Original Link: https://www.anandtech.com/show/2562
Container-Based OS Virtualization
by Liz van Dijk on July 8, 2008 1:30 AM EST- Posted in
- IT Computing
Introduction
When reading about virtualization, it's often easy to get lost in the masses of possible meanings given to the word by various sources. At AnandTech IT, we've been trying to cut a clear path, attempting to provide our readers with a complete overview of what each technology entails so they are always able to make the right choices for the right situations. Previous articles included overviews of both hypervisor-based virtualization and application virtualization. Following that trend, we now present you with container-based OS virtualization, providing an alternative solution - one that's quite regularly overlooked, despite its merits. We hope it gives you a clear overview of the possibilities this technology offers, as we go in-depth into what makes it tick.

How Does It Work?
If you have been keeping up with our IT articles, you have undoubtedly come across Johan's overview of hypervisor-based virtualization. We will take a similar approach to its container-based counterpart, giving you a strong introduction into what makes it work and guiding you through the strengths and weaknesses of the technology.
To get started, a clear view of what the system "looks" like is needed. Unlike hypervisors and application virtualization solutions, the isolation happens inside the actual OS layer, where certain additions are included to allow for the isolation of each OS subsystem. Every container is essentially no more than a shielded part of the host OS.
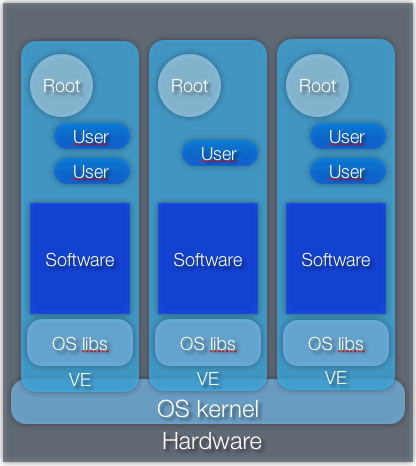
This means there is no need to virtualize the machine's different hardware components, as direct access through the OS is not compromised. Instead, several environments are running on the same kernel, each with their own processes, libraries, root, and users. This method is somewhat limiting, as it means that Linux and Windows operating systems cannot be combined on the same host; however, the technology's extremely small overhead allows for an enormous density. In addition, using a single kernel does not prevent users from running different distributions next to each other, which does counter the lack of diversity somewhat.
There are numerous software packages offering this type of virtualization - Solaris Containers, FreeBSD Jails, and Linux-VServer to name a few. However, we decided to focus on a pair of products that is closely tied together, while still allowing us to go in-depth into its inner workings: OpenVZ and Parallels Virtuozzo. OpenVZ is an open source initiative, backed by Parallels, and can be seen as a testing platform for future developments of its proprietary product, Virtuozzo. Technically, both products are used for the same purpose but are aimed at different users in the same market space.
Virtuozzo is the more robust product; it's aimed at corporate customers and comes with a very large feature set. It has support for both Windows and Linux platforms and incorporates most of OpenVZ's features. At this point, it is one of the most advanced and widely used products in the container-based OS virtualization market.
A view of Parallel's Management console, which is used to manage the Virtuozzo containers.
On the other hand, OpenVZ is freely available, although it's only for use on Linux systems. While still sporting a powerful and varied feature set, its limited management tools make it better suited for smaller scale environments where Linux is the primary OS in use. Since it is open source, however, OpenVZ allows us to dig deep into its inner workings. Moreover, because OpenVZ is in a sense the testing ground for Virtuozzo, we believe gaining insight into the former will provide our readers a solid base to better understand the latter, as well as other similar products.
From an administrator's point of view, OpenVZ employs a system that allows them to use the "base" OS as their access to management tools and monitoring. This is what we will be referring to as the host environment, and is for all intents and purposes a perfectly normal and usable OS. In production environments, however, it is best not to assign it a large personal workload to ensure functionality of the management system at times of peak load. From the host environment, we are able to see a complete overview of the resources consumed by the different guests, and run tools like vzctl to make live changes to them. Furthermore, we have full access to all containers' file systems, so the admin can make live changes without even having to log into the guest containers.
Isolation of the containers runs quite deep, ranging from a virtualized file structure to their own root users and user groups, process trees, and inter-process communication objects. This allows a container's root user high levels of customization and tweaking of everything apart from the kernel itself.
Handling of different distributions is taken care of by so-called templates. These are the blueprints for every environment installed on top of the OpenVZ kernel. In reality, they are no more than that distribution's files rounded up in a GZIP-compressed TAR, which will be set up in an isolated part of the file system for the container to run in. Templates for many distributions are freely available on the OpenVZ wiki, and while these are usually as lightweight as systems can get, it is possible to create your own once you have familiarized yourself with the system a bit.
Let's Rewind
Before continuing, let's have another quick look at what separates this virtualization technology from the others:
- Unlike with hypervisors, isolation
happens from within the kernel. No layers are actually added to the standard model;
they are only modified.
- Although more limited in diversity, it allows for a very high density
(tens of containers on a single machine) as long as all containers are able to run
on the same kernel.
- A single kernel and centralized management tools allow for comfortable global administration of all environments.
As it stands, despite its obvious merits, we believe container-based OS virtualization is not as well known and widespread as it could be, so we will be taking a closer look at the situations this technology is applied in today, and in what fields it can really shine. Keep in mind, in this next part we will not be focusing on OpenVZ specifically, but rather give a general overview of the possibilities offered by containers, as well as their downsides.
Uses of Container-Based OS Virtualization
When would we generally suggest containers to be a viable solution? Looking at the situations in which the technology is most often applied, we see the importance of density coming up. Density can be seen as the amount of containers we are able to place on a single hardware platform. Many hosting companies are making use of containers in order to provide their customers with a heavily customizable environment in which to run their web servers. Hardware platforms running over 100 environments are no exception here.
We need to keep in mind that the total memory and CPU footprint of a container is little more than that of the sum of its processes, so density scales inversely proportional to the "weight" of all containers bundled together. In common terms, we could say that the lighter the containers' workload, the more we are able to place on a single machine. When high density is a priority for whatever reason, containers can provide a solid solution as opposed to a hypervisor-based one, which despite its high flexibility is still quite limited in terms of scalability.
Compare the memory footprint of a simple process group to that of a full-fledged OS along with that process group. Considering that Windows Server 2003 can easily fill up about 350MB of RAM by itself, on a fairly standard configuration, the below graph would barely allow for two systems on the same memory configuration, without even adding an actual workload!
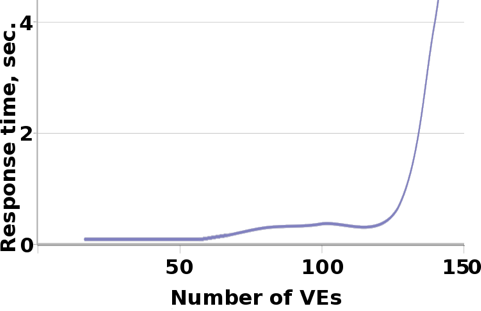
A graph from the OpenVZ wiki, depicting the amount of containers that, when running Apache, init, syslogd, crond and sshd, keep giving reasonable response times on a 768MB RAM box: they put the number at 120. The system's limitation beyond that point is RAM.
We have to admit that the comparison is not entirely fair: the OS used in the graph is undoubtedly a very light-weight Linux-based system. Nonetheless, it is able to provide a sense of scale. At the absolute minimum of allowed configurations for Windows Server 2003 (128MB of RAM), 120 hypervisor-based systems would still consume about 15GB of RAM together. The use of containers here would theoretically reduce the OS footprint by 14.8GB.
On the other hand, containers can be very interesting when performance is prioritized. Naturally, as the workload per container is increased, the maximum amount of containers on a single hardware system is decreased, but even then they provide a solid solution. Since all containers' processes have direct access to the kernel, native I/O subsystems remain intact, allowing the full power of the hardware platform to be used. This gives the technology another edge over its "rivals". Another fun fact here is that in Virtuozzo (OpenVZ's "bigger brother") applications can actually share their libraries over several containers. What this means is that the application is loaded into the memory only once, while still allowing different users to use it concurrently, albeit using a small amount of extra memory for their respective unique data.
Another situation where containers can come in handy is where many user space environments need to be rolled out in a very short time span. What we are thinking of here are mostly classrooms and hands-on sessions where quick and simple deployment is of the essence. Demos of certain pieces of software often require careful planning and a controlled environment, so applications like VirtualPC or VMWare Server/Workstation are used with "temporary" full-sized virtual machines to make sure everybody is able to run them correctly. Since the creation of a container takes about as long as the actual decompression of its template environment and the startup of its processes, a single server can easily be used for participants or students to log into through SSH or even VNC, giving each user an easily administrated environment while still allowing them to experiment with high-level permissions.
In this case, it is also beneficial that everything happens on a single system that is completely accessible to the root user of the "host" container. In this sense, containers reduce both server sprawl and OS sprawl, allowing for high manageability. For example, using a single kernel reduces the amount of time spent patching every individual virtual machine separately, since a plain shell script can take care of each container automatically. "Broken" containers are easily removed and recreated on the fly, as making use of templates removes the need to go through the steps of installing a fresh OS every time a new environment is needed.
Thinking further along this line brings us to the next point of interest: using containers as a base for VDI purposes. Combining all of the above factors, it is easy to see the technology's merits as a means to bundle desktop environments onto a central server. Since Virtuozzo is able to provide high container-density on Windows, it is possible to allow a very large number of users a full-fledged environment to work with, which is still perfectly manageable. At a time when providing desktop virtualization tempts many a system administrator but still seems out of reach due to its impractical resource demands, containers seem to provide the ideal solution.
The Big Trade-Off
There are undeniably a few downsides to this way of approaching virtualization. The first that comes to mind is that when density on a single hardware platform increases, so does its needs for constant availability. Using a single kernel in this case raises the concern on whether the kernel becomes an important single point of failure in the system. Unlike hypervisors, which are in a sense very light-weight and therefore very stable kernels, container-based OS virtualization depends on a slightly modified version of already existing kernels, thus essentially taking over existing weaknesses of both the Windows and Linux platforms.
It has to be noted that a lot of work is put into ensuring kernel stability on all container-based solutions, and unexpected kernel crashes are at least deemed "unlikely". Nevertheless, a bit of healthy paranoia when IT is involved is certainly not an obsolete luxury.
Secondly, while a strong feature set is definitely maintained, containers do take away a lot of flexibility from the hypervisor-based solutions. For one, many might find the inability to use different OSes next to each other a big handicap. Moreover, while support for live migration does exist on Linux systems (both OpenVZ and Virtuozzo have implemented this), it is still missing on Windows implementations. In addition, changing critical system-wide settings is not allowed from within a container - e.g., users are not able to partition their own disk and change file systems at their leisure.
Sadly enough, despite all its possibilities, container-based OS virtualization is most limited, it seems, by its plain invisibility in the current market place. For some reason, it has been quietly pushed into the background by all the current hype surrounding different virtualization technologies, with major software companies fighting for domination of this "gold mine". While it is currently used by most if not all hosting companies, this type of virtualization seems unable to expand its customer base beyond that. Whether through lack of marketing power or a seemingly less attractive feature list, most businesses seem unaware of its potential. Naturally, it goes without saying that just like hypervisors aren't the perfect "one size fits all" solution, neither are containers, but it is still rather peculiar how a solution this prevalent in the IT world could escape the recent surge of interest into virtualization and all its aspects.
Now, it's time to dive straight into the inner workings of what make containers happen.
A Closer Look into OpenVZ's Inner Workings
Now that we have given a clear overview of containers in general, it is time to move on to the more technical stuff, namely figuring out how they do in fact work. As stated before, most of our research into the subject has gone into OpenVZ, but we feel the actual subjects tackled here do a great job of illustrating the challenges faced by any developer of container-based solutions.
To gain a full understanding of how the partitioning of an operating system takes place, it is important to grasp the basics of how an OS operates. Since entire books have been written on that subject alone, and it is mostly outside the scope of this article, we'll direct those new to the subject to page 2 of Johan's article on hypervisors and their inner workings.
For now, it is important to know that in our modern day x86 architecture, there are two modes a process can run in, namely a privileged kernel mode and a user mode. The CPU is able to distinguish between these two modes by each process' assigned memory addresses, where a 2-bit code makes the difference between kernel space addresses and user space addresses. The reason they are called addresses is because each of them points to a specific piece of memory. These pieces are generally called "pages"; they're the smallest unit of memory allocation an operating system can use, and in x86 systems they are usually blocks of 4kB each.
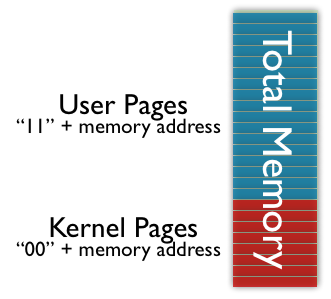
In this picture, we can see the RAM as divided into pages. The memory addresses all have a 2-bit code (11 or 00), so the CPU can tell user and kernel pages apart.
The above description introduces two important factors.
- Since containers all share the same kernel, kernel mode processes are not isolated but run outside the containers themselves. Therefore, containers are to be used only for isolation of applications running in the user space.
- We raise the issue of memory management. Evidently, a single OS has an elaborate system in place for this, but how is it approached in a partitioned OS? In short, how do we prevent one container from using up all resources needed to support another?
OpenVZ has implemented a system called beancounters to address these factors. In the following pages, we'll have a look at how this and other methods are combined to achieve isolation and efficient resource management.
Beancounters
Current day resource management in Linux is certainly adequate for management of a conventional operating system, but when trying to provide limited resource sets for contained groups of processes, it falls a bit short. Of these resources, memory is the most notable, so an important task is to keep track of the amount of pages each process is allowed to use.
For this reason, OpenVZ has implemented an addition to the kernel called beancounters (BC). These kernel-level objects keep track of the resources available and can notify the kernel of user space processes that are overstepping their boundaries.
Since containers are no more than groups of processes, actual allocation of memory and other resources requires no large changes. However, upon creation of a new container, an "init" process is made for it. Readers familiar with Linux-based systems will recognize this process as the proverbial mother of all processes, and in containers it is no different. Upon creation, the process is assigned to a beancounter object by the OpenVZ software. As a result, each of its child processes is bound to it. From that point on, the BC controls the maximum amount of resources available to that container.
Think of the BC as containing a sort of table, of which the columns contain the resources currently held, the maximum of resources held during the session and a barrier value, at which the BC will send a warning to the kernel to stop allocating resources. Furthermore, an absolute limit for moments of burst usage and the number of failed allocations due to a shortage of still available resources can be tracked. The rows, in turn, contain the different types of resources the BC can keep track of, including but not limited to:
- the user memory
- network buffers
- # of tasks
- # of files
- # of sockets
- # of file locks
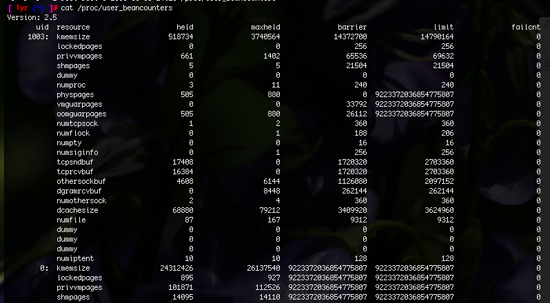
We're able to see the current status of beancounters for each existing container by outputting the contents of /proc/user_beancounters
We'll try to cover the actual accounting of some types of resources as short and as clear as possible.
Memory accounting
Accounting of memory is divided into several parts and discussing all of them would fill up several pages. The following paragraphs dip into the logic behind the system a bit more deeply, and discuss some of the challenges faced in allocating memory to several containers while showing examples of how beancounters can be put to use in a container-based environment.
Virtual Memory Area lengths:
Processes can make requests for extra memory pages, without necessarily putting them to use immediately or even using them at all. Instead of receiving the full amount on the physical RAM, it is given an amount of "virtual" pages, so that only the number of pages actually used are loaded into the RAM, while "empty" pages remain free for other processes to use.
This way, each process works with the impression that the full amount of virtual pages is always available, and even though it isn't currently using the free pages, it can do so in the future if the need arises. The issue here is that the total amount of virtual memory for all processes is usually much larger than what is available in the RAM.
When a lot of processes start actually using most of their virtual pages, the RAM might not suffice, and will need to swap certain data to the first available storage space to make room: the hard disk. As the hard disk is a much slower medium, this is a situation to avoid, especially when many users need to make use of the same system. One user could technically put all the others out of business by starting up some processes that are able to fill up the entirety of the physical RAM.
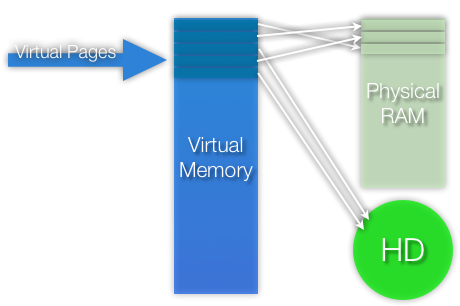
In the above picture, we can see pages in the virtual memory that exist physically in either the RAM or the HD. The total amount of Virtual Memory available is the sum of what is available in the RAM along with a certain amount assigned to it on the HD. The beancounter keeps track of the total amount of virtual pages allocated, so it can anticipate troublesome situations and deny requests for more virtual pages if needed.
Resident Set Size
RSS is a term used to denote only the actual "used" pages by a process that exist in the physical RAM. The problem here is that, even though a page is the smallest possible unit for memory allocation, it is sometimes possible for a page to be mapped by several processes (i.e. when the same file is used). Therefore, a single page in use on two different beancounters would count as two pages in total, making the count inaccurate. Therefore, RSS is calculated with a system of parts, as follows:
- BC1 encounters a used page, and counts it as a whole = 1
- BC2 encounters the same page, and both beancounters count half a page = 1/2, 1/2
- BC3 encounters the same page and one of the present beancounters splits half the page = 1/2, 1/4, 1/4
- When BC4 arrives, the other half is split, and so on. = 1/4, 1/4, 1/4, 1/4
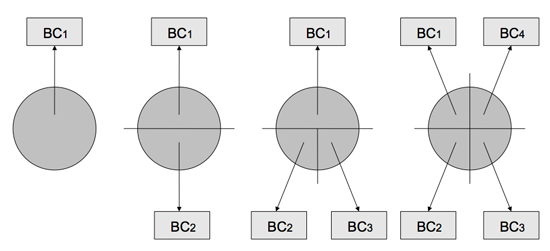
In this picture from Pavlov Emelyanov's explanation on beancounters, we can see the division of pages explained. This is an efficient way of keeping the RSS count accurate, as the arrival of a new beancounter only triggers a change in one of the others, as opposed to the full group.
CPU Scheduling and I/O Scheduling
All this talk of resource management could almost make us forget the complete story, so let's quickly rewind again. It should be obvious at this point that container-based OS virtualization is not achieved by a single, easily implementable solution. OSes today consist of a rather large number of subsystems, and several different methods are combined to make containers a reality. The way resource management for each container is handled was explained by an introduction to beancounters. Memory is not the only thing a user needs on a system however. Their processes require time on the CPU to run properly, and they perform I/O by using their allowed hard drive space and interacting with the system.
Multi-core CPUs have allowed us to drastically increase the number of tasks a CPU can handle, but even as we increase the number of cores the basic problem remains the same. A core can only take on one job at a time, so it must spend time switching between different tasks. Therefore, scheduling is required to achieve a "fair" result for each of the containers. To this extent, OpenVZ makes use of two scheduling systems: Fair-Share CPU Scheduling and Completely Fair Queuing for I/O.
Fair-share CPU scheduling
This is a system for scheduling time slices on the CPU on a per-user or per-group basis, rather than the usual per-process approach. In OpenVZ, it is used with set weights given to every container, allowing for full control of how much time is put into each one.
Time scheduled per container happens as follows: In a situation where there are four containers and each one is given a weight of, e.g. 100, they will all receive the same amount of CPU time. When one container is given a weight of 200, two others remain at 100, and one is scaled back to 50, the CPU time will be handed out proportionally, being roughly 45%/22%/22%/11%.
When CPU time has been fairly distributed over the different containers, standard Linux process priorities apply when selecting exactly what process within the container gets which time slice.
I/O: Completely Fair Queuing
Just like the CPU, I/O devices like the hard drive are forced to take one job at a time. This job list can pile up over time, as the CPU does not need to wait for the I/O device to finish an existing job before sending it a new one. If all jobs were simply carried out in the order they were called for by the software, there would be no possibility to control on the amount of I/O time allotted to each process. For this reason, another scheduler is introduced, one that is not only used by OpenVZ but is integrated into most modern-day Linux distributions.
In CFQ, each process is given a separate queue for synchronous requests and an I/O priority. Asynchronous requests for each process are all jumbled together in separate queues, depending on their priority. As the queues fill up with requests to perform I/O, the amount of time available to each queue is proportional to its given priority. When the queue's turn comes up, the I/O device works through it as quickly as possible, until the time slice has passed and the queue has to wait for its turn again.
File System
To keep disk usage of each container in check, disk quotas are available for use on both the container-level as well as the actual user and group levels. This gives the global administrator full control over the disk usage of each separate container, while each container's root user is still able to distribute quotas according to their wishes.
Isolation and Virtualization
While all the previous subjects document the changes required to an OS to even allow for containers, what we haven't discussed are the actual measures taken to create a seemingly separate OS environment for each container. This is handled by what we will call the "virtualization additions" of OpenVZ to the kernel. We put them in a slightly different group, because they are what actual make containers "look like" containers to their users.
As we know by now, to the kernel "containers" are nothing more than groups of processes with groups of users, using slightly different kinds of resource management and scheduling. They exist in an otherwise perfectly normal unified user space. To make a container look like a confined but complete space to users, some barriers need to be put in place to prevent them from seeing the complete picture. To this extent, virtualization is integrated into all parts of the OS.
For example, container-users (as well as their processes) can see only a standard root-directory structure, complete with virtualized /proc and /sys, adapted to include only their personal usage. Because each container has its own config files under /etc and contained processes are able to see only their own versions of these folders, users are able to change all configuration files and affect only their own setup.


In the above pictures, we can see a view of the container's directory structure, as seen from the host container, along with a view of the container's virtualized /proc from inside the container. Likewise, containers make use of virtualized process IDs, so a container user's process tree looks just like a normal tree. As each container has its own init process, the user's view of the tree is limited to that personal init and its child processes.
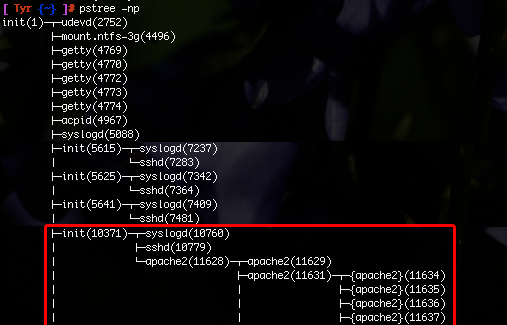
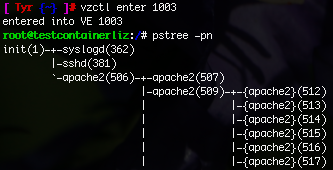
In this picture, we can see a full view of the host system's process tree (some processes are edited out to remove clutter). The inits below the original init are process groups for each of our containers. In the second picture, we can see the view of one of these containers' own process tree, namely the one running apache. As can also be seen in the picture, the process IDs inside the container are virtualized: while the init's PID is in reality 10371, the container believes it to be 1.
Moreover, network virtualization is implemented to allow each container to have its own (or even multiple) IP address. Traffic is isolated per container so that traffic snooping is impossible, and users can even set up their own firewall rules from within the container.
To this extent, OpenVZ makes use of two kinds of virtualized network interfaces: venet and veth. The first is the default used by every container and is a standard virtual device with limited options, mostly used to allow containers to have their own static IP address. veth is the heavyweight alternative, sporting its own MAC address, allowing it to be used in fully customized per-container network configurations.
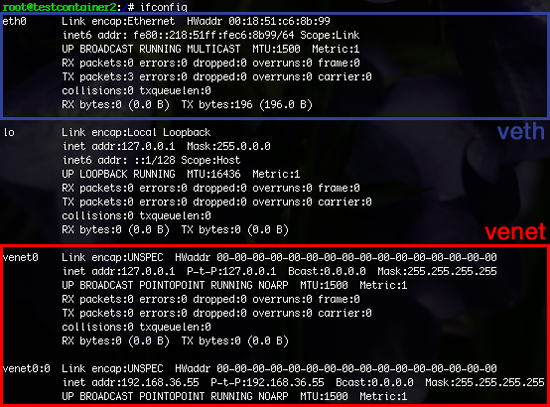
In the above picture, we can see the two different kinds of interface implemented into containers. venet has no actual MAC address, and thus cannot be used in custom network configurations. The veth interface behaves just like a regular interface would, though it is a real heavyweight in comparison.
Conclusion
When first doing our research on container-based OS virtualization, we more or less expected the proclaimed feature lists to be on the exaggerated side. Surely, a technology as powerful as this would not have slipped under the media's radar. We figured one of the big players in the market had already bought some smaller company working on it, and then rebranded it to fit into their big "virtualization suites".
However, the deeper we delve into "virtualization" the more it becomes apparent that virtualization can be just as impressive a feature, rather than an all-encompassing solution. The philosophy behind OpenVZ seems to be based on this idea of using virtualization as a lightweight tool to improve a system, rather than using it to shield the system from the hardware and other virtual machines.
Containers shouldn't be competing with full-fledged hypervisors for the same market, as the many comparisons between Xen and OpenVZ often seem to suggest. Though they provide some of the same functionality, there is more than enough space to let both systems complement each other, as neither provides a solution to all problems.
Nonetheless, we found containers to be an incredibly solid solution, and despite the fact that we've spent most of our time with it on the supposedly less user-friendly open source version, working with it has been really straightforward and fairly simple.
What we believe the technology might actually need the most now is a solid marketing strategy, and we're looking at Parallels to take that leap. The recent changes that company has undergone do point in a good direction, but Virtuozzo could use some more functionality to support its presence in high availability solutions, and most importantly, the virtualized datacenter. Perhaps some live migration for Windows containers, Parallels?
Sources






