Original Link: https://www.anandtech.com/show/10158/the-intel-xeon-e5-v4-review
The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell

We have been spoiled. Since the introduction of the Xeon "Nehalem" 5500 (Xeon 5500, March 2009), Intel has been increasing the core counts of their Xeon CPUs by nearly 50% almost every 18 months. We went from four to six (Xeon 5600) on June 2010. Sandy Bridge (Xeon E5-2600, March 2012) increased the core count to 8. That is only 33% more cores, but each core was substantially faster than the previous generation. Ivy Bridge EP (Xeon E5-2600 v2, launched September 2013) increased the core count from 8 to 12, the Haswell-EP (Xeon E5-2600 v3, sept 2014) surprised with an 18-core flagship SKU.
However it could not go on forever. Sooner or later Intel would need to slow down a bit on adding cores, for both power and space reasons, and today Intel has finally pumped the brakes a bit.
Launching today is the latest generation of Intel's Xeon E5 processors, the Xeon E5 v4 series.Fifteen months after Intel's Broadwell architecture and 14nm process first reached consumers, Broadwell has finally reached the multi-socket server space with Broadwell-EP. Like past EP cores, Broadwell-EP is the bigger, badder sibling of the consumer Broadwell parts, offering more cores, more memory bandwidth, more cache, and more server-focused features. And thanks to the jump from their 22nm process to their current-generation 14nm process, Intel gets to reap the benefits of a smaller, denser process.
Getting back to our discussion of core counts then, even with the jump to 14nm, Intel has played it more conservatively with their core counts. Compared to the Xeon E5 v3 (Haswell-EP), Xeon E5 v4 (Broadwell-EP) makes a smaller jump, going from 18 cores to 24 cores, for an increase of 33%. Yet even then, for the new Xeon E5 v4 "only" 22 cores are activated, so we won't get to see everything Broadwell-EP is capable of right away.
Meanwhile the highest (turbo) clockspeed is still 3.6 GHz, base clocks are reduced with one or two steps and the core improvements are very modest (+5%). Consequently, performance wise, this is probably the least spectacular product refresh we have seen in many years.
But there are still enough paper specs that make the Broadwell version of the Xeon E5 attractive. It finds a home in the same LGA 2011-3 socket. Few people will in-place upgrade from Xeon E5 v3s to Xeon E5 v4s, but using the same platform means less costs for the server vendors, and more software maturity (drivers etc.) for the buyers.

They look very different but fit in the same socket: Xeon E5 v4 on top, Xeon E5 v3 at the bottom
Broadwell also has several features that make it a more attractive processor for virtualized servers. Finer granular control over how applications share the uncore (caches and memory bandwidth) to avoid scenarios where low priority applications slow down high priority ones. Meanwhile quite a few improvements have been made to make the I/O intensive applications run smoother on top of a virtualized layer. Most businesses run their applications virtualized and virtualization is still the key ingredient of the fast growing cloud services (Amazon, Digital Ocean, Azure...), and more and more telecom operators are starting to virtualized their services, so these new features will definitely be put to good use. And of course, Intel made quite a few subtle - but worth talking about - tweaks to keep the HPC (mostly "simulation" and "scientific calculation software) crowd happy.
But don't make the mistake to think that only virtualization and HPC are the only candidates for the new up-to-22-cores Xeons. The newest generation of data analytics frameworks have made enormous performance steps forward by widening the network and storage bandwidth bottlenecks. One example is Apache Spark, which can crunch through terabytes of data much more efficiently than its grandparent Hadoop by making better use of RAM. To get results out of a massive hump of text data, for example, you can use some of most advanced statistical and machine learning algorithms. Mix machine learning with data mining and you get an application that is incredibly CPU-hungry but does not need the latest and fastest NVMe-based SSDs to keep the CPU busy.
Yes, we are proud to present our new benchmark based upon Apache Spark in this review. Combining analytics software with machine learning to get deeper insights is one of the most exciting trends in the enterprise world. And it is also one of the reason why even a 22-core Broadwell is still not fast enough.
Broadwell-EP: A 10,000 Foot View
What are the building blocks of a 22-core Xeon? The short answer: 24 cores, 2.5 MB L3-cache per core, 2 rings connected by 2 bridges (s-boxes) and several PCIe/QPI/home "agents".
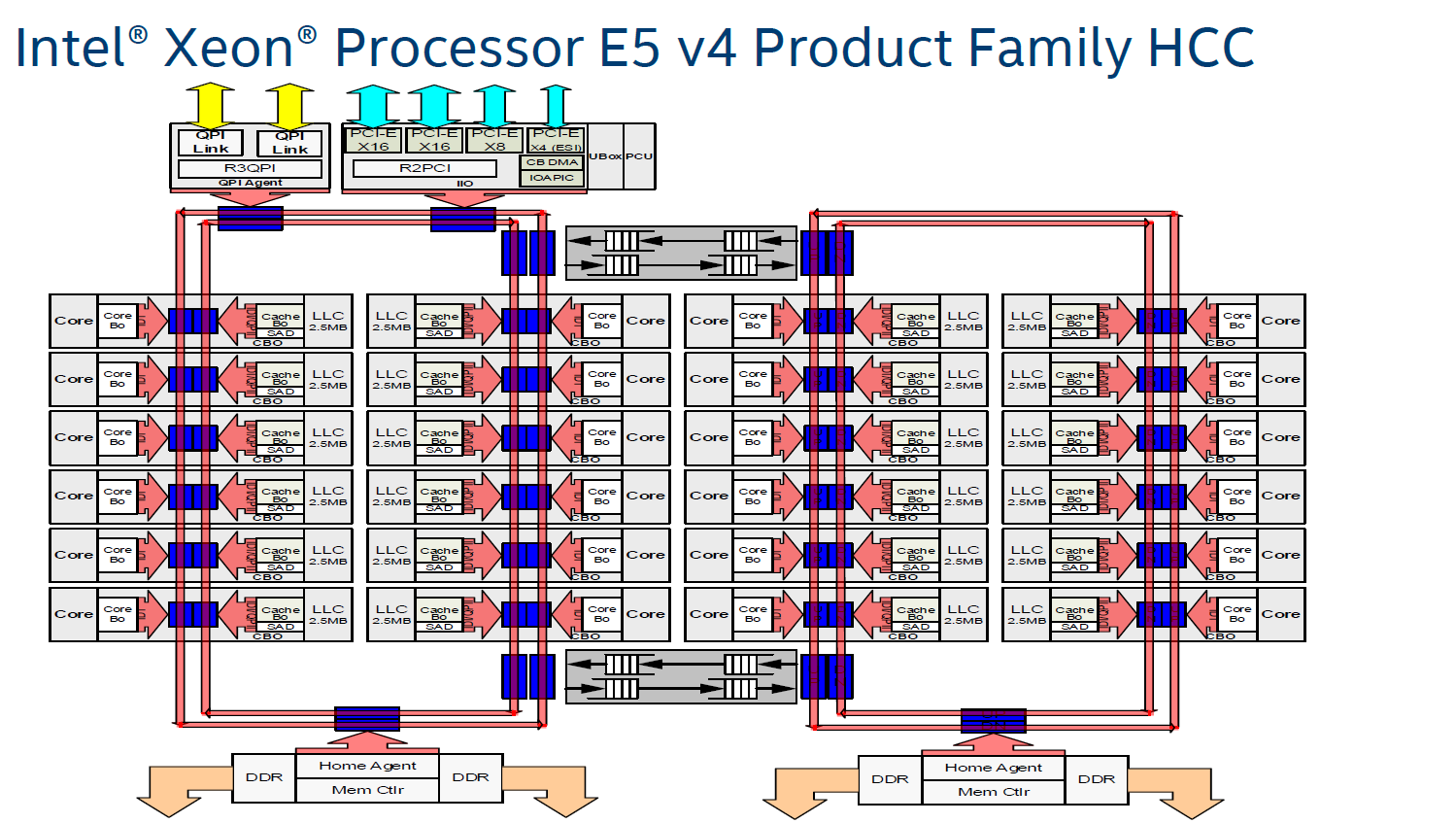
The fact that only 22 of those 24 cores are activated in the top Xeon E5 SKU is purely a product differentiation decision. The 18 core Xeon E5 v3 used exactly the same die as the Xeon E7, and this has not changed in the new "Broadwell" generation.
The largest die (+/- 454 mm²), highest core (HCC) count SKUs still work with a two ring configuration connected by two bridges. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. The blue points indicate where data can jump onto the ring buses. Physical addresses are evenly distributed over the different cache slices (each 2.5 MB) to make sure that L3-cache accesses are also distributed, as a "hotspot" on one L3-cache slice would lower performance significantly. The L3-cache latency is rather variable: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles..
Meanwhile rings and other entities of the uncore work on a separate voltage plane and frequency. Power can be dynamically allocated to these entities, although the uncore parts are limited to 3 GHz.
Just like Haswell-EP, the Broadwell-EP Xeon E5 has three different die configurations. The second configuration supports 12 to 15 cores and is a smaller version (306mm²) of the third die configuration that we described above. These dies still have two memory controllers.
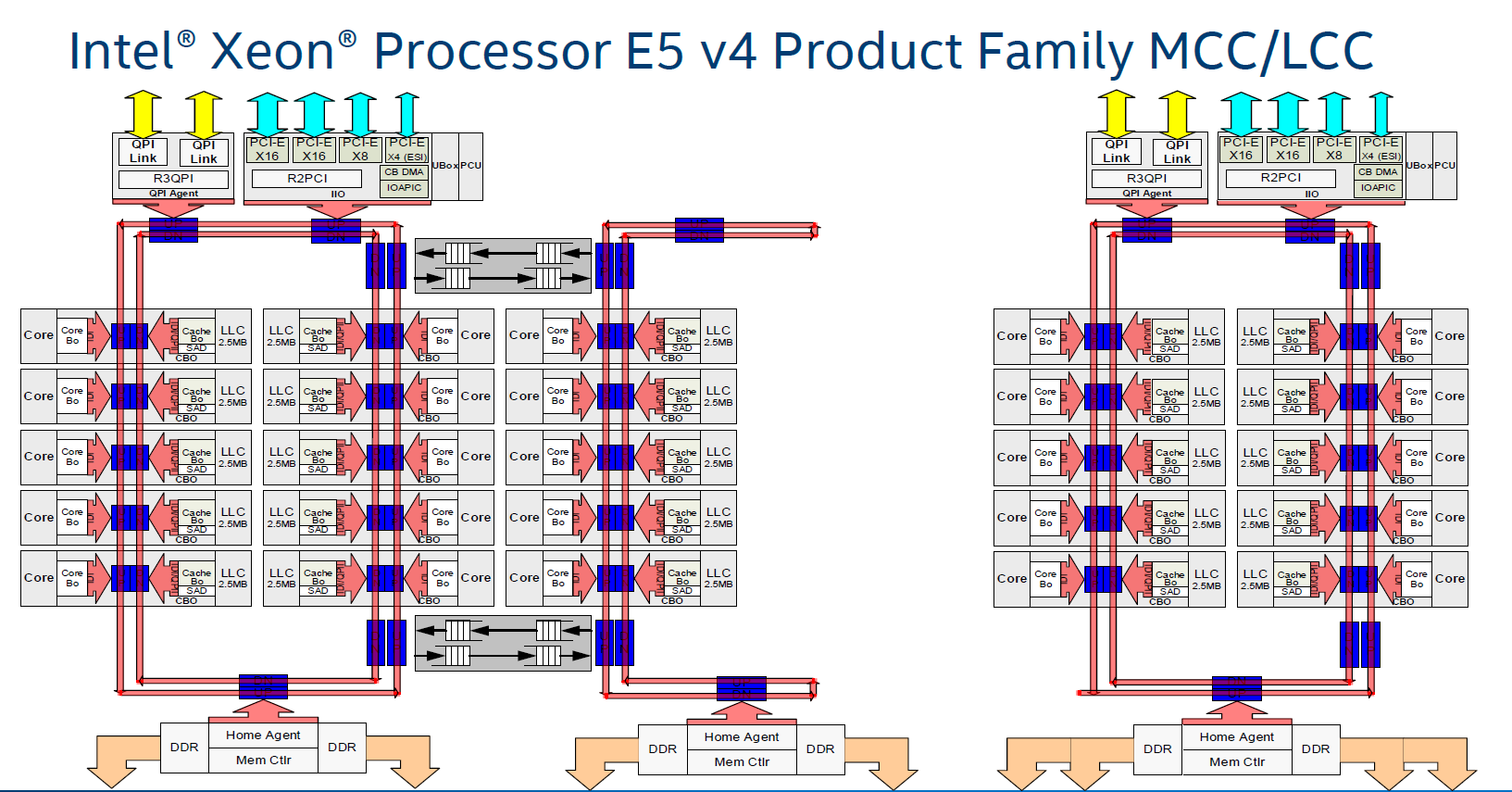
Otherwise the smallest 10 core die uses only one dual ring, two columns of cores, and only one memory controller. However, the memory controller drives 4 channels instead of 2, so there is a very small bandwidth penalty (5-10%) compared to the larger dies (HCC+MCC) with two memory controllers. The smaller die has a smaller L3-cache of course (25 MB max.). As the L3-cache gets smaller, latency is also a bit lower.
Cache Coherency
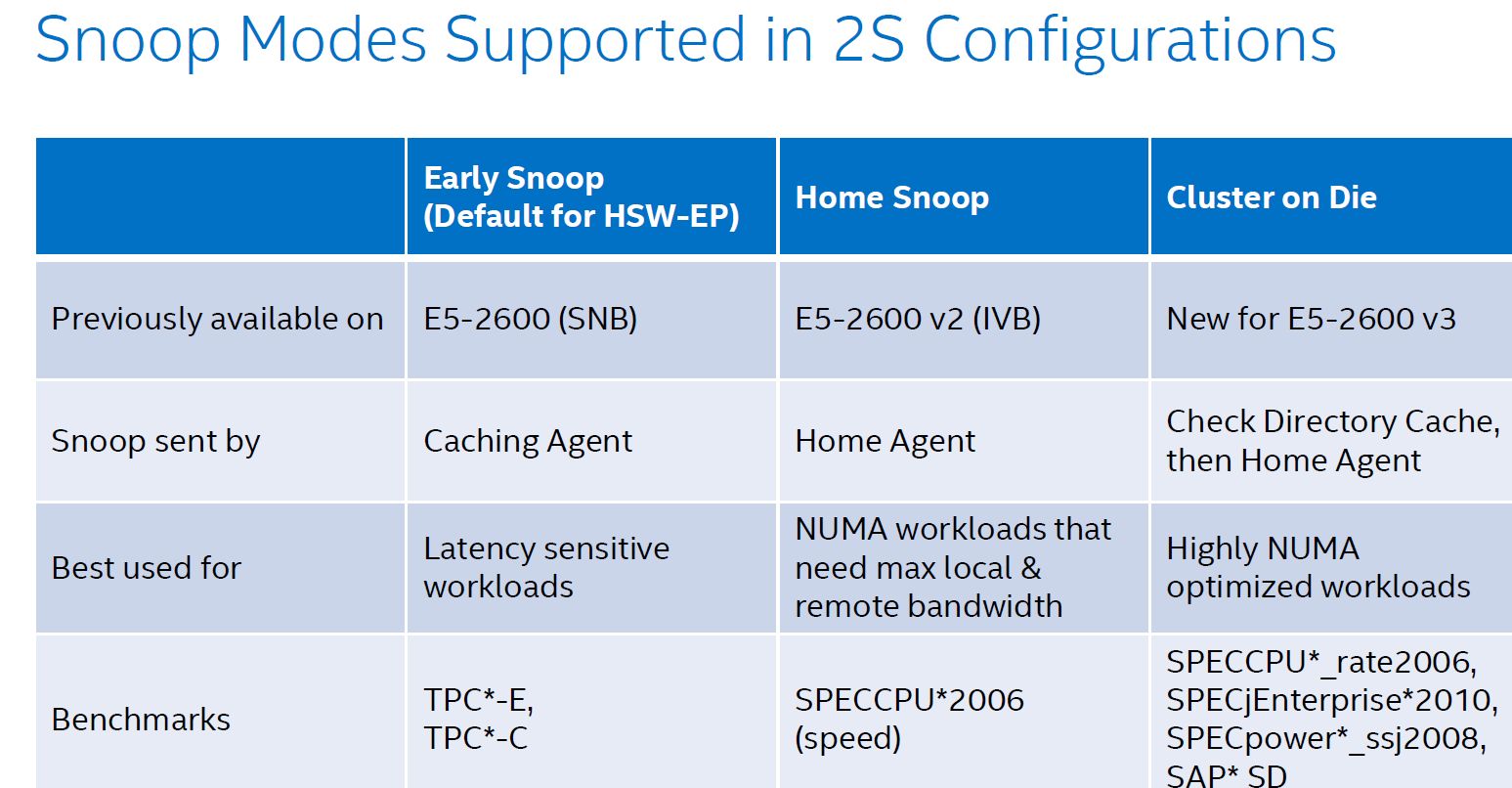
As the core count goes up, it gets increasingly complex to keep cache coherency. Intel uses the MESIF (Modified, Exclusive, shared, Invalid and Forward) protocol for cache coherency. The Home Agents inside the memory controller and the caching agents inside the L3-cache slice implement the cache coherency. To maintain consistency, a snoop mechanism is necessary. There are now no less than 4 different snoop methods.
The first, Early Snoop, was available starting with Sandy Bridge-EP models. With early snoop, caching agents broadcast snoop requests in the event of an L3-cache miss. Early snoop mode offers low latency, but it generates massive broadcasting traffic. As a result, it is not a good match for high core count dies running bandwidth intensive applications.
The second mode, Home Snoop, was introduced with Ivy Bridge. Cache line requests are no longer broadcasted but forwarded to the home agent in the home node. This adds a bit of latency, but significantly reduces the amount of cache coherency traffic.
Haswell-EP added a third mode, Cluster on Die (CoD). Each home agent has 14 KB directory cache. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. In the event of a request, it is checked first, and the directory cache returns a hit, snoops are only sent to indicated (by the directory cache) agents.
On Broadwell-EP, the dice are indeed split along the rings: all cores on one ring are one NUMA node, all other cores on the other ring make the second NUMA node. On Haswell-EP, the split was weirder, with one core of the second ring being a member of the first cluster. On top of that, CoD splits the processor in two NUMA nodes, more or less one node per ring.
The fourth mode, introduced with Broadwell EP, is the "home snoop" method, but improved with the use of the directory cache and yet another refinement called opportunistic snoop broadcast. This mode already starts snoops to the remote socket early and does the read of the memory directory in parallel instead of waiting for the latter to be done. This is the default snoop method on Broadwell EP.
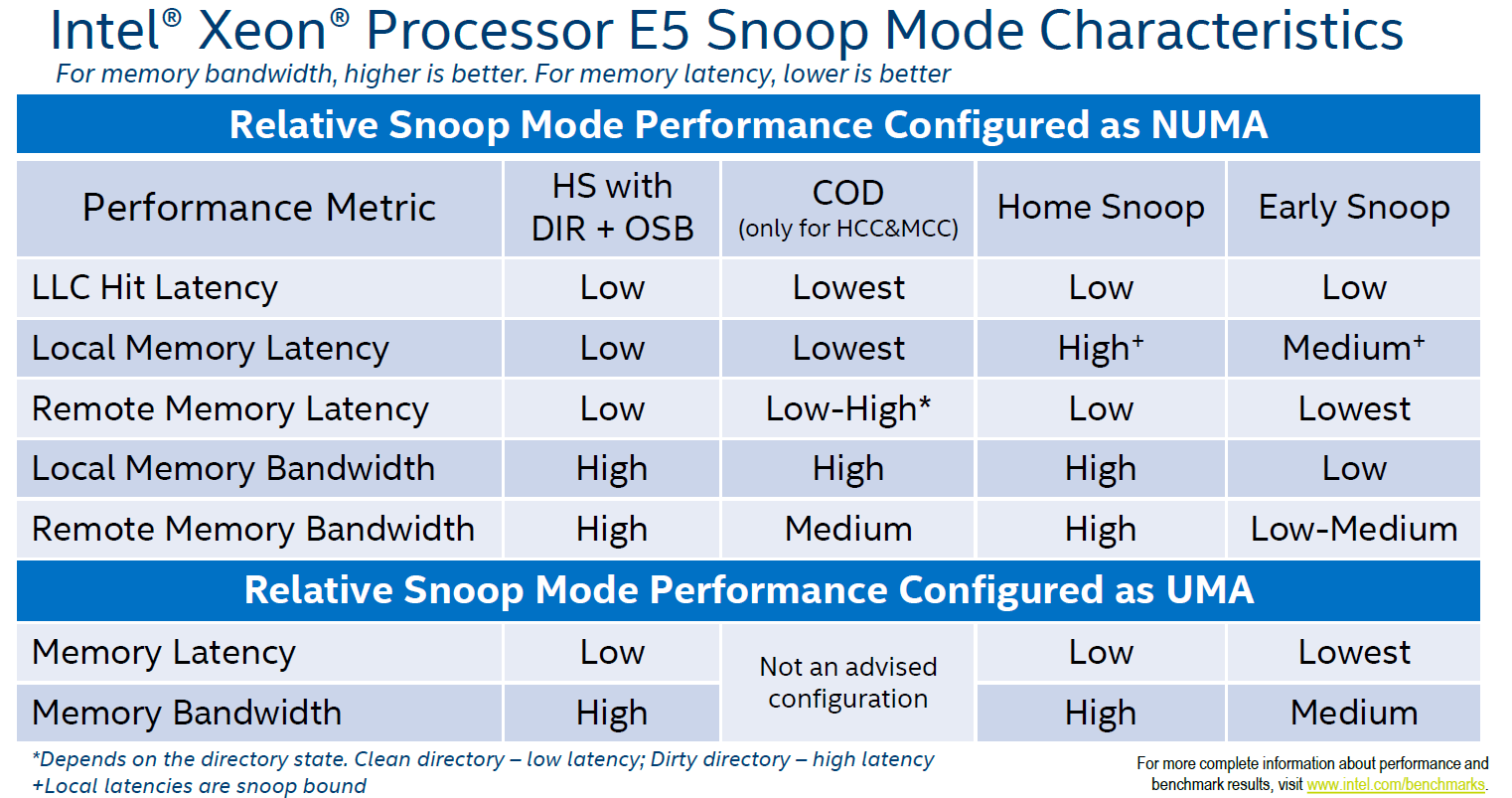
This opportunistic snooping lowers the latency to remote memory.
These snoop modes can be set in the BIOS as you can see above.
A Modest Tick
As Broadwell is a tick - a die shrink of an existing architecture, rather than a new architecture - so you should expect modest IPC improvements. Most Xeon E5 v4 SKUs have slightly lower clockspeeds compared to their Haswell v3 brethren, so overall the single threaded performance has hardly improved. Clock for clock, Intel tells us that their simulation tools show that Broadwell delivers about 5% better performance per clock in non-AVX2 traces.
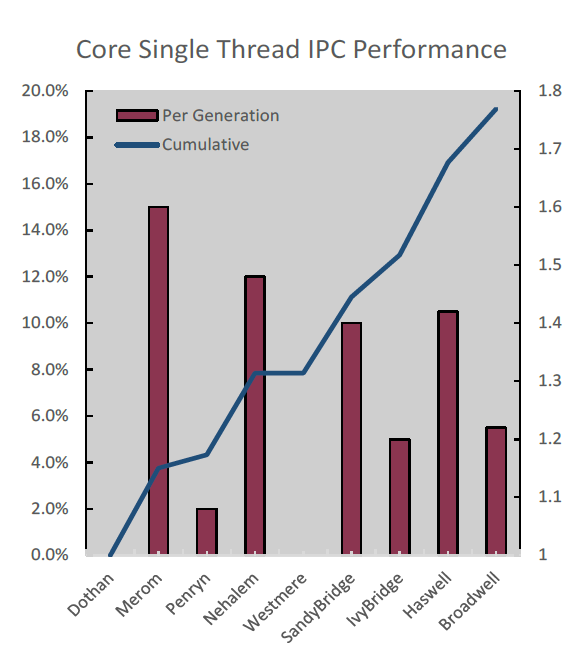
First Y-axis + bars: simulated single threaded performance improvement. Blue line + second Y-axis is the cumulative improvement.
In that sense, Broadwell is basically a Haswell made on Intel's 14nm second generation tri-gate transistor process. Intel did make a few subtle improvements to the micro-architecture:
- Faster divider: lower latency & higher throughput
- AVX multiply latency has decreased from 5 to 3
- Bigger TLB (1.5k vs 1k entries)
- Slightly improved branch prediction (as always)
- Larger scheduler (64 vs 60)
None of these improvements will yield large performance improvements. The larger improvements must come from other features.
New Features
Compared to Haswell-EP, Broadwell-EP also includes some new features. The first one is the improved power control unit.
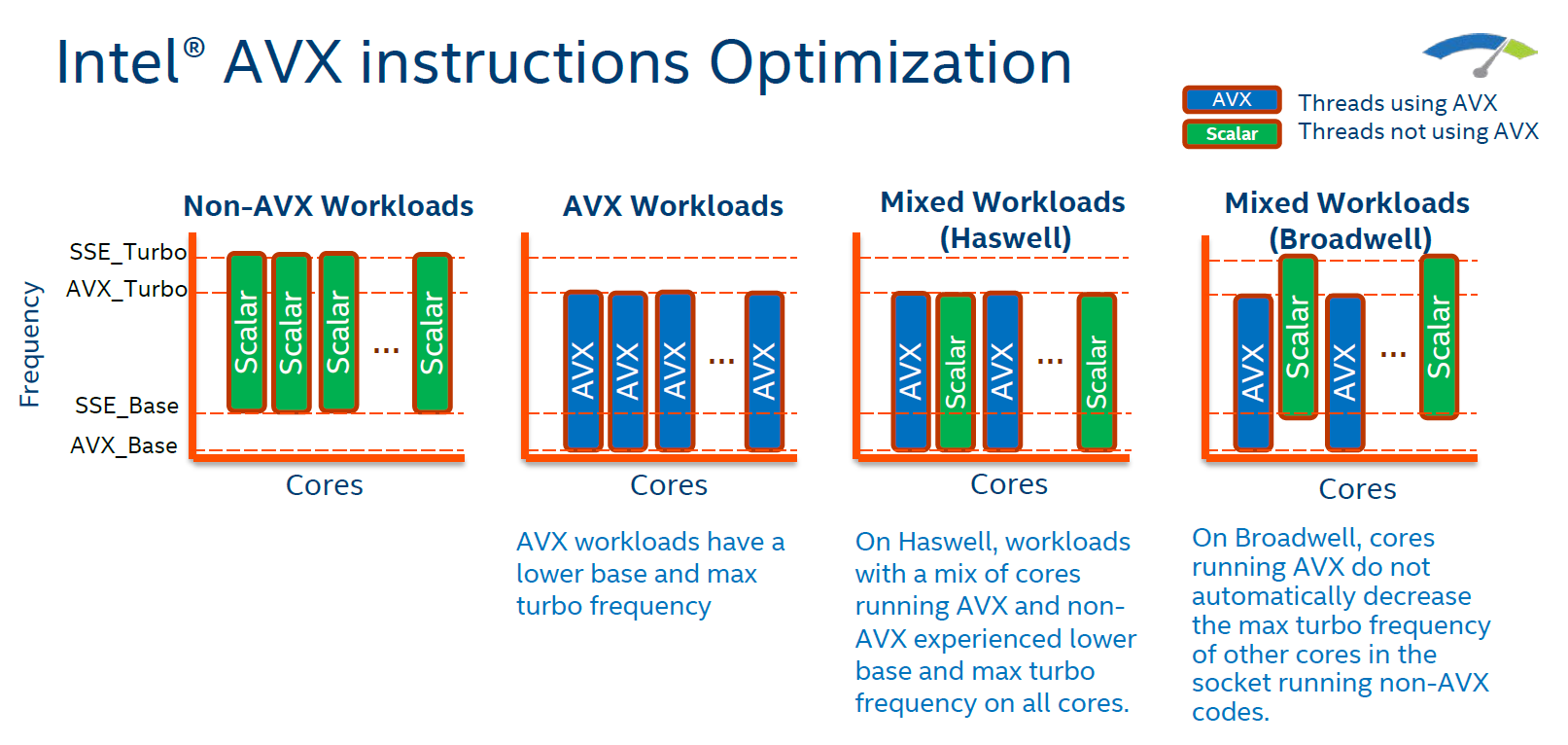
On Haswell, one AVX instruction on one core forced all cores on the same socket to slow down their clockspeed by around 2 to 4 speed bins (-200,-400 MHz) for at least 1 ms, as AVX has a higher power requirement that reduces how much a CPU can turbo. On Broadwell, only the cores that run AVX code will be reducing their clockspeed, allowing the other cores to run at higher speeds.
The other performance feature is the vastly improved PCLMULQDQ (carry-less multiplication) instruction: throughput has been doubled, and latency reduced from 7 cycles to 5.

This increases AES (symmetric) encryption performance by 20-25%, and CRCs (Cyclic Redundancy check) are up to 90% faster. Broadwell also has some new ADCX/ADOX instructions to speed up asymmetric encryption algorithms such as the popular RSA. These improvements are implemented in OpenSSL 1.0.2-beta3. But don't expect too much from it.. The compute intensive asymetric encryption is mostly used to initiate a secure connection. Most modern web applications keep their sessions "alive", and as a result, events that require asymmetric encryption happen a lot less frequentely . Symmetric encryption (like AES) which is used to send encrypted data is a lot lighter, so even on a fully encrypted website with long encrypted data streams, encryption is only a small percentage (<5%) of the total computing load.
Sharing Cache and Memory Resources
In a virtualized environment, the hosted VMs are sharing both the CPU caches and the overall DRAM memory bandwidth. One cache-hungry application can quickly hog most of the shared L3 caches, and a bandwidth intensive one can do the same with the available and shared memory bandwidth. These VMs create the "noisy neighbor" problem. That is bad news for anyone consolidating a lot of VMs on top of a Xeon server, but it is complete show stopper for telco and other scenarios where service providers want to guarantee "Quality-of-Service" (QoS) and thus predictable latency. For Intel this is a notable scenario to address, as the telco market is one of the few markets where the Xeons still have some room to grow. Many telco applications still run on proprietary boxes, which makes virtualization a tantalizing option if Intel can deliver the necessary latency.
Haswell had already some features to monitor cache usage, which in turn allowed you to identify the noisy neighbors. However the "Resource Director Technology" (RDT) of Broadwell can do a lot more.
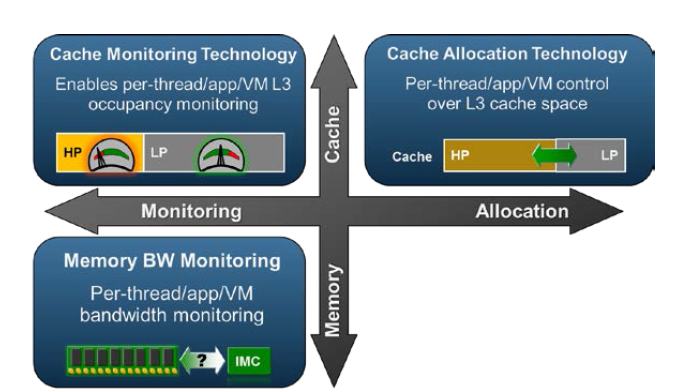
RDT can not only monitor L3 cache usage and memory bandwidth, but it can also allocate L3-cache space on a per thread/process/virtual machine basis. Threads are assigned a Resource Monitoring ID. Eight of these RMID are available per core/cache slice. Sixteen different classes of service can be assigned to an RMID: higher priority threads/applications can get a higher class, and thus a larger portion of the L3-cache.
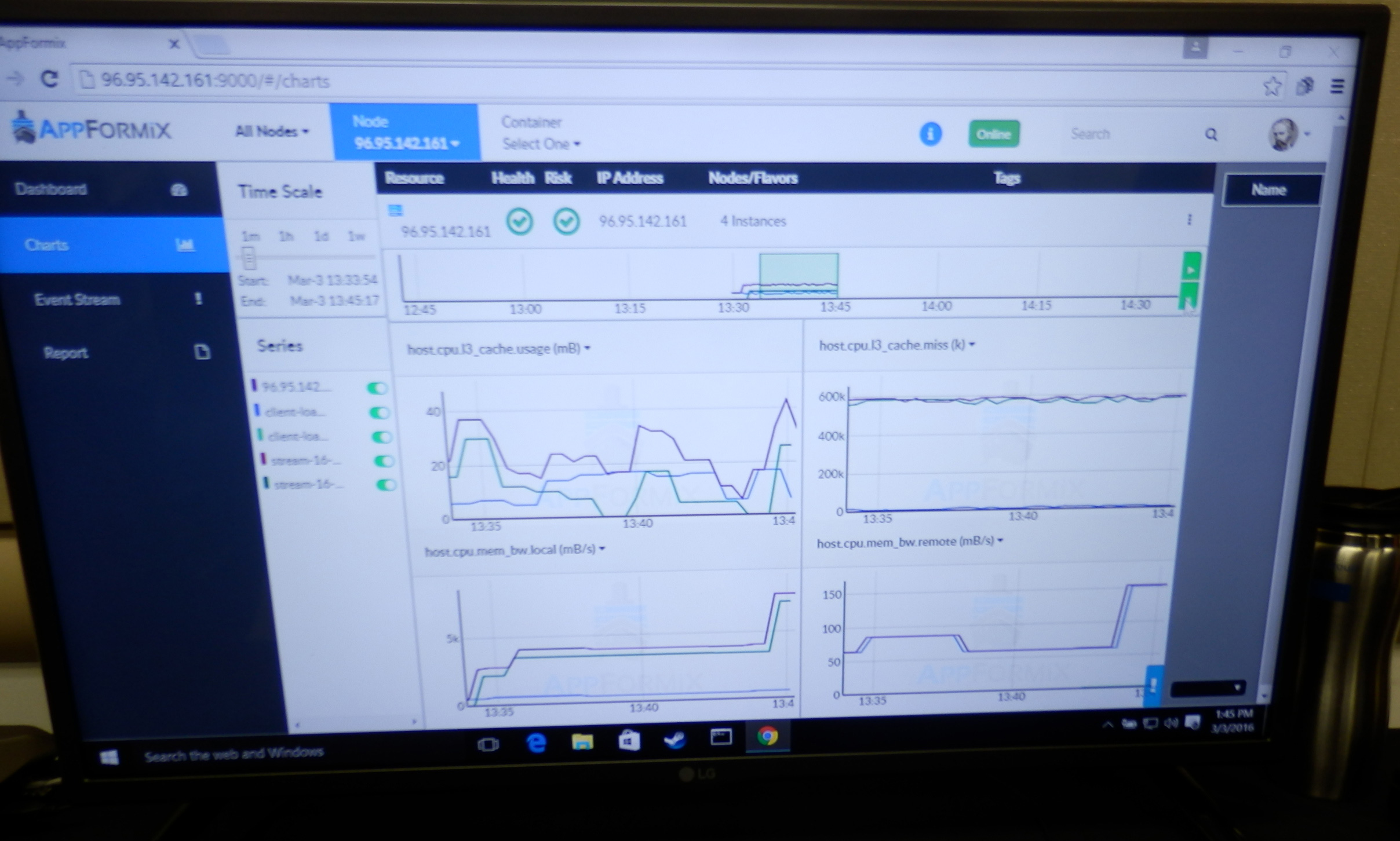
Intel has already demonstrated an application that made use of these new MSRs to read out memory bandwidth and L3 cache consumption on different levels.
TSX
TSX or Transactional Synchronization Extensions is Intel's cache-based transactional memory system. Intel launched TSX with Haswell, but a bug threw a spanner in the works. Broadwell in turn got it right. The chicken is finally there, now it's time to enjoy the eggs.
Faster Virtualization
Virtualization overhead is (for most people) a thing of the past. The performance overhead with bare metal hypervisors (ESXi, Hyper-V, Xen, KVM..) is less than a few percent. There is one exception however: applications where I/O dominates. And of course, the packet switching telco applications are the prime examples. Intel, VMware and the server vendors really want to convert the telcos from their Firewall/Router/VPN "black boxes" to virtual ones using Software Defined Networking (SDN) infrastructure. To that end, Intel has continued to work on reducing the virtualization performance overhead. Virtualization overhead can be described as the number of VM exits (VM stops and hypervisor takes over) times the VM exit latency. In IO intensive application, VM exits happen frequently, which in turn leads to hard to predict and high IO latency, exactly what the telco people hate.
Intel wants to conquer the telco's datacenter by turning it into a SDN
So Intel worked on both factors. So Broadwell-DP VM exit latency is once again reduced from 500 cycles to 400.
It seems that the "ticks" also get a VM exit reduction. This slide of the Ivy Bride EP presentation gives you a very good overview of the VM exits in a network intensive application; in this case a networkd bandwidth benchmark application.
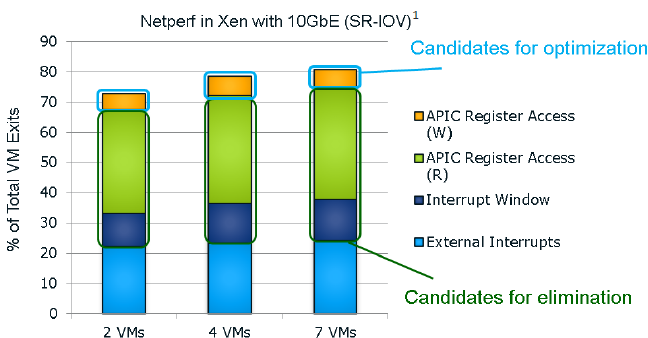
I quote from our Ivy Bridge-EP review:
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparently, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
In summary, Intel eliminated the green and dark blue components of the VM exit overhead with APICv. Broadwell now takes on the VM exits due to the external interrupts.
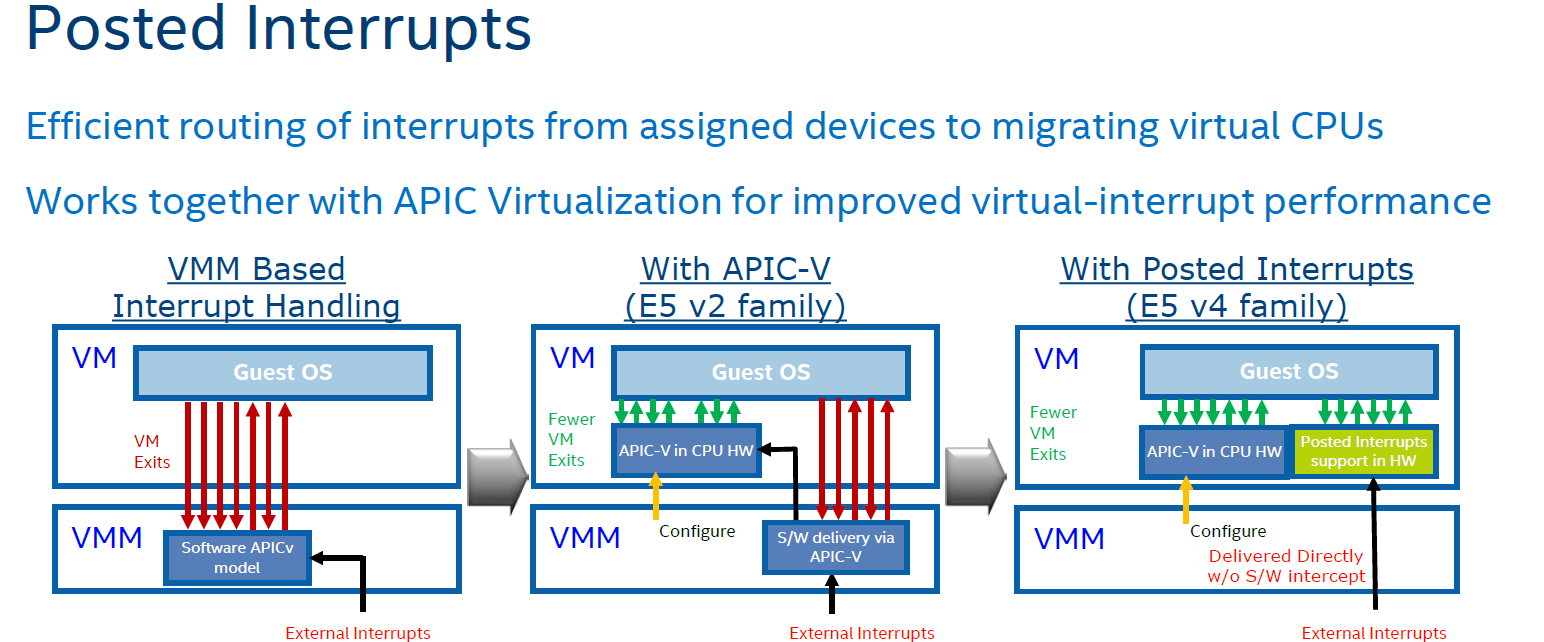
The technology on Broadwell-EP to do this is called posted interrupt. Essentially, posted interrupts enables direct interrupt delivery to the virtual machine without incurring a VM exit, courtesy of an interrupt remapping table. It is very similar to VT-D, which allowed DMA remapping thanks to the physical to virtual memory mapping table. Telco applications - among others - are very latency sensitive. Intel's Edwin Verplancke gave us one such example: before posted interrupts, a telco application had a latency varying from 4 to 47 (!) µsec, depending on the load. Posted interrupts made this a lot less variable, and latency varied from 2.4 to 5.2 µsecs.
As far as we are aware, KVM and Xen seem to have already implemented support for posted interrupts.
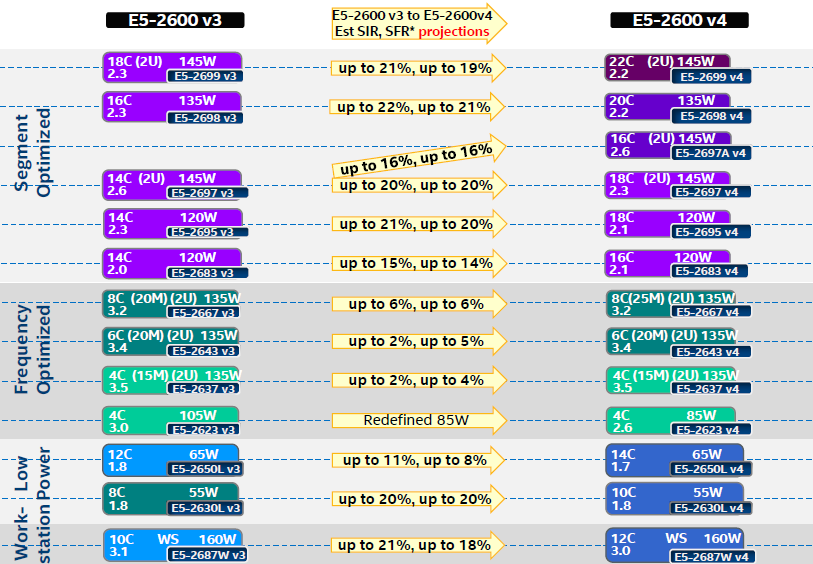
Xeon E5 v4 SKUs and Pricing
As of press time we don't have precise Xeon E5 v4 pricing. But overall prices seem to be about 1-2% higher than the comparable Xeon E5 v3..
| Intel Xeon E5 v4 SKUs | ||||||
| Cores/Threads | TDP | Base Clockspeed | Price | |||
| E5-2699 v4 | 22/44 | 145W | 2.2GHz | $4115 | ||
| E5-2698 v4 | 20/40 | 135W | 2.2GHz | $3228 | ||
| E5-2697A v4 | 16/32 | 145W | 2.6GHz | $2891 | ||
| E5-2697 v4 | 18/36 | 145W | 2.3GHz | $2702 | ||
| E5-2695 v4 | 18/36 | 120W | 2.1GHz | $2424 | ||
| E5-2690 v4 | 14/28 | 135W | 2.6GHz | $2090 | ||
| E5-2687W v4 | 12/24 | 160W | 3.0GHz | $2141 | ||
| E5-2683 v4 | 16/32 | 120W | 2.1GHz | $1846 | ||
| E5-2680 v4 | 14/28 | 120W | 2.4GHz | $1745 | ||
| E5-2667 v4 | 8/16 | 135W | 3.2GHz | $2057 | ||
| E5-2660 v4 | 14/28 | 105W | 2.0GHz | $1445 | ||
| E5-2650L v4 | 14/28 | 65W | 1.7GHz | $1329 | ||
| E5-2650 v4 | 12/24 | 105W | 2.2GHz | $1166 | ||
| E5-2643 v4 | 6/12 | 135W | 3.4GHz | $1552 | ||
| E5-2640 v4 | 10/20 | 90W | 2.4GHz | $939 | ||
| E5-2637 v4 | 4/8 | 135W | 3.5GHz | $996 | ||
| E5-2630 v4 | 10/20 | 85W | 2.2GHz | $667 | ||
| E5-2630L v4 | 10/20 | 55W | 1.8GHz | $612 | ||
| E5-2623 v4 | 4/8 | 85W | 2.6GHz | $444 | ||
| E5-2620 v4 | 8/16 | 85W | 2.1GHz | $417 | ||
| E5-2609 v4 | 8/8 | 85W | 1.7GHz | $306 | ||
| E5-2603 v4 | 6/6 | 85W | 1.7GHz | $213 | ||
Meanwhile Intel's own performance estimations are not exactly exhilarating. Their estimates are based upon the almost perfectly scaling SPECrate benchmarks, and even these "perfect world" gains are simply modest, almost uninspiring in fact. We have said it before: this market desperately needs some competition if we want a new generation to bring more exciting improvements in performance-per-dollar metrics..
Benchmark Configuration and Methodology
All of our testing was conducted on Ubuntu Server 14.04 LTS. Admittedly, that might seem like an old distribution to some of our readers, but enterprises prefer stability and support over the latest software. We did upgrade this distribution to the latest release (14.04.4), which gives us more extensive hardware support.
To make things more interesting, we tested 4 different SKUs and included the previous generation Xeon E5 v3s, the Xeon E5-2697v2 (high end Ivy Bridge EP), and the E5-2690 (high end Sandy Bridge EP). We even included the Xeon X5680 for comparison reasons. The Xeon E5-2695 v4 is interesting to compare to the Xeon E5-2699 v3 as it has the same core count and more or less the same clockspeed. That way we could quantify the improvement that the Broadwell core offers over the Haswell core.
Last but not least, we want to note how the performance graphs have been color-coded. Orange is the latest generation (v4), dark blue the previous one (v3), and light blue is the generation that the current (v4) is (arguably) supposed to replace (Xeon E5 v1).
Intel's Xeon E5 Server – S2600WT (2U Chassis)
| CPU | Two Intel Xeon processor E5-2699v4 (2.2 GHz, 22c, 55MB L3, 145W) Two Intel Xeon processor E5-2695v4 (2.1 GHz, 18c, 45MB L3, 145W) Two Intel Xeon processor E5-2699v3 (2.3 GHz, 18c, 45MB L3, 145W) Two Intel Xeon processor E5-2695v3 (2.3 GHz, 14c, 35MB L3, 120W) Two Intel Xeon processor E5-2667v3 (3.2 GHz, 8c, 20MB L3, 135W) |
| RAM | 128GB (8x16GB) Kingston DDR-2400 |
| Internal Disks | 2x Intel SSD3500 400GB |
| Motherboard | Intel Server Board Wildcat Pass |
| Chipset | Intel Wellsburg B0 |
| BIOS version | 1/28/2016 |
| PSU | Delta Electronics 750W DPS-750XB A (80+ Platinum) |
The typical BIOS settings can be seen below.
SuperMicro 6027R-73DARF (2U Chassis)
| CPU | Two Intel Xeon processor E5-2697 v2 (2.7GHz, 12c, 30MB L3, 130W) Two Intel Xeon processor E5-2690 (2.9GHz, 8c, 20MB L3, 135W) |
| RAM | 128GB (8x16GB) Samsung at 1866 MHz |
| Internal Disks | 2x Intel SSD3500 400GB |
| Motherboard | SuperMicro X9DRD-7LN4F |
| Chipset | Intel C602J |
| BIOS version | R 3.0a (December the 6th, 2013) |
| PSU | Supermicro 740W PWS-741P-1R (80+ Platinum) |
All C-states are enabled in both the BIOS.
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs.
Single Core Integer Performance With SPEC CPU2006
In past server reviews, I used LZMA (7-zip) compression and decompression to evaluate single threaded performance. But I was well aware that while it was a decent integer test, it also gave a very myopic view in the process. After noticing that my colleagues used SPEC CPU2006, and after discussing the matter with several people, I realized that running SPEC CPU2006 was a much better way to evaluate single core performance. Even though SPEC CPU2006 is more HPC and workstation oriented, it contains a good variety of integer workloads.
I also wanted to keep the settings as "normal" as possible. So I used:
- 64 bit gcc : most used compiler on linux, good all round compiler that does not try to "break" benchmarks (libquantum...)
- gcc version 4.8.4: 4.8.x has been around for a long time, very mature version
- -O2 -fno-strict-aliasing: standard compiler settings that many developers use
- Run 2 copies and bind them to the first core
The ultimate objective is to measure performance in non-"aggressively optimized" applications where for some reason - as is frequently the case - a "multi thread unfriendly" task keeps us waiting. As we want to be able to compare these numbers to other architectures such as the IBM POWER 8, we decided to use all threads available on a single core. In case of Intel, this means one physical and two simultaneous threads running on top of it.
We included the Opteron 6376 for nostalgic reasons. We are showing the results of 2 threads running on top of one module with 2 "integer cores".
| Subtest | Xeon E5-2690 | Opteron 6376 | Xeon E5-2697v2 | Xeon E5-2667 v3 | Xeon E5-2699 v3 | Xeon E5-2699 v4 |
| 400.perlbench | 41.1 | 29.3 | 37.6 | 42.6 | 39.9 | 36.6 |
| 401.bzip2 | 33.4 | 24.1 | 30.1 | 33.1 | 29.9 | 25.3 |
| 403.gcc | 40.2 | 26.7 | 38.9 | 42.4 | 36.4 | 33.3 |
| 429.mcf | 45.1 | 31.7 | 46.8 | 46.4 | 41.6 | 43.9 |
| 445.gobmk | 36.4 | 25.5 | 33.2 | 34.9 | 31.7 | 27.7 |
| 456.hmmer | 30.4 | 26.1 | 27.6 | 31 | 27.1 | 28.4 |
| 458.sjeng | 35.2 | 24.7 | 32.8 | 35.2 | 30.5 | 28.3 |
| 462.libquantum | 74.9 | 39.9 | 79.3 | 84.4 | 62.2 | 67.3 |
| 464.h264ref | 51.7 | 34.2 | 48.1 | 52.1 | 45.2 | 40.7 |
| 471.omnetpp | 24.5 | 25.3 | 26.8 | 29.4 | 26.6 | 29.9 |
| 473.astar | 28.2 | 20.7 | 26.1 | 27.9 | 24 | 23.6 |
| 483.xalancbmk | 41.5 | 28.2 | 41.4 | 48.2 | 42.4 | 41.8 |
Unless you are used to seeing these numbers, this does not tell you too much. As Sandy Bridge EP (Xeon E5 v1) is about 4 years old, the servers based upon this CPU are going to get replaced by newer ones. So Sandy Bridge is our reference, and Sandy Bridge performance is considered to be 100%.
| Subtest | Application type | Xeon E5-2690 | Opteron 6376 | Xeon E5-2697v2 | Xeon E5-2667 v3 | Xeon E5-2699 v3 | Xeon E5-2699 v4 |
| 400.perlbench | Spam filter | 100% | 71% | 91% | 104% | 97% | 89% |
| 401.bzip2 | Compression | 100% | 72% | 90% | 99% | 90% | 76% |
| 403.gcc | Compiling | 100% | 66% | 97% | 105% | 91% | 83% |
| 429.mcf | Vehicle scheduling | 100% | 70% | 104% | 103% | 92% | 97% |
| 445.gobmk | Game AI | 100% | 70% | 91% | 96% | 87% | 76% |
| 456.hmmer | Protein seq. analyses | 100% | 86% | 91% | 102% | 89% | 93% |
| 458.sjeng | Chess | 100% | 70% | 93% | 100% | 87% | 80% |
| 462.libquantum | Quantum sim | 100% | 53% | 106% | 113% | 83% | 90% |
| 464.h264ref | Video encoding | 100% | 66% | 93% | 101% | 87% | 79% |
| 471.omnetpp | Network sim | 100% | 103% | 109% | 120% | 110% | 122% |
| 473.astar | Pathfinding | 100% | 73% | 93% | 99% | 85% | 84% |
| 483.xalancbmk | XML processing | 100% | 68% | 100% | 116% | 102% | 101% |
Many smart people have spent weeks - if not months - on SPEC CPU2006 analysis, so we will not pretend we can offer you a complete picture in a few days. If you want a detailed analysis of compilers and CPU 2006, I recommend the very detailed article of SPEC CPU 2006 meister Andreas Stiller in the February issue of C'T (German computer magazine).
We need much more profiling data than we could gather in the past weeks. But for what we can do, we'll start with the most important parameter: clockspeed.
One of the most important things to realize is that - especially with badly threaded workloads - these massive multi-core CPUs almost never work at their advertised clockspeed.
- The Xeon E5-2690 can run at 3.3 GHz with all cores busy, and is capable of boosting up to 3.8 GHz
- The Xeon E5-2697 v2 can run at 3 GHz with all cores busy, and is capable of boosting up to 3.5 GHz
- The Xeon E5-2699 v3 can run at 2.8 GHz with all cores busy, and is capable of boosting up to 3.6 GHz
- The Xeon E5-2667 v3 3.2 GHz is a specialized high frequency model. It can run at 3.4 GHz with all cores busy, and is capable of boosting up to 3.6 GHz
- The Xeon E5-2699 v4 can run at 2.8 GHz with all cores busy, and is capable of boosting up to 3.6 GHz
So that already explains a lot. In contrast to the many benchmark applications, SPEC CPU2006 runs for a long time (5 to 15 minutes per test), and our first impression is that the HCC parts are not able to keep all of their cores at their maximum turbo boost. Otherwise there is no reason why a Xeon E5-2699 v3 or v4 would perform worse than a Xeon E5-2667 v3: both can run at 3.6 GHz when one core is active.
The low IPC, memory intensive network simulator omnetppp seems to be the only test that runs significantly better on the newer cores (Haswell, Broadwell) compared to Sandy Bridge. That also seems to be the only benchmark where the high core count chips (E5-2699 v4, E5-2699 v3) continue to outperform Sandy Bridge. We could pinpoint the reason by testing with different memory speeds and channels. The E5-2699 v4 can offer the highest performance thanks to the larger L3-cache (55 MB) and the higher DIMM speed (DDR4-2400) compared to Sandy Bridge (20 MB, DDR3-1600). Otherwise when we keep the clockspeed more or less constant, by looking at the Xeon E5-2667v3 and the Xeon E5-2690, we get a 1-5% speed difference, and only the memory intensive subtests (omnetpp, Libquantum) and xalancbmk (low IPC, branch intensive) show higher improvements.
Once we test both top SKUs with "-Ofast" (a more aggressive compiler setting), the results change quite a bit:.
| Subtest | Application type | Xeon E5-2699 v4 vs Xeon E5-2690 (-Ofast) | Xeon E5-2699 v4 vs Xeon E5-2690 (-O2) |
| 400.perlbench | Spam filter | 111% | 89% |
| 401.bzip2 | Compression | 94% | 76% |
| 403.gcc | Compiling | 95% | 83% |
| 429.mcf | Vehicle scheduling | 114% | 97% |
| 445.gobmk | Game AI | 90% | 76% |
| 456.hmmer | Protein seq. analyses | 106% | 93% |
| 458.sjeng | Chess | 93% | 80% |
| 462.libquantum | Quantum sim | 101% | 90% |
| 464.h264ref | Video encoding | 89% | 79% |
| 471.omnetpp | Network sim | 132% | 122% |
| 473.astar | Pathfinding | 98% | 84% |
| 483.xalancbmk | XML processing | 105% | 101% |
Switching from -O2 to -Ofast improves Broadwell-EP's absolute performance by over 19%. Meanwhile the relative performance advantage versus the Xeon E5-2690 averages 3%. As a result, the clockspeed disadvantage of the latest Xeon is negated by the increase in IPC. Clearly the latest generation of Xeons benefit more from aggressive optimizations than the previous ones. That is unsurprising of course, but it is interesting that the newest Xeons need more optimization to "hold the line" in single core performance.
So far we can conclude that if you were to upgrade from a Xeon E5-2xxx v1 to a similar v4 model, your single threaded integer code will not run faster without recompiling and optimizing. The process improvements have been used mostly to add more cores in the same power envelope, while at same time Intel also traded a few speed bins in to add even more cores in the top models. As a result single core integer performance basically holds the line, nothing more. The only exception are memory intensive applications who benefit from every growing L3-cache and the faster DRAM technology.
Memory Subsystem: Bandwidth
For this review we completely overhauled our testing of John McCalpin's Stream bandwidth benchmark. We compiled the stream 5.10 source code with the Intel compiler for linux version 16 or gcc 4.8.4, both 64 bit. The following compiler switches were used on icc:
-fast -openmp -parallel
The results are expressed in GB per second. The following compiler switches were used on gcc:
-O3 –fopenmp –static
Stream allows us to estimate the maximum performance increase that DDR-2400 (Xeon E5 v4) can offer over DDR-2133 (Xeon E5 v3).
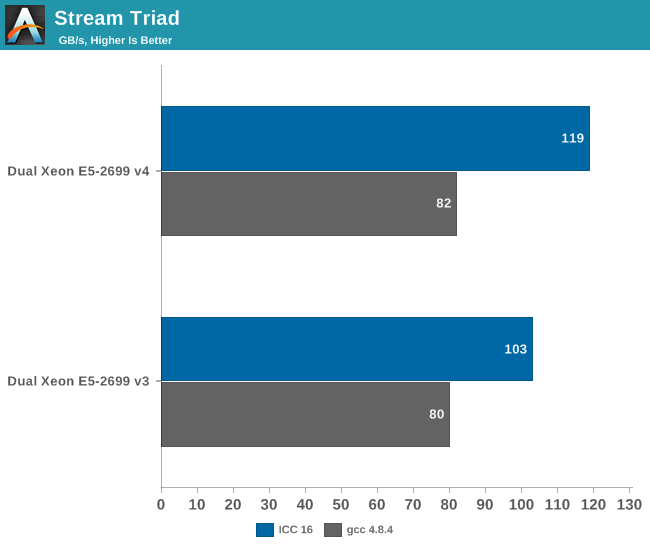
The Xeon E5 v4 with DDR4-2400 delivers about 15% higher performance then the v3 when we compile Stream with icc. To put this into perspective: DDR-4 @ 1600 delivered 80 GB/s.
The difference between DDR-4 2400 and DDR-4 2133 is negligible with gcc.
Memory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
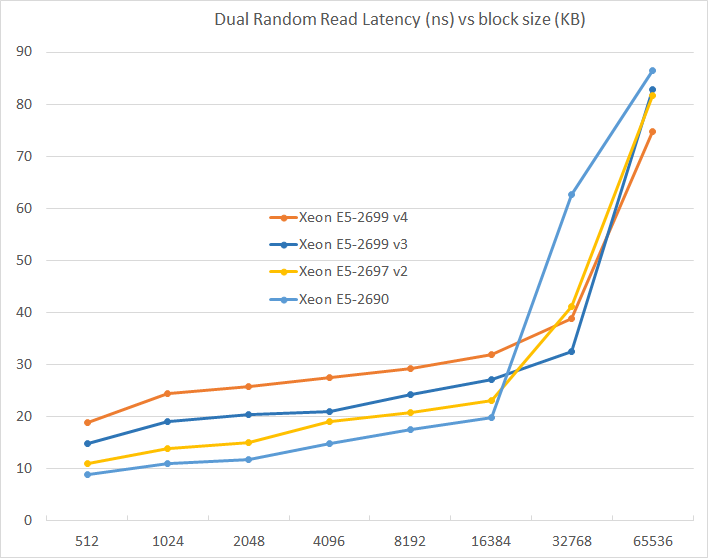
The larger the L3 caches get, the higher the latency. Latency has almost doubled from the Xeon E5 v1 to the Xeon E5 v4 while capacity has almost tripled (55 MB vs 20 MB). Still, this will result in a small performance hit in many non-virtualized applications that do no need such a large L3.
Multi-Threaded Integer Performance
While compression and decompression are not real world benchmarks in and of themselves (at least as far as servers go), more and more servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization).
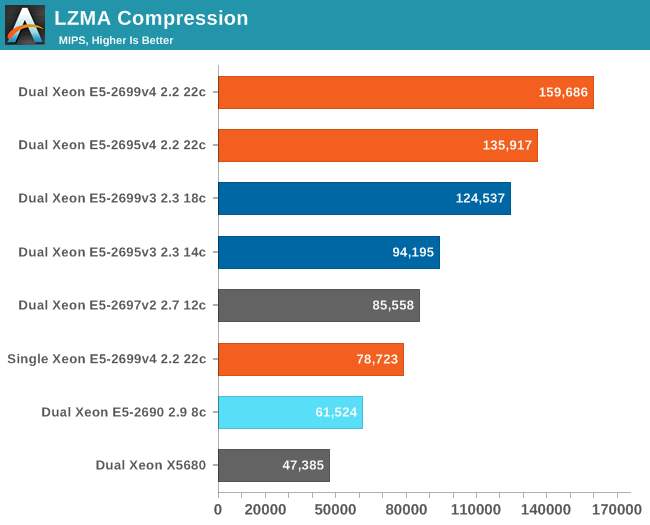
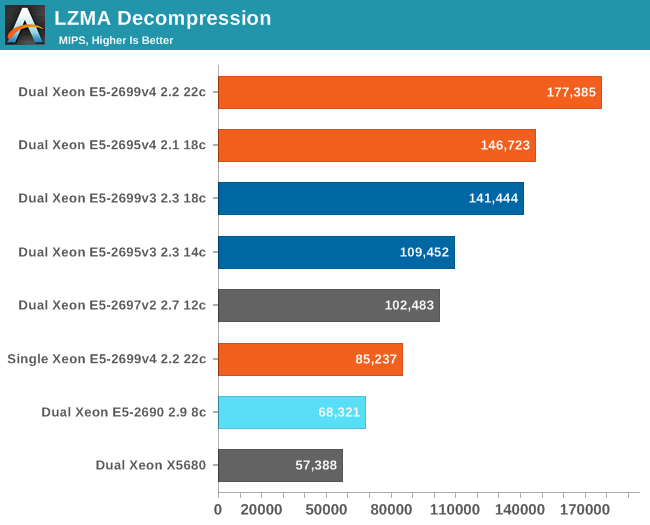
These are two applications that really benefit from Intel's philosophy of "as many lower power cores in one die as possible, while holding the line on single threaded performance". The best Xeon E5 version 4 is no less than 2.6 times faster than the Xeon E5 version 1.
MySQL 5.7.0
Thanks to the excellent repository of Percona, we were able to vastly improve our MySQL benchmark with Sysbench. However due to these changes, you cannot compare this with any similar Sysbench based benchmarking we have done before.
In updating our SQL benchmarking, we first upgraded the standard mysql installation to the better performing Percona Server 5.7. Secondly, we used sysbench 0.5 (instead of 0.4) and we implemented the (lua) scripts that allow us to use multiple tables (8 in our case) instead of the default one. This makes the Sysbench benchmark much more realistic as running with one table creates a very artificial bottleneck.
For our testing we used the read-only OLTP benchmark, which is slightly less realistic, but still much more interesting than most other Sysbench tests. This allows us to measure CPU performance without creating an I/O bottleneck. Our humble S3500 SSDs were fast enough in this scenario.
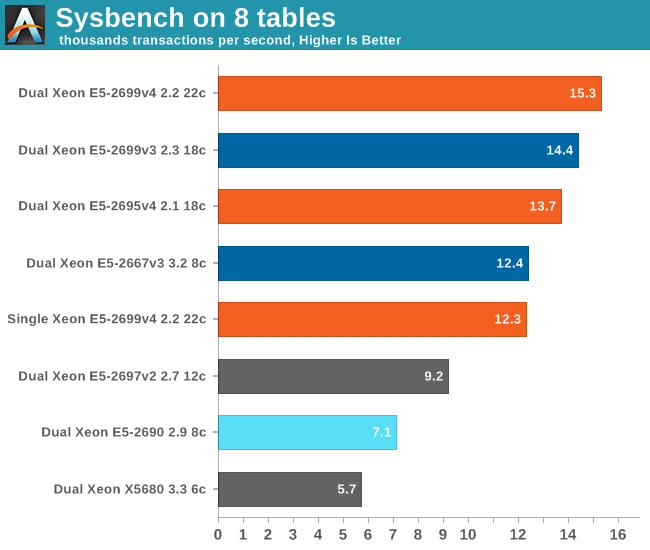
We used to apply all kinds of hacks to get around the limited scalability of both mysql and the way sysbench tested. Any version older than 5.5 could hardly scale beyond 8 cores. It is still not perfect, but MySQL uses the first 22 cores and 44 threads of the Xeon E5-2699 v4 amazingly well. We only get a 24% performance increase if we double the core count again with a second CPU, but we are honestly surprised that MySQL can now make good use of those 88 threads. Thanks to our better testing methods and a more scalable mysql, we can now report that the latest Xeon is capable of doubling the performance of the best Xeon that was launched 4 years ago. Well done Oracle, Percona, and Intel!
Application Development: Linux Kernel Compile
A more real world benchmark to test the integer processing power of our Xeon servers is a Linux kernel compile. Although few people compile their own kernel, compiling other software on servers is a common task and this will give us a good idea of how the CPUs handle a complex build.
To do this we have downloaded the 3.11 kernel from kernel.org. We then compiled the kernel with the "time make -jx" command, where x is the maximum number of threads that the platform is capable of using. To make the graph more readable, the number of seconds in wall time was converted into the number of builds per hour.
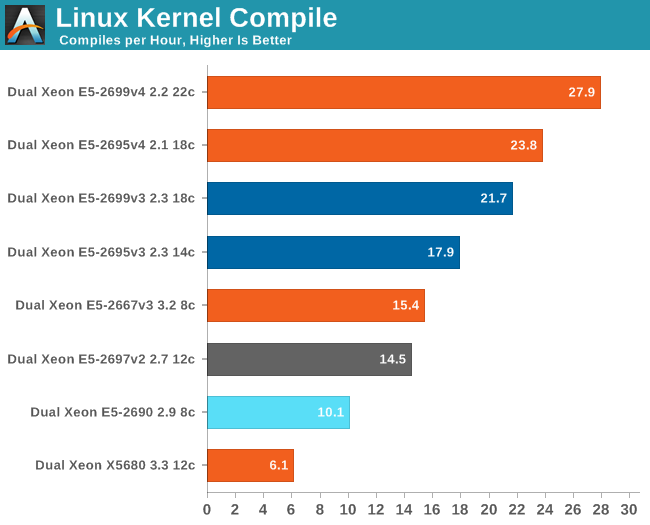
A kernel compile does not scale perfectly with more cores, but the Xeon E5-2699 v4 offers up to 2.7 times better performance than the Xeon it is supposed to replace. This kind of workload really seems to favor the new Broadwell core: even at slightly lower clockspeeds, the 18 core Xeon E5-2695 v4 beats the v3 version with the same number of cores by 9%.
SAP S&D
The SAP S&D 2-Tier benchmark has always been one of my favorites. This is probably the most real world benchmark of all the server benchmarks done by the vendors. It is a full-blown application living on top of a heavy relational database. And don't forget that SAP is one of the most successful software companies out there, the market leader of Enterprise Resource Planning.
We analyzed the SAP Benchmark in-depth in one of our earlier articles:
- Very parallel resulting in excellent scaling
- Low to medium IPC, mostly due to "branchy" code
- Somewhat limited by memory bandwidth
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
Let us see how the new Xeon E5 fares in this ERP benchmark.
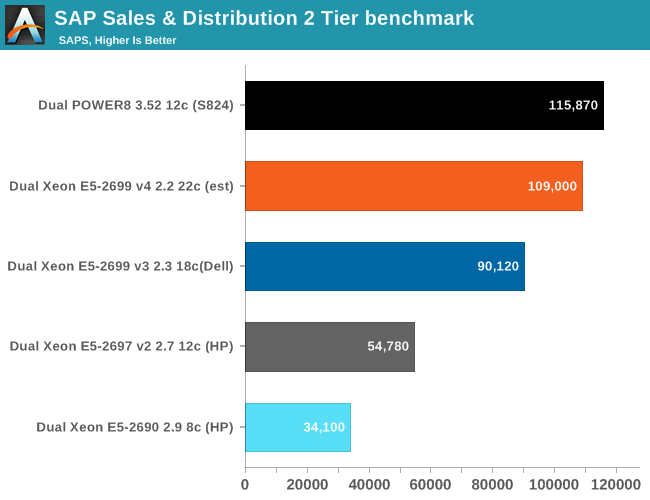
(est) = Preliminary data
The ever-increasing L3 cache, high core counts, and better NUMA coherency support of Broadwell-EP play well with SAP. It is almost like Intel builds these Xeons for SAP alone. The result is that the current Xeon is no less than 3 times faster than the Xeon 2690 (v1).
Big Data 101
Many of you have experienced this: you got a massive (text) file (a log of several weeks, some crawled web data) and you need to extract data from it. Moving it inside a text editor will not help you. The text editor will probably collapse and crash as it cannot handle the hundreds of gigabytes of text. Even if it doesn’t, repeated searches (via grep for example) are not exactly a very fast nor are they scientific way to analyze what is hidden inside that enormous hump of data.
Importing and normalizing it into a SQL database via the typical Extract, Transform and Load (ETL) process is tedious and extremely slow. SQL databases are built to handle limited amounts of structured data after all.
That is why Google created MapReduce: by splitting up those massive amounts of data in smaller slices (mapping) and reducing (aggregating, calculating, counting) them to the results that matters to you, you can avoid the rather sequential and slow query execution plans that need to evaluate the whole database to provide meaningful results. Combine this with a redundant and distributed filesystem HDFS that keeps data close to the processing node. The result is that you do not need to import data before you can use it, you do not need the ultimate SSD to quickly load so much data at once, and you can distribute your data mining over a large cluster.
I am of course talking about the grandfather of all Big Data crunching: Hadoop. However Hadoop had two significant disadvantages: although it could crunch through terabytes of data where most other data mining systems collapsed, it was pretty slow the moment you had go through iterative steps, as it wrote the intermediate results to disk. It also was pretty bad if you just want to launch a quick simple query.
Apache Spark 1.5: The Ultimate Big Data Cruncher

This brings us to Spark. In addressing Hadoop’s disadvantages, the members of UC Berkeley’s AMPlab invented a method of keeping the slices of data that need the same kind of operations in memory (Resilient Distributed Datasets). So Spark makes much better use of DRAM than MapReduce, and also avoids many write operations.
But there is more: the Spark framework also includes machine learning / AI libraries that you can use inside your scala/python code. The resulting workload is a marriage of machine learning and data mining that is highly parallel and does not need the best I/O technology to crunch through hundreds of gigabytes of data. In summary, Spark absolutely craves more CPU power and better RAM technology.
Meanwhile, according to Intel, this kind of big data technology is top growth driver of enterprise compute demand in the next few years, as enterprise demand is expected to grow by 67%. And Intel is not the only one that has seen the opportunity; IBM has a Spark Technology Center in San Francisco and launched "Insight Cloud Services", a cloud service based on top of Spark.
Intel now has a specialized Big Data Solutions group, led by Ananth Sankaranarayanan. This group spearheaded the "Big Bench" benchmark development, which was adopted by a TPC group as TPCx-BB. The benchmark is expressed in BBQs per minute...(BBQ = Big Bench Queries). (ed: yummy)
Among the contributors are Cloudera, Cisco, VMware and ... IBM and Huawei. Huawei is the parent company of the HiSilicon ARM processor, and IBM of course has the POWER 8. Needless to say, the new benchmark is going to be an important battleground which might decide whether or not Intel will remain the dominant enterprise CPU vendor. We have yet to evaluate TPC-BBx, but the next page gives you some hard benchmark numbers.
Spark Benchmarking
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive.
Here are the results:
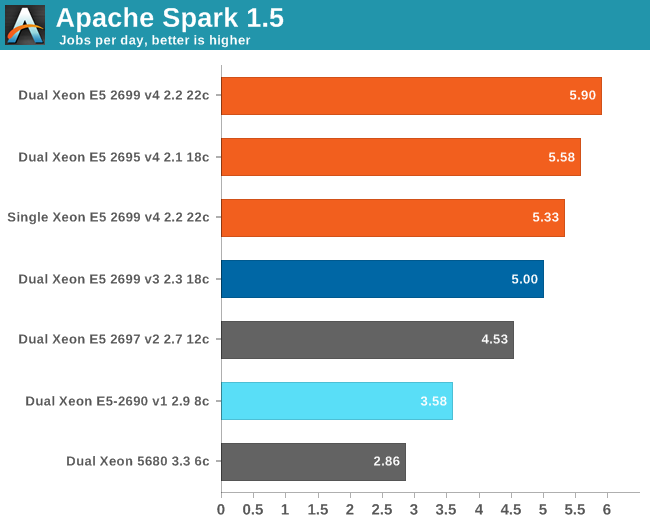
Spark threw us back into nineties, to the time that several workloads still took ages on high-end computers. It takes no less than six and half hours on a 16-core Xeon E5-2690 running at 2.9 GHz to crunch through 300 GB of web data and extract anything meaningful out of it. So we have to express our times in "jobs per day" instead of the usual "jobs per hour". Another data point: a Xeon D-1540 (8 Broadwell cores at 2.6 GHz) needs no less than 11 hours to do the same thing. Using DDR4 at 2400 MHz instead of 1600 MHz gives a boost of around 5 to 8%.
About 10% of the time is spent on splitting up the workload in slices, 30% of the time is spent in language processing, and 50% of the time is spent on aggregating and counting. Only 3% is spent waiting on disk I/O, which is pretty amazing as we handle 300 GB of data and perform up to 55 GB of (Shuffle) writes. The ALS phase scales badly, but takes only 3 to 5% of the time. But there is no escaping on Amdahl's law: throwing more cores gives diminishing returns. Meanwhile the use of remote memory seriously slows processing down: the dual Xeon increases performance only by 11% compared to the single CPU. Broadwell does well here: a Broadwell core at 2.2 GHz is 12% faster than a Haswell at 2.3 GHz.
We are still just starting to understand what really makes Spark fly and version 1.6 might still change quite a bit. But it is clear that this is one of the workloads that will make top SKUs popular: a real killer app for the most potent CPUs. You can replace a dual Xeon 5680 with one Xeon E5-2699 v4 and almost double your performance while halving the CPU power consumption.
HPC: Fluid Dynamics with OpenFOAM
Computational Fluid Dynamics is a very important part of the HPC world. Several readers told us that we should look into OpenFOAM, and my lab was able to work with the professionals of Actiflow. Actiflow specializes in combining aerodynamics and product design. Calculating aerodynamics involves the use of CFD software, and Actiflow uses OpenFOAM to accomplish this. To give you an idea what these skilled engineers can do, they worked with Ferrari to improve the underbody airflow of the Ferrari 599 and increase its downforce.
We were allowed to use one of their test cases as a benchmark, however we are not allowed to discuss the specific solver. All tests were done on OpenFOAM 2.2.1 and openmpi-1.6.3. The reason why we still run with OpenFOAM 2.2.1 is that our current test case does not work well with higher versions.
We also found AVX code inside OpenFoam 2.2.1, so we assume that this is one of the cases where AVX improves FP performance.
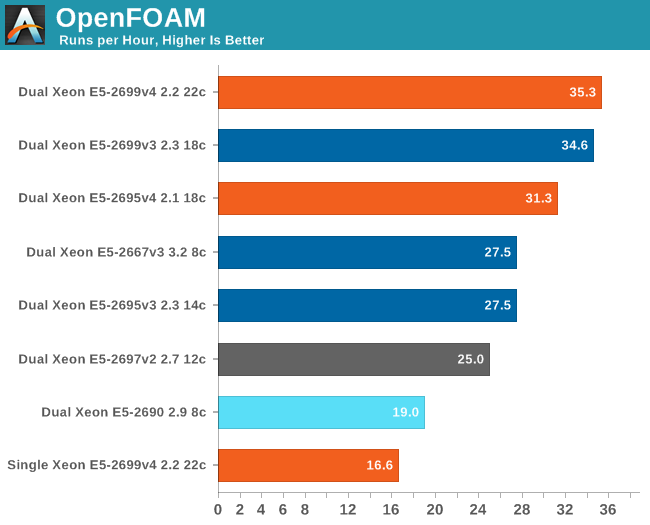
As this is AVX code, the clock speed of our Xeon processors can be lower than Intel's official specifications, and turbo boost speeds are also lower. Despite the fact that on Broadwell the only cores that reduce their clock when running AVX code are the AVX-active cores themseves (the others can continue at higher speeds), OpenFOAM does not run appreciably faster on the top of the line Xeon E5 v4 than it did on the E5 v3.
It is not as if OpenFOAM does not scale: 22% more cores delivers 13% higher performance (E5-2699v4 vs E5-2695v4). No, our first impression is that the new Xeon v4 needs to lower the clockspeed more than the old one. The official specifications tell us that both the Xeon E5-2699 v4 and v3 should run AVX code at up to 2.6 GHz with all cores enabled. The reality is however that Broadwell runs at a lower clock on average.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP.
We used the "NAMD_2.10_Linux-x86_64-multicore" binary for our Xeons. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day.
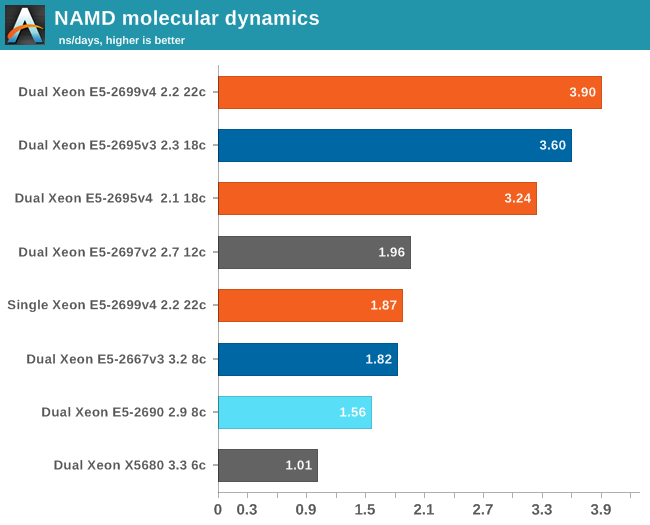
To put this in perspective: our best Xeon performs slightly slower than the early Xeon Phi (7120 1.2 GHz: 4.4). A top NVIDIA GPU with CUDA based NAMD can score up to 20 and more. So it is clear that this kind of software will be run mostly on GPU accelerated servers and scales "embarrassingly well".
We found out that we can boost the NAMD performance of the Xeon E5 quite a bit by disabling hyperthreading in the BIOS. In this case, core for core, the Broadwell Xeon (Xeon E5-2695 v4) loses compared to the similar Xeon E5-2699v3. Our suspicion that Broadwell does not keep the clockspeeds as high as Haswell seems justified.
Closing Thoughts
With the limited amount of time we had to spend with the new Broadwell-EP Xeons ahead of today's embargo, we spent most of our time on our new benchmarks. However we did a quick check on power as well. It looks like both idle power and load power when running a full floating point workload have decreased a little bit, but we need to do a more extensive check to further confirm and characterize this.
Meanwhile, considering what a wonderful offering the Xeon E5-2650L v3 was, it is a pitty that Intel did not include such a low power SKU among our samples for review. The Xeon E5-2699 v4 is a solid product, but it's not a home run. Either this is just an hiccup of our current setup (firmware?), but it seems the new Xeon E3 v4s do not reach the same turbo speeds as our Xeon E5 v3s. As a result, single threaded performance is (sometimes) slightly slower, and the new processor needs more cores to beat the previous one.
We noticed this mostly in the HPC applications, where the new Xeon is a bit of mixed bag. Still, considering that 72 to 88 threads are a bit much for lots of interesting applications (Spark, SQL databases...) there is definitely room for processors that sacrifice high core counts for higher single threaded performance (without exagerating). We have been stuck at 3.6 GHz for way too long.
With that said, there is little doubt that the Xeon E5-2699 v4 delivers in the one application that matter the most: virtualization.
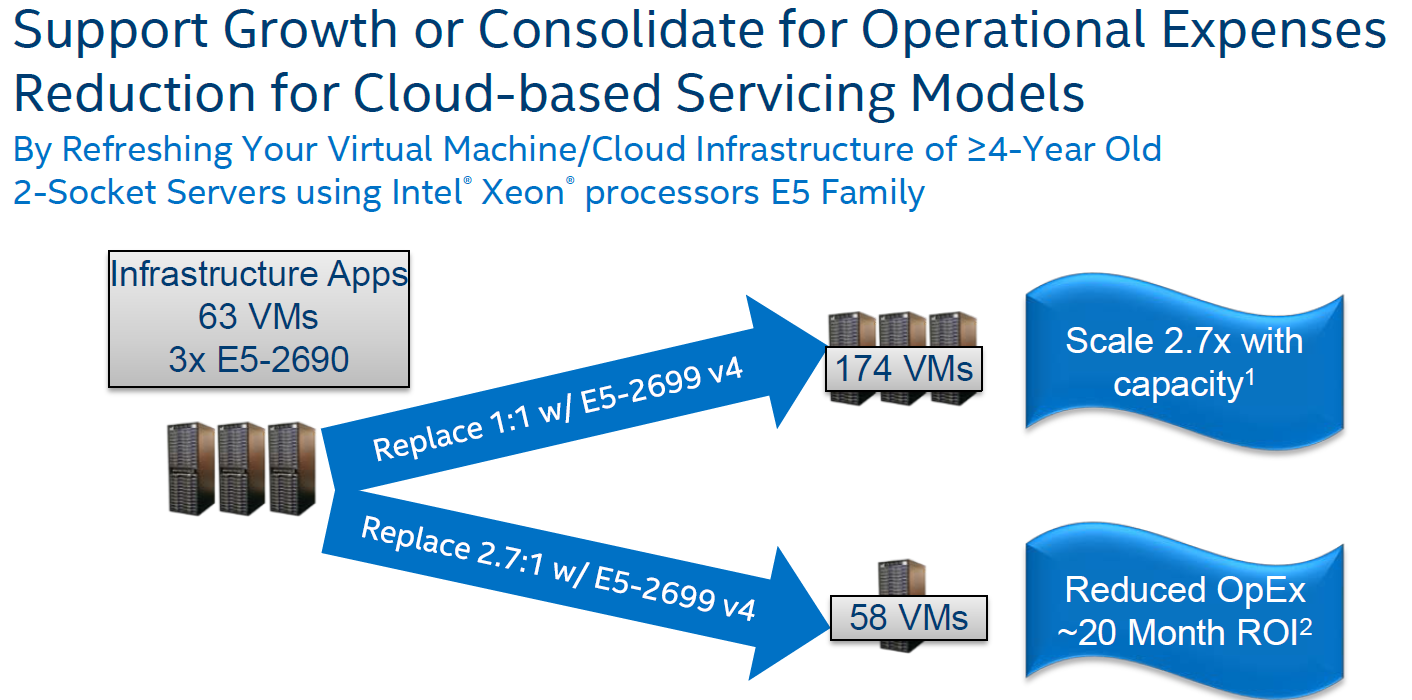
Although we have not yet extensively tested on top of an hypervisor, we are pretty sure that the extra cores and the lower VMexit latencies will make this CPU perform well in virtualized environments. Intel's resource director technology and many improvements (posted interrupts) that help the hypervisor to perform better in I/O intensive tasks are very attractive features.
Although it is not much, as compared to the Haswell-EP based Xeon E5 v3s, performance has also increased by about 20% in key applications such as databases and ERP applications. And while we can complain all we want about the slightly regression in single threaded performance in some cases, the fact of the matter is that Intel has increased performance by 2 to 2.7 times in four years in those key applications, all the while holding power consumption at more or less the same. In other words, it will pay off to upgrade those Sandy Bridge-EP servers. And for many enterprises, that is what matters.






