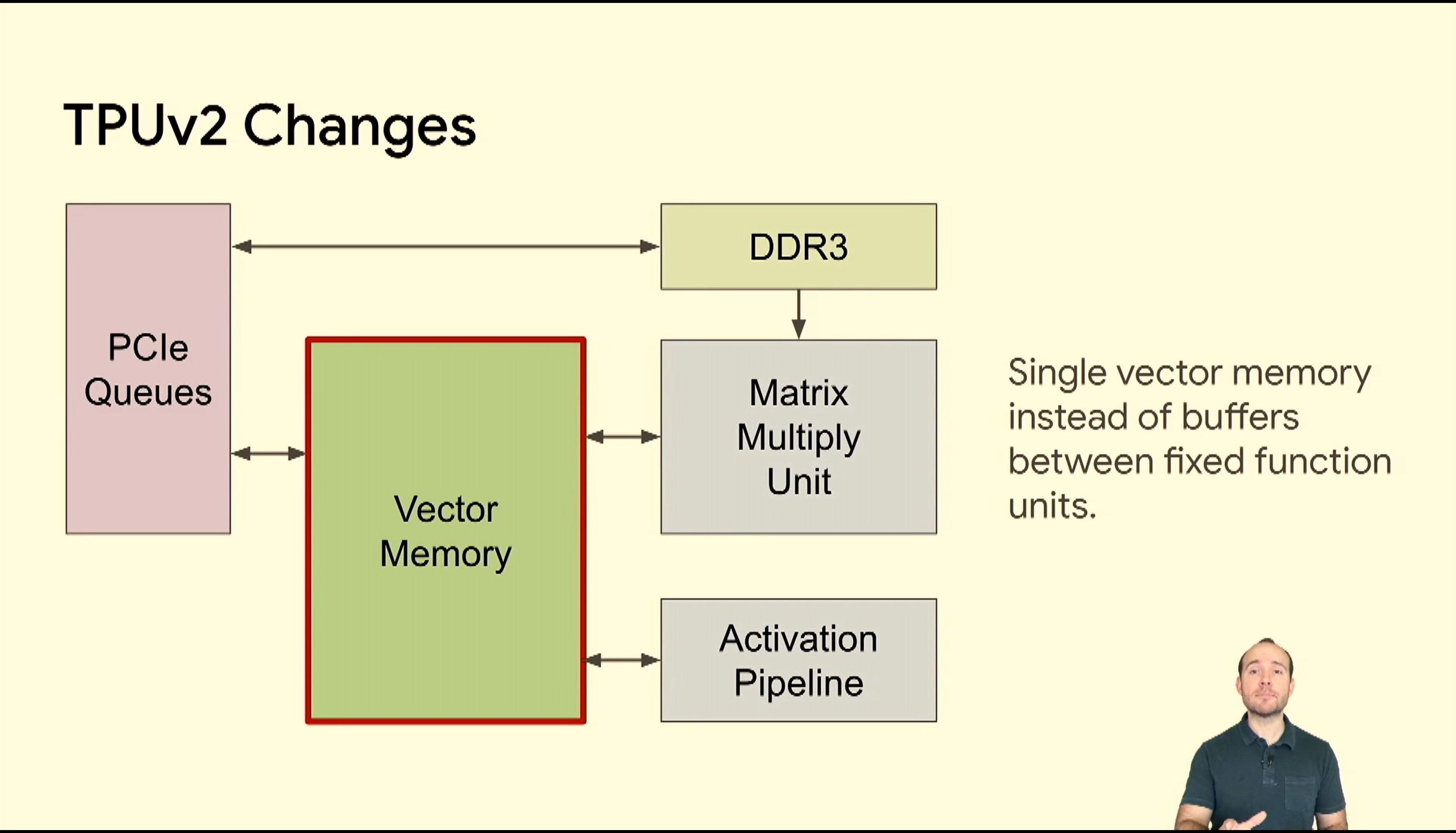
05:40PM EDT - Make it more vector focused
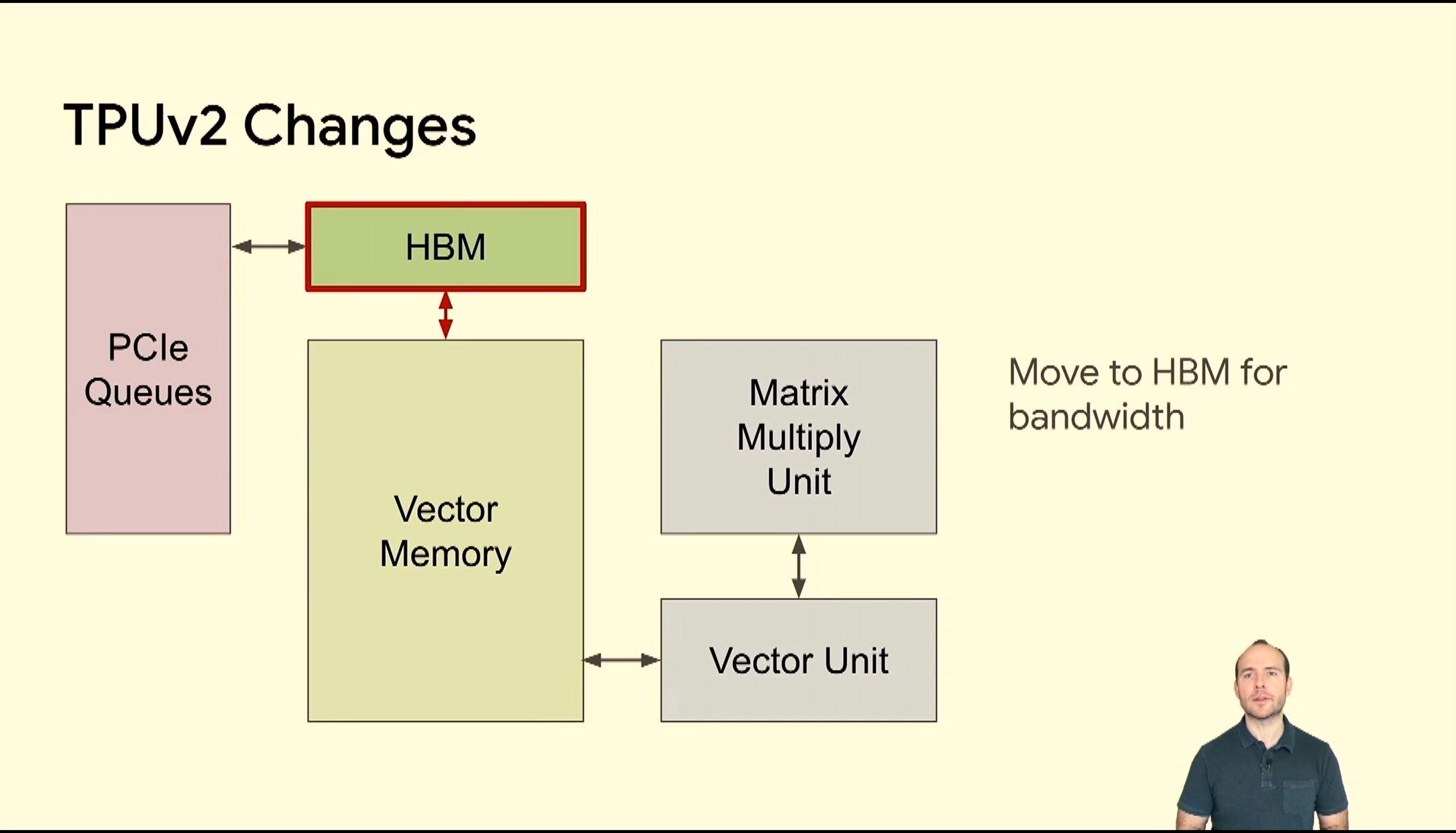
05:40PM EDT - Memory uplift
05:40PM EDT - interconnect fabric
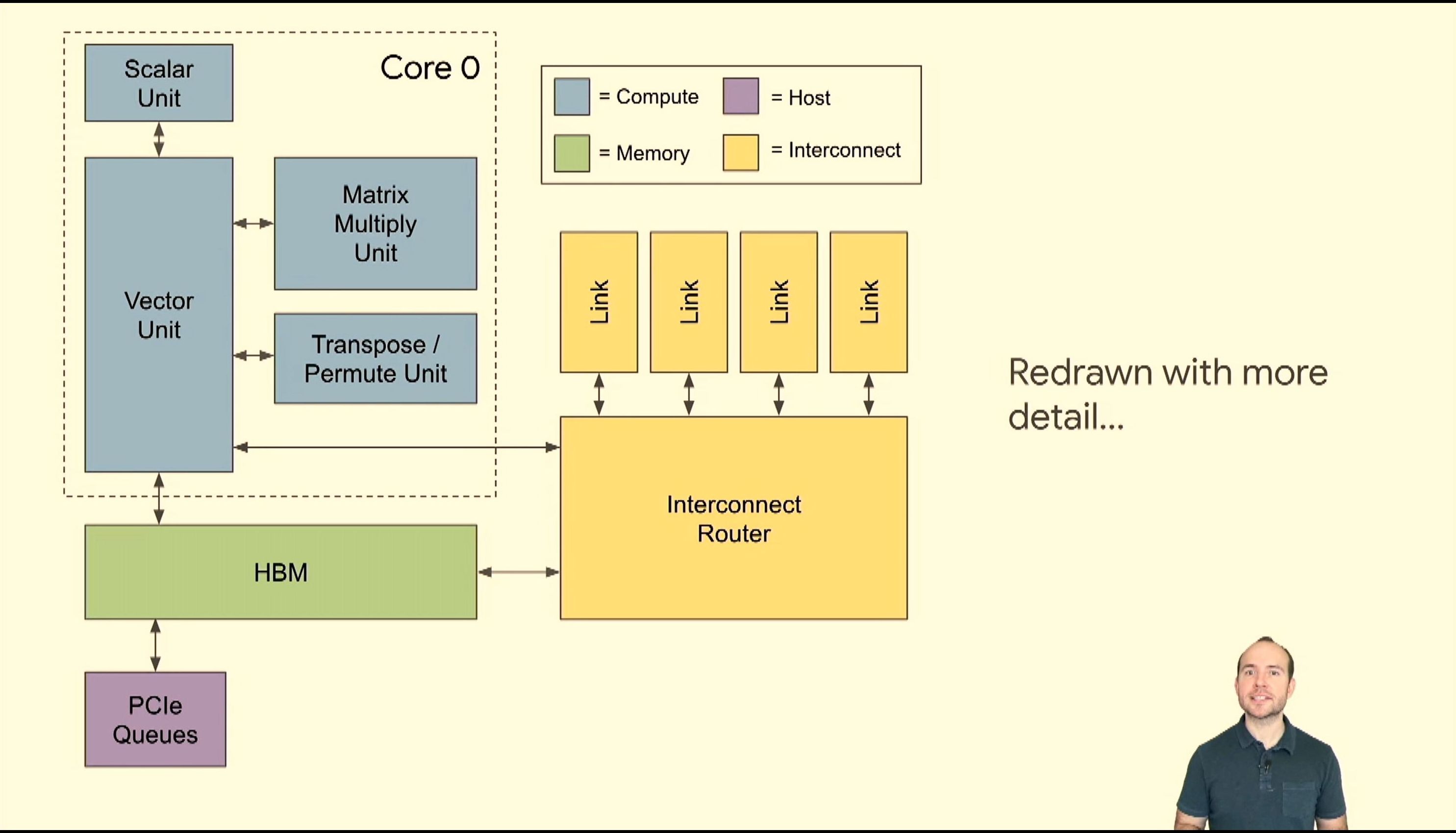
05:41PM EDT - Here's how it fits in TPUv2
05:41PM EDT - Multiple cores
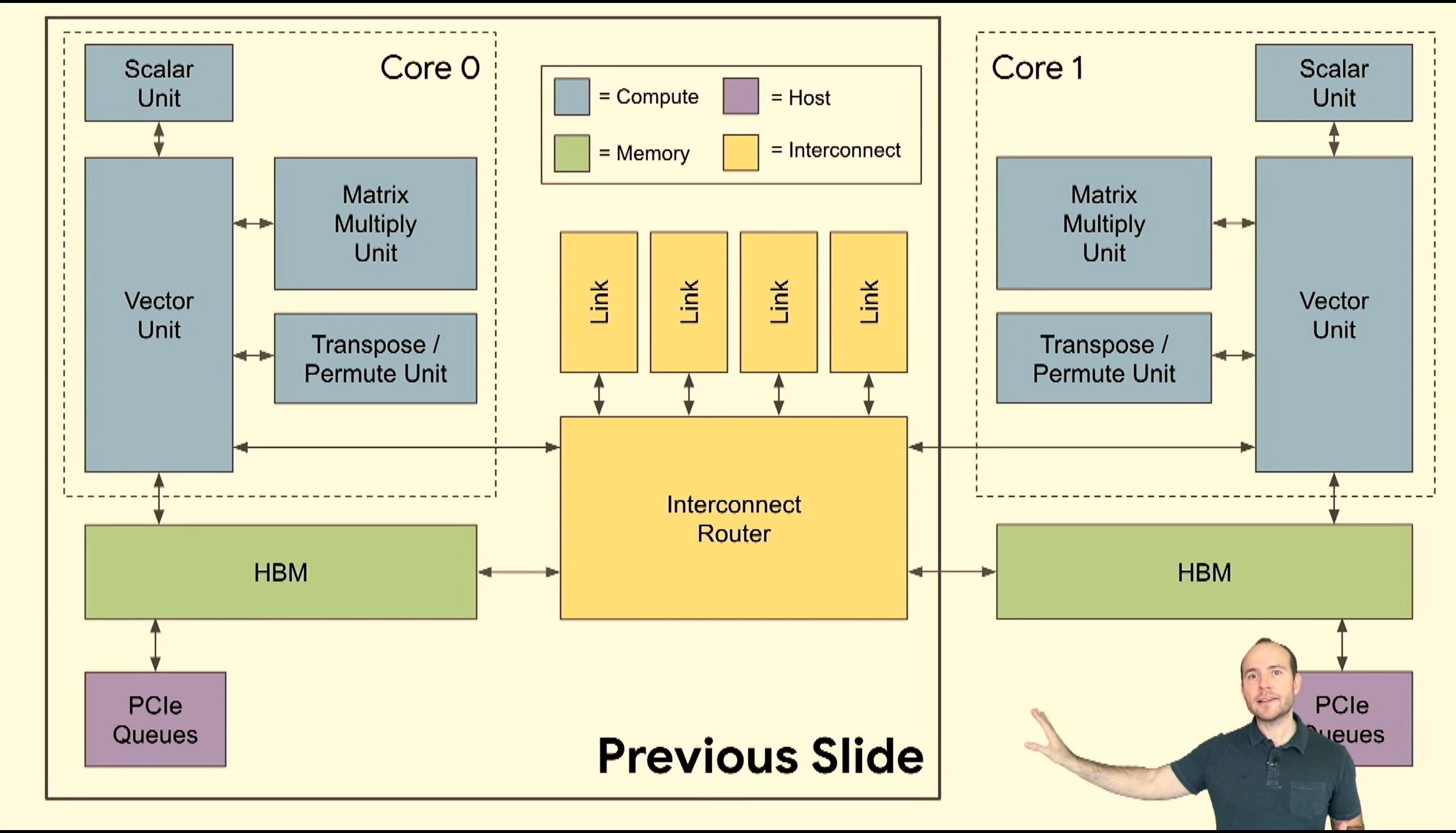
05:41PM EDT - prefer fewer cores - big data problem and single instruction stream makes it easier to program
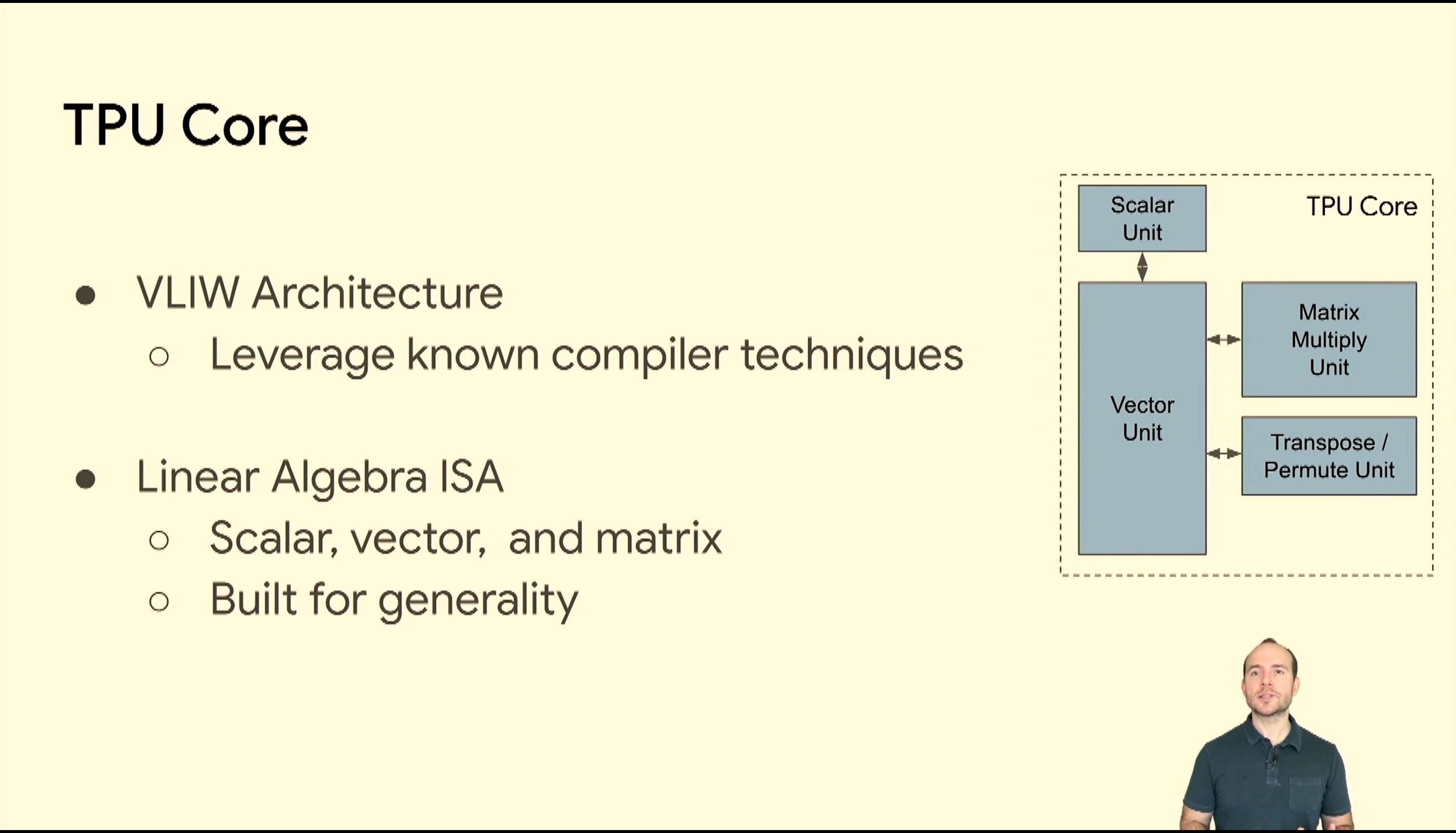
05:41PM EDT - VLIW

05:42PM EDT - 322bit VLIW bundle
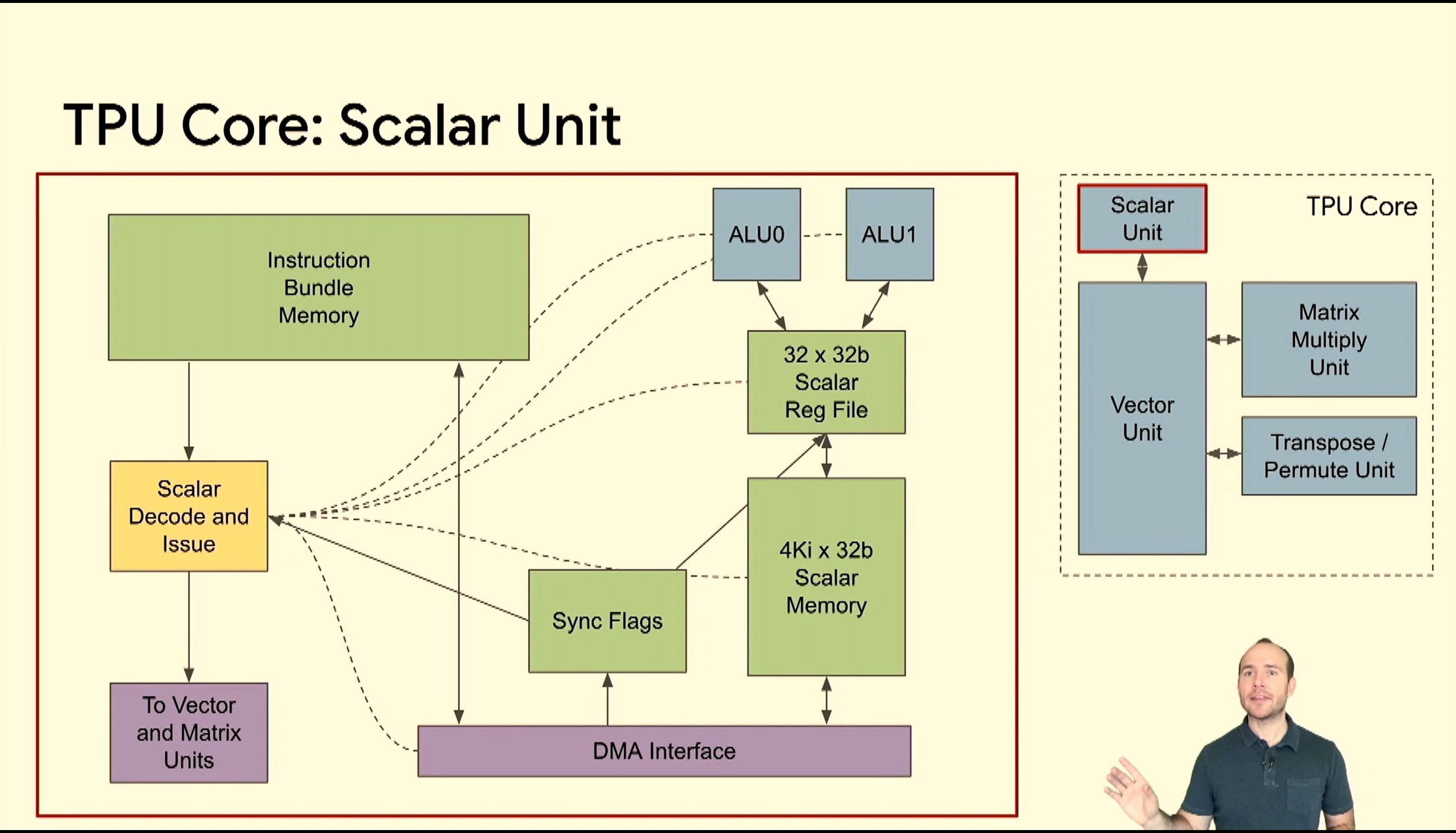
05:42PM EDT - No i-cache, Instruction bundle memory with DMA
05:42PM EDT - keeping it good enough and old school
05:43PM EDT - dual issue ALU
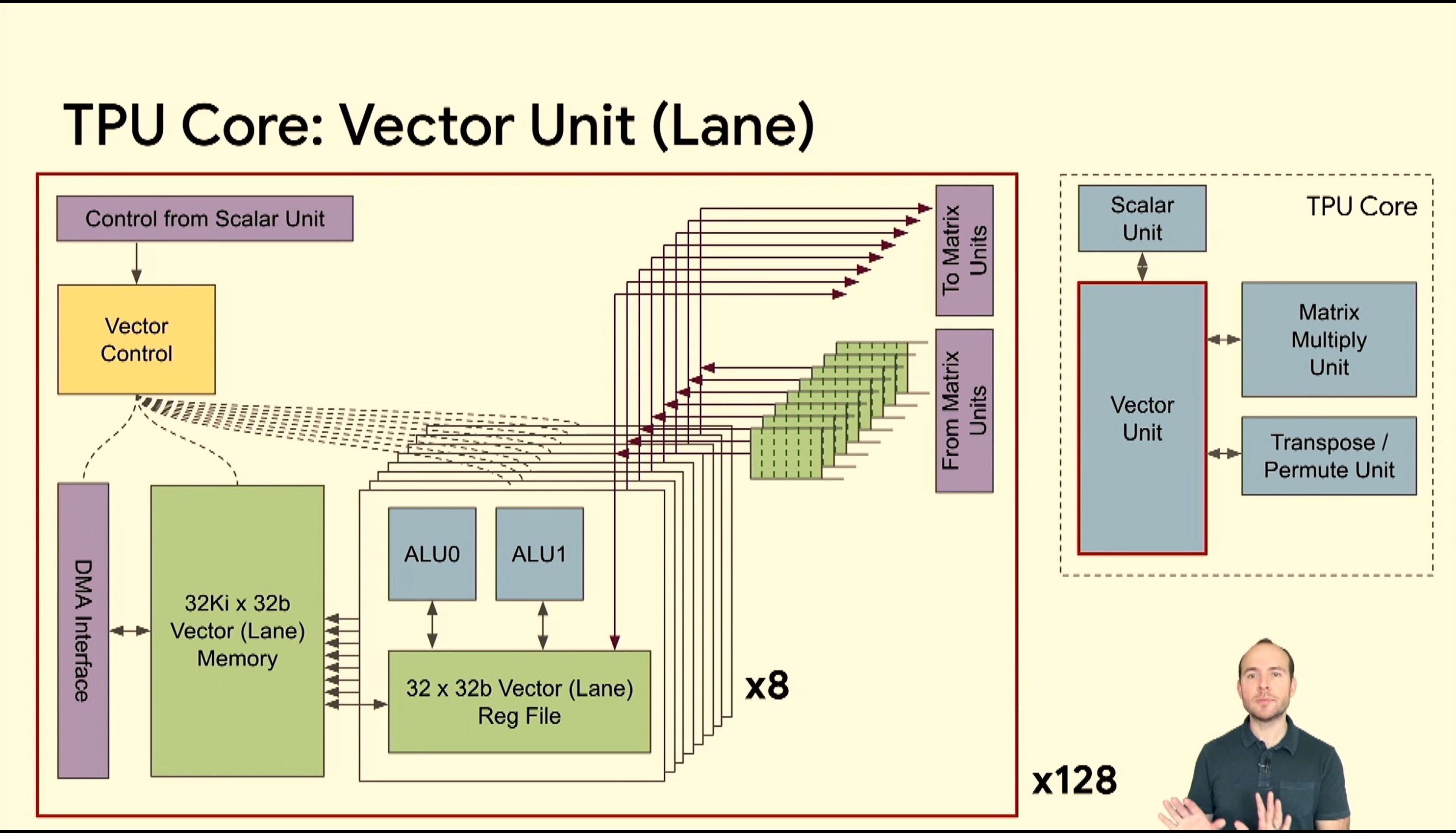
05:43PM EDT - 128 instances of these lanes
05:43PM EDT - 8 sets of 128-wide vectors per cycle
05:43PM EDT - connectivity into matrix units

05:44PM EDT - 128x128 systolic array
05:44PM EDT - BF16 multiply
05:44PM EDT - Not the biggest aspect of chip area though
05:44PM EDT - hardware savings are money savings
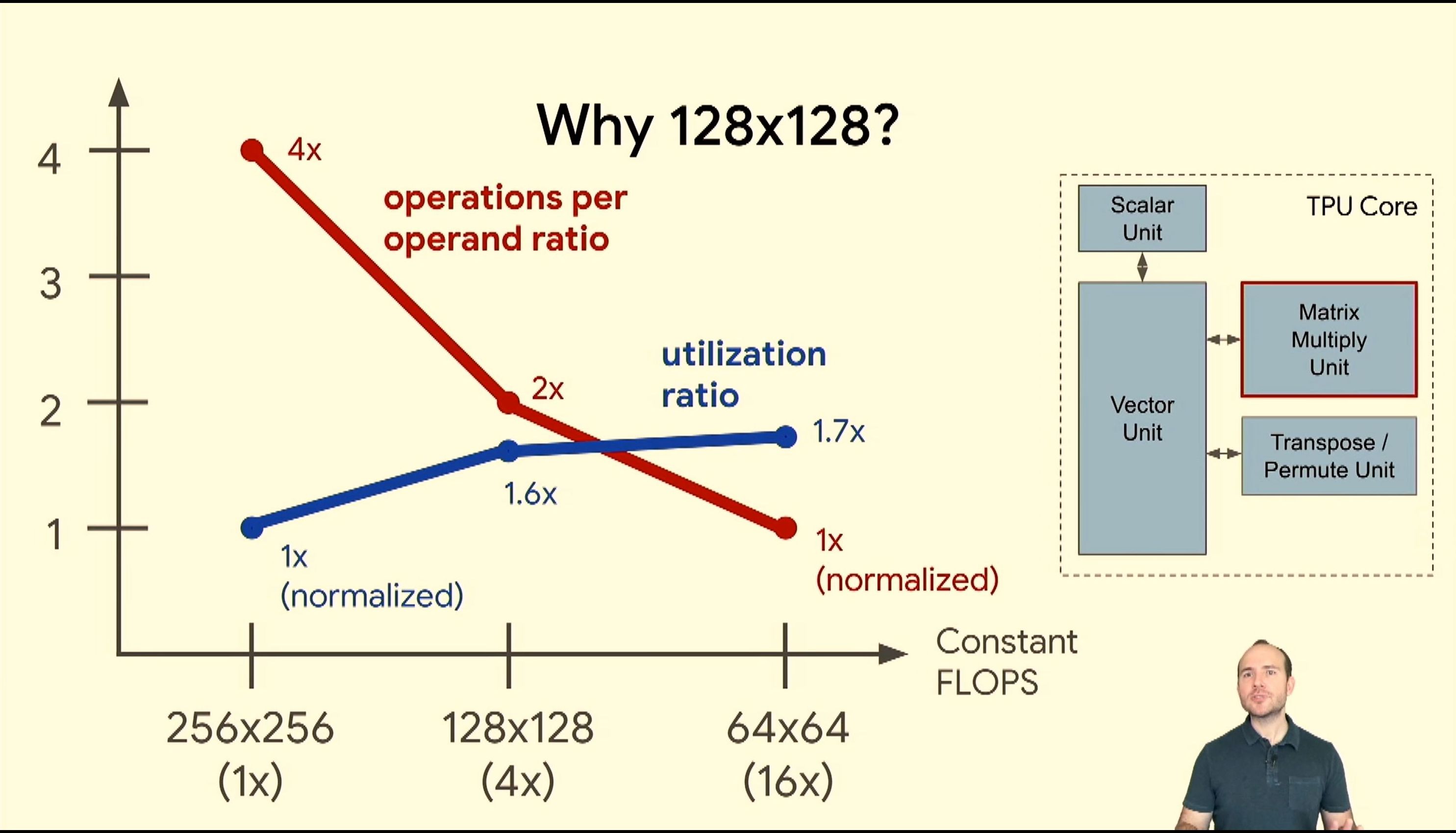
05:45PM EDT - Why 128x128?
05:45PM EDT - sweetspot for utilization without devoting more area to wiring
05:46PM EDT - SRAM scratchpad memories, software visible
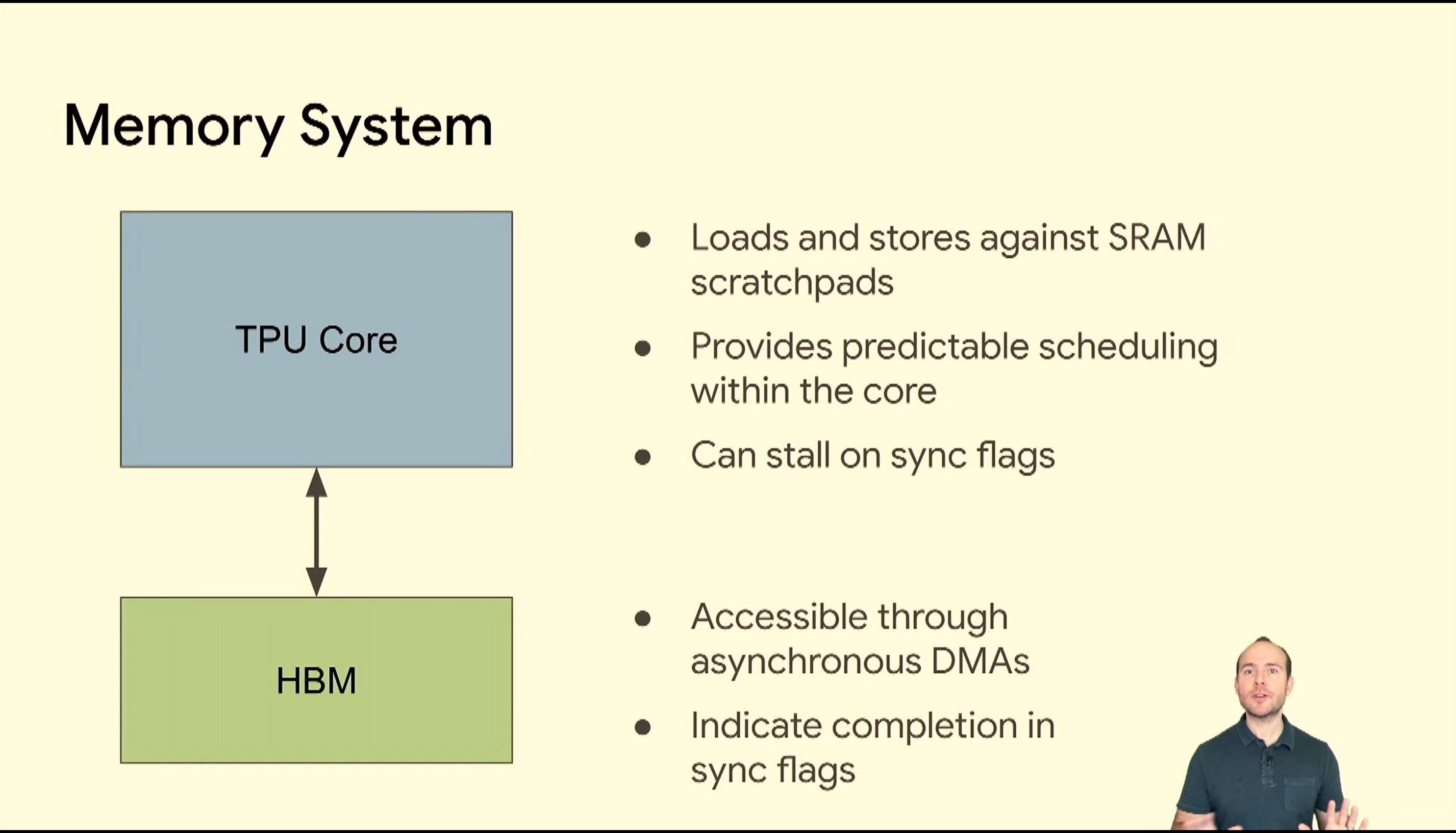
05:46PM EDT - In-package HBM
05:46PM EDT - Async DMAs
05:46PM EDT - HBM stores vectors and matrices - strides over vectors
05:46PM EDT - 700 GB/s per chip due to HBM
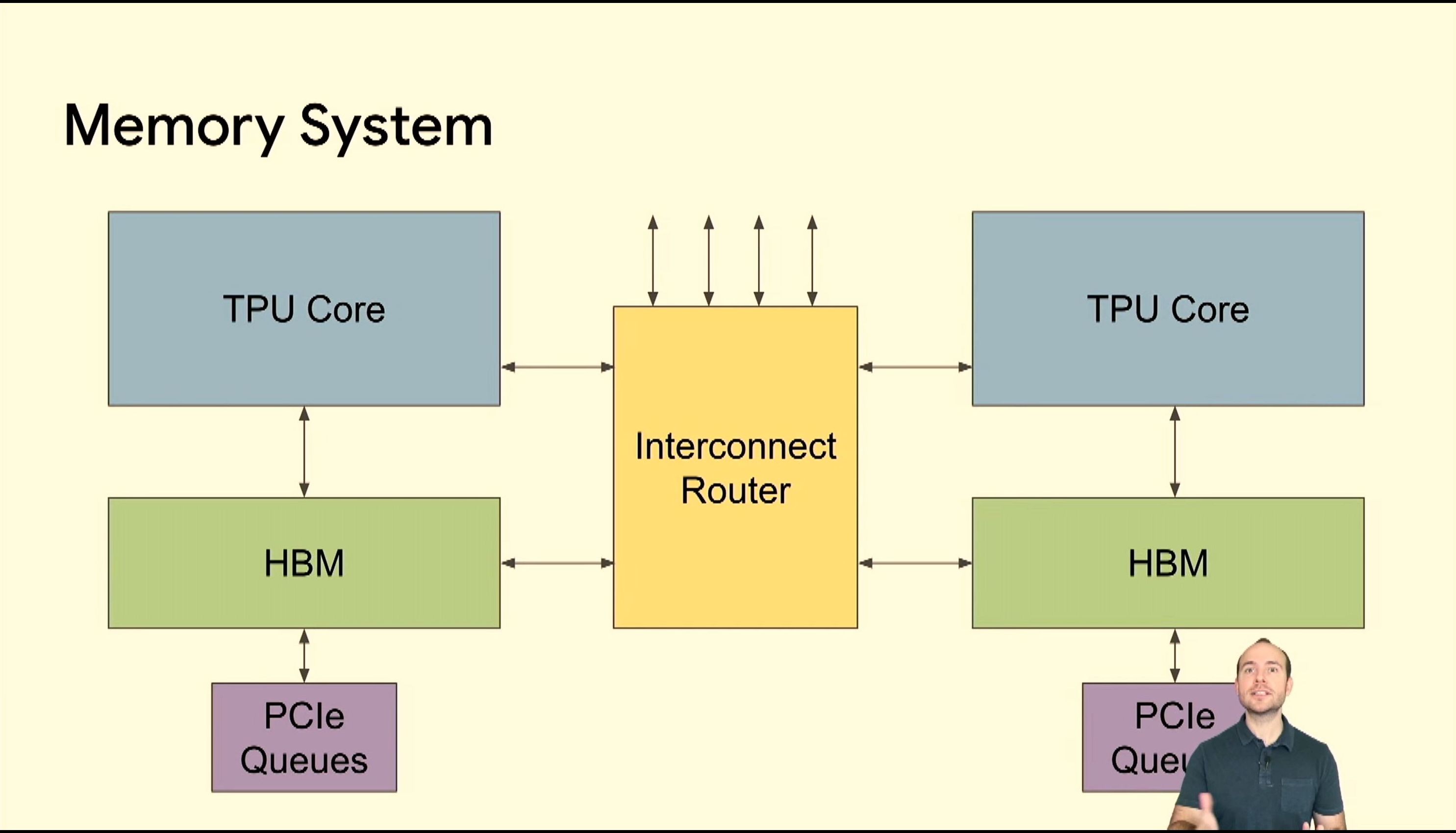
05:47PM EDT - Interconnect router
05:47PM EDT - Easier to build the memory system this way
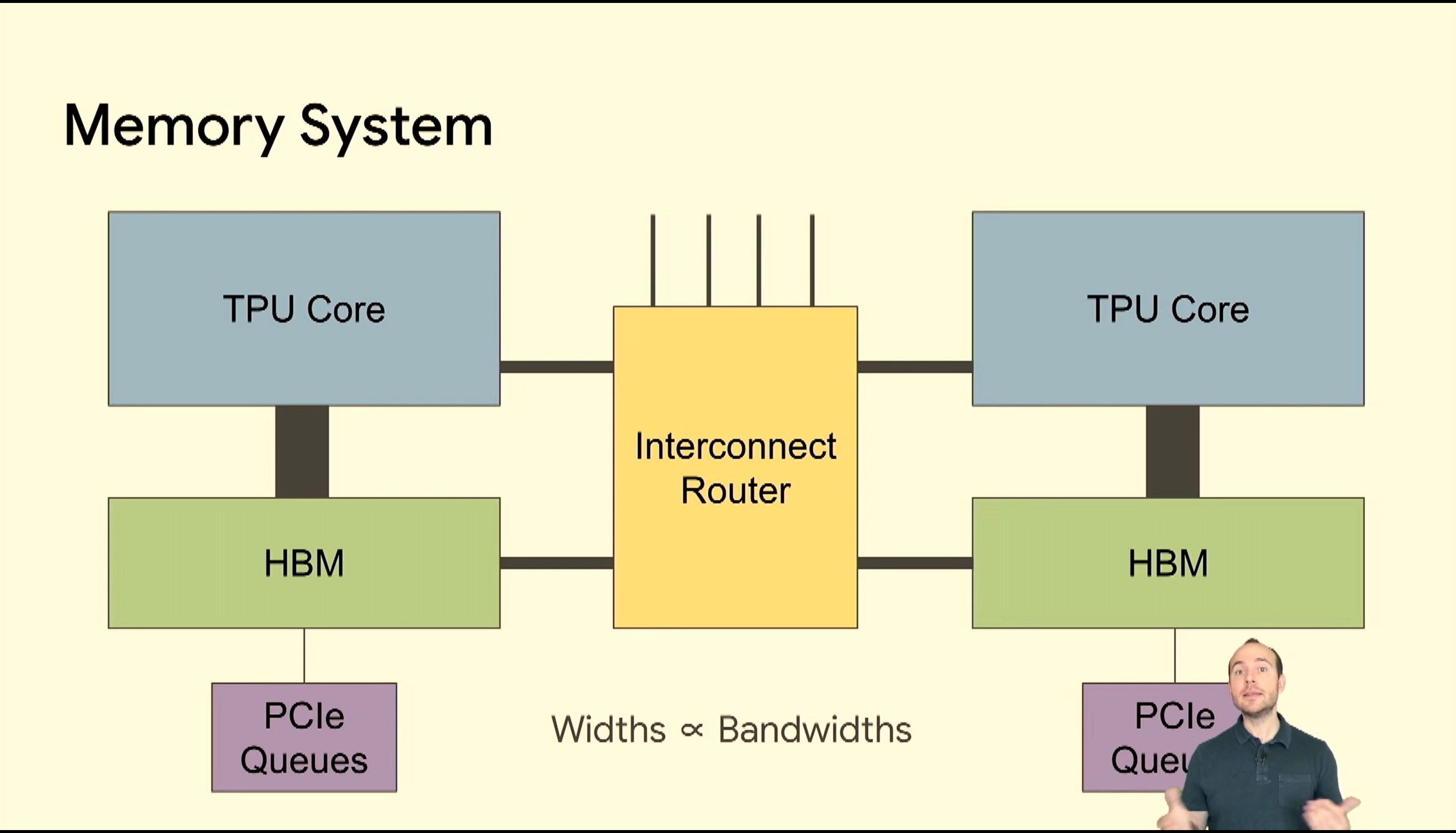
05:47PM EDT - TPU has to be flexible enough
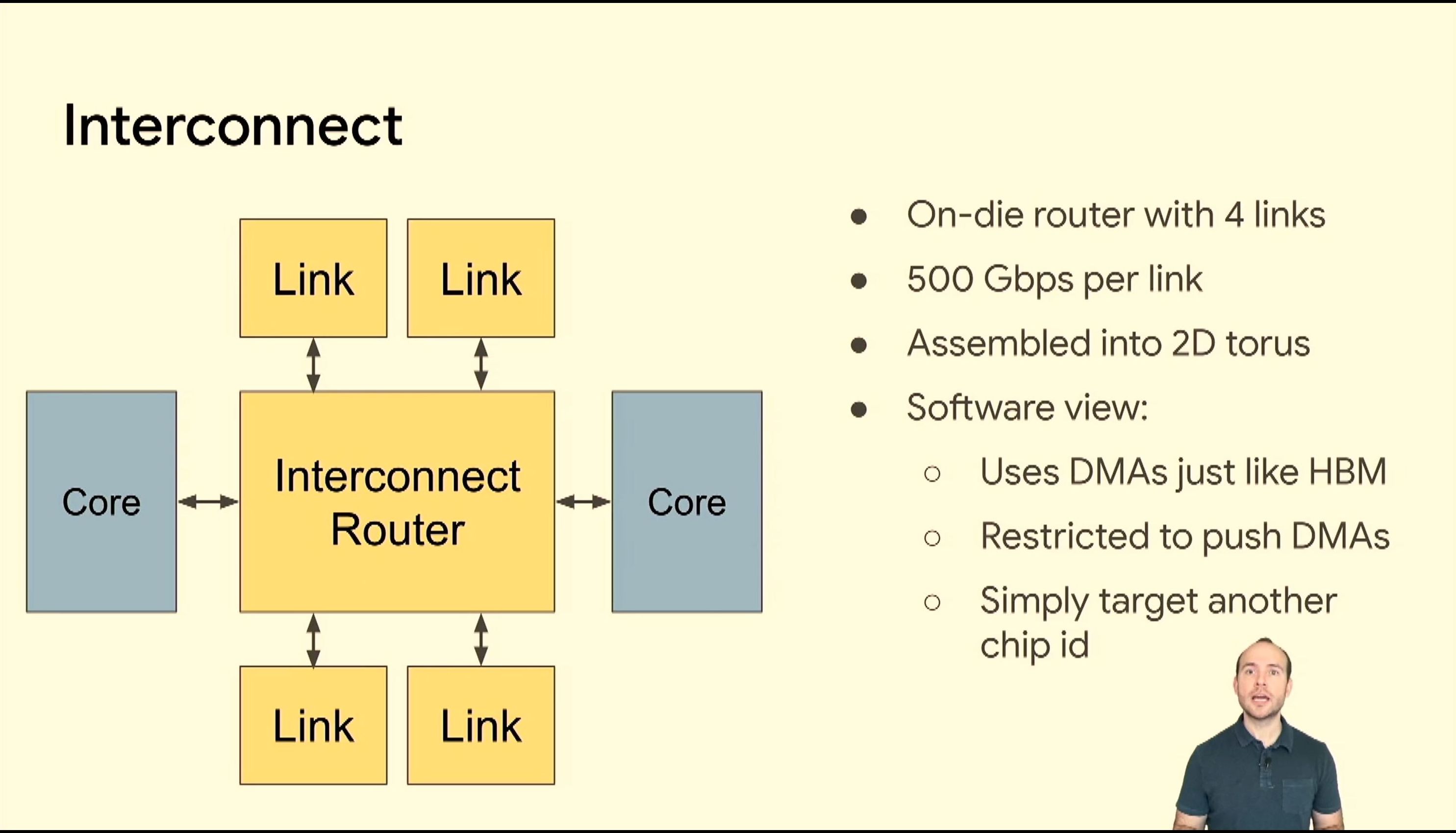
05:47PM EDT - 2D torus
05:48PM EDT - DMA into other memory
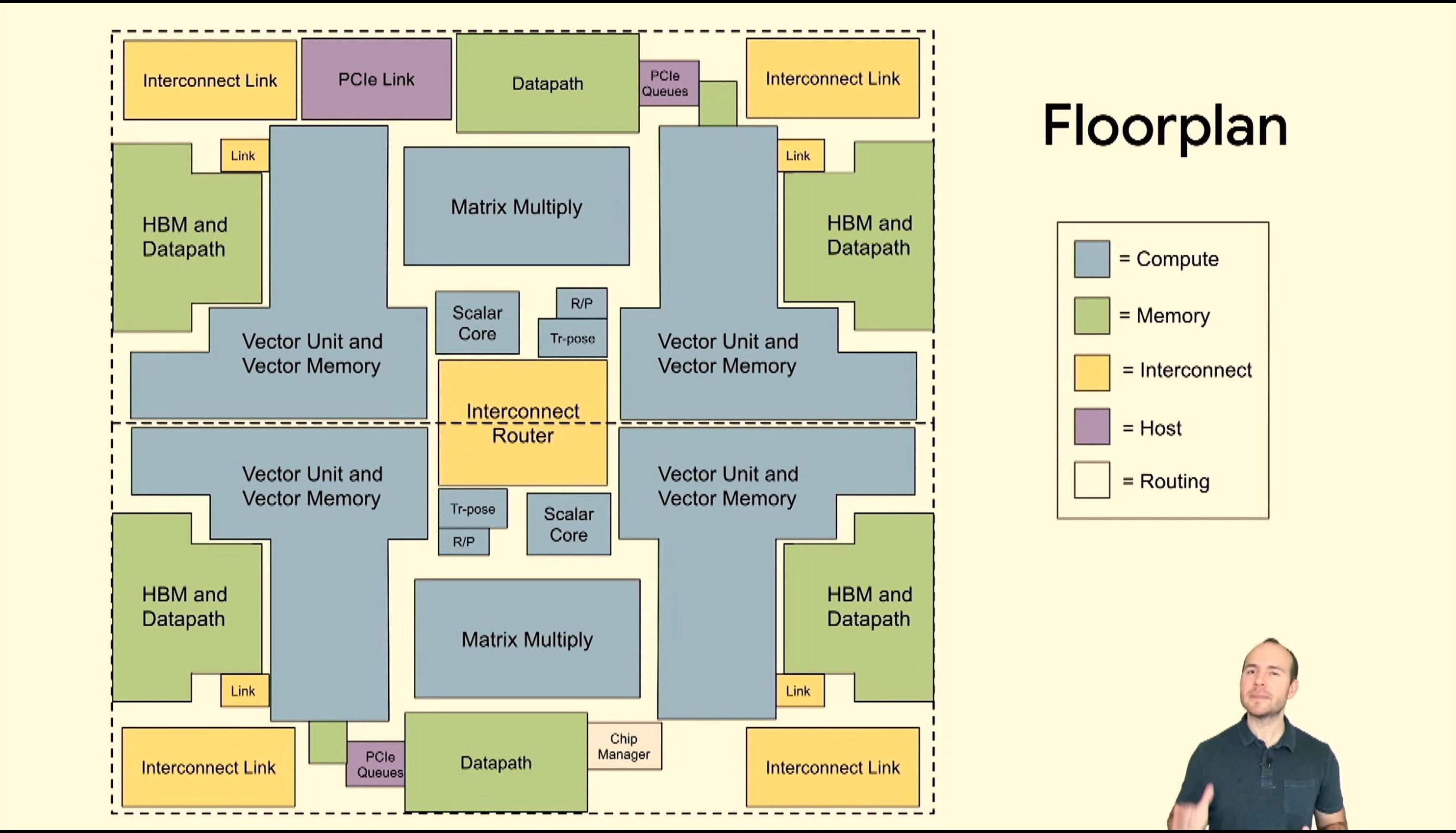
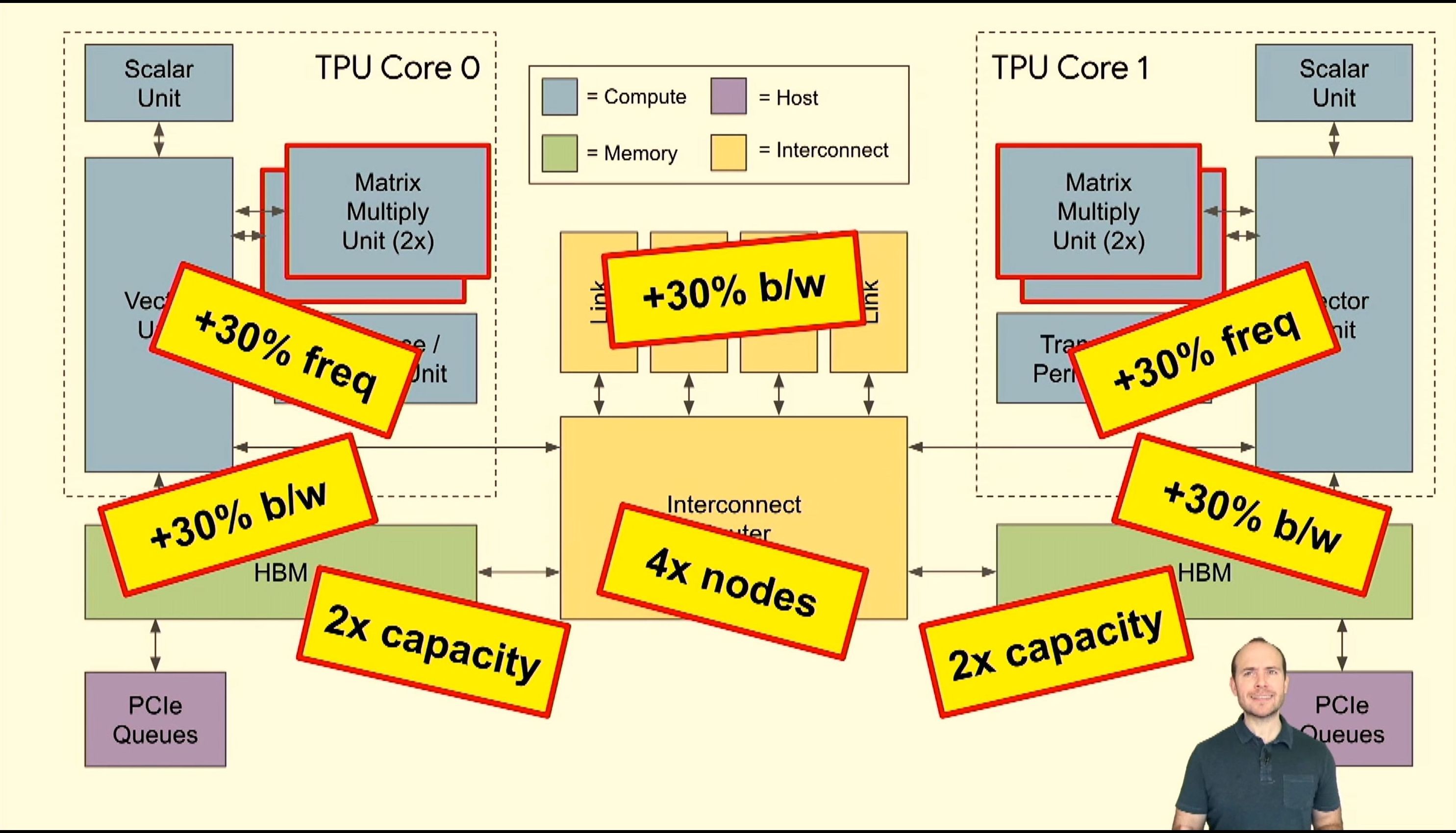
05:48PM EDT - Now TPUv3

05:49PM EDT - 2x mat mul units
05:49PM EDT - Clock 700 to 940 MHz
05:49PM EDT - HBM +30%
05:49PM EDT - 2x HBM
05:49PM EDT - 650 GB/s interconnect
05:49PM EDT - Supports 4x nodes per interconnect
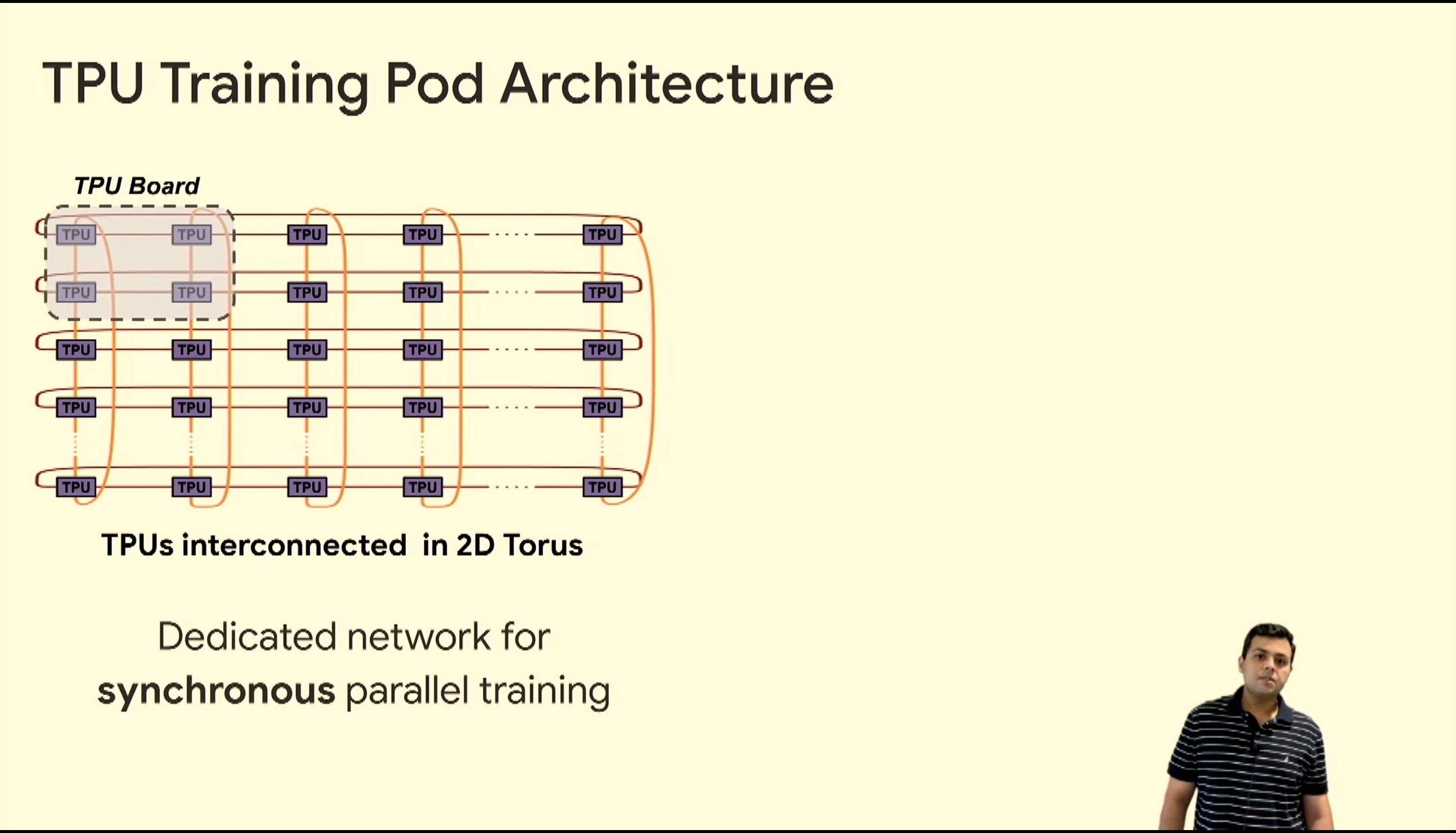
05:49PM EDT - 1024 chip v3 systems
05:50PM EDT - XLA compiler optimizations


05:52PM EDT - Storage over datacenter network

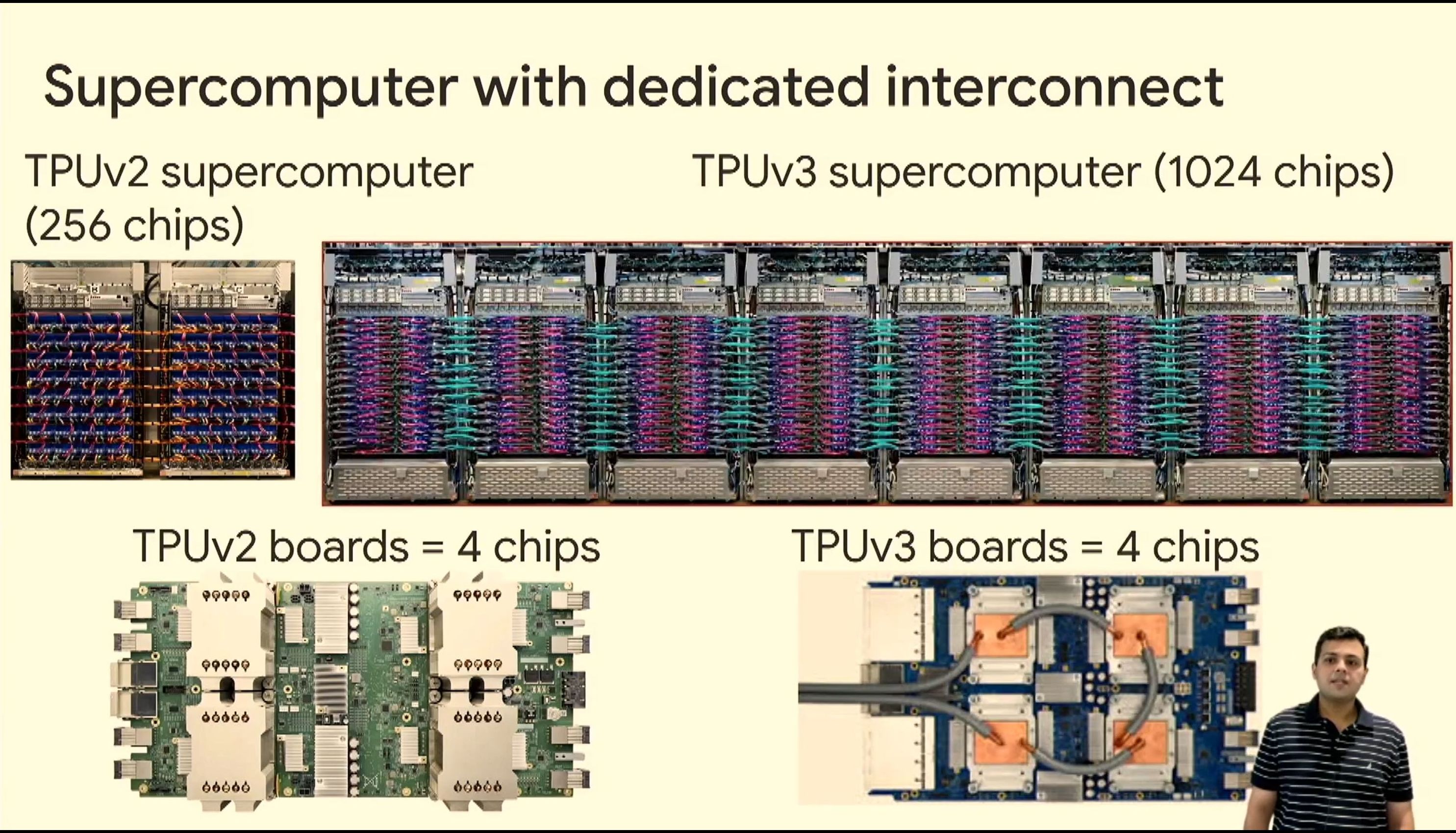

05:53PM EDT - >100 PF in TPUv3 pod

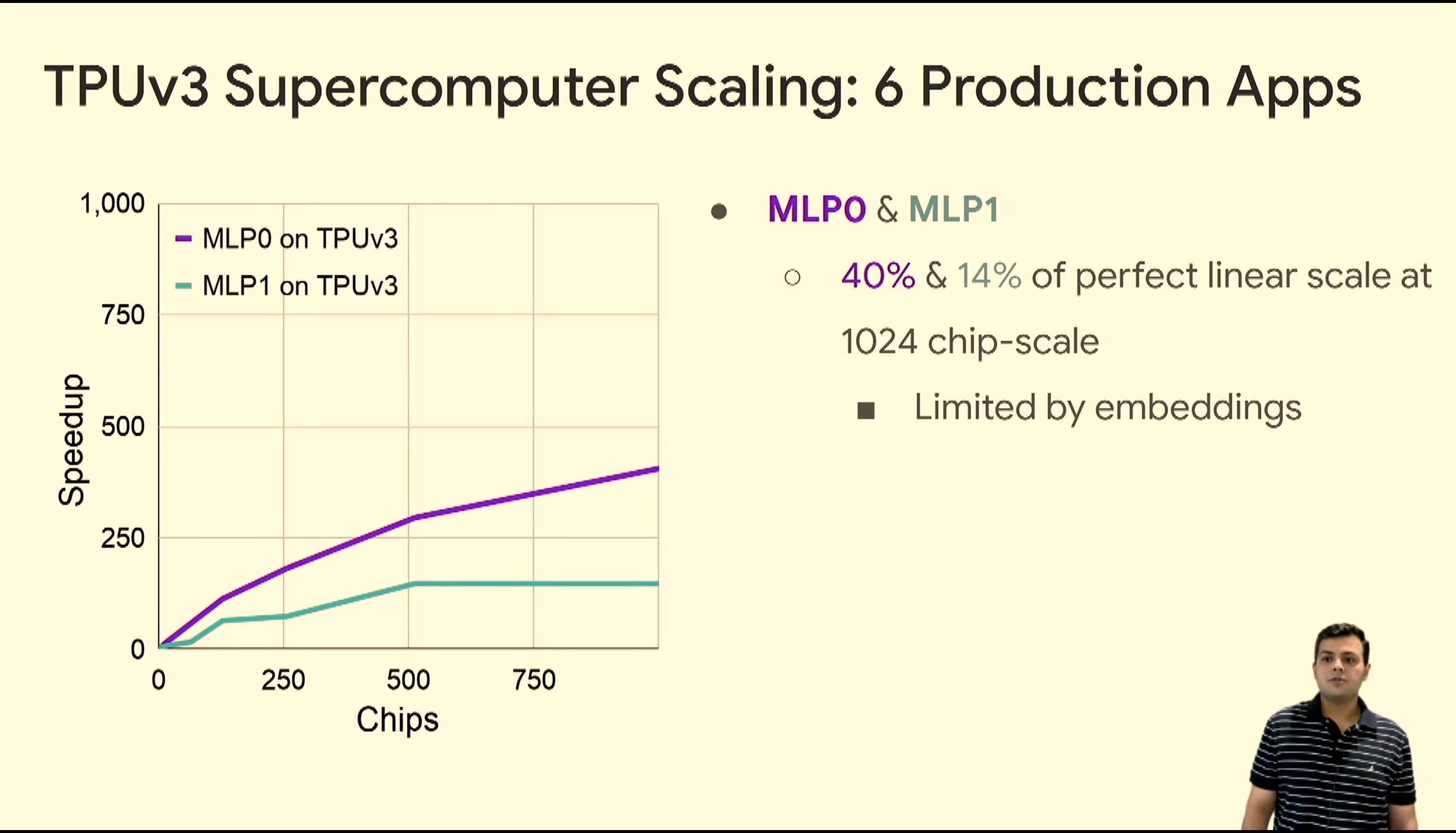
05:54PM EDT - Near ideal scaling on certain workloads
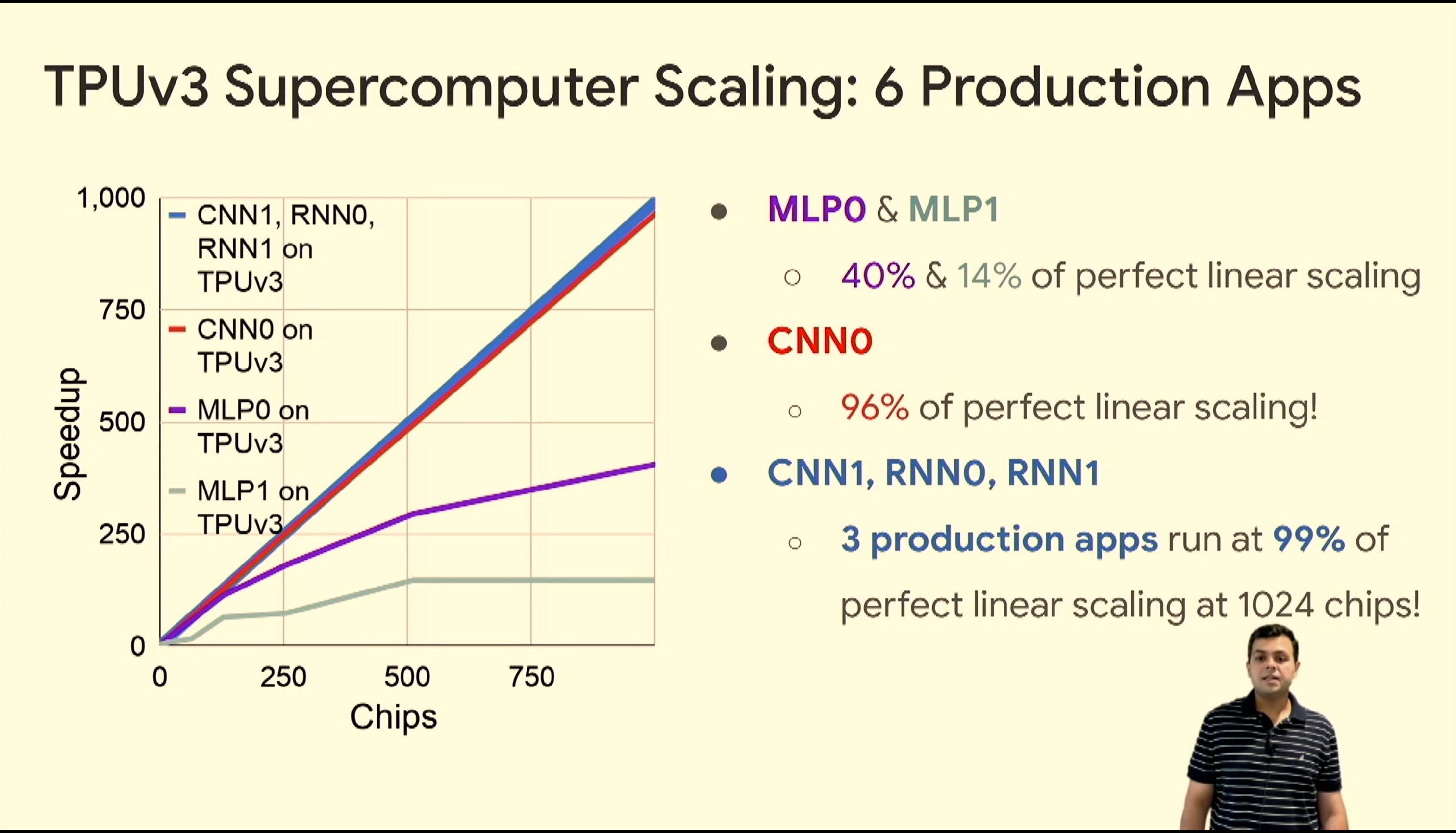
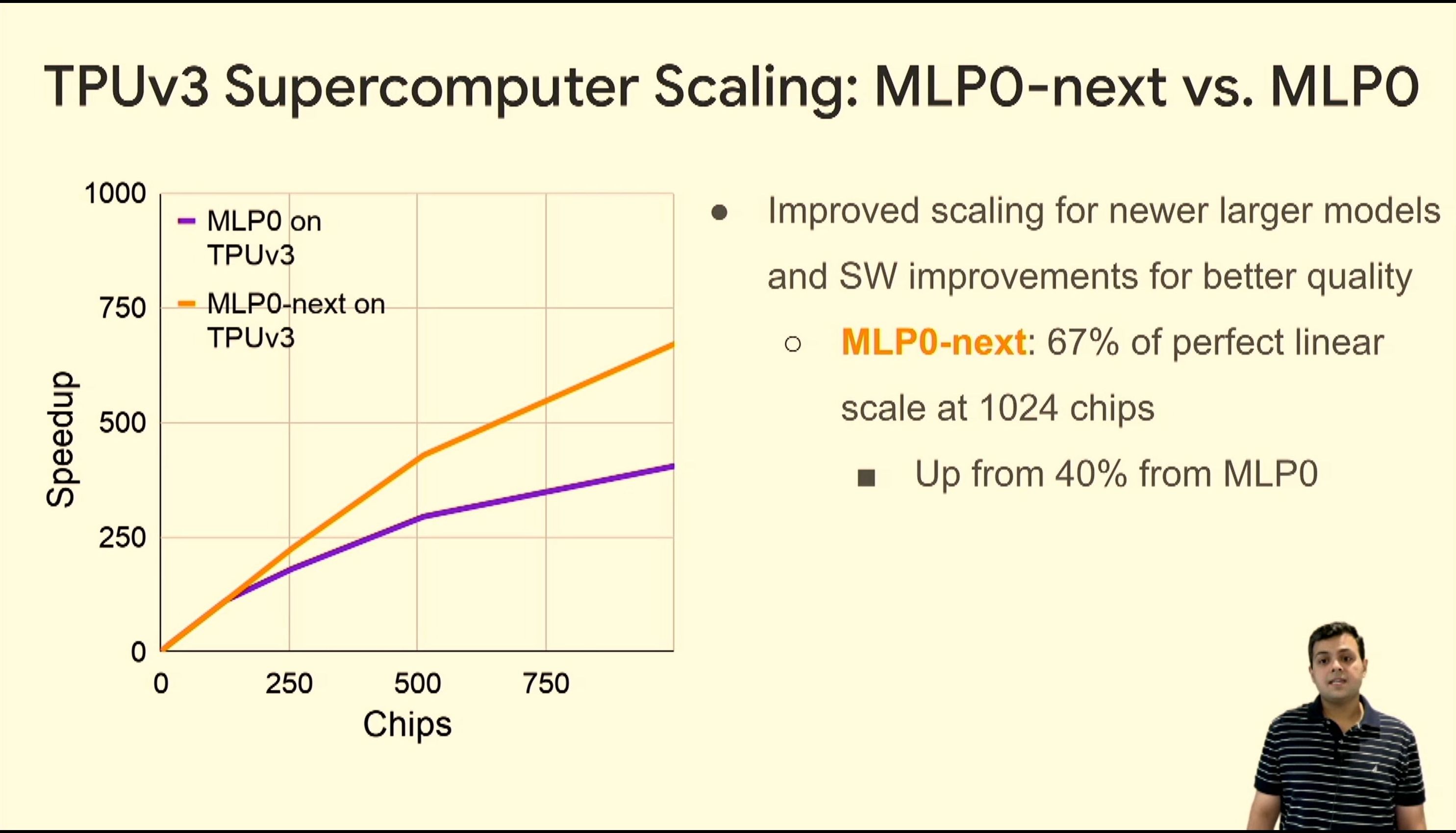
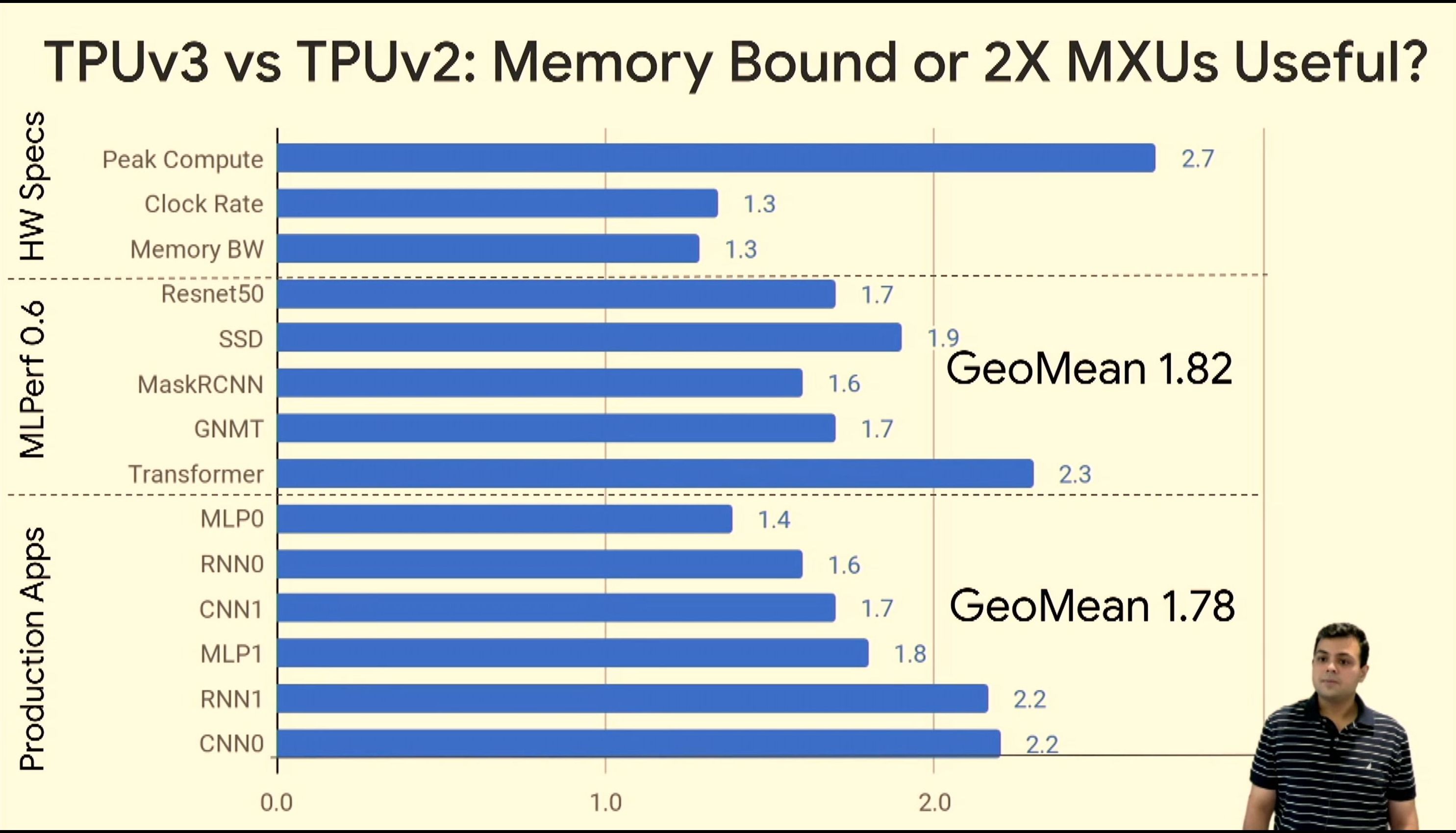
05:54PM EDT - TPUv3 perf uplift
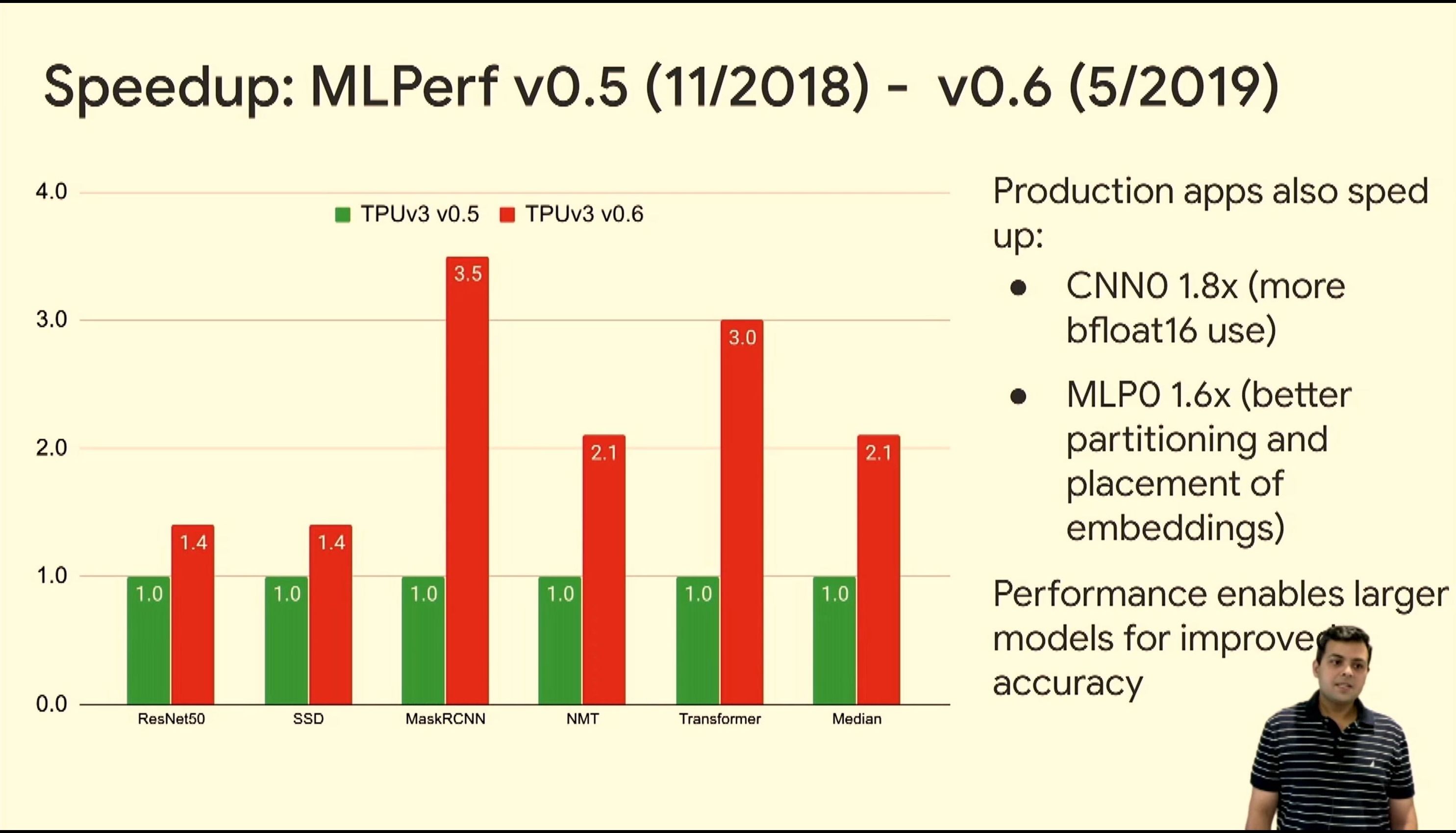
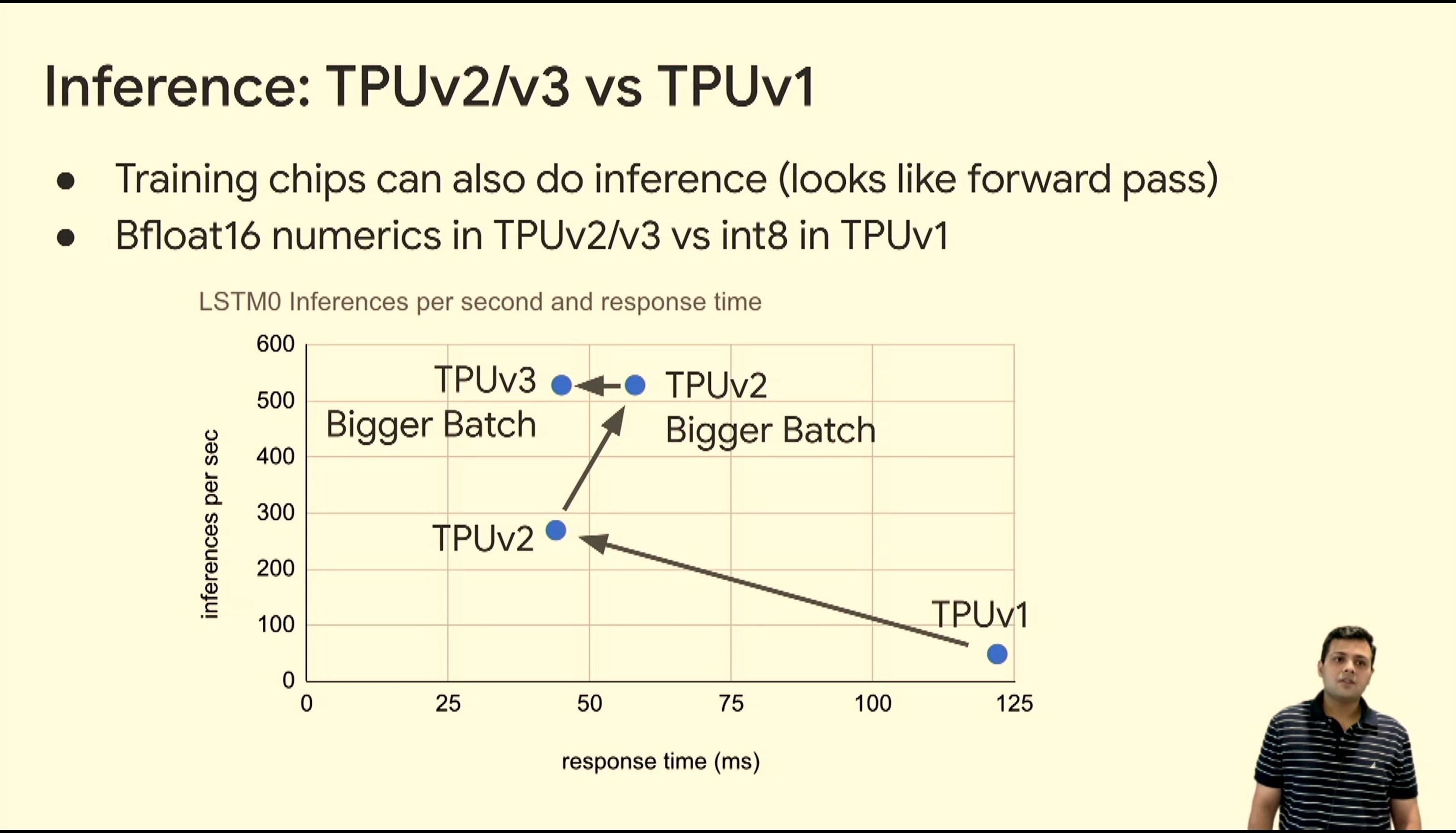
05:56PM EDT - Can also do inference

05:58PM EDT - Q&A time
05:58PM EDT - Q: TPUv4 on GCP? A: Don't have a roadmap. Internal only for now.
05:59PM EDT - Q: How do you deal with 100GBs of embedding tables? A: Partitioned across the chips. We use the fast ICI network to communicate between the chips
05:59PM EDT - Q: Are there chip level features that are there to help MLP? A: Those models are complex to model for. We have various techniques we use.
06:00PM EDT - Q: Trade-off of 2D torus vs switch based? A: Both are valid. One of the biggest advantages with us is taht we didn't have to build a switch or manage those things. Scaling up to large systems and our network traffic patterns work with torus?
06:01PM EDT - *torus.
06:01PM EDT - Q: Protocol over interconnect? A: Custom but super fast
06:02PM EDT - Q: Given benefits in every TPU gen, do you tradeoff market and features? A: Our biggest constraint! Have to do a good job. We prioritize. It's important not to go too far, but you have to go sufficiently far. We have teams working on this. Field is also changing rapidly, so we TTM quick.
06:02PM EDT - End of talk, next is Cerebras Wafer Scale!






