Original Link: https://www.anandtech.com/show/15959/nvme-zoned-namespaces-explained
The Next Step in SSD Evolution: NVMe Zoned Namespaces Explained
by Billy Tallis on August 6, 2020 12:00 PM EST- Posted in
- Storage
- SSDs
- Western Digital
- NVMe
- SMR
- Radian Memory

In June we saw an update to the NVMe standard. The update defines a software interface to assist in actually reading and writing to the drives in a way to which SSDs and NAND flash actually works.
Instead of emulating the traditional block device model that SSDs inherited from hard drives and earlier storage technologies, the new NVMe Zoned Namespaces optional feature allows SSDs to implement a different storage abstraction over flash memory. This is quite similar to the extensions SAS and SATA have added to accommodate Shingled Magnetic Recording (SMR) hard drives, with a few extras for SSDs. ‘Zoned’ SSDs with this new feature can offer better performance than regular SSDs, with less overprovisioning and less DRAM. The downside is that applications and operating systems have to be updated to support zoned storage, but that work is well underway.
The NVMe Zoned Namespaces (ZNS) specification has been ratified and published as a Technical Proposal. It builds on top of the current NVMe 1.4a specification, in preparation for NVMe 2.0. The upcoming NVMe 2.0 specification will incorporate all the approved Technical Proposals, but also reorganize that same functionality into multiple smaller component documents: a base specification, plus one for each command set (block, zoned, key-value, and potentially more in the future), and separate specifications for each transport protocol (PCIe, RDMA, TCP). The standardization of Zoned Namespaces clears the way for broader commercialization and adoption of this technology, which so far has been held back by vendor-specific zoned storage interfaces and very limited hardware choices.

Zoned Storage: An Overview
The fundamental challenge of using flash memory for a solid state drive is all of our computers are built around the concept of how hard drives work, and flash memory doesn't behave like a hard drive. Flash is organized very differently from a hard drive, and so optimizing our computers for the enhanced performance characteristics of flash memory will make it worth the trouble.
Magnetic platters are a fairly analog storage medium, with no inherent structure to dictate features like sector sizes. The long-lived standard of 512-byte sectors was chosen merely for convenience, and enterprise drives now support 4K byte sectors as we reach drive capacities in the multi-TB range. By contrast, a flash memory chip has several levels of structure baked into the design. The most important numbers are the page size and erase block size. Data can be read with page size granularity (typically on the order of several kB) and an empty page can be written to with a program operation, but erase operations clear an entire multi-MB block. The substantial size mismatch between read/program operations and erase operations is a complication that ordinary mechanical hard drives don't have to deal with. The limited program/erase cycle endurance of flash memory also adds to challenge, as writing fewer times increases the lifespan.
Almost all SSDs today are presented to software as an abstraction of a simple HDD-like block storage device with 512-byte or 4kB sectors. This hides all the complexities of SSDs that we’ve gone into detail over the years, such as page and erase block sizes, wear leveling and garbage collection. This abstraction is also part of why SSD controllers and firmware are so much bigger and more complicated (and more bug-prone) than hard drive controllers. For most purposes, the block device abstraction is still the right compromise, because it allows unmodified software to enjoy most of the performance benefits of flash memory, and the downsides like write amplification are manageable.
For years, the storage industry has been exploring alternatives to the block storage abstraction. There have been several proposals for Open Channel SSDs, which expose many of the gory details of flash memory directly to the host system, moving many of the responsibilities of SSD firmware over to software running on the host CPU. The various open channel SSD standards that have been promoted have struck different balances along the spectrum, between a typical SSD with a fully drive-managed flash translation layer (FTL) to a fully software-managed solution. The industry consensus was that some of the earliest standards, like the LightNVM 1.x specification, exposed too many details, requiring software to handle some differences between different vendors' flash memory, or between SLC, MLC, TLC, etc. Newer standards have sought to find a better balance and a level of abstraction that will allow for easier mass adoption while still allowing software to bypass the inefficiencies of a typical SSD.
Tackling the problem from the other direction, the NVMe standard has been gaining features that allow drives to share more information with the host about optimal patterns for data access and layout. For the most part, these are hints and optional features that software can take advantage of. This works because software that isn't aware of these features will still function as usual. Directives and Streams, NVM Sets, Predictable Latency Mode, and various alignment and granularity hints have all been added over the past few revisions of the NVMe specification to make it possible for software and SSDs to better cooperate.
Lately, a third approach has been gaining momentum, influenced by the hard drive market. Shingled Magnetic Recording (SMR) is a technique for increasing storage density by partially overlapping tracks on hard drive platters. The downside of this approach is that it's no longer possible to directly modify arbitrary bytes of data without corrupting adjacent overlapping tracks, so SMR hard drives group tracks into zones and only allow sequential writes within a zone. This has severe performance implications for workloads that include random writes, which is part of why drive-managed SMR hard drives have seen a mixed reception at best in the marketplace. However, in the server storage market, host-managed SMR is also a viable option: it requires the OS, filesystem and potentially the application software to be directly aware of zones, but making the necessary software changes is not an insurmountable challenge when working with a controlled environment.
The zoned storage model used for SMR hard drives turns out to also be a good fit for use with flash, and is a precursor to NVMe Zoned Namespaces. The zone-like structure of SMR hard drives mirrors the page and erase block structure of an SSD. The restrictions on writes aren't an exact match, but it comes close enough.

In this article, we’ll cover what NVMe Zoned Namespaces are, and why this is an important thing.
How to Enable NVMe Zoned Namespaces
Hardware changes for ZNS
At a high level, in order to enable ZNS, most drives on the market only require a firmware update. ZNS doesn't put any new requirements on SSD controllers or other hardware components; this feature can be implemented for existing drives with firmware changes alone.
The critical element in hardware comes down to when an SSD is designed to support only zoned namespaces. First and foremost, a ZNS-only SSD doesn't need anywhere near as much overprovisioning as a traditional enterprise SSD. ZNS SSDs are still responsible for performing wear leveling, but this no longer requires a large spare area for the garbage collection process. Used properly, ZNS allows the host software to avoid almost all of the circumstances that would lead to write amplification inside the SSD. Enterprise SSDs commonly use overprovisioning ratios up to 28% (800GB usable per 1024GB of flash on typical 3 DWPD models) and ZNS SSDs can expose almost all of that capacity to the host system without compromising the ability to deliver high sustained write performance. ZNS SSDs still need some reserve capacity (for example, to cope with failures that crop up in flash memory as it wears out), but Western Digital says we can expect ZNS to allow roughly a factor of 10 reduction in overprovisioning ratios.

Better control over write amplification also means QLC NAND is a more viable option for use cases that would otherwise require TLC NAND. Enterprise storage workloads often lead to write amplification factors of 2-5x. With ZNS, the SSD itself causes virtually no write amplification and clever host software can avoid causing much write amplification, so the overall effect is a boost to drive lifespan that offsets the lower endurance of QLC compared to TLC (or beyond QLC). Even in a ZNS SSD, QLC NAND is still fundamentally slower than TLC, but that same near-elimination of background data management within the SSD means a QLC-based ZNS SSD can probably compete with TLC-based traditional SSDs on QoS metrics even if the total throughput is lower.
The other major hardware change enabled by ZNS is a drastic reduction in DRAM requirements. The Flash Translation Layer (FTL) in traditional block-based SSDs requires about 1GB of DRAM for every 1TB of NAND flash. This is used to store the address mapping or indirection tables that record the physical NAND flash memory address that is currently storing each Logical Block Address (LBA). The 1GB per 1TB ratio is a consequence of the FTL managing the flash with a granularity of 4kB. Right off the bat, ZNS gets rid of that requirement by letting the SSD manage whole zones that are hundreds of MB each. Tracking which physical NAND erase blocks comprise each zone now requires so little memory that it could be done with on-controller SRAM even for SSDs with tens of TB of flash. ZNS doesn't completely eliminate the need for SSDs to include DRAM, because the metadata that the drive needs to store about each zone is larger than what a traditional FTL needs to store for each LBA, and drives are likely to also use some DRAM for caching writes - more on this later.
The Software Model
Drivers (and other software) written for traditional block storage devices need several modifications to work with zoned storage devices. The most obvious is that the host software must obey the new constraints on only writing sequentially within a zone, but that's not the end of the story. Zoned storage also makes the host software responsible for more of the management of data placement. Handling that starts with keeping track of each zone's state. That is more complex than it might sound at first. ZNS adopts the same concept of possible zone states that are used for host-managed SMR hard drives. Technically, this is with ZBC and ZAC extensions to the SCSI and ATA command sets respectively:
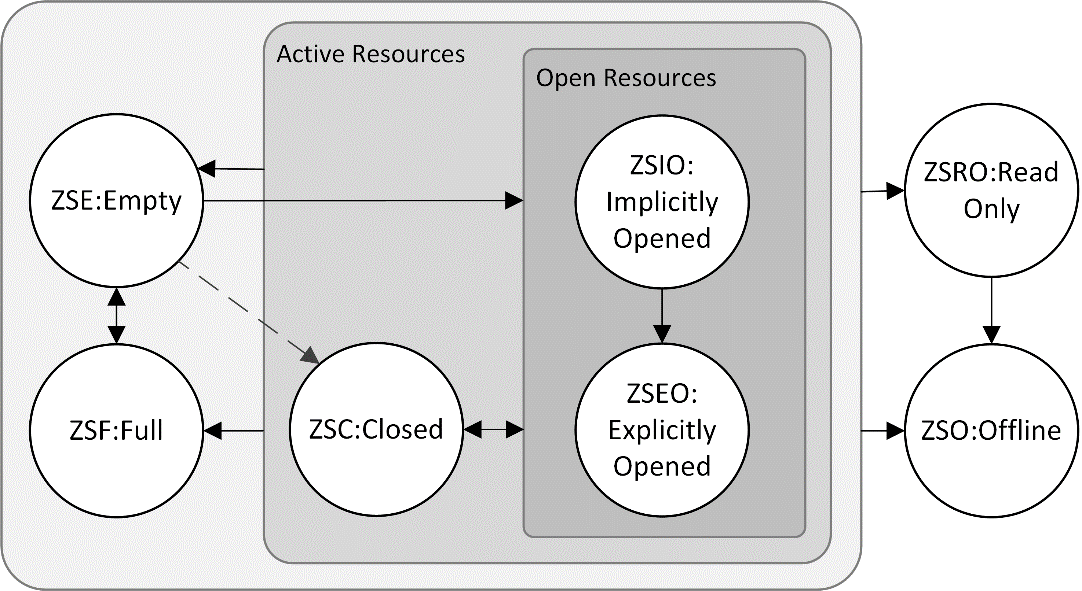
Each of these seven circles represents a possible state of one of the zones on a Zoned Namespace SSD. A few of these seven states have an obvious purpose: empty and full zones are pretty much self-explanatory.
(A zone may be put into the full state without actually storing as much data as its capacity allows. In those scenarios, putting a zone into the full state is like finalizing an optical disc after burning: nothing more can be written to the zone until it is reset (erased).)
The read-only and offline states are error states used when a drive's flash is failing. While ZNS SSDs reduce write amplification, they still have to perform wear leveling at the hardware level. The read-only and offline states are only expected to come into play when the drive as a whole is at the end of its life. Consequently, a lot of software targeting zoned storage won't do anything interesting with these states and will simply treat the entire device as dead once a zone fails into one of these states.
That still leaves three states: implicitly opened, explicitly opened, and closed.
A zone that is in any one of these three states is considered active. Drives will tend to have limits on the number of zones that can be opened (explicitly or implicitly) or active at any given time. These limitations arise because active or open zones require a bit of extra tracking information beyond just knowing what state the zone is in. For every active zone, the drive needs to keep track of the write pointer, which indicates how full the zone is and where the next write to the zone will go. A write pointer isn't needed for full or empty zones because full zones cannot accept more writes, and empty zones will be written to starting at the beginning of the zone.
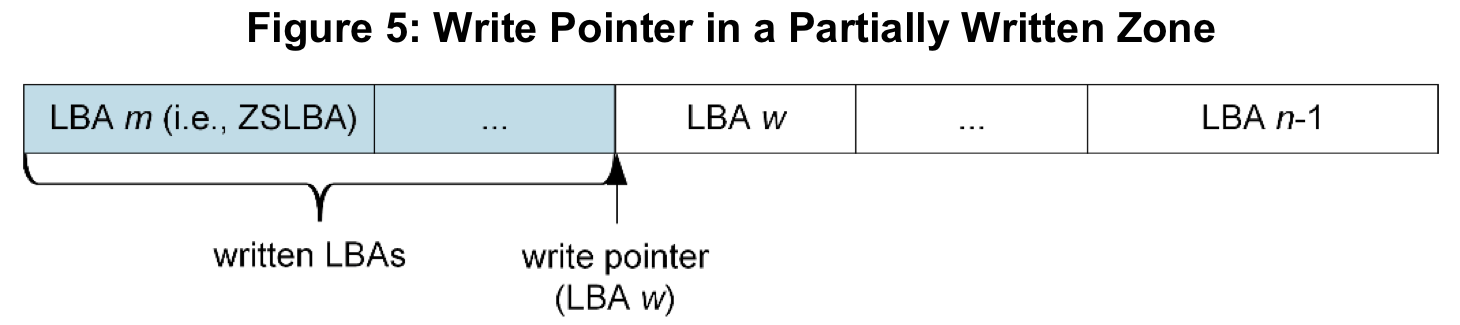
A zone must be opened in order to accept new writes. Zones can be implicitly opened by simply issuing a write command, or they can be explicitly opened using a zone management command to open (it doesn't actually write new data).
The distinction between implicitly and explicitly opened zones is that the SSD controller is free to automatically close a zone that was opened implicitly through a write command. An explicitly opened zone, one that was issued with an ‘open’ command, will only be put in the closed state when the host software commands it.
If a ZNS SSD is operating at its limit for the number of zones that can be open and they're all explicitly opened, then any attempt to open a new zone will fail. However, if some of the zones are only implicitly opened, then trying to open a new zone will cause the SSD to close one of those implicitly open zones.
The distinction between open and closed zones allows drives to keep a practical limit on the internal resources (eg. buffers) needed to handle new writes to zones. To some extent, this is just a holdover from SMR hard drives, but there is a relevant limitation in how flash memory works. These days, NAND flash memory typically has page sizes of about 16kB, but ZNS SSDs still support writes of individual LBAs that will typically be 4kB (or 512 bytes). That means writing to a zone can leave flash memory cells in a partially programmed state. Even when doing only page-sized and properly aligned writes, cells may be left in a partially programmed state until further writes arrive, due to how SSDs commonly map pages to physical memory cells.
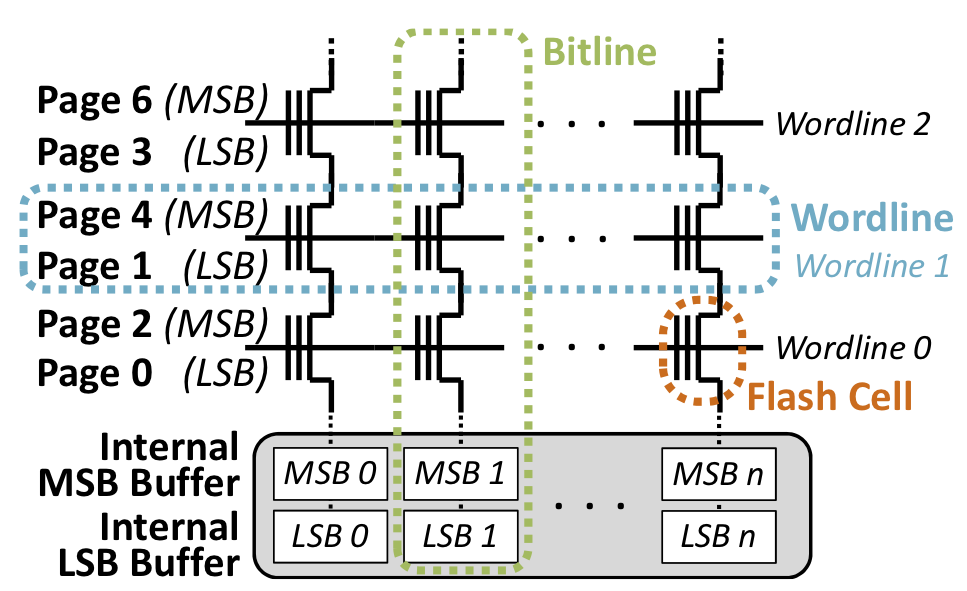
Flash memory cells that are in a partially programmed state are particularly at risk of suffering from a read disturb error, where attempts to read from that cell or an adjacent cell may change the voltage of the partially programmed cell. Open Channel SSDs deal with this by simply disallowing reads from such pages, but the zoned storage model tries to avoid imposing extra restrictions on read commands. ZNS SSDs will typically cache recently-written data so that a read command can be handled without touching partially programmed NAND pages. The available memory for such caching is what leads to a limit on the number of open zones.
If an open zone with some partially programmed memory cells is to be closed, the drive has two choices: finish programming those cells using some filler data, keep track of the hole in the zone, and hope the host doesn't try to use the full zone capacity later. Alternatively, the drive can keep buffering recently-written data even for closed zones. Depending on how many active zones a drive wants to support, this can still allow for a ZNS SSD to get by with much less DRAM than a conventional SSD, so this approach is what's more likely to be used in practice. A SSD that supports both zoned and block IO namespaces will probably be able to keep all of its zones active or open simultaneously.
In principle, a ZNS SSD could expose each individual flash erase block as a separate zone that would be several megabytes, depending on the underlying flash memory. This would mean writes to a single zone are limited to the write speed of a single NAND flash die. For recent TLC NAND flash, single die write speeds go up to about 82 MB/s (Samsung 6th-gen V-NAND) and for QLC the single-die write speed can be below 10MB/s. In practice, drives will tend to support zone sizes that aggregate many erase blocks across multiple dies and all of the controller's channels, so that sequential writes (or reads) to a single zone can be as fast as would be supported on a conventional FTL-based SSD.
A recent Western Digital demo with a 512GB ZNS prototype SSD showed the drive using a zone size of 256MB (for 2047 zones total) but also supporting 2GB zones. Within a single zoned namespace, all zones will use the same zone size, but a drive can support reformatting a namespace to change its zone size or multiple namespaces with different zone sizes.
Hints or Warnings
Many recent NVMe features allow SSDs and host software to exchange optional hints about data layout, access patterns and lifetimes. This is an SSD driven feature to the host, rather than requiring both sides to support using this information. ZNS makes zones an explicit concept that the host must deal with directly, but takes the hinting approach for some of the remaining internal operations of the SSD.
ZNS SSDs don't perform garbage collection in the sense of traditional SSDs, but they are still responsible for wear leveling. That can sometimes mean the drive will have to re-locate data to different physical NAND erase blocks, especially if the drive is relatively full with data that is infrequently modified. Rewriting an entire zone of, say, 256MB is a pretty big background job that would have a noticeable impact on the latency of handling IO commands coming from the host. A ZNS SSD can notify the host that it recommends resetting a zone because it plans to do some background work on that zone soon, and can include an estimate of how many seconds until that will happen. This gives the host an opportunity to reset the zone, which may involve the host doing some garbage collection of its own if only some of the data in the zone is still needed. (To help with such situations, NVMe has also added a Copy command to collect disparate chunks of data into a single contiguous chunk, without the data having to leave the SSD.)
Similarly, a ZNS SSD can recommend that an active zone should be moved to the Full state by the host either writing to the rest of the zone's capacity, or issuing a Zone Finish command.
When the host software pays heed to both of the above hints and takes the recommended actions, the SSD will be able to avoid almost all of the background operations that have a large impact on performance or write amplification. But because these are merely hints, if the host software ignores them or simply isn't in a position to comply, the SSD is still obligated to preserve user data throughout its background processing. There may still be some side effects, such as the drive having to move an open or active zone to the full state in exceptional circumstances, and host software must be written to tolerate these events. It's also impossible to completely eliminate write amplification. For example, static data may need to be rewritten eventually to prevent uncorrectable errors from accumulated read disturb errors.
Supporting Multiple Writers
The requirement to write data sequentially within a zone presents obvious challenges for software to manage data layout and especially updates to existing data. But it also creates a performance bottleneck when multiple threads want to write to the same zone. Each write command sent to the SSD needs to be addressed to the LBA currently pointed to by the zone's write pointer. When multiple threads are writing to a zone, there's a race condition where the write pointer can be advanced by another thread's write between when a thread checks for the location of the write pointer and when its write command gets to the SSD. That will lead to writes being rejected by the SSD. To prevent this, software has to synchronize between threads to properly serialize writes to each zone. The resulting locking overhead will tend to cause write performance to decrease when more threads are writing, and it is difficult to get the queue depth above 1.

To address this limitation, the ZNS specification includes an optional append command that can be used instead of the write command. Append commands are always addressed to the beginning of the zone, but the SSD will write the data wherever the write pointer is when it gets around to processing that command. When signaling completion of that command, the SSD returns to the host the LBAs of where the data actually landed. This eliminates the synchronization requirement and allows many threads to write new data to a zone simultaneously with no core-to-core communication at all. The downside is that even more complexity has been moved into host software, which now must record data locations after the fact instead of trying to allocate space before writing data. Even returning the address where data ended up to the application has proven to be a challenge for existing IO APIs, which are usually only set up to return error codes to the application.

The append command isn't the only possible solution to this scalability challenge; it's just the one that has been standardized with this initial version of the NVMe ZNS specification. Other solutions have been proposed and implemented in prototypes or non-standard zoned SSDs. Radian Memory has been supporting their own form of zoned storage on their SSDs for years. Their solution is to allow out of order writes within a certain distance ahead of the write pointer. The SSD will cache these writes and advance the write pointer up to the first gap in data that has arrived so far. There's another NVMe Technical Proposal on its way toward standardization to define a Zone Random Write Area (ZRWA) that allows random writes and in-place overwriting of data while it's still in the SSD's cache. Both of these methods require more resources on the SSD than the Zone Append command, but arguably make life easier for software developers. Since Zone Append, ZRWA and any other solution has to be an optional extension to the basic ZNS feature set, there's potential for some annoying fragmentation here.
Comparison With Other Storage Paradigms
Zoned storage is just one of several efforts to enable software to make its IO more SSD-friendly and to reduce unnecessary overhead from the block storage abstraction. The NVMe specification already has a collection of features that allow software to issue writes with appropriate sizes and alignment for the SSD, and features like Streams and NVM Sets to help ensure unrelated IO doesn't land in the same erase block. When supported by the SSD and host software, these features can provide most of the QoS benefits ZNS can achieve, but they aren't as effective at preventing write amplification. Applications that go out of their way to serialize writes (eg. log-structured databases) can expect low write amplification, but only if the filesystem (or another layer of the IO stack) doesn't introduce fragmentation or reordering commands. Another downside is that these several features are individually optional, so applications must be prepared to run on SSDs that support only a subset of the features the application wants.
The Open Channel SSD concept has been tried in several forms. Compared to ZNS, Open Channel SSDs put even more requirements on the host software (such as wear leveling), which has hindered adoption. However, capable hardware has been available from several vendors. The LightNVM Open Channel SSD specification and associated projects have now been discontinued in favor of ZNS and other standard NVMe features, which can provide all of the benefits and functionality of the Open Channel 2.0 specification while placing fewer requirements on host software (but slightly more on SSD firmware). The other vendor-specific open channel SSD specifications will probably be retired when the current hardware implementations reach end of life.

ZNS and Open Channel SSDs can both be seen as modifications to the block storage paradigm, in that they continue to use the concept of a linear space of Logical Block Addresses of a fixed size. Another recently approved NVMe TP adds a command set for Key-Value Namespaces, which completely abandon the fixed-size LBA concept. Instead, the drive acts as a key-value database, storing objects of potentially variable size, identified by keys of a few bytes. This storage abstraction looks nothing like how the underlying flash memory works, but KV databases are very common in the software world. A KV SSD allows such a database's functionality to be almost completely offloaded from the CPU to the SSD. Implementing a KV database directly in the SSD firmware avoids a lot of the overhead of implementing a KV database on top of block storage that is running on top of a traditional Flash Translation Layer, so this is another viable route to making IO more SSD-friendly. KV SSDs don't really have the cost advantages that a ZNS-only SSD can offer, but for some workloads they can provide similar performance and endurance benefits, and save some CPU time and RAM in the process.
Ecosystem Status: Users and Use Cases
The software changes required, both in firmware and OS support/software, will keep zoned SSDs in the datacenter for the foreseeable future. Most of the early interest and adoption will be with the largest cloud computing companies that have the resources to optimize their software stacks top to bottom for zoned storage. But a lot of software work has already been done: software targeting host-managed SMR hard drives or open-channel SSDs can be easily extended to also support zoned SSDs. This includes both applications and filesystem drivers that have been modified to work on devices that do not support in-place modification of data.
Linux Kernel version 5.9 will update the NVMe driver with ZNS support, which plugs in to the existing zoned block device framework. Multiple Linux filesystems either already support running directly on zoned devices, or such support has been developed but not yet merged into a stable kernel release. The device mapper framework already includes a component to emulate a regular block device on top of a zoned device like a ZNS SSD, so unmodified filesystems and applications can be used. Western Digital has released a userspace library to help applications interact directly with zoned devices without using one of the kernel's filesystems on the device.
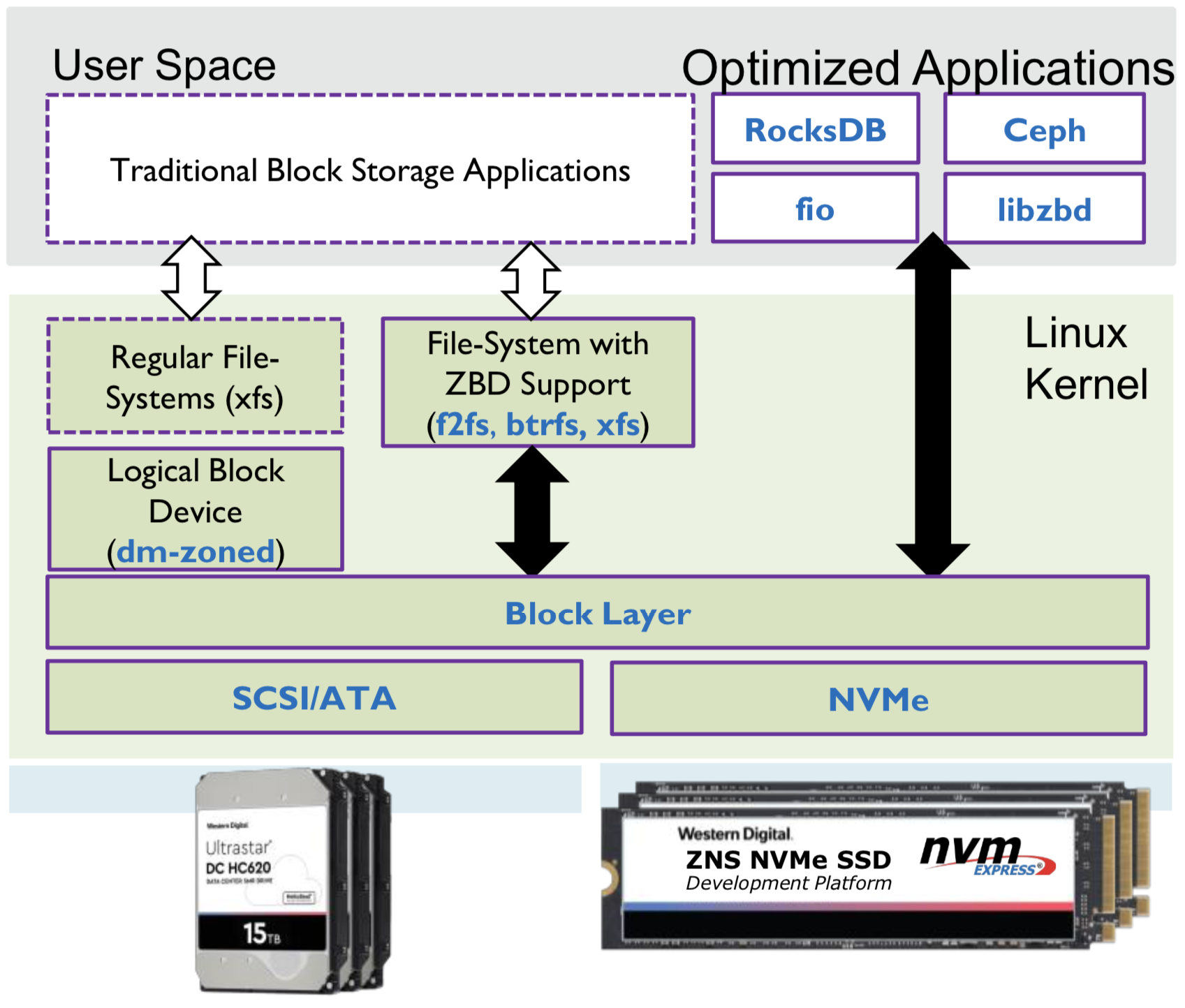
Only a few applications have publicly released support for ZNS SSDs. The Ceph clustered storage system has a backend that supports zoned storage, including ZNS SSDs. Western Digital has developed a zoned storage backend for the RocksDB key-value database (itself used by Ceph), but the patches are still a work in progress. Samsung has released a cross-platform library for accessing NVMe devices, with support for ZNS SSDs. They've written their own RocksDB backend using this library. As with host-managed SMR hard drives, most production use of ZNS (at least early on) will be behind the scenes in large datacenters. Because ZNS gives the host system a great degree of control over data placement on the SSD, it allows for good isolation of competing tasks. This makes it easier to ensure good storage performance QoS in multi-tenant cloud environments, but the relative lack of zone-aware software means there isn't much demand for such a hosting environment yet.
The most enthusiastic and prolific supporter of ZNS and zoned storage in general has been Western Digital, which stands to benefit from the overlap between ZNS and SMR hard drives. But it is very much a multi-vendor effort. The ZNS standard lists authors from all the other major NAND flash manufacturers (Samsung, Intel, Micron, SK Hynix, Kioxia), controller vendors (Microchip), cloud computing hyperscalers (Microsoft, Alibaba), and other familiar names like Seagate, Oracle and NetApp.
Longtime zoned SSD provider Radian Memory recently published a case study conducted with IBM Research. They ported an existing software-based log-structured storage system to run on Radian's non-standard zoned SSDs, and measured significant improvements to throughput, QoS and write amplification compared to running on a block storage SSD.
Most SSD vendors have not yet announced production models supporting ZNS (Radian Memory being the exception), so it's hard to tell what market segments, capacities and form factors will be most common among ZNS SSDs. The most compelling opportunity is probably for ZNS-only QLC based drives with reduced DRAM and overprovisioning, but the earliest models to market will probably be more conventional hardware configurations with updated firmware supporting ZNS.
Overall, ZNS is one of the next steps in mirroring the use of SSDs in the way SSDs are actually designed, rather than an add-on to hard drive methodology. It is a promising new feature. It looks likely to see more widespread adoption than previous efforts like open-channel SSDs, and the cost and capacity advantages should be more significant than what SMR hard drives have offered relative to CMR hard drives.






