Original Link: https://www.anandtech.com/show/13258/hot-chips-2018-fujitsu-afx64-arm-core-live-blog
Hot Chips 2018: Fujitsu's A64FX Arm Core Live Blog
by Dr. Ian Cutress on August 21, 2018 8:25 PM EST- Posted in
- CPUs
- Arm
- Hot Chips
- HPC
- Trade Shows
- Fujitsu
- Enterprise CPUs
- ARMv8
- Live Blog
- AFX64

08:30PM EDT - Remember back when Arm announced Scalable Vector Extensions? Well Fujitsu has made an Arm CPU that uses it with a 512-bit width. The presentation looks super interesting, so follow along with our live blog. The talk is set to start at 5:30pm PT / 12:30am UTC.

08:32PM EDT - Last time we were here, had a 3-min presentation about Post-K
08:32PM EDT - Called A64FX

08:32PM EDT - First chip to use Arm SVE
08:32PM EDT - Scalable Vector Extensions
08:33PM EDT - New microarch maximises SVE perf
08:33PM EDT - Fujitsu has been making processors for 60 years

08:34PM EDT - SPARC? Remember that?
08:34PM EDT - UNIX, HPC, Mainframe, now HPC + AI
08:34PM EDT - New CPU inherits DNA from Fujitsu

08:34PM EDT - Reliability, speed, flexibility, high perf/watt
08:34PM EDT - end up with CPU w/ extremely high throughput
08:35PM EDT - low power
08:35PM EDT - (A64FX doesn't mean Athlon 64, FX)
08:35PM EDT - Optimized for massively parallel
08:35PM EDT - Four features
08:35PM EDT - Perf: FP64 through to INT8
08:36PM EDT - Throughput: 512-bit SIMD x 2 pipes/core, HBM2, 48-cores, Tofu interconnect

08:36PM EDT - Efficiency: GEMM and Triad perf
08:37PM EDT - Standards: Arm v8.2 + SVE + SBSA level 3 (Server Base System Architecture)
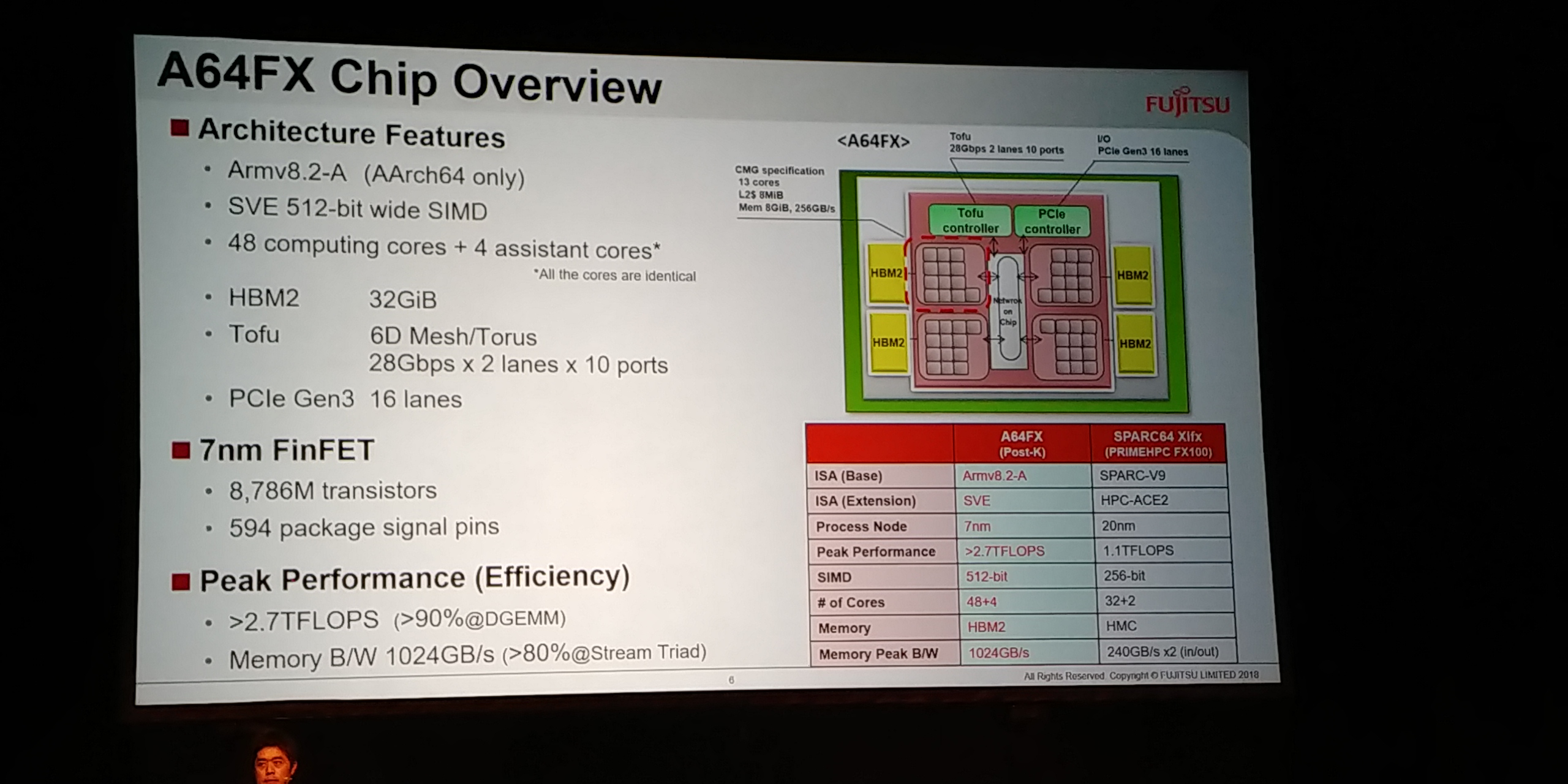
08:37PM EDT - AArch64 only, no 32
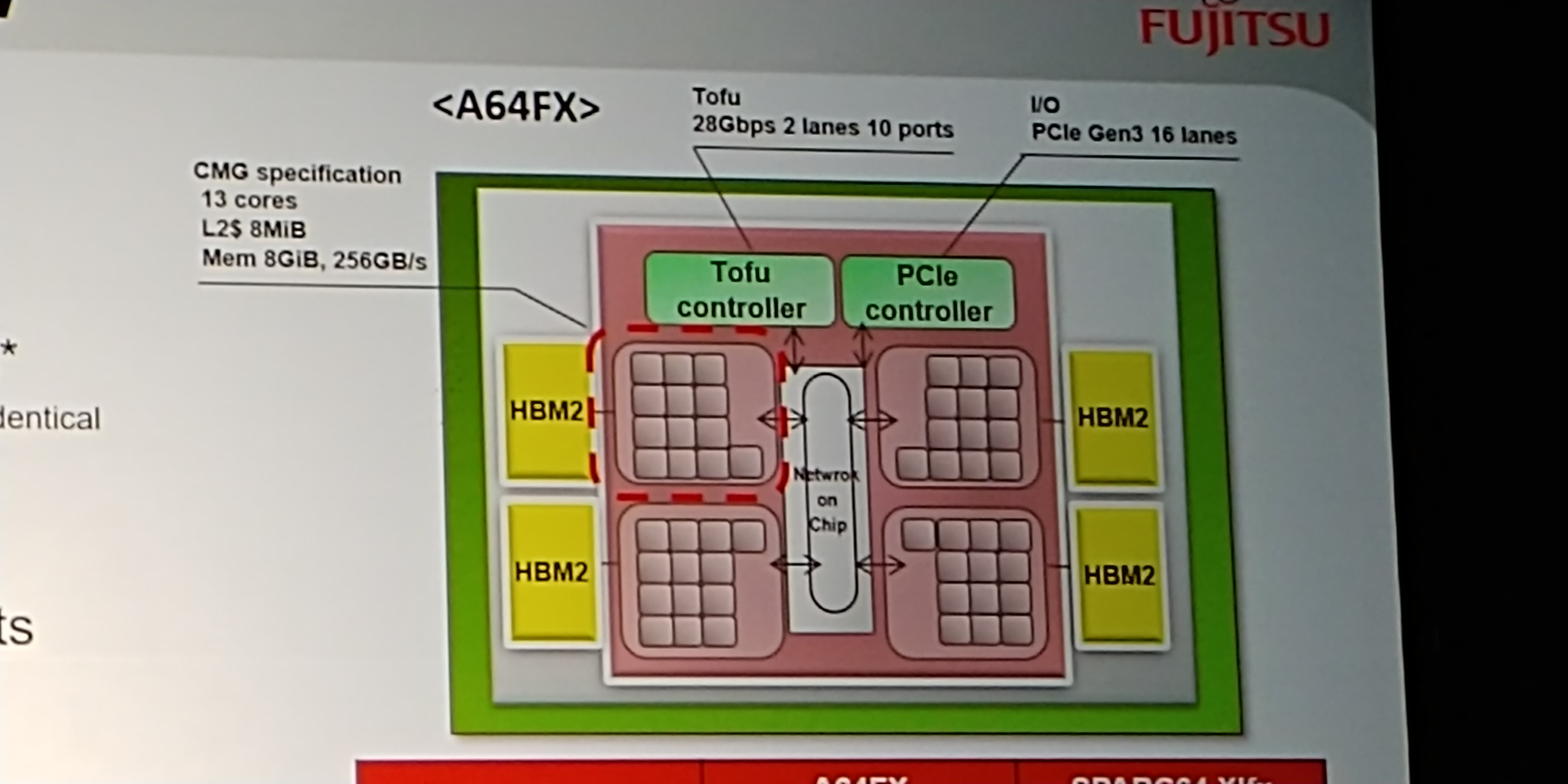
08:37PM EDT - 48 computing cores and 4 identical assistant cores
08:37PM EDT - 32GiB HBM2
08:38PM EDT - 6D Mesh - 28 Gbps x 2 lanes x 10 ports
08:38PM EDT - PCIe 3.0 x16
08:38PM EDT - Built on 7nm FinFET
08:38PM EDT - 8.786B transistors, but only 594 pin
08:38PM EDT - 2.7 TFLOPS
08:38PM EDT - 1TB/s memory bandwidth
08:39PM EDT - ISA feature support
08:39PM EDT - Optimized SVE for wide range of applications
08:39PM EDT - INT8 Dot Product
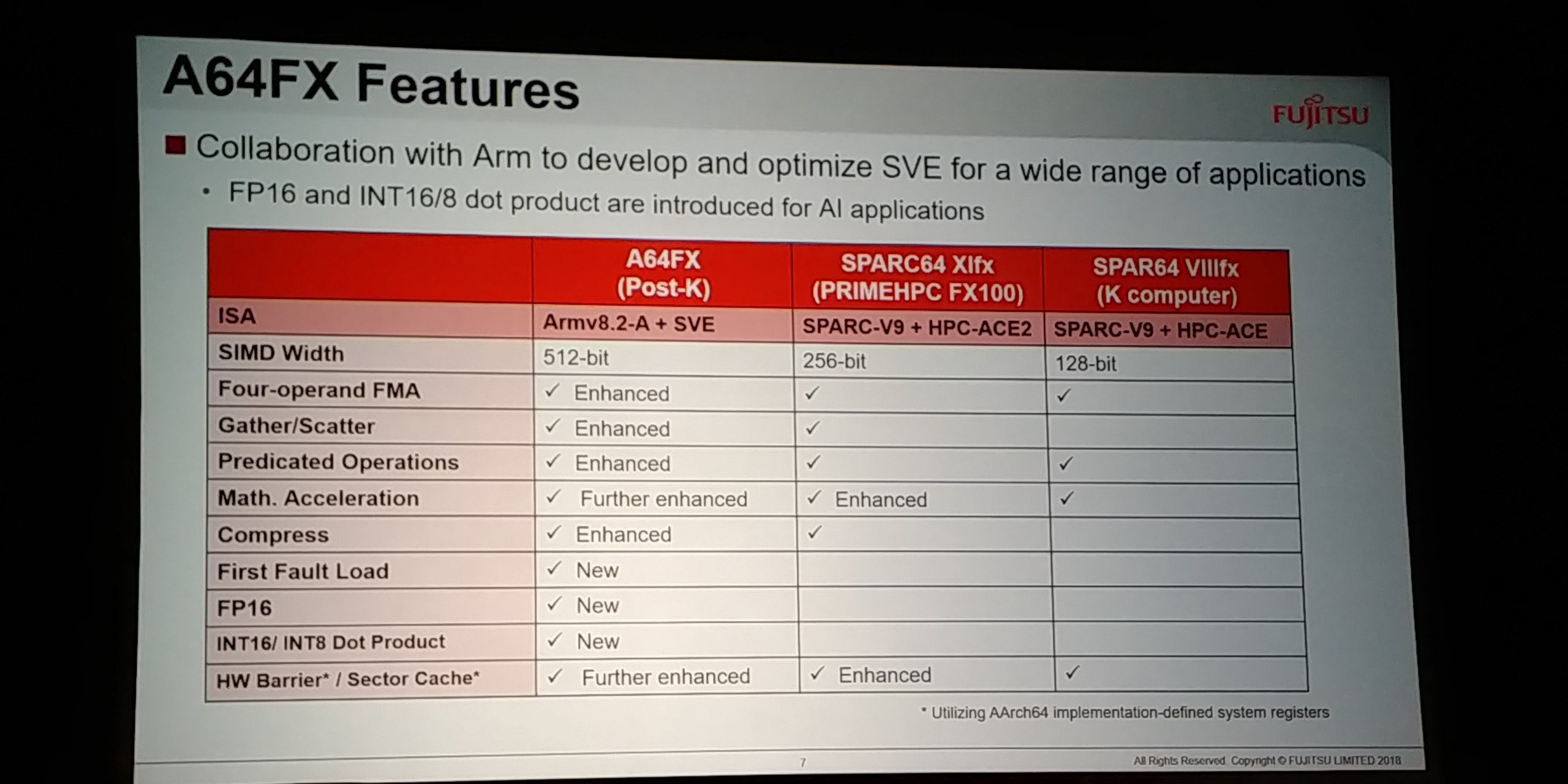
08:39PM EDT - Enhanced compression
08:39PM EDT - AI applications
08:40PM EDT - HW Barrier and Sector cache - implementation defined system registers from AArch64
08:40PM EDT - Enahnced blocks in chip
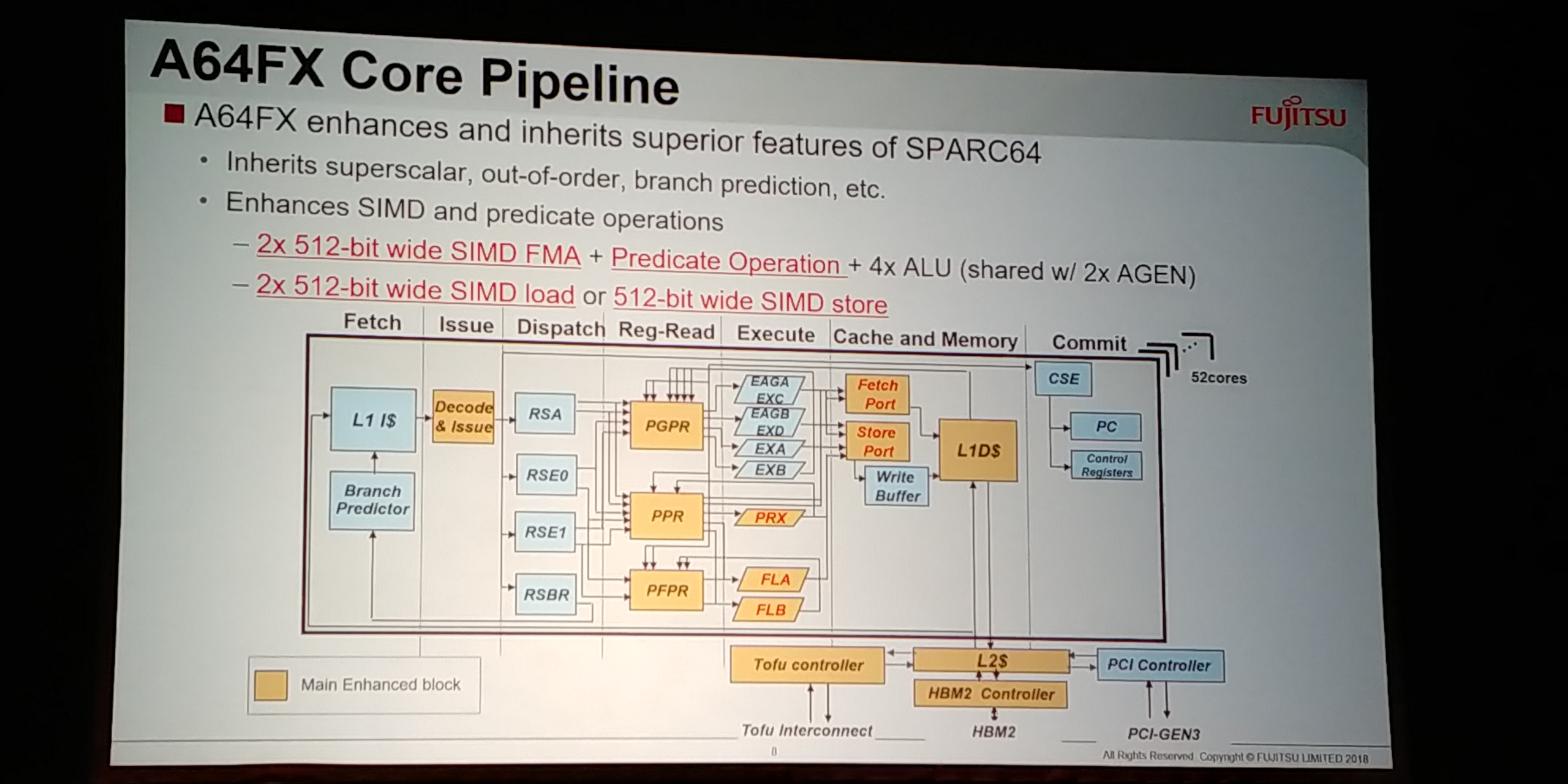
08:40PM EDT - Predicated operations dedicated pipe
08:41PM EDT - SVE has limitation on operands - FMA equivalent requires destructive 3-operand FMA3

08:41PM EDT - MOVPRFX instruction
08:41PM EDT - hides overhead of main pipelin
08:42PM EDT - 21.6 TOPS for INT8 dot product
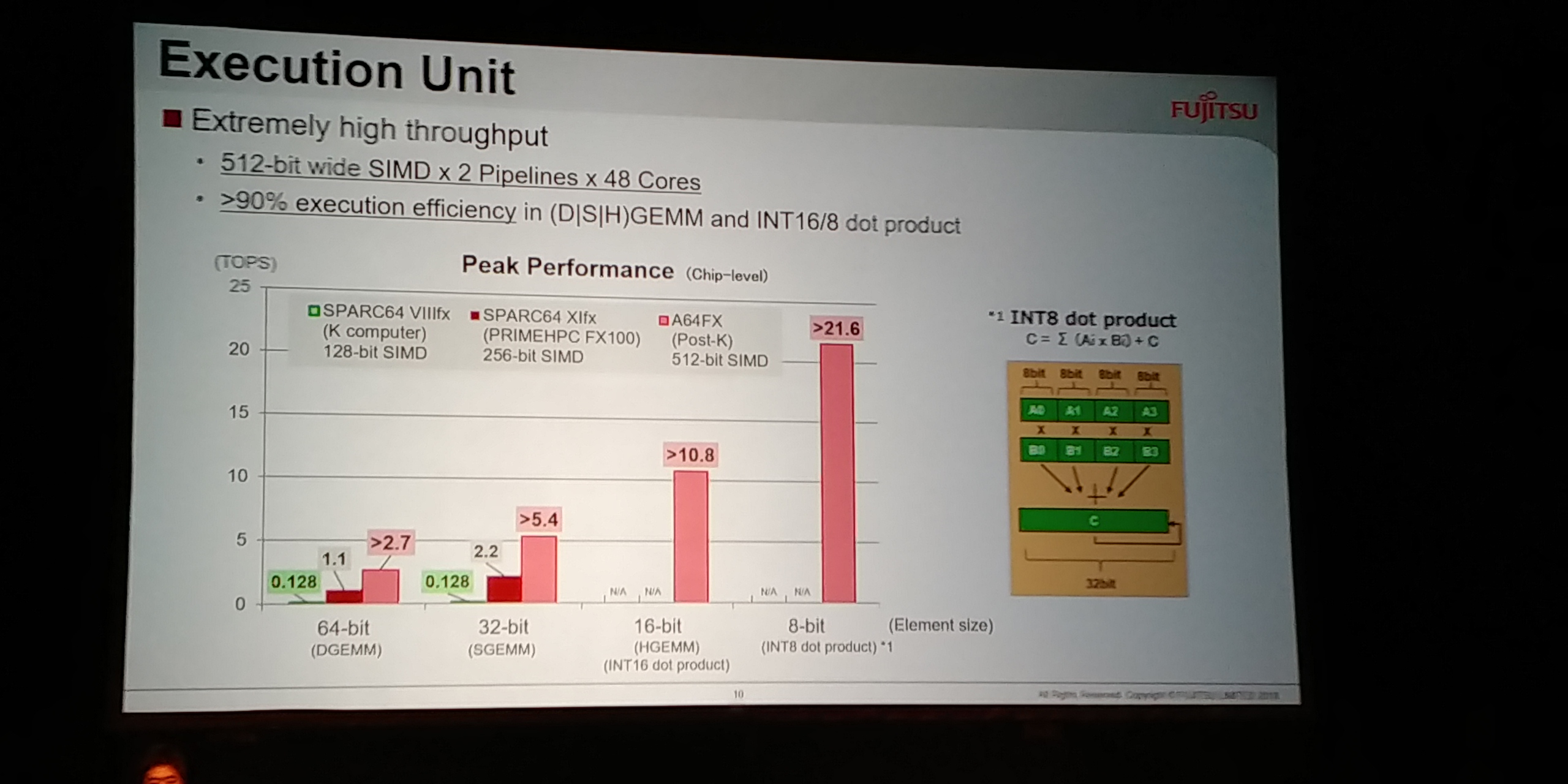
08:42PM EDT - 90% execution efficiency
08:42PM EDT - Still 2x in 64-bit DGEMM over SPARC64 PrimeHPC FX100
08:43PM EDT - Almost 20x the K comp in DGEMM
08:43PM EDT - L1 cache is key to design for 512-bit SIMD
08:43PM EDT - Combined Gather mechanism to increase throughput
08:44PM EDT - Combined Gather enables return up to two consecutive elements in a 128-byte aligned block

08:44PM EDT - Throughput per core is 32 bytes/cycle
08:44PM EDT - Full chip is Divided into four memory groups
08:45PM EDT - One CMG is 13 cores, an L2 cache, and a memory controller
08:45PM EDT - One core handles Daemon/IO

08:45PM EDT - Cache coherency by ccNUMA with on-chip directory
08:45PM EDT - X-bar connection for L2 cache efficiency
08:45PM EDT - Process binding ensures scaling
08:45PM EDT - Wide Ring Bus for IO across whole chip
08:46PM EDT - Bandwidth in cache and memory is key

08:46PM EDT - Out-of-order mechanisms in cores, caches, and IMCs
08:46PM EDT - L1 cache at 11.0 TB/s
08:46PM EDT - L2 cache is 3.6 TB/s
08:47PM EDT - Normalized compared to previous processor, perf is 2x across wide range of workloads
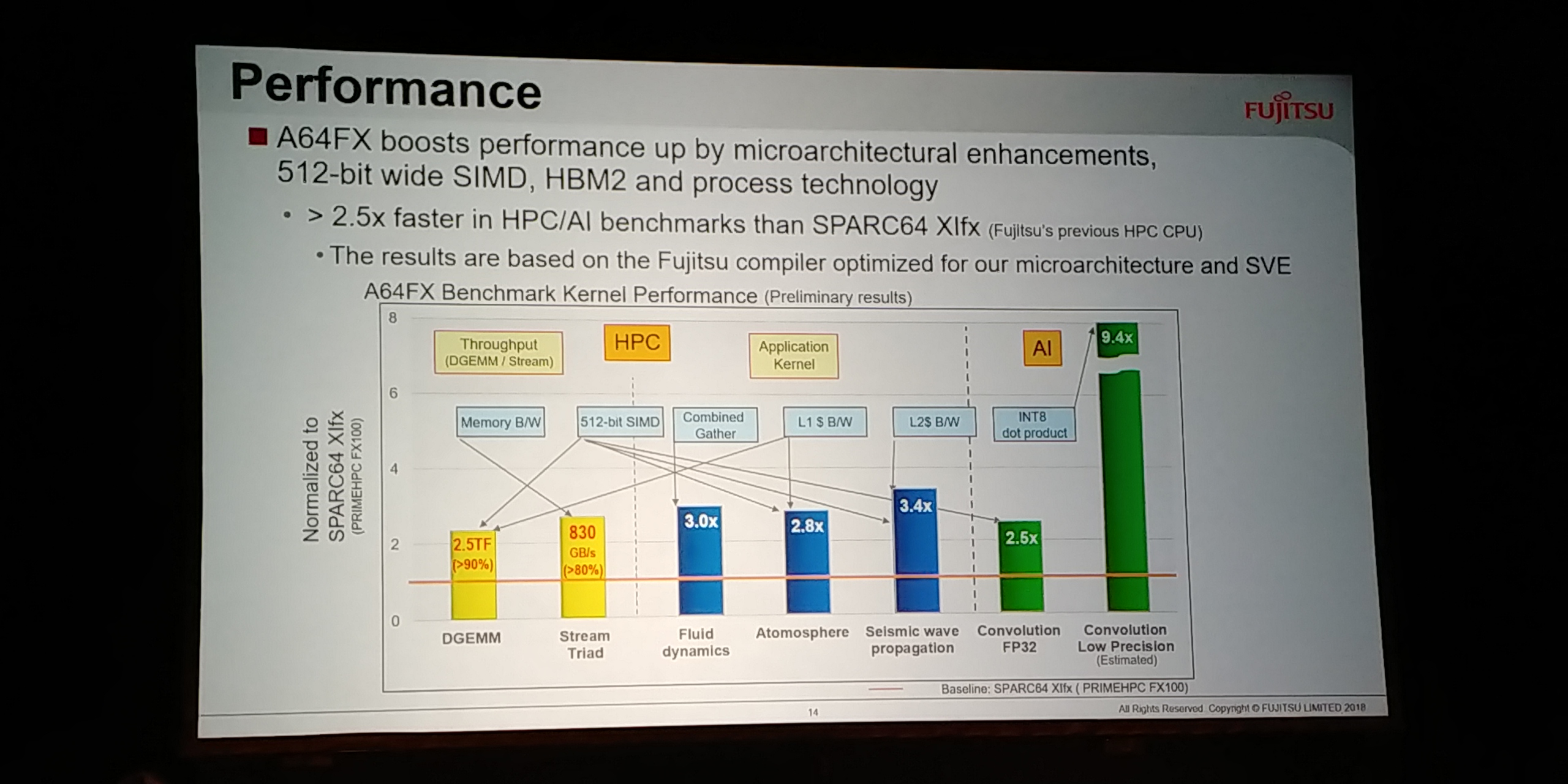
08:48PM EDT - For AI, convolution low precision is 9.4x using INT8 dot product
08:48PM EDT - Each chip has energy monitor in msec
08:49PM EDT - Each core has energy analyzer in nanosec
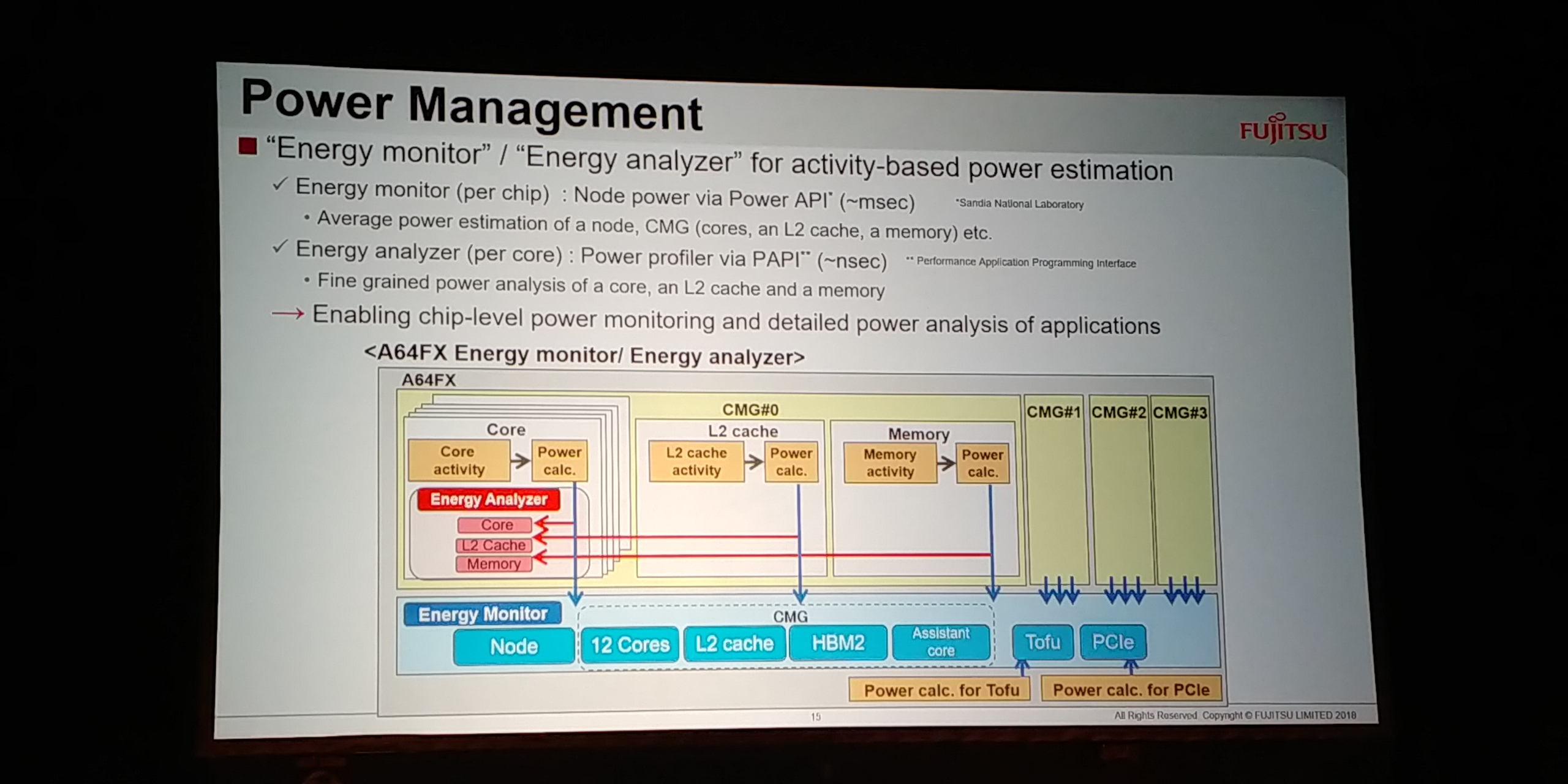
08:49PM EDT - Fine grained power analysis of a core, an L2 cache and memory
08:49PM EDT - Power Knob for optimization
08:49PM EDT - Can change hardware config for power
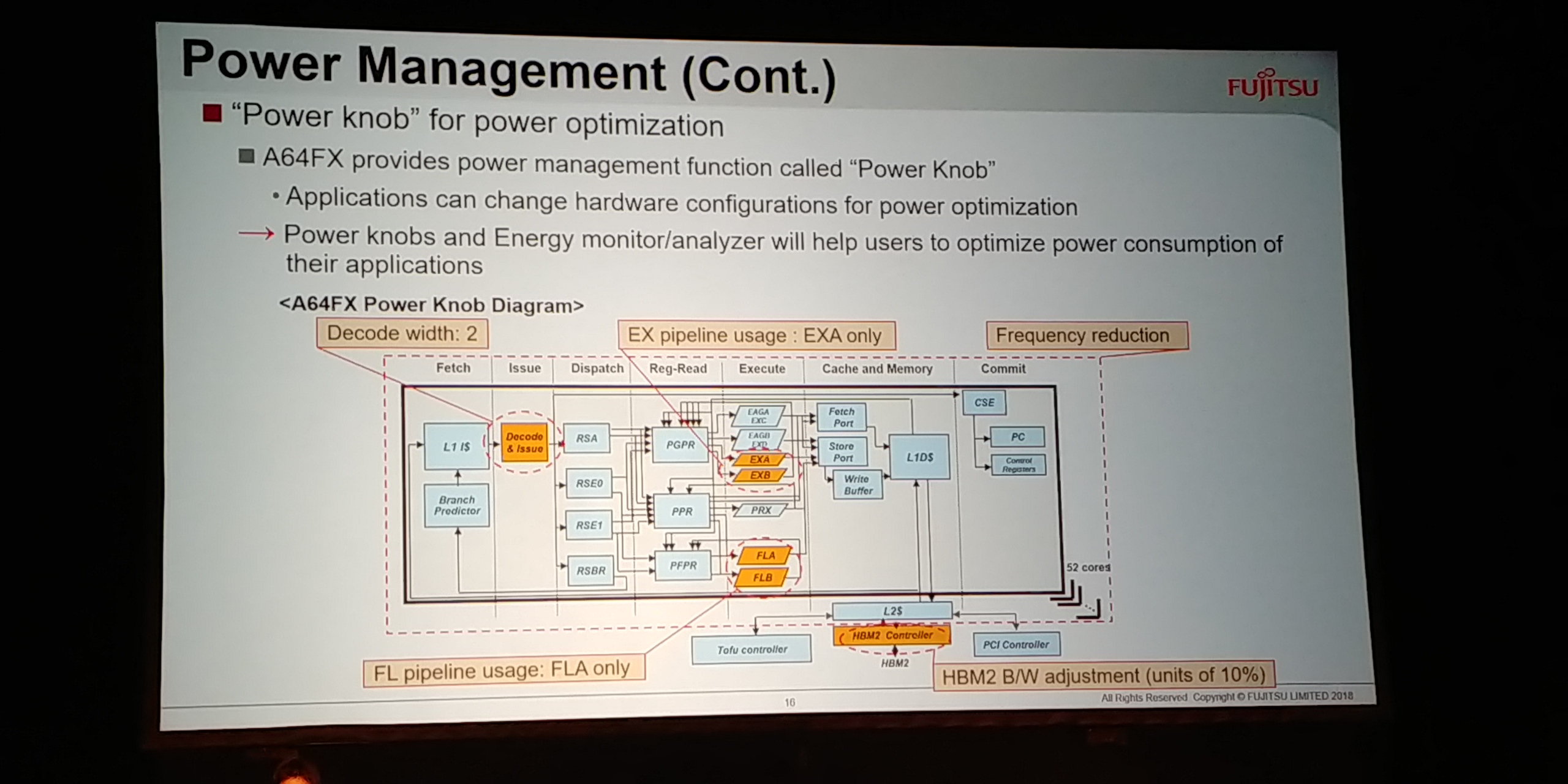
08:50PM EDT - Change decode width, floating point pipeline, and general frequency reduction
08:50PM EDT - Extensive RAS
08:50PM EDT - ECC on all caches
08:50PM EDT - Parity cehc on execution units
08:50PM EDT - 128400 error checkers

08:50PM EDT - Parity Check* on execution units

08:51PM EDT - Hardware instruction retry
08:52PM EDT - Software stacks developed by RIKEN and Fujitsu

08:52PM EDT - Will continue to use Arm in the future
08:52PM EDT - Work with partners

08:53PM EDT - Q&A time
08:54PM EDT - Q: When can you reach exascale? A: The Post-K system will be available in 2021. 100x perf from K-comp. But exa-scale not answerable
08:55PM EDT - Q: nanosecond level power monitoring - what techniques do you use? A: Activity based on coefficient based on operations
08:56PM EDT - Q: Support 64-bit FP, not 128-bit? A: No.
08:59PM EDT - That's a wrap. Next talk is on the NEC Vector processor: https://www.anandtech.com/show/13259/hot-chips-2018-nec-vector-processor-live-blog






