Original Link: https://www.anandtech.com/show/10435/assessing-ibms-power8-part-1
Assessing IBM's POWER8, Part 1: A Low Level Look at Little Endian
by Johan De Gelas on July 21, 2016 8:45 AM EST
It is the widest superscalar processor on the market, one that can issue up to 10 instructions and sustain 8 per clock: IBM's POWER8. IBM's POWER CPUs have always captured the imagination of the hardware enthusiast; it is the Tyrannosaurus Rex, the M1 Abrams of the processor world. Still, despite a flood of benchmarks and reports, it is very hard to pinpoint how it compares to the best Intel CPUs in performance wise. We admit that our own first attempt did not fully demystify the POWER8 either, due to the fact that some immature LE Linux software components (OpenJDK, MySQL...) did not allow us to run our enterprise workloads.
Hence we're undertaking another attempt to understand what the strengths and weaknesses are of Intel's most potent challenger. And we have good reasons besides curiosity and geekiness: IBM has just recently launched the IBM S812LC, the most affordable IBM POWER based server ever. IBM advertises the S812LC with "Starting at $4,820". That is pretty amazing if you consider that this is not some basic 1U server, but a high expandable 2U server with 32 (!) DIMM slots, 14 disk bays, 4 PCIe Gen 3 slots, and 2 redundant power supplies.

Previous "scale out" models SL812 and SL822 were competitively priced too ... until you start populating the memory slots! The required CDIMMs cost no less than 4(!) times more than RDIMMs, which makes those servers very unattractive for the price conscious buyers that need lots of memory. The S812LC does not have that problem: it makes use of cheap DDR3 RDIMMs. And when you consider that the actual street prices are about 20-25% lower, you know that IBM is in Dell territory. There is more: servers from Inventec, Inspur, and Supermicro are being developed, so even more affordable POWER8 servers are on the way. A POWER8 server is thus quite affordable now, and it looks like the trend is set.
To that end, we decided that we want to more accurately measure how the POWER8 architecture compares to the latest Xeons. In this first article we are focusing on characterizing the microarchitecture and the "raw" integer performance. Although the POWER8 architecture has been around for 2 years now, we could not find any independent Little Endian benchmark data that allowed us to compare POWER8 processors with Intel's Xeon processors in a broad range of applications.
Notice our emphasis on "Little Endian". In our first review, we indeed tested on a relatively immature LE Ubuntu 14.04 for OpenPOWER. Some people felt that this was not fair as the POWER8 would do a lot better on top of a Big Endian operating system simply because of the software maturity. But the market says otherwise: if IBM does not want to be content with fighting Oracle in an ever shrinking high-end RISC market, they need to convince the hyper scalers and the thousands of smaller hosting companies. POWER8 Server will need to find a place inside their x86 dominated datacenters. A rich LE Linux software ecosystem is the key to open the door to those datacenters.
When it comes to taking another crack at our testing, we found out that running Ubuntu 15.10 (16.04 was just out yet when we started testing) solved a lot of the issues (OpenJDK, MySQL) that made our previous attempt at testing the POWER8 so hard and incomplete. Therefore we felt that despite 2 years of benchmarking on POWER8, an independent LE Linux-focused article could still add value.
Inside the Beast(s)
When the POWER8 was first launched, the specs were mind boggling. The processor could decode up to 8 instructions, issue 8 instructions, and execute up to 10 and all this at clockspeed up to 4.5 GHz. The POWER8 is thus an 8-way superscalar out of order processor. Now consider that
- The complexity of an architecture generally scales quadratically with the number of "ways" (hardware parallelism)
- Intel's most advanced architecture today - Skylake - is 5-way
and you know this is a bold move. If you superficially look at what kind of parallelism can be found in software, it starts to look like a suicidal move. Indeed on average, most modern CPU compute on average 2 instructions per clockcycle when running spam filtering (perlbench), video encoding (h264.ref) and protein sequence analyses (hmmer). Those are the SPEC CPU2006 integer benchmarks with the highest Instruction Per Clockcycle (IPC) rate. Server workloads are much worse: IPC of 0.8 and less are not an exception.
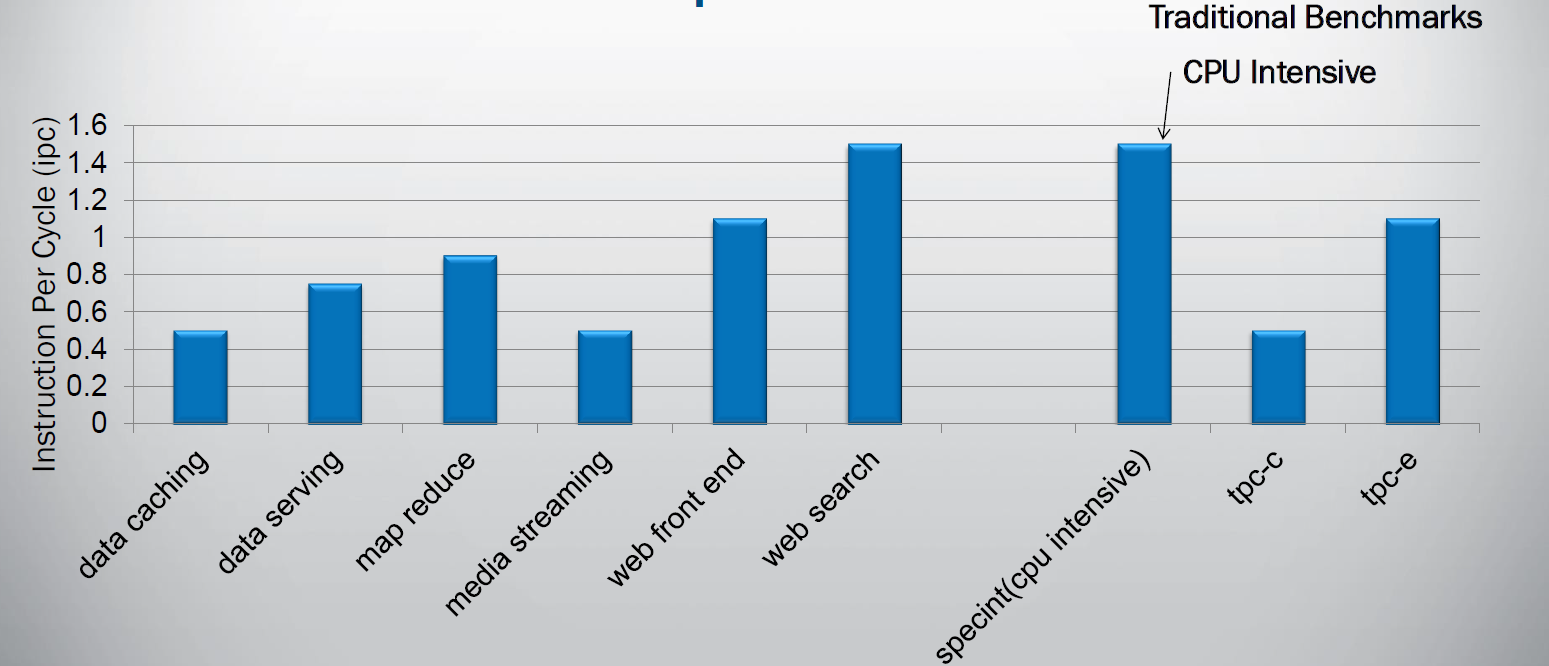
It is clear that simply widening a design will not bring good results, so IBM chose to run up to 8 threads simultaneously on their core. But running lots of threads is not without risk: you can end up with a throughput processor which delivers very poor performance in a wide range of applications that need that single threaded speed from time to time.
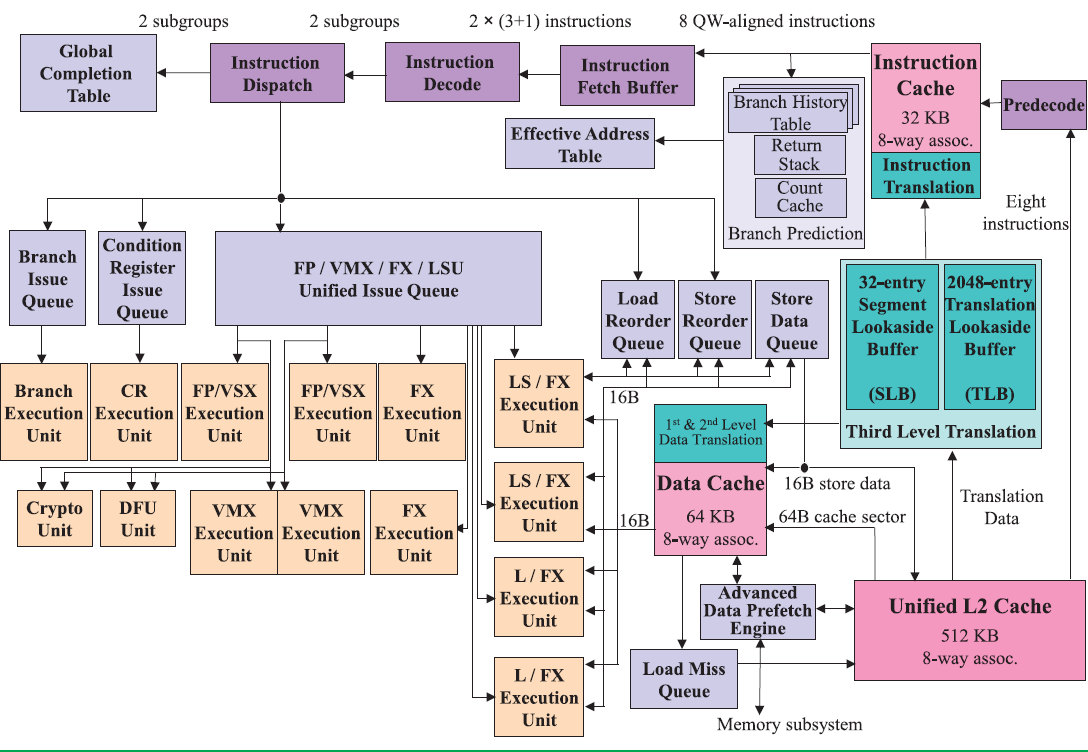
The picture below shows the wide superscalar architecture of the IBM POWER8. The image is taken from the white paper "IBM POWER8 processor core architecture", written by B. Shinharoy and many others.
The POWER8+ will have very similar microarchitecture. Since it might have to face a Skylake based Xeon, we thought it would be interesting to compare the POWER8 with both Haswell/Broadwell as Skylake.
The second picture is a very simplified architecture plan that we adapted from an older Intel Powerpoint presentation about the Haswell architecture, to show the current Skylake architecture. The adaptations were based on the latest Intel optimization manuals. The Intel diagram is much simpler than the POWER8's but that is simply because I was not as diligent as the people at IBM.
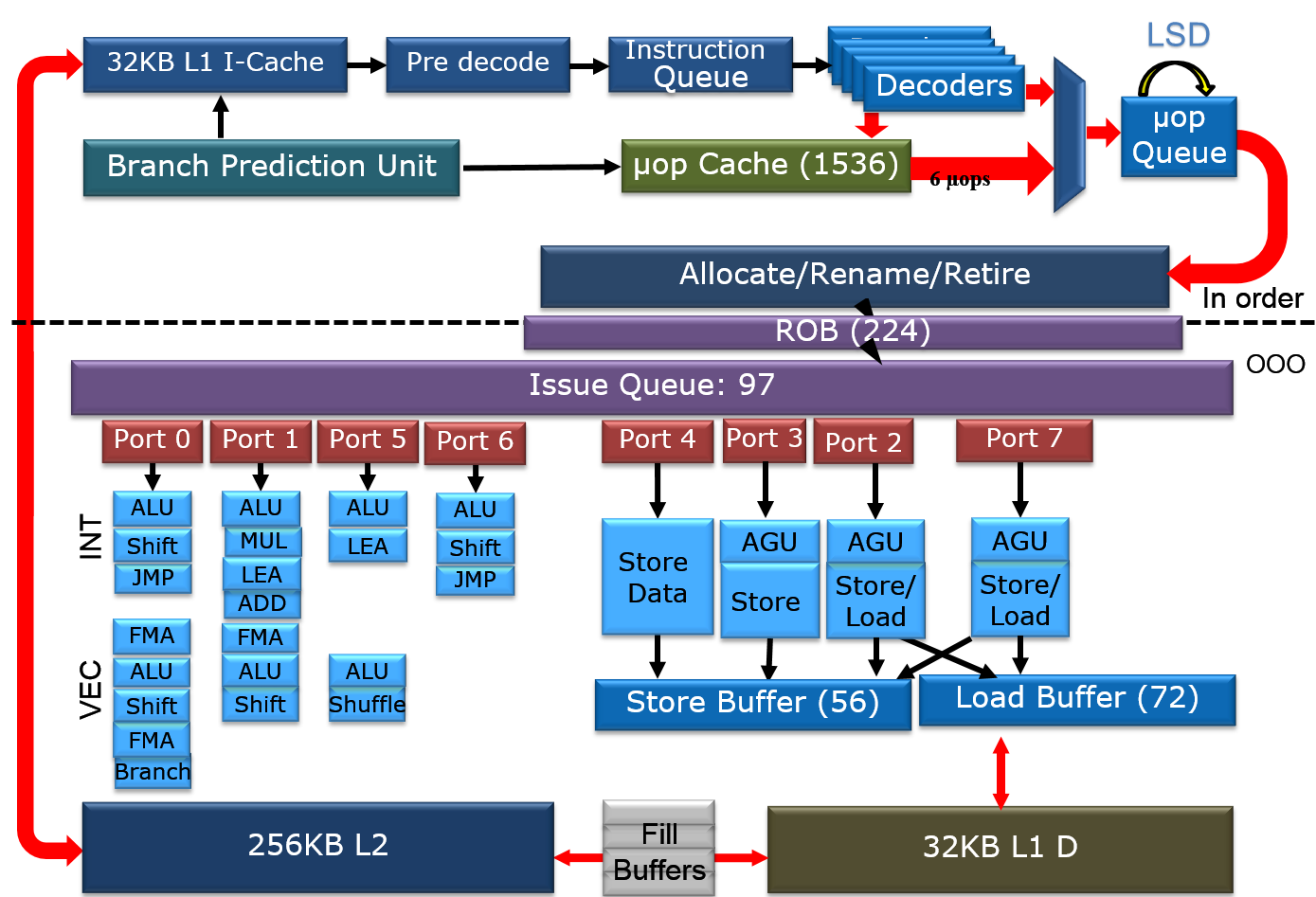
It is above our heads to compare the different branch prediction systems, but both Intel and IBM combine several different branch predictors to choose a branch. Both make use of a very large (16 K entries) global branch history table. Both processors scan 32 bytes in advance for branches. In case of IBM this is exactly 8 instructions. In case of Intel this is twice as much as it can fetch in one cycle (16 Bytes).
On the POWER8, data is fetched from the L2-cache and then predecoded into the L1-cache. Predecoding includes adding branch, exception, and grouping. This makes sure that predecoding is out the way before the actual computing ("Von Neuman Cycle") starts.
In Intel Haswell/Skylake, instructions are only predecoded after they are fetched. Predecoding performs macro-op fusion: fusing two x86 instructions together to save decode bandwidth. Intel's Skylake has 5 decoders and up to 5 µop instructions are sent down the pipelines. The current Xeon based upon Broadwell has 4 decoders and is limited to 4 instructions per clock. Those decoded instructions are sent into a µ-op cache, which can contain up to 1536 instructions (8-way), about 100 bits wide. The hitrate of the µop cache is estimated at 80-90% and up to 6 µops can be dispatched in that case. So in some situations, Skylake can run 6 instructions in parallel but as far as we understand it cannot sustain it all the time. Haswell/Broadwell are limited to 4. The µop cache can - most of the time - reduce the branch misprediction penalty from 19 to 14.
Back to the POWER8. Eight instructions are sent to the IBM POWER8 fetch buffer, where up 128 instructions can be held for two thread(s). A single thread can only use half of that buffer (64 instructions). This method of allocation gives each of two threads as much resources as one (i.e. no sharing), which is one of the key design philosophies for the POWER8 architecture.
Just like in the x86 world, the decoding unit breaks down the more complex RISC instructions into simpler internal instructions. Just like any modern Intel CPU, the opposite is also possible: the POWER8 is capable of fusing some combinations of 2 adjacent instructions into one instruction. Saving internal bandwidth and eliminating branches is one of the way this kind of fusion increases performances.
Contrary to the Intel's unified queue, the IBM POWER has 3 different issue queues: branch, condition register, and the "Load/Store/FP/Integer" queue. The first two can issue one instruction per clock, the latter can send off 8 instructions, for a combined total of 10 instructions per cycle. Intel's Haswell-Skylake cores can issue 8 µops per cycle. So both the POWER8 and Intel CPU have more than ample issue and execution resources for single threaded code. More than one thread is needed to really make use of all those resources.
Notice the difference in focus though. The Intel CPU has half of the load units (2), but each unit has twice the bandwidth (256 bit/cycle). The POWER8 has twice the amount of load units (4), but less bandwidth per unit (128 bit per cycle). Intel went for high AVX (HPC) performance, IBM's focus was on feeding 2 to 8 server threads. Just like the Intel units, the LSUs have Address Generation Units (AGUs). But contrary to Intel, the LSUs are also capable of doing simple integer calculations. That kind of massive integer crunching power would be a total waste on the Intel chip, but it is necessary if you want to run 8 threads on one core.
Comparing with Intel's Best
Comparing CPUs in tables is always a very risky game: those simple numbers hide a lot of nuances and trade-offs. But if we approach with caution, we can still extract quite a bit of information out of it.
| Feature | IBM POWER8 |
Intel Broadwell (Xeon E5 v4) |
Intel Skylake |
| L1-I cache Associativity |
32 KB 8-way |
32 KB 8-way |
32 KB 8-way |
| L1-D cache Associativity |
64 KB 8-way |
32 KB 8-way |
32 KB 8-way |
| Outstanding L1-cache misses | 16 | 10 | 10 |
| Fetch Width | 8 instructions | 16 bytes (+/- 4-5 x86) | 16 bytes (+/- 4-5 x86) |
| Decode Width | 8 | 4 µops | 5-6* µops (*µop cache hit) |
| Issue Queue | 64+15 branch+8 CR = 87 |
60 unified | 97 unified |
| Issue Width/Cycle | 10 | 8 | 8 |
| Instructions in Flight | 224 (GCT SMT-8 modus) | 192 (ROB) | 224 (ROB) |
| Archi regs Rename regs |
32 (ST), 2x32 (SMT-2) 92 (ST), 2x92 (SMT-2) |
16 168 |
16 180 |
| Load Bandwidth (per unit) Load Queue Size |
4 per cycle 16B/cycle 44 entries |
2 per cycle 32B/cycle 72 entries |
2 per cycle 32B/cycle 72 entries |
| Store Bandwidth Store Queue Size |
2 per cycle 16B/cycle 40 entries |
1 per cycle 32B/cycle 42 entries |
1 per cycle 32B/cycle 56 entries |
| Int. Pipeline Length |
18 stages |
19 stages |
19 stages 14 stage from µop cache |
| TLB | 2048 4-way |
128I + 64D L1 1024 8-way |
128I + 64D L1 1536 8-way |
| Page Support | 4 KB, 64 KB, 16 MB, 16 GB | 4 KB, 2/4 MB, 1 GB | 4 KB, 2/4 MB, 1 GB |
Both CPUs are very wide brawny Out of Order (OoO) designs, especially compared to the ARM server SoCs.
Despite the lower decode and issue width, Intel has gone a little bit further to optimize single threaded performance than IBM. Notice that the IBM has no loop stream detector nor µop cache to reduce branch misprediction. Furthermore the load buffers of the Intel microarchitecture are deeper and the total number of instructions in flight for one thread is higher. The TLB architecture of the IBM POWER8 has more entries while Intel favors speedy address translations by offering a small level one TLB and a L2 TLB. Such a small TLB is less effective if many threads are working on huge amounts of data, but it favors a single thread that needs fast virtual to physical address translation.
On the flip side of the coin, IBM has done its homework to make sure that 2-4 threads can really boost the performance of the chip, while Intel's choices may still lead to relatively small SMT related performance gains in quite a few applications. For example, the instruction TLB, µop cache (Decode Stream Buffer) and instruction issue queues are divided in 2 when 2 threads are active. This will reduced the hit rate in the micro-op cache, and the 16 byte fetch looks a little bit on the small side. Let us see what IBM did to make sure a second thread can result in a more significant performance boost.
Multi Threading Prowess
The gains of 2-way SMT (Hyperthreading) on Intel processors are still relatively small (10-20%) in many applications. The reason is that threads have to share most of the critical resources such as L1-cache, the instruction TLB, µop cache, and instruction queue. That IBM uses 8-way SMT and still claims to get significant performance gains piqued our interest. Is this just benchmarketing at best or did they actually find a way to make 8-way SMT work?
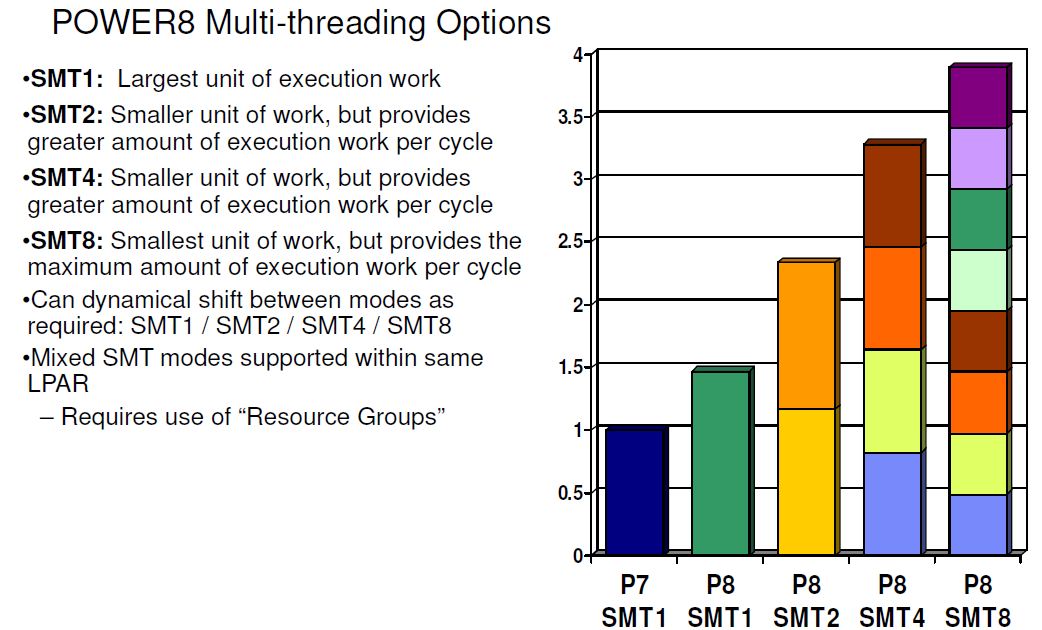
It is interesting to note that with 2-way SMT, a single thread is still running at about 80% of its performance without SMT. IBM claims no less than a 60% performance increase due to 2-way SMT, far beyond what Intel has ever claimed (30%). This can not be simply explained by the higher amount of issue slots or decoding capabilities.
The real reason is a series of trade-offs and extra resource investments that IBM made. For example, the fetch buffer contains 64 instructions in ST mode, but twice as many entries are available in 2-way SMT mode, ensuring each thread still has a 64 instruction buffer. In SMT4 mode, the size of the fetch buffer for each thread is divided in 2 (32 instructions), and only in SMT8 mode things get a bit cramped as the buffer is divided by 4.
The design philosophy of making sure that 2 threads do not hinder each other can be found further down the pipeline. The Unified Issue Queue (UniQueue) consists of two symmetric halves (UQ0 and UQ1), each with 32 entries for instructions to be issued.
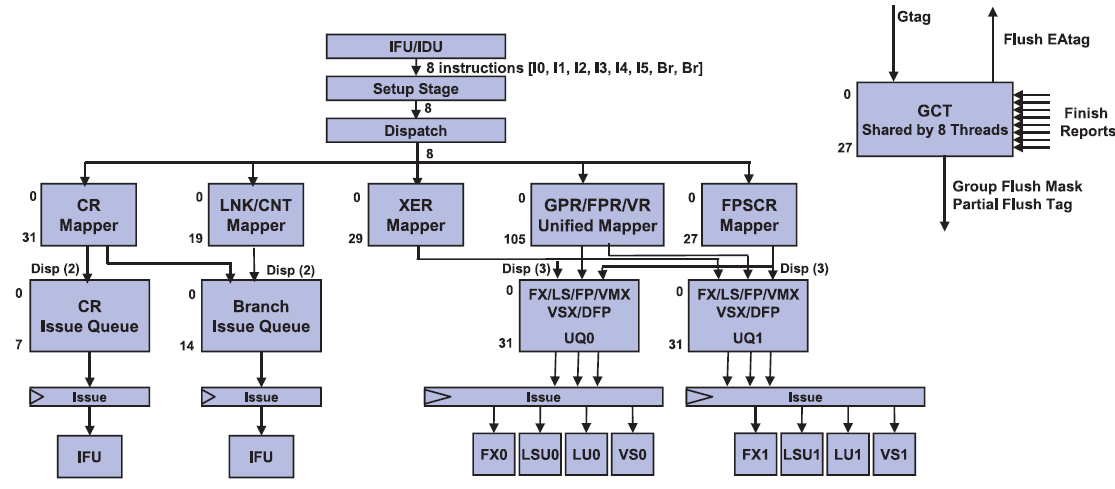
Each of these UQs can issue instructions to their own reserved Load/Store, Integer (FX), Load, and Vector units. A single thread can use both queues, but this setup is less flexible (and thus less performant) than a single issue queue. However, once you run 2 threads on top of a core (SMT-2), the back-end acts like it consists of two full-blown 5-way superscalar cores, each with their own set of physical registers. This means that one thread cannot strangle the other by using or blocking some of the resources. That is the reason why IBM can claim that two threads will perform so much better than one.
It is somewhat similar to the "shared front-end, dual-core back-end" that we have seen in Bulldozer, but with (much) more finesse. For example, the data cache is not divided. The large and fast 64 KB D-cache is available for all threads and has 4 read ports. So two threads will be able to perform two loads at the same time. Another example is that a single thread is not limited to one half, but can actually use both, something that was not possible with Bulldozer.
Dividing those ample resources in two again (SMT-4) should not pose a problem. All resources are there to run most server applications fast and one of the two threads will regularly pause when a cache miss or other stalls occur. The SMT-8 mode can sometimes be a step too far for some applications, as 4 threads are now dividing up the resources of each issue queue. There are more signs that SMT-8 is rather cramped: instruction prefetching is disabled in SMT-8 modus for bandwidth reasons. So we suspect that SMT-8 is only good for very low IPC, "throughput is everything" server applications. In most applications, SMT-8 might increase the latency of individual threads, while offering only a small increase in throughput performance. But the flexibility is enormous: the POWER8 can work with two heavy threads but can also transform itself into a lightweight thread machine gun.
System Specs
Lastly, let's take a look at some high level specs. It is interesting to note that the IBM POWER8 inside our S812LC server is a 10-core Single Chip Module. In other words it is a single 10-core die, unlike the 10-core chip in our S822L server which was made of two 5-core dies. That should improve performance for applications that use many cores and need to synchronize, as the latency of hopping from one chip to another is tangible.
The SKU inside the S812LC is available to third parties such Supermicro and Tyan. This cheaper SKU runs at "only" 2.92 GHz, but will easily turbo to 3.5 GHz.
| Feature | IBM POWER8 (Available in LC servers) |
Intel Broadwell (Xeon E5 v4) |
| Process tech. | 22nm SOI | 14nm FinFET |
| Max clock | 2.92-3.5 GHz | 2.2-3.6 GHz |
| Max. core count Max. thread count |
[email protected] GHz (3.5 GHz Turbo) 80 SMT |
[email protected] GHz (2.8 GHz turbo) 44 SMT |
| TDP | 190W | 145W |
| L1-I / L1-D Cache | 32 KB/64 KB | 32 KB/32 KB |
| L2 Cache | 512 KB SRAM per core | 256 KB SRAM per core |
| L3 Cache | 8 MB eDRAM per core | 2.5 MB SRAM per core |
| L4 Cache | 16 MB eDRAM per MBC (64 MB total) |
None |
| Memory | 1 TB per socket - 32 slots (32 GB per DIMM) |
0.768 TB per socket - 12 slots (64 GB per DIMM) |
| Theoretical Memory Bandwidth | 76.8 GB/s Read 38.4 GB/s Write |
76.8 GB/s Read or Write |
| PCIe 3.0 Lanes | 32 Lanes | 40 Lanes |
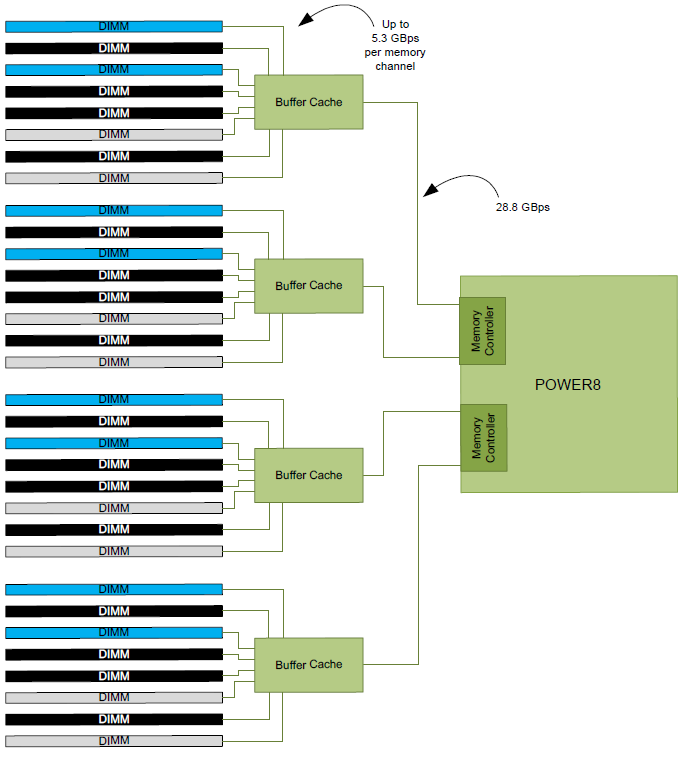
The Xeon and IBM POWER8 have totally different memory subsystems. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have each a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. This is a more efficient connection than the Xeon which has a simpler half-duplex connection to the RAM: it can either write with 76.8 GB/s to the 4 channels or read from the 4 channels. Considering that reads happen twice as much as writes, the IBM architecture is - in theory - better balanced and has more aggregated bandwidth.
Benchmark Selection
Our testing was conducted on Ubuntu Server 15.10 (kernel 4.2.0) with gcc compiler version 5.2.1.
The choice of comparing the IBM POWER8 2.92 10-core with the Xeon E5-2699 v4 22-core might seem weird, as the latter is three-times as expensive as the former. However, for this review, where we evaluate single thread/core performance, pricing does not matter. As this is one of the lowest clocked POWER8 CPUs, an Intel Xeon with a high base clock - something that's common for Intel's chips with fewer cores - would make it harder to compare the two microarchitectures. We also wanted an Intel chip that could reach high turbo clockspeeds thanks to a high TDP.
And last but not least we did not have very many Xeon E5 v4 SKUs in the lab...
Configuration
IBM S812LC (2U)
The IBM S812LC is based up on Tyan's "Habanero" platform. The board inside the IBM server is thus designed by Tyan.
| CPU | One IBM POWER8 2.92 GHz (up to 3.5 GHz Turbo) |
| RAM | 256 GB (16x16GB) DDR3-1333 |
| Internal Disks | 2x Samsung 850Pro 960 GB |
| Motherboard | Tyan SP012 |
| PSU | Delta Electronics DSP-1200AB 1200W |
Intel's Xeon E5 Server – S2600WT (2U Chassis)
This is the same server that we used in our latest Xeon v4 review.
| CPU |
Xeon E5-2699 v4 |
| RAM | 256 GB (8x32GB) Samsung DDR4-2400 |
| Internal Disks | 2x Samsung 850Pro 960 GB |
| Motherboard | Intel Server Board Wildcat Pass |
| PSU | Delta Electronics 750W DPS-750XB A (80+ Platinum) |
Hyperthreading, Turbo, C1 and C6 were enabled in the BIOS.
Other Notes
All servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs in our Sizing Servers Lab.
Memory Subsystem: Bandwidth
As we mentioned before, the IBM POWER8 has a memory subsystem which is more similar to the Xeon E7's than the E5's. The IBM POWER8 connects to 4 "Centaur" buffer cache chips, which have both a 19.2 GB/s read and 9.6 GB/s write link to the processor, or 28.8 GB/s in total. So the 105 GB/s aggregate bandwidth of the POWER8 is not comparable to Intel's peak bandwidth. Intel's peak bandwidth is the result of 4 channels of DDR4-2400 that can either write or read at 76.8 GB/s (2.4 GHz x 8 bytes per channel x 4 channels).
Bandwidth is of course measured with John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with gcc 5.2.1 64 bit. The following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=120000000
The latter option makes sure that stream tests with array sizes which are not cacheable by the Xeons' huge L3 caches.
It is important to note why we use the GCC compiler and not vendors' specialized compilers: the GCC compiler is not as good at vectorizing the code. Intel's ICC compiler does that very well, and as result shows the bandwidth available to highly optimized HPC code, which is great for that code in the real world, but it's not realistic for multi-threaded server applications.
With ICC, Intel can use the very wide 256-bit load units to their full potential and we measured up to 65 GB/s per socket. But you also have to consider that ICC is not free, and GCC is much easier to integrate and automate into the daily operations of any developer. No licensing headaches, no time consuming registrations.
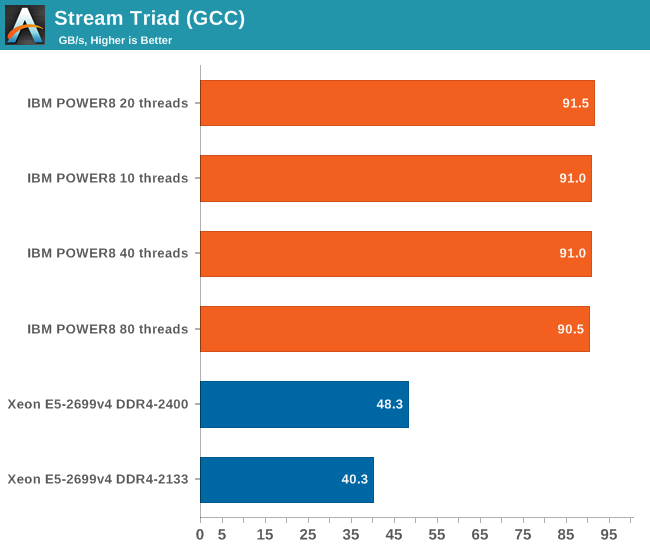
The combination of the powerful four load and two store subsystem of the POWER8 and the read/write interconnect between the CPU and the Centaur chips makes it much easier to offer more bandwidth. The IBM POWER8 delivers a solid 90 GB/s despite using old DDR3-1333 memory technology.
Intel claims higher bandwidth numbers, but those numbers can only be delivered in vectorized software.
Memory Subsystem: Latency Measurements
There is no doubt about it: the performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure latency. Our favorite tool to do this, Tinymembench, does not support the POWER architecture yet. That is a pity, because it is a lot more accurate and modern (as it can test with two outstanding requests).
The numbers we looked at were "Random load latency stride=16 Bytes" (LMBench).
| Mem Hierarchy |
IBM POWER8 | Intel Broadwell Xeon E5-2640v4 DDR4-2133 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache (cycles) | 3 | 4 | 4 |
| L2 Cache (cycles) | 13 | 12-15 | 12-15 |
| L3 Cache 4-8 MB(cycles) | 27-28 (8 ns) | 49-50 | 50 |
| 16 MB (ns) | 55 ns | 26 ns | 21 ns |
| 32-64 MB (ns) | 55-57 ns | 75-92 ns | 80-96 ns |
| Memory 96-128 MB (ns) | 67-74 ns | 90-91 ns | 96 ns |
| Memory 384-512 MB (ns) | 89-91 ns | 91-93 ns | 95 ns |
(Note that the numbers for Intel are higher than what we reported in our Cavium ThunderX review. The reason is that we are now using the numbers of LMBench and not those of Tinymembench.)
A 64 KB L1 cache with 4 read ports that can run at 4+ GHz speeds and still maintain a 3 cycle load latency is nothing less than the pinnacle of engineering. The L2 cache excels too, being twice as large (512 KB) and still offering the same latency as Intel's L2.
Once we get to the eDRAM L3 cache, our readings get a lot more confusing. The L3 cache is blistering fast as long as you only access the part that is closest to the core (8 MB). Go beyond that limit (16 MB), and you get a latency that is no less than 7 times worse. It looks like we actually hitting the Centaur chips, because the latency stays the same at 32 and 64 MB.
Intel has a much more predictable latency chart. Xeon's L3 cache needs about 50 cycles, and once you get into DRAM, you get a 90-96 ns latency. The "transistion phase" from 26 ns L3 to 90 ns DRAM is much smaller.
Comparatively, that "transition phase" seems relatively large on the IBM POWER8. We have to go beyond 128 MB before we get the full DRAM latency. And even then the Centaur chip seems to handle things well: the octal DDR-3 1333 MHz DRAM system delivers the same or even slightly better latency as the DDR4-2400 memory on the Xeon.
In summary, IBM's POWER8 has a twice as fast 8 MB L3, while Intel's L3 is vastly better in the 9-32 MB zone. But once you go beyond 32 MB, the IBM memory subsystem delivers better latency. At a significant power cost we must add, because those 4 memory buffers need about 64 Watts.
Single-Threaded Integer Performance: SPEC CPU2006
Even though SPEC CPU2006 is more HPC and workstation oriented, it contains a good variety of integer workloads. Running SPEC CPU2006 is a good way to evaluate single threaded (or core) performance. The main problem is that the results submitted are "overengineered" and it is very hard to make any fair comparisons.
For that reason, we wanted to keep the settings as "real world" as possible. So we used:
- 64 bit gcc 5.2.1: most used compiler on Linux, good all round compiler that does not try to "break" benchmarks (libquantum...)
- -Ofast: compiler optimization that many developers may use
- -fno-strict-aliasing: necessary to compile some of the subtests
- base run: every subtest is compiled in the same way.
The ultimate objective is to measure performance in applications where for some reason – as is frequently the case – a "multi-thread unfriendly" task keeps us waiting.
Here is the raw data. Perlbench failed to compile on Ubuntu 15.10, so we skipped it. Still we are proud to present you the very first SPEC CPU2006 benchmarks on Little Endian POWER8.
On the IBM server, numactl was used to physically bind the 2, 4, or 8 copies of SPEC CPU to the first 2, 4, or 8 threads of the first core. On the Intel server, the 2 copy benchmark was bound to the first core.
| Subtest SPEC CPU2006 Integer |
Application Type |
IBM POWER8 [email protected] Single Thread |
IBM POWER8 [email protected] SMT-2 |
IBM POWER8 [email protected] SMT-4 |
IBM POWER8 [email protected] SMT-8 |
Xeon E5-2699 v4 2.2-3.6 |
Xeon E5-2699 v4 2.2-3.6 (+HT) |
| 400.perlbench | Spam filter | N/A | N/A | N/A | N/A | 32.2 | 36.6 |
| 401.bzip2 | Compress | 17.5 | 26.9 | 33.7 | 35.2 | 19.2 | 25.3 |
| 403.gcc | Compiling | 32.1 | 44.6 | 56.6 | 61.5 | 28.9 | 33.3 |
| 429.mcf | Vehicle scheduling | 47.1 | 50 | 64.1 | 73.5 | 39 | 43.9 |
| 445.gobmk | Game AI | 20.2 | 31.3 | 41.4 | 43.1 | 22.4 | 27.7 |
| 456.hmmer | Protein seq. analyses | 19.1 | 27.1 | 28.6 | 22.5 | 24.2 | 28.4 |
| 458.sjeng | Chess | 17.1 | 25.4 | 32.6 | 33.1 | 24.8 | 28.3 |
| 462.libquantum | Quantum sim |
44.7 | 82.1 | 109 | 108 | 59.2 | 67.3 |
| 464.h264ref | Video encoding | 32.7 | 45.4 | 53.3 | 48.8 | 40.7 | 40.7 |
| 471.omnetpp | Network sim |
23.5 | 29.1 | 37.1 | 42.5 | 23.5 | 29.9 |
| 473.astar | Pathfinding | 16.5 | 24.8 | 33.5 | 36.9 | 18.9 | 23.6 |
| 483.xalancbmk | XML processing | 24.9 | 35.3 | 44.7 | 48.4 | 35.4 | 41.8 |
First we look at how well SMT-2, SMT-4 and SMT-8 work on the IBM POWER8.
| Subtest SPEC CPU2006 Integer |
Application Type |
IBM POWER8 [email protected] Single Thread |
IBM POWER8 [email protected] SMT-2 |
IBM POWER8 [email protected] SMT-4 |
IBM POWER8 [email protected] SMT-8 |
| 400.perlbench | Spam filter | N/A | N/A | N/A | N/A |
| 401.bzip2 | Compress | 100% | 154% | 193% | 201% |
| 403.gcc | Compiling | 100% | 139% | 176% | 192% |
| 429.mcf | Vehicle scheduling | 100% | 106% | 136% | 156% |
| 445.gobmk | Game AI | 100% | 155% | 205% | 213% |
| 456.hmmer | Protein seq. analyses | 100% | 142% | 150% | 118% |
| 458.sjeng | Chess | 100% | 149% | 191% | 194% |
| 462.libquantum | Quantum sim |
100% | 184% | 244% | 242% |
| 464.h264ref | Video encoding | 100% | 139% | 163% | 149% |
| 471.omnetpp | Network sim |
100% | 124% | 158% | 180% |
| 473.astar | Pathfinding | 100% | 150% | 203% | 224% |
| 483.xalancbmk | XML processing | 100% | 142% | 180% | 194% |
The performance gains from single threaded operation to two threads are very impressive, as expected. While Intel's SMT-2 offers in most subtests between 10 and 25% better performance, the dual threaded mode of the POWER8 boosts performance by 40 to 50% in most applications, or more than twice as much relative to the Xeons. Not one benchmark regresses when we throw 4 threads upon the IBM POWER8 core. The benchmarks with high IPC such as hmmer peak at SMT-4, but most subtests gain a few % when running 8 threads.
Multi-Threaded Integer Performance on one core: SPEC CPU2006
Broadly speaking, the value of SPEC CPU2006's int rate test is questionable, as it puts too much emphasis on bandwidth and way too little emphasis on data synchronization. However, it does give some indication of the total "raw" integer compute power available.
We will make an attempt to understand the differences between IBM and Intel, but to be really accurate we would need to profile the software and runs dozens of tests while looking at the performance counters. That would have set back this article a bit too much. So we can only make an educated guess based upon what the existing academic literature says and our experiences with both architectures.
The Intel CPU performance is the 100% baseline in each column.
| Subtest SPEC CPU2006 Integer |
Application Type |
IBM POWER8 vs Xeon E5-2699v4 Single Thread |
IBM POWER8 vs Xeon E5-2699v4 Max Thread |
IBM POWER8 vs Xeon E5-2699v4 Top performance |
| 400.perlbench | Spam filter | N/A | N/A | N/A |
| 401.bzip2 | Compress | 91% | 139% | 139% |
| 403.gcc | Compiling | 111% | 185% | 185% |
| 429.mcf | Vehicle scheduling | 121% | 167% | 167% |
| 445.gobmk | Game AI | 90% | 156% | 156% |
| 456.hmmer | Protein seq. analyses | 79% | 79% | 101% |
| 458.sjeng | Chess | 69% | 117% | 117% |
| 462.libquantum | Quantum sim |
76% | 160% | 162% |
| 464.h264ref | Video encoding | 80% | 120% | 131% |
| 471.omnetpp | Network sim |
100% | 141% | 141% |
| 473.astar | Pathfinding | 87% | 156% | 156% |
| 483.xalancbmk | XML processing | 70% | 116% | 116% |
On (geometric) average, a single thread running on the IBM POWER8 core runs about 13% slower than on an Intel Broadwell architecture core. So our suspicion that Intel is still a bit better at extracting parallelism when running a single thread is confirmed.
Intel gains the upper-hand in the applications where branch prediction plays an important role: chess (sjeng), pathfinding (astar), protein seq. analysis (hmmer), and AI (gobmk). Intel's branch misprediction penalty is lower if the other branch is available in the µop cache (the Decode Stream Buffer) and Intel has a few clever tricks that the IBM core does not have like the loop stream detector.
Where the POWER8 core shines is in the benchmarks where memory latency is important and where the load units are a bottleneck, like vehicle scheduling (mcf). This is also true, but in lesser degree, for the network simulation (omnetpp). The reason might be that omnetpp puts a lot of pressure on the OoO buffers, and Intel's architecture offers more room with its unified buffers, whereas IBM POWER8's buffers are more partitioned (see for example the issue queue). Meanwhile XML processing does a lot of pointer chasing, but quick profiling has shown that this benchmark mostly hits the L2, and somewhat the L3. So there's no disadvantage for Intel there. On the flip side, Xalancbmk is the benchmark with the highest pressure on the ROB. Again, the larger OOO buffers for one thread might help Intel to do better.
POWER8 also does well in GCC, which has a high percentage of branches in the instruction mix, but very few branch mispredictions. GCC compiling is latency sensitive, so a 3 cycle L1, a 13 cycle L2, and the fast 8MB L3 help.
Finally, the pathfinding (astar) benchmark does some intensive pointer chasing, but it misses the L1- and L2-cache much less often than xalancbmk, and has the highest amount of branch misprediction. So the impact of the pointer chasing and memory latency is thus minimal.
Once all threads are active, the IBM POWER8 core is able to outperform the Intel CPU by 41% (geomean average).
Closing Thoughts
Testing both the IBM POWER8 and the Intel Xeon V4 with an unbiased compiler gave us answers to many of the questions we had. The bandwidth advantage of POWER8's subsystem has been quantified: IBM's most affordeable core can offer twice as much bandwidth than Intel's, at least if your application is not (perfectly) vectorized.
Despite the fact that POWER8 can sustain 8 instructions per clock versus 4 to 5 for modern Intel microarchitectures, chips based on Intel's Broadwell architecture deliver the highest instructions per clock cycle rate in most single threaded situations. The larger OoO buffers (available to a single thread!) and somewhat lower branch misprediction penalty seem to the be most likely causes.
However, the difference is not large: the POWER8 CPU inside the S812LC delivers about 87% of the Xeon's single threaded performance at the same clock. That the POWER8 would excel in memory intensive workloads is not a suprise. However, the fact that the large L2 and eDRAM-based L3 caches offer very low latency (at up to 8 MB) was a surprise to us. That the POWER8 won when using GCC to compile was the logical result but not something we expected.

The POWER8 microarchitecture is clearly built to run at least two threads. On average, two threads gives a massive 43% performance boost, with further peaks of up to 84%. This is in sharp contrast with Intel's SMT, which delivers a 18% performance boost with peaks of up to 32%. Taken further, SMT-4 on the POWER8 chip outright doubles its performance compared to single threaded situations in many of the SPEC CPU subtests.
All in all, the maximum throughput of one POWER8 core is about 43% faster than a similar Broadwell-based Xeon E5 v4. Considering that using more cores hardly ever results in perfect scaling, a POWER8 CPU should be able to keep up with a Xeon with 40 to 60% more cores.
To be fair, we have noticed that the Xeon E5 v4 (Broadwell) consumes less power than its formal TDP specification, in notable contrast to its v3 (Haswell) predecessor. So it must be said that the power consumption of the 10 core POWER8 CPU used here is much higher. On paper this is 190W + 64W Centaur chips, versus 145W for the Intel CPU. Put in practice, we measured 221W at idle on our S812LC, while a similarly equipped Xeon system idled at around 90-100W. So POWER8 should be considered in situations where performance is a higher priority than power consumption, such as databases and (big) data mining. It is not suited for applications that run close to idle much of the time and experience only brief peaks of activity. In those markets, Intel has a large performance-per-watt advantage. But there are definitely opportunities for a more power hungry chip if it can deliver significantly greater performance.
Ultimately the launch of IBM's LC servers deserves our attention: it is a monumental step forward for IBM to compete with Intel in a much larger part of the market. Those servers seem to be competitively priced with similar Xeon systems and can access the same Little Endian data as an x86 server. But can POWER8 based system really deliver a significant performance advantage in real server applications? In the next article we will explore the S812LC and its performance in a real server situations, so stay tuned.






