Original Link: https://www.anandtech.com/show/13243/hot-chips-2018-amd-on-raven-ridge-optimizations
Hot Chips 2018: AMD APU Optimization Live Blog (Noon PT, 7pm UTC)
by Ian Cutress on August 20, 2018 2:55 PM EST- Posted in
- CPUs
- AMD
- Hot Chips
- APUs
- GPUs
- Trade Shows
- SoCs
- Live Blog
- Ryzen
- Raven Ridge

03:01PM EDT - AMD is also at Hot Chips, speaking about Raven Ridge and its APUs. The key elements to this talk will be the optimizations made for Raven Ridge, specifically around power and data management. We'll be live blogging the talk for everyone to follow.

03:02PM EDT - Working on APUs for several years
03:02PM EDT - Raven Ridge allowed the users to experience an uplift in performance
03:03PM EDT - Focusing on power and power efficiency
03:03PM EDT - GPUs have an appetite for memory - getting efficiency is important, as is power
03:03PM EDT - Battery life is a key consideration too
03:03PM EDT - 4C/8T, 11 Vega CUs
03:04PM EDT - ALmost everything is new - new Upgraded display engine, new audio coprocessor, new IO subsystem, USB 3.1 and USB-C native
03:05PM EDT - Went big on the GPU
03:05PM EDT - Up 60% transistors from Bristol
03:05PM EDT - But 16% smaller based on process note
03:05PM EDT - BGA package
03:06PM EDT - Also in desktop
03:06PM EDT - Dedicated L2 cache in the GPU
03:06PM EDT - Flexible geometry engine
03:06PM EDT - 16 pixel units
03:06PM EDT - two render back-ends
03:06PM EDT - 1200 Tri/sec at 1200 MHz

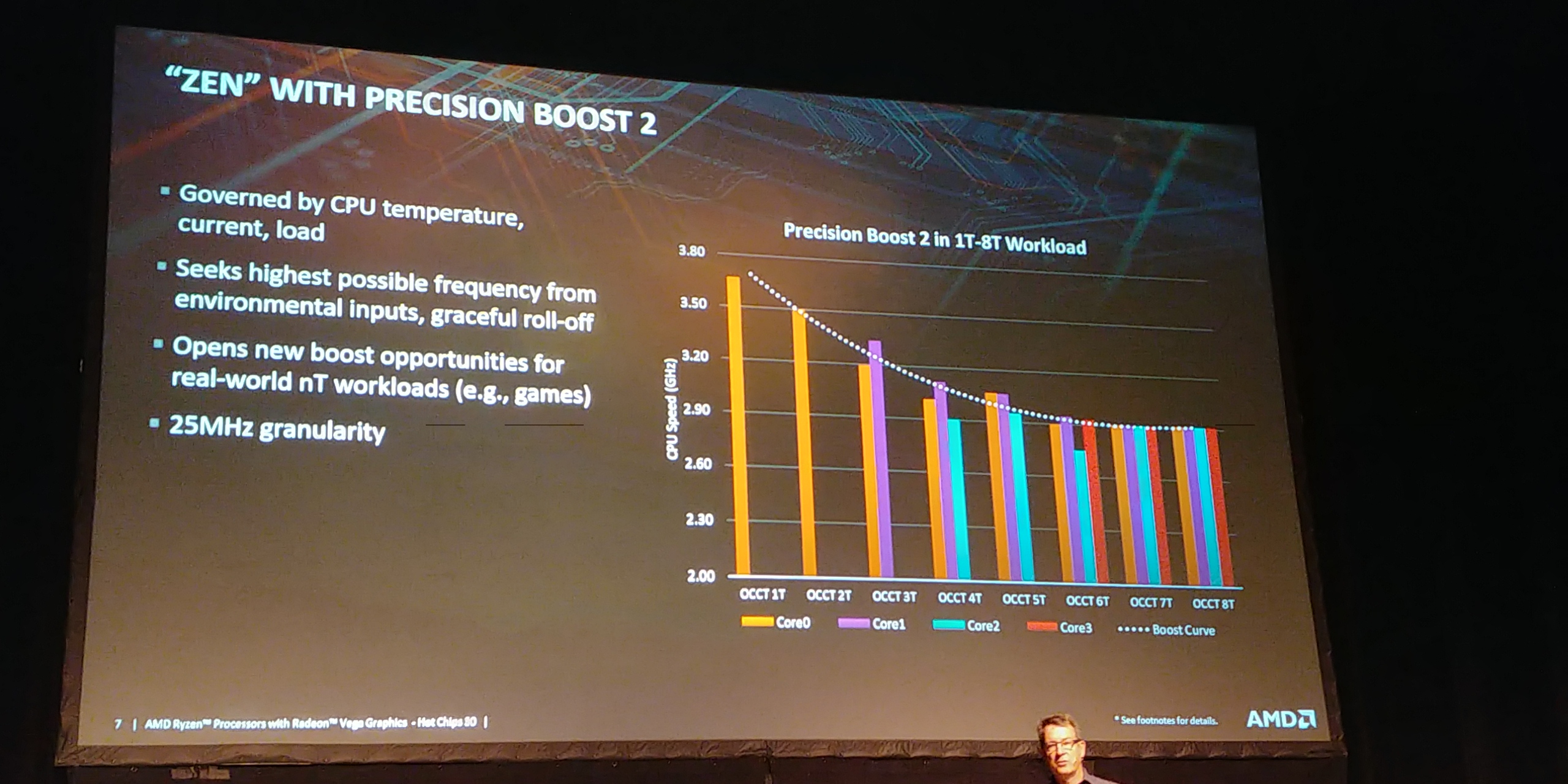
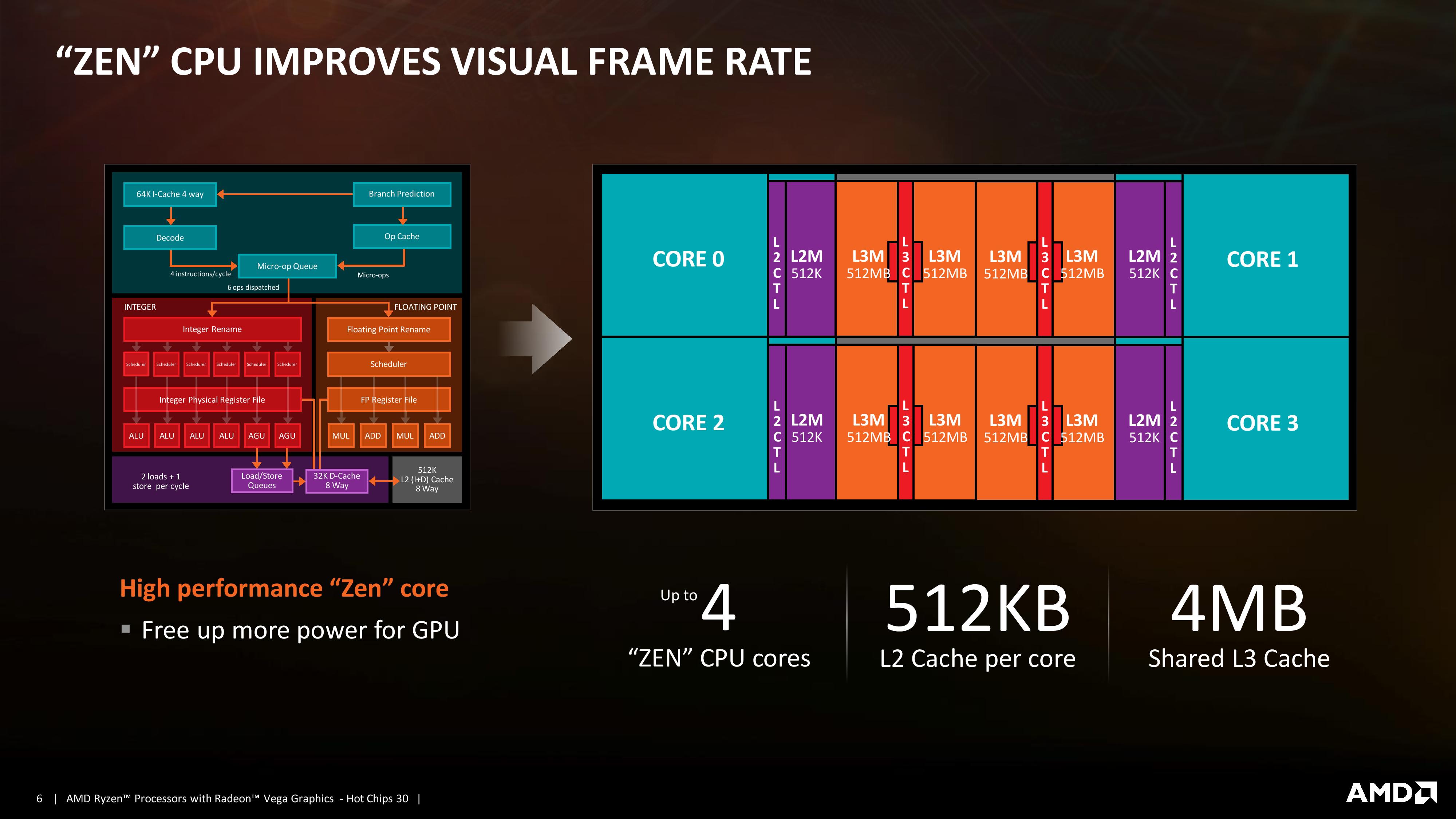
03:08PM EDT - Smaller L3 cache than desktop
03:08PM EDT - Smaller L3 cache than desktop
03:08PM EDT - Precision Boost 2 for dynamic core frequency
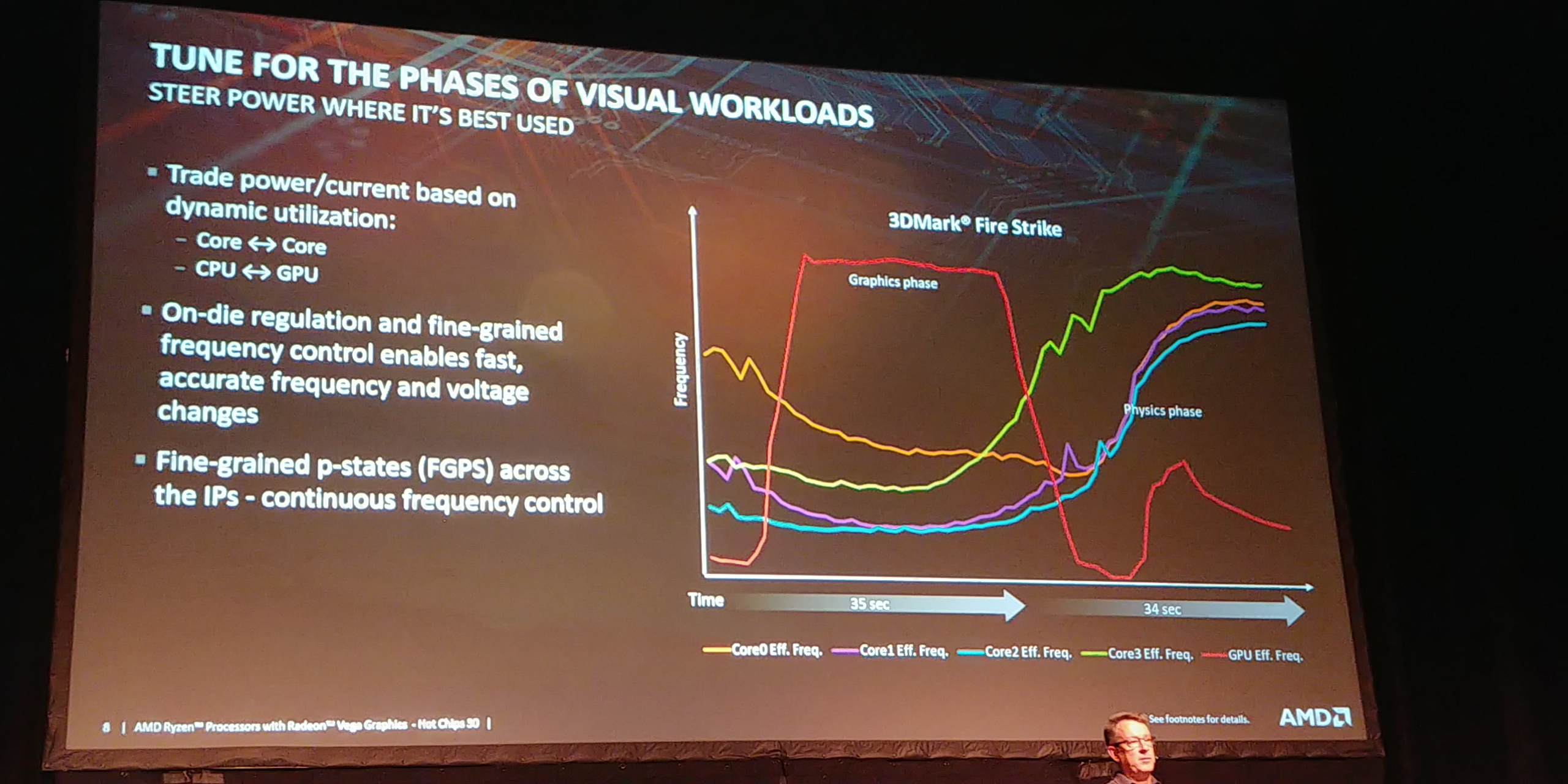
03:09PM EDT - GPU workloads tends to go through phases of render and physics phases
03:09PM EDT - Can adjust power based on where it is needed
03:09PM EDT - Fine grained p-states
03:09PM EDT - On die power regulation
03:09PM EDT - Can exploit all the power

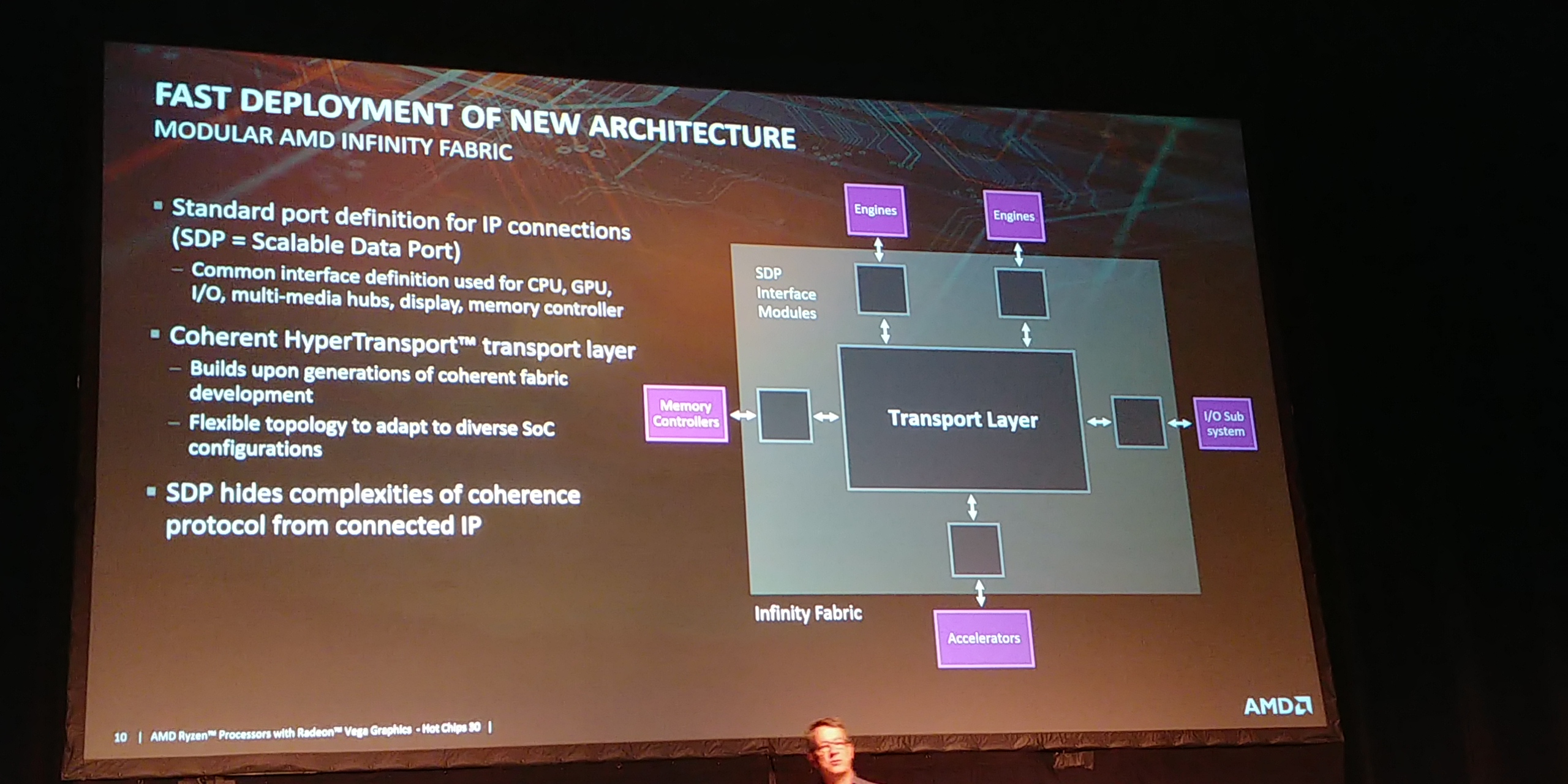
03:10PM EDT - Heart of the chip is the fabric
03:10PM EDT - oen coherent protocol - Infinity Fabric
03:10PM EDT - Manages the full SoC
03:10PM EDT - Overall power budget and management
03:10PM EDT - Enhanced flow for powering on and off components
03:11PM EDT - Knew in 2013/2014 AMD was going to major reset the CPU portfolio
03:11PM EDT - IF was designed to scale from Server to high-end graphics into smaller mobile SoCs and desktop
03:11PM EDT - IF is a Transport Layer
03:12PM EDT - Scalable Data Ports and SDP interface modules to the transport layer
03:12PM EDT - SDP hides complexities of coherence protocol from connected IP
03:12PM EDT - CPU, GPU, Memory, IO, all use an SDPIM into the transport layer
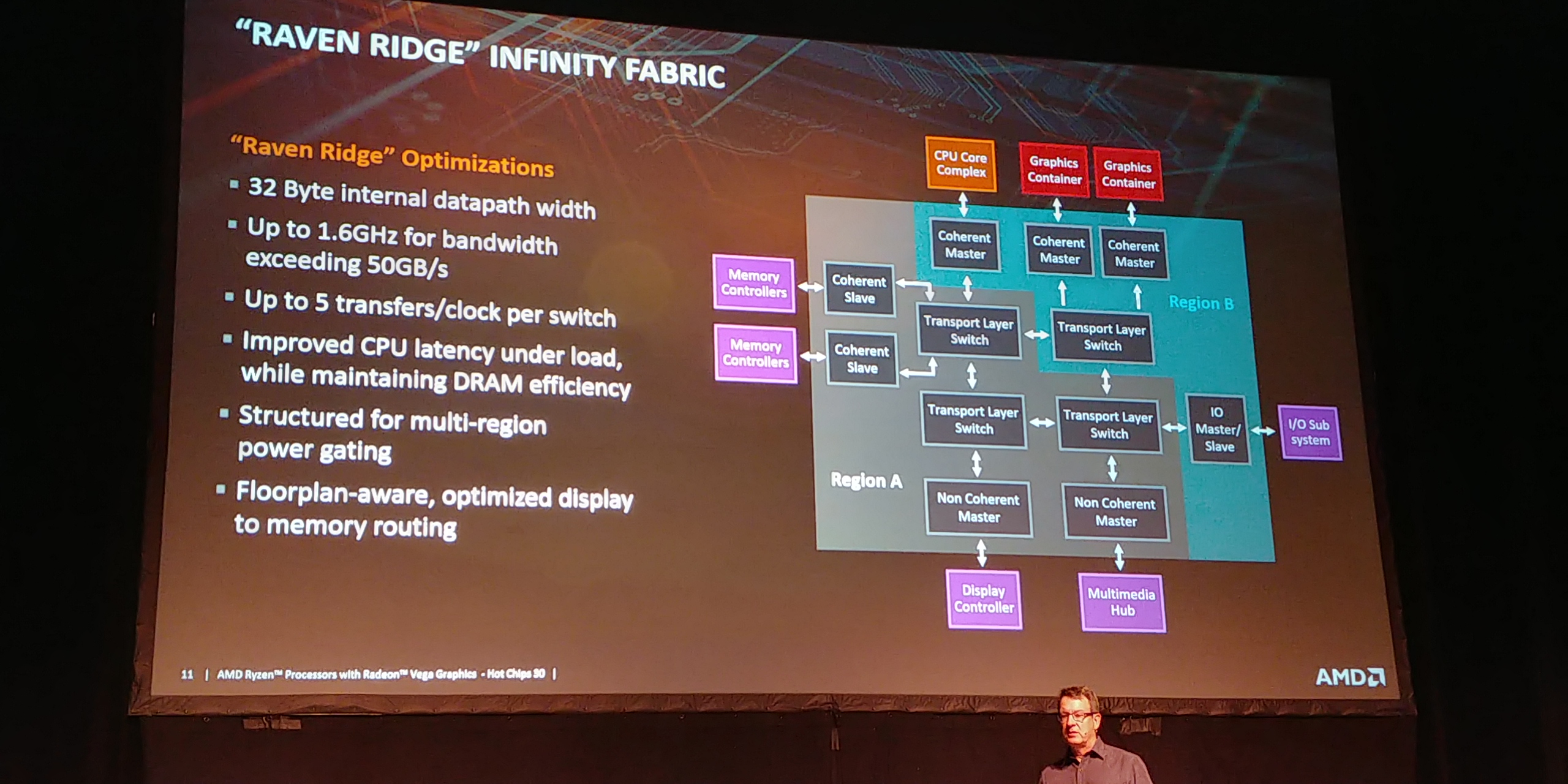
03:13PM EDT - Transport Layer Switches are crossbars
03:13PM EDT - Coherent ports in region A/B
03:13PM EDT - Structured for multi-region power gating
03:13PM EDT - Up to 5 transfers per clock per switch
03:14PM EDT - Turn off bits of the fabric that are not needed to save power

03:14PM EDT - Transport request queues at each entry point into the fabric
03:14PM EDT - Hard Real Time, Soft Real Time, and Non-Real Time
03:15PM EDT - Within this, multiple virtual queues and channels
03:15PM EDT - Also priority classes end-to-end
03:15PM EDT - Can escalate through the entire fabric

03:15PM EDT - Need to improve mem bandwidth for GPU
03:15PM EDT - Bigger CPU and GPU caches helped a lot
03:16PM EDT - Caching algorithms and lossless compression (DCC) helps
03:16PM EDT - Direct reads of compressed memory
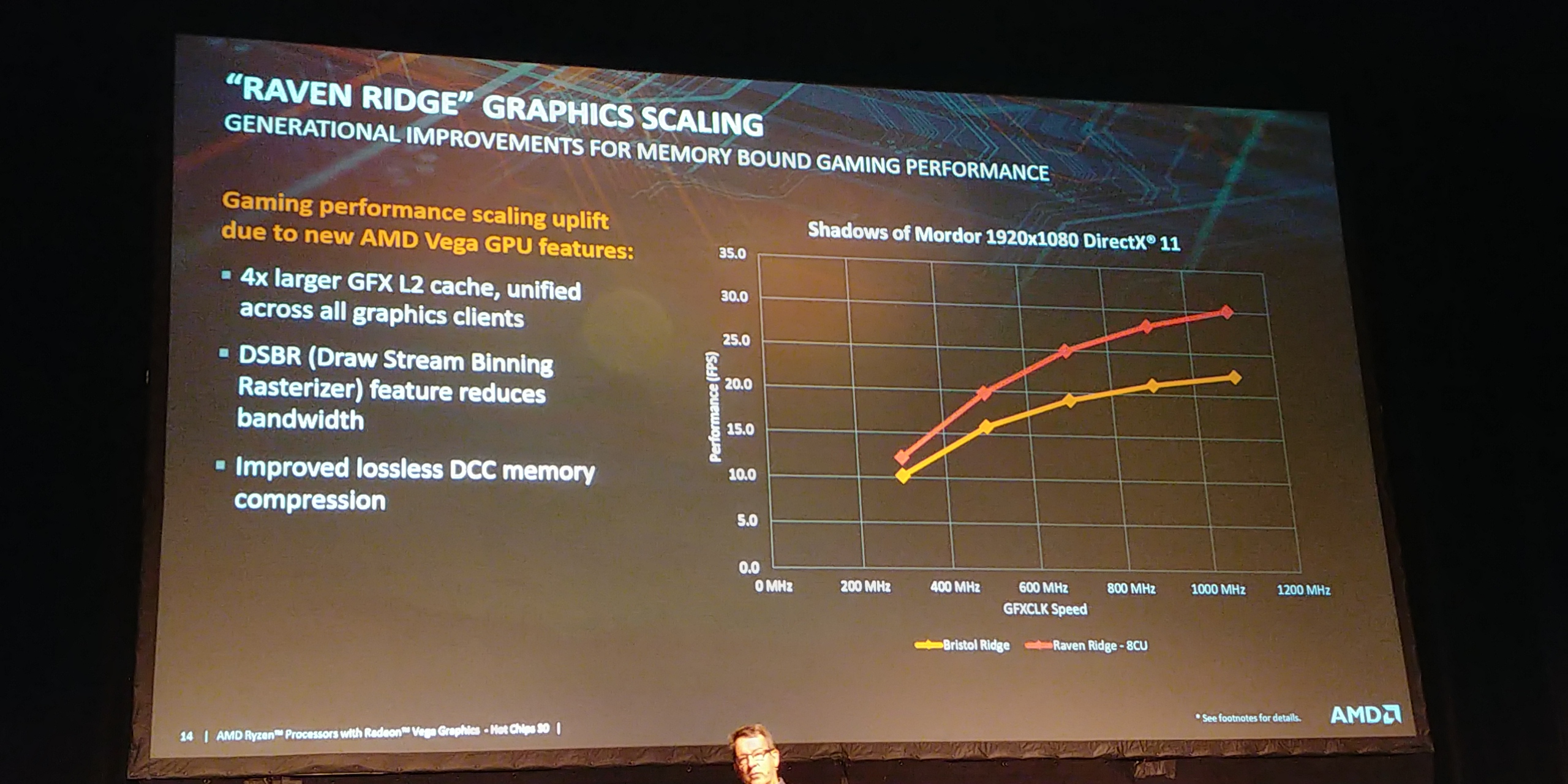
03:16PM EDT - Shadow of Mordor seems more memory active
03:17PM EDT - Direct compare Bristol Ridge and Ravin Ridge
03:17PM EDT - Draw Stream Binning Radterizer improves bandwidth

03:18PM EDT - Increase display engines - reset the engine and set a target to do a 4K display at Vmin (lowest voltage of process)
03:18PM EDT - Four pipes and flexibility to combine pipes or act independent
03:18PM EDT - 4x throuput over Bristol
03:18PM EDT - Keeping up with codec improvements

03:19PM EDT - Rather than 3 rails (CPU, GPU, IO), now have one
03:19PM EDT - 3 rail methods meant overprovisioning required - very inefficient. Now can be very efficient
03:19PM EDT - In-chip, rather than do FIVR, do individual LDO in each CPU core and graphics
03:19PM EDT - Allows more fine grained power delivery
03:20PM EDT - Allows for better control
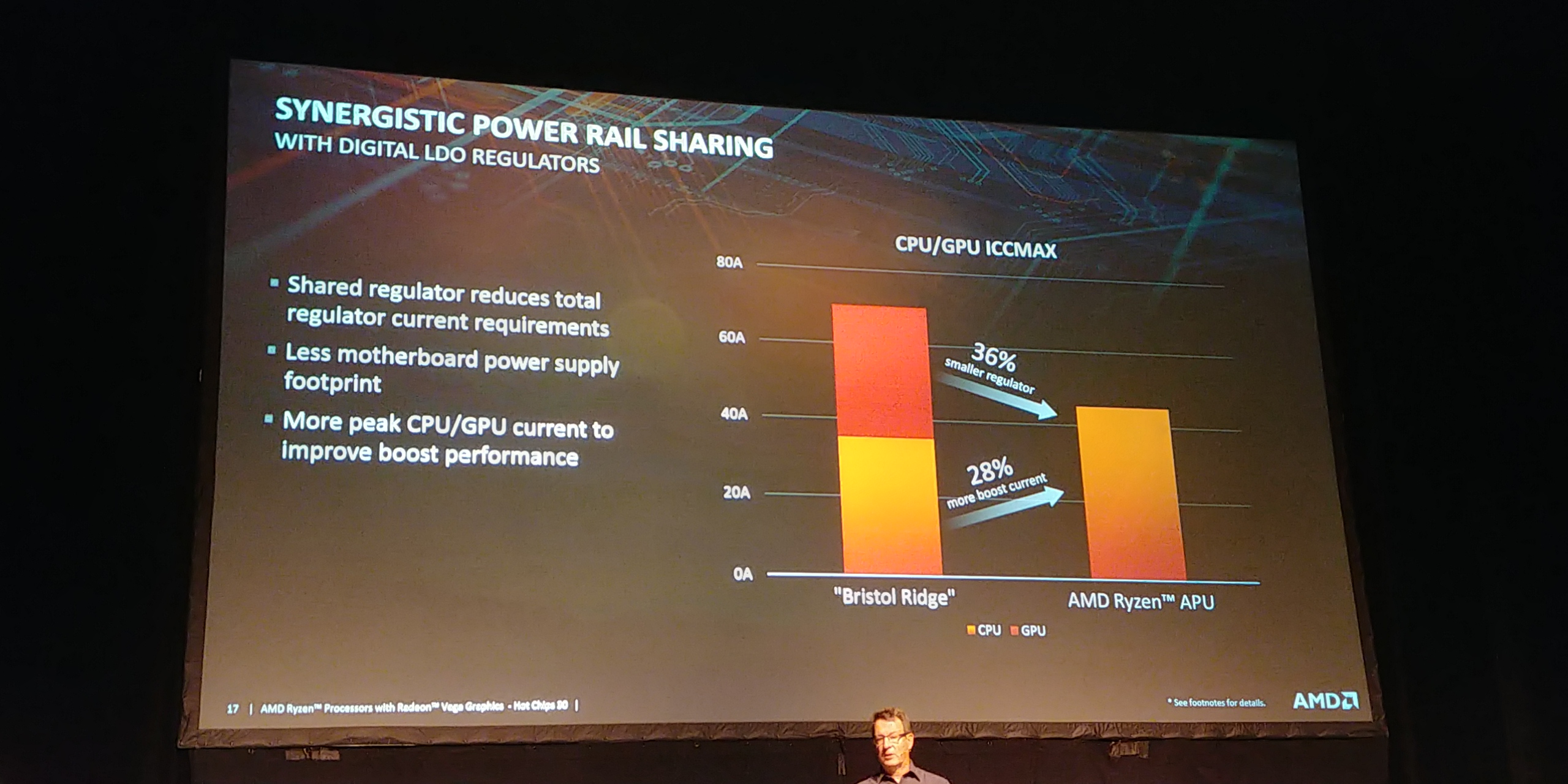
03:20PM EDT - From Bristol Ridge, higher boost current but smaller regulator, overall lower ICCMax for CPU+GPU
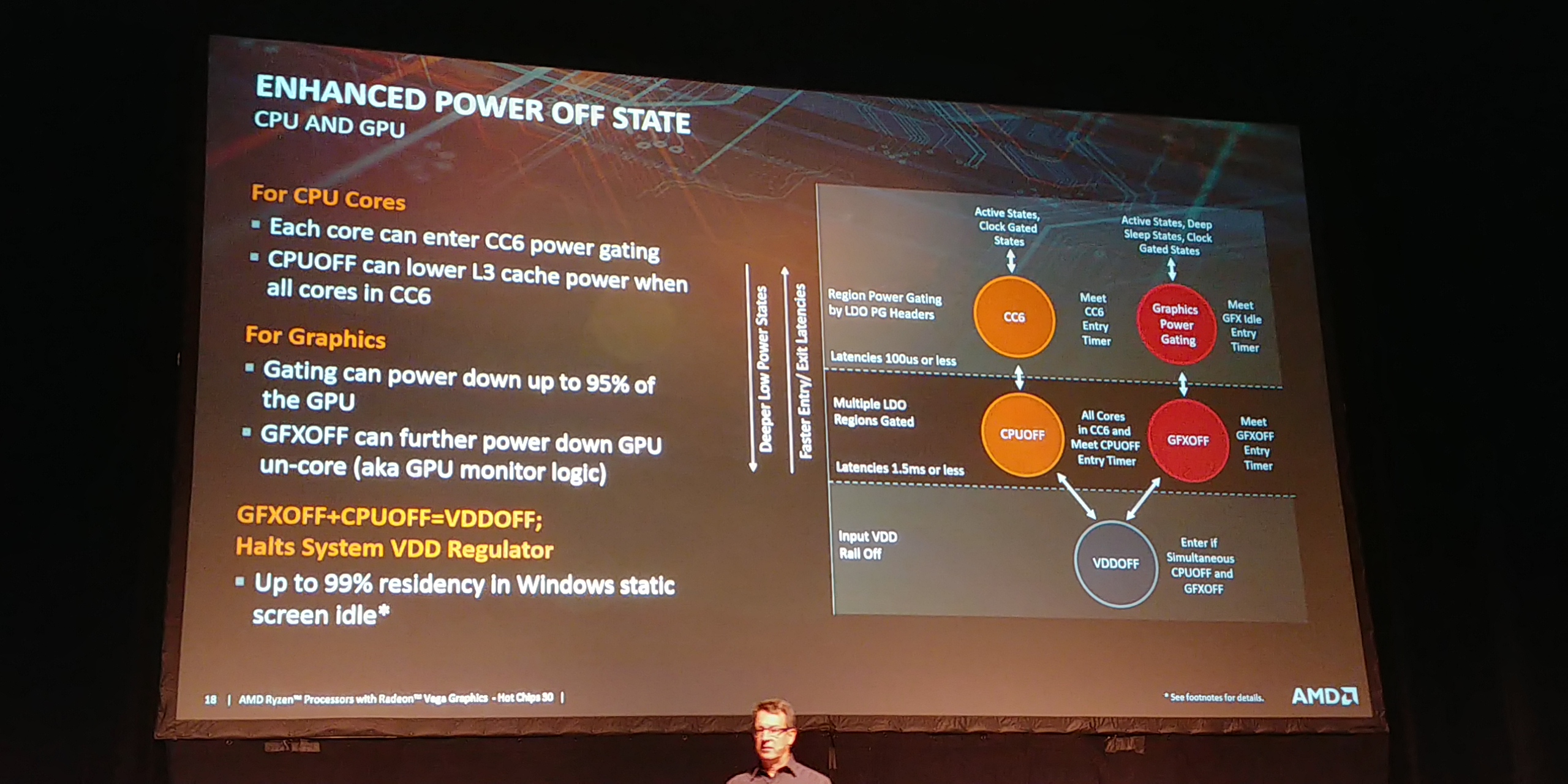
03:21PM EDT - Each core has a regulator, so can control power states and power down each core when idle
03:21PM EDT - Fast graphics off and power down when needed
03:21PM EDT - New power modes

03:22PM EDT - managing a lot of skin temps through STAPM
03:22PM EDT - Skin Temperature Aware Power management
03:22PM EDT - Previous gen didn't exploit thermal headroom
03:22PM EDT - Now can go into thermal budgets and maximise performance
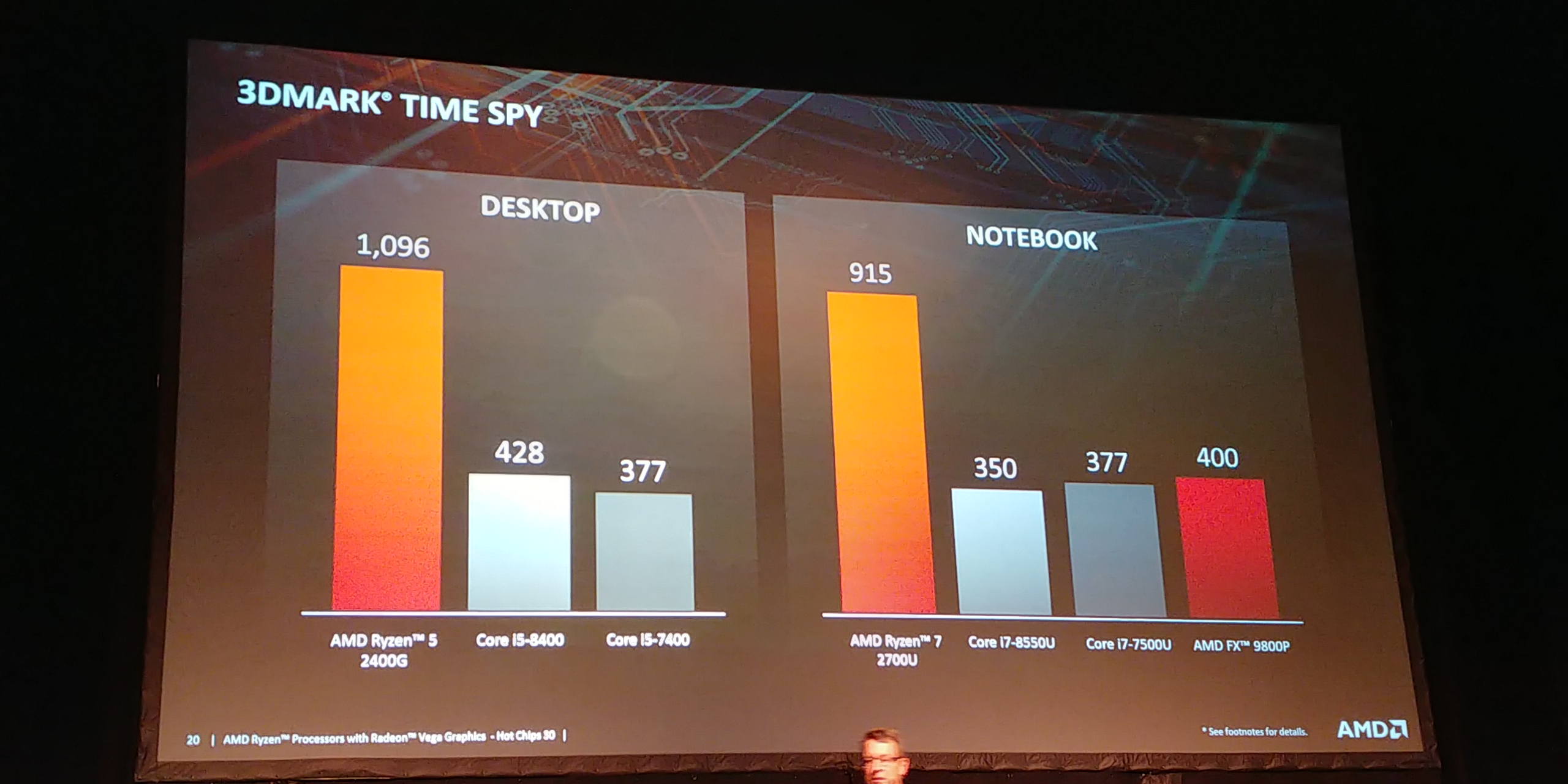
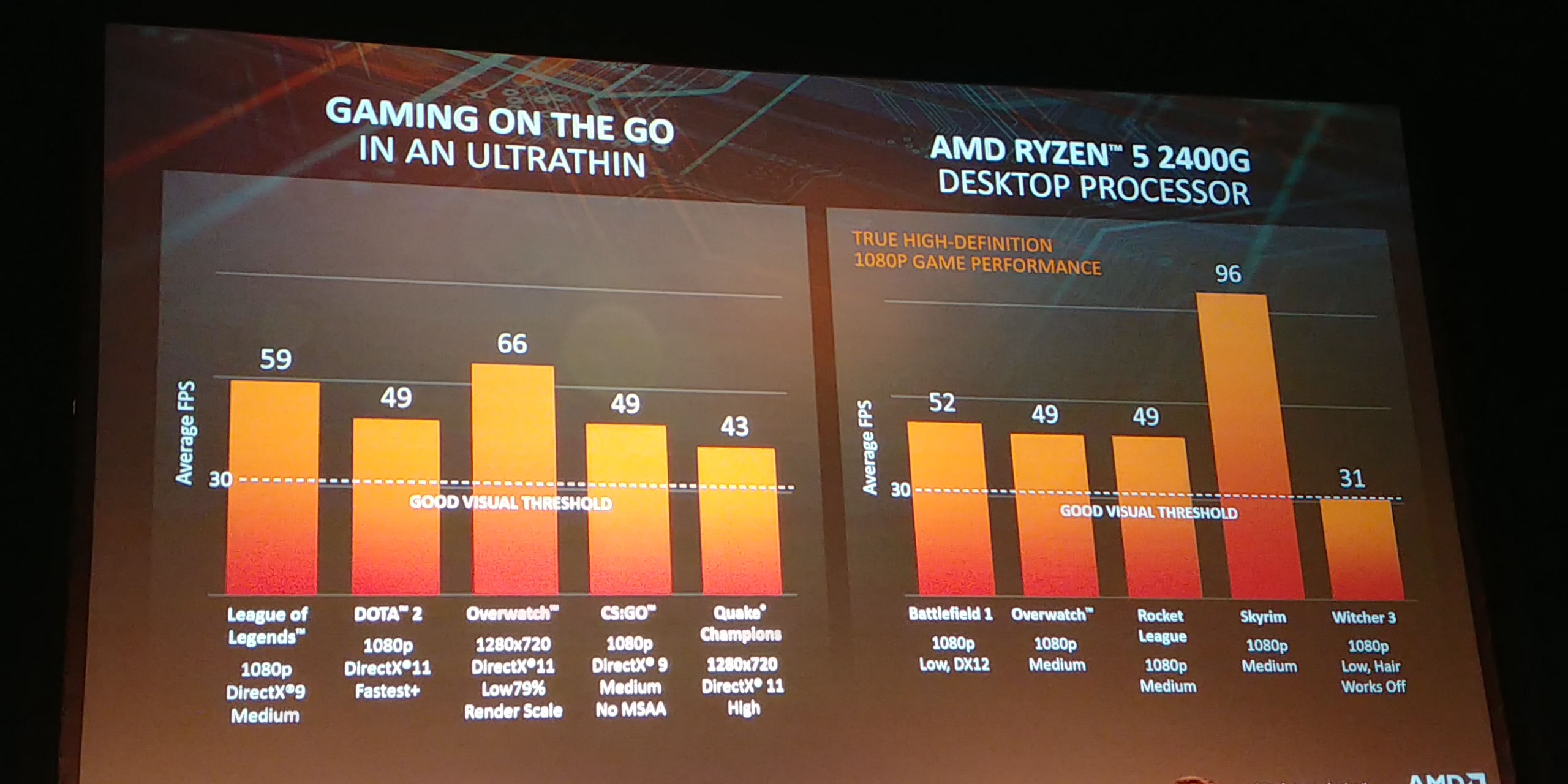
03:23PM EDT - Performance goes up
03:23PM EDT - Now 25x20 goal
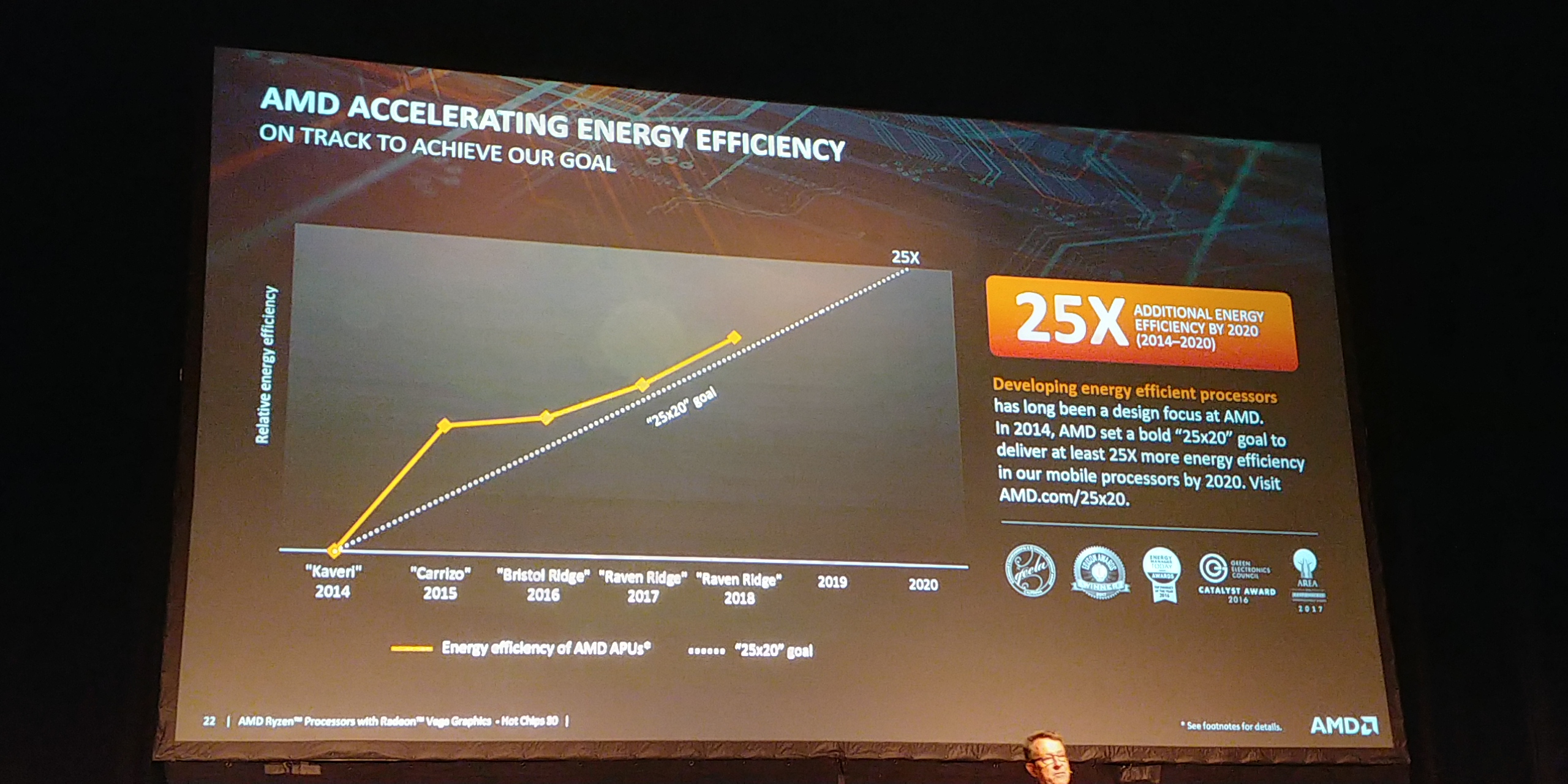
03:24PM EDT - Above progress goal
03:24PM EDT - New systems will come out in the future to meet the target

03:25PM EDT - Q&A Time
03:27PM EDT - Q: Talk coherency and master/slave. A: The masters are participating in the protocol, slaves are the memory controllers. Manage all coherent / non coherent traffic
03:28PM EDT - Q: Are the display controllers coherent? A: The frame buffer is considered non-coherent memory
03:29PM EDT - Q: Moore's Law is painful but you can stay on course for 25x20 ? A: We are seeing improvements, looking forward to 7nm. Looking beyond that. Challenges today are more like IO scaling. If we start looking at IO bottlenecks, such as mem and mem throughput, that's our bigger challenges. Also, thermal management, thermal density, trying to tune every last bit in the device.
03:29PM EDT - That's a wrap. Next Live Blog at 4pm PT.






