Original Link: https://www.anandtech.com/show/1301
What Went Wrong with NV3x: A Moratorium
by Derek Wilson on April 19, 2004 4:12 PM EST- Posted in
- GPUs
Introduction
There has been a lot of buzz over NVIDIA's latest offering in the GeForce 6800's NV40 GPU. To be assured, NV40 offers performance that is hands and feet above that of NV3x, but what we want to know is why.
Yes, NV3x is a different architecture, but just how different is it from its bigger brother? What are the reasons we didn't see the performance we would have liked from NV3x? How exactly did NV40 manage to improve on NV3x's architecture to allow the 6800 to strech its legs so far?

These are the questions we want to answer, and we will take a look at the details of the architectures as a whole, and some individual elements of their pipelines in order to try and understand just what went wrong to spark NVIDIA's darkest 12 months.
The Pixel Pipe Performance Picture
The ultimate goal of graphics hardware is to determine the color of every visible pixel. From this unassuming end extend a vast array of operations that need to be performed to get the job done. As the demand for ever increasing graphics quality asserts itself on the industry, more and more work needs to be done in graphics hardware rather than in software on the CPU. All the work that ends up needing to be done on a per pixel basis translates to what is known as the pixel pipeline. To draw on an oft used analogy in computer engineering, this is basically the assembly line of a pixel.One of the more fortunate aspects of computer graphics is that determining the color of one pixel can be done completely independently of any other pixels (though NVIDIA chooses to work on four pixel units internally called "quads"), so computer graphics is infinitely parallelizable. If we had enough processing power, we could actually process every single pixel on the screen at the same time. Even though going to such extremes is currently not an option (I wonder where we'll be in another decade or two), currently graphics cards are able to process multiple pixels at a time. Just how many pixels can be rendered in parallel is described by the "width" of the architecture.
Behind NV3x is a 4x2 pixel pipe (though there was some confusion over this we will get to later). This means that NV3x based cards could draw 4 pixels with 2 textures per pixel at a time (texturing a pixel involves mapping a position on a surface to (usually) a color in a texture map -- in a two texture per pixel architecture this lookup operation can be performed with two different textures at the same time). In contrast, ATI's R300 architecture is 8x1 meaning that 8 pixels with 1 texture per pixel can be drawn at a time. Unfortunately, in single texture environments, NVIDIA could still only draw four pixels per clock at a maximum.
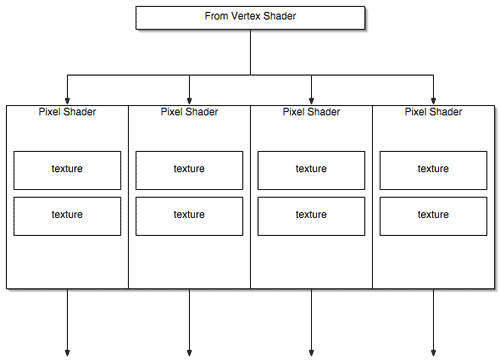
The layout of the architecture (in as much as it appears to software) is 4 pixel shader units each with two texture units. Maximum texture fill rate is twice the maximum number of pixels per second the card can draw, which means that a lot of power is going to waste when only one texture is being used per surface.
The decision NVIDIA made for NV3x makes sense considering that many effects in fixed function and early programmable hardware (the DirectX 7 and 8 timeframe) were better suited to creating and applying multiple textures to a surface (this is called multitextureing for obvious reasons). Implementing Light maps, environment maps and cube maps (reflections), and bump maps, in addition to the traditional color map, are all examples of ways developers can exploit multitextureing to add realism to their environment.
Most multitextureing effects can be done using vertex and pixel shader programs. Shader programs are able to offer a higher degree of control to developers and artists and can eliminate the need for multitextureing at the same time. While this is fortunate for developers, artists, end users, and ATI, the NV3x architecture is not suited to the current climate and thus its real world performance falls much shorter than its theoretical max than NVIDIA would like.
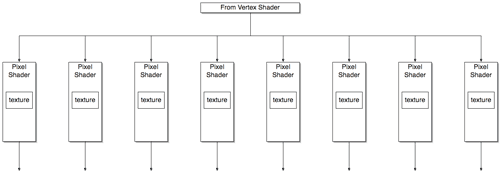
When moving to NV40 from the NV3x architecture, more of a focus was placed on single texturing while enhancing the internal performance of the vertex and pixel shaders. This was done by essentially quadrupling the number of pixel shader pipelines while only doubling the capacity of the GPU to handle textures (making it a 16x1 architecture). On NV40, maximum pixel and texture fill rates are the same leading to a more balanced use of hardware in real world conditions. When handling multitextureing, NV40 can also run in an 8x2 mode where half of the pipeline is dedicated to each texture. In this multitexture mode, NV40's texture fill rate is the same as its single texture mode while its pixel fill rate is halved.
Aside from color and texturing, 3D graphics cards also need to deal with the third dimension: depth "into" the screen. This depth, or z, value keeps track of how near or far a pixel on a surface is from the viewer. If at any point in the pipeline something is determined to be "behind" another thing, it can be thrown out or turned off (this is known as occlusion culling). One of the best ways to enhance performance in 3D graphics is to do less work, and the key is knowing what not to do. Calculating and tracking z values is a key part of eliminating work. NVIDIA's architectures can handle stenciling in the same bit of hardware that handles z operations. Stenciling is difficult to explain, but it may be easier to grasp by looking at a simplified explanation of a common application: shadowing. Shadows can be implemented by "rendering" z values as viewed from a light source. Anything that gets turned off (is behind something) from the perspective of the light source is shadowed, and can remain off when rendering the scene from the perspective of the viewer (who will see a shadow due to the light where pixels were turned off). Doing "good" shadowing is much more complicated than this, but that's the general idea.
In both NV3x and NV40 architectures, z and color can be calculated per pixel at the same time. In addition, rather than coloring a pixel, a z or stencil operation can be performed in the color unit. This allows NV3x to perform 8 z or stencil ops per clock and NV40 to perform 32 z or stencil ops per clock. NVIDIA has started to call this "8x0" and "32x0", respectively, as no new pixels are drawn. This mode is very useful if a z only pass is performed first, or if stencil shadows are used (as is the case with Doom 3).
Of course, there is more to graphics performance than how many pixel pipes are under the hood. There were other reasons NV3x performance wasn't what it could have been, not the least of which was the internal layout of the vertex and pixel shaders.
Shedding Light On Shader Performance
Explaining where shaders fit in requires a brief explanation of what happens on the whole when rendering 3D graphics on modern hardware. When moving from software to the screen through the graphics pipeline, there are quite a few things that happen, generally moving from the large scale to the small scale. On the top end, objects and geometry are handled. The position and direction of the viewer of the 3D scene, along with 3D positional data are translated, rotated, and otherwise manipulated as necessary very early on. If we were going for a two color wireframe scene, we would be just about finished. As we continue looking down the graphics pipeline, the operations being performed on the scene get more and more finely grained. We start looking not at an entire scene's geometry, but at a surface's normals to help determine how it will be lit. Moving on we texture surfaces, and further still down the line we start looking at the individual pixels being drawn on the screen and what color a particular pixel will be based on all the processing that has happened previously. This is a simplified overview, but generally the further down the pipeline the smaller the scale of the unit being operated on.A side effect of how scenes are processes is that moving down the pipeline, the set of data being worked on grows as the size of the unit being worked on shrinks. For instance, a normal scene will have a bunch of objects in it which are all made up of a bunch of polygons that have 3 or more vertices each. When a scene is finally rendered, we have gone from one scene with some objects to many more polygons, even more vertices, and millions of pixels to worry about. As a side note, all of this means that it is generally more efficient for developers to get as much work done as early in the pipeline as possible.
Shader hardware is a kind of like a fractal of the graphics pipeline as a whole. First, we operate over vertex data, then this data is manipulated and sent down to the pixel pipes where pixel shaders operate per pixel.
Inside the shaders, we are able to perform a vast array of operations on vertices and pixels, and the longer the shader program, the more impact the shader program will have on performance. Another way to look at this is that longer shader programs require more efficient shader hardware to run well.
Just saying "more efficient shaders" doesn't really paint a clear picture of the issue. shader specifications are requiring that parts of the GPU become more and more like a CPU. With this evolution come all the problems and difficulties associated with architecting a powerful CPU. The most interesting aspects of CPU design to look at when trying to understand the reason NV3x fell short of what it could have been: instruction scheduling.
Scheduling is generally viewed as a compiler design issue, but there are plenty of considerations that need to be made from the hardware side. The main issues we will look at that affect scheduling from an NV3x hardware standpoint are: functional unit availability and register pressure.
First, each shader pipeline has a handful of units inside it that can be doing work at any given time. The pixel pipeline of NV3x can handle a texture and a math operation, and in order to keep the pipeline running at full speed, developers need to keep all of these units working at the same time. If instructions in a shader program aren't ordered such that math and texture operations are interleaved, the NVIDIA architecture suffers as half the work that could be getting done won't be getting done. The compiler will do its best to take a program and reorder it so that it interleaves texture and math operations while maintaining the same output in the end. This is a very difficult problem to overcome, but it is also key to NV3x performance. Enabling the compiler back when the 50 series drivers were released was the reason we saw, in some cases, up to a 25% increase in performance essentially "for free".
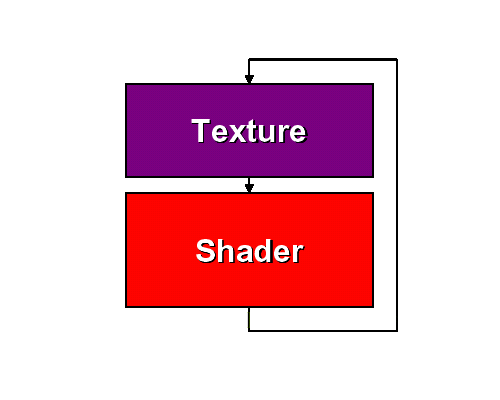
This is the front end of an NV3x pixel shader pipe.
The next scheduling hurdle is register pressure. Not having enough space to store temporary data in local registers forces a lot of time to be wasted on simply juggling data around. The traditional analogy in computer engineering when dealing with managing registers is Tetris. It's not exactly the same, but it can get just as difficult to optimally fill register space as it can be to optimally drop a block in Tetris without knowing what's coming next. It gets even more difficult when there is less space to do everything in (imagine if the Tetris playing field were even less wide than it already is). This is definitely undesirable as we would like to focus on getting some actual work done rather than just playing hot potato with data. The compiler comes in very handy here as well, and takes care of managing register usage in order to optimize program runtime. Unfortunately, if the hardware isn't well suited to the type of programs being run on it, no compiler will be able to solve all the problems.
The way NVIDIA overcame these issues in NV40 was to revamp the internals of their shader pipelines by adding an extra math unit to all the pixel pipes (pixel shaders can now execute two math instructions at the same time, or a math and texture instruction), and expanding the number of registers available for shader programs to use.
This is the front end of an NV40 pixel shader pipe.
The two math units in the NV40 pixel pipe can be used at the same time when there is no texturing going on, allowing math intensive shader programs to avoid running into scheduling problems, and the registers add more space for easier "bin packing" which alleviates the rest of the large scheduling problems seen in NV3x. In the end, from quadrupling the number of pixel pipes and adding the second math unit, NV40 can push up to 8x the shader performance of NV3x under the right conditions. This very impressive increase in performance was definitely sorely needed as NV3x shader performance was much less than optimal. Vertex shader performance was also essentially doubled in the same manner pixel shader performance was increased up to 8x.
NV40, with its well refined vertex pipes (6) and pixel pipes (16x1) brings a lot of power to the architectural style based in NV3x.
Final Words
In talking about pure pixel drawing power, NV35 and NV38 didn't have it too bad as their clock speed helped push fill rate up to 1800 and 1900 Mpixels/s at their theoretic peaks. This number is simply a multiplication of how many pixels can be drawn at a time and clock speed. The NV3x architecture could also push twice as many textured pixels (if multitextureing was employed) or twice as many z / stencil operations as pixels. The problems with performance in NV3x didn't come in theoretical maximum limitations, but rather in not being able to come anywhere near theoretical maximums in the real world due to all the issues we have explored in addition to a couple other caveats. Here's a brief rundown of the bottlenecks.If a game uses single textures rather than multitextures, texture rate is automatically cut in half. If very complex vertex or pixel shaders are used, multiple clock cycles can be spent per pixel without drawing anything. This is heavily affected both by how many pixels we can be working on at one time, as well as how able the shaders are to handle common shader code. Enabling antialiasing incurs a performance hit, as does trilinear and anisotropic filtering. There will always be some overdraw (pixels being drawn on top of other pixels), which also wastes time. This all translates into a good amount of time spent not drawing pixels on an architecture without a lot of leeway for this.
In moving to NV40 there were lots of evolutionary fixes that really helped bring the performance of the architecture up. The most significant improvements were touched on earlier: the quadrupling of the pixel pipes while doubling the number of texture units (creating a 16x1 architecture), and increasing the number of vertex shader units while adding a second math unit and more registers to pixel shaders to avoid scheduling issues. Further improvements in NV40 were made to the help eliminate hidden pixels earlier in the pipeline at the vertex shaders (which helps keep from doing unnecessary work), and optimizations were made to the anisotropic filtering engine to match ATI's method of doing things with approximated (rather than actual) distances.
In the end, it wasn't the architecture of the NV3x GPU that was flawed, but rather an accumulation of an unfortunate number smaller issues that held the architecture back from its potential.
It is important to take away from this that NV40 is very evolutionary, and that NVIDIA were pushing very hard to make this next step an incredible leap in performance. In order to do so, they have had to squeeze 222 million transistors on something in the neighborhood of a 300mm^2 die. By its very nature, graphics rendering is infinitely parallelizable, and NVIDIA has taken clear advantage of this, but it has certainly come at a cost. They needed the performance leap, and now they will be in a tough position when it comes to making money on this chip. Yields will be lower than NV3x, but retail prices are not going to move beyond the $500 mark.
On a side note, ATI will most likely not be this aggressive with their new chip. The performance of the R300 was very good with what we have seen of current games, and they just won't need to push as hard as NVIDIA did this time around. Their architecture was already well suited to the current climate, and we can expect small refinements as well as an increase in the width of their pixel pipe (which also looks like it will be 16x1). Of course, ATI's performance this time around will be increased, but just how much will have to remain a mystery for a couple more weeks.






