Original Link: https://www.anandtech.com/show/15036/sifive-announces-first-riscv-ooo-cpu-core-the-u8series-processor-ip
SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM EST
In the last few year’s we’ve seen an increasing amount of talk about RISC-V and it becoming real competitor to the Arm in the embedded market. Indeed, we’ve seen a lot of vendors make the switch from licensing Arm’s architecture and IP designs to the open-source RISC-V architecture and either licensed or custom-made IP based on the ISA. While many vendors do choose to design their own microarchitectures to replace Arm-based microcontroller designs in their products, things get a little bit more complicated once you scale up in performance. It’s here where SiFive comes into play as a RISC-V IP vendor offering more complex designs for companies to license – essentially a similar business model to Arm’s – just that it’s based on the new open ISA.
Today’s announcement marks a milestone in SiFive’s IP offering as the company is revealing its first ever out-of-order CPU microarchitecture, promising a significant performance jump over existing RISC-V cores, and offering competitive PPA metrics compared to Arm’s products. We’ll be taking a look at the microarchitecture of the new U8 Series CPU and how it’s built and what it promises to deliver.


As a bit of background on the company, SiFive was founded in 2015 by the researchers who invented the RISC-V instruction set at UC Berkeley back in 2010. The company’s goal was to develop and implement CPUs and IP based on the RISC-V ISA and produce the first hardware based on the technology. The company first full-blown CPU IP that was able to run a full OS such as Linux was the U54 series which was released in 2017, and ever since SiFive has been in an upward trend of success and hypergrowth.
Introducing the U8-Series - A Scalable Out-of-Order RISC-V CPU Core
Up until now, it’s been relatively unsurprising that if you’re designing a new CPU based on a new ISA, you first start out small and then iterate as you continue to add more complexity to your design. SiFive’s U5 and U7 series as such have been relatively more simplistic in-order CPU microarchitectures. While offering functionality and being very cost-effective options and alternatives compared to Arm’s low-end and microcontroller cores, they really weren’t up to the task of more complex workloads that needed more raw performance.

The new U8-Series addresses these concerns by massively improving the performance that can be delivered by the new microarchitecture – outpacing the U54 and U74 by factors of up to 5-4x, a quite significant performance jump that we don’t usually see very often in the industry.

The new CPU IP’s performance promises to vastly expand SiFive’s and the RISC-V’s ecosystem viability in end-point products, and really be able to offer alternatives to the embedded Arm products in the world today and in the future.

SiFive’s design goals for the U8-Series are quite straightforward: Compared to an Arm Cortex-A72, the U8-Series aims to be comparable in performance, while offering 1.5x better power efficiency at the same time as using half the area. The A72 is quite an old comparison point by now, however SiFive’s PPA targets are comparatively quite high, meaning the U8 should be quite competitive to Arm’s latest generation cores.
The U8-Series Microarchitecture
We’ve had the pleasure of being briefed on the key aspects of the U8 microarchitecture, and we’ll be able to have a more in-depth look (albeit high-level) at how the new CPU design functions.
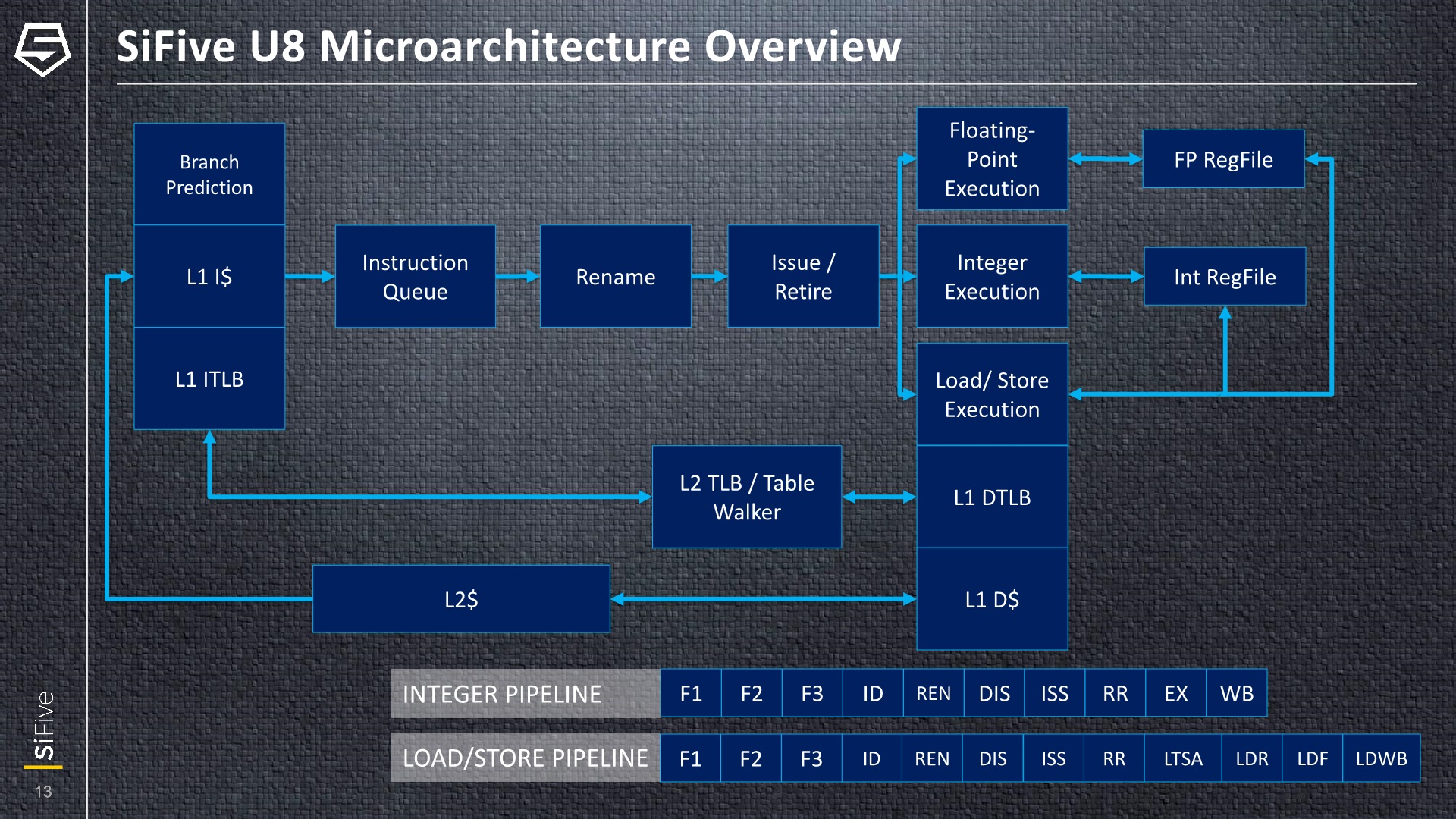
At the highest level, the U8 is a 3-wide issue out-of-order CPU with a pipeline depth of 12 stages, feeding 3 execution units. It’s a pretty traditional OoO-design and the noteworthy design choice here is the core’s use of physical register files instead of an architectural one, such as seen in initial Arm designs such as the A72.
One thing to note as we’re covering the microarchitecture is that SiFive didn’t disclose the exact sizes of some of the structures, which is somewhat natural given the core’s purported scalable configuration design where one can change many aspects of the IP, and we’re only covering the generic U8-Series microarchitecture as individual implementations (Such as an U84) will have different configurations.
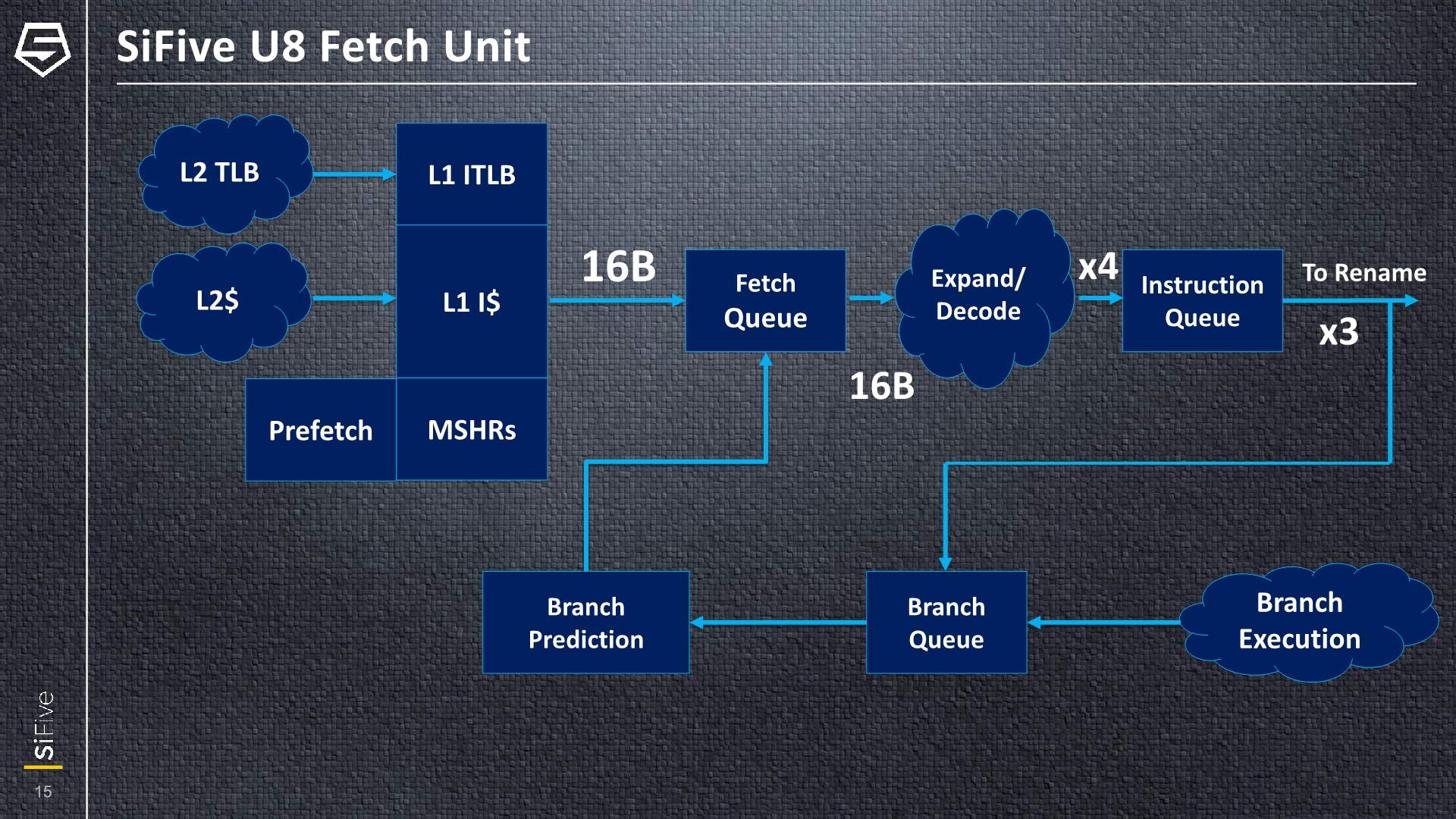
The fetch unit of the core is able to request instructions out of the L1I at 16 bytes per cycle and put it into the fetch queue of the front-end. The RISC-V ISA has a variable instruction encoding size, so it’s not possible to map this to an exact number on instructions as one can on the Arm ISA, but if we naively assume a 32-bit average, it would correspond to 4 instructions per cycle. Of course, this isn’t surprising as the decoder on the U8 is 4-wide, feeding expanded instructions into the instruction queue.
The interesting thing here about the core is that the instruction queue is only able to issue 3 instructions out to the rename stage. Having the fetch width being higher than your issuing rate helps in the case of branch mispredictions and bubbles and allows the front-end to catch up with the execution backend, something we’ve also seen in other cores; however, we never quite saw an implementation in which the decoder was wider than the issue rate (Actually, only Intel's recent Tremont microarchitecture would also fit this characteristic). Beyond it being a deliberate design decision for the balance of the microarchitecture, maybe it’s also a forward-looking implementation on the part of the decoder whilst we may see wider issue configurations in future U8 designs.
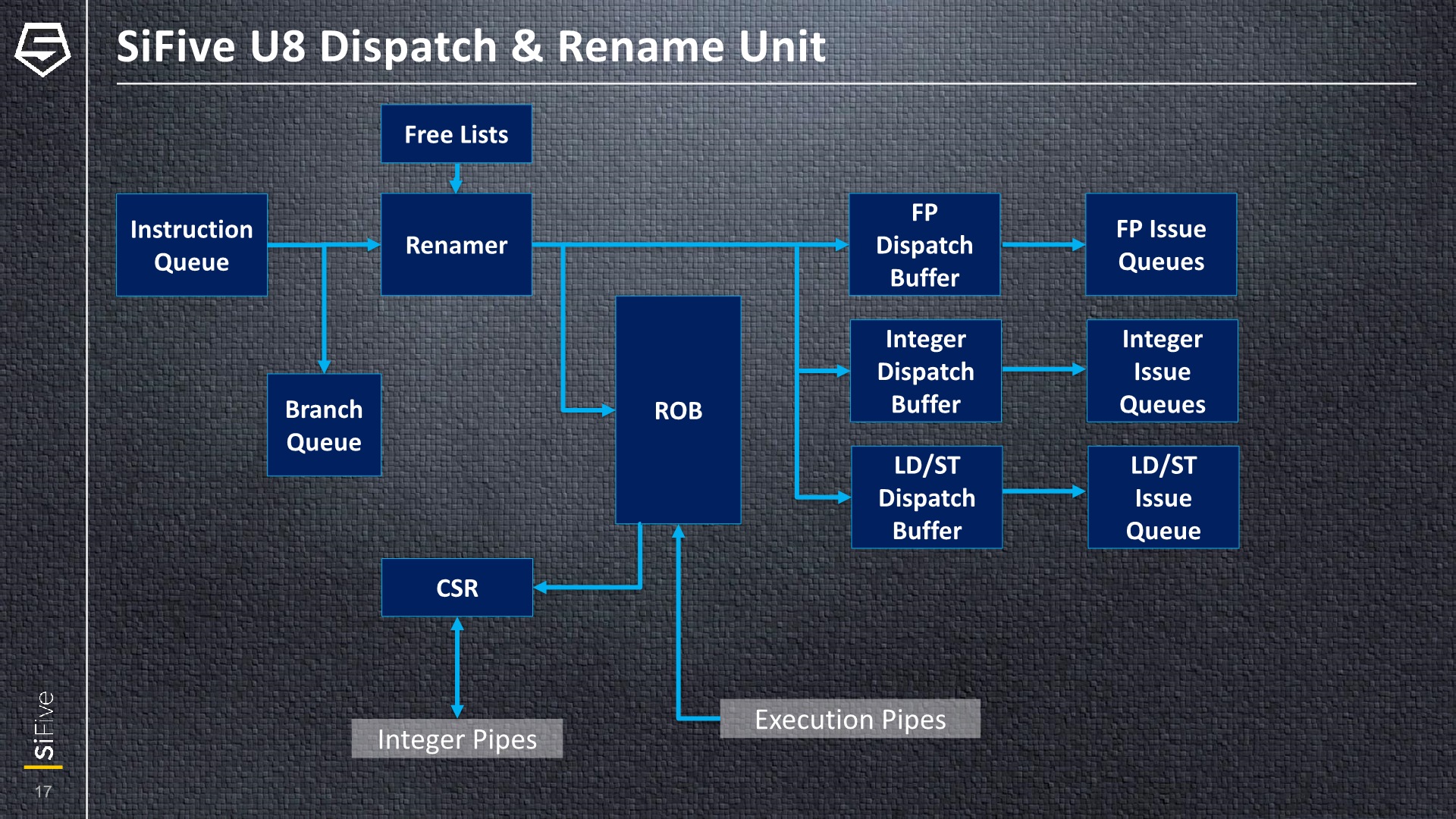
Moving on to the mid-core, we see a traditional design into the rename stage, a re-order buffer and three dispatch engines feeding into the execution pipelines. The diagram here is a bit misleading in terms of the arrows going into the issue queues – it doesn’t mean that it’s only one instruction per issue queue, the core can still dispatch up to 3 instructions into the integer issue queues for example.
It would have been interesting to hear about the exact structure sizes on this part of the core but SiFive didn’t cover these details during the presentation.
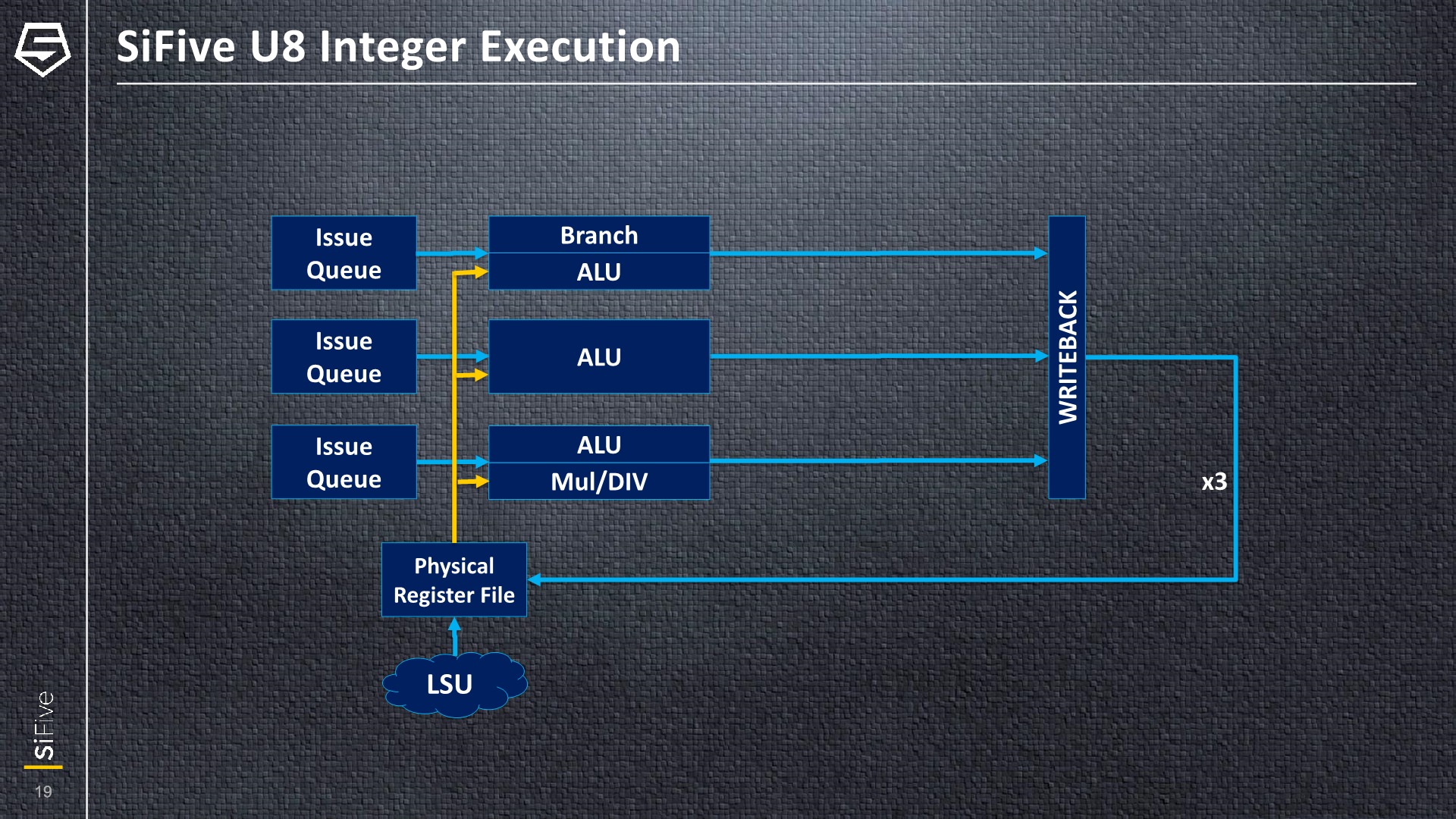
On the integer execution block, we see that it’s actually composed of three execution pipelines. Each has its own issue queue, feeding into three ALU pipelines with different capabilities. One pipeline serves just as a regular ALU, a second one shares the port with the branch unit, while the third pipeline is a more complex one capable of integer multiplication and division.
Unfortunately, SiFive didn’t go into any detail of the floating-point pipelines or the L/S units. On the FP side, things should be relatively simple in terms of the execution capabilities, at least on the U84 core. Currently, RISC-V does not have any SIMD/Vector instructions as that ISA extension has not been finalized yet. SiFive explains that this might happen at the end of the year, and the U87 is poised to adopt the new vector capabilities next year.
Performance Targets, PPA and Conclusion
The U8-Series microarchitecture will initially be productized as two IP offerings: The U84 and the U87 CPU cores:

The U87 will only be available later next year, whilst the U84 is also being finalised right now. The company has the U84 IP running internally on FPGA platforms.
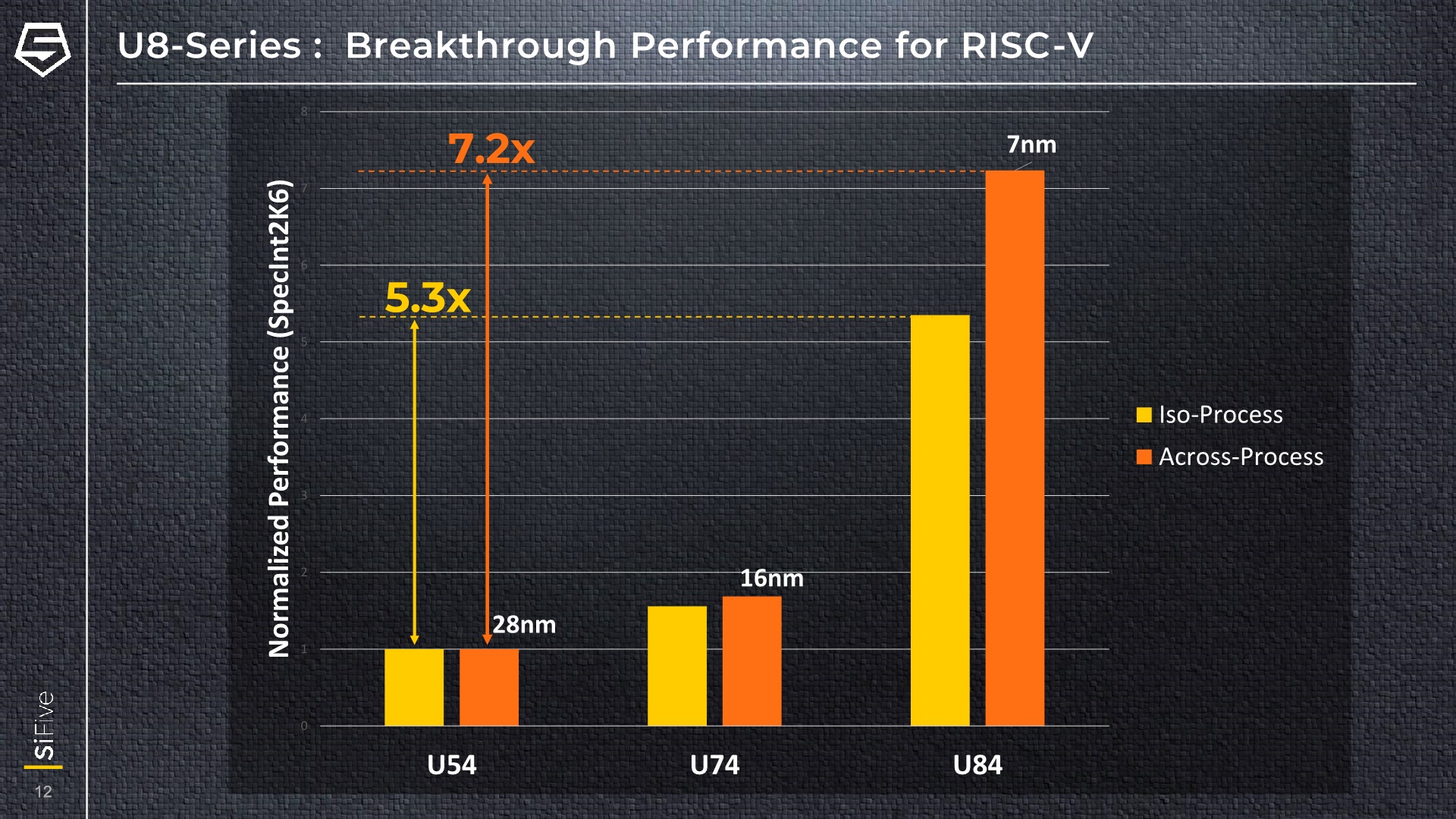
The performance increases compared to previous generation SiFive cores are extremely impressive: Against a U54 at ISO-process, the new U84 features a 5.3x performance increase in SPECint2006. When taking into account the process node improvements that allow the U84 to clock higher, the generational increases that we’d be seeing in products will be more akin to a factor of 7.2x.
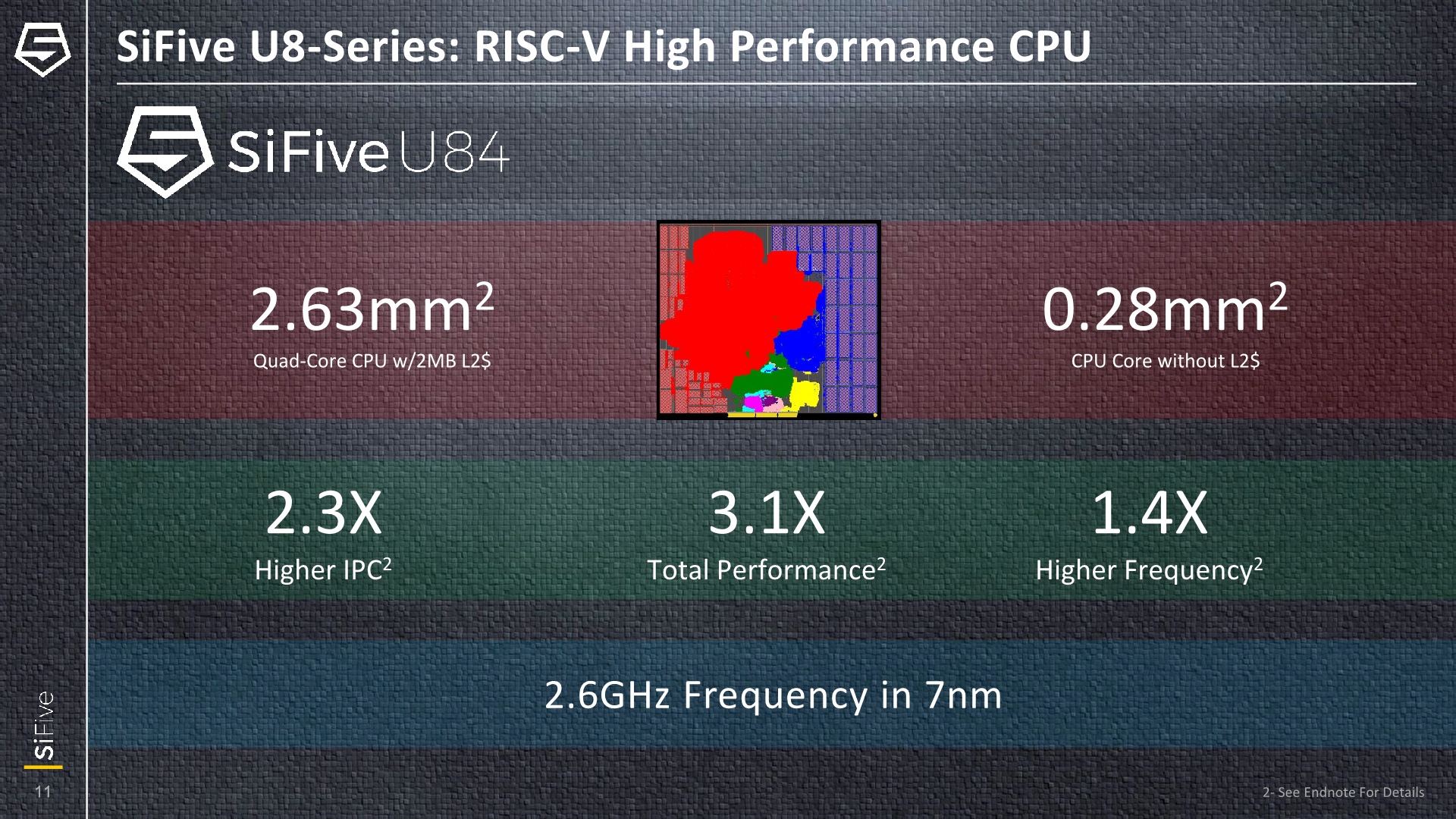
In terms of PPA, compared to a U7-series CPU, IPC increases come in at 2.3x resulting in 3.1x higher performance (ISO-process). A lot of the performance increases of the U8-series come thanks to the increased frequencies capabilities which are 1.4x higher this generation, with the core scaling up to 2.6GHz on 7nm.
On the same 7nm process, the U84 lands in at 0.28mm² per core and a cluster comprising four cores and a 2MB L2 cache measure in at 2.63mm². For comparison, a Arm Cortex-A55 as measured on the Kirin 980, also on 7nm, a core with its 128KB private L2 cache comes in at 0.36mm². Given that SiFive promises of similar performance to a Cortex-A72, which in turn would be more than double the performance of an A55, it looks like SiFive’s U84 core would be extremely competitive in terms of its PPA.

Finally, SiFive is able to configure of up to 9 CPU cores into a coherent cluster with a shared L2. The IP is also able to this in a heterogeneous way, similar to Arm’s big.LITTLE approach, employing both U8 and U7 series and even S-Series CPUs into the same cluster.
Conclusion - A Big Step In a Long Journey
Overall, SiFive’s new U8 core is I think a very important and major step for the company in terms of pushing its products and as well as pushing the RISC-V ecosystem forward. The key takeaway from the U8 is the massively improved performance of the core that now suddenly allows the company to seriously compete against some of Arm’s low- and mid-range cores.
I’m not really expecting to see the core employed in products such as smartphones any time soon as frankly SiFive still has a very long road ahead in terms of improving absolute performance. That being said, in the IoT and embedded markets, I think we’ll see faster and wider adoption of RISC-V cores, and SiFive is certain to see continued growth and interest for years to come. We’re looking forward in observing this future develop.






