Original Link: https://www.anandtech.com/show/14694/amd-rome-epyc-2nd-gen
AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM EST
If you examine the CPU industry and ask where the big money is, you have to look at the server and datacenter market. Ever since the Opteron days, AMD's market share has been rounded to zero percent, and with its first generation of EPYC processors using its new Zen microarchitecture, that number skipped up a small handful of points, but everyone has been waiting with bated breath for the second swing at the ball. AMD's Rome platform solves the concerns that first gen Naples had, plus this CPU family is designed to do many things: a new CPU microarchitecture on 7nm, offer up to 64 cores, offer 128 lanes of PCIe 4.0, offer 8 memory channels, and offer a unified memory architecture based on chiplets. Today marks the launch of Rome, and we have some of our own data to share on its performance.
Review edited by Dr. Ian Cutress
First Boot
Sixty-four cores. Each core with an improved Zen 2 core, offering ~15% better IPC performance than Naples (as tested in our consumer CPU review), and doubled AVX2/FP performance. The chip has a total of 256 MB of L3 cache, and 128 PCIe 4.0 lanes. AMD's second generation EPYC, in this case the EPYC 7742, is a behemoth.
Boot to BIOS, check the node information.
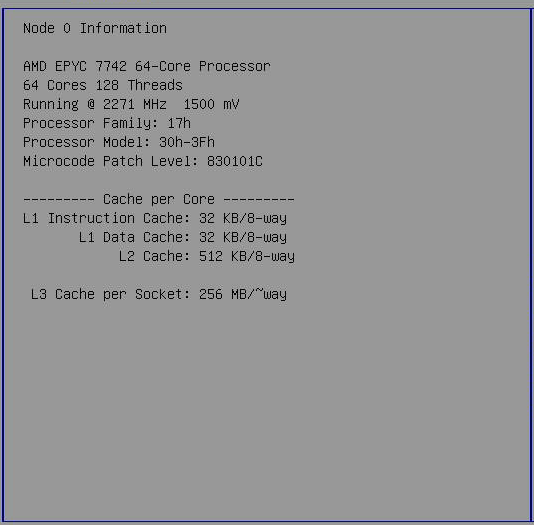
[Note: That 1500 mV reading in the screenshot is the same reading we see on consumer Ryzen platforms; it seems to be the non-DVFS voltage as listed in the firmware, but isn't actually observed]
It is clear that the raw specifications of our new Rome CPU is some of the most impressive on the market. The question then goes to whether or not this is the the new fastest server chip on the market - a claim that AMD is putting all its weight behind. If this is the new fastest CPU on the market, the question then becomes 'by how much?', and 'how much does it cost?'.
I have been covering server CPUs since the launch of the Opteron in 2003, but this is nothing like I have seen before: a competitive core and twice as much of them on a chip than what the competition (Intel, Cavium, even IBM) can offer. To quote AMD's SVP of its Enterprise division, Forrest Norrod:
"We designed this part to compete with Ice Lake, expecting to make some headway on single threaded performance. We did not expect to be facing re-warmed Skylake instead. This is going to be one of the highlights of our careers"
Self-confidence is at all times high at AMD, and on paper it would appear to be warranted. The new Rome server CPUs have improved core IPC, a doubling of the core count at the high end, and it is using a new manufacturing process (7 nm) technology in one swoop. Typically we see a server company do one of those things at a time, not all three. It is indeed a big risk to take, and the potential to be exciting if everything falls into place.

To put this into perspective: promising up to 2x FP performance, 2x cores, and a new process technology would have sounded so odd a few years ago. At the tail end of the Opteron days, just 4-5 years ago, Intel's best CPUs were up to three times faster. At the time, there was little to no reason whatsoever to buy a server with AMD Opterons. Two years ago, EPYC got AMD back into the server market, but although the performance per dollar ratio was a lot better than Intel's, it was not a complete victory. Not only was AMD was still trailing in database performance and AVX/FP performance, but partners and OEMs were also reluctant to partner with the company without a proven product.
So now that AMD has proven its worth with Naples, and AMD promising more than double the deployed designs of Rome with a very quick ramp to customers, we have to compare the old to the new. For the launch of the new hardware, AMD provided us with a dual EPYC 7742 system from Quanta, featuring two 64-core CPUs.
Better Core in Zen 2
Just in case you have missed it, in our microarchitecture analysis article Ian has explained in great detail why AMD claims that its new Zen2 is significantly better architecture than Zen1:
- a different second-stage branch predictor, known as a TAGE predictor
- doubling of the micro-op cache
- doubling of the L3 cache
- increase in integer resources
- increase in load/store resources
- support for two AVX-256 instructions per cycle (instead of having to combine two 128 bit units).
All of these on-paper improvements show that AMD is attacking its key markets in both consumer and enterprise performance. With the extra compute and promised efficiency, we can surmise that AMD has the ambition to take the high-performance market back too. Unlike the Xeon, the 2nd gen EPYC does not declare lower clocks when running AVX2 - instead it runs on a power aware scheduler that supplies as much frequency as possible within the power constraints of the platform.
Users might question, especially with Intel so embedded in high performance and machine learning, why AMD hasn't gone with an AVX-512 design? As a snap back to the incumbent market leader, AMD has stated that not all 'routines can be parallelized to that degree', as well as a very clear signal that 'it is not a good use of our silicon budget'. I do believe that we may require pistols at dawn. Nonetheless, it will be interesting how each company approaches vector parallelisation as new generations of hardware come out. But as it stands, AMD is pumping its FP performance without going full-on AVX-512.
In response to AMD's claims of an overall 15% IPC increase for Zen 2, we saw these results borne out of our analysis of Zen 2 in the consumer processor line, which was released last month. In our analysis, Andrei checked and found that it is indeed 15-17% faster. Along with the performance improvements, there have been also security hardening updates, improved virtualization support, and new but proprietary instructions for cache and memory bandwidth Quality of Service (QoS). (The QoS features seem very similar to what Intel has introduced in Broadwell/Xeon E5 version 4 and Skylake - AMD is catching up in that area).
Rome Layout: Simple Makes It a Lot Easier
When we analyzed AMD's first generation of EPYC, one of the big disadvantages was the complexity. AMD had built its 32-core Naples processors by enabling four 8-core silicon dies, and attaching each one to two memory channels, resulting in a non-uniform memory architecutre (NUMA). Due to this 'quad NUMA' layout, a number of applications saw quite a few NUMA balancing issues. This happened in almost every OS, and in some cases we saw reports that system administrators and others had to do quite a bit optimization work to get the best performance out of the EPYC 7001 series.
The New 2nd Gen EPYC, Rome, has solved this. The CPU design implements a central I/O hub through which all communications off-chip occur. The full design uses eight core chiplets, called Core Complex Dies (CCDs), with one central die for I/O, called the I/O Die (IOD). All of the CCDs communicate with this this central I/O hub through dedicated high-speed Infinity Fabric (IF) links, and through this the cores can communicate to the DRAM and PCIe lanes contained within, or other cores.
The CCDs consist of two four-core Core CompleXes (1 CCD = 2 CCX). Each CCX consist of a four cores and 16 MB of L3 cache, which are at the heart of Rome. The top 64-core Rome processors overall have 16 CCX, and those CCX can only communicate with each other over the central I/O die. There is no inter-chiplet CCD communication.

This is what this diagram shows. On the left we have Naples, first Gen EPYC, which uses four Zepellin dies each connected to the other with an IF link. On the right is Rome, with eight CCDs in green around the outside, and a centralized IO die in the middle with the DDR and PCIe interfaces.
As Ian reported, while the CCDs are made at TSMC, using its latest 7 nm process technology. The IO die by contrast is built on GlobalFoundries' 14nm process. Since I/O circuitry, especially when compared to caching/processing and logic circuitry, is notoriously hard to scale down to smaller process nodes, AMD is being clever here and using a very mature process technology to help improve time to market, and definitely has advantages.
This topology is clearly visible when you take off the hood.

Main advantage is that the 2nd Gen 'EPYC 7002' family is much easier to understand and optimize for, especially from a software point of view, compared to Naples. Ultimately each processor only has one memory latency environment, as each core has the same latency to speak to all eight memory channels simultanously - this is compared to the first generation Naples, which had two NUMA regions per CPU due to direct attached memory.
As seen in the image below, this means that in a dual socket setup, a Naples processor will act like a traditional NUMA environment that most software engineers are familiar with.

Ultimately the only other way to do this is with a large monolithic die, which for smaller process nodes is becoming less palatable when it comes to yields and pricing. In that respect, AMD has a significant advantage in being able to develop small 7nm silicon with high yields and also provide a substantial advantage when it comes to binning for frequency.
How a system sees the new NUMA environment is quite interesting. For the Naples EPYC 7001 CPUs, this was rather complicated in a dual socket setup:
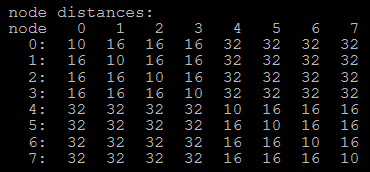
Here each number shows the 'weighting' given to the delay to access each of the other NUMA domains. Within the same domain, the weighting is light at only 10, but then a NUMA domain on the same chip was given a 16. Jumping off the chip bumped this up to 32.
This changed significantly on Rome EPYC 7002:

Although there are situations where the EPYC 7001 CPUs communicated faster, but the fact that the topology is much simpler from the software point of view is worth a lot. It makes getting good performance out of the chip much easier for everyone that has to used it, which will save a lot of money in Enterprise, but also help accelerate adoption.
PCIe 4.0
As the first commerical x86 server CPU supporting PCIe 4.0, the I/O capabilities of second generation EPYC servers are top of the class. One PCIe 4.0 x16 offers up to 32 GB/s in both direction, so each socket offers up to 256 GB/s in both directions, for a full 128 PCIe 4.0 lanes per CPU.

Each CPU has 8 x16 PCIe 4.0 links available which can be split up among up to 8 devices per PCIe root, as shown above. There is also full PCIe peer-to-peer support both within a single socket and across sockets.
With the previous generation, in order to enable a dual socket configuration, 64 PCIe lanes from each CPU were used to link them together. For EPYC, AMD still allows for 64 PCIe lanes to be used, but these are PCIe 4.0 lanes now. There is also another feature that AMD has here - socket-to-socket IF link bandwidth management - which allows OEM partners to design dual-socket systems with less socket-to-socket bandwidth and more PCIe lanes if needed.
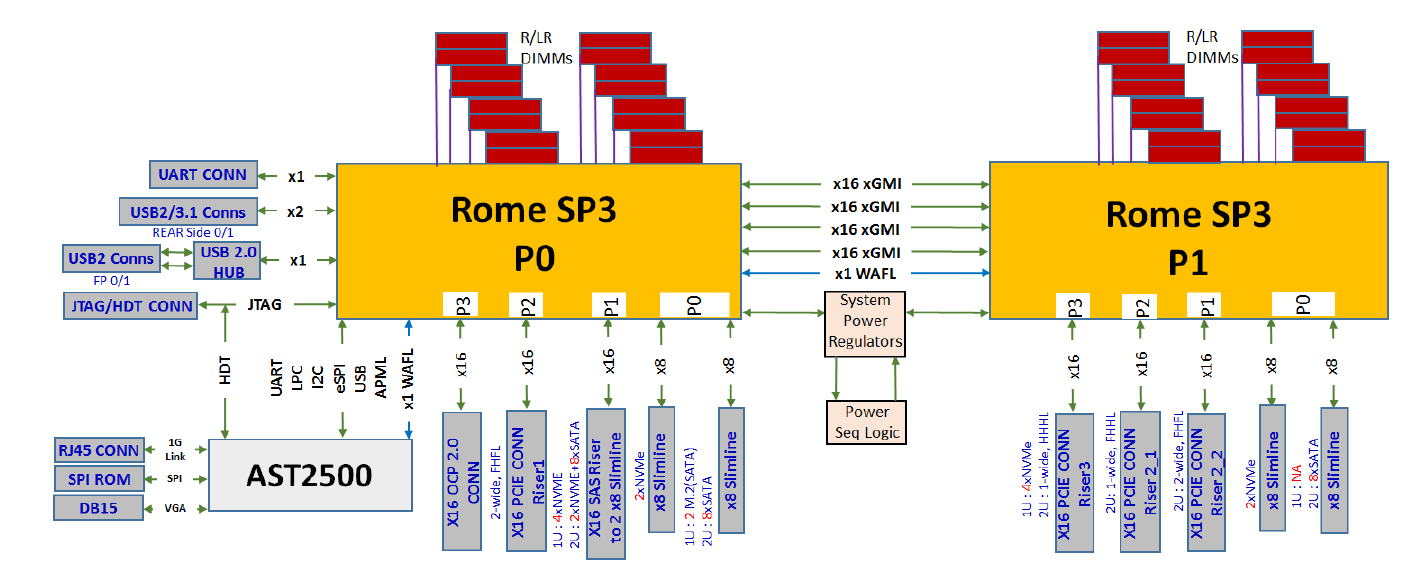
We also learned that there are in fact 129 PCIe 4.0 lanes on each CPU. On each CPU there is one extra PCIe lane for the BMC (the chip that controls the server). Considering we are living in the age of AI acceleration, the EPYC 7002 servers will be great as hosts for quite a few GPUs or TPUs. Density has never looked so fun.
Rome CPUs: Core Counts and Frequencies
There has been little doubt that on paper Rome and the EPYC 7002 family will be a competitive product compared to Intel's Xeon Scalable when it comes to performance or performance per watt. As always, it comes down to paring which part offers the right competition. With Rome, AMD is once again attacking performance per dollar, as well as peak performance and performance per watt.
EPYC 7000 nomenclature
The naming of the CPUs is kept consistent with the previous generation.
- EPYC = Brand
- 7 = 7000 Series
- 25-74 = Dual Digit Number indicative of stack positioning / performance (non-linear)
- 1/2 = Generation
- P = Single Socket, not present in Dual Socket
AMD is introducing 19 total CPUs to the Rome family, 13 of which are aimed at the dual socket market. All CPUs have 128 PCIe 4.0 lanes available for add-in cards, and all CPUs support up to 4 TiB of DDR4-3200.
| AMD EPYC 7001 & 7002 Processors (2P) | ||||||
| Cores Threads |
Frequency (GHz) | L3* | TDP | Price | ||
| Base | Max | |||||
| EPYC 7742 | 64 / 128 | 2.25 | 3.40 | 256 MB | 225 W | $6950 |
| EPYC 7702 | 64 / 128 | 2.00 | 3.35 | 256 MB | 200 W | $6450 |
| EPYC 7642 | 48 / 96 | 2.30 | 3.20 | 256 MB | 225 W | $4775 |
| EPYC 7552 | 48 / 96 | 2.20 | 3.30 | 192 MB | 200 W | $4025 |
| EPYC 7542 | 32 / 64 | 2.90 | 3.40 | 128 MB | 225 W | $3400 |
| EPYC 7502 | 32 / 64 | 2.50 | 3.35 | 128 MB | 200 W | $2600 |
| EPYC 7452 | 32 / 64 | 2.35 | 3.35 | 128 MB | 155 W | $2025 |
| EPYC 7402 | 24 / 48 | 2.80 | 3.35 | 128 MB | 155 W | $1783 |
| EPYC 7352 | 24 / 48 | 2.30 | 3.20 | 128 MB | 180 W | $1350 |
| EPYC 7302 | 16 / 32 | 3.00 | 3.30 | 128 MB | 155 W | $978 |
| EPYC 7282 | 16 / 32 | 2.80 | 3.20 | 64 MB | 120 W | $650 |
| EPYC 7272 | 12 / 24 | 2.90 | 3.20 | 64 MB | 155 W | $625 |
| EPYC 7262 | 8 / 16 | 3.20 | 3.40 | 128 MB | 120 W | $575 |
| EPYC 7252 | 8 / 16 | 3.10 | 3.20 | 64 MB | 120 W | $475 |
| Select EPYC 7001 Naples CPUs | ||||||
| EPYC 7601 | 32 / 64 | 2.20 | 3.20 | 64 MB | 180 W | $4200 |
| EPYC 7551 | 32 / 64 | 2.00 | 3.00 | 64 MB | 180 W | >$3400 |
| EPYC 7501 | 32 / 64 | 2.00 | 3.00 | 64 MB | 155 W | $3400 |
| EPYC 7451 | 24 / 48 | 2.30 | 3.20 | 64 MB | 180 W | $2400 |
| EPYC 7371 | 16 / 32 | 3.10 | 3.80 | 64 MB | 200 W | $1550 |
| EPYC 7251 | 8 / 16 | 2.10 | 2.90 | 32 MB | 120 W | $475 |
| Special CPUs worth noting listed in bold * We are awaiting full L3 cache information |
||||||
The top part is the EPYC 7742, which is the CPU we were provided for in this comparison. It is the most expensive non-custom AMD CPU ever. We will discuss whether the price is a bargain or suitable after we have done some benchmarking.
But one thing is for sure: AMD is definitely improving the performance per dollar. The real star is the 7502, as it offers 32 Zen2 cores at 2.50/3.35 GHz for $2600. This means that you get higher clocks, better cores, twice the L3, and just as much cores as the 7601 had - in other words, the 7502 is better in every way, but compared to the 7601 it comes with an impressive 40% discount ($2600 vs $4200).
There is more to it. Unlike Intel's market segmentation strategy, which makes the life of enterprise infrastructure people more complicated than it should be, AMD does not blow fuses on cheaper SKUs to create artificial 'value' for buying more expensive SKUs. The cheapest 8-core 7252 has all 128 PCIe 4.0 lanes, it supports up to 4 TB per socket, it has infinity fabric at the same speed, and includes all virtualization and security features as the best product.
Comparison to Intel
In the table below we have done a base example comparison with some of Intel's SKU list. Given that Intel is dominant in the market, prospective buyers must get a significant price bonus or significantly lower TCO before they switch to AMD.
| Intel Second Gen Xeon Scalable (Cascade Lake) |
AMD Second Gen EPYC ("Rome") |
||||||||||
| Cores | Freq | TDP (W) |
Price | AMD | Cores | Freq | TDP | Price | |||
| Xeon Platinum 8200 | Rome | ||||||||||
| 8280 | M | 28 | 2.7/4.0 | 205 | $13012 | 7742 | 64 | 2.25/3.40 | 225 | $6950 | |
| 8280 | 28 | 2.7/4.0 | 205 | $10009 | |||||||
| 8276 | M | 28 | 2.2/4.0 | 165 | $11722 | 7742 | 64 | 2.25/3.40 | 225 | $6950 | |
| 8270 | 26 | 2.7/4.0 | 205 | $7405 | |||||||
| 8268 | 24 | 2.9/3.9 | 205 | $6302 | |||||||
| 8260 | M | 24 | 2.4/3.9 | 165 | $7705 | 7702 | 64 | 2.00/3.35 | 225 | $6450 | |
| 8260 | 24 | 2.4/3.9 | 165 | $4702 | 7552 | 48 | 2.20/3.50 | 200 | $4025 | ||
| 8253 | 16 | 2.2/3.0 | 165 | $3115 | 7502 | 32 | 2.50/3.35 | 200 | $2600 | ||
| Xeon Gold 6200 | Rome | ||||||||||
| 6252 | 24 | 2.1/3.7 | 150 | $3665 | |||||||
| 6248 | 20 | 2.5/3.9 | 150 | $3072 | |||||||
| 6242 | 16 | 2.8/3.9 | 150 | $2529 | 7452 | 32 | 2.35/3.35 | 155 | $2025 | ||
| 6238 | 22 | 2.1/3.7 | 140 | $2612 | 7402 | 24 | 2.80/3.35 | 155 | $1783 | ||
| 6226 | 12 | 2.8/3.7 | 125 | $1776 | |||||||
| Xeon Silver 4200 | Rome | ||||||||||
| 4216 | 16 | 2.1/3.2 | 100 | $1002 | 7282 | 16 | 2.80/3.20 | 120 | $625 | ||
| 4214 | 2x12 | 2.2/3.2 | 2x85 | 2x$694 | 7402P | 24 | 2.80/3.35 | 180 | $1250 | ||
In our comparison, we've also ignored the fact that AMD supports up to 4 TB per socket and has 128 PCIe 4.0 lanes, which it beats Intel on both fronts. While the number of people that will buy 256 GB DIMMs is minimal at best, within the error margin of the market, to us it is simply is ridiculous that Intel expect enterprise users to cough up another few thousand dollars per CPU for a model that supports 2 TB, while you get that for free from AMD.
Going on paper, especially in the high-end, Intel is completely outclassed. A 28-core Xeon 8276M has a list price of ~$12k, while AMD charges "only" $7k for more than twice as many cores. The only advantage Intel keeps is a slightly higher single threaded clock (4 GHz) and AVX-512 support. You could argue that the TDP is lower, but that has to be measured, and frankly there is a good chance that one 64 core (at 2.25-3.2 GHz) is able to keep with two Intel Xeon 8276 (2x28 cores at 2.2-2.8 GHz), while offering much lower power consumption (single socket board vs dual board, 225W vs 2x165W).
AMD is even more generous in the mid-range. The EPYC 7552 offers twice the amout of cores at higher clocks than the Xeon Platinum 8260, which is arguably one of the more popular Xeon Platinum CPUs. The same is true for the EPYC 7452, which still costs less than the Xeon Gold 6242. It is only at the very low end, that the diffences get smaller.
Single Socket
For single socket systems, AMD will offer the following five processors below. These processors mirror the specifications of the 2P counterparts, but have a P in the name and slightly different pricing.
| AMD EPYC Processors (1P) | ||||||
| Cores Threads |
Frequency (GHz) | L3 | TDP | Price | ||
| Base | Max | |||||
| EPYC 7702P | 64 / 128 | 2.00 | 3.35 | 256 MB | 200 W | $4425 |
| EPYC 7502P | 32 / 64 | 2.50 | 3.35 | 128 MB | 200 W | $2300 |
| EPYC 7402P | 24 / 48 | 2.80 | 3.35 | 128 MB | 200 W | $1250 |
| EPYC 7302P | 16 / 32 | 3.00 | 3.30 | 128 MB | 155 W* | $825 |
| EPYC 7232P | 8 / 16 | 3.10 | 3.20 | 32 MB | 120 W | $450 |
| *170W TDP mode also available | ||||||
This table makes also clear how much extra frequency AMD extracted out of the 7 nm TSMC process. The sixteen core EPYC 7302P runs at 3.0 GHz with all cores, while the EPYC 7351 was limited to 2.4 GHz at the same 155W TDP.
Again, the EPYC 7502P looks like one of the best deals of the server CPU market. This SKU can offer a lot of advantages compared to the current dual socket servers. If offers very potent single thread performance (3.35 GHz boost) and a very high 2.5 GHz when all cores are used, even when running AVX2 code. Secondly, a single socket server has a lower BOM and has lower power consumption (200W) compared to a dual 16-core system. Lastly, it supports up to 1-2 TB realistically (64-128 GB DIMMs) and has ample I/O bandwidth with 128 PCIe 4.0 lanes.
Murphy's Law
Anything That Can Go Wrong, Will Go Wrong
For those of you that may not know, I am an Academic Director of MCT at Howest University here in Belgium. I perform research in our labs here on big data analytics, virtualization, cloud computing, and server technology in general. We do all the testing here in the lab, and I also do launch article testing for AnandTech.
Undoubtedly, like most academic institutions, we have a summer vacation, where our labs are locked and we are told to get some sunlight. AMD's Rome launch has happened just as our lab closing started, and so I had the Rome server delivered to my home lab instead. The only issue was that our corresponding Intel server was still in the academic lab. Normally this isn't really a problem - even when the lab is open, I issue testing through remote access and process the data that way, in order to reboot the system and run tests and so forth. If a hardware change is needed, I need to be physically there, but usually this isn't a problem.
However, as Murphy's Law would have it, during testing for this review, our Domain Controller also crashed while our labs were closed. We could not reach our older servers any more. This has limited us somewhat in our testing - while I can test this Rome system during normal hours at the home lab (can't really run it overnight, it is a server and therefore loud), I couldn't issue any benchmarks to our Naples / Cascade Lake systems in the lab.
As a result, our only option was to limit ourselves to the benchmarks already done on the EPYC 7601, Skylake, and Cascade Lake machines. Rest assured that we will be back with our usual Big Data/AI and other real world tests once we can get our complete testing infrastructure up and running.
Benchmark Configuration and Methodology
All of our testing was conducted on Ubuntu Server 18.04 LTS, except for the EPYC 7742 server, which was running Ubuntu 19.04. The reason was simple: we were told that 19.04 had validated support for Rome, and with two weeks of testing time, we wanted to complete what was possible. Support (including X2APIC/IOMMU patches to utilize 256 threads) for Rome is available with Linux Kernel 4.19 and later.
You will notice that the DRAM capacity varies among our server configurations. This is of course a result of the fact that Xeons have access to six memory channels while EPYC CPUs have eight channels. As far as we know, all of our tests fit in 128 GB, so DRAM capacity should not have much influence on performance.
AMD Daytona - Dual EPYC 7742
AMD sent us the "Daytona XT" server, a reference platform build by ODM Quanta (D52BQ-2U).
| CPU | AMD EPYC 7742 (2.25 GHz, 64c, 256 MB L3, 225W) |
| RAM | 512 GB (16x32 GB) Micron DDR4-3200 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Micron 9300 3.84 TB (data) |
| Motherboard | Daytona reference board: S5BQ |
| PSU | PWS-1200 |
Although the 225W TDP CPUs needs extra heatspipes and heatsinks, there are still running on air cooling...

AMD EPYC 7601 – (2U Chassis)

| CPU | Two EPYC 7601 (2.2 GHz, 32c, 8x8MB L3, 180W) |
| RAM | 512 GB (16x32 GB) Samsung DDR4-2666 @2400 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Intel SSD3710 800 GB (data) |
| Motherboard | AMD Speedway |
| PSU | 1100W PSU (80+ Platinum) |
Intel's Xeon "Purley" Server – S2P2SY3Q (2U Chassis)
| CPU | Two Intel Xeon Platinum 8280 (2.7 GHz, 28c, 38.5MB L3, 205W) Two Intel Xeon Platinum 8176 (2.1 GHz, 28c, 38.5MB L3, 165W) |
| RAM | 384 GB (12x32 GB) Hynix DDR4-2666 |
| Internal Disks | SAMSUNG MZ7LM240 (bootdisk) Micron 9300 3.84 TB (data) |
| Motherboard | Intel S2600WF (Wolf Pass baseboard) |
| Chipset | Intel Wellsburg B0 |
| PSU | 1100W PSU (80+ Platinum) |
We enabled hyper-threading and Intel virtualization acceleration.
Memory Subsystem: Bandwidth
As we have reported before, measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark has become a matter of extreme tuning, requiring a very deep understanding of the platform.
If we used our previous binaries, both the first and second generation EPYC could not get past 200-210 GB/s. It gave the impression of running into a "bandwidth wall", despite the fact that we now had 8-channel DDR4-3200. So we used the results that Intel and AMD best binaries produce using AVX-512 (Intel) and AVX-2 (AMD).
The results are expressed in gigabytes per second.
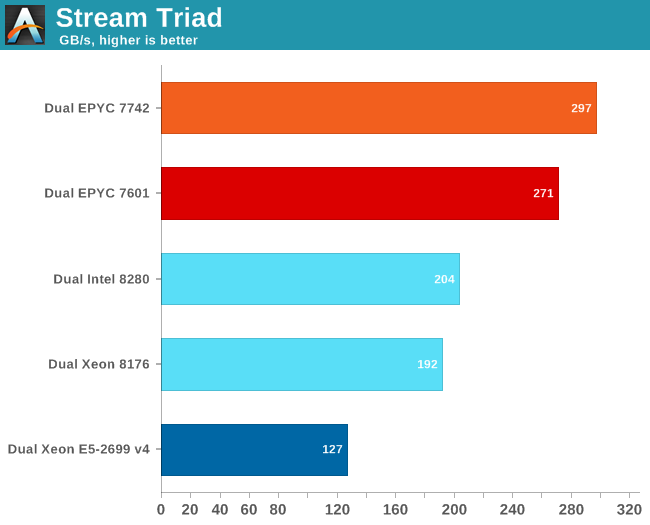
AMD can reach even higher numbers with the setting "number of nodes per socket" (NPS) set to 4. With 4 nodes per socket, AMD reports up to 353 GB/s. NPS4 will cause the CCX to only access the memory controllers with the lowest latency at the central IO Hub chip.
Those numbers only matter to a small niche of carefully AVX(-256/512) optimized HPC applications. AMD claims a 45% advantage compared to the best (28-core) Intel SKUs. We have every reason to believe them but it is only relevant to a niche.
For the rest of the enterprise world (probably 95+%), memory latency has much larger impact than peak bandwidth.
Memory Subsystem: Latency
AMD chose to share a core design among mobile, desktop and server for scalability and economic reasons. The Core Complex (CCX) is still used in Rome like it was in the previous generation.

What has changed is that each CCX communicates with the central IO hub, instead of four dies communicating in 4 node NUMA layout (This option is still available to use via the NPS4 switch, keeping each CCD local to its quadrant of the sIOD as well as those local memory controllers, avoiding hops between sIOD quadrants which encour a slight latency penalty). So as the performance of modern CPUs depends heavily on the cache subsystem, we were more than curious what kind of latency a server thread would see as it accesses more and more pages in the cache hierarchy.
We're using our own in-house latency test. In particular what we're interested in publishing is the estimated structural latency of the processors, meaning we're trying to account for TLB misses and disregard them in these numbers, except for the DRAM latencies where latency measurements get a bit more complex between platforms, and we revert to full random figures.
| Mem Hierarchy |
AMD EPYC 7742 DDR4-3200 (ns @ 3.4GHz) |
AMD EPYC 7601 DDR4-2400 (ns @ 3.2GHz) |
Intel Xeon 8280 DDR-2666 (ns @ 2.7GHz) |
|
| L1 Cache | 32KB 4 cycles 1.18ns |
32KB 4 cycles 1.25ns |
32KB 4 cycles 1.48ns |
|
| L2 Cache | 512KB 13 cycles 3.86ns |
512KB 12 cycles 3.76ns |
1024KB 14 cycles 5.18ns |
|
| L3 Cache | 16MB / CCX (4C) 256MB Total ~34 cycles (avg) ~10.27 ns |
16MB / CCX (4C) 64MB Total |
38.5MB / (28C) Shared ~46 cycles (avg) ~17.5ns |
|
| DRAM 128MB Full Random |
~122ns (NPS1) ~113ns (NPS4) |
~116ns |
~89ns |
|
| DRAM 512MB Full Random |
~134ns (NPS1) ~125ns (NPS4) |
~109ns |
||
Update 2019/10/1: We've discovered inaccuracies with our originally published latency numbers, and have subsequently updated the article with more representative figures with a new testing tool.
Things get really interesting when starting to look at cache depths beyond the L2. Naturally Intel here this happens at 1MB while for AMD this is after 512KB, however AMD’s L2 has a speed advantage over Intel’s larger cache.
Where AMD has an ever more clearer speed advantage is in the L3 caches that are clearly significantly faster than Intel’s chips. The big difference here is that AMD’s L3’s here are only local to a CCX of 4 cores – for the EPYC 7742 this is now doubled to 16MB up from 8MB on the 7601.
Currently this is a two-edged sword for the AMD platforms: On one hand, the EPYC processors have significantly more total cache, coming in at a whopping 256MB for the 7742, quadruple the amount over the 64MB of the 7601, and a lot more than Intel’s platforms, which come in at 38.5MB for the Xeon 8180, 8176, 8280, and a larger 55MB for the Xeon E5-2699 v4.
The disadvantage for AMD is that while they have more cache, the EPYC 7742 rather consist of 16 CCX which all have a very fast 16 MB L3. Although the 64 cores are one big NUMA node now, the 64-core chip is basically 16x 4 cores, each with 16 MB L3-caches. Once you get beyond that 16 MB cache, the prefetchers can soften the blow, but you will be accessing the main DRAM.
A little bit weird is the fact that accessing data that resides at the same die (CCD) but is not within the same CCX is just as slow as accessing data is on a totally different die. This is because regardless of where the other CCX is, whether it is nearby on the same die or on the other side of the chip, the data access still has to go through the IF to the IO die and back again.
Is that necessarily a bad thing? The answer: most of the time it is not. First of all, in most applications only a low percentage of accesses must be answered by the L3 cache. Secondly, each core on the CCX has no less than 4 MB of L3 available, which is far more than the Intel cores have at their disposal (1.375 MB). The prefetchers have a lot more space to make sure that the data is there before it is needed.
But database performance might still suffer somewhat. For example, keeping a large part of the index in the cache improve performance, and especially OLTP accesses tend to quite random. Secondly the relatively slow communication over a central hub slow down synchronization communication. That is a real thing is shown by the fact that Intel states that the OLTP hammerDB runs 60% faster on a 28-core Intel Xeon 8280 than on EPYC 7601. We were not able to check it before the deadline, but it seems reasonable.
But for the vast majority of these high-end CPUs, they will be running many parallel applications, like running microservices, docker containers, virtual machines, map/reducing smaller chunks of data and parallel HPC Jobs. In almost all cases 16 MB L3 for 4 cores is more than enough.
Although come to think of it, when running an 8-core virtual machine there might be small corner cases where performance suffers a (little) bit.
In short, AMD leaves still a bit of performance on table by not using a larger 8-core CCX. We await to see what happens in future platforms.
Memory Subsystem: TinyMemBench
We doublechecked our LMBench numbers with Andrei's custom memory latency test.
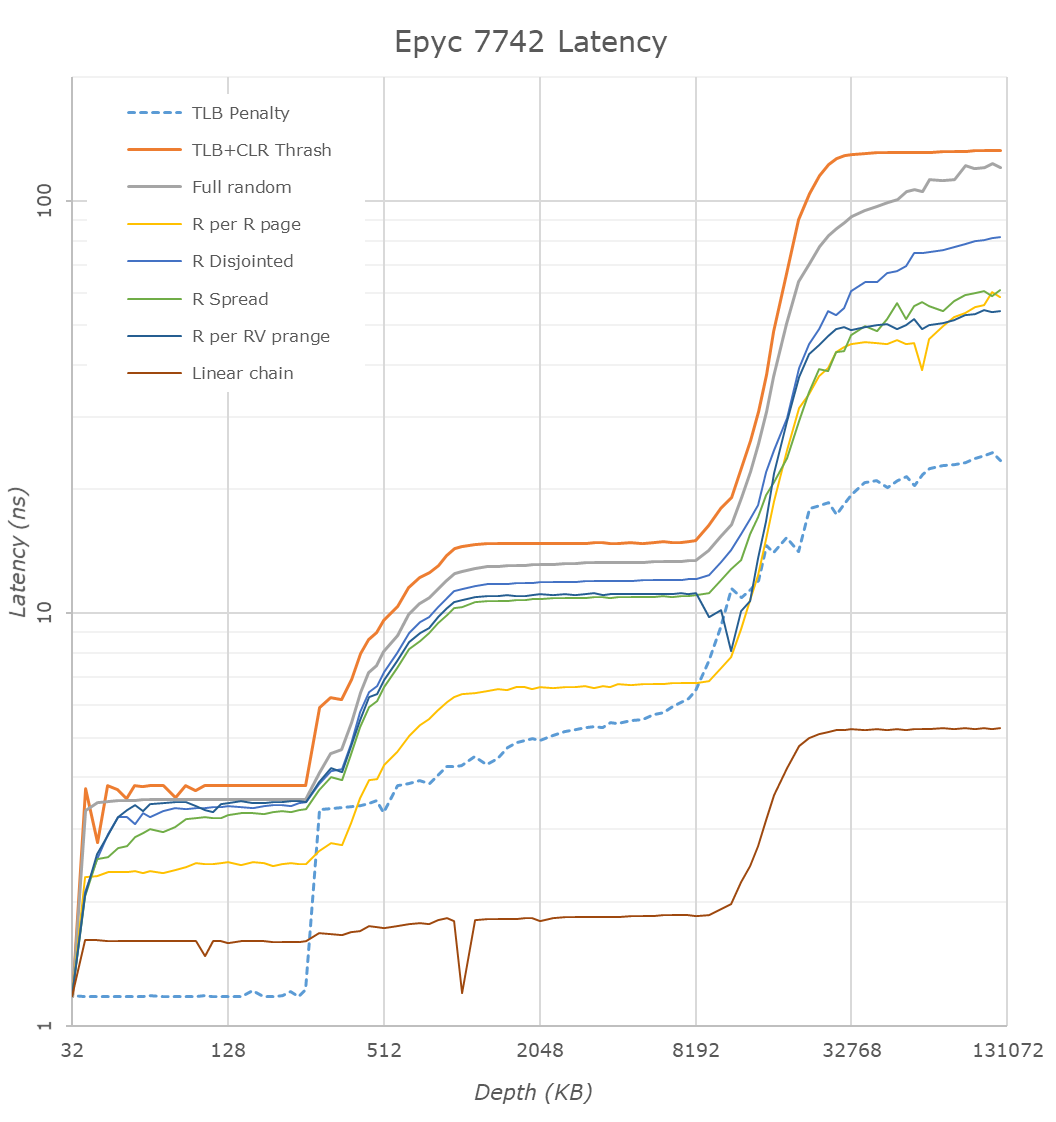
The latency tool also measures bandwidth and it became clear than once we move beyond 16 MB, DRAM is accessed. When Andrei compared with our Ryzen 9 3900x numbers, he noted:
The prefetchers on the Rome platform don't look nearly as aggressive as on the Ryzen unit on the L2 and L3
It would appear that parts of the prefetchers are adjusted for Rome compared to Ryzen 3000. In effect, the prefetchers are less aggressive than on the consumer parts, and we believe that AMD has made this choice by the fact that quite a few applications (Java and HPC) suffer a bit if the prefetchers take up too much bandwidth. By making the prefetchers less aggressive in Rome, it could aid performance in those tests.
While we could not retest all our servers with Andrei's memory latency test by the deadline (see the "Murphy's Law" section on page 5), we turned to our open source TinyMemBench benchmark results. The source was compiled for x86 with GCC and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
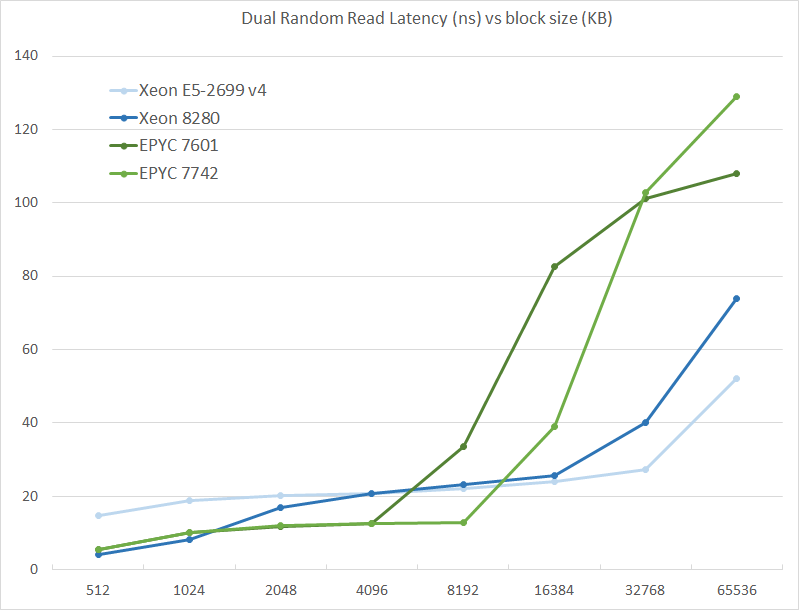
The graph shows how the larger L3 cache of the EPYC 7742 resulting in a much lower latency between 4 and 16 MB, compared to the EPYC 7601. The L3 cache inside the CCX is also very fast (2-8 MB) compared to Intel's Mesh (8280) and Ring topologies (E5).
However, once we access more than 16 MB, Intel has a clear advantage due to the slower but much larger shared L3 cache. When we tested the new EPYC CPUs in a more advanced NUMA setting (with NPS = 4 setting, meaning 4 nodes per socket), latency at 64 MB lowered from 129 to 119. We quote AMD's engineering:
In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM. In NPS1 the 8ch are hardware-interleaved and there is more latency to get to further ones. It varies by pairs of DRAM channels, with the furthest one being ~20-25ns (depending on the various speeds) further away than the nearest. Generally, the latencies are +~6-8ns, +~8-10ns, +~20-25ns in pairs of channels vs the physically nearest ones."
So that also explains why AMD states that select workloads achieve better performance with NPS = 4.
Single-Thread SPEC CPU2006 Estimates
While it may have been superceded by SPEC2017, we have built up a lot of experience with SPEC CPU2006. Considering the trouble we experience with our datacenter infrastructure, it was our best first round option for raw performance analysis.
Single threaded performance continues to be very important, especially in maintainance and setup situations. These examples may include running a massive bash script, trying out a very complex SQL query, or configuring new software - there are lots of times where a user simply does not use all the cores.
Even though SPEC CPU2006 is more HPC and workstation oriented, it contains a good variety of integer workloads. It is our conviction that we should try to mimic how performance critical software is compiled instead of trying to achieve the highest scores. To that end, we:
- use 64 bit gcc : by far the most used compiler on linux for integer workloads, good all round compiler that does not try to "break" benchmarks (libquantum...) or favor a certain architecture
- use gcc version 7.4 and 8.3: standard compiler with Ubuntu 18.04 LTS and 19.04.
- use -Ofast -fno-strict-aliasing optimization: a good balance between performance and keeping things simple
- added "-std=gnu89" to the portability settings to resolve the issue that some tests will not compile
The ultimate objective is to measure performance in non-aggressively optimized"applications where for some reason – as is frequently the case – a multi-thread unfriendly task keeps us waiting. The disadvantage is there are still quite a few situations where gcc generates suboptimal code, which causes quite a stir when compared to ICC or AOCC results that are optimized to look for specific optimizations in SPEC code.
First the single threaded results. It is important to note that thanks to turbo technology, all CPUs will run at higher clock speeds than their base clock speed.
- The Xeon E5-2699 v4 ("Broadwell") is capable of boosting up to 3.6 GHz. Note: these are old results compiled w GCC 5.4
- The Xeon 8176 ("Skylake-SP") is capable of boosting up to 3.8 GHz.
- The EPYC 7601 ("Naples") is capable of boosting up to 3.2 GHz.
- The EPYC 7742 ("Rome") boosts to 3.4 GHz. Results are compiled with GCC 7.4 and 8.3
Unfortunately we could not test the Intel Xeon 8280 in time for this data. However, the Intel Xeon 8280 will deliver very similar results, the main difference being that it runs a 5% higher clock (4 GHz vs 3.8 GHz). So we basically expect the results to be 3-5% higher than the Xeon 8176.
As per SPEC licensing rules, as these results have not been officially submitted to the SPEC database, we have to declare them as Estimated Results.
| Subtest | Application Type | Xeon E5-2699 v4 |
EPYC 7601 |
Xeon 8176 |
EPYC 7742 |
EPYC 7742 |
| Frequency | 3.6 GHz | 3.2 GHz | 3.8 GHz | 3.4 GHz | 3.4 GHz | |
| Compiler | gcc 5.4 | gcc 7.4 | gcc 7.4 | gcc 7.4 | gcc 8.3 | |
| 400.perlbench | Spam filter | 43.4 | 31.1 | 46.4 | 41.3 | 43.7 |
| 401.bzip2 | Compression | 23.9 | 24.0 | 27.0 | 26.7 | 27.2 |
| 403.gcc | Compiling | 23.7 | 35.1 | 31.0 | 42.3 | 42.6 |
| 429.mcf | Vehicle scheduling | 44.6 | 40.1 | 40.6 | 39.5 | 39.6 |
| 445.gobmk | Game AI | 28.7 | 24.3 | 27.7 | 32.8 | 32.7 |
| 456.hmmer | Protein seq. | 32.3 | 27.9 | 35.6 | 30.3 | 60.5 |
| 458.sjeng | Chess | 33.0 | 23.8 | 32.8 | 27.7 | 27.6 |
| 462.libquantum | Quantum sim | 97.3 | 69.2 | 86.4 | 72.7 | 72.3 |
| 464.h264ref | Video encoding | 58.0 | 50.3 | 64.7 | 62.2 | 60.4 |
| 471.omnetpp | Network sim | 44.5 | 23.0 | 37.9 | 23.0 | 23.0 |
| 473.astar | Pathfinding | 26.1 | 19.5 | 24.7 | 25.4 | 25.4 |
| 483.xalancbmk | XML processing | 64.9 | 35.4 | 63.7 | 48.0 | 47.8 |
A SPEC CPU analysis is always complicated, being a mix of what kind of code the compiler produces and CPU architecture.
| Subtest | Application type | EPYC 7742 (2nd gen) vs 7601 (1st gen) |
EPYC 7742 vs Intel Xeon Scalable |
Gcc 8.3 |
| 400.perlbench | Spam filter | +33% | -11% | +6% |
| 401.bzip2 | Compression | +11% | -1% | +2% |
| 403.gcc | Compiling | +21% | +28% | +1% |
| 429.mcf | Vehicle scheduling | -1% | -3% | 0% |
| 445.gobmk | Game AI | +35% | +18% | +0% |
| 456.hmmer | Protein seq. analyses | +9% | -15% | +100% |
| 458.sjeng | Chess | +16% | -16% | -1% |
| 462.libquantum | Quantum sim | +5% | -16% | -1% |
| 464.h264ref | Video encoding | +24% | -4% | -3% |
| 471.omnetpp | Network sim | +0% | -39% | 0% |
| 473.astar | Pathfinding | +30% | +3% | 0% |
| 483.xalancbmk | XML processing | +36% | -25% | 0% |
First of all, the most interesting datapoint was the fact that the code generated by gcc 8 seems to have improved vastly for the EPYC processors. We repeated the single threaded test three times, and the rate numbers show the same thing: it is very consistent.
hmmer is one of the more branch intensive benchmarks, and the other two workloads where the impact of branch prediction is higher (somewhat higher percentage of branch misses) - gobmk, sjeng - perform consistingly better on the second generation EPYC with it's new TAGE predictor.
Why the low IPC omnetpp ("network sim") does not show any improvement is a mystery to us, we expected that the larger L3 cache would help. However this is a test that loves very large caches, as a result the Intel Xeons have the advantage (38.5 - 55 MB L3).
The video encoding benchmark "h264ref" also relies somewhat on the L3 cache, but that benchmark relies much more on DRAM bandwidth. The fact that the EPYC 7002 has higher DRAM bandwidth is clearly visible.
The pointer chasing benchmarks – XML procesing and Path finding – performed less than optimal on the previous EPYC generation (compared to the Xeons), but show very significant improvements on EPYC 7002.
Multi-core SPEC CPU2006
For the record, we do not believe that the SPEC CPU "Rate" metric has much value for estimating server CPU performance. Most applications do not run lots of completely separate processes in parallel; there is at least some interaction between the threads. But since the benchmark below caused so much discussion, we wanted to satisfy the curiosity of our readers.
| 2P SPEC CPU2006 Estimates | ||||||
| Subtest | Xeon 8176 |
EPYC 7601 |
EPYC 7742 |
EPYC 7742 |
Zen2 vs Zen1 |
EPYC 7742 Vs Xeon |
| Cores | 56C | 64C | 128C | |||
| Frequency | 2.8 G | 2.7G | 2.5-3.2G | 2.5-3.2G | ||
| GCC | 7.4 | 7.4 | 7.4 | 8.3 | 7.4 | 7.4 |
| 400.perlbench | 1980 | 2020 | 4680 | 4820 | +132% | +136% |
| 401.bzip2 | 1120 | 1280 | 3220 | 3250 | +152% | +188% |
| 403.gcc | 1300 | 1400 | 3540 | 3540 | +153% | +172% |
| 429.mcf | 927 | 837 | 1540 | 1540 | +84% | +66% |
| 445.gobmk | 1500 | 1780 | 4160 | 4170 | +134% | +177% |
| 456.hmmer | 1580 | 1700 | 3320 | 6480 | +95% | +110% |
| 458.sjeng | 1570 | 1820 | 3860 | 3900 | +112% | +146% |
| 462.libquantum | 870 | 1060 | 1180 | 1180 | +11% | +36% |
| 464.h264ref | 2670 | 2680 | 6400 | 6400 | +139% | +140% |
| 471.omnetpp | 756 | 705 (*) | 1520 | 1510 | +116% | +101% |
| 473.astar | 976 | 1080 | 1550 | 1550 | +44% | +59% |
| 483.xalancbmk | 1310 | 1240 | 2870 | 2870 | +131% | +119% |
We repeat: the SPECint rate test is likely unrealistic. If you start up 112 to 256 instances, you create a massive bandwidth bottleneck, no synchronization is going on and there is a consistent CPU load of 100%, all of which is very unrealistic in most integer applications.
The SPECint rate estimate results emphasizes all the strengths of the new EPYC CPU: more cores, much higher bandwidth. And at the time it ignores one of smaller disadvantages: higher intercore latency. So this is really the ideal case for the EPYC processors.
Nevertheless, even if we take into account that AMD has an 45% memory bandwidth advantage and that Intel latest chip (8280) offers about 7 to 8% better performance, this is amazing. The SPECint rate numbers of the EPYC 7742 are - on average - simply twice as high as those of the best available socketed Intel Xeons.
Interestingly, we saw that most rate benchmarks ran at P1 clock or the highest p-state minus one. For example, this is what we saw when running libquantum:
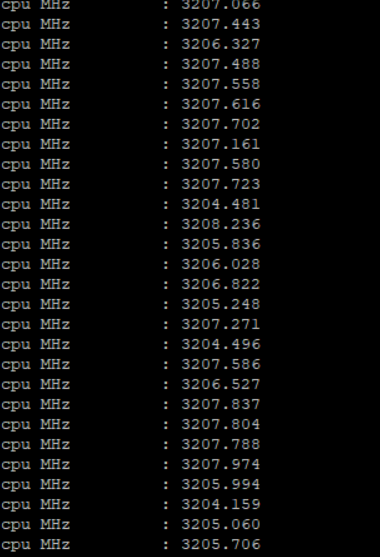
While some benchmarks like h264ref were running at lower clocks.
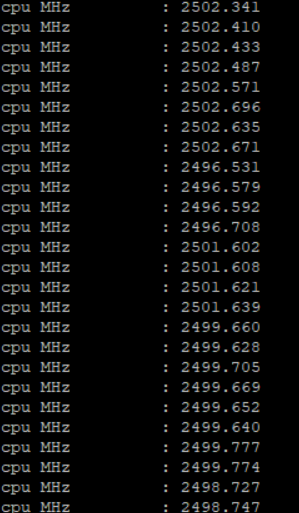
The current server does not allow us to do accurate power measuring but if the AMD EPYC 7742 can stay within the 225W TDP while running integer workloads at all cores at 3.2 GHz, that would be pretty amazing. Long story short: the new EPYC 7742 seems to be able to sustain higher clocks than comparable Intel models while running integer workloads on all cores.
Legacy: 7-zip
While standalone compression and decompression are not real world benchmarks (at least as far as servers go), servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization). With that said, we suggest you take these benchmarks with a large grain of salt, as they are not really important in grand scheme of things. We still use 7zip 9.2, so you can compare with much older results.
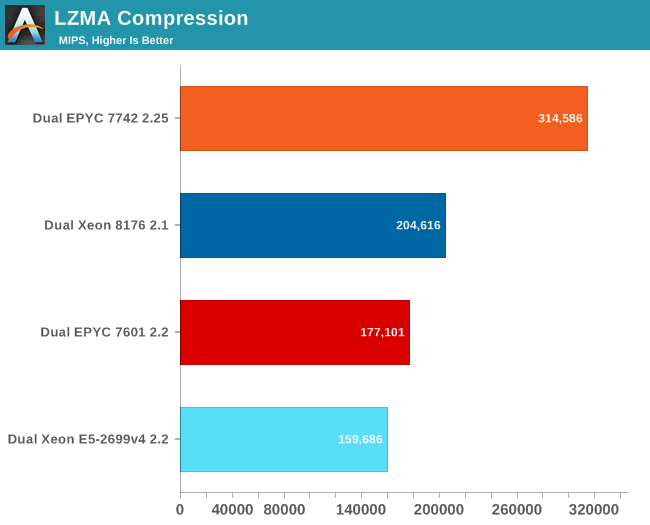
Compression on modern cores relies almost solely on cache, memory latency, and TLB efficiency. This is definitely not the ideal situation for AMD's EPYC CPU, but the EPYC 7742 scales very well, offering 77% higher performance than Naples. That is better than expected scaling.
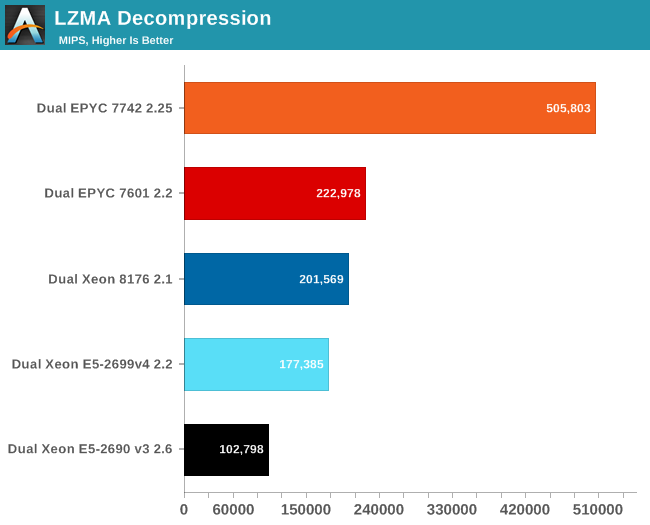
Decompression relies on less common integer instructions (shift, multiply). AMD's Zen2 core handles these instructions even better because doubling the cores results in no less than 127% (!) better performance.
Even though this benchmark is not that important, it is nevertheless impressive how AMD engineering made this graph look. Never have we seen AMD dominating benchmarks by such a wide margin.
Before people accuse us of choosing a benchmark that shows AMD in the best light, consider this benchmark as one of our synthetic tests more than anything else, designed to showcase core execution port potential. It is not really indicative of any real-world performance, but acts as a synthetic for those that have requested this data.
Java Performance
The SPECjbb 2015 benchmark has 'a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations'. It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
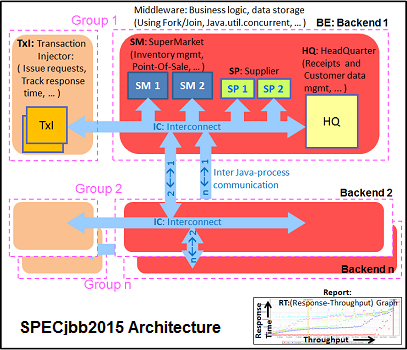
We test SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice.
The Java version was OpenJDK 1.8.0_222. We used the older JDK 8 as the most recent JDK 11 has removed some deprecated JAVA EE modules that SPECJBB 1.01 needs. We applied relatively basic tuning to mimic real-world use, while aiming to fit everything inside a server with 128 GB of RAM:
We tested with huge pages on and off.
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test. Since the test is almost identical to the one that we have used in our ThunderX2 review (JDK8 1.8.0_166), we also include Cavium's server CPU.
Ultimately we publish these numbers with a caveat: you should not compare this with the official published SPECJBB2015 numbers, because we run our test slightly differently to the official run specifications. We believe our numbers make as much sense (and maybe more) as most professionals users will not go for the last drop of performance. Using these ultra optimized settings can result in unrepeateable and hard to debug inconsistent errors - at best they will result in subpar performance as they are so very specific to SPECJBB. It is simply not worth it, a professional will stick with basic and reliable optimization in the real non-HPC world. In the HPC world, you simply rerun your job in case of an error. But in the rest of the enterprise world you just made a lot users very unhappy and created a lot of work for (hopefully) well paid employees.
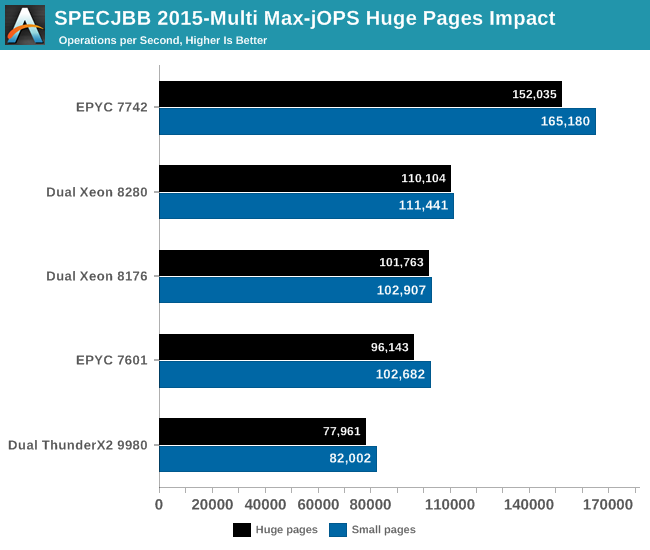
The EPYC 7742 performance is excellent, outperforming the best available Intel Xeon by 48%.
Notice that the EPYC CPU performs better with small pages (4 KB) than with large ones (2 MB). AMD's small pages TLB are massive and as result page table walks (PTW) are seldom with large pages. If the number of PTW is already very low, you can not get much benefit from increasing the page size.
What about Cavium? Well, the 32-core ThunderX2 was baked with a 16 nm process technology. So do not discount them - Cavium has a unique opportunity as they move the the ThunderX3 to 7 nm FFN TSMC too.
To be fair to AMD, we can improve performance even higher by using numactl and binding the JVM to certain CPUs. However, you rarely want to that, and happily trade that extra performance for the flexibility of being able to start new JVMs when you need them and let the server deal with it. That is why you buy those servers with massive core counts. We are in the world of micro services, docker containers, not in the early years of 21st century.
Ok, what if you do that anyway? AMD offered some numbers, while comparing them to the officialy published SPEJBB numbers of Lenovo ThinkSystem SR650 (Dual Intel 8280).

AMD achieves 335600 by using 4 JVM per node, binding them to "virtual NUMA nodes".
Just like Intel, AMD uses the Oracle JDK, but there is more to these record breaking numbers. A few tricks that only benchmarking people can use to boost SPECJBB:
- Disabling p-states and setting the OS to maximum performance (instead of balanced)
- Disabling memory protection (patrol scrub)
- Using older garbage collector because they happen to better at Specjbb
- Non-default kernel settings
- Aggressive java optimizations
- Disabling JVM statistics and monitoring
- ...
In summary, we don't think that it is wise to mimic these settings, but let us say that AMD's new EPYC 7742 is anywhere between 48 and 72% faster. And in both cases, that is significant!
Java Performance
Even though our testing is not the ideal case for AMD (you would probably choose 8 or even 16 back-ends), the EPYC edges out the Xeon 8176. Using 8 JVMs increases the gap from 1% to 4-5%.
The Critical-jOPS metric is a throughput metric under response time constraint.
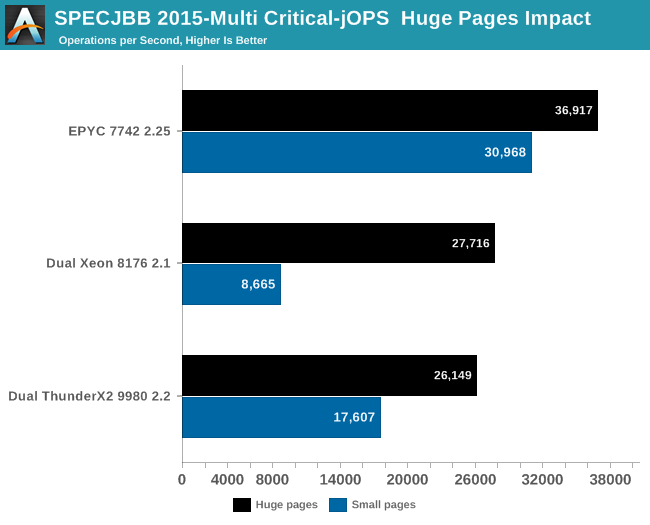
With this number of threads active, you can get much higher Critical-jOps by significantly increasing the RAM per JVM. However, we did not want that as this would mean we can not compare with systems that can only accommodate 128 GB of RAM. Notice how badly the Intel system needs huge pages.
The benchmark data of Intel and AMD can be found below.
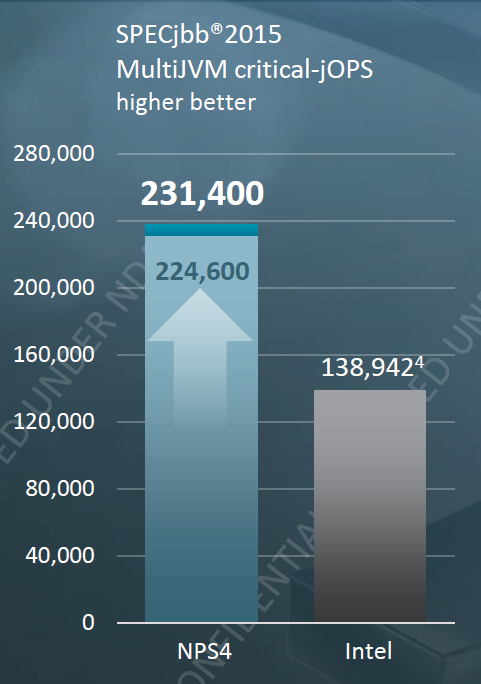
According to AMD, the EPYC 7742 can be up to 66% faster. However note that these kind of high scores for critical-jOPS are sometimes configured with 1 TB of RAM and more.
HPC: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX and AVX-512.
The NAMD binary is compiled with Intel ICC, optimized for AVX and mostly single preciscion floating point (fp32). For our testing, we used the "NAMD_2.13_Linux-x86_64-multicore" binary. At some point we want to use this test with AOCC or similar AMD optimized binary, but were unable to do so for this review.
We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
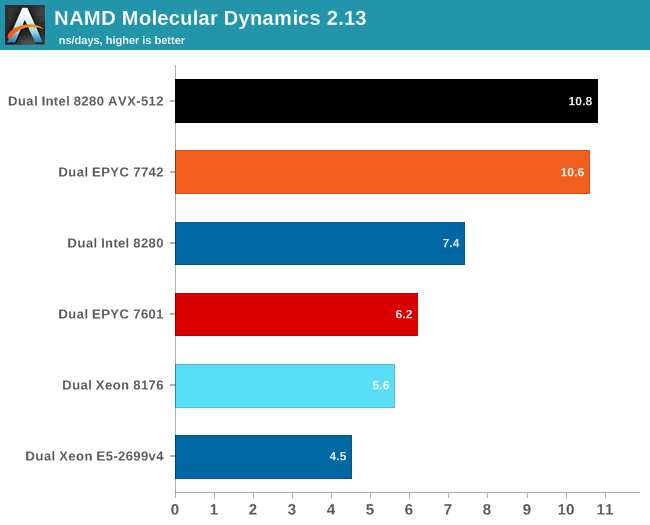
Even without AVX-512 and optimal AVX optimization, the 7742 is already offering the same kind of performance as an ultra optimized Intel binary on top of the top of the line Xeon 8280. When do an apples-to-apples comparison, the EPYC 7742 is no less than 43% faster.
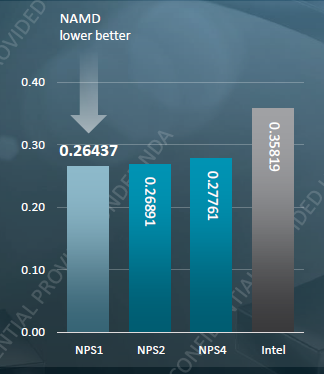
AMD claims a 35% advantage (3.8 ns/days vs 2.8 ns/days) and that seems to confirm our own preliminary benchmarking.
First Impressions
Due to bad luck and timing issues we have not been able to test the latest Intel and AMD servers CPU in our most demanding workloads. However, the metrics we were able to perform shows that AMD is offering a product that pushes out Intel for performance and steals the show for performance-per-dollar.
For those with little time: at the high end with socketed x86 CPUs, AMD offers you up to 50 to 100% higher performance while offering a 40% lower price. Unless you go for the low end server CPUs, there is no contest: AMD offers much better performance for a much lower price than Intel, with more memory channels and over 2x the number of PCIe lanes. These are also PCIe 4.0 lanes. What if you want more than 2 TB of RAM in your dual socket server? The discount in favor of AMD just became 50%.
We can only applaud this with enthusiasm as it empowers all the professionals who do not enjoy the same negotiating power as the Amazons, Azure and other large scale players of this world. Spend about $4k and you get 64 second generation EPYC cores. The 1P offerings offer even better deals to those with a tight budget.
So has AMD done the unthinkable? Beaten Intel by such a large margin that there is no contest? For now, based on our preliminary testing, that is the case. The launch of AMD's second generation EPYC processors is nothing short of historic, beating the competition by a large margin in almost every metric: performance, performance per watt and performance per dollar.
Analysts in the industry have stated that AMD expects to double their share in the server market by Q2 2020, and there is every reason to believe that AMD will succeed. The AMD EPYC is an extremely attractive server platform with an unbeatable performance per dollar ratio.

Intel's most likely immediate defense will be lowering their prices for a select number of important customers, which won't be made public. The company is also likely to showcase its 56-core Xeon Platinum 9200 series processors, which aren't socketed and only available from a limited number of vendors, and are listed without pricing so there's no firm determination on the value of those processors. Ultimately, if Intel wanted a core-for-core comparison here, we would have expected them to reach out and offer a Xeon 9200 system to test. That didn't happen. But keep an eye out on Intel's messaging in the next few months.
As you know, Ice lake is Intel's most promising response, and that chip will be available somewhere in the mid of 2020. Ice lake promises 18% higher IPC, eight instead of six memory channels and should be able to offer 56 or more cores in reasonable power envelope as it will use Intel's most advanced 10 nm process. The big question will be around the implementation of the design, if it uses chiplets, how the memory works, and the frequencies they can reach.
Overall, AMD has done a stellar job. The city may be built on seven hills, but Rome's 8x8-core chiplet design is a truly cultural phenomenon of the semiconductor industry.

We'll be revisiting more big data benchmarks through August and September, and hopefully have individual chip benchmark reviews coming soon. Stay tuned for those as and when we're able to acquire the other hardware.
Can't wait? Then read our interview with AMD's SVP and GM of the Datacenter and Embedded Solutions Group, Forrest Norrod, where we talk about Napes, Rome, Milan, and Genoa. It's all coming up EPYC.
An Interview with AMD’s Forrest Norrod: Naples, Rome, Milan, & Genoa






