Original Link: https://www.anandtech.com/show/15813/arm-cortex-a78-cortex-x1-cpu-ip-diverging
Arm's New Cortex-A78 and Cortex-X1 Microarchitectures: An Efficiency and Performance Divergence
by Andrei Frumusanu on May 26, 2020 9:00 AM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- GPUs
- SoCs
- Cortex
- Cortex A78
- Cortex X1
- Mali G78

2019 was a great year for Arm. On the mobile side of things one could say it was business as usual, as the company continued to see successes with its Cortex cores, particularly the new Cortex-A77 which we’ve now seen employed in flagship chipsets such as the Snapdragon 865. The bigger news for the company over the past year however hasn’t been in the mobile space, but rather in the server space, where one can today rent Neoverse-N1 CPUs such as Amazon’s impressive Graviton2 chip, with more vendors such as Ampere expected to release their server products soon.
While the Arm server space is truly taking off as we speak, aiming to compete against AMD and Intel, Arm hasn't reached the pinnacle of the mobile market – at least, not yet. Arm’s mobile Cortex cores have lived in the shadow of Apple’s custom CPU microarchitectures over the past several years, as Apple has seemingly always managed to beat Cortex designs by significant amounts. While there’s certainly technical reasons to the differences – it was also a lot due to business rationale on Arm’s side.
Today for Arm’s 2020 TechDay announcements, the company is not just releasing a single new CPU microarchitecture, but two. The long-expected Cortex-A78 is indeed finally making an appearance, but Arm is also introducing its new Cortex-X1 CPU as the company’s new flagship performance design. The move is not only surprising, but marks an extremely important divergence in Arm’s business model and design methodology, finally addressing some of the company’s years-long product line compromises.
The New Cortex-A78: Doubling Down on Efficiency
The new Cortex-A78 isn’t exactly a big surprise – Arm had first publicly divulged the Hercules codename over two years ago when they had presented the company’s performance roadmap through 2020. Two years later, and here we are, with the Cortex-A78 representing the third iteration of Arm’s new Austin-family CPU microarchitecture, which had started from scratch with the Cortex-A76.

The new Cortex-A78 pretty much continues Arm’s traditional design philosophy, that being that it’s built with a stringent focus on a balance between performance, power, and area (PPA). PPA is the name of the game for the wider industry, and here Arm is pretty much the leading player on the scene, having been able to provide extremely competitive performance at with low power consumption and small die areas. These design targets are the bread & butter of Arm as the company has an incredible range of customers who aim for very different product use-cases – some favoring performance while some other have cost as their top priority.
All in all (we’ll get into the details later), the Cortex-A78 promises a 20% improvement in sustained performance under an identical power envelope. This figure is meant to be a product performance projection, combining the microarchitecture’s improvements as well as the upcoming 5nm node advancements. The IP should represent a pretty straightforward successor to the already big jump that were the A76 and A77.
The New Cortex-X1: Breaking the Design Constraint Chains
Arm’s existing business model was aimed at trying to create a CPU IP that covers the widest range of customer needs. This creates the problem that you cannot hyper-focus on any one area of the PPA triangle without making compromises in the other two. I mentioned that Arm’s CPU cores have for years lived in the shadow of Apple’s CPU cores, and whilst for sure, the Apple's cores were technical superior, one very large contributing factor in Arm's disadvantage was that the business side of Arm just couldn’t justify building a bigger microarchitecture.
As the company is gaining more customers, and is ramping up R&D resources for designing higher performance cores (with the server space being a big driver), it seems that Arm has finally managed to get to a cross-over point in their design abilities. The company is now able to build and deliver more than a single microarchitecture per year. In a sense, we sort of saw the start of this last year with the introduction of the Neoverse-N1 CPU, already having some more notable microarchitectural changes over its Cortex-A76 mobile sibling.

Taking a quick look at the new Cortex-X1, we find the X1 higher up in Arm’s Greek pantheon family tree of CPU microarchitectures. Codenamed Hera, the design at least is named similarly to its Hercules sibling, denominating their close design relationship. The X1 is much alike the A78 in its fundamental design – in fact both CPUs were created by the same Austin CPU design team in tandem, but with the big difference that the X1 breaks the chains on its power and area constraints, focusing to get the very best performance with very little regard to the other two metrics of the PPA triangle.
The Cortex-X1 was designed within the frame of a new program at Arm, which the company calls the “Cortex-X Custom Program”. The program is an evolution of what the company had previously already done with the “Built on Arm Cortex Technology” program released a few years ago. As a reminder, that license allowed customers to collaborate early in the design phase of a new microarchitecture, and request customizations to the configurations, such as a larger re-order buffer (ROB), differently tuned prefetchers, or interface customizations for better integrations into the SoC designs. Qualcomm was the predominant benefactor of this license, fully taking advantage of the core re-branding options.

The new Cortex-X program is an evolution of the BoACT license, this time around making much more significant microarchitectural changes to the “base” design that is listed on Arm’s product roadmap. Here, Arm proclaims that it allows customers to customize and differentiate their products more; but the real gist of it is that the company now has the resources to finally do what some of its lead customers have been requesting for years.
One thing to note, is that while Arm names the program the “Cortex-X Custom Program”, it’s not to be confused with actual custom microarchitectures by vendors with an architectural license. The custom refers to Arm’s customization of their roadmap CPU cores – the design is still very much built by Arm themselves and they deliver the IP. For now, the X1 IP will also be identical between all licensees, but the company doesn’t rule out vendor-specific changes the future iterations – if there’s interest.
This time around Arm also maintains the marketing and branding over the core, meaning we’ll not be seeing the CPU under different names. All in all, the whole marketing disclosure around the design program is maybe a bit confusing – the simple matter of fact is that the X1 is simply another separate CPU IP offering by Arm, aimed at its leading partners, who are likely willing to pay more for more performance.

At the end of the day, what we're getting are two different microarchitectures – both designed by the same team, and both sharing the same fundamental design blocks – but with the A78 focusing on maximizing the PPA metric and having a big focus on efficiency, while the new Cortex-X1 is able to maximize performance, even if that means compromising on higher power usage or a larger die area.
It’s an incredible design philosophy change for Arm, as the company is no longer handicapped in the ultra-high-tier performance ring with the big players such as Apple, AMD, or Intel – all whilst still retaining their bread & butter design advantages for the more cost-oriented vendors out there who deliver hundreds of millions of devices.
Let’s start by dissecting the microarchitecture changes of the new CPUs, starting off with the Cortex-A78…
The Cortex-A78 Micro-architecture: PPA Focused
The new Cortex-A78 had been on Arm’s roadmaps for a few years now, and we have been expecting the design to represent the smallest generational microarchitectural jump in Arm’s new Austin family. As the third iteration of Arm's Austin core designs, A78 follows the sizable 25-30% IPC improvements that Arm delivered on the Cortex-A76 and A77, which is to say that Arm has already picked a lot of the low-hanging fruit in refining their Austin core.

As the new A78 now finds itself part of a sibling pairing along side the higher performance X1 CPU, we naturally see the biggest focus of this particular microarchitecture being on improving the PPA of the design. Arm’s goals were reasonable performance improvements, balanced with reduced power usage and maintaining or reducing the area of the core.
It’s still an Arm v8.2 CPU, sharing ISA compatibility with the Cortex-A55 CPU for which it is meant to be paired with in a DynamIQ cluster. We see similar scaling possibilities here, with up to 4 cores per DSU, with an L3 cache scaling up to 4MB in Arm’s projected average target designs.

Microarchitectural improvements of the core are found throughout the design. On the front-end, the biggest change has been on the part of the branch predictor, which now is able to process up to two taken branches per cycle. Last year, the Cortex-A77 had introduced as secondary branch execution unit in the back-end, however the actual branch unit on the front-end still only resolved a single branch per cycle.
The A78 is now able to concurrently resolve two predictions per cycle, vastly increasing the throughput on this part of the core and better able to recover from branch mispredictions and resulting pipeline bubbles further downstream in the core. Arm claims their microarchitecture is very branch prediction driven so the improvements here add a lot to the generational improvements of the core. Naturally, the branch predictors themselves have also been improved in terms of their accuracy, which is an ongoing effort with every new generation.
Arm focused on a slew of different aspects of the front-end to improve power efficiency. On the part of the L1I cache, we're now seeing the company offer a 32KB implementation option for vendors, allowing customers to reduce area of the core for a small hit on performance, but with gains in efficiency. Other changes were done to some structures of the branch predictors, where the company downsized some of the low return-on-investment blocks which had a larger cost on area and power, but didn’t have an as large impact on performance.
The Mop cache on the Cortex-A78 remained the same as on the A77, housing up to 1500 already decoded macro-ops. The bandwidth from the front-end to the mid-core is the same as on the A77, with an up to 4-wide instruction decoder and fetching up to 6 instructions from the macro-op cache to the rename stage, bypassing the decoder.
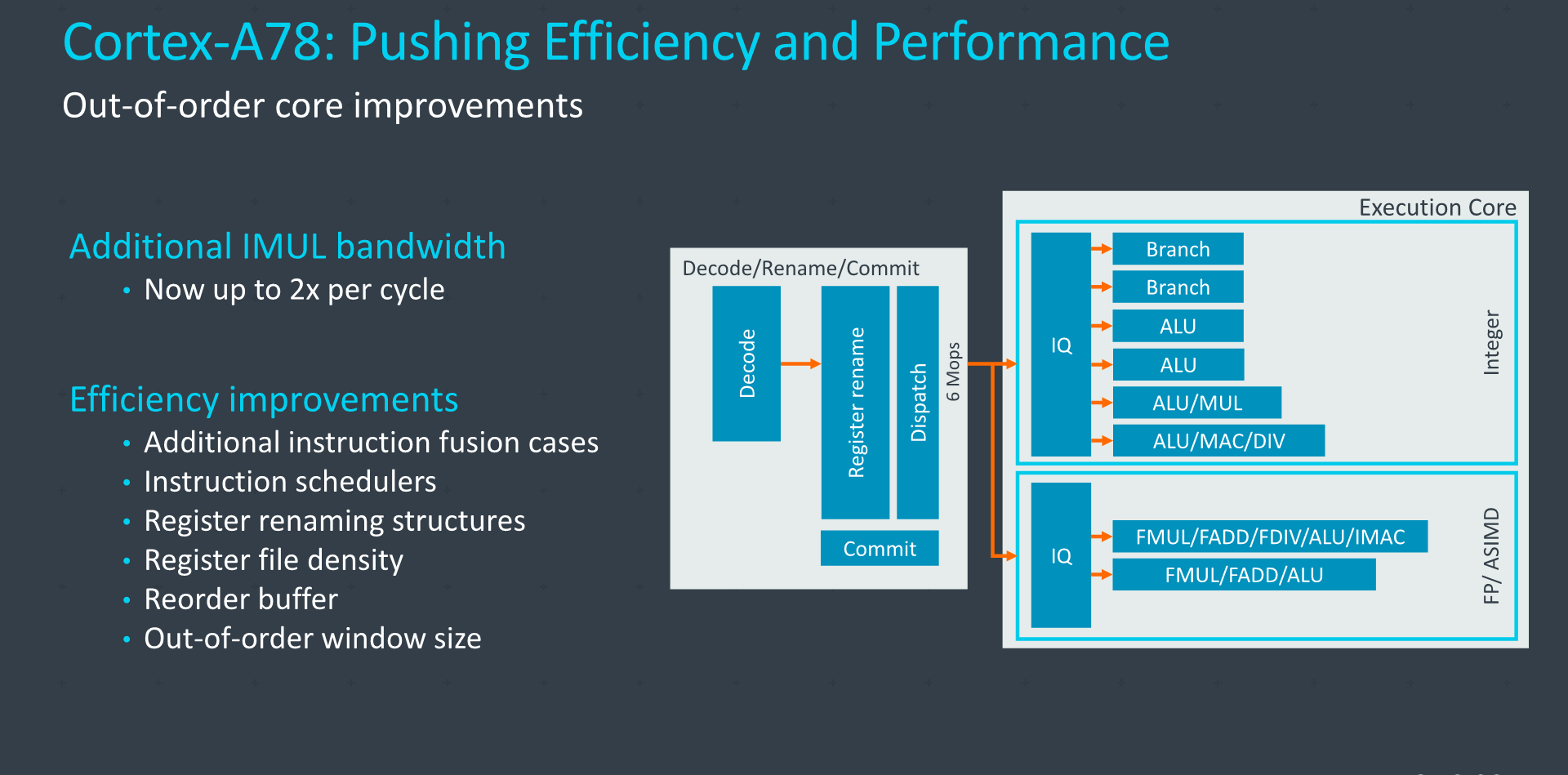
In the mid-core and execution pipelines, most of the work was done in regards to improving the area and power efficiency of the design. We’re now seeing more cases of instruction fusions taking place, which helps not only performance of the core, but also power efficiency as it now uses up less resources for the same amount of work, using less energy.
The issue queues have also seen quite larger changes in their designs. Arm explains that in any OOO-core these are quite power-hungry features, and the designers have made some good power efficiency improvements in these structures, although not detailing any specifics of the changes.
Register renaming structures and register files have also been optimized for efficiency, sometimes seeing a reduction of their sizes. The register files in particular have seen a redesign in the density of the entries they’re able to house, packing in more data in the same amount of space, enabling the designers to reduce the structures’ overall size without reducing their capabilities or performance.
On the re-order-buffer side, although the capacity remains the same at 160 entries, the new A78 improves power efficiency and the density of instructions that can be packed into the buffer, increasing the instructions per unit area of the structure.
Arm has also fine-tuned the out-of-order window size of the A78, actually reducing it in comparison to the A77. The explanation here is that larger window sizes generally do not deliver a good return on investment when scaling up in size, and the goal of the A78 is to maximize efficiency. It’s to be noted that the OOO-window here not solely refers to the ROB which has remained the same size, Arm here employs different buffers, queues, and structures which enable OOO operation, and it’s likely in these blocks where we’re seeing a reduction in capacity.
On the diagram, here we see Arm slightly changing its descriptions on the dispatch stage, disclosing a dispatch bandwidth of 6 macro-ops (Mops) per cycle, whereas last year the company had described the A77 as dispatching 10 µops. The apples-to-apples comparison here is that the new A78 increases the dispatch bandwidth to 12 µops per cycle on the dispatch end, allowing for a wider execution core which houses some new capabilities.
On the integer execution side, the only big addition has been the upgrade of one of the ALUs to a more complex pipeline which now also handles multiplications, essentially doubling the integer MUL bandwidth of the core.
The rest of the execution units have seen very little to no changes this generation, and are pretty much in line with what we’ve already seen in the Cortex-A77. It’s only next year where we expect to see a bigger change in the execution units of Arm’s cores.

On the back-end of the core and the memory subsystem, we actually find some larger changes for performance improvements. The first big change is the addition of a new load AGU which complements the two-existing load/store AGUs. This doesn’t change the store operations executed per cycle, but gives the core a 50% increase in load bandwidth.
The interface bandwidth from the LD/ST queues to the L1D cache has been doubled from 16 bytes per cycle to 32 bytes per cycle, and the core’s interfaces to the L2 has also been doubled up in terms of both its read and write bandwidth.
Arm seemingly already has some of the most advanced prefetchers in the industry, and here they claim the A78 further improves the designs both in terms of their memory area coverage, accuracy and timeliness. Timeliness here refers to their quick latching on onto emerging patterns and bringing in the data into the lower caches as fast as possible. You also don’t watch the prefetchers to kick in too early or too late, such as needlessly prefetching data that’s not going to be used for some time.
Much like the L1I cache, the A78 now also offers an 32KB L1D option that gives vendors the choice to configure a smaller core setup. The L2 TLB has also been reduced from 1280 to 1024 pages – this essentially improves the power efficiency of the structure whilst still retaining enough entries to allow for complete coverage of a 4MB L3 cache, still minimizing access latency in that regard.
Overall, the Cortex-A78’s microarchitectural disclosures might sound surprising if the core were to be presented in a vacuum, as we’re seeing quite a lot of mentions of reduced structure sizes and overall compromises being made in order to maximize energy efficiency. Naturally this makes sense given that the Cortex-X1 focuses on performance…
The Cortex-X1 Micro-architecture: Bigger, Fatter, More Performance
While the Cortex-A78 seems relatively tame in its performance goals, today’s biggest announcement is the far more aggressive Cortex-X1. As already noted, Cortex-X1 is a significant departure from Arm's usual "balanced" design philosophy, with Arm designing a core that favors absolute performance, even if it comes at the cost of energy efficiency and space efficiency.

At a high level, the design could be summed up as being a ultra-charged A78 – maintaining the same functional principles, but increasing the structures of the core significantly in order to maximize performance.
Compared to an A78, it’s a wider core, going up from a 4- to a 5-wide decoder, increasing the renaming bandwidth to up to 8 Mops/cycle, and also vastly changing up some of the pipelines and caches, doubling up on the NEON unit, and double the L2 and L3 caches.

On the front-end (and valid the rest of the core as well), the Cortex-X1 adopts all the improvements that we’ve already covered on the Cortex-A78, including the new branch units. On top of the changes the A78 introduced, the X1 further grows some aspects of the blocks here. The L0 BTB has been upgraded from 64 entries on the Cortex-A77 and A78, to up to 96 entries on the X1, allowing for more zero latency taken branches. The branch target buffers are still of a two-tier hierarchy with the L0 and L2 BTBs, which Arm in previous disclosures referred to as the nanoBTB and mainBTB. The microBTB/L1 BTB was present in the A76 but had been subsequently discontinued.
The macro-op cache has been outright doubled from 1.5K entries to 3K entries, making this a big structure amongst the publicly disclosed microarchitectures out there, bigger than even Sunny Cove’s 2.25K entries, but shy of Zen2’s 4K entry structure - although we do have to make the disambiguation that Arm talks about macro-ops while Intel and AMD talk about micro-op caches.
The fetch bandwidth out of the L1I has been bumped up 25% from 4 to 5 instructions with a corresponding increase in the decoder bandwidth, and the fetch and rename bandwidth out of the Mop-cache has seen a 33% increase from 6 to 8 instructions per cycle. In effect, the core can act as a 8-wide machine as long as it’s hitting the Mop cache.
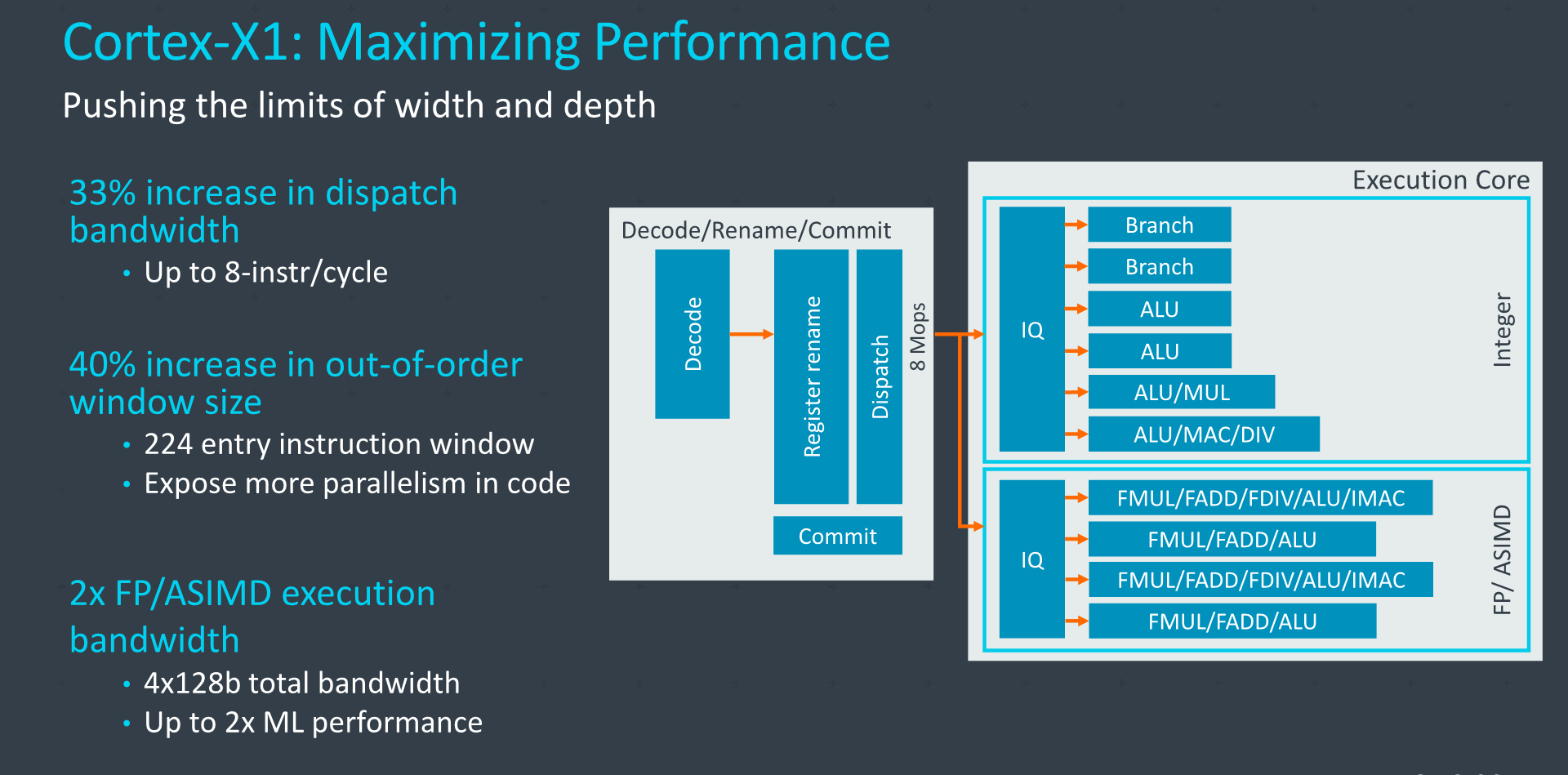
On the mid-core, Arm here again talks about increasing the dispatch bandwidth in terms of Mops or instructions per cycle, increasing it by 33% from 6 to 8 when comparing the X1 to the A78. In µops terms the core can handle up to 16 dispatches per cycle when cracking Mops fully into smaller µops, in that regard, representing a 60% increase compared to the 10µops/cycle the A77 was able to achieve.
The out-of-order window size has been increased from 160 to 224 entries, increasing the ability for the core to extract ILP. This had always been an aspect Arm had been hesitant to upgrade as they had mentioned that performance doesn’t scale nearly as linearly with the increased structure size, and it comes at a cost of power and area. The X1 here is able to make those compromises given that it doesn’t have to target an as wide range of vendor implementations.
On the execution side, we don’t see any changes on the part of the integer pipelines compared to the A78, however the floating point and NEON pipelines more significantly diverge from past microarchitectures, thanks to the doubling of the pipelines. Doubling here can actually be taken in the literal sense, as the two existing pipelines of the A77 and A78 are essentially copy-pasted again, and the two pairs of units are identical in their capabilities. That’s a quite huge improvement and increase in execution resources.
In effect, the Cortex-X1 is now a 4x128b SIMD machine, pretty much equal in vector execution width as some desktop cores such as Intel’s Sunny Cove or AMD’s Zen2. Though unlike those designs, Arm's current ISA doesn't allow for individual vectors to be larger than 128b, which is something to be addressed in a next generation core.

On the memory subsystem side, the Cortex-X1 also sees some significant changes – although the AGU setup is the same as that found on the Cortex-A78.
On the part of the L1D and L2 caches, Arm has created new designs that differ in their access bandwidth. The interfaces to the caches here aren’t wider, but rather what’s changed is the caches designs themselves, now implementing double the memory banks. What this solves is possible bank conflicts when doing multiple concurrent accesses to the caches, it’s something that we may have observed with odd “zig-zag” patterns in our memory tests of the Cortex-A76 cores a few years back, and still present in some variations of that µarch.
The L1I and L1D caches on the X1 are meant to be configured at 64KB. On the L2, because it’s a brand new design, Arm also took the opportunity to increase the maximum size of the cache which now doubles up to 1MB. Again, this actually isn’t the same 1MB L2 cache design that we first saw on the Neoverse-N1, but a new implementation. The access latency is 1 cycle better than the 11-cyle variant of the N1, achieving 10 cycles on the X1, regardless of the size of the cache.
The memory subsystem also increases the capability to support more loads and stores, increasing the window here by 33%, adding even more onto the MLP ability of the core. We have to note that this increase not merely refers to the store and load buffers but the whole system’s capabilities with tracking and servicing requests.
Finally, the L2 TLB has also seen a doubling in size compared to the A78 (66% increase vs A77) with 2K entries coverage, serving up to 8MB of memory at 4K pages, which makes for a good fit for the envisioned 8MB L3 cache for target X1 implementations.
The doubling of the L3 cache in the DSU doesn’t necessarily mean that it’s going to be a slower implementation, as the latency can be the same, but depending on partner implementations it can mean a few extra cycles of latency. Likely what this is referring to is likely the option for banking the L3 with separated power management. To date, I haven’t heard of any vendors using this feature of the DSU as most implementers such as Qualcomm have always had the 4MB L3 fully powered on all the time. It is possible that with a 8MB DSU that some vendors might look into power managing this better, for example it having being only partially powered on as long as only little cores are active.
Overall, what’s clear here about the Cortex-X1 microarchitecture is that it’s largely consisting of the same fundamental building blocks as that of the Cortex-A78, but only having bigger and more of the structures. It’s particularly with the front-end and the mid-core where the X1 really supersizes things compared to the A78, being a much wider microarchitecture at heart. The arguments about the low return on investment on some structures here just don’t apply on the X1, and Arm went for the biggest configurations that were feasible and reasonable, even if that grows the size of the core and increases power consumption.
I think the real only design constraints the company set themselves here is in terms of the frequency capabilities of the X1. It’s still a very short pipeline design with a 10-cycle branch mispredict penalty and a 13-stage deep frequency design, and this remains the same between the A78 and X1, with the latter’s bigger structures and wider design not handicapping the peak frequencies of the core.
Performance & Power Projections: Best of Both Worlds
We quickly looked at some projected figures at the start of the article, but now that we've had a chance to dig through the new CPUs, let's more precisely define the expected performance, power and area gains that the new Cortex-A78 and X1 cores are supposed to achieve.
Starting off with the Cortex-A78, the first comparison figures here are meant to represent the generational improvements the A78 would achieve in a target 2021 system on a TSMC N5 node. So the figures here contain both the microarchitectural gains as well as the expected process node improvements.
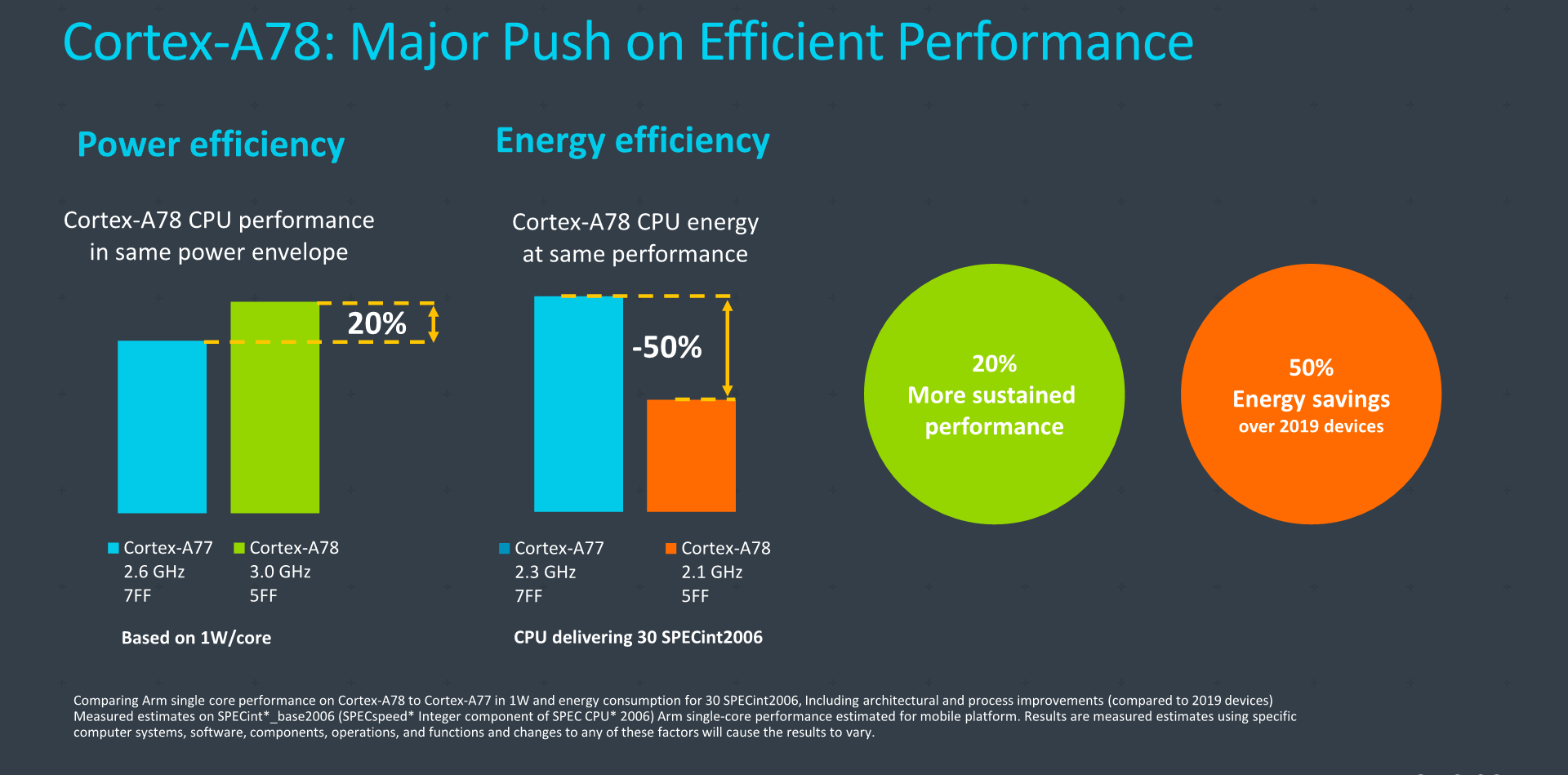
In terms of performance, at an ISO-power target of 1W for a core, Arm says that an A78 implementation would bring with it a 20% increase in performance, which is a healthy upgrade. A 2.6GHz A77 here on N7 here grossly matches the MediaTek Dimensity 1000(+), and the 1W power figure also roughly matches the power I’ve measured on that SoC.
Meanwhile at an ISO-performance comparison, the A78 would be able to halve the power and energy consumption compared to a 2.3GHz A77 on N7. This comparison is likely aimed at various mid-core implementations out there in the market, it is a bit of an arbitrary comparison but Arm also showcases some better figures we’ll go over in just a bit.
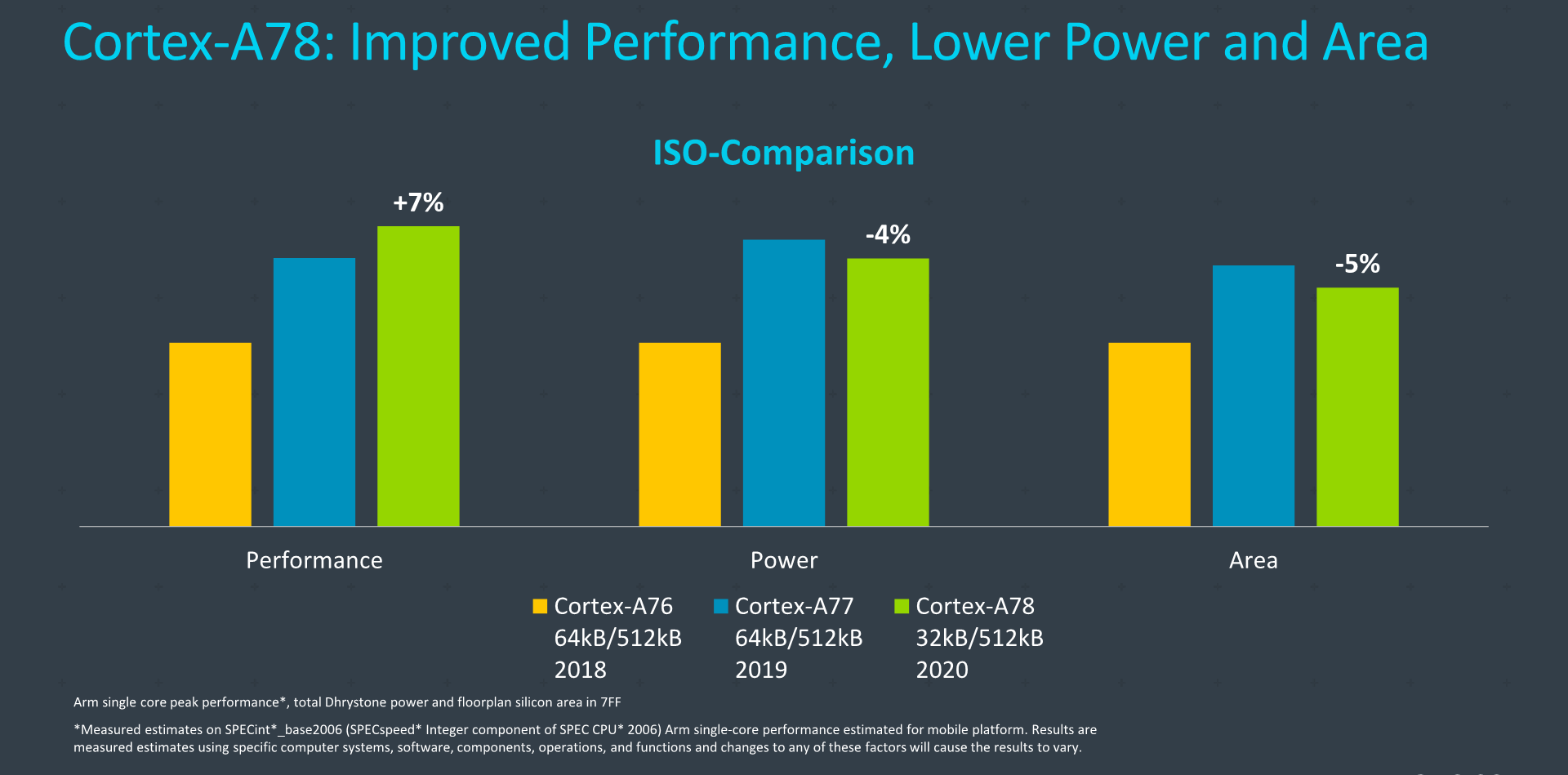
When actually looking at an ISO-process node comparison with a similar core configuration (essentially what Arm expects to be most commonly implemented), we’re seeing the A78 improve performance by roughly 7% over a Cortex-A77, all while reducing power by 4% and reducing area by 4%. It’s again important to note that while these figures sound maybe a little timid, Arm’s projected figures here do showcase an A78 with a lower-bounds configuration such as only 32KB L1D and L1I caches. I think the best way to interpret these numbers is to assume that this would be an implementation vendors would use to implement as their middle performance cores, leaving the higher perf targets for the X1.

Interestingly, Arm here for the first time ever published a whole performance/power curve of a microarchitecture, comparing the A77 to the A78. We see the higher cost at higher operating frequencies and the quadratic increase in power with increased voltage that is required to reach those higher frequencies (P = f * V²).
At the same peak performance point the A77 was able to achieve, the new A78 would use up 36% less power. At a more intermediate performance level (I think they might be using the process’ nominal voltage point here), this power reduction would be 30%. Finally, at the same power level, the A78 can increase performance by 7%.
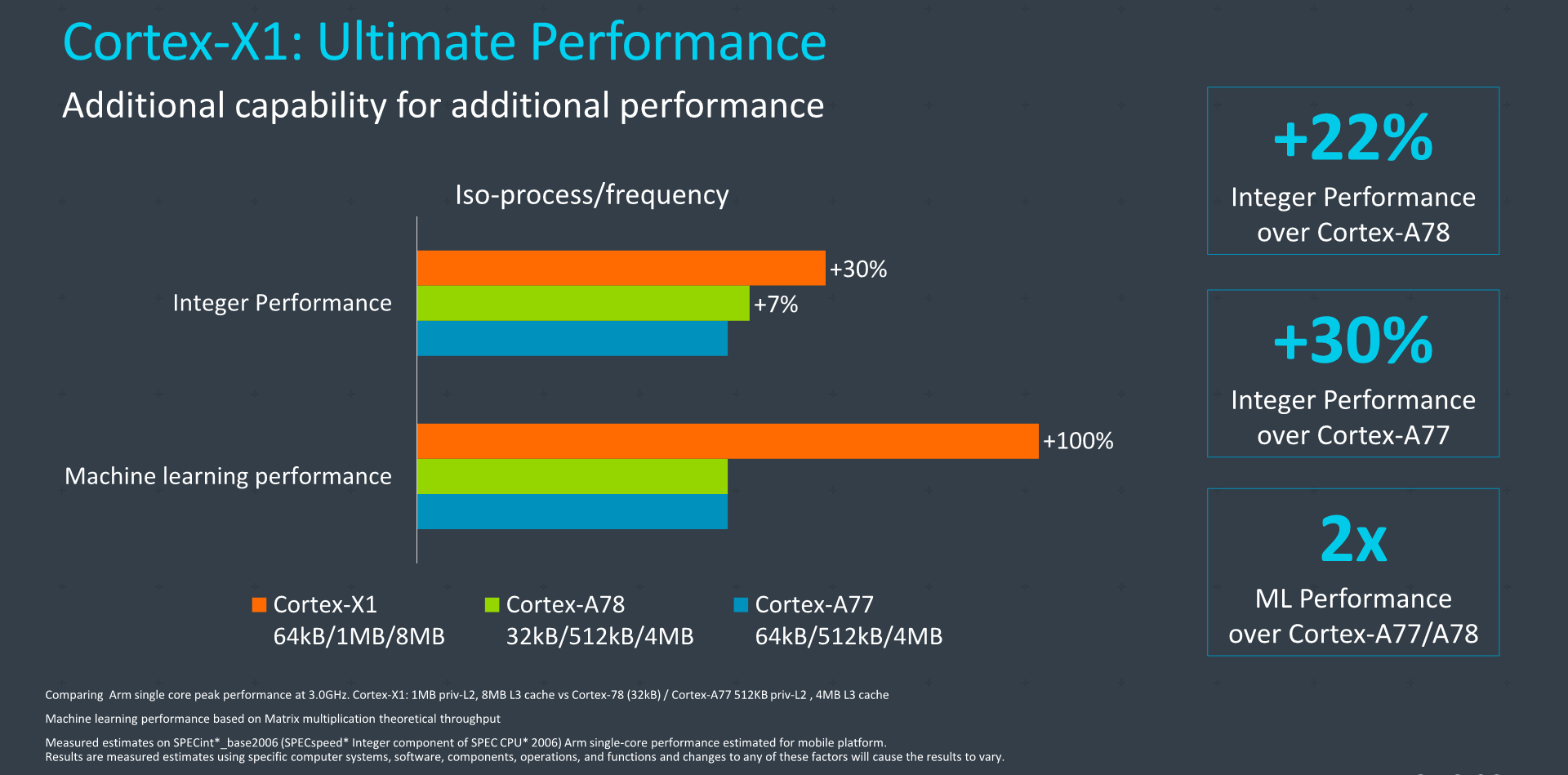
Moving onto the Cortex-X1, the generational performance improvements here are a lot more impressive, and we’re seeing an increase of +30% in terms of peak performance at the same frequencies versus the A77. This comparison would actually be a maximally configured X1 versus a maximally configured A77. It's to be noted that we never saw a 3GHz A77 by vendors, meaning the real-world performance boost would actually be even bigger than this (I’m actually expecting vendors to finally hit that 3GHz target this time around, on 5nm, fingers crossed).

The 30% IPC improvements versus the A77 cover both integer and floating-point suites of SPEC2006, which is extremely impressive. Arm also showcased Stream bandwidth improvements as well as Octane performance boosts, although I don’t find these to be quite as relevant, although they do serve as pointers of what to expect of the microarchitectures in such workloads.
Arm was relatively vague on the power and area efficiency of the X1, quoting that they aren’t quite as public with these figures for these “custom” parts as they are with public roadmap designs such as the Cortex-A78, but I was able to figure out a few rough metrics. In terms of area, on a similar process, we should expect an X1 cores to be roughly 1.5x the size of an A78 – including the difference between maximized L1 and L2 caches. Power should also be roughly in that ballpark figure.
If vendors are able to actually do a good implementation and there aren't any bad surprises with the upcoming 5nm processes, we should be seeing something similar to these projections:
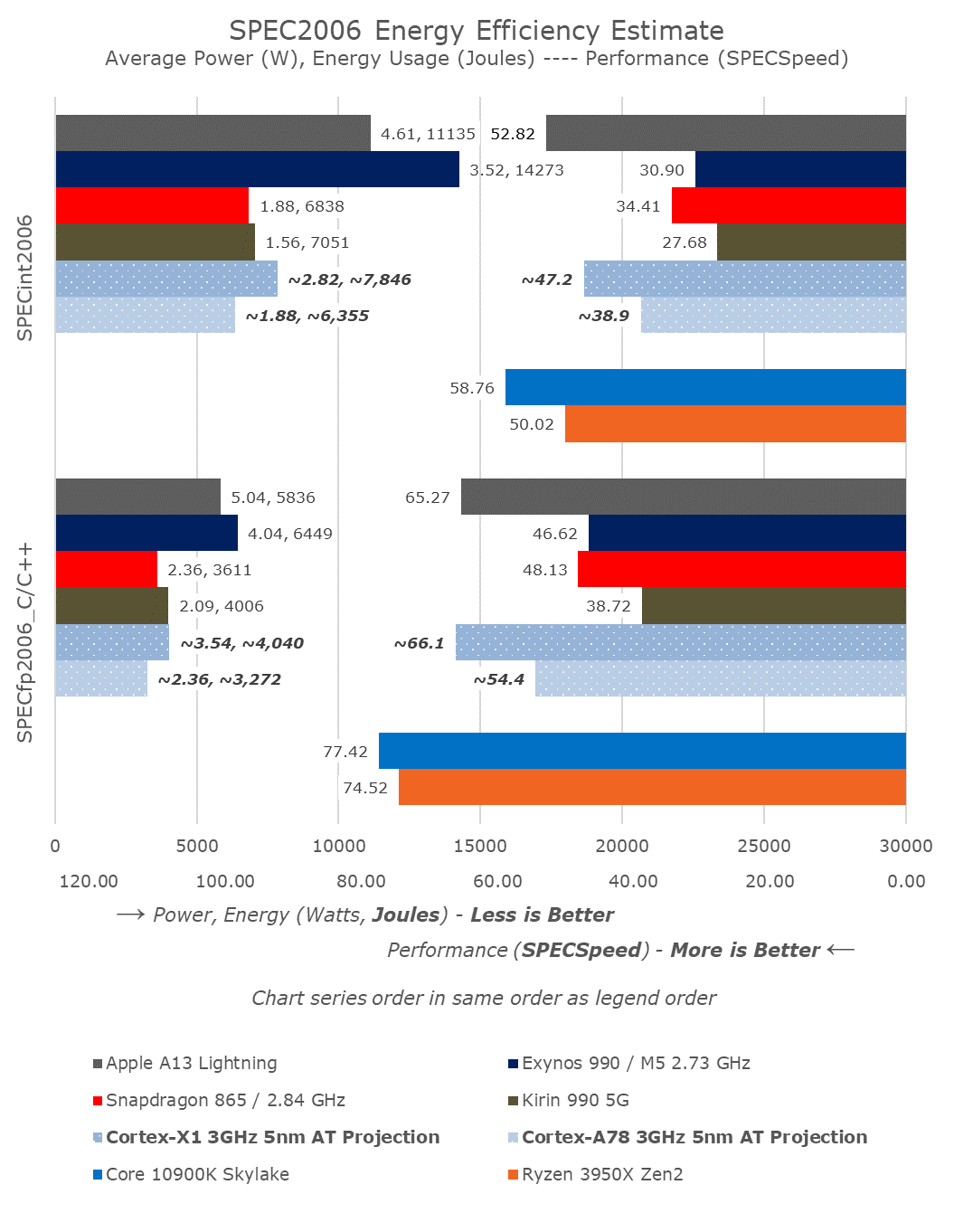
Again, as a big note – these figures are largely my own projections based on the various data-points that Arm has presented. This can end up differently in actual products, but in the past our predictions of the A76 and A77 ended up extremely close to the actual silicon, if not even pessimistically worse than what the real figures ended up at.
This generation, I do expect vendors to actually hit the 3GHz target for the Cortex-X1, as I have heard this being one of the goals the vendors are aiming to achieve for next year’s SoCs. I’m not too sure how many vendors will be doing for this for the Cortex-A78, which will more likely end up at lower clock speeds and implemented with a greater focus on power efficiency and area.
The Cortex-A78 would generally end up with the same power usage as current generation A77 products such as the Snapdragon 865 – with the vendors possibly using the process gains to get the last hundred MHz required to reach the 3GHz mark. The performance projection here is largely based on Arm’s +7% performance boost as well as a small clock boost. It would be a respectable upgrade, but nothing too earth-shattering in terms of generational updates.
The performance bump of an X1 system would be extremely competitive here, essentially being 37% faster than a Snapdragon 865 SoC today. That’s a huge generational bump and would put Arm very much in distance of Apple’s A13 cores, although in reality its competition would be the upcoming A14.
What’s really shocking here is how close Arm would be getting to Intel and AMD’s current best desktop systems in terms of performance. If both incumbent x86 vendors weren’t already worried about Arm’s yearly rate of improvement over the last few generations, they should outright panic at these figures if they actually materialize – and I do expect them to materialize.
The Cortex-X1 here is projected to use 1.5x the power of an A78. This might end up slightly lower but I’m being overly cautious here and prefer to be on the more pessimistic side. Here’s the real kicker though: the X1 could very well use up to 2x the power of a Cortex-A77/A78 and it would still be able to compete with Apple’s cores in terms of energy efficiency – the core’s increased performance largely makes up for its increased power draw, meaning its energy efficiency at the projected power would roughly only be 23% worse than an A78, and only 11-14% worse than say a current generation Snapdragon 865. Arm has such a big leeway in power efficiency at the moment that I just don’t see any scenario where the X1 would end up disappointing.
For years we’ve wanted Arm to finally go for no-compromise performance, and the Cortex-X1 is seemingly exactly that. That’s really exciting.
Implementations Choices & Customers
Naturally, the Cortex-X1 is expected to be quite bigger than a Cortex-A78, but not dramatically more. Arm does warn though that for mobile designs it’s extremely unlikely that we’ll see implementations with more than two X1 cores. The company here is essentially embracing the industry trend of going for a three tier core hierarchy, and with the introduction of the A78 and X1, they’re allowing customers to build such systems with much more flexibility and more differentiation than the frequency and process library differentiation we’ve been seeing on today’s “mid” and performance cores.

There’s still going to be customers who may be cost averse or simply not take part in the “Cortex-X Program”, who might just avoid the X1 and just go with A78 cores. The comparison Arm is making here is against an equivalent A77 setup, and the A78 cores would indeed bring a good amount of area savings all while improving performance.
Cortex-X1 implementers would very likely go for a hybrid cluster implementation with X1, A78 and A55 cores in a DSU. Arm here depicts Qualcomm’s favorite 1+3+4 configuration, and it's a logical setup that we’d expect to see in a future Snapdragon chip.
Today’s announcement of the Arm cores also came with an unusual quote from Samsung LSI:
“Samsung and Arm have a strong technology partnership and we are very excited to see the new direction Arm is taking with Cortex-X Custom program, enabling innovation in the Android ecosystem for next-gen user experiences.”
- Joonseok Kim, vice president of SoC design team at Samsung Electronics
It’s extremely rare to hear Samsung talk about a new Arm IP like this during a launch, and I think it’s pretty safe to say that this is very much an indirect confirmation that they’re a licensee of the X1 cores. In which case, we’ll be seeing the core in the next generation of flagship Exynos chipsets. Looking back at what happened with Samsung’s custom CPU design team last year as well as their lackluster performance of their custom cores, the very existence of the X1 probably further sealed the fate for their custom core efforts. The only remaining questions for me is whether they’ll go for a 1+3+4, or a 2+2+4 setup, and if Samsung’s 5nm will showcase better competitiveness compared to their lagging 7nm node.
Meanwhile HiSilicon, being in the middle of political turmoil, probably won't get to produce an X1 chip; plus the vendor has a tendency not always use the latest CPU IPs anyhow. MediaTek would be the last candidate licensee for the X1 – but here I’m also relatively uncertain if the company’s cost-oriented mantra actually fits well with the X1’s philosophy of going all out on area, with the likelihood that it’s also more expensive to license.
First Impressions - Arm Finally Going For Pure Performance
Today’s reveal of the Cortex-A78 and Cortex-X1 brought both the expected and the unexpected. I've had relatively modest expectations of the A78, as for years we had been told it would be the smallest upgrade amongst the new Austin family of Arm CPU microarchitectures. The A76 and A77 were after all both big leaps in performance and IPC. What I didn’t expect was for Arm to really focus on maximizing the PPA of the design, with efficiency being a first-class citizen in terms of design priorities. In that sense, the A78’s performance improvements might be a little tame compared to previous generations, but seemingly it’s still going to be an excellent core that is going to continue Arm's recent strides in outstandingly efficient computing.
Meanwhile the Cortex-X1 is a big change for Arm. And that change has less to do with the technology of the cores, and more with the business decisions that it now opens up for the company, although both are intertwined. For years many people were wondering why the company didn't design a core that could more closely compete with what Apple had built. In my view, one of the reasons for that was that Arm has always been constrained by the need to create a “one core fits all” design that could fit all of their customers’ needs – and not just the few flagship SoC designs.
The Cortex-X program here effectively unshackles Arm from these business limitations, and it allows the company to provide the best of both worlds. As a result, the A78 continues the company’s bread & butter design philosophy of power-performance-area leadership, whilst the X1 and its successors can now aim for the stars in terms of performance, without such strict area usage or power consumption limitations.
In this regard, the X1 seems really, really impressive. The 30% IPC improvement over the A77 is astounding and not something I had expected from the company this generation. The company has been incessantly beating the drum of their annual projected 20-25% improvements in performance – a pace which is currently well beyond what the competition has been able to achieve. These most recent projected performance figures are getting crazy close to the best that what we’ve seeing from the x86 players out there right now. That’s exciting for Arm, and should be worrying for the competition.






