Original Link: https://www.anandtech.com/show/9266/amd-hbm-deep-dive
AMD Dives Deep On High Bandwidth Memory - What Will HBM Bring AMD?
by Ryan Smith on May 19, 2015 8:40 AM EST
Though it didn’t garner much attention at the time, in 2011 AMD and memory manufacturer Hynix (now SK Hynix) publicly announced plans to work together on the development and deployment of a next generation memory standard: High Bandwidth Memory (HBM). Essentially pitched as the successor to GDDR, HBM would implement some very significant changes in the working of memory in order to further improve memory bandwidth and turn back the dial on memory power consumption.
AMD (and graphics predecessor ATI) for their part have in the last decade been on the cutting edge of adopting new memory technologies in the graphics space, being the first to deploy products based on the last 2 graphics DDR standards, GDDR4, and GDDR5. Consequently, AMD and Hynix’s announcement, though not a big deal at the time, was a logical extension of AMD’s past behavior in continuing to explore new memory technologies for future products. Assuming everything were to go well for the AMD and Hynix coalition – something that was likely, but not necessarily a given – in a few years the two companies would be able to bring the technology to market.

AMD Financial Analyst Day 2015
It’s now 4 years later, and successful experimentation has given way to productization. Earlier this month at AMD’s 2015 Financial Analyst day, the company announced that they would be releasing their first HBM-equipped GPU – the world’s first HBM-equipped GPU, in fact – to the retail market this quarter. Since then there have been a number of questions of just what AMD intends to do with HBM and just what it means for their products (is it as big of a deal as it seems?), and while AMD is not yet ready to reveal the details of their forthcoming HBM-equipped GPU, the company is looking to hit the ground running on HBM in order to explain what the technology is and what it can do for their products ahead of the GPU launch later that quarter.
To date there have been a number of presentations released on HBM, including by memory manufactures, the JEDEC groups responsible for shaping HBM, AMD, and even NVIDIA. So although the first HBM products have yet to hit retail shelves, the underpinnings of HBM are well understood, at least inside of engineering circles. In fact it’s the fact that HBM is really only well understood within those technical circles that’s driving AMD’s latest disclosure today. AMD sees HBM as a significant competitive advantage over the next year, and with existing HBM presentations having been geared towards engineers, academia, and investors, AMD is looking to take the next step and reach out to end-users about HBM technology.

This brings us to the topic of today’s article: AMD’s deep dive disclosure on High Bandwidth Memory. Looking to set the stage ahead of their next GPU launch, AMD is reaching out to technical and gaming press to get the word out about HBM and what it means for AMD’s products. Ideally for AMD, an early disclosure on HBM can help to drum up interest in their forthcoming GPU before it launches later this quarter, but if nothing else it can help answer some burning questions about what to expect ahead of the launch. So with that in mind, let’s dive in.
I'd also like to throw out a quick thank you to AMD Product CTO and Corporate Fellow Joe Macri, who fielded far too many questions about HBM.
History: Where GDDR5 Reaches Its Limits
To really understand HBM we’d have to go all the way back to the first computer memory interfaces, but in the interest of expediency and sanity, we’ll condense that lesson down to the following. The history of computer and memory interfaces is a consistent cycle of moving between wide parallel interfaces and fast serial interfaces. Serial ports and parallel ports, USB 2.0 and USB 3.1 (Type-C), SDRAM and RDRAM, there is a continual process of developing faster interfaces, then developing wider interfaces, and switching back and forth between them as conditions call for.
So far in the race for PC memory, the pendulum has swung far in the direction of serial interfaces. Though 4 generations of GDDR, memory designers have continued to ramp up clockspeeds in order to increase available memory bandwidth, culminating in GDDR5 and its blistering 7Gbps+ per pin data rate. GDDR5 in turn has been with us on the high-end for almost 7 years now, longer than any previous memory technology, and in the process has gone farther and faster than initially planned.
But in the cycle of interfaces, the pendulum has finally reached its apex for serial interfaces when it comes to GDDR5. Back in 2011 at an AMD video card launch I asked then-graphics CTO Eric Demers about what happens after GDDR5, and while he expected GDDR5 to continue on for some time, it was also clear that GDDR5 was approaching its limits. High speed buses bring with them a number of engineering challenges, and while there is still headroom left on the table to do even better, the question arises of whether it’s worth it.

AMD 2011 Technical Forum and Exhibition
The short answer in the minds of the GPU community is no. GDDR5-like memories could be pushed farther, both with existing GDDR5 and theoretical differential I/O based memories (think USB/PCIe buses, but for memory), however doing so would come at the cost of great power consumption. In fact even existing GDDR5 implementations already draw quite a bit of power; thanks to the complicated clocking mechanisms of GDDR5, a lot of memory power is spent merely on distributing and maintaining GDDR5’s high clockspeeds. Any future GDDR5-like technology would only ratchet up the problem, along with introducing new complexities such as a need to add more logic to memory chips, a somewhat painful combination as logic and dense memory are difficult to fab together.
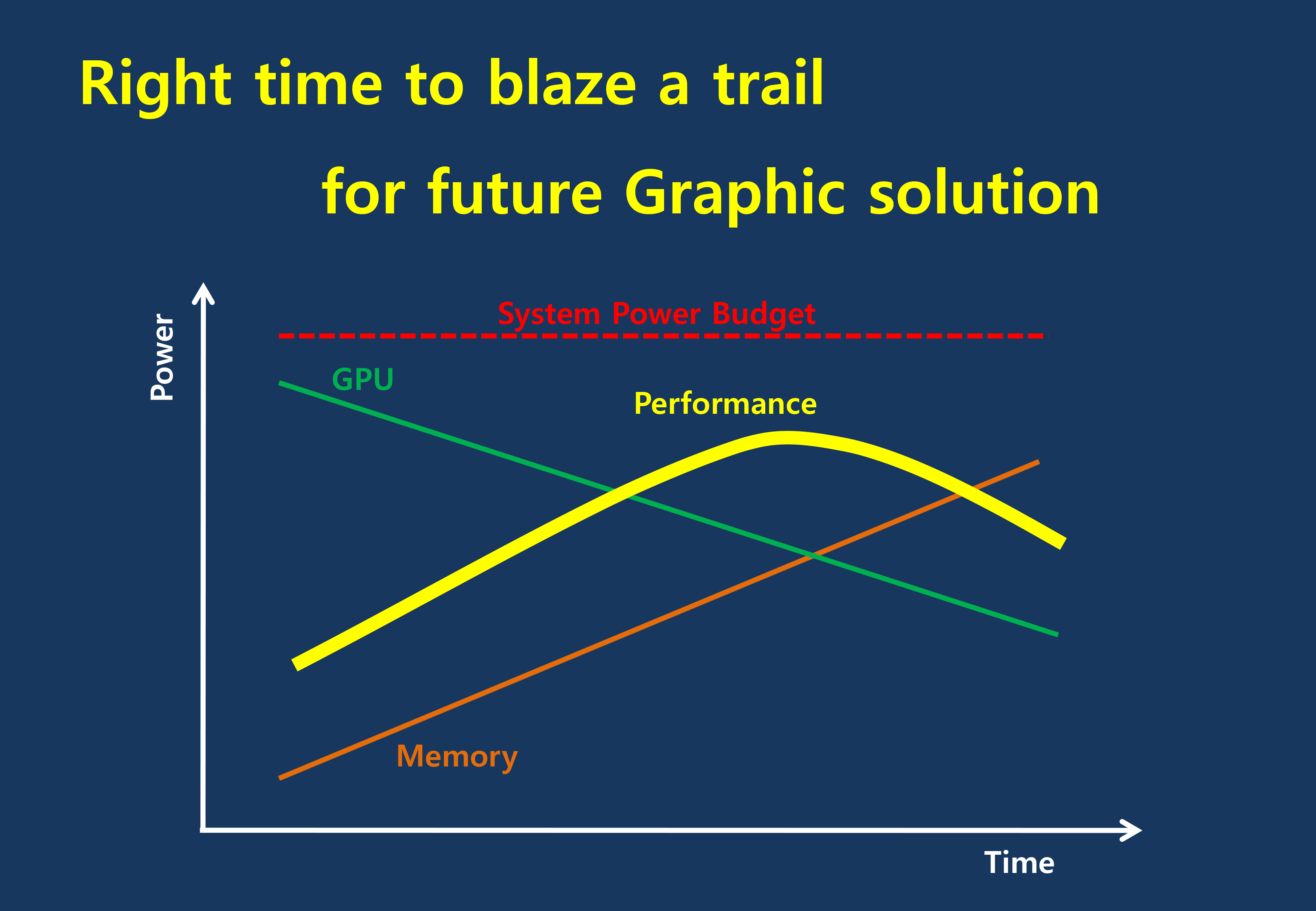
The current GDDR5 power consumption situation is such that by AMD’s estimate 15-20% of Radeon R9 290X’s (250W TDP) power consumption is for memory. This being even after the company went with a wider, slower 512-bit GDDR5 memory bus clocked at 5GHz as to better contain power consumption. So using a further, faster, higher power drain memory standard would only serve to exacerbate that problem.
All the while power consumption for consumer devices has been on a downward slope as consumers (and engineers) have made power consumption an increasingly important issue. The mobile space, with its fixed battery capacity, is of course the prime example, but even in the PC space power consumption for CPUs and GPUs has peaked and since come down some. The trend is towards more energy efficient devices – the idle power consumption of a 2005 high-end GPU would be intolerable in 2015 – and that throws yet another wrench into faster serial memory technologies, as power consumption would be going up exactly at the same time as overall power consumption is expected to come down, and individual devices get lower power limits to work with as a result.

Finally, coupled with all of the above has been issues with scalability. We’ll get into this more when discussing the benefits of HBM, but in a nutshell GDDR5 also ends up taking a lot of space, especially when we’re talking about 384-bit and 512-bit configurations for current high-end video cards. At a time when everything is getting smaller, there is also a need to further miniaturize memory, something that GDDR5 and potential derivatives wouldn’t be well suited to resolve.
The end result is that in the GPU memory space, the pendulum has started to swing back towards parallel memory interfaces. GDDR5 has been taken to the point where going any further would be increasingly inefficient, leading to researchers and engineers looking for a wider next-generation memory interface. This is what has led them to HBM.
HBM: Wide & Slow Makes It Fast
Given the challenges faced in pushing GDDR5 and similar memory technologies even further, development of high bandwidth memory technology has in the last decade shifted back towards wider, slower interfaces. As serial interfaces reach their limits, parallel interfaces become an increasingly viable alternative. And although they bring with them their own challenges – there’s a reason serial interfaces have been dominant most recently, after all – the ramp up of challenges in further improving serial interfaces has coincided with the development of technologies that make parallel interfaces easier to implement. As a result the pendulum has swung back to parallel interfaces and HBM.
HBM in a nutshell takes the wide & slow paradigm to its fullest. Rather than building an array of high speed chips around an ASIC to deliver 7Gbps+ per pin over a 256/384/512-bit memory bus, HBM at its most basic level involves turning memory clockspeeds way down – to just 1Gbps per pin – but in exchange making the memory bus much wider. How wide? That depends on the implementation and generation of the specification, but the examples AMD has been showcasing so far have involved 4 HBM devices (stacks), each featuring a 1024-bit wide memory bus, combining for a massive 4096-bit memory bus. It may not be clocked high, but when it’s that wide, it doesn’t need to be.

Of course while extra memory bandwidth is nice, the far more interesting part is how HBM delivers this. Although the idea of a wide, slow parallel bus is easy enough to comprehend on paper, implementing it is a whole other matter. A 4096-bit memory bus involves thousands of traces, far more than GDDR5, all of which must be carefully constructed in order to make HBM work. As a result there are a couple of fundamental technologies that are seeing their big (though not necessarily initial) introduction with HBM.
The first and most fundamental matter is how do you efficiently route a 4096-bit memory bus? Even the best surface mounting BGA technologies have their limits, and as it is Hawaii was pushing things with its 512-bit GDDR5 memory bus. An even wider bus only makes that harder, inviting issues both with the routing such a wide bus on a PCB or chip substrate, and in using BGA to connect a chip to those traces.
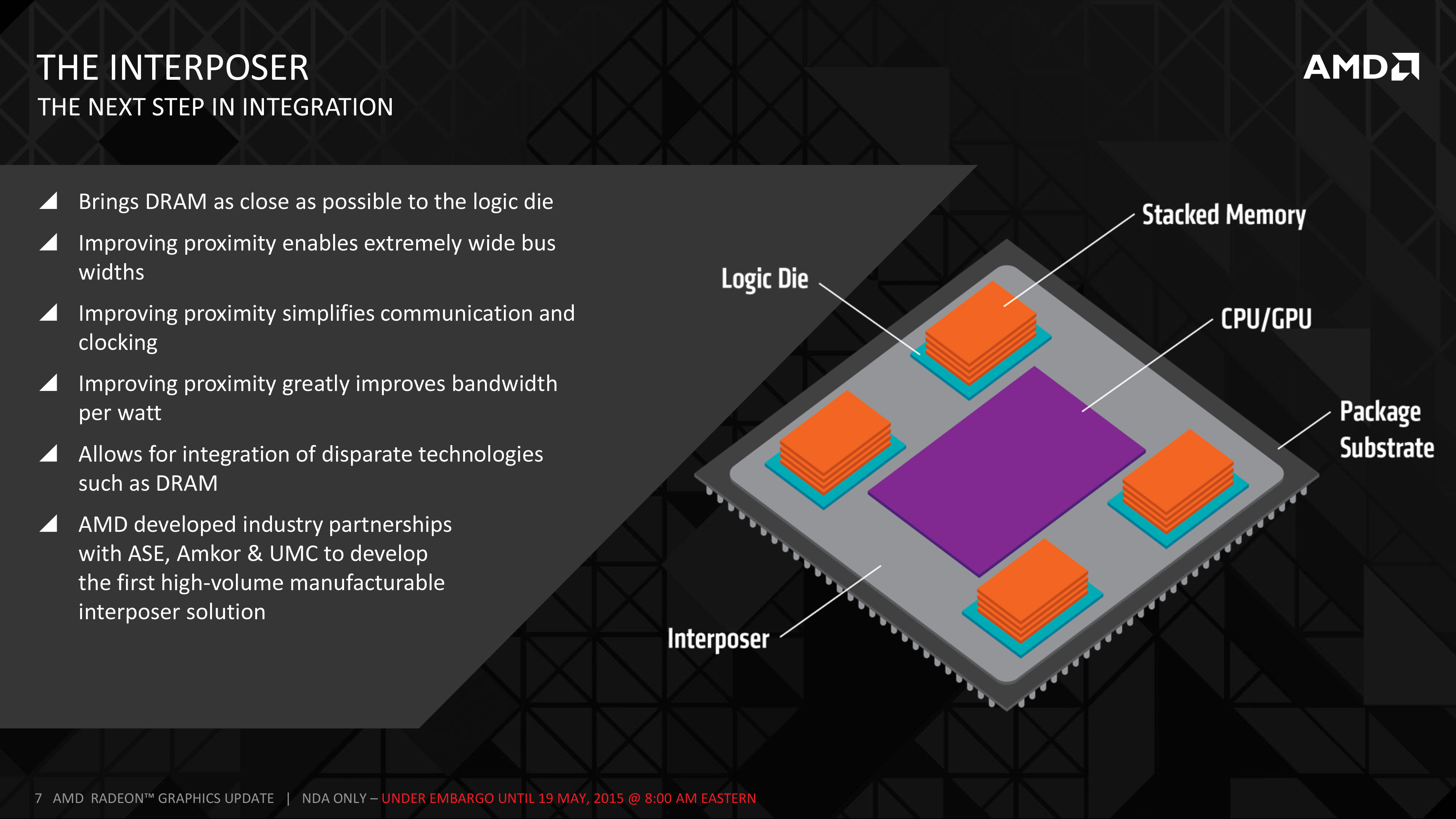
First part of the solution to that in turn was to develop something capable of greater density routing, and that something was the silicon interposer. The interposer in its broadest terms is a partially fabbed silicon chip that instead of being developed into a full ASIC packed with logic, is only developed as far as having metal layers, in order to route signals and power among devices. The interposer in turn works because it exploits some of the core advantages of modern photolithographic processes, allowing for very fine paths to be created that would otherwise not be possible/practical on traditional PCBs and substrates.
Using a silicon interposer solves some of the fundamental problems with HBM, but it also provides some ancillary benefits as well. Along with solving the obvious routing issue, the interposer allows for DRAM to be placed very close to an ASIC, but without being placed on top of it (ala Package-on-package), which is impractical for high TDP devices like GPUs. By being able to place DRAM so close to the ASIC, it avoids the drawbacks of long memory paths, making the shorter paths both simpler to construct and require less power in the process. It also benefits integration, as similar to PoP technology, you can have more of the device’s functionality located on the same package as the ASIC, reducing the number of devices that need to be placed off-package and routed to the ASIC.
Of course the interposer does come with a drawback as well, and that’s cost. While AMD is not talking about costs in great detail – this is a technology deep dive, not an analyst meeting – the fact that the interposer is essentially a very large, partially developed silicon chip means that it’s relatively expensive to produce, especially compared to the very low costs of PCBs and traditional substrates. Mitigating this is the fact that interposers don’t need to go through the most complex and expensive phases of photolithography – the actual front-end lithography – so the cost is only the silicon wafer itself, along with the work required to create the metal layers, with the final interposer only being some 100 microns thick. Furthermore this doesn’t require cutting-edge fabs – old, fully amortized 65nm equipment works quite well – which further keeps the costs down. The end result is that the interposer is still a significant cost, but it is not as bad as it initially seems. This ultimately is why HBM will first be introduced on high margin products like high-end video cards before potentially making its way down to cheaper devices like APUs.
Meanwhile AMD and their vendors will over the long run also benefit from volume production. The first interposers are being produced on retooled 65nm lithographic lines, however once volume production scales up, it will become economical to develop interposer-only lines that are cheaper to operate since they don’t need the ability to offer full lithography as well. Where that cut-off will be is not quite clear at this time, though it sounds like it will happen sooner than later.
Looking at the broader picture, in the grand scheme of things the interposer becomes a new layer on a complete chip, sitting between the traditional substrate and any DRAM/ASICs mounted on top of it. Microbumps will connect the DRAM and ASICs to the interposer, and the interposer will then be connected to the substrate, before finally the substrate is connected to its partner PCB. PCB mounting itself will become a bit easier in the process, as there’s no longer a need to route memory traces through the substrate, which means the only remaining connections are data (PCIe bus, etc) and power for the ASIC and DRAM. All the complex routing is essentially localized to occurring at the interposer layer.

Moving on, the other major technological breakthrough here is the creation of through-silicon vias (TSVs). With the interposer to enable the routing of a dense memory bus, the other issue to solve was the creation of dense memory. The solution to this was to stack multiple memory dies together into a single device/stack, in order to create the single 1024-bit stack, and TSVs are in turn what make this possible.
The reason for stacking DRAM is pretty straightforward: it makes production easier by reducing the DRAM to fewer discrete devices, not to mention it saves space. The challenge here is that you can’t have traditional surface mount connections since the DRAM is stacked, and traditional edge connections (as used in PoP) are neither dense enough nor do they scale well to the kind of stacks HBM would require.
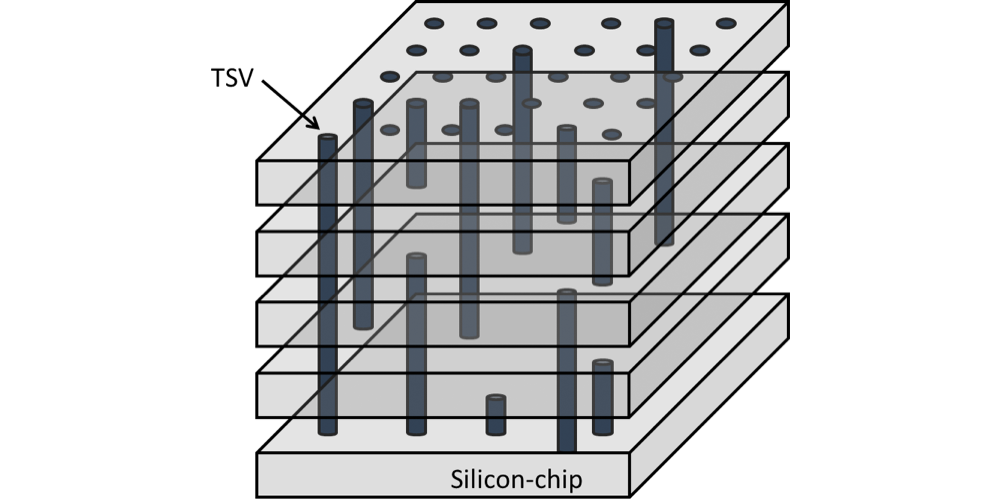
TSVs. Image Courtesy The International Center for Materials Nanoarchitectonics
As a result a means was needed to route DRAM connections though the lower layers of the stack, and this problem was solved with TSVs. Whereas regular vias offer the ability to connect two layers together, TSVs extend this principle by running the vias straight through silicon devices in order to connect layers farther out. The end result is something vaguely akin to DRAM dies surface mounted on top of each other via microbumps, but with the ability to communicate through the layers. From a manufacturing standpoint, between the silicon interposer and TSVs, TSVs are the more difficult technology to master as it essentially combines all the challenges of DRAM fabbing with the challenges of stacking those DRAM dies on top of each other.
Having developed the means to stack DRAM, the final component of an HBM stack is a logic die that lies on the bottom of the stack. Similarly outfitted with TSVs, the logic die is responsible for actually operating the DRAM dies above it, and then handling the operation of the HBM bus between the stack and the ASIC. This actually ends up being a rather interesting development since the net result is more logic added despite the simplicity of the HBM bus, but at the same time thanks to TSVs and the interposer, it’s easier than ever to add that logic.
The Net Benefits of HBM
Now that we’ve had a chance to talk about how HBM is constructed and the technical hurdles in building it, we can finally get to the subject of the performance and design benefits of HBM. HBM is of course first and foremost about further increasing memory bandwidth, but the combination of stacked DRAM and lower power consumption also opens up some additional possibilities that could not be pursued with GDDR5.
We’ll start with the bandwidth capabilities of HBM. The amount of bandwidth ultimately depends on the number of stacks in use along with the clockspeed of those stacks. HBM uses a DDR signaling interface, and while AMD is not disclosing final product specifications at this time, they have given us enough information to begin to build a complete picture.
| GPU Memory Math | |||||
| AMD Radeon R9 290X | NVIDIA GeForce GTX Titan X | Theoretical 4-Stack HBM1 | |||
| Total Capacity | 4GB | 12GB | 4GB | ||
| Bandwidth Per Pin | 5Gbps | 7Gbps | 1Gbps | ||
| Number of Chips/Stacks | 16 | 24 | 4 | ||
| Bandwidth Per Chip/Stack | 20GB/sec | 14GB/sec | 128GB/sec | ||
| Effective Bus Width | 512-bit | 384-bit | 4096-bit | ||
| Total Bandwidth | 320GB/sec | 336GB/sec | 512GB/sec | ||
| Estimated DRAM Power Consumption |
30W | 31.5W | 14.6W | ||
The first generation of HBM AMD is using allows for each stack to be clocked up to 500MHz, which after DDR signaling leads to 1Gbps per pin. For a 1024-bit stack this means a single stack can deliver up to 128GB/sec (1024b * 1G / 8b) of memory bandwidth. HBM in turn allows from 2 to 8 stacks to be used, with each stack carrying 1GB of DRAM. AMD’s example diagrams so far (along with NVIDIA’s Pascal test vehicle) have all been drawn with 4 stacks, in which case we’d be looking at 512GB/sec of memory bandwidth. This of course is quite a bit more than the 320GB/sec of memory bandwidth for the R9 290X or 336GB/sec for NVIDIA’s GTX titan X, working out to a 52-60% increase in memory bandwidth.
At the same time this also calls into question memory capacity – 4 1GB stacks is only 4GB of VRAM – though AMD seems to be saving that matter for the final product introduction later this quarter. Launching a new, high-end GPU with 4GB could be a big problem for AMD, but we'll see just what they have up their sleeves in due time.
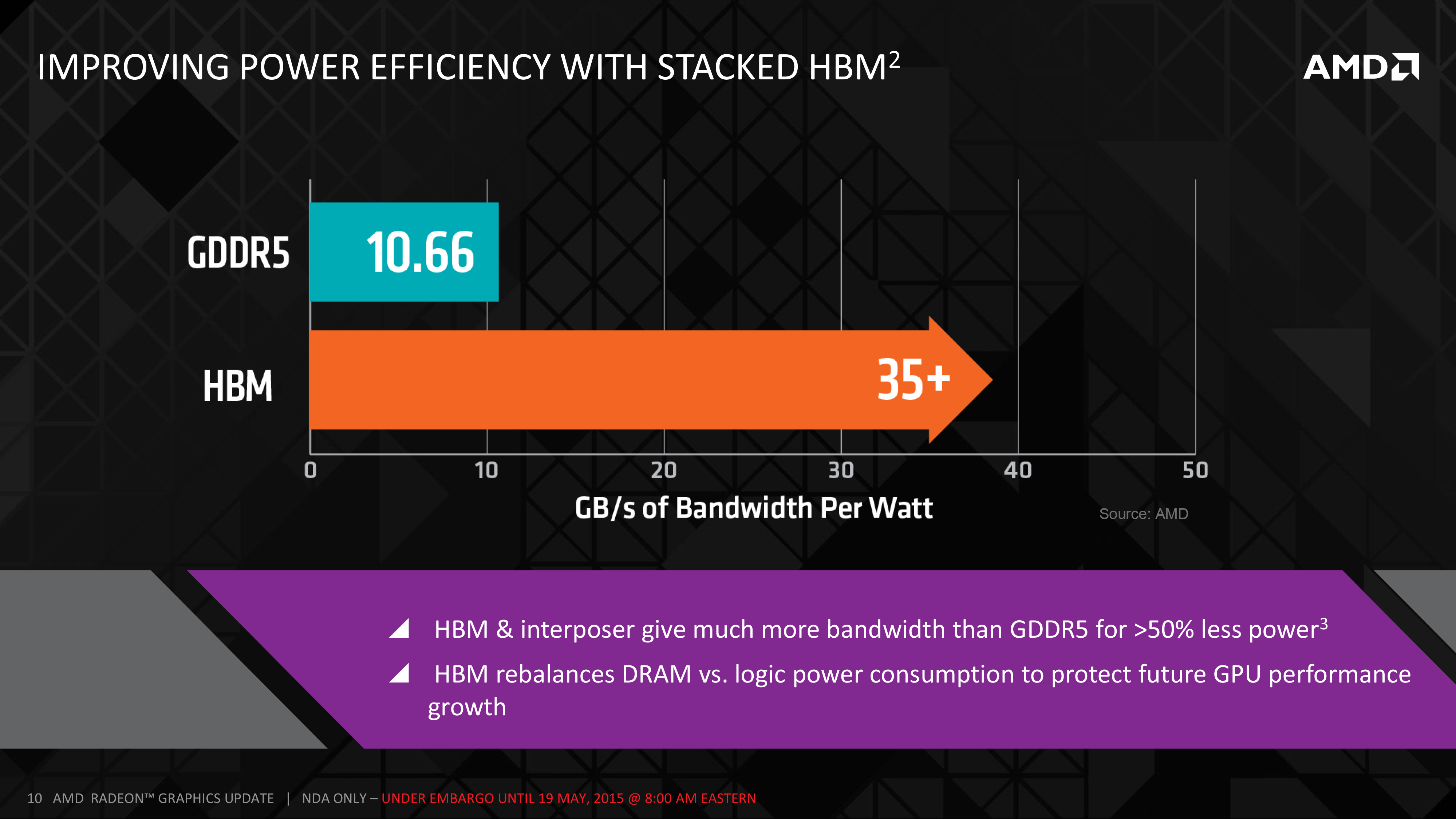
What’s perhaps more interesting is what happens to DRAM energy consumption with HBM. As we mentioned before, R9 290X spends 15-20% of its 250W power budget on DRAM, or roughly 38-50W of power on an absolute basis. Meanwhile by AMD’s own reckoning, GDDR5 is good for 10.66GB/sec of bandwidth per watt of power, which works out to 30W+ via that calculation. HBM on the other hand delivers better than 35GB/sec of bandwidth per watt, an immediate 3x gain in energy efficiency per watt.
Of course AMD is then investing some of those gains back in to coming up with more memory bandwidth, so it’s not as simple as saying that memory power consumption has been cut by 70%. Rather given our earlier bandwidth estimate of 512GB/sec of memory bandwidth for a 4 stack configuration, we would be looking at about 15W of power consumption for a 512GB/sec HBM solution, versus 30W+ for a 320GB/sec GDDR5 solution. The end result then points to DRAM power consumption being closer to halved, with AMD saving 15-20W of power.
What’s the real-world advantage of a 15-20W reduction in DRAM power consumption? Besides being able to invest that in reducing overall video card power consumption, the other option is to invest it in increasing clockspeeds. With PowerTune putting a hard limit on power consumption, a larger GPU power budget would allow AMD to increase clockspeeds and/or run at the maximum GPU clockspeed more often, improving performance by a currently indeterminable amount. Now as fair warning here, higher GPU clockspeeds typically require higher voltages, which in turn leads to a rapid increase in GPU power consumption. So although having additional power headroom does help the GPU, it may not be good for quite as much of a clockspeed increase as one might hope.
Meanwhile the performance increase from the additional memory bandwidth is equally nebulous until AMD’s new product is announced and benchmarked. As a rule of thumb GPUs are virtually always memory bandwidth bottlenecked – they are after all high-throughput processors capable of trillions of calculations per second working with only hundreds of billions of bytes of bandwidth – so there is no doubt that the higher memory bandwidths of HBM will improve performance. However memory bandwidth increases currently don’t lead to 1:1 performance increases even on AMD’s current cards, and it’s unlikely to be any different on future products.
Throwing an extra wrinkle into matters, any new AMD product would be based on GCN 1.2 or newer, which introduced AMD’s latest generation of color compression technology. The net result is that on identical workloads, memory bandwidth pressure is going down exactly at the same time as memory bandwidth availability is going up. AMD will end up gaining a ton of effective memory bandwidth – something that will be very handy for high resolutions – but it also makes it impossible to predict what the final performance impact might be. Still, it will be interesting to see what AMD can do with a 2x+ increase in effective memory bandwidth for graphics workloads.
The final major benefit AMD is looking at taking advantage of with HBM – and that this point they’re not even being subtle about – is new form factor designs from the denser designs enabled by HBM. With the large GDDR5 memory chips replaced with much narrower HBM stacks, AMD is telling us that the resulting ASIC + RAM setups can be much smaller.
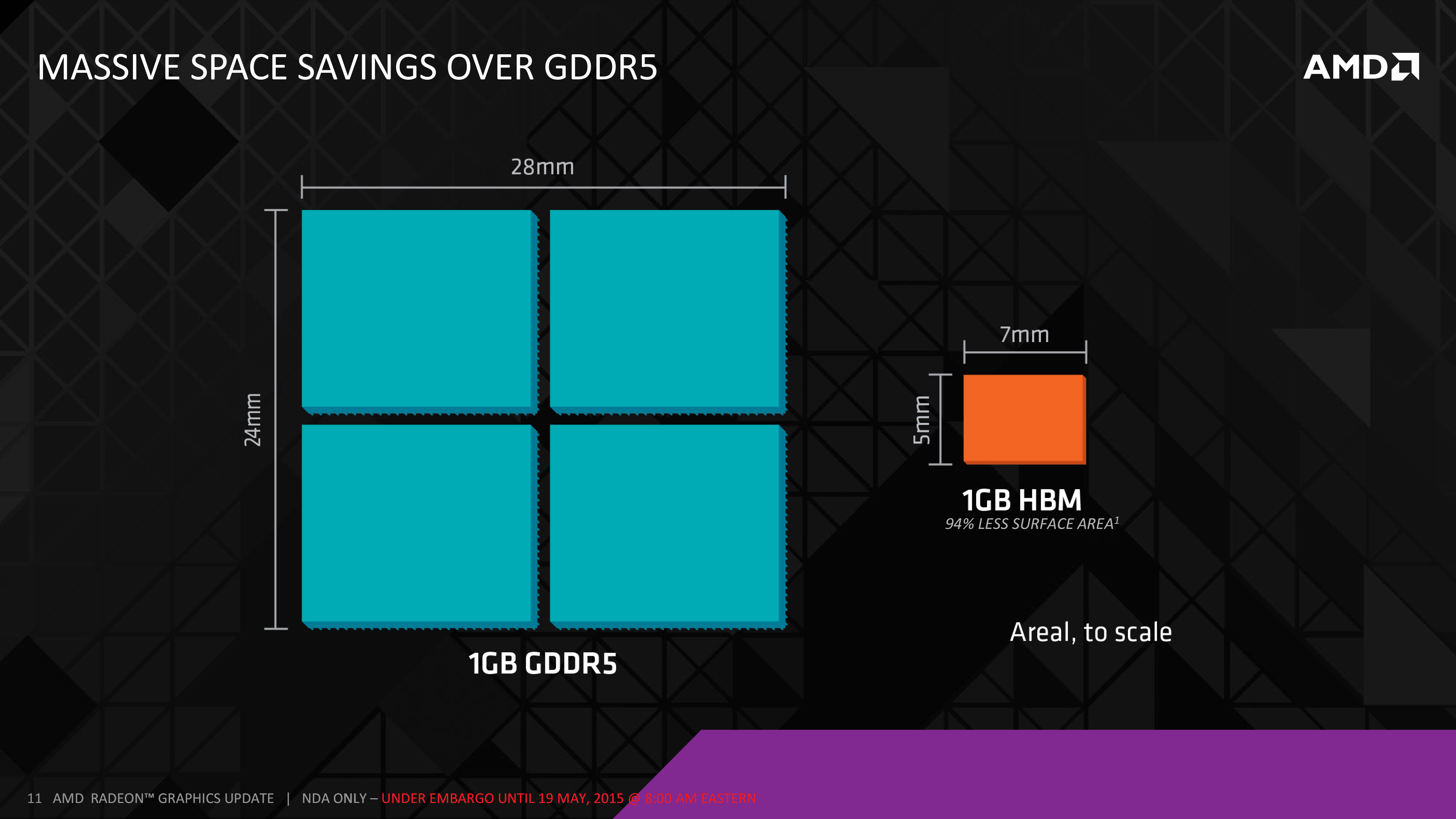
How much smaller? Well 1GB of GDDR5, composed of 2Gbit modules (the standard module size for R9 290X) would take up 672mm2, versus just 35mm2 for the same 1GB of DRAM as an HBM stack. Even if we refactor this calculation for 4Gbit modules – the largest modules used in currently shipping video cards – then we still end up with 336mm2 versus 35mm2, which is still a savings of 89% for 1GB of DRAM. Ultimately the HBM stack itself is composed of multiple DRAM dies, so there’s still quite a bit of silicon in play, however its 2D footprint is reduced significantly thanks to stacking.

By AMD’s own estimate, a single HBM-equipped GPU package would be less than 70mm X 70mm (4900mm2), versus 110mm X 90mm (9900mm2) for R9 290X. Throw in additional space savings from the fact that HBM stacks don’t require quite as complex power delivery circuitry, and the card space savings could be significant. By our reckoning the total card size will still be fairly big – all of those VRMs and connectors need to go somewhere – but there is potential for significant savings. What AMD intends to do with those savings remains to be seen, but with apologies to AMD on this one, NVIDIA has already shown off their Pascal test vehicle for their mezzanine connector design, and it goes without saying that such a form factor opens up some very interesting possibilities.

With apologies to AMD: NVIDIA’s Pascal Test Vehicle, An Example Of A Smaller, Non-Traditional Video Card Design
Finally, aftermarket enthusiasts may or may not enjoy one final benefit from the use of HBM. Because the DRAM and GPU are now on the same package, AMD is going to be capping the package with an integrated heat spreader (IHS) to compensate for any differences in height between the HBM stacks and GPU die, to protect the HBM stacks, and to supply the HBM stacks with sufficient cooling. High-end GPU dies have been bare for some time now, so an IHS brings with it the same kind of protection for the die that IHSs brought to CPUs. At the same time however this means it’s no longer possible to make direct contact with the GPU, so extreme overclockers may come away disappointed. We’ll have to see what the shipping products are like and whether in those cases it’s viable to remove the IHS.
Closing Thoughts
Bringing this deep dive to a close, as the first GPU manufacturer to be shipping an HBM solution – in fact AMD expects to be the only vendor to ship an HBM1 solution – AMD has set into motion some very aggressive product goals thanks to the gains from HBM. Until we know more about AMD’s forthcoming video card I find it prudent to keep expectations in check here, as HBM is just one piece of the complete puzzle that is a GPU. But at the same time let’s be clear here: HBM is the future memory technology of GPUs, there is potential for significant performance increases thanks to the massive increase in memory bandwidth offers, and for roughly the next year AMD is going to be the only GPU vendor offering this technology.
AMD for their part is looking to take as much of an advantage of their lead as they can, both at the technical level and the consumer level. At the technical level AMD has said very little about performance so far, so we’ll have to wait and see just what their new product brings. But AMD is being far more open about their plans to exploit the size advantage of HBM, so we should expect to see some non-traditional designs for high-end GPUs. Meanwhile at the consumer level, expect to see HBM enter the technology lexicon as the latest buzzword for high-performance products – almost certainly to be stamped on video card boxes today just as GDDR5 has been for years – as AMD looks to let everyone know about their advantage.

Meanwhile shifting gears towards the long term, high-end GPUs are just the first of what AMD expects to be a wider rollout for HBM. Though AMD is not committing to any other products at this time, as production ramps up and costs come down, HBM is expected to become financially viable in a wider range, including lower-end GPUs, HPC products (e.g. FirePro S and AMD’s forthcoming HPC APU), high-end communications gear, and of course AMD’s mainstream consumer APUs. As lower-margin products consumer APUs will likely be among the farthest off, however in the long-run they may very well be the most interesting use case for HBM, as APUs are among the most bandwidth-starved graphics products out there. But before we get too far ahead of ourselves, let’s see what AMD is able to do with HBM on their high-end video cards later this quarter.






