Original Link: https://www.anandtech.com/show/15995/hot-chips-2020-marvell-details-thunderx3
Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
by Andrei Frumusanu on August 17, 2020 4:30 PM EST- Posted in
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- Servers
- ThunderX3

Today as part of HotChips 2020 we saw Marvell finally reveal some details on the microarchitecture of their new ThunderX3 server CPUs and core microarchitectures. The company had announced the existence of the new server and infrastructure processor back in March, and is now able to share more concrete specifications about how the in-house CPU design team promises to distinguish itself from the quickly growing competition that is the Arm server market.
We had reviewed the ThunderX2 back in 2018 – at the time still a Cavium product before the designs and teams were acquired by Marvell only a few months later that year. Ever since, the Arm server ecosystem has been jump-started by Arm’s Neoverse N1 CPU core and partner designs such as from Amazon (Graviton2) and Ampere (Altra), a quite different set of circumstances and alongside AMD’s successful return in the market, a very different landscape.
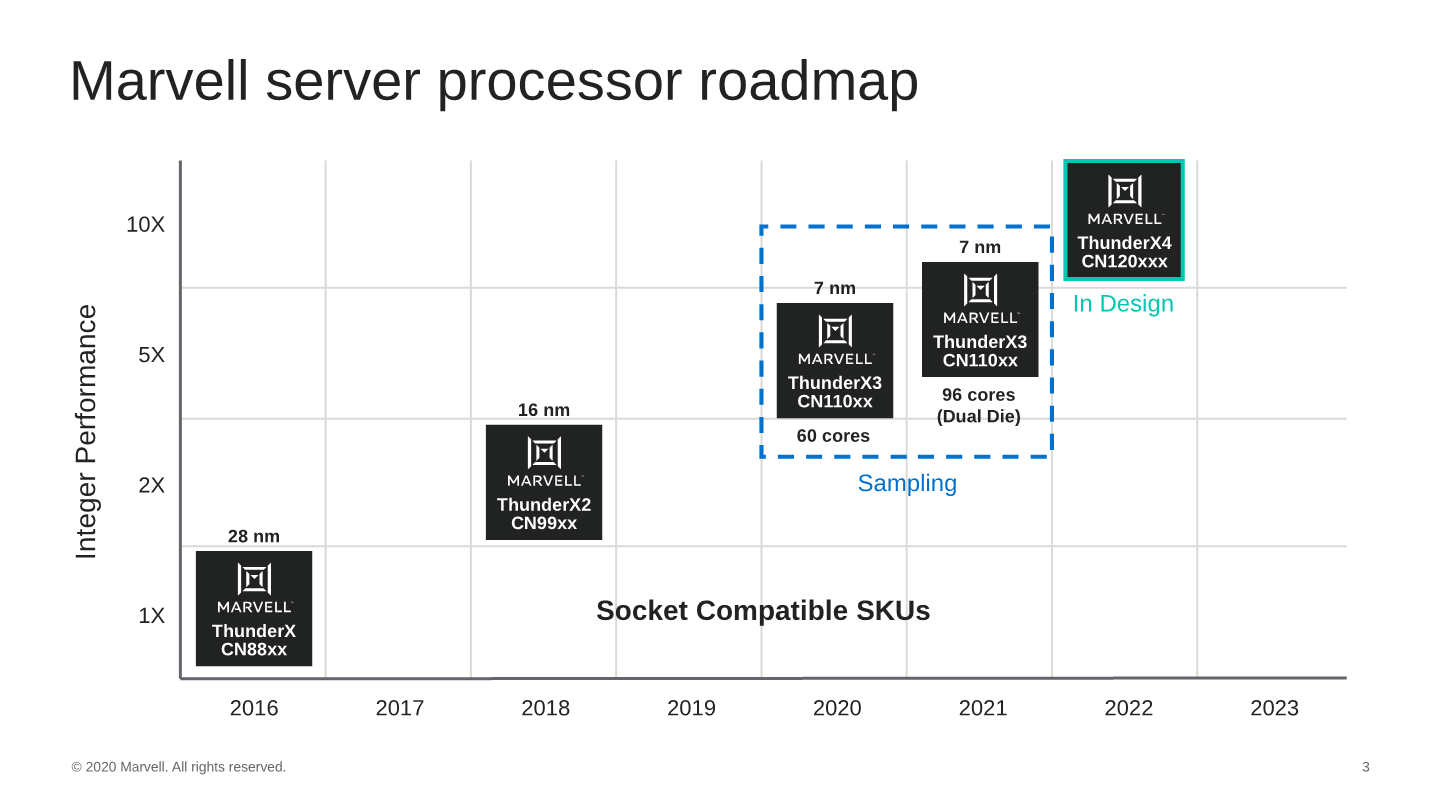
Marvell started off the HotChips presentation with a roadmap of its products, detailing that the ThunderX3 generation isn’t merely just a single design, but actually represents a flexible approach using multiple dies, with the first generation 60-core CN110xx SKUs using a single die as a monolithic design in 2020, and next year seeing the release of a 96-core dual-die variant aiming for higher performance.
The use of a dual-die approach like this is very interesting as it represents a mid-point between a completely monolithic design, and a chiplet approach from vendors such as AMD. Each die here is identical in the sense that it can be used independently as standalone products.
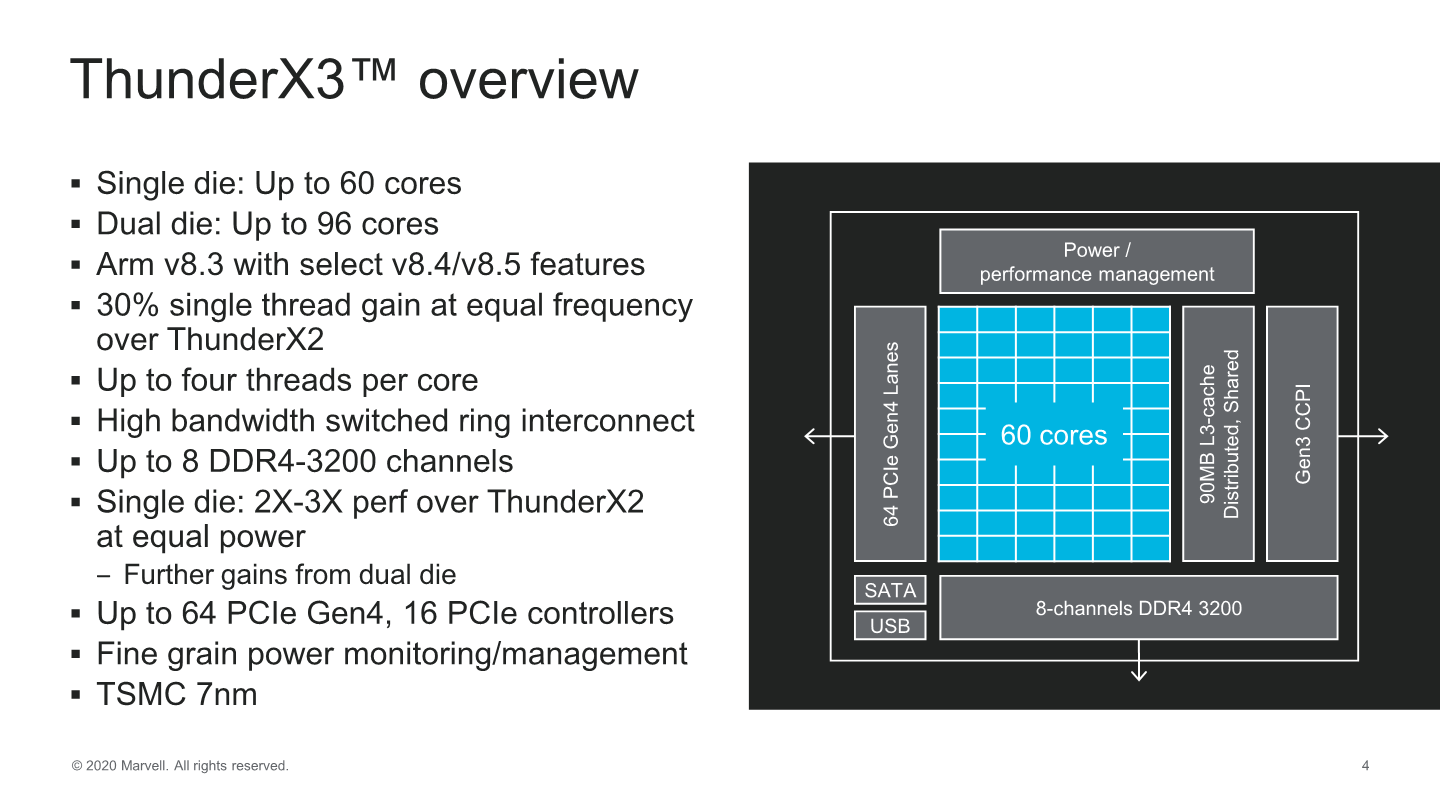
From a SoC-perspective, the ThunderX3 die scales up to 60 cores, with the 2-die variant scaling up to 96. The first thing question that comes to mind when seeing these figures is why the 2-die variant doesn’t scale up to the full 120-cores- Marvell didn’t cover this during the talk but there were a few clues in the presentation.
Marvell had made the performance improvement claim of 2-3x over a ThunderX2 at equal power levels. This latter had a TDP of 180W – if the TX3 maintains this thermal envelope then it would mean that a dual-die design would have had to grow TDPs to up to 360W which far beyond what one can air cool in a typical server form-factor and rack in terms of power density. Assuming just a linear cut-down to 96 cores as advertised we’d end up around 288W – which is more in line with the current high-end server CPU deployments without water-cooling. Of course – this is all our own analysis and take of the matter.
A single die supports 8 channels of DDR4-3200 which is standard for this generation of a server product and essentially in line with everybody else in the market. I/O wise, we see a disclosure of 64 lanes of PCIe 4.0 – which is again in line with competitors but half of what higher-end alternatives from Ampere or AMD can achieve.
One big unknown right now is how the dual-die product will segment the I/O and memory controllers – if this is going to be a 50-50 split in terms of resources between the two dies, or whether we’ll see an imbalanced setup – or if the platform can actually handle the full resources from each die and transform itself into a 16-channel 128 lane beast?
| Comparison of Major Arm Server CPUs | |||||
| Marvell ThunderX3 110xx |
Cavium ThunderX2 9980-2200 |
Ampere Altra Q80-33 |
Amazon Graviton2 |
||
| Process Technology | TSMC 7nm |
TSMC 16 nm |
TSMC 7 nm |
TSMC 7nm |
|
| Die Type | Monolithic or Dual-Die MCM |
Monolithic | Monolithic | Monolithic | |
| Micro-architecture | Triton | Vulcan | Neoverse N1 (Ares) | ||
| Cores | 60 (1 Die) Swiched 3x Ring 96 (2 Die) |
32 Ring bus |
80 Mesh |
64 Mesh |
|
| Threads | 240 (1 Die) 384 (2 Die) |
128 | 80 | 64 | |
| Max. number of sockets | 2 | 2 | 2 | 1 | |
| Base Frequency | ? | 2.2 GHz | - | - | |
| Turbo Frequency | 3.1 GHz | 2.5 GHz | 3.3 GHz | 2.5 GHz | |
| L3 Cache | 90MB | 32 MB | 32 MB | 32 MB | |
| DRAM | 8-Channel DDR4-3200 |
8-Channel DDR4-2667 |
8-Channel DDR4-3200 |
8-Channel DDR4-3200 |
|
| PCIe lanes | 4.0 x 64 (1 Die) |
3.0 x 56 | 4.0 x 128 | 4.0 x 64 | |
| TDP | ~180W (1 Die) (unconfirmed) |
180W | 250 W | ~110-130W (unconfirmed) |
|
On paper at least, the ThunderX3 seems quite similar to Amazon’s Graviton2 as they both share a similar amount of CPU cores and similar memory and IO configurations. The bigger differences that one can immediately point out to is that the ThunderX3 employs SMT4 in its CPU cores and thus supports up to 240 threads per die. There’s also a TDP difference, but I attribute this to the Graviton2 being conservative with its clock frequencies, whilst Ampere’s SKUs being more in line with the ThunderX3, particularly the 64-core 3.0GHz 180W Q64-30 being the closest match in specifications.
Another thing that stands out for the ThunderX3 is the 90MB of L3 cache that dwarfs the 32MB of the previous generation as well as the 32MB configurations of Ampere and Amazon.
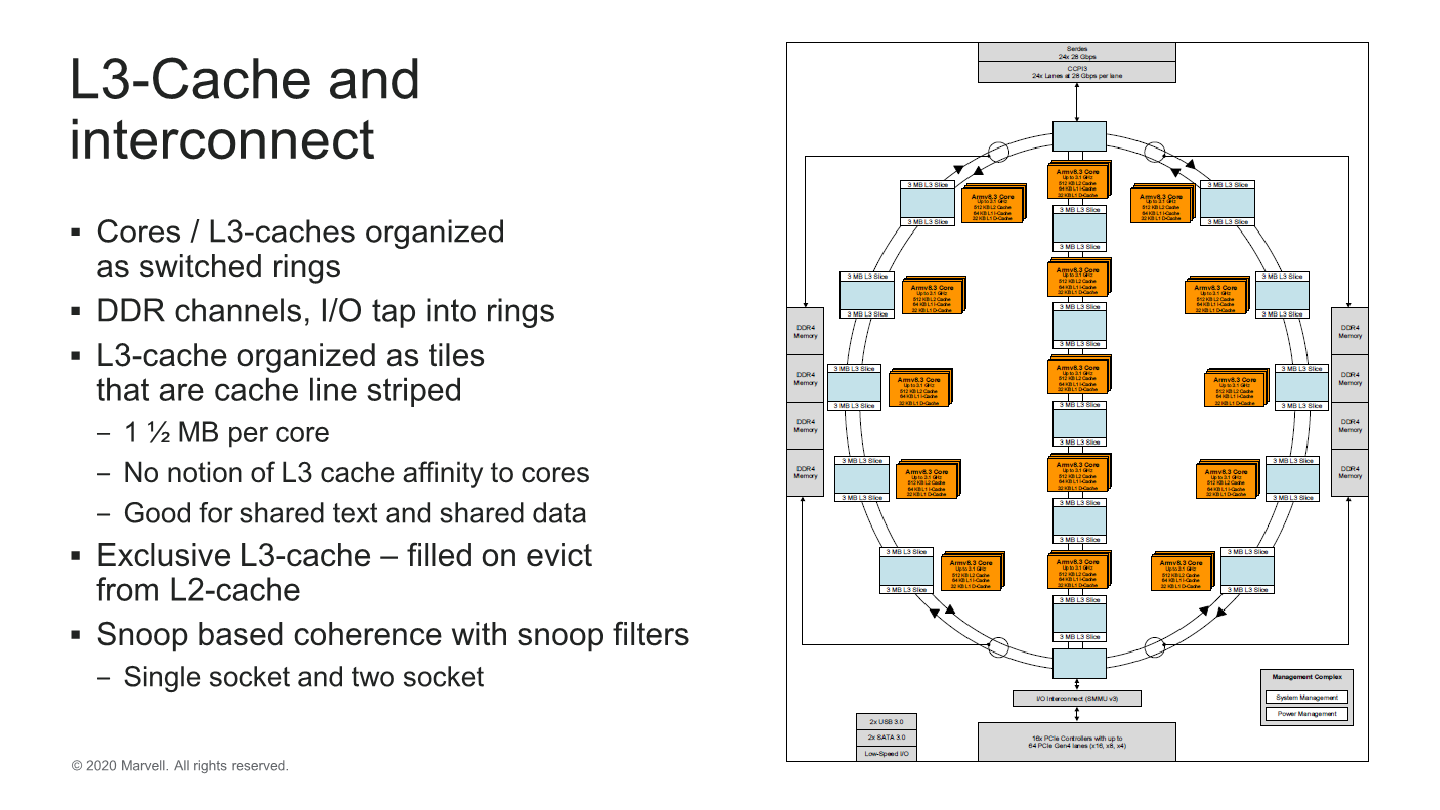
Marvell here opted to evolve its own interconnect microarchitecture which has now evolved from a simple ring design, to a switched ring with three sub-rings, or columns. Ring stops consist of CPU tiles with 4 cores and two L3-slices with 3MB of cache. This gives a full die with 15 ring stops (3x5 columns) and the full 60 cores 90MB of total L3 cache which is a quite respectable amount.
In the Q&A sessions, Marvell disclosed that their rationale for a switched ring topology versus a single ring, or a mesh design was that a single ring wouldn’t have been able to scale up in performance and bandwidth at higher core counts. A mesh design would have been a big change, and it would have required a reduction in core count. A switched ring represented a good trade-off between the two architectures. Indeed, if this is what enabled Marvell to include up to 3x the cache versus its nearest competitors, it seems to have been a good choice.
One odd thing I noted is that the system is still using a snoop-based coherency algorithm which comes in contrast with other directory-based systems in the industry. This might reduce implementation complexity and area, but might lag behind in terms of power efficiency and coherency traffic for the chip.
The memory controllers tap into the rings, and Marvell’s inter-socket/die CCPI3 interface here serves up to 84GB/s of bandwidth.
The Triton CPU Core - Evolution From Vulcan
Moving on onto the core level, we see the first disclosures on Marvell’s new Triton CPU microarchitecture. The design is an evolution of the ThunderX2’s Vulcan cores with the company widening a lot of the aspects of the core, both in the front-end and on the back-end.
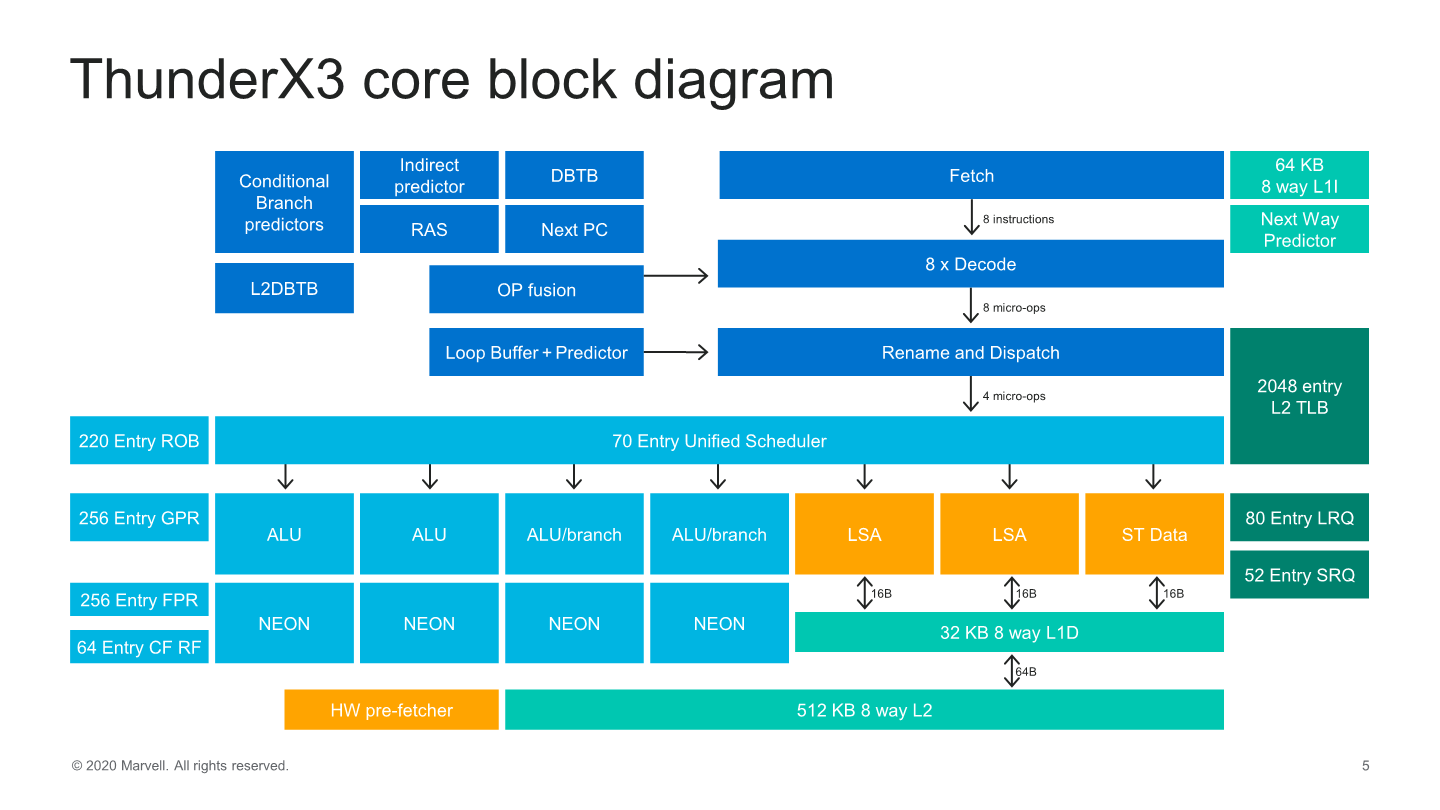
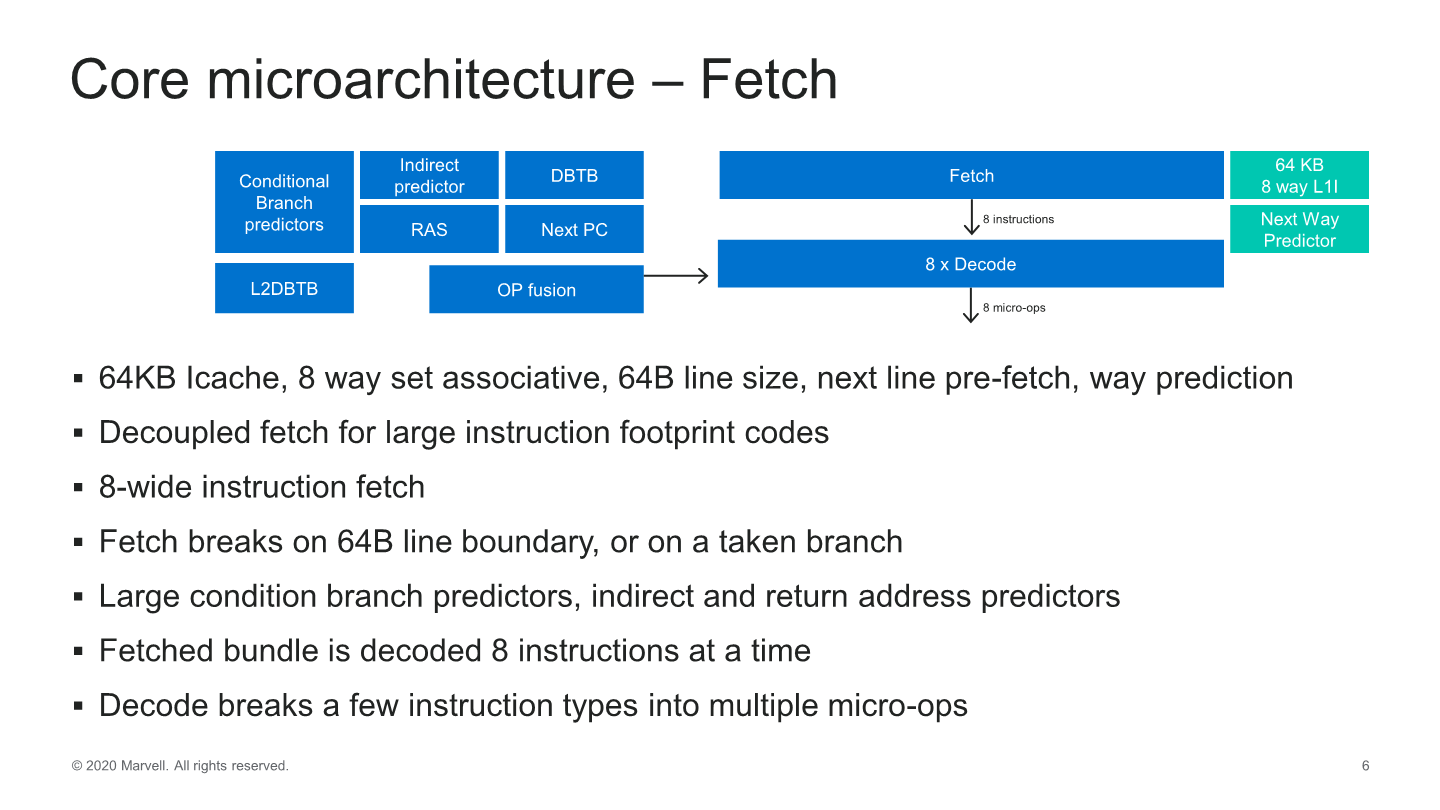
Starting off with the front-end side of the core, we see some very significant changes as we’ve almost seen a literal doubling of most structures and bandwidth in the core. The instruction cache has been doubled up from 32KB to 64KB, which now feeds into an 8-wife fetch unit, also double the previous generation.
Much like Arm’s recent microarchitectures, this is a new decoupled fetch unit that allows for better power savings. The decode unit matches the fetch bandwidth at 8 instructions wide – which actually along with the Power10 core from IBM now represents the widest decoders in the industry right now, which is quite surprising.
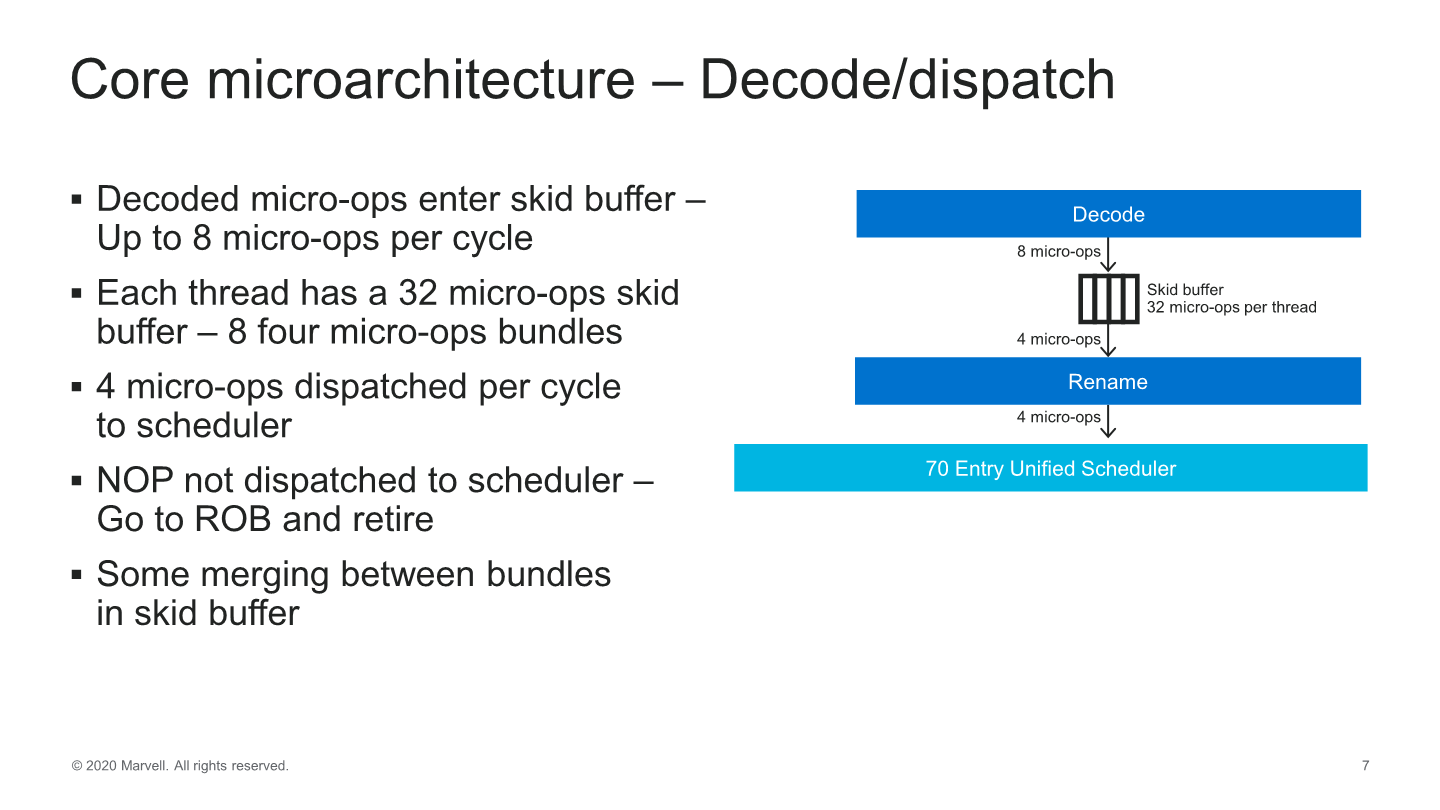
In the mid-core we see the decode unit feed into what Marvell calls a “Skid buffer”, which is essentially a loop buffer, which is segmented into 32 micro-ops per thread, further divided into eight four-wide micro-op bundles. It’s one of the rare structures in the core which is statically partitioned between threads, and it represents the boundary between the front-end and the mid-core of the microarchitecture.
The most interesting and confusing part of the Trition microarchitecture is at this part of the core, as even though the fetch and decode units of the core are 8-wide, micro-ops out of the Skid-buffer and into the rename unit and dispatched to the backend of the core only happens at 4 micro-ops per clock. So what seems to be happening here is that Marvell is taking advantage of a very wide front-end design not to actually feed a large back-end, but rather to better hide pipeline bubbles working in wider “bursts”.
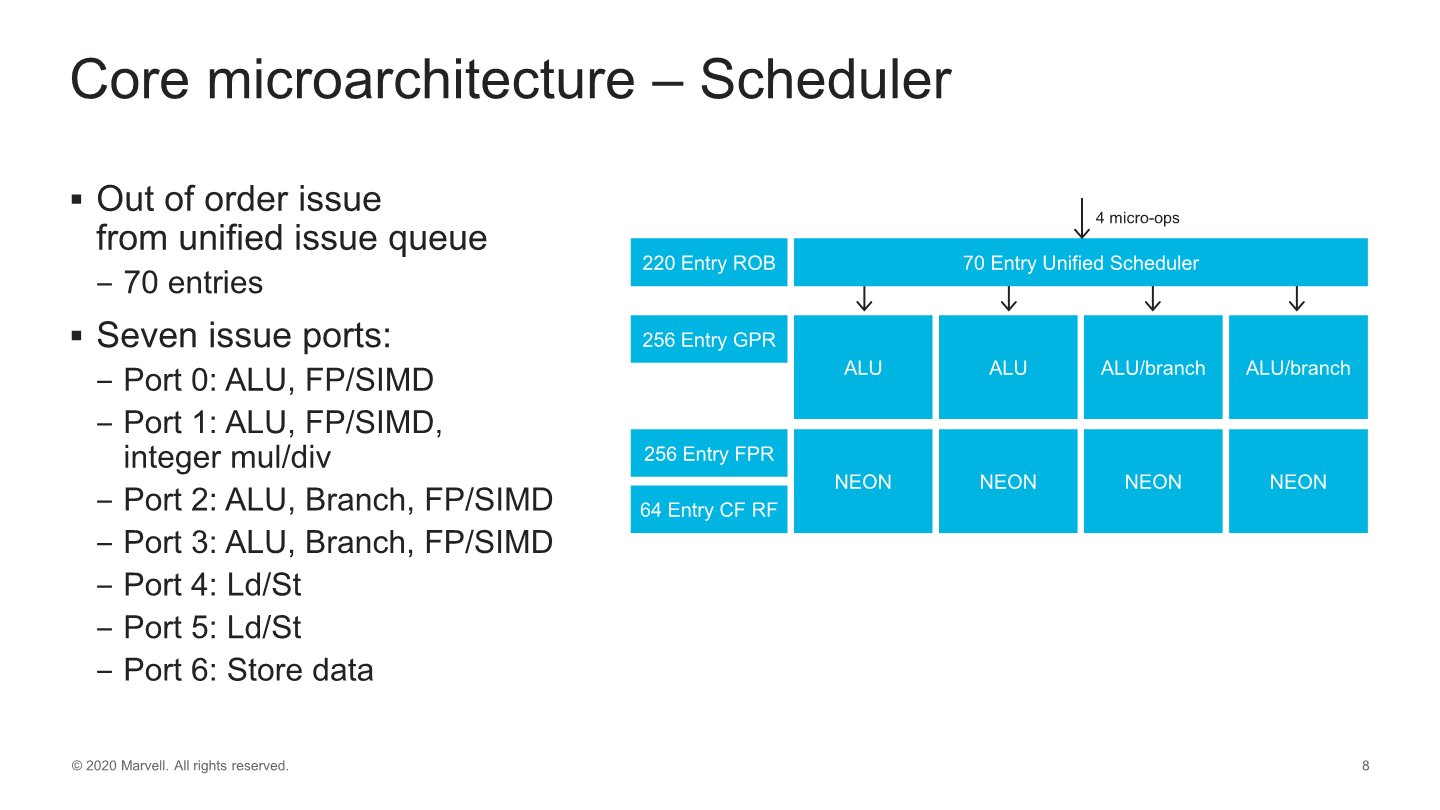
Dispatch into the backend of the core we see continued usage of a global unified scheduler that feeds into 7 execution ports. At the scheduler-level, we’ve seen a slight increase from 60 to 70 entries.
The out-of-order window of the core has increased slightly, such as the re-order buffer (ROB) growing from 180 to 220 entries.
On the execution ports, the big change has been the addition of a fourth execution pipeline capable of ALU instructions and a second branch port, meaning we’re seeing a 33% increase in simple integer ALU execution throughput and a doubling of the branch forwarding of the core. Alongside of these improvements, all four execution pipelines have been expanded with FP/SIMD capabilities which means there’s now a generational doubling of throughput for these instructions, making the Triton core one of the rare 4x128b machines out there.
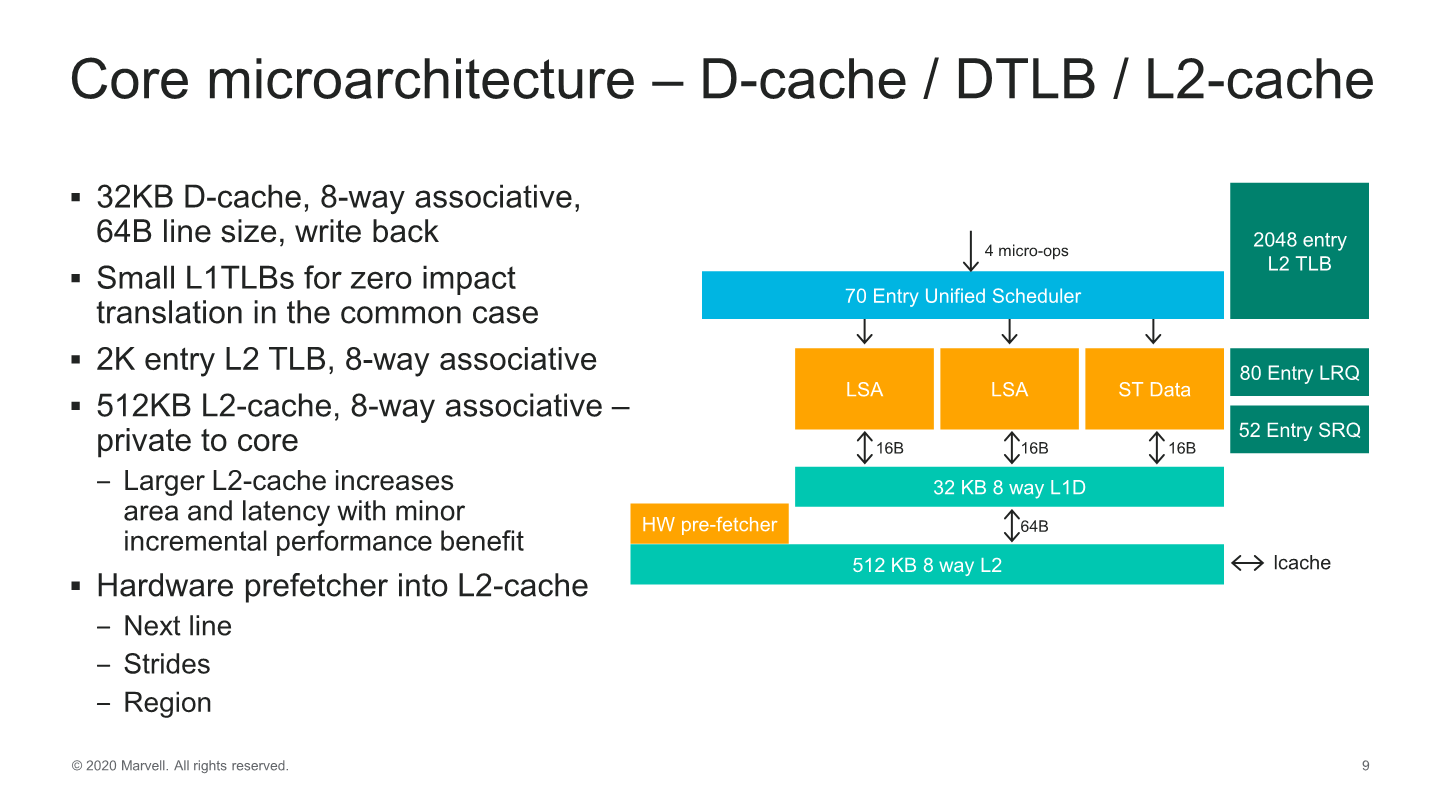
On the memory subsystem part of the core, improvements have been relatively small as we don’t seem to have major high-level changes of the microarchitecture. We still see two load-store units and a store data unit with bandwidths of 16 Bytes/cycle per unit feeding and fetching data from a 32KB L1 data cache. The load and store queues have been increased in their depth and have increased respectively from 64 to 80 entries for loads, and 36 to 48 entries for stores.
The core’s L2 has also doubled from 256KB to 512KB, but Marvell’s wording here on this change is interesting as they say it increases area and latency with only “minor incremental performance benefits”, which sounds quite disappointing in tone. We’ll see in the next slide this means 2.5%.
The hardware prefetchers are quite simplistic, with your traditional next-line, stride, and region-based designs pulling data into the L2.
Overall, generational IPC improvements of the new core sum up to 30% in SPECint, and Marvell was generous enough to give us an overview of the new core’s features and how each is accounts for the total improvement:
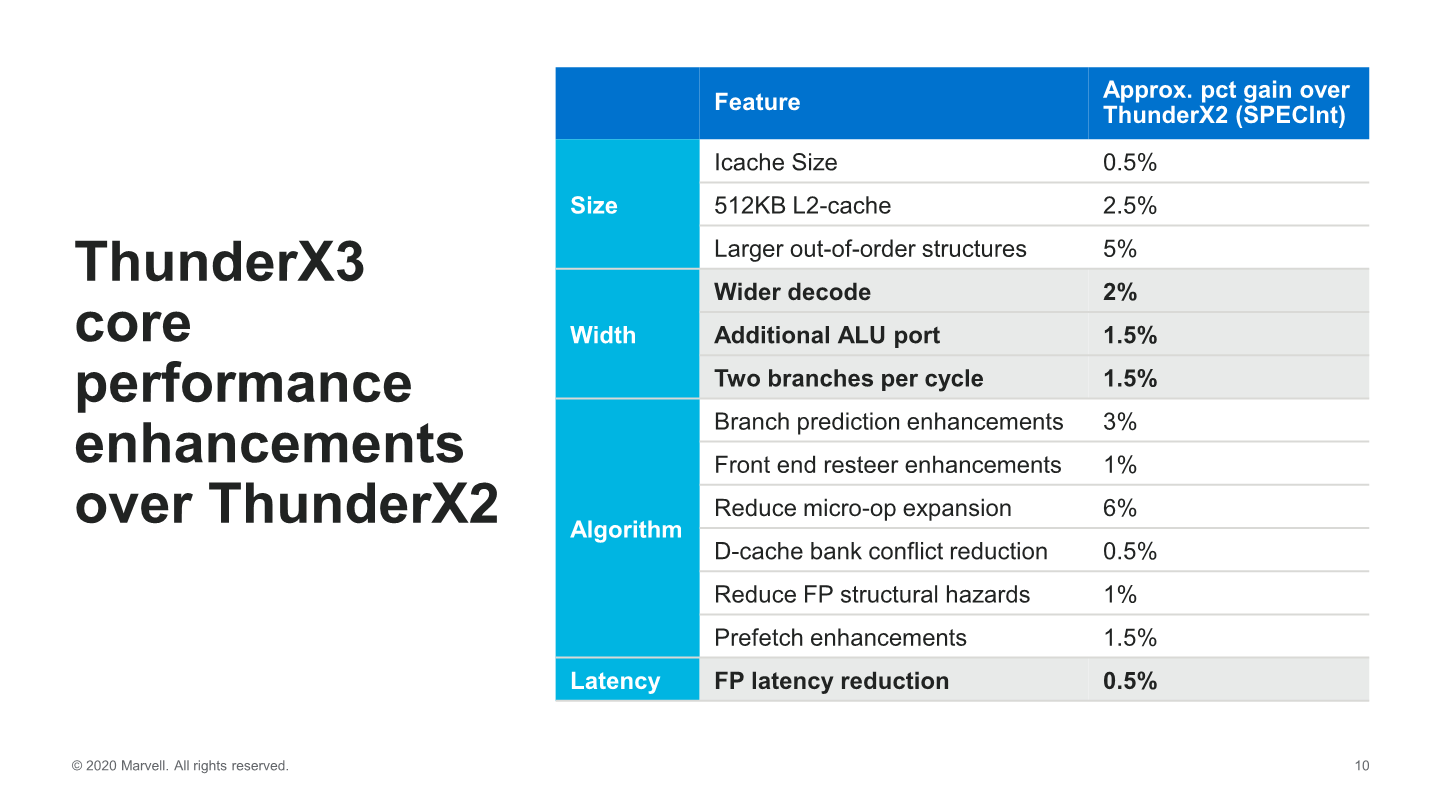
On the structure side increases of things, the biggest improvements were due to the larger OoO increases in the mid-core which, although the increases weren’t all that big, represent a 5% IPC improvement. This seems a quite good trade-off versus some other doubling of structures such as the L1I and the L2 cache increases which only got a 0.5% and 2.5% benefit.
The front-end’s doubling and wider decode from 4 to 8 only accounted for only 2% improvement in performance which is extremely tame, but is likely bottlenecked given the narrow mid-core dispatch and comparatively narrow execution back-end.
The biggest improvement in IPC was due to reduced micro-op expansion from the decoder – Marvell here stated that they had been too aggressive in this regard on the ThunderX2 Vulcan cores in expanding instructions into multiple micro-ops, so they’ve reduced this significantly, and this probably alleviating the bottleneck on the mid-core and resulting into better back-end utilisation per actual instruction.
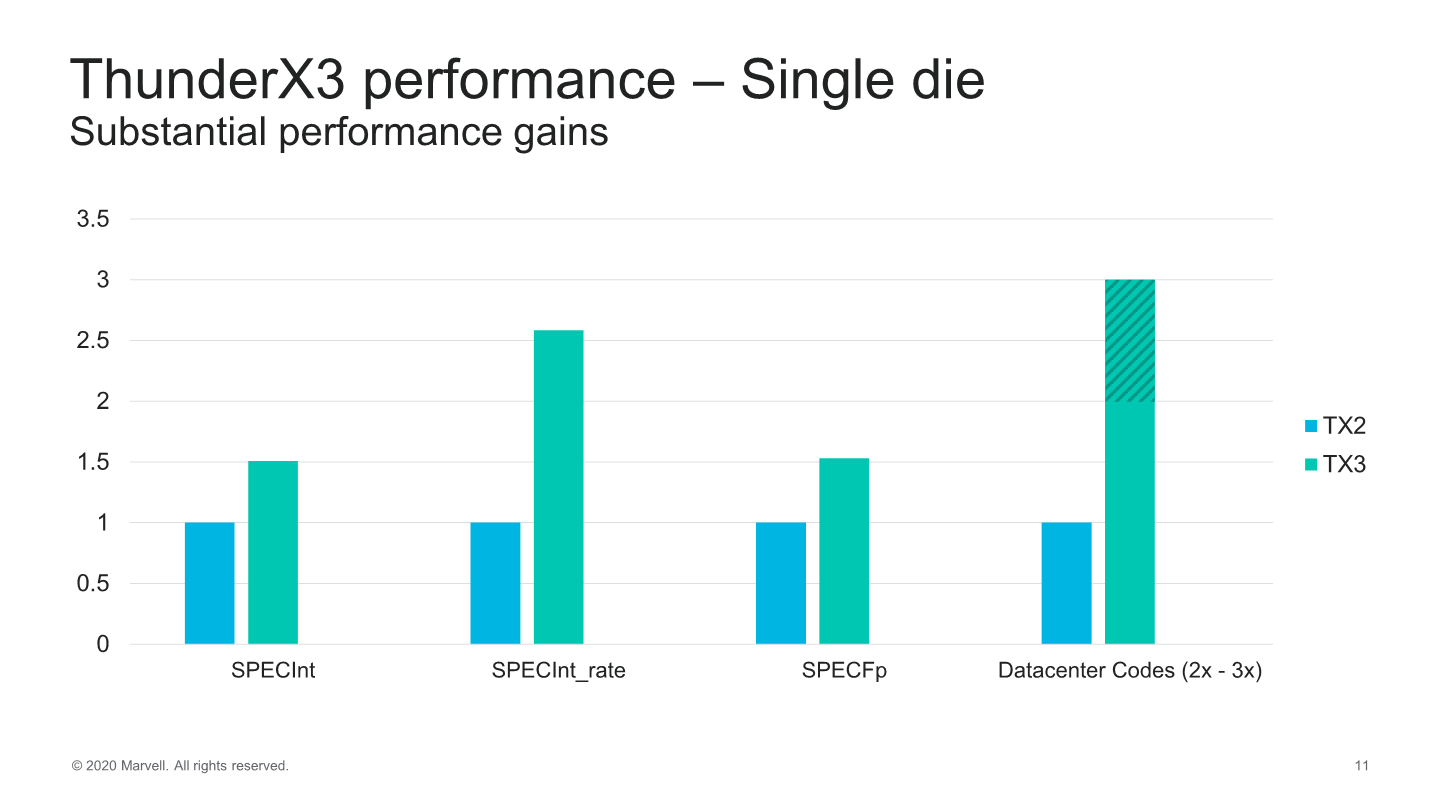
Generational performance improvements accounting for the IPC gains as well as frequency gains, we’re expected to see a 1.5x gain in SPECint. Given our historical numbers on the TX2, by these projections we should thus expect the TX3 to outperform the Graviton2 by around 10%.
SPECrate gains are naturally higher at around 2.5x the performance, thanks to the new design’s higher core count further amplifying the microarchitectural improvements.
SMT4 Details - Four Threads Per Core
One of the things that makes the Thunder line-up stand out from the competition is its inclusion of 4-way SMT, meaning that each core can execute up to 4 threads.
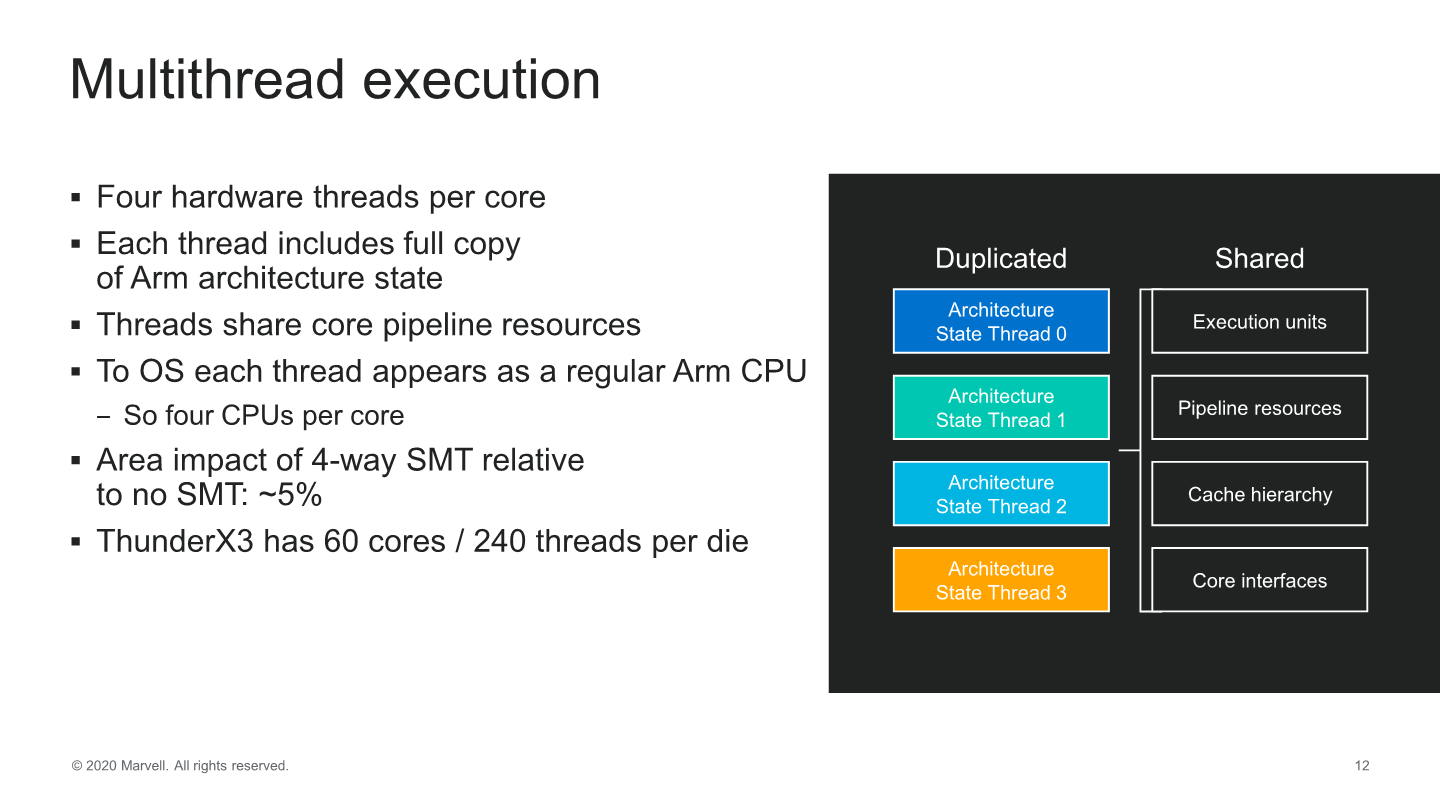
Each thread is viewed from the OS as a fully independent CPU and each has its own independent Arm architecture state, sharing the vast majority of the core’s resources bar a very few exceptions such as the aforementioned Skid Buffer.
The microarchitecture had always been multi-threaded, but Marvell went ahead to re-account for the area impact of SMT and discloses that it only takes about 5% of a core.
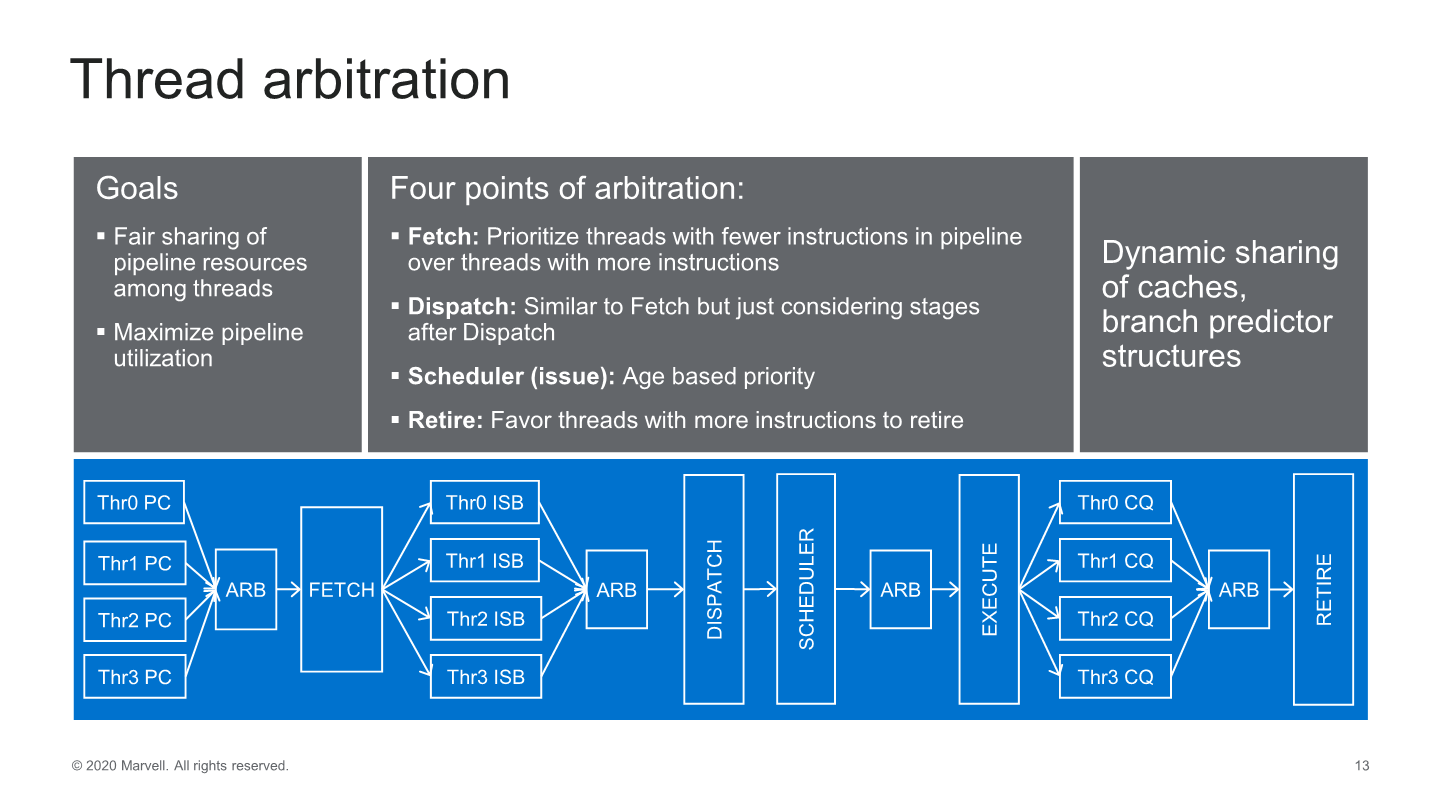
The company further details some of the mechanisms of its SMT, such as its arbitration mechanism between threads. During the fetch stage for example, the core will pick the thread which currently has the least amount of instructions live in the core’s pipelines, ensuring that the number of micro-ops and instructions further down the pipeline are balanced between the threads. We see a similar logic in the dispatch stage, and the thread with the fewest instructions downstream in the pipeline is picked out of the Skid Buffer.
The back-end has no notion of threads and simply executes the micro-ops which are oldest first. Retiring happens with priority in regards to the threads that have most backed up instructions for retiring.
Marvell says that this thread arbitrations works quite well on most codes, with the execution latencies between threads being quite uniform.

The speed-up that SMT can bring to the table is reversely correlated with the IPC of a given workload, meaning that a low IPC workload will see the biggest improvements with SMT. Other way to describe this is data-plane centric workloads which have a high latency to data fetching for execution are better suited to hide these kind of bottlenecks and idle-periods of the core through SMT.
Low-IPC workloads such as databases see a quite big gain in IPC and performance reaching up to 2x for 4 threads. Higher IPC workloads with a smaller data footprint will see more limited benefit to IPC.
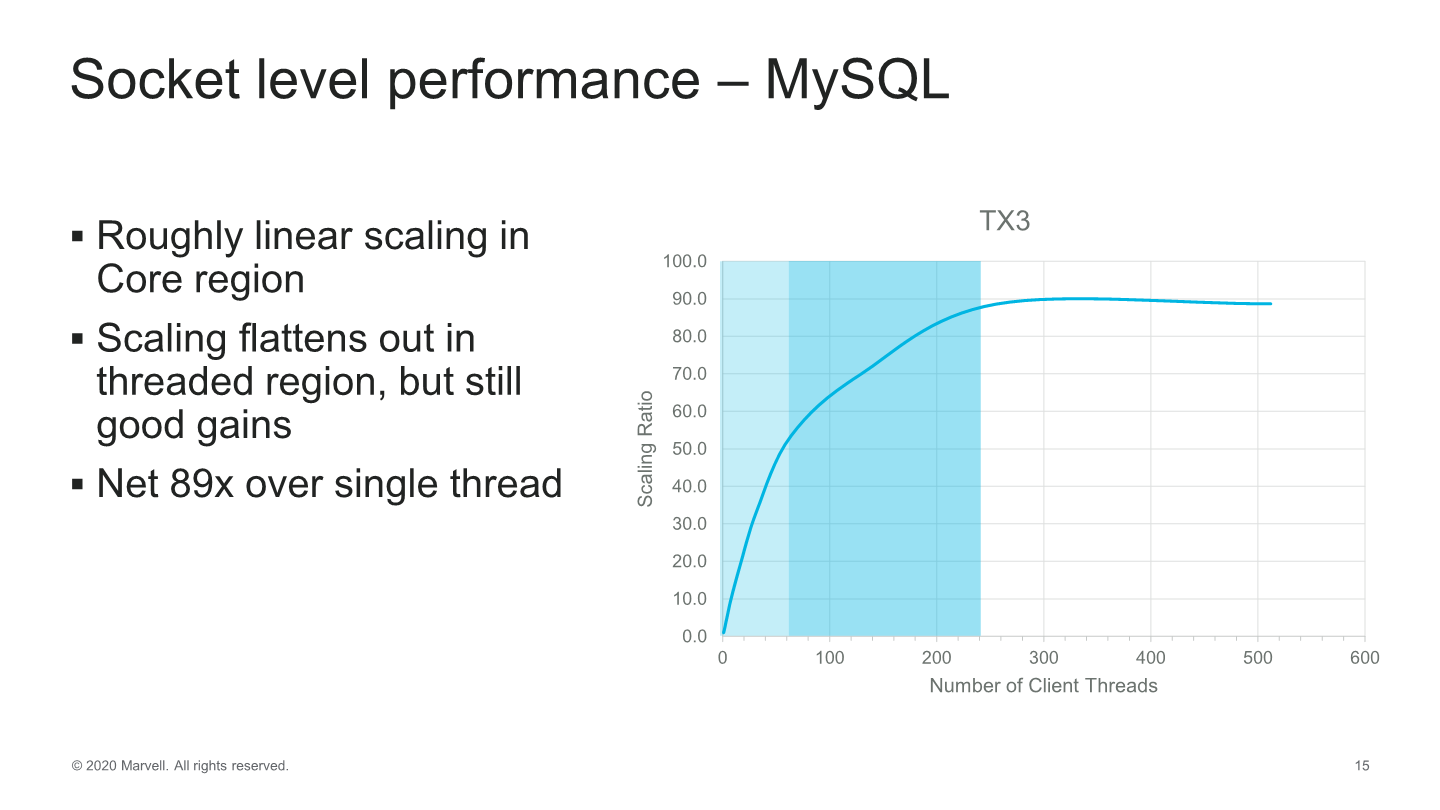
Translating this to socket-level performance, we see a great scaling up to 60 cores which is essentially the physical core count of the processor, and a more sub-linear, but still quite respectable scaling up to 240 threads. Performance from 60 to 240 threads increases by roughly 60% which is a nice gain considering the very low area impact of SMT4 on Marvell’s cores.

When asked about how its ThudnerX3 is positioned against the competition, Marvell says that against Intel based products the company will slightly lag behind in single-thread performance, but will offer vastly greater multi-threaded throughput. Against AMD (we assume Rome), the TX3 is said to perform better in single-threaded performance with AMD taking the lead in workloads with low data sharing, although the TX3 to do better in workloads with more data-sharing such as database applications. Graviton2 is said to be a very good chip, although it offered low frequency and no threading support, so those are the areas the TX3 would be better in.
Overall, the TX3 seems like a solid candidate in the current server space, however I don’t feel like it differentiates itself very much aside from the fact that it offers SMT support. I feel like the CPU’s microarchitecture is still quite narrow, and although the IPC improvements are generationally good, Marvell also has significantly longer time between releases than Arm. In that regard, only slightly beating the Graviton2 here doesn’t seem enough and I do expect Altra-based designs to be faster.
We’ll have to see how the ThunderX3 ends up in terms of performance and power efficiency, but aside from dataplane heavy workloads that can fully take advantage of SMT, I feel like it might be a too close for comfort race for Marvell. For the consumer and enterprises, it’s exciting either way as this means we’ll have a ton of viable options in the near future.
Related Reading:
- Hot Chips 2020 Live Blog: Marvell ThunderX3 (10:30am PT)
- Marvell Announces ThunderX3: 96 Cores & 384 Thread 3rd Gen Arm Server Processor
- Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
- Marvell Unveils its Comprehensive Custom ASIC Offering
- Next Generation Arm Server: Ampere’s Altra 80-core N1 SoC for Hyperscalers against Rome and Xeon
- Ampere’s Product List: 80 Cores, up to 3.3 GHz at 250 W; 128 Core in Q4
- Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute






