Original Link: https://www.anandtech.com/show/13405/intel-10nm-cannon-lake-and-core-i3-8121u-deep-dive-review
Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM EST
Anyone interested in leading edge semiconductors knows that Intel is late with its newest manufacturing process. The '10nm' node was first announced in 2014, to be released in 2016. While officially 'shipping for revenue' by 31 December 2017, the only way we knew to get hold of an Intel 10nm x86 CPU was if you happened to be a Chinese school and work with a specific distributor to buy a specific laptop.We pulled in a few favors from within the industry and managed to source the laptop for review.
Intel's Sole 10nm Processor
The single processor from Intel built on 10nm falls under the Core 8th generation family, and is called the Core i3-8121U. The cores are built with Intel's Cannon Lake microarchitecture, a variant of the Skylake architecture built on 14nm, and it is manufactured as a dual core with integrated graphics. The part nominally has a standard 'GT2' graphics configuration, but is actually shipped without the graphics enabled - some analysts believe that this is because it doesn't work (see more on the next page). Norminally this is a 2+2 design (two cores, GT2 graphics), however it might also be referred to as a 2+0 design.
| Intel 10nm Cannon Lake CPUs | ||||||
| Cores | Base Freq |
Turbo Freq |
Graphics | DRAM | TDP | |
| Core i3-8121U | 2 (4) | 2.2 GHz | 3.2 GHz | None (GT2 Fused Off) |
DDR4-2400 LPDDR4-2400 |
15W |
The two cores run at a 2.2 GHz base frequency at 15W thermal design power, and offers a 3.2 GHz turbo frequency. Memory support includes LPDDR4, one of very few Intel processors to do so, but also this processor has AVX-512 capabilities, allowing it to process vector math much like Intel's Enterprise class hardware but now in a low end chip. We'll dive deep into all these points in this review.
What Do We Have
The sole laptop which has an Intel Core i3-8121U inside is a specific model of the Chinese Lenovo Ideapad E330-15ICN.

The advert from the listing
This is an educational focused device, with educational focused specifications - a 15.6-inch screen running at a 1366x768 resolution with a TN panel (with limited viewing angles), a small 33.4 Wh battery, 8GB of DRAM, a 256GB SSD, and a 1TB mechanical hard-drive. Because the chip has no integrated graphics, Lenovo had to add a physical GPU, which will be the same one as found in the upcoming NUC: AMD's Radeon RX540. This adds another 50W thermal design power to the whole unit, which complicates the cooling system considerably compared to a standard 15W CPU on its own. Along the educational theme, it also comes with an ethernet port, a HDMI port, two USB ports, a 3.5mm jack, a Type-C USB connector, a 720p webcam, a microSD card slot, an 802.11ac Wi-Fi module, and an optional DVD slot (which loses the second SATA HDD).

The design is very unassuming. The grey finish means that it won't stand out at Starbucks, aside from the bulk of a heavy 15.6-inch device. As is perhaps to be expected, it feels very utilitarian. No-one is buying this for looks or for style.

The keyboard fits in with the cost-down implementation here, although having used it for a few events to take notes, it is very usable. Despite being a Chinese device, we ended up with a US keyboard, but with half-height arrow buttons. The keypad is also present, with some media keys at the top. Unfortunately the power key is on the top right, above the minus sign, making it very easy to hit for prolific users of a keypad.

On the top is the webcam. This unit has massive bezels for the display, which contributes a lot to the bulk of the system. The webcam is usable for meetings at least, and the microphones do work but are cheap as we expect.

Welcome to the heart - Intel Core i3 plus AMD Radeon graphics. Sadly not an impressive combination like Kaby G.

On the sides are all of the ports. They are all located on the left side, and include the power connector, the gigabit Ethernet port, a HDMI port, two USB ports, a 3.5mm jack, a Type-C USB port, and an SD card slot. On the other side of the unit is the removable bay.

On the rear, we get intakes at the front, and an intake in the middle of the bottom of the chassis. There are small rubber feet to help lift the laptop when on a table, but these do not really help on a lap. Given the amount of heat that needs to be dissipated in this system, this isn't great - the exhaust is found in the hinge between the main body and the display. The fan inside has to cope with all of this, as we'll see in a bit.

Going inside the system, and removing the removable bay, looks a bit like this.

On the left is the 256GB SSD, branded as an 'MT Black Gold 400' drive in a 2.5-inch chassis. This unit is very gold. It is a budget drive, featuring the DRAM-less Silicon Motion SM2246XT controller combined with Spektek NAND flash (rebadged cheap Micron NAND). This unit is clearly part of a series of SSDs, given the number of empty pads. But I guess even having an SSD is still an interesting upgrade over a purely mechanical drive.


The other drive in the system, not pictured in the main image, is spinning rust - a 1TB WD Blue. This is actually pretty commendable to have this drive in a system like this, although the 5400RPM platter speed means that it will be slow for almost everything. It makes me wonder if drives like this should be using the SSD as a caching technology instead.

The WiFi module has a Lenovo part number but underneath is a Realtek RTL8821CE 802.11ac module, supporting 433 Mbps speed (1T1R) and Bluetooth. This is an M.2 module, which means it could be upgraded at a later date fairly easily. It is a dual band module, which as an educational system should be more than suitable for the classroom that has an access point close by.

The battery, as mentioned above, is a tiny battery. The 33.4Wh lithium-ion unit is a 2-cell device, which equates to 4400 mAh at 7.6 V, and is made for Lenovo in Thailand by the Nanjing Nexcon Electronics Co.

For system memory, the unit has 4GB soldered onto the rear of the PCB, and offers a single SO-DIMM slot for an additional module. The base configuration for this device has 4GB of memory in single channel mode, however up to 16GB more can be added. The configurations we were offered showed another 4GB module, bringing the total up to 8GB. Again, having 8GB of DRAM in an educational device probably sits about right, and kudos for them being in dual channel as well.

The meat of the laptop, the CPU and GPU, are found near the center and have blower cooling. Despite the 15W TDP of the CPU and the 50W TDP of the GPU, there is a single flat heatpipe going from the CPU to the GPU and to the heatsink connected to the thin blower fan. This feels like a cheap fan paired with aluminum fins. This feels woefully inadequate for such the system, and the power consumption combined with the small battery leads to interesting figures for battery life. In thermals, the system does get warm to the touch around the cooler area, which is thankfully a little way away from the keyboard and not really felt when active.

The GPU area has a sizable copper heatsink fixed in two spots to the PCB.

The CPU area is instead attached at three points, and there is an additional pad to stop the chassis from rubbing against the heatpipe. This means that the chip height combined with the PCB and the heatsink is enough to start to worry how the chassis brushes up against the internals? Interesting.

Underneath the heatsink is this chip. What we have here is the 2+2 die from Intel (with graphics disabled, so 2+0 as shipped), along with the chipset. Back when Intel showed off a full wafer of these chips, we calculated a rough die size of 8.2mm by 8.6mm, or 70.5mm2 per die. In actual fact, we were essentially accurate in our estimation. This means there can be up to 850 dies per 300mm wafer. How many of those actually work at the level Intel wanted? That would be a fun question to have answered.

The base model of this device retailed for around $450 from our source in China - that's the 4GB model with a 500GB HDD. With the extra memory (up to 8GB) and storage (256GB SSD + 1TB HDD) the cost to us was around $650, plus postage. It took about six weeks to get the device, after calling in a few favors from friends in the region. For everyone else, a NUC was recently released onto shelves in December.
This Review
Within this article we want to do several things. Firstly, discuss and describe the history behind Intel's 10nm plans, the claims and the marketing, as well as what we currently know about what is in this 10nm Cannon Lake processor. Then we will go into what Cannon Lake brings to the table in its microarchitecture based on what we can find out, using tools, microbenchmarks, and also calling in some investigative experts. Following this is some benchmarks - we want to look into both generational improvements and chip production performance increases, coming at the performance angle but also a nod towards power and memory performance. Finally we'll end with a discussion about the future of this version of Intel's 10nm.
It should be noted that Intel did not offer or provide the device for this article - we purchased this device ourselves. When asked about diving deeper into the design of the chip about a month ago, Intel never really responded to my request. I currently have a more recent request to discuss the topic, and I'm waiting on a response.
Intel’s Path to 10nm: 2010 to 2019
The manufacturing history from Intel has been a very successful one. Being vertically integrated has meant that it can save costs, but also tailor its manufacturing processes to exactly what it needs without relying on an external company to do the tweaking. Since as far back as 2005 and the 65nm process, Intel embarked on a strategy of ‘Tick-Tock’, meaning that on alternate generations of products the company would release either a new process technology or a new processor microarchitecture. This allowed Intel to either reap the benefits of a faster processor design in the new microarchitecture, or reap the benefits of a smaller process node allowing for lower voltage, lower power, and smaller transistors to add in new features.
| Intel's Core Architecture Cadence | |||||
| Core Generation | Microarchitecture | Process Node | Release Year | ||
| 2nd | Sandy Bridge | 32nm | 2011 | ||
| 3rd | Ivy Bridge | 22nm | 2012 | ||
| 4th | Haswell | 22nm | 2013 | ||
| 5th | Broadwell | 14nm | 2014 | ||
| 6th | Skylake | 14nm | 2015 | ||
| 7th | Kaby Lake | 14nm+ | 2016 | ||
| 8th | Kaby Lake Refresh Coffee Lake Cannon Lake |
14nm+ 14nm++ 10nm |
2017 2017 2017* |
||
| 9th | Coffee Lake Refresh | 14nm++ | 2018 | ||
| Unknown | Ice Lake (Consumer) | 10nm class | 2019 | ||
| Cascade Lake (Server) Cooper Lake (Server) Ice Lake (Server) |
14nm class 14nm class 10nm class |
2019 2019? 2020 |
|||
| * Single CPU For Revenue ** Intel '14nm Class' is the new designation, moving away from '+' |
|||||
During this time, Intel held its annual Intel Developer Forum conference, known as IDF. IDF was a great show for the company to showcase its latest and greatest, as well as talk about what the future holds. It also allowed journalists and developers to discover the interesting technological advantages and platforms that Intel had built in order to accelerate computer code and projects. Being able to fully use the extra performance or extra power each generation enabled the product stack to be taken up to its zenith, as well as discuss future product lines and features.
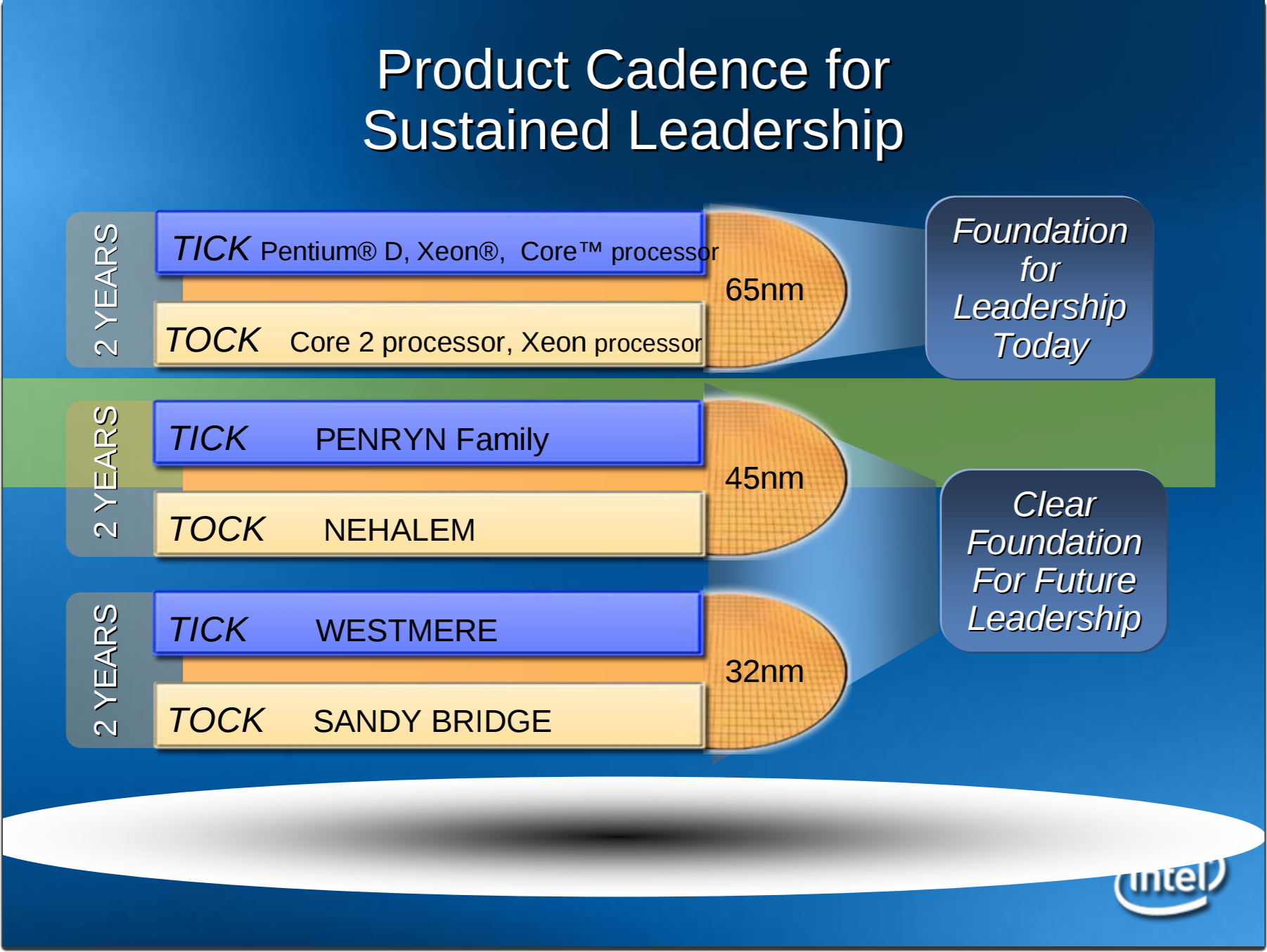
As this image shows, each combination ‘Tick-Tock’ was designed to be around two years apiece. Ticks were new process nodes, and Tocks were new microarchitecture. One of the famous comments of the era was the phrase ‘real men don’t tick tock, they tock tock tock’ (implying that microarchitecture improvements were more important in the long run than new process nodes).
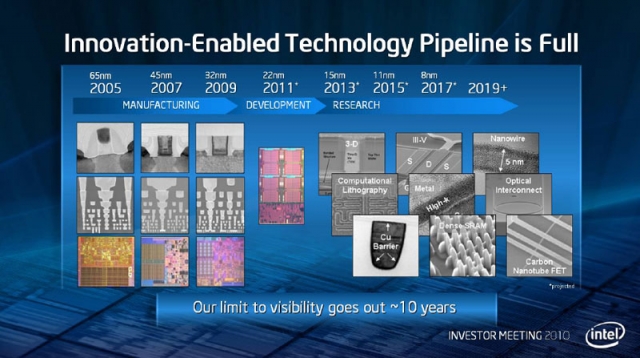
It is worth noting that Intel typically quotes that their development and research model goes to the next ten years of products, offering visibility and implementations that might cause the next paradigm of computing. Here, in this 2010 Investor Meeting slide, we see that Intel had 22nm in development for 2011, and was expecting ‘15nm’ to hit in 2013, ’11 nm’ for 2015, and ‘8nm’ for 2017. These names are different to the 14nm, 10nm, and 7nm we call them today, likely due to an International Technology Roadmap for Semiconductors (ITRS) report which originally had these nodes listed as 15, 11, and 8. It very quickly changed into the following slide:
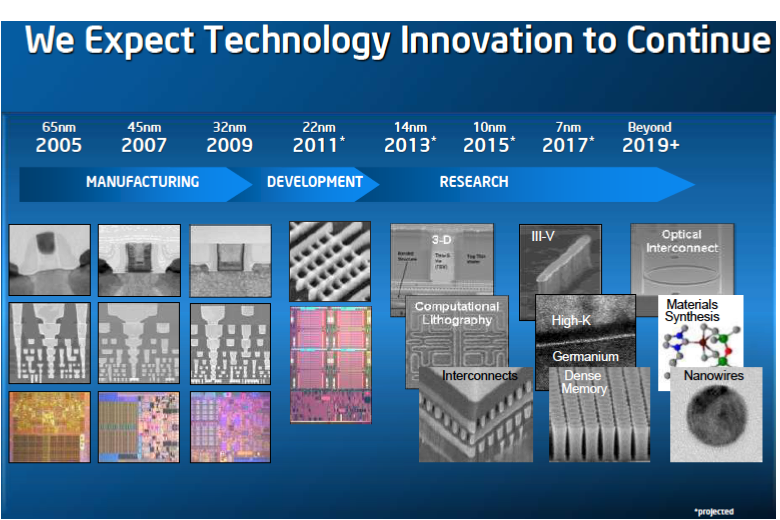
Here we see some of what Intel was working on: 3D transistors, computational lithography, interconnects, III-V materials, High-K metal gates with Germanium, Dense SRAM, Optical Interconnects, Material Synthesis, and Nanowires. Some, all, or fewer of these projects are still in play today in 2019.
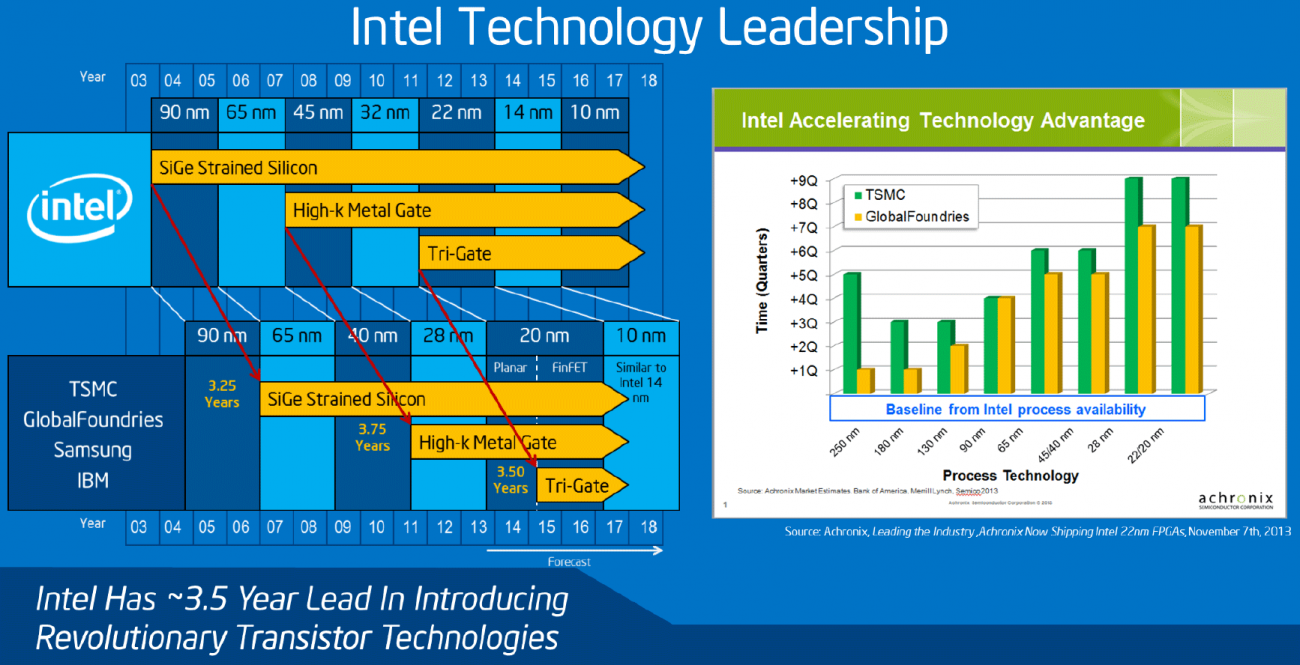
Intel has often used these technologies as a marker for its industry prowess against the foundry players in the marketplace, such as TSMC, GlobalFoundries, and Samsung. In this slide from 2014, we see Intel showing that it had a 3.25-year lead against others in Silicon-Germanium strained silicon, a 3.75-year lead in High-K metal gate technology, and a 3.5-year lead to tri-gate transistors, as well as the transition to FinFETs. Intel introduced FinFETs at 22nm, whereas the rest of the industry had them at 16nm.
It’s worth noting that on this 2014 diagram, Intel has 14nm listed as a 2014 technology, while 10nm is listed as a 2016 technology.
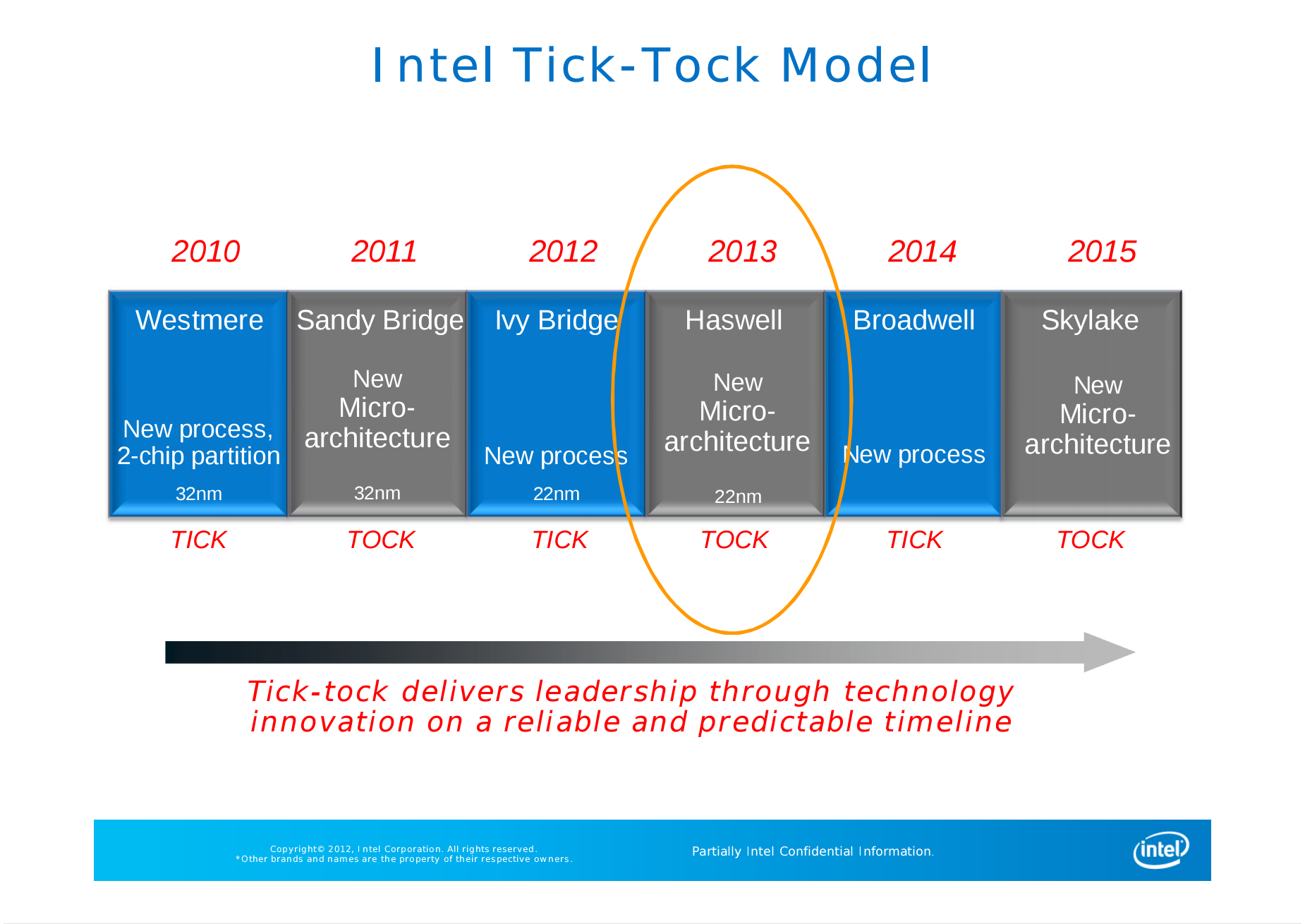
From 2010 onwards, Intel introduced the Core brand for its microarchitecture, which is still prevalent today (although with many generations of enhancements). At around 2012, Intel still expected to remain on Tick-Tock for several years at a minimum, moving from 32nm to 22nm, then to 14nm and 10nm. Unfortunately, Intel experienced delays bringing 14nm to market.
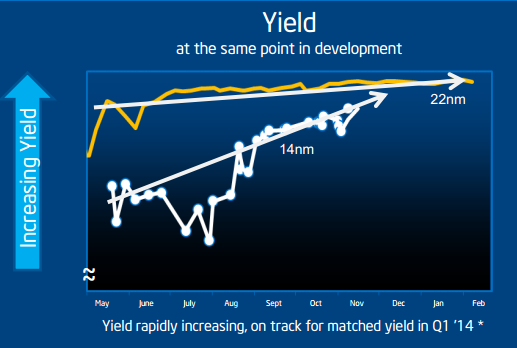
Despite originally being a product for 2013, the yields on 14nm fell short of targets, and compared to 22nm, it was clear that the jump to the next generation of FinFETs with a combination of density increases, active power decreases, and performance per watt increases was harder and harder to achieve. At this point in November 2013, Intel was expecting to match the yield of 22nm in Q1. However 14nm wasn’t just delayed into the beginning of 2014.
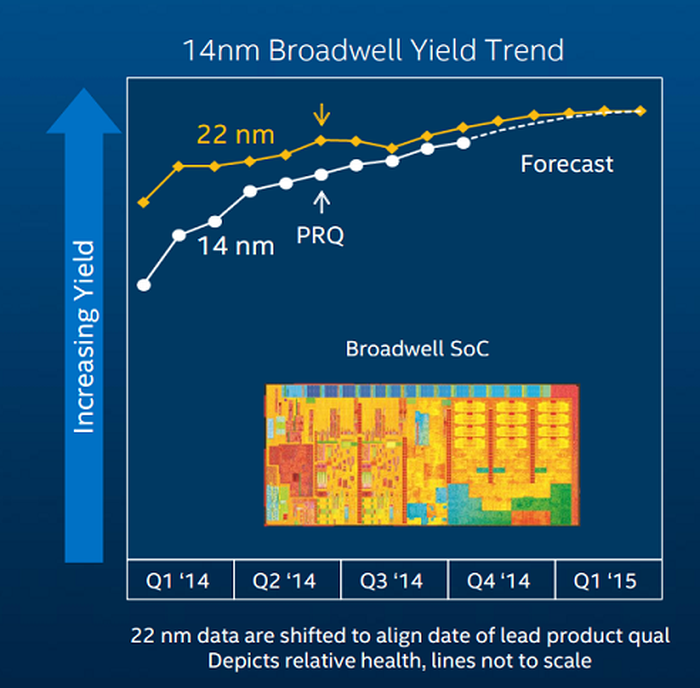
In mid-2014, Intel published this graph showing that even with expected advances, they weren’t going to match 22nm yields into 2015. However the key point here is the PRQ date, or Production Release Qualification date, meaning that Intel was sufficiently happy that yields were high enough and the performance was suitable for silicon to be made for retail products. Intel gave a deep dive into its 14nm technology in August 2014, and Ryan did a great write up here. The detail is key – it is genuinely possible to see why 14nm was so much harder than 22nm.
The first products on 14nm were the smallest designs for the ‘Broadwell-Y’ family of processors. These 4.5W processors were marketed to enable thinner and lighter form factor mobile devices, due to the decreased power consumption of the new process. Ultimately, these chips were easier to manufacture (yield decreases with an increase in chip size) as well, allowing Intel to start selling processors despite a higher-than-expected defect rate. These processors were officially on the market in the September/October 2014 timeframe.

Ultimately it was 2015 when we saw something bigger from Intel’s 14nm process. In Q1, we saw a launch of mid-range laptop and notebook processors on this first generation 14nm process, with higher performance Core i7 processors in June 2015. Intel did actually launch a couple of desktop processors as part of this Broadwell family, the Core i7-5775R and the Core i5-7675R, in June 2015 however they were not widely available and short lived. The far more successful second generation of 14nm processors, Skylake, was launched on the desktop in August 2015 with a couple of high-end parts, followed by the rest of the stack in Q3/Q4 of that year.
Speaking to some in the industry, one of the main reasons why Intel had so much trouble with Broadwell and its first generation 14nm process was related to its integrated graphics. Reports suggested that Intel’s high-performance transistors on 14nm were not suited to the high-frequency design of the newest graphics libraries, with one report stating that Intel had promised a certain level of graphics performance and wasn’t able to achieve it, ultimately leading to a launched product with lower graphics performance than expected. Over time Intel has improved its 14nm process to get that frequency back (it took a couple more generations), although this will play into our discussions on 10nm as well.
In 2015, this was Intel’s official roadmap:
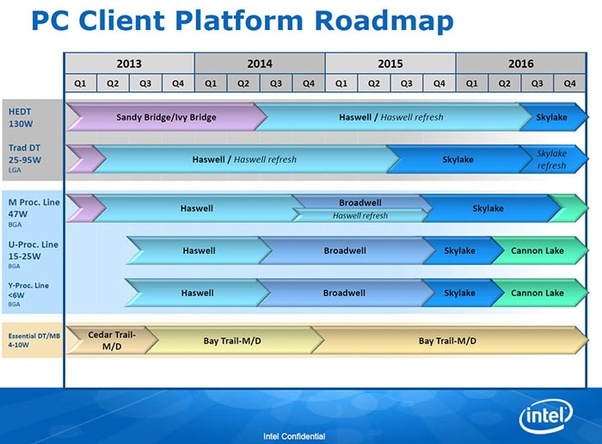
Here we see the late 2014 launch of 14nm Broadwell for the mobile processors, and the complete rejection that Broadwell for the traditional desktop even existed, going straight into the second generation of 14nm with Skylake in Q2 2015. At this point I want to draw attention to the bits in green. Under Intel’s Tick Tock process, the first generation 10nm process, Cannon Lake, was set to follow Skylake very quickly with a launch in Q2 2016.
If Intel was aiming at Q2 2016 for 10nm products to be on shelves, it would have seemed very reasonable at the time, given that at the start of 2015, Intel had its usual array of discussions and presentations at the International Solid-State Circuits Conference (ISSCC) in February. As part of those presentations, 10nm was a key part of it, with Intel stating that while 10nm was set to have more masking layers than 14nm, the company expected that the delays that bogged down 14nm would not be present in bringing 10nm to market. We specifically reported at the time:
In this, the key part is that Intel had identified where it went wrong in 14nm, and was ready to remove those bottlenecks in its development of 10nm. Intel stated that 10nm would come with innovation, however going beyond to 7nm will require new materials and processes that Intel would introduce progressively. After ISSCC, Skylake on 14nm was launched in mid-to-late 2015.
In a report by Intel in March 2016, it was clear that 10nm Cannon Lake was not ready. The company released the following statement in its annual 10-K filing:
What this means is that Intel was extending its product cycle for 14nm. Intel’s famous Tick-Tock cadence, which had served them well for several cycles, was now being split into a ‘Process Architecture Optimization’ strategy. Under this heading, Intel would release three versions of processors under a given process node: one focused on transitioning to the new process, one to introduce a new microarchitecture, and one to optimize both the process and the architecture.
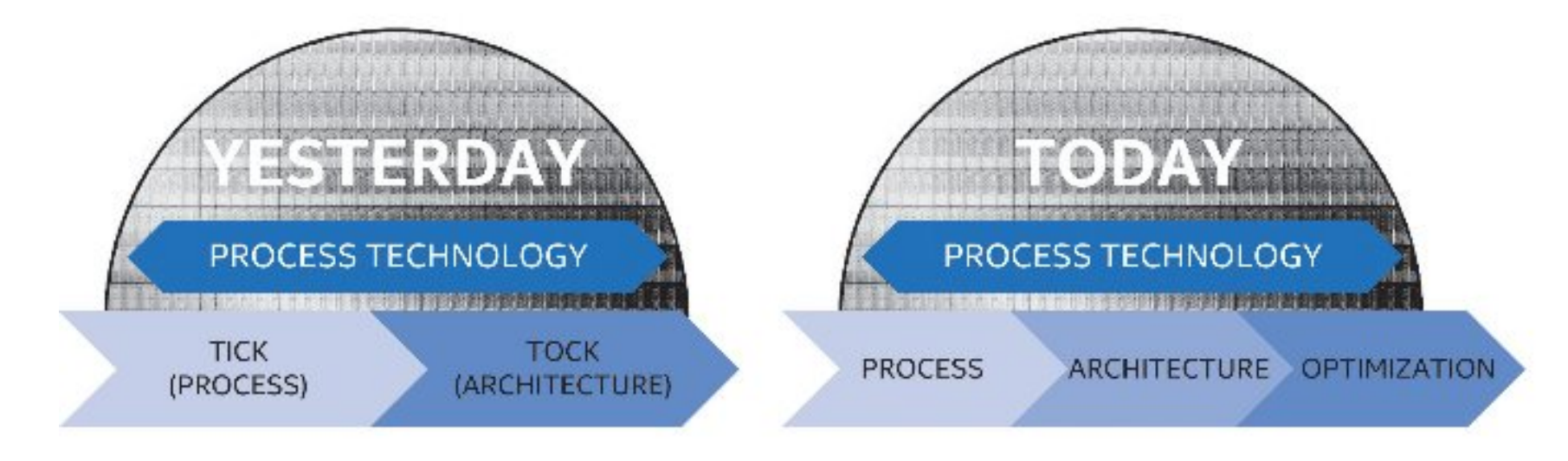
For roadmaps and product lines, this meant that the second generation of 14nm called Skylake would transition into the third generation of 14nm, called Kaby Lake. Officially this process optimization was dubbed ‘14nm+’, with the plus indicating it had a little bit extra. Explicitly, the new process had improved transistor channel strain along with other minor enhancements that enabled Intel to extract 100-300 MHz more out of the design without increasing the capacitance. The overall improvement allowed for an additional +12% drive current, leading to increased performance.

Kaby Lake was officially launched in August 2016, starting with the 4.5W parts again, with the desktop processors coming in January 2017.
To kick of 2017, at CES, Intel held a presentation focused on VR. At some point towards the end, the CEO held up a 2-in-1 laptop that he said was 10nm. It was for all accounts the first presentation of 10nm we had seen. Nothing was run on the device, and the device was held up for only a few brief seconds.

This happened within the first two minutes of the presentation, with the former CEO Brian Krzanich stating categorically that Intel would be shipping 10nm by the end of the year.
Soon after at an Intel Investor Day in February 2017, Intel dropped a bombshell about its product portfolio for the upcoming year. The company announced that the data center would be first to new process nodes (later clarified to mean 10nm+), and that it would be taking another swing at 14nm for its consumer product lines. Within one generation of products, Intel’s ‘Process-Architecture-Optimization’ was given a double dose of the Optimization.
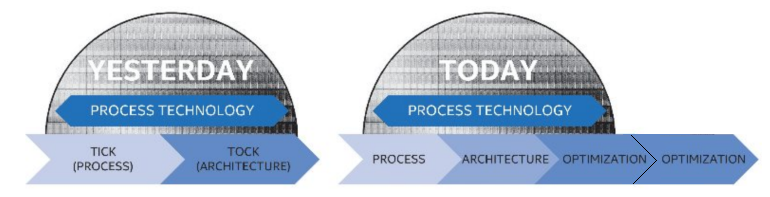
This would mark the fourth generation of 14nm products for Intel, which ended up being called Coffee Lake, and was formally launched in May 2017. This fourth generation of 14nm was even given the process labelling of ‘14nm++’, following Broadwell (14nm), Skylake (14nm), and Kaby Lake (14nm+). We were still waiting on news for the first generation of 10nm, Cannon Lake, would have been expected to debut in mobile processors first. Remember, the original predicted date of 10nm was 2015, so at this point Intel is two years late.
After the Investor Day in February 2017, the company had its first Intel Manufacturing Day at the end of March 2017. The company went into more detail about its 10nm plans, and specifically regarding some of the new technology designs integrated into its 10nm process. Presentations were made by Stacy Smith, the then CTO, Mark Bohr, Dr. Murthy Renduchintala, Ruth Brain, and Kaizad Mistry, with a focus on Intel’s latest technology and foundry processes.

Mark Bohr’s Presentation on Moore’s Law
We’ll go into more details about the specifics on 10nm in the next page, however the Manufacturing Day was very well received by media and analysts alike. The company explained that it was focusing on transistor density improvement, showing improvements in fin pitch, metal pitch, cell height, and gate pitch, as well as new technologies such as single dummy gates and Contact Over Active Gate (COAG). The key takeaway is that Intel was aiming for 100 million transistors per square millimeter with its 10nm process, and this would allow it to keep its 3.5 year lead over other foundry offerings, with Intel predicting that their own 10nm offering would be better than TSMC/GF/Samsung’s 7nm. Some in the media were blown away with the numbers, others were not so easily impressed, pointing out Intel’s wordiness to make some of the numbers work.
Another takeaway is that after not saying much about 10nm for a while, Intel was opening up. However, the company very quickly became quiet again.
After manufacturing day, we saw the launch of Coffee Lake, but the next update on 10nm was given in mid-August, where Intel announced the name of the second generation of 10nm: Ice Lake.
As mentioned at the time, announcing the name of the n+2 processor family seemed a little odd, especially given the first 10nm generation had been delayed at least twice already and had not been released. It would later become evident, in mid-2018, that the Ice Lake naming was pushed out due to its use in the first generation of 10nm for Intel’s Xeon server line of products.
In September, Intel re-ran its Manufacturing Day event in Beijing, again discussing its lead in process technology and the upcoming 10nm ‘revolution’. Nothing new was said at the event, except that a 10nm wafer was shown on stage and in the breakout sessions for the event.

Based on this wafer, we estimated that the 2+2 (dual core with GT2 graphics) configuration for a chip (which this wafer was built on) would be around 70.5 mm2 of die area. It turns out this was a pretty accurate estimation. Nonetheless, the pattern was set: we should expect to see 10nm in a 2+2 configuration coming to market as the first 10nm chip. At this point, we’re still expecting Intel’s Cannon Lake to be part of a full family of products.
After September, Intel went into radio silence mode again. The rest of 2017 came and went, with not much of a peep from the company. December came and went, and aside for an update on parts of the 10nm design at the IEDM conference, not a word came from outside Intel’s R&D efforts, with the company seemingly missing its own target of shipping 10nm in 2017. In early January is the annual industry CES trade show, where Intel had a keynote presentation, so we perhaps might hear something then.
Intel’s CES 2018 Keynote presentation, led by former CEO Brian Krzanich, was all pomp and ceremony. There was a mention of the recent Spectre and Meltdown security issues that were just announced, but the event focused on Intel enabling customers, as well as flashy drones, 3D volumetric video, AI, and LEDs.

In the presentation, Intel’s work in both neuromorphic computing and quantum computing was mentioned, along with showing a quantum chip on stage. However nothing relating to the next generation of general purpose computing processors was mentioned. AT ALL. Despite the CEO making the proclamation at CES 2017 of shipping by the end of the year, he didn’t even address the topic in the entire keynote in 2018. Something was afoot. We had a few words with our Intel spokespeople, who told us to be at the Intel booth at 8am the next morning for a small presentation.
In that small presentation, Gregory Bryant, SVP of the Client Computing Group, spent 10 minutes discussing how Intel was achieving its goals to bring the best computing experiences to its users. It was, in all honesty, a lot of fluff. Then in the final sentence of the ten minute presentation, he stated an update on 10nm, that the company had shipped product in 2017 for revenue. Then the presentation ended – no elaboration of what, or scope, or customer, or anything. It was a certain attempt to both mention 10nm at the show and not mention it all at the same time.

SVP Gregory Bryant mentioning 10nm, briefly
We all thought this was a bit odd. We knew that Cannon Lake was a consumer product, so this wasn’t a case of Intel shipping a server processor to top customers before announcing it (a common practice). But Intel at this point had given us very little details about the configurations, the performance, the pricing. For a company that takes pride on its engineering prowess, this was about as low-key of an announcement as you could get. We were very skeptical indeed.
The next mention of Cannon Lake was during February 2018, when Intel accidentally exposed in official documents that it had updated its microcode for two Cannon Lake processors. This update was to mitigate against certain Spectre and Meltdown vulnerabilities, confirming in a way that the hardware design for this family of processors was complete.
Also in 2018, Intel once again presented 10nm at the ISSCC conference in February. The focus of this talk ended up being once again about density, in this case the SRAM cells which showed a 0.63x scaling.
Fast forward several months later, to May 2018, and we still had not heard anything from Intel. To be ‘shipping in 2017’ but still have no product by mid-2018 was getting weirder and weirder. It wasn’t until we saw a listing for an educational laptop from a Lenovo reseller in China did we believe it actually existed.
The Lenovo IdeaPad 330-15ICN contained the i3-8121U, which is still to date the only Cannon Lake processor that has ever ‘launched’. This device is a large and bulky 15.6-inch machine with a small battery and a 13x7 inch display that was built for classrooms. Normally educational devices like this do not get put into the retail channel, however for some reason (and because it’s China), it was made available to the public.
Configurations for the device varied from a HDD and 4GB of memory, to 8GB with an SSD and HDD. It also came with discrete graphics, rather than integrated graphics, and depending on the configuration was priced from $445 to $580. I called in a few favors from friends with contacts in China, and two months later, our unit arrived. This is the unit we are reviewing here today. But that isn’t the end of the story of Intel’s 10nm product. At this point, Intel still hadn’t told us anything about the Cannon Lake processor inside.
It wasn’t until we actively posted about this laptop being available that Intel started talking about the processor. Its ARK page (Intel’s online database of processors) was now made visible to the public, and shows that the processor was officially launched in Q2 2018. Here was a dual core 15W processor with the integrated graphics disabled, and with lower clock frequencies than an almost-equivalent Kaby Lake 15W processor. Lots of questions were asked as to how the new 10nm process was, on paper, less efficient than the previous generation processor. Intel still refused to discuss exactly the changes in the hardware, or the expected performance numbers.
We since have confirmed that the graphics is indeed fused off. Intel’s official line is that this processor was released with a specific target market in mind, and it fulfils the role required. What exactly this market is, and at what price point, is still a mystery, even in 2019. However some analysts believe the graphics was a dodo out of the door due to uneconomically viable yields, as well as this chip not making any sense commercially for the product segment it ended up in – it was put into the market just to fulfil a promise to investors.
Moving from May to August, and no new processors or devices relating to Intel’s 10nm were announced. However Charlie over at SemiAccurate published knowledge that there were issues with Intel’s 10nm process as currently presented. He reports that Intel’s yields were sub-10% for the Cannon Lake 10nm CPU, well below the 60% Intel had expected at this point. He points to several issues with the process that were well behind schedule and/or expected performance: SAQP, COAG, Cobalt, and tuning – each one could be a potential showstopper if not fixed (we’ll go into these on the next page). Creating silicon is a multi-variable strategy, and turning one dial to get better characteristics in one direction might cause three other properties of the design to get worse, and finding a balance is key. What makes this process harder is when a semiconductor fab gets aggressive, and implements many changes at once, which was had been a key part of Intel’s messaging on 10nm up to this point.

Charlie’s report is that Intel was having great difficulty with the 10nm process as it was currently designed, which was a major reason for missing production targets and why the only 10nm processor up to this point is a low clocked, no-graphics version in an obscure device.
Within days of this report, but unrelated, Intel held a Data Center Summit in Santa Clara and announced that it would be bringing 10nm to the enterprise market in the form of Ice Lake Xeon Scalable (Ice Lake-SP). This would be released after Cascade Lake on 14nm (2018, actually now 2019 for general release), and Cooper Lake on 14nm (2019).

Intel was very coy to say anything about 10nm at this time. Despite repeated requests for Intel to confirm that the version of 10nm that they intend to use in Ice Lake-SP was the same as the already released Cannon Lake, representatives of the company refused to commit to any details. Part of this is because Cannon Lake is a consumer product, and Ice Lake-SP is an enterprise product, and never the twain shall meet.
No less than two weeks later, Intel made another 10nm announcement: the company would be releasing the 10nm Cannon Lake CPU in its NUC form factor. The new unit, sold under the code name Crimson Canyon, is essentially the Lenovo Ideapad laptop mentioned above but in a mini-PC form factor.

Similarly to the laptop, it uses the Core i3-8121U as the processor and due to the lack of integrated graphics it uses an RX540 AMD mobile chip for graphics. Two SO-DIMM slots are on offer, and the system comes with an M.2 slot for NVMe storage, unlike the laptop. This unit is ultimately better for thermal performance than the laptop, by virtue of being a mini-PC with a more substantial cooler. This unit, despite being announced in August 2018, didn’t actually make it on to shelves until December.
At the end of August is the annual Hot Chips conference, which is usually a hot bed for chip discussions, and Intel did not present anything new about 10nm there. It is important to remember that to date, Intel has not openly discussed Cannon Lake’s microarchitecture or improvements, for example. September was quiet, and then in October Intel held a Fall PC Event in New York.
At the Fall PC Event, Intel disclosed its 9th Gen Core processors, codenamed ‘Coffee Lake Refresh’, which included the Core i9-9900K, the Core i7-9700K, and the Core i5-9600K that came to retail a couple of weeks later. These were not 10nm, and instead we were treated to another generation of 14nm products. This is officially the fifth generation of 14nm products for the desktop, and it showed that within a process Intel has been able to make frequency and efficiency gains, as well as scale the product up to eight cores with a turbo speed of 5.0 GHz, but it was still nothing about 10nm. We were promised more news on 10nm later in the year.
Here's a table to keep up with Intel's 14nm:
| Intel's 14nm Family | |||||
| Generation | Microarchitecture | Process Node | Release Year | ||
| 1st | Broadwell | 14nm | 2014 | ||
| 2nd | Skylake | 14nm | 2015 | ||
| 3rd | Kaby Lake | 14nm+ | 2016 | ||
| 4th | Coffee Lake | 14nm++ | 2017 | ||
| 5th | Coffee Lake Refresh | 14nm++ | 2018 | ||
Very soon after the launch of the 5th Generation of 14nm, a report was released stating that Intel’s known 10nm design was, for lack of a better term, ‘dead’. The report cited core issues with some of the new parts of Intel’s design, such as COAG, which were not yielding appropriately, plus by Intel’s own admission back at Manufacturing Day, even with perfect yield, they were not expecting to meet the performance of their latest version of 14nm until the third generation of 10nm. Intel immediately refuted (via Twitter) they were ending work on 10nm, making good progress on 10nm, and improving yields consistently. Again, the company refused to state if the future of the 10nm manufacturing design was identical to that found in the 10nm processor that was already launched.
Media reports published today that Intel is ending work on the 10nm process are untrue. We are making good progress on 10nm. Yields are improving consistent with the timeline we shared during our last earnings report.
— Intel News (@intelnews) October 22, 2018
November was relatively uneventful, and in early December we finally saw the first Intel NUC devices with the Core i3-8121U for sale, starting at $530 with 8GB of DDR4 and a 1TB mechanical drive. On December 12th 2018, Intel held an Architecture Day where it started to lift the lid on its plans for 10nm, and what we should expect in 2019.

Ice Lake-U (15W) Demo Chip
This included a long discussion about its second generation 10nm product, Ice Lake, which would be coming to notebooks in a 15W form factor at the end of 2019, as well as the next two generations of cores.
| Intel Core Microarchitecture Roadmap | |||
| Core Name | Year | Process Node | Improvements |
| Broadwell | 2014 | 14nm | First Gen 14nm |
| Skylake | 2015 | 14 nm | Single Threaded Performance Lower Power Other Optimizations |
| Kaby Lake | 2016 | 14 nm+ | Frequency |
| Coffee Lake | 2017 | 14 nm++ | Frequency |
| Coffee Refresh | 2018 | 14 nm++ | Frequency |
| Sunny Cove (Ice Lake) |
2019 | 10 nm | Single Threaded Performance New Instructions Improved Scalability |
| Willow Cove | 2020 ? | 10 nm ? | Cache Redesign New Transistor Optimization Security Features |
| Golden Cove | 2021 ? | 7 / 10 nm ? | Single Threaded Performance AI Performance Networking / 5G Performance Security Features |
It is worth noting that the first generation Cannon Lake processor has ‘Cannon Lake’ cores inside, however the second generation ‘Ice Lake’ will have ‘Sunny Cove’ cores inside, which are a more radical departure in microarchitecture than the nth generation Skylake cores that Cannon Lake was based on. Details about Sunny Cove were limited, barring a mention that certain aspects of the core design had been increased.
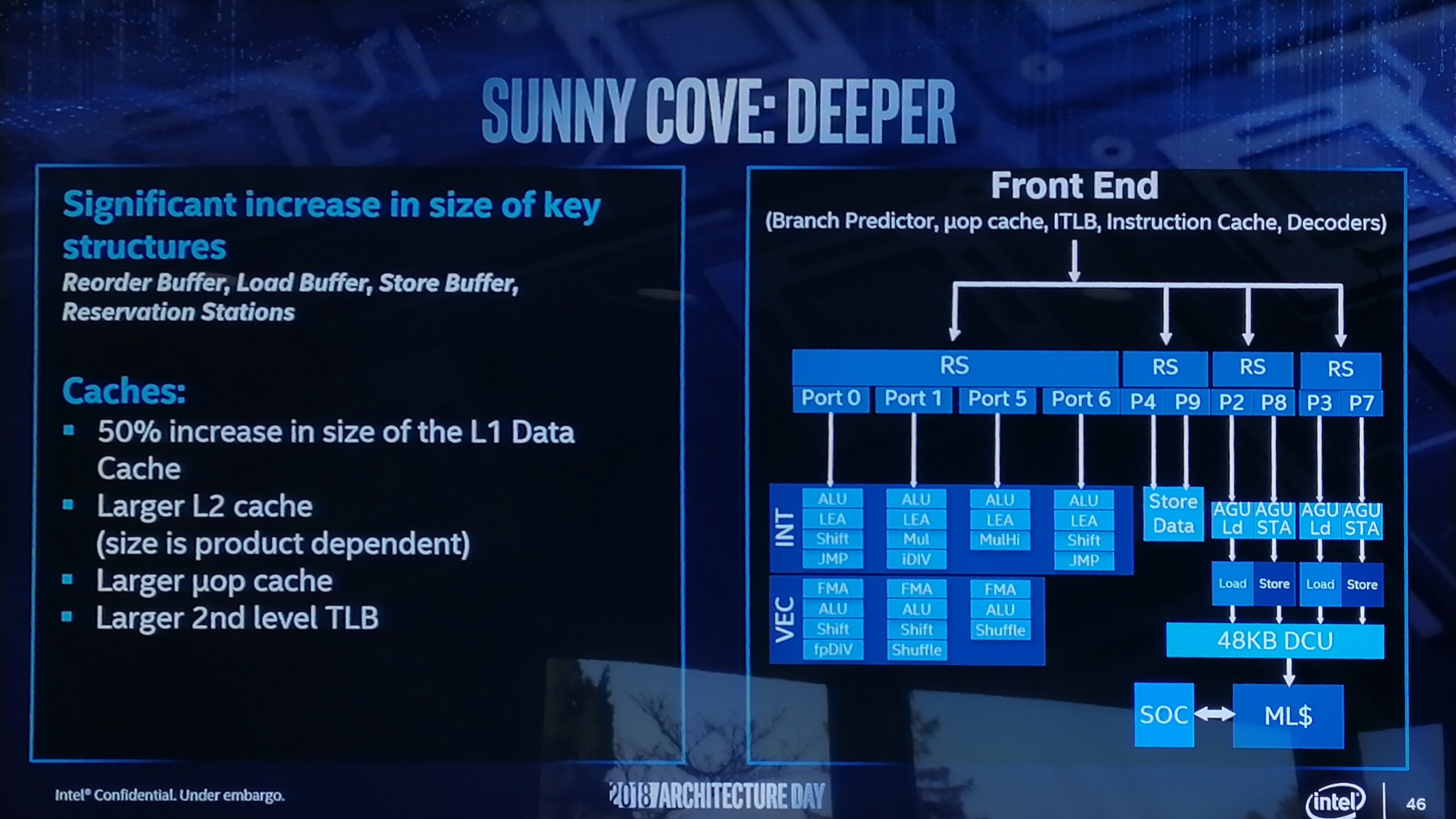
Along with Sunny Cove, Intel mentioned in a bit of detail its Gen11 graphics architecture, also set to debut on 10nm. One Intel representative stated that this was Intel's first graphics architecture on 10nm, which essentially confirms that the Cannon Lake graphics design did not work.
Also on 10nm, Intel gave its first presentation and demonstration of a new packaging technology called Foveros. This technology allows Intel to stack silicon dies on one another, and drive TSVs (through silicon vias) to connect the chips to the power plane. The demonstration chip, now known as Lakefield, used CPU and GPU cores on the top chip, with IO on the bottom chip. The idea here is that it can save x-y dimensions for products that need it. Using this technology, Intel showed its first hybrid x86 solution, with one Sunny Cove core and four Atom cores, all on 10nm. This chip is expected to be in production in late 2019.
As part of this presentation, Intel opened up a little into its manufacturing naming scheme. According to the charts, Intel is working on several versions of 10nm, known as P1274, P1273, P1222, P1274.7, and P1274.12.

For those keeping track, these are the process names for the 10nm product lines for Ice Lake and Foveros (manufacturing), future version of 10nm (P1274.7, P1274.11), Future process nodes on 7nm (P1276, P1275), and beyond 7nm. According to Wikichip, the official process name used for Cannon Lake was P1274, suggesting that Ice Lake and Cannon Lake share the same process. However, at this time, it would appear that Intel is dropping the ‘+’ nomenclature from its 10nm and beyond products – they all fall under ‘10nm’ class, so it is impossible to say if Cannon Lake and Ice Lake share the same design layout rules.
Also presented at the Architecture Day was a server based 10nm chip - Ice Lake Xeon Scalable. According to reports, these had only entered the Intel labs a couple of weeks prior, so were quite raw in tuning. This is the chip Intel has promised for 2020 for enterprise.

As was perhaps to be expected, Intel refused to comment on the core count of this chip, the expected power consumption, and such. Typically one of Intel’s enterprise chips, even the low core count models, are in the 250mm2 or above range, which would be a sizeable leap from the 70.5mm2 on the dual core Cannon lake design.
Moving into 2019, and it marks a full year since Intel said that they were shipping 10nm for revenue at the end of 2017. So far in 2019, Intel reiterated the announcements from Architecture Day during its CES presentation, and it also introduced a new ‘Snow Ridge’ processor design built on 10nm aimed at 5G and AI workloads. Intel also clarified that it expects to see 10nm in notebooks by the end of 2019. We expect this means that desktop processors will be coming in 2020, along with enterprise processors.
That’s where we are today on Intel’s route to 10nm.
Intel’s 10nm Cannon Lake Silicon Design
Many thanks to David Schor of WikiChip for his articles on Intel’s 10nm. This page uses his material extensively as the primary source. I highly recommended several of his articles, including his write-ups from IEDM 2017, ISSCC 2018, IEDM 2018, and his page on Cannon Lake.
Measuring The Chip
The first true glimpse of a physical Cannon Lake chip, beyond the brief showing of what was supposedly an early Cannon Lake laptop at CES 2017, was during the Chinese version of Intel’s Technology and Manufacturing day in September 2017. Intel presented a full 300mm wafer of Cannon Lake 10nm chips, and through luck we were able to get some clear definition of the chips.
Based on this wafer, we estimated that the chip would be around 70.5 mm2 of die area, and at the time we assumed this was a dual core design with ‘GT2’ graphics, the standard graphics configuration. After the Lenovo Ideapad was made available in China, the experts at TechInsights got hold of a unit and took their saws to the design.

Photo: Techinsights, Measurements by WikiChip
It turns out we weren’t too far off on the die area. This photo of the chip in the system (with IO die on the right) gives a die area of 70.52 mm2, well within an acceptable margin of error. This chip does indeed have two Cannon Lake CPU cores, and 40 Gen10 execution units on the integrated graphics, although the graphics are disabled. This qualifies as a 2+2 design.
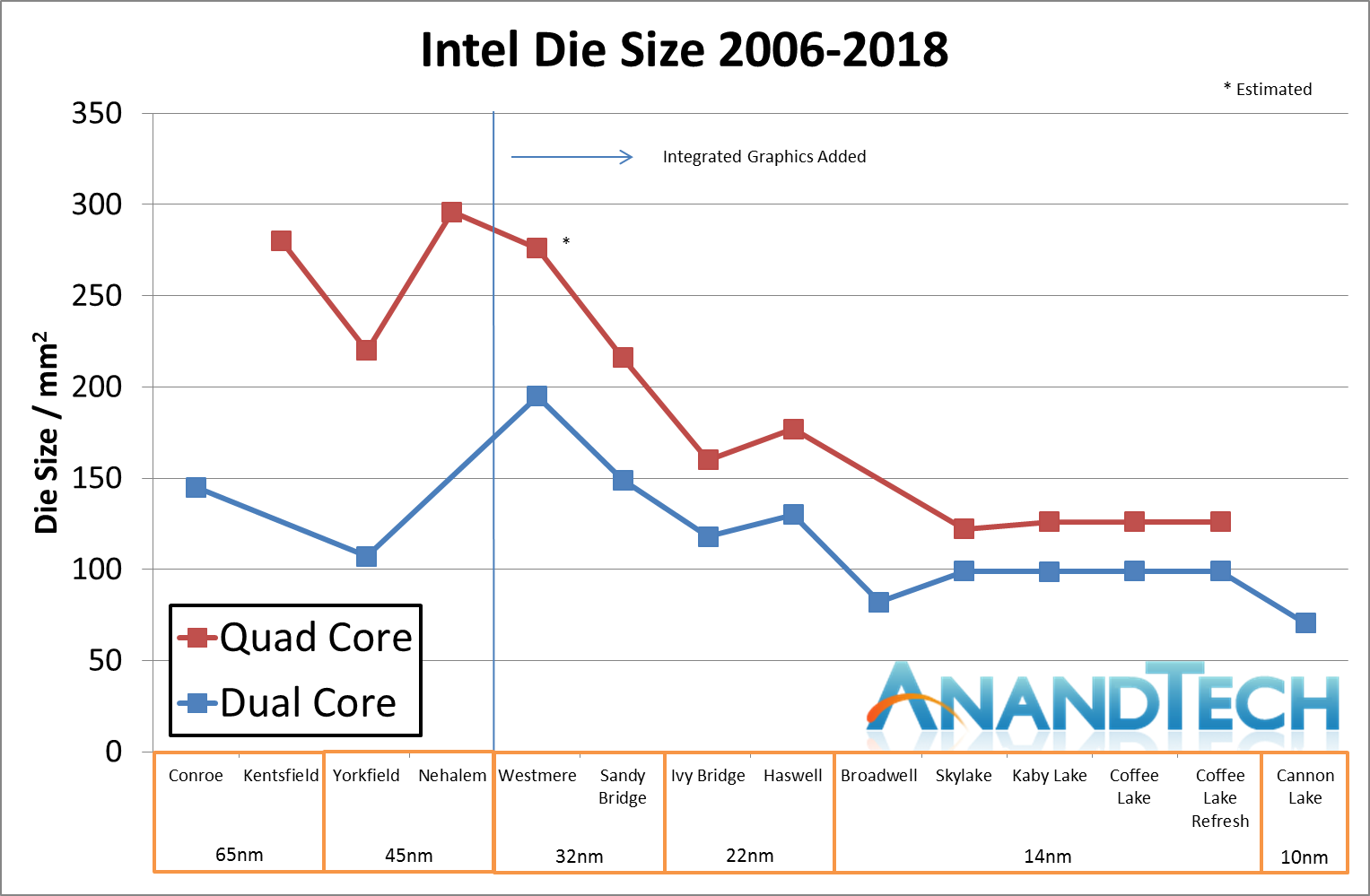
For comparison to Intel’s previous dual core designs, this marks Intel’s smallest dual-core design to date. The nearest would be Broadwell, at 82 mm2, but this chip also had a lower proportion of integrated graphics compared to Skylake and newer.
The Ultimate Metric: Transistors Per mm2
One of the metrics used for determining how good a semiconductor process is relates to how many transistors per square millimeter are in a standard chip made on that process. A processor isn’t all transistors though – there are SRAM cells, and also ‘dead’ silicon designed to act as thermal buffers between areas in order to increase the longevity of the parts. There are also different ways to count transistors, as a 2-input NAND logic cell is much smaller than a complex scan flip-flop logic cell, for example. Nonetheless, most in the industry have this metric as a key factor when discussing processes, and hitting certain milestones is usually congratulatory.

Back at Intel’s 2017 Technology and Manufacturing day, the company put out this slide, showing the millions of transistors per mm2 (MTr/mm2). This shows Intel making a very sizable 2.7x jump from 37.5 MTr/mm2 on its best 14nm node up to 100.8 MTr/mm2 on its 10nm node.
At the same time, Intel has suggested that the industry use a new way to measure transistor counts, based on the sizes of the two most common types of transistors in modern microprocessors.

Under this metric, Intel wants the number of transistors per unit area to be divided into NAND2 cells and Scan Flip Flop Cells, and weight them 60/40 accordingly. This is how Intel gets to the 100.8 MTr/mm2 number.
However, at IEDM 2018, Intel presented some different numbers for older processes. They also went into detail about some of the numbers on Cannon Lake.
| Intel's Process Node Density | |||||||||
| 90 nm |
65 nm |
45 nm |
32 nm |
22 nm |
14 nm |
14 ++ |
10 nm |
7 nm* |
|
| Year | 2004 | 2006 | 2008 | 2010 | 2012 | 2014 | 2018 | 2019 | 2023 |
| Density MTr/mm2 |
1.45 | 2.08 | 3.33 | 7.11 | 16.5 | 44.67 | 37.22 | 100.76 | 237.18 |
| * Estimated | |||||||||
(The reason that 14nm++ is less dense than 14nm is that in order to improve frequency, Intel relaxed some of the design rules to allow for greater margins in design.)
Intel’s new method of counting adds a bit to Intel’s older processes, but 10nm stays where it is. This value, the company stated, is a combination of 90.78 MTr/mm2 for NAND2 gates and 115.74 MTr/mm2 for Scan Flip Flops.
There’s More To It
Intel also disclosed at IEDM that it has three types of logic libraries at 10nm, depending on the functionality required. These are short libraries (HD, high density), mid-height libraries (HP, high performance), and tall libraries (UHP, ultra-high performance). The shorter the library, the lower the power and the higher the density, however the peak performance is also lower. Ultimately the chip design is often a mixture of libraries – the shorter libraries work well for cost-sensitive applications, or for IO, and uncore. The larger libraries, by being less dense and having higher drive currents, are usually afforded for the most critical paths in the design.
The three libraries on Intel’s 10nm as a result come in three different densities. Only the high density library actually has the full 100.78 MTr/mm2:
| Intel 10nm Cell Libraries | ||||
| Name | Density MTr/mm2 |
Fins | Cell Height |
|
| HD | High Density | 100.78 | 8 | 272 nm |
| HP | High Performance | 80.61 | 10 | 340 nm |
| UHP | Ultra High Performance | 67.18 | 12 | 408 nm |
The reason why these cells differ in size is due to the number of fins in each cell, and thus fins per transistor. The number of fins adjusts the cell height, and additional fins allows more drive current for more performance, at the expense of power and area.
This graph from WikiChip shows the relationship between them for power and performance:
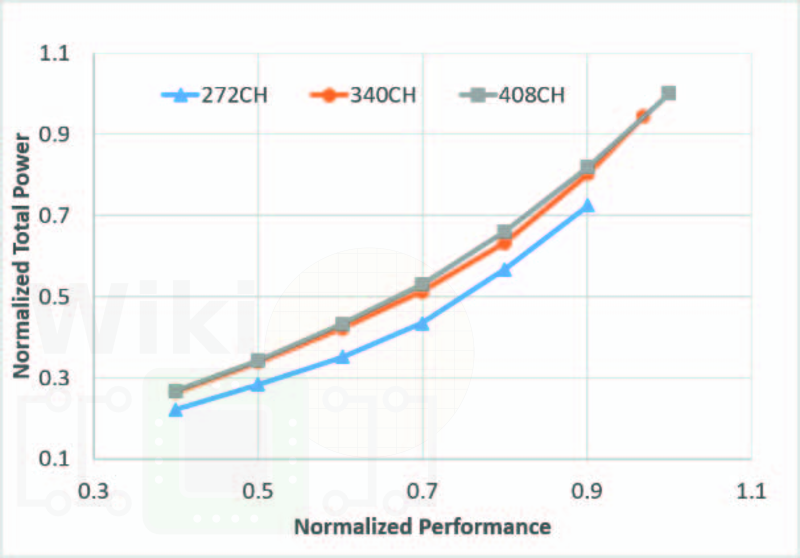
This makes a strong case for the HD cells for almost everything non-performance related, HP cells for most performance things, and UHP cells along the critical path. Ultimately the density that Intel uses from chip to chip is going to change depending on what cells they use and in what proportions. However within a specific chip design (say, a mid-core count Xeon), all chips built on that design will have the same cell layouts.
Fin Mechanics
In order to understand a lot of what Intel is doing at 10nm, we need to discuss fin, gate, and cell mechanics as well as define some terms relating to transistors and FinFETs. Starting with a diagram of a traditional FinFET:

The source-to-drain of a transistor is provided by a fin (in grey) going through a gate (in green) while imbedded in an oxide. The key metrics here are the fin height, the fin width, and the gate length. The idea is to make each of these as small as possible but still perform both at speed and as intended. During Intel’s 22nm the company used ‘tri-gate’ transistors that involve multiple fins together to increase total drive current for better performance.
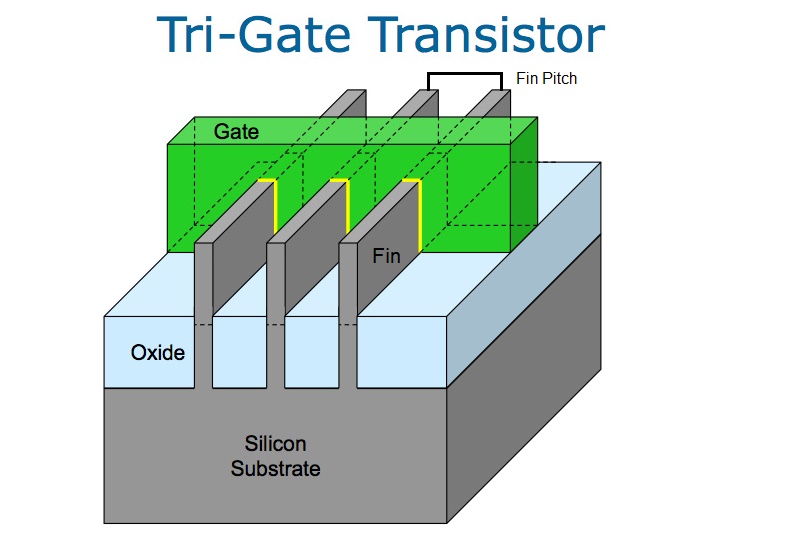
This introduces a new metric, the ‘fin pitch’, as the distance between fins. Similarly, if a fin passes through multiple gates, the distance between the gates is known as the ‘gate pitch’. Origianl diagrams come from Intel with our modifications.
In reality, we see images that look like this, showing the fins:
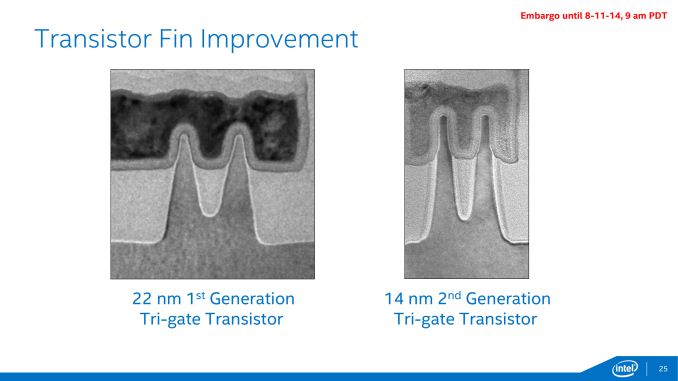
In this image Intel showed the improvement from 22nm to 14nm, with taller fin heights, smaller fin widths, and shorter fin pitches, with more of the peak of the fin imbedded into the gate.
The more contact between the fin and metal gate, and the smaller the fin and fin pitch, the lower the leakage and the better the performance. It’s all a question of increasing drive current, but also managing stray capacitance and gate capacitance.
When it comes to 10nm, Intel is being aggressive in its fin design. Here are the basic numbers.
| Comparing Intel 14nm to Intel 10nm | |||
| 14nm | 10nm | Change | |
| Rated Density | 44.67 | 100.78 | 2.26 x |
| Fin Pitch | 42 nm | 34 nm | 0.81 x |
| Fin Width | 8 nm | 7 nm | 0.88 x |
| Fin Height | 42 nm | 43-54 nm | 1.02-1.29 x |
| Gate Length | 20 nm | 18 nm | 0.90 x |
| Contact Gate Pitch | 70 nm | 54 nm | 0.77 x |
| Minimum Gate Pitch | 52 nm | 36 nm | 0.69 x |
At IEDM 2017, Intel presented a fin height of 43 nm to 54 nm (officially, 46 nm), increased from 42 nm, with more contact between the fin and the gate. The fin height can be adjusted depending on the needs of the transistor. The fin width moves from 8nm down to 7nm, which means there is actually something in this process smaller than 10nm. The fin pitch needs to be small, to avoid parasitic capacitance, but the technology becomes more and more challenging to do this – for 10nm, Intel moves from a 42nm pitch to a 34 nm pitch, which is where its ability to do ‘Self-Aligned Quad Patterning’ (SAQP, more later) comes in.
I’m going to quote David from WikiChip here, who explains how this is done:
Adding more steps to the process naturally incurs a penalty in production time and a potential loss in yield.
The end result for the fins is a diagram that looks like this, showing Intel’s improvements from its first generation of FinFET technology:

It doesn’t exactly look like much, but this is part of what it takes to drive new generations of semiconductor performance. At this scale, every nanometer counts. The fins are now more densely packed, and have more contact area with the gate. This helps with the drive current, the capacitance, and ultimately, density. Intel also improved the source and drain diffusion regions by adding a conformal titanium layer. The contact area between the fin and the trench (the grey bit under the gate) requires a lot of attention, with the idea to minimize contact resistance between the two. For 10nm, Intel changes this tungsten contact for a cobalt one, which according to the materials affords a 60% reduction in contact line resistance.
Building A Cell, and Managing Cell Size
A cell is a combination of a fixed number of fins with a varying amount of gates. Each cell has to connect ground and power at the top and bottom, which at a predefined position keeps it easier for routing and other analysis. Cells are almost like mix and match – multiple cells of a uniform height are laid in order, depending if the cell is for capping a logic cell, a logic cell itself, or voltage stability/isolation etc.

Here is an Intel SEM image from its 22nm process, showing cells with six fins and two fins, but varying lengths of gates.
Within each cell, there are active fins that pass current, and inactive fins that act as spacers. Intel’s highest density cell, HD, has a total of eight fins, however only five of which are active fins.

Image from WikiChip
These cells are used for cost-sensitive applications where density is required, or for non-high performance situations such as IO. With eight fins, this cell has two active ‘P’ fins and two active ‘N’ fins, with an optinonal additional active ‘N’ fin for various logic functions where prioritization is needed (such as NAND over NOR).
The other cell sizes that Intel uses, HP and UHP, have ten and twelve fins respectively. In each case there is one additional P fin and one additional N fin, both of which help provide additional drive current to aid peak performance at the expense of efficiency. The total height of the cell is the fin pitch (distance between fins) multiplied by the number of fins.
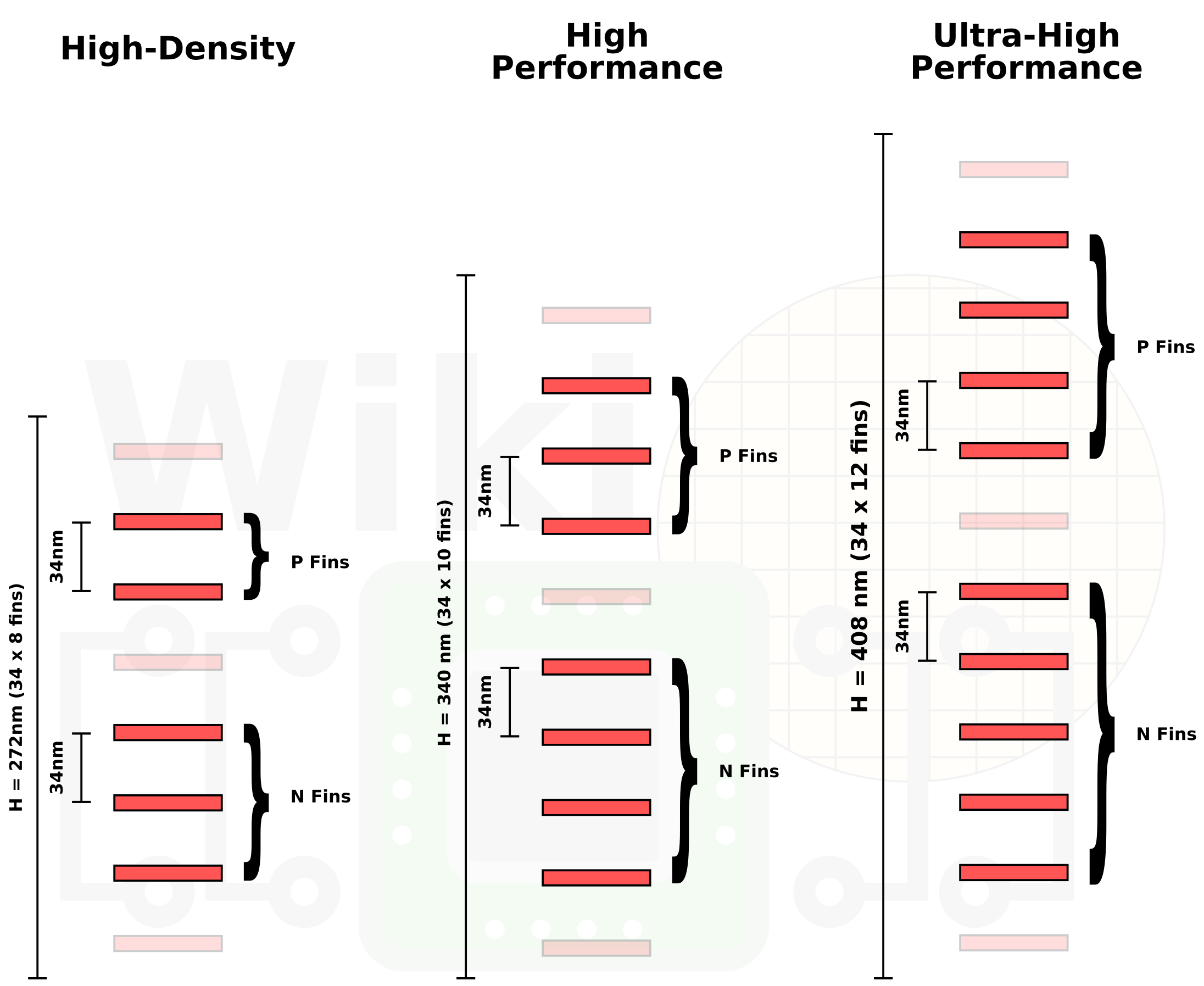
Image from WikiChip
It is worth noting that the faded out fins are usually present in the design, but are just dummy fins as part of the design.
One of the ways to measure density in this context is to multiply the Gate Pitch (or specifically, the Contact Poly Pitch) by the Fin Pitch (or Minimum Metal Pitch), known as the CPPxMMP metric. Because saying ‘10nm’ or ‘7nm’ has little bearing on the process at this point in history, this metric gives some idea of exactly how dense a process is.
| Comparing Different Process Nodes CPPxMMP |
||||||||||
| Intel | TSMC | Samsung | ||||||||
| CPP | MMP | CPP | MMP | CPP | MMP | |||||
| 28 nm | - | - | 117 nm | 90 nm | - | - | ||||
| - | 10530 nm2 | - | ||||||||
| 22 nm | 90 nm | 80 nm | - | - | - | - | ||||
| 7200 nm2 | - | - | ||||||||
| 16 / 14 nm | 70 nm | 52 nm | 90 nm | 64 nm | 78 nm | 64 nm | ||||
| 3640 nm2 | 5760 nm2 | 4992 nm2 | ||||||||
| 10 nm | 54 nm | 44 nm | 66 nm | 44 nm | 68 nm | 48 nm | ||||
| 2376 nm2 | 2904 nm2 | 3264 nm2 | ||||||||
| 7 nm | - | - | 54 nm | 40 nm | 56 nm | 40 nm | ||||
| - | 2160 nm2 | 2240 nm2 | ||||||||
From this metric, you would believe that TSMC’s 7nm amd Samsung's 7nm were both slightly denser than Intel’s 10nm. This is one reason why Intel wanted to change the way we define density into a mixture of cell sizes. But this metric doesn’t accurately reflect different cell libraries that use different heights (and thus a different number of fins per cell). However, cell size is not the only trick in the book.
Dummy Gates
Between cells there will often be a number of dummy gates used as spacers. In Intel’s 14nm designs, a cell would have a dummy gate at either end, meaning that between cells there would be two dummy gates. For the 10nm process, two adjacent cells can now share a single dummy gate.

This mainly has density advantages, with Intel claiming a 20% area saving across a chip. Based on images that Intel showed at ISSCC, there isn’t actually a physical gate there, but actually a really deep trench.
Contact Over Active Gate (COAG)
Within a transistor, the gate contact is the control point where the current for the gate is applied to control between the source and the drain sides of the fin. Normally the gate contact is beyond the standard cell, as shown in this diagram:

This adds extra space to the x/y dimension, but is somewhat unavoidable. For 10nm, or at least the version currently in Cannon Lake, Intel is deploying a method called ‘Contact Over Active Gate’ (COAG) which places the gate contact over the cell.
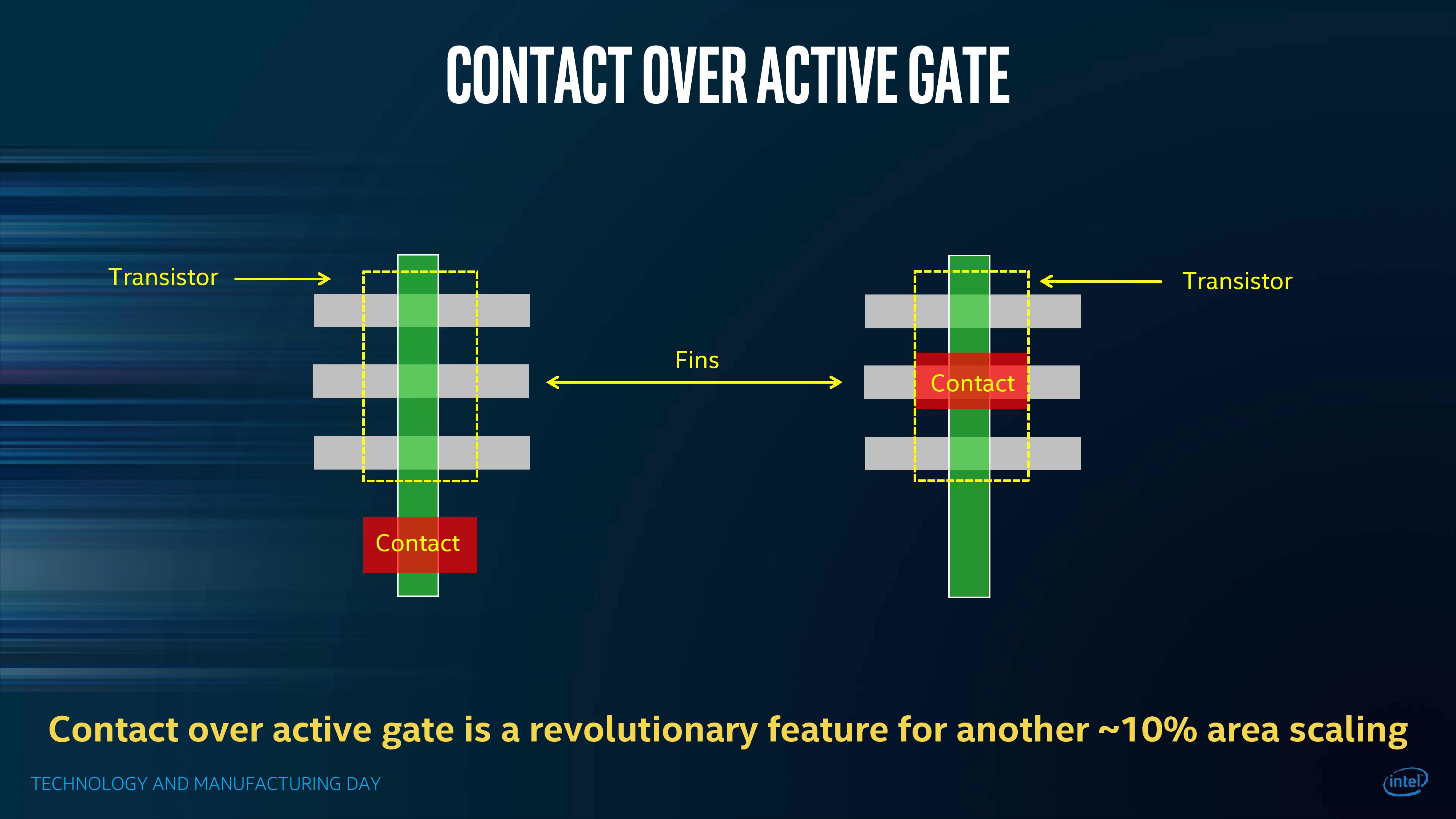
This is a complex change – the contact has to sit above the cell but not directly interfere with any of its properties. It adds several steps to the manufacturing process (one etch, one deposition, and one polish), but affords a potential ~10% better area scaling over the whole chip.
One of the reports about Intel’s 10nm process is that COAG is a risky implementation, and that while Intel has got it to work, it is not as reliable as expected due to relying on self-aligned diffusion to form a tight contact. Based on our discussions, the COAG design in Cannon Lake only seems to be working at low performance/low power, or at high performance/super-high power, which is at the ends of the spectrum but not in the middle. We expect Intel to mention how they’ve adjusted the design as and when they want to discuss an updated 10nm in detail.

Overall, with the CPPxMMP adjustments, Dummy Gates, and COAG, Intel claims to have achieved a scaling factor of 0.37x over 14nm.
Applying Power Delivery: Double The Design Effort
In a standard cell design, power delivery is often managed by automated EDA tools. This is often a lot quicker than hand placement, improving time to market. However, in order to get the density improvements to work, Intel had to work with EDA tool vendors in order to apply power delivery both at the ‘block’ level, and for different cell alignments. This was an industry effort that afforded a number of optimizations.
A standard chip is built up as a series of metal layers to help deliver data and power. This series of metal layers is called the metallization stack, and forms part of the ‘back-end of line’ (BEOL) of how the chip is made, and can be independent of the transistor design.
Intel’s 10nm metal stack is 13 layers, one more than 14nm, and two more than 22nm. Intel’s official design rules for its metal stack are as follows
| Intel's 10nm Metal Stack | |||
| Layer | Metal | Pitch | Patterning |
| Fin | 34 nm | Quad | |
| Gate | Copper / Cobalt | 43-54 nm | Dual |
| Metal 0 | Cobalt | 40 | Quad |
| Metal 1 | Cobalt | 36 | Quad |
| Metal 2, 3, 4 | Copper | 44 | Dual |
| Metal 5 | Copper | 52 | Dual |
| Metal 6 | Copper | 84 | Single |
| Metal 7, 8 | Copper | 112 | Single |
| Metal 8, 10 | Copper | 160 | Single |
| Thick Metal 0 | Copper | 1080 | Single |
| Thick Metal 1 | Copper | 11000 | Single |
Cobalt is a ‘barrier-less’ conductor, which means that compared to copper it does not need a barrier layer between wires, plus it also scales down further than copper, providing more beneficial characteristics at smaller sizes. TechInsights also reports detecting Ruthenium in the lower layers on their Cannon Lake processor, however Intel has not mentioned it in its disclosures.
Dealing with placing wires on each layer is different to building fins and trenches, which is why the pitch changes through the stack. However joining the metal power rails in the right way is an important requirement in design. The power stubs of each cell are typically found on the corners, connecting the cell to the Metal 2 layer through the Metal 1 layer. As a result, the stubs are thought of being at the ‘cell level’. Intel has changed this and moved the power stubs to the ‘block level’, by identifying common groups of cells and placing them at optimum positions.
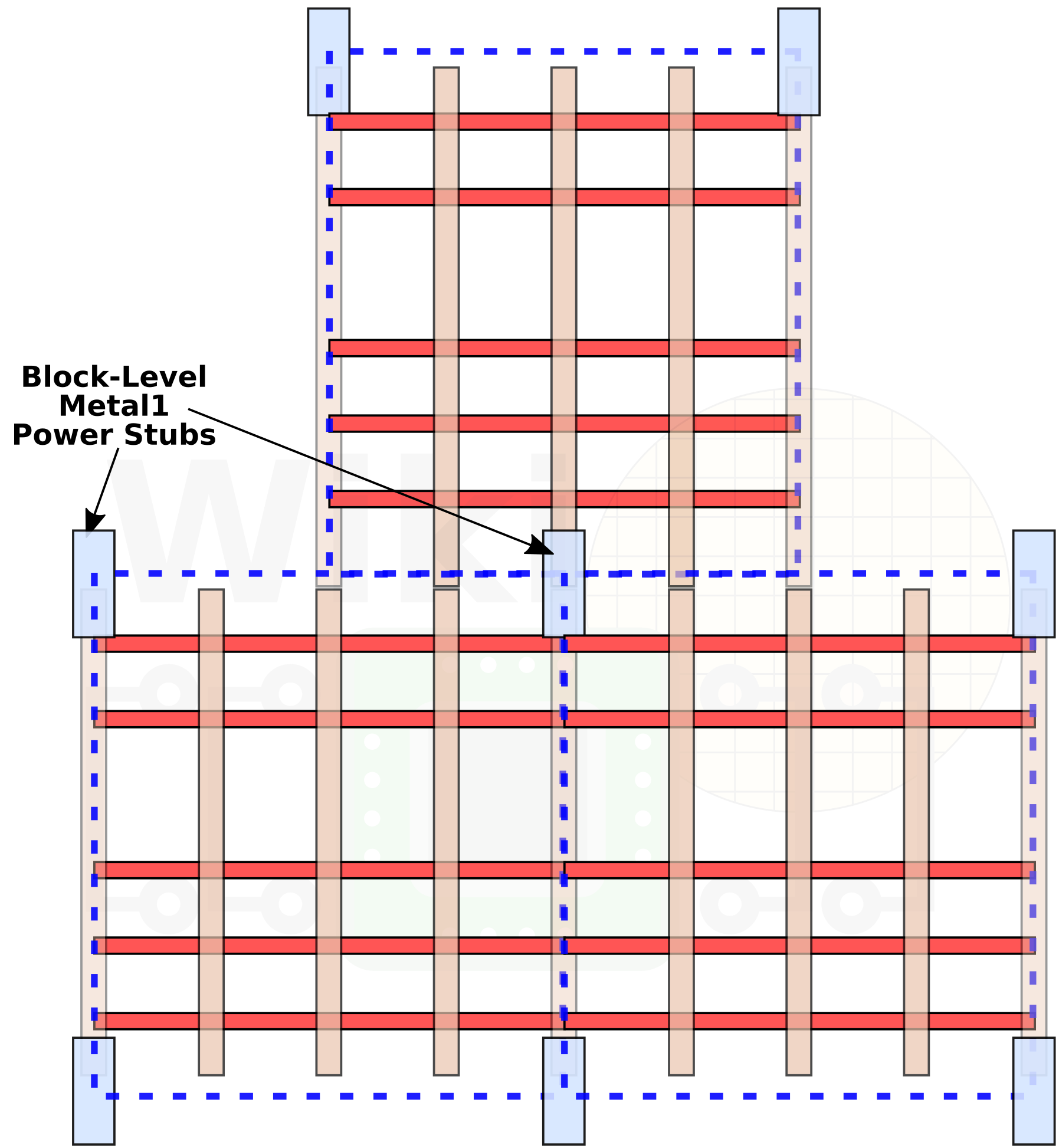
Image from WikiChip
This is not a trivial change. It hasn’t been possible until Intel’s 10nm to do with the automated EDA tools – it was possible by hand, but that increases the design time of the chip. The step Intel made with the EDA tool makers is to develop ‘block aware’ automation, so this can happen fully inside the tools. This also allows the Metal 1 layer to be less densely populated, which actually helps with cell level density.
It should be noted that in order for this to work, the gate pitch in the cell and the Metal 1 layer pitch needs to align. As shown in the table above, the Gate pitch is 54nm, while the M1 pitch is only 36nm, which isn’t equal. While it is not equal, it is in a 3:2 whole ratio. This whole ratio means that while there is a potential for misalignment, it happens at the block level. The EDA tools have to deal with this, usually by adding in spacers, which reduces density. To get around this, Intel duplicated its entire cell library for two formats: for cells with misaligned contacts and for cells with aligned contacts. This means that the if EDA placement tools know that two different versions exist, it can use the version required depending on the location, ultimately saving density without having to use gaps. Being ‘alignment aware’ was a significant step for both Intel to create two versions of every cell but also for the tools to implement this feature. The alignment aware feature has repercussions through the metal stack, and Intel stated that depending on the cell density this could give another 5-10% density improvement. Not bad for double the work (!).
It should be stated that Intel calls this ‘a solved problem’, and we are expecting the company to use it in all products going forward where the pitch mechanics make it applicable.
Scaling Wires
Going smaller with wires has one significant issue: resistance. Having a lower cross-sectional area for electrons to travel through means that they are cramped into a smaller space, resulting in an increased resistance, and relationship between the two is inversely proportional.
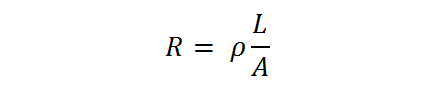
The resistance of the wire is the resistivity (a function of the metal) multiplied by the length divided by the cross-sectional area. So ideally as area decreases, using a metal with a lower resistivity helps a lot. Otherwise, additional drive current is needed, which has other knock-on effects such as electromigration.
So at this time Intel is moving from Copper to Cobalt for its thinnest wires in the lower metal layers. The thing is, the resistivity of Cobalt is actually higher than that of Copper, almost four times as much. The reason why Copper gets the nod is two things – scaling, and electomigration.
Electromigration is when the high-speed electrons knock metal atoms out of their spots in the metal structure by momentum transfer. Normally this isn’t an issue, however as the current increases and the cross sectional area decreases, and more electrons are present, this can become a concern. The more atoms out of place, the higher the resistance of the wire, until there is a complete disconnect. Electromigration happens more often at grain boundaries in the metal, and when the average mean free path is long. A circuit that fails due to electromigration cannot be repaired.
A lot of effort is put into controlling electromigration, and EDA tools are automatically designed to mitigate against it. This means adding in diffusion barriers and liners, which add to the overall wire placement dimensions. However, these liners do not scale as much as the wire does.

Yet another awesome image from Wikichip.
So when a copper wire is given as a certain value for its width, part of that is taken up by these diffusion barriers and liners, meaning that the actual cross section of copper is a lot lower, and as we scale down, much, much lower.
This is where cobalt wins over copper, in several areas in fact. While the resistivity of cobalt is 4x higher, the nature of cobalt means that the diffusion barriers need only be 1nm, allowing for more of the wire volume to be bulk cobalt. This allows cobalt to scale down to much smaller wire widths. The mean free path is shorter, down from 40nm to sub-10nm, meaning that electomigration is less of an issue.
Obviously cobalt isn’t used for everything; when the wire widths are wide enough, then the traditional copper implantation is a tried and tested method with lower resistivity which wins the day (the gain in area from cobalt doesn’t offset the resistivity disadvantage). For the layers where it matters, particularly M0 and M1, Intel states that cobalt affords a 2x reduction in layer-to-layer resistance (via resistance) and a 5-10x improvement in electromigration within the layers.
As David from Wikichip points out, in future node advancements, as more and more layers go over the cobalt-copper crossover point, we will start to see cobalt move up the stack. Or, as Techinsights found, Ruthenium might be making itself known in some layers.
Putting It All Together
Back at the beginning, we mentioned that Intel’s key metric on its 10nm process is meeting the 100 million transistors per square millimeter mark. This is for its high density cell libraries, rather than for its ultra-high-performance cell libraries, but it is still an impressive feat nonetheless. When approaching this sort of scaling, every area needs to be improved – 10% here, 15% there, another 10% somewhere else, and it all adds up. At Intel’s Technology and Manufacturing Day at 2017, Intel stated that for a given chip design on 45nm, what would have taken 100 square millimeters then can now fit into 7.6 square millimeters today.

What is interesting to note is the slide that appeared in this deck only two clicks later, discussing the capacitance and performance of Intel’s planned generations of 10nm.
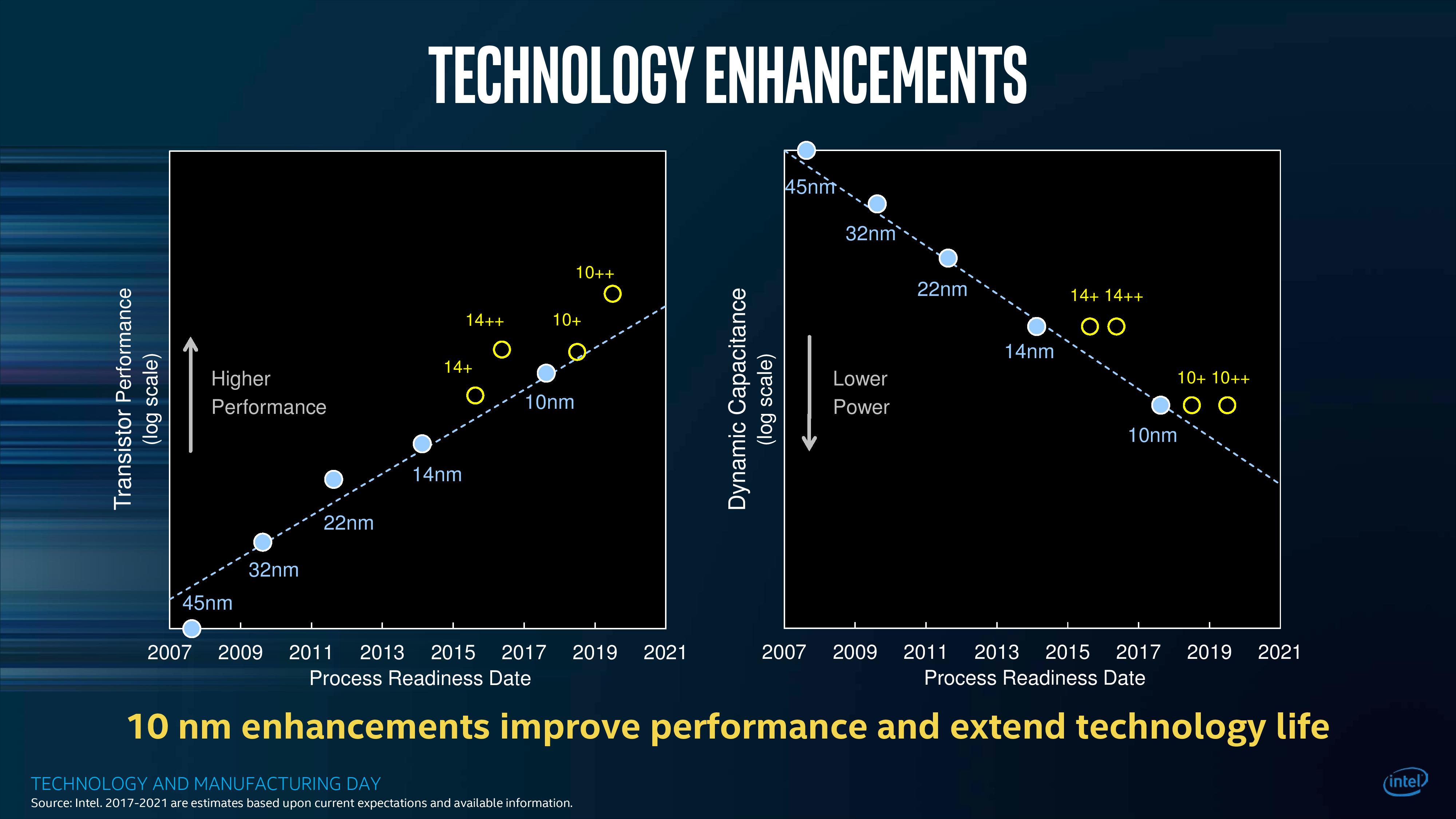
On the right, Intel shows that every version of 10nm in its pipeline has a lower dynamic capacitance than 14nm, which is a good thing. However, in terms of transistor performance on the graph on the left, both 10nm and 10nm+ have a lower transistor performance than the latest version of 14nm++.
For reference, Cannon Lake is on what Intel calls its ‘10nm’ process node. Ice Lake, the product destined for consumer devices at the end of 2019 (in 8-10 months from now), is on the ‘10nm+’ process node. This means that the products in December 2019 will still be behind in transistor performance to the products launched in October 2017. The new chips will have some benefits, such as power and new microarchitectures, but this is worth noting what Intel has already stated to the press and investors.
Sources. Well Worth The Read
[1] https://fuse.wikichip.org/news/525/iedm-2017-isscc-2018-intels-10nm-switching-to-cobalt-interconnects/
[2] https://fuse.wikichip.org/news/2004/iedm-2018-intels-10nm-standard-cell-library-and-power-delivery/
[3] https://fuse.wikichip.org/news/1371/a-look-at-intels-10nm-std-cell-as-techinsights-reports-on-the-i3-8121u-finds-ruthenium/
[4] https://techinsights.com/technology-intelligence/overview/latest-reports/intel-10-nm-logic-process/
[5] https://www.anandtech.com/show/8367/intels-14nm-technology-in-detail
Uncovering the Microarchitecture Secrets
When we approached Intel to see if they would disclose the full microarchitecture, just as usually do in the programming manuals for all the other microarchitectures they’ve released, the response was underwhelming. There is one technical document related to Cannon Lake I can’t access without a corporate NDA, which would be no use for an article like this. These documents usually fall under corporate NDA before the official launch, and eventually become public a short time after. However, when we requested the document, as well as details on the microarchitecture, we received a combination of ‘we’re not disclosing it at this time’ and ‘well tell us what you’ve found and we’ll tell you what is right’. That was less helpful than I anticipated.
As a result I pulled in a few helpful peers around the industry to try and crack this egg. Here’s what we think Cannon Lake looks like.
On the whole, the system is ultimately designed as a mix between the Skylake Desktop core and the Skylake-SP core from the enterprise world. While it has a standard Skylake design using a 4+1 decode and eight execution ports, along with a standard Skylake desktop L1+L2+L3 cache structure, it brings over a single AVX-512 port from the enterprise side as well as support for 2x512B/cycle read from the L1D cache and 1x512B/cycle write.
What we’ve ended up here is with a hybrid of the Skylake designs. To go even further, it’s also part of the way to a Sunny Cove core, Intel’s future second generation 10nm core design which the company disclosed part of in December. This is based on some of the instruction features not present in Skylake but found on both Cannon Lake and Sunny Cove.
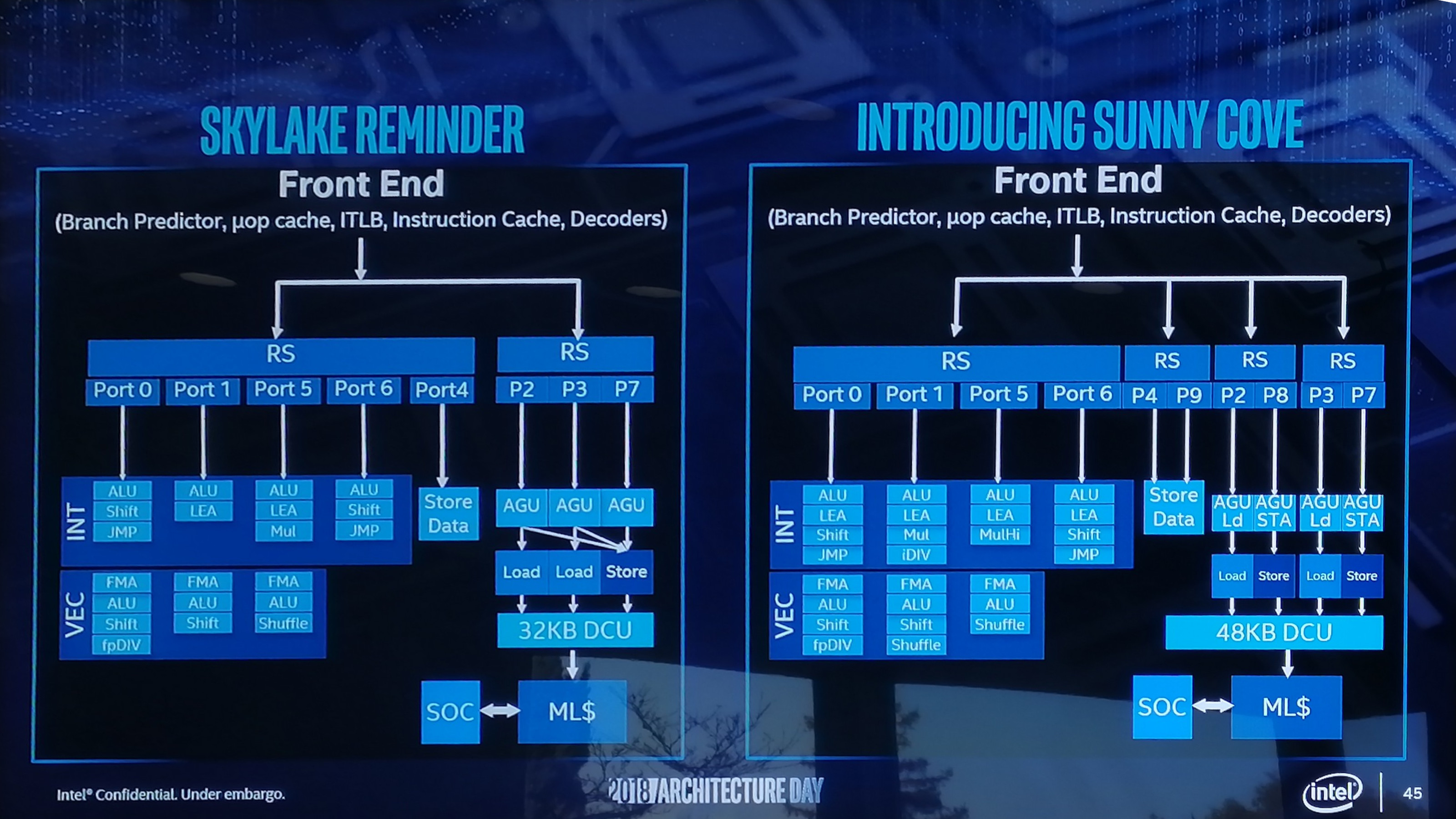
Mostly Column A, A Little of Column B
It’s mostly desktop Skylake at the end of the day – both Cannon Lake and Sunny Cove have the same AVX512 compatibility, just with the Skylake cache structure. We’re not too clear on most front end changes on Cannon Lake as those are difficult to measure, although we can tell that the re-order buffer size is the same as Skylake (224 uops). However, most of the features mentioned in the Sunny Cove announcement (doubling store bandwith, more execution ports, and capabilities per execution port) are not in Cannon Lake.
| Microarchitecture Comparison | ||||||
| Skylake Desktop |
Skylake Xeon |
Cannon Lake | Sunny Cove* | Ryzen | ||
| L1-D Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
48 KiB/core ?-way |
64 KiB/core 4-way |
|
| L1-I Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
32 KiB/core 8-way |
? | 32 KiB/core 8-way |
|
| L2 Cache |
256 KiB/core 4-way |
1 MiB/core 16-way |
256 KiB/core 4-way |
256 KiB/core ?-way |
512 KiB/core 8-way |
|
| L3 Cache |
2 MiB/core 16-way |
1.375 MiB/core 11-way |
2 MiB/core 16-way |
? | 2 MiB/core | |
| L3 Cache Type | Inclusive | Non-Inclusive | Inclusive | ? | Non-Inclusive | |
| Decode | 4 + 1 | 4 + 1 | 4 + 1 | 5(?) + 1 | 4 | |
| uOP Cache | 1536 | 1536 | 1536 (?) | >1536 | ~2048 | |
| Reorder Buffer | 224 | 224 | 224 | ? | 192 | |
| Execution Ports | 8 | 8 | 8 | 10 | 10 | |
| AGUs | 2 + 1 | 2 + 1 | 2 + 1 | 2 + 2 | 2 | |
| AVX-512 | - | 2 x FMA | 1 x FMA | ? x FMA | - | |
| * Sunny Cove numbers for Client. Server will have different L2/L3 cache and FMA, like Skylake | ||||||
There are several parts to the story on Cannon Lake:
- New Instructions and AVX-512 Instruction Support
- Major Changes in Existing Instructions and Other Minor Changes
New Instructions and AVX-512 Instruction Support
The three new instructions supported on Cannon Lake are Integer Fused Multiply Add (IFMA), Vector Byte Manipulation Instructions (VBMI), and hardware based SHA (Secure Hash Algorithm) support. Intel has already stated that IFMA is supported on Ice Lake/Sunny Cove, although no word on VBMI. The hardware based SHA is already present in Goldmont, however our tests show the Goldmont version is actually better.
IFMA is a 52-bit Integer fused multiply add (FMA) behaves identically to AVX512 floating point FMA, offering a latency of four clocks and a throughput of two per clock (for xmm/ymm, zmm is four and one). This instruction is commonly listed as helping cryptographic functionality, but also means there is now added support for arbitrary precision arithmetic. Alexander Yee, the developer of the hyper optimized mathematical constant calculator y-cruncher, explained to be why IFMA helps his code when calculating constants like Pi:
The standard double-precision floating-point hardware in Intel CPUs has a very powerful multiplier that has been there since antiquity. But it couldn't be effectively tapped into because that multiplier was buried inside the floating-point unit. The SIMD integer multiply instructions only let you utilize up to 32x32 out of the 52x52 size of the double-precision multiply hardware with additional overhead needed. This inefficiency didn't go unnoticed, so people ranted about it, hence why we now have IFMA.
The main focus of research papers on this is that big number arithmetic that wants the largest integer multiplier possible. On x64 the largest multiplier was the 64 x 64 -> 128-bit scalar multiply instruction. This gives you (64*64 = 4096 bits) of work per cycle. With AVX512, the best you can do is eight 32 x 32 -> 64-bit multiply via the VPMULDQ instruction, which gets you (8 SIMD lanes * 32*32 * 2FMA = 16384 bits) of work per cycle. But in practice, it ends up being about half of that because you have the overhead of additions, shifts, and shuffles competing for the same execution ports.
With AVX512-IFMA, users can unleash the full power of the double-precision hardware. A low/high IFMA pair will get you (8 SIMD lanes * 52*52 = 21632 bits) of work. That's 21632/cycle with 2 FMAs or 10816/cycle with 1 FMA. But the fused addition and 12 "spare bits" allows the user to eliminate nearly all the overhead that is needed for the AVX512-only approach. Thus it is possible to achieve nearly the full 21632/cycle of efficiency with the right port configuration (CNL only has 1 FMA).
There's more to the IFMA arbitrary precision arithmetic than just the largest multiplier possible. RSA encryption is probably one of the only applications that will get the full benefit of the IFMA as described above. y-cruncher benefits partially. Prime95 will not benefit at all.
For the algorithms that can take advantage of it, this boils down to the following table:
| IFMA Performance | |||
| Scalar x64 | AVX512-F | AVX512-IFMA | |
| Single 512b FMA | 4096-bit/cycle | ~4000-bit/cycle | 10816-bit/cycle |
| Dual 512b FMA | 4096-bit/cycle | ~8000-bit/cycle | 21632-bit/cycle |
VBMI is useful in byte shuffling scenarios, offering several instructions:
| VBMI Intructions | |||
| Description | Latency | Throughput | |
| VPERMB | 64-byte any-to-any shuffle | 3 clocks | 1 per clock |
| VPERMI2B | 128-byte any-to-any overwriting indexes |
5 clocks | 1 per 2 clocks |
| VPERMT2B | 128-byte any-to-any overwriting tables |
5 clocks | 1 per 2 clocks |
| VPMULTISHIFTQB | Base64 conversion | 3 clocks | 1 per clock |
Alex says that y-cruncher could benefit from VBMI, however it is one of those things he has to test with hardware on hand rather than on an emulator. Intel hasn’t specified if the Sunny Cove core supports VBMI, which would be an interesting omission.
For hardware accelerated SHA, this is designed purely to accelerate cryptography. However our tools show that the Cannon Lake implementation is slower than both Ryzen and Goldmont, which means it isn’t particularly useful. Cannon Lake also supports Vector-AES, which allows AES instructions to use more of the AVX-512 unit at once, multiplying throughput. Intel has stated that Sunny Cove has implemented SHA and SHA-NI instructions, along with Galois Field instructions and Vector-AES, although to what extent we do not know.
Changes in Existing Instructions
Most generations, Intel will add additional logic to improve the instructions already in place, typically for increasing throughput or decreasing latency (or both).
The big change here is with 64-bit integer divisions now being hardware supported, rather than split into several instructions. Divisions are time consuming at the best of times, however implementing a hardware radix divider means that Cannon Lake can complete at 64-bit IDIV in 18 clocks, compared to 45 on Ryzen and 97 on Skylake. This adjustment is also in the second generation 10nm Sunny Cove core.
For block storage of strings, all of the REP STOS* series of instructions can now use the 512-bit execution write port, allowing a throughput of 61 bits per clock, compared to 43 on Skylake-SP, 31 on Skylake, and 14 on Ryzen.
The AVX512BW command VPERMW, for permuting word integer vectors, has decreased in latency from six clocks to four clocks, and doubled throughput to one per clock compared to one per two clocks. Similarly with vectors, moving or merging vectors of single or double precision scalars using VMOVSS and VMOVSD commands now behaves identically to other MOV commands. This is also present in Sunny Cove.
Other beneficial adjustments to the instruction set include making ZMM divisions and square roots one clock faster, and increasing throughput of some GATHER functions from one per four clocks to one per three clocks.
Regressions come in the form of old x87 commands, with x87 DIV, SQRT, REP CMPS, LFENCE, and MFENCE all being one clock slower. Other x87 transcendentals are many clocks slower, with the goal of deprecation.
There other points to mention:
The VPCONFLICT* commands, which had a latency of 3 clocks and a throughput of one per clock are still slow on Cannon Lake, with the DWORD ZMM form having a latency of 26 clocks and a throughput of one per 20 clocks. This change has not made its way across platforms as of yet.
The cache line write back function, CLWB, was introduced in Skylake-SP to help assist with persistent memory support. It writes back modified data of a cache line, but avoids invalidating the line from the cache (and instead transitions the line to non-modified state). CLWB attempts to minimize the compulsory cache miss if the same data is accessed temporally after the line is flushed if the same data is accessed temporally after the line is flushed. The idea is that this instruction will help with Optane Persistent DC Memory and databases, hence its inclusion in SKL-SP, however it is not in Cannon Lake. Intel’s own documents suggest it will be a feature in Sunny Cove.
There is also no Software Guard Extension (SGX) support on Cannon Lake.
Frequency Analysis: Cutting Back on AVX2 vs Kaby Lake
Analyzing a new CPU family as a mobile chip is relatively difficult. Here we have a platform that is very much hamstrung by its thermal settings and limitations. Not only that, the BIOS adjustments available for mobile platforms are woeful in comparison to what we can test on desktop. This applies to the Intel NUC that came to retail in December as well as the Lenovo Ideapad E330-15ICN that we have for testing.
The issue is that for a 15W processor, even when built in a ’35 W’ capable environment, might still hit thermal limits depending on the configuration. We’ve covered why Intel’s TDP often bares little relation to power consumption, and it comes down to the different power levels that a system defines. It can also depend a lot on how the chip performs – most processors have a range of valid voltage/power curves which are suitable for that level of performance, and users could by chance either get a really good chip that stays cool, or a bad chip that rides the thermal limits. Ideally we would have all comparison chips in a desktop-like environment, such as when we tested the ‘Customer Reference Board’ version of Broadwell, which came in a desktop-like design. Instead, we have to attach as big of a cooling system as we can, along with extra fans, just in case. Otherwise potential variations can affect performance.
For our testing, we chose Intel’s Core i3-8130U mobile processor as the nearest competition. This is a Kaby Lake dual core processor, which despite the higher number in its name is using the older 14nm process and older Kaby Lake microarchitecture. This processor is a 15W part, like our Cannon Lake Core i3-8121U, with the same base frequency, but with a slightly higher turbo frequency. Ultimately this means that this older 14nm processor, on paper, should be more efficient than Intel’s latest 10nm process. Add on to this, the Core i3-8130U has active integrated graphics, while the Cannon Lake CPU does not.
Because both CPUs have turbo modes, it’s important to characterize the frequencies during testing. Here are the specifications and turbo tables for each processor:
| Comparing Cannon Lake to Kaby Lake | |||||
| 10m Cannon Lake Core i3-8121U |
AnandTech | 14nm Kaby Lake Core i3-8130U |
|||
| 2 / 4 | Cores / Threads | 2 / 4 | |||
| 15 W | Rated TDP | 15 W | |||
| 2.2 GHz | Base Frequency | 2.2 GHz | |||
| 3.2 GHz | Single Core Turbo | 3.4 GHz | |||
| 3.1 GHz | Dual Core Turbo | 3.4 GHz | |||
| 2.2 GHz | AVX2 Frequency | 2.8 GHz | |||
| 1.8 GHz | AVX512 Frequency | - | |||
The Cannon Lake processor loses frequency as the cores are loaded, and severely loses frequency when AVX2/AVX512 is applied based on our testing. Comparing that to the Kaby Lake on Intel’s mature 14nm node, it keeps its turbo and only loses a few hundred MHz with AVX2. This part does not have AVX512, which is a one up for the Cannon Lake.
The biggest discrepancy we observed for AVX2 was in our POV-Ray test.
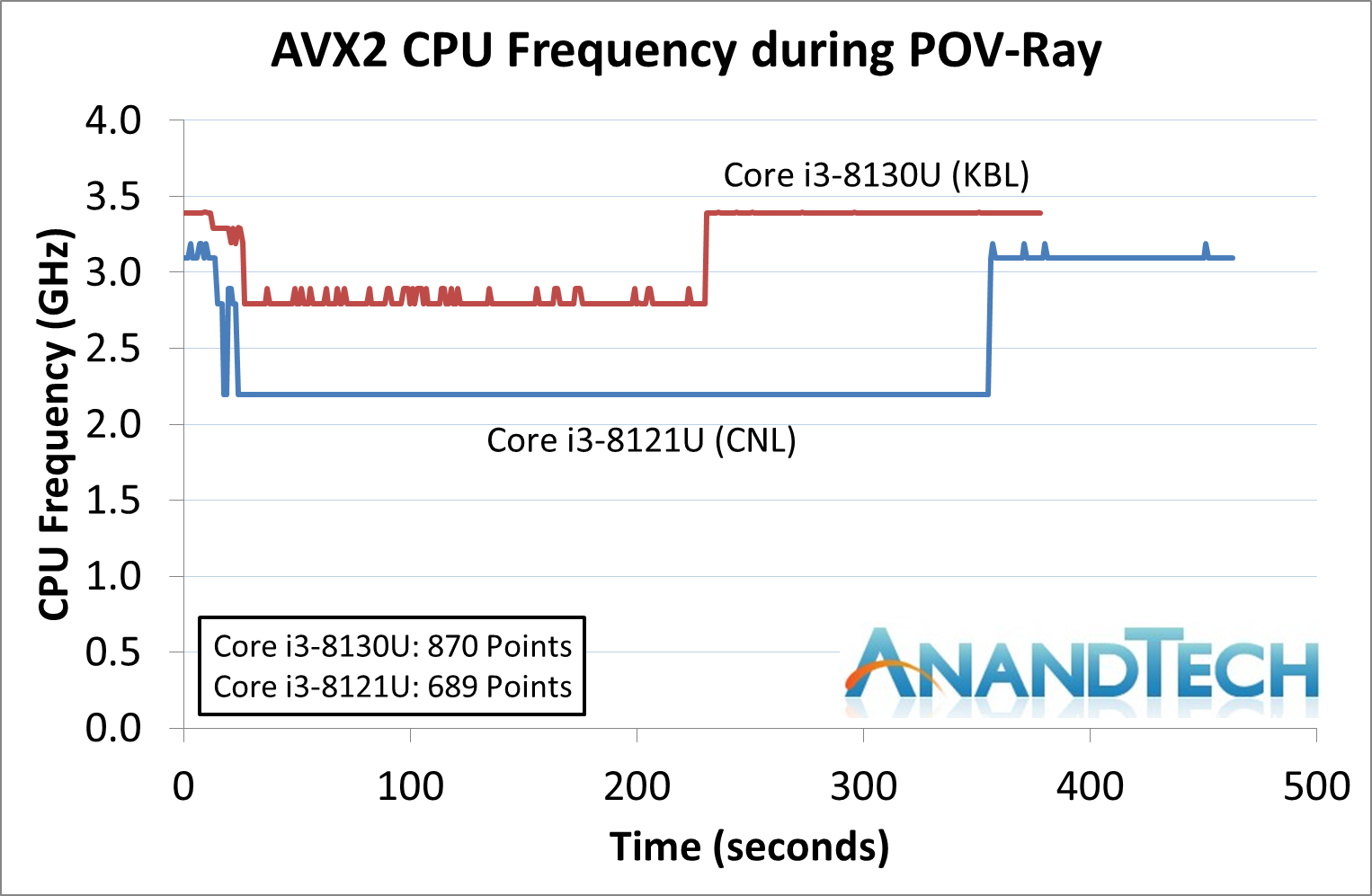
Here the Kaby Lake processor sustains a much higher AVX2 frequency, and completes the test quicker for a 26% better performance. This doesn’t affect every test as we’ll see in the next few pages, and for AVX-512 capable tests, the Cannon Lake goes above and beyond, despite the low AVX-512 frequency. For example, at 2.2 GHz, the Kaby Lake chip scores 615 in our 3DPM test in AVX2 mode, whereas the Cannon Lake chip scores 3846 in AVX512 mode, over 6x higher.
The system we are using for the Core i3-8130 is ASUS’ PN60 Mini-PC. This device is an ultra-compact mini-PC that measures 11.5mm square and under 5cm tall. It is just big enough for me to install our standard Crucial MX200 1TB SSD and 2x4GB of G.Skill DDR4-2400 SO-DIMMs.


For the Cannon Lake based Lenovo Ideapad 330-15ICN, we removed the low-end SSD and HDD that was shipped with the design and put in our own Crucial MX200 1TB and 2x4 GB DDR4 SO-DIMMs for testing. Unfortunately we can’t probe the exact frequency the memory seems to be running at, nor the sub-timings, because of the nature of the system. However the default SPD of the modules is DDR4-2400 17-17-17.
Our Testing Suite for 2018 and 2019
Spectre and Meltdown Hardened
In order to keep up to date with our testing, we have to update our software every so often to stay relevant. In our updates we typically implement the latest operating system, the latest patches, the latest software revisions, the newest graphics drivers, as well as add new tests or remove old ones. As regular readers will know, our CPU testing revolves an automated test suite, and depending on how the newest software works, the suite either needs to change, be updated, have tests removed, or be rewritten completely. Last time we did a full re-write, it took the best part of a month, including regression testing (testing older processors).
One of the key elements of our testing update for 2018 (and 2019) is the fact that our scripts and systems are designed to be hardened for Spectre and Meltdown. This means making sure that all of our BIOSes are updated with the latest microcode, and all the steps are in place with our operating system with updates. In this case we are using Windows 10 x64 Enterprise 1709 with April security updates which enforces Smeltdown (our combined name) mitigations. Uses might ask why we are not running Windows 10 x64 RS4, the latest major update – this is due to some new features which are giving uneven results. Rather than spend a few weeks learning to disable them, we’re going ahead with RS3 which has been widely used.
Our previous benchmark suite was split into several segments depending on how the test is usually perceived. Our new test suite follows similar lines, and we run the tests based on:
- Power
- Memory
- SPEC2006 Speed
- Office
- System
- Render
- Encoding
- Web
- Legacy
- Integrated Gaming
- CPU Gaming
Depending on the focus of the review, the order of these benchmarks might change, or some left out of the main review. All of our data will reside in our benchmark database, Bench, for which there is a new ‘CPU 2019’ section for all of our new tests.
Within each section, we will have the following tests:
Power
Our power tests consist of running a substantial workload for every thread in the system, and then probing the power registers on the chip to find out details such as core power, package power, DRAM power, IO power, and per-core power. This all depends on how much information is given by the manufacturer of the chip: sometimes a lot, sometimes not at all.
We are currently running POV-Ray as our main test for Power, as it seems to hit deep into the system and is very consistent. In order to limit the number of cores for power, we use an affinity mask driven from the command line.
Memory
These tests involve disabling all turbo modes in the system, forcing it to run at base frequency, and them implementing both a memory latency checker (Intel’s Memory Latency Checker works equally well for both platforms) and AIDA64 to probe cache bandwidth.
SPEC Speed
- All integer tests from SPEC2006
- All the C++ floating point tests from SPEC2006
Office
- Chromium Compile: Windows VC++ Compile of Chrome 56 (same as 2017)
- PCMark10: Primary data will be the overview results – subtest results will be in Bench
- 3DMark Physics: We test every physics sub-test for Bench, and report the major ones (new)
- GeekBench4: By request (new)
- SYSmark 2018: Recently released by BAPCo, currently automating it into our suite (new, when feasible)
System
- Application Load: Time to load GIMP 2.10.4 (new)
- FCAT: Time to process a 90 second ROTR 1440p recording (same as 2017)
- 3D Particle Movement: Particle distribution test (same as 2017) – we also have AVX2 and AVX512 versions of this, which may be added later
- Dolphin 5.0: Console emulation test (same as 2017)
- DigiCortex: Sea Slug Brain simulation (same as 2017)
- y-Cruncher v0.7.6: Pi calculation with optimized instruction sets for new CPUs (new)
- Agisoft Photoscan 1.3.3: 2D image to 3D modelling tool (updated)
Render
- Corona 1.3: Performance renderer for 3dsMax, Cinema4D (same as 2017)
- Blender 2.79b: Render of bmw27 on CPU (updated to 2.79b)
- LuxMark v3.1 C++ and OpenCL: Test of different rendering code paths (same as 2017)
- POV-Ray 3.7.1: Built-in benchmark (updated)
- CineBench R15: Older Cinema4D test, will likely remain in Bench (same as 2017)
Encoding
- 7-zip 1805: Built-in benchmark (updated to v1805)
- WinRAR 5.60b3: Compression test of directory with video and web files (updated to 5.60b3)
- AES Encryption: In-memory AES performance. Slightly older test. (same as 2017)
- Handbrake 1.1.0: Logitech C920 1080p60 input file, transcoded into three formats for streaming/storage:
- 720p60, x264, 6000 kbps CBR, Fast, High Profile
- 1080p60, x264, 3500 kbps CBR, Faster, Main Profile
- 1080p60, HEVC, 3500 kbps VBR, Fast, 2-Pass Main Profile
Web
- WebXPRT3: The latest WebXPRT test (updated)
- WebXPRT15: Similar to 3, but slightly older. (same as 2017)
- Speedometer2: Javascript Framework test (new)
- Google Octane 2.0: Depreciated but popular web test (same as 2017)
- Mozilla Kraken 1.1: Depreciated but popular web test (same as 2017)
Legacy (same as 2017)
- 3DPM v1: Older version of 3DPM, very naïve code
- x264 HD 3.0: Older transcode benchmark
- Cinebench R11.5 and R10: Representative of different coding methodologies
Scale Up vs Scale Out: Benefits of Automation
One comment we get every now and again is that automation isn’t the best way of testing – there’s a higher barrier to entry, and it limits the tests that can be done. From our perspective, despite taking a little while to program properly (and get it right), automation means we can do several things:
- Guarantee consistent breaks between tests for cooldown to occur, rather than variable cooldown times based on ‘if I’m looking at the screen’
- It allows us to simultaneously test several systems at once. I currently run five systems in my office (limited by the number of 4K monitors, and space) which means we can process more hardware at the same time
- We can leave tests to run overnight, very useful for a deadline
- With a good enough script, tests can be added very easily
Our benchmark suite collates all the results and spits out data as the tests are running to a central storage platform, which I can probe mid-run to update data as it comes through. This also acts as a mental check in case any of the data might be abnormal.
We do have one major limitation, and that rests on the side of our gaming tests. We are running multiple tests through one Steam account, some of which (like GTA) are online only. As Steam only lets one system play on an account at once, our gaming script probes Steam’s own APIs to determine if we are ‘online’ or not, and to run offline tests until the account is free to be logged in on that system. Depending on the number of games we test that absolutely require online mode, it can be a bit of a bottleneck.
Benchmark Suite Updates
As always, we do take requests. It helps us understand the workloads that everyone is running and plan accordingly.
A side note on software packages: we have had requests for tests on software such as ANSYS, or other professional grade software. The downside of testing this software is licensing and scale. Most of these companies do not particularly care about us running tests, and state it’s not part of their goals. Others, like Agisoft, are more than willing to help. If you are involved in these software packages, the best way to see us benchmark them is to reach out. We have special versions of software for some of our tests, and if we can get something that works, and relevant to the audience, then we shouldn’t have too much difficulty adding it to the suite.
CPU Performance: Memory and Power
Memory
With the same memory setup as the standard Skylake-style core, without any other improvements, we should expect Cannon Lake to perform exactly similar. Here’s a recap of the memory configuration:
| Memory Comparison | ||
| Skylake Desktop | Cannon Lake | |
| L1-D Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
| L1-I Cache |
32 KiB/core 8-way |
32 KiB/core 8-way |
| L2 Cache |
256 KiB/core 4-way |
256 KiB/core 4-way |
| L3 Cache |
2 MiB/core 16-way |
2 MiB/core 16-way |
| L3 Cache Type | Inclusive | Inclusive |
For this test we put our Cannon Lake and Kaby Lake processors through our Memory Latency Checker test. Both systems had turbo modes disabled, forcing them to run at 2.2 GHz for parity and a direct microarchitecture comparison.
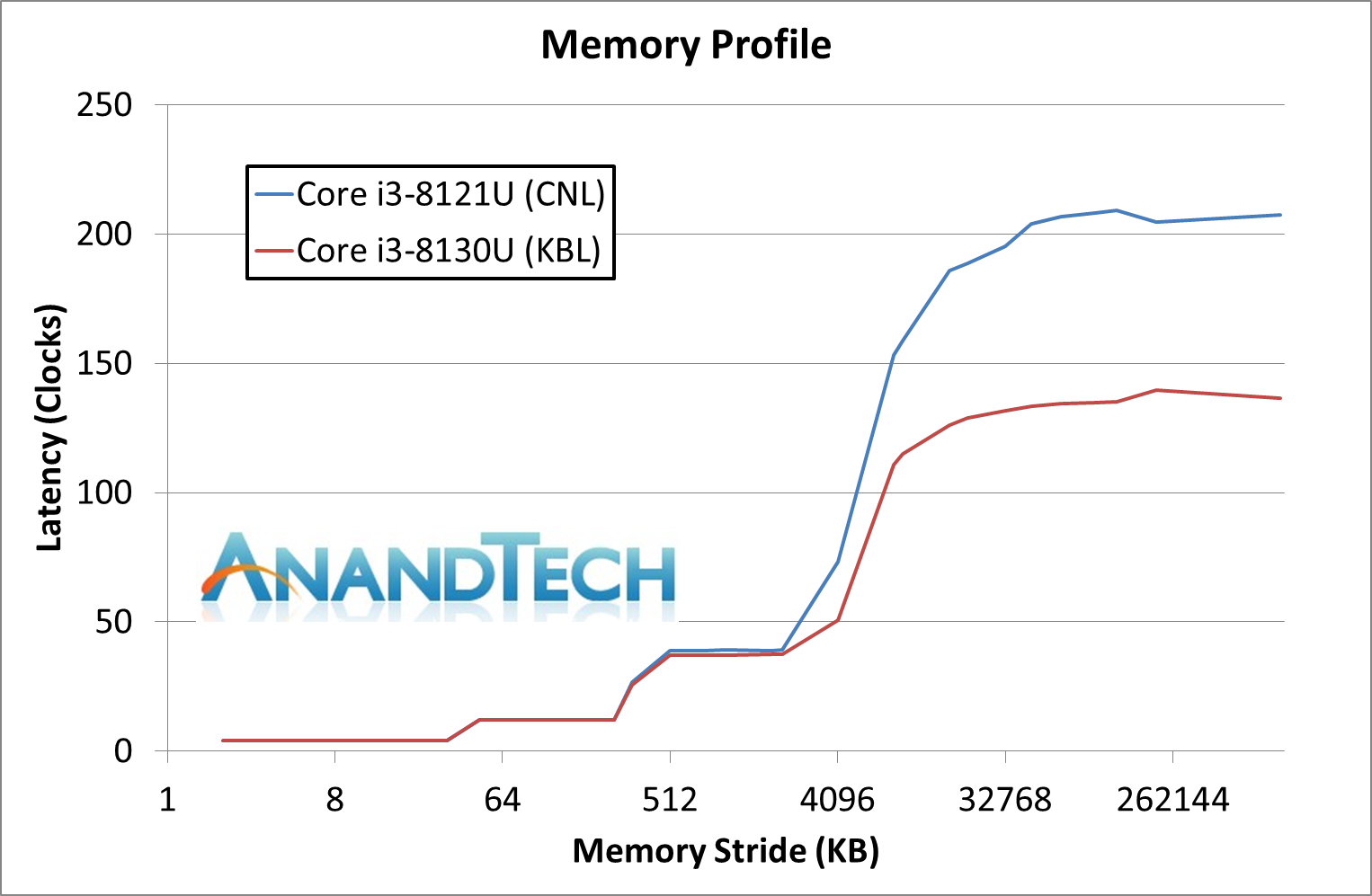
In this instance we see very little different between the two through the caches of the chip. Up to about 2MiB, both chips perform practically identical. Beyond this however, going out to main memory, there is a big discrepancy between the Kaby Lake and the Cannon Lake processor. In essence, accessing Cannon Lake main memory has an additional 50% latency.
At first we thought this was a bug. For both systems to have dual channel memory and running DDR4-2400, something had to be wrong. We double checked the setups – both systems were running in dual channel mode, giving the same memory bandwidth. The Cannon Lake processor was running at DDR4-2400 17-17-17, whereas the Kaby Lake system was at DDR4-2400 16-16-16 (due to memory SPD differences), which isn’t a big enough change to have such a big difference. The only reason we can come up with is that the memory controller on Cannon Lake must have additional overhead from the core to the memory controller – either a slower than expected PLL or something.
Power
Measuring the power of these thermally limited systems is somewhat frustrating in that we are at the whims of the quality of silicon at play. Bad silicon can get hotter faster, causing thermal throttling, or it depends on how the systems are set up for the peak power numbers. We use AIDA’s power monitoring tool to give us the power numbers for the CPUs during our POV-Ray test.
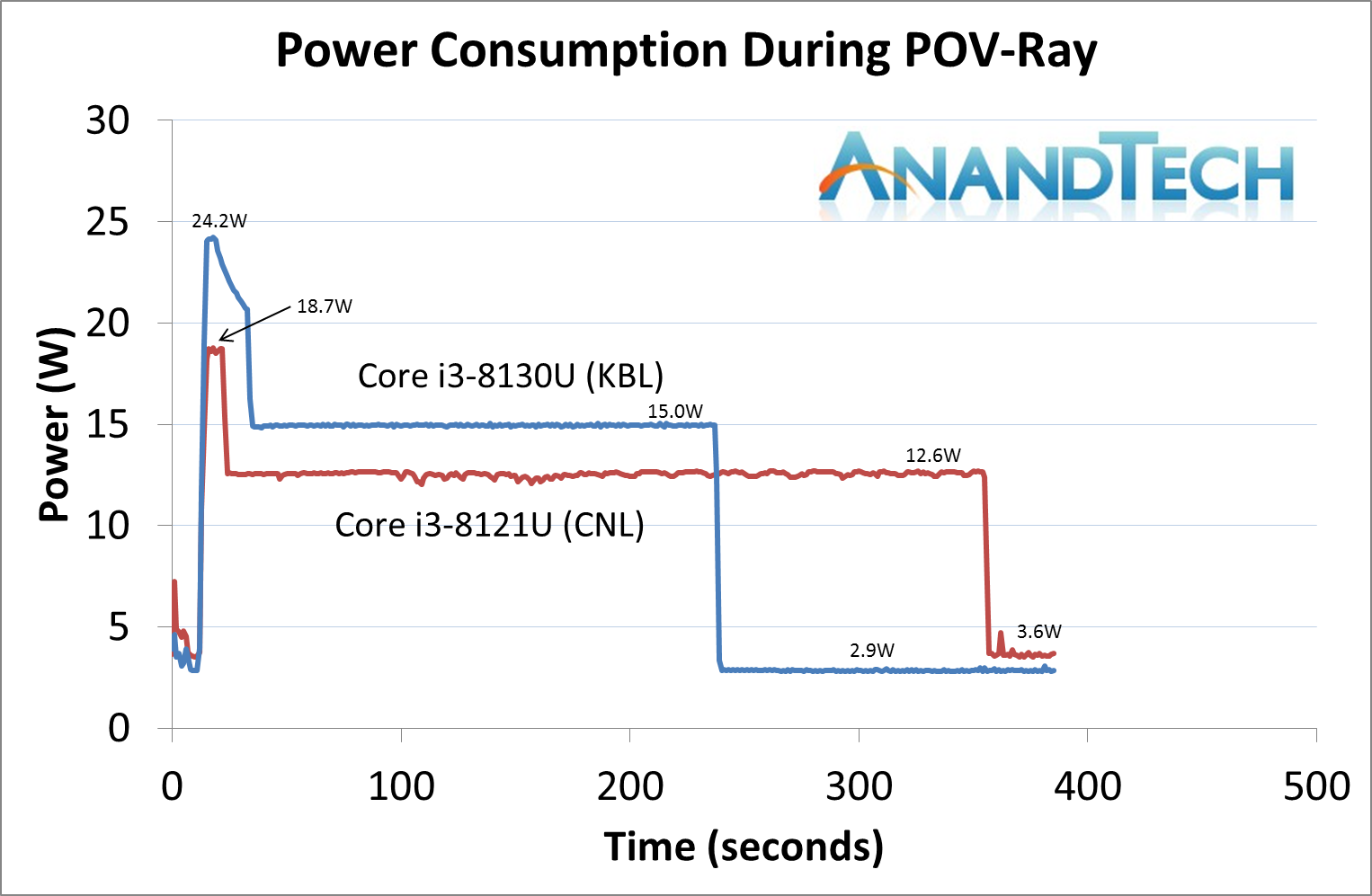
If you saw our How Intel Measures TDP article, you may be familiar with the concept of Power Limits. Intel processors have several power limits set in firmware – these values are set by the system manufacturer, and Intel provides ‘guidelines’. The two key values are Power Limit 1 (PL1), which describes a steady state scenario, and Power Limit 2 (PL2) which describes a turbo scenario. The reason why the system manufacturer gets control of these is because they might put a high wattage processor into a small form factor system, and need to manage performance – this is why we sometimes see a Core i7 be outperformed by a Core i5 in the same system design.
In most cases, PL1 is set to the TDP of the processor – in this case, it should be 15W. As shown on the graph above, this is true for our Core i3-8130U system, which shows a steady state power consumption of 15.0W. The Cannon Lake processor however only peaks at 12.6W.
PL2, the turbo power of the processor, can also be determined. For the Kaby Lake processor, we see a peak of 24.2 W, while the Cannon Lake has a turbo only of 18.7 W. We see that the turbo time period for the Cannon Lake processor is also much shorter, leading to a PL1 / steady state power much sooner.
Part of this is because we are pitting the Cannon Lake laptop against the Kaby Lake mini-PC. That being said, the Cannon Lake laptop is a beefy 15.6-inch unit, and has cooling for both the CPU and the discrete RX540 graphics, which isn’t doing much during this test except showing a basic 2D display.
That is arguably a lot more cooling than the mini-PC provides, plus we are cooling it with additional fans. These settings are more a function of both Lenovo doing what it wants to in firmware that we can’t change, but also the chip as engineered.
We can also calculate some level of efficiency here. By taking the area under the graph and correcting for the base line power (2.9 W on KBL, 3.6 W on CNL), we can calculate the total power consumed during the test. We get the following:
- Core i3-8121U (CNL) consumes 867 mWh
- Core i3-8130U (KBL) consumes 768 mWh
So this means that Cannon Lake is slower in AVX2 frequency, consumes more power, and scores 25% less in POV-Ray (see previous pages). That’s damning for the design.
To further look into this data, we disabled the turbo modes on both processors and ran our POV-Ray workload adjusting the number of threads being loaded and then measured the power consumption. In this scenario we are running at the same frequency, measuring the steady state power, and are thus at the whims of both the voltage set on both processors and the efficiency. Our tool also lets us measure the power of just the cores, so we’ll plot core power against threads loaded.
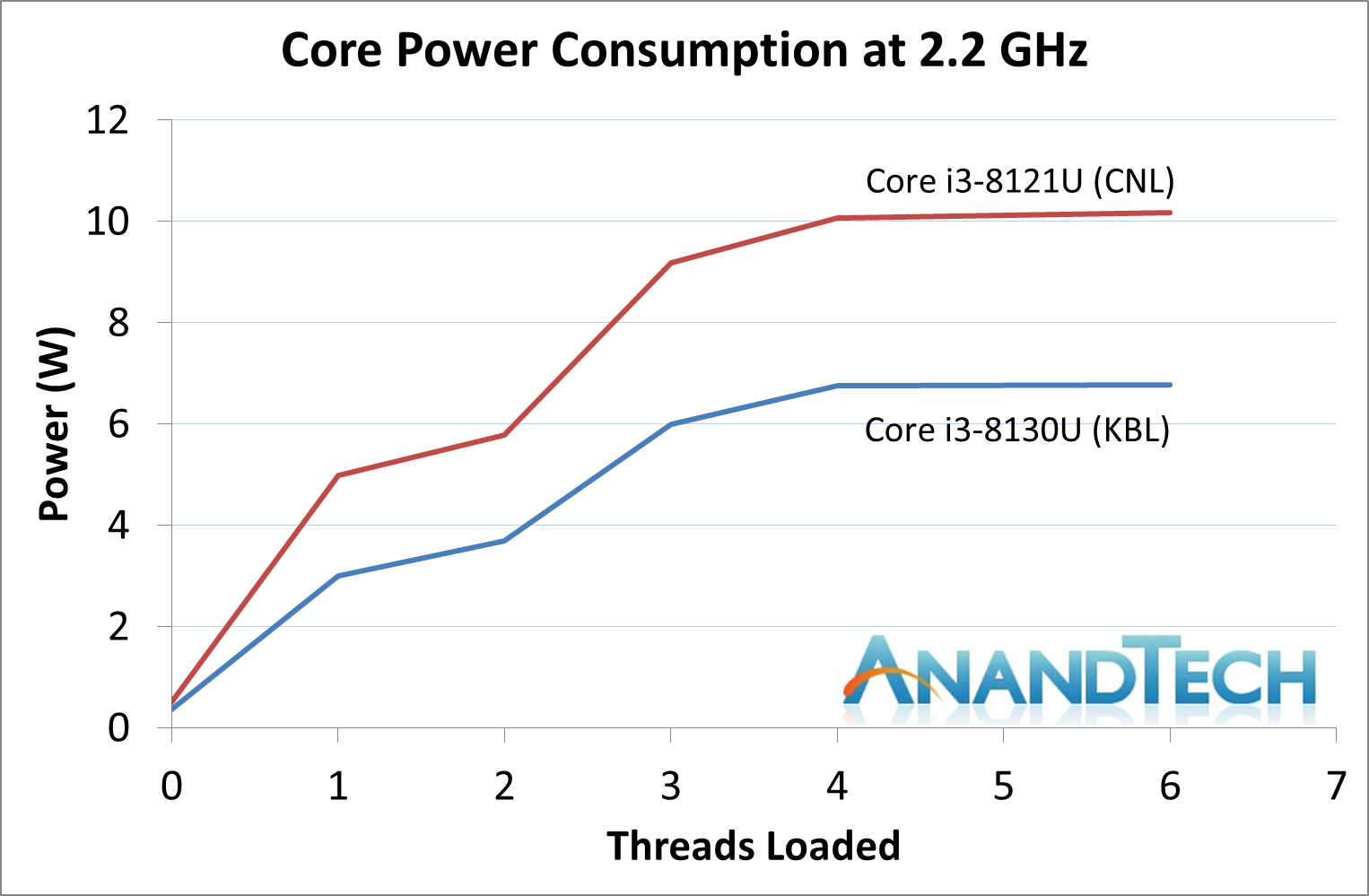
If this graph was the definitive graph, it shows that Cannon Lake is vastly inefficient (at 2.2 GHz) compared to Kaby Lake.
CPU Performance: SPEC2006 at 2.2 GHz
Aside from power, the other question is if the Cannon Lake microarchitecture is an efficient design. For most code paths, it holds the same core design elements as Skylake and Kaby Lake, and it does have additional optimizations for certain instructions, as we detailed earlier in this review. In order to do a direct IPC comparison, we are running SPEC2006 Speed on both of our comparison points at a fixed frequency of 2.2 GHz.
In order to get a fixed frequency on our chips required adjusting the relevant registers to disable the turbo modes. There is no setting in the BIOS to do this, but thankfully the folks at AIDA64 have a tool to do this and it works great. Choosing these two processors that both have a base frequency of 2.2 GHz make this a lot easier.
SPEC2006 is a series of industry standard tests designed to help differentiate performance levels between different architectures, microarchitectures, and compilers. All official submitted results from OEMs and manufacturers are posted online for comparison, and many vendors try and get the best results. From our perspective, these workloads are very well known, which enables a good benchmark for IPC analysis.
Credit for arranging the benchmarks goes completely to our resident Senior Mobile Editor, Andrei Frumusanu, who developed a suitable harness and framework to generate the relevant binaries for both mobile and PC. On PC, we run SPEC2006 through the Windows Subsystem for Linux – we still need to do testing for overhead (we’ll do it with SPEC2017 when Andrei is ready), but for the purposes of this test today, comparing like for like both under WSL is a valid comparison. Andrei compiled SPEC2006 for AVX2 instructions, using Clang 8. We run SPEC2006 Speed, which runs one copy of each test on one thread, of all the integer tests as well as the C++ based floating point tests.
Here are our results:
| SPEC2006 Speed (Estimated Results)* |
|||||
| Intel Core i3-8121U 10nm Cannon Lake |
AnandTech | Intel Core i3-8130U 14nm Kaby Lake |
|||
| Integer Workloads | |||||
| 24.8 | 400.perlbench | 26.1 | |||
| 16.6 | 401.bzip2 | 16.8 | |||
| 27.6 | 403.gcc | 27.3 | |||
| 25.9 | 429.mcf | 28.4 | |||
| 19.0 | 445.gobmk | 19.1 | |||
| 23.5 | 456.hmmr | 23.1 | |||
| 22.2 | 458.sjeng | 22.4 | |||
| 70.5 | 462.libquantum | 75.4 | |||
| 39.7 | 464.h264ref | 37.2 | |||
| 17.5 | 471.omnetpp | 18.2 | |||
| 14.2 | 473.astar | 14.1 | |||
| 27.1 | 483.xalancbmk | 28.4 | |||
| Floating Point Workloads | |||||
| 24.6 | 433.milc | 23.8 | |||
| 23.0 | 444.namd | 23.0 | |||
| 39.1 | 450.soplex | 37.3 | |||
| 34.1 | 453.povray | 33.5 | |||
| 59.9 | 470.lbm | 68.4 | |||
| 43.2 | 482.sphinx3 | 44.2 | |||
* SPEC rules dictate that any results not verified on the SPEC website are called 'estimated results', as they have not been verified.
By and large, we actually get parity between both processors on almost all the tests. The Kaby Lake processor seems to have a small advantage in libquantum and lbm, which are SIMD related, which could be limited by the memory latency difference shown on the previous page.
Stock CPU Performance: System Tests
Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Application Load: GIMP 2.10.4
One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker.
In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.
The CNL platform here does particularly well in loading software, which correlates with what I felt actually using the system - it felt faster than some Core i7 notebooks I've used. This might be down to the GPU acting on the display however. But it doesn't explain the extreme regression when we fix the clock speed.
FCAT: Image Processing
The FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.

The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
At stock speeds, both of our CNL and KBL chips score within half a second of each other. At fixed frequency, CNL comes out slightly ahead.
3D Particle Movement v2.1: Brownian Motion
Our 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures.
A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews.
For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible.
3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
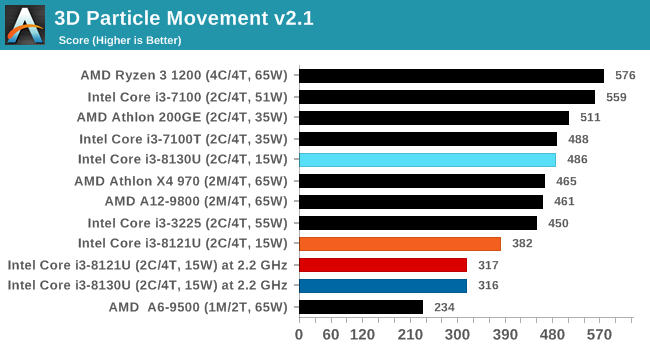
When AVX isn't on show, the KBL processor takes a lead, however it is worth nothing that at fixed frequency both CNL and KBL perform essentially the same.
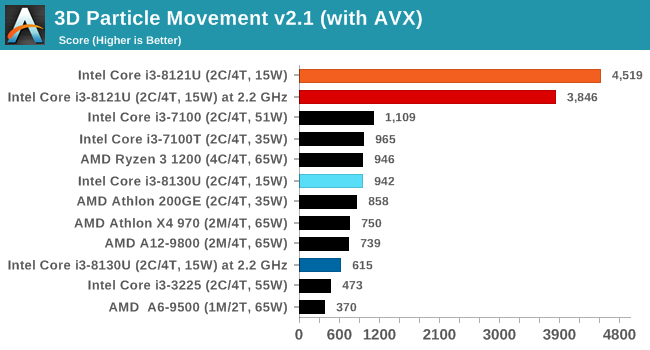
When we crank on the AVX2 and AVX512, there is no stopping the Cannon Lake chip here. At a score of 4519, it beats a full 18-core Core i9-7980XE processor running in non-AVX mode which scores 4185. That's insane. Truly a big plus in Cannon Lake's favor.
Dolphin 5.0: Console Emulation
One of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware.
For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds.
The latest version of Dolphin can be downloaded from https://dolphin-emu.org/

Both CPUs perform roughly the same at fixed frequency, however KBL has a slight lead at stock frequencies, likely due to its extra 200 MHz and ability to keep that frequency regardless of what's running in the background.
DigiCortex 1.20: Sea Slug Brain Simulation
This benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.

Example of a 2.1B neuron simulation
We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount.
DigiCortex can be downloaded from http://www.digicortex.net/
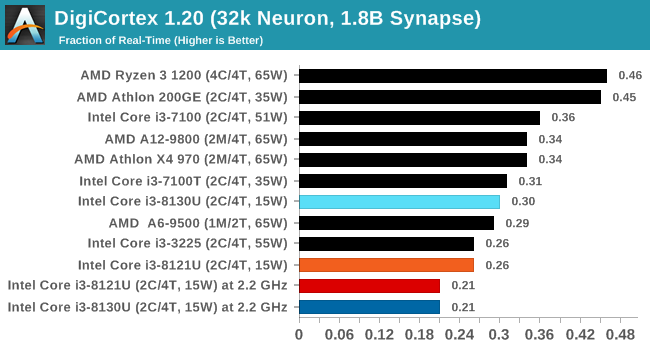
At a fixed frequency, both processors perform the same, but at stock frequencies the lower DRAM latency means that the Cannon Lake CPU only improves a little bit, whereas the Kaby Lake adds another 50% performance.
y-Cruncher v0.7.6: Microarchitecture Optimized Compute
I’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware.
For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test.
Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
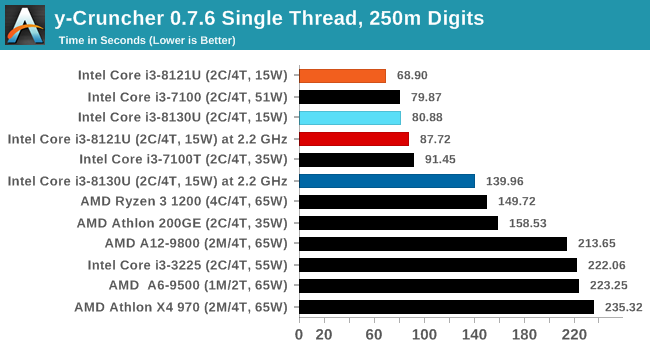
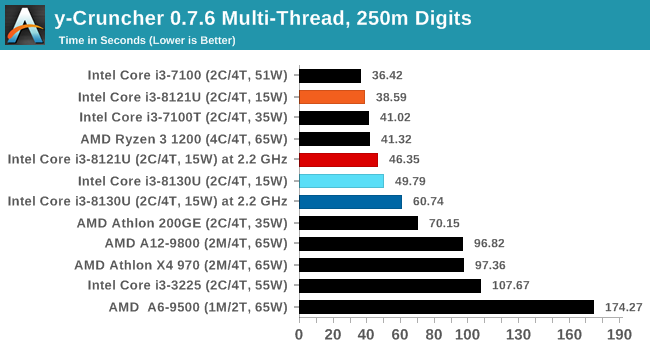
y-Cruncher is another AVX-512 test, and in both ST and MT modes, Cannon Lake wins. Interestingly in MT mode, CNL at 2.2 GHz scores better than KBL at stock frequencies.
Agisoft Photoscan 1.3.3: 2D Image to 3D Model Conversion
One of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.

In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process.
Agisoft’s Photoscan website can be found here: http://www.agisoft.com/

KBL takes a big lead here at stock frequencies, while at fixed frequencies the results are similar. We might be coming up against the power difference here - the KBL system has a higher steady state power limit.
Stock CPU Performance: Rendering Tests
Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: Performance Render
An advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand.
The Corona benchmark website can be found at https://corona-renderer.com/benchmark
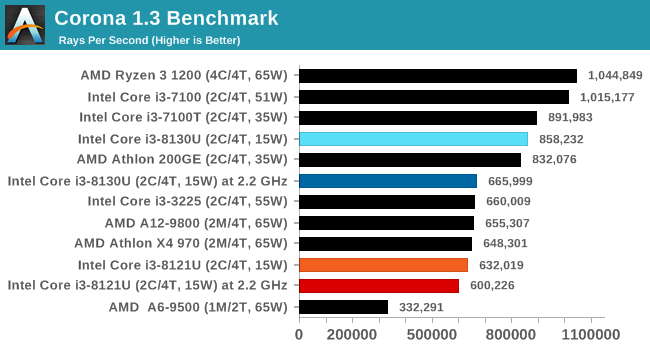
Corona is an AVX2 benchmark, and it would appear that the Cannon Lake CPU can't take full advantage of the functionality. There's still a 10% difference at fixed frequency.
Blender 2.79b: 3D Creation Suite
A high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render.
Blender can be downloaded at https://www.blender.org/download/
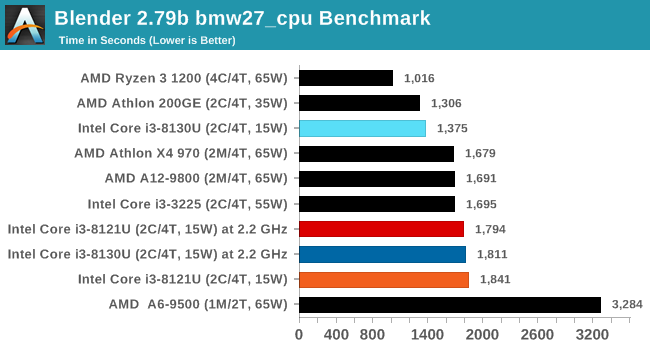
Blender also uses an AVX2 code path, and we see that the CNL processor scored worse at stock settings than at fixed frequency settings. Again, this is likely due to a power or thermal issue.
LuxMark v3.1: LuxRender via Different Code Paths
As stated at the top, there are many different ways to process rendering data: CPU, GPU, Accelerator, and others. On top of that, there are many frameworks and APIs in which to program, depending on how the software will be used. LuxMark, a benchmark developed using the LuxRender engine, offers several different scenes and APIs.
Taken from the Linux Version of LuxMark
In our test, we run the simple ‘Ball’ scene on both the C++ and OpenCL code paths, but in CPU mode. This scene starts with a rough render and slowly improves the quality over two minutes, giving a final result in what is essentially an average ‘kilorays per second’.
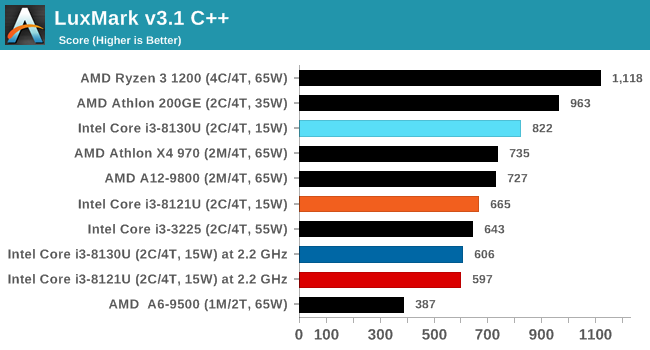
POV-Ray 3.7.1: Ray Tracing
The Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line.
POV-Ray can be downloaded from http://www.povray.org/
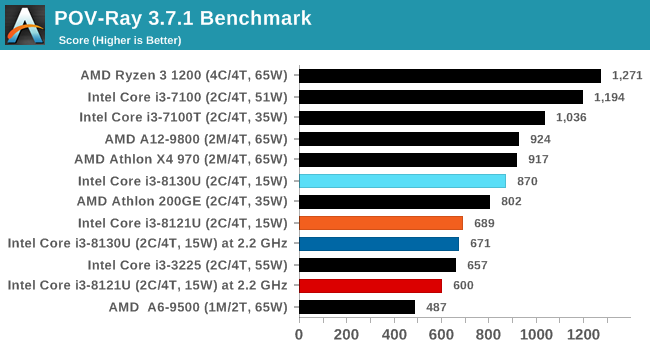
Stock CPU Performance: Office Tests
The Office test suite is designed to focus around more industry standard tests that focus on office workflows, system meetings, some synthetics, but we also bundle compiler performance in with this section. For users that have to evaluate hardware in general, these are usually the benchmarks that most consider.
All of our benchmark results can also be found in our benchmark engine, Bench.
3DMark Physics: In-Game Physics Compute
Alongside PCMark is 3DMark, Futuremark’s (UL’s) gaming test suite. Each gaming tests consists of one or two GPU heavy scenes, along with a physics test that is indicative of when the test was written and the platform it is aimed at. The main overriding tests, in order of complexity, are Ice Storm, Cloud Gate, Sky Diver, Fire Strike, and Time Spy.
Some of the subtests offer variants, such as Ice Storm Unlimited, which is aimed at mobile platforms with an off-screen rendering, or Fire Strike Ultra which is aimed at high-end 4K systems with lots of the added features turned on. Time Spy also currently has an AVX-512 mode (which we may be using in the future).
For our tests, we report in Bench the results from every physics test, but for the sake of the review we keep it to the most demanding of each scene: Ice Storm Unlimited, Cloud Gate, Sky Diver, Fire Strike Ultra, and Time Spy.
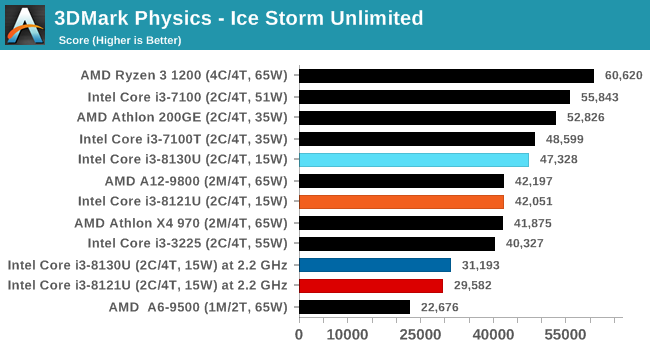
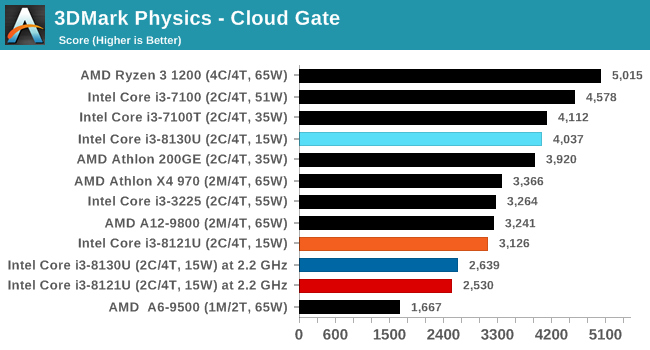


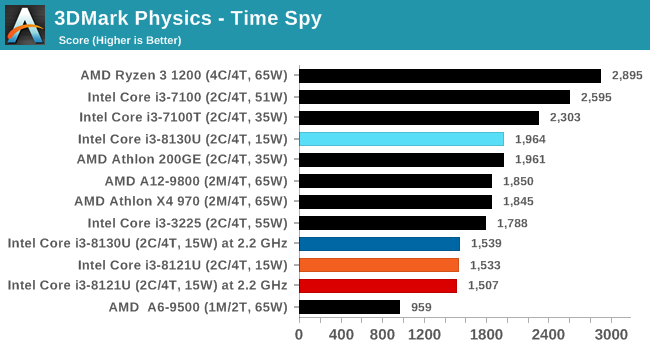
In all tests, at fixed frequency, the processors act identical, however at stock frequencies that Kaby Lake chip just has more headroom to push.
GeekBench4: Synthetics
A common tool for cross-platform testing between mobile, PC, and Mac, GeekBench 4 is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We record the main subtest scores (Crypto, Integer, Floating Point, Memory) in our benchmark database, but for the review we post the overall single and multi-threaded results.
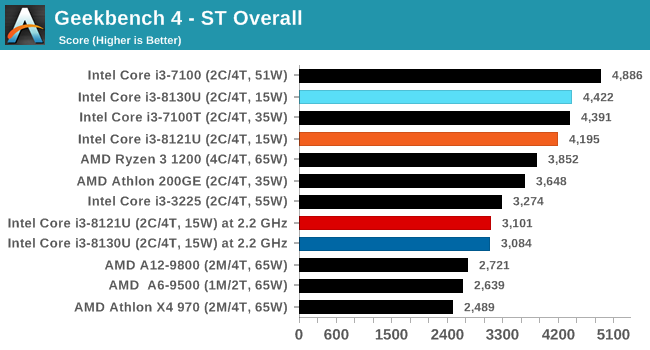
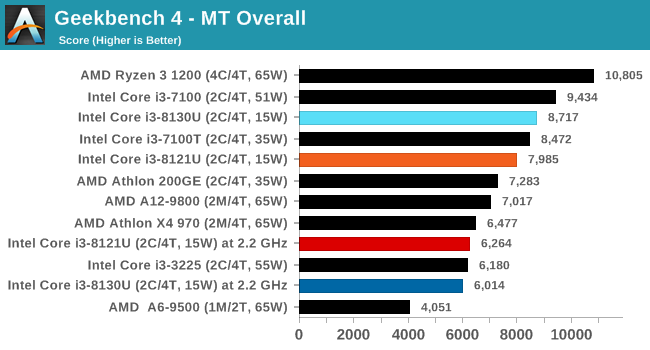
Stock CPU Performance: Encoding Tests
With the rise of streaming, vlogs, and video content as a whole, encoding and transcoding tests are becoming ever more important. Not only are more home users and gamers needing to convert video files into something more manageable, for streaming or archival purposes, but the servers that manage the output also manage around data and log files with compression and decompression. Our encoding tasks are focused around these important scenarios, with input from the community for the best implementation of real-world testing.
All of our benchmark results can also be found in our benchmark engine, Bench.
Handbrake 1.1.0: Streaming and Archival Video Transcoding
A popular open source tool, Handbrake is the anything-to-anything video conversion software that a number of people use as a reference point. The danger is always on version numbers and optimization, for example the latest versions of the software can take advantage of AVX-512 and OpenCL to accelerate certain types of transcoding and algorithms. The version we use here is a pure CPU play, with common transcoding variations.
We have split Handbrake up into several tests, using a Logitech C920 1080p60 native webcam recording (essentially a streamer recording), and convert them into two types of streaming formats and one for archival. The output settings used are:
- 720p60 at 6000 kbps constant bit rate, fast setting, high profile
- 1080p60 at 3500 kbps constant bit rate, faster setting, main profile
- 1080p60 HEVC at 3500 kbps variable bit rate, fast setting, main profile
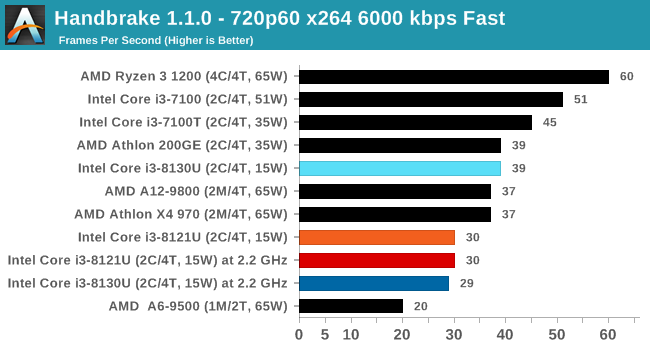
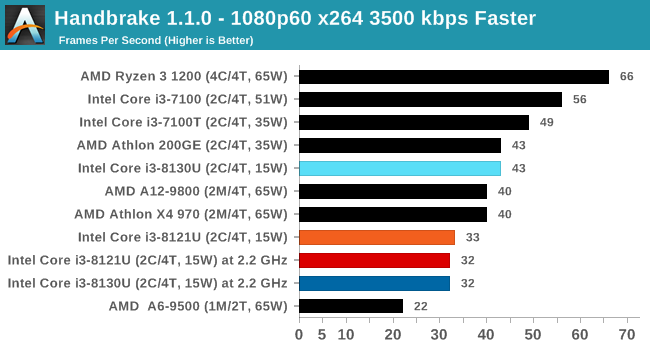
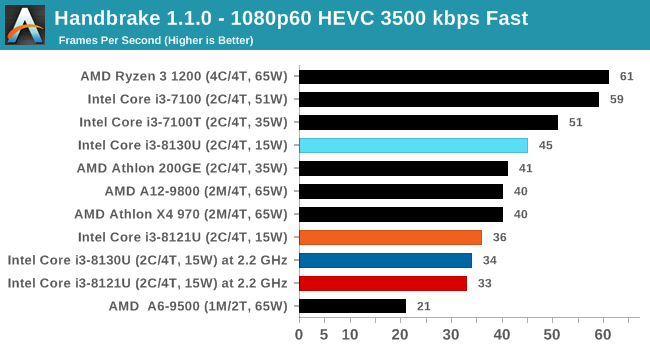
7-zip v1805: Popular Open-Source Encoding Engine
Out of our compression/decompression tool tests, 7-zip is the most requested and comes with a built-in benchmark. For our test suite, we’ve pulled the latest version of the software and we run the benchmark from the command line, reporting the compression, decompression, and a combined score.
It is noted in this benchmark that the latest multi-die processors have very bi-modal performance between compression and decompression, performing well in one and badly in the other. There are also discussions around how the Windows Scheduler is implementing every thread. As we get more results, it will be interesting to see how this plays out.
Please note, if you plan to share out the Compression graph, please include the Decompression one. Otherwise you’re only presenting half a picture.
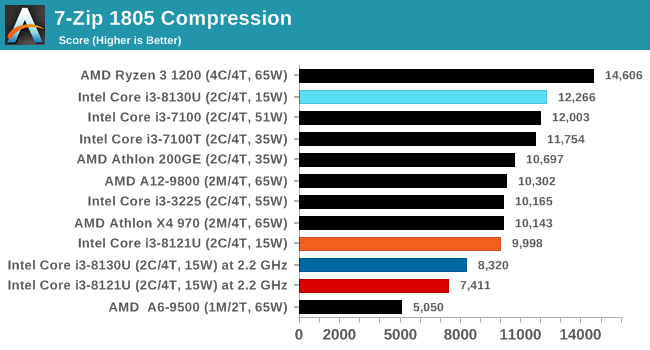

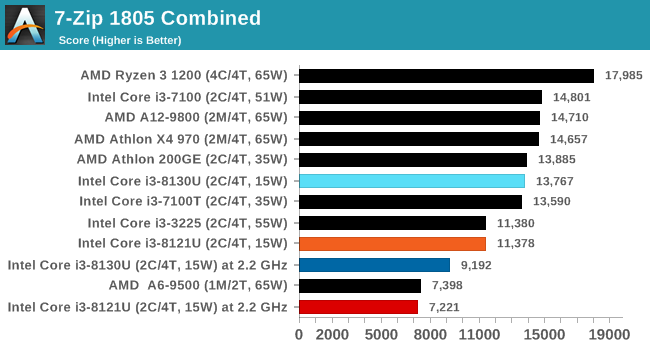
WinRAR 5.60b3: Archiving Tool
My compression tool of choice is often WinRAR, having been one of the first tools a number of my generation used over two decades ago. The interface has not changed much, although the integration with Windows right click commands is always a plus. It has no in-built test, so we run a compression over a set directory containing over thirty 60-second video files and 2000 small web-based files at a normal compression rate.
WinRAR is variable threaded but also susceptible to caching, so in our test we run it 10 times and take the average of the last five, leaving the test purely for raw CPU compute performance.
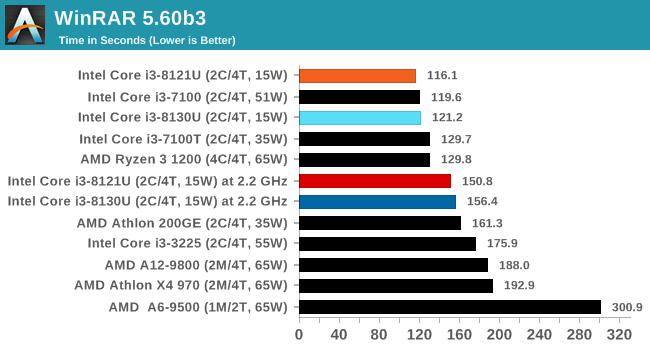
AES Encryption: File Security
A number of platforms, particularly mobile devices, are now offering encryption by default with file systems in order to protect the contents. Windows based devices have these options as well, often applied by BitLocker or third-party software. In our AES encryption test, we used the discontinued TrueCrypt for its built-in benchmark, which tests several encryption algorithms directly in memory.
The data we take for this test is the combined AES encrypt/decrypt performance, measured in gigabytes per second. The software does use AES commands for processors that offer hardware selection, however not AVX-512.
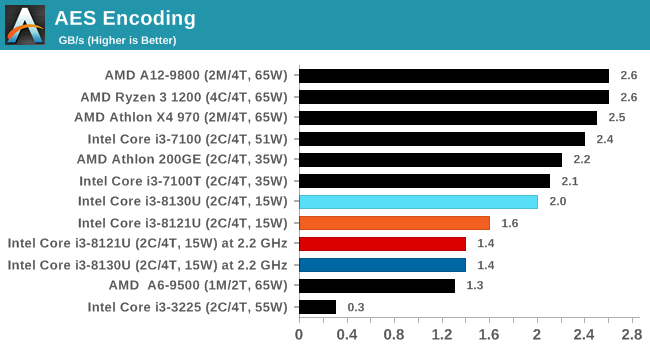
Stock CPU Performance: Legacy Tests
We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks.
All of our benchmark results can also be found in our benchmark engine, Bench.
3DPM v1: Naïve Code Variant of 3DPM v2.1
The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes).
In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures.
3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
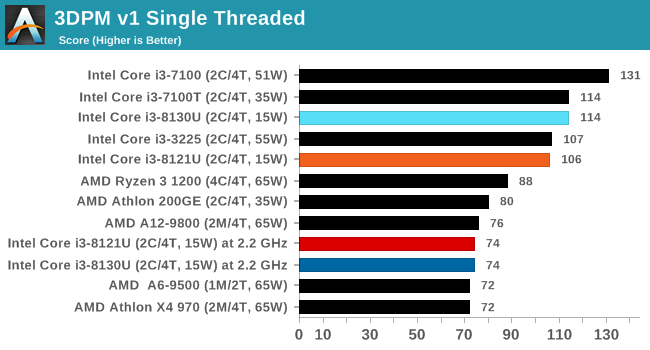
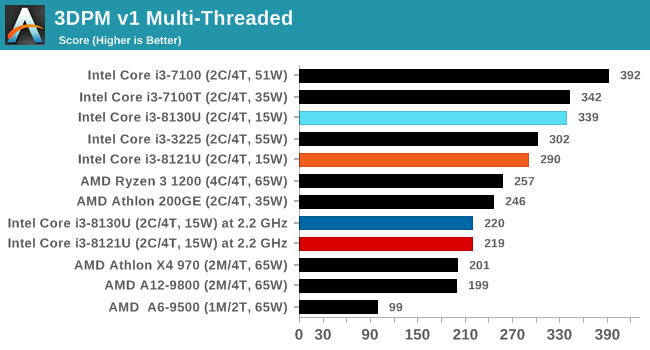
x264 HD 3.0: Older Transcode Test
This transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.
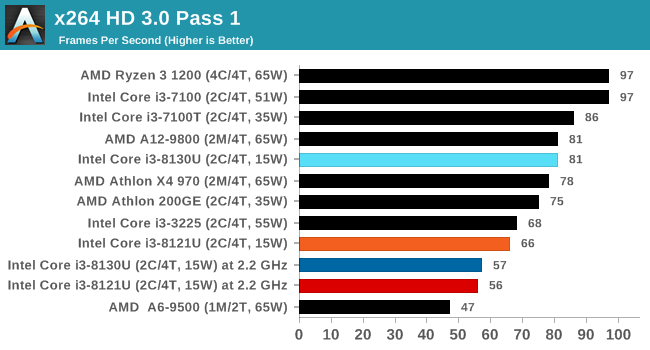
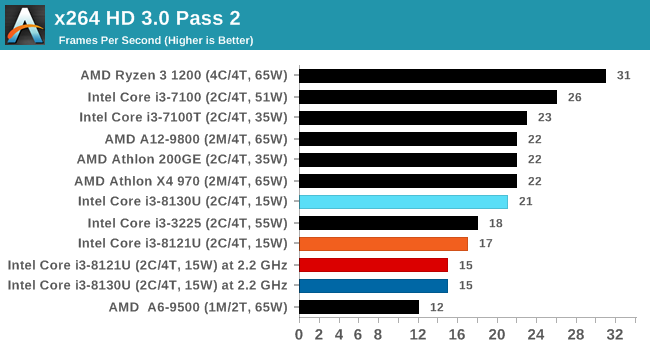
Conclusion: I Actually Used the Cannon Lake Laptop as a Daily System
When we ordered the Lenovo laptop, not only was I destined to test it to see how well Intel’s 10nm platform performs, but I also wanted to see what the device was like to actually use. Once I’d removed the terrible drives it came with and put in a 1TB Crucial MX200 SSD, I started to put it to good use.
The problem with this story is that because this is a really bad configuration of laptop, it gives the hardware very little chance to show its best side. We covered this in our overview of Carrizo several years ago, after OEM partners kept putting chips with reasonable performance into the worst penny pinching designs. The same thing goes with this laptop – it is an education focused 15.6-inch laptop whose screen is only 1366x768, and the TN panel’s best angle to view is as it is tilted away from you. It is bulky and heavy but only has a 34 Wh battery, whereas the ideal laptop is thin and light and lasts all day on a single charge. From the outset, using this device was destined to be a struggle.
I first used the device when I attended Intel’s Data Summit in mid-August. On the plane I didn’t have any space issues because I had reserved a bulkhead economy seat, however after only 4 hours or so of light word processing on a low screen brightness, I was already out of battery. Thankfully I could work on other things on my second laptop (always take two laptops to events, maybe not day-to-day at a show, but always fly with two). At the event, I planned to live blog the day of presentations. This means being connected online, uploading text, and being of a sufficient brightness to see the screen. After 90 minutes, I had 24% battery left. This device has terrible battery life, a terrible screen, is bulky, and weighs a lot.
I will say this though, it does have several positives. Perhaps this is because the RX540 is in the system, but the Windows UI was very responsive. Now of course this is a subjective measure, however I have used laptops with Core i7 and MX150 hardware that were slower to respond than this. It did get bogged down when I went into my full workflow with many programs, many tabs, and many messaging software tools, but I find that any system with only 8GB of memory will hit my workflow limits very quickly. On the natural responsiveness front, I can’t fault it.
Ultimately I haven’t continued to use the laptop much more – the screen angle required to get a good image, the battery life, and the weight are all critical issues that individually would cause me to ditch the unit. At this price, there are plenty of Celeron or Atom notebooks that would fit the bill and feel nicer to use. I couldn’t use this Ideapad unit with any confidence that I would make it through an event, either a live blog or a note taking session, without it dying. As a journalist, we can never guarantee there will be a power outlet (or an available power outlet) at the events we go to, so I always had to carry a second laptop in my bag regardless. The issue is that the second laptop I use often lasts all day at an event on its own.
Taking Stock of Intel’s 10nm Cannon Lake Design
When we lived in a world with Intel’s Tick Tock, Cannon Lake would be a natural tick – a known microarchitecture with minor tweaks but on a new process node. The microarchitecture is a tried and tested design, as we now have had four generations of it from Skylake to Coffee Lake Refresh, however the chip just isn’t suitable for prime time.

Looking at how Intel has presented its improvements on 10nm, with features like using Cobalt, Dummy Gates, Contact Over Active Gates, and new power design rules, if we assume that every advancement works perfectly then 10nm should have been a hit out of the gate. The problem is, semiconductor design is like having 300 different dials to play with, and tuning one of those dials causes three to ten others to get worse. This is the problem Intel has had with 10nm, and it is clear that some potential features work and others do not – but the company is not saying which ones for competitive and obvious reasons.
At Intel’s Architecture Day in December, the Chief Engineering Officer Dr. Murthy Renduchintala was asked if the 10nm design had changed. His response was contradictory and cryptic: ‘It is changing, but it hasn’t changed’. At that event the company was firmly in the driving seat of committing to 10nm by the end of 2019, in a quad core Ice Lake mobile processor, in a new 3D packaging design called Lakefield, in an Ice Lake server CPU for 2020, and in a 5G/AI focused processor called Snow Ridge. Whatever 10nm variant of the process they’re planning to use, we will have to wait and see.
I’ll go back to this slide that Intel presented back at the Technology and Manufacturing Day:
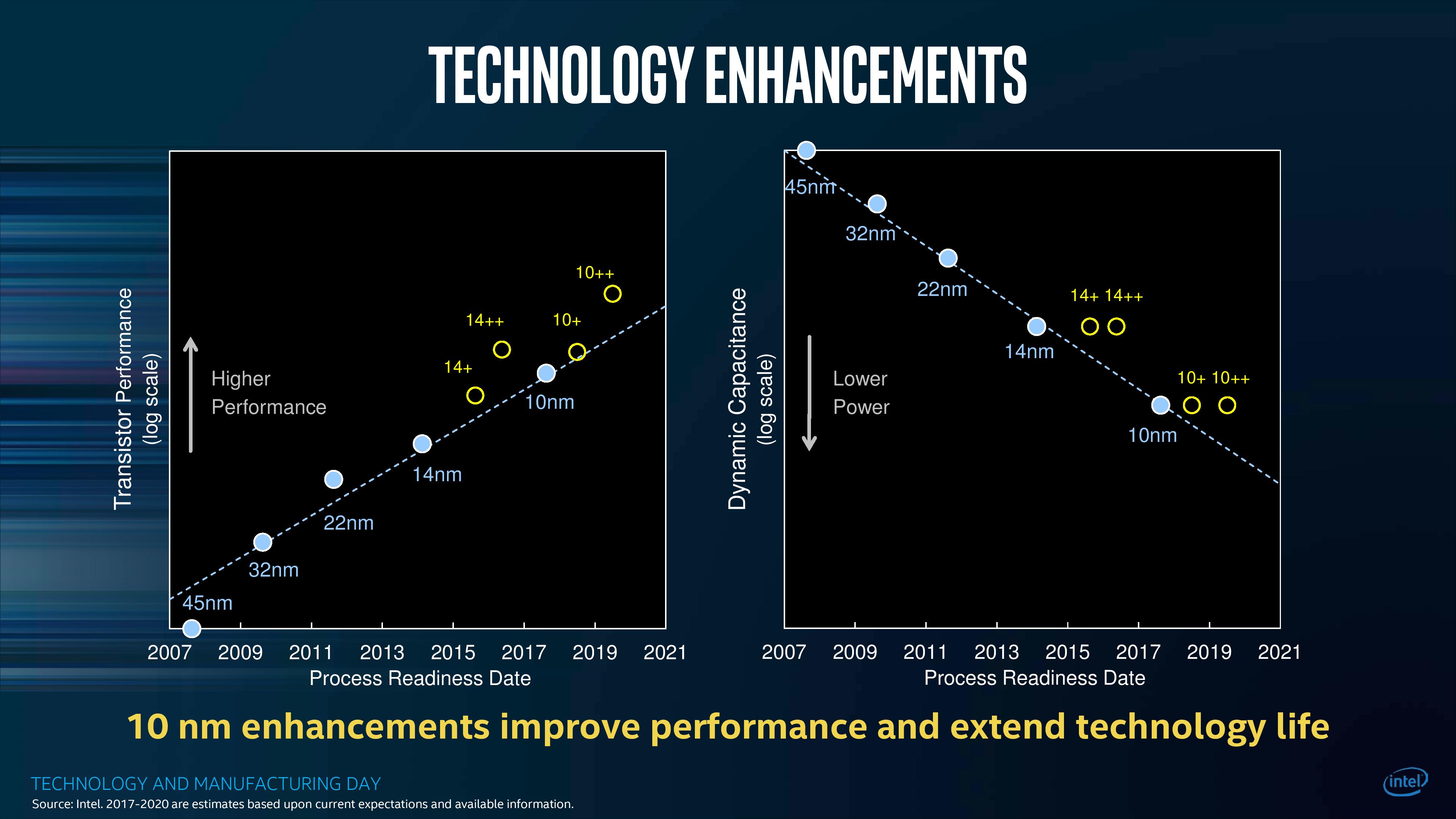
In this slide it shows on the right that 10nm (and its variants) have lower power through lower dynamic capacitance. However, on the left, Intel shows both 10nm (Cannon Lake) and 10nm+ (Ice Lake) as having lower transistor performance than 14nm++, the current generation of Coffee Lake processors.
This means we might not see a truly high-performance processor on 10nm until the third generation of the process is put into place. Right now, based on our numbers on Cannon Lake, it’s clear that the first generation of 10nm was not ready for prime time.
Cannon Lake: The Blip That Almost Didn’t Happen
We managed to snap up a Cannon Lake chip by calling in a few favors to buy it from a Chinese reseller who I’m pretty sure should not have been selling them to the public. They were educational laptops that may not have sold well, and the reseller just needed to get rid of them. Given Intel’s reluctance to talk about anything 10nm at CES 2018, and we find that the chips ‘shipped for revenue’ end up in a backwater design like this, then it would look like that Intel was trying to hide them. That was our thought for a good while, until Intel announced the Cannon Lake NUC. Even then, from launch announcement to being at general retail took four months, and by that time most people had lost interest.
At some point Intel had to make good on its promises to investors by shipping something 10nm to somewhere. Exactly how many chips were sold (and to whom) is not discussed by Intel, but I have heard some numbers flying around. Based on our performance numbers, it’s obvious why Intel didn’t want to promote it. On the other hand, at least being told about it beyond a simple sentence would have been nice.
After testing the chip, the only way I’d recommend one of these things is for the AVX512 performance. It blows everything else in that market out of the water, however AVX512 enabled programs are few and far between. Plus, given what Intel has said about the Sunny Cove core, that part will have it instead. If you really need AVX512 in a small form factor, Intel will sell you a NUC.
Cannon Lake, and the system we have with it inside, is ultimately now nothing more than a curio on the timeline of processor development. Which is where it belongs.






