Original Link: https://www.anandtech.com/show/6993/intel-iris-pro-5200-graphics-review-core-i74950hq-tested
Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
by Anand Lal Shimpi on June 1, 2013 10:01 AM EST
The Prelude
As Intel got into the chipset business it quickly found itself faced with an interesting problem. As the number of supported IO interfaces increased (back then we were talking about things like AGP, FSB), the size of the North Bridge die had to increase in order to accommodate all of the external facing IO. Eventually Intel ended up in a situation where IO dictated a minimum die area for the chipset, but the actual controllers driving that IO didn’t need all of that die area. Intel effectively had some free space on its North Bridge die to do whatever it wanted with. In the late 90s Micron saw this problem and contemplating throwing some L3 cache onto its North Bridges. Intel’s solution was to give graphics away for free.
The budget for Intel graphics was always whatever free space remained once all other necessary controllers in the North Bridge were accounted for. As a result, Intel’s integrated graphics was never particularly good. Intel didn’t care about graphics, it just had some free space on a necessary piece of silicon and decided to do something with it. High performance GPUs need lots of transistors, something Intel would never give its graphics architects - they only got the bare minimum. It also didn’t make sense to focus on things like driver optimizations and image quality. Investing in people and infrastructure to support something you’re giving away for free never made a lot of sense.
Intel hired some very passionate graphics engineers, who always petitioned Intel management to give them more die area to work with, but the answer always came back no. Intel was a pure blooded CPU company, and the GPU industry wasn’t interesting enough at the time. Intel’s GPU leadership needed another approach.
A few years ago they got that break. Once again, it had to do with IO demands on chipset die area. Intel’s chipsets were always built on a n-1 or n-2 process. If Intel was building a 45nm CPU, the chipset would be built on 65nm or 90nm. This waterfall effect allowed Intel to help get more mileage out of its older fabs, which made the accountants at Intel quite happy as those $2 - $3B buildings are painfully useless once obsolete. As the PC industry grew, so did shipments of Intel chipsets. Each Intel CPU sold needed at least one other Intel chip built on a previous generation node. Interface widths as well as the number of IOs required on chipsets continued to increase, driving chipset die areas up once again. This time however, the problem wasn’t as easy to deal with as giving the graphics guys more die area to work with. Looking at demand for Intel chipsets, and the increasing die area, it became clear that one of two things had to happen: Intel would either have to build more fabs on older process nodes to keep up with demand, or Intel would have to integrate parts of the chipset into the CPU.
Not wanting to invest in older fab technology, Intel management green-lit the second option: to move the Graphics and Memory Controller Hub onto the CPU die. All that would remain off-die would be a lightweight IO controller for things like SATA and USB. PCIe, the memory controller, and graphics would all move onto the CPU package, and then eventually share the same die with the CPU cores.
Pure economics and an unwillingness to invest in older fabs made the GPU a first class citizen in Intel silicon terms, but Intel management still didn’t have the motivation to dedicate more die area to the GPU. That encouragement would come externally, from Apple.
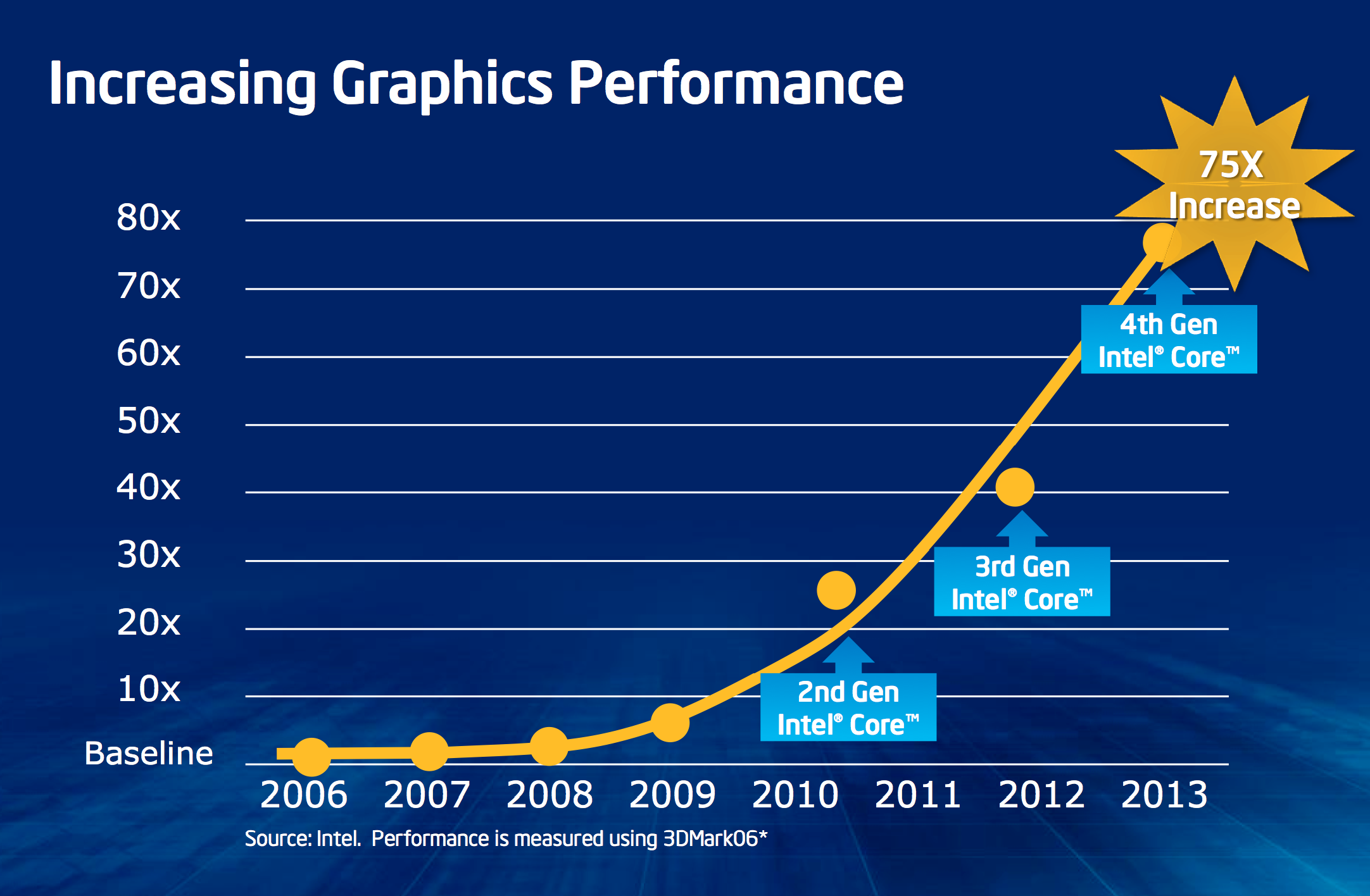
Looking at the past few years of Apple products, you’ll recognize one common thread: Apple as a company values GPU performance. As a small customer of Intel’s, Apple’s GPU desires didn’t really matter, but as Apple grew, so did its influence within Intel. With every microprocessor generation, Intel talks to its major customers and uses their input to help shape the designs. There’s no sense in building silicon that no one wants to buy, so Intel engages its customers and rolls their feedback into silicon. Apple eventually got to the point where it was buying enough high-margin Intel silicon to influence Intel’s roadmap. That’s how we got Intel’s HD 3000. And that’s how we got here.
Haswell GPU Architecture & Iris Pro
In 2010, Intel’s Clarkdale and Arrandale CPUs dropped the GMA (Graphics Media Accelerator) label from its integrated graphics. From that point on, all Intel graphics would be known as Intel HD graphics. With certain versions of Haswell, Intel once again parts ways with its old brand and introduces a new one, this time the change is much more significant.
Intel attempted to simplify the naming confusion with this slide:
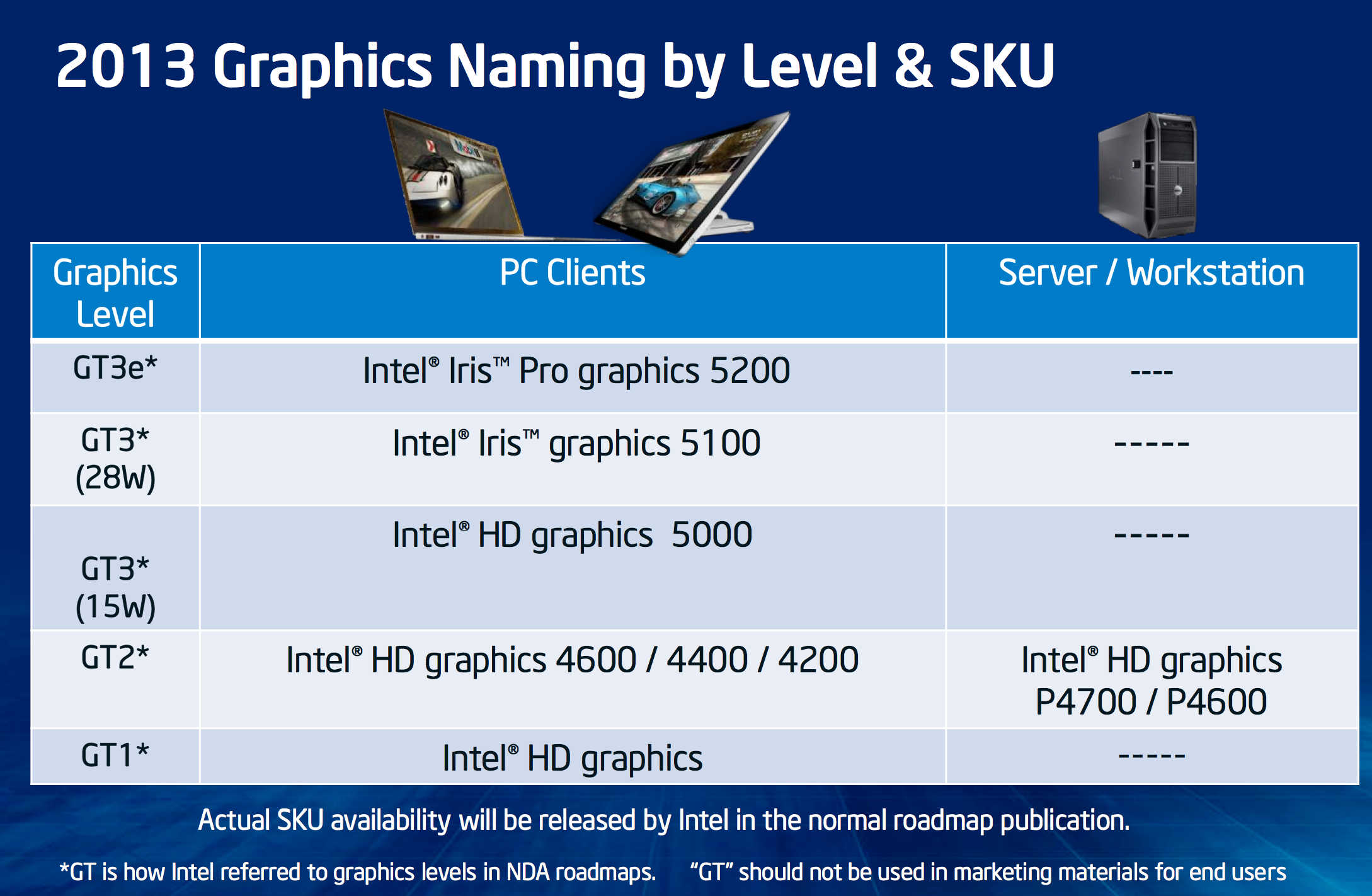
While Sandy and Ivy Bridge featured two different GPU implementations (GT1 and GT2), Haswell adds a third (GT3).
Basically it boils down to this. Haswell GT1 is just called Intel HD Graphics, Haswell GT2 is HD 4200/4400/4600. Haswell GT3 at or below 1.1GHz is called HD 5000. Haswell GT3 capable of hitting 1.3GHz is called Iris 5100, and finally Haswell GT3e (GT3 + embedded DRAM) is called Iris Pro 5200.
The fundamental GPU architecture hasn’t changed much between Ivy Bridge and Haswell. There are some enhancements, but for the most part what we’re looking at here is a dramatic increase in the amount of die area allocated for graphics.
All GPU vendors have some fundamental building block they scale up/down to hit various performance/power/price targets. AMD calls theirs a Compute Unit, NVIDIA’s is known as an SMX, and Intel’s is called a sub-slice.
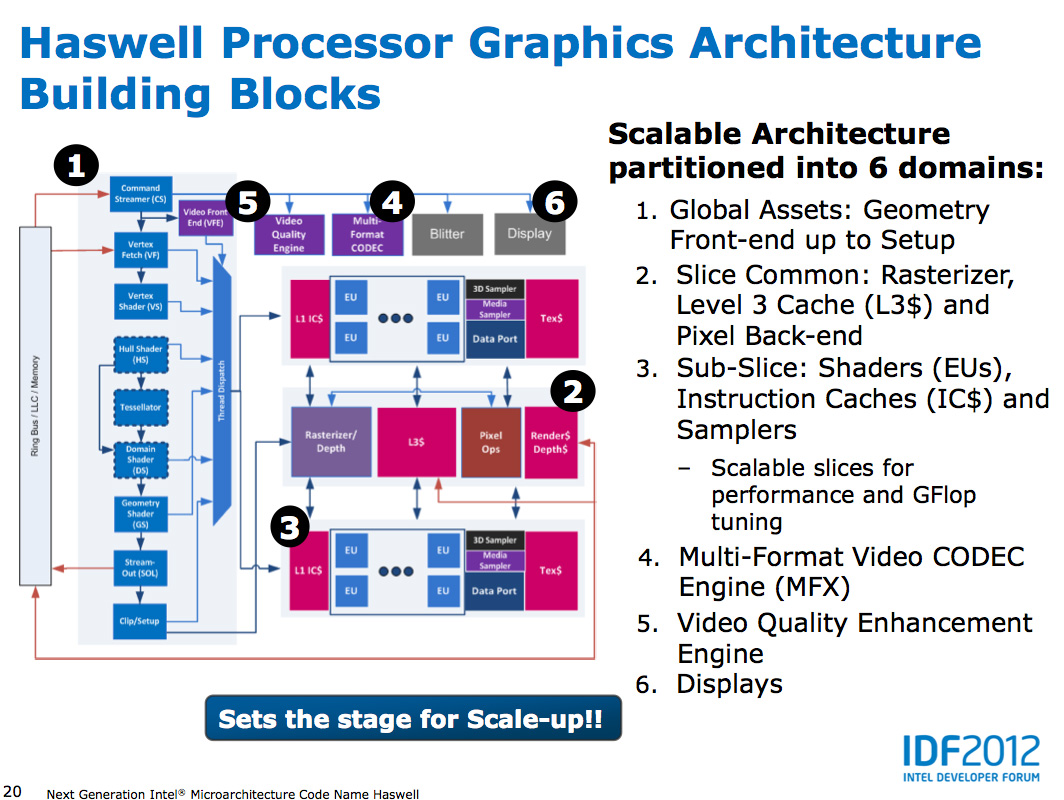
In Haswell, each graphics sub-slice features 10 EUs. Each EU is a dual-issue SIMD machine with two 4-wide vector ALUs:
| Low Level Architecture Comparison | ||||||||||||||||
| AMD GCN | Intel Gen7 Graphics | NVIDIA Kepler | ||||||||||||||
| Building Block | GCN Compute Unit | Sub-Slice | Kepler SMX | |||||||||||||
| Shader Building Block | 16-wide Vector SIMD | 2 x 4-wide Vector SIMD | 32-wide Vector SIMD | |||||||||||||
| Smallest Implementation | 4 SIMDs | 10 SIMDs | 6 SIMDs | |||||||||||||
| Smallest Implementation (ALUs) | 64 | 80 | 192 | |||||||||||||
There are limitations as to what can be co-issued down each EU’s pair of pipes. Intel addressed many of the co-issue limitations last generation with Ivy Bridge, but there are still some that remain.
Architecturally, this makes Intel’s Gen7 graphics core a bit odd compared to AMD’s GCN and NVIDIA’s Kepler, both of which feature much wider SIMD arrays without any co-issue requirements. The smallest sub-slice in Haswell however delivers a competitive number of ALUs to AMD and NVIDIA implementations.
Intel had a decent building block with Ivy Bridge, but it chose not to scale it up as far as it would go. With Haswell that changes. In its highest performing configuration, Haswell implements four sub-slices or 40 EUs. Doing the math reveals a very competent looking part on paper:
| Peak Theoretical GPU Performance | ||||||||||||||||
| Cores/EUs | Peak FP ops per Core/EU | Max GPU Frequency | Peak GFLOPs | |||||||||||||
| Intel Iris Pro 5100/5200 | 40 | 16 | 1300MHz | 832 GFLOPS | ||||||||||||
| Intel HD Graphics 5000 | 40 | 16 | 1100MHz | 704 GFLOPS | ||||||||||||
| NVIDIA GeForce GT 650M | 384 | 2 | 900MHz | 691.2 GFLOPS | ||||||||||||
| Intel HD Graphics 4600 | 20 | 16 | 1350MHz | 432 GFLOPS | ||||||||||||
| Intel HD Graphics 4000 | 16 | 16 | 1150MHz | 294.4 GFLOPS | ||||||||||||
| Intel HD Graphics 3000 | 12 | 12 | 1350MHz | 194.4 GFLOPS | ||||||||||||
| Intel HD Graphics 2000 | 6 | 12 | 1350MHz | 97.2 GFLOPS | ||||||||||||
| Apple A6X | 32 | 8 | 300MHz | 76.8 GFLOPS | ||||||||||||
In its highest end configuration, Iris has more raw compute power than a GeForce GT 650M - and even more than a GeForce GT 750M. Now we’re comparing across architectures here so this won’t necessarily translate into a performance advantage in games, but the takeaway is that with HD 5000, Iris 5100 and Iris Pro 5200 Intel is finally walking the walk of a GPU company.
Peak theoretical performance falls off steeply as soon as you start looking at the GT2 and GT1 implementations. With 1/4 - 1/2 of the execution resources as the GT3 graphics implementation, and no corresponding increase in frequency to offset the loss the slower parts are substantially less capable. The good news is that Haswell GT2 (HD 4600) is at least more capable than Ivy Bridge GT2 (HD 4000).
Taking a step back and looking at the rest of the theoretical numbers gives us a more well rounded look at Intel’s graphics architectures :
| Peak Theoretical GPU Performance | ||||||||||||||||
| Peak Pixel Fill Rate | Peak Texel Rate | Peak Polygon Rate | Peak GFLOPs | |||||||||||||
| Intel Iris Pro 5100/5200 | 10.4 GPixels/s | 20.8 GTexels/s | 650 MPolys/s | 832 GFLOPS | ||||||||||||
| Intel HD Graphics 5000 | 8.8 GPixels/s | 17.6 GTexels/s | 550 MPolys/s | 704 GFLOPS | ||||||||||||
| NVIDIA GeForce GT 650M | 14.4 GPixels/s | 28.8 GTexels/s | 900 MPolys/s | 691.2 GFLOPS | ||||||||||||
| Intel HD Graphics 4600 | 5.4 GPixels/s | 10.8 GTexels/s | 675 MPolys/s | 432 GFLOPS | ||||||||||||
| AMD Radeon HD 7660D (Desktop Trinity, A10-5800K) | 6.4 GPixels/s | 19.2 GTexels/s | 800 MPolys/s | 614 GFLOPS | ||||||||||||
| AMD Radeon HD 7660G (Mobile Trinity, A10-4600M) | 3.97 GPixels/s | 11.9 GTexels/s | 496 MPolys/s | 380 GFLOPS | ||||||||||||
Intel may have more raw compute, but NVIDIA invested more everywhere else in the pipeline. Triangle, texturing and pixel throughput capabilities are all higher on the 650M than on Iris Pro 5200. Compared to AMD's Trinity however, Intel has a big advantage.
Addressing the Memory Bandwidth Problem
Integrated graphics solutions always bumped into a glass ceiling because they lacked the high-speed memory interfaces of their discrete counterparts. As Haswell is predominantly a mobile focused architecture, designed to span the gamut from 10W to 84W TDPs, relying on a power-hungry high-speed external memory interface wasn’t going to cut it. Intel’s solution to the problem, like most of Intel’s solutions, involves custom silicon. As a owner of several bleeding edge foundries, would you expect anything less?
As we’ve been talking about for a while now, the highest end Haswell graphics configuration includes 128MB of eDRAM on-package. The eDRAM itself is a custom design by Intel and it’s built on a variant of Intel’s P1271 22nm SoC process (not P1270, the CPU process). Intel needed a set of low leakage 22nm transistors rather than the ability to drive very high frequencies which is why it’s using the mobile SoC 22nm process variant here.
Despite its name, the eDRAM silicon is actually separate from the main microprocessor die - it’s simply housed on the same package. Intel’s reasoning here is obvious. By making Crystalwell (the codename for the eDRAM silicon) a discrete die, it’s easier to respond to changes in demand. If Crystalwell demand is lower than expected, Intel still has a lot of quad-core GT3 Haswell die that it can sell and vice versa.
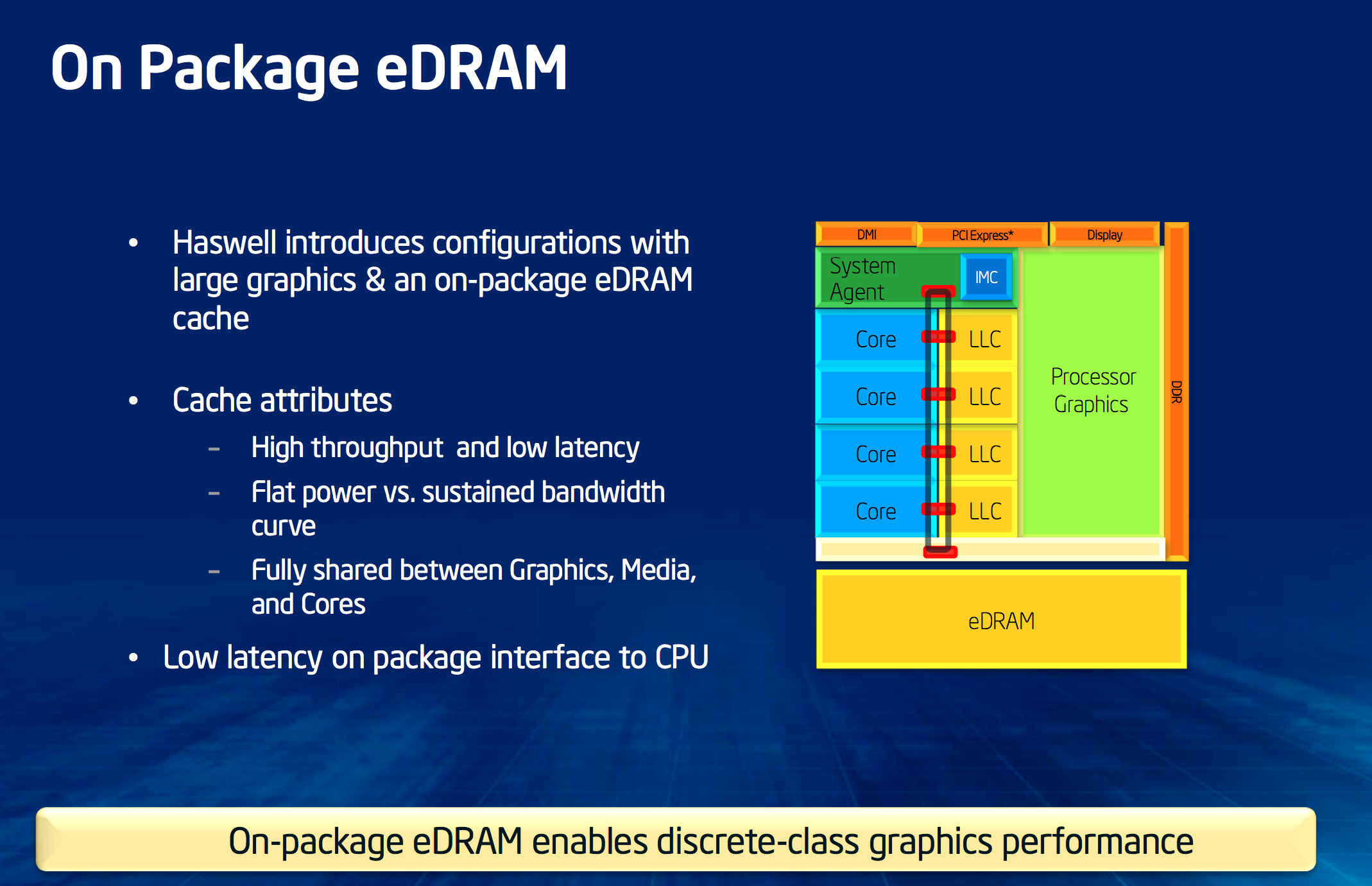
Crystalwell Architecture
Unlike previous eDRAM implementations in game consoles, Crystalwell is true 4th level cache in the memory hierarchy. It acts as a victim buffer to the L3 cache, meaning anything evicted from L3 cache immediately goes into the L4 cache. Both CPU and GPU requests are cached. The cache can dynamically allocate its partitioning between CPU and GPU use. If you don’t use the GPU at all (e.g. discrete GPU installed), Crystalwell will still work on caching CPU requests. That’s right, Haswell CPUs equipped with Crystalwell effectively have a 128MB L4 cache.
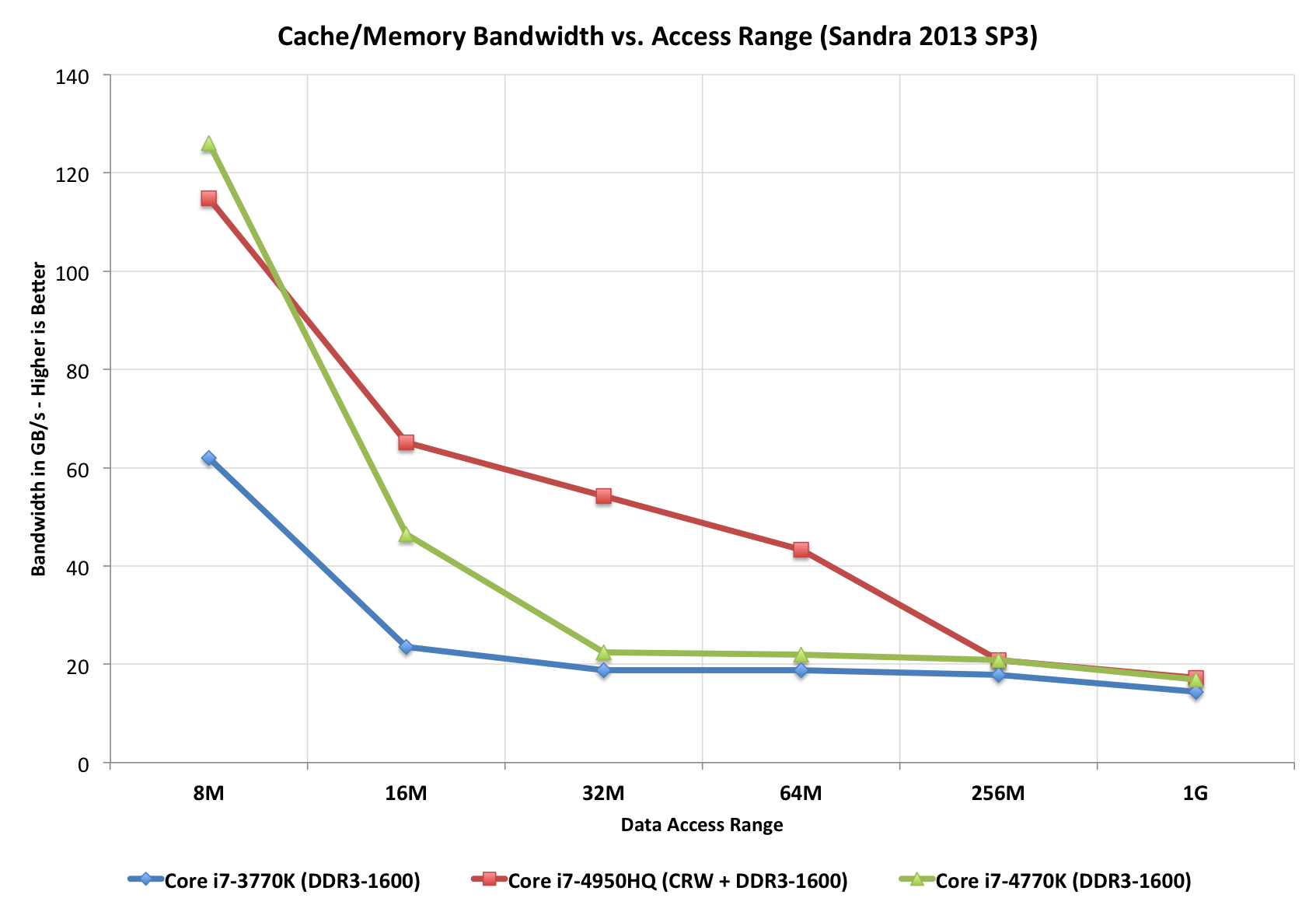
Intel isn’t providing much detail on the connection to Crystalwell other than to say that it’s a narrow, double-pumped serial interface capable of delivering 50GB/s bi-directional bandwidth (100GB/s aggregate). Access latency after a miss in the L3 cache is 30 - 32ns, nicely in between an L3 and main memory access.
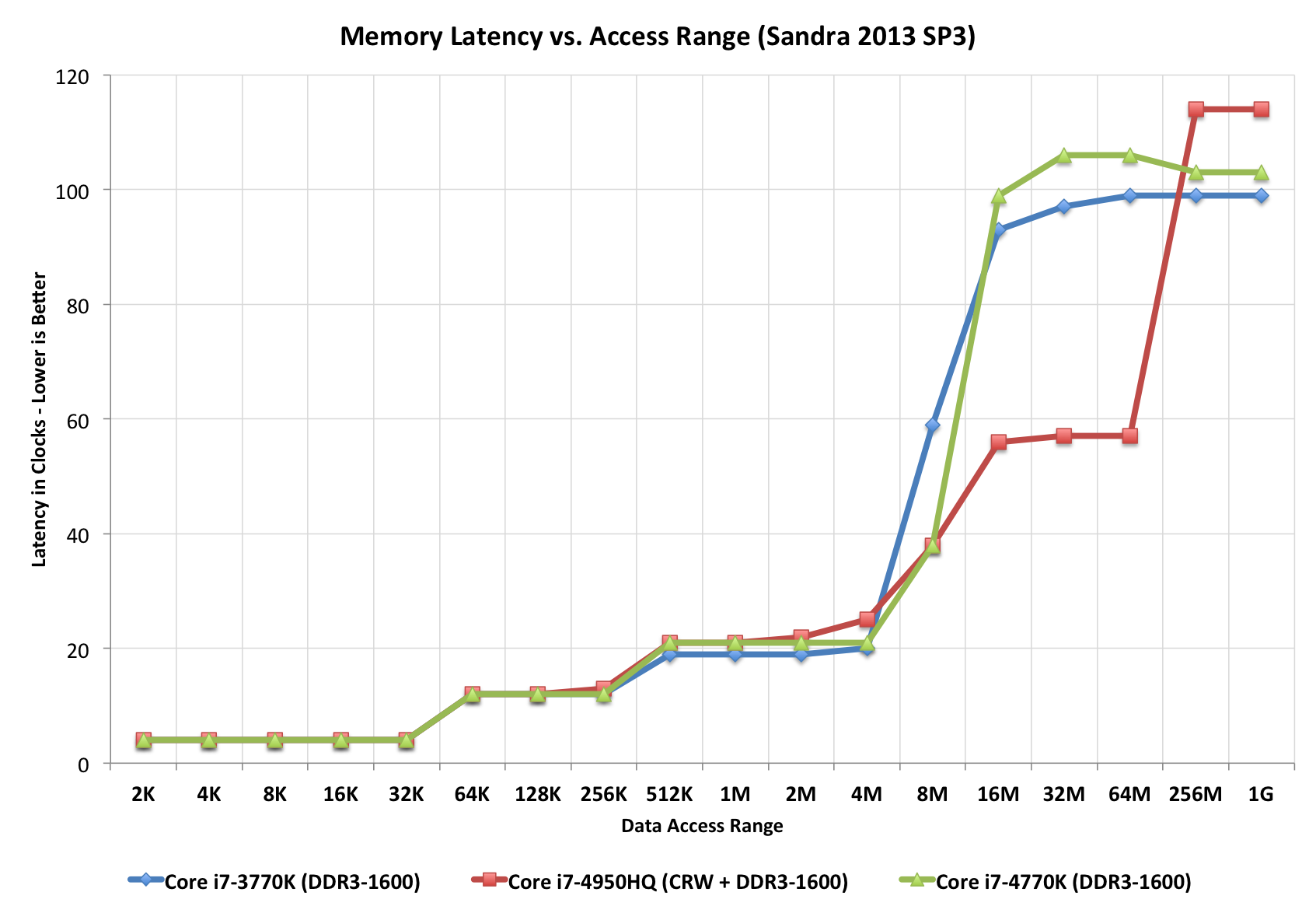
The eDRAM clock tops out at 1.6GHz.
There’s only a single size of eDRAM offered this generation: 128MB. Since it’s a cache and not a buffer (and a giant one at that), Intel found that hit rate rarely dropped below 95%. It turns out that for current workloads, Intel didn’t see much benefit beyond a 32MB eDRAM however it wanted the design to be future proof. Intel doubled the size to deal with any increases in game complexity, and doubled it again just to be sure. I believe the exact wording Intel’s Tom Piazza used during his explanation of why 128MB was “go big or go home”. It’s very rare that we see Intel be so liberal with die area, which makes me think this 128MB design is going to stick around for a while.
The 32MB number is particularly interesting because it’s the same number Microsoft arrived at for the embedded SRAM on the Xbox One silicon. If you felt that I was hinting heavily at the Xbox One being ok if its eSRAM was indeed a cache, this is why. I’d also like to point out the difference in future proofing between the two designs.
The Crystalwell enabled graphics driver can choose to keep certain things out of the eDRAM. The frame buffer isn’t stored in eDRAM for example.
| Peak Theoretical Memory Bandwidth | ||||||||||||||||
| Memory Interface | Memory Frequency | Peak Theoretical Bandwidth | ||||||||||||||
| Intel Iris Pro 5200 | 128-bit DDR3 + eDRAM | 1600MHz + 1600MHz eDRAM | 25.6GB/s + 50GB/s eDRAM (bidirectional) | |||||||||||||
| NVIDIA GeForce GT 650M | 128-bit GDDR5 | 5016MHz | 80.3 GB/s | |||||||||||||
| Intel HD 5100/4600/4000 | 128-bit DDR3 | 1600MHz | 25.6GB/s | |||||||||||||
| Apple A6X | 128-bit LPDDR2 | 1066MHz | 17.1 GB/s | |||||||||||||
Intel claims that it would take a 100 - 130GB/s GDDR memory interface to deliver similar effective performance to Crystalwell since the latter is a cache. Accessing the same data (e.g. texture reads) over and over again is greatly benefitted by having a large L4 cache on package.
I get the impression that the plan might be to keep the eDRAM on a n-1 process going forward. When Intel moves to 14nm with Broadwell, it’s entirely possible that Crystalwell will remain at 22nm. Doing so would help Intel put older fabs to use, especially if there’s no need for a near term increase in eDRAM size. I asked about the potential to integrate eDRAM on-die, but was told that it’s far too early for that discussion. Given the size of the 128MB eDRAM on 22nm (~84mm^2), I can understand why. Intel did float an interesting idea by me though. In the future it could integrate 16 - 32MB of eDRAM on-die for specific use cases (e.g. storing the frame buffer).
Intel settled on eDRAM because of its high bandwidth and low power characteristics. According to Intel, Crystalwell’s bandwidth curve is very flat - far more workload independent than GDDR5. The power consumption also sounds very good. At idle, simply refreshing whatever data is stored within, the Crystalwell die will consume between 0.5W and 1W. Under load, operating at full bandwidth, the power usage is 3.5 - 4.5W. The idle figures might sound a bit high, but do keep in mind that since Crystalwell caches both CPU and GPU memory it’s entirely possible to shut off the main memory controller and operate completely on-package depending on the workload. At the same time, I suspect there’s room for future power improvements especially as Crystalwell (or a lower power derivative) heads towards ultra mobile silicon.
Crystalwell is tracked by Haswell’s PCU (Power Control Unit) just like the CPU cores, GPU, L3 cache, etc... Paying attention to thermals, workload and even eDRAM hit rate, the PCU can shift power budget between the CPU, GPU and eDRAM.
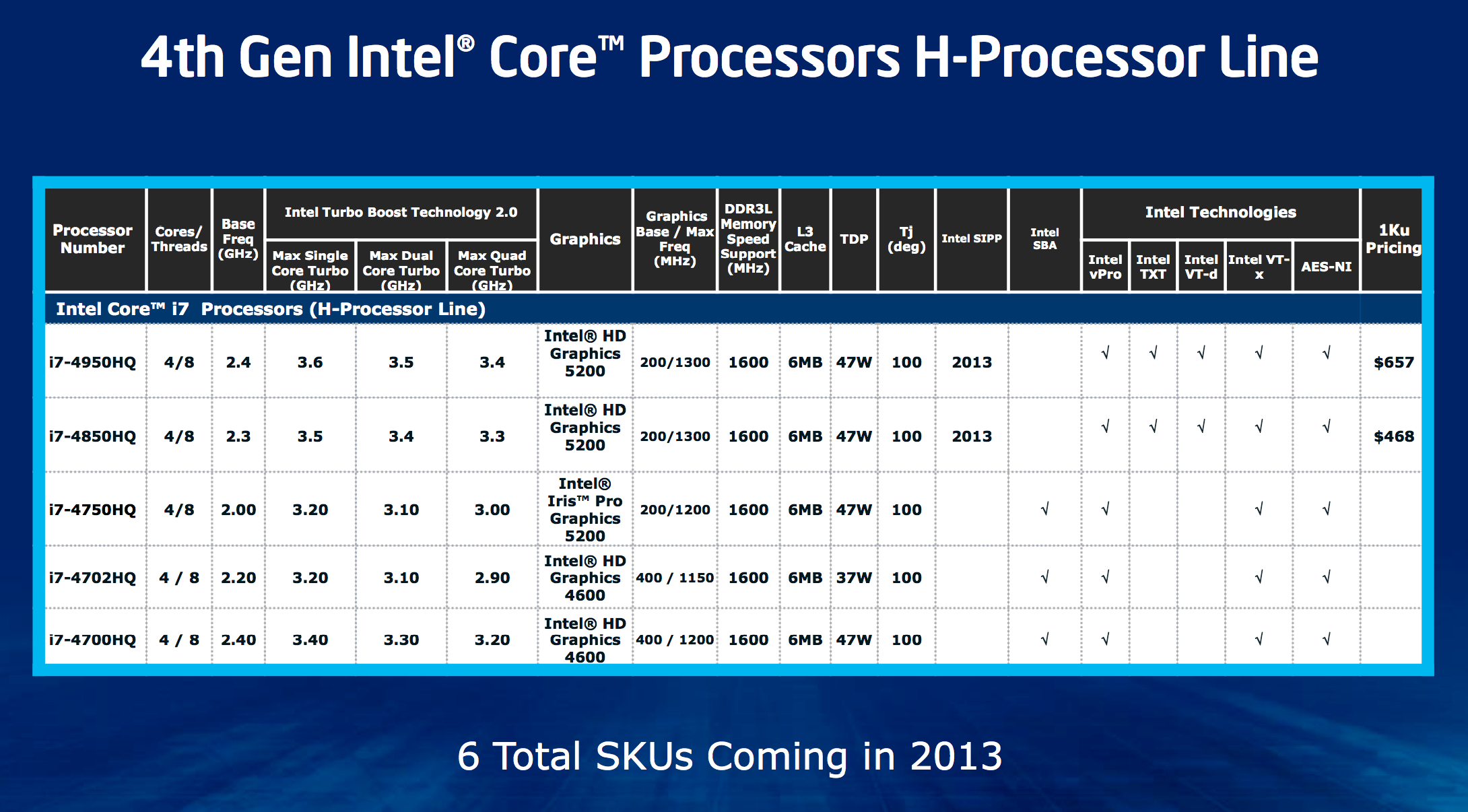
Crystalwell is only offered alongside quad-core GT3 Haswell. Unlike previous generations of Intel graphics, high-end socketed desktop parts do not get Crystalwell. Only mobile H-SKUs and desktop (BGA-only) R-SKUs have Crystalwell at this point. Given the potential use as a very large CPU cache, it’s a bit insane that Intel won’t even offer a single K-series SKU with Crystalwell on-board.
As for why lower end parts don’t get it, they simply don’t have high enough memory bandwidth demands - particularly in GT1/GT2 graphics configurations. According to Intel, once you get to about 18W then GT3e starts to make sense but you run into die size constraints there. An Ultrabook SKU with Crystalwell would make a ton of sense, but given where Ultrabooks are headed (price-wise) I’m not sure Intel could get any takers.
The Core i7-4950HQ Mobile CRB
At a high level, Iris Pro 5200 would seem to solve both problems that plagued Intel graphics in the past: a lack of GPU hardware and a lack of memory bandwidth. As a mostly mobile-focused design, and one whose launch partner isn’t keen on giving out early samples, it seemed almost impossible to evaluate Iris Pro in time for the Haswell launch. That was until a week ago when this showed up:

What may look like a funny mid-tower from a few years ago is actually home to one of Intel’s mobile Customer Reference Boards (CRB). Although the chassis is desktop-sized, everything inside is optimized for mobile. It’s just easier to build things larger, especially when it comes to testing and diagnosing problems.
The silicon on-board is a 47W Core i7-4950HQ, the lowest end launch SKU with Iris Pro 5200 graphics. The chassis is obviously overkill for a 47W part, but the performance we get with this machine should be representative of any i7-4950HQ system with a cooler capable of dissipating 47W.

If you read our Haswell CPU review you’ll know that Intel tried to be stingy with telling us die sizes and transistor counts for the bulk of the Haswell lineup, electing to only give us data on dual-core Haswell GT3 and quad-core Haswell GT2. Knowing that mobile parts ship without integrated heat spreaders, I went to work on pulling off the i7-4950HQ’s heatsink (after I finished testing, just in case).


With the heatsink off and thermal paste wiped off, I used my bargain basement calipers to get a rough idea of die area. This is what I came up with:
| Intel Haswell | |||||||||||||||||
| CPU Configuration | GPU Configuration | Die Size | Transistor Count | ||||||||||||||
| Haswell GT3e (QC) | Quad-Core | GT3e | 264mm2 + 84mm2 | ? | |||||||||||||
| Haswell GT2 (QC) | Quad-Core | GT2 | 177mm2 | 1.4B | |||||||||||||
| Haswell ULT GT3 | Dual-Core | GT3 | 181mm2 | 1.3B | |||||||||||||
The Crystalwell die measures 7mm x 12mm (84mm^2), while the quad-core Haswell + GT3 die is a whopping 264mm^2 (16.2mm x 16.3mm). Working backwards from the official data Intel provided (177mm^2 for quad-core GT2), I came up with an 87mm^2 adder for the extra hardware in Haswell GT3 vs. GT2. Doubling that 87mm^2 we get a rough idea of how big the full 40 EU Haswell GPU might be: 174mm^2. If my math is right, this means that in a quad-core Haswell GT3 die, around 65% of the die area is GPU. This is contrary to the ~33% in a quad-core Haswell GT2. I suspect a dual-core + GT3 design is at least half GPU.
The Comparison Points
Intel sort of dropped this CRB off without anything to compare it to, so I scrambled over the past week looking for things to put Iris Pro’s performance in perspective. The obvious candidate was Apple’s 15-inch MacBook Pro with Retina Display. I expect its successor will use Iris Pro 5200, making this a perfect comparison point. The 15-inch rMBP is equipped with a GeForce GT 650M with a 900MHz core clock and a 5GHz memory datarate.
I also dusted off a GeForce GT 640 desktop card to shed a little more light on the 650M comparison. The 640 has a slightly higher core clock (925MHz) but it only has 1.7GHz DDR3, working out to be 27GB/s of memory bandwidth compared to 83GB/s for the 650M. Seeing how Iris Pro compares to the GT 640 and 650M will tell us just how good of a job Crystalwell is doing.
Next up is the desktop Core i7-4770K with HD 4600 graphics. This is a Haswell GT2 implementation, but at a much higher TDP than the 47W mobile part we’re comparing it to (84W). In a notebook you can expect a much bigger gap in performance between the HD 4600 and Iris Pro than what we’re showing here. Similarly I also included a 77W HD 4000 for a comparison to Ivy Bridge graphics.

On the AMD front I have the 35W A10-4600M (codename Trinity), featuring AMD’s 7660G processor graphics. I also included the 100W A10-5800 as a reference point since we were largely pleased with the GPU performance of Trinity on the desktop.
I listed TDPs with all of the parts I’m comparing here. In the case of the GT 640 I’m adding the TDP of the CPU (84W) and the GPU (65W). TDP is half of the story with Iris Pro, because the CPU, GPU and eDRAM all fit into the same 47W power envelope. With a discrete GPU, like the 650M, you end up with an extra 45W on top of the CPU’s TDP. In reality the host CPU won’t be running at anywhere near its 45W max in that case, so the power savings are likely not as great as you’d expect but they’ll still be present.

At the request of at least one very eager OEM, Intel is offering a higher-TDP configuration of the i7-4950HQ. Using Intel’s Extreme Tuning Utility (XTU) I was able to simulate this cTDP up configuration by increasing the sustained power limit to 55W, and moving the short term turbo power limit up to 69W. OEMs moving from a 2-chip CPU + GPU solution down to a single Iris Pro are encouraged to do the same as their existing thermal solutions should be more than adequate to cool a 55W part. I strongly suspect this is the configuration we’ll see in the next-generation 15-inch MacBook Pro with Retina Display.
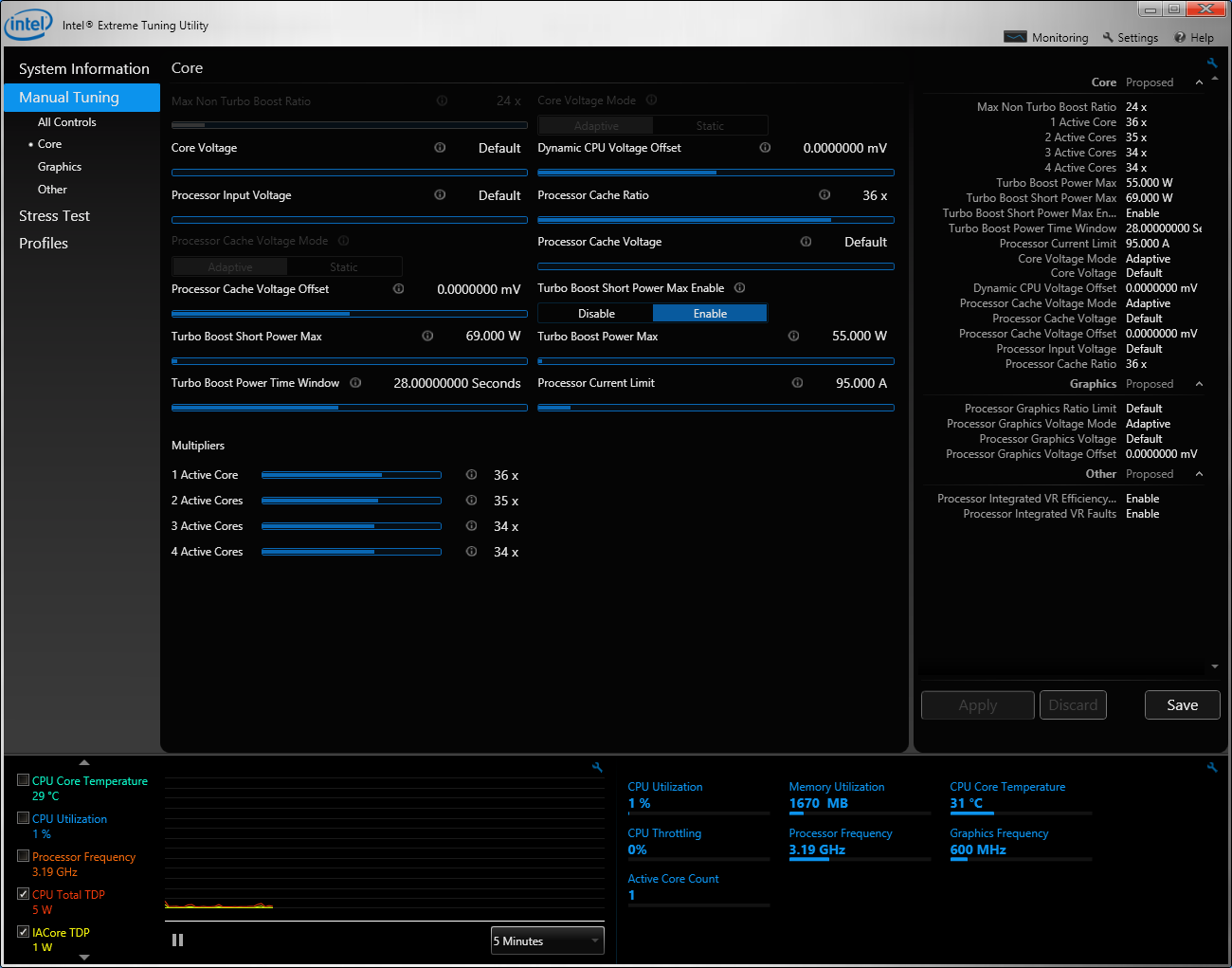
To remove as many bottlenecks as possible I configured all integrated GPU options (other than Iris Pro 5200) with the fastest supported memory. That worked out to being DDR3-2133 on desktop Trinity and desktop IVB, and DDR3-2400 on desktop Haswell (HD 4600). The mobile platforms, including Iris Pro 5200, all used DDR3-1600.
On the software side I used NVIDIA's GeForce R320 v320.18, AMD's Catalyst 13.6 beta and Intel's 9.18.10.3177 drivers with Crystalwell support.
Metro: Last Light
Metro: Last Light is the latest entry in the Metro series of post-apocalyptic shooters by developer 4A Games. Like its processor, Last Light is a game that sets a high bar for visual quality, and at its highest settings an equally high bar for system requirements thanks to its advanced lighting system. This doesn’t preclude it from running on iGPUs thanks to the fact that it scales down rather well, but it does mean that we have to run at fairly low resolutions to get a playable framerate.

Metro is a pretty heavy game to begin with, but Iris Pro starts off with an extremely good showing here. In its 55W configuration, Iris Pro is only 5% slower than the GeForce GT 650M. At 47W the gap is larger at 11% however. At 1366 x 768 the difference seems less memory bandwidth related and has more to do with efficiency of the graphics hardware itself.
The comparison to mobile Trinity is a walk in the park for Iris Pro. Even a 100W desktop Trinity part is appreciably slower here.

Increasing the resolution and quality settings changes things quite a bit. The 650M pulls ahead, and now the Iris Pro 5200 basically equals the performance of the GT 640. Intel claims a very high hit rate on the L4 cache, however it could be that 50GB/s is just not enough bandwidth between the GPU and Crystalwell. The performance improvement compared to all other processor graphics solutions, regardless of TDP, is still well in favor of Iris Pro. The i7-4950HQ holds a 50% advantage over the desktop i7-4770K and is almost 2x the speed of the i7-3770K.
Comparing mobile to mobile, Iris Pro delivers over 2x the frame rate of Trinity.
BioShock: Infinite
Bioshock Infinite is Irrational Games’ latest entry in the Bioshock franchise. Though it’s based on Unreal Engine 3 – making it our obligatory UE3 game – Irrational had added a number of effects that make the game rather GPU-intensive on its highest settings. As an added bonus it includes a built-in benchmark composed of several scenes, a rarity for UE3 engine games, so we can easily get a good representation of what Bioshock’s performance is like.

Both the 650M and desktop GT 640 are able to outperform Iris Pro here. Compared to the 55W configuration, the 650M is 32% faster. There's not a huge difference in performance between the GT 640 and 650M, indicating that the performance advantage here isn't due to memory bandwidth but something fundamental to the GPU architecture.
In the grand scheme of things, Iris Pro does extremely well. There isn't an integrated GPU that can touch it. Only the 100W desktop Trinity approaches Iris Pro performance but at more than 2x the TDP.

The standings don't really change at the higher resolution/quality settings, but we do see some of the benefits of Crystalwell appear. A 9% advantage over the 100W desktop Trinity part grows to 18% as memory bandwidth demands increase. Compared to the desktop HD 4000 we're seeing more than 2x the performance, which means in mobile that number will likely grow even further. The mobile Trinity comparison is a shut out as well.
Sleeping Dogs
A Square Enix game, Sleeping Dogs is one of the few open world games to be released with any kind of benchmark, giving us a unique opportunity to benchmark an open world game. Like most console ports, Sleeping Dogs’ base assets are not extremely demanding, but it makes up for it with its interesting anti-aliasing implementation, a mix of FXAA and SSAA that at its highest settings does an impeccable job of removing jaggies. However by effectively rendering the game world multiple times over, it can also require a very powerful video card to drive these high AA modes.

At 1366 x 768 with medium quality settings, there doesn't appear to be much of a memory bandwidth limitation here at all. Vsync was disabled but there's a definite clustering of performance close to 60 fps. The gap between the 650M and Iris Pro is just under 7%. Compared to the 77W HD 4000 Iris Pro is good for almost a 60% increase in performance. The same goes for the mobile Trinity comparison.

At higher resolution/higher quality settings, there's a much larger gap between the 650M and Iris Pro 5200. At high quality defaults both FXAA and SSAA are enabled, which given Iris Pro's inferior texture sampling and pixel throughput results in a much larger victory for the 650M. NVIDIA maintains a 30 - 50% performance advantage here. The move from a 47W TDP to 55W gives Iris Pro an 8% performance uplift. If we look at the GT 640's performance relative to the 5200, it's clear that memory bandwidth alone isn't responsible for the performance delta here (although it does play a role).
Once more, compared to all other integrated solutions Iris Pro has no equal. At roughly 2x the performance of a 77W HD 4000, 20% better than a desktop Trinity and 40% better than mobile Trinity, Iris Pro looks very good.
Tomb Raider (2013)
The simply titled Tomb Raider is the latest entry in the Tomb Raider franchise, making a clean break from past titles in plot, gameplay, and technology. Tomb Raider games have traditionally been technical marvels and the 2013 iteration is no different. iGPUs aren’t going to have quite enough power to use its marquee feature – DirectCompute accelerated hair physics (TressFX) – however even without it the game still looks quite good at its lower settings, while providing a challenge for our iGPUs.
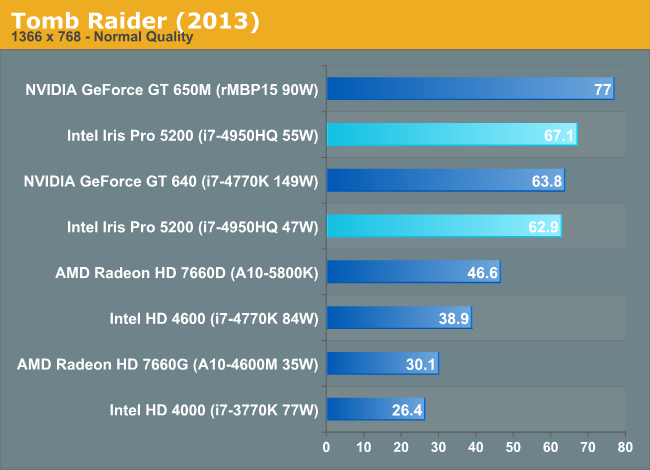
Once again, at 1366 x 768 the gap between 650M and Iris Pro 5200 is at its smallest. Here NVIDIA holds a 15% advantage over the 55W Iris Pro.

Increase the resolution and image quality and the gap widens considerably. Again the problem here appears to be AA impacting Iris Pro much more than the 650M.
Battlefield 3
Our multiplayer action game benchmark of choice is Battlefield 3, DICE’s 2011 multiplayer military shooter. Its ability to pose a significant challenge to GPUs has been dulled some by time and drivers at the high-end, but it’s still a challenge for more entry-level GPUs such as the iGPUs found on Intel and AMD's latest parts. Our goal here is to crack 60fps in our benchmark, as our rule of thumb based on experience is that multiplayer framerates in intense firefights will bottom out at roughly half our benchmark average, so hitting medium-high framerates here is not necessarily high enough.

The move to 55W brings Iris Pro much closer to the GT 650M, with NVIDIA's advantage falling to less than 10%. At 47W, Iris Pro isn't able to remain at max turbo for as long. The soft configurable TDP is responsible for nearly a 15% increase in performance here.
Iris Pro continues to put all other integrated graphics solutions to shame. The 55W 5200 is over 2x the speed of the desktop HD 4000 and the same for the mobile Trinity. There's even a healthy gap between it and desktop Trinity/Haswell.

Ramp up resolution and quality settings and Iris Pro once again looks far less like a discrete GPU. NVIDIA holds over a 50% advantage here. Once again I don't believe this is memory bandwidth related, Crystalwell appears to be doing its job. Instead it looks like fundamental GPU architecture issue.

The gap narrows slightly with an increase in resolution, perhaps indicating that as the limits shift to memory bandwidth Crystalwell is able to win some ground. Overall, there's just an appreciable advantage to NVIDIA's architecture here.
The iGPU comparison continues to be an across the board win for Intel. It's amazing what can happen when you actually dedicate transistors to graphics.
Crysis 3
With Crysis 3, Crytek has gone back to trying to kill computers, taking back the “most punishing game” title in our benchmark suite. Only in a handful of setups can we even run Crysis 3 at its highest (Very High) settings, and the situation isn't too much better for entry-level GPUs at its lowest quality setting. In any case Crysis 1 was an excellent template for the kind of performance required to drive games for the next few years, and Crysis 3 looks to be much the same for 2013.

All of these GPUs need to run at low quality settings to get decent frame rates, but Iris Pro is actually the first Intel integrated solution that can break 30 fps here. Only AMD's desktop Trinity can claim the same. NVIDIA holds a 30% advantage, one that shrinks to 10% on the GT 640. Given the only difference between those two parts is memory bandwidth, I wonder if Crystalwell might need to run at a higher frequency here.


Crysis Warhead
Up next is our legacy title for 2013, Crysis: Warhead. The stand-alone expansion to 2007’s Crysis, at over 4 years old Crysis: Warhead can still beat most systems down. Crysis was intended to be future-looking as far as performance and visual quality goes, and it has clearly achieved that. We’ve only finally reached the point where high-end single-GPU cards have come out that can hit 60fps at 1920 with 4xAA, while low-end GPUs are just now hitting 60fps at lower quality settings and resolutions.

I can't believe it. An Intel integrated solution actually beats out an NVIDIA discrete GPU in a Crysis title. The 5200 does well here, outperforming the 650M by 12% in its highest TDP configuration. I couldn't run any of the AMD parts here as Bulldozer based parts seem to have a problem with our Crysis benchmark for some reason.
Crysis: Warhead is likely one of the simpler tests we have in our suite here, which helps explain Intel's performance a bit. It's also possible that older titles have been Intel optimization targets for longer.

Ramping up the res kills the gap between the highest end Iris Pro and the GT 650M.

Moving to higher settings and at a higher resolution gives NVIDIA the win once more. The margin of victory isn't huge, but the added special effects definitely stress whatever Intel is lacking within its GPU architecture.
GRID 2
GRID 2 is a new addition to our suite and our new racing game of choice, being the very latest racing game out of genre specialty developer Codemasters. Intel did a lot of publicized work with the developer on this title creating a high performance implementation of Order Independent Transparency for Haswell, so I expected it to be well optimized. I ran out of time in testing this one and couldn't include all of the parts here. I did use GRID 2 as an opportunity to look at the impact of MSAA on Iris Pro's performance.
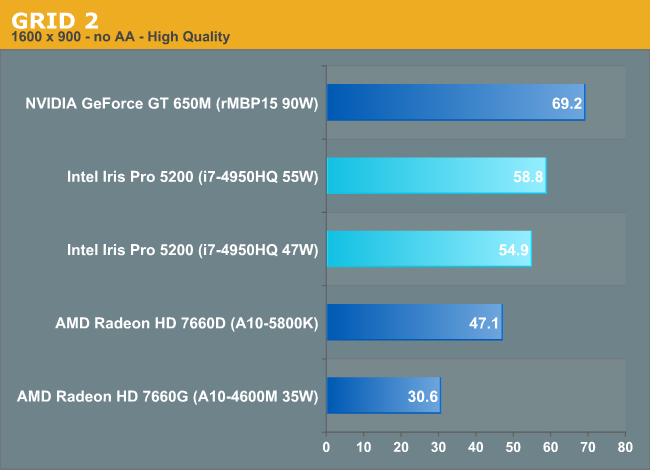
Without AA, Iris Pro does well, with the 650M pulling ahead by low double digits. Mobile Trinity is roughly half the speed of Iris, with desktop Trinity bridging the gap.
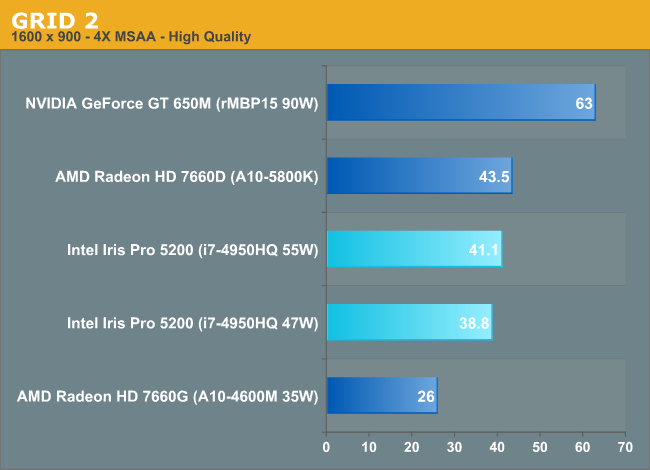
Turn up the resolution, add AA, and NVIDIA pulls ahead by a large margin. The desktop Trinity part also inches ahead.

Ramp up the quality settings however and Iris Pro ends up ahead of the GT 650M. Desktop Trinity falls behind considerably, likely running into memory bandwidth limitations. Crystalwell seems to save Iris Pro here.
Image Quality
Software compatibility and image quality remain understandable concerns, however Intel has improved tremendously in these areas over the past couple of years. I couldn't run Total War: Shogun 2 on Iris Pro, but other than that every other game I threw at the system ran without errors - a significant improvement over where things were not too long ago. On the compute side, I couldn't get our Folding@Home benchmark to work but otherwise everything else ran well.

On the image quality front I didn't see too much to be concerned about. I noticed some occasional texture flashing in Battlefield 3, but it was never something I was able to grab a screenshot of quickly enough. Intel seems pretty quick about addressing any issues that crop up and as a company it has considerably increased staffing/resources on the driver validation front.
The gallery below has a series of images taken from some of the benchmarks in our suite. I didn't notice any obvious differences between Intel and NVIDIA render quality. By virtue of experience and focus I expect software compatiblity, image quality and driver/hardware efficiency to be better on the NVIDIA side of the fence. At the same time, I have no reason to believe that Intel isn't serious about continuing to address those areas going forward. Intel as a company has gone from begging software developers to at least let their code run on Intel integrated graphics, to actively working with game developers to introduce new features and rendering techniques.






Synthetics
Our synthetic benchmarks can sometimes tell us a lot about what an architecture is capable of. In this case, we do have some unanswered questions about why Intel falls short of the GT 650M in some cases but not in others. We'll turn to 3DMark Vantage first to stress ROP and texel rates.

Iris Pro doesn't appear to have a ROP problem, at least not in 3DMark Vantage. NVIDIA can output more pixels than Iris Pro though, so it's entirely possible that we're just not seeing any problems because we're looking at a synthetic test. Comparing the HD 4600 to the Iris Pro 5200 we see near perfect scaling in pixel throughput. Remember the ROP hardware is located in slice common, which is doubled when going from GT2 to GT3. Here we see a near doubling of pixel fillrate as a result.
Moving on, we have our 3DMark Vantage texture fillrate test, which does for texels and texture mapping units what the previous test does for ROPs.

Now this is quite interesting. NVIDIA has a 50% advantage in texturing performance, that's actually higher than what the raw numbers would indicate. It's entirely possible that this is part of what we're seeing manifest itself in some of the game benchmarks.
Finally we’ll take a quick look at tessellation performance with TessMark.

Iris Pro doesn't appear to have a geometry problem. Tessellation performance is very good.
3DMarks & GFXBenchmark
We don't use 3DMark to draw GPU performance conclusions but it does make for a great optimization target. Given what we've seen thus far, and Intel's relative inexperience in the performance GPU space, I wondered if Iris Pro might perform any differently here than in the games we tested.
It turns out, Iris Pro does incredibly well in all of the 3DMarks. Ranging from tying the GT 650M to outperforming it. Obviously none of this has any real world impact, but it is very interesting. Is Intel's performance here the result of all of these benchmarks being lighter on Intel's weaknesses, or is this an indication of what's possible with more driver optimization?

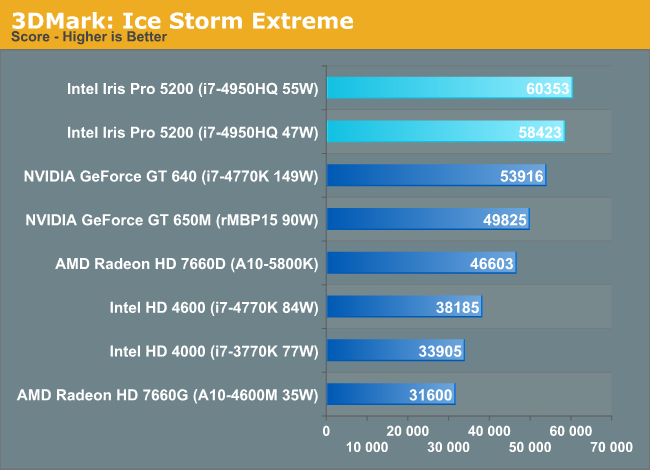




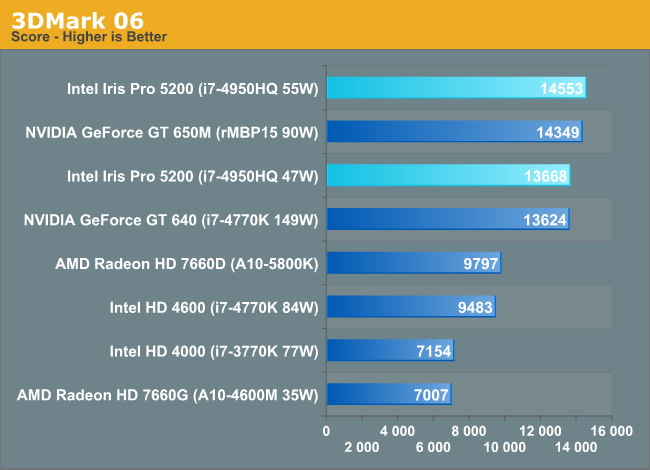
I also included GFXBenchmark 2.7 (formerly GL/DXBenchmark) as another datapoint for measuring the impact of MSAA on Iris Pro:


Iris Pro goes from performance competitive with the GT 650M to nearly half its speed once you enable 4X MSAA. Given the level of performance Iris Pro offers, I don't see many situations where AA will be enabled, but it's clear that this is a weak point of the microarchitecture.
Compute Performance
With Haswell, Intel enables full OpenCL 1.2 support in addition to DirectX 11.1 and OpenGL 4.0. Given the ALU-heavy GPU architecture, I was eager to find out how well Iris Pro did in our compute suite.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
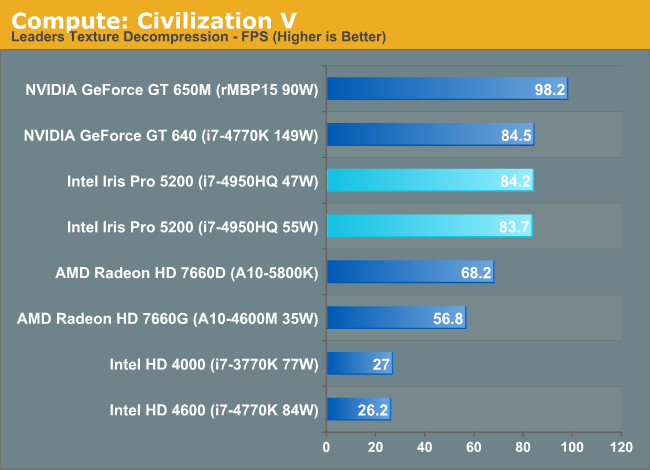
Iris Pro does very well here, tying the GT 640 but losing to the 650M. The latter holds a 16% performance advantage, which I can only assume has to do with memory bandwidth given near identical core/clock configurations between the 650M and GT 640. Crystalwell is clearly doing something though because Intel's HD 4600 is less than 1/3 the performance of Iris Pro 5200 despite having half the execution resources.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.

Moving to OpenCL, we see huge gains from Intel. Kepler wasn't NVIDIA's best compute part, but Iris Pro really puts everything else to shame here. We see near perfect scaling from Haswell GT2 to GT3. Crystalwell doesn't appear to be doing much here, it's all in the additional ALUs.
Our 3rd benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


Once again, Iris Pro does a great job here, outpacing everything else by roughly 70% in the Fluid Simulation test.
Our final compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.

Iris Pro rounds out our compute comparison with another win. In fact, all of the Intel GPU solutions do a good job here.
Quick Sync Performance
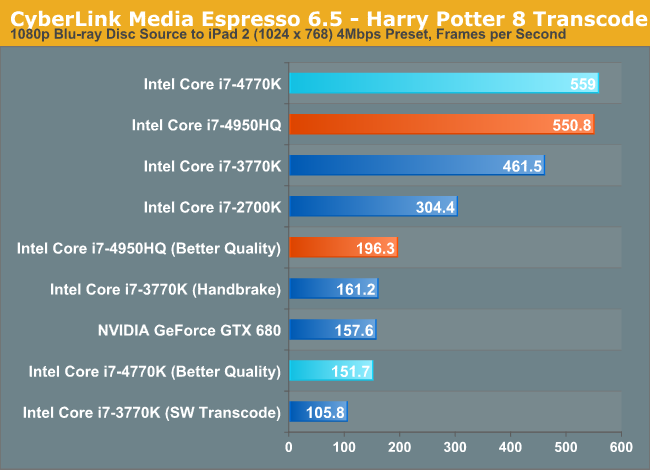
The 128MB eDRAM has a substantial impact on QuickSync performance. At a much lower TDP/clock speed, the i7-4950HQ is able to pretty much equal the performance of the i7-4770K. Running Haswell's new better quality transcode mode, the 4950HQ is actually 30% faster than the fastest desktop Haswell. This is just one of many reasons that we need Crystalwell on a K-series socketed desktop part.
CPU Performance
I spent most of the week wrestling with Iris Pro and gaming comparisons, but I did get a chance to run some comparison numbers between the i7-4950HQ CRB and the 15-inch MacBook Pro with Retina Display running Windows 8 in Boot Camp. In this case the 15-inch rMBP was running a 2.6GHz Core i7-3720QM with 3.6GHz max turbo. Other than the base clock (the i7-4950HQ features a 2.4GHz base clock), the two parts are very comparable as they have the same max turbo frequencies. I paid attention to turbo speeds while running all of the benchmarks and for the most part found the two systems were running at the same frequencies, for the same duration.
To put the results in perspective I threw in i7-3770K vs. i7-4770K results. The theory is that whatever gains the 4770K shows over the 3770K should be mirrored in the i7-4950HQ vs. i7-3720QM comparison. Any situations where the 4950HQ exceeds the 4770K's margin of victory over Ivy Bridge are likely due to the large 128MB L4 cache.
| Peak Theoretical GPU Performance | |||||||||||||||||||||
| Cinebench 11.5 (ST) | Cinebench 11.5 (MT) | POV-Ray 3.7RC7 (ST) | POV-Ray 3.7RC7 (MT) | 7-Zip Benchmark | 7-Zip Benchmark (Small) | x264 HD - 1st Pass | x264 HD - 2nd Pass | ||||||||||||||
| Intel Core i7-4770K | 1.78 | 8.07 | - | 1541.3 | 23101 | - | 79.1 | 16.5 | |||||||||||||
| Intel Core i7-3770K | 1.66 | 7.61 | - | 1363.6 | 22810 | - | 74.8 | 14.6 | |||||||||||||
| Haswell Advantage | 7.2% | 6.0% | - | 13.0% | 1.3% | - | 5.7% | 13.0% | |||||||||||||
| Intel Core i7-4950HQ | 1.61 | 7.38 | 271.7 | 1340.9 | 21022 | 14360 | 73.9 | 14.0 | |||||||||||||
| Intel Core i7-3720QM | 1.49 | 6.39 | 339.1 | 1178.3 | 19749 | 12670 | 66.2 | 12.9 | |||||||||||||
| Haswell Advantage | 8.1% | 15.5% | 24.8% | 13.8% | 6.4% | 13.3% | 11.6% | 8.5% | |||||||||||||
| Crystalwell Advantage | 0.9% | 9.5% | - | 0.8% | 5.1% | - | 5.9% | -4.5% | |||||||||||||
I didn't have a ton of time to go hunting for performance gains, but a couple of these numbers looked promising. Intel claims that with the right workload, you could see huge double digit gains. After I get back from Computex I plan on poking around a bit more to see if I can find exactly what those workloads might be.
Pricing
Intel's launch lineup with Haswell is pretty spartan, but we do have enough information to get a general idea of what Crystalwell will cost as an addition.
| Peak Theoretical GPU Performance | |||||||||||||||||||
| CPU Cores/Threads | CPU Clock (Base/4C/2C/1C Turbo) | Graphics | GPU Clock (Base/Max Turbo) | TDP | Price | ||||||||||||||
| Intel Core i7-4950HQ | 4/8 | 2.4/3.4/3.5/3.6GHz | Intel Iris Pro 5200 | 200/1300MHz | 47W | $657 | |||||||||||||
| Intel Core i7-4850HQ | 4/8 | 2.3/3.3/3.4/3.5GHz | Intel Iris Pro 5200 | 200/1300MHz | 47W | $468 | |||||||||||||
| Intel Core i7-4800MQ | 4/8 | 2.7/3.5/3.6/3.7GHz | Intel HD 4600 | 400/1300MHz | 47W | $378 | |||||||||||||
The i7-4950HQ and i7-4850HQ are the only two Iris Pro 5200 parts launching today. A slower 2GHz i7-4750HQ will follow sometime in Q3. CPU clocks are a bit lower when you go to GT3, likely to preserve yield. Compared to the i7-4800MQ the 4850HQ carries a $90 premium. That $90 gives you twice the number of graphics EUs as well as the 128MB of eDRAM. Both adders are likely similar in terms of die area, putting the value of both at $45 a piece. Now you are giving up a bit on the CPU frequency side, so the actual cost could be closer to $50 or so for each. Either way, Iris Pro 5200 doesn't come cheap - especially compared to Intel's HD 4600.
From talking to OEMs, NVIDIA seems to offer better performance at equivalent pricing with their GT 740M/750M solutions, which is why many PC OEMs have decided to go that route for their Haswell launch platforms. What Intel hopes however is that the power savings by going to a single 47W part will win over OEMs in the long run, after all, we are talking about notebooks here.
Final Words
For the past few years Intel has been threatening to make discrete GPUs obsolete with its march towards higher performing integrated GPUs. Given what we know about Iris Pro today, I'd say NVIDIA is fairly safe. The highest performing implementation of NVIDIA's GeForce GT 650M remains appreciably quicker than Iris Pro 5200 on average. Intel does catch up in some areas, but that's by no means the norm. NVIDIA's recently announced GT 750M should increase the margin a bit as well. Haswell doesn't pose any imminent threat to NVIDIA's position in traditional gaming notebooks. OpenCL performance is excellent, which is surprising given how little public attention Intel has given to the standard from a GPU perspective.
Where Iris Pro is dangerous is when you take into account form factor and power consumption. The GT 650M is a 45W TDP part, pair that with a 35 - 47W CPU and an OEM either has to accept throttling or design a cooling system that can deal with both. Iris Pro on the other hand has its TDP shared by the rest of the 47W Haswell part. From speaking with OEMs, Iris Pro seems to offer substantial power savings in light usage (read: non-gaming) scenarios. In our 15-inch MacBook Pro with Retina Display review we found that simply having the discrete GPU enabled could reduce web browsing battery life by ~25%. Presumably that delta would disappear with the use of Iris Pro instead.
Lower thermal requirements can also enabler smaller cooling solutions, leading to lighter notebooks. While Iris Pro isn't the fastest GPU on the block, it is significantly faster than any other integrated solution and does get within striking distance of the GT 650M in many cases. Combine that with the fact that you get all of this in a thermal package that a mainstream discrete GPU can't fit into and this all of the sudden becomes a more difficult decision for an OEM to make.

Without a doubt, gaming focused notebooks will have to stick with discrete GPUs - but what about notebooks like the 15-inch MacBook Pro with Retina Display? I have a dedicated PC for gaming, I use the rMBP for work and just need a GPU that's good enough to drive everything else in OS X. Intel's HD 4000 comes close, and I suspect Iris Pro will completely negate the need for a discrete GPU for non-gaming use in OS X. Iris Pro should also be competent enough to make modern gaming possible on the platform as well. Just because it's not as fast as a discrete GPU doesn't mean that it's not a very good integrated graphics solution. And all of this should come at a much lower power/thermal profile compared to the current IVB + GT 650M combination.
Intel clearly has some architectural (and perhaps driver) work to do with its Gen7 graphics. It needs more texture hardware per sub-slice to remain competitive with NVIDIA. It's also possible that greater pixel throughput would be useful as well but that's a bit more difficult to say at this point. I would also like to see an increase in bandwidth to Crystalwell. While the 50GB/s bi-directional link is clearly enough in many situations, that's not always the case.
Intel did the right thing with making Crystalwell an L4 cache. This is absolutely the right direction for mobile SoCs going forward and I expect Intel will try something similar with its low power smartphone and tablet silicon in the next 18 - 24 months. I'm pleased with the size of the cache and the fact that it caches both CPU and GPU memory. I'm also beyond impressed that Intel committed significant die area to both GPU and eDRAM in its Iris Pro enabled Haswell silicon. The solution isn't perfect, but it is completely unlike Intel to put this much effort towards improving graphics performance - and in my opinion, that's something that should be rewarded. So I'm going to do something I've never actually done before and give Intel an AnandTech Editors' Choice Award for Haswell with Iris Pro 5200 graphics.

This is exactly the type of approach to solving problems I expect from a company that owns around a dozen modern microprocessor fabs. Iris Pro is the perfect example of what Intel should be doing across all of the areas it competes in. Throw smart architecture and silicon at the problem and don't come back whining to me about die area and margins. It may not be the fastest GPU on the block, but it's definitely the right thing to do.
I'm giving Intel our lowest award under the new system because the solution needs to be better. Ideally I wouldn't want a regression from GT 650M performance, but in a pinch for a mostly work notebook I'd take lower platform power/better battery life as a trade in a heartbeat. This is absolutely a direction that I want to see Intel continue to explore with future generations too. I also feel very strongly that we should have at least one (maybe two) socketed K-series SKUs with Crystalwell on-board for desktop users. It is beyond unacceptable for Intel to not give its most performance hungry users the fastest Haswell configuration possible. Most companies tend to lose focus of their core audience as they pursue new markets and this is a clear example of Intel doing just that. Desktop users should at least have the option of buying a part with Crystalwell on-board.
So much of Intel's march towards improving graphics has been driven by Apple, I worry about what might happen to Intel's motivation should Apple no longer take such an aggressive position in the market. My hope is that Intel has finally realized the value of GPU performance and will continue to motivate itself.






