Original Link: https://www.anandtech.com/show/1367
NVIDIA's Scalable Link Interface: The New SLI
by Derek Wilson on June 28, 2004 2:00 PM EST- Posted in
- GPUs
Introduction
The major trend in computing as of late has been toward parallelism. We are seeing Hyperthreading and the promise of dual core CPUs on the main stage, and supporting technologies like NCQ that will optimize the landscape for multitasking environments. Even multi-monitor support has caught on everywhere from the home to the office.One of the major difficulties with this is that most user space applications (especially business applications like word processors and such) are not inherently parallel. Sure, we can throw in things like check-as-you-type spelling and grammar, and we can make the OS do more and more things in the background, but the number of things going at once is still relatively small.
Performance in this type of situation is dominated by the single threaded (non-parallel) case: how fast the system can accomplish the next task that the user has issued. Expanding parallelism in this type of computing environment largely contributes to smoothness, and the perception that the system is highly responsive to the user.
But since the beginning of the PC, and for the foreseeable future, there is an aspect of computing that benefits almost linearly with parallelism: 3D graphics.

NVIDIA 6800 Ultras connected in parallel.
For an average 3D scene in a game, there will be a bunch of objects on the screen, all which need to be translated, rotated, or scaled as per the requirements for the next frame of animation of the game. These objects have anywhere from just a few to thousands of triangles that make them up. For every triangle that we can't eliminate (clip) as unseen, we have to project it onto the screen (from back to front objects which are further from the viewer are covered by closer ones).
What really puts it into perspective (pardon the pun) is resolution. At 1600x1200, 1,920,000 pixels need to be drawn to the screen. And we haven't even mentioned texture mapping or vertex and pixel shader programs. And all that stuff needs to happen in less than 1/60th of a second to satisfy most discriminating gamers. In this case, performance is dominated by how many things can get done at one time rather than how fast one thing can be done.
And if you can't pack any more parallelism onto single bit of silicon, what better way to garner more power (and better performance) than by strapping two cards together?
Scalable Link Interface
As we first saw during Computex this year, the enigmatic NV45 had a rather odd looking slot-like connector on the top of the card. We assumed that this connector would be for internal NVIDIA purposes, as companies often add testing and diagnostic interfaces to very early hardware. As it turns out, this is NVIDIA's Scalable Link Interface connector.
Notice the gold connector at the top of the card.
In order to make use of NVIDIA's SLI technology, two NVIDIA cards are placed in a system (which requires 2 PCIe x16 slots - more on this later), and the cards are linked together using a special piece of hardware. Currently, this communications hardware is a small PCB with a slot connector at each end. No pass through cable is needed, and one video card acts as the master (connected to the monitor) and the other is the slave.

SLI PCB top view.

SLI PCB bottom view.
When asked whether it would be possible to connect the cards together with something along the lines of a cable, NVIDIA indicated that the PCB approach had afforded them superior signaling qualities, but that they continued to look into the viability of other media. As this is new technology, NVIDIA is slightly weary of sharing some of the lower level details with us. We asked whether their SLI uses a serial or parallel interface (usually fast parallel interfaces are more sensitive to signal routing), but we were told that they may or may not be able to get back to us with that information. Either way, this is going to have to be a very high bandwidth connection as it's over this path that the GPUs will communicate (this includes sending framebuffer data for display).
As previously mentioned, this setup requires having 2 PCIe x16 slots available on one's motherboard. Not only is this going to be difficult to come by in the first few months of PCIe motherboard availability, but currently, none of Intel's chipsets support more than 24 PCIe lanes. The current prototypes of motherboards with two PCI Express x16 slots are actually only using one PCI Express x16 interface and one x8 interface, simply with an x16 connector (so it's physically an x16 slot, but electrically, an x8 slot). This reduces the bandwidth available to the 2GB/s up and down (which is still more than AGP 8x can handle). That's not to say that PCIe bandwidth is necessary for gaming at the moment. The real problem is that there would be no other PCIe slots available for expansion cards. But x1 and x4 PCIe expansion cards haven't been making many waves, so until chipsets support more than 24 PCIe lanes and more PCIe expansion cards come out, it might be possible to get away with this.

NVIDIA Quadro connected in SLI configuration.
Until now, we've just mentioned NV45 as supporting this, but NVIDIA seems to be indicating that all their PCIe cards will have the capability to run in SLI configurations. This includes the Quadro line of workstation graphics cards. This is very interesting, as it shows NVIDIA's commitment to enhancing performance without degrading quality (CAD/CAM professionals can't put up with any graphical artifacts or rendering issues and can always use more graphics power).
But let's move on to the meat of the technology.
It's Really Not Scanline Interleaving
So, how does this thing actually work? Well, when NVIDIA was designing NV4x, they decided it would be a good idea to include a section on the chip designed specifically to communicate with another GPU in order to share rendering duties. Through a combination of this block of transistors, the connection on the video card, and a bit of software, NVIDIA is able to leverage the power of two GPUs at a time.
NV40 core with SLI section highlighted.
As the title of this section should indicate, NVIDIA SLI is not Scanline Interleaving. The choice of this moniker by NVIDIA is due to ownership and marketing. When they acquired 3dfx, the rights to the SLI name went along with it. In its day, SLI was very well known for combining the power of two 3d accelerators. The technology had to do with rendering even scanlines on one GPU and odd scanlines on another. The analog output of both GPUs was then combined (generally via a network of pass through cables) to produce a final signal to send to the monitor. Love it or hate it, it's a very interesting marketing choice on NVIDIA's part, and the new technology has nothing to do with its namesake. Here's what's really going on.
First, software (presumably in the driver) analyses what's going on in the scene currently being rendered and divides for the GPUs. The goal of this (patent-pending) load balancing software is to split the work 50/50 based on the amount of rendering power it will take. It might not be that each card renders 50% of the final image, but it should be that it takes each card the same amount of time to finish rendering its part of the scene (be it larger or smaller than the part the other GPU tackled). In the presentation that NVIDIA sent us, they diagramed how this might work for one frame of 3dmark's nature scene.
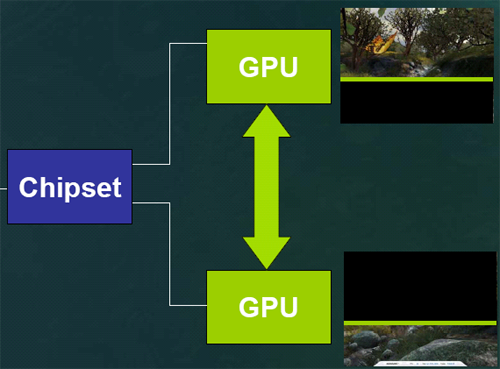
This shows one GPU rendering the majority of the less complex portion of a scene.
Since the work is split on the way from the software to the hardware, everything from geometry and vertex processing to pixel shading and anisotropic filtering is divided between the GPUs. This is a step up from the original SLI, which just split the pixel pushing power of the chips.
If you'll remember, Alienware was working on a multiple graphics card solution that, to this point, resembles what NVIDIA is doing. But rather than scan out and use pass through connections or some sort of signal combiner (as is the impression that we currently have of the Alienware solution), NVIDIA is able to send the rendered data digitally over the SLI (Scalable Link Interface) from the slave GPU to the master for compositing and final scan out.

Here, the master GPU has the data from the slave for rendering.
For now, as we don't have anything to test, this is mostly academic. But unless their SLI has an extremely high bandwidth, half of a 2048x1536 scene rendered into a floating point framebuffer will be tough to handle. More normally used resolutions and pixel formats will most likely not be a problem, especially as scenes increase in complexity and rendering time (rather than the time it takes to move pixels) dominates the time it takes to get from software to the monitor. We are really anxious to get our hands on hardware and see just how it responds to these types of situations. We would also like to learn (though testing may be difficult) whether the load balancing software takes into account the time it would take to transfer data from the slave to the master.
Final Words
In our conversation with NVIDIA, we noted that this technology should work with all software without any modification necessary, and NVIDIA was quoting numbers around 1.87x performance increase over a single card (under 3dmark '03). Of course, this may be an exception rather than the rule, and we do want to run our own tests (as impact will change over graphical complexity). Even more intriguing is the fact that NVIDIA talked about developers being able to take advantage of this technology in their games. It was indicated that, by doing so, games could see a linear (2x) performance increase. If realized, this would be unprecedented in real-world applications of this type of technology.In speaking about why multiple graphics card configurations haven't seen more light in the recent past, NVIDIA mentioned that the PCI bus was the limiting factor in being able to execute something like this on modern hardware. At this point, they still have an unbalanced bandwidth situation due to the x8 bandwidth limit on secondary x16 PCIe slots, but that's nothing like the difference between PCI and AGP (especially as full PCI bus bandwidth can't always be guaranteed to one device).
And then there's the problem of finding motherboards with multiple PCIe slots. The only one that we've seen so far is a multiprocessor board, which hasn't been released yet. To be fair, NVIDIA is targeting the system builders first, and won't be pushing a consumer SLI upgrade package until later (possibly this fall). The success or failure of this product will likely not rest on its technical merits, but rather on the availability of suitable motherboards, and the cost of the upgrade. We can see some hardcore gamers out there spending $500 on a card. We could see some even going so far as to upgrade their entire PC if it meant better performance. But it is hard for us to see very many people justifying spending $1000 on two NV45 based cards even for 2x the performance of one very fast GPU; perhaps if NVIDIA cripples some of its GPUs to work only as slaves and sells them for a (very) reduced price as an upgrade option. Even then, this isn't going to have as easy a time in the marketplace as the original 3dfx SLI solutions.
Now, what would really work in NVIDIA's favor is if they engineer their NV5x GPUs with backwards compatible SLI technology. Even the promise of such a thing might be enough to get some people to pick up an NV45 with the knowledge that their future upgrade would actually be an upgrade. For those who upgrade every generation, there would be a way to get more power for "free", and those who wait 2 or more generations to upgrade might have a new reason to take the plunge. This scenario is probably wishful thinking, but we can dream, can't we?






