Original Link: https://www.anandtech.com/show/1781
Since the site’s inception, we’ve been massing large amounts of content on which millions of people have come to depend. We have numerous ways of getting to the content, but the quickest and easiest way to find specific information is to search for it.
AnandTech Search 1.0 (ColdFusion Verity)
The first version of the site used a search server included with ColdFusion named “Verity”. Most people have heard of Verity; they are one of the industry leaders in enterprise search software. The version of Verity that was included with ColdFusion back then was a light version of the full-blown Verity Search server. Although it did quite well at locating content via Boolean searches, it lacked flexibility and wasn’t all that of a performant.AnandTech Search 2.0 (Microsoft FullText Search)
After we migrated to Microsoft SQL Server, we decided to use the Full Text search that is built-in to SQL Server. SQL Server Full Text came to be in version 7.0, and allows you to create catalogs that can contain multiple indexes on text column types. You can then configure Full Text to index the data in the background, or perform one time or scheduled indexing of the data.There are, however, a couple of caveats with Microsoft Full Text search. The first is that it throws errors when your search criteria contain “noise words”. By default, Full Text search is configured with a list of “noise words”. Microsoft (and many other search engines) consider words like “because,been,before,being,between,both,but,by” to be common words that should not be contained in an index. Of course, you can trap this error easily in your application, but realistically, the search engine should just filter the words out of the search phrase itself.
The second and more important issue is how Full Text handles acronyms and numerical values in search strings. We never really did get to the bottom of the problem, but even with all of the noise words removed from Full Text, certain search phrases that contained acronym and numerical data wouldn’t return results. Since our data is full of technical acronyms and numerical model numbers, this was a major issue for us.
Along came Google
The company we know as "Google" came to be on September 7 th, 1998 and grew exponentially from there. "Google", derived from the "googol", which refers to the number represented by the numeral 1 followed by 100 zeros, is now a household name for just about everything internet. Search, Web Mail, Maps, Ads, Blogging, Photos are just a few of the tangents that Google has taken over the years.As the success of Google's Search engine increased, Google started selling search appliances that brought the power of the Google Search engine into corporate IT server rooms. When the appliances first came out, they carried a fairly hefty price tag, even for the entry level appliance. But, on April 6, 2005, the price of the Google Mini came down to a very reasonable $2,995, which is a sweet spot for IT managers to charge to their credit cards.
Once the price drop came into effect, we decided to purchase a unit and move our entire site searches over to the Mini.
Opening the Box
The Mini arrived in a box with Google printed in large letters along the side. Our UPS courier asked us what was in the box; it's not too often that you see Google on anything physical:






Examining the Google Mini
The Mini itself is actually your run-of-the-mill 1U server, with the chassis painted blue.

Click to enlarge.

Behind this grill is a slim-line CD-ROM drive, not meant to be used by the user.


The two Ethernet ports are color-coded to match the cables provided with the Google Mini.
Getting Inside the Mini
It’s very clear that Google doesn’t want you playing around with the innards of the Mini as most of the screws have no usable head:
The grey screw above the rightmost Ethernet port features no usable head. Luckily, removing the screw only requires a little patience and some pliers.

The screw is threaded - it just can’t be undone with a regular screwdriver.
The top of the Mini is actually one large piece of plastic with adhesive on its back that not only makes the unit look better, but also acts as another safeguard against curious users gaining access to the internals of the machine. Peeling back the front edge of the top breaks the adhesive and allows us to slide off the front cover.


Click to enlarge.



We were curious to see what was under those heatsinks, so of course, we pulled one off:

The motherboard features a VIA chipset, as is evident by the VIA South Bridge pictured below:






Setting up the Google Mini
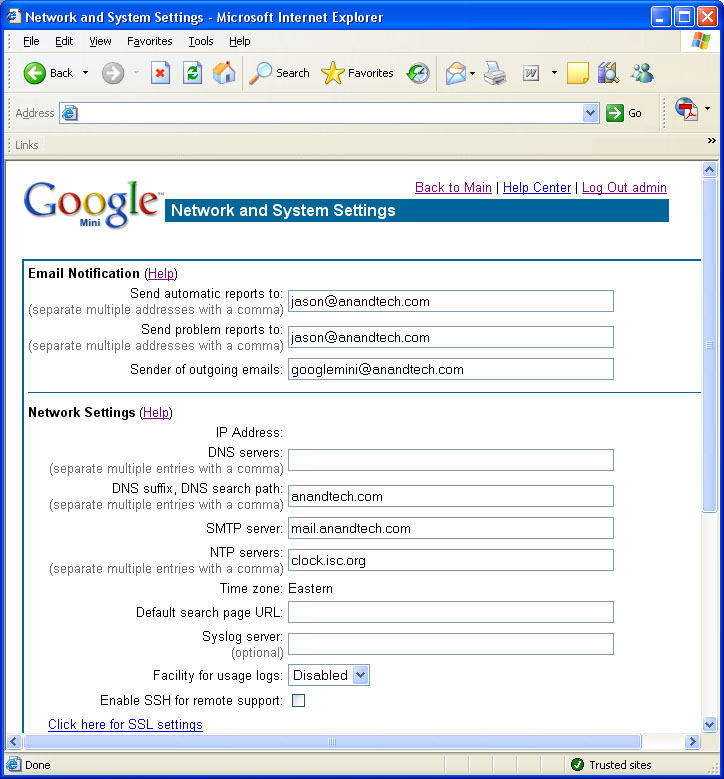
When you first login to the Google Mini, you are presented with a web-based interface to configure the general parameters. These settings include the device IP Address, DNS Server, Admin E-mail address, Time zone, etc. Nothing fancy here, although we did have to configure an internal DNS server due to some firewall routing issues.Configuring your first Collection
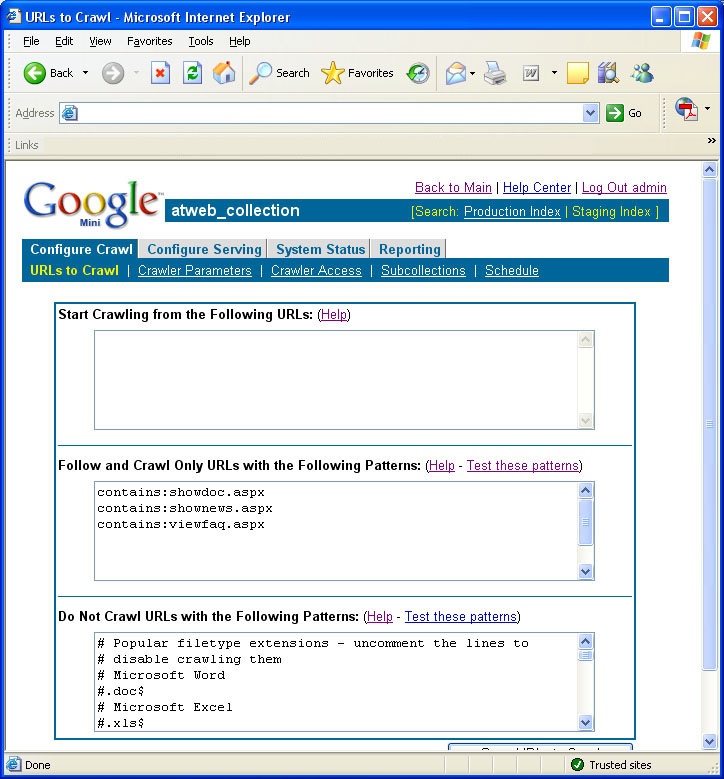
Like most any search product, the first task is to create a collection of what you want searched. The Google Mini supports one collection while its larger brother, the “Google Search Appliance, supports an unlimited number of collections. Collections can contain sub-collections (which I’ll explain a bit later).Once you’ve created your first collection, the first step is to edit the collection parameters and set it up for indexing. URLs to Crawl was where we started, which contains a few parameters, Starting URLs from which to crawl, Follow and Crawl certain URLs or parts thereof and Do Not Crawl URLs matching certain patterns. This was probably where we spent 99% of our time configuring the Mini. The mini allows for 100,000 documents/URLs to be stored in a collection, and AnandTech contains approximately 40,000 articles, news and blog entries.
When we first set up the Mini, we told it to start in each of the website’s sections (for example, http://www.anandtech.com/it/) and in the web news area. The Mini considers any unique URL string to be a unique document, which makes sense (but is a bit surprising the first time that you run an index).
After four hours of indexing, the Mini had managed to reach its document limit and we had to improvise. After several attempts at filtering out various URL patterns and restricting the crawling as much as we could, we ended up writing some code. We created a file to which a link to every article, news post and blog post that have been published on the site would be dumped. That file is cached for a few hours as we update the index 3 times a week. We then configured the Mini to start at those URLs and restricted it only to URLs ending in showdoc.aspx, shownews.aspx and a few others. It worked - the next index was around 38,000 documents. A word to the wise: don’t let the Mini crawl your entire site without keeping a close eye on it.
Sub-collections
Before you let the Google Mini go off and crawl to its hearts content, consider creating some sub-collections if they are required. Sub-collections are simply small collections containing specific fragments of your site. For instance, on AnandTech, we have Articles, News, Blogs and FAQs as sub-collections. Each of these can be searched separately within the collection to allow us to have targeted searches within the various sections of the web site.KeyMatch/Synonyms
Like the google.com search, the Google Mini supports key matches that allow you to have links appear at the top of your search results, which match keywords that you enter in the Google Mini interface. Another useful feature that is included is Synonyms, which allow you to enter synonyms for various search terms. We have a few created. Try typing “ iram” into our search, and you’ll notice that it suggests “i-ram” as a possible search.Look and feel integration
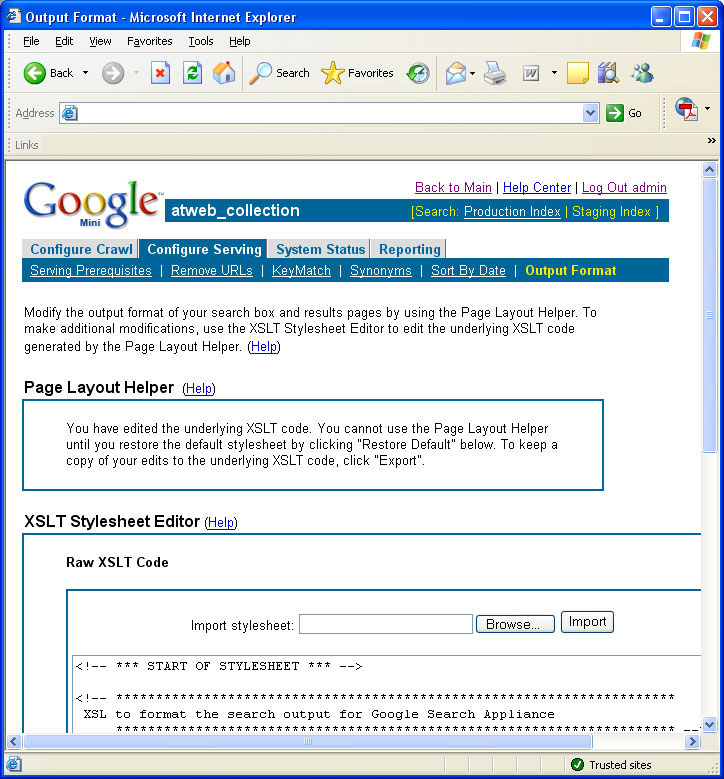
The last thing that we worked on was making the Mini look like it is part of AnandTech.com. There are two ways to go about this in the Mini admin. One is to use their built-in page layout helper, which allows you to wrap the search screens with a custom header and footer. The other way (which we prefer) is to use the XSLT Stylesheet editor and modify the stylesheet to meet your needs.All in all, our integration went fairly smoothly, and the Mini has made it exponentially easier to find content on AnandTech.com.
Screen Shots
 Settings |
 Collection |
 Output |
 Subcollections |






