Original Link: https://www.anandtech.com/show/14543/nvme-14-specification-published
NVMe 1.4 Specification Published: Further Optimizing Performance and Reliability
by Billy Tallis on June 14, 2019 1:00 PM ESTJust over two years after the last major update, a new version of the NVM Express protocol specification for SSDs has been published. In recent years the NVMe standards body has taken a different approach to adding new features to the specification: rather than bundle them up into major spec updates that are published years apart, new features that are ready have been individually ratified and published as Technical Proposals (TPs) so that vendors can begin implementing and deploying support for those features without delay and without having to target a mere draft standard. Some of these features were implemented and publicly demonstrated by vendors just a few months after the NVMe 1.3 spec was published.
NVMe 1.4 incorporates 28 TPs that build atop NVMe 1.3, plus the various corrections and clarifications that went into versions 1.3a through 1.3d. Overall, NVMe 1.4 seems to be a much bigger update than 1.3 was. Several sections now have more in-depth explanations of new and existing features, so the specification is easier to understand even though it has grown from 298 pages for 1.3d to 403 pages for 1.4. Most of the diagrams below are straight out of the spec itself, and are much appreciated.
As usual, the new features aren't all relevant to all use cases for NVMe SSDs: some only make sense for embedded systems or hyperscaler deployments making heavy use of NVMe over Fabrics and virtualization, and as a result most of the new features are optional for SSDs to implement. The companion standards NVMe Management Interface and NVMe over Fabrics have also been evolving: NVMe-MI 1.1 was ratified in December, and NVMe over TCP has emerged as a third transport protocol for NVMeoF, joining the Fiber Channel and RDMA transports. Some of the additions to the base NVMe specification serve to accommodate changes to these companion standards.
The new optional features require updates to both the SSDs and the NVMe drivers in operating systems; without support on both sides, drives will fall back to using only older feature sets. Some changes higher up the software stack will also be required in order to make meaningful use of the new capabilities; in particular, many storage administration tools will benefit from being aware of new information and capabilities provided by SSDs. These software updates often take longer to develop than the relevant SSD firmware changes, so support for these new features will be showing up in specialized environments long before they are used by general-purpose OS distributions.
The NVMe SSD market is at the beginning of a period of major performance improvement enabled by the transition to PCIe 4.0, but this doesn't require any changes to the NVMe spec. The NVMe 1.4 spec does include some performance optimizations that rely on being smarter about how the storage is used, with better cooperation between the SSD and the host system. The other big category of new features pertains to error handling, with particular relevance to RAID rebuilds. Below are highlights from the new specification, but this is not an exhaustive list of what's new, and our analysis of potential use cases may not match what the hardware vendors are planning.
More Block Size and Alignment hints
NVMe SSDs behave like regular block devices with sector sizes that are usually 512 bytes or 4kB. Modern NAND flash memory has native page sizes larger than 4kB, and erase block sizes measured in megabytes. This mismatch is the source of most of the complexity in the flash translation layer implemented by each SSD. The FTL allows software to continue to function correctly with the fiction that their storage has small block sizes, but some awareness of the real block and page sizes can allow the operating system or applications to make the job easier for the SSD and enable higher performance. The NVMe 1.3 spec introduced the Namespace Optimal IO Boundary feature, allowing SSDs to inform the host system of the basic alignment requirements for read and write commands to perform best. We've seen cases of drives that allow small block size access, but have very poor performance for transfers smaller than 4kB:
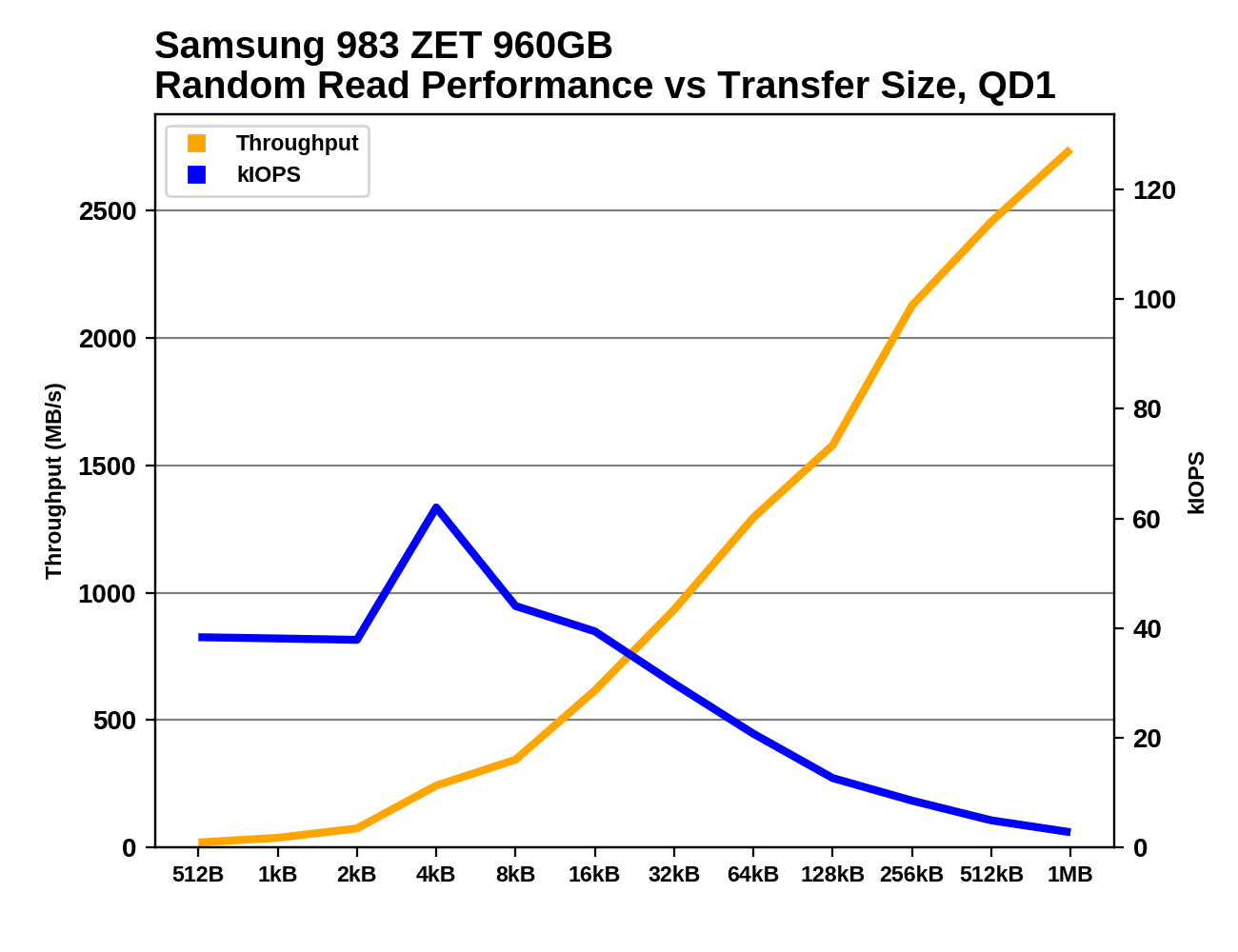
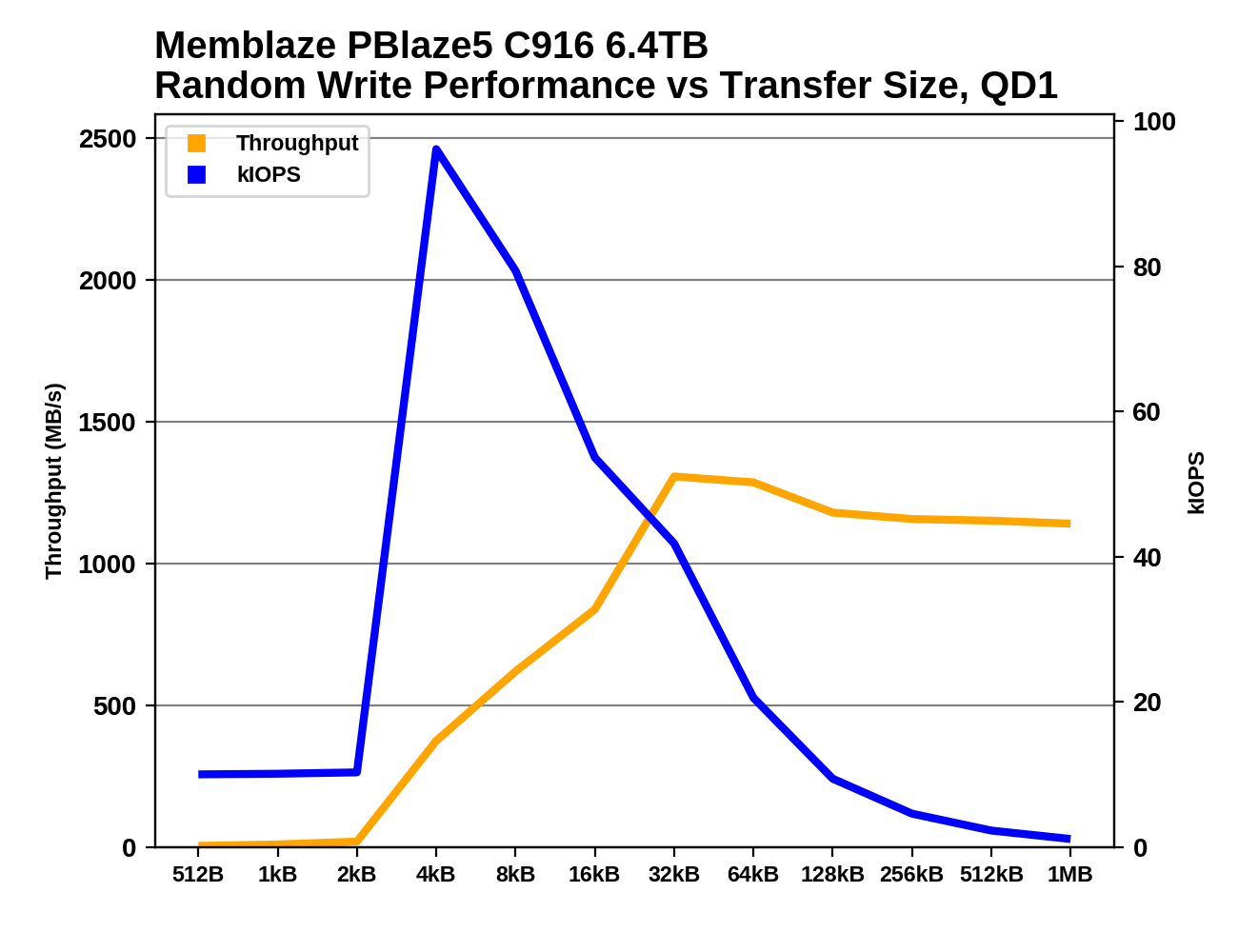
In the worst cases, drives should really just be dropping support for 512B sectors and defaulting to 4kB sectors, but where compatibility with older systems is required, hints about what access patterns work well can help. NVMe 1.4 gives SSDs the ability to communicate much more detailed information so that write and deallocate (TRIM) commands can match page and erase block sizes.
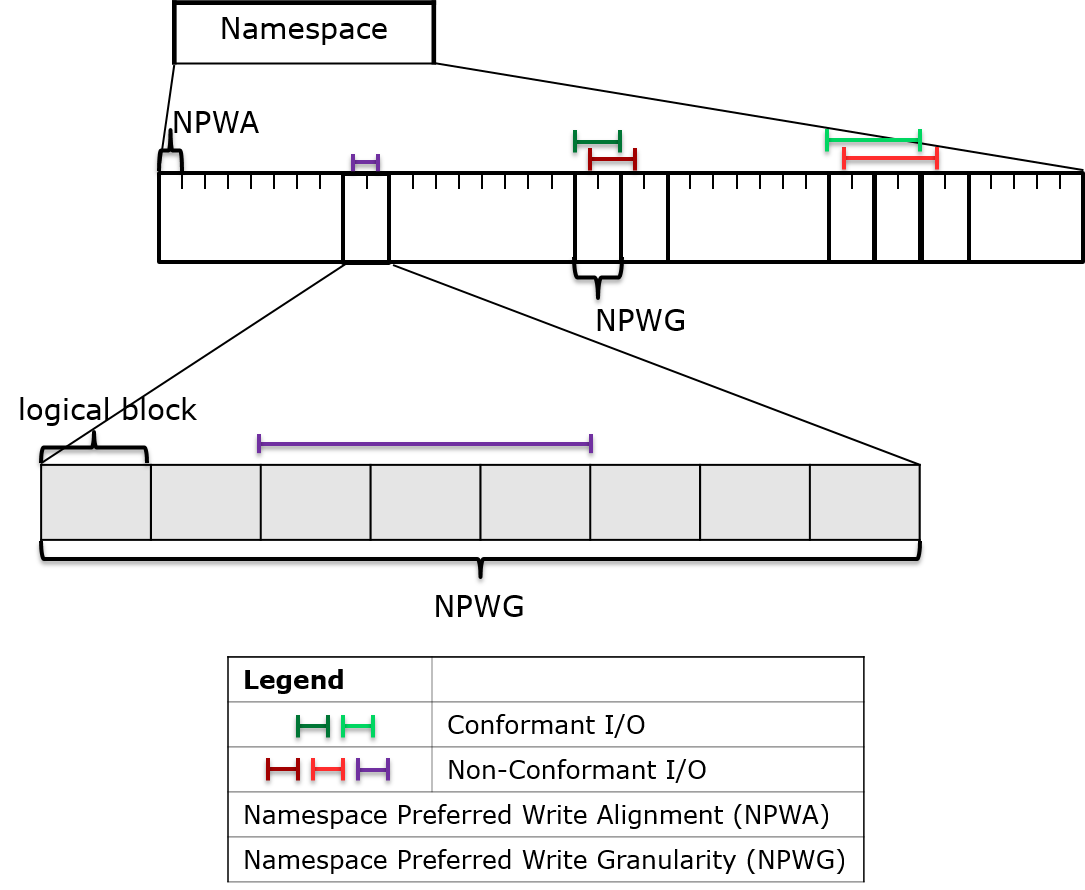
Drives may now report Namespace Preferred Write Alignment and Namespace Preferred Write Granularity values that will minimize the read-modify-write cycles that result from writing to only part of a NAND page. Likewise, the Namespace Preferred Deallocate Alignment and Namespace Preferred Deallocate Granularity apply to NVMe deallocate commands, the analog of ATA TRIM commands. Deallocate/TRIM commands that cover small data ranges or large but misaligned ranges are hard for SSDs to handle without increasing write amplification defeating much of the purpose of using explicit deallocation commands in the first place.
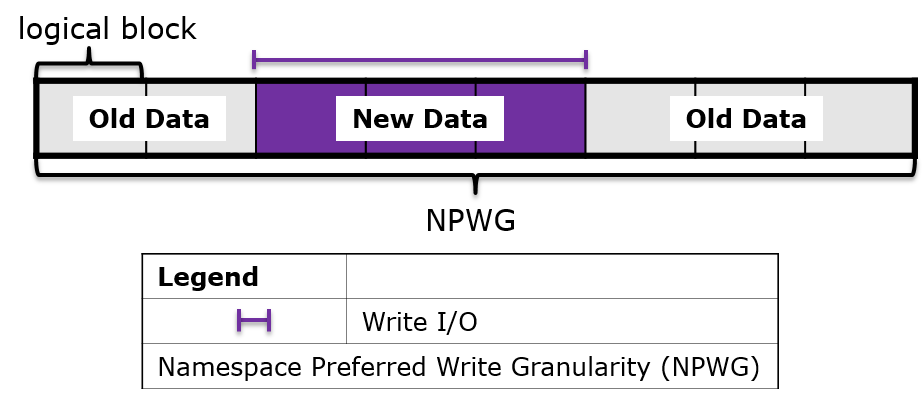
Above: Undersized writes may require the SSD to perform a read-modify-write operation
Below: Optimally sized but misaligned writes also hurt performance and increase write amplification

Drives that support the NVMe 1.3 Streams feature can also provide hints for the preferred write and deallocate granularity when using Streams, and these values will usually be a multiple of the above hints.
The responsibility for making good use of these hints will mostly fall to the OS and filesystem. RAID stripe sizes and filesystem block sizes can be set based on this information, and applications like databases that try to optimize storage performance by bypassing much of the OS's storage stack should also pay heed.
Faster Error Detection and Recovery
NVMe 1.4 introduces several new features to help with handling unrecoverable read errors and corrupted data, especially in RAID and similar scenarios where the host system may be able to recover data more quickly by simply fetching it from somewhere else.
The Read Recovery Level feature lets the host system configure how hard the SSD should try to recover corrupted data. SSDs usually have several layers of error correction, each more robust but slower and more power-hungry than the last. In a RAID-1 or similar scenario, the host system will usually prefer to get an error quickly so it can try reading the same data from the other side of the mirror rather than wait for the drive to re-try a read and fall back to slower levels of ECC. NVMe already supports Time-Limited Error Recovery (TLER), but this only allows the host system to put a cap on error handling time in increments of 100ms. Read Recovery Levels allow drives to provide up to 16 different levels of error handling strategies, but drives implementing this feature are only required to implement a minimum of two different modes. This feature is configured on a per- NVM Set level.
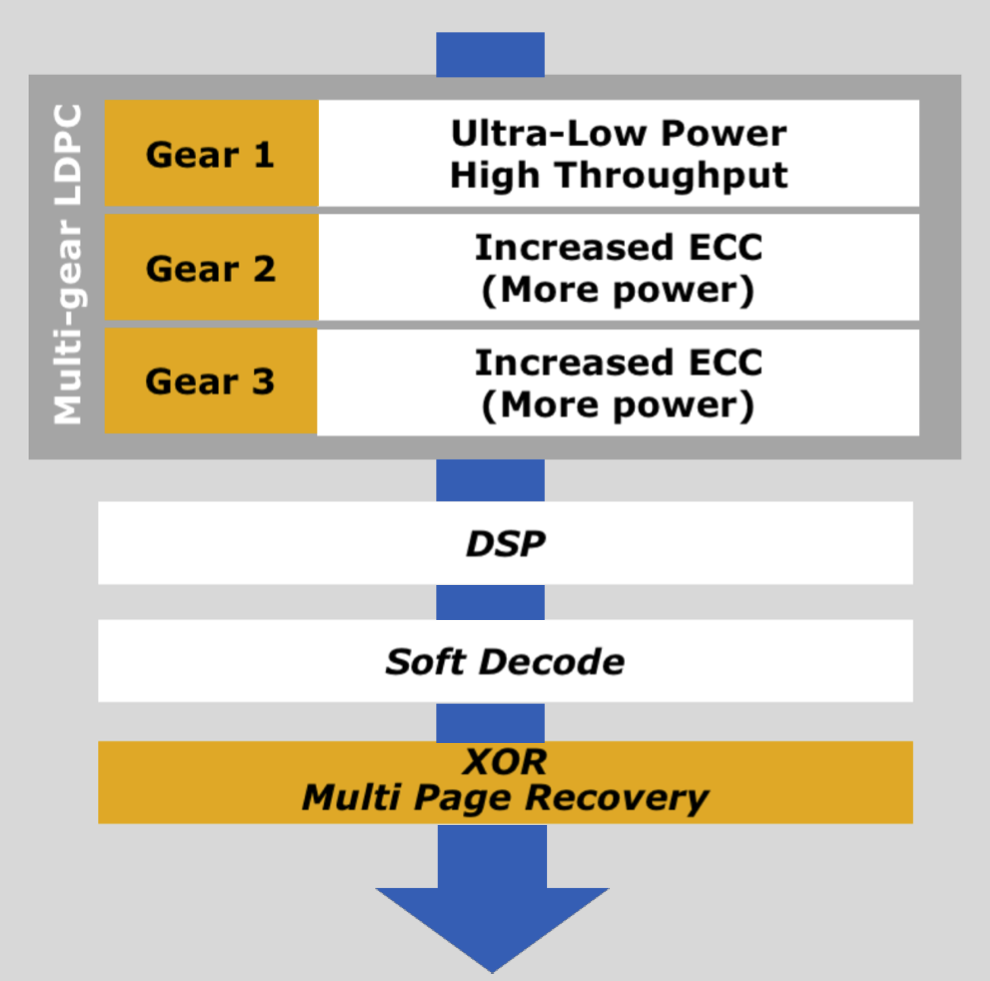
Western Digital's client NVMe controller error correction layers
For proactively avoiding unrecoverable read errors, NVMe 1.4 adds Verify and Get LBA Status commands. The Verify command is simple: it does everything a normal read command does, except for returning the data to the host system. If a read command would return an error, a verify command will return the same error. If a read command would be successful, a verify command will be as well. This makes it possible to do a low-level scrub of the stored data without being bottlenecked by the host interface bandwidth. Some SSDs will react to a fixable ECC error by moving or re-writing degraded data, and a verify command should trigger the same behavior. Overall, this should reduce the need for filesystem-level checksum scrubbing/verification. Each Verify command is tagged with a bit indicating whether the SSD should fail fast or try hard to recover data, similar to but overriding the above Read Recovery Level setting.
The Get LBA Status feature allows the drive to provide the host with a list of blocks that will probably result in an unrecoverable read error if a read or verify command is attempted. The SSD may have already detected ECC errors during automatic background scanning, or in severe cases it may be able to report which LBAs are affected by the failure of an entire NAND die or channel. The Get LBA Status feature also can be used to ask the drive to perform a scan of selected data ranges before returning the list of probably-unrecoverable blocks.
When the host system finds out about corrupted or lost data either from the Get LBA Status feature or from issuing read or verify commands and receiving an error in response, it can re-write that data to the same LBAs using a copy obtained elsewhere (backups or RAID recovery) and then carry on using those logical blocks normally, while the SSD will retire the affected physical blocks if necessary.
Persistent Memory Region
Most NVMe SSDs have a substantial amount of DRAM in addition to flash memory. The primary purpose of this DRAM is to serve as a cache for the flash translation layer's tables that track the mapping between logical block addresses and physical flash memory addresses. But NVMe has been exploring other ways to put that DRAM to use. The 1.2 spec introduced the Controller Memory Buffer, which makes some of the SSD's DRAM directly accessible through PCI address space. This allows the IO command submission and completion queues to live in the SSD's memory instead of the host CPU's memory, which can reduce latency on the submission side, and can cut out some unnecessary copying in NVMe over Fabrics situations where peer to peer DMA between the SSD and the network card allows data to bypass the host DRAM entirely. The new Persistent Memory Region (PMR) feature in NVMe 1.4 operates similarly—the host system can read or write to this memory directly using basic PCIe transfers, without any of the overhead of command queues. In practice a Controller Memory Buffer is usually intended to be used in support of normal NVMe operation, but a PMR won't be involved in any of that. Instead, it's a general-purpose chunk of memory that is made persistent thanks to the same power loss protection capacitors that allow a typical enterprise SSD's internal caches to be safely flushed in the event of an unexpected loss of host power. The contents of the PMR will automatically be written out to flash, and when the host system comes back up it can ask the SSD to reload the contents of the PMR.
The performance and capacity of a PMR won't come anywhere close to what NVDIMMs can provide, but a PMR provides some of the same benefits. Accessing the PMR is much simpler and faster than constructing a NVMe IO command and waiting for its completion. A typical implementation of the PMR feature will be able to accept a very high volume of writes without wearing out any flash memory, because its contents only need to be saved to flash in the event of a power failure. This makes a PMR a great place to store a database or filesystem journal that sees constant writes and can easily become a bottleneck.
(Lite-On has implemented a similar feature in one of their datacenter SSDs, exposing a portion of its capacitor-protected DRAM as an additional NVMe namespace alongside the regular flash storage namespace. This provides similar performance consistency to a PMR and doesn't require any application or driver changes to support, but the raw performance can't be quite as high as a PMR.)
NVM Sets and Endurance Groups
NVM Sets and Endurance Groups are two new high-level organizational constructs for managing pools of storage that are larger than an individual NVMe namespace. Since support for multiple namespaces is itself largely reserved for high-end enterprise SSDs, some of the features that depend on NVM Sets or Endurance Groups only make sense for multi-port drives, virtualized environments or NVMe over Fabrics arrays—situations where one NVMe controller is behaving like or providing access to multiple drives. However, some of these new features are still useful even on drives that only provide a single endurance group containing a single NVM set.
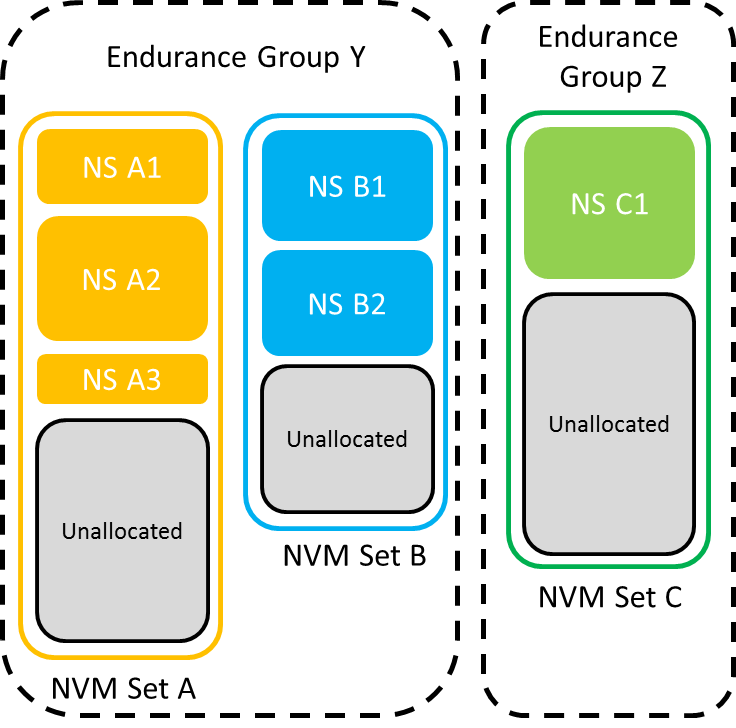
An Endurance Group is a collection of NVM Sets, which consist of namespaces and unallocated storage. Each endurance group is a separate pool of storage for wear leveling purposes. They have their own dedicated pool of spare blocks, and the drive reports separate wear statistics for each endurance group. On drives with more than one endurance group, it will be possible to completely wear out one endurance group and cause it to go read-only while other endurance groups remain usable.

Marvell's dual-chip NVMe controller architecture, a great candidate for multiple endurance groups
A drive can be designed to map specific NAND dies or channels to different NVM sets or endurance groups, essentially splitting it into multiple relatively independent drives. This can not only provide for separation of wearout, but also rigidly partitioning performance. Cloud hosting providers can put VMs from separate customers on different NVM sets or endurance groups to ensure that a busy workload from one customer doesn't hurt the latency experienced by another.
Predictable Latency Mode
The new Predictable Latency Mode feature allows the host to temporarily pause any background work the SSD controller is performing, ensuring that there is nothing to get in the way of immediately processing new IO commands arriving from the host system. This allows drives to offer their best-case and most consistent performance. SSDs cannot operate in this mode indefinitely, and will eventually need to leave deterministic mode to catch up on background work. The drive provides running estimates of how long it can remain in a deterministic window before it will have to switch itself back to non-deterministic performance, in terms of time and in terms of how many more 4kB random reads and optimal-sized writes it can handle deterministically.
Predictable Latency Mode will typically be used in environments where the host software can load-balance across multiple drives. High-priority IO can be directed to drives that are currently in a deterministic window, and drives that are in a non-deterministic window can either be left alone to catch up on background work, or used to handle low-priority IO. Each individual drive in the pool will alternate between deterministic and non-deterministic operation, and the timing of these windows will depend on the workload. If the load balancer is working well, it will stop issuing latency-sensitive IO to a drive and manually take it out of deterministic mode before the drive reaches its limit. Drives can be configured to provide a warning at a customizable threshold before the limits are reached, so host systems won't need to constantly check the status indicators to see whether the drive is close to leaving its deterministic window. Predictable Latency Mode is configured on a per-NVM Set basis, so drives that provide multiple sets can have some in each mode at any given time and perform load balancing between NVM Sets.

This isn't the first NVMe feature for controlling when the drive performs background work: NVMe 1.3 added the Non-Operational Power State Permissive Mode feature so that host systems could ask drives not do background work when in a low-power idle state. The intent here is to defer background work while running on battery power or with the system's fans off, and this feature does not affect background work while the drive is in an active power state.
Submission Queue Associations
NVMe SSDs typically support multiple command submission and completion queues. Currently, the main use case for this is to give each CPU core its own queues so that no core-to-core synchronization is necessary at the driver level to perform ordinary IO. There's also been recent work on the Linux NVMe driver to add support for using queues for specialized purposes, such as having dedicated queues for high-priority commands that will be polled for completion instead of waiting for an interrupt, or having separate queues per core for read and write commands. NVMe 1.4 and Predictable Latency Mode add another potential use case for multiple queues: associating a queue with a specific NVM Set. NVMe 1.4 allows the host system to inform the SSD of which NVM Set it plans to use each queue with, which can give the SSD controller the opportunity to further reduce latency or improve QoS when using Predictable Latency Mode. This feature is optional even for drives that support Predictable Latency Mode.
Namespace Write Protection
The new Namespace Write Protection feature is pretty self-explanatory. An NVMe namespace can be put into one of three read-only modes: read-only until the next power cycle, read-only until the first power cycle after the write protect feature is disabled, or permanently read-only for the lifetime of the drive. This provides a range of options for protecting critical data in embedded or high-security systems.
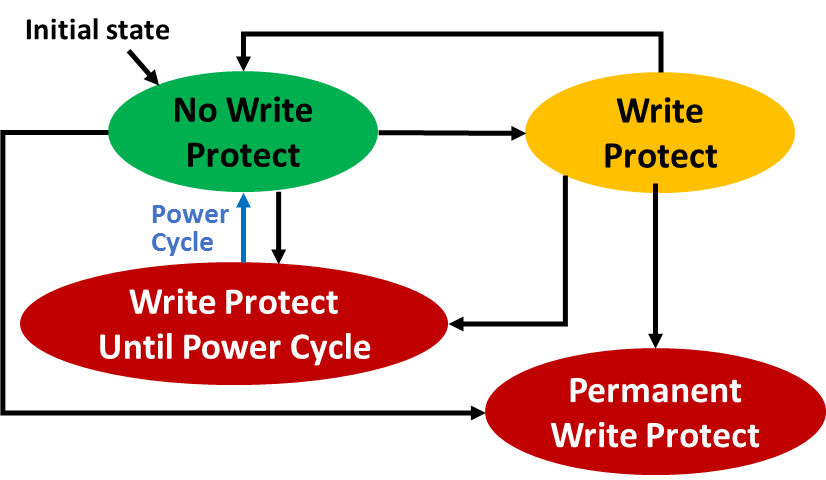
A typical use case will be to put the OS or a minimal recovery system on a write-protected namespace, and keep user data and apps on a regular read+write namespace. This is one of the first NVMe features to start providing a compelling case for client SSDs to support multiple namespaces, since protected operating systems or recovery partitions are already commonplace for both mobile and desktop operating systems. Write-protected namespaces can get the drive itself involved in helping protect the OS against accidental or malicious tampering, and this feature is much simpler than the existing Replay Protected Memory Block feature.
What's Next
Open Channel SSDs have been around in some form or another for several years. These expose more of the inner workings of the SSD and move all or part of the flash translation layer out of the drive and onto the host CPU. Several NVMe features have already been inspired in part by open channel SSDs, including the above hints about optimal block sizes and data alignment and the NVM Sets and Endurance Groups features. Last year Microsoft formed Project Denali to explore what is the best balance between the low-level control afforded by open channel SSDs and the easy to use abstraction of traditional block storage, with the ultimate goal of producing new standards that can be more broadly adopted than existing open channel efforts. That and related work is likely to continue influencing NVMe, but the general approach for NVMe has been to prefer exchanging hints rather than imposing hard restrictions on IO patterns.
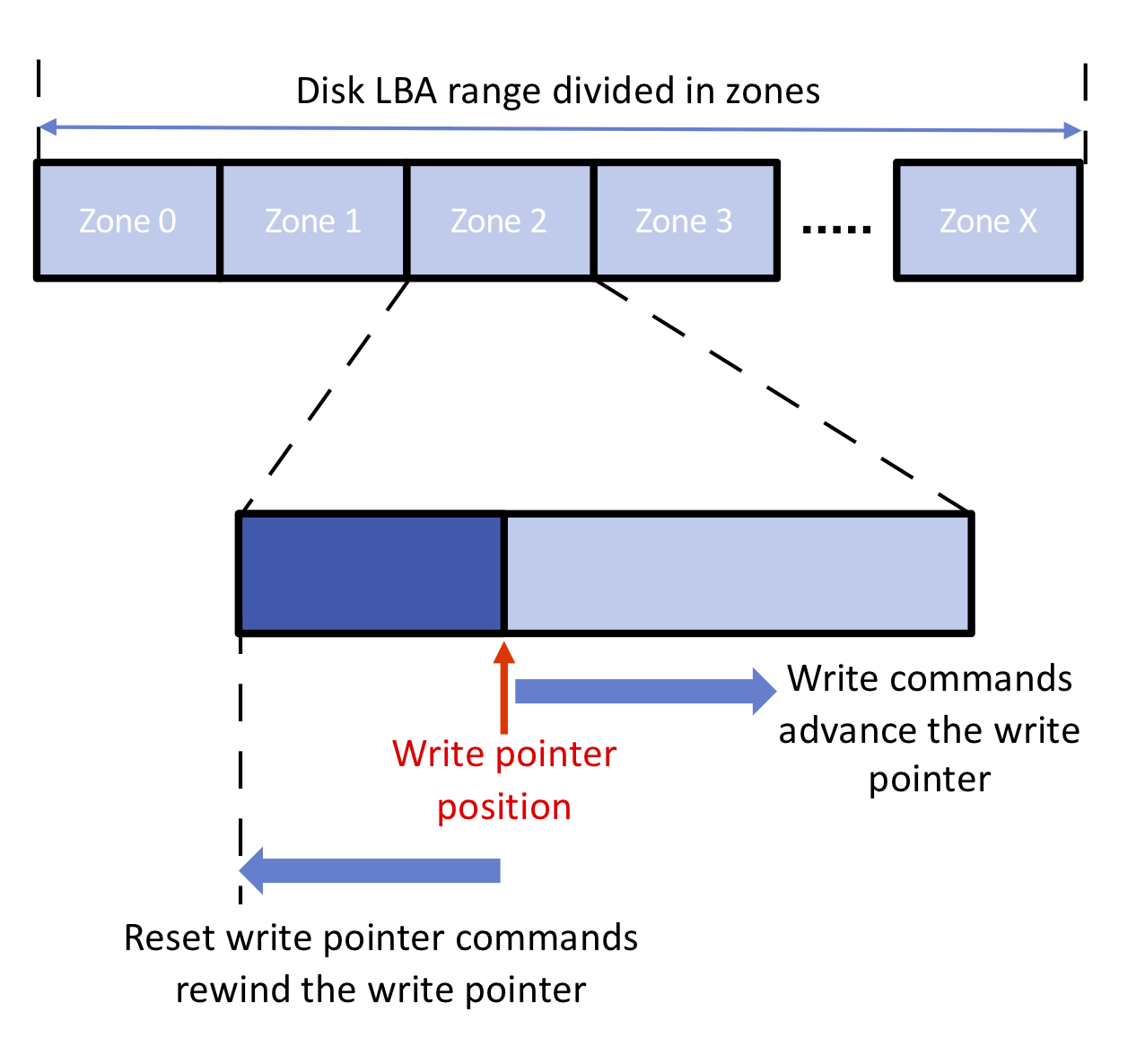
(source: Western Digital presentation at USENIX Vault 2019)
In a similar vein, there is a Technical Proposal in the NVMe working group to implement a Zoned Namespace feature that borrows ideas from how Shingled Magnetic Recording hard drives are handled. Host-managed SMR hard drives have similar constraints to NAND flash in that they have large regions that can support random reads but not overwriting of existing data; for NAND flash these regions are the erase blocks. Software and filesystems that have already been modified to support host-managed SMR drives can easily support zoned SSDs. It's not at all trivial to modify software to work without random write support, but a lot of that work has already been done. Making use of it on SSDs can reduce write amplification, improve latency and cut down on how much DRAM an SSD needs.
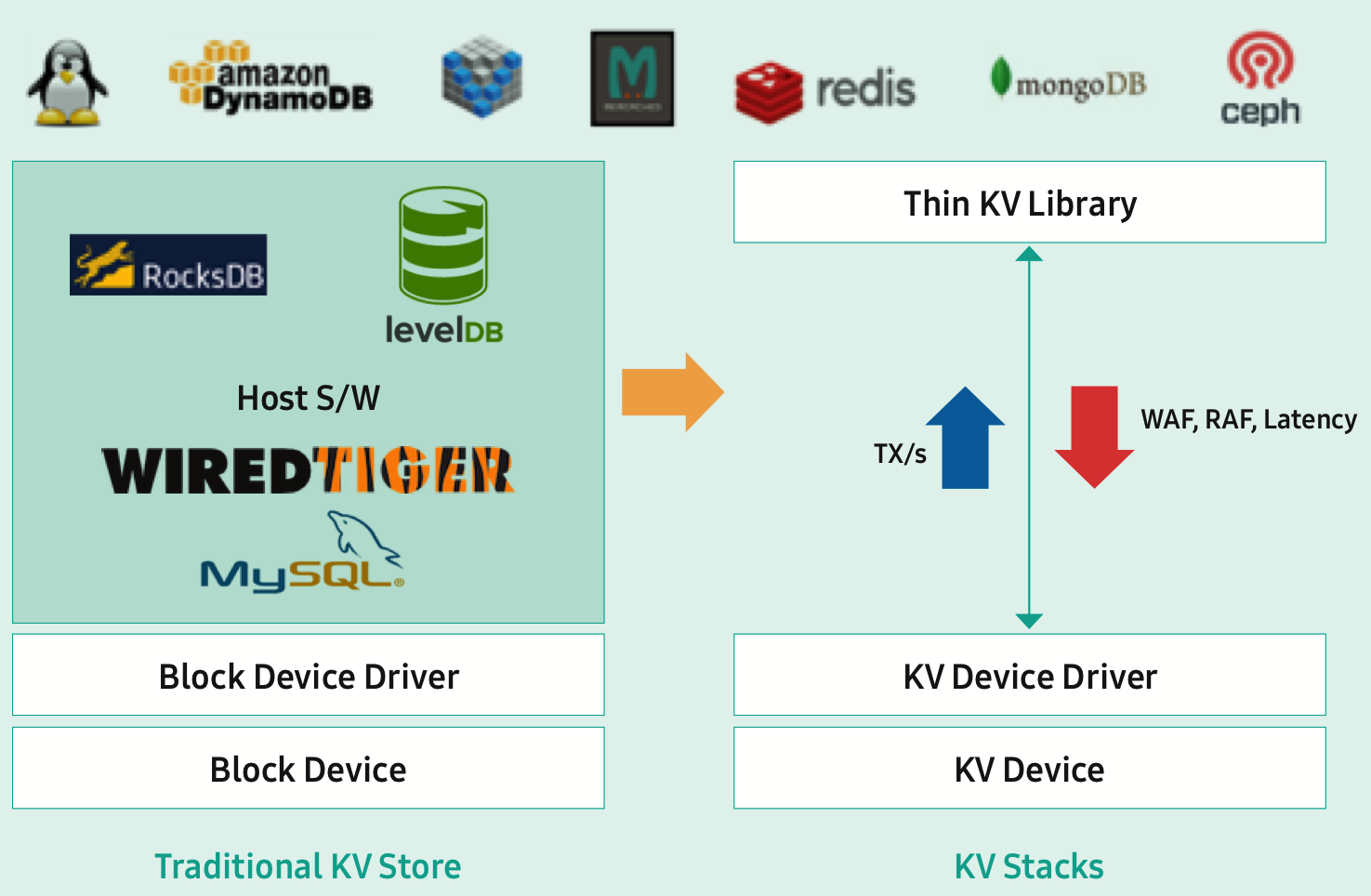
(source: Samsung Key-Value SSD product brief)
Several vendors have been developing SSDs that present a key-value database interface instead of a traditional block device. Supporting this only adds a little bit of complexity to the SSD's flash translation layer but it cuts out a lot of redundant abstractions on the host software side, so performance can be surprisingly high compared to running a key-value database application on top of a filesystem on a traditional SSD. We will probably see a standard for key-value namespaces added to NVMe sooner rather than later.
Further down the road, there are hopes of producing standards for computational storage devices and accelerators/coprocessors that can build atop NVMe infrastructure. There are a lot of companies working on or already shipping devices to offload tasks like compression, encryption, searching and AI inferencing from CPUs and instead performing these computational tasks closer to where the data is stored. Work to standardize the interfaces to such devices is still in its infancy, but in two or three years when it's time for NVMe 1.5, some of these ideas may have matured enough to start yielding standards for the basic infrastructure around computational storage.
Source: NVM Express






